LeNet网络复现
文章目录
- 1. LeNet历史背景
- 1.1 早期神经网络的挑战
- 1.2 LeNet的诞生背景
- 2. LeNet详细结构
- 2.1 总览
- 2.2 卷积层与其特点
- 2.3 子采样层(池化层)
- 2.4 全连接层
- 2.5 输出层及激活函数
- 3. LeNet实战复现
- 3.1 模型搭建model.py
- 3.2 训练模型train.py
- 3.3 测试模型test.py
- 4. LeNet的变种与实际应用
- 4.1 LeNet-5及其优化
- 4.2 从LeNet到现代卷积神经网络
1. LeNet历史背景
1.1 早期神经网络的挑战
早期神经网络面临了许多挑战。首先,它们经常遇到训练难题,例如梯度消失和梯度爆炸,特别是在使用传统激活函数如sigmoid或tanh时。另外,当时缺乏大规模、公开的数据集,导致模型容易过拟合并且泛化性能差。再者,受限于当时的计算资源,模型的大小和训练速度受到了很大的限制。最后,由于深度学习领域还处于萌芽阶段,缺少许多现代技术来优化和提升模型的表现。
1.2 LeNet的诞生背景
LeNet的诞生背景是为了满足20世纪90年代对手写数字识别的实际需求,特别是在邮政和银行系统中。Yann LeCun及其团队意识到,对于图像这种有结构的数据,传统的全连接网络并不是最佳选择。因此,他们引入了卷积的概念,设计出了更适合图像处理任务的网络结构,即LeNet。
2. LeNet详细结构
2.1 总览
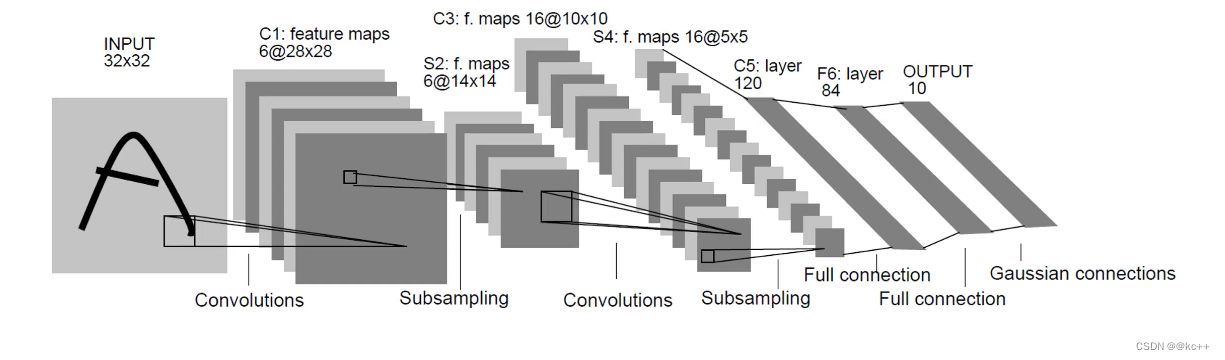
2.2 卷积层与其特点
卷积层是卷积神经网络(CNN)的核心。这一层的主要目的是通过卷积操作检测图像中的局部特征。
特点:
- 局部连接性: 卷积层的每个神经元不再与前一层的所有神经元相连接,而只与其局部区域相连接。这使得网络能够专注于图像的小部分,并检测其中的特征。
- 权值共享: 在卷积层中,一组权值在整个输入图像上共享。这不仅减少了模型的参数,而且使得模型具有平移不变性。
- 多个滤波器: 通常会使用多个卷积核(滤波器),以便在不同的位置检测不同的特征。
2.3 子采样层(池化层)
池化层是卷积神经网络中的另一个关键组件,用于缩减数据的空间尺寸,从而减少计算量和参数数量。
主要类型:
- 最大池化(Max pooling): 选择覆盖区域中的最大值作为输出。
- 平均池化(Average pooling): 计算覆盖区域的平均值作为输出。
2.4 全连接层
在卷积神经网络的最后,经过若干卷积和池化操作后,全连接层用于将提取的特征进行“拼接”,并输出到最终的分类器。
特点:
- 完全连接: 全连接层中的每个神经元都与前一层的所有神经元相连接。
- 参数量大: 由于全连接性,此层通常包含网络中的大部分参数。
- 连接多个卷积或池化层的特征: 它的主要目的是整合先前层中提取的所有特征。
2.5 输出层及激活函数
输出层:
输出层是神经网络的最后一层,用于输出预测结果。输出的数量和类型取决于特定任务,例如,对于10类分类任务,输出层可能有10个神经元。
激活函数:
激活函数为神经网络提供了非线性,使其能够学习并进行复杂的预测。
- Sigmoid: 取值范围为(0, 1)。
- Tanh: 取值范围为(-1, 1)。
- ReLU (Rectified Linear Unit): 最常用的激活函数,将所有负值置为0。
- Softmax: 常用于多类分类的输出层,它返回每个类的概率。
3. LeNet实战复现
3.1 模型搭建model.py
import torch
from torch import nn# 自定义网络模型
class LeNet(nn.Module):# 1. 初始化网络(定义初始化函数)def __init__(self):super(LeNet, self).__init__()# 定义网络层self.Sigmoid = nn.Sigmoid()self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)self.s2 = nn.AvgPool2d(kernel_size=2, stride=2)self.c3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)self.s4 = nn.AvgPool2d(kernel_size=2, stride=2)self.c5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)# 展开self.flatten = nn.Flatten()self.f6 = nn.Linear(120, 84)self.output = nn.Linear(84, 10)# 2. 前向传播网络def forward(self, x):x = self.Sigmoid(self.c1(x))x = self.s2(x)x = self.Sigmoid(self.c3(x))x = self.s4(x)x = self.c5(x)x = self.flatten(x)x = self.f6(x)x = self.output(x)return xif __name__ == "__main__":x = torch.rand([1, 1, 28, 28])model = LeNet()y = model(x)
3.2 训练模型train.py
import torch
from torch import nn
from model import LeNet
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
import os# 数据转换为tensor格式
data_transformer = transforms.Compose([transforms.ToTensor()
])# 加载训练的数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transformer, download=True)
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)# 加载测试的数据集
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transformer, download=True)
test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)# 使用GPU进行训练
device = "cuda" if torch.cuda.is_available() else "cpu"# 调用搭好的模型,将模型数据转到GPU上
model = LeNet().to(device)# 定义一个损失函数(交叉熵损失)
loss_fn = nn.CrossEntropyLoss()# 定义一个优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)# 学习率每隔10轮, 变换原来的0.1
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):loss, current, n = 0.0, 0.0, 0for batch, (x, y) in enumerate(dataloader):# 前向传播x, y = x.to(device), y.to(device)output = model(x)cur_loss = loss_fn(output, y)_, pred = torch.max(output, axis=1)cur_acc = torch.sum(y == pred)/output.shape[0]optimizer.zero_grad()cur_loss.backward()optimizer.step()loss += cur_loss.item()current += cur_acc.item()n = n + 1print("train_loss" + str(loss/n))print("train_acc" + str(current/n))# 定义测试函数
def val(dataloader, model, loss_fn):model.eval()loss, current, n = 0.0, 0.0, 0with torch.no_grad():for batch, (x, y) in enumerate(dataloader):# 前向传播x, y = x.to(device), y.to(device)output = model(x)cur_loss = loss_fn(output, y)_, pred = torch.max(output, axis=1)cur_acc = torch.sum(y == pred) / output.shape[0]loss += cur_loss.item()current += cur_acc.item()n = n + 1print("val_loss" + str(loss / n))print("val_acc" + str(current / n))return current/n# 开始训练
epoch = 50
min_acc = 0for t in range(epoch):print(f'epoch{t+1}\n-----------------------------------------------------------')train(train_dataloader, model, loss_fn, optimizer)a = val(test_dataloader, model, loss_fn)# 保存最好的模型权重if a > min_acc:folder = "sava_model"if not os.path.exists(folder):os.mkdir("sava_model")min_acc = aprint("sava best model")torch.save(model.state_dict(), 'sava_model/best_model.pth')
print('Done!')3.3 测试模型test.py
import torch
from model import LeNet
from torchvision import datasets, transforms
from torchvision.transforms import ToPILImage# 数据转换为tensor格式
data_transformer = transforms.Compose([transforms.ToTensor()
])# 加载训练的数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transformer, download=True)
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)# 加载测试的数据集
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transformer, download=True)
test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)# 使用GPU进行训练
device = "cuda" if torch.cuda.is_available() else "cpu"# 调用搭好的模型,将模型数据转到GPU上
model = LeNet().to(device)# 加载模型权重并设置为评估模式
model.load_state_dict(torch.load("./sava_model/best_model.pth"))
model.eval()# 获取结果
classes = ["0","1","2","3","4","5","6","7","8","9",
]# 把tensor转换为图片, 方便可视化
show = ToPILImage()# 进入验证
for i in range(5):x, y = test_dataset[i]show(x).show()x = torch.unsqueeze(x, dim=0).float().to(device)with torch.no_grad():pred = model(x)predicted, actual = classes[torch.argmax(pred[0])], classes[y]print(f'Predicted: {predicted}, Actual: {actual}')4. LeNet的变种与实际应用
4.1 LeNet-5及其优化
LeNet-5是由Yann LeCun于1998年设计的,并被广泛应用于手写数字识别任务。它是卷积神经网络的早期设计之一,主要包含卷积层、池化层和全连接层。
结构:
- 输入层:接收32×32的图像。
- 卷积层C1:使用5×5的滤波器,输出6个特征图。
- 池化层S2:2x2的平均池化。
- 卷积层C3:使用5×5的滤波器,输出16个特征图。
- 池化层S4:2x2的平均池化。
- 卷积层C5:使用5×5的滤波器,输出120个特征图。
- 全连接层F6。
- 输出层:10个单元,对应于0-9的手写数字。
激活函数:Sigmoid或Tanh。
优化:
- ReLU激活函数: 原始的LeNet-5使用Sigmoid或Tanh作为激活函数,但现代网络更喜欢使用ReLU,因为它的训练更快,且更少受梯度消失的影响。
- 更高效的优化算法: 如Adam或RMSProp,它们通常比传统的SGD更快、更稳定。
- 批量归一化: 加速训练,并提高模型的泛化能力。
- Dropout: 在全连接层中引入Dropout可以增强模型的正则化效果。
4.2 从LeNet到现代卷积神经网络
从LeNet-5开始,卷积神经网络已经经历了巨大的发展。以下是一些重要的里程碑:
- AlexNet (2012): 在ImageNet竞赛中取得突破性的成功。它具有更深的层次,使用ReLU激活函数,以及Dropout来防止过拟合。
- VGG (2014): 由于其统一的结构(仅使用3×3的卷积和2x2的池化)而闻名,拥有多达19层的版本。
- GoogLeNet/Inception (2014): 引入了Inception模块,可以并行执行多种大小的卷积。
- ResNet (2015): 引入了残差块,使得训练非常深的网络变得可能。通过这种方式,网络可以达到上百甚至上千的层数。
- DenseNet (2017): 每层都与之前的所有层连接,导致具有非常稠密的特征图。
相关文章:
LeNet网络复现
文章目录 1. LeNet历史背景1.1 早期神经网络的挑战1.2 LeNet的诞生背景 2. LeNet详细结构2.1 总览2.2 卷积层与其特点2.3 子采样层(池化层)2.4 全连接层2.5 输出层及激活函数 3. LeNet实战复现3.1 模型搭建model.py3.2 训练模型train.py3.3 测试模型test…...

Oracle 慢查询排查步骤
目录 1. Oracle 慢查询排查步骤1.1. 前言1.2. 排查步骤1.2.1. 查询慢查询日志1.2.2. Oracle 查询 SQL 语句执行的耗时1.2.3. 定位系统里面哪些 SQL 脚本存在 TABLE ACCESS FULL (扫全表) 行为1.2.4. 查看索引情况1.2.5. 查看锁的竞争情况1.2.6. 其他锁语句 1.3. 慢查询优化1.3.…...

互联网Java工程师面试题·MyBatis 篇·第二弹
目录 16、Xml 映射文件中,除了常见的 select|insert|updae|delete标签之外,还有哪些标签? 17、Mybatis 的 Xml 映射文件中,不同的 Xml 映射文件,id 是否可以重复? 18、为什么说 Mybatis 是半自动 ORM 映射…...
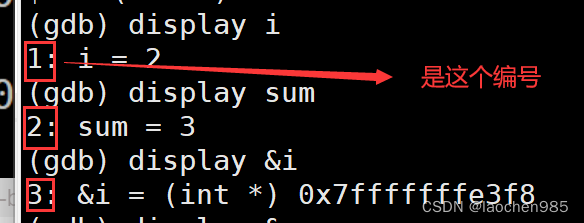
Linux 下如何调试代码
debug 和 release 在Linux下的默认模式是什么? 是release模式 那你怎么证明他就是release版本? 我们知道如果一个程序可以被调试,那么它一定是debug版本,如果它是release版本,它是没法被调试的,所以说我们可以来调试一…...
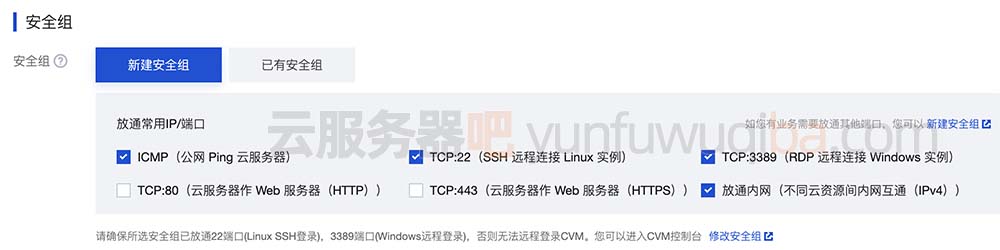
腾讯云服务器简介和使用流程
腾讯云服务器在云服务器CVM或轻量应用服务器页面自定义购买价格比较贵,但是自定义购买云服务器CPU内存带宽配置选择范围广,活动上购买只能选择固定的活动机,选择范围窄,但是云服务器价格便宜比较省钱。腾讯云服务器网来详细说下腾…...

python 二分查找
1.二分查找首先被查找的序列是一个有序的。 2.明确序列的左右边界 3.找出序列中间的元素,判断如果是要查找的元素,返回元素 4.如果中间元素,大于或者小于查找的元素,那么改变左右边间,直到中间的数等于查找的元素。…...

通过async方式在浏览器中调用web worker
通过async方式在浏览器中调用web worker 近年来,网络应用程序变得越来越复杂,增加了越来越多的功能。因此,性能和响应性已成为 Web 开发人员关注的重点。解决这个问题的一个办法是使用web worker。 web worker简介 web worker是一个 javas…...

FPGA project : TFT_LCD
实验目标: 驱动TFT_LCD显示十色彩条。 重点掌握的知识: 1,液晶显示器,简称LCD(Liquid Crystal Display),相对于上一代CRT显示器(阴极射线管显示器),LCD显示器具有功耗低、体积小、承载的信息量大及不伤眼…...
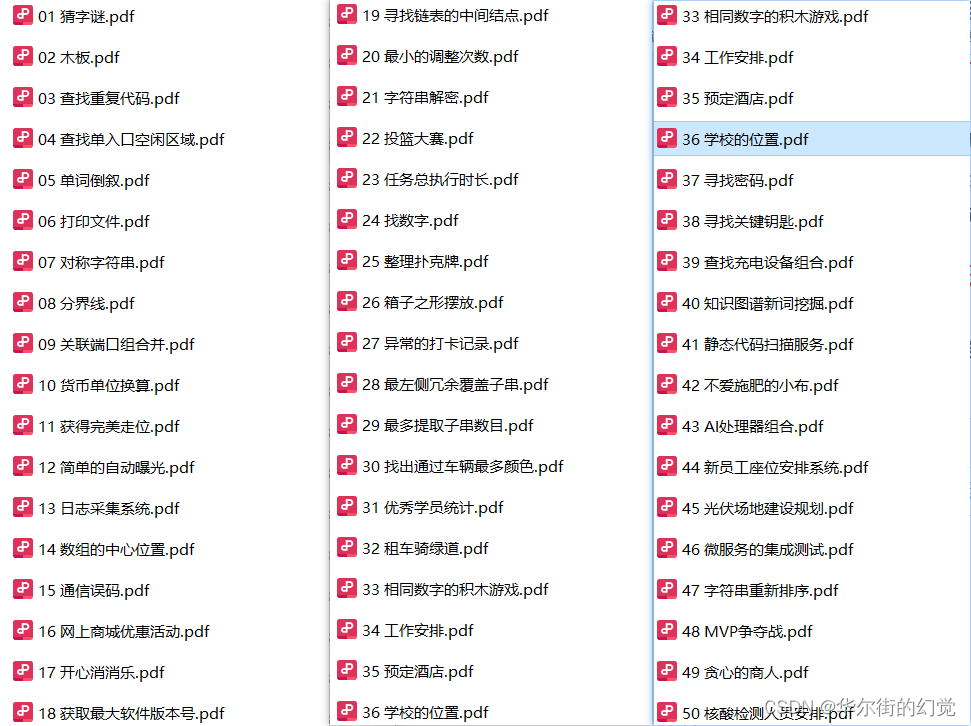
2023年-华为机试题库B卷(Python)【满分】
华为机试题库B卷 已于5月10号 更新为2023 B卷 (2023-10-04 更新本文) 华为机试有三道题目,前两道属于简单或中等题,分值为100分,第三道为中等或困难题,分值为200分。总分为 400 分,150分钟考试…...
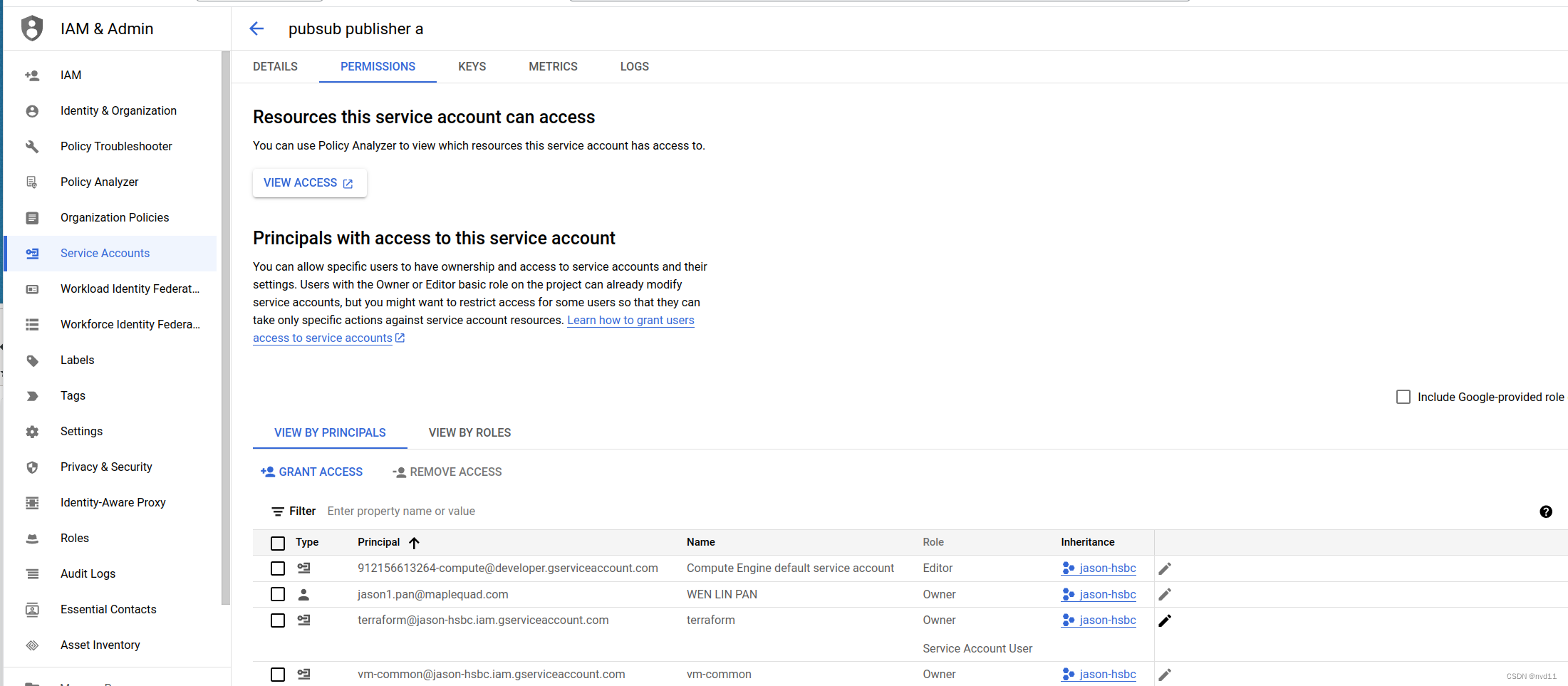
创建GCP service账号并管理权限
列出当前GCP项目的所有service account 我们可以用gcloud 命令 gcloud iam service-accounts list gcloud iam service-accounts list DISPLAY NAME EMAIL DISABLED terraform …...

想要精通算法和SQL的成长之路 - 验证二叉树
想要精通算法和SQL的成长之路 - 验证二叉树 前言一. 验证二叉树1.1 并查集1.2 入度以及边数检查 前言 想要精通算法和SQL的成长之路 - 系列导航 并查集的运用 一. 验证二叉树 原题链接 思路如下: 对于一颗二叉树,我们需要做哪些校验? 首先…...
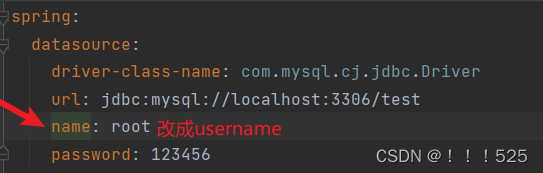
ERROR 6400 --- [ main] com.zaxxer.hikari.pool.HikariPool : root - Exception
在引用的日志中,报告了Hikari连接池初始化期间的异常。具体异常信息是"Exception during pool initialization"。这个异常可能是由于与MySQL数据库的通信链接失败导致的。在引用中也提到了与SSL连接相关的错误。 根据引用中提供的代码,可以看到…...

CART算法解密:从原理到Python实现
目录 一、简介CART算法的背景例子:医疗诊断 应用场景例子:金融风控 定义与组成例子:电子邮件分类 二、决策树基础什么是决策树例子:天气预测 如何构建简单的决策树例子:动物分类 决策树算法的类型例子:垃圾…...
C++项目:【高并发内存池】
文章目录 一、项目介绍 二、什么是内存池 1.池化技术 2.内存池 3.内存池主要解决的问题 4.malloc 三、定长的内存池 四、高并发内存池整体框架设计 1.高并发内存池--thread cache 1.1申请内存: 1.2释放内存: 1.3用TLS实现thread cache无锁访…...

[论文笔记]BitFit
引言 今天带来一篇参数高效微调的论文笔记,论文题目为 基于Transformer掩码语言模型简单高效的参数微调。 BitFit,一种稀疏的微调方法,仅修改模型的偏置项(或它们的子集)。对于小到中等规模数据,应用BitFit去微调预训练的BERT模型能达到(有时超过)微调整个模型。对于大规…...

浅谈yolov5中的anchor
默认锚框 YOLOv5的锚框设定是针对COCO数据集中大部分物体来拟定的,其中图像尺寸都是640640的情况。 anchors参数共3行: 第一行是在最大的特征图上的锚框 第二行是在中间的特征图上的锚框 第三行是在最小的特征图上的锚框 在目标检测中,一…...
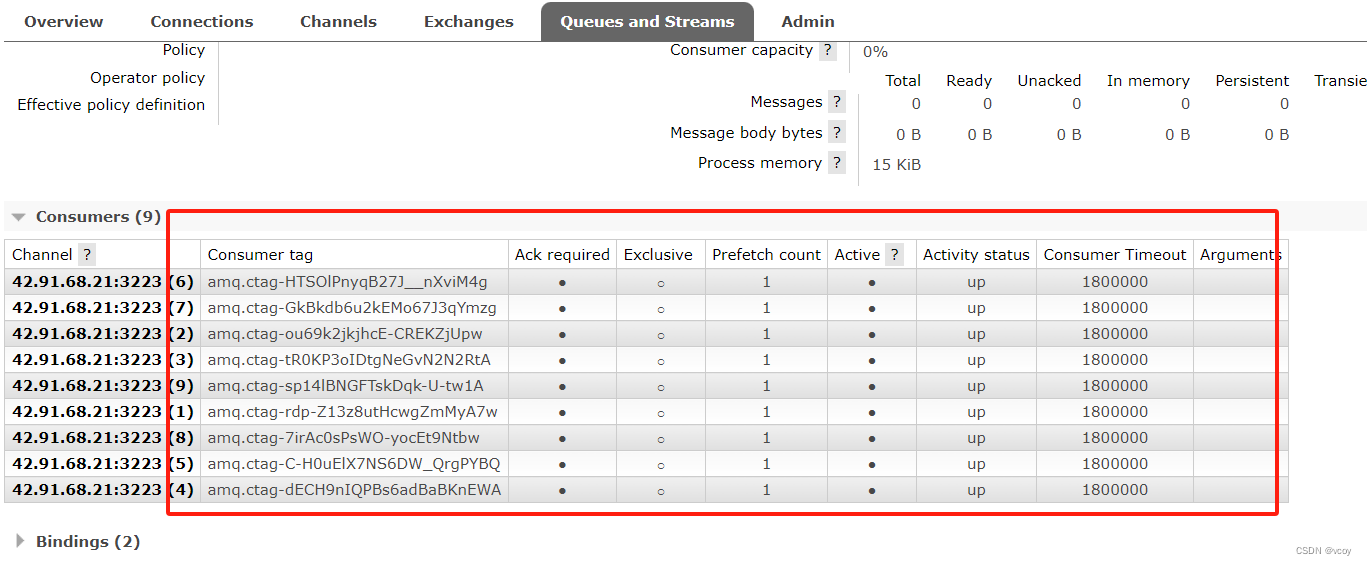
RabbitMQ-工作队列
接上文 RabbitMQ-死信队列 1 工作队列模式 xx模式只是一种设计思路,并不是指具体的某种实现,可理解为实现XX模式需要怎么去写业务代码。 之前的是简单的一个消费者一个生产者模式,下边是一个生产者多个消费者的情况: 这里先定义两…...

网站安全防护措施
网络安全的重要性在网站和app的发展下已经被带到了全新的高度,已然成为各大运维人员工作里不可或缺的环节,重视网络安全能给我们的网站带来更好的口碑,也能为企业生产创造更稳定的环境。下面我们一起来看看有哪些是我们运维人员能够做的。 1、…...
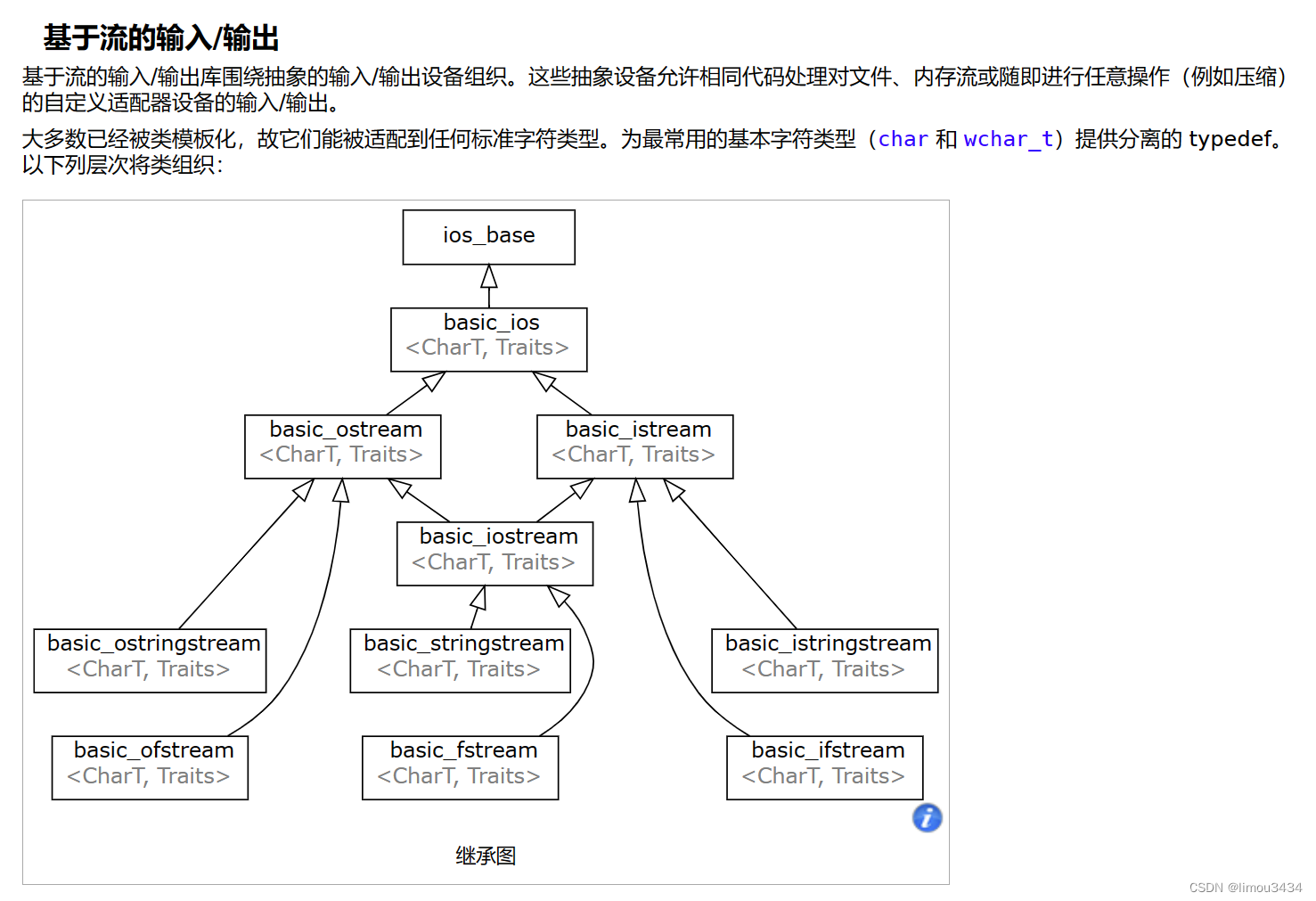
C++的继承基础和虚继承原理
1.继承概念 “继承”是面向对象语言的三大特性之一(封装、继承、多态)。 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性基础上进行扩展,增加功能&…...
)
第三章:最新版零基础学习 PYTHON 教程(第十三节 - Python 运算符—Python 中的运算符函数 - 套装2)
Python 中的运算符函数 - 套装1 本文将讨论更多功能。 1. setitem(ob, pos, val):- 该函数用于在容器中的 特定位置分配值。操作 – ob[pos] = val 2. delitem(ob, pos):- 该函数用于删除容器中 特定位置的值。 操作 – del ob[pos] 3. getitem(ob, pos)&#x...

用CC2530 DIY一个无线串口透传模块:基于Zigbee的无线数据收发实践
基于CC2530的Zigbee无线串口透传模块实战指南 在物联网和智能硬件开发领域,无线数据传输一直是核心需求之一。CC2530作为一款集成了Zigbee射频前端的经典芯片,其成本效益和成熟生态使其成为众多开发者的首选。本文将带您深入探索如何利用两块CC2530开发板…...

Kubernetes智能运维助手:基于LLM的kube-copilot实战指南
1. 项目概述:当Kubernetes遇上AI副驾驶如果你和我一样,每天都要和Kubernetes集群打交道,那你肯定对下面这些场景不陌生:凌晨三点被告警叫醒,面对一个不断重启的Pod,需要手动执行一串kubectl describe、kube…...

从零构建企业级API客户端:设计模式、类型安全与工程实践
1. 项目概述与核心价值最近在对接一个名为“Seedance2”的第三方API服务时,我遇到了一个不大不小的麻烦。这个服务本身功能强大,提供了从数据同步、事件处理到复杂业务逻辑编排等一系列能力,但它的官方SDK要么文档语焉不详,要么在…...

四川全行业 APP 开发服务商参考
随着四川各行业数字化进程加快,APP 开发覆盖政务、电商、教育、生活服务、企业管理等多元场景,市场服务商在行业适配、技术能力、服务保障上各有侧重。本文结合多行业落地案例、技术全面性、交付稳定性、运维支持能力,整理全行业适配的 APP 开…...

月薪2万+,2026年AI智能体工程师,这个岗位火了
AI智能体工程师负责设计、搭建、调优和维护AI智能体系统,让AI能自主感知环境、做出决策并执行动作。该岗位需求大,薪资高,适合具备逻辑拆解能力、Prompt工程能力和工具链认知的人。文章建议从体验AI智能体产品、学习相关课程和尝试搭建mini智…...

慢速乘与快速幂
慢速乘 在写程序进行乘法运算时,我们有时会遇到大数溢出的情况(比如两个 101810^{18}1018 的数相乘对 1018710^{18}710187 取模)。 这个时候我们就可以用慢速乘(你用 __int128_t 的话就可以不用管)。 一、原理 利用乘法…...

ARM NEON指令集VLD1加载操作原理与优化实践
1. ARM SIMD指令集与VLD1加载操作概述在现代处理器架构中,SIMD(Single Instruction Multiple Data)技术已成为提升计算性能的关键手段。作为ARM架构中Advanced SIMD指令集(俗称NEON)的重要组成部分,VLD1系列…...

【Prometheus】当 Prometheus 内存使用率过高时,应该从哪些方面入手进行排查和优化?
Prometheus 内存溢出深度排查指南:从 TSDB Head 到 Goroutine 泄露的全链路优化 用户问题原文:“当 Prometheus 内存使用率过高时,应该从哪些方面入手进行排查和优化?” 在支撑单集群500万+时间序列的生产环境中,Prometheus 的内存管理是 SRE 团队的核心挑战。一次未被及时…...
)
微分方程详解(理工科)
一句总纲:微分方程不是在求一个数,而是在求一个函数。它研究的是:如果我知道一个系统“怎么变化”,能不能反推出它“长什么样”。普通方程:未知量是一个数 (x)。微分方程:未知量是一个函数 y(x)。它的意思是…...

如何快速解析SWF文件:JPEXS免费Flash反编译器的完整指南
如何快速解析SWF文件:JPEXS免费Flash反编译器的完整指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler JPEXS Free Flash Decompiler是一款功能强大的开源Flash逆向工程工具…...