GPT系列论文解读:GPT-3
GPT系列
GPT(Generative Pre-trained Transformer)是一系列基于Transformer架构的预训练语言模型,由OpenAI开发。以下是GPT系列的主要模型:
-
GPT:GPT-1是于2018年发布的第一个版本,它使用了12个Transformer编码器层和1.5亿个参数。GPT-1的训练数据包括了互联网上的大量文本。
-
GPT-2:GPT-2于2019年发布,是GPT系列的第二个版本。它比GPT-1更大更强大,使用了24个Transformer编码器层和1.5亿到15亿个参数之间的不同配置。GPT-2在生成文本方面表现出色,但由于担心滥用风险,OpenAI最初选择限制了其训练模型的发布。
-
GPT-3:GPT-3于2020年发布,是GPT系列的第三个版本,也是目前最先进和最强大的版本。它采用了1750亿个参数,拥有1750亿个可调节的权重。GPT-3在自然语言处理(NLP)任务中表现出色,可以生成连贯的文本、回答问题、进行对话等。
-
GPT-3.5:GPT-3.5是在GPT-3基础上进行微调和改进的一个变种,它是对GPT-3的进一步优化和性能改进。
GPT系列的模型在自然语言处理领域取得了巨大的成功,并在多个任务上展示出了强大的生成和理解能力。它们被广泛用于文本生成、对话系统、机器翻译、摘要生成等各种应用中,对自然语言处理和人工智能领域的发展有着重要的影响。
GPT系列是当前自然语言处理领域下最流行,也是商业化效果最好的自然语言大模型,并且他的论文也对NLP的领域产生巨大影响,GPT首次将预训练-微调模型真正带入NLP领域,同时提出了多种具有前瞻性的训练方法,被后来的BERT等有重大影响的NLP论文所借鉴。
目录
- GPT系列
- 前言
- 问题的提出
- 介绍
- 方法
- 模型规模
- GPT-3模型和架构
- 训练数据
- 训练过程
- 评估
- 总结
前言
在GPT-2论文中,谷歌团队致力于将GPT应用于Zero-shot领域,当然取得了不错的结果,但是这种结果离真正能在市场上应用还差得远,所以在GPT-3这篇论文中,谷歌团队又将目光转回Few-shot领域中来,论文标题“Language Models are Few-Shot Learners”也写明了GPT-3不再追求极致的零样本,即在一个子任务上完全不给语言模型任何样例,转而将样本数量控制在较小范围。
问题的提出
近年来,NLP系统中出现了一种趋势,即以越来越灵活和任务无关的方式在下游传输中使用预先训练好的语言表示。首先,使用词向量学习单层表示,并将其反馈给任务特定的体系结构,然后使用具有多层表示和上下文状态的RNN形成更强的表示(尽管仍适用于任务特定的体系结构),最近,经过预训练的递归或Transformer语言模型已经过直接微调,完全消除了对任务特定架构的需求。
这最后一种范式在许多具有挑战性的NLP任务上取得了实质性进展,如阅读理解、问答、文本蕴涵和其他许多任务,并在新的架构和算法基础上不断进步。然而,这种方法的一个主要限制是,虽然体系结构与任务无关,但仍然需要特定于任务的数据集和特定于任务的微调:要在所需任务上实现强大的性能,通常需要对特定于该任务的数千到几十万个示例的数据集进行微调。出于几个原因,消除这一限制是可取的。
首先,从实践的角度来看,每项新任务都需要一个大型的标记示例数据集,这限制了语言模型的适用性。存在着非常广泛的可能有用的语言任务,包括从纠正语法到生成抽象概念的示例,再到评论短篇小说的任何内容。对于许多此类任务,很难收集大型有监督的训练数据集,尤其是在每个新任务都必须重复该过程的情况下。
其次,随着模型的表达能力和训练分布的狭窄,利用训练数据中虚假相关性的潜力从根本上增加。这可能会给预训练+微调范式带来问题,在这种范式中,模型设计得很大,以便在预训练期间吸收信息,但随后会在非常狭窄的任务分布上进行微调。有证据表明,在这种范式下实现的泛化可能很差,因为该模型对训练分布过于具体,并且在其之外没有很好的泛化。因此,微调模型在特定基准上的性能,即使名义上处于人的水平,也可能夸大基本任务的实际性能。
第三,人类学习大多数语言任务不需要大型有监督的数据集——自然语言中的简短指令(例如,“请告诉我这句话描述的是快乐还是悲伤”)或至多少量的演示(例如,“这里有两个勇敢的人的例子;请给出第三个勇敢的例子”)通常足以让人类执行新任务至少达到合理的能力水平。除了指出我们当前NLP技术的概念局限性外,这种适应性还具有实际优势——它允许人类无缝地混合在一起或在许多任务和技能之间切换,例如在长时间的对话中执行加法。为了广泛使用,希望有一天我们的NLP系统具有相同的流动性和通用性。
介绍
近年来,transformer语言模型的容量大幅增加,从1亿个参数,增加到3亿个参数,增加到15亿个参数,增加到80亿个参数,110亿个参数,最后增加到170亿个参数。每一次增加都带来了文本合成和/或下游NLP任务的改善,有证据表明,log损失与许多下游任务密切相关,随着规模的增加,呈现平稳的改善趋势。由于情境上下文学习涉及在模型参数范围内吸收许多技能和任务,因此,情境学习能力可能会随着规模的扩大而表现出类似的强劲增长。
在本文中,论文通过训练一个1750亿参数的自回归语言模型(Transformer Decoder)(称之为GPT-3)并测量其上下文学习能力来检验这一假设。具体而言,论文评估了二十多个NLP数据集上的GPT-3,以及一些旨在测试对训练集中不可能直接包含的任务的快速适应的新任务。对于每项任务,论文在3种条件下评估GPT-3:
(a)“few-shot learning”,或在上下文学习中,允许尽可能多的演示,以适应模型的上下文窗口(通常为10到100)
(b)“one-shot learning”,只允许一次演示,
(c)“zero-shot learning”,不允许演示,仅向模型提供自然语言说明。
GPT-3原则上也可以在传统的微调设置中进行评估,但论文将此留给未来的工作。
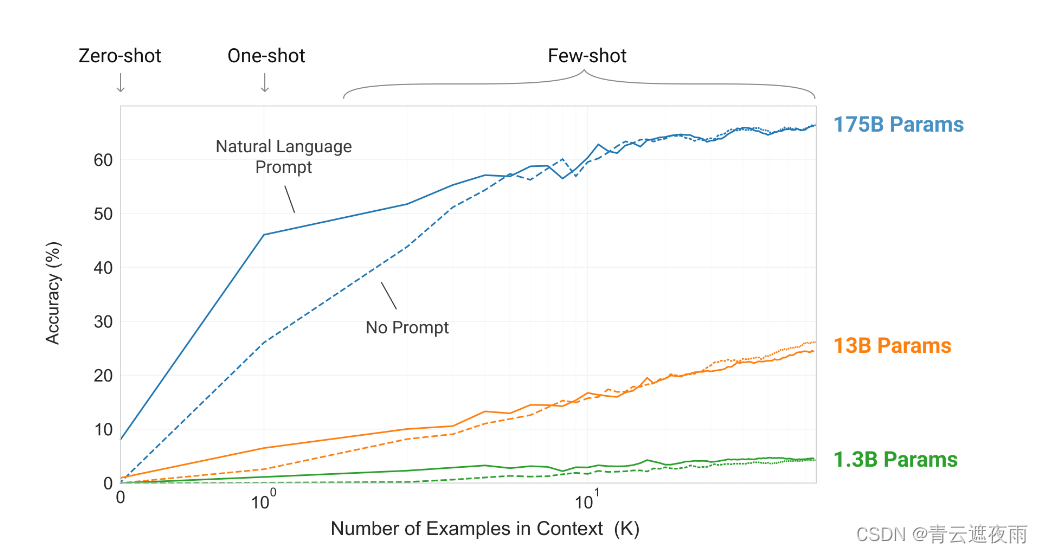
上图说明了论文研究的条件,并显示了需要模型从单词中删除无关符号的简单任务的few-shot学习。通过添加自然语言任务描述和模型上下文中的示例数量,模型性能得到了提高。few-shot学习也随着模型大小的增加而显著提高。虽然这种情况下的结果特别引人注目,但在论文研究的大多数任务中,模型大小和上下文中的示例数量的总体趋势都适用。论文强调,这些“学习”曲线不涉及梯度更新或微调,只是增加了作为条件作用的演示次数。
方法
论文的基本预训练方法,包括模型、数据和训练,与GPT-2中描述的过程类似,相对简单地扩大了模型大小、数据集大小和多样性以及训练长度。我们对情境学习的使用也与 GPT-2类似,但在这项工作中,我们系统地探索了情境中学习的不同设置。因此,我们首先明确定义和对比我们将评估 GPT-3 或原则上评估 GPT-3 的不同设置。这些设置可以被视为取决于它们倾向于依赖多少特定于任务的数据。

图中我们可以看出在微调时GPT-3不需要进行梯度的更新,这也是GPT-3的卖点之一
- 微调(FT):是近年来最常见的方法,它涉及通过对特定于所需任务的监督数据集进行训练来更新预训练模型的权重。通常使用数千到数十万个带标签的示例。微调的主要优点是在许多基准测试中表现出色。主要缺点是每个任务都需要一个新的大型数据集,分布外泛化能力差的可能性,以及利用训练数据的虚假特征的可能性,这可能会导致与人类表现进行不公平的比较。在这项工作中,我们没有对 GPT-3 进行微调,因为我们的重点是与任务无关的性能,但 GPT-3 原则上可以进行微调,这是未来工作的一个有希望的方向。
- Few-Shot (FS):Few-Shot (FS) 是我们在这项工作中使用的术语,指的是这样的设置:在推理时为模型提供一些任务演示作为条件,但不允许权重更新。如上图所示,对于典型的数据集,示例具有上下文和所需的完成(例如英语句子和法语翻译),通过给出 K 个上下文和完成的示例,然后提供一个最终示例,可以进行少样本工作上下文,模型有望提供完成。我们通常将 K 设置在 10 到 100 的范围内,因为这是模型上下文窗口中可以容纳的示例数量 ( n c t x n_{ctx} nctx = 2048)。 Few-shot 的主要优点是大大减少了对特定任务数据的需求,并降低了从大而窄的微调数据集中学习过于狭窄的分布的潜力。主要缺点是,迄今为止,这种方法的结果比最先进的微调模型要差得多。此外,仍然需要少量任务特定数据。正如名称所示,此处描述的语言模型的小样本学习与 ML 中其他上下文中使用的小样本学习相关 - 两者都涉及基于任务的广泛分布的学习(在这种情况隐含在预训练数据中),然后快速适应新任务。
- One-Shot (1S):One-Shot (1S) 与 Few-shot 相同,只是只允许进行一次演示,此外还需要对任务进行自然语言描述,区分 One-shot 和 Few-shot 的原因零样本(上图)的优点是它最接近某些任务与人类沟通的方式。例如,当要求人类在人类工作者服务(例如 Mechanical Turk)上生成数据集时,通常会给出一个任务演示。相比之下,如果不给出示例,有时很难传达任务的内容或格式。
- Zero-Shot (0S):Zero-Shot与One-Shot相同,只是不允许进行演示,并且模型仅被给予描述任务的自然语言指令。这种方法提供了最大的便利性、鲁棒性的潜力,并避免了虚假相关性(除非它们在预训练数据的大型语料库中广泛出现),但也是最具挑战性的设置。在某些情况下,如果没有先前的示例,人类甚至可能很难理解任务的格式,因此这种设置在某些情况下“相当困难”。例如,如果有人被要求“制作一个 200m 短跑的世界纪录表”,这个请求可能会含糊不清,因为可能不清楚该表应该具有什么格式或应该包含什么(即使仔细考虑)澄清、准确理解想要的东西可能很困难)。尽管如此,至少对于某些设置来说,零样本最接近人类执行任务的方式 。
模型规模
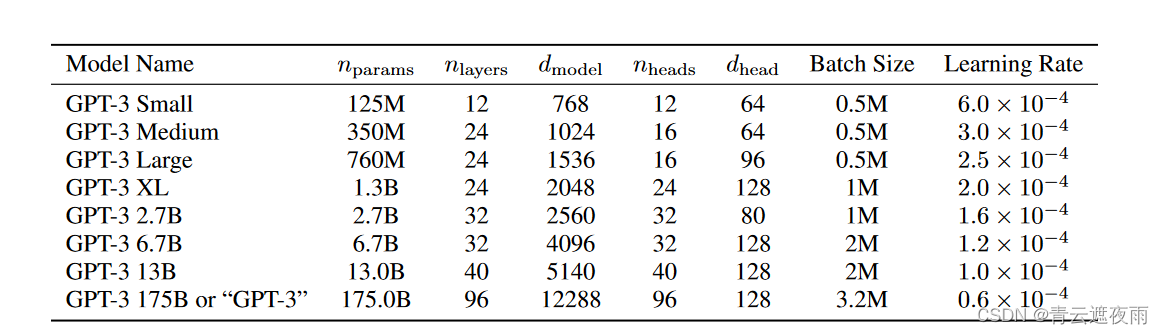
GPT-3模型和架构
论文使用与 GPT-2相同的模型和架构,包括其中描述的修改后的初始化、预归一化和可逆标记化,不同之处在于我们在Transformer,类似于Sparse Transformer。为了研究 ML 性能对模型大小的依赖性,我们训练了 8 种不同大小的模型,范围从 1.25 亿个参数到 1750 亿个参数三个数量级,最后一个是我们称为 GPT-3 的模型。之前的工作表明,如果有足够的训练数据,损失函数的缩放应该近似为大小函数的平滑幂律;许多不同大小的训练模型使我们能够测试这个假设的验证损失和下游语言任务。上图显示了论文 8 个模型的尺寸和架构。这里 n p a r a m s n_{params} nparams 是可训练参数的总数, n l a y e r s n_{layers} nlayers 是总层数, d m o d e l d_{model} dmodel 是每个瓶颈层中的单元数(我们的前馈层始终是瓶颈层大小的四倍, d f f = 4 ∗ d m o d e l d_{ff} = 4 * d_{model} dff=4∗dmodel) , d h e a d d_{head} dhead 是每个注意力头的维度。所有模型都使用 n c t x = 2048 n_{ctx} = 2048 nctx=2048 个token的上下文窗口。我们沿着深度和宽度维度跨 GPU 划分模型,以最大程度地减少节点之间的数据传输。每个模型的精确架构参数是根据计算效率和跨 GPU 模型布局的负载平衡来选择的。之前的工作 表明验证损失在相当宽的范围内对这些参数并不强烈敏感。
原论文就写了这么少的内容,并没有说清楚具体的模型细节
训练数据
语言模型的数据集迅速扩展,最终形成了包含近万亿个单词的 Common Crawl 数据集。这种大小的数据集足以训练我们最大的模型,而无需对同一序列进行两次更新。然而,我们发现未经过滤或轻度过滤的 Common Crawl 版本往往比经过精心策划的数据集质量较低。因此,我们采取了 3 个步骤来提高数据集的平均质量:
(1)我们根据与一系列高质量参考语料库的相似性下载并过滤 CommonCrawl 的版本,(2)我们在文档级别执行模糊重复数据删除,在数据集内部和数据集之间,以防止冗余并保持我们保留的验证集的完整性,作为过度拟合的准确度量,
(3)我们还在训练组合中添加了已知的高质量参考语料库,以增强 CommonCrawl 并提高其多样性。
最终的数据集如下:
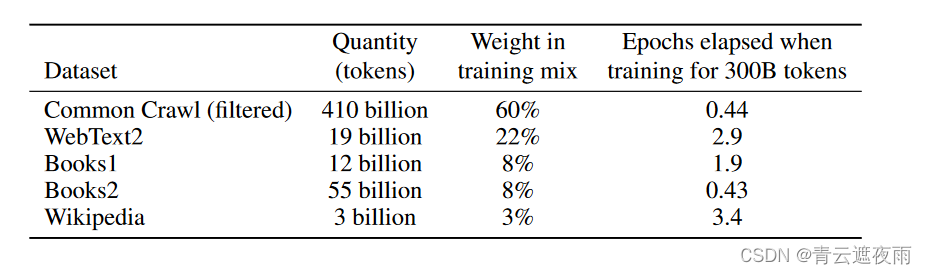
我们可以看出,虽然Common Crawl数据集的大小是其他数据集之和的数倍,但是每个Batch只采样百分之60,这种做法既能保证数据集足够大来训练这个175B的大模型,又能保证高质量数据在总数据集比重较大,保证模型的准确性。
训练过程
较大的模型通常可以使用较大的批量大小,但需要较小的学习率。我们在训练期间测量梯度噪声尺度,并用它来指导我们选择批量大小。为了在不耗尽内存的情况下训练更大的模型,我们在每个矩阵乘法中混合使用模型并行性,并在网络各层之间使用模型并行性。所有模型均在 Microsoft 提供的高带宽集群的 V100 GPU 上进行训练。
评估
对于少样本学习,我们通过从该任务的训练集中随机抽取 K 个示例作为条件来评估评估集中的每个示例,根据任务以 1 或 2 个换行符分隔。对于 LAMBADA 和 Storycloze,没有可用的监督训练集,因此我们从验证集中抽取条件示例并在测试集上进行评估。对于 Winograd(原始版本,不是 SuperGLUE 版本),只有一个数据集,因此我们直接从中绘制条件示例。
K 可以是从 0 到模型上下文窗口允许的最大数量的任何值,对于所有模型来说, n c t x n_{ctx} nctx = 2048,通常适合 10 到 100 个示例。 K 值越大越好,但并不总是越好,因此当有单独的验证集和测试集可用时,我们会在验证集上尝试几个 K 值,然后在测试集上运行最佳值。对于某些任务,除了(或对于 K = 0,而不是)演示之外,我们还使用自然语言提示。
对于涉及从多个选项(多项选择)中选择一个正确完成的任务,论文提供了 K 个上下文示例加上正确完成,然后仅提供一个上下文示例,并比较每个完成的 LM 可能性。对于大多数任务,我们比较每个标记的可能性(对长度进行标准化),但是,在少数数据集(ARC、OpenBookQA 和 RACE)上,我们通过对每个标记的无条件概率进行标准化,在开发集上衡量,获得了额外的好处完成,通过计算 P ( c o m p l e t i o n ∣ c o n t e x t ) P ( c o m p l e t i o n ∣ a n s w e r c o n t e x t ) \frac{P (completion|context)}{ P (completion|answer context) } P(completion∣answercontext)P(completion∣context),其中答案上下文是字符串“Answer:”或“A:”,用于提示完成应该是答案,但在其他方面是通用的。
在涉及二元分类的任务中,我们为选项赋予更具语义意义的名称(例如“True”或“False”而不是 0 或 1),然后将任务视为多项选择。
总结
论文提出了一个 1750 亿个参数的语言模型,该模型在零样本、单样本和少样本设置中的许多 NLP 任务和基准测试中显示出强大的性能,在某些情况下几乎与 4 个最先进的性能相匹配微调系统,以及在动态定义的任务中生成高质量的样本和强大的定性性能。我们在不使用微调的情况下记录了大致可预测的性能扩展趋势。论文还讨论了此类模型的社会影响。尽管存在许多限制和弱点,但这些结果表明,非常大的语言模型可能是开发适应性强的通用语言系统的重要组成部分。
谷歌团队似乎不愿透露GPT系列模型的细节内容,GPT系列论文花了大量的时间来展示GPT模型在不同任务上的实验结果,在模型方法和训练方法上一带而过,是一篇带有“炫技性”的论文,并不是一篇适合读者去学习自然语言大模型的论文。
相关文章:
GPT系列论文解读:GPT-3
GPT系列 GPT(Generative Pre-trained Transformer)是一系列基于Transformer架构的预训练语言模型,由OpenAI开发。以下是GPT系列的主要模型: GPT:GPT-1是于2018年发布的第一个版本,它使用了12个Transformer…...
神经网络中的知识蒸馏
多分类交叉熵损失函数:每个样本的标签已经给出,模型给出在三种动物上的预测概率。将全部样本都被正确预测的概率求得为0.70.50.1,也称为似然概率。优化的目标就是希望似然概率最大化。如果样本很多,概率不断连乘,就会造…...

jmeter利用自身代理录制脚本
在利用代理录制脚本时一定要安装java jdk,不然不能录制的。 没有安装过java jdk安装jmeter后打开时会提示安装jdk,但是mac系统中直接打开提示安装jdk页面后下载的java并不是jdk(windows中没有试验过,笔者所说的基本全部指的是在ma…...
【漏洞复现】时空智友企业流程化管控系统 session泄露
漏洞描述 时空智友企业流程化管控系统 session 泄露 免责声明 技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危害国家安全、荣誉和利益,未经授权请勿利用…...

获取泛型的类型
示例一:获取父类的泛型的类型 public class Emp<T, Q> {class Stu extends Emp<String, Integer> {}Testvoid fun() {final Type type Emp.class.getGenericSuperclass();final ParameterizedType parameterizedType (ParameterizedType) type;Syste…...

[Python进阶] Pyinstaller打包问题
5.9 Pyinstaller打包问题 5.9.1 找不到指定的模块 Pyinstaller在进行打包时,会解析打包的Python文件,自动寻找py源文件的依赖模块。但是Pyinstaller解析模块时可能会遗漏某些模块,这个时候就会报错:No Module named xxx。 如果是…...

计算机竞赛 题目:基于机器视觉opencv的手势检测 手势识别 算法 - 深度学习 卷积神经网络 opencv python
文章目录 1 简介2 传统机器视觉的手势检测2.1 轮廓检测法2.2 算法结果2.3 整体代码实现2.3.1 算法流程 3 深度学习方法做手势识别3.1 经典的卷积神经网络3.2 YOLO系列3.3 SSD3.4 实现步骤3.4.1 数据集3.4.2 图像预处理3.4.3 构建卷积神经网络结构3.4.4 实验训练过程及结果 3.5 …...

竞赛选题 机器学习股票大数据量化分析与预测系统 - python 竞赛选题
文章目录 0 前言1 课题背景2 实现效果UI界面设计web预测界面RSRS选股界面 3 软件架构4 工具介绍Flask框架MySQL数据库LSTM 5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 机器学习股票大数据量化分析与预测系统 该项目较为新颖&am…...

智慧驿站:为城市带来全新智慧公厕未来形态
随着城市发展和科技进步的不断推进,智慧公厕逐渐成为城市规划和公共设施建设的重要组成部分。而集合了创意的外观设计、全金属结构工艺、智慧公厕、自动售货、共享设备、广告大屏、小型消防站、小型医疗站,并能根据需要而灵活组合的智慧驿站成为其中重要…...

Java获取汉字首字母
Java获取汉字的首字母,例如:中国香港,则返回ZGXG;Tom 中国欢迎你,则返回 TOM ZGHYN,如果为英文,则返回英文的大写形式,传空字符串则什么也不返回。 其中需要引用的maven依赖…...
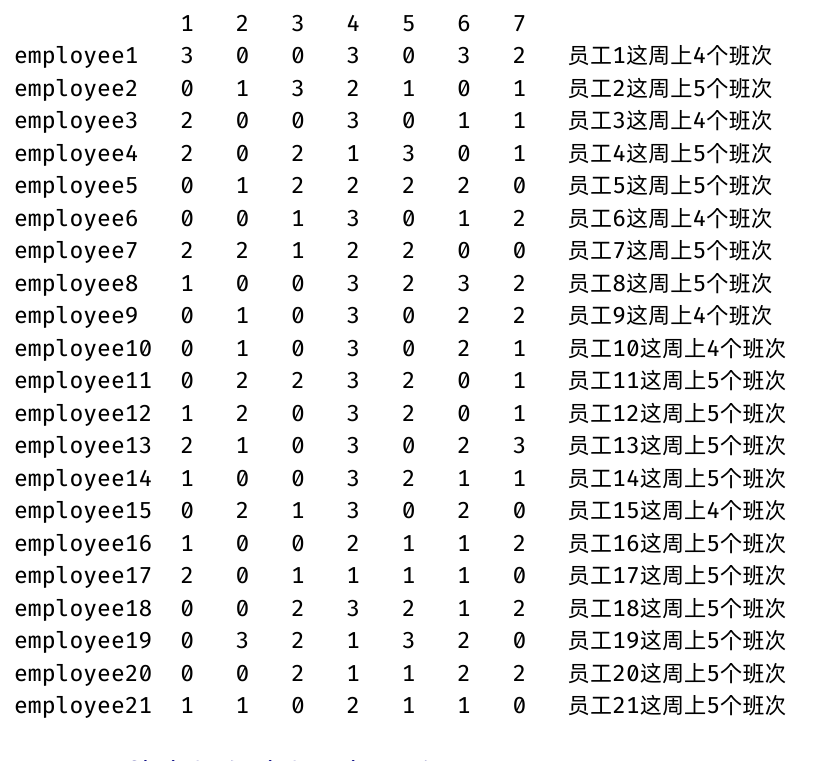
基于or-tools的人员排班问题建模求解(JavaAPI)
使用Java调用or-tools实现了阿里mindopt求解器的案例(https://opt.aliyun.com/platform/case)人员排班问题。 这里写目录标题 人员排班问题问题描述数学建模编程求解(ortoolsJavaAPI)求解结果 人员排班问题 随着现在产业的发展&…...
设备管理团队如何做好停机维护工作_基于PreMaint设备数字化平台
在现代工业生产中,设备的正常运行对于企业的生产效率和利润至关重要。而停机维护作为设备管理的重要环节,旨在确保设备的安全性、可靠性和性能稳定。本文将介绍停机维护的概念,讨论如何计划停机维护,并重点探讨如何通过PreMaint设…...

c++ qt--线程(二)(第九部分)
c qt–线程(二)(第九部分) 一.线程并发 1.并发问题: 多个线程同时操作同一个资源(内存空间、文件句柄、网络句柄),可能会导致结果不一致的问题。发生的前提条件一定是多线程下…...

企业数据泄露不断,深信服EDR助企业构建数据“安全屋”
随着数字时代不断发展,数据泄露问题愈发严峻,个人信息安全面临着严重的威胁。近日,加拿大电信巨头加拿大贝尔(Bell Canada)对外披露了一起大规模数据泄露事件,该公司承认黑客入侵其系统,并窃取了190万个用户电子邮件地址以及约1700个用户姓名及活跃电话号码信息,相关损失无法估…...

单线复用iptv影响网速吗?
IPTV单线复用对网速有影响吗?这是一个比较常见的问题。如果你家的局域网是老的100M局域网LAN的路由器,走单线复用会影响你上网速度。但是如果你家的局域网是千兆网络,IPTV单线复用叠加上去的这点流量算不上什么,可以认为不占用网速…...

C语言中常用的字符串处理函数(strlen、strcpy、strcat、strcmp)
文章目录 写在前面1. strlen1.1 函数介绍1.2 模拟实现 2. strcpy2.1 函数介绍2.2 模拟实现 3. strcat3.1 函数介绍3.2 模拟实现 4. strcmp4.1 函数介绍4.2 模拟实现 写在前面 本篇文章介绍了C语言中常用的字符串处理函数,包括strlen、strcpy、strcat和strcmp。文章…...

Suricata – 入侵检测、预防和安全工具
一、Suricata介绍 Suricata是一个功能强大、用途广泛的开源威胁检测引擎,提供入侵检测 (IDS)、入侵防御 (IPS) 和网络安全监控功能。它执行深度数据包(网络流量)检查以及模式匹配,在威胁检测中非常强大。 工作流程: 主…...
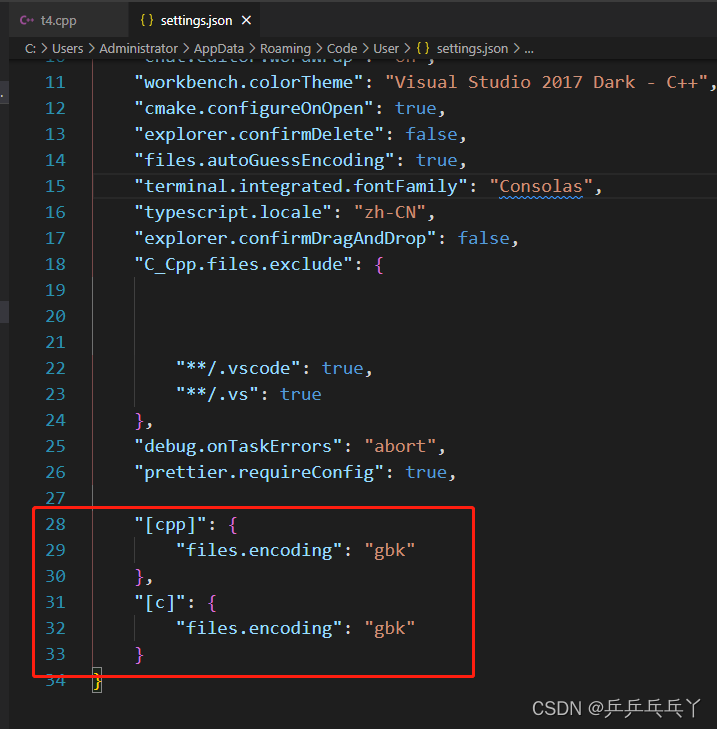
vscode 乱码解决
windows 10 系统 vs code 编译运行和调试 C/C_vscode windows编译_雪的期许的博客-CSDN博客 VS Code默认文件编码时UTF-8,这对大多数情况是没有问题的,却偏偏对C/C有问题。如果以UTF-8编码保存C/C代码,那么只能输出英文,另外使用…...
:Spring Cloud Alibaba 综合集成架构演示)
SpringCloud(37):Spring Cloud Alibaba 综合集成架构演示
Spring Cloud是一个较为全面的微服务框架集,集成了如服务注册发现、配置中心、消息总线、负载均衡、断路器、API网关等功能实现。而在网上经常会发现Spring Cloud与阿里巴巴的Dubbo进行选择对比,这样做其实不是很妥当,前者是一套较为完整的架构方案,而Dubbo只是服务治理与R…...
【单片机】15-AD和DA转换
1.AD转换及其相关背景知识 1.基本概念 1.什么是AD转换? A(A,analog,模拟的,D,digital,数字的) 现实世界是模拟的,连续分布的,无法被分成有限份;…...

如何在macOS上免费解锁QQ音乐加密文件:完整指南
如何在macOS上免费解锁QQ音乐加密文件:完整指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

为什么软件开发偏爱 Linux?深度剖析 Linux 相较于 Windows 的核心优势
引言 在软件开发的世界里,一个有趣的现象是:无论是大型互联网公司的服务器集群,还是资深程序员的个人开发机,Linux 操作系统的身影无处不在。与之形成鲜明对比的是,尽管 Windows 在个人消费市场占据绝对主导地位&…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

Unity动态自然系统:Forest Environment-Dynamic Nature深度解析
1. 这不是“贴图堆砌”,而是自然系统级建模:Forest Environment-Dynamic Nature 的真实定位你有没有试过在Unity里拖进几棵树、铺点草、加个天空盒,然后发现场景像一张静止的风景明信片——风不动、叶不摇、雨不落、雾不散?我做过…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...