基于知识蒸馏的两阶段去雨去雪去雾模型学习记录(三)之知识测试阶段与评估模块
去雨去雾去雪算法分为两个阶段,分别是知识收集阶段与知识测试阶段,前面我们已经学习了知识收集阶段,了解到知识阶段的特征迁移模块(CKT)与软损失(SCRLoss),那么在知识收集阶段的主要重点便是HCRLoss(硬损失),事实上,知识测试阶段要比知识收集阶段简单,因为这个模块只需要训练学生网络即可。
模型创新点
在进行知识测试阶段的代码学习之前,我们来回顾一下去雨去雪去雾网络的创新点:
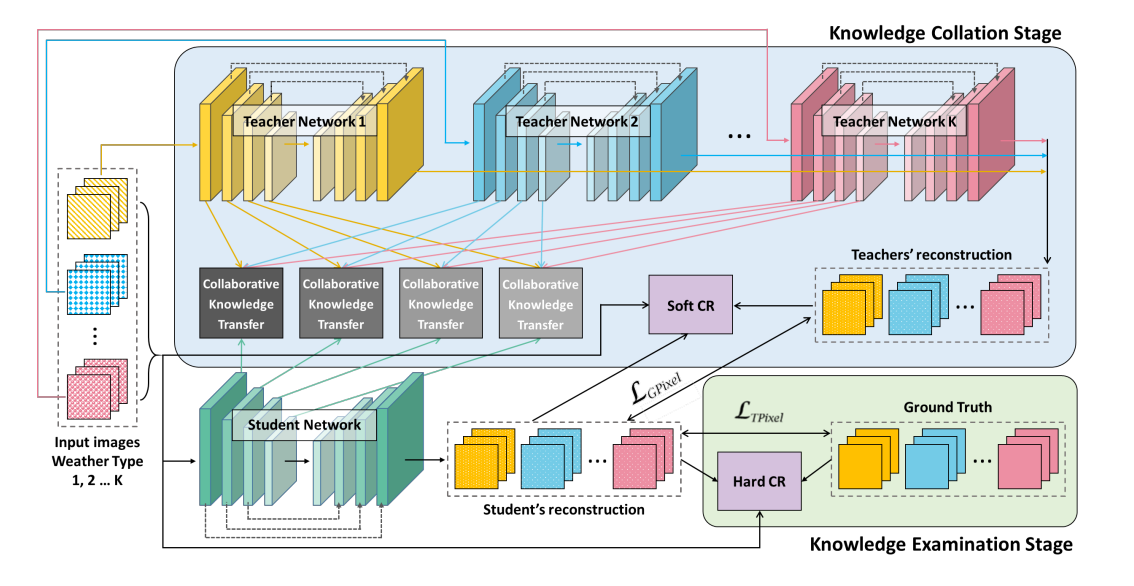
首先是提出两阶段的知识蒸馏网络,即构建三个教师网络与一个学生网络,设置总训练次数为250,其中前125个epoch教师网络与学生网络一同训练,这里的训练是指将图像输入教师网络,随后将教师网络的输出结果与中间特征图保留,将其作为真值指导学生网络进行训练。
其次便是提出知识迁移模块(CKT)该模块的作用是将教师网络的特征迁移到学生网络。
随后便是软损失与硬损失计算了,这个其实是知识蒸馏中的概念。
总体来看去雨去雾去雪网络的设计虽然较为新颖,但事实上就是知识蒸馏网络的架构,本着这一点,程序理解起来也就容易多了。
接下来开始代码的学习:
小插曲(算力不足)
首先需要指出,前面将batch-size设置为4,但却会报错:
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
开始时博主以为是cuDNN与CUDA版本不匹配导致的,但后来一想不对呀,先前已经运行过呀,那么问题很可能便是batch出问题了,果然将batch改为3后就正常了,这是由于算力不足导致的,注意算力不足和显存不足还是有区别的。
将batch-size改为3后重新运行,开始知识测试阶段的探索。
知识测试阶段
事实上,知识测试阶段的实现与知识收集阶段几乎相同,并且要比知识收集阶段简单,其只是训练学生网络,并计算一个硬损失而已。
由于知识测试阶段与知识收集阶段几乎相同,因此有许多地方是重复的,这里博主便会简要介绍。
首先相同的是使用train_loader进行训练集的加载,并使用tqdm进行封装。
随后便是遍历过程,这个过程就要简单很多了,没有使用到教师网络,直接将图像输入学生网络进行预测即可,这里的学生网络与教师网络的构造是完全相同的,将结果分别计算L1损失与HCR_loss即可。不过需要注意的是由于该阶段不需要与教师网络进行特征迁移,因此就不需要返回中间特征图了,即设置return_feat=False
for target_images, input_images in pBar:if target_images is None: continuetarget_images = target_images.cuda()input_images = torch.cat(input_images).cuda()preds = model(input_images, return_feat=False)G_loss = criterion_l1(preds, target_images)HCR_loss = 0.2 * criterion_hcr(preds, target_images, input_images)total_loss = G_loss + HCR_loss
至于其他的基本就相同了,需要注意的是这里的batch设置为3。接下来记录一下数据的变化情况:
input_images:输入图像,torch.Size([3, 3, 224, 224])第一个3是指图像数量,第二个3是指通道维度
target_images:目标图像(真值),torch.Size([3, 3, 224, 224])第一个3是指图像数量,第二个3是指通道维度
preds:预测图像(去噪后的图像),torch.Size([3, 3, 224, 224])第一个3是指图像数量,第二个3是指通道维度

随后计算L1损失与HCRLoss,由于在学生网络中使用的事实上是混合数据集,即不区分去噪类型,因此输入图像等都是直接使用tesnor格式,而非list格式。
G_loss:tensor(0.5621, device='cuda:0', grad_fn=<L1LossBackward>)
HCRLoss
与SCRLoss相同,HCRLoss也是先将图像进行特征转换后再计算损失的
HCRLoss((vgg): Vgg19((slice1): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True))(slice2): Sequential((2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True))(slice3): Sequential((7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True))(slice4): Sequential((12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(17): ReLU(inplace=True)(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True))(slice5): Sequential((21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(24): ReLU(inplace=True)(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(26): ReLU(inplace=True)(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)))(l1): L1Loss()
)
HCRLoss:tensor(0.3274, device='cuda:0', grad_fn=<MulBackward0>)
评估模块
至此,知识测试阶段便完成了,随后便是模型评估了。这里默认设置评估时的batch-size为1,即每次输入一张图像。
所谓的评估指的是对学生网络的评估,该模块其实与知识测试阶段类似,不同之处在于这里是需要计算SSIM与PSNR的。至于其他则是完全相同,核心代码如下:
for target, image in pBar:if torch.cuda.is_available():image = image.cuda()target = target.cuda()pred = model(image) psnr_list.append(torchPSNR(pred, target).item())ssim_list.append(pytorch_ssim.ssim(pred, target).item())
由于batch-size设置为1,因此target为torch.Size([1, 3, 480, 640]),image也为torch.Size([1, 3, 480, 640]),这里需要注意的是,在训练阶段(包含知识收集与知识测试阶段),数据集中的图像都要转换为224x224的大小,而在评估阶段则不需要进行转换了,即使用的是原图像的大小。
直接将输入图输入模型,获的去噪后的图像pred大小为torch.Size([1, 3, 480, 640])
pred = model(image)

随后将预测图像与真值图像进行计算PSNR与SSIM
psnr_list.append(torchPSNR(pred, target).item())
ssim_list.append(pytorch_ssim.ssim(pred, target).item())
PSNR计算
@torch.no_grad()
def torchPSNR(prd_img, tar_img):if not isinstance(prd_img, torch.Tensor):prd_img = torch.from_numpy(prd_img)tar_img = torch.from_numpy(tar_img)imdff = torch.clamp(prd_img, 0, 1) - torch.clamp(tar_img, 0, 1)rmse = (imdff**2).mean().sqrt()ps = 20 * torch.log10(1/rmse)return ps
SSIM计算
class SSIM(torch.nn.Module):def __init__(self, window_size = 11, size_average = True):super(SSIM, self).__init__()self.window_size = window_sizeself.size_average = size_averageself.channel = 1self.window = create_window(window_size, self.channel)def forward(self, img1, img2):(_, channel, _, _) = img1.size()if channel == self.channel and self.window.data.type() == img1.data.type():window = self.windowelse:window = create_window(self.window_size, channel) if img1.is_cuda:window = window.cuda(img1.get_device())window = window.type_as(img1) self.window = windowself.channel = channelreturn _ssim(img1, img2, window, self.window_size, channel, self.size_average)
def ssim(img1, img2, window_size = 11, size_average = True):(_, channel, _, _) = img1.size()window = create_window(window_size, channel) if img1.is_cuda:window = window.cuda(img1.get_device())window = window.type_as(img1)return _ssim(img1, img2, window, window_size, channel, size_average)
将每个循环得到的psnr与ssim加入列表
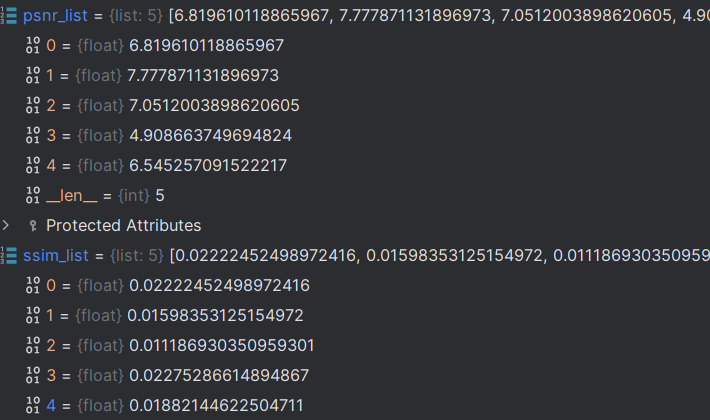
最后的PSNR与SSIM是对list中的所有值求平均:
print("PSNR: {:.3f}".format(np.mean(psnr_list)))
print("SSIM: {:.3f}".format(np.mean(ssim_list)))
至此,知识测试阶段与评估模块就讲解完成了,接下来博主将对该模型进行改进。
相关文章:
基于知识蒸馏的两阶段去雨去雪去雾模型学习记录(三)之知识测试阶段与评估模块
去雨去雾去雪算法分为两个阶段,分别是知识收集阶段与知识测试阶段,前面我们已经学习了知识收集阶段,了解到知识阶段的特征迁移模块(CKT)与软损失(SCRLoss),那么在知识收集阶段的主要重点便是HCRLoss(硬损失…...

代码随想录二刷day46
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣139. 单词拆分二、力扣动态规划:关于多重背包,你该了解这些! 前言 提示:以下是本篇文章正文内容&#x…...

计算机竞赛 行人重识别(person reid) - 机器视觉 深度学习 opencv python
文章目录 0 前言1 技术背景2 技术介绍3 重识别技术实现3.1 数据集3.2 Person REID3.2.1 算法原理3.2.2 算法流程图 4 实现效果5 部分代码6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习行人重识别(person reid)系统 该项目…...

在线图片转BASE64、在线BASE64转图片
图片转BASE64、BASE64转图片...

什么是RPA?一文了解RPA发展与进程!
RPA(Robotic Process Automation,机器人流程自动化)是一种通过软件机器人模拟人类在计算机上执行重复性任务的技术。RPA的核心理念是将规则、过程和数据“机器人化”,从而实现对业务流程的自动化。RPA技术可以显著提高企业的工作效…...
【云备份项目】【Linux】:环境搭建(g++、json库、bundle库、httplib库)
文章目录 1. g 升级到 7.3 版本2. 安装 jsoncpp 库3. 下载 bundle 数据压缩库4. 下载 httplib 库从 Win 传输文件到 Linux解压缩 1. g 升级到 7.3 版本 🔗链接跳转 2. 安装 jsoncpp 库 🔗链接跳转 3. 下载 bundle 数据压缩库 安装 git 工具 sudo yum…...

工信部教考中心:什么是《研发效能(DevOps)工程师》认证,拿到证书之后有什么作用!(下篇)丨IDCF
拿到证书有什么用? 提高职业竞争力:通过学习认证培训课程可以提升专业技能,了解项目或产品研发全生命周期的核心原则,掌握端到端的研发效能提升方法与实践,包括组织与协作、产品设计与运营、开发与交付、测试与安全、…...
Linux进程相关管理(ps、top、kill)
目录 一、概念 二、查看进程 1、ps命令查看进程 1)ps显示某个时间点的程序运行情况 2)查看指定的进程信息 2、top命令查看进程 1)信息统计区: 2)进程信息区 3)交互式命令 三、信号控制进程 四、…...
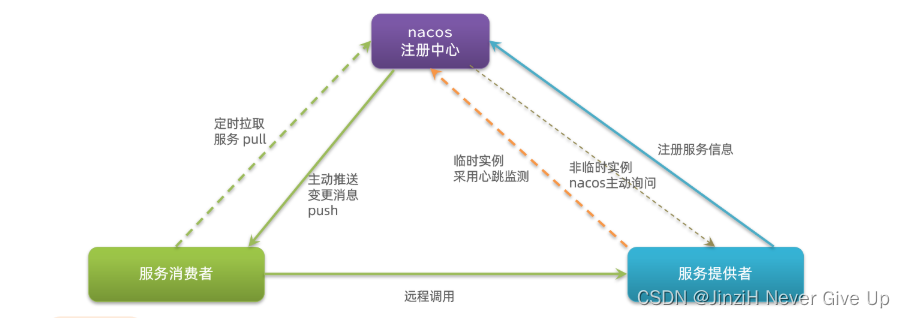
微服务技术栈-Ribbon负载均衡和Nacos注册中心
文章目录 前言一、Ribbon负载均衡1.LoadBalancerInterceptor(负载均衡拦截器)2.负载均衡策略IRule 二、Nacos注册中心1.Nacos简介2.搭建Nacos注册中心3.服务分级存储模型4.环境隔离5.Nacos与Eureka的区别 总结 前言 在上面那个文章中介绍了微服务架构的…...

知识图谱和大语言模型的共存之道
源自:开放知识图谱 “人工智能技术与咨询” 发布 导 读 01 知识图谱和大语言模型的历史 图1 图2 图3 图4 图5 02 知识图谱和大语言模型作为知识库的优缺点 图6 图7 表1 表2 图8 图9 03 知识图谱和大语言模型双知识平台融合 图10 图11 04 总结与展望 声明:公众号转…...

enum, sizeof, typedef
枚举类型enum enum 是 C 语言中的一种自定义类型enum 值是可以根据需要自定义的整型值第一个定义的 enum 值默认为 0默认情况下的 enum 值在前一个定义值得基础上加 1enum 类型的变量只能取定义时得离散值 void code() {enum Color{GREEN, // 0RED 2, // 2BLUE, …...

(二)激光线扫描-相机标定
1. 何为相机标定? 当相机拍摄照片时,我们看到的图像通常与我们实际看到的不完全相同。这是由相机镜头引起的,而且发生的频率比我们想象的要高。 这种图像的改变就是我们所说的畸变。一般来说,畸变是指直线在图像中出现弯曲或弯曲。 这种畸变我们可以通过相机标定来进行解…...

pytorch 数据载入
在PyTorch中,数据载入是训练深度学习模型的重要一环。 本文将介绍三种常用的数据载入方式:Dataset、DataLoader、以及自定义的数据加载器。 使用 Dataset 载入数据 方法: from torch.utils.data import Datasetclass CustomDataset(Dataset…...
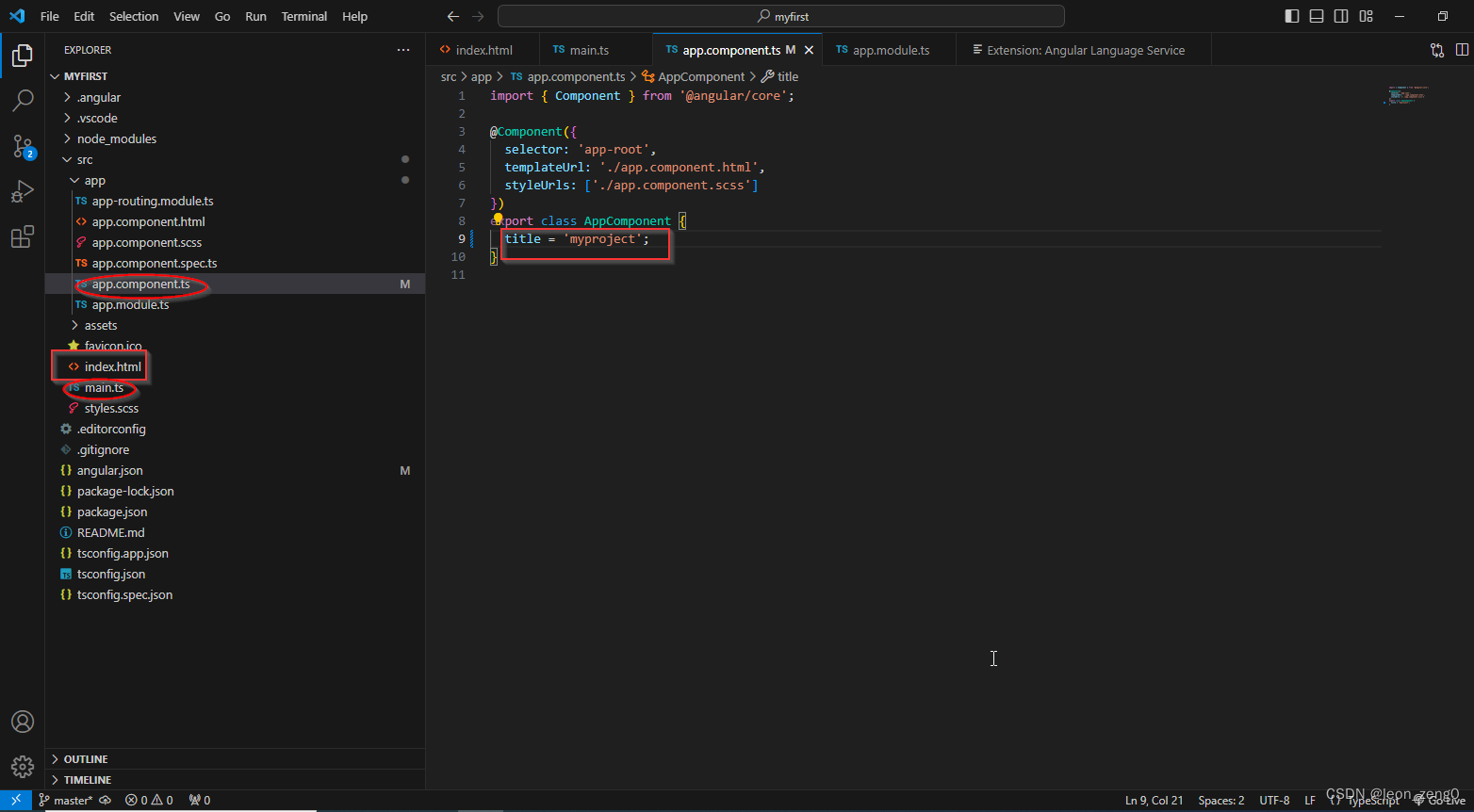
angular 在vscode 下的hello world
Angulai 是google 公司开发的前端开发框架。Angular 使用 typescript 作为编程语言。typescript 是Javascript 的一个超集,提升了某些功能。本文介绍运行我的第一个angular 程序。 前面部分参考: Angular TypeScript Tutorial in Visual Studio Code 一…...

Django、Nginx、uWSGI详解及配置示例
一、Django、Nginx、uWSGI的概念、联系与区别 Django、Nginx 和 uWSGI 都是用于构建和运行 Web 应用程序的软件,这三个软件的概念如下: Django:Django 是一个基于 Python 的开源 Web 框架,它提供了一套完整的工具和组件…...
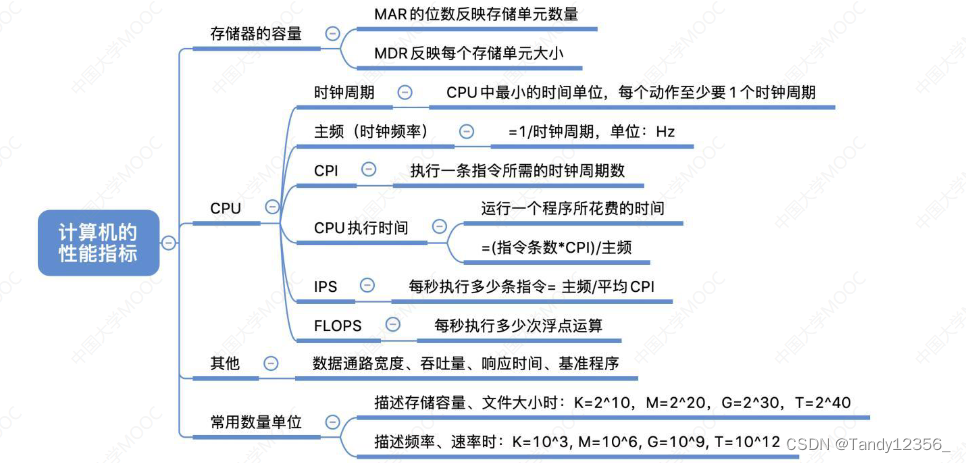
王道考研计算机组成原理——计算机硬件的基础知识
计算机组成原理的基本概念 计算机硬件的针脚都是用来传递信息,传递数据用的: 服务程序包含一些调试程序: 计算机硬件的基本组成 控制器通过电信号来协调其他部件的工作,同时负责解析存储器里存放的程序指令,然后指挥…...

[晕事]今天做了件晕事21;设置代理访问网站的时候需注意的问题
今天在家上班,设置好VPN,通过代理来访问公司内部的一个系统浏览器的反应如下: Hmmm… can’t reach this page ***.com refused to connect. 这个返回的错误,非常的具有迷惑性,提示的意思:拒绝链接…...

Go通过reflect.Value修改值
到目前为止,反射还只是程序中变量的另一种读取方式。然而,在本节中我们将重点讨论如何通过反射机制来修改变量。 回想一下,Go语言中类似x、x.f[1]和*p形式的表达式都可以表示变量,但是其它如x 1和f(2)则不是变量。一个变量就是一…...

【MySql】4- 实践篇(二)
文章目录 1. SQL 语句为什么变“慢”了1.1 什么情况会引发数据库的 flush 过程呢?1.2 四种情况性能分析1.3 InnoDB 刷脏页的控制策略 2. 数据库表的空间回收2.1 innodb_file_per_table参数2.2 数据删除流程2.3 重建表2.4 Online 和 inplace 3. count(*) 语句怎样实现…...

获取多个接口的数据并进行处理,使用Promise.all来等待所有接口请求完成
Promise.all (等待机制) 方法 它调用了多个函数,这些函数返回了Promise对象,每个Promise对象代表了一个异步操作。 然后,使用Promise.all将这多个Promise对象包装成一个新的Promise对象,它会等待所有的Promise都完成(或…...

深度测试在2D渲染中的性能优化实践
1. 深度测试在2D渲染中的创新应用在移动设备上,2D应用和游戏的渲染性能优化一直是个棘手的问题。传统2D渲染采用简单的后向前(back-to-front)绘制顺序来处理透明混合,这种方法虽然直观,但存在严重的过度绘制࿰…...

终极魔兽争霸III地图编辑器HiveWE:从缓慢加载到秒级编辑的完整指南
终极魔兽争霸III地图编辑器HiveWE:从缓慢加载到秒级编辑的完整指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器缓慢的加载速度而烦恼吗?还在为复杂的…...

深入GORM源码:手把手教你为自定义字段打造专属‘Clause钩子’
深入GORM源码:手把手教你为自定义字段打造专属‘Clause钩子’ 在当今快速迭代的业务场景中,数据库操作早已不再是简单的CRUD。当我们面对复杂的状态流转、多租户隔离或敏感数据加密时,往往需要在数据持久化层植入特定的业务逻辑。GORM作为Go生…...

MATLAB仿真实战:手把手绘制LFM信号的模糊函数,看懂“斜刀刃”形状的由来
MATLAB仿真实战:手把手绘制LFM信号的模糊函数,看懂“斜刀刃”形状的由来 雷达信号处理中,模糊函数是理解信号分辨特性的关键工具。对于初学者而言,仅通过数学公式往往难以直观把握其物理意义。本文将通过MATLAB实战,从…...

Rails AI上下文模块设计:领域驱动与AI服务集成实践
1. 项目概述:当植物病理学遇上AI代码助手最近在整理一个老项目时,我遇到了一个非常有意思的命名:“Peronosporaceaevenography165/rails-ai-context”。乍一看,这像是一个典型的GitHub仓库命名风格,前半部分是极其专业…...

专业指南:Anno 1800 Mod Loader完整使用教程与架构解析
专业指南:Anno 1800 Mod Loader完整使用教程与架构解析 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com/gh_mirrors/an…...

ESP8266+STM32远程控制实战:如何通过华为云中转指令与数据
ESP8266STM32远程控制实战:华为云物联网全链路开发指南 在智能家居和工业监控领域,远程设备控制一直是核心技术痛点。当ESP8266遇上STM32,再通过华为云物联网平台搭建通信桥梁,这个组合能爆发出怎样的生产力?本文将带您…...

3步解锁百度网盘下载限速:零成本体验高速下载的完整指南
3步解锁百度网盘下载限速:零成本体验高速下载的完整指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘的蜗牛速度而苦恼吗…...

告别“对方已撤回“!PC版微信QQ防撤回补丁终极指南
告别"对方已撤回"!PC版微信QQ防撤回补丁终极指南 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitco…...

终极图片去重神器:AntiDupl.NET帮你一键清理重复图片释放磁盘空间
终极图片去重神器:AntiDupl.NET帮你一键清理重复图片释放磁盘空间 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾因电脑里堆积如山的重复照片而烦…...