mmap底层驱动实现(remap_pfn_range函数)
mmap底层驱动实现
myfb.c(申请了128K空间)
#include <linux/init.h>
#include <linux/tty.h>
#include <linux/device.h>
#include <linux/export.h>
#include <linux/types.h>
#include <linux/module.h>
#include <linux/export.h>
#include <linux/mm_types.h>
#include <linux/mm.h>
#include <linux/slab.h>#define BUFF_SIZE (32 * 4 * 1024)static char *buff;
static int major;
static struct class * myfb_class;static int myfb_mmap (struct file *fp, struct vm_area_struct *vm)
{int res;//表示该vma在虚拟地址空间中的偏移地址,单位是页(4K)//unsigned long offset = vm->vm_pgoff << PAGE_SHIFT; //计算被映射的物理内存的物理页帧号(物理地址+偏移),以页为单位, virt_to_phys将虚拟地址转成物理地址//vm->pgoff表示的是用户空间映射时在VMA中的偏移(即mmap最后一个参数,单位是字节,但vm->pgoff自动转成页单位)unsigned long pfn_start = (virt_to_phys(buff) >> PAGE_SHIFT); res = remap_pfn_range(vm, vm->vm_start, pfn_start + vm->vm_pgoff, //在物理页帧号上加上偏移vm->vm_end - vm->vm_start, vm->vm_page_prot);if(res){printk("remap_pfn_range failed\n");return -1;}printk("[kernel] pfn_start = 0x%lx, vm->vm_pgoff = 0x%lx, \\n[kernel] vm->vm_start = 0x%lx, vm->vm_end = 0x%lx, vir_ker_start = 0x%lx\n", \pfn_start, vm->vm_pgoff, vm->vm_start, vm->vm_end, (unsigned long)buff);return 0;
}static struct file_operations myfb_fops = {.owner = THIS_MODULE,.mmap = myfb_mmap,
};static int myfb_init(void)
{buff = kzalloc(BUFF_SIZE, GFP_KERNEL);if (!buff){printk("kzalloc failed!\n");return -ENOMEM;}printk("kzalloc success!\n");major = register_chrdev(0, "myfb", &myfb_fops);myfb_class = class_create(THIS_MODULE, "myfb_class");device_create(myfb_class, NULL, MKDEV(major, 0), NULL, "myfb");return 0;
}static void myfb_exit(void)
{device_destroy(myfb_class, MKDEV(major, 0));class_destroy(myfb_class);unregister_chrdev(major, "myfb");kfree(buff);
}module_init(myfb_init);
module_exit(myfb_exit);
MODULE_LICENSE("GPL");mmap_read.c
#include <stdio.h>
#include <sys/mman.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <signal.h>
#include <unistd.h>#define PAGE_SIZE (4*1024)
#define BUFF_SIZE (1 * PAGE_SIZE)
#define OFFSET (2 * PAGE_SIZE)char *p;
int fd;void ctrlc(int signum)
{munmap(p, BUFF_SIZE);close(fd);
}int main(void)
{signal(SIGINT, ctrlc);fd = open("/dev/myfb", O_RDWR);p = (char *)mmap(NULL, BUFF_SIZE, PROT_READ | PROT_WRITE , MAP_SHARED, fd, OFFSET);if(p){printf("mmap addr = 0x%x\n", p);printf("data = %s\n", p);}else{printf("mmap failed\n");}while(1){sleep(1);}return 0;
}
mmap_write.c
#include <stdio.h>
#include <sys/mman.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <signal.h>
#include <unistd.h>#define PAGE_SIZE (4*1024)
#define BUFF_SIZE (1 * PAGE_SIZE)
#define OFFSET (0 * PAGE_SIZE)char *p;
int fd;void ctrlc(int signum)
{munmap(p, BUFF_SIZE);close(fd);
}int main(void)
{signal(SIGINT, ctrlc);fd = open("/dev/myfb", O_RDWR);p = (char *)mmap(NULL, BUFF_SIZE, PROT_READ | PROT_WRITE , MAP_SHARED, fd, OFFSET);if(p){printf("mmap addr = 0x%x\n", p);memcpy(p, "hello world", 20);}else{printf("mmap failed\n");}while(1){sleep(1);}return 0;
}
Makefile
KERNEL_DIR = /home/me/Kernel_Uboot/linux-imx-rel_imx_4.1.15_2.1.0_ga_alientekall:make -C $(KERNEL_DIR) M=`pwd` modules$(CROSS_COMPILE)gcc mmap_read.c -o mmap_read$(CROSS_COMPILE)gcc mmap_write.c -o mmap_writeclean:make -C $(KERNEL_DIR) M=`pwd` modules cleanobj-m += myfb.o
当读和写的进程内存映射地址的偏移都为0时,读进程能把写进程写入的数据读出

当写进程内存映射地址偏移为0,读进程内存映射地址**偏移为2(单位页)**时,读进程读出数据为空

PS:注意到读写进程的pfn_start相同,这个值是映射的物理内存地址,vm->vm_pgoff 是偏移(单位页,一页=4K(4096))
但是两个进程映射的虚拟地址结果不一定相同,虚拟地址是进程自己独有的,这点很容易理解。
1. 查看虚拟内存分布
查看读写进程的pid

写进程的虚拟内存分布

读进程的虚拟内存分布

1.1 分析虚拟内存映射部分
以读进程为例,/dev/myfb所在行即是内存映射的部分
76ffa000: vm->vm_start 的值
76ffb000: vm->vm_end 的值
rw-s: 表示的是 vm->vm_flags,"rw"表示可读可写,"s"表示 share共享,"p"表示 private 私有
00000000: 表示偏移量,即 vm->vm_pgoff(单位页,此处的偏移量单位是字节,需要做一下换算)
00:06 : 表示主次设备号
2564: 表示 inode 值
/dev/myfb: 表示设备节点名
1.2 关于偏移量
将读进程中mmap函数最后一个参数改为2*4096(2页)后,进程的虚拟内存映射部分的地址分布如下。
可以看到偏移量为 00002000,即 2*4096字节 = 2页 = 8K
偏移量指的是mmap最后一个参数、同样也是vm->vm_pgoff(单位页),指的是映射时在文件的物理内存上的偏移,只映射了文件的部分内容,单位是页4K

2. remap_pfn_range函数
2.1 remap_pfn_range函数原型
/*** remap_pfn_range - remap kernel memory to userspace* @vma: user vma to map to* @addr: target user address to start at* @pfn: physical address of kernel memory* @size: size of map area* @prot: page protection flags for this mapping** Note: this is only safe if the mm semaphore is held when called.*/
int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,unsigned long pfn, unsigned long size, pgprot_t prot)
| 参数 | 含义 |
|---|---|
| vm | 虚拟内存区域描述符,用于表示映射的虚拟内存区域 |
| addr | 映射的虚拟内存区域的首地址 |
| pfn | 物理页帧号 |
| size | 映射区域的大小 |
| prot | 物理页面的操作属性,例如读/写/执行权限 |
2.2 remap_pfn_range函数使用
这里主要搞懂 myfb.c 驱动代码中的 remap_pfn_range 中的如下代码
unsigned long pfn_start = (virt_to_phys(buff) >> PAGE_SHIFT); res = remap_pfn_range(vm, vm->vm_start, pfn_start + vm->vm_pgoff, //在物理页帧号上加上偏移vm->vm_end - vm->vm_start, vm->vm_page_prot);
- vm: 调用mmap时内核自动生成的VMA(虚拟内存描述符)
- vm->vm_start: 该VMA的起始地址
- vm->_end: 该VMA的结束地址
- virt_to_phys: 将虚拟地址转成物理地址
- PAGE_SHIFT: 宏,值为12,1<<PAGE_SHIFT表示4096,即4K,一页的大小
- vm->vm_pgoff: 指的是映射时在文件的物理内存上的偏移,只映射了文件的部分内容,单位是页(4K)
- vm->vm_page_prot: 该虚拟内存的访问权限,由mmap的参数决定,例如可读可写,共享等
相关文章:
mmap底层驱动实现(remap_pfn_range函数)
mmap底层驱动实现 myfb.c(申请了128K空间) #include <linux/init.h> #include <linux/tty.h> #include <linux/device.h> #include <linux/export.h> #include <linux/types.h> #include <linux/module.h> #inclu…...

品牌如何查窜货
当渠道中的产品出现不按规定区域销售时,这种行为就叫做窜货,窜货不仅会扰乱渠道的健康发展,损害经销商的利益,同时会滋生低价、假货的发生,有效的管控窜货,需要品牌先将窜货链店铺找出来,才能进…...
Java基于SpringBoot的车辆充电桩
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W,Csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 文章目录 1、效果演示效果图 技术栈2、 前言介绍(完整源码请私聊)3、主要技术3.4.1…...

【ARM】(1)架构简介
前言 ARM既可以认为是一个公司的名字,也可以认为是对一类微处理器的通称,还可以认为是一种技术的名字。 ARM公司是专门从事基于RISC技术芯片设计开发的公司,作为知识产权(IP)供应商,本身不直接从事芯片生产…...

企业完善质量、环境、健康安全三体系认证的作用及其意义!
一、ISO三体系标准作用 ISO9001:质量管理体系,专门针对企业的质量管理,投标首选,很多大客户要求企业必备这项。 ISO14001:环境管理体系,针对企业的生产环境,排污,节能环保…...

<HarmonyOS第一课>运行Hello World——闯关习题及答案
判断题 1.DevEco Studio是开发HarmonyOS应用的一站式集成开发环境。( 对 ) 2.main_pages.json存放页面page路径配置信息。( 对 ) 单选题 1.在stage模型中,下列配置文件属于AppScope文件夹的是?ÿ…...
NLP 02 RNN
一、RNN RNN(Recurrent Neural Network),中文称作循环神经网络它一般以序列数据为输入通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出。 传统神经网络(包括CNN),输入和输出都是互相独立的。但有些任务,后续的输出和之前…...

@PostConstruct注解
PostConstruct注解 PostConstruct注解是javax.annotation包下的一个注解,用于标记一个方法,在构造函数执行之后,依赖注入(如Autowired,意味着在方法内部可以安全地使用依赖注入的成员变量,而不会出现空指针异常&#…...

拓世AI|中秋节营销攻略,创意文案和海报一键生成
秋风意境多诗情,中秋月圆思最浓。又是一年中秋节,作为中国传统的重要节日之一,中秋节的意义早已不再仅仅是一家团圆的节日,更是一场商业盛宴。品牌方们纷纷加入其中,希望能够借助这一节日为自己的产品赢得更多的关注和…...
基于知识蒸馏的两阶段去雨去雪去雾模型学习记录(三)之知识测试阶段与评估模块
去雨去雾去雪算法分为两个阶段,分别是知识收集阶段与知识测试阶段,前面我们已经学习了知识收集阶段,了解到知识阶段的特征迁移模块(CKT)与软损失(SCRLoss),那么在知识收集阶段的主要重点便是HCRLoss(硬损失…...

代码随想录二刷day46
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣139. 单词拆分二、力扣动态规划:关于多重背包,你该了解这些! 前言 提示:以下是本篇文章正文内容&#x…...

计算机竞赛 行人重识别(person reid) - 机器视觉 深度学习 opencv python
文章目录 0 前言1 技术背景2 技术介绍3 重识别技术实现3.1 数据集3.2 Person REID3.2.1 算法原理3.2.2 算法流程图 4 实现效果5 部分代码6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习行人重识别(person reid)系统 该项目…...

在线图片转BASE64、在线BASE64转图片
图片转BASE64、BASE64转图片...

什么是RPA?一文了解RPA发展与进程!
RPA(Robotic Process Automation,机器人流程自动化)是一种通过软件机器人模拟人类在计算机上执行重复性任务的技术。RPA的核心理念是将规则、过程和数据“机器人化”,从而实现对业务流程的自动化。RPA技术可以显著提高企业的工作效…...
【云备份项目】【Linux】:环境搭建(g++、json库、bundle库、httplib库)
文章目录 1. g 升级到 7.3 版本2. 安装 jsoncpp 库3. 下载 bundle 数据压缩库4. 下载 httplib 库从 Win 传输文件到 Linux解压缩 1. g 升级到 7.3 版本 🔗链接跳转 2. 安装 jsoncpp 库 🔗链接跳转 3. 下载 bundle 数据压缩库 安装 git 工具 sudo yum…...

工信部教考中心:什么是《研发效能(DevOps)工程师》认证,拿到证书之后有什么作用!(下篇)丨IDCF
拿到证书有什么用? 提高职业竞争力:通过学习认证培训课程可以提升专业技能,了解项目或产品研发全生命周期的核心原则,掌握端到端的研发效能提升方法与实践,包括组织与协作、产品设计与运营、开发与交付、测试与安全、…...
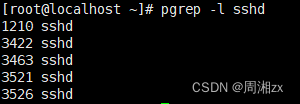
Linux进程相关管理(ps、top、kill)
目录 一、概念 二、查看进程 1、ps命令查看进程 1)ps显示某个时间点的程序运行情况 2)查看指定的进程信息 2、top命令查看进程 1)信息统计区: 2)进程信息区 3)交互式命令 三、信号控制进程 四、…...
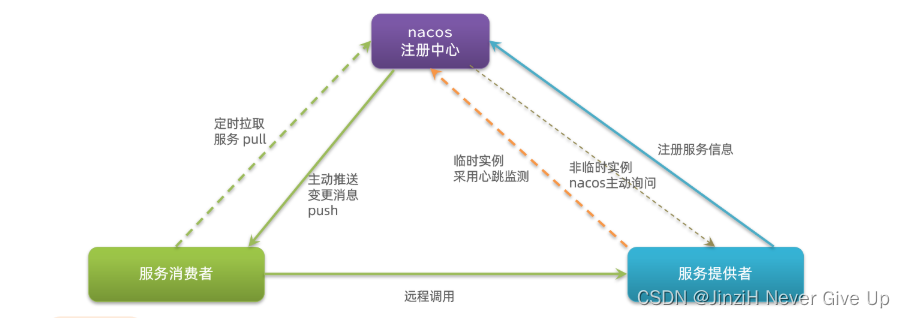
微服务技术栈-Ribbon负载均衡和Nacos注册中心
文章目录 前言一、Ribbon负载均衡1.LoadBalancerInterceptor(负载均衡拦截器)2.负载均衡策略IRule 二、Nacos注册中心1.Nacos简介2.搭建Nacos注册中心3.服务分级存储模型4.环境隔离5.Nacos与Eureka的区别 总结 前言 在上面那个文章中介绍了微服务架构的…...

知识图谱和大语言模型的共存之道
源自:开放知识图谱 “人工智能技术与咨询” 发布 导 读 01 知识图谱和大语言模型的历史 图1 图2 图3 图4 图5 02 知识图谱和大语言模型作为知识库的优缺点 图6 图7 表1 表2 图8 图9 03 知识图谱和大语言模型双知识平台融合 图10 图11 04 总结与展望 声明:公众号转…...

enum, sizeof, typedef
枚举类型enum enum 是 C 语言中的一种自定义类型enum 值是可以根据需要自定义的整型值第一个定义的 enum 值默认为 0默认情况下的 enum 值在前一个定义值得基础上加 1enum 类型的变量只能取定义时得离散值 void code() {enum Color{GREEN, // 0RED 2, // 2BLUE, …...

BridgesLLM Portal:统一AI模型调用的门户框架设计与实践
1. 项目概述:一个面向AI应用开发的“门户”框架最近在AI应用开发领域,一个名为“BridgesLLM-ai/portal”的项目引起了我的注意。乍一看这个名字,可能会觉得有些抽象——“portal”是门户的意思,而“BridgesLLM”似乎暗示着它与大语…...

开源技能管理工具rei-skills:从零构建个人技术能力图谱
1. 项目概述与核心价值 最近在折腾个人知识库和技能树管理,发现了一个挺有意思的开源项目 rootcastleco/rei-skills 。这项目名字乍一看有点神秘, rei 在日语里是“零”或“灵”的意思,结合 skills ,我理解它想表达的是一种…...

Latte文本到视频生成实战:打造个性化AI视频的终极指南
Latte文本到视频生成实战:打造个性化AI视频的终极指南 【免费下载链接】Latte [TMLR 2025] Latte: Latent Diffusion Transformer for Video Generation. 项目地址: https://gitcode.com/gh_mirrors/la/Latte Latte是一款基于TMLR 2025研究成果的文本到视频…...

2026 最稳 AI 论文工具合集:好用不踩雷
毕业季的论文关卡,早已不是 “单打独斗” 的时代。从选题迷茫、大纲混乱,到文献难找、格式崩溃,再到查重超标、AI 率预警,每一个卡点都在消耗本科生的时间与精力。随着 AI 技术深度渗透学术场景,一批专注毕业论文写作的…...

Taotoken CLI工具一键配置团队开发环境实战指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken CLI工具一键配置团队开发环境实战指南 1. 场景与需求 在团队协作开发中,统一管理大模型调用环境是一个常见且…...

专业术语统计报告_园区综合能源系统多时间尺度协同优化运行方法研究
专业术语统计报告_园区综合能源系统多时间尺度协同优化运行方法研究 一、概要简析 【概要分析】 本文档《园区综合能源系统多时间尺度协同优化运行方法研究》超用心地围绕研究主题展开了系统性探讨哦😜!文档总字符数足足有158527,其中中文字符53671个,英文字词12011个,…...

你的进化树图够‘炫’吗?从Straight Tree到Circle Tree,用iTOL在线工具5分钟搞定高分文章插图
科研图表升级指南:5分钟打造高颜值进化树可视化 在学术论文和科研报告中,一张精美的进化树图表往往能成为研究成果的"门面担当"。许多研究者花费数月时间完成数据分析,却在最后的可视化环节遭遇瓶颈——默认生成的矩形树图…...

工程师创意竞赛全流程策划:从社区激活到公平投票的实战指南
1. 项目概述:一场别开生面的工程师创意竞赛又到了二月底,这意味着我们年初启动的那个“独轮车”图片配文竞赛,终于要进入最激动人心的投票环节了。我记得很清楚,那是2012年2月初,编辑部觉得冬天太沉闷,想找…...

从零构建:基于Air724UG的4G LTE物联网数据透传系统
1. 认识Air724UG模块:你的物联网数据搬运工 第一次拿到Air724UG这个巴掌大的4G模块时,我完全没想到它能成为我物联网项目的核心组件。这个来自合宙通信的Cat.1模块,最大的特点就是用2G的价格享受4G的体验。实测在市区环境下,它的上…...
)
Gemini插件无法访问本地PDF/网页源码?手把手教你绕过Chrome沙箱限制(含Manifest V3兼容性补丁代码)
更多请点击: https://intelliparadigm.com 第一章:Gemini插件本地资源访问受限的本质原因 沙箱隔离机制的强制约束 Gemini 插件运行于 Chromium 扩展沙箱环境中,该环境默认禁用所有 Node.js API(如 fs、 child_process…...