milvus 结合Thowee 文本转向量 ,新建表,存储,搜索,删除
1.向量数据库科普
【上集】向量数据库技术鉴赏
【下集】向量数据库技术鉴赏
milvus连接
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
connections.connect(host='124.****', port='19530')
2.milvus + Thowee 文本转向量 使用
@app.route("/es",methods=["GET","POST"])
def es_sous():ans_pipe = (pipe.input('subject').map('subject', 'vector', ops.text_embedding.dpr(model_name="facebook/dpr-ctx_encoder-single-nq-base"))#将输入的问题文本转换为向量表示,使用名为 "facebook/dpr-ctx_encoder-single-nq-base" 的预训练模型进行文本嵌入。.map('vector', 'vector', lambda x: x / np.linalg.norm(x, axis=0))#对上一步得到的向量进行归一化处理,使得向量的每个维度都被缩放到相同尺度。.output('vector'))param = request.args.get('prop')#传入一个文本ans = ans_pipe(param)#文本转向量ans = DataCollection(ans)#格式化ans.show() #print(type(ans[0].vector))list1 = ans[0].vector.tolist()return list1
3.milvus + openai 文本转向量 使用
import openai
OPENAI_ENGINE = 'text-embedding-ada-002'#使用哪种嵌入模型
openai.api_key = 'sk-*****'#您的 OpenAI 帐户密钥
def embed(texts): #返回 向量embeddings = openai.Embedding.create(input=texts,engine=OPENAI_ENGINE)return [x['embedding'] for x in embeddings['data']]
4. milvus + 微软openai 文本转向量 使用
import openai
openai.api_key = "0**********" # Azure 的密钥
openai.api_base = "https://zhan.op*****" # Azure 的终结点
openai.api_type = "azure"
openai.api_version = "2023-03-15-preview" # API 版本,未来可能会变
model = "text" # 模型的部署名
def embed(texts):embeddings = openai.Embedding.create(input=texts,engine=model)return [x['embedding'] for x in embeddings['data']]
5.milvus 新建表
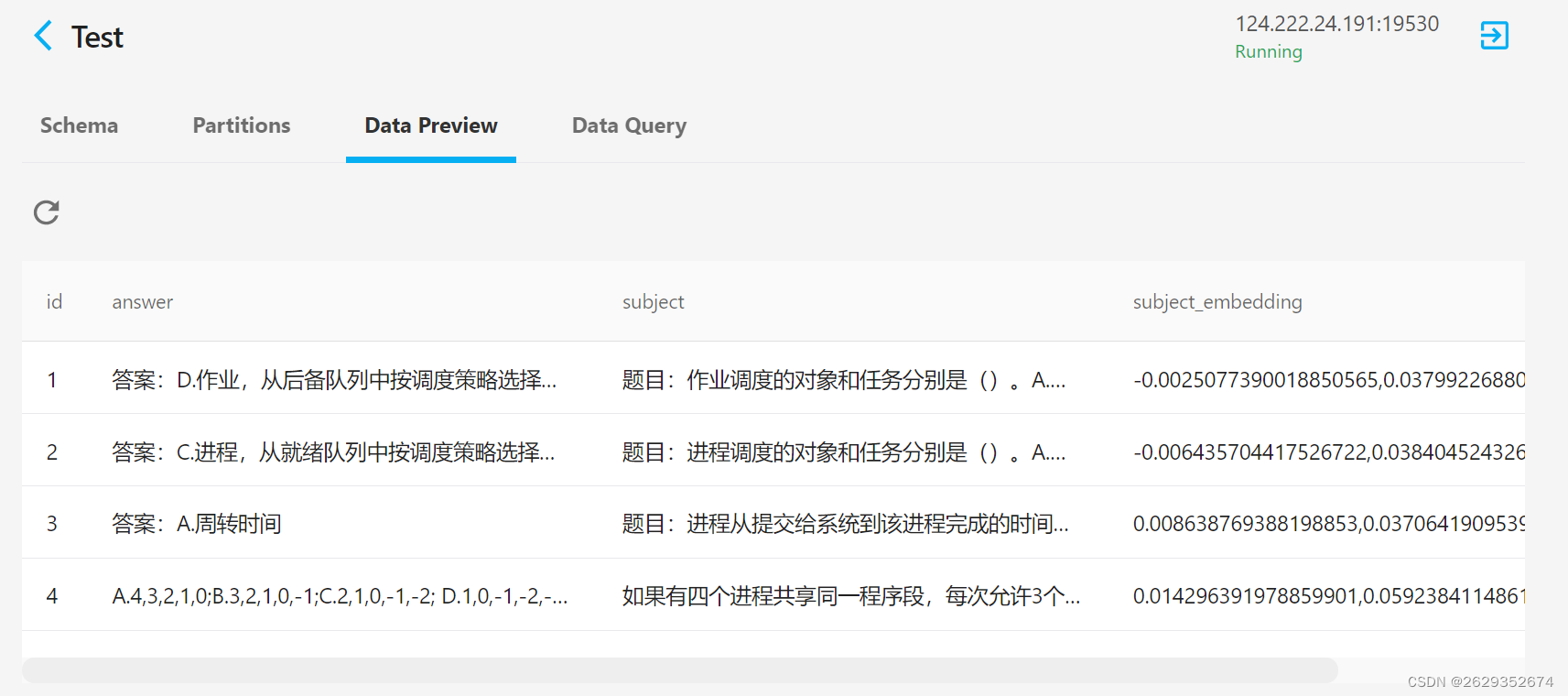
def create_milvus_collection(collection_name,dim):if utility.has_collection(collection_name):utility.drop_collection(collection_name)fields = [FieldSchema(name = 'id',dtype=DataType.INT64,description='ids',is_primary=True),FieldSchema(name='answer',dtype=DataType.VARCHAR,max_length = 2000,description='答案'),FieldSchema(name='subject',dtype=DataType.VARCHAR,max_length = 1000,description='题目'),FieldSchema(name='subject_embedding', dtype=DataType.FLOAT_VECTOR, dim=dim,description = '题目矢量'),FieldSchema(name='url', dtype=DataType.VARCHAR, max_length = 255,description = '路径')]# CollectionSchema:这是一个用于定义数据表结构的类。schema = CollectionSchema(fields = fields,description='Test')collection = Collection(name=collection_name,schema=schema)index_params = {'metric_type': 'L2','index_type': "IVF_FLAT",'params': {"nlist": 2048}}collection.create_index(field_name="subject_embedding",index_params=index_params)return collection
collections = create_milvus_collection('Test',768) # 表名 , 模型维度
6.milvus存储
1.milvus存储 和 thowee 管道
insert = (pipe.input('id','subject','answer','url','subject_embedding')#将输入的问题文本转换为向量表示,使用名为 "facebook/dpr-ctx_encoder-single-nq-base" 的预训练模型进行文本嵌入。.map('subject','vec',ops.text_embedding.dpr(model_name='facebook/dpr-ctx_encoder-single-nq-base'))# 对上一步得到的向量进行归一化处理,使得向量的每个维度都被缩放到相同尺度。.map('vec', 'vec', lambda x: x / np.linalg.norm(x, axis=0)).map(('id','answer','subject','vec','url'),'insert_status',ops.ann_insert.milvus_client(host='124。*****', port='19530', collection_name='Test'))#进行存储.output()#返回
)
2.milvus存储 和 原始的存储方案
milvus = Milvus(host=HOST, port=PORT) # milvus 连接data1 = [[],[],# subject[],# option[],# answer[],#knowledgepoints[],#img[],#video[],#parse]data1[0].append(None)data1[1].append(request.args.get('subject'))data1[2].append(request.args.get('option'))data1[3].append(request.args.get('answer'))data1[4].append(request.args.get('knowledgepoints'))data1[5].append(request.args.get('img'))data1[6].append(request.args.get('video'))data1[7].append(request.args.get('parse'))data1.append(embed(data1[1]))# 转向量milvus.insert(collection_name=COLLECTION_NAME,entities=data1)# 调用 insert 新增 表名+数据return "ok"
7.milvus 搜索
# milvus 搜索
# 搜索 索引
QUERY_PARAM = {"metric_type": "L2","params": {"ef": 64},
}collection.search()res = collection.search(embed(request.args.get('subject')), anns_field='subject_embedding', param=QUERY_PARAM, limit = 1, output_fields=['id', 'subject', 'answer','option'])
# 向量 , 指定被搜索字段,索引,top1,返回字段______________________________________________例子
import openai
from pymilvus import connections, utility, FieldSchema, Collection, CollectionSchema, DataType
HOST = '124.**********'
PORT = 19530
COLLECTION_NAME = 'mo'#在 Milvus 中如何命名
DIMENSION = 1536 #嵌入的维度
OPENAI_ENGINE = 'text-embedding-ada-002'#使用哪种嵌入模型
openai.api_key = 'sk-***************'#您的 OpenAI 帐户密钥
QUERY_PARAM = {"metric_type": "L2","params": {"ef": 64},
}
connections.connect(host=HOST, port=PORT)
def embed(texts):embeddings = openai.Embedding.create(input=texts,engine=OPENAI_ENGINE)return [x['embedding'] for x in embeddings['data']]
collection = Collection(COLLECTION_NAME)
def query(query, top_k = 5):text = queryres = collection.search(embed(text), anns_field='subject_embedding', param=QUERY_PARAM, limit = top_k, output_fields=['id', 'subject', 'answer'])print(res)
my_query = ('P、V操作是一种')query(my_query)

milvus 搜索 + thowee管道 搜索
ans_pipe = (pipe.input('subject').map('subject', 'vector', ops.text_embedding.dpr(model_name="facebook/dpr-ctx_encoder-single-nq-base"))#将输入的问题文本转换为向量表示,使用名为 "facebook/dpr-ctx_encoder-single-nq-base" 的预训练模型进行文本嵌入。.map('vector', 'vector', lambda x: x / np.linalg.norm(x, axis=0))#对上一步得到的向量进行归一化处理,使得向量的每个维度都被缩放到相同尺度。.flat_map('vector', ('id','score', 'answer','subject'), ops.ann_search.milvus_client(host='124.222.24.191',port='19530',collection_name='Test',output_fields=['answer','subject'])).output('subject','id','score','answer')
)
ans = ans_pipe('恶性肿瘤是什么?')
ans = DataCollection(ans)
ans.show()
8.milvus 删除
emb_collection.delete(expr=f"id == [{emb_id}]") # failedemb_collection.delete(expr=f"id in [{emb_id}]") # Success
相关文章:
milvus 结合Thowee 文本转向量 ,新建表,存储,搜索,删除
1.向量数据库科普 【上集】向量数据库技术鉴赏 【下集】向量数据库技术鉴赏 milvus连接 from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility connections.connect(host124.****, port19530)2.milvus Thowee 文本转向量 使用 …...
GEO生信数据挖掘(三)芯片探针ID与基因名映射处理
检索到目标数据集后,开始数据挖掘,本文以阿尔兹海默症数据集GSE1297为例 目录 处理一个探针对应多个基因 1.删除该行 2.保留分割符号前面的第一个基因 处理多个探针对应一个基因 详细代码案例一删除法 详细代码案例二 多个基因名时保留第一个基因名…...

力扣 -- 96. 不同的二叉搜索树
解题步骤: 参考代码: class Solution { public:int numTrees(int n) {vector<int> dp(n1);//初始化dp[0]1;//填表for(int i1;i<n;i){for(int j1;j<i;j){//状态转移方程dp[i](dp[j-1]*dp[i-j]);}}//返回值return dp[n];} }; 你学会了吗&…...
)
经典算法-枚举法(百钱买百鸡问题)
题目: 条件:现有 100 元,一共要买公鸡、母鸡、小鸡三种鸡,已知公鸡 5 元一只,母鸡 3 元一只,1 元可以买三只小鸡。 要求:公鸡、母鸡、小鸡都要有,一共买 100 只鸡。有哪几种买法&am…...
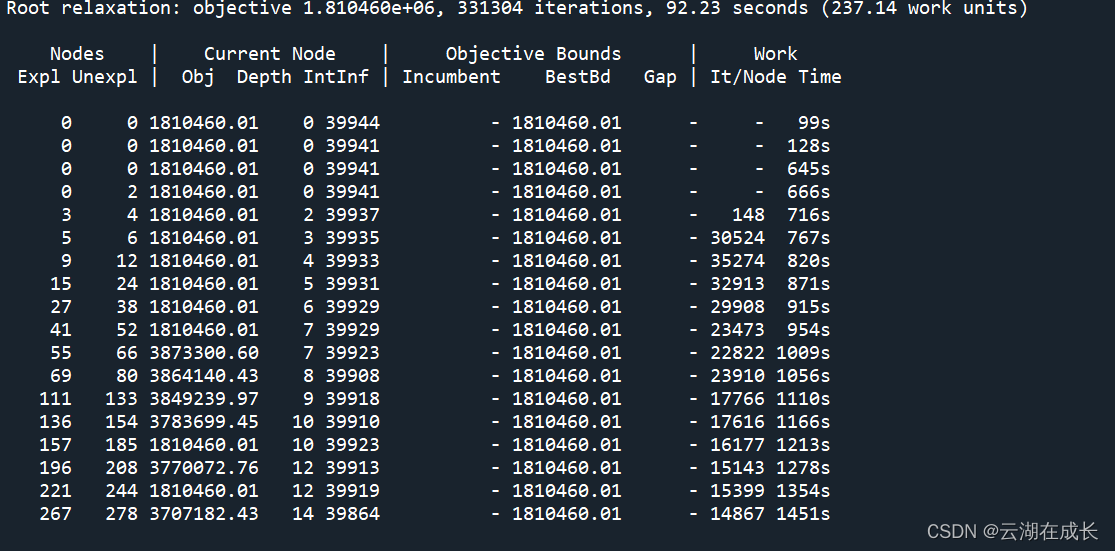
Gurobi设置初始可行解
目录 1. 决策变量的Start属性直接设置变量的初始值 1.1 Start:MIP变量的起始值(初值)double类型,可更改 1.2 StartNodeLimit:限制了在完善一组输入部分变量的初始解时,MIP所探索的分支定界的节点的数量 …...
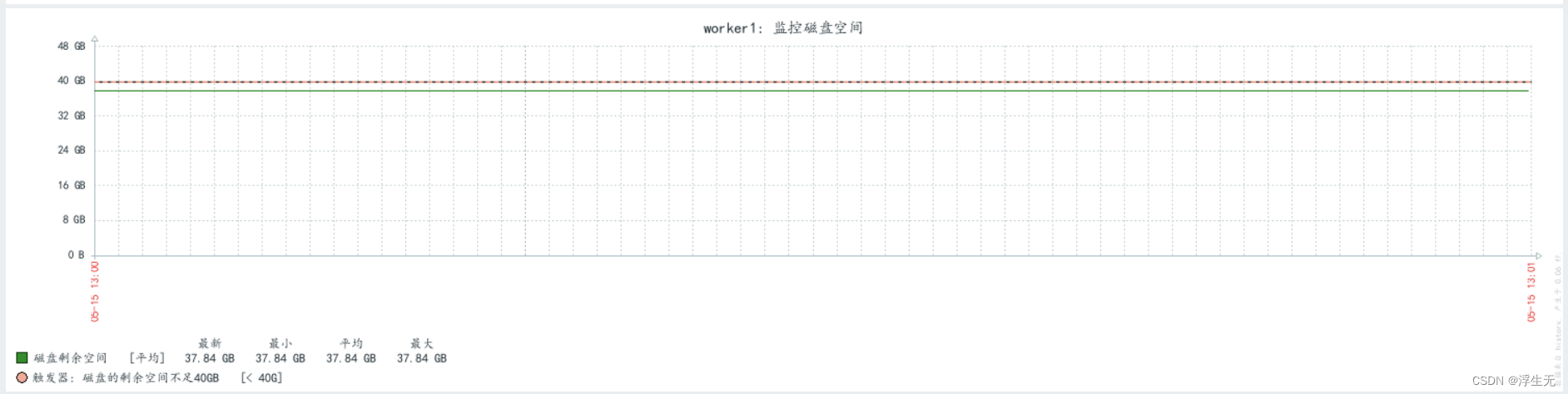
Zabbix配置监控文件系统可用空间小于30GB自动告警
一、创建监控项 二、配置监控项 #输入名称–>键值点击选择 #找到磁盘容量点击 注: 1、vfs 该键值用于检测磁盘剩余空间,zabbix 内置了非常多的键值可以选着使用 2、单位B不需要修改,后期图表中单位和G拼接起来就是GB 3、更新时间 10S…...

进程调度算法之先来先服务(FCFS),短作业优先(SJF)以及高响应比优先(HRRN)
1.先来先服务(FCFS) first come first service 1.算法思想 主要从“公平”的角度考虑(类似于我们生活中排队买东西的例子) 2.算法规则 按照作业/进程到达的先后顺序进行服务。 3.用于作业/进程调度 用于作业调度时,考虑的是哪个作业先…...
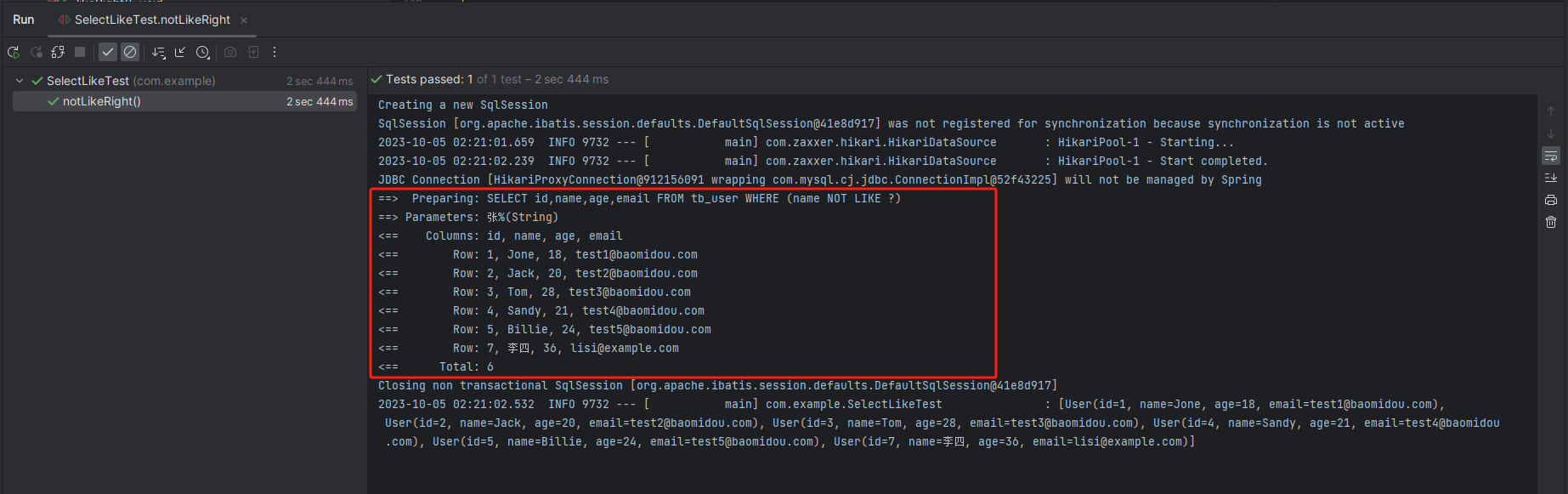
MyBatisPlus(九)模糊查询
说明 模糊查询,对应SQL语句中的 like 语句,模糊匹配“要查询的内容”。 like /*** 查询用户列表, 查询条件:姓名包含 "J"*/Testvoid like() {String name "J";LambdaQueryWrapper<User> wrapper ne…...
Spring 原理
它是一个全面的、企业应用开发一站式的解决方案,贯穿表现层、业务层、持久层。但是 Spring仍然可以和其他的框架无缝整合。 1 Spring 特点 轻量级控制反转面向切面容器框架集合 2 Spring 核心组件 3 Spring 常用模块 4 Spring 主要包 5 Spring 常用注解 bean…...

基于微信小程序的明星应援小程序设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言系统主要功能:具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计…...

try catch 中的finally什么时候运行
try catch 中的finally什么时候运行 在Java、C#等编程语言中,try-catch-finally语句块用于处理异常。finally块的执行时机通常是在try块中的代码执行完毕之后,无论try块中的代码是否引发了异常。 具体执行顺序如下: 1、try块中的代码首先被…...

力扣 -- 322. 零钱兑换(完全背包问题)
参考代码: 未优化代码: class Solution { public:int coinChange(vector<int>& coins, int amount) {int n coins.size();const int INF 0x3f3f3f3f;//多开一行,多开一列vector<vector<int>> dp(n 1, vector<i…...

[python]pip安装requiements.txt跳过错误包继续安装
在linux上可以用下面操作进行 while read requirement; do sudo pip install $requirement; done < requirement.txt 在windows上写个脚本 import sys from pip._internal import main as pip_maindef install(package):pip_main([--default-timeout1000,install,-U, pac…...

1.5 计算机网络的类别
思维导图: 1.5.1 计算机网络的定义 我的笔记: #### 精确定义: 计算机网络没有统一的精确定义,但一种较为接近的定义是:计算机网络主要由一些通用的、可编程的硬件互连而成,这些硬件并非专门用来实现某一特…...
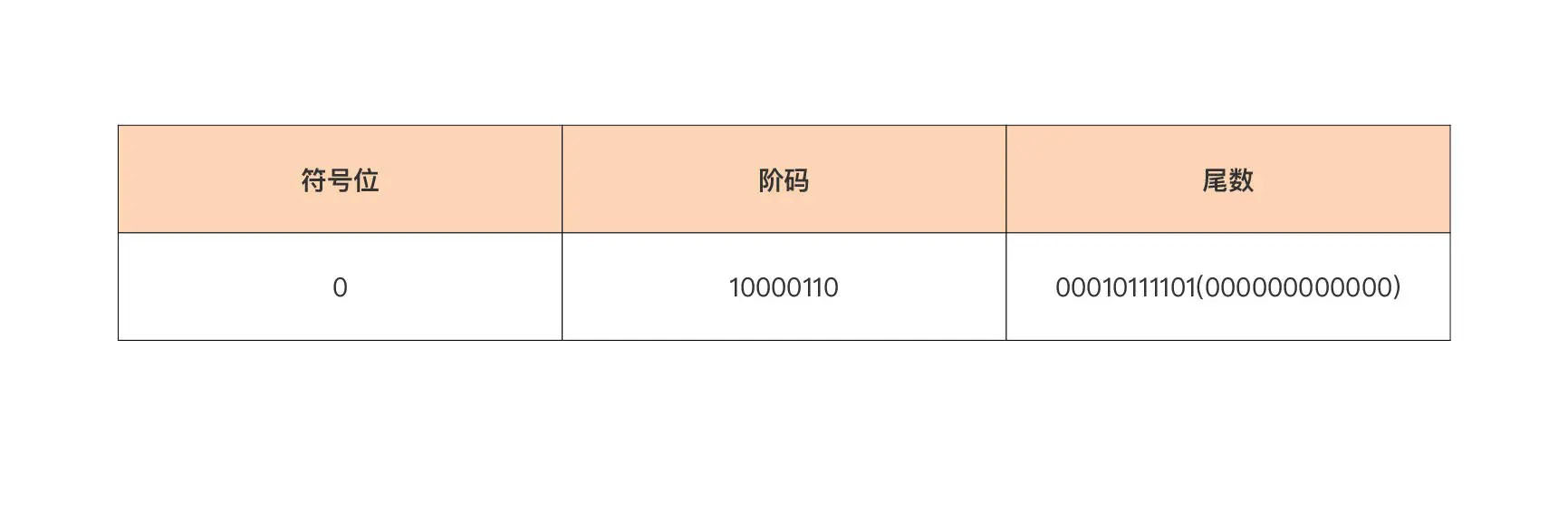
Go 基本数据类型和 string 类型介绍
Go 基础之基本数据类型 文章目录 Go 基础之基本数据类型一、整型1.1 平台无关整型1.1.1 基本概念1.1.2 分类有符号整型(int8~int64)无符号整型(uint8~uint64) 1.2 平台相关整型1.2.1 基本概念1.2.2 注意点1.2.3 获取三个类型在目标…...
打印如何不换行?)
Python中print()打印如何不换行?
文章目录 Python中print()打印如何不换行python2.xpython3.x print()函数语法objects基本语法sep基本语法end基本语法 Python中print()打印如何不换行 print() 函数用于打印输出,是python中最常见的一个内置函数。 如何在Python中打印两个或多个变量、语句时而不进…...

python 学习随笔 4
列表list 将序列前几个进行替换(数量可以不同) 将序列进行间隔替换(必须保证数量相同,否则报错) 删除序列内元素 向序列后新增一个元素 向序列后新增多个元素 将序列进行数乘(不是产生几个序列哦࿰…...

【网络安全-信息收集】网络安全之信息收集和信息收集工具讲解
一,域名信息收集 1-1 域名信息查询 可以用一些在线网站进行收集,比如站长之家 域名Whois查询 - 站长之家站长之家-站长工具提供whois查询工具,汉化版的域名whois查询工具。https://whois.chinaz.com/ 可以查看一下有没有有用的信息…...
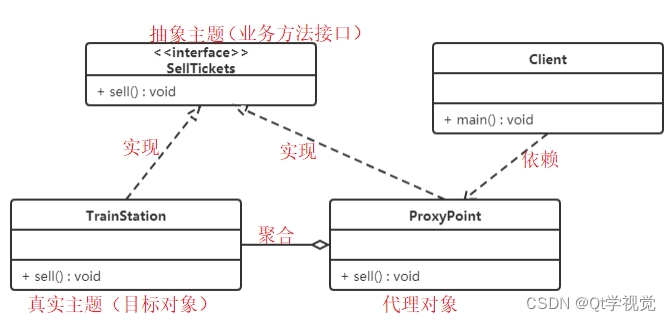
设计模式12、代理模式 Proxy
解释说明:代理模式(Proxy Pattern)为其他对象提供了一种代理,以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。 抽…...

ZXing - barcode scanning library for Java, Android
官网 GitHub - zxing/zxing: ZXing ("Zebra Crossing") barcode scanning library for Java, Android 使用说明 Getting Started Developing zxing/zxing Wiki GitHub 参考 Android中二维码的扫描与生成(zxing库)_android 二维码生成-C…...

如何突破微信设备限制?WeChatPad带来的多设备协同新体验
如何突破微信设备限制?WeChatPad带来的多设备协同新体验 【免费下载链接】WeChatPad 强制使用微信平板模式 项目地址: https://gitcode.com/gh_mirrors/we/WeChatPad 问题引入:微信生态的设备枷锁 当代数字生活中,微信已成为不可或缺…...

如何快速完成黑苹果安装?OpCore Simplify终极简化指南
如何快速完成黑苹果安装?OpCore Simplify终极简化指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 厌倦了繁琐的黑苹果配置过程&#x…...

树莓派无头模式终极指南:不接显示器,用SSH+VNC搞定所有开发调试
树莓派无头模式终极指南:不接显示器,用SSHVNC搞定所有开发调试 当你把树莓派塞进机器人底盘、挂在墙上作为智能家居中枢,或是藏在机柜里充当服务器时,最不想看到的就是拖着一堆显示器和线材。作为嵌入式开发老手,我经历…...

VIBE革命性视频人体姿态估计:CVPR2020获奖论文完整实现解析
VIBE革命性视频人体姿态估计:CVPR2020获奖论文完整实现解析 【免费下载链接】VIBE Official implementation of CVPR2020 paper "VIBE: Video Inference for Human Body Pose and Shape Estimation" 项目地址: https://gitcode.com/gh_mirrors/vi/VIBE …...

在Windows 11上用Bochs调试Linux 0.00:从BIOS加载到保护模式切换的完整实战
在Windows 11上用Bochs调试Linux 0.00:从BIOS加载到保护模式切换的完整实战 如果你对操作系统的底层实现充满好奇,想亲手探索计算机从加电到运行第一个用户程序的完整过程,那么这次实验将是一次绝佳的实践机会。我们将使用Bochs模拟器&#x…...

UICKeyChainStore常见问题解答:解决开发者遇到的典型问题
UICKeyChainStore常见问题解答:解决开发者遇到的典型问题 【免费下载链接】UICKeyChainStore UICKeyChainStore is a simple wrapper for Keychain on iOS, watchOS, tvOS and macOS. Makes using Keychain APIs as easy as NSUserDefaults. 项目地址: https://gi…...

深度解析GARbro:如何高效破解200+视觉小说资源格式的技术奥秘
深度解析GARbro:如何高效破解200视觉小说资源格式的技术奥秘 【免费下载链接】GARbro Visual Novels resource browser 项目地址: https://gitcode.com/gh_mirrors/gar/GARbro GARbro是一款面向视觉小说爱好者和游戏资源研究者的专业工具,基于.NE…...

零基础玩转OpenClaw:Qwen3-32B镜像快速入门5个示例
零基础玩转OpenClaw:Qwen3-32B镜像快速入门5个示例 1. 为什么选择OpenClawQwen3-32B组合? 去年冬天,当我第一次看到同事用自然语言命令电脑自动整理桌面文件时,仿佛打开了新世界的大门。经过两周的折腾,我终于在本地…...
 函数实战:从语法到场景的深度解析)
MYSQL中 find_in_set() 函数实战:从语法到场景的深度解析
1. 揭开find_in_set()函数的神秘面纱 第一次在项目中看到find_in_set()这个函数时,我也是一头雾水。它看起来和IN操作符很像,但又有明显的不同。经过多次实战应用后,我发现它其实是处理逗号分隔字符串的利器。 这个函数的语法非常简单&#x…...
)
Python 3.14 JIT动态优化实战(企业级成本控制白皮书)
第一章:Python 3.14 JIT编译器演进与企业级定位Python 3.14 引入了首个官方集成的、生产就绪的 JIT(Just-In-Time)编译器——PyJIT,标志着 CPython 从纯解释执行向混合执行模型的战略跃迁。该 JIT 并非替代现有字节码解释器&#…...