【小工具-生成合并文件】使用python实现2个excel文件根据主键合并生成csv文件
1 小工具说明
1.1 功能说明
一般来说,我们会先有一个老的文件,这个文件内容是定制好相关列的表格,作为每天的报告。
当下一天来的时候,需要根据新的报表文件和昨天的报表文件做一个合并,合并的时候就会出现有些事新增条目、有些是可能要删除的条目、有些是要更新状态的条目。
当前使用python编写的练习就是达到这个简单目的。
1.2 配置文件
配置文件内容样例:
yesterday=F:\projects\daily_merge_tool\test_files\scene1_no_diff\yesterday.xlsx
today=F:\projects\daily_merge_tool\test_files\scene1_no_diff\today.xlsx
report=F:\projects\daily_merge_tool\test_files\scene1_no_diff\report.csv
yesterday_primary_key_column=D
yesterday_status_column=E
today_primary_key_column=F
today_status_column=E
today_mapping_yesterday=C:B,D:C,F:D,E:E,H:F,I:G,J:H,K:I,L:J,M:K
yesterday的值为昨天的报表文件绝对路径
today的值为今天从其他系统新导出来的报表文件的绝对路径
report的值为存放合并当天最新报表的csv文件的绝对路径
yesterday_primary_key_column的值为昨天的报表文件中能够唯一代表一行数据的属性所在的列,例如:如果值是字母A是excel表格的第一列
yesterday_status_column的值为昨天的报表文件中当前行数据的状态列,例如:如果值是字母A是excel表格的第一列
today_primary_key_column值为今天的报表文件中能够唯一代表一行数据的属性所在的列,例如:如果值是字母A是excel表格的第一列
today_status_column的值为今天的报表文件中当前行数据的状态列,例如:如果值是字母A是excel表格的第一列
today_mapping_yesterday的值为昨天报表文件中各个列的数据来源映射到今天新导出的报表文件中的列
1.3 几个文件的样例
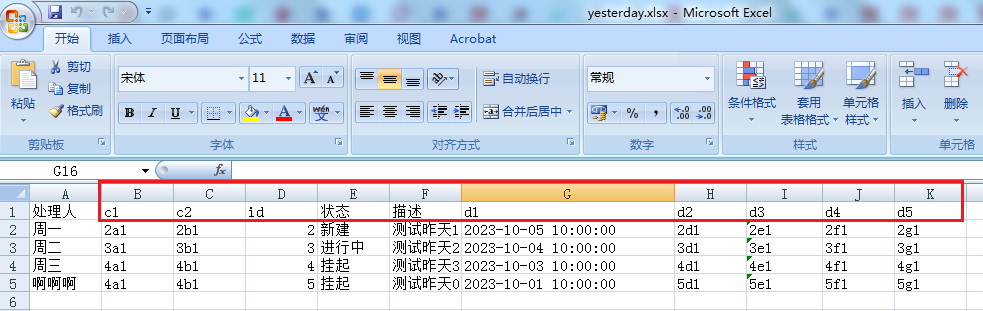
yesterday.xlsx
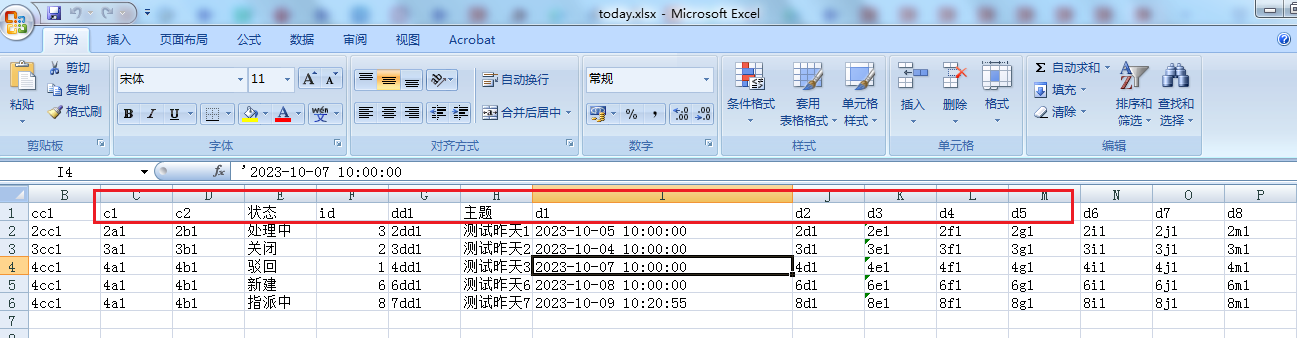
today.xlsx
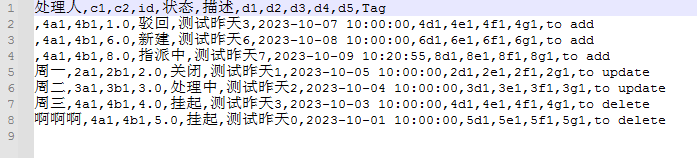
生成的report.csv,相比yesterday.xlsx,增加了1列Tag,标示当前行是新加还是修改了状态还是确认是否要删除
2 工具代码
https://download.csdn.net/download/WolfOfSiberian/88399882
import sys
import datetime
import xlrddef read_excel(excel_file_path):print("read excel: " + str(excel_file_path))readfile = xlrd.open_workbook(excel_file_path)names = readfile.sheet_names()obj_sheet = readfile.sheet_by_name(names[0])row = obj_sheet.nrows# col = obj_sheet.ncolsresult = [0 for i in range(row)]for i in range(row):result[i] = obj_sheet.row_values(i)return resultdef get_id_list(filepath, primary_key_column):print(str(datetime.datetime.now()) + " method get_id_list() invoked.")file_arrary = read_excel(filepath)data_row_num = len(file_arrary)id_list = []for i in range(1, data_row_num):id_list.append(file_arrary[i][ord(primary_key_column) - ord('A')])print(str(datetime.datetime.now()) + "file: " + filepath + ", id list:" + str(id_list))return id_listdef get_operation_list(yesterday_filepath, today_filepath,yesterday_primary_key_column,today_primary_key_column):yesterday_id_list = get_id_list(yesterday_filepath, yesterday_primary_key_column)today_id_list = get_id_list(today_filepath, today_primary_key_column)to_add = []to_del = []to_update = []operationList = [yesterday_id_list, today_id_list, to_add, to_del, to_update]for i in range(len(yesterday_id_list)):is_exist_in_today = 0curr_yesterday_id = yesterday_id_list[i]for j in range(len(today_id_list)):if curr_yesterday_id == today_id_list[j]:if curr_yesterday_id not in to_update:to_update.append(curr_yesterday_id)is_exist_in_today = 1breakif is_exist_in_today == 0:if curr_yesterday_id not in to_del:to_del.append(curr_yesterday_id)is_exist_in_today = 0 #reset statusfor i in range(len(today_id_list)):curr_today_id = today_id_list[i]if curr_today_id not in yesterday_id_list:if curr_today_id not in to_add:to_add.append(curr_today_id)print("operationList: \nyesterday_id_list," + str(operationList[0])+ ",\ntoday_id_list" + str(operationList[1])+ ",\nto_add" + str(operationList[2]) + ",\nto_del" + str(operationList[3]) + ",\nto_update" + str(operationList[4]))return operationListdef get_status_by_id(id, primary_key_column, status_column, total_result):for i in range(1, len(total_result)):if id == total_result[i][ord(primary_key_column) - ord('A')]:return total_result[i][ord(status_column) - ord('A')]return "N/A"def read_configurations(configuration_filepath):#configuration.txt内容例子# yesterday=F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\yesterday.xlsx# today=F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\today.xlsx# report=F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\report.csv# yesterday_primary_key_column=D# yesterday_status_column=E# today_primary_key_column=F# today_status_column=E# today_mapping_yesterday=C:B,D:C,F:D,E:E,H:F,I:G,J:H,K:I,L:J,M:Kprint("configuration filepath:" + configuration_filepath)configuration_file = open(configuration_filepath, mode='r')lines = configuration_file.readlines()configurations = {}for line in lines:entry = line.strip().split("=")if "," in entry[1]:# today_mapping_yesterdaymapping_entry_array = entry[1].split(",")today_mapping_yesterday = {}for mapping_entry in mapping_entry_array:mapping_key_value = mapping_entry.split(":")today_mapping_yesterday[mapping_key_value[0]] = mapping_key_value[1]configurations[entry[0]] = today_mapping_yesterdayelse :configurations[entry[0]] = entry[1]return configurationsdef generate_today_report(configuration_filepath):yesterday = "F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\yesterday.xlsx"# today = "F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\today.xlsx"# report = "F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\report.csv"# yesterday_primary_key_column = 'D'# yesterday_status_column = 'E'# today_primary_key_column = 'F'# today_status_column = 'E'# today_mapping_yesterday = {'C':'B',# 'D':'C',# 'F':'D',# 'E':'E',# 'H':'F',# 'I':'G',# 'J':'H',# 'K':'I',# 'L':'J',# 'M':'K'}configurations = read_configurations(configuration_filepath)today = configurations['today']report = configurations['report']yesterday_primary_key_column = configurations['yesterday_primary_key_column']yesterday_status_column = configurations['yesterday_status_column']today_primary_key_column = configurations['today_primary_key_column']today_status_column = configurations['today_status_column']today_mapping_yesterday = configurations['today_mapping_yesterday']yesterday_result = read_excel(yesterday)today_result = read_excel(today)operation_list = get_operation_list(yesterday, today, yesterday_primary_key_column, today_primary_key_column)try:report_file = open(report, mode='w')#write titlefor i in range(len(yesterday_result[0])):report_file.write(yesterday_result[0][i]) report_file.write(",")report_file.write("Tag")report_file.write("\n")#write contentfor i in range(1, len(today_result)):id = operation_list[1][i - 1]if id in operation_list[2]:#add#extract for report according by column index mappingto_add_report_record = []for x in range(len(yesterday_result[0])):to_add_report_record.append("")for j in range(len(today_result[i])):current_today_column = chr(j + ord('A'))if current_today_column in today_mapping_yesterday:to_add_report_record[ord(today_mapping_yesterday[current_today_column]) - ord('A')] = today_result[i][j]#write to report for m in range(len(to_add_report_record)):report_file.write(str(to_add_report_record[m]))report_file.write(",")report_file.write("to add")report_file.write("\n")for i in range(1, len(yesterday_result)):id = operation_list[0][i - 1]if id in operation_list[3]:#deletefor j in range(len(yesterday_result[i])):report_file.write(str(yesterday_result[i][j]))report_file.write(",")report_file.write("to delete")else :#updatefor j in range(len(yesterday_result[i])):today_status = get_status_by_id(id, today_primary_key_column, today_status_column, today_result)if j == ord(yesterday_status_column) - ord('A'):report_file.write(today_status)else :report_file.write(str(yesterday_result[i][j]))report_file.write(",")report_file.write("to update")report_file.write("\n")except Exception as e:print("failed to generate report.")print(e)finally:report_file.close()print("generate report successfully.")return
print("==^^==^^==")
if len(sys.argv) <= 1:print("please input the configuration filepath when running this python file.")
else :generate_today_report(sys.argv[1])
print("==^^==^^==")
3 参考资料
解决python中XLRDError: Excel xlsx file; not supported
https://blog.csdn.net/qq_53464193/article/details/128407954
VSCode使用 - 搭建python运行调试环境
https://zhuanlan.zhihu.com/p/625844895?utm_id=0&wd=&eqid=b12208f700185aeb000000036498f302
Python读取Excel文件
https://blog.csdn.net/weixin_49895216/article/details/127812149
python操作Excel读写–使用xlrd
https://blog.csdn.net/qq_36396104/article/details/77875703
相关文章:
【小工具-生成合并文件】使用python实现2个excel文件根据主键合并生成csv文件
1 小工具说明 1.1 功能说明 一般来说,我们会先有一个老的文件,这个文件内容是定制好相关列的表格,作为每天的报告。 当下一天来的时候,需要根据新的报表文件和昨天的报表文件做一个合并,合并的时候就会出现有些事新增…...
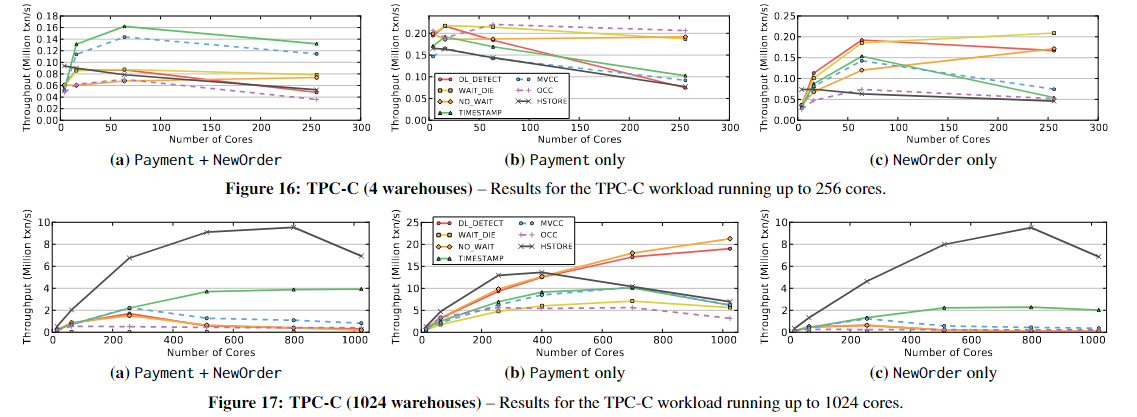
【论文阅读】An Evaluation of Concurrency Control with One Thousand Cores
An Evaluation of Concurrency Control with One Thousand Cores Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores ABSTRACT 随着多核处理器的发展,一个芯片可能有几十乃至上百个core。在数百个线程并行运行的情况下&…...
网页版”高德地图“如何设置默认城市?
问题: 每次打开网页版高德地图时默认定位的都是“北京”,想设置起始点为目前本人所在城市,烦恼的是高德地图默认的初始位置是北京。 解决: 目前网页版高德地图暂不支持设置起始点,打开默认都是北京,只能将…...

小谈设计模式(8)—代理模式
小谈设计模式(8)—代理模式 专栏介绍专栏地址专栏介绍 代理模式代理模式角色分析抽象主题(Subject)真实主题(Real Subject)代理(Proxy) 应用场景远程代理虚拟代理安全代理智能引用代…...

queryWrapper的使用教程
大于、等于、小于 eq 等于 例:queryWrapper.eq("属性","lkm") ——> 属性 lkm ne 不等于 例:queryWrapper.ne("属性","lkm") ——> 属性<> lkm gt 大于 例:queryWrapper.gt("属性…...

数组模拟双链表
文章目录 QuestionIdeasCode Question 实现一个双链表,双链表初始为空,支持 5 种操作: 在最左侧插入一个数; 在最右侧插入一个数; 将第 k 个插入的数删除; 在第 k 个插入的数左侧插入一个数; …...
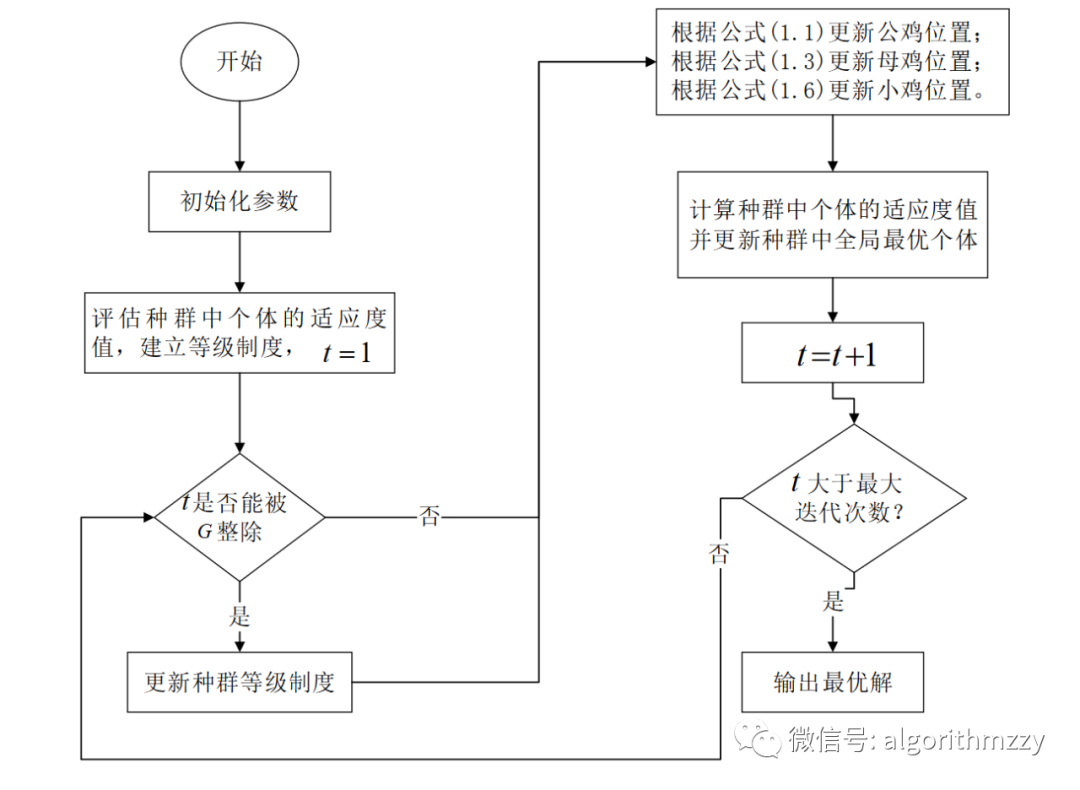
鸡群优化(CSO)算法(含MATLAB代码)
先做一个声明:文章是由我的个人公众号中的推送直接复制粘贴而来,因此对智能优化算法感兴趣的朋友,可关注我的个人公众号:启发式算法讨论。我会不定期在公众号里分享不同的智能优化算法,经典的,或者是近几年…...
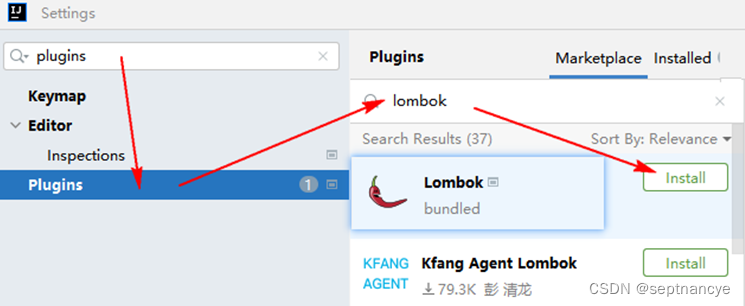
3. 安装lombok maven镜像设置
安装lombok & maven镜像设置 一、maven镜像设置 Maven:负责进行项目管理、依赖工具管理的 软件。 快捷解决方案: 1.方法一 直接配置系统默认的文件 各个人因为登录的用户名不同,所以目录名不同。 2.方法二 自定义本地仓库的位置 完成之后重新打…...

详谈Spring
作者:爱塔居 专栏:JavaEE 目录 一、Spring是什么? 1.1 Spring框架的一些核心特点: 二、IoC(控制反转)是什么? 2.1 实现手段 2.2 依赖注入(DI)的实现原理 2.3 优点 三、AO…...
PyTorch入门之【AlexNet】
参考文献:https://www.bilibili.com/video/BV1DP411C7Bw/?spm_id_from333.999.0.0&vd_source98d31d5c9db8c0021988f2c2c25a9620 AlexNet 是一个经典的卷积神经网络模型,用于图像分类任务。 目录 大纲dataloadermodeltraintest 大纲 各个文件的作用&…...
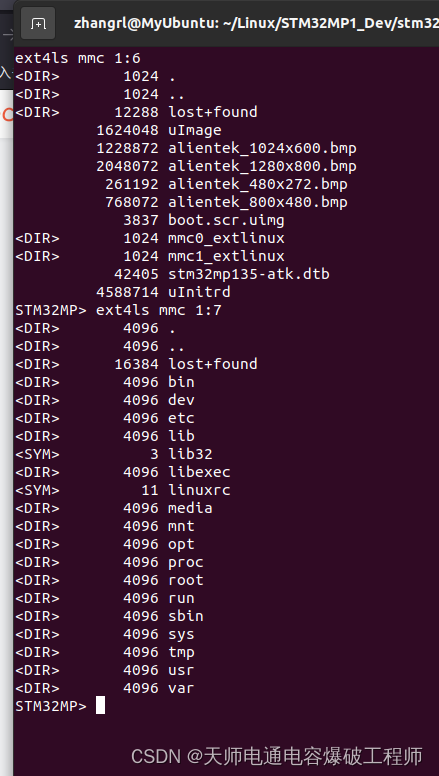
(六)正点原子STM32MP135移植——内核移植
目录 一、概述 二、编译官方代码 三、移植 四、编译 一、概述 前面已经移植好了TF-A、optee、u-boot,在u-boot能正常跑起来的情况下,现在来移植内核。 二、编译官方代码 进入kernel目录 2.1 解压源码、打补丁 /* 解压源码 */ tar xf linux-6.1.28.…...

自媒体工作内容管理助手
内容助手 访问地址:editor.yunwow.cn 背景介绍 最近在学习流量运营, 流量运营的第一站是内容创作, 我试过不少原创内容,都是跟生活相关的例如:录一段联琴的视频、录一段秋天的风景、写一段生活感悟、发一段小宠物的生…...

Echarts 教程一
Echarts 教程一 可视化大屏幕适配方案可视化大屏幕布局方案Echart 图表通用配置部分解决方案1. titile2. tooltip3. xAxis / yAxis 常用配置4. legend5. grid6. series7.color Echarts API 使用全局echarts对象echarts实例对象 可视化大屏幕适配方案 rem flexible.js 关于flex…...

【Kubernetes】Kubernetes 对象是什么?
什么是 Kubernetes 对象?常见的 Kubernetes 对象参考🔎感谢 💖 什么是 Kubernetes 对象? Kubernetes 对象是持久化的实体,用于描述整个集群的状态和配置。它们是在 etcd 等持久化存储中存储的,因此它们的状…...

【C++设计模式之模板模式】分析及示例
C之模板模式 描述实现原理示例步骤1步骤1 分析步骤2步骤2 分析调用输出结果 结论 描述 模板模式(Template Pattern)是设计模式中的一种行为型模式。 该模式定义一个操作中的算法骨架,而将具体的算法实现延迟到子类中。 模板模式使得子类可以…...
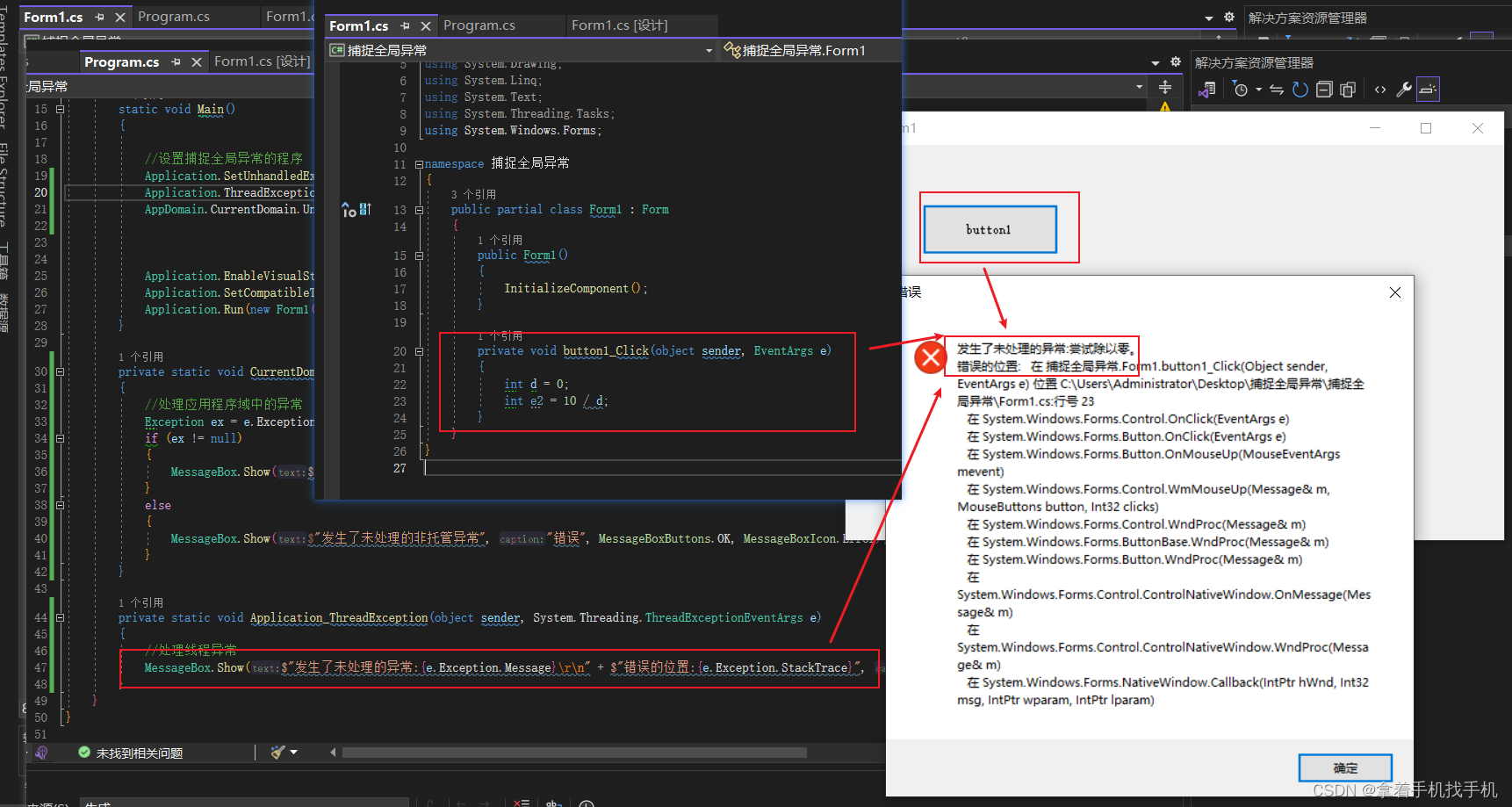
C#捕捉全局异常
1.运行图片 2.源码 using System; using System.Collections.Generic; using System.Linq; using System.Threading.Tasks; using System.Windows.Forms;namespace 捕捉全局异常 {internal static class Program{/// <summary>/// 应用程序的主入口点。/// </summary…...

java.text.ParseException: Unparseable date: “2023-09-06T09:08:18“
问题描述: java.text.ParseException: Unparseable date: “2023-09-06T09:08:18” 这是在String类型转Date类型出现的错误,主要是String类型时间中间有一个T在转换的过程出现问题. 解决方法: SimpleDateFormat simpleDateFormat new SimpleDateFormat…...

macOS 下如何优雅的使用 Burp Suite 汉化
转载 https://www.sqlsec.com/2019/11/macbp.html 主要内容是根据上面的来的 下面总结个人出现错误的地方 主要是优雅配置方面 不要直接复制粘贴 看清楚人家的内容 下面的可以直接复制粘贴 --add-opensjava.desktop/javax.swingALL-UNNAMED --add-opensjava.base/java.lang…...

进程同步与进程互斥
1.进程同步 知识点回顾: 进程具有异步性的特征。 异步性是指,各并发执行的进程以各自独立的、不可预知的速度向前推进。 如何解决这种异步问题,就是“进程同步”所讨论的内容。 同步亦称直接制约关系,它是指为完成某种任务而建立的两个或多…...

公司安防工程简要介绍及系统需求分析
多年来 从事安保监控领域的经验,在系统的功能要求、设备选型、施 工控制、 后期维护、人员配备等各方面反复论证,最终形成了本方案。在系统 的硬件选择上,把系统的稳定性、安全性、可靠性放在第一位。根据 招标文件的要求选用当今安防行业具…...

SaaS级AI员工系统源码商用版,多租户+计费系统+API分销,一套源码搞定
温馨提示:文末有资源获取方式最近“龙虾AI”的热度居高不下,到处都在讨论如何“养龙虾”。但观察下来发现,这类应用对普通用户而言技术门槛还是偏高,部署、配置、调试都需要专人跟进,最终往往沦为摆设。源码获取方式在…...

编译原理避坑指南:自顶向下语法分析的5个常见错误及解决方法
编译原理避坑指南:自顶向下语法分析的5个常见错误及解决方法 第一次接触自顶向下语法分析时,我盯着那个无限循环的递归文法整整三天没想明白——为什么明明按照教材步骤操作,程序却始终报错?直到助教指出我忽略了间接左递归的隐蔽…...

AutoUnipus:重新定义U校园学习效率的智能解决方案
AutoUnipus:重新定义U校园学习效率的智能解决方案 【免费下载链接】AutoUnipus U校园脚本,支持全自动答题,百分百正确 2024最新版 项目地址: https://gitcode.com/gh_mirrors/au/AutoUnipus 还在为U校园平台上堆积如山的网课任务而焦虑吗?每天花费…...

Dify工作流终极指南:3天从新手到专家的完整免费教程
Dify工作流终极指南:3天从新手到专家的完整免费教程 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Dify-Wo…...

大模型应用指南:小白程序员必收藏,轻松入门AI前沿技术!
2025年大模型技术已在IT、金融、制造等领域广泛应用,从智能客服到数据分析,助力企业转型。沙丘智库《大模型应用跟踪月报》收录504个案例,揭示行业分布、应用场景及发展趋势。大模型不仅是技术突破,更是时代标志,小白程…...

Realistic Vision V5.1镜像部署实操:解决‘模型路径不存在’异常的完整排查链
Realistic Vision V5.1镜像部署实操:解决‘模型路径不存在’异常的完整排查链 1. 引言:从“模型路径不存在”说起 如果你在部署Realistic Vision V5.1虚拟摄影棚时,满怀期待地启动程序,结果却在控制台看到一行冰冷的“模型路径不…...

腾讯王者荣耀强化学习环境:打造专业AI训练平台的完整指南
腾讯王者荣耀强化学习环境:打造专业AI训练平台的完整指南 【免费下载链接】hok_env Honor of Kings AI Open Environment of Tencent 项目地址: https://gitcode.com/gh_mirrors/ho/hok_env 在人工智能研究领域,游戏环境一直是强化学习算法的理想…...

智慧交通落地难题:为什么80%的智能信号灯项目效果不达预期?
智慧交通落地困境:从技术神话到现实瓶颈的深度解构 清晨7点30分,北京东三环的某个十字路口,20名交警正在手动调节信号灯——这个造价480万元的智能信号系统在早高峰时段被完全弃用。类似的场景正在全国至少17个城市重复上演,某头部…...

Charticulator:颠覆式图表构建引擎如何让数据工作者实现零代码可视化创新
Charticulator:颠覆式图表构建引擎如何让数据工作者实现零代码可视化创新 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 数据可视化领域长期面临着模…...

终极指南:nanoGPT如何让每个人都能训练自己的AI语言模型?
终极指南:nanoGPT如何让每个人都能训练自己的AI语言模型? 【免费下载链接】nanoGPT The simplest, fastest repository for training/finetuning medium-sized GPTs. 项目地址: https://gitcode.com/GitHub_Trending/na/nanoGPT 想要训练自己的AI…...