【RabbitMQ 实战】08 集群原理剖析
上一节,我们用docker-compose搭建了一个RabbitMQ集群,这一节我们来分析一下集群的原理
一、基础概念
1.1 元数据
前面我们有介绍到 RabbitMQ 内部有各种基础构件,包括队列、交换器、绑定、虚拟主机等,他们组成了 AMQP 协议消息通信的基础,而这些构件以元数据的形式存在,它始终记录在 RabbitMQ 内部,它们分别是:
- 队列元数据:队列名称和它们的属性
- 交换器元数据:交换器名称、类型和属性
- 绑定元数据:一张简单的表格展示了如何将消息路由到队列
- vhost 元数据:为 vhost 内的队列、交换器和绑定提供命名空间和安全属性
PS:元数据,指的是包括队列名字属性、交换机的类型名字属性、绑定信息、vhost等基础信息,不包括队列中的消息数据。
1.2 RabbitMQ 存储数据有两种方案:
- 内存模式:这种模式会将数据存储在内存当中,如果服务器突然宕机重启之后,那么附加在该节点上的队列和其关联的绑定都会丢失,并且消费者可以重新连接集群并重新创建队列;
- 磁盘模式:这种模式会将数据存储磁盘当中,如果服务器突然宕机重启,数据会自动恢复,该队列又可以进行传输数据了,并且在恢复故障磁盘节点之前,不能在其它节点上让消费者重新连到集群并重新创建队列,如果消费者继续在其它节点上声明该队列,会得到一个 404 NOT_FOUND 错误,这样确保了当故障节点恢复后加入集群,该节点上的队列消息不会丢失,也避免了队列会在一个节点以上出现冗余的问题。
在单节点 RabbitMQ 上,仅允许该节点是磁盘节点,这样确保了节点发生故障或重启节点之后,所有关于系统的配置与元数据信息都会从磁盘上恢复。
而在 RabbitMQ 集群上,至少有一个磁盘节点,也就是在集群环境中需要添加 2 台及以上的磁盘节点,这样其中一台发生故障了,集群仍然可以保持运行。其它节点均设置为内存节点,这样会让队列和交换器声明之类的操作会更加快速,元数据同步也会更加高效。
二、集群节点类型
在单个节点上,RabbitMQ 存储数据有两种方案:
- 内存模式:这种模式会将数据存储在内存当中,如果服务器突然宕机重启之后,那么附加在该节点上的队列和其关联的绑定都会丢失,并且消费者可以重新连接集群并重新创建队列;
- 磁盘模式:这种模式会将数据存储磁盘当中,如果服务器突然宕机重启,数据会自动恢复,该队列又可以进行传输数据了,并且在恢复故障磁盘节点之前,不能在其它节点上让消费者重新连到集群并重新创建队列,如果消费者继续在其它节点上声明该队列,会得到一个 404 NOT_FOUND 错误,这样确保了当故障节点恢复后加入集群,该节点上的队列消息不会丢失,也避免了队列会在一个节点以上出现冗余的问题。
如下图所示,三个节点的集群,有两个磁盘模式,一个内存模式

在集群中的每个节点,要么是内存节点,要么是磁盘节点,如果是内存节点,会将所有的元数据信息仅存储到内存中,而磁盘节点则不仅会将所有元数据存储到内存上, 还会将其持久化到磁盘。
在单节点 RabbitMQ 上,仅允许该节点是磁盘节点,这样确保了节点发生故障或重启节点之后,所有关于系统的配置与元数据信息都会从磁盘上恢复。
而在 RabbitMQ 集群上,至少有一个磁盘节点,也就是在集群环境中需要添加 2 台及以上的磁盘节点,这样其中一台发生故障了,集群仍然可以保持运行。其它节点均设置为内存节点,这样会让队列和交换器声明之类的操作会更加快速,元数据同步也会更加高效。
三、集群的几种模式
集群主要有两种模式主备模式(Warren)和镜像模式(Mirror)
下面分别对两种模式进行说明
主备模式(Warren)
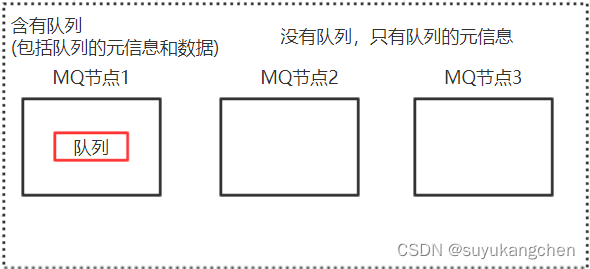
1、基本特征
- 交换机和队列的元数据存在于所有的节点上
- queue队列中的完整数据只存在于创建该队列的节点上
- 其他节点只保存队列的元数据信息以及指向当前队列的owner node的指针
2、数据消费
进行数据消费时随机连接到一个节点,当队列不是当前节点创建的时候,需要有一个从创建队列的实例拉取队列数据的开销。此外由于需要固定从单实例获取数据,因此会出现单实例的瓶颈。
3、优点:
可以由多个节点消费单个队列的数据,提高了吞吐量
4、缺点:
节点实例需要拉取数据,因此集群内部存在大量的数据传输可用性保障低,一旦创建队列的节点宕机,只有等到该节点恢复其他节点才能继续消费消息
镜像模式(Mirror)
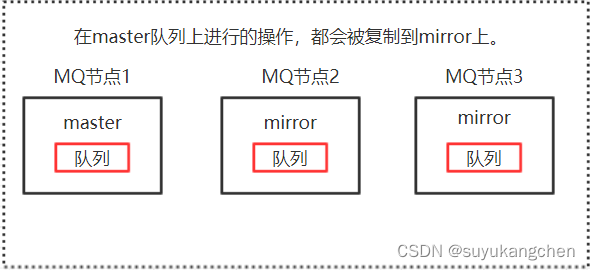
1、基本特征
创建的queue,不论是元数据还是完整数据都会在每一个节点上保存一份
向queue中写消息时,都会自动同步到每一个节点上
2、优点:
- 保障了集群的高可用
- 配置方便,只需要在后台配置相应的策略,就可以将指定数据同步到指定的节点或者全部节点
3、缺点:
- 性能开销较大,网络带宽压力和消耗很严重,所以镜像队列的吞吐量会低于主备模式
- 无法线性扩展,例如单个queue的数据量很大,每台机器都要存储同样大量的数据
集群实操
集群的部署
下面的链接是最快最简单的一种集群部署方法
3分钟部署一个RabbitMQ集群
由于是docker部署,所以我任意找一个节点,进入集群节点
先docker ps查看运行的进程,然后根据容器id,进入容器
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4d75d7be9cf5 bitnami/rabbitmq "/opt/bitnami/script…" 7 minutes ago Up 7 minutes 4369/tcp, 5551-5552/tcp, 5671-5672/tcp, 15671-15672/tcp, 25672/tcp mycompose-queue-disc1-1
b4f7618ffdd4 bitnami/rabbitmq "/opt/bitnami/script…" 7 minutes ago Up 7 minutes 4369/tcp, 5551-5552/tcp, 5671-5672/tcp, 15671/tcp, 25672/tcp, 0.0.0.0:15672->15672/tcp, :::15672->15672/tcp mycompose-stats-1
f3a97e8d74de bitnami/rabbitmq "/opt/bitnami/script…" 7 minutes ago Up 7 minutes 4369/tcp, 5551-5552/tcp, 5671-5672/tcp, 15671-15672/tcp, 25672/tcp mycompose-queue-ram1-1
[root@localhost ~]# docker exec -it 4d /bin/bash
查看集群状态
I have no name!@4d75d7be9cf5:/$ rabbitmqctl cluster_status
Cluster status of node rabbit@queue-disc1 ...
Basics
#下面是主节点名称
Cluster name: rabbit@4d75d7be9cf5
#下面是磁盘节点,有两个
Disk Nodesrabbit@queue-disc1
rabbit@stats
#下面是内存节点,有一个
RAM Nodesrabbit@queue-ram1
#下面表示有三个节点在运行
Running Nodesrabbit@queue-disc1
rabbit@queue-ram1
rabbit@stats
# 下面是版本号
Versionsrabbit@queue-disc1: RabbitMQ 3.9.11 on Erlang 24.2
rabbit@queue-ram1: RabbitMQ 3.9.11 on Erlang 24.2
rabbit@stats: RabbitMQ 3.9.11 on Erlang 24.2Maintenance statusNode: rabbit@queue-disc1, status: not under maintenance
Node: rabbit@queue-ram1, status: not under maintenance
Node: rabbit@stats, status: not under maintenanceAlarms(none)Network Partitions(none)ListenersNode: rabbit@queue-disc1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@queue-disc1, interface: [::], port: 15692, protocol: http/prometheus, purpose: Prometheus exporter API over HTTP
Node: rabbit@queue-disc1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@queue-ram1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@queue-ram1, interface: [::], port: 15692, protocol: http/prometheus, purpose: Prometheus exporter API over HTTP
Node: rabbit@queue-ram1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@stats, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@stats, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@stats, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0Feature flagsFlag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: stream_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled从上面可以看到,有三个节点,其中有两个磁盘节点,一个内存节点
相关文章:
【RabbitMQ 实战】08 集群原理剖析
上一节,我们用docker-compose搭建了一个RabbitMQ集群,这一节我们来分析一下集群的原理 一、基础概念 1.1 元数据 前面我们有介绍到 RabbitMQ 内部有各种基础构件,包括队列、交换器、绑定、虚拟主机等,他们组成了 AMQP 协议消息…...

2023年 2月3月 工作经历
2月 #pragma make_public(type) 托管C导出传统C类,另一个托管C项目使用不了。传统C类make_public后,就可以使用了。对模板类无效,比如:std::string。 C#线程绑定CPU 我的方案: 假定我们想把 CPU0 设置成专有CPU。 定…...

selenium京东商城爬取
该项目主要参考与:http://c.biancheng.net/python_spider/selenium-case.html 你看完上述项目内容之后,会发现京东登录是一个比较坑的点,selenium控制浏览器没有登录京东,导致我们自动爬取网页被重定向到京东登录注册页面。 因此,我们要单独…...

用pandas处理数据时,使变量能够在不同的Notebook会话页面进行传递,魔法命令%store
【需求来源】 在使用pandas时,有的时候我想将.ipynb文件分开写 其中一个写清洗数据代码另外一个写数据可视化代码 【解决方案】 但是会涉及到变量转移问题,这个时候我通常使用的方法是: 1、在清洗完数据后导出到本地 2、在文件后面增加当…...

选择适合户外篷房企业的企业云盘解决方案
“户外篷房企业用什么企业云盘好?Zoho WorkDrive企业网盘可以帮助户外篷房企业实现文档统一管理、提高工作效率、加强团队协作,并且支持各种文件类型的预览和编辑。” S公司是一家注重管理规范的大型户外篷房企业,已经有10余年的经验。作为设…...
松鼠搜索算法(SSA)(含MATLAB代码)
先做一个声明:文章是由我的个人公众号中的推送直接复制粘贴而来,因此对智能优化算法感兴趣的朋友,可关注我的个人公众号:启发式算法讨论。我会不定期在公众号里分享不同的智能优化算法,经典的,或者是近几年…...

折半+dp之限制转状态+状压:CF1767E
https://vjudge.net/problem/CodeForces-1767E/origin 首先40,必然折半。然后怎么做? 分析性质。每次可以走1步or2步,等价什么?等价任意相邻2个必选一个!然后就可以建图 这个图是个限制图,我们折半后可以…...

如何写出优质代码
(本文转载自其他博主但是个人忘记了出处) 优质代码是什么? 优质代码是指那些易于理解、易于维护、可读性强、结构清晰、没有冗余、运行效率高、可复用性强、稳定性好、可扩展性强的代码。 这类代码不仅能够准确执行预期功能,同时也便于其他开发者理解…...
ChatGLM2-6B的通透解析:从FlashAttention、Multi-Query Attention到GLM2的微调、源码解读
前言 本文最初和第一代ChatGLM-6B的内容汇总在一块,但为了阐述清楚FlashAttention、Multi-Query Attention等相关的原理,以及GLM2的微调、源码解读等内容,导致之前那篇文章越写越长,故特把ChatGLM2相关的内容独立抽取出来成本文 …...
3D人脸生成的论文
一、TECA 1、论文信息 2、开源情况:comming soon TECA: Text-Guided Generation and Editing of Compositional 3D AvatarsGiven a text description, our method produces a compositional 3D avatar consisting of a mesh-based face and body and NeRF-based ha…...

解决问题:可以用什么方式实现自动化部署
自动化部署可以使用多种工具来实现: 脚本编写:可以使用 Bash、Python 等编写脚本来实现自动化部署。例如,可以使用 Bash 脚本来自动安装、配置和启动应用程序。 配置管理工具:像 Ansible、Puppet、Chef、Salt 等配置管理工具可以…...

【数据结构】链表栈
目录: 链表栈 1. 链式栈的实现2. 链表栈的创建3. 压栈4. 弹栈 链表栈 栈的主要表示方式有两种,一种是顺序表示,另一种是链式表示。本文主要介绍链式表示的栈。 链栈实际上和单链表差别不大,唯一区别就在于只需要对链表限定从头…...

Android笔记:Android 组件化方案探索与思考
组件化项目,通过gradle脚本,实现module在编译期隔离,运行期按需加载,实现组件间解耦,高效单独调试。 先来一张效果图 组件化初衷 APP版本不断的迭代,新功能的不断增加,业务也会变的越来越复杂…...
MeterSphere v2.10.X-lts 双节点HA部署方案
一、MeterSphere高可用部署架构及服务器配置 1.1 服务器信息 序号应用名称操作系统要求配置要求描述1负载均衡器CentOS 7.X /RedHat 7.X2C,4G,200GB部署Nginx,实现负载路由。 部署NFS服务器。2MeterSphere应用节点1CentOS 7.X /RedHat 7.X8C,16GB,200G…...
Java进阶篇--网络编程
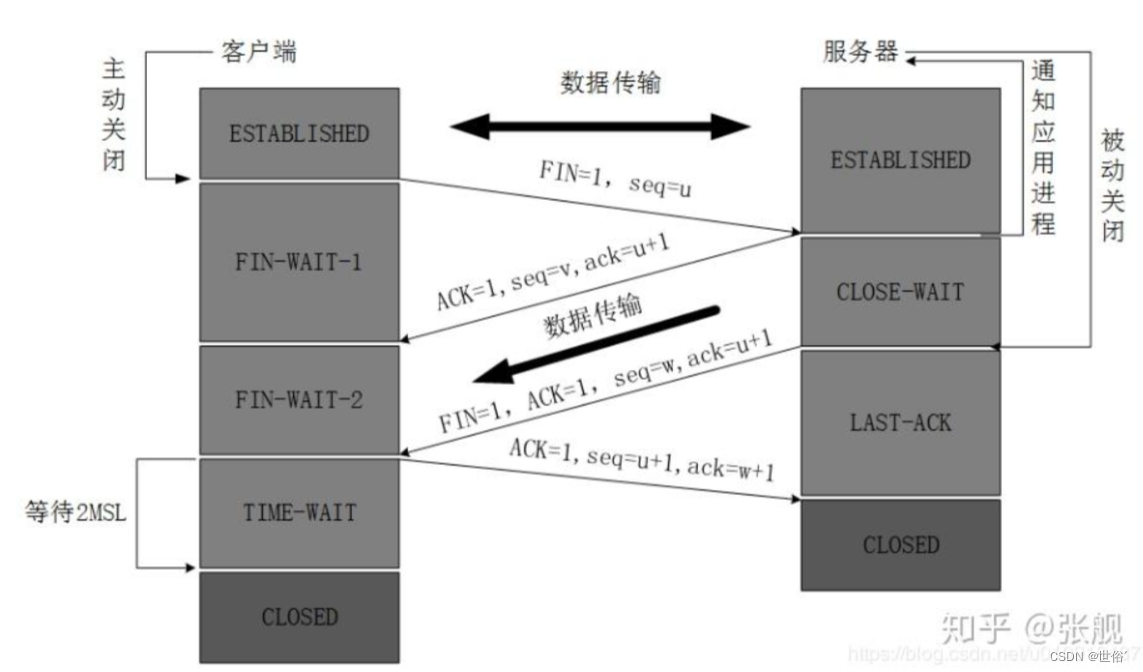
目录 计算机网络体系结构 什么是网络协议? 为什么要对网络协议分层? 网络通信协议 TCP/IP 协议族 应用层 运输层 网络层 数据链路层 物理层 TCP/IP 协议族 TCP的三次握手四次挥手 TCP报文的头部结构 三次握手 四次挥手 …...

PyTorch入门之【CNN】
参考:https://www.bilibili.com/video/BV1114y1d79e/?spm_id_from333.999.0.0&vd_source98d31d5c9db8c0021988f2c2c25a9620 书接上回的MLP故本章就不详细解释了 目录 traintest train import torch from torchvision.transforms import ToTensor from torchvi…...

马斯洛需求层次模型之安全需求之云安全浅谈
在互联网云服务领域,安全需求是用户首要考虑的因素之一。用户希望在将数据和信息托付给云服务提供商时,这些数据和信息能够得到充分的保护,避免遭受未经授权的访问、泄露或破坏。这种安全需求的满足,对于用户来说是至关重要的&…...
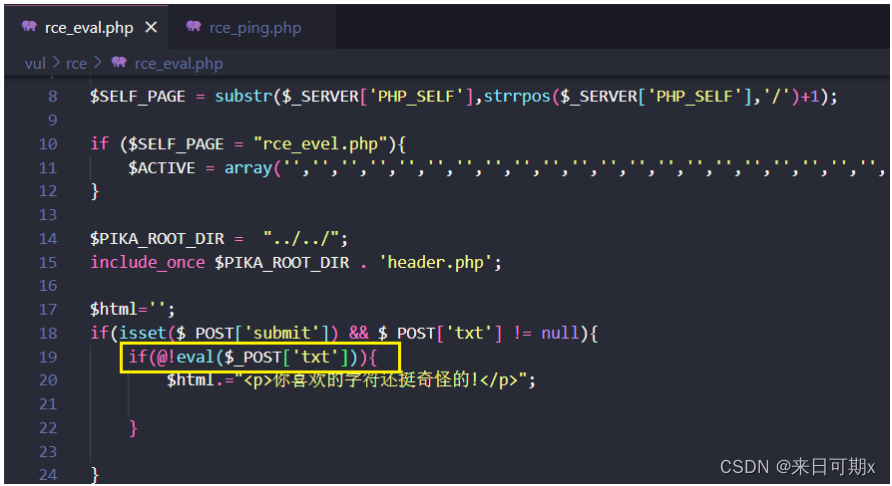
Pikachu靶场——远程命令执行漏洞(RCE)
文章目录 1. RCE1.1 exec "ping"1.1.1 源代码分析1.1.2 漏洞防御 1.2 exec "eval"1.2.1 源代码分析1.2.2 漏洞防御 1.3 RCE 漏洞防御 1. RCE RCE(remote command/code execute)概述: RCE漏洞,可以让攻击者直接向后台服务器远程注入…...
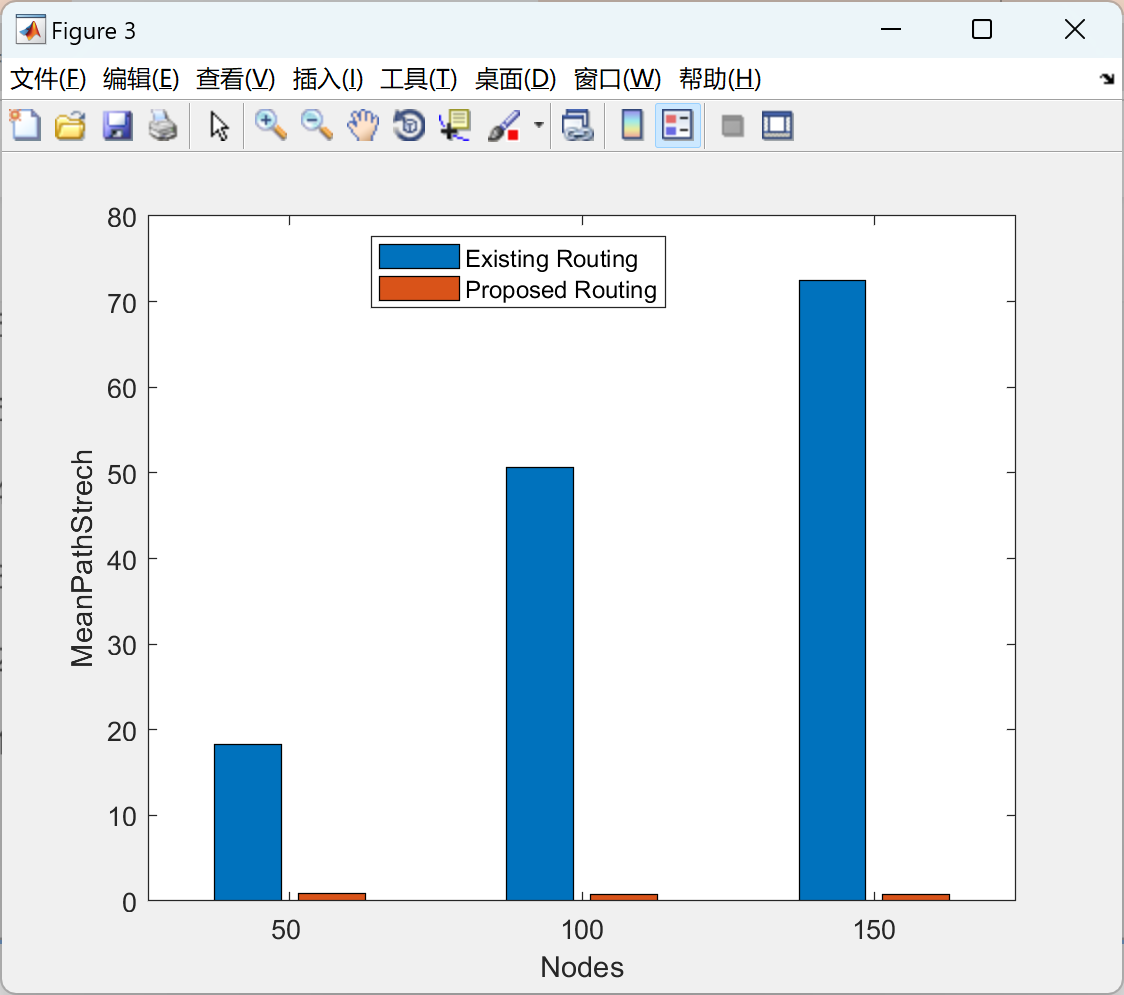
【WSN】无线传感器网络 X-Y 坐标到图形视图和位字符串前缀嵌入方法研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Linux定时任务
文章目录 前言设置定时任务流程定时规则例子 终止定时任务列出当前的定时任务重启任务调度 前言 在Linux系统中有时侯需要周期性的自动执行一些命令,这时候Linux定时任务就派上用场了 设置定时任务流程 进入定时任务的编辑模式 crontab -e编辑定时任务ÿ…...

3步掌握League Akari:高效智能的英雄联盟本地自动化工具
3步掌握League Akari:高效智能的英雄联盟本地自动化工具 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于英…...

Windows风扇控制终极解决方案:FanControl深度配置指南
Windows风扇控制终极解决方案:FanControl深度配置指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa…...

非确定有限自动机—计算机等级考试—软件设计师考前备忘录—东方仙盟
1. 先明确:圆圈里的数字是什么?圆圈里的 0,1,2,3,4,5 是状态编号,不是输入符号,也不是要识别的字符串内容。比如 状态0 是起始状态,状态5 是终止(接受)状态。箭头边上的 0,1,ε 才是输入符号&am…...

GDScript Mod Loader:为Godot游戏打造专业模组生态的完整指南
1. 项目概述:为你的Godot游戏注入社区活力如果你是一名使用Godot引擎的独立游戏开发者,或者是一位热衷于为喜爱的游戏创造新内容的玩家,那么“模组”这个概念你一定不陌生。模组,或者说Mod,是游戏社区生命力的重要源泉…...

基于MCP协议实现AI助手个性化:Terminal Buddies项目实战解析
1. 项目概述:当你的终端伙伴遇见AI助手 如果你和我一样,每天有大量时间泡在终端和代码编辑器里,那么一个能带来些许乐趣和陪伴感的“数字伙伴”或许能点亮枯燥的编码时光。Terminal Buddies 正是这样一个巧妙结合了复古 ASCII 艺术、轻量级游…...

从学生成绩表到销售报表:手把手教你用ag-grid列组/行组构建复杂业务表格
企业级销售报表实战:用ag-grid行组与列组构建动态分析系统 当业务数据从Excel迁移到前端可视化系统时,开发团队常面临多维分析的挑战。某零售企业曾因无法实时查看"华东区→浙江省→杭州市"三级维度下的季度销售趋势,导致错失库存调…...
)
【AI原生架构黄金法则】:SITS 2026现场实录的7条反直觉设计铁律(仅限首批参会专家内部流出)
AI原生应用架构设计:SITS 2026技术专家实战经验分享 更多请点击: https://intelliparadigm.com 第一章:SITS 2026现场共识与AI原生架构范式跃迁 在SITS 2026全球智能系统技术峰会上,来自37个国家的架构师、AI平台工程师与标准化组…...

怪物猎人世界终极叠加层工具:HunterPie 5分钟快速上手指南
怪物猎人世界终极叠加层工具:HunterPie 5分钟快速上手指南 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/hu/HunterPi…...
的安全与应用)
别再只复制粘贴了!深入理解阿里云IoT设备三元组(ProductKey/DeviceName/DeviceSecret)的安全与应用
阿里云IoT设备三元组安全实践指南:从基础认知到高级防护策略 在物联网项目开发中,设备身份认证是保障系统安全的第一道防线。许多开发者虽然能够快速完成设备接入,但对认证核心——设备三元组(ProductKey/DeviceName/DeviceSecret…...

LeagueAkari英雄联盟自动化工具终极使用指南:本地化智能助手全面解析
LeagueAkari英雄联盟自动化工具终极使用指南:本地化智能助手全面解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾为英…...