初识Java 12-3 流
目录
终结操作
将流转换为一个数组(toArray)
在每个流元素上应用某个终结操作(forEach)
收集操作(collect)
组合所有的流元素(reduce)
匹配(*Match)
选择一个元素(find*)
获得流相关的信息
本笔记参考自: 《On Java 中文版》
终结操作
||| 终结操作:这些操作会接受一个流,并生成一个最终结果。
终结操作不会把任何东西发给某个后端的流。因此,终结操作总是我们在一个管线内可以做的最后一件事。
将流转换为一个数组(toArray)
可以通过toArray()操作将流转换为数组:
- toArray():将流元素转换到适当的数组中。
- toArray(generator):generator用于在特定情况下分配自己的数组存储。
在流操作生成的内容必须以数组形式进行使用时,toArray()就很有用了:
【例子:将随机数存储在数组中,以流的形式复用】
import java.util.Arrays;
import java.util.Random;
import java.util.stream.IntStream;public class RandInts {private static int[] rints =new Random(47).ints(0, 1000).limit(100).toArray();public static IntStream rands() {return Arrays.stream(rints);}
}通过这种方式,我们可以保证每次得到的是相同的流。
在每个流元素上应用某个终结操作(forEach)
有两个很常见的终结操作:
- forEach(Consumer)
- forEachOrdered(Consumer):这个版本可以确保forEach对元素的操作顺序是原始的流的顺序。
通过使用parallel()操作,可以使forEach以任何顺序操作元素。
parallel()的介绍:这一操作会让Java尝试在多个处理器上执行操作。parallel()可以将流进行分割,并在不同处理器上运行每个流。
下面的例子通过引入parallel()来展示forEachOrdered(Consumer)的作用。
【例子:forEachOrdered(Consumer)的作用】
import static streams.RandInts.*;public class ForEach {static final int SZ = 14;public static void main(String[] args) {rands().limit(SZ).forEach(n -> System.out.format("%d ", n));System.out.println();rands().limit(SZ).parallel().forEach(n -> System.out.format("%d ", n));System.out.println();rands().limit(SZ).parallel().forEachOrdered(n -> System.out.format("%d ", n));System.out.println();}
}程序执行的结果是:

在第一个流中,因为没有使用parallel(),所以结果显示的顺序就是它们从rands()中出现的顺序。而在第二个流中,parallel()的使用使得输出的顺序发生了变化。这就是因为有多个处理器在处理这个问题(若多执行几次,会发现输出的顺序会不一样,这就是多处理器处理带来的不确定性)。
在最后一个流中,尽管使用了parallel(),但forEachOrdered()使得结果回到了原始的顺序。
所以,对非parallel()的流,使用forEachOrdered()不会有任何影响。
收集操作(collect)
- collect(Collector):使用这个Collector将流元素累加到一个结果集合中。
- collect(Supplier, BiConsumer, BiConsumer):和上一个collect()不同的地方在于:
- Supplier会创建一个新的结果集合。
- 第一个BiConsumer用来将下一个元素包含到结果集合中。
- 第二个BiConsumer用来将两个值进行组合。
collect()的第二个版本,会在每次被调用时,使用Supplier生成一个新的结果集合。这些集合就是通过第二个BiConsumer组合成一个最终结果的。
可以将流元素收集到任何特定种类的集合中。例如:假设我们需要把条目最终放入到一个TreeSet中。尽管Collectors中没有特定的toTreeSet()方法,但我们可以使用Collectors.toCollection(),将任何类型的构造器引用传递给toCollection()。
【例子:将提取的单词放入到TreeSet()中】
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.Set;
import java.util.TreeSet;
import java.util.stream.Collectors;public class TreeSetOfWords {public static void main(String[] arg) throws Exception {Set<String> words2 =Files.lines(Paths.get("TreeSetOfWords.java")).flatMap(s -> Arrays.stream(s.split("\\W+"))) .filter(s -> !s.matches("\\d+")) // 删除数字.map(String::trim) // 删除可能存在的留白.filter(s -> s.length() > 2).limit(100).collect(Collectors.toCollection(TreeSet::new));System.out.println(words2);}
}程序执行的结果是:

在这里,Arrays.stream(s.split("\\W+"))会将接收的文本行进行分割,获得的数组会变为Stream,然后其结果又通过flatMap()被展开成一个由单词组成的Stream。
【例子:从流生成一个Map】
import java.util.Iterator;
import java.util.Map;
import java.util.Random;
import java.util.stream.Collectors;
import java.util.stream.Stream;class Pair { // 一个基本的数据对象Pairpublic final Character c;public final Integer i;public Pair(Character c, Integer i) {this.c = c;this.i = i;}public Character getC() {return c;}public Integer getI() {return i;}@Overridepublic String toString() {return "Pair{" +"c=" + c +", i=" + i +'}';}
}class RandomPair {Random rand = new Random(47);// 这是一个无限大的迭代器,指向随机生成的大写字母Iterator<Character> capChars = rand.ints(65, 91) // 65~91,即大写字母对应的ASCII值.mapToObj(i -> (char) i).iterator();public Stream<Pair> stream() { // 生成一个Pair流return rand.ints(100, 1000).distinct() // 移除流中的重复元素.mapToObj(i -> new Pair(capChars.next(), i)); // 组合成Pair对象的流}
}public class MapCollector {public static void main(String[] args) {Map<Integer, Character> map =new RandomPair().stream().limit(8).collect(Collectors.toMap(Pair::getI, Pair::getC));System.out.println(map);}
}程序执行的结果是:
![]()
在大多数情况下,java.util.stream.Collectors中都会存在我们所需的Collector。而如果找不到我们所需要的,这时候就可以使用collect()的第二种形式。
【例子:collect()的第二种形式】
import java.util.ArrayList;public class SpecialCollector {public static void main(String[] arg) throws Exception {ArrayList<String> words =FileToWords.stream("Cheese.dat").collect(ArrayList::new, // 创建新的结果集合ArrayList::add, // 将下一个元素加入集合中ArrayList::addAll); // 组合所有的ArrayListwords.stream().filter(s -> s.equals("cheese")).forEach(System.out::println);}
}程序执行的结果是:
![]()
组合所有的流元素(reduce)
- reduce(BinaryOperator):使用BinaryOperator来组合所有的元素。若流为空,返回一个Optional。
- reduce(identity, BinaryOperator):和上述一致,不同之处在于会将identity作为这个组合的初始值。因此若流为空,会得到一个identity作为结果。
- reduce(identity, BiFuncton, BinaryOperator):BiFunction提供累加器,BinaryOperator提供组合函数。这种形式会更为高效。但若只论效果,可以通过组合显式的map()和reduce()操作来替代。
这些操作之所以使用reduce命名,是因为它们会获取一系列的输入元素,并将它们组合(简化)成一个单一的汇总结果。
【例子:reduce()操作的演示】
import java.util.Random;
import java.util.stream.Stream;class Frobnitz {int size;Frobnitz(int sz) {size = sz;}@Overridepublic String toString() {return "Frobnitz{" +"size=" + size +'}';}// 生成器static Random rand = new Random(47);static final int BOUND = 100;static Frobnitz supply() {return new Frobnitz(rand.nextInt(BOUND));}
}public class Reduce {public static void main(String[] args) {Stream.generate(Frobnitz::supply).limit(10).peek(System.out::println).reduce((fr0, fr1) -> fr0.size < 50 ? fr0 : fr1) // 若fr0的size小于50,接受fr0,否则接受fr1.ifPresent(System.out::println);}
}程序执行的结果是:

Forbnitz有一个自己的生成器,叫做supply()。在上述例子中,我们把方法引用Frobnitz::supply传递给了Stream.generate,因为它和Supplier<Frobnitz>是签名兼容的(又称结构一致性)。
Supplier是一个函数式接口。在这里Supplier<Frobnitz>相当于一个返回Frobnitz对象的无参函数。
在使用reduce()时,我们没有使用identity作为初始值。这意味着reduce()会生成一个Optional,当结果不为empty时,才会执行Consumer<Frobnitz>(即lambda表达式)。再看lambda表达式本身:
(fr0, fr1) -> fr0.size < 50 ? fr0 : fr1其中的第一个参数fr0是上次调用这个reduce()时带回的结果,第二个参数fr1是来自流中的新值。
匹配(*Match)
- allMatch(Predicate):通过Predicate检测流中的元素,若每一个元素结果都为true,则返回true。若遇到false,则发生短路 —— 在遇到第一个false后,停止计算。
- anyMatch(Predicate):同样使用Predicate进行检测,若任何一个元素得到true,则返回true。在遇到第一个true时,发生短路。
- noneMatch(Predicate):进行检测,若没有元素得到true,则返回true。在遇到第一个true时,发生短路。
【例子:Match引发的短路行为】
import java.util.function.BiPredicate;
import java.util.function.Predicate;
import java.util.stream.IntStream;
import java.util.stream.Stream;interface Matcher extends // 能够匹配所有的Stream::*Match函数的模式BiPredicate<Stream<Integer>, Predicate<Integer>> {
}public class Matching {static void show(Matcher match, int val) {System.out.println(match.test(IntStream.rangeClosed(1, 9) // 返回一个从1~9递增的Integer序列.boxed().peek(n -> System.out.format("%d ", n)),n -> n < val));}public static void main(String[] args) {show(Stream::allMatch, 10);show(Stream::allMatch, 4);show(Stream::anyMatch, 2);show(Stream::anyMatch, 0);show(Stream::noneMatch, 5);show(Stream::noneMatch, 0);}
}程序执行的结果是:

BiPredicate是一个二元谓词,所以他会接受两个参数,并返回true和false。其中,第一个参数是我们要测试的数值的流,第二个参数是谓词Predicate本身。
选择一个元素(find*)
- findFirst():返回一个Optional,其中包含了流中的第一个元素。若流中没有元素,则返回Optional.empty。
- findAny():返回一个Optional,其中包含了流中的某个元素。若流中没有元素,则返回Optional.empty。
【例子:find*操作的使用】
import static streams.RandInts.*;public class SelectElement {public static void main(String[] args) {System.out.println(rands().findFirst().getAsInt());System.out.println(rands().parallel().findFirst().getAsInt());System.out.println(rands().findAny().getAsInt());System.out.println(rands().parallel().findAny().getAsInt());}
}程序执行的结果是:

无论流是否并行,findFirst()总会选择流中的第一个元素。但findAny()有些不同,在非并行的流中,findAny()会选择第一个元素,而当这个流是并行流时,findAny()有可能选择第一个元素之外的元素。
若需要某个流中的最后一个元素,可以使用reduce():
【例子:选择流中的最后一个元素】
import java.util.Optional;
import java.util.OptionalInt;
import java.util.stream.IntStream;
import java.util.stream.Stream;public class LastElement {public static void main(String[] args) {OptionalInt last = IntStream.range(10, 20).reduce((n1, n2) -> n2);System.out.println(last.orElse(-1));// 对于非数值对象Optional<String> lastobj =Stream.of("one", "two", "three").reduce((n1, n2) -> n2);System.out.println(lastobj.orElse("不存在任何元素"));}
}程序执行的结果是:
![]()
reduce((n1, n2) -> n2)语句可以用两个元素这的后一个替换这两个元素,通过这种方式就可以获得流中的最后一个元素了。
获得流相关的信息
- count():获得流中元素的数量。
- max(Comparator):通过Comparator确定这个流中的“最大元素”。
- min(Comparator):确定这个流中的“最小元素”。
【例子:使用String预设的Comparator获取信息】
public class Informational {public static void main(String[] args) throws Exception {System.out.println(FileToWords.stream("Cheese.dat").count());System.out.println(FileToWords.stream("Cheese.dat").min(String.CASE_INSENSITIVE_ORDER).orElse("NONE"));System.out.println(FileToWords.stream("Cheese.dat").max(String.CASE_INSENSITIVE_ORDER).orElse("NONE"));}
}程序执行的结果是:

其中,max()和min()都会返回Optional,这里出现的orElse()是用来获取其中的值的。
获得数值化流相关的信息
- average():获得平均值。
- max()和min():因为处理的是数值化的流,所以不需要Comparator。
- sum():将流中的数值进行累加。
- summaryStatistics():返回可能有用的摘要数据(但我们也可以使用直接方法获取这些数据)。
【例子:数值化流的信息获取(以IntStream为例)】
import static streams.RandInts.*;public class NumericStreamInfo {public static void main(String[] args) {System.out.println(rands().average().getAsDouble());System.out.println(rands().max().getAsInt());System.out.println(rands().min().getAsInt());System.out.println(rands().sum());System.out.println(rands().summaryStatistics());}
}程序执行的结果是:

相关文章:
初识Java 12-3 流
目录 终结操作 将流转换为一个数组(toArray) 在每个流元素上应用某个终结操作(forEach) 收集操作(collect) 组合所有的流元素(reduce) 匹配(*Match) 选…...
、416. 分割等和子集)
代码随想录算法训练营第42天|动态规划:01背包理论基础、动态规划:01背包理论基础(滚动数组)、416. 分割等和子集
动态规划:01背包理论基础 动态规划:01背包理论基础(滚动数组) 以上两个问题的代码未本地化保存 416. 分割等和子集 https://leetcode.cn/problems/partition-equal-subset-sum/ 复杂的解法 class Solution { public:bool ca…...

(详解)Linux常见基本指令(1)
目录 目录: 1:有关路径文件下的操作(查看,进入) 1.1 ls 1.2 pwd 1.3 cd 2:创建文件或目录 2.1 touch 2.2 mkdir 3:删除文件或目录 3.1 rm与rmdir 4:复制剪切文件 4.1 cp 4.2 mv 1:有关路径的操作 1 ls 指令 语法:ls [选项] [目录或文…...

紫光同创FPGA图像视频采集系统,提供2套PDS工程源码和技术支持
目录 1、前言免责声明 2、紫光同创FPGA相关方案推荐3、设计思路框架视频源选择OV7725摄像头配置及采集OV5640摄像头配置及采集动态彩条HDMA图像缓存输入输出视频HDMA缓冲FIFOHDMA控制模块 HDMI输出 4、PDS工程1详解:OV7725输入5、PDS工程2详解:OV5640输入…...
第一章 函数 极限 连续(解题方法须背诵)
(一)求极限的常用方法 方法1 利用有理运算法则求极限 方法2 利用基本极限求极限 方法3 利用等价无穷小求极限 方法4 利用洛必达法则求极限 方法5 利用泰勒公式求极限 方法6 利用夹逼准则求极限 方法7 利用定积分的定义求极限 方法8 利用单调有界…...
selenium +IntelliJ+firefox/chrome 环境全套搭配
1第一步:下载IntelliJ idea 代码编辑器 2第二步:下载浏览器Chrome 3第三步:下载JDK 4第四步:配置环境变量(1JAVA_HOME 2 path) 5第五步:下载Maven 6第六步:配置环境变量&#x…...
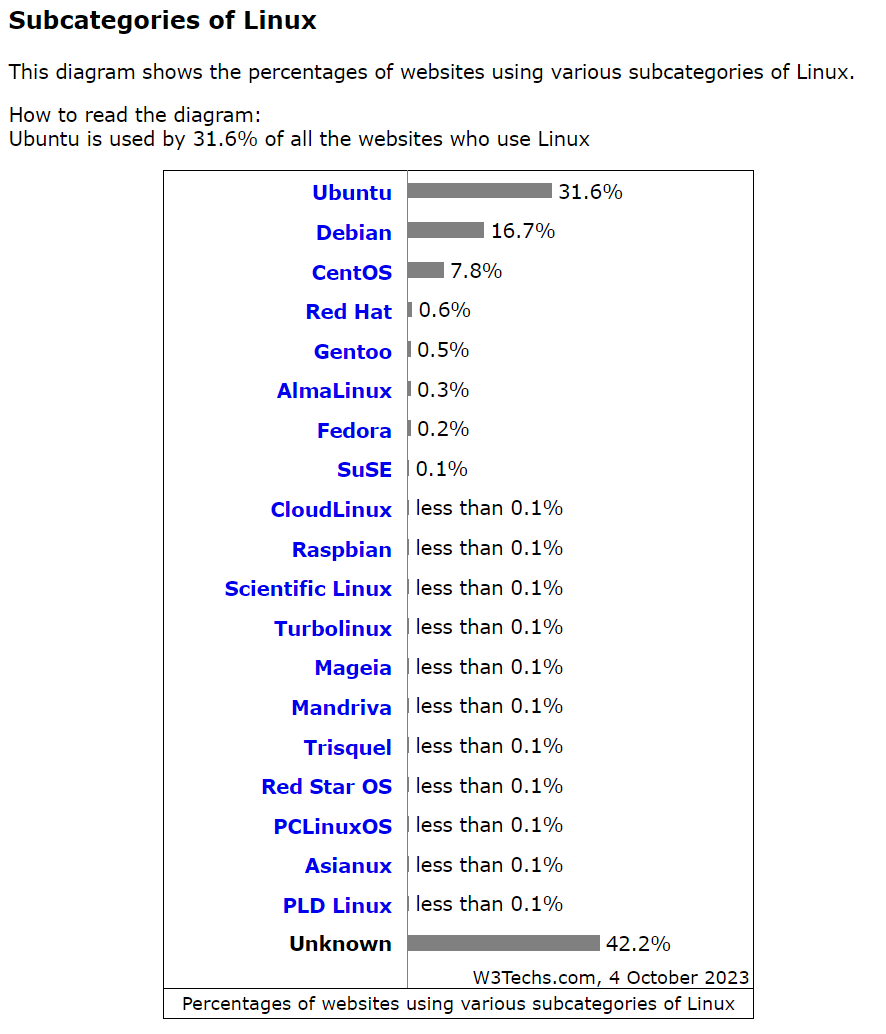
CentOS 7 停止维护后如何平替你的生产系统?
Author:rab 目录 前言一、Debian 家族1.1 Debian1.2 Ubuntu 二、RHEL 家族2.1 Red Hat Enterprise Linux2.2 Fedora2.3 CentOS2.4 Rocky Linux2.5 AlmaLinux 三、如何选择?思考? 前言 CentOS 8 系统 2021 年 12 月 31 日已停止维护服务&…...

第81步 时间序列建模实战:Adaboost回归建模
基于WIN10的64位系统演示 一、写在前面 这一期,我们介绍AdaBoost回归。 同样,这里使用这个数据: 《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndr…...

135.【JUC并发编程_01】
JUC 并发编程 (一)、基本概述1.概述 (二)、进程与线程1.进程与线程(1).进程_介绍(2).线程_介绍(3).进程与线程的区别 2.并行和并发(1).并发_介绍(2).并行_介绍(3).并行和并发的区别 3.应用(1).异步调用_较少等待时间(2).多线程_提高效率 (三)、Java 线程1.创建线程和运行线程(1…...
VC++创建windows服务程序
目录 1.关于windows标准可执行程序和服务程序 2.服务相关整理 2.1 VC编写服务 2.2 服务注册 2.3 服务卸载 2.4 启动服务 2.5 关闭服务 2.6 sc命令 2.7 查看服务 3.标准程序 3.1 后台方式运行标准程序 3.2 查找进程 3.3 终止进程 以前经常在Linux下编写服务器程序…...
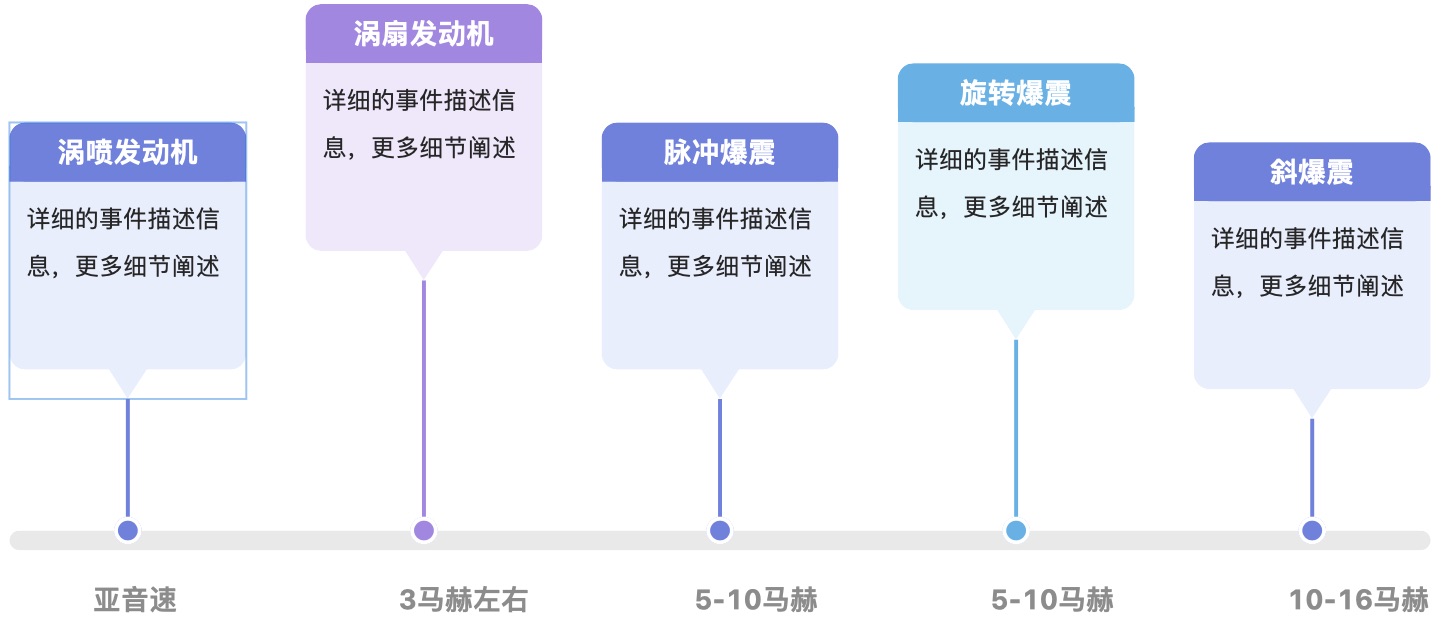
连续爆轰发动机
0.什么是爆轰 其反应区前沿为一激波。反应区连同前驱激波称为爆轰波。爆轰波扫过后,反应区介质成为高温高压的爆轰产物。能够发生爆轰的系统可以是气相、液相、固相或气-液、气-固和液-固等混合相组成的系统。通常把液、固相的爆轰系统称为炸药。 19世纪80年代初&a…...
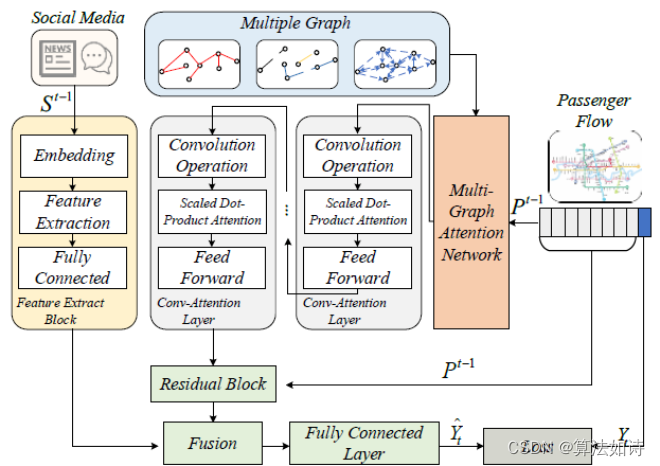
交通物流模型 | 基于时空注意力融合网络的城市轨道交通假期短时客流预测
短时轨道交通客流预测对于交通运营管理非常重要。新兴的深度学习模型有效提高了预测精度。然而,大部分现有模型主要针对常规工作日或周末客流进行预测。由于假期客流的突发性和无规律性,仅有一小部分研究专注于假期客流预测。为此,本文提出一个全新的时空注意力融合网络(ST…...

2.2.1 嵌入式工程师必备软件
1 文件比较工具 在开发过程中,不论是对代码的对比,还是对log的对比,都是必不可不少的,通过对比,我们可以迅速找到差异,定位问题。当前常用的对比工具有:WinMerge,Diffuse,Beyond Compare,Altova DiffDog,AptDiff,Code Compare等。这里推荐使用Beyond Compare,它不…...
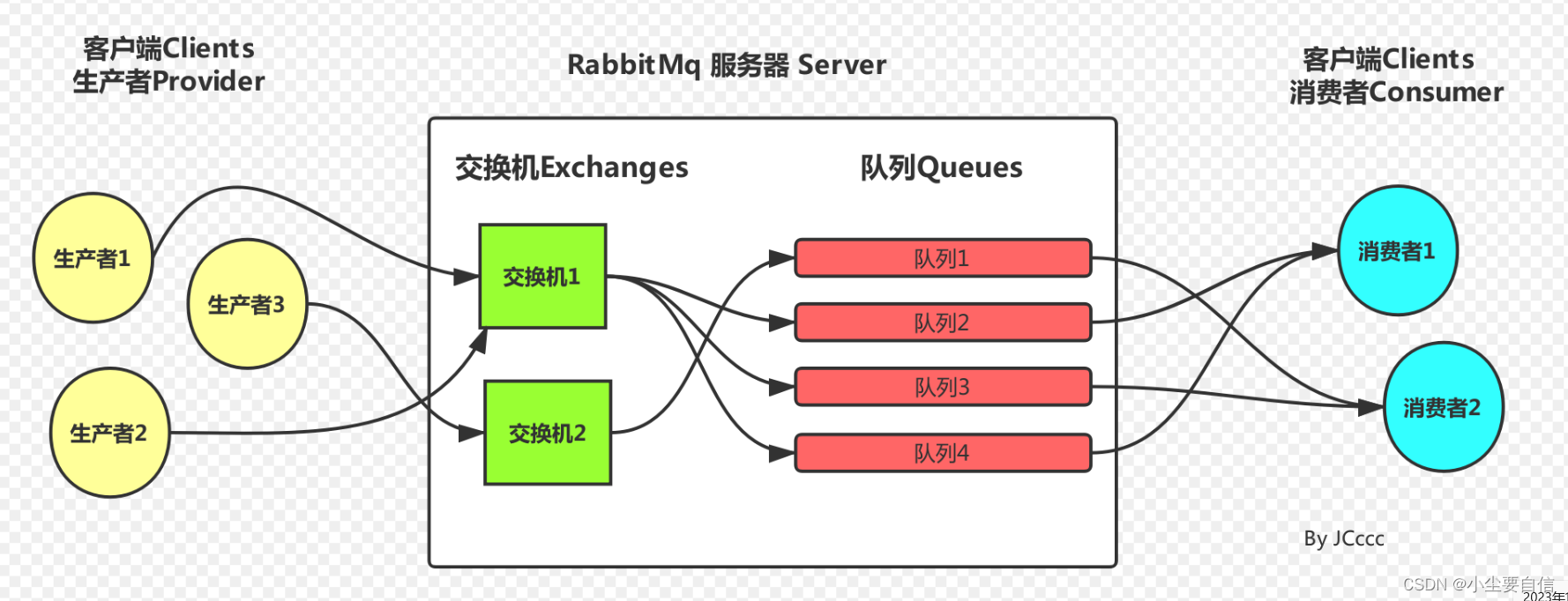
深入了解 RabbitMQ:高性能消息中间件
目录 引言:一、RabbitMQ 介绍二、核心概念三、工作原理四、应用场景五、案例实战 引言: 在现代分布式系统中,消息队列成为了实现系统间异步通信、削峰填谷以及解耦组件的重要工具。而RabbitMQ作为一个高效可靠的消息队列解决方案,…...

【数据库——MySQL】(14)过程式对象程序设计——游标、触发器
目录 1. 游标1.1 声明游标1.2 打开游标1.3 读取游标1.4 关闭游标1.5 游标示例 2. 触发器2.1 创建触发器2.2 修改触发器2.3 删除触发器2.4 触发器类型2.5 触发器示例 参考书籍 1. 游标 游标一般和存储过程一起配合使用。 1.1 声明游标 要使用游标,需要用到 DECLAR…...
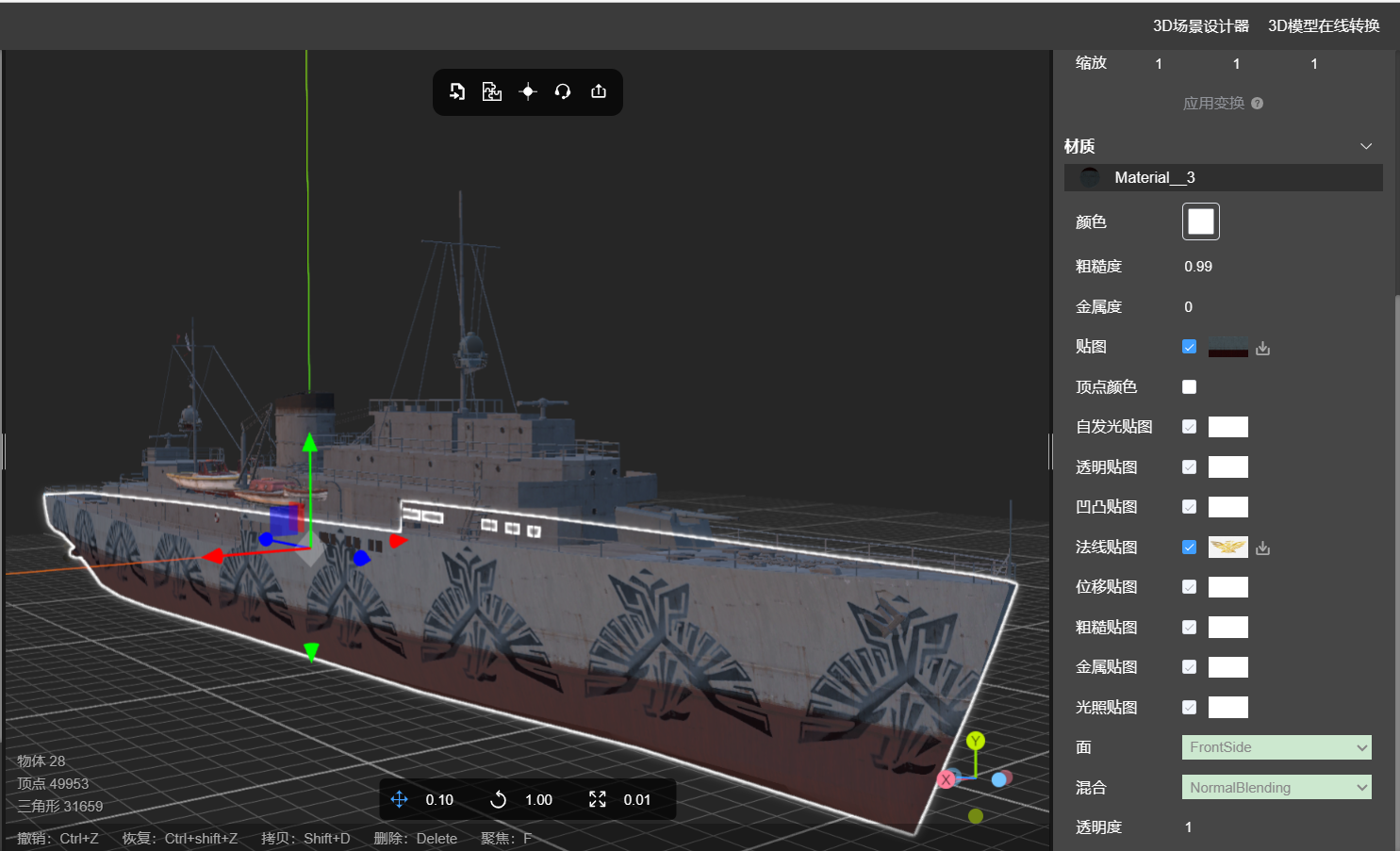
位移贴图和法线贴图的区别
位移贴图和法线贴图都是用于增强模型表面细节和真实感的纹理贴图技术,但是它们之间也存在着差异。 1、什么是位移贴图 位移贴图:位移贴图通过在模型顶点上定义位移值来改变模型表面的形状。该贴图包含了每个像素的高度值信息,使得模型的细节…...
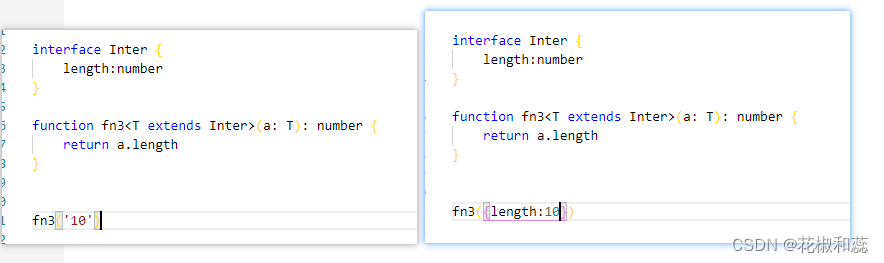
【typescript】面向对象(下篇),包含接口,属性的封装,泛型
假期第八篇,对于基础的知识点,我感觉自己还是很薄弱的。 趁着假期,再去复习一遍 面向对象:程序中所有的操作都需要通过对象来完成 计算机程序的本质就是对现实事物的抽象,抽象的反义词是具体。比如照片是对一个具体的…...
基于SpringBoot的视频网站系统
目录 前言 一、技术栈 二、系统功能介绍 用户信息管理 视频分享管理 视频排名管理 交流论坛管理 留言板管理 三、核心代码 1、登录模块 2、文件上传模块 3、代码封装 前言 使用旧方法对视频信息进行系统化管理已经不再让人们信赖了,把现在的网络信息技术运…...
23.3 Bootstrap 框架4
1. 轮播 1.1 轮播样式 在Bootstrap 5中, 创建轮播(Carousel)的相关类名及其介绍: * 1. carousel: 轮播容器的类名, 用于标识一个轮播组件. * 2. slide: 切换图片的过渡和动画效果. * 3. carousel-inner: 轮播项容器的类名, 用于包含轮播项(轮播图底下椭圆点, 轮播的过程可以显…...

ESP32设备驱动-I2C-LCD1602显示屏驱动
I2C-LCD1602显示屏驱动 1、LCD1602介绍 LCD1602液晶显示器是广泛使用的一种字符型液晶显示模块。它是由字符型液晶显示屏(LCD)、控制驱动主电路HD44780及其扩展驱动电路HD44100,以及少量电阻、电容元件和结构件等装配在PCB板上而组成。 通过前面的实例我们知道,并口方式…...

技术干货!!DeepSeek API 实战:从零到生产级的 Python 调用指南 — 流式、Function Calling、多轮对话、成本优化全覆盖
DeepSeek V3 的 API 性价比在 2026 年依然没有对手——同等能力价格只有 GPT-5.5 的 1/5。但翻了一圈中文技术社区,发现大多数「教程」只讲到第一段 chat.completions.create 就停了。生产环境真正需要的东西——流式输出怎么接、Function Calling 踩了什么坑、高并…...

Claude任务大师浏览器扩展:AI自动化工作流与Chrome插件开发实战
1. 项目概述与核心价值最近在折腾AI自动化工作流,发现一个痛点:虽然像Claude这样的AI助手能力很强,但每次想让它帮我处理网页内容,都得手动复制粘贴,效率实在太低。直到我发现了GitHub上一个名为“claude-task-master-…...

基于Code Llama的本地AI编程助手:VSCode插件部署与优化实战
1. 项目概述:为什么我们需要一个更聪明的代码助手?在VSCode的插件市场里搜索“AI代码补全”,结果可能会让你眼花缭乱。从基于GPT的Copilot到各种开源模型驱动的工具,选择很多,但痛点也很明显:要么需要稳定的…...

C++头文件和cpp文件的原理分析
通常,在一个C程序中,只包含两类文件——.cpp文件和.h文件。 .cpp文件被称作C源文件,里面放的都是C的源代码.h文件则被称作C头文件,里面放的也是C的源代码,头文件不用被编译 C语言支持“分别编译”(separa…...

【51单片机倒计时清翔的板子2片573驱动数码管】2023-10-28
缘由51单片机模拟定时炸弹_编程语言-CSDN问答 用矩阵键盘在数码管上输入数字作为炸弹的倒计时,独立键盘控制倒计时开始,暂停,提前引爆键,倒计时最后三秒蜂鸣器随倒计时响,求源码。 以下代码演示相关功能实现。 #inc…...

基于词汇统计的个人技能量化管理系统:从理论到实践
1. 项目概述:当词汇统计遇上技能图谱最近在整理个人技能库时,我遇到了一个挺有意思的问题:如何用一种更科学、更直观的方式,来量化和管理自己那看似杂乱无章、不断增长的技能树?传统的简历列表或者简单的熟练度评级&am…...

Yii2开启URI伪静态的相关配置
Yii2 开启URI伪静态的相关配置 Yii2支持url伪静态链接转换,在配置文件config/web.php中加入 # config/web.php $config [components > [// URI伪静态化配置urlManager > [enablePrettyUrl > true, // 启用美化 URL(隐藏 index.php)…...

Cursor编辑器深度美化:CSS注入与动态特效实现全解析
1. 项目概述:当代码编辑器拥有了“皮肤”与“特效”如果你和我一样,每天有超过8小时的时间是在代码编辑器里度过的,那么你一定理解一个顺眼、顺手、甚至有点“酷”的编辑环境意味着什么。它不仅仅是生产力的工具,更是我们开发者思…...

GPT-Image-2 老是生成失败?完整排查和修复指南,5 个真根因逐个击破
GPT-Image-2 老是生成失败?完整排查和修复指南,5 个真根因逐个击破GPT-Image-2 的处理时间比文字模型长很多——高质量 1024px 需要 145-280 秒。大多数所谓的"生成失败"其实不是模型问题,而是网络链路(CDN、反代、SDK&…...

Arm架构在中国市场的潜力与挑战:从技术选型到实践落地
1. 项目概述:从一次技术选型引发的深度思考最近在为一个边缘计算项目做硬件选型,团队里关于采用x86还是Arm架构的服务器争论了好几天。这让我想起,这几年在国内的云计算、数据中心、甚至个人消费电子领域,Arm架构的声音是越来越响…...