Kafka 搭建过程
目录
- 1.关于Kafka
- 2.Kafka 搭建过程
- 3.参考
本文主要介绍Kafka基本原理,以及搭建过程。
1.关于Kafka
Apache Kafka是一个开源的分布式事件流平台,被设计用来实现实时数据流的发布、订阅、存储和处理。
Kafka的主要特性包括:
- 高吞吐量:Kafka可以处理高速流动的数据,并保证数据的写入和读取的高速性。
- 分布式:Kafka集群由多个服务器(Broker)组成,数据会被分布存储。
- 持久性:Kafka可以将数据持久化到磁盘,因此可以用于长期存储数据。
- 容错性:Kafka可以容忍服务器(Broker)的故障,保证数据的可靠性。
- 实时性:Kafka可以实时处理流数据。
Kafka可以应用于多种场景,主要包括:
- 消息队列:Kafka可以作为一个大规模的消息队列服务,处理生产者和消费者之间的消息传递。
- 日志收集:Kafka可以用于收集不同来源的日志数据,并将这些数据集中存储在一个地方,方便后续的日志分析。
- 用户活动跟踪:Kafka可以用于跟踪用户的在线活动,如页面浏览、搜索、点击等事件。
- 实时流处理:配合流处理框架(如Apache Flink、Apache Storm、Apache Samza等),Kafka可以用于实时处理和分析数据流。
- 事件源:Kafka可以作为事件驱动型微服务的事件源,存储事件的历史记录。
- 指标和日志聚合:Kafka可以用于收集各种指标(如系统监控指标、业务指标等)和日志,然后将这些数据聚合后发送到后端的存储系统。
- 集成和解耦:在微服务架构中,Kafka可以用于解耦服务之间的依赖,每个服务只与Kafka进行交互,从而实现服务的解耦。
以上只是Kafka的部分应用场景,实际上,Kafka的应用非常广泛,可以应用于任何需要处理实时数据流的场景。
Kafka如此强大,背后的工作原理主要涉及到以下几个方面:
- 发布-订阅模型:Kafka基于发布-订阅模型,生产者(Producer)将消息发布到特定的主题(Topic)上,消费者(Consumer)订阅主题并消费其中的消息。
- 分布式消息系统:Kafka集群由多个Broker组成,每个Broker是一个独立的服务器。主题(Topic)中的消息被分成多个分区(Partition),每个分区的消息可以存储在不同的Broker上,实现了数据的分布式存储。
- 消息持久化:Kafka将所有的消息持久化到硬盘上,即使系统发生故障,消息也不会丢失。消费者在消费消息时,只是改变了一个指向消息的偏移量(Offset),而不会删除消息。
- 高吞吐量:Kafka通过批量发送消息、零拷贝等技术提高了系统的吞吐量,可以处理大量的实时数据。
- 容错性:Kafka的每个分区都可以有多个副本(Replica),副本之间可以互相备份数据,提高了系统的容错性。如果某个Broker发生故障,Kafka可以自动从其他副本中恢复数据。
- 消费者组:Kafka的消费者可以组成消费者组(Consumer Group),组内的每个消费者负责消费不同的分区,实现了负载均衡。如果某个消费者发生故障,Kafka可以自动将其分区分配给其他消费者。
以上是Kafka的主要工作原理,具体的实现可能会根据Kafka的版本和配置进行调整。详细的原理和实现可以参考Kafka的官方文档。
另外,简单介绍下 Topic、Partition、Replica之间的关系。
在Kafka中,Topic和Partition是数据组织的基本单位。Topic负责对消息进行分类,Partition则是实现数据存储和读写的基本单位。
- Topic:Topic是消息的类别或者说是消息的主题,生产者将消息发布到特定的Topic,消费者从特定的Topic中订阅消息。每个Topic包含一或多个Partition。
- Partition:Partition是Topic的分区,每个Topic可以分为一个或多个Partition。Partition是Kafka实现高吞吐量和数据冗余的关键,每个Partition可以在不同的Broker上,数据被写入不同的Partition可以并行进行。在Kafka中,每条消息在每个Partition中都有一个唯一的偏移量(Offset),消费者通过Offset来定位消息。每个Partition在设计上是不可分割的,即消费者在消费一个Partition的数据时,必须按照Offset的顺序进行。
- 副本(Replica)是Partition的备份,用于实现数据的冗余存储,提高数据的可靠性。每个Partition可以有一个或多个副本,这些副本分布在不同的Broker上。其中,有一个副本被指定为Leader,其他的副本称为Follower。所有的读写操作都由Leader处理,Follower只负责从Leader同步数据。当Leader宕机时,Kafka会从Follower中选举出一个新的Leader,这个过程称为Leader Election。这样,即使某个Broker宕机,只要有副本存在,数据就不会丢失,读写操作也可以继续进行。副本的数量可以在创建Topic时指定,通过
--replication-factor参数设置。副本数量的设置需要根据数据的重要性和集群的容量来决定,副本数量越多,数据的可靠性越高,但是会占用更多的存储空间和网络带宽。
可能大家还有一个疑问,Kafka 是如何实现高吞吐的?
Kafka能够实现高吞吐的原理主要基于以下几个方面:
- 分布式架构:Kafka集群由多个Broker组成,每个Topic可以分为多个Partition,每个Partition可以在不同的Broker上,这样可以并行处理多个Partition的读写请求,提高了吞吐量。
- 磁盘顺序写:Kafka将所有的消息持久化到硬盘,而且是顺序写入的。顺序写磁盘的速度远高于随机写,因此Kafka的写入性能非常高。
- 零拷贝:Kafka在发送消息时使用了零拷贝技术,避免了数据在用户态和内核态之间的多次拷贝,减少了CPU的使用,提高了吞吐量。
- 批处理:Kafka的Producer会将多个消息打包成一个Batch发送,Consumer也会一次性从Broker读取多个消息,这样可以减少网络请求的次数,提高了吞吐量。
- 消息压缩:Kafka支持消息的压缩,可以减少网络传输的数据量,提高吞吐量。
以上是Kafka实现高吞吐的主要原理,具体的实现可能会根据Kafka的版本和配置进行调整。详细的原理和实现可以参考Kafka的官方文档。
2.Kafka 搭建过程
搭建Kafka集群的基本步骤如下:
(1)环境准备
Kafka运行需要Java环境,所以首先需要在服务器上安装Java。
(2)下载并解压Kafka
从Kafka官网下载Kafka的tar包,然后解压。
tar -xzf kafka_2.x.tgz
cd kafka_2.x
(3) 配置Kafka
修改Kafka的配置文件(位于config/server.properties),主要需要配置的参数包括Broker的ID(broker.id)、监听的地址和端口(listeners)、Zookeeper的地址(zookeeper.connect)等。
(4) 启动Zookeeper
如果没有单独的Zookeeper集群,可以使用Kafka自带的Zookeeper。
bin/zookeeper-server-start.sh config/zookeeper.properties
(5) 启动Kafka
启动Kafka Broker。
bin/kafka-server-start.sh config/server.properties
(6) 创建Topic
创建一个Kafka Topic:
bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
(7) 测试Kafka
可以通过Kafka自带的生产者和消费者进行测试。
#在一个终端中启动生产者
bin/kafka-console-producer.sh --topic test --bootstrap-server localhost:9092
# 在另一个终端中启动消费者
bin/kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server localhost:9092
以上是搭建单节点Kafka集群的基本步骤,搭建多节点集群的步骤类似,只是需要在多台服务器上重复以上步骤,并且需要为每个Broker配置一个唯一的ID,以及正确的监听地址和Zookeeper地址。
3.参考
Apache Kafka文档
包含了Kafka的详细介绍、快速入门指南、配置说明、API文档等内容,是学习和使用Kafka的重要参考资料。
相关文章:

Kafka 搭建过程
目录 1.关于Kafka2.Kafka 搭建过程3.参考 本文主要介绍Kafka基本原理,以及搭建过程。 1.关于Kafka Apache Kafka是一个开源的分布式事件流平台,被设计用来实现实时数据流的发布、订阅、存储和处理。 Kafka的主要特性包括: 高吞吐量&#x…...
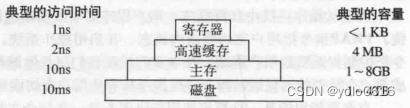
七、2023.10.1.Linux(一).7
文章目录 1、 Linux中查看进程运行状态的指令、查看内存使用情况的指令、tar解压文件的参数。2、文件权限怎么修改?3、说说常用的Linux命令?4、说说如何以root权限运行某个程序?5、 说说软链接和硬链接的区别?6、说说静态库和动态…...
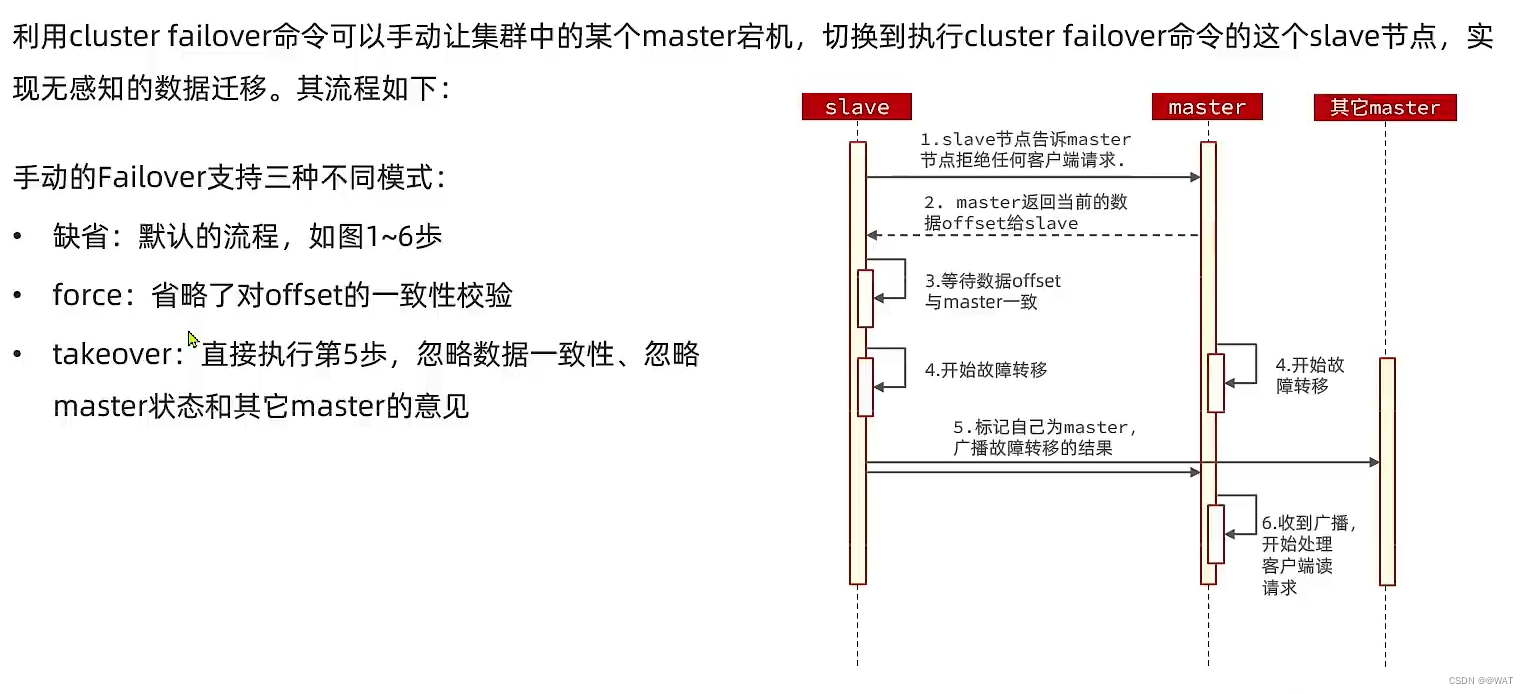
一文教你搞懂Redis集群
一、Redis主从 1.1、搭建主从架构 单节点的Redis的并发能力是有上限的,要进一步的提高Redis的并发能力,据需要大家主从集群,实现读写分离。 共包含三个实例,由于资源有限,所以在一台虚拟机上,开启多个red…...

树上启发式合并 待补
对于每个子树,直接遍历所有轻儿子,继承重儿子 会了板子后,修改维护的东西和莫队是一样的 洛谷 U41492 #include <bits/stdc.h> #define ll long long #define ull unsigned long long constexpr int N1e55; std::vector<int> e…...

minio分布式文件存储
基本介绍 什么是 MinIO MinIO 是一款基于 Go 语言的高性能、可扩展、云原生支持、操作简单、开源的分布式对象存储产品。基于 Apache License v2.0 开源协议,虽然轻量,却拥有着不错的性能。它兼容亚马逊S3云存储服务接口。可以很简单的和其他应…...

Linux新的IO模型io_uring
一、Linux下的网络通信模型 在网络开发的过程中,需要处理好几个问题。首先是通信的内核支持问题;其次是通信的模型问题;最后是框架问题。这些问题在闭源的OS如Windows上,基本上不算什么大问题(因为只能用人家的API&am…...
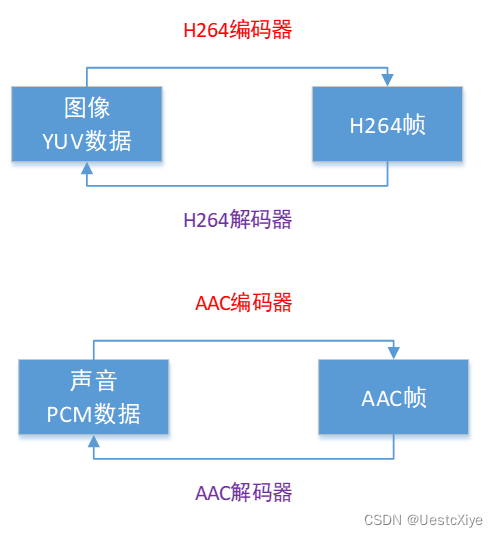
FFmpeg 命令:从入门到精通 | FFmpeg 基本介绍
FFmpeg 命令:从入门到精通 | FFmpeg 基本介绍 FFmpeg 命令:从入门到精通 | FFmpeg 基本介绍FFmpeg 简介FFmpeg 基础知识复用与解复用编解码器码率和帧率 资料 FFmpeg 命令:从入门到精通 | FFmpeg 基本介绍 本系列文章要解决的问题࿱…...

数组篇 第一题:删除排序数组中的重复项
更多精彩内容请关注微信公众号:听潮庭。 第一题:删除排序数组中的重复项 给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应…...
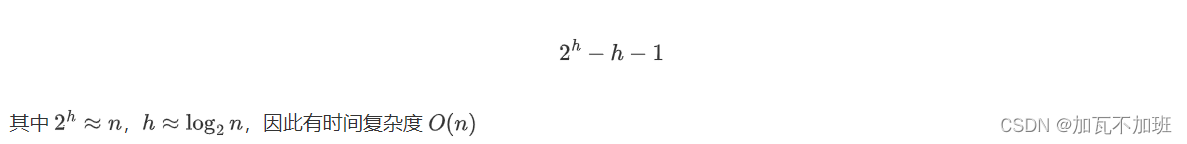
堆的初步认识
在学习本节文章前要先了解:大顶堆与小顶堆: (优先级队列_加瓦不加班的博客-CSDN博客) 堆实现 计算机科学中,堆是一种基于树的数据结构,通常用完全二叉树实现。 什么叫完全二叉树? 答&#x…...

CycleGAN模型之Pytorch实战
一、CycleGAN基本介绍 1. CycleGAN论文:《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》 2. 原文代码:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix 3. 网传精简代码:https://github.com/aitorzip/PyTorch-CycleGAN …...
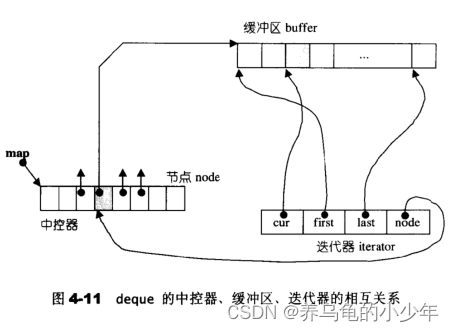
C++(STL容器适配器)
前言: 适配器也称配接器(adapters)在STL组件的灵活组合运用功能上,扮演着轴承、转换器的角色。 《Design Patterns》对adapter的定义如下:将一个class的接口转换为另一个class的接口,使原本因接口不兼容而…...
)
软考 系统架构设计师系列知识点之软件架构风格(7)
接前一篇文章:软考 系统架构设计师系列知识点之软件架构风格(6) 这个十一注定是一个不能放松、保持“紧”的十一。由于报名了全国计算机技术与软件专业技术资格(水平)考试,11月4号就要考试,因此…...

【Vue3】自定义指令
除了 Vue 内置的一系列指令 (比如 v-model 或 v-show) 之外,Vue 还允许你注册自定义的指令 (Custom Directives)。 1. 生命周期钩子函数 一个自定义指令由一个包含类似组件生命周期钩子的对象来定义。钩子函数会接收到指令所绑定元素作为其参数。 在 <script …...

UG\NX CAM二次开发 加工模块获取 UF _ask_application_module
文章作者:代工 来源网站:NX CAM二次开发专栏 简介: UG\NX CAM二次开发 加工模块获取 UF _ask_application_module 代码: void MyClass::do_it() { // TODO: add your code here // 获取NX当前所在的模块 int module_id = 0; // UF_ask_application_module(&…...

借助GPU算力编译Android
借助GPU算力编译Android 借助GPU编译Android代码的意义在于提高编译的效率和速度。传统的CPU编译方式在处理大量代码时可能会遇到性能瓶颈,而GPU编译利用了显卡的并行计算能力,可以同时处理多个任务,加快编译过程。通过利用GPU的并行计算能力,可以将编译过程中的多个任务分…...

docker-compose一键部署mysql
1.创建安装目录 mnt为硬盘挂载目录,根据实际情况修改 mkdir -p /mnt/mysql cd /mnt/mysql vim docker-compose.yml2.编写docker-compose.yml version: 3.1 services:db:image: mysql:5.7 #mysql版本volumes:- ./data/db:/var/lib/mysql #数据文件- ./etc/my.cnf:/…...
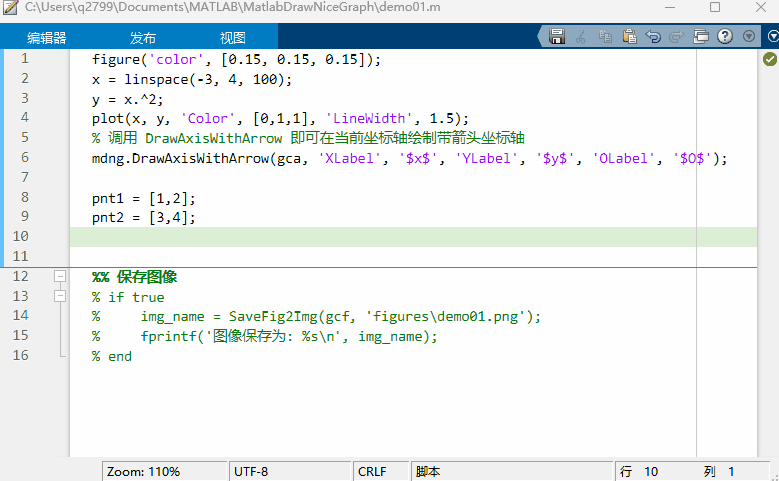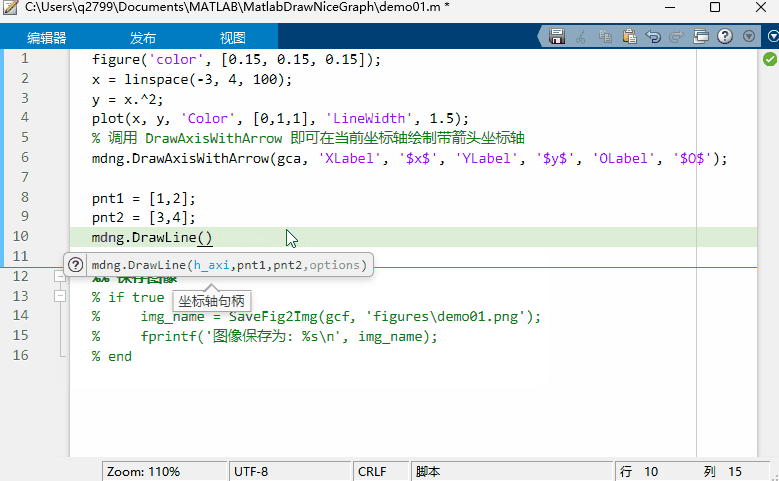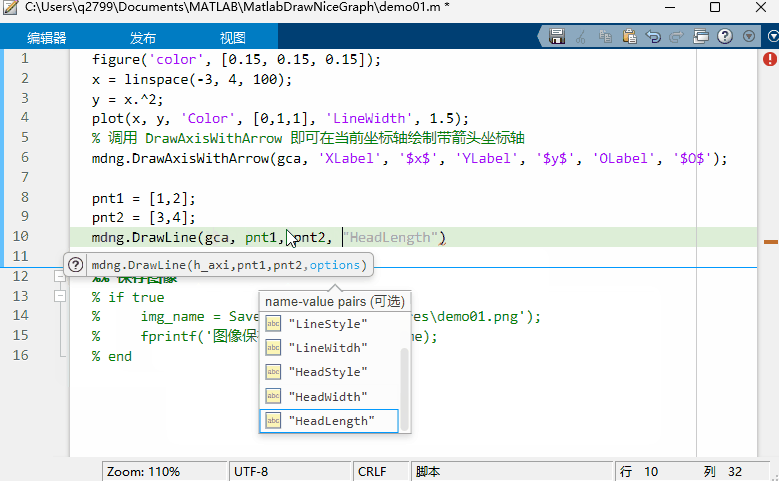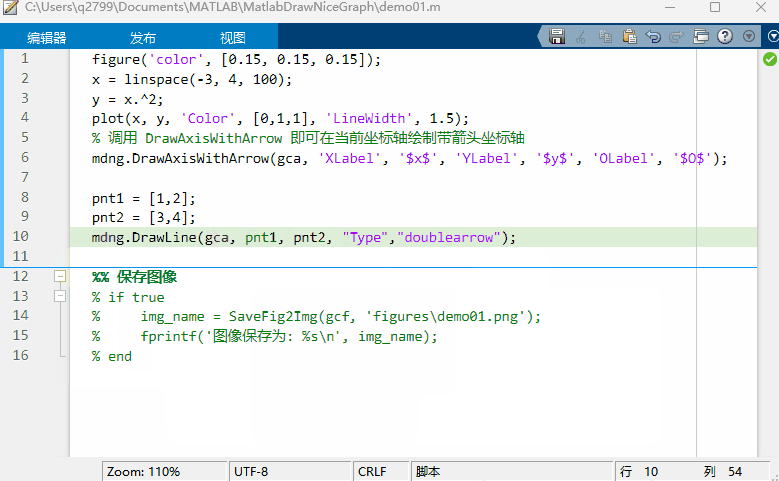
MATLAB 函数签名器
文章目录 MATLAB 函数签名器注释规范模板参数类型 kind数据格式 type选项的支持 使用可执行程序封装为m函数程序输出 编译待办事项推荐阅读附录 MATLAB 函数签名器 MATLAB 函数签名器 (FUNCSIGN) ,在规范注释格式的基础上为函数文件或类文件自动生成函数签名&#…...
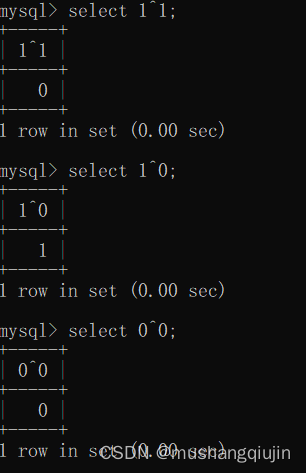
2019强网杯随便注bugktu sql注入
一.2019强网杯随便注入 过滤了一些函数,联合查询,报错,布尔,时间等都不能用了,尝试堆叠注入 1.通过判断是单引号闭合 ?inject1-- 2.尝试堆叠查询数据库 ?inject1;show databases;-- 3.查询数据表 ?inject1;show …...

Html+Css+Js计算时间差,返回相差的天/时/分/秒(从未来的一个日期时间到当前日期时间的差)。
Html部分 <!DOCTYPE html> <html><head><meta charset"utf-8" /><title></title><link rel"stylesheet" type"text/css" href"css/index.css" /><script src"js/index.js" t…...
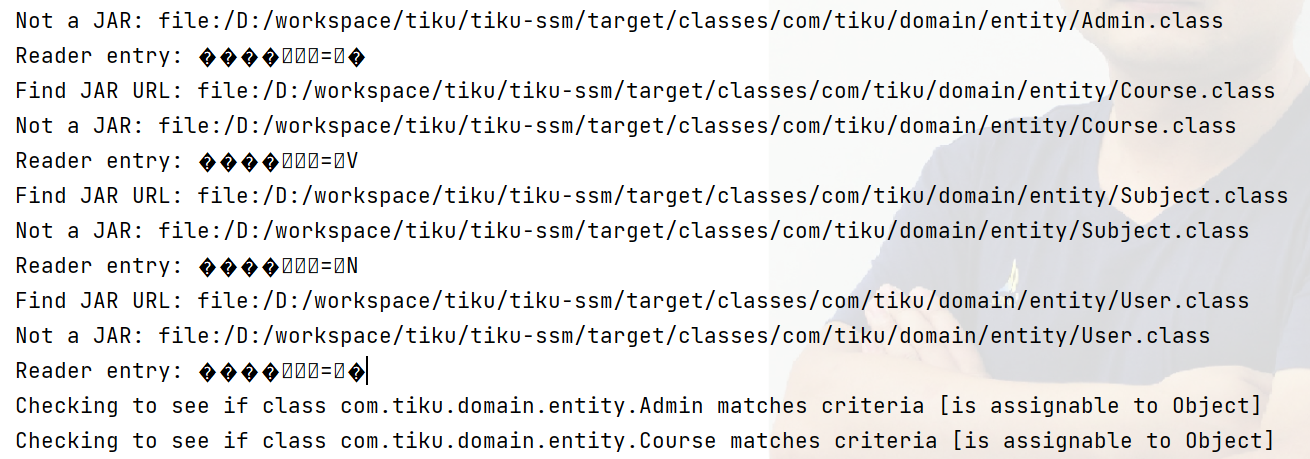
mybatis项目启动报错:reader entry: ���� = v
问题再现 解决方案一 由于指定的VFS没有找,mybatis启用了默认的DefaultVFS,然后由于DefaultVFS的内部逻辑,从而导致了reader entry乱码。 去掉mybatis配置文件中关于别名的配置,然后在mapper.xml文件中使用完整的类名。 待删除的…...

从零部署Discord AI聊天机器人:基于ChatGPT API与Firestore的实践指南
1. 项目概述:打造一个属于你自己的Discord AI聊天机器人 如果你在运营一个Discord社区,无论是游戏公会、技术讨论组还是兴趣社团,肯定遇到过这样的场景:成员们总有一些稀奇古怪的问题,或者需要一个随时在线的“智能助…...

MCP Analytics Suite:用自然语言驱动AI数据分析,零代码生成专业报告
1. 项目概述:当AI助手遇上专业数据分析如果你和我一样,日常工作中需要处理大量的业务数据——可能是Shopify的订单报表、Stripe的支付流水,或者是一堆从各个渠道导出的CSV文件——那你一定体会过那种“数据在手,却无从下手”的焦虑…...

从RISC-V到SSITH:构建下一代硬件安全架构的开放之路
1. 项目概述:从“亡羊补牢”到“未雨绸缪”的硬件安全范式转移在智能设备无处不在的今天,我们正面临一个尴尬的现实:许多产品的安全设计,更像是在一栋已经建好的毛坯房里,见缝插针地安装防盗门和监控摄像头。这种“事后…...

逆光也能精准识别人脸,门禁不再卡壳
人脸门禁普及的路上,安全质疑从未停止:照片能不能骗过摄像头?视频冒充会不会被放行?尤其在学校、幼儿园、医院等需要高度核验身份的场所,一丁点伪冒漏洞都可能酿成风险。ZUU中优云联ZU-YK751人脸识别门禁终端ÿ…...

号卡系统后台一键生图换图添加随心ai密钥教程
号卡产品全新上线随心ai一键生图、智能换图功能,操作极简,秒出优质素材,告别手动作图。 1.登录号卡系统后台首页先更新版本2.到号卡系统设置——系统系统设置——号卡设置——下滑就可以看到随心AI密钥入口需要填写密钥3.随心ai密钥申请入口h…...

Intel Quark SoC X1000:物联网边缘计算的核心技术解析
1. Intel Quark SoC X1000:物联网边缘计算的小型化革命在工业自动化现场,一台装备了温度传感器的风机正在持续监测轴承状态。传统方案需要将每秒数百个采样点全部上传云端,不仅占用带宽,延迟更是达到秒级。而采用Intel Quark SoC …...

企业微信代开发应用:CallBackUrl验证失败排查与CorpID加密升级实战
1. 企业微信代开发应用验证失败的典型场景 最近不少服务商朋友反馈,代开发应用在验证CallBackUrl时频繁失败。这个问题其实源于企业微信在2022年6月底进行的一次安全升级。当时官方发布公告称,为了提升账户安全性,所有新建的代开发应用都需要…...

别再只会用WinHex看十六进制了!这5个隐藏功能帮你搞定90%的数据恢复难题
WinHex高阶数据恢复实战:5个被低估的杀手级功能解析 在数据恢复领域,WinHex早已超越了简单的十六进制编辑器定位。这款由X-Ways公司开发的专业工具集成了磁盘编辑、内存分析、数据解释等多项强大功能,但大多数用户仅停留在基础的文件浏览和简…...

2026 年 TanStack npm 供应链遭入侵:42 个包 84 版本受影响,多方面待解决问题待明确
总结2026 年 5 月 11 日 19:20 至 19:26 UTC 期间,攻击者通过结合“Pwn Request”模式的 pull_request_target、跨越分叉↔主库信任边界的 GitHub Actions 缓存投毒,以及从 GitHub Actions 运行器进程中提取 OIDC 令牌,在 42 个 tanstack/* n…...

Vinkius Cloud扩展:在IDE中无缝管理MCP AI网关运行时
1. 项目概述:在IDE中管理你的AI网关运行时如果你正在开发或使用基于MCP(Model Context Protocol)的AI应用,那么你很可能已经体会过在多个AI客户端(比如Cursor、Claude Desktop、Windsurf)之间管理和维护后端…...