机器学习必修课 - 编码分类变量 encoding categorical variables
1. 数据预处理和数据集分割
import pandas as pd
from sklearn.model_selection import train_test_split
- 导入所需的Python库
!git clone https://github.com/JeffereyWu/Housing-prices-data.git
- 下载数据集
# Read the data
X = pd.read_csv('/content/Housing-prices-data/train.csv', index_col='Id')
X_test = pd.read_csv('/content/Housing-prices-data/test.csv', index_col='Id')
- 使用Pandas的
read_csv函数从CSV文件中读取数据,分别读取了训练数据(train.csv)和测试数据(test.csv),并将数据的索引列设置为’Id’。
# Remove rows with missing target, separate target from predictors
X.dropna(axis=0, subset=['SalePrice'], inplace=True)
y = X.SalePrice
X.drop(['SalePrice'], axis=1, inplace=True)
- 删除了训练数据中带有缺失目标值(‘SalePrice’)的行。
- 然后,将目标值(房屋销售价格)存储在变量y中,并从特征中删除了目标列,以便在后续的训练中使用特征数据。
# To keep things simple, we'll drop columns with missing values
cols_with_missing = [col for col in X.columns if X[col].isnull().any()]
X.drop(cols_with_missing, axis=1, inplace=True)
X_test.drop(cols_with_missing, axis=1, inplace=True)
- 删除数据中带有缺失值的列。
- 通过遍历每一列,使用
X[col].isnull().any()来检查每列是否包含任何缺失值,如果某列中至少有一个缺失值,就将其列名添加到cols_with_missing列表中。 - 使用
drop方法将这些带有缺失值的列从训练数据X和测试数据X_test中删除。
# Break off validation set from training data
X_train, X_valid, y_train, y_valid = train_test_split(X, y,train_size=0.8, test_size=0.2,random_state=0)
- 使用
train_test_split函数将训练数据X和目标值y分成训练集(X_train和y_train)和验证集(X_valid和y_valid)。 train_size参数指定了训练集的比例(80%),test_size参数指定了验证集的比例(20%),random_state参数用于控制随机分割的种子,以确保每次运行代码时分割结果都一样。
2. 评估不同方法在机器学习模型上的性能
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error# function for comparing different approaches
def score_dataset(X_train, X_valid, y_train, y_valid):model = RandomForestRegressor(n_estimators=100, random_state=0)model.fit(X_train, y_train)preds = model.predict(X_valid)return mean_absolute_error(y_valid, preds)
3. 从训练数据和验证数据中选择只包含数值类型特征(列)的子集
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])
- 使用Pandas中的
select_dtypes方法,它允许你根据数据类型来筛选数据框中的列。 exclude=['object']参数指定了要排除的数据类型是’object’类型,通常’object’类型表示非数值型数据,例如字符串或类别数据。
print("MAE from Approach 1 (Drop categorical variables):")
print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid))
MAE from Approach 1 (Drop categorical variables):
17837.82570776256
4. 查看训练数据和验证数据中特定列('Condition2’列)的唯一值
print("Unique values in 'Condition2' column in training data:", X_train['Condition2'].unique())
print("\nUnique values in 'Condition2' column in validation data:", X_valid['Condition2'].unique())
X_train['Condition2'].unique()的部分用于获取训练数据中’Condition2’列中的所有不重复的数值。这可以帮助你了解这一列包含哪些不同的数值或类别。- 输出验证数据中’Condition2’列的唯一值,同样使用了
X_valid['Condition2'].unique()。 - 这可以帮助你了解验证数据中这一列的不同数值或类别,通常用于检查验证数据是否与训练数据具有相似的分布,以确保模型在新数据上的泛化性能。
Unique values in ‘Condition2’ column in training data: [‘Norm’ ‘PosA’ ‘Feedr’ ‘PosN’ ‘Artery’ ‘RRAe’]
Unique values in ‘Condition2’ column in validation data: [‘Norm’ ‘RRAn’ ‘RRNn’ ‘Artery’ ‘Feedr’ ‘PosN’]
如果你现在编写代码来执行以下操作:
- 在训练数据上训练一个有序编码器(ordinal encoder)。
- 使用该编码器来转换训练数据和验证数据。
那么你将会遇到一个错误。
- 如果验证数据包含训练数据中没有出现的值,编码器将会报错,因为这些值没有与之对应的整数标签。
- 验证数据中的’Condition2’列包含了值’RRAn’和’RRNn’,但这些值在训练数据中并没有出现。因此,如果我们尝试使用Scikit-learn中的有序编码器,代码将会抛出错误。
5. 找出哪些列可以进行有序编码(ordinal encoding),哪些列需要从数据集中删除
# Categorical columns in the training data
object_cols = [col for col in X_train.columns if X_train[col].dtype == "object"]# Columns that can be safely ordinal encoded
good_label_cols = [col for col in object_cols if set(X_valid[col]).issubset(set(X_train[col]))]# Problematic columns that will be dropped from the dataset
bad_label_cols = list(set(object_cols)-set(good_label_cols))print('Categorical columns that will be ordinal encoded:', good_label_cols)
print('\nCategorical columns that will be dropped from the dataset:', bad_label_cols)
- 创建了一个名为
object_cols的列表,用于存储训练数据X_train中的所有数据类型为"object"(通常表示字符串或类别型数据)的列。 - 创建了一个名为
good_label_cols的列表,用于存储可以安全进行有序编码的列。这些列的特点是验证数据中的所有唯一值都存在于训练数据的相应列中。通过使用set来比较验证数据和训练数据中的唯一值,可以确定哪些列可以进行有序编码,因为它们的唯一值是一致的。 - 创建了一个名为
bad_label_cols的列表,用于存储需要从数据集中删除的问题列。这些列包含了一些在验证数据中出现但在训练数据中没有出现的唯一值,因此无法进行有序编码,需要在数据预处理中删除。
Categorical columns that will be ordinal encoded: [‘MSZoning’, ‘Street’, ‘LotShape’, ‘LandContour’, ‘Utilities’, ‘LotConfig’, ‘LandSlope’, ‘Neighborhood’, ‘Condition1’, ‘BldgType’, ‘HouseStyle’, ‘RoofStyle’, ‘Exterior1st’, ‘Exterior2nd’, ‘ExterQual’, ‘ExterCond’, ‘Foundation’, ‘Heating’, ‘HeatingQC’, ‘CentralAir’, ‘KitchenQual’, ‘PavedDrive’, ‘SaleType’, ‘SaleCondition’]
Categorical columns that will be dropped from the dataset: [‘Functional’, ‘Condition2’, ‘RoofMatl’]
6. 对数据进行有序编码
from sklearn.preprocessing import OrdinalEncoder# Drop categorical columns that will not be encoded
label_X_train = X_train.drop(bad_label_cols, axis=1)
label_X_valid = X_valid.drop(bad_label_cols, axis=1)# Apply ordinal encoder
ordinal_encoder = OrdinalEncoder()
label_X_train[good_label_cols] = ordinal_encoder.fit_transform(X_train[good_label_cols])
label_X_valid[good_label_cols] = ordinal_encoder.transform(X_valid[good_label_cols])
- 删除不需要进行编码的分类列,
bad_label_cols列表中包含了需要删除的列的名称。 - 使用
fit_transform方法将编码器拟合到训练数据的good_label_cols列上,并将结果存储在label_X_train中。 - 使用
transform方法将同样的编码器应用到验证数据的good_label_cols列上,并将结果存储在label_X_valid中。
print("MAE from Approach 2 (Ordinal Encoding):")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))
MAE from Approach 2 (Ordinal Encoding):
17098.01649543379
7. 统计每个分类(categorical)数据列中唯一条目的数量
# Get number of unique entries in each column with categorical data
object_nunique = list(map(lambda col: X_train[col].nunique(), object_cols))
d = dict(zip(object_cols, object_nunique))# Print number of unique entries by column, in ascending order
sorted(d.items(), key=lambda x: x[1])
- 创建了一个名为
object_nunique的列表,用于存储每个分类数据列中唯一条目的数量。 - 它使用
map函数遍历object_cols中的每一列,并对每一列使用X_train[col].nunique()来计算该列的唯一条目数量。 nunique()函数返回该列中不同数值的数量,因此可以用来统计分类数据中的不同类别数量。- 创建了一个字典d,将分类数据列的名称作为键,唯一条目数量作为值。这里使用
zip函数将列名和唯一条目数量一一对应,然后将其转换为字典。 - 使用
sorted函数将字典中的项按照唯一条目数量升序排列,并以列表的形式返回结果。
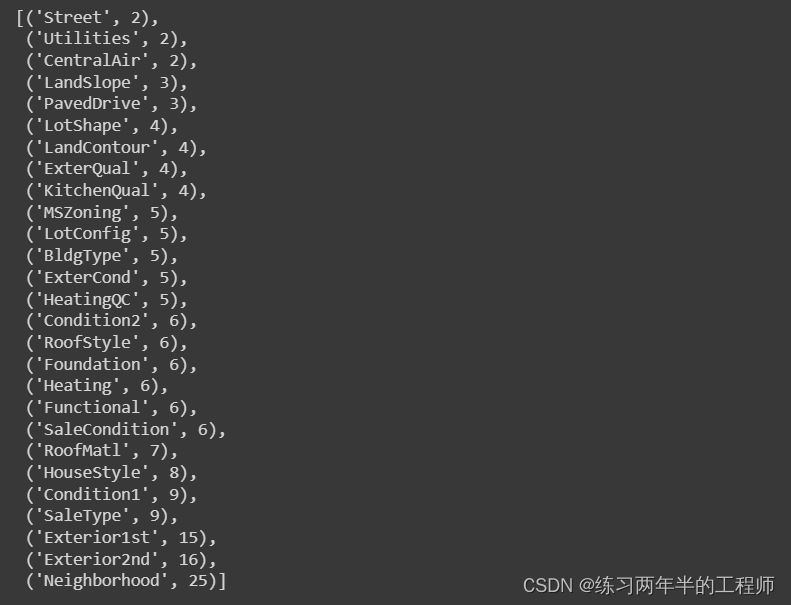
8. 与其对数据集中的所有分类变量进行编码,只为基数(唯一值数量)小于10的列创建独热编码(One-Hot Encoding)
# Columns that will be one-hot encoded
low_cardinality_cols = [col for col in object_cols if X_train[col].nunique() < 10]# Columns that will be dropped from the dataset
high_cardinality_cols = list(set(object_cols)-set(low_cardinality_cols))print('Categorical columns that will be one-hot encoded:', low_cardinality_cols)
print('\nCategorical columns that will be dropped from the dataset:', high_cardinality_cols)
- 遍历
object_cols中的每一列,并使用X_train[col].nunique()来获取每列的唯一值数量,如果唯一值数量小于10,则将该列添加到low_cardinality_cols中。 - 使用集合操作
set(object_cols) - set(low_cardinality_cols)来找出不在low_cardinality_cols中的分类列,然后将这些列的名称存储在high_cardinality_cols中。
Categorical columns that will be one-hot encoded: [‘MSZoning’, ‘Street’, ‘LotShape’, ‘LandContour’, ‘Utilities’, ‘LotConfig’, ‘LandSlope’, ‘Condition1’, ‘Condition2’, ‘BldgType’, ‘HouseStyle’, ‘RoofStyle’, ‘RoofMatl’, ‘ExterQual’, ‘ExterCond’, ‘Foundation’, ‘Heating’, ‘HeatingQC’, ‘CentralAir’, ‘KitchenQual’, ‘Functional’, ‘PavedDrive’, ‘SaleType’, ‘SaleCondition’]
Categorical columns that will be dropped from the dataset: [‘Exterior1st’, ‘Neighborhood’, ‘Exterior2nd’]
9. 执行独热编码(One-Hot Encoding),将低基数(唯一值数量小于10)的分类(categorical)列转换为二进制形式,并将它们与数值特征合并在一起
from sklearn.preprocessing import OneHotEncoderOH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
OH_X_train = pd.DataFrame(OH_encoder.fit_transform(X_train[low_cardinality_cols]))
OH_X_valid = pd.DataFrame(OH_encoder.transform(X_valid[low_cardinality_cols]))# One-hot encoding removed index; put it back
OH_X_train.index = X_train.index
OH_X_valid.index = X_valid.index# Remove categorical columns (will replace with one-hot encoding)
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)# Add one-hot encoded columns to numerical features
OH_X_train = pd.concat([num_X_train, OH_X_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_X_valid], axis=1)# Ensure all columns have string type
OH_X_train.columns = OH_X_train.columns.astype(str)
OH_X_valid.columns = OH_X_valid.columns.astype(str)
- 使用
fit_transform方法将独热编码应用到训练数据的low_cardinality_cols列上,并将结果存储在OH_X_train中。接着,使用transform方法将同样的编码器应用到验证数据的low_cardinality_cols列上,并将结果存储在OH_X_valid中。 - 将独热编码后的数据的索引设置为与原始训练数据和验证数据相同,以确保它们可以正确对齐。
- 删除了原始数据中的分类列,因为它们已经被独热编码取代。
- 将独热编码后的数据与原始的数值特征合并在一起,以创建一个包含所有特征的新数据集。
- 确保新数据集中的所有列都以字符串类型表示,以便与其他列一致。这是因为独热编码会生成以0和1表示的二进制列,需要将其列名转换为字符串类型。这样,数据就准备好用于训练机器学习模型了,其中包括数值特征和独热编码后的分类特征。
print("MAE from Approach 3 (One-Hot Encoding):")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))
MAE from Approach 3 (One-Hot Encoding):
17525.345719178084
相关文章:
机器学习必修课 - 编码分类变量 encoding categorical variables
1. 数据预处理和数据集分割 import pandas as pd from sklearn.model_selection import train_test_split导入所需的Python库 !git clone https://github.com/JeffereyWu/Housing-prices-data.git下载数据集 # Read the data X pd.read_csv(/content/Housing-prices-data/t…...

ClickHouse进阶(二十二):clickhouse管理与运维-服务监控
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Kerberos安全认证-CSDN博客 📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情! 👍点赞:赞同优秀创作,你的点赞是对我创…...
Hadoop使用hdfs指令查看hdfs目录的根目录显示被拒
背景 分布式部署hadoop,服务机只有namenode节点,主机包含其他所有节点 主机关机后,没有停止所有节点,导致服务机namenode继续保存 再次开启主机hadoop,使用hdfs查看hdfs根目录的时候显示访问被拒 解决方案 1.主机再次开启hadoop并继续执行关闭 2.服务器再次开启hadoop并继…...

[Mac] 安装paddle-pipelines出现 ERROR: Failed building wheel for lmdb
今天在mac换了新系统,然后重新安装paddle-piplines的时候出现了下面的问题: xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools), missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrunerror: comma…...

LED灯亮灭
.text .global _start _start: 设置GPIO寄存器的时钟使能 RCC_MP_AHB4ENSETR[4]->1 0x50000a28LDR R0,0x50000A28LDR R1,[R0] 从R0为起始地址的4个字节数据取出放入R1中ORR R1,R1,#(0x1<<4) 第四位设置为1STR R1,[R0] 写回LDR R0,0x5000…...
)
Acwing.143 最大异或对(trie树)
题目 在给定的N个整数A1,A2 . …Ax中选出两个进行xor(异或)运算,得到的结果最大是多少? 输入格式 第一行输入一个整数N。 第二行输入N个整数A1~AN。 输出格式 输出一个整数表示答案。 数据范围 1 ≤N ≤105,0≤A<231 输入样例: 3 1 2 3输出样…...

day10.8ubentu流水灯
流水灯 .text .global _start _start: 1.设置GPIOE寄存器的时钟使能 RCC_MP_AHB4ENSETR[4]->1 0x50000a28LDR R0,0X50000A28LDR R1,[R0] 从r0为起始地址的4字节数据取出放在R1ORR R1,R1,#(0x1<<4) 第4位设置为1STR R1,[R0] 写回2.设置PE10管脚为输出模式 G…...
transformer系列5---transformer显存占用分析
Transformer显存占用分析 1 影响因素概述2 前向计算临时Tensor显存占用2.1 self-attention显存占用2.2 MLP显存占用 3 梯度和优化器显存占用3.1 模型训练过程两者显存占用3.2 模型推理过程两者显存占用 1 影响因素概述 模型训练框架:例如pytorch框架的cuda context…...
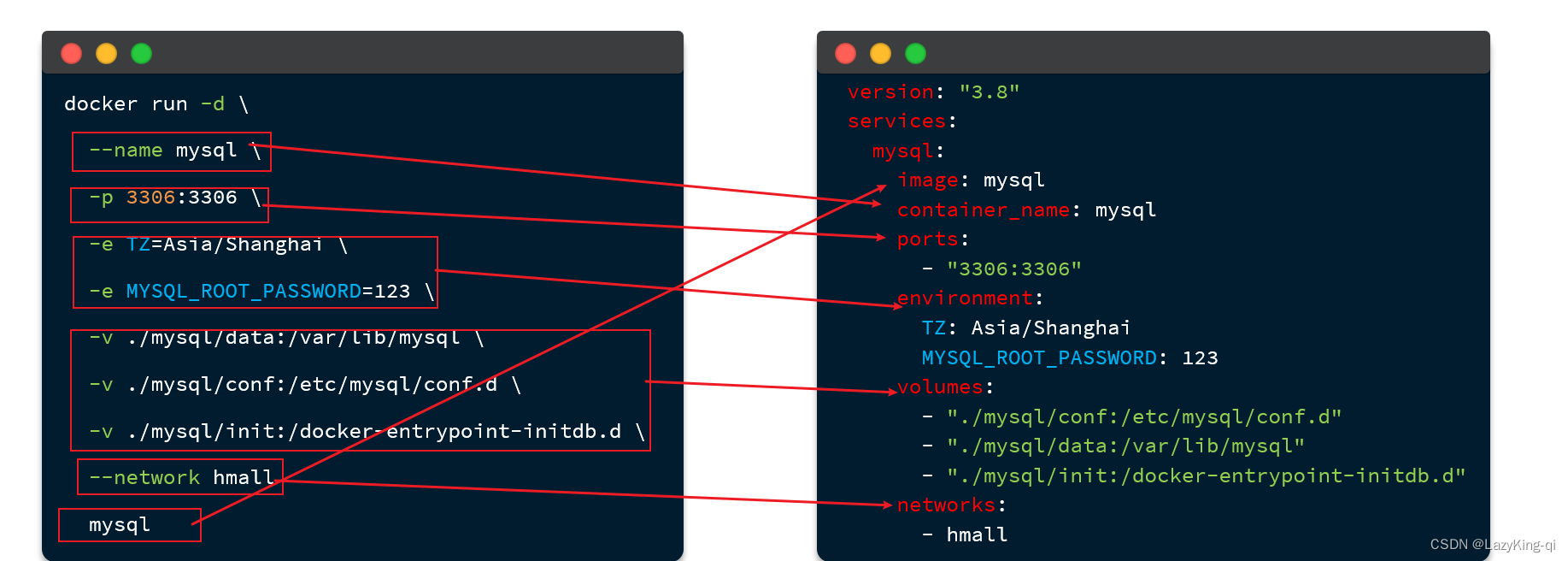
Docker项目部署
目录 一、前端项目部署 1、上传文件 2、开启容器 3、测试 二、后端项目部署 1、打包java项目 2、将jar包和Dockerfile文件长传到Linux系统 3、构建镜像 4、开启容器 5、测试 三、DockerCompose快速部署 基本语法 一、前端项目部署 1、上传文件 里面包括页面和配置文…...

vue3实现文本超出鼠标移入的时候文本滚动
判断文本长度是否大于容器长度 鼠标移入的时候判断,此处使用了tailwindcss,注意一下要设置文本不换行。 <divref"functionsItems"mouseenter"enterFunctionsItem($event, index)"><img class"w-5 h-5" :src&quo…...
光伏系统MPPT、恒功率控制切换Simulink仿真
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
mysql双主互从通过KeepAlived虚拟IP实现高可用
mysql双主互从通过KeepAlived虚拟IP实现高可用 在mysql 双主互从的基础上, 架构图: Keepalived有两个主要的功能: 提供虚拟IP,实现双机热备通过LVS,实现负载均衡 安装 # 安装 yum -y install keepalived # 卸载 …...
苹果应用高版本出现:“无法安装此app,因为无法验证其完整性”是怎么回事?竟然是错误的?
最近经常有同学私聊我问苹果应用签名后用落地页下载出现高版本是什么意思?我一脸懵!还有这个操作?高版本是个啥玩意!所以我就上了一下科技去搜索引擎搜索了下,哈哈哈,然后了解下来发现是这样的首先我们确定…...
回环地址写数据速度对比)
AF_UNIX和127.0.0.1(AF_INET)回环地址写数据速度对比
在linux下,存在着这样的情况,本地的进程间通信,并且其中一个是服务端,另外的都是客户端。 服务端通过绑定端口,客户端往127.0.0.1的对应端口发送,即可办到,不过这样会浪费一个端口,同…...
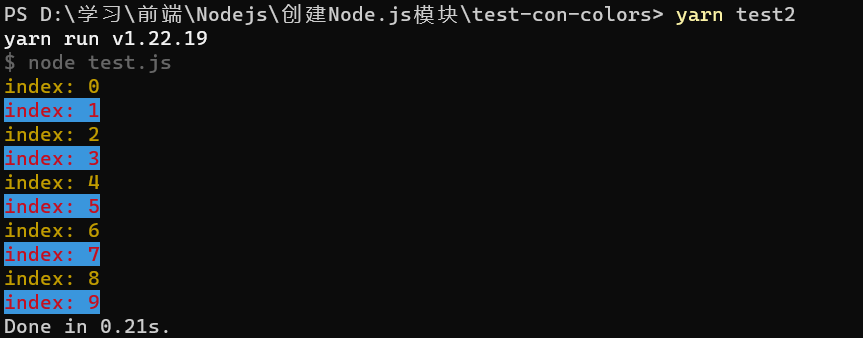
我在 NPM 发布了新包: con-colors
链接地址:npmjs.com con-colors 安装依赖 yarn add con-colors使用 导入: import { print } from "con-colors";使用: print.succ("成功的消息"); print.err("失败的消息")例子: import { p…...

【python数据建模】Scipy库
常用模块列表 模块名功能scipy.constants数学常量scipy.fft离散傅里叶变换scipy.integrate积分scipy.interpolate插值scipy.interpolate线性代数scipy.cluster聚类分析、向量量化scipy.io数据输入输出scipy.misc图像处理scipy.ndimagen维图像scipy.odr正交距离回归scipy.optim…...

C# App.xaml.cs的一些操作
一、保证只有一个进程 1.1 关闭旧的,打开新的 protected override void OnStartup(StartupEventArgs e) {base.OnStartup(e);var process Process.GetProcessesByName("Dog");if (process.Count() > 1) {var list process.ToList();list.Sort((p1,p2…...
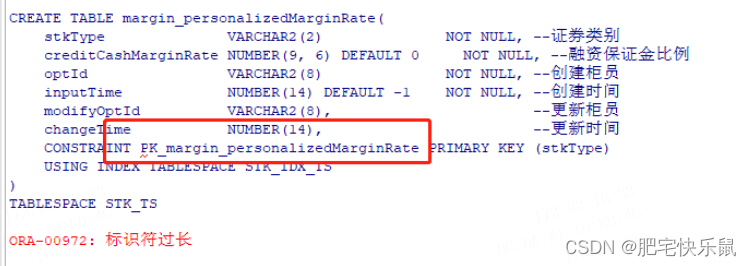
【ORACLE】ORA-00972:标识符过长
问题 执行创建表结构sql,提示 ORA-00972:标识符过长; 如图所示,约束名称超过30个字符了 原因 一、11G and before 在使用11G数据库时,经常会遇到报错ORA-00972,原因是因为对象名称定义太长,…...

【Vue】Vue快速入门、Vue常用指令、Vue的生命周期
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 Vue 一、 Vue快速入门二、Vue常用指令2.1 v…...

Pandas 数据处理 类别数据和数值数据
要是作深度学习的话,可以直接用tensoflow框架的预处理层,我试过,比PyTorch自己写出来的会好一点,主要是简单好用。处理CSV文件 它类别的处理逻辑是onehot,比较标准稀疏,数值的话就是归一化了。 有时候不需…...

Qwen3-Embedding-4B入门必看:Embedding模型vs LLM生成模型的核心差异
Qwen3-Embedding-4B入门必看:Embedding模型vs LLM生成模型的核心差异 1. 引言:从关键词搜索到语义理解 你是否曾经遇到过这样的困扰:在搜索引擎中输入"苹果",结果既出现了水果苹果的信息,又出现了苹果公司…...

Fun-ASR语音识别新手入门:3步启动Web服务,麦克风实时转文字实测
Fun-ASR语音识别新手入门:3步启动Web服务,麦克风实时转文字实测 1. 快速认识Fun-ASR Fun-ASR是由钉钉与通义实验室联合推出的语音识别系统,专为中文场景优化设计。与市面上常见的云端语音识别服务不同,它最大的特点是支持本地化…...

图图的嗨丝造相-Z-Image-Turbo保姆级教学:提示词中‘蓝色校服’‘黑色低帮鞋’等实体关联
图图的嗨丝造相-Z-Image-Turbo保姆级教学:提示词中‘蓝色校服’‘黑色低帮鞋’等实体关联 你是不是也遇到过这种情况:想用AI生成一张特定风格的图片,比如一个穿着蓝色校服、黑色低帮鞋,搭配渔网袜的校园少女,但写出来…...
)
马西奎《电磁场与电磁波》学习记录-第 2 章学前准备-坐标系的深入 + 微分元(dl、dS、dV)
一、正交坐标系的一般概念1. 什么是正交曲线坐标系三组坐标面互相垂直正交单位矢量处处正交:⊥⊥直角、圆柱、球坐标都属于这一类。2. 坐标变量与拉梅系数(度量系数)对一般正交曲线坐标 (,,):坐标面:常数、…...

Phi-4-mini-reasoning vLLM高级特性:LoRA适配器热插拔与多任务推理切换
Phi-4-mini-reasoning vLLM高级特性:LoRA适配器热插拔与多任务推理切换 1. 模型概述 Phi-4-mini-reasoning 是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理。作为Phi-4模型家族的一员,它特别强化了数学推理能力…...

WaveTools实战:鸣潮性能优化的5个技术秘诀
WaveTools实战:鸣潮性能优化的5个技术秘诀 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 问题定位:帧率异常的底层原因分析 作为《鸣潮》玩家,你是否遇到过这样的困扰…...

如何使用MQTTnet客户端工厂模式:对象创建与资源管理的终极指南
如何使用MQTTnet客户端工厂模式:对象创建与资源管理的终极指南 【免费下载链接】MQTTnet MQTTnet is a high performance .NET library for MQTT based communication. It provides a MQTT client and a MQTT server (broker). The implementation is based on the …...

Minecraft 1.12.2 彩色渐变字体模组:打造个性化聊天与物品命名
1. RGB Chat模组:让你的Minecraft文字绚丽多彩 还在用单调的白色文字聊天吗?RGB Chat模组彻底改变了Minecraft 1.12.2版本的文字显示方式。这个轻量级模组只有几百KB大小,却能给你的游戏体验带来质的飞跃。我第一次在服务器里看到彩色渐变文字…...
)
二叉树面试送分题|力扣101对称+226翻转(递归极简写法,手写无压力)
兄弟们!二叉树面试中,有两道“送分题”必须拿捏——力扣101.对称二叉树和力扣226.翻转二叉树。这两道题难度不高,核心都能用递归轻松解决,代码简洁、逻辑直观,新手练一遍就能记住,面试手写直接加分…...

银发健康消费“新战场”:线下渠道红利期开启,10+嘉宾重磅分享实战方法论
银发经济与连锁药店转型的双向奔赴整理 | AgeClub内容团队前言当前,中国银发经济已成为国内增长最快的赛道之一。数据显示,我国银发经济市场规模已突破 10 万亿元,未来整体规模有望超过 30 万亿元。精准对接优质渠道,成为众多银…...