计算机竞赛 题目:基于深度学习的中文汉字识别 - 深度学习 卷积神经网络 机器视觉 OCR
文章目录
- 0 简介
- 1 数据集合
- 2 网络构建
- 3 模型训练
- 4 模型性能评估
- 5 文字预测
- 6 最后
0 简介
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的中文汉字识别
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 数据集合
学长手有3755个汉字(一级字库)的印刷体图像数据集,我们可以利用它们进行接下来的3755个汉字的识别系统的搭建。
用深度学习做文字识别,用的网络当然是CNN,那具体使用哪个经典网络?VGG?RESNET?还是其他?我想了下,越深的网络训练得到的模型应该会更好,但是想到训练的难度以及以后线上部署时预测的速度,我觉得首先建立一个比较浅的网络(基于LeNet的改进)做基本的文字识别,然后再根据项目需求,再尝试其他的网络结构。这次任务所使用的深度学习框架是强大的Tensorflow。
2 网络构建
第一步当然是搭建网络和计算图
其实文字识别就是一个多分类任务,比如这个3755文字识别就是3755个类别的分类任务。我们定义的网络非常简单,基本就是LeNet的改进版,值得注意的是我们加入了batch
normalization。另外我们的损失函数选择sparse_softmax_cross_entropy_with_logits,优化器选择了Adam,学习率设为0.1
#network: conv2d->max_pool2d->conv2d->max_pool2d->conv2d->max_pool2d->conv2d->conv2d->max_pool2d->fully_connected->fully_connecteddef build_graph(top_k):keep_prob = tf.placeholder(dtype=tf.float32, shape=[], name='keep_prob')images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1], name='image_batch')labels = tf.placeholder(dtype=tf.int64, shape=[None], name='label_batch')is_training = tf.placeholder(dtype=tf.bool, shape=[], name='train_flag')with tf.device('/gpu:5'):#给slim.conv2d和slim.fully_connected准备了默认参数:batch_normwith slim.arg_scope([slim.conv2d, slim.fully_connected],normalizer_fn=slim.batch_norm,normalizer_params={'is_training': is_training}):conv3_1 = slim.conv2d(images, 64, [3, 3], 1, padding='SAME', scope='conv3_1')max_pool_1 = slim.max_pool2d(conv3_1, [2, 2], [2, 2], padding='SAME', scope='pool1')conv3_2 = slim.conv2d(max_pool_1, 128, [3, 3], padding='SAME', scope='conv3_2')max_pool_2 = slim.max_pool2d(conv3_2, [2, 2], [2, 2], padding='SAME', scope='pool2')conv3_3 = slim.conv2d(max_pool_2, 256, [3, 3], padding='SAME', scope='conv3_3')max_pool_3 = slim.max_pool2d(conv3_3, [2, 2], [2, 2], padding='SAME', scope='pool3')conv3_4 = slim.conv2d(max_pool_3, 512, [3, 3], padding='SAME', scope='conv3_4')conv3_5 = slim.conv2d(conv3_4, 512, [3, 3], padding='SAME', scope='conv3_5')max_pool_4 = slim.max_pool2d(conv3_5, [2, 2], [2, 2], padding='SAME', scope='pool4')flatten = slim.flatten(max_pool_4)fc1 = slim.fully_connected(slim.dropout(flatten, keep_prob), 1024,activation_fn=tf.nn.relu, scope='fc1')logits = slim.fully_connected(slim.dropout(fc1, keep_prob), FLAGS.charset_size, activation_fn=None,scope='fc2')# 因为我们没有做热编码,所以使用sparse_softmax_cross_entropy_with_logitsloss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels))accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits, 1), labels), tf.float32))update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)if update_ops:updates = tf.group(*update_ops)loss = control_flow_ops.with_dependencies([updates], loss)global_step = tf.get_variable("step", [], initializer=tf.constant_initializer(0.0), trainable=False)optimizer = tf.train.AdamOptimizer(learning_rate=0.1)train_op = slim.learning.create_train_op(loss, optimizer, global_step=global_step)probabilities = tf.nn.softmax(logits)# 绘制loss accuracy曲线tf.summary.scalar('loss', loss)tf.summary.scalar('accuracy', accuracy)merged_summary_op = tf.summary.merge_all()# 返回top k 个预测结果及其概率;返回top K accuracypredicted_val_top_k, predicted_index_top_k = tf.nn.top_k(probabilities, k=top_k)accuracy_in_top_k = tf.reduce_mean(tf.cast(tf.nn.in_top_k(probabilities, labels, top_k), tf.float32))return {'images': images,'labels': labels,'keep_prob': keep_prob,'top_k': top_k,'global_step': global_step,'train_op': train_op,'loss': loss,'is_training': is_training,'accuracy': accuracy,'accuracy_top_k': accuracy_in_top_k,'merged_summary_op': merged_summary_op,'predicted_distribution': probabilities,'predicted_index_top_k': predicted_index_top_k,'predicted_val_top_k': predicted_val_top_k}3 模型训练
训练之前我们应设计好数据怎么样才能高效地喂给网络训练。
首先,我们先创建数据流图,这个数据流图由一些流水线的阶段组成,阶段间用队列连接在一起。第一阶段将生成文件名,我们读取这些文件名并且把他们排到文件名队列中。第二阶段从文件中读取数据(使用Reader),产生样本,而且把样本放在一个样本队列中。根据你的设置,实际上也可以拷贝第二阶段的样本,使得他们相互独立,这样就可以从多个文件中并行读取。在第二阶段的最后是一个排队操作,就是入队到队列中去,在下一阶段出队。因为我们是要开始运行这些入队操作的线程,所以我们的训练循环会使得样本队列中的样本不断地出队。
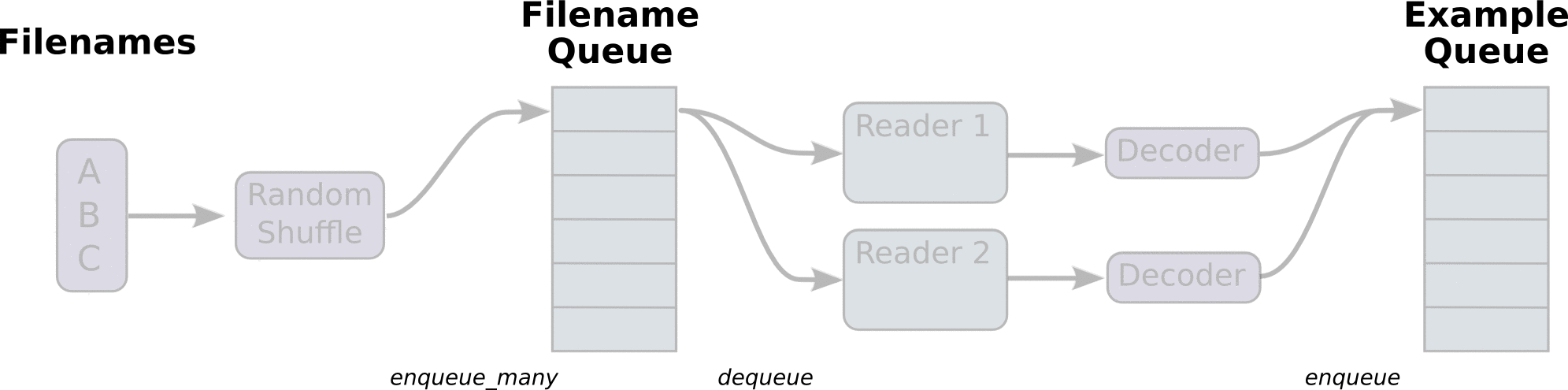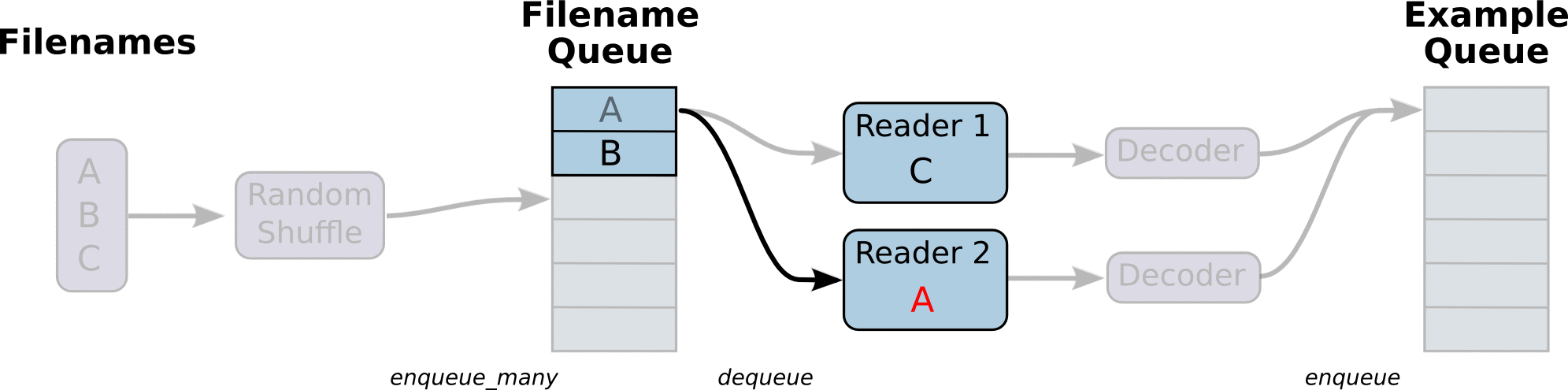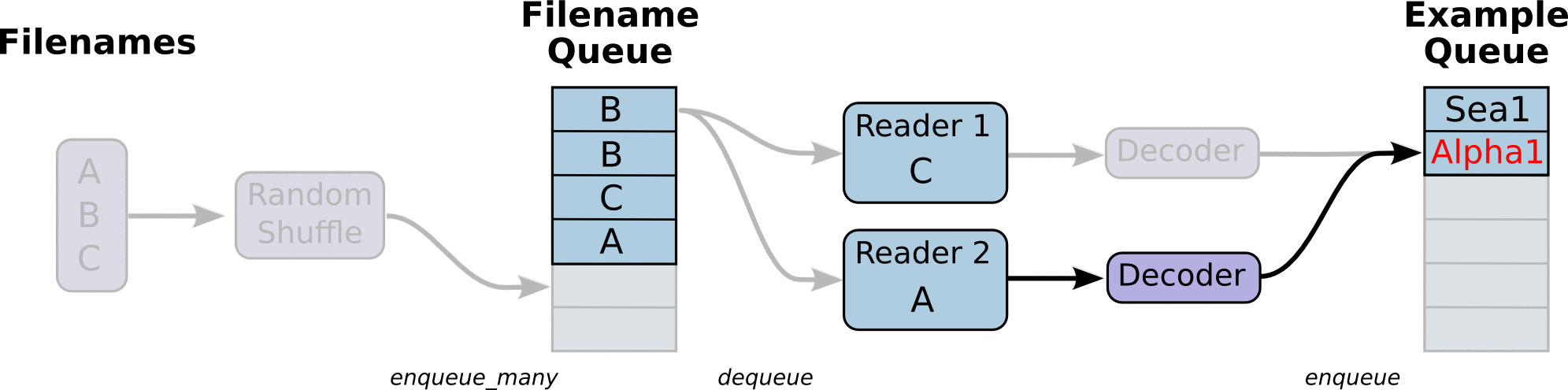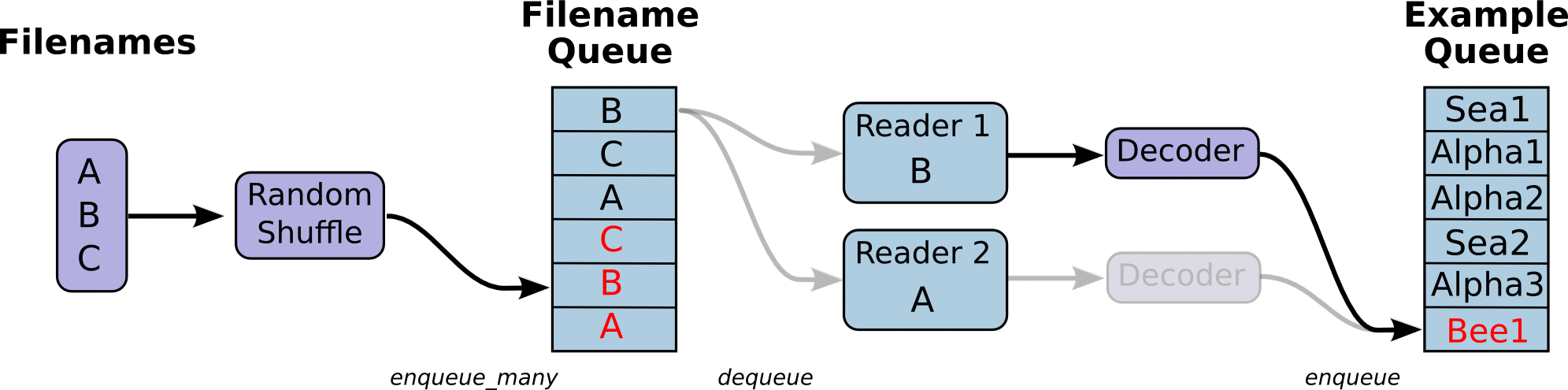
入队操作都在主线程中进行,Session中可以多个线程一起运行。 在数据输入的应用场景中,入队操作是从硬盘中读取输入,放到内存当中,速度较慢。
使用QueueRunner可以创建一系列新的线程进行入队操作,让主线程继续使用数据。如果在训练神经网络的场景中,就是训练网络和读取数据是异步的,主线程在训练网络,另一个线程在将数据从硬盘读入内存。
# batch的生成
def input_pipeline(self, batch_size, num_epochs=None, aug=False):# numpy array 转 tensorimages_tensor = tf.convert_to_tensor(self.image_names, dtype=tf.string)labels_tensor = tf.convert_to_tensor(self.labels, dtype=tf.int64)# 将image_list ,label_list做一个slice处理input_queue = tf.train.slice_input_producer([images_tensor, labels_tensor], num_epochs=num_epochs)labels = input_queue[1]images_content = tf.read_file(input_queue[0])images = tf.image.convert_image_dtype(tf.image.decode_png(images_content, channels=1), tf.float32)if aug:images = self.data_augmentation(images)new_size = tf.constant([FLAGS.image_size, FLAGS.image_size], dtype=tf.int32)images = tf.image.resize_images(images, new_size)image_batch, label_batch = tf.train.shuffle_batch([images, labels], batch_size=batch_size, capacity=50000,min_after_dequeue=10000)# print 'image_batch', image_batch.get_shape()return image_batch, label_batch
训练时数据读取的模式如上面所述,那训练代码则根据该架构设计如下:
def train():print('Begin training')# 填好数据读取的路径train_feeder = DataIterator(data_dir='./dataset/train/')test_feeder = DataIterator(data_dir='./dataset/test/')model_name = 'chinese-rec-model'with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, allow_soft_placement=True)) as sess:# batch data 获取train_images, train_labels = train_feeder.input_pipeline(batch_size=FLAGS.batch_size, aug=True)test_images, test_labels = test_feeder.input_pipeline(batch_size=FLAGS.batch_size)graph = build_graph(top_k=1) # 训练时top k = 1saver = tf.train.Saver()sess.run(tf.global_variables_initializer())# 设置多线程协调器coord = tf.train.Coordinator()threads = tf.train.start_queue_runners(sess=sess, coord=coord)train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train', sess.graph)test_writer = tf.summary.FileWriter(FLAGS.log_dir + '/val')start_step = 0# 可以从某个step下的模型继续训练if FLAGS.restore:ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)if ckpt:saver.restore(sess, ckpt)print("restore from the checkpoint {0}".format(ckpt))start_step += int(ckpt.split('-')[-1])logger.info(':::Training Start:::')try:i = 0while not coord.should_stop():i += 1start_time = time.time()train_images_batch, train_labels_batch = sess.run([train_images, train_labels])feed_dict = {graph['images']: train_images_batch,graph['labels']: train_labels_batch,graph['keep_prob']: 0.8,graph['is_training']: True}_, loss_val, train_summary, step = sess.run([graph['train_op'], graph['loss'], graph['merged_summary_op'], graph['global_step']],feed_dict=feed_dict)train_writer.add_summary(train_summary, step)end_time = time.time()logger.info("the step {0} takes {1} loss {2}".format(step, end_time - start_time, loss_val))if step > FLAGS.max_steps:breakif step % FLAGS.eval_steps == 1:test_images_batch, test_labels_batch = sess.run([test_images, test_labels])feed_dict = {graph['images']: test_images_batch,graph['labels']: test_labels_batch,graph['keep_prob']: 1.0,graph['is_training']: False}accuracy_test, test_summary = sess.run([graph['accuracy'], graph['merged_summary_op']],feed_dict=feed_dict)if step > 300:test_writer.add_summary(test_summary, step)logger.info('===============Eval a batch=======================')logger.info('the step {0} test accuracy: {1}'.format(step, accuracy_test))logger.info('===============Eval a batch=======================')if step % FLAGS.save_steps == 1:logger.info('Save the ckpt of {0}'.format(step))saver.save(sess, os.path.join(FLAGS.checkpoint_dir, model_name),global_step=graph['global_step'])except tf.errors.OutOfRangeError:logger.info('==================Train Finished================')saver.save(sess, os.path.join(FLAGS.checkpoint_dir, model_name), global_step=graph['global_step'])finally:# 达到最大训练迭代数的时候清理关闭线程coord.request_stop()coord.join(threads)
执行以下指令进行模型训练。因为我使用的是TITAN
X,所以感觉训练时间不长,大概1个小时可以训练完毕。训练过程的loss和accuracy变换曲线如下图所示
然后执行指令,设置最大迭代步数为16002,每100步进行一次验证,每500步存储一次模型。
python Chinese_OCR.py --mode=train --max_steps=16002 --eval_steps=100 --save_steps=500

4 模型性能评估
我们的需要对模模型进行评估,我们需要计算模型的top 1 和top 5的准确率。
执行指令
python Chinese_OCR.py --mode=validation

def validation():print('Begin validation')test_feeder = DataIterator(data_dir='./dataset/test/')final_predict_val = []final_predict_index = []groundtruth = []with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options,allow_soft_placement=True)) as sess:test_images, test_labels = test_feeder.input_pipeline(batch_size=FLAGS.batch_size, num_epochs=1)graph = build_graph(top_k=5)saver = tf.train.Saver()sess.run(tf.global_variables_initializer())sess.run(tf.local_variables_initializer()) # initialize test_feeder's inside statecoord = tf.train.Coordinator()threads = tf.train.start_queue_runners(sess=sess, coord=coord)ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)if ckpt:saver.restore(sess, ckpt)print("restore from the checkpoint {0}".format(ckpt))logger.info(':::Start validation:::')try:i = 0acc_top_1, acc_top_k = 0.0, 0.0while not coord.should_stop():i += 1start_time = time.time()test_images_batch, test_labels_batch = sess.run([test_images, test_labels])feed_dict = {graph['images']: test_images_batch,graph['labels']: test_labels_batch,graph['keep_prob']: 1.0,graph['is_training']: False}batch_labels, probs, indices, acc_1, acc_k = sess.run([graph['labels'],graph['predicted_val_top_k'],graph['predicted_index_top_k'],graph['accuracy'],graph['accuracy_top_k']], feed_dict=feed_dict)final_predict_val += probs.tolist()final_predict_index += indices.tolist()groundtruth += batch_labels.tolist()acc_top_1 += acc_1acc_top_k += acc_kend_time = time.time()logger.info("the batch {0} takes {1} seconds, accuracy = {2}(top_1) {3}(top_k)".format(i, end_time - start_time, acc_1, acc_k))except tf.errors.OutOfRangeError:logger.info('==================Validation Finished================')acc_top_1 = acc_top_1 * FLAGS.batch_size / test_feeder.sizeacc_top_k = acc_top_k * FLAGS.batch_size / test_feeder.sizelogger.info('top 1 accuracy {0} top k accuracy {1}'.format(acc_top_1, acc_top_k))finally:coord.request_stop()coord.join(threads)return {'prob': final_predict_val, 'indices': final_predict_index, 'groundtruth': groundtruth}
5 文字预测
刚刚做的那一步只是使用了我们生成的数据集作为测试集来检验模型性能,这种检验是不大准确的,因为我们日常需要识别的文字样本不会像是自己合成的文字那样的稳定和规则。那我们尝试使用该模型对一些实际场景的文字进行识别,真正考察模型的泛化能力。
首先先编写好预测的代码
def inference(name_list):print('inference')image_set=[]# 对每张图进行尺寸标准化和归一化for image in name_list:temp_image = Image.open(image).convert('L')temp_image = temp_image.resize((FLAGS.image_size, FLAGS.image_size), Image.ANTIALIAS)temp_image = np.asarray(temp_image) / 255.0temp_image = temp_image.reshape([-1, 64, 64, 1])image_set.append(temp_image)# allow_soft_placement 如果你指定的设备不存在,允许TF自动分配设备with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options,allow_soft_placement=True)) as sess:logger.info('========start inference============')# images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1])# Pass a shadow label 0. This label will not affect the computation graph.graph = build_graph(top_k=3)saver = tf.train.Saver()# 自动获取最后一次保存的模型ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)if ckpt: saver.restore(sess, ckpt)val_list=[]idx_list=[]# 预测每一张图for item in image_set:temp_image = itempredict_val, predict_index = sess.run([graph['predicted_val_top_k'], graph['predicted_index_top_k']],feed_dict={graph['images']: temp_image,graph['keep_prob']: 1.0,graph['is_training']: False})val_list.append(predict_val)idx_list.append(predict_index)#return predict_val, predict_indexreturn val_list,idx_list
这里需要说明一下,我会把我要识别的文字图像存入一个叫做tmp的文件夹内,里面的图像按照顺序依次编号,我们识别时就从该目录下读取所有图片仅内存进行逐一识别。
# 获待预测图像文件夹内的图像名字
def get_file_list(path):list_name=[]files = os.listdir(path)files.sort()for file in files:file_path = os.path.join(path, file)list_name.append(file_path)return list_name
那我们使用训练好的模型进行汉字预测,观察效果。首先我从一篇论文pdf上用截图工具截取了一段文字,然后使用文字切割算法把文字段落切割为单字,如下图,因为有少量文字切割失败,所以丢弃了一些单字。
从一篇文章中用截图工具截取文字段落。

切割出来的单字,黑底白字。

最后将所有的识别文字按顺序组合成段落,可以看出,汉字识别完全正确,说明我们的基于深度学习的OCR系统还是相当给力!

至此,支持3755个汉字识别的OCR系统已经搭建完毕,经过测试,效果还是很不错。这是一个没有经过太多优化的模型,在模型评估上top
1的正确率达到了99.9%,这是一个相当优秀的效果了,所以说在一些比较理想的环境下的文字识别的效果还是比较给力,但是对于复杂场景的或是一些干扰比较大的文字图像,识别起来的效果可能不会太理想,这就需要针对特定场景做进一步优化。
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 题目:基于深度学习的中文汉字识别 - 深度学习 卷积神经网络 机器视觉 OCR
文章目录 0 简介1 数据集合2 网络构建3 模型训练4 模型性能评估5 文字预测6 最后 0 简介 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的中文汉字识别 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! &a…...

Django跨域访问 nginx转发 开源浏览器
Django跨域访问 https://blog.csdn.net/lonelysnowman/article/details/128086205 nginx转发 https://blog.csdn.net/faye0412/article/details/75200607/ 开源浏览器 https://www.oschina.net/p/chromiumengine 浏览器油猴开发 https://blog.csdn.net/mukes/article/detail…...

Docker Alist 在线网盘部署
文章目录 拉取镜像创建并运行查看容器自动生成的密码在浏览器中进行访问 挂载本地磁盘 拉取镜像 docker pull xhofe/alist-aria2创建并运行 # -v /data/alist:/opt/alist/data 挂载本地目录 docker run -d --restartalways -v /data/alist:/opt/alist/data -p 5244:5244 -e P…...

Jmeter吞吐量控制器使用小结
吞吐量控制器(Throughput Controller)场景: 在同一个线程组里, 有10个并发, 7个做A业务, 3个做B业务,要模拟这种场景,可以通过吞吐量模拟器来实现.。 添加吞吐量控制器 用法1: Percent Executions 在一个线程组内分别建立两个吞吐量控制器, 分别放业务A和业务B 吞吐量控制器采…...
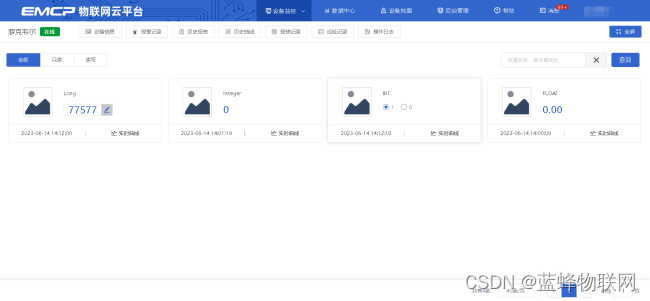
3分钟轻松实现网关网口连接罗克韦尔AB CompactLogix系列PLC
目录 EG网关网口连接罗克韦尔AB CompactLogix系列PLC 一. 准备工作 1.1 在对接前我们需准备如下物品 1.2 EG20网关准备工作 1.3 PLC准备工作 二. EMCP平台设置 2.1 新增EG设备 2.2 远程配置网关 2.3 网关绑定 2.4 通讯参数设置 2.5 创建设备驱动 2.5.1 添加变量 2.…...
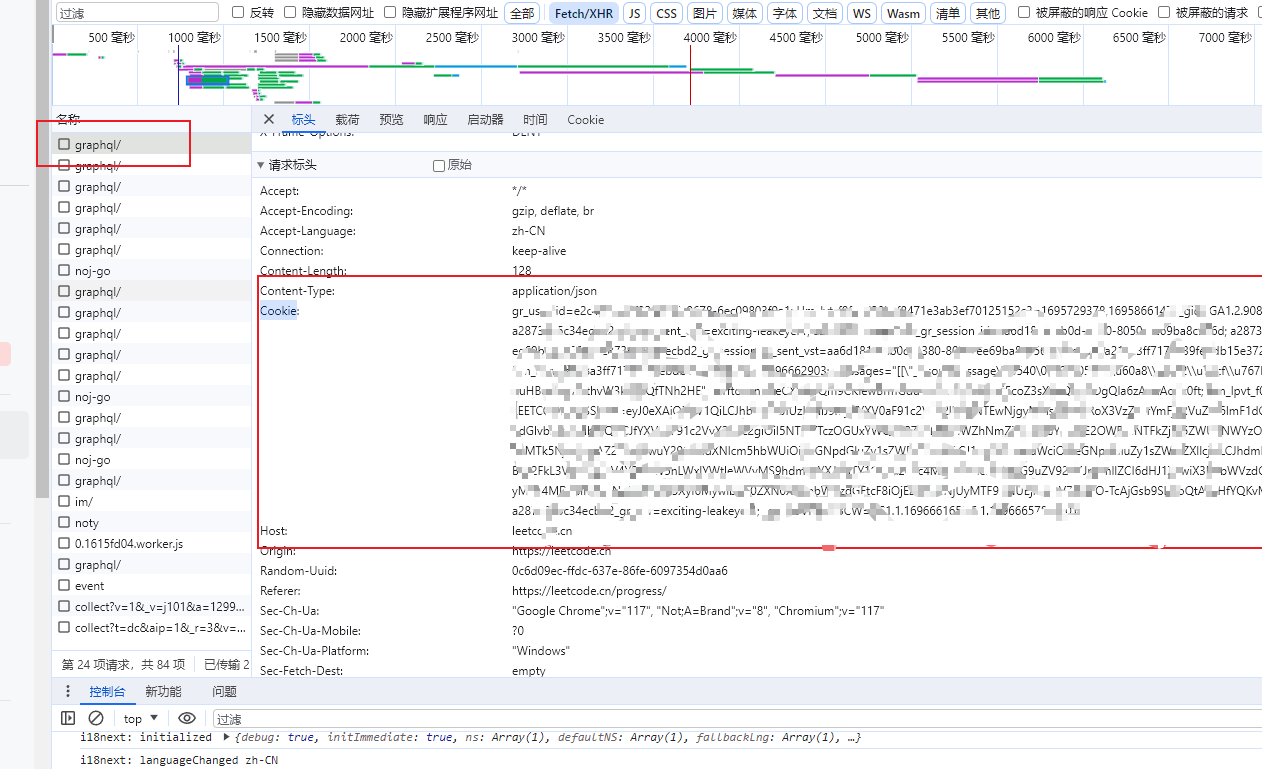
vscode刷leetcode使用Cookie登录
1、打开vscode,选择扩展,搜索leetcode,选择第一个,带有中文力扣字样,安装后重启 2、选择这个小球,切换中文版本,切换后,会显示一个打勾 3、选择小球旁边的有箭头的小门࿰…...

每次启动Docker容器指定IP、hosts和端口
每次启动Docker容器指定IP、hosts和端口 1问题描述1解决办法1.1启动容器指定好IP、hostname、端口等信息1.2通过docker-compose启动容器,可以配置extra_hosts属性1.3通过k8s来管理容器,则在可以在创建pod的yaml文件通过hostAliases添加域名IP映射 2问题描…...

PL/SQL增量同步
PL/SQL全量同步_枯河垂钓的博客-CSDN博客 目录 增量同步 增量同步存储过程 ORACEL 独有的 增量更新 merge into 增量同步 逻辑: 用源表的数据更新目标表,数据存在则更新,数据不存在,则插入 实现的逻辑: 1. 首先判断目标表是否有源表的数据 2. 如果有,则用源表的数据更新…...
C++——多态底层原理
虚函数表 先来看这个问题: class Base { public: virtual void Func1() { cout << "Func1()" << endl; } private: int _b 1; }; sizeof(Base)是多少? 答案是:8 因为Base中除了成员变量_b,还有一个虚函数表_vfp…...

asdTools-ReID热力图可视化
文章首发见博客:https://mwhls.top/4869.html。 无图/格式错误/后续更新请见首发页。 更多更新请到mwhls.top查看 欢迎留言提问或批评建议,私信不回。 Github - 开源代码及Readme Blog - 工具介绍 摘要:基于TorchCam实现ReID的热力图可视化的…...

CSS学习笔记
目录 1.CSS简介1.什么是CSS2.为什么使用CSS3.CSS作用 2.基本用法1.CSS语法2.CSS应用方式1. 内部样式2.行内样式3.外部样式1.使用 link标签 链接外部样式文件2.import 指令 导入外部样式文件3.使用举例 3.选择器1.基础选择器1.标签选择器2.类选择器3.ID选择器4.使用举例 2.复杂选…...

linux操作命令
VMware版本: 17.0 ubantu版本:22.04.3 命令: # 查看当前目录文件 ls# 切换路径 []内是路径 cd [snap/] cd ../ #返回上一层# 创建文件 []内是文件名 touch [test.txt]# 创建文件夹 []内是文件夹名 mkdir [myself]# 测试一下网络 ping www.b…...
)
猜数字游戏(Python)
一、猜数字游戏是一个古老的密码破译类、益智类小游戏,通常由两个人参与,一个人设置一个数字,一个人猜数字,当猜数字的人说出一个数字,由出数字的人告知是否猜中:若猜测的数字大于设置的数字,出…...

可视化模块
目录 可视化送入网络的图片可视化网络层的热力图 可视化送入网络的图片 送入的数据为imgs,其大小为(8,3,256,256),并以2行8列进行展示 import matplotlib.pyplot as plt import numpy as np# 假设你的张量名为 tensor,形状为 (8, 3, 256, 2…...

MyBatis insert标签
<insert id"addWebsite" parameterType"string">insert into website(name)values(#{name}) </insert> 在 WebsiteMapper 接口中定义一个 add() 方法 public int addWebsite(String name); 参数为 Sting 类型的字符串;返回值为 …...

扬尘监测:智能化解决方案让生活更美好
随着工业化和城市化的快速发展,扬尘污染问题越来越受到人们的关注。扬尘不仅影响城市环境,还会对人们的健康造成威胁。为了解决这一问题,扬尘监测成为了一个重要的手段。本文将介绍扬尘监测的现状、重要性以及智能化解决方案,帮助…...

【AI视野·今日NLP 自然语言处理论文速览 第四十五期】Mon, 2 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 2 Oct 2023 Totally 44 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Efficient Streaming Language Models with Attention Sinks Authors Guangxuan Xiao, Yuandong Tian, Beidi C…...

The little schemer 学习
参考文章: The Little Schemer 阅读笔记-CSDN博客 前言 原子是Scheme的基本元素之一。首先定义了过程atom?,用来判断一个S-表达式是不是原子: (define atom?(lambda (x)(and (not (pair? x)) (not (null? x))))) 这个“pair”实际上…...

yolov5+bytetrack算法在华为NPU上进行端到端开发
自从毕业后开始进入了华为曻腾生态圈,现在越来越多的公司开始走国产化路线了,现在国内做AI芯片的厂商比如:寒武纪、地平线等,虽然我了解的不多,但是相对于瑞芯微这样的AI开发板来说,华为曻腾的生态比瑞芯微…...

【Java-LangChain:使用 ChatGPT API 搭建系统-1】简介
简介 欢迎来到课程《使用 ChatGPT API 搭建系统》 , 旨在指导开发者如何基于 ChatGPT 搭建完整的智能问答系统。 使用 ChatGPT 不仅仅是一个单一的 Prompt 或单一的模型调用,本课程将分享使用 LLM 构建复杂应用的最佳实践。 本课程以构建客服助手为例,…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...