文本挖掘入门
文本挖掘的基础步骤
文本挖掘是从文本数据中提取有用信息的过程,通常包括文本预处理、特征提取和建模等步骤。以下是文本挖掘的基础入门步骤:
-
数据收集:首先,收集包含文本数据的数据集或文本文档。这可以是任何文本数据,如文章、评论、社交媒体帖子等。
-
文本预处理:对文本数据进行清洗和预处理,以便进一步的分析。预处理步骤包括:
- 文本分词:将文本拆分成单词或词汇单位。
- 停用词去除:去除常见但不包含有用信息的词汇。
- 词干提取或词形还原:将单词转化为其基本形式。
- 去除特殊字符和标点符号。
- 大小写统一化。
-
特征提取:将文本数据转化为可供机器学习算法使用的数值特征。常见的特征提取方法包括:
- 词袋模型(Bag of Words,BoW):将文本表示为单词的频率向量。
- TF-IDF(词频-逆文档频率):衡量单词在文本中的重要性。
- Word Embeddings:将单词嵌入到低维向量空间中,如Word2Vec和GloVe。
-
建模:选择合适的机器学习或深度学习算法,根据任务类型进行建模,例如文本分类、情感分析、主题建模等。
-
训练和评估模型:使用标注好的数据集训练模型,并使用评估指标(如准确度、F1分数、均方误差等)来评估模型性能。
-
调优:根据评估结果进行模型调优,可能需要调整特征提取方法、算法参数或尝试不同的模型。
-
应用:将训练好的模型用于实际文本数据的分析或预测任务。
-
持续改进:文本挖掘是一个迭代过程,可以不断改进模型和数据预处理流程,以提高性能。
1.文本预处理
-
分词(Tokenization):将文本拆分成词语或标记。
import jieba text = "我喜欢自然语言处理" words = jieba.cut(text) print(list(words))使用NLTK库:
from nltk.tokenize import word_tokenize text = "文本挖掘知识点示例" tokens = word_tokenize(text) print(tokens) -
*停用词去除:去除常见但无用的词语。
stopwords = ["的", "我", "喜欢"] filtered_words = [word for word in words if word not in stopwords]使用NLTK库:
from nltk.corpus import stopwords stop_words = set(stopwords.words("english")) filtered_tokens = [word for word in tokens if word.lower() not in stop_words] print(filtered_tokens)
自然语言处理(NLP)工具
使用流行的NLP库,如NLTK(Natural Language Toolkit)或Spacy,以便更灵活地进行文本处理、分析和解析。
import nltk from nltk.tokenize import word_tokenize nltk.download('punkt') words = word_tokenize(text)
2.文本表示
-
词袋模型(Bag of Words, BoW):将文本转换成词频向量。
使用Scikit-learn库:from sklearn.feature_extraction.text import CountVectorizer corpus = ["文本挖掘知识点示例", "文本挖掘是重要的技术"] vectorizer = CountVectorizer() X = vectorizer.fit_transform(corpus) print(X.toarray()) -
TF-IDF(Term Frequency-Inverse Document Frequency):考虑词语在文档集合中的重要性。
使用Scikit-learn库:from sklearn.feature_extraction.text import TfidfVectorizer tfidf_vectorizer = TfidfVectorizer() tfidf_matrix = tfidf_vectorizer.fit_transform(corpus) print(tfidf_matrix.toarray())
3.文本分类
-
朴素贝叶斯分类器:用于文本分类的简单算法。文本分类示例:
from sklearn.naive_bayes import MultinomialNB clf = MultinomialNB() clf.fit(X_tfidf, labels)from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import accuracy_score clf = MultinomialNB() clf.fit(X_train, y_train) y_pred = clf.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy) -
深度学习模型(使用Keras和TensorFlow)文本分类示例:
from keras.models import Sequential from keras.layers import Embedding, LSTM, Dense model = Sequential() model.add(Embedding(input_dim=vocab_size, output_dim=embed_dim, input_length=max_seq_length)) model.add(LSTM(units=100)) model.add(Dense(num_classes, activation='softmax'))
深度学习
深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)在文本分类、文本生成等任务中表现出色。
from tensorflow.keras.layers import Embedding, LSTM, Dense深度学习基本框架:
1. 数据预处理
- 文本清洗:去除特殊字符、标点符号和停用词。
- 分词:将文本分割成词语或标记。
- 文本向量化:将文本转换成数字向量,常见的方法包括词袋模型和词嵌入(Word Embeddings)。
import nltk from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import train_test_split# 分词 tokenizer = nltk.tokenize.TreebankWordTokenizer() text_tokens = [tokenizer.tokenize(text) for text in corpus]# 使用词袋模型进行向量化 vectorizer = CountVectorizer(max_features=1000) X = vectorizer.fit_transform([" ".join(tokens) for tokens in text_tokens])2. 构建深度学习模型
- 使用神经网络:通常采用循环神经网络(RNN)、卷积神经网络(CNN)或变换器模型(Transformer)来处理文本。
- 嵌入层:将词嵌入层用于将词汇映射到低维向量表示。
- 隐藏层:包括多个隐藏层和激活函数,以学习文本的特征。
- 输出层:通常是 softmax 层,用于多类别分类。
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Embedding, LSTM, Densemodel = Sequential() model.add(Embedding(input_dim=1000, output_dim=128, input_length=X.shape[1])) model.add(LSTM(128)) model.add(Dense(num_classes, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])3. 训练和评估模型
- 划分数据集为训练集和测试集。
- 使用反向传播算法进行模型训练。
- 使用评估指标(如准确率、精确度、召回率)来评估模型性能。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)model.fit(X_train, y_train, epochs=10, batch_size=64, validation_split=0.2)loss, accuracy = model.evaluate(X_test, y_test)4. 模型调优和改进
- 超参数调优:调整学习率、批处理大小、隐藏层大小等超参数。
- 数据增强:增加数据量,改善模型泛化能力。
- 使用预训练的词嵌入模型(如Word2Vec、GloVe)。
4.情感分析
- 情感词典:使用情感词典来分析文本情感。
from afinn import Afinn afinn = Afinn() sentiment_score = afinn.score(text) - 使用TextBlob进行情感分析:
from textblob import TextBlob text = "这个产品非常出色!" analysis = TextBlob(text) sentiment_score = analysis.sentiment.polarity if sentiment_score > 0:print("正面情感") elif sentiment_score < 0:print("负面情感") else:print("中性情感")
5.主题建模
- 使用Gensim进行LDA主题建模:
from gensim import corpora, models dictionary = corpora.Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts] lda_model = models.LdaModel(corpus, num_topics=5, id2word=dictionary, passes=15) topics = lda_model.print_topics(num_words=5) for topic in topics:print(topic)
6.命名实体识别(NER)
- 使用spaCy进行NER:
import spacy nlp = spacy.load("en_core_web_sm") text = "Apple Inc. was founded by Steve Jobs in Cupertino, California." doc = nlp(text) for ent in doc.ents:print(ent.text, ent.label_)
7.文本聚类
- 使用K-means文本聚类:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(tfidf_matrix)
clusters = kmeans.labels_
8.信息检索
- 使用Elasticsearch进行文本检索:
from elasticsearch import Elasticsearch
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
query = "文本挖掘知识点"
results = es.search(index='your_index', body={'query': {'match': {'your_field': query}}})
9.文本生成
- 使用循环神经网络(RNN)生成文本:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embed_dim, input_length=max_seq_length))
model.add(LSTM(units=100, return_sequences=True))
model.add(Dense(vocab_size, activation='softmax'))
词嵌入(Word Embeddings)
学习如何使用词嵌入模型如Word2Vec、FastText或BERT来获得更好的文本表示。
from gensim.models import Word2Vec word2vec_model = Word2Vec(sentences, vector_size=100, window=5, min_count=1)词嵌入(Word Embeddings)在循环神经网络(RNN)中生成文本时起着重要作用,它们之间有密切的关系。下面解释了它们之间的关系以及如何使用RNN生成文本:
1. 词嵌入(Word Embeddings):
- 词嵌入是将文本中的单词映射到连续的低维向量空间的技术。
- 它们捕捉了单词之间的语义关系,使得相似的单词在嵌入空间中距离较近。
- 常见的词嵌入算法包括Word2Vec、GloVe和FastText。
import gensim from gensim.models import Word2Vec# 训练Word2Vec词嵌入模型 model = Word2Vec(sentences, vector_size=100, window=5, min_count=1)2. 循环神经网络(RNN):
- RNN是一类神经网络,专门用于处理序列数据,如文本。
- 它们具有内部状态(隐藏状态),可以捕捉文本中的上下文信息。
- RNN的一个常见应用是文本生成,例如生成文章、故事或对话。
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Embedding, LSTM, Dense# 创建一个基本的RNN文本生成模型 model = Sequential() model.add(Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=seq_length)) model.add(LSTM(256, return_sequences=True)) model.add(Dense(vocab_size, activation='softmax'))3. 结合词嵌入和RNN进行文本生成:
- 在文本生成任务中,通常使用预训练的词嵌入模型来初始化Embedding层。
- RNN模型接收嵌入后的单词作为输入,以及之前生成的单词作为上下文信息,生成下一个单词。
# 使用预训练的词嵌入来初始化Embedding层 model.layers[0].set_weights([embedding_matrix]) model.layers[0].trainable = False # 可选,冻结嵌入层的权重# 编译模型并进行训练 model.compile(loss='categorical_crossentropy', optimizer='adam')# 在训练中生成文本 generated_text = generate_text(model, seed_text, next_words, max_sequence_length)在这里,
generate_text函数将使用RNN模型生成文本,它会根据先前生成的文本以及上下文信息来预测下一个单词。总之,词嵌入是一种有助于RNN模型理解文本语义的技术,而RNN则用于在文本生成任务中考虑文本的顺序和上下文信息,从而生成连贯的文本。这两者通常结合使用以实现文本生成任务。
10.文本摘要
- 使用Gensim实现文本摘要:
from gensim.summarization import summarize
text = "这是一段较长的文本,需要进行摘要。"
summary = summarize(text)
print(summary)
11.命名实体链接(NER):
- 使用spaCy进行NER链接:
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Apple Inc. was founded by Steve Jobs in Cupertino, California."
doc = nlp(text)
for ent in doc.ents:print(ent.text, ent.label_, ent._.wikilinks)
12.文本语义分析
- 使用BERT进行文本语义分析:
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
text = "这是一个文本示例"
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
13.文本相似度计算
- 使用余弦相似度计算文本相似度:
from sklearn.metrics.pairwise import cosine_similarity
doc1 = "这是文本示例1"
doc2 = "这是文本示例2"
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform([doc1, doc2])
similarity = cosine_similarity(tfidf_matrix[0], tfidf_matrix[1])
print("文本相似度:", similarity[0][0])
14.文本生成(以GPT-3示例)
- 使用OpenAI的GPT-3生成文本的示例,这需要访问GPT-3 API,首先需要获取API密钥。
import openaiopenai.api_key = "YOUR_API_KEY"
prompt = "生成一段关于科学的文本:"
response = openai.Completion.create(engine="text-davinci-002",prompt=prompt,max_tokens=50 # 生成的最大文本长度
)
generated_text = response.choices[0].text
print(generated_text)
15.多语言文本挖掘
- 多语言分词和情感分析示例,使用多语言支持的库:
from polyglot.text import Texttext = Text("Ceci est un exemple de texte en français.")
words = text.words
sentiment = text.sentiment
print("分词结果:", words)
print("情感分析:", sentiment)
16.文本生成(GPT-2示例)
- 使用GPT-2生成文本的示例,需要Hugging Face Transformers库:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torchtokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")input_text = "生成一段新闻摘要:"
input_ids = tokenizer.encode(input_text, return_tensors="pt")output = model.generate(input_ids, max_length=50, num_return_sequences=1)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
17.文本翻译
- 使用Google Translate API进行文本翻译,需要设置API密钥:
from googletrans import Translatortranslator = Translator()
text = "Hello, how are you?"
translated_text = translator.translate(text, src='en', dest='es')
print("翻译结果:", translated_text.text)
18.文本挖掘工具包
- 使用NLTK进行文本挖掘任务,包括情感分析和词性标注:
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
from nltk.corpus import stopwords
nltk.download('vader_lexicon')
nltk.download('stopwords')text = "这是一个情感分析的示例文本。"
sia = SentimentIntensityAnalyzer()
sentiment = sia.polarity_scores(text)
print("情感分析:", sentiment)stop_words = set(stopwords.words('english'))
words = nltk.word_tokenize(text)
filtered_words = [word for word in words if word.lower() not in stop_words]
print("去除停用词后的词汇:", filtered_words)
19.文本数据可视化
- 使用Word Cloud生成词云:
from wordcloud import WordCloud
import matplotlib.pyplot as plttext = "这是一段用于生成词云的文本示例。"
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
相关文章:

文本挖掘入门
文本挖掘的基础步骤 文本挖掘是从文本数据中提取有用信息的过程,通常包括文本预处理、特征提取和建模等步骤。以下是文本挖掘的基础入门步骤: 数据收集:首先,收集包含文本数据的数据集或文本文档。这可以是任何文本数据ÿ…...

【C++ techniques】Smart Pointers智能指针
Smart Pointers智能指针 看起来、用起来、感觉起来像内置指针,但提供更多的机能。拥有以下各种指针行为的控制权: 构造和析构;复制和赋值;解引。 Smart Pointers的构造、赋值、析构 C的标准程序库提供的auto_ptr template: au…...
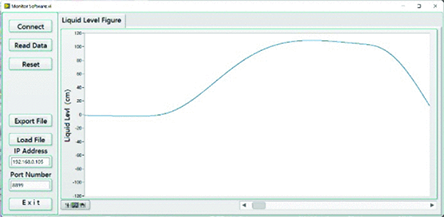
LabVIEW利用以太网开发智能液位检测仪
LabVIEW利用以太网开发智能液位检测仪 目前,工业以太网接口在国内外的发展已经达到了相当深入的程度,特别是在自动化控制和工业控制领域有着非常广泛的应用。在工业生产过程中,钢厂的连铸机是前后的连接环节,其中钢水从大钢包进入…...
 数组文字循环播放)
文字转语音:语音合成(Speech Synthesis) 数组文字循环播放
前言: HTML5中和Web Speech相关的API实际上有两类,一类是“语音识别(Speech Recognition)”,另外一个就是“语音合成(Speech Synthesis)”, 这两个名词实际上指的分别是“语音转文字”,和“文字变语音”。 speak() –…...
Spark基础
一、spark基础 1、为什么使用Spark Ⅰ、MapReduce编程模型的局限性 (1) 繁杂 只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码 (2) 处理效率低 Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据 任务调度与启动开销大 (…...
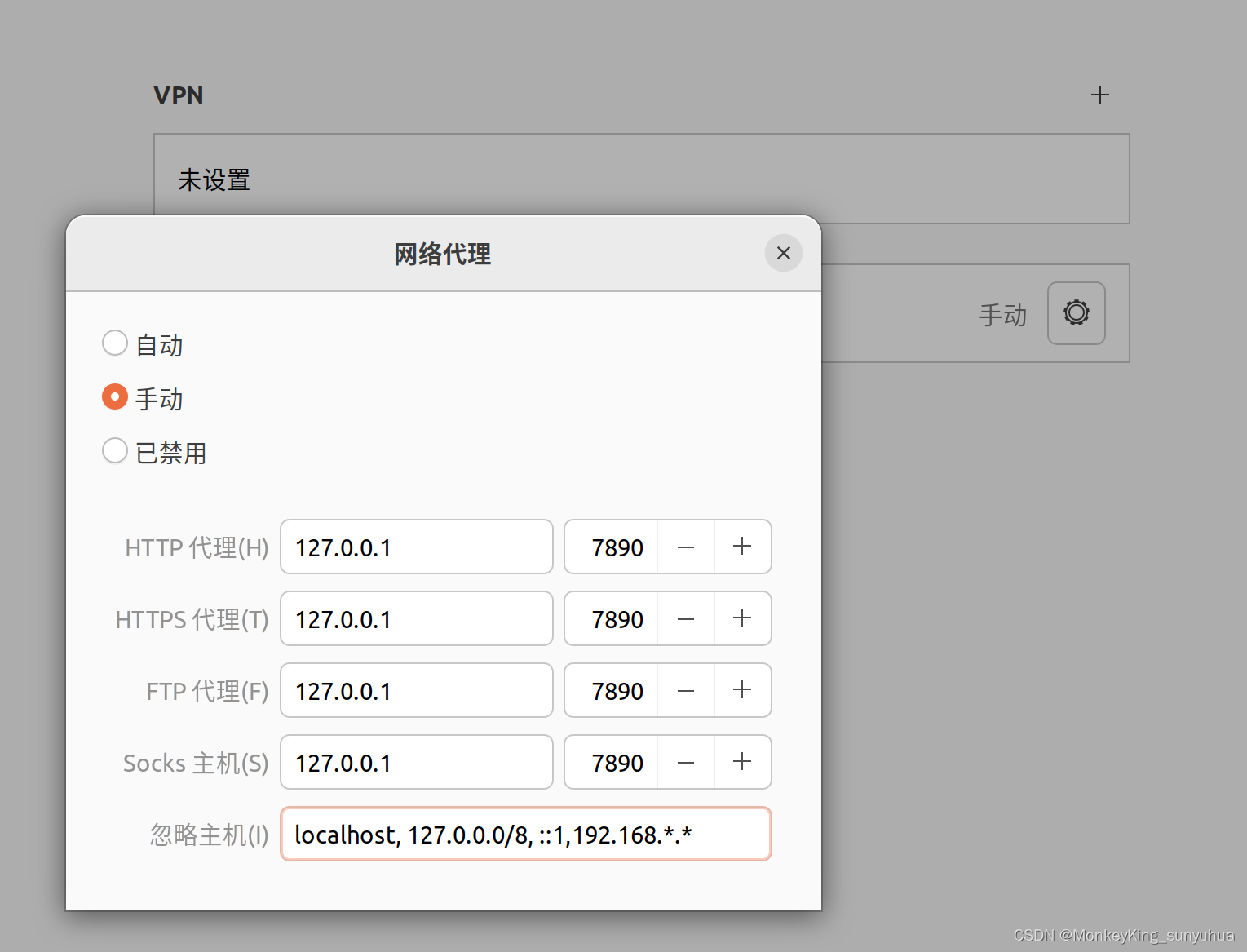
localhost和127.0.0.1都可以访问项目,但是本地的外网IP不能访问
使用localhost和127.0.0.1都可以访问接口,比如: http://localhost:8080/zhgl/login/login-fy-list或者 http://127.0.0.1:8080/zhgl/login/login-fy-list返回json {"_code":10000,"_msg":"Success","_data":…...
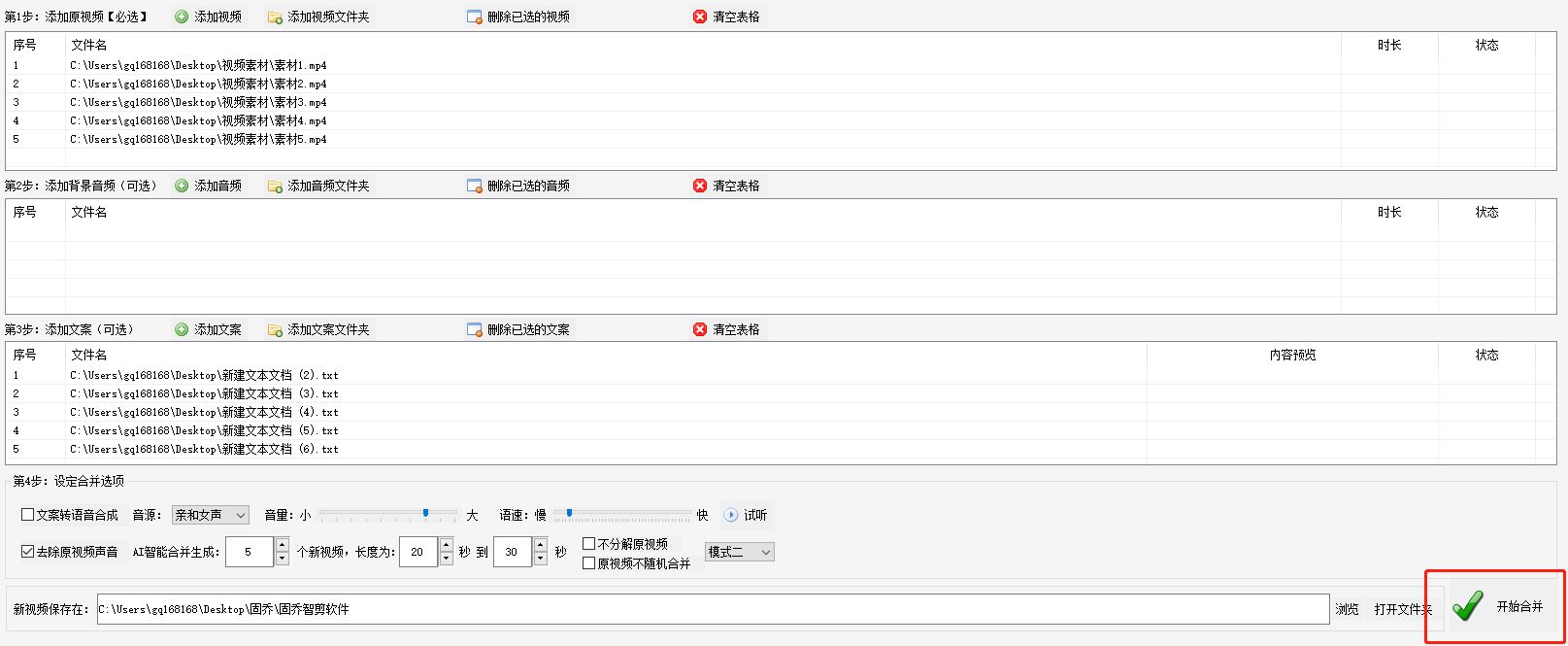
快速掌握批量合并视频
在日常的工作和生活中,我们经常需要对视频进行编辑和处理,而合并视频、添加文案和音频是其中常见的操作。如何快速而简便地完成这些任务呢?今天我们介绍一款强大的视频编辑软件——“固乔智剪软件”,它可以帮助我们轻松实现批量合…...
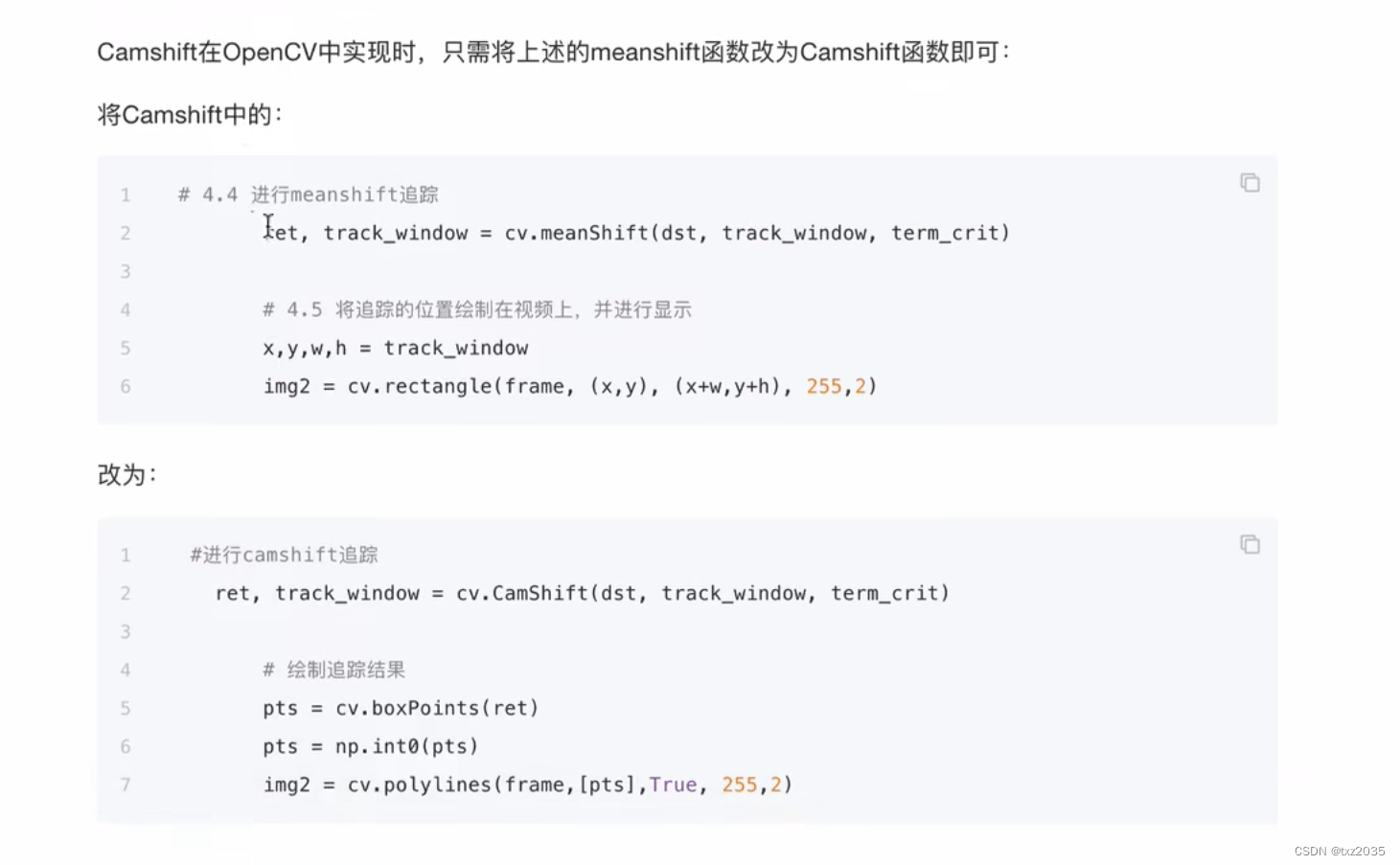
OpenCV利用Camshift实现目标追踪
目录 原理 做法 代码实现 结果展示 原理 做法 代码实现 import numpy as np import cv2 as cv# 读取视频 cap cv.VideoCapture(video.mp4)# 检查视频是否成功打开 if not cap.isOpened():print("Error: Cannot open video file.")exit()# 获取第一帧图像&#x…...

使用pywin32读取doc文档的方法及run输出乱码 \r\x07
想写一个读取doc文档中表格数据,来对文档进行重命名。经查资料,py-docx无法读取doc文档,原因是这种是旧格式。所以,采用pywin32来进行读取。 import win32com.client as win32word win32.gencache.EnsureDispatch(Word.Applicati…...

一天一八股——TCP保活keepalive和HTTP的Keep-Alive
TCP属于传输层,关于TCP的设置在内核态完成 HTTP属于用户层的协议,主要用于web服务器和浏览器之间的 http的Keep-Alive都是为了减少多次建立tcp连接采用的保持长连接的机制,而tcp的keepalive是为了保证已经建立的tcp连接依旧可用(双端依旧可以…...

头部品牌停业整顿,鲜花电商的中场战事迎来拐点?
鲜花电商行业再次迎来标志性事件,曾经4年接连斩获6轮融资的明星品牌花加,正式宣布停业整顿。 梳理来看,2015年是鲜花电商赛道的发展爆发期,彼时花加等品牌相继成立,并掀起一波投资热潮,据媒体统计…...
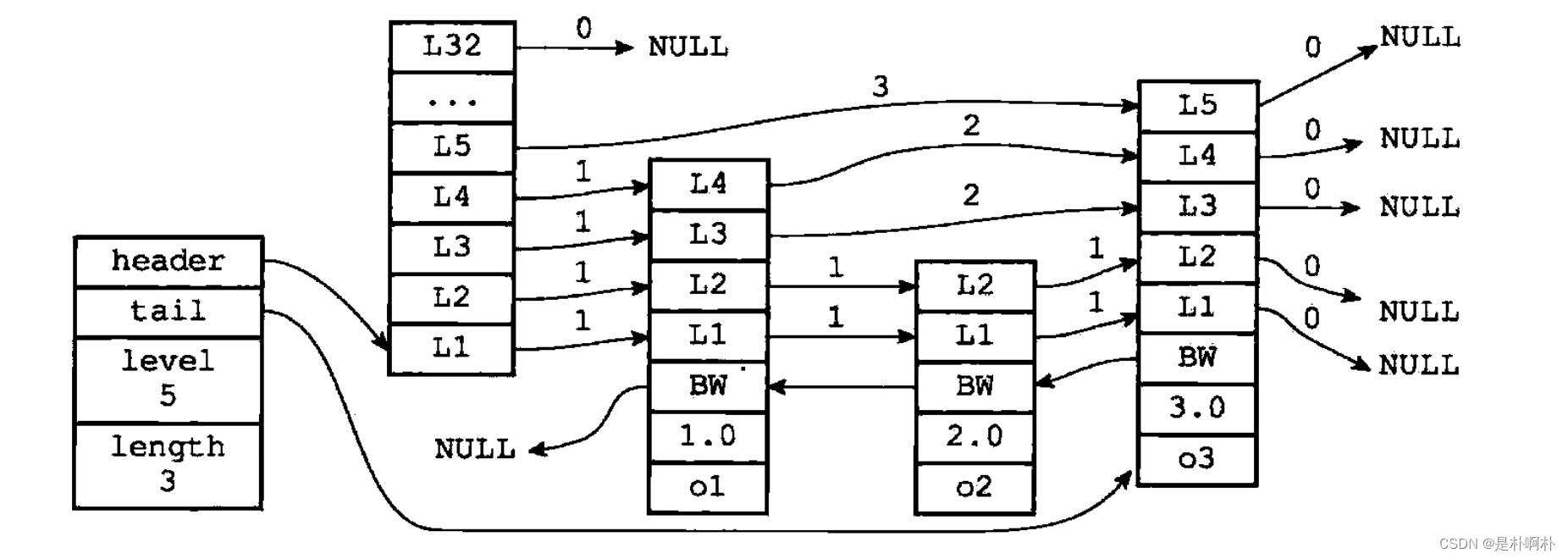
深入解读redis的zset和跳表【源码分析】
1.基本指令 部分指令,涉及到第4章的api,没有具体看实现,但是逻辑应该差不多。 zadd <key><score1><value1><score2><value2>... 将一个或多个member元素及其score值加入到有序集key当中。根据zslInsert zran…...
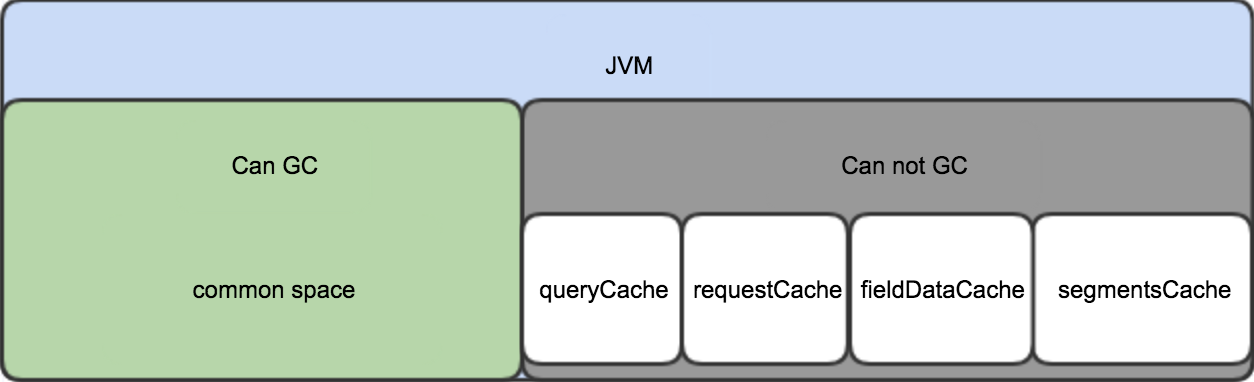
elasticsearch内存占用详细分析
内存占用 ES的JVM heap按使用场景分为可GC部分和常驻部分。 可GC部分内存会随着GC操作而被回收; 常驻部分不会被GC,通常使用LRU策略来进行淘汰; 内存占用情况如下图: common space 包括了indexing buffer和其他ES运行需要的clas…...

【研究生学术英语读写教程翻译 中国科学院大学Unit3】
研究生学术英语读写教程翻译 中国科学院大学Unit1-Unit5 Unit3 Theorists,experimentalists and the bias in popular physics理论家,实验家和大众物理学的偏见由于csdn专栏机制修改,请想获取资料的同学移步b站工房,感谢大家支持!研究生学术英语读写教程翻译 中国科学院大学…...
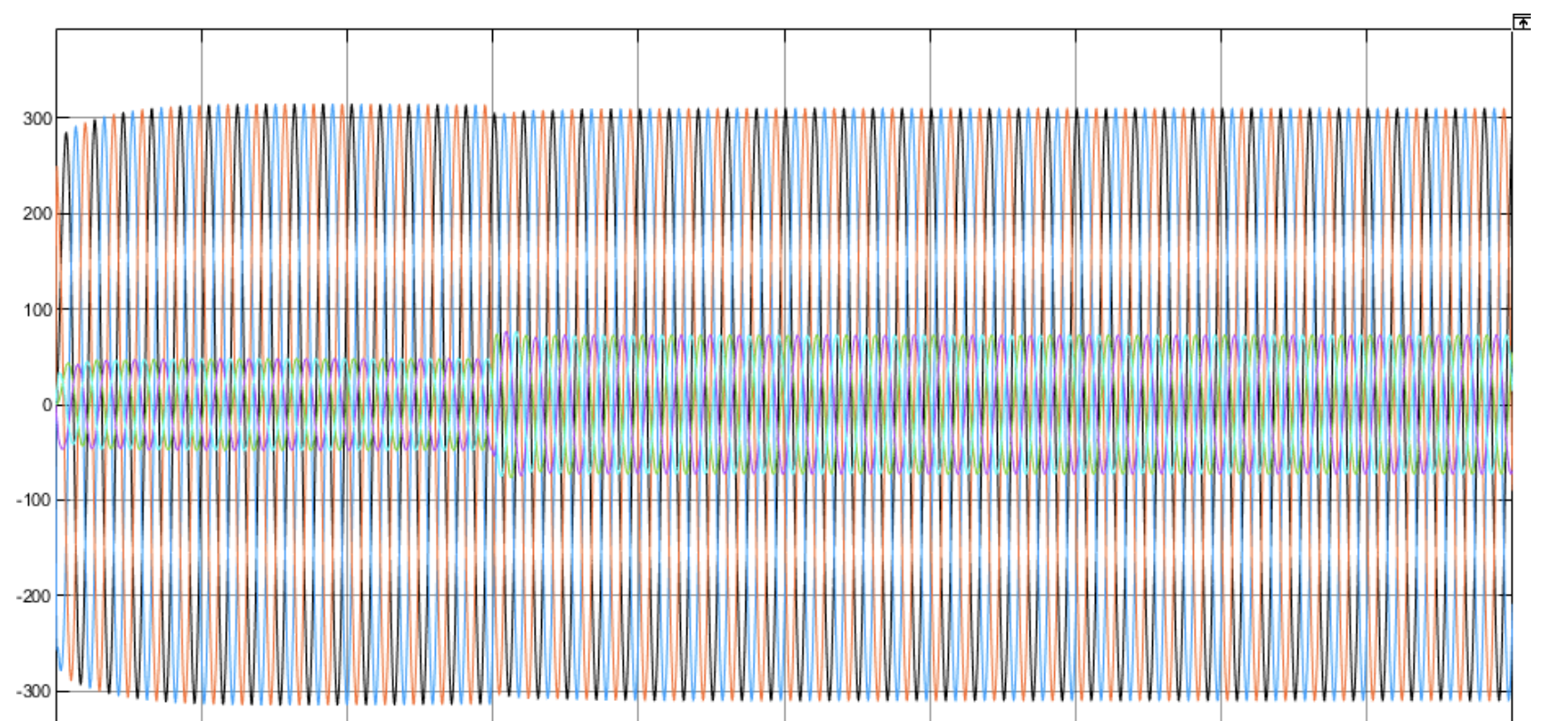
基于虚拟同步发电机控制的双机并联Simulink仿真模型
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

微信小程序开发——自定义堆叠图
先看效果图 点击第一张图片实现折叠,再次点击实现展开 思路 图片容器绑定点击事件获取当前图片索引,触发onTap函数,根据索引判断当前点击的图片是否为第一张,并根据当前的折叠状态来更新每张图片的位置,注意图片向上…...

国庆day5
QT实现TCP服务器客户端搭建的代码 ser.h #ifndef SER_H #define SER_H#include <QWidget> #include<QTcpServer> #include<QTcpSocket> #include<QMessageBox> #include<QList> QT_BEGIN_NAMESPACE namespace Ui { class …...

经典算法----迷宫问题(找出所有路径)
目录 前言 问题描述 算法思路 定义方向 回溯算法 代码实现 前言 前面我发布了一篇关于迷宫问题的解决方法,是通过栈的方式来解决这个问题的(链接:经典算法-----迷宫问题(栈的应用)-CSDN博客)ÿ…...

macOS下 /etc/hosts 文件权限问题修复方案
文章目录 前言解决方案权限验证 macOS下 etc/hosts 文件权限问题修复 前言 当在 macOS 上使用 vi编辑 /etc/hosts 文件时发现出现 Permission Denied 的提示,就算在前面加上 sudo 也照样出现一样的提示,解决方案如下; 解决方案 可以尝试使用如下命令尝试解除锁定; sudo chf…...
 playbook)
【星海出品】ansible入门(二) playbook
核心是管理配置进行批量节点部署。 执行其中的一些列tasks。 playbook由YAML语言编写。 YAML的格式如下: 文件名应该以 .yml 结尾 1.文件的第一行应该以“—”(三个连字符)开始,表明YAML文件的开始。 2.在同一行中,#之…...

实战分享:用STM32F4的ADC+DMA+FFT,我做了个能自动识别波形的便携示波器
从零构建智能波形识别仪:STM32F4的ADCDMAFFT实战全解析 在电子测量领域,示波器一直是工程师不可或缺的工具。但传统示波器体积庞大、价格昂贵,而市面上廉价的手持示波器又往往功能单一。本文将带你用STM32F4系列单片机,结合ADC采样…...

Windows网络性能测试终极指南:iperf3-win-builds完整使用教程
Windows网络性能测试终极指南:iperf3-win-builds完整使用教程 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds iperf3作为专业的网络性能…...

CodePush-Server社区贡献指南:如何参与开源项目开发与协作
CodePush-Server社区贡献指南:如何参与开源项目开发与协作 【免费下载链接】code-push-server CodePush service is hot update services which adapter react-native-code-push and cordova-plugin-code-push - 热更新 项目地址: https://gitcode.com/gh_mirrors…...

LLMFarm性能优化技巧:提升模型推理速度和内存效率的10个方法
LLMFarm性能优化技巧:提升模型推理速度和内存效率的10个方法 【免费下载链接】LLMFarm llama and other large language models on iOS and MacOS offline using GGML library. 项目地址: https://gitcode.com/gh_mirrors/ll/LLMFarm LLMFarm是一款在iOS和ma…...

pkrelay:轻量级端口转发工具的设计原理与生产实践
1. 项目概述:一个轻量级、高可用的端口转发与流量中继工具在分布式系统、微服务架构以及混合云部署的日常运维和开发调试中,我们经常会遇到一个经典问题:如何安全、便捷地将一个网络环境中的服务端口,暴露给另一个网络环境访问&am…...

Kubernetes智能运维助手:基于LLM的kube-copilot实战指南
1. 项目概述:当Kubernetes遇上AI副驾驶如果你和我一样,每天都要和Kubernetes集群打交道,那你肯定对下面这些场景不陌生:凌晨三点被告警叫醒,面对一个不断重启的Pod,需要手动执行一串kubectl describe、kube…...

深入Logos FPGA的PCB布局:如何针对FBG256、FBG484和LPG封装优化你的设计
深入Logos FPGA的PCB布局:如何针对FBG256、FBG484和LPG封装优化你的设计 在硬件设计领域,FPGA的PCB布局一直是工程师面临的核心挑战之一。特别是当项目需要在性能、成本和尺寸之间寻找平衡点时,封装选择往往成为决定成败的关键因素。Logos系列…...

usehooks-ts:React Hooks工具集,提升开发效率与代码质量
1. 项目概述:一个现代React Hooks的“瑞士军刀”如果你正在用React做项目,尤其是TypeScript项目,那么你大概率经历过这样的场景:为了一个简单的“防抖”功能,去网上搜一段代码,复制粘贴,然后发现…...

AGENTS.md:为AI编码助手定制的项目说明书,提升人机协作效率
1. 项目概述:为什么你的项目需要一个“AI专属说明书”?如果你最近在尝试用GitHub Copilot、Cursor或者Claude Code来辅助开发,大概率遇到过这样的场景:你满怀期待地给AI下达一个指令,比如“帮我给这个React组件添加一个…...
小型文件系统)
基于C语言实现(控制台)小型文件系统
♻️ 资源 大小: 3.40MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430288 小型文件系统 一、需求分析 1.1 小型文件系统介绍 科技的进步已将人类带入了信息大爆炸的时代,随着计算机科学技术的不断发展,计算…...