AdaBoost(上):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
🐴作者:秋无之地🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、留言💬、关注🤝,关注必回关
上一篇文章已经跟大家介绍过《PageRank(下):数据分析 | 数据挖掘 | 十大算法之一》,相信大家对PageRank(下)都有一个基本的认识。下面我讲一下,AdaBoost(上):数据分析 | 数据挖掘 | 十大算法之一
一、AdaBoost背景
在数据挖掘中,分类算法可以说是核心算法,其中 AdaBoost 算法与随机森林算法一样都属于分类算法中的集成算法。
集成的含义就是集思广益,博取众长,当我们做决定的时候,我们先听取多个专家的意见,再做决定。集成算法通常有两种方式,分别是投票选举(bagging)和再学习(boosting)。投票选举的场景类似把专家召集到一个会议桌前,当做一个决定的时候,让 K 个专家(K 个模型)分别进行分类,然后选择出现次数最多的那个类作为最终的分类结果。再学习相当于把 K 个专家(K 个分类器)进行加权融合,形成一个新的超级专家(强分类器),让这个超级专家做判断。
所以你能看出来,投票选举和再学习还是有区别的。Boosting 的含义是提升,它的作用是每一次训练的时候都对上一次的训练进行改进提升,在训练的过程中这 K 个“专家”之间是有依赖性的,当引入第 K 个“专家”(第 K 个分类器)的时候,实际上是对前 K-1 个专家的优化。而 bagging 在做投票选举的时候可以并行计算,也就是 K 个“专家”在做判断的时候是相互独立的,不存在依赖性。
二、AdaBoost 的工作原理
了解了集成算法的两种模式之后,我们来看下今天要讲的 AdaBoost 算法。
AdaBoost 的英文全称是 Adaptive Boosting,中文含义是自适应提升算法。它由 Freund 等人于 1995 年提出,是对 Boosting 算法的一种实现。
什么是 Boosting 算法呢?Boosting 算法是集成算法中的一种,同时也是一类算法的总称。这类算法通过训练多个弱分类器,将它们组合成一个强分类器,也就是我们俗话说的“三个臭皮匠,顶个诸葛亮”。为什么要这么做呢?因为臭皮匠好训练,诸葛亮却不好求。因此要打造一个诸葛亮,最好的方式就是训练多个臭皮匠,然后让这些臭皮匠组合起来,这样往往可以得到很好的效果。这就是 Boosting 算法的原理。
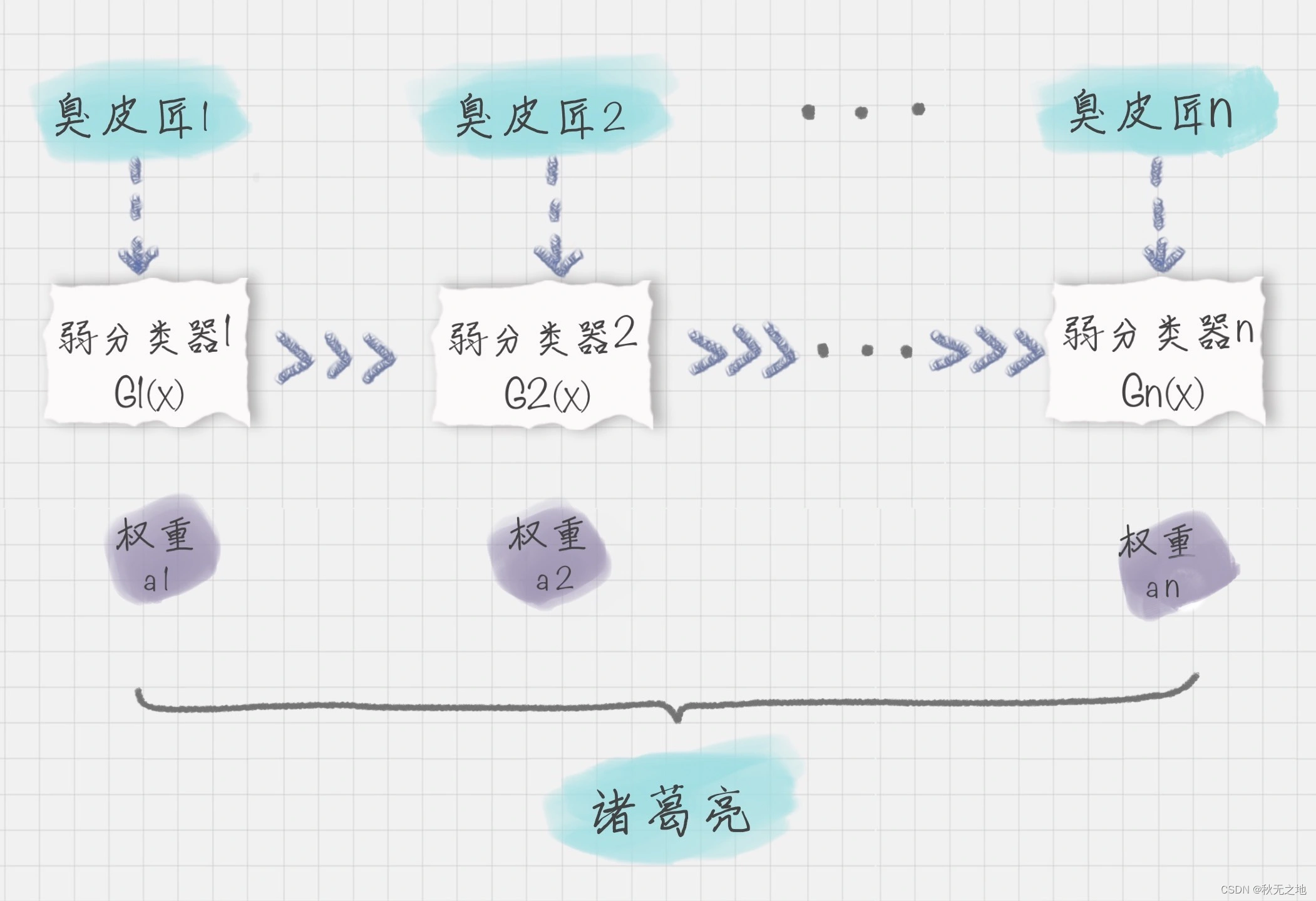
我可以用上面的图来表示最终得到的强分类器,你能看出它是通过一系列的弱分类器根据不同的权重组合而成的。
假设弱分类器为 Gi(x),它在强分类器中的权重 αi,那么就可以得出强分类器 f(x):
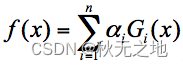
有了这个公式,为了求解强分类器,你会关注两个问题:
- 如何得到弱分类器,也就是在每次迭代训练的过程中,如何得到最优弱分类器?
- 每个弱分类器在强分类器中的权重是如何计算的?
我们先来看下第二个问题。实际上在一个由 K 个弱分类器中组成的强分类器中,如果弱分类器的分类效果好,那么权重应该比较大,如果弱分类器的分类效果一般,权重应该降低。所以我们需要基于这个弱分类器对样本的分类错误率来决定它的权重,用公式表示就是:
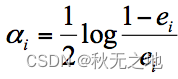
其中 ei 代表第 i 个分类器的分类错误率。
然后我们再来看下第一个问题,如何在每次训练迭代的过程中选择最优的弱分类器?
实际上,AdaBoost 算法是通过改变样本的数据分布来实现的。AdaBoost 会判断每次训练的样本是否正确分类,对于正确分类的样本,降低它的权重,对于被错误分类的样本,增加它的权重。再基于上一次得到的分类准确率,来确定这次训练样本中每个样本的权重。然后将修改过权重的新数据集传递给下一层的分类器进行训练。这样做的好处就是,通过每一轮训练样本的动态权重,可以让训练的焦点集中到难分类的样本上,最终得到的弱分类器的组合更容易得到更高的分类准确率。
我们可以用 Dk+1 代表第 k+1 轮训练中,样本的权重集合,其中 Wk+1,1 代表第 k+1 轮中第一个样本的权重,以此类推 Wk+1,N 代表第 k+1 轮中第 N 个样本的权重,因此用公式表示为:

第 k+1 轮中的样本权重,是根据该样本在第 k 轮的权重以及第 k 个分类器的准确率而定,具体的公式为:

三、AdaBoost 算法示例
了解 AdaBoost 的工作原理之后,我们看一个例子,假设我有 10 个训练样本,如下所示:

现在我希望通过 AdaBoost 构建一个强分类器。
该怎么做呢?按照上面的 AdaBoost 工作原理,我们来模拟一下。
首先在第一轮训练中,我们得到 10 个样本的权重为 1/10,即初始的 10 个样本权重一致,D1=(0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1)。
假设我有 3 个基础分类器:

我们可以知道分类器 f1 的错误率为 0.3,也就是 x 取值 6、7、8 时分类错误;分类器 f2 的错误率为 0.4,即 x 取值 0、1、2、9 时分类错误;分类器 f3 的错误率为 0.3,即 x 取值为 3、4、5 时分类错误。
这 3 个分类器中,f1、f3 分类器的错误率最低,因此我们选择 f1 或 f3 作为最优分类器,假设我们选 f1 分类器作为最优分类器,即第一轮训练得到:

根据分类器权重公式得到:

然后我们对下一轮的样本更新求权重值,代入 Wk+1,i 和 Dk+1 的公式,可以得到新的权重矩阵:D2=(0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。
在第二轮训练中,我们继续统计三个分类器的准确率,可以得到分类器 f1 的错误率为 0.1666*3,也就是 x 取值为 6、7、8 时分类错误。分类器 f2 的错误率为 0.0715*4,即 x 取值为 0、1、2、9 时分类错误。分类器 f3 的错误率为 0.0715*3,即 x 取值 3、4、5 时分类错误。
在这 3 个分类器中,f3 分类器的错误率最低,因此我们选择 f3 作为第二轮训练的最优分类器,即:

根据分类器权重公式得到:

同样,我们对下一轮的样本更新求权重值,代入 Wk+1,i 和 Dk+1 的公式,可以得到 D3=(0.0455,0.0455,0.0455,0.1667, 0.1667,0.01667,0.1060, 0.1060, 0.1060, 0.0455)。
在第三轮训练中,我们继续统计三个分类器的准确率,可以得到分类器 f1 的错误率为 0.1060*3,也就是 x 取值 6、7、8 时分类错误。分类器 f2 的错误率为 0.0455*4,即 x 取值为 0、1、2、9 时分类错误。分类器 f3 的错误率为 0.1667*3,即 x 取值 3、4、5 时分类错误。
在这 3 个分类器中,f2 分类器的错误率最低,因此我们选择 f2 作为第三轮训练的最优分类器,即:

我们根据分类器权重公式得到:

假设我们只进行 3 轮的训练,选择 3 个弱分类器,组合成一个强分类器,那么最终的强分类器 G(x) = 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)。
实际上 AdaBoost 算法是一个框架,你可以指定任意的分类器,通常我们可以采用 CART 分类器作为弱分类器。通过上面这个示例的运算,你体会一下 AdaBoost 的计算流程即可。
四、总结
今天我给你讲了 AdaBoost 算法的原理,你可以把它理解为一种集成算法,通过训练不同的弱分类器,将这些弱分类器集成起来形成一个强分类器。在每一轮的训练中都会加入一个新的弱分类器,直到达到足够低的错误率或者达到指定的最大迭代次数为止。实际上每一次迭代都会引入一个新的弱分类器(这个分类器是每一次迭代中计算出来的,是新的分类器,不是事先准备好的)。
在弱分类器的集合中,你不必担心弱分类器太弱了。实际上它只需要比随机猜测的效果略好一些即可。如果随机猜测的准确率是 50% 的话,那么每个弱分类器的准确率只要大于 50% 就可用。AdaBoost 的强大在于迭代训练的机制,这样通过 K 个“臭皮匠”的组合也可以得到一个“诸葛亮”(强分类器)。
当然在每一轮的训练中,我们都需要从众多“臭皮匠”中选择一个拔尖的,也就是这一轮训练评比中的最优“臭皮匠”,对应的就是错误率最低的分类器。当然每一轮的样本的权重都会发生变化,这样做的目的是为了让之前错误分类的样本得到更多概率的重复训练机会。
同样的原理在我们的学习生活中也经常出现,比如善于利用错题本来提升学习效率和学习成绩。
版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。
相关文章:
AdaBoost(上):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

Py之pygraphviz:pygraphviz的简介、安装、使用方法之详细攻略
Py之pygraphviz:pygraphviz的简介、安装、使用方法之详细攻略 目录 pygraphviz的简介 pygraphviz的安装 Graphviz:可视化工具Graphviz的简介、安装、使用方法、经典案例之详细攻略 pygraphviz的使用方法 1、基础用法 2、进阶案例 Algorithm&#…...

acwing算法基础之基础算法--前缀和算法
目录 1 知识点2 模板 1 知识点 前缀后下标尽量从1开始,当然不从1开始也是ok的。 a 1 , a 2 , a 3 , . . . , a n a_1,a_2,a_3,...,a_n a1,a2,a3,...,an S 1 , S 2 , S 3 , . . . S n S_1,S_2,S_3,...S_n S1,S2,S3,...Sn S i S_i Si࿱…...

华为云云耀云服务器L实例评测|Ubuntu 22.04部署edusoho-ct企培版教程 | 支持华为云视频点播对接CDN加速
华为云云耀云服务器L实例评测|Ubuntu 22.04部署edusoho企培版教程 1、选择购买 华为云耀云服务器L实例 简单上云第一步 2、选择你要安装的操作系统,例如 Ubuntu 22.04 server 64bit 3、然后支付订单就行了 4、华为云云耀云服务器L实例创建好之后&#x…...

土木硕设计院在职转码上岸
一、个人介绍 双非土木硕,98年,目前在北京,职位为前端开发工程师,设计院在职期间自学转码上岸🌿 二、背景 本人于19年开始土木研究生生涯,研二期间去地产实习近半年(碧桂园和世茂,这两家的地产…...

js查询月份开始和结束日期
js查询月份开始和结束日期 月份开始和结束 月份开始和结束 整体不是很复杂,使用new Date()方法自带获取最后一天的时间 new Date(a,b,c),传递参数 参数a:是要获取的年份 参数b:是要获取的月份 参数c:是要获取的日期 传递日期为…...

mybatis开发部分核心代码
pom.xml<?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 ht…...

Springboot中查看gradle工程使用了哪些仓库
在springboot项目开发中,由于初始化配置文件(init.gradle)可能存在多个目录中(不只一份),可能导致多次重复引入仓库。也有可能配置文件放置位置错误,导致gradle编译时找不到相应的仓库。如果能在编译时查看gradle到底引用了哪些库,…...
c#中的接口
使用IEnumerable统一迭代变量类型 class Program {static void Main(string[] args){int[] nums1 new int[] { 1, 2, 3, 4, 5 };ArrayList nums2 new ArrayList { 1, 2, 3, 4, 5 };Console.WriteLine(Sum(nums1));Console.WriteLine(Sum(nums2));Console.WriteLine(Avg(nums…...
)
老卫带你学---leetcode刷题(76. 最小覆盖子串)
76. 最小覆盖子串 问题: 给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。 注意: 对于 t 中重复字符,我们寻找的子字符串中该字符数量必…...

Maven-DskipTests和-Dmaven.test.skip=true的区别
DskipTeststrue和-Dmaven.test.skiptrue的区别 1、 -DskipTeststrue 不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下,如: mvn clean package -DskipTeststrue2、 -Dmaven.test.skiptrue 完全忽略测试代码的…...

conda中cuda、cuda-toolkit、cuda-nvcc、cuda-runtime的区别
conda中cuda、cuda-toolkit、cuda-nvcc、cuda-runtime的区别 cuda cuda-toolkit cuda-runtime cuda-toolkit 包含 cuda-nvcc CUDA cuda nvidia/label/cuda-11.8.0/linux-64::cuda-11.8.0-0 cuda-cccl nvidia/label/cuda-11.8.0/linux-64::cuda-cccl-11.8.89-0 cuda-comma…...

增强现实抬头显示AR-HUD
增强现实抬头显示(AR-HUD)可以将当前车身状态、障碍物提醒等信息3D投影在前挡风玻璃上,并通过自研的AR-Creator算法,融合实际道路场景进行导航,使驾驶员无需低头即可了解车辆实时行驶状况。结合DMS系统,可以…...

力扣-367.有效的完全平方数
暴力 class Solution { public:bool isPerfectSquare(int num) {for(long i 1; i * i < num; i) {if(i * i num) return true;}return false;} };二分查找 class Solution { public:bool isPerfectSquare(int num) {int left 1, right num;while(left < right) {in…...

小白必看!上位机控制单片机原理
嗨,大家好!今天,我们要探讨一个有趣的话题——"以上位机控制单片机"。不要担心,我们会用最简单的方式来解释这个概念。 首先,你可以把以上位机想象成一台超级聪明的电脑,就像你用来上网、玩游戏、…...

通过套接字手动写一个回显服务器吧
背景:程序员主要编写应用层的代码。真正要发送的数据需要上层协议调用下层协议,而应用层调用传输层时,传输层(系统内核)给应用层提供的一组API统称为Socket API。 系统提供给Java程序员的Socket API主要有两组: 基于UDP的API基于TCP的API目录 一、为什么需要网络编程?——…...

python读取CSV格式文件,遇到的问题20231007
python读取的CSV文件必须是具备相同列数的吗? 在Python中,读取CSV文件时不一定要求每一行都具有相同的列数。CSV文件可以包含不同数量的列,但你需要小心处理不同列数的情况,以确保代码能够正常处理。 通常情况下,CSV文…...

【面试题精讲】为什么重写equals时必须重写hashCode方法?
“ 有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top ” 首发博客地址[1] 面试题手册[2] 系列文章地址[3] equals() 方法用于比较两个对象是否相等,而 hashCode() 方法用于获取对象的哈希码…...

一文搞懂pytorch hook机制
pytorch的hook机制允许我们在不修改模型class的情况下,去debug backward、查看forward的activations和修改梯度。hook是一个在forward和backward计算时可以被执行的函数。在pytorch中,可以对Tensor和nn.Module添加hook。hook有两种类型,forwa…...

文本挖掘入门
文本挖掘的基础步骤 文本挖掘是从文本数据中提取有用信息的过程,通常包括文本预处理、特征提取和建模等步骤。以下是文本挖掘的基础入门步骤: 数据收集:首先,收集包含文本数据的数据集或文本文档。这可以是任何文本数据ÿ…...

Windows 11 LTSC系统恢复微软商店:3分钟快速安装完整指南
Windows 11 LTSC系统恢复微软商店:3分钟快速安装完整指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否在使用Windows 11 LTSC版本…...

win11的自带媒体播放器-可以设置它的播放速度。在右小角的三个点里面。。。
win11的自带媒体播放器-可以设置它的播放速度。在右小角的三个点里面。。。...

el-tree 动态子节点注入:从点击事件到数据更新的完整实践
1. 理解动态子节点注入的核心需求 在实际开发中,我们经常会遇到需要动态加载树形数据的场景。比如一个文件管理系统,用户点击文件夹时才加载其中的内容;或者一个组织架构图,只有展开某个部门时才显示下属员工。这种按需加载的方式…...

从单体到微服务:基于参考架构的7步平滑迁移终极指南 [特殊字符]
从单体到微服务:基于参考架构的7步平滑迁移终极指南 🚀 【免费下载链接】reference-architecture The Reference Architecture for Agility is a technology-neutral logical architecture based on a disaggregated cloud-based model. 项目地址: htt…...

Next.js SEO优化实战:用next-seo库高效管理元标签与结构化数据
1. 项目概述:SEO 优化的现代 React 解决方案 如果你正在用 Next.js 开发一个需要被搜索引擎收录的网站,比如企业官网、博客或者电商平台,那么“SEO”这个词一定让你又爱又恨。爱的是,它意味着流量和用户;恨的是&#…...
 完全使用教程)
终极显卡驱动清理指南:Display Driver Uninstaller (DDU) 完全使用教程
终极显卡驱动清理指南:Display Driver Uninstaller (DDU) 完全使用教程 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-driv…...
)
NotebookLM播客生成质量分析(行业首份LMM音频语义保真度测评报告)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM播客生成质量分析 NotebookLM 作为 Google 推出的实验性 AI 助手,其播客(Podcast)生成功能依托于对用户上传文档的理解与结构化重述。该功能并非端到端语音…...

喷墨设备怎么选?2026年UV喷码技术深度评测与选购指南
面对市场上琳琅满目的工业喷墨设备,尤其是UV喷墨设备厂家,采购者如何做出明智选择?本文将从技术前沿、核心参数与行业应用三大维度,为您提供一份详尽的评测与选购指南,并深度剖析以中防uv喷码机为代表的专业制造商如何…...

基于Rust构建命令行任务监控与通知工具:openclaw-tui-notify实践
1. 项目概述与核心价值最近在折腾一个后台数据处理脚本,它经常一跑就是好几个小时。问题来了,我总不能一直盯着终端看它什么时候结束吧?有时候去开个会、吃个饭,回来发现脚本早就跑完了,白白浪费了时间等结果。更头疼的…...

对比自行维护多个API密钥Taotoken的密钥管理带来了哪些便利
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个API密钥,Taotoken的密钥管理带来了哪些便利 在构建基于大模型的应用时,开发者常常需要接入…...