超详细:正则表达式从入门到入门
文章目录
- 匹配字符
- \d \D
- \s \S
- 量词:匹配多个字符
- 星号*
- 加号+
- 问号?
- 大括号{}
- 集合字符[]
- 明确字符
- 范围字符
- 补集字符
- 常见字符集
- 贪婪模式和非贪婪模式
- 匹配开头和结尾
- 贪婪模式和非贪婪模式
- 常用函数
- re.findall()
- re.search()
- re.compile()
- re.split()
- re.sub()
本文章首发于公众号Python for Finance
链接:https://mp.weixin.qq.com/s/boLdKv1L31377dLOKQ6irw
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
匹配字符
| 代码 | 功能 |
|---|---|
| . | 通配符,匹配任意1个字符(除了\n换行) |
| [ ] | 匹配[ ]中列举的字符,里面的元素之间存在“或”的关系,[abc]只能匹配a或b或c |
| \d | 匹配数字,等价于[0,9] |
| \D | 匹配非数字,等价于[^0-9] |
| \s | 匹配空白,常见的空白符的形式有空格、制表符 (\t)、换行 (\n) 和回车 (\r) |
| \S | 匹配非空白 |
| \w | 匹配非特殊字符,即a-z、A-Z、0-9、_、中文 |
| \W | 匹配特殊字符 |
\d \D
匹配数字
import restr0 = """北向资金尾盘回流,全天净买入18.54亿元,连续4日加仓"""
result = re.findall(r'\d', str0) # 加上r模式是为了防止Python中的转义字符与正则表达式中的元字符
print(result)
结果为:
['1', '8', '5', '4', '4']
匹配非数字
import restr0 = """北向资金尾盘回流,全天净买入18.54亿元,连续4日加仓"""
result = re.findall(r'\D', str0) # 加上r模式是为了防止Python中的转义字符与正则表达式中的元字符
print(result)
结果为:
['北', '向', '资', '金', '尾', '盘', '回', '流', ',', '全', '天', '净', '买', '入', '.', '亿', '元', ',', '连', '续', '日', '加', '仓']
\s \S
text = '''please don't
leave me
alone'''result = re.findall(r'\s',text)
print(result)
结果为:
[' ', ' ', '\n', ' ', ' ', '\n']
量词:匹配多个字符
某个字符后的数量限定符(* 、 ? 、 +)用来限定前面这个字符允许出现的个数。最常见的数量限定符包括 * 、 ? 和 +(不加数量限定则代表出现一次且仅出现一次)
| 符号 | 匹配规则 | 示例 |
|---|---|---|
| * | 匹配前一个字符出现0到多次,即可有可无,等价于{0,} | ab*c 匹配 ac, abc, abbc, abbbc |
| + | 匹配前一个字符出现1到多次,即至少有1次,等价于{1,} | colou?r 匹配 color 和 colour |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有,等价于{0,1} | ab+c 匹配 abc, abbc, abbbc 等等,但不匹配 ac |
| {n} | 匹配前一个字符出现n次 | |
| {n,} | 匹配前一个字符至少出现n次 | |
| {n,m} | 匹配前一个字符出现从n到m次 |
import restr0 = """北向资金尾盘回流,全天净买入18.54亿元,连续4日加仓;其中沪股通净买入26.41亿元,深股通净卖出7.87亿元。"""
result = re.findall(r'\d+', str0)
print(result)
“+”在正则表达式里代表的是“匹配前面的子表达式一次或多次”。
在“\d+”中,子表达式就是“\d”,一个“\d”是匹配一个数字,“\d+”则就是匹配一个或者多个数字。
结果为:
['18', '54', '4', '26', '41', '7', '87']
在以上结果中,数字被小数点分开了,如18.54被分成了18和54。那么我们可以再做这样的改进。
result = re.findall(r'[\d.]+', str0)
print(result)
[]方括号代表字符集合。匹配所包含的任意一个字符。“[\d.]”即匹配一个“\d”或者一个“.”字符,再带上加“+”,就可以匹配一个或者多个了。
结果为:
['18.54', '4', '26.41', '7.87']
星号*
*+:字符u可以出现0次或1次或者多次
a = re.findall(r'colou*r', 'color')
print(a)
b = re.findall(r'colou*r', 'colour')
print(b)
c = re.findall(r'colou*r', 'colouuur')
print(c)
结果为:
['color']
['colour']
['colouuur']
加号+
u+:字符u可以出现 1 次或多次
a = re.findall(r'colou+r', 'color')
print(a)
b = re.findall(r'colou+r', 'colour')
print(b)
c = re.findall(r'colou+r', 'colouuur')
print(c)
结果为:
[]
['colour']
['colouuur']
问号?
u?:字符u可以出现 0 次或 1 次
a = re.findall(r'colou?r', 'color')
print(a)
b = re.findall(r'colou?r', 'colour')
print(b)
c = re.findall(r'colou?r', 'colouuur')
print(c)
结果为:
['color']
['colour']
[]
大括号{}
有的时候我们非常明确要匹配的字符出现几次,比如
- 中国的手机号位数是 13 位,n = 13
- 密码需要 8 位以上,n ≥ 8
- 用户名需要在 8 到 16 位之间,8 ≤ n ≤ 16
这时我们可以设定具体的上界或(和)下界,使得代码更加有效也更好读懂,规则如下:
- {n} 左边的字符串是否出现 n 次
- {n, } 左边的字符串是否出现大于等于 n 次
- {, n} 左边的字符串是否出现小于等于 n 次
- {n, m} 左边的字符串是否出现在 n 次和 m 次之间
import rea = re.findall(r'[a-z]{1}','a11bbb2222ccccc')
print(a)
b = re.findall(r'[0-9]{2,}','a11bbb2222ccccc')
print(b)
c = re.findall(r'[a-z]{1,4}','a11bbb2222ccccc')
print(c)
d = re.findall(r'[0-9]{2,3}','a11bbb2222ccccc')
print(d)
结果为:
['a', 'b', 'b', 'b', 'c', 'c', 'c', 'c', 'c']
['11', '2222']
['a', 'bbb', 'cccc', 'c']
['11', '222']
集合字符[]
中括号表示一个字符集,即创建的模式匹配中括号里指定字符集中的任意一个字符,字符集有三种方式来表现:
- 明确字符:
[abc]会匹配字符 a,b 或者 c - 范围字符:
[a-z]会匹配字符 a 到 z - 补集字符:
[^6]会匹配除了 6 以外的字符
明确字符
import reresult = re.findall(r'[abc]','abandon')
print(result)
结果为:
['a', 'b', 'a']
范围字符
在 [ ] 中加入 - 即可设定范围,比如:
- [a-e] = [abcde]
- [1-4] = [1234]
- [a-ep] = [abcdep]
- [0-38] = [01238]
- [A-Za-z0-9_] = 大小写字母、数字、下划线
补集字符
在 [ ] 中加入 ^ 即可除去后面的字符集,比如
- [^abc] 就是非 a, b, c 的字符
- [^123] 就是非 1, 2, 3 的字符
import reresult = re.findall(r'[^abc]','baba')
print(result)
result = re.findall(r'[^abc]','steven')
print(result)result = re.findall(r'[^123]','456')
print(result)
result = re.findall(r'[^123]','1+2=3')
print(result)
结果为:
[]
['s', 't', 'e', 'v', 'e', 'n']
['4', '5', '6']
['+', '=']
常见字符集
常见的字符集有:
[A-Za-z0-9]表示匹配任意大小写字母和单个数字[a-z]表示匹配a至z之间的一个小写英文字母[A-Z]表示匹配A至Z之间的一个大写英文字母[0-9]表示匹配0至9之间的一个数字[\u4e00-\u9fa5]表示匹配中文字符
当然,也可以进行组合,比如说:
[a-zA-Z0-9_\u4e00-\u9fa5]+表示匹配至少一个汉字、数字、字母、下划线
import restr0 = """北向资金尾盘回流,全天净买入18.54亿元,连续4日加仓;其中沪股通净买入26.41亿元,深股通净卖出7.87亿元。"""
result = re.findall(r"[\u4e00-\u9fa5]+", str0) # 匹配中文字符
print(result)
结果为:
['北向资金尾盘回流', '全天净买入', '亿元', '连续', '日加仓', '其中沪股通净买入', '亿元', '深股通净卖出', '亿元']
贪婪模式和非贪婪模式
匹配开头和结尾
| 符号 | 匹配规则 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
import rea = re.findall(r'^s','son')
print(a)
b = re.findall(r'^s','abs')
print(b)
c = re.findall(r's$','son')
print(c)
d = re.findall(r's$','abs')
print(d)
结果为:
['s']
[]
[]
['s']
贪婪模式和非贪婪模式
在Python的正则表达式中,默认是贪婪模式,尽可能多的匹配;在量词后面直接加上一个问号"?",可以将贪婪模式转换成为非贪婪模式,尽可能少的匹配,即一旦匹配到结果就结束。
量词包括如下:
-
{m,n}
-
*:{0,}。
-
+:{1,}。
-
?:{0,1}。
【例1】
import re# '.*' 表示匹配 0 个或多个任意字符
a = re.search('11.*11', '11-22-11-22-11')
print('贪婪模式:',a.group())# 加上 '?' 设置为非贪婪模式
b = re.search('11.*?11', '11-22-11-22-11')
print('非贪婪模式:',b.group())
结果为:
贪婪模式: 11-22-11-22-11
非贪婪模式: 11-22-11
【例2】
# '.*' 表示匹配 0 个或多个任意字符
a = re.search(r'a.*c', 'sljad38c32ic')
print('贪婪模式:',a.group())# 变为非贪婪模式,尽可能少的匹配
b = re.search(r'a.*?c', 'sljad38c32ic')
print('非贪婪模式:',b.group())
结果为:
贪婪模式: ad38c32ic
非贪婪模式: ad38c
【例3】
# 想要取b2个到5个,非贪婪模式尽可能少取,取2个,贪婪模式全取
a = re.search(r'ab{2,5}', 'abbbbbb')
print('贪婪模式:', a.group())
b = re.search(r'ab{2,5}?', 'abbbbbb')
print('非贪婪模式:', b.group())
结果为:
贪婪模式: abbbbb
非贪婪模式: abb
【例4】
# 在满足条件的基础上尽可能少取,下面全取才能满足匹配条件
a = re.search(r'ab(\d+)sd', 'ab2345sdd')
print('贪婪模式:',a.group())
b = re.search(r'ab(\d+?)sd', 'ab2345sdd')
print('非贪婪模式:',b.group())
结果为:
贪婪模式: ab2345sd
非贪婪模式: ab2345sd
【例5】
reg_string = "pythonnnnnnnnnpythonHellopytho"
a = re.findall("python*",reg_string)
print(a)
b = re.findall("python+",reg_string)
print(b)
c = re.findall("python*?",reg_string)
print(c)
d = re.findall("python+?",reg_string)
print(d)
结果为:
['pythonnnnnnnnn', 'python', 'pytho']
['pythonnnnnnnnn', 'python']
['pytho', 'pytho', 'pytho']
['python', 'python']
【例8】
heading = r'<>TITLE</h1>'
a = re.findall("<.+>",heading)
print(a)
b = re.findall("<.+?>",heading)
print(b)
c = re.findall("<.8>",heading)
print(c)
d = re.findall("<.*?>",heading)
print(d)
结果为:
['<>TITLE</h1>']
['<>TITLE</h1>']
['<>TITLE</h1>']
['<>', '</h1>']
常用函数
re.findall()
re.findall() 方法用于在字符串中查找正则表达式匹配的所有子串,并返回一个列表。如果没有匹配项,返回一个空列表。
re.findall(pattern, string, flags=0)
- pattern:匹配的正则表达式,必选参数。
- string:要匹配的字符串,必选参数。
- flags:标志位。
import reresult = re.findall(r"\d", "2 apples, 5 bananas, 1 orange")
print(result) # ['2', '5', '1']
re.search()
re.search扫描整个字符串并返回第一个成功的匹配。
re.match(pattern, string, flags = 0)
- pattern:匹配的正则表达式,必选参数。
- string:要匹配的字符串,必选参数。
- flags:标志位。
import reresult = re.search(r"\d", "2 apples, 5 bananas, 1 orange")
print(result)
结果为:
<re.Match object; span=(0, 1), match='2'>
re.search将返回一个 MatchObject,属性如下表所示。
| 方法/属性 | 作用 |
|---|---|
| group() | 返回被re 匹配的字符串 |
| start() | 返回匹配开始的位置 |
| end() | 返回匹配结束的位置 |
| span() | 返回一个元组包含匹配 (开始,结束) 的位置 |
import reresult = re.search(r"\d", "2 apples, 5 bananas, 1 orange")
print(result.group())
print(result.start())
print(result.end())
print(result.span())
结果为:
2
0
1
(0, 1)
re.compile()
re.compile() 方法用于将正则表达式编译为一个模式对象,该模式对象可以用于匹配字符串。
import reregex = re.compile(r"\d+")
result = regex.findall("2 apples, 5 bananas, 1 orange")
print(result) # ['2', '5', '1']
re.split()
re.split() 方法用于在字符串中使用正则表达式进行分割,并返回一个列表。
re.split(pattern, string, maxsplit=0, flags=0)
- pattern:匹配的正则表达式,必选参数。
- string:要匹配的字符串,必选参数。
- maxsplit:分割的最大次数
- flags:标志位。
import reresult = re.split(r"\s+", "hello world")
print(result) # ['hello', 'world']
在这个例子中,正则表达式 pattern 是 “\s+”,要分割的字符串是 “hello world”,“\s+” 表示匹配一个或多个空格。re.split() 方法将字符串按照正则表达式进行分割,并返回一个列表,列表中的每个元素都是分割后的子串。
re.sub()
re.sub() 方法用于在字符串中查找正则表达式匹配的子串,并将其替换为指定的字符串。re.sub() 方法返回替换后的字符串。
re.sub(pattern, repl, string, count=0, flags=0)
- pattern:匹配的正则表达式,必选参数。
- repl:想要替换成的内容,必选参数。
- string:要匹配的字符串,必选参数。
- count:替换的次数,默认替换所有匹配到的结果;可选参数,默认为 0,为 0 时表示替换所有的匹配项。
- flags:标志位。
import re
# 将空格替换为-
result = re.sub(r"\s+", "-", "hello world")
print(result) # 'hello-world'text = "A股全面注册制下蓝筹股盛宴能否延续?"
# 将蓝筹股替换为绩优股
result = re.sub("蓝筹股", "绩优股", text)
print(result) # 输出结果:"A股全面注册制下绩优股盛宴能否延续。"
# 将问号去掉
result = re.sub("?", "", text)
print(result)
# 输出结果:"A股全面注册制下蓝筹股盛宴能否延续"
相关文章:

超详细:正则表达式从入门到入门
文章目录匹配字符\d \D\s \S量词:匹配多个字符星号*加号问号?大括号{}集合字符[]明确字符范围字符补集字符常见字符集贪婪模式和非贪婪模式匹配开头和结尾贪婪模式和非贪婪模式常用函数re.findall()re.search()re.compile()re.split()re.sub()本文章首发…...

jupyter notebook小技巧
1、.ipynb 文件转word文档 将 jupyter notebook(.ipynb 文件)转换为 word 文件(.docx)的最简单方法是使用 pandoc。 首先安装pip install pandoc, 安装后,在将 Jupyter notebook文件目录cmd 然后输入打开…...
考研复试机试 | c++ | 王道复试班
目录n的阶乘 (清华上机)题目描述代码汉诺塔问题题目:代码:Fibonacci数列 (上交复试)题目代码:二叉树:题目:代码:n的阶乘 (清华上机) …...

js闭包简单理解
js里面的闭包是一个难点也是它的一个特色,是我们必须掌握的js高级特性,那么什么是闭包呢?它又有什么作用呢? 1,提到闭包我们这里先讲解一下js作用域的问题 js的作用域分两种,全局和局部,基于我…...

「JVM 编译优化」编译器优化技术
后端编译(即时编译、提前编译)的目标时将字节码翻译成本地机器码,而难点是输出优化质量较高的机器码; 文章目录1. 优化技术概览2. 方法内联(Inlining)3. 逃逸分析(Escape Analysis)4…...
回溯问题(子集型回溯、组合型回溯、排列型回溯)【零神基础精讲】
来源0x3f:https://space.bilibili.com/206214 回溯分为【子集型回溯】【组合型回溯】【排列型回溯】 文章目录回溯基本概念[17. 电话号码的字母组合](https://leetcode.cn/problems/letter-combinations-of-a-phone-number/)子集型回溯(分割问题也可以看…...

源代码配置安装Apache
源代码配置安装Apache 📒博客主页: 微笑的段嘉许博客主页 💻微信公众号:微笑的段嘉许 🎉欢迎关注🔎点赞👍收藏⭐留言📝 📌本文由微笑的段嘉许原创! …...

css水平垂直居中各种方法实现方式
不定宽高水平垂直居中? 面试题回答方式: 通过display:flex;justify-content:center; align-items:center;就可以让子元素不定宽高水平垂直居中 也可以父display:flex;,子设置一个margin&#…...
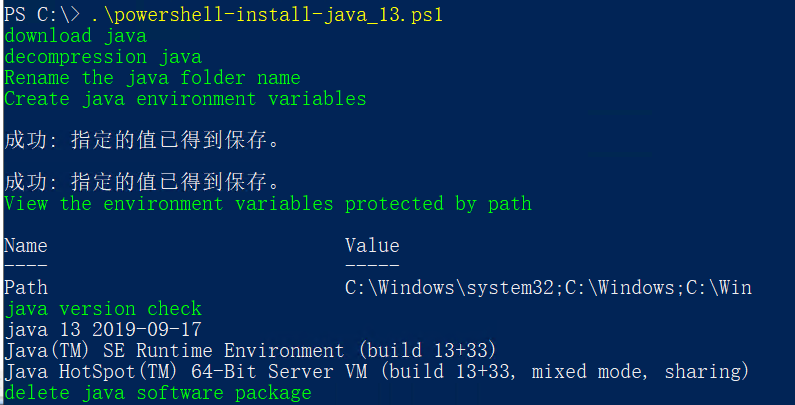
PowerShell Install java 13
java 前言 Java具有大部分编程语言所共有的一些特征,被特意设计用于互联网的分布式环境。Java具有类似于C语言的形式和感觉,但它要比C语言更易于使用,而且在编程时彻底采用了一种以对象为导向的方式。 java download javadownloadPowersh…...
Python的PyQt框架的使用(汇总)
Python的PyQt框架的使用一、前言二、安装PyQt三、使用第三方开发工具四 、创建主窗体五、常用控件篇1.QLineEdit 文本框2.QPushButton按钮控件3.QRadioButton 单选按钮六、布局管理篇1.通过布局管理器布局2.绝对布局七、信号与槽的关联1.编辑信号/槽2.信号/槽编辑器八、资源文件…...

力扣热题100Day05:15.三数之和,17. 电话号码的字母组合,19. 删除链表的倒数第 N 个结点
15.三数之和 题目链接:15. 三数之和 - 力扣(Leetcode) 思路: (1)双指针,在外层for循环里加入两个指针,left和right (2)排序:为了更好地进行去…...

探索开源:获取完整的 GitHub 社区数据集
本篇文章聊聊 GitHub 开放数据集的获取和整理,分享一些数据整理的细节技巧,以及一些相对粗浅的数据背后的事情。 写在前面 分析 GitHub 上的项目和开发者获取是深入、真实的了解开源世界演进的方法之一。 在 GHArchive 项目中,我们能够看到…...
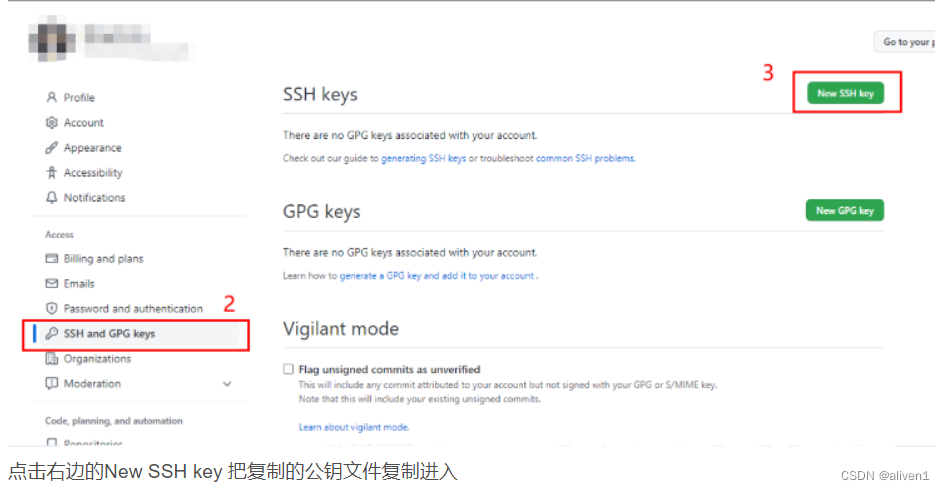
github ssh密钥配置,克隆远程仓库
GitHub的SSH配置 在往github上push项目的时候,如果走https的方式,每次都需要输入账号密码,非常麻烦。而采用ssh的方式,就不再需要输入,只需要在github自己账号下配置一个ssh key即可! 很多朋友在用github管…...

突破年薪百万难关!吃透这套Java真题合集
前言我相信大多 Java 开发的程序员或多或少经历过BAT一些大厂的面试,也清楚一线互联网大厂 Java 面试是有一定难度的,小编经历过多次面试,有满意的也有备受打击的。因此呢小编想把自己这么多次面试经历以及近期的面试真题来个汇总分析&#x…...
[黑马程序员SSM框架教程] Spring-11-setter注入
思考:向一个类中传递数据要几种? set方法构造方法 思考:依赖注入描述了在容器中建立bean与bean之间依赖关系的过程,如果bean运行需要数字或字符呢 引用类型简单类型(基本数据类型和字符串) 注入方式&#x…...
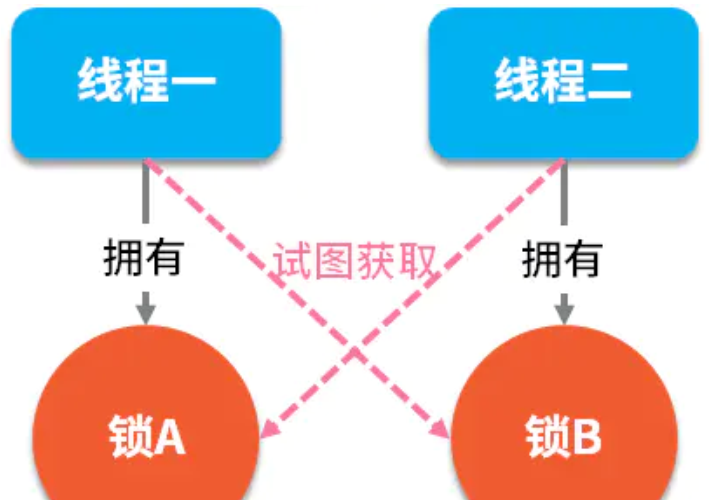
Java多线程(一)--多线程基础知识
1. 为什么要使用并发编程提升多核CPU的利用率:一般来说一台主机上的会有多个CPU核心,我们可以创建多个线程,理论上讲操作系统可以将多个线程分配给不同的CPU去执行,每个CPU执行一个线程,这样就提高了CPU的使用效率&…...

AutoDock, AutoDock-vina等对接工具安装
AutoDock, AutoDock-vina等对接工具安装 AutoDock-GPU安装 下载地址: https://autodock.scripps.edu/downloads/ 将压缩包传送至安装目录中,并解压到当前路径 unzip AutoDock-GPU-develop.zip 找到服务器的cuda的路径,cuda的路径一般默认…...
)
MySQL常见面试题(2023年最新)
目录1.char和varchar的区别2.数据库的三大范式3.索引是什么4.索引的优点和缺点5.索引怎么设计(优化)6.索引的类型7.索引的数据类型8.索引为什么使用树结构9.二叉查找树、B树、B树10.为什么使用B树不用B树11.最左匹配原则12.MylSAM和InnoDB的区别13.什么是事务14.事务的四大特性…...

C# 泛型详解
C# 泛型详解1、泛型概述2、定义泛型3、泛型的特性4、泛型委托5、泛型的优点在 C# 中,泛型(Generic)是一种规范,它允许我们使用占位符来定义类和方法,编译器会在编译时将这些占位符替换为指定的类型,利用泛型…...

数据仓库相关术语
数据仓库数据集市事实维度级别数据清洗数据采集数据转换联机分析处理(OLAP OnlineAnalytical Processing )切片切块星型模式雪花模式粒度度量度量值口径指标 原子指标:派生指标衍生指标标签自然键持久键代理键退化维度下钻上卷T0与T1数据挖掘数据科学家总线架构总线…...

pi.dev 域名获赠,一文了解 Pi Agent Harness 项目开发、贡献等全方面信息
pi.dev 域名由 exe.dev 慷慨捐赠新贡献者提交的新问题和拉取请求(PR)默认会自动关闭。维护者会每天审核自动关闭的问题,详情请参阅 CONTRIBUTING.md。Pi Agent Harness 单仓库这里是 pi agent harness 项目的主页,其中包含我们可自…...

大模型---MetaGPT
目录 1.MetaGPT 2.SOP工作流 3.总结 1.MetaGPT 参考论文: [2308.00352] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework MetaGPT将Standardized Operating Procedures(SOPs)编码进prompt sequence,让不同角色的Agent像流水线一样处理复杂任务…...

告别内存泄漏!Cocos Creator 2.4+ AssetManager资源释放的完整避坑指南
Cocos Creator 2.4 AssetManager资源释放的完整避坑指南在游戏开发中,资源管理一直是影响性能和稳定性的关键因素。随着Cocos Creator 2.4版本推出全新的AssetManager系统,开发者获得了更强大的资源管理能力,但也面临着新的挑战。本文将深入探…...

AI写论文神器合集!4款AI论文写作工具,解决你的论文烦恼!
AI写论文工具测评 在2025年,学术写作正在经历一场智能化的浪潮,越来越多的人开始尝试使用AI写论文工具。尽管这些工具的数量众多,但在撰写硕士或博士论文等长篇学术作品时,它们往往面临很多挑战。许多AI写论文工具缺乏必要的理论…...

DMA优化与MIMO系统性能分析:6G通信关键技术
1. DMA优化与MIMO系统性能分析概述动态超表面天线(Dynamic Metasurface Antenna, DMA)作为6G通信系统的关键技术突破,正在重新定义大规模MIMO系统的设计范式。与传统的相控阵天线相比,DMA通过可编程的超表面单元实现对电磁波的精确…...

m4s-converter深度解析:3步高效解决B站m4s文件转MP4的完整技术方案
m4s-converter深度解析:3步高效解决B站m4s文件转MP4的完整技术方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter m4s-converter是一…...

Shannon AI:面向业务流的自动化渗透测试工具
1. 这不是“AI替代人”,而是把渗透测试工程师从重复劳动里解救出来我第一次在客户现场用Shannon AI跑完Juice Shop靶场,盯着终端里滚动的日志,心里想的不是“哇这工具真快”,而是“原来我过去三年有将近200小时,都花在…...

ARM SME架构下BFloat16矩阵运算优化实践
1. ARM SME架构与BFloat16计算概述在当今高性能计算领域,特别是机器学习和人工智能应用中,计算效率和内存带宽利用率成为了关键瓶颈。ARMv9架构引入的SME(Scalable Matrix Extension)扩展正是针对这一需求而设计,其中B…...

终极Chrome画中画扩展:免费实现多任务视频观看的完整指南
终极Chrome画中画扩展:免费实现多任务视频观看的完整指南 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 你是否曾经希望在浏览网页、处理文档或使用其他应用时&…...

从 OpenCV 模板匹配到 YOLO:TFT 截图识别模块的一次升级
摘要在前几篇文章中,项目已经完成了 TFT 阵容顾问的资源构建、英雄识别、装备识别和截图路由层。旧方案主要依赖 tft_screen_capture.py,通过 OpenCV 完成六边形边框检测、HSV 直方图粗筛、灰度 NCC 模板匹配等流程。这套方案的优点是实现清晰、依赖轻、…...