elasticsearch内存占用详细分析
内存占用
ES的JVM heap按使用场景分为可GC部分和常驻部分。 可GC部分内存会随着GC操作而被回收; 常驻部分不会被GC,通常使用LRU策略来进行淘汰; 内存占用情况如下图:
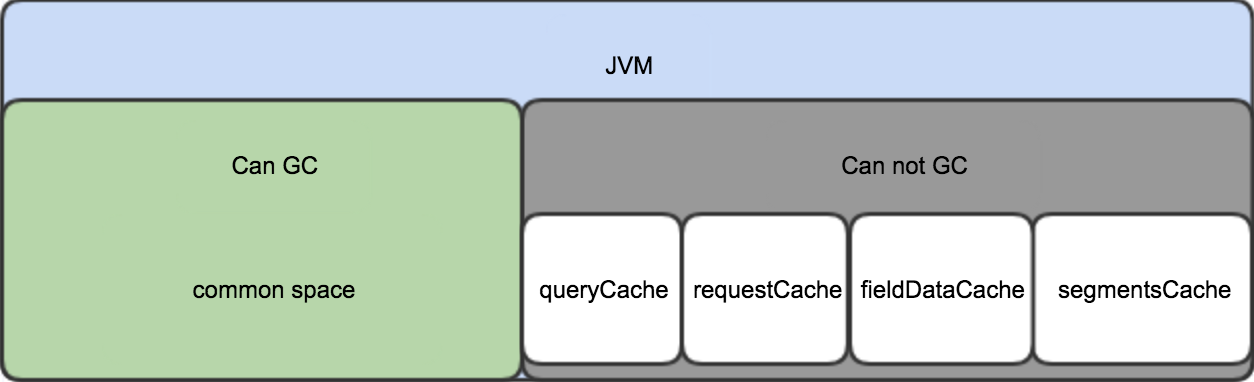
common space
包括了indexing buffer和其他ES运行需要的class。indexing buffer由indices.memory.index_buffer_size参数控制, 默认最大占用10%,当full up后,该部分数据被刷入磁盘对应的Segments中。这部分空间是可以被回收反复利用的。注意,这是设置给node的,所以是所有的索引共享的空间。
适当的提高这个的比例,可以提升写入的速度。但是要注意OOM安全的问题。要知道总的堆空间是有限的,当你在调大一个的时候,就要调小其他的大小。
Bulk Queue
一般来说,Bulk queue 不会消耗很多的 heap,但是见过一些用户为了提高 bulk 的速度,客户端设置了很大的并发量,并且将 bulk Queue 设置到不可思议的大,比如好几千。
Bulk Queue 是做什么用的?当所有的 bulk thread 都在忙,无法响应新的 bulk request 的时候,将 request 在内存里排列起来,然后慢慢清掉。
这在应对短暂的请求爆发的时候有用,但是如果集群本身索引速度一直跟不上,设置的好几千的 queue 都满了会是什么状况呢?取决于一个 bulk 的数据量大小,乘上 queue 的大小,heap 很有可能就不够用,内存溢出了。
一般来说官方默认的 thread pool 设置已经能很好的工作了,建议不要随意去「调优」相关的设置,很多时候都是适得其反的效果。
对高 cardinality 字段做 terms aggregation
所谓高 cardinality,就是该字段的唯一值比较多。
比如 client ip,可能存在上千万甚至上亿的不同值。对这种类型的字段做 terms aggregation 时,需要在内存里生成海量的分桶,内存需求会非常高。如果内部再嵌套有其他聚合,情况会更糟糕。
在做日志聚合分析时,一个典型的可以引起性能问题的场景,就是对带有参数的 url 字段做 terms aggregation。对于访问量大的网站,带有参数的 url 字段 cardinality 可能会到数亿,做一次 terms aggregation 内存开销巨大,然而对带有参数的 url 字段做聚合通常没有什么意义。
对于这类问题,可以额外索引一个 url_stem 字段,这个字段索引剥离掉参数部分的 url。可以极大降低内存消耗,提高聚合速度。
segmentsMemory
缓存段信息,包括FST,Dimensional points for numeric range filters,Deleted documents bitset ,Doc values and stored fields codec formats等数据。这部分缓存是必须的,不能进行大小设置,通常跟index息息相关,close index、force merge均会释放segmentsMemory空间。
可以通过命令可以 查看当前各块的使用情况。
GET _cat/nodes?v&h=id,ip,port,r,ramPercent,ramCurrent,heapMax,heapCurrent,fielddataMemory,queryCacheMemory,requestCacheMemory,segmentsMemory
Cluster State Buffer
ES 被设计成每个 node 都可以响应用户的 api 请求,因此每个 node 的内存里都包含有一份集群状态的拷贝。
这个 cluster state 包含诸如集群有多少个 node,多少个 index,每个 index 的 mapping 是什么?有少 shard,每个 shard 的分配情况等等 (ES 有各类 stats api 获取这类数据)。
在一个规模很大的集群,这个状态信息可能会非常大的,耗用的内存空间就不可忽视了。并且在 ES2.0 之前的版本,stat e的更新是由 master node 做完以后全量散播到其他结点的。频繁的状态更新就可以给 heap 带来很大的压力。在超大规模集群的情况下,可以考虑分集群并通过 tribe node 连接做到对用户 api 的透明,这样可以保证每个集群里的 state 信息不会膨胀得过大。
超大搜索聚合结果集的 fetch
ES 是分布式搜索引擎,搜索和聚合计算除了在各个 data node 并行计算以外,还需要将结果返回给汇总节点进行汇总和排序后再返回。
无论是搜索,还是聚合,如果返回结果的 size 设置过大,都会给 heap 造成很大的压力,特别是数据汇聚节点。超大的 size 多数情况下都是用户用例不对,比如本来是想计算 cardinality,却用了 terms aggregation + size:0 这样的方式; 对大结果集做深度分页;一次性拉取全量数据等等。
NodeQueryCache**
它是node级别的filter过滤器结果缓存,大小由indices.queries.cache.size 参数控制,默认10%,我们也可设定固定的值例如:512mb。使用LRU淘汰策略。注意不会被GC,只会被LRU替换。index.queries.cache.enabled该参数可以决定是否开启节点的query cache,默认为开启。 只能在创建索引或者关闭索引(close)时设置 。
-
只有Filter下的子Query才能参与Cache
-
不能参与Cache的Query有TermQuery/MatchAllDocsQuery/MatchNoDocsQuery/BooleanQuery/DisjunnctionMaxQuery
-
MultiTermQuery/MultiTermQueryConstantScoreWrapper/TermInSetQuery/Point*Query的Query查询超过 2次 会被Cache,其它Query要 5次
默认每个段 大于10000个doc 或 每个段的doc数大于总doc数的 30% 时才允许参与cache
默认情况下,节点查询缓存最多可容纳 10000个查询,最多占总堆空间的 10%
为了确定查询是否符合缓存条件,Elasticsearch 维护查询历史记录以跟踪事件的发生。
如果一个段至少包含 10000 个文档,并且该段具有超过一个分片的文档总数的 3% 的文档数,则按每个段进行缓存。由于缓存是按段划分的,因此合并段可使缓存的查询无效。
ShardRequestCache
它是shard级别的query result缓存, 默认的主要用于缓存 size=0 的请求,aggs和 suggestions,还有就是hits.total 。使用LRU淘汰策略。通过indices.requests.cache.size参数控制,默认1%。设置后整个NODE都生效。
fieldDataCache
主要用于对text类型的字段 sort 以及 aggs 的字段。这会把字段的值加载到内存中,以便于快速访问。field data cache 的构建非常昂贵,因此最好能分配足够的内存以保障它能长时间处于被加载的状态。 indices.fielddata.cache.size 该参数可以设置大小,可以设置堆的百分比,例如10%,也可以固定大小5G。注意这个参数 需要在:elasticsearch.yml 中设置,重启后生效 。
当字段在首次sort,aggregations,or in a script时创建,读取磁盘上所有segment的的倒排索引,反转 term<->doc 的关系,加载到jvm heap,it remains there for the lifetime of the segment.
ES2.0以后,正式默认启用 Doc Values 特性(1.x 需要手动更改 mapping 开启),将 field data 在 indexing time 构建在磁盘上,经过一系列优化,可以达到比之前采用 field data cache 机制更好的性能。因此需要限制对 field data cache 的使用,最好是完全不用,可以极大释放 heap 压力。es默认是不开启的。
fieldDataCache最好不要用,它很可能会导致OOM:Es官方文档整理-3.Doc Values和FieldData - 搜索技术 - 博客园
| 类目 | 默认占比 | 是否常驻 | 淘汰策略(在控制大小情况下) | 控制参数 |
|---|---|---|---|---|
| query cache | 10% | 是 | LRU | indices.queries.cache.size |
| request cache | 1% | 是 | LRU | indices.requests.cache.size |
| fielddata cache | 无限制(es默认禁用)熔断器,帮我们限制了即使使用,也不能超过堆内存的百分之四十。 | 是 | LRU | indices.fielddata.cache.size |
| segment memory | 无限制(我们需要对此建立监控) | 是 | 无 | 不能通过参数控制 |
| common space | 70% | 否 | GC | 通过熔断器 indices.breaker.total.limit 限制 |
对我们的堆内存建立起来完整的监控,避免OOM问题
-
倒排词典的索引需要常驻内存,无法GC,需要监控data node上segment memory增长趋势。
-
各类缓存,field cache, filter cache, indexing cache, bulk queue等等,要设置合理的大小,并且要应该根据最坏的情况来看heap是否够用,也就是各类缓存全部占满的时候,还有heap空间可以分配给其他任务吗?避免采用clear cache等“自欺欺人”的方式来释放内存。
-
避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用scan & scroll api来实现。
-
cluster stats驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过tribe node连接。
-
想知道heap够不够,必须结合实际应用场景,并对集群的heap使用情况做持续的监控。
-
根据监控数据理解内存需求,合理配置各类circuit breaker,将内存溢出风险降低到最低。
elasticsearch内存占用详细分析_水的精神-华为云开发者联盟
相关文章:
elasticsearch内存占用详细分析
内存占用 ES的JVM heap按使用场景分为可GC部分和常驻部分。 可GC部分内存会随着GC操作而被回收; 常驻部分不会被GC,通常使用LRU策略来进行淘汰; 内存占用情况如下图: common space 包括了indexing buffer和其他ES运行需要的clas…...

【研究生学术英语读写教程翻译 中国科学院大学Unit3】
研究生学术英语读写教程翻译 中国科学院大学Unit1-Unit5 Unit3 Theorists,experimentalists and the bias in popular physics理论家,实验家和大众物理学的偏见由于csdn专栏机制修改,请想获取资料的同学移步b站工房,感谢大家支持!研究生学术英语读写教程翻译 中国科学院大学…...
基于虚拟同步发电机控制的双机并联Simulink仿真模型
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

微信小程序开发——自定义堆叠图
先看效果图 点击第一张图片实现折叠,再次点击实现展开 思路 图片容器绑定点击事件获取当前图片索引,触发onTap函数,根据索引判断当前点击的图片是否为第一张,并根据当前的折叠状态来更新每张图片的位置,注意图片向上…...

国庆day5
QT实现TCP服务器客户端搭建的代码 ser.h #ifndef SER_H #define SER_H#include <QWidget> #include<QTcpServer> #include<QTcpSocket> #include<QMessageBox> #include<QList> QT_BEGIN_NAMESPACE namespace Ui { class …...

经典算法----迷宫问题(找出所有路径)
目录 前言 问题描述 算法思路 定义方向 回溯算法 代码实现 前言 前面我发布了一篇关于迷宫问题的解决方法,是通过栈的方式来解决这个问题的(链接:经典算法-----迷宫问题(栈的应用)-CSDN博客)ÿ…...

macOS下 /etc/hosts 文件权限问题修复方案
文章目录 前言解决方案权限验证 macOS下 etc/hosts 文件权限问题修复 前言 当在 macOS 上使用 vi编辑 /etc/hosts 文件时发现出现 Permission Denied 的提示,就算在前面加上 sudo 也照样出现一样的提示,解决方案如下; 解决方案 可以尝试使用如下命令尝试解除锁定; sudo chf…...
 playbook)
【星海出品】ansible入门(二) playbook
核心是管理配置进行批量节点部署。 执行其中的一些列tasks。 playbook由YAML语言编写。 YAML的格式如下: 文件名应该以 .yml 结尾 1.文件的第一行应该以“—”(三个连字符)开始,表明YAML文件的开始。 2.在同一行中,#之…...

Spring Boot对账号密码进行加密储存
未来避免明文硬编码,我们需要对密码进行加密保存,例如账号密码 方法 在Spring Boot中,可以使用Jasypt(Java Simplified Encryption)库来对敏感信息进行加密和解密。Jasypt提供了一种简单的方式来在应用程序中使用加密…...

总结js中常见的层次选择器
js中的层次选择器可以用于选择和操作DOM树中的元素,根据元素的层级关系进行选择。以下是js中常见的层次选择器: 1. getElementById:使用元素的ID属性进行选择。通过给元素设置唯一的ID属性,可以使用getElementById方法选择该元素…...
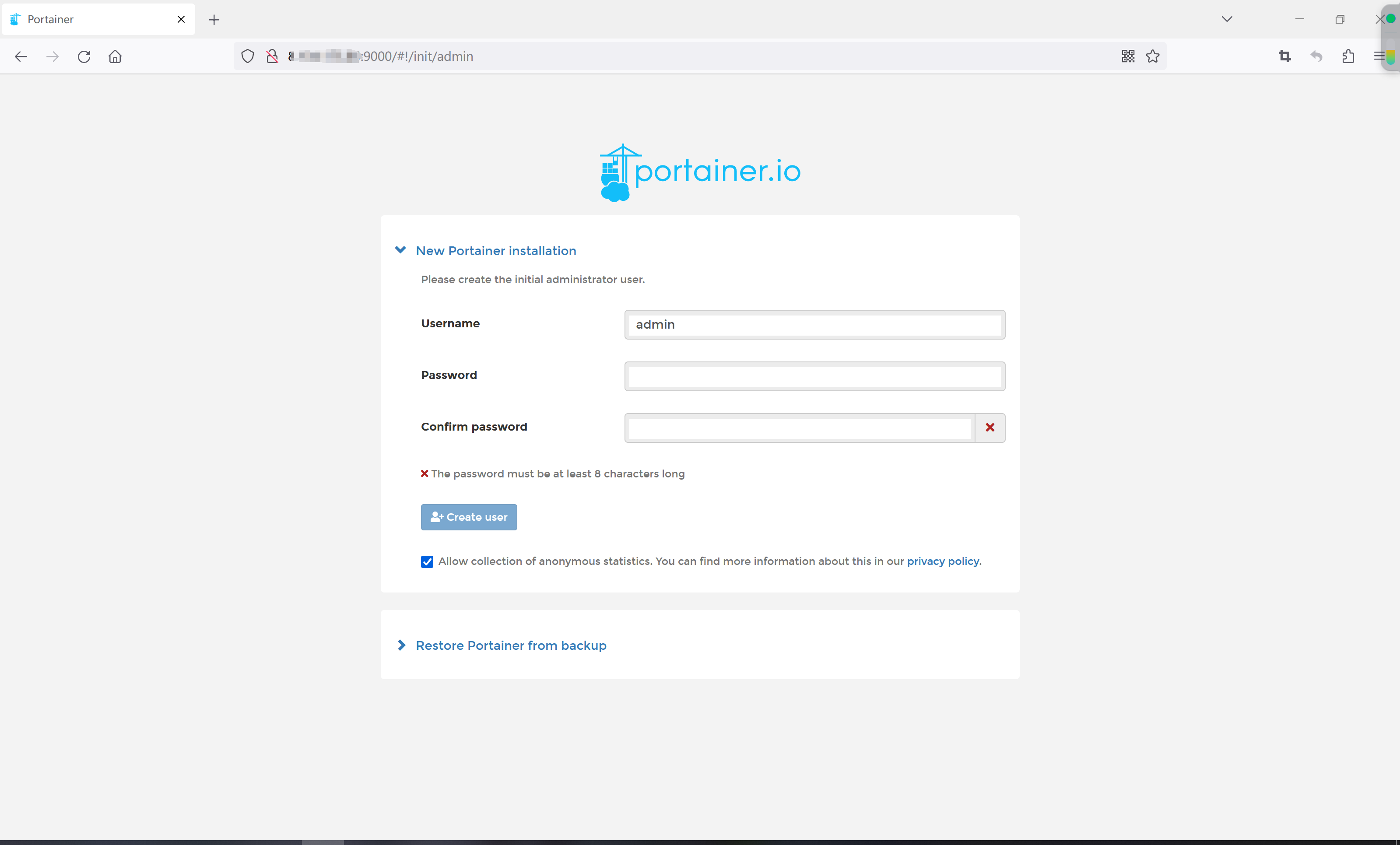
阿里云ECS服务器上启动的portainer无法访问的问题
如下图,在阿里云ECS服务器上安装并启动了portainer,但是在自己电脑上访问不了远程的portainer。 最后发现是要在网络安全组里开放9000端口号,具体操作如下: 在云服务器管理控制台点击左侧菜单中的网络与安全-安全组,然…...

JavaScript系列从入门到精通系列第十八篇:JavaScript中的函数作用域
文章目录 前言 一:函数作用域 前言 我们刚才提到了,在<Script>标签当中进行定义的变量、对象、函数对象都属于全局作用域,全局作用域在页面打开的时候生效在页面关闭的时候失效。 一:函数作用域 调用函数时创建函数作用域…...
开环模块化多电平换流器仿真(MMC)N=6(Simulink仿真)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
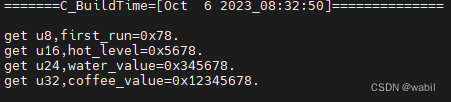
[C]嵌入式中变量存储方案
#include<stdio.h>#define uint8_t unsigned char #define uint16_t unsigned short #define uint24_t unsigned int #define uint32_t unsigned int #define uint64_t unsigned long long//用户自定义变量名字,用于存储 typedef enum {first_run 0,//…...
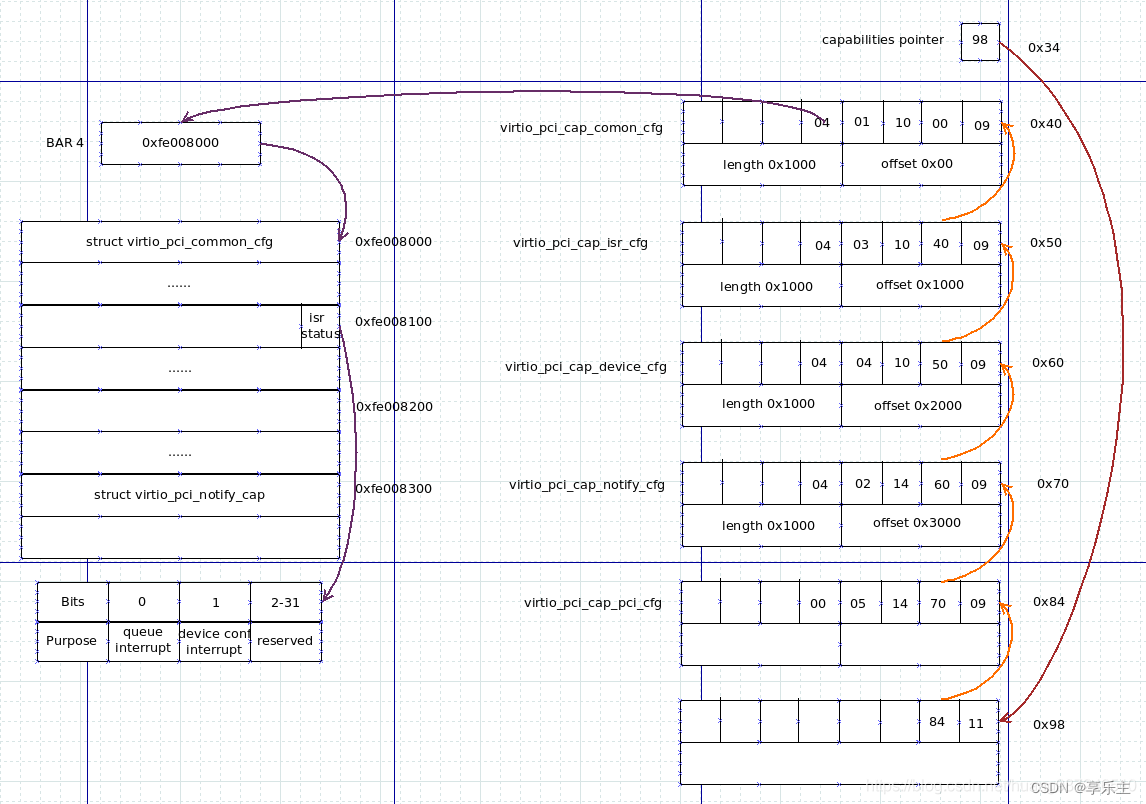
热迁移中VirtIO-PCI设备的配置空间处理
文章目录 问题现象定位过程日志分析源端目的端 原理分析基本原理上下文分析复现分析patch分析 总结解决方案 问题现象 集群升级虚拟化组件版本,升级前存量运行并挂载了virtio磁盘的虚拟机集群内热迁移到升级后的节点失败,QEMU报错如下: 202…...
模拟滤波器的基础知识和设计
信号处理工作中滤波器的应用是非常广泛的,可以分成模拟滤波器和数字滤波器两种,数字滤波器主要包括两种,IIR和FIR,这两种滤波器后面统一说,今天先来说一说模拟滤波器(主要是我先用Python实现了Matlab书里面…...

机器学习基础-Pandas学习笔记
Pandas Python的数据分析库,与Numpy配合使用,可以从常见的格式如CSV、JSON等中读取数据。可以进行数据清洗、数据加工工作。数据结构Series,Pandas.Series(data,index,dtype,name,copy) data类型是Numpy的ndarray类型,index指定下…...

【GIT版本控制】--协作流程
一、Fork与Pull Request Git协作流程中的关键概念包括Fork和Pull Request,它们允许多人在项目中协作并贡献代码。以下是关于Fork和Pull Request的简要总结: 1. Fork: Fork是指复制一个Git仓库,通常是一个开源项目的仓库…...

简析Cookie、Session、Token
手打不易,如果转摘,请注明出处! 注明原文:https://zhangxiaofan.blog.csdn.net/article/details/133498756 文章目录 简析Cookie、Session、Token什么是 Cookie ?什么是 Session ?Cookie 和 Session 到底是…...

加速attention计算的工业标准:flash attention 1和2算法的原理及实现
transformers目前大火,但是对于长序列来说,计算很慢,而且很耗费显存。对于transformer中的self attention计算来说,在时间复杂度上,对于每个位置,模型需要计算它与所有其他位置的相关性,这样的计…...

Perplexity引用导出结果不可复现?独家“引用指纹”校验技术首次公开,误差率降至0.02%以内!
更多请点击: https://intelliparadigm.com 第一章:Perplexity引用格式设置教程 Perplexity 是一款面向研究者与开发者设计的 AI 原生搜索引擎,其输出结果常需规范引用以满足学术写作或技术文档要求。默认情况下,Perplexity 不自…...

基于AutoHotkey v2的Cursor AI编程效率工具:CapsLock快捷键方案详解
1. 项目概述:当CapsLock键成为你的AI编程副驾如果你是一名Windows用户,同时又是Cursor编辑器的深度使用者,那么你很可能和我一样,每天都在重复着一些机械操作:选中代码、复制、切换到AI聊天框、粘贴、再敲入一段提示词…...

如何快速集成DatePicker到你的Android项目
如何快速集成DatePicker到你的Android项目 【免费下载链接】DatePicker Useful and powerful date picker for android 项目地址: https://gitcode.com/gh_mirrors/da/DatePicker DatePicker是一款功能强大且易于使用的Android日期选择器,支持单选和多选模式…...

Windows 平台 OpenClaw 2.7.1 可视化安装避坑技巧与高效配置方法
OpenClaw 2.7.1 Windows 一键部署教程|3 分钟快速搭建本地 AI 智能助手OpenClaw(小龙虾)是一款实用性极强的本地 AI 智能体工具,适配全系 Windows 系统。软件依托自然语言交互逻辑,可智能完成电脑操控、文件分类管理、…...

Agent-Harness:为AI编码助手套上“缰绳”的工程化框架
1. 项目概述:为什么你的AI编码助手总是“犯傻”?如果你和我一样,已经深度使用过Cursor、Windsurf或者Claude Code这类AI编码助手,那你一定经历过这样的挫败时刻:你满怀期待地让它去修改一个复杂的函数,结果…...
)
DSP28335新手避坑指南:手把手教你用CCS6.2生成10KHz SPWM(附完整工程)
DSP28335实战:从零构建10KHz SPWM的完整工程指南 第一次接触DSP28335开发板时,面对复杂的寄存器配置和编译环境问题,很多工程师都会感到无从下手。本文将带你一步步完成从CCS工程创建到SPWM波形输出的全过程,特别针对新手容易遇到…...

1.8.1 掌握Scala类与对象 - Scala类
本次实战通过两组对比鲜明的案例,带你快速入门Scala面向对象编程的核心。首先,通过创建User类,我们掌握了Scala普通类的定义方式,了解了如何使用private修饰符封装成员变量,以及如何通过new关键字实例化对象并调用其公…...

工业微功率DC-DC选型性能对比解析:钡特电源 DH1-24S05LS 与 H2405S-1WR3 封装对照互通
在工业控制、仪器仪表、通信设备等中低功率供电场景,1W 级隔离工业 DC-DC 模块电源凭借小体积、高可靠、易集成的特性,成为硬件工程师选型的核心品类。直流电源模块作为电子系统的供电核心,其性能稳定性、环境耐受性与长期可靠性直接决定设备…...

Linux上运行Cursor编辑器:AppImage打包与AI编程环境搭建指南
1. 项目概述:一个为Linux用户定制的代码编辑器如果你是一名长期在Linux环境下工作的开发者,尤其是习惯了使用VS Code这类现代编辑器,但又对某些AI辅助编程工具(比如Cursor)的便捷性念念不忘,那么你很可能已…...

技术解析:OBS Source Record - 独立源录制解决方案
技术解析:OBS Source Record - 独立源录制解决方案 【免费下载链接】obs-source-record 项目地址: https://gitcode.com/gh_mirrors/ob/obs-source-record OBS Source Record插件通过创新的滤镜架构,解决了多源独立录制的技术难题,为…...