Elasticsearch:ES|QL 查询语言简介
警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。 Elastic 将尽最大努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束。在目前的 Elastic Stack 8.10 中此功能还没有提供。
Elasticsearch 查询语言 (ES|QL) 是一种支持迭代探索数据的查询语言。
ES|QL 查询由一系列由管道分隔的命令组成。 每个查询都以源命令(FROM, ROW, SHOW <item>)开始。 源命令会生成一个表,通常包含来自 Elasticsearch 的数据。
源命令后面可以跟一个或多个处理命令。 处理命令通过添加、删除或更改行和列来更改输入表。

你可以链接处理命令,并用竖线字符分隔:|。 每个处理命令都作用于前一个命令的输出表。

查询的结果是最终处理命令生成的表。
运行 ES|QL 查询
ES|QL API
使用 _query 端点运行 ES|QL 查询:
POST /_query
{"query": """FROM library| EVAL year = DATE_TRUNC(1 YEARS, release_date)| STATS MAX(page_count) BY year| SORT year| LIMIT 5"""
}结果按行返回:
{"columns": [{ "name": "MAX(page_count)", "type": "integer"},{ "name": "year" , "type": "date"}],"values": [[268, "1932-01-01T00:00:00.000Z"],[224, "1951-01-01T00:00:00.000Z"],[227, "1953-01-01T00:00:00.000Z"],[335, "1959-01-01T00:00:00.000Z"],[604, "1965-01-01T00:00:00.000Z"]]
}默认情况下,结果以 JSON 形式返回。 要返回文本、CSV 或 TSV 格式的结果,请使用 format 参数:
POST /_query?format=txt
{"query": """FROM library| EVAL year = DATE_TRUNC(1 YEARS, release_date)| STATS MAX(page_count) BY year| SORT year| LIMIT 5"""
}上述查询的 LIMIT 命令将结果限制为 5 行。
如果未指定,LIMIT 默认为 500。无论 LIMIT 值如何,单个查询都不会返回超过 10,000 行。
Kibana
在 Discover 中使用 ES|QL 探索数据集。 从数据视图下拉列表中,选择 Try ES|QL 开始。
注意:Discover 和 Lens 中的 ES|QL 查询受时间过滤器选择的时间范围的限制。
限制
- ES|QL 目前支持以下字段类型:
- alias
- boolean
- data
- double(float、half_float、scaled_float 表示为 double)
- ip
- keyword 系列,包括 keyword、constant_keyword 和 wildcard
- int(short 和 byte 均表示为 int)
- long
- null
- text
- unsigned_long
- version
- 无论 LIMIT 命令的值如何,单个查询都不会返回超过 10,000 行。
ES|QL 语法参考
基本语法
ES|QL 查询由一个源命令组成,后跟一系列可选的处理命令,并用竖线字符分隔:|。 例如:
source-command
| processing-command1
| processing-command2查询的结果是最终处理命令生成的表。
为了便于阅读,本文档将每个处理命令放在一个新行中。 但是,你可以将 ES|QL 查询编写为一行。 以下查询与前一个查询相同:
source-command | processing-command1 | processing-command2注释
ES|QL 使用 C++ 风格的注释:
- 双斜杠 // 用于单行注释
- /* 和 */ 用于块注释
// Query the employees index
FROM employees
| WHERE height > 2FROM /* Query the employees index */ employees
| WHERE height > 2FROM employees
/* Query the* employees* index */
| WHERE height > 2运算符
支持以下二进制比较运算符:
- 平等:==
- 不等式:!=
- 小于:<
- 小于或等于:<=
- 大于:>
- 大于或等于:>=
IN 运算符允许测试字段或表达式是否等于文字 (literals)、字段 (fields) 或表达式 (expressions) 列表中的元素:
ROW a = 1, b = 4, c = 3
| WHERE c-a IN (3, b / 2, a)对于使用通配符或正则表达式的字符串比较,请使用 LIKE 或 RLIKE:
- 使用 LIKE 来匹配使用通配符的字符串。 支持以下通配符:
- * 匹配零个或多个字符。
- ? 匹配一个字符。
FROM employees
| WHERE first_name LIKE "?b*"
| KEEP first_name, last_name- 使用 RLIKE 使用正则表达式来匹配字符串:
FROM employees
| WHERE first_name RLIKE ".leja.*"
| KEEP first_name, last_name支持以下布尔运算符:
- AND
- OR
- NOT
Predicates - 谓词
对于 NULL 比较,请使用 IS NULL 和 IS NOT NULL 谓词:
FROM employees
| WHERE birth_date IS NULL
| KEEP first_name, last_name
| SORT first_name
| LIMIT 3| first_name:keyword | last_name:keyword |
|---|---|
| Basil | Tramer |
| Florian | Syrotiuk |
| Lucien | Rosenbaum |
FROM employees
| WHERE is_rehired IS NOT NULL
| STATS count(emp_no)| count(emp_no):long |
|---|
| 84 |
Timespan literals
日期时间间隔和时间跨度可以使用时间跨度文字来表示。 时间跨度文字是数字和限定符的组合。 支持这些限定符:
millisecond/millisecondssecond/secondsminute/minuteshour/hoursday/daysweek/weeksmonth/monthsyear/years
时间跨度文字对空格不敏感。 这些表达式都是有效的:
1day1 day1 day
ES|QL 源命令
ES|QL 源命令会生成一个表,通常包含来自 Elasticsearch 的数据。

ES|QL 支持以下源命令:
- FROM
- ROW
- SHOW <item>
FROM
FROM source 命令返回一个表,其中包含来自数据流、索引或别名的最多 10,000 个文档。 结果表中的每一行代表一个文档。 每列对应一个字段,并且可以通过该字段的名称进行访问。
FROM employees你可以使用 date math 来引用索引、别名和数据流。 这对于时间序列数据很有用,例如访问今天的索引:
FROM <logs-{now/d}>使用逗号分隔的列表或通配符查询多个数据流、索引或别名:
FROM employees-00001,other-employees-*使用 METADATA 指令启用元数据字段:
FROM employees [METADATA _id]ROW
ROW source 命令生成一行,其中包含一个或多个列,这些列具有你指定的值。 这对于测试很有用。
ROW a = 1, b = "two", c = null
| a:integer | b:keyword | c:null |
|---|---|---|
| 1 | "two" | null |
使用方括号创建多值列:
ROW a = [2, 1]ROW 支持使用函数:
ROW a = ROUND(1.23, 0)SHOW <item>
SHOW <item> source 命令返回有关部署及其功能的信息:
- 使用 SHOW INFO 返回部署的版本、构建日期和哈希值。
- 使用 SHOW FUNCTIONS 返回所有支持的函数的列表以及每个函数的概要。
ES|QL 处理命令
ES|QL 处理命令通过添加、删除或更改行和列来更改输入表。
ES|QL 支持这些处理命令:
- DISSECT
- DROP
- ENRICH
- EVAL
- GROK
- KEEP
- LIMIT
- MV_EXPAND
- RENAME
- SORT
- STATS ... BY
- WHERE
DISSECT
DISSECT 使你能够从字符串中提取结构化数据。 DISSECT 将字符串与基于分隔符的模式进行匹配,并将指定的键提取为列。
有关 dissect 模式的语法,请参阅 dissect processor 文档。
ROW a = "1953-01-23T12:15:00Z - some text - 127.0.0.1;"
| DISSECT a "%{Y}-%{M}-%{D}T%{h}:%{m}:%{s}Z - %{msg} - %{ip};"
| KEEP Y, M, D, h, m, s, msg, ip| Y:keyword | M:keyword | D:keyword | h:keyword | m:keyword | s:keyword | msg:keyword | ip:keyword |
|---|---|---|---|---|---|---|---|
| 1953 | 01 | 23 | 12 | 15 | 00 |
DROP
使用 DROP 删除列:
FROM employees
| DROP height你可以使用通配符删除名称与模式匹配的所有列,而不是按名称指定每个列:
FROM employees
| DROP height*
ENRICH
你可以使用 ENRICH 将现有索引中的数据添加到传入记录中。 它与 ingest enrich 类似,但它在查询时工作。
ROW language_code = "1"
| ENRICH languages_policy| language_code:keyword | language_name:keyword |
|---|---|
| 1 | English |
ENRICH 需要执行 enrich policy。 丰富策略定义了一个匹配字段(关键字段)和一组丰富字段。
ENRICH 将根据匹配字段值在 enrich index 中查找记录。 输入数据集中的匹配键可以使用 ON <field-name> 定义; 如果未指定,则将在与 enrich policy 中定义的匹配字段同名的字段上执行匹配。
ROW a = "1"
| ENRICH languages_policy ON a| a:keyword | language_name:keyword |
|---|---|
| 1 | English |
你可以使用 WITH <field1>, <field2>... 语法指定必须将哪些属性(在策略中定义为丰富字段的属性之间)添加到结果中。
ROW a = "1"
| ENRICH languages_policy ON a WITH language_name| a:keyword | language_name:keyword |
|---|---|
| 1 | English |
还可以使用 WITH new_name=<field1> 重命名属性
ROW a = "1"
| ENRICH languages_policy ON a WITH name = language_name| a:keyword | name:keyword |
|---|---|
| 1 | English |
默认情况下(如果未定义 WITH),ENRICH 会将 enrich policy 中定义的所有丰富字段添加到结果中。
如果发生名称冲突,新创建的字段将覆盖现有字段。
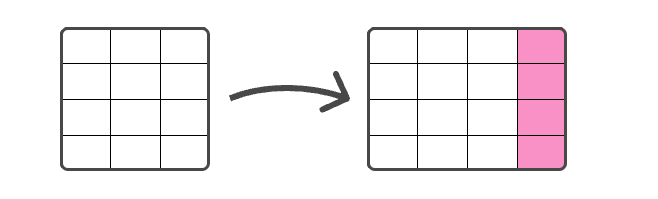
EVAL
EVAL 使你能够附加新列:
FROM employees
| SORT emp_no
| KEEP first_name, last_name, height
| EVAL height_feet = height * 3.281, height_cm = height * 100| first_name:keyword | last_name:keyword | height:double | height_feet:double | height_cm:double |
|---|---|---|---|---|
| Georgi | Facello | 2.03 | 6.66043 | 202.99999999999997 |
如果指定的列已存在,则现有列将被删除,新列将追加到表中:
FROM employees
| SORT emp_no
| KEEP first_name, last_name, height
| EVAL height = height * 3.281| first_name:keyword | last_name:keyword | height:double |
|---|---|---|
| Georgi | Facello | 6.66043 |
Functions
EVAL 支持各种计算值的函数。 请参阅函数了解更多信息。
GROK
GROK 使你能够从字符串中提取结构化数据。 GROK 基于正则表达式将字符串与模式进行匹配,并将指定的模式提取为列。
有关 grok 模式的语法,请参阅 grok 处理器文档。
例如:
ROW a = "1953-01-23T12:15:00Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"
| KEEP date, ip, email, num| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
| 1953-01-23T12:15:00Z | 127.0.0.1 | some.email@foo.com | 42 |
KEEP
KEEP 命令使你能够指定返回哪些列以及返回它们的顺序。
要限制返回的列,请使用以逗号分隔的列名称列表。 列按指定顺序返回:
FROM employees
| KEEP emp_no, first_name, last_name, height| emp_no:integer | first_name:keyword | last_name:keyword | height:double |
|---|---|---|---|
| 10001 | Georgi | Facello | 2.03 |
| 10002 | Bezalel | Simmel | 2.08 |
| 10003 | Parto | Bamford | 1.83 |
| 10004 | Chirstian | Koblick | 1.78 |
| 10005 | Kyoichi | Maliniak | 2.05 |
你可以使用通配符返回名称与模式匹配的所有列,而不是按名称指定每个列:
FROM employees
| KEEP h*星号通配符 (*) 本身会转换为与其他参数不匹配的所有列。 此查询将首先返回名称以 h 开头的所有列,然后是所有其他列:
FROM employees
| KEEP h*, *LIMIT
LIMIT 处理命令使你能够限制行数:
FROM employees
| SORT emp_no ASC
| LIMIT 5如果未指定,LIMIT 默认为 500。无论 LIMIT 值如何,单个查询都不会返回超过 10,000 行。
MV_EXPAND
MV_EXPAND 处理命令将多值(multivalued)字段扩展为每个值一行,并复制其他字段:
ROW a=[1,2,3], b="b", j=["a","b"]
| MV_EXPAND a| a:integer | b:keyword | j:keyword |
|---|---|---|
| 1 | b | ["a", "b"] |
| 2 | b | ["a", "b"] |
| 3 | b | ["a", "b"] |
RENAME
使用 RENAME 使用以下语法重命名列:
RENAME <old-name> AS <new-name>例如:
FROM employees
| KEEP first_name, last_name, still_hired
| RENAME still_hired AS employed如果具有新名称的列已存在,它将被新列替换。
可以使用单个 RENAME 命令重命名多个列:
FROM employees
| KEEP first_name, last_name
| RENAME first_name AS fn, last_name AS lnSORT
使用 SORT 命令对一个或多个字段上的行进行排序:
FROM employees
| KEEP first_name, last_name, height
| SORT height默认排序顺序为升序。 使用 ASC 或 DESC 设置显式排序顺序:
FROM employees
| KEEP first_name, last_name, height
| SORT height DESC具有相同排序键的两行被视为相等。 你可以提供额外的排序表达式来分裁定:
FROM employees
| KEEP first_name, last_name, height
| SORT height DESC, first_name ASCnull values
默认情况下,null 值被视为大于任何其他值。 对于升序排序,空值排在最后,而对于降序排序,空值排在最前面。 你可以通过提供 NULLS FIRST 或 NULLS LAST 来更改它:
FROM employees
| KEEP first_name, last_name, height
| SORT first_name ASC NULLS FIRSTSTATS ... BY
使用 STATS ... BY 根据公共值对行进行分组,并计算分组行上的一个或多个聚合值。
FROM employees
| STATS count = COUNT(emp_no) BY languages
| SORT languages| count:long | languages:integer |
|---|---|
| 15 | 1 |
| 19 | 2 |
| 17 | 3 |
| 18 | 4 |
| 21 | 5 |
| 10 | null |
如果省略 BY,则输出表仅包含一行,并且聚合应用于整个数据集:
FROM employees
| STATS avg_lang = AVG(languages)| avg_lang:double |
|---|
| 3.1222222222222222 |
可以计算多个值:
FROM employees
| STATS avg_lang = AVG(languages), max_lang = MAX(languages)还可以按多个值进行分组(仅支持 long 字段和 keyword 族字段):
FROM employees
| EVAL hired = DATE_FORMAT("YYYY", hire_date)
| STATS avg_salary = AVG(salary) BY hired, languages.long
| EVAL avg_salary = ROUND(avg_salary)
| SORT hired, languages.long支持以下聚合函数:
- AVG
- COUNT
- COUNT_DISTINCT
- MAX
- MEDIAN
- MEDIAN_ABSOLUTE_DEVIATION
- MIN
- PERCENTILE
- SUM
WHERE
使用 WHERE 生成一个表,其中包含输入表中所提供的条件评估为 true 的所有行:
FROM employees
| KEEP first_name, last_name, still_hired
| WHERE still_hired == true如果 still_hired 是布尔字段,则可以简化为:
FROM employees
| KEEP first_name, last_name, still_hired
| WHERE still_hired运算符
有关支持的运算符的概述,请参阅上面的运算符部分。
函数
WHERE 支持各种计算值的函数。 请参阅函数了解更多信息。
FROM employees
| KEEP first_name, last_name, height
| WHERE length(first_name) < 4相关文章:
Elasticsearch:ES|QL 查询语言简介
警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。 Elastic 将尽最大努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束。在目前的 Elastic Stack 8.10 中此功能还没有提供。 Elasticsearch 查询语言 (ES|…...

qt qml中listview出现卡顿情况时的常用处理方法
如果在qt QML中使用ListView时出现卡顿情况,可能是因为渲染大量的数据或者在模型中进行复杂的数据处理。以下是常用的解决方法: 1. 设置ListView的缓存策略:通过设置ListView的cacheBuffer属性为适当的值,可以提高滚动的流畅性。…...

Elasticsearch基础操作演示总结
一、索引操作 (一)创建索引 创建Elasticsearch(ES)索引是在ES中存储和管理数据的重要操作之一。索引是用于组织和检索文档的结构化数据存储。 当创建Elasticsearch索引时,通常需要同时指定索引的设置(Se…...

Spring 作用域解析器AnnotationScopeMetadataResolver
博主介绍:✌全网粉丝近5W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经…...
如何发布一个 NPM 包
首先初始化: npm init 文件夹结构 .gitignore Git 库忽略文件清单.npmignore 不包括在 npm 注册库中的文件清单LECENSE 模块的授权文件README.md 说明文档bin 保存模块可执行文件的文件夹doc 保存模块文档的文件夹example 保存模块实际示例lib 保存模块代码man 保存模块的手册…...
)
Flask小项目教程(含MySQL与前端部分)
CONTENTS 1. 环境配置2. 快速搭建Flask应用程序 1. 环境配置 首先我们在项目的根目录下创建一个 Python 虚拟环境,打开命令行输入以下指令: python -m venv venv启动虚拟环境: .\venv\Scripts\Activate.ps1如果遇到报错:.\venv…...
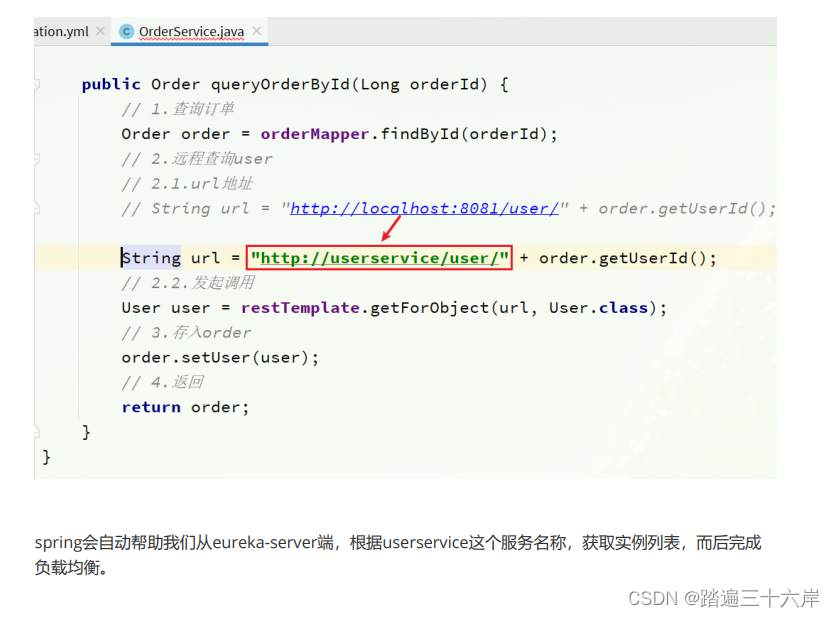
Eureka
大家好我是苏麟今天带来Eureka的使用 . 提供者和消费者 在服务调用关系中,会有两个不同的角色: 服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务) 服务消费者:一次业务…...
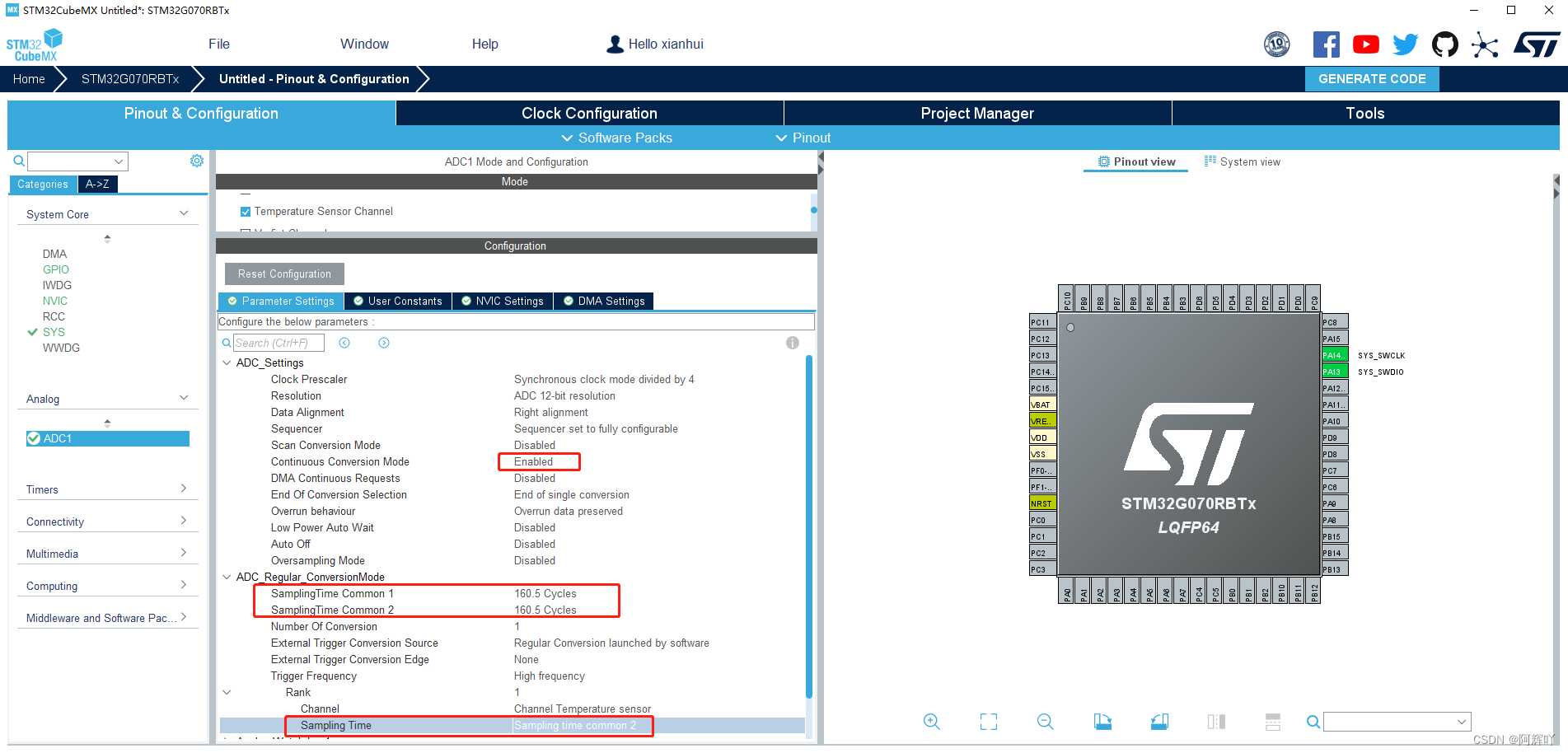
STM32G070RBT6-MCU温度测量(ADC)
1、借助STM32CubeMX生成系统及外设相关初始化代码。 在以上配置后就可以生成相关初始化代码了。 /* ADC1 init function */ void MX_ADC1_Init(void) {/* USER CODE BEGIN ADC1_Init 0 *//* USER CODE END ADC1_Init 0 */ADC_ChannelConfTypeDef sConfig {0};/* USER COD…...

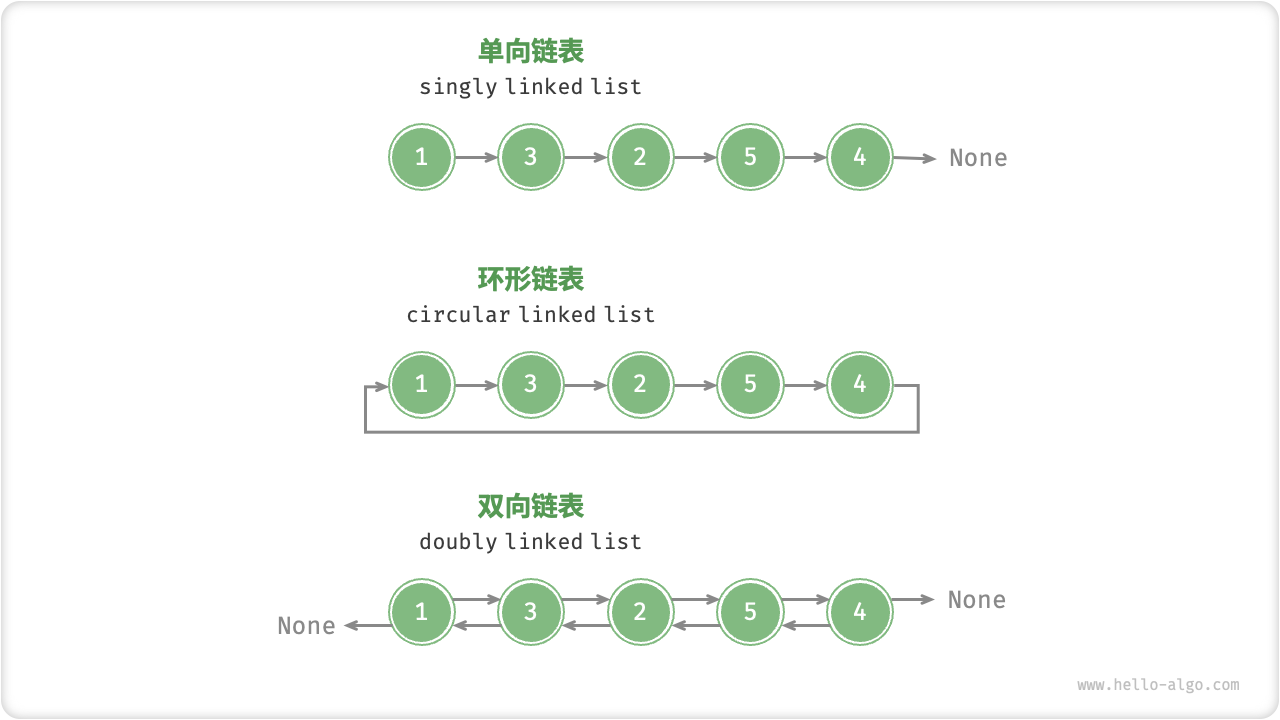
数据结构之带头双向循环链表
目录 链表的分类 带头双向循环链表的实现 带头双向循环链表的结构 带头双向循环链表的结构示意图 空链表结构示意图 单结点链表结构示意图 多结点链表结构示意图 链表创建结点 双向链表初始化 销毁双向链表 打印双向链表 双向链表尾插 尾插函数测试 双向链表头插 …...

adb详细教程(四)-使用adb启动应用、关闭应用、清空应用数据、获取设备已安装应用列表
adb对于安卓移动端来说,是个非常重要的调试工具。本篇介绍常用的adb指令 文章目录 一、启动应用:adb shell am start二、使用浏览器打开指定网址:adb shell am start三、杀死应用进程adb shell am force-stop/adb shell am kill四、删除应用所…...
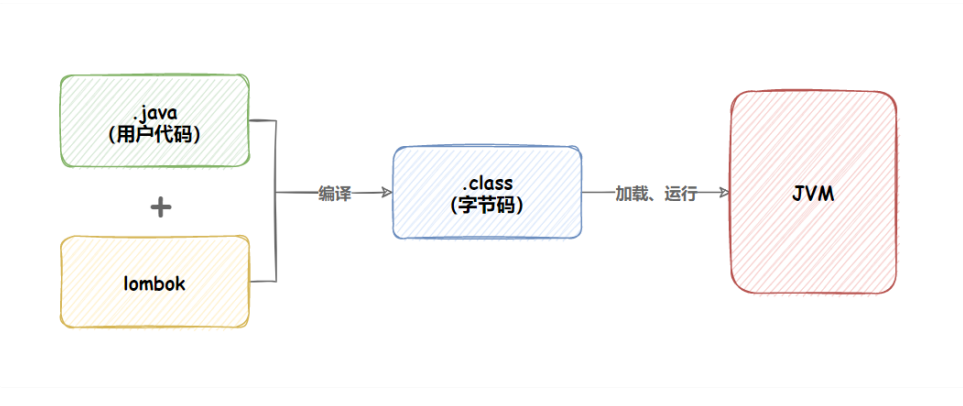
【Spring Boot】日志文件
日志文件 一. 日志文件有什么用二. 日志怎么用三. ⾃定义⽇志打印1. 在程序中得到⽇志对象2. 使⽤⽇志对象打印⽇志3. ⽇志格式说明 四. 日志级别1. ⽇志级别有什么⽤2. ⽇志级别的分类与使⽤ 五. 日志持久化六. 更简单的⽇志输出—lombok1. 添加 lombok 依赖2. 输出⽇志3. lom…...

图像处理与计算机视觉--第五章-图像分割-Canny算子
文章目录 1.边缘检测算子分类2.Canny算子核心理论2.1.Canny算子简单介绍2.2.Canny算子边缘检测指标2.3.Canny算子基本原理 3.Canny算子处理流程3.1.高斯滤波去噪声化3.2.图像梯度搜寻3.3.非极大值抑制处理3.4.双阈值边界处理3.5.边界滞后技术跟踪3.6.Canny算子边缘检测的特点 4…...
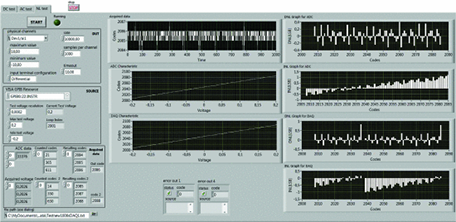
LabVIEW开发教学实验室自动化INL和DNL测试系统
LabVIEW开发教学实验室自动化INL和DNL测试系统 如今,几乎所有的测量仪器都是基于微处理器的设备。模拟输入量在进行数字处理之前被转换为数字量。对于参加电气和电子测量课程的学生来说,了解ADC以及如何欣赏其性能至关重要。ADC的不确定性可以根据其传输…...
数据结构: 数组与链表
目录 1 数组 1.1 数组常用操作 1. 初始化数组 2. 访问元素 3. 插入元素 4. 删除元素 5. 遍历数组 6. 查找元素 7. 扩容数组 1.2 数组优点与局限性 1.3 数组典型应用 2 链表 2.1 链表常用操作 1. 初始化链表 2. 插入节点 3. 删除…...
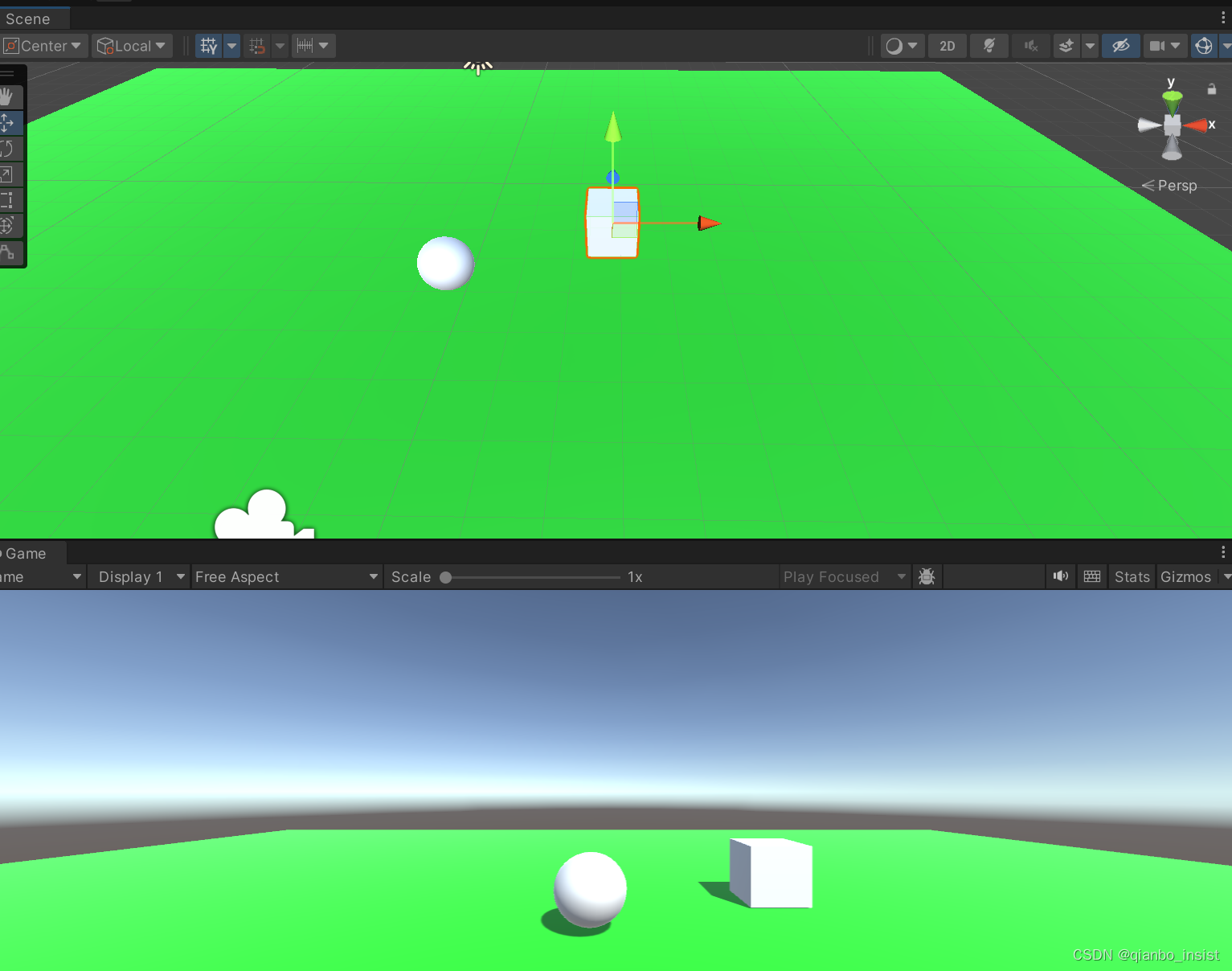
unity 控制玩家物体
创建场景 放上一个plane,放上一个球 sphere,假定我们的球就是我们的玩家,使用控制键w a s d 来控制球也就是玩家移动。增加一个材质,把颜色改成绿色,把材质赋给plane,区分我们增加的白球。 增加组件和脚…...
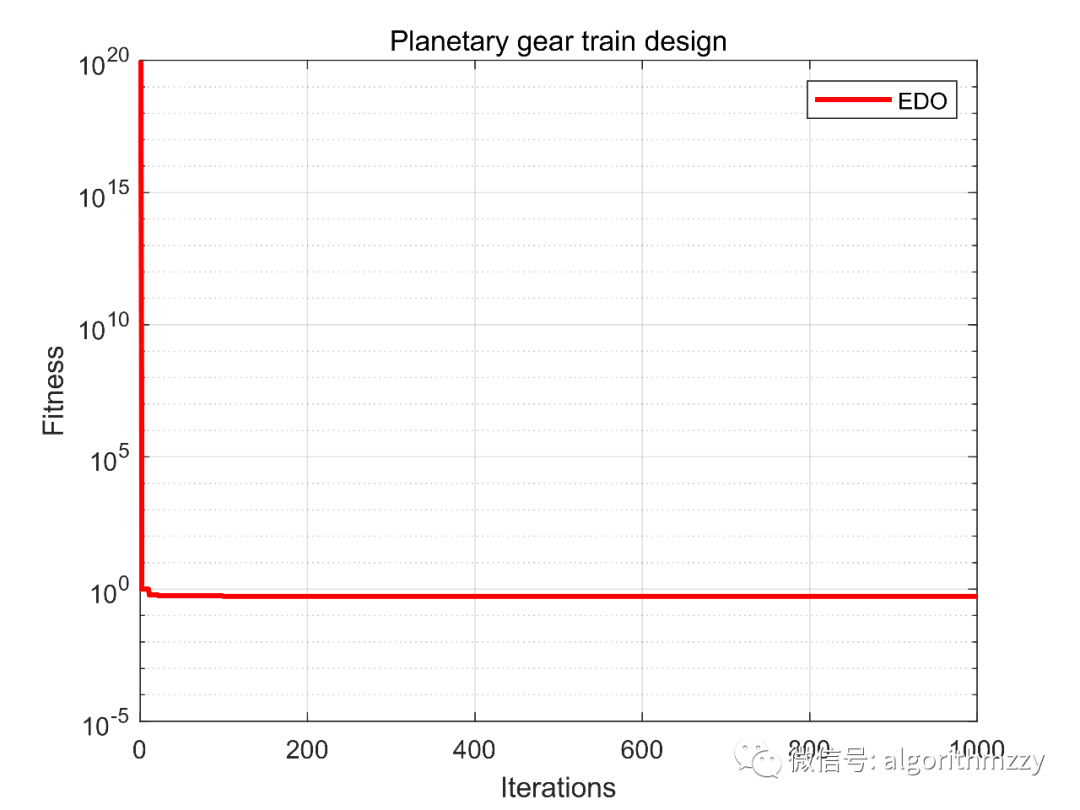
指数分布优化器(EDO)(含MATLAB代码)
先做一个声明:文章是由我的个人公众号中的推送直接复制粘贴而来,因此对智能优化算法感兴趣的朋友,可关注我的个人公众号:启发式算法讨论。我会不定期在公众号里分享不同的智能优化算法,经典的,或者是近几年…...

Java 时间的加减处理
时间的加减处理 Date date new Date(操作时间(类型Date)-(60000*60*1));600001分钟 60000*60*1 1小时...

基于A4988/DRV8825的四路步进电机驱动器
概述 简化板的CNC sheild V3.0,仅保留步进电机速度与方向的控制引脚STEP/DIR、使能端EN、芯片供电VCC\GND,共计11个引脚。PCB四周开设四个M3通孔,以便于安装固定。此外,将板载的焊死的保险丝更改为可更换的保险座保险丝ÿ…...

万字总结网络原理
目录 一、网络基础 1.1认识IP地址 1.2子网掩码 1.3认识MAC地址 1.4一跳一跳的网络数据传输 1.5总结IP地址和MAC地址 二、网络设备及相关技术 2.1集线器:转发所有端口 2.2交换机:MAC地址转换表+转发对应端口 2.3主机:网络分层从上到下封装 2.4主机&路由器:ARP…...

【AI视野·今日CV 计算机视觉论文速览 第262期】Fri, 6 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Fri, 6 Oct 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers Improved Baselines with Visual Instruction Tuning Authors Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee大型多模…...

MySQL 基础:SELECT、WHERE、JOIN 的第一次使用
不用怕数据库,跟着这三个单词,你就能查到你想要的一切。欢迎来到 《大一突围》 专栏。很多大一同学第一次接触 MySQL,看到“数据库”三个字就觉得很难。其实,你日常生活中每天都在“查数据”——查成绩、翻通讯录、筛选淘宝商品……...

浙大推出让AI会「导演」的角色扮演框架!四通道消息沉浸式交互|ACL 2026
AdaMARP团队 投稿量子位 | 公众号 QbitAIAI能实现真正的沉浸式扮演了。大语言模型在角色扮演任务上进展迅速,但现有系统往往缺乏沉浸感和适应性:环境信息未被充分建模,场景与角色也多为静态,难以支撑多角色调度、场景切换、动态引…...
)
保姆级教程:手把手教你用Intel RealSense D435i进行动态标定(附打印目标尺寸)
深度相机动态标定实战:从原理到精准优化的完整指南 在计算机视觉和机器人领域,深度相机的标定质量直接决定了三维感知的精度。许多开发者在初次使用Intel RealSense D435i这类设备时,常常会遇到深度图像噪点多、边缘模糊或数据空洞等问题。这…...

终极指南:如何彻底解锁《原神》60帧限制?完整免费解决方案
终极指南:如何彻底解锁《原神》60帧限制?完整免费解决方案 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 你是一个文章写手,你负责为开源项目写专业易…...

Zotero Duplicates Merger终极指南:3分钟彻底告别文献库重复烦恼
Zotero Duplicates Merger终极指南:3分钟彻底告别文献库重复烦恼 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 还在为Zotero文献…...

终极低光照图像数据集ExDark:从实战应用到最新研究进展
终极低光照图像数据集ExDark:从实战应用到最新研究进展 【免费下载链接】Exclusively-Dark-Image-Dataset Exclusively Dark (ExDARK) dataset which to the best of our knowledge, is the largest collection of low-light images taken in very low-light enviro…...

【开发实战】【memtester】嵌入式系统内存稳定性保障:从工具原理到压力测试场景全解析
1. 为什么嵌入式系统需要内存稳定性测试 在嵌入式产品量产前,内存稳定性测试是硬件验证中最容易被忽视却至关重要的环节。我曾参与过一个智能家居网关项目,设备在实验室运行一切正常,但批量部署后却频繁出现随机重启。经过两周的排查…...

揭秘SITS 2026调度内核:如何用1个轻量CRD替代3类Operator+2个Admission Webhook,实现离线推理任务零配置交付?
更多请点击: https://intelliparadigm.com 第一章:AI原生批处理优化:SITS 2026离线推理任务调度策略 SITS 2026(Scalable Intelligent Task Scheduler)是专为AI原生工作负载设计的离线推理调度引擎,其核心…...

ZYNQ PL端纯Verilog逻辑固化踩坑记:为什么我的bit文件烧不进Flash?
ZYNQ PL端逻辑固化深度解析:从硬件启动原理到避坑实践 第一次尝试在ZYNQ上固化纯PL端逻辑时,很多工程师都会遇到一个令人困惑的现象——明明在普通FPGA上能轻松实现的bit文件烧录,到了ZYNQ平台却屡屡失败。这背后隐藏着ZYNQ芯片独特的启动机制…...
)
UE4项目里用Lua写逻辑,我踩过的坑和高效配置(VSCode+Emmylua)
UE4项目中用Lua开发的高效避坑指南:从VSCode配置到实战技巧 当Unreal Engine 4项目规模逐渐扩大,纯蓝图和C的开发模式开始暴露出编译时间长、热更新困难等问题。这时引入Lua作为脚本语言成为许多团队的选择。但实际开发中,从环境搭建到编写可…...