pyspark常用功能记录
前言
pyspark中很多常用的功能,过段时间没有使用就容易忘记,需要去网上搜索,这里总结一下,省的以后还去去搜,供自己以后参考。
withColumn
def hot_func(info_str):if info_str:eturn "1"return "0"
df = df.withColumn("is_hot", F.udf(hot_func, StringType())(F.col("your_col_name")))
自定义函数
from pyspark.sql.functions import udf
# 定义并注册函数
@udf(returnType=StringType())
def f_parse_category(info):x = json.loads(info)['category']return x if x is not None else ''
spark.udf.register('f_parse_category', f_parse_category)
# 在sql中使用注册的函数
sql = """
select *, f_parse_category(info) category,
from your_table
where info is not null
"""
df = spark.sql(sql).cache()
groupby处理
按groupby处理,保留goupby字段,并对groupby的结果处理。正常情况下,使用df.groupBy即可,但需要处理多列并逻辑较为复杂时,可以使用这种方式。
from pyspark.sql.functions import pandas_udf
from pyspark.sql.functions import PandasUDFType
from pyspark.sql.types import StructField, LongType, StringType, StructType
from collections import Counterpattern = re.compile(r'\b\w+(?:' + '|'.join(['_size', '_sum']) + r')\b')group_cols = ['category']
value_cols = ['sales_sum', 'stat_size']schema = StructType( [StructField(col, LongType()) if len(re.findall(pattern, col))>0 else StructField(col, StringType()) for col in group_cols+value_cols],)@pandas_udf(schema, functionType=PandasUDFType.GROUPED_MAP)
def group_stat(df):# 获取l = [df[item].iloc[0] for item in group_cols]df = df[[col for col in df.columns if col not in group_cols]]sales_sum = df['sales'].sum().item()stat_size = len(df)# d: {"key": "value"}df['first_attr'] = df['attr'].transform(lambda d: list(json.loads(d).keys())[0])attr_dict = json.dumps({k:v for k, v in Counter(df['first_attr'].value_counts().to_dict()).most_common()}, ensure_ascii=0)counter = sum(df['brand_name'].apply(lambda x:Counter(json.loads(x))), Counter())ct = len(counter)brand_list = df["brand"].to_list()values = [sales_sum, stat_size, attr_dict, ct, infobox_brand_stat, brand_list]return pd.DataFrame([l + values])# df 包含字段:category, sales, attr, brand_name, brand
df = df.groupby(group_cols).apply(group_stat).cache()patition By & orderBy
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number, dense_rank
# 根据department分区,然后按salary排序编号
windowSpec = Window.partitionBy("department").orderBy("salary")
df.withColumn("row_number",row_number().over(windowSpec)) \.show(truncate=False)
# dense_rank: 相同值排序编号一致
sql的方式:
select name, category, sales, DENSE_RANK() OVER (PARTITION BY category ORDER BY b.sales DESC) as sales_rank
from your_tb
dataframe转正rdd处理行
该中情况一般在需要处理过个行的情况下使用,如果是少数的行处理,可以使用withColumn
def hot_func(info_str):if info_str:eturn "1"return "0"
df = df.withColumn("is_hot", F.udf(hot_func, StringType())(F.col("your_col_name")))
转为rdd的处理方式为:
def gen_norm(row):# 转为字段处理row_dict = row.asDict(recursive=True)process_key = row_dict["key"]row_dict["process_key"] = process_keyreturn Row(**row_dict)
# sampleRatio=0.01 为推断列类型的抽样数据比例
df = df.rdd.map(gen_norm).toDF(sampleRatio=0.01).cache()
df.show()
相关文章:

pyspark常用功能记录
前言 pyspark中很多常用的功能,过段时间没有使用就容易忘记,需要去网上搜索,这里总结一下,省的以后还去去搜,供自己以后参考。 withColumn def hot_func(info_str):if info_str:eturn "1"return "0&…...
Spring面试题学习: 单例Bean是单例模式吗?
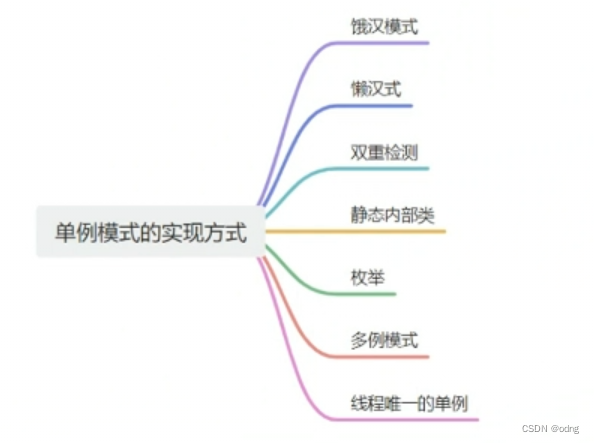
单例Bean是单例模式吗 学习背景答案扩展知识单例模式Spring BeanJava Bean单例Bean 个人评价我的回答 学习背景 想换工作. 学习记录, 算是一个输出. 答案 通常来说, 单例模式是指在一个JVM中, 一个类只能构造出一个对象. 有很多方法来实现单例模式, 比如饿汉模式. 但是我们通…...
EM@常用三角函数图象性质(中学部分)
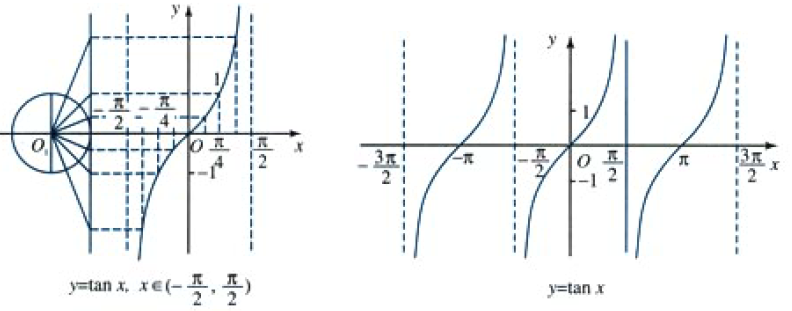
文章目录 abstract正弦函数正弦型函数转动相关概念旋转角速度转动周期转动频率初相小结 余弦函数的图象与性质性质 正切函数的图象和性质由已知三角函数值求角任意角范围内反三角函数(限定范围内)反正弦反余弦反正切 abstract 讨论 sin , cos , tan \sin,\cos,\tan s…...
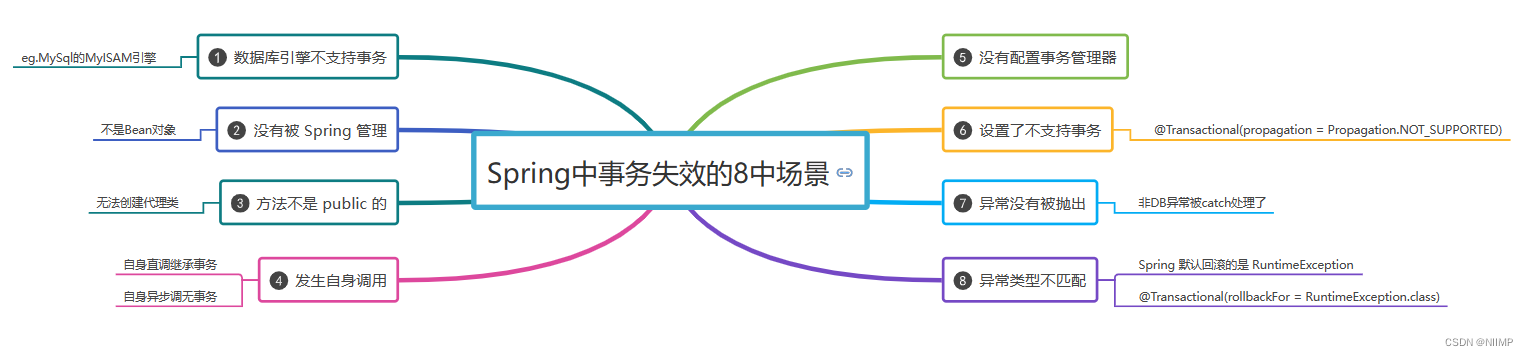
一文拿捏Spring事务之、ACID、隔离级别、失效场景
1.🌟Spring事务 1.编程式事务 事务管理代码嵌入嵌入到业务代码中,来控制事务的提交和回滚,例如TransactionManager 2.声明式事务 使用aop对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,执行完目…...
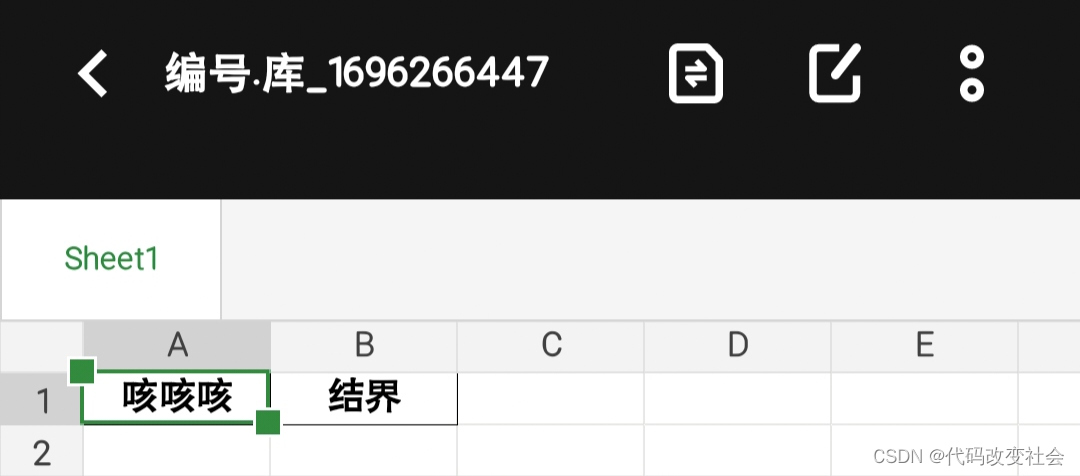
input输入表头保存excel文件
input输入表头 input输入表头 (input内除了/,空格 回车 标点符号等 全部作为单元格分隔符)保存/storage/emulated/0/代码文件/ 没有就创建文件名命名方法:编号. 库 时间戳嗨!听说你有个需求,想根据用户输入…...

DataBinding双向绑定简介
一、简介 在Vue中使用的是MVVM架构。通过ViewModel可以实现M层和V层数据的双向绑定。Model层的数据发生变化后,会自动更新View层UI。UI层数据发生变化(用户输入),可以驱动Model层的数据发生变化,借助于Vue框架中的View…...
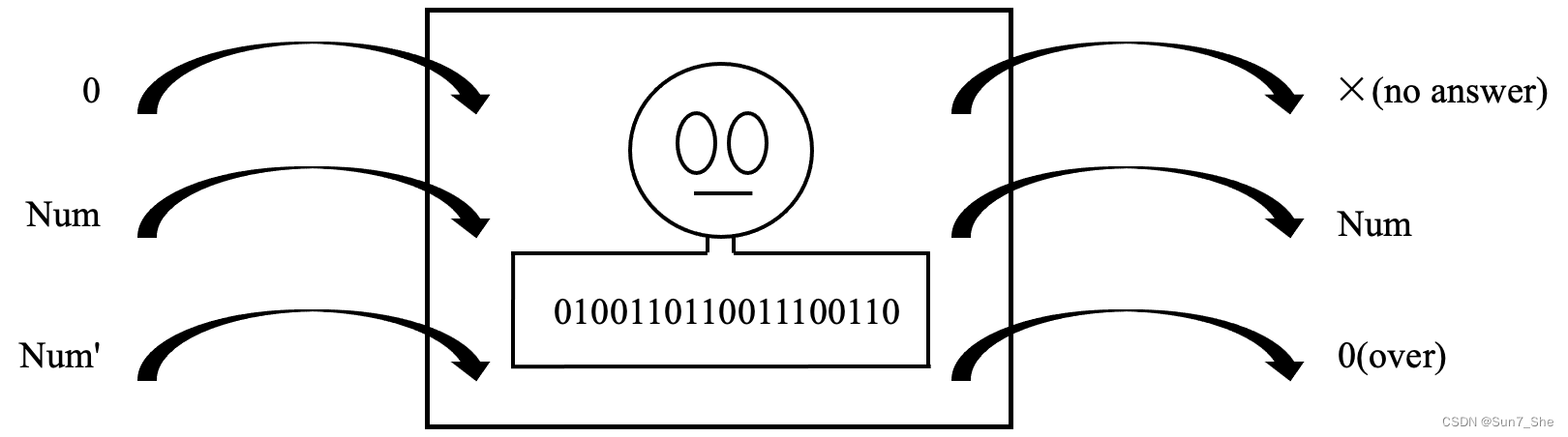
Is This The Intelligent Model(这是智能模型吗)
Is This The Intelligent Model 这是智能模型吗 Ruoqi Sun Academy of Military Science Defense Innovation Institute, Beijing, 100091, China E-mail: ruoqisun7163.com The exposed models are called artificial intelligent models[1-3]. These models rely on knowled…...

MySQL事务:特性、使用、并发事务问题和隔离级别
什么是事务? 在数据库中,事务是一组SQL操作,它们被视为一个单一的工作单元。事务必须同时成功或失败,以确保数据库的一致性。事务通常遵循ACID属性,即原子性(Atomicity)、一致性(Co…...

FFmpeg日志系统、文件与目录、操作目录
目录 FFmpeg日志系统 FFmpeg文件与目录操作 FFmpeg文件的删除与重命名 FFmpeg操作目录及list的实现 操作目录重要函数 操作目录重要结构体 FFmpeg日志系统 下面看一个简单的 demo。 #include <stdio.h> #include <libavutil/log.h>int main(int argc,char* …...

好奇喵 | Surface Web ---> Deep Web ---> Dark Web
前言 我们可能听说过深网(deep Web)、暗网(dark Web)等名词,有些时候可能会认为它们是一个东西,其实不然,两者的区别还是比较大的。 什么是deep web? 深网是网络的一部分,与之相对应的是表层网络(surface …...
三、thymeleaf基本语法
3.1、基本语法 3.1.1变量表达式:${...} 变量表达式用于在页面中输出指定的内容,此内容可以是变量,可以是集合的元素,也可以是对象的属性。主要用于填充标签的属性值,标签内的文本,以及页面中js变量的值等…...

创建一个新的IDEA插件项目
启动IntelliJ IDEA并按照以下步骤创建新的插件项目: 打开IntelliJ IDEA并单击“Create New Project”(创建新项目)。 在左侧菜单栏中选择“IntelliJ Platform Plugin”(IntelliJ平台插件)。 在右侧窗格中,…...

Doris数据库BE——冷热数据方案
新的冷热数据方案是在整合了存算分离模型的基础上建立的,其核心思路是:DORIS本地存储作为热数据的载体,而外部集群(HDFS、S3等)作为冷数据的载体。数据在导入的过程中,先作为热数据存在,存储于B…...
Python无废话-办公自动化Excel格式美化
设置字体 在使用openpyxl 处理excel 设置格式,需要导入Font类,设置Font初始化参数,常见参数如下: 关键字参数 数据类型 描述 name 字符串 字体名称,如Calibri或Times New Roman size 整型 大小点数 bold …...

竞赛 机器视觉的试卷批改系统 - opencv python 视觉识别
文章目录 0 简介1 项目背景2 项目目的3 系统设计3.1 目标对象3.2 系统架构3.3 软件设计方案 4 图像预处理4.1 灰度二值化4.2 形态学处理4.3 算式提取4.4 倾斜校正4.5 字符分割 5 字符识别5.1 支持向量机原理5.2 基于SVM的字符识别5.3 SVM算法实现 6 算法测试7 系统实现8 最后 0…...
)
Django 数据库迁移(Django-04)
一 数据库迁移 数据库迁移是一种数据库管理技术,它用于在应用程序的开发过程中,根据模型(Model)的变化自动更新数据库结构,以保持数据库与代码模型的一致性。数据库迁移的主要目的是确保数据库与应用程序的模型定义同…...

Redis相关概念
1. 什么是Redis?它主要用来什么的? Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提…...
Scala第十八章节
Scala第十八章节 scala总目录 文档资料下载 章节目标 掌握Iterable集合相关内容.掌握Seq集合相关内容.掌握Set集合相关内容.掌握Map集合相关内容.掌握统计字符个数案例. 1. Iterable 1.1 概述 Iterable代表一个可以迭代的集合, 它继承了Traversable特质, 同时也是其他集合…...

JAVA学习(4)-全网最详细~
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...
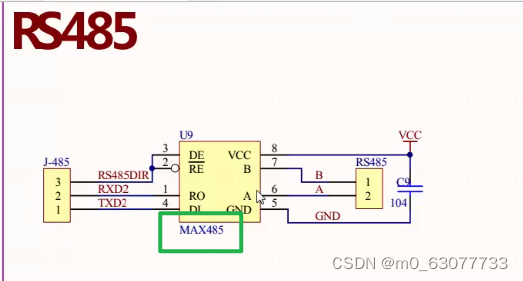
【单片机】12-串口通信和RS485
1.通信有关的常见概念 区分:串口,COM口,UART,USART_usart和串口区别-CSDN博客 串口、COM口、UART口, TTL、RS-232、RS-485区别详解-CSDN博客 1.什么是通信 (1)人和人之间的通信:说话ÿ…...

03-从Chat到Act-Agent行动闭环的产品心理学拆解
从Chat到Act:Agent行动闭环的产品心理学拆解系列一:AI Agent GAP模型 | 第3篇(深度型) 从"一问一答"到"自主行动",拆解Agent行动闭环背后的行为设计逻辑。本文你将获得 🔄 Agent行动闭…...

七、数据与存储
一、 数据库操作 1、QSqlDatabase 连接管理深度剖析 连接生命周期与内部机制 QSqlDatabase 的连接管理不走寻常路——它内部是一个全局静态哈希表,存储着所有命名连接。这带来了几个重要的设计约束: // QSqlDatabase 内部实现的核心数据结构(简化还原)// Qt 源码中通过 QH…...
,搞定业务中的因果推断难题)
别再只做AB测试了!用Python实战倾向性得分匹配(PSM),搞定业务中的因果推断难题
用Python实战倾向性得分匹配(PSM):超越AB测试的因果推断利器 在数据驱动的决策时代,企业经常面临一个核心问题:如何准确评估策略或干预措施的真实效果?传统AB测试虽然简单直观,但在面对历史数据、观测数据等非随机实验…...

CGRA架构与工具链:可重构计算加速技术解析
1. CGRA架构与工具链概述粗粒度可重构阵列(Coarse-Grained Reconfigurable Array, CGRA)是一种介于FPGA和ASIC之间的可重构计算架构,特别适合加速多维嵌套循环计算。与FPGA的细粒度可编程逻辑单元不同,CGRA采用粗粒度的处理单元&a…...

Java 100 天进阶之路 | 从入门到上岗就业 · 完整目录导航
📚 Java 100 天进阶之路 | 从入门到上岗就业 完整目录导航 不背八股文,不堆概念。44篇基础56篇进阶,100天助你达到Java就业水平,从容面对技术面试。 零差评Java教程,从入门到微服务,每篇都有代码、避坑和面…...

局域网监控软件评测:从数据主权视角看企业效能工具的取舍
很多管理者在巡视办公室时,看到员工手指在键盘上飞速跳动,屏幕上代码或表格交织,心中却往往悬着一块石头:他们是在攻克项目难关,还是在处理私人兼职?这种管理上的“黑盒状态”,不仅是效率的损耗…...

机器学习在资产管理中的应用:从数据到投资组合的端到端框架
1. 项目概述:当机器学习遇见资产管理如果你在资产管理行业待过,或者对量化投资感兴趣,那你肯定不止一次想过:那些复杂的市场数据、财报、新闻,能不能让机器来帮我们分析,甚至做出决策?firmai/ma…...

Apple Watch深度体验:从传感器融合到物联网节点的技术实践
1. 从怀疑到依赖:一个技术编辑的Apple Watch真实体验说实话,一开始我压根没打算写这篇关于Apple Watch的东西。作为一名在技术媒体圈混了十多年的老编辑,我太清楚这里面的“坑”了——只要你写点苹果产品的好话,就容易被贴上“果粉…...

Redis_7_Streams与高可用集群实战
Redis 7.0 Streams与高可用集群部署实战 从消息队列到分布式架构,全面掌握Redis核心能力 前言 Redis不只是一个缓存数据库。Redis 5.0引入的Streams让它具备了消息队列的能力,Redis 7.0进一步增强了Streams的稳定性和性能。很多团队在用Kafka/RabbitMQ处理消息队列时,其实R…...

用电脑自动玩小红书,OpenClaw+ADB让效率翻倍!附详细教程“
本文介绍了如何使用OpenClaw(运行在MacOS上)结合ADB工具实现Android手机的自动化操作。内容涵盖Android手机配置(开启开发者选项和USB调试)、MacOS环境准备(安装ADB工具和配置ADBKeyboard支持中文输入)&…...