分布式文件系统HDFS(林子雨慕课课程)
文章目录
- 3. 分布式文件系统HDFS
- 3.1 分布式文件系统HDFS简介
- 3.2 HDFS相关概念
- 3.3 HDFS的体系结构
- 3.4 HDFS的存储原理
- 3.5 HDFS数据读写
- 3.5.1 HDFS的读数据过程
- 3.5.2 HDFS的写数据过程
- 3.6 HDFS编程实战
3. 分布式文件系统HDFS
3.1 分布式文件系统HDFS简介
-
HDFS就是解决海量数据的分布式存储问题
-
为什么会出现分布式文件系统?

-
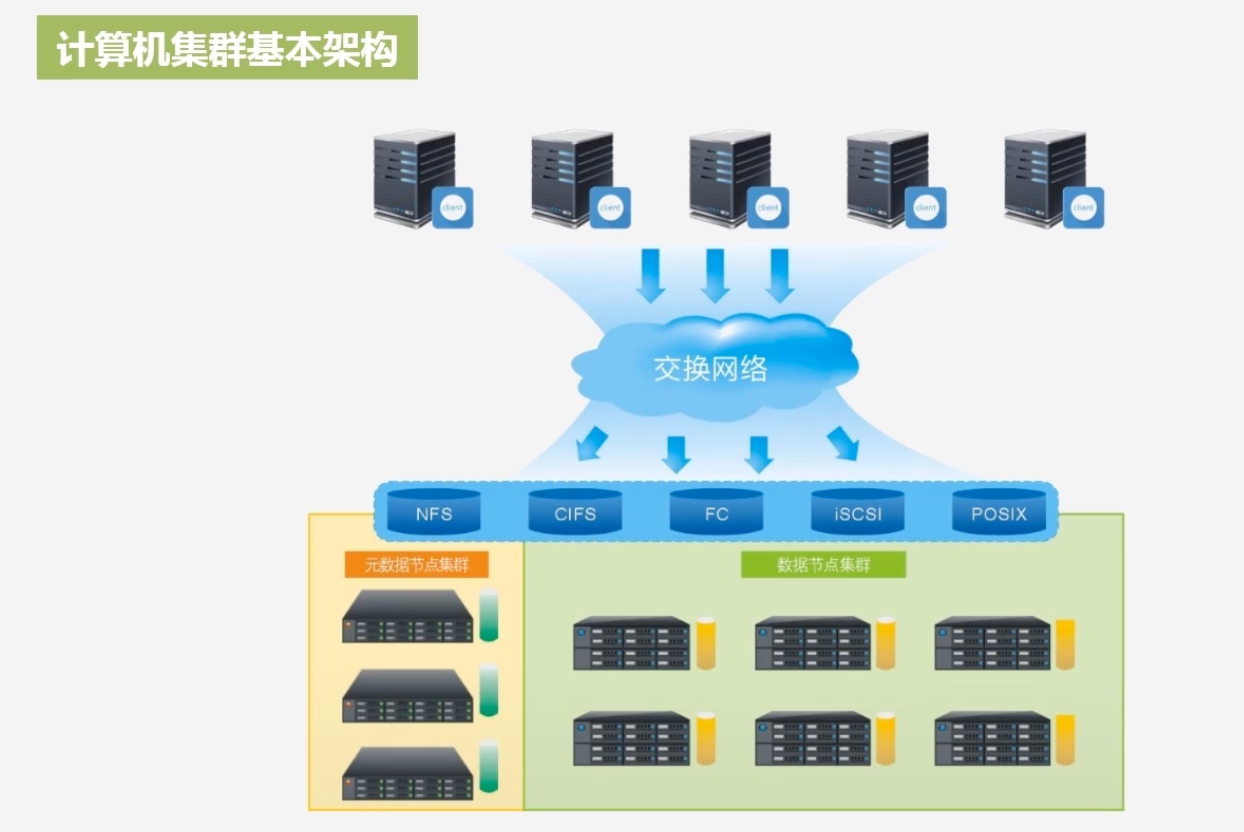
计算机集群基本架构
- 每个机架由若干个节点构成

-
机架的内部之间是通过光纤交换机进行连接,机架与机架通过带宽更高的光纤交换机进行连接
-
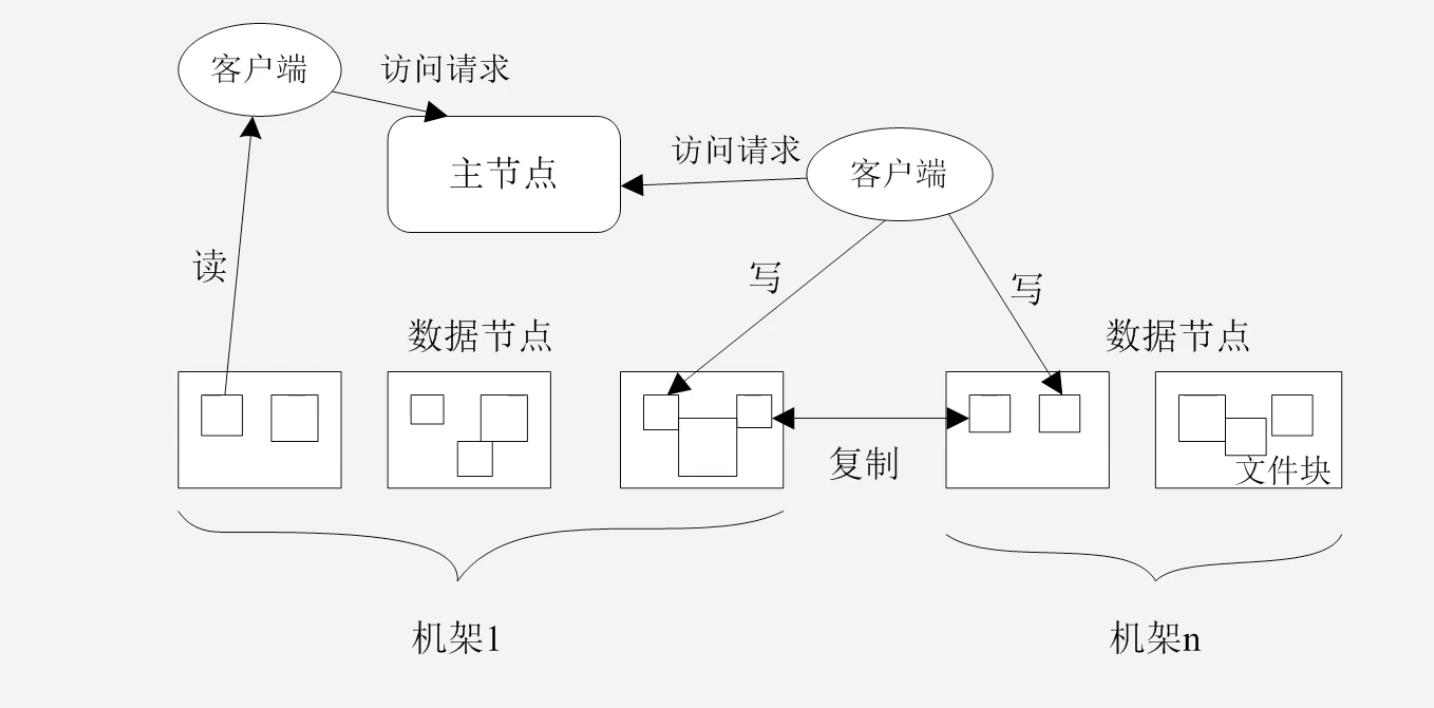
分布式文件系统的存储结构
-
主节点存储相关的元数据服务:目录存储服务,从节点需要完成相关的数据存储任务
-
-
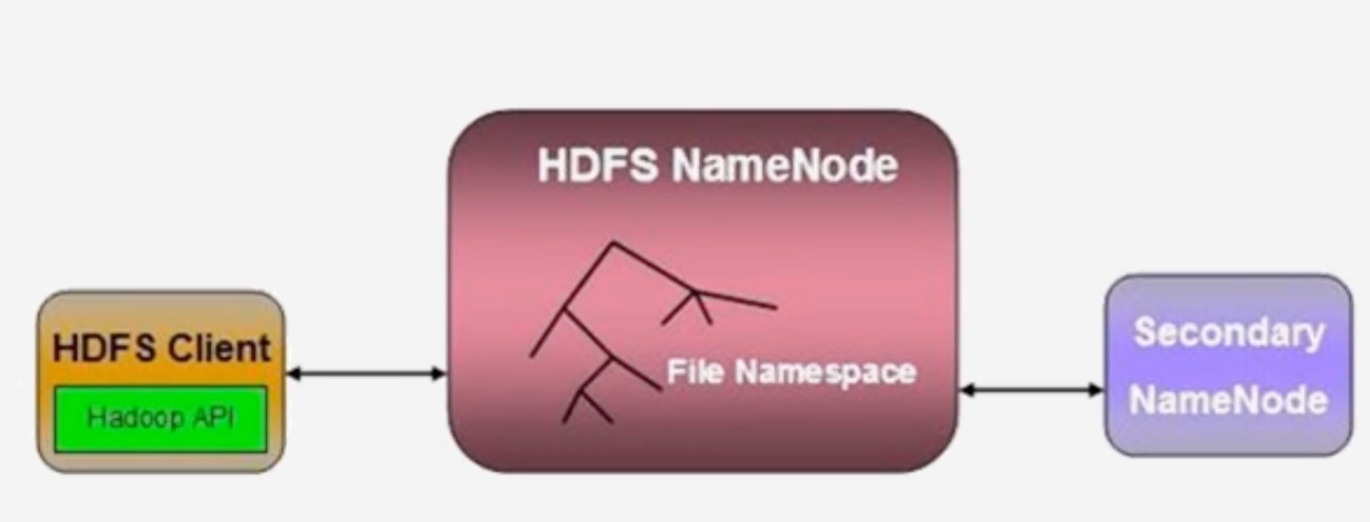
HDFS是非常流行的一个分布式存储系统
-
HDFS实现的目标
- 兼容廉价的硬件设备
- 实现流数据读写
- 支持大数据集
- 支持简单的文件模型
- 强大的跨平台兼容性:基于JAVA语言开发,JAVA语言有着良好的跨平台特性
-
HDFS局限性
- 不适合低延迟数据访问:不能满足实时的处理需求
- 无法高效存储大量小文件:因为HDFS是通过元数据指引到客户端的哪个节点找文件,这些namenode会被保存到内存中去,到内存中检索索引数据结构,如果小文件太多,这个索引结构会过于庞大,在索引结构中搜索的效率会越来越低
- 不支持多用户写入以及任意修改文件
3.2 HDFS相关概念
-
块的概念
- 块的大小比普通文件系统大很多,普通文件系统可能几字节,它可以达到64M或者128M
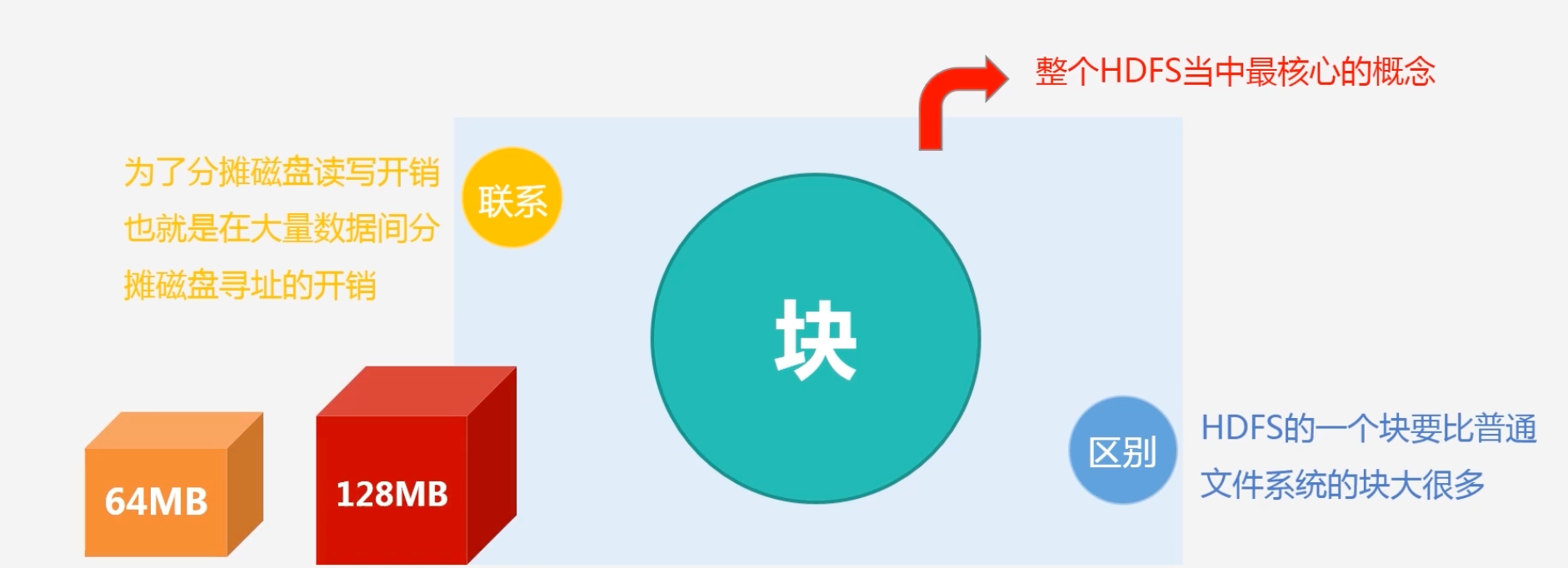
- HDFS采用这种抽象的块的概念设计好处?为什么要这样设计块?
- 为了支持面向大规模的数据存储:对大文件进行切割,可以分别存储在不同的数据节点,可以突破单机存储的上线
- 简化系统设计:通过块设计方便元数据管理,块大小固定,可以很容易知道一个文件需要几个块进行存储
- 适合数据备份:一个块可以冗余的存储到多个不同的节点上
- 同时降低分布式节点的寻址开销:访问HDFS数据需要经过三级寻址:元数据目录–>数据节点–>取数据
- 块是否是设置的越大越好?
- 不是,如果块过大会导致MapReduce就一两个任务时,在执行完全牺牲了MapReduce的并行度,发挥不了分布式并行处理的效果
-
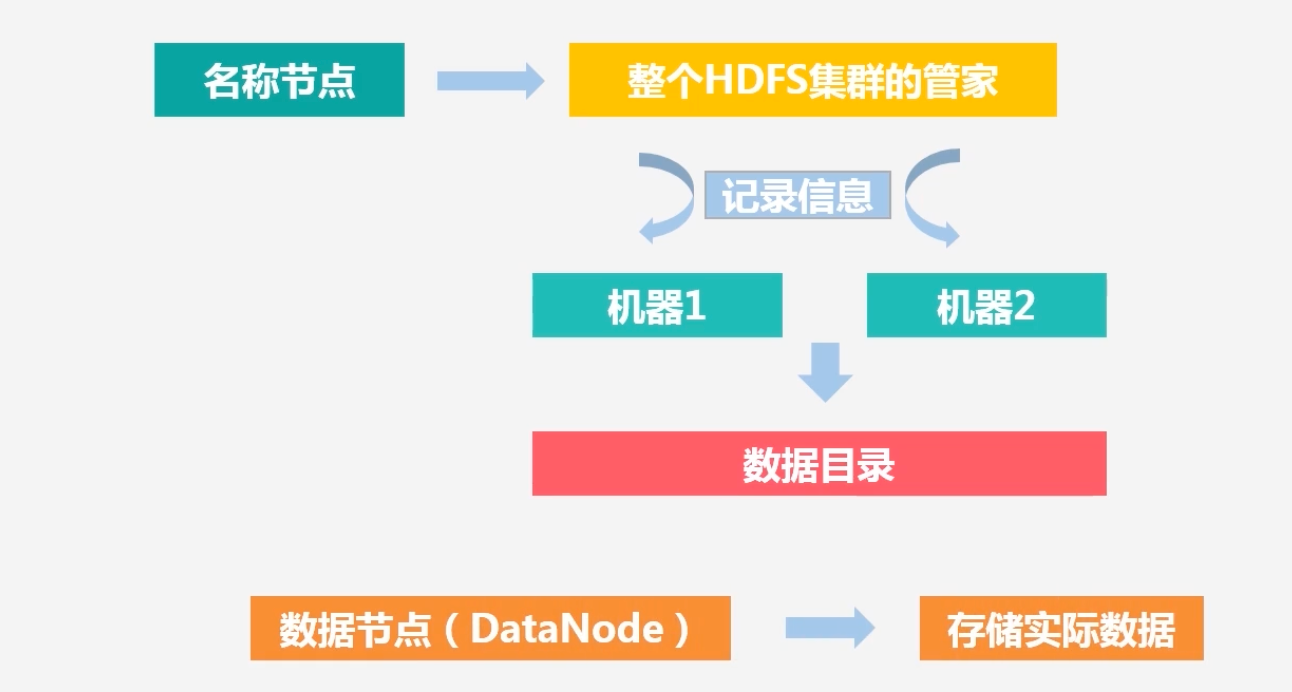
HDFS的两大组件
-
名称节点(NameNode):整个HDFS集群的管家,假如客户端访问一个特别大的文件,通过NameNode可以知道这个大文件的每一个块被放置在哪个机器节点之上
-
数据节点(DateNode):负责存储实际数据,将数据保存到本地的Linux文件系统中去
-
-
元数据的作用?

-
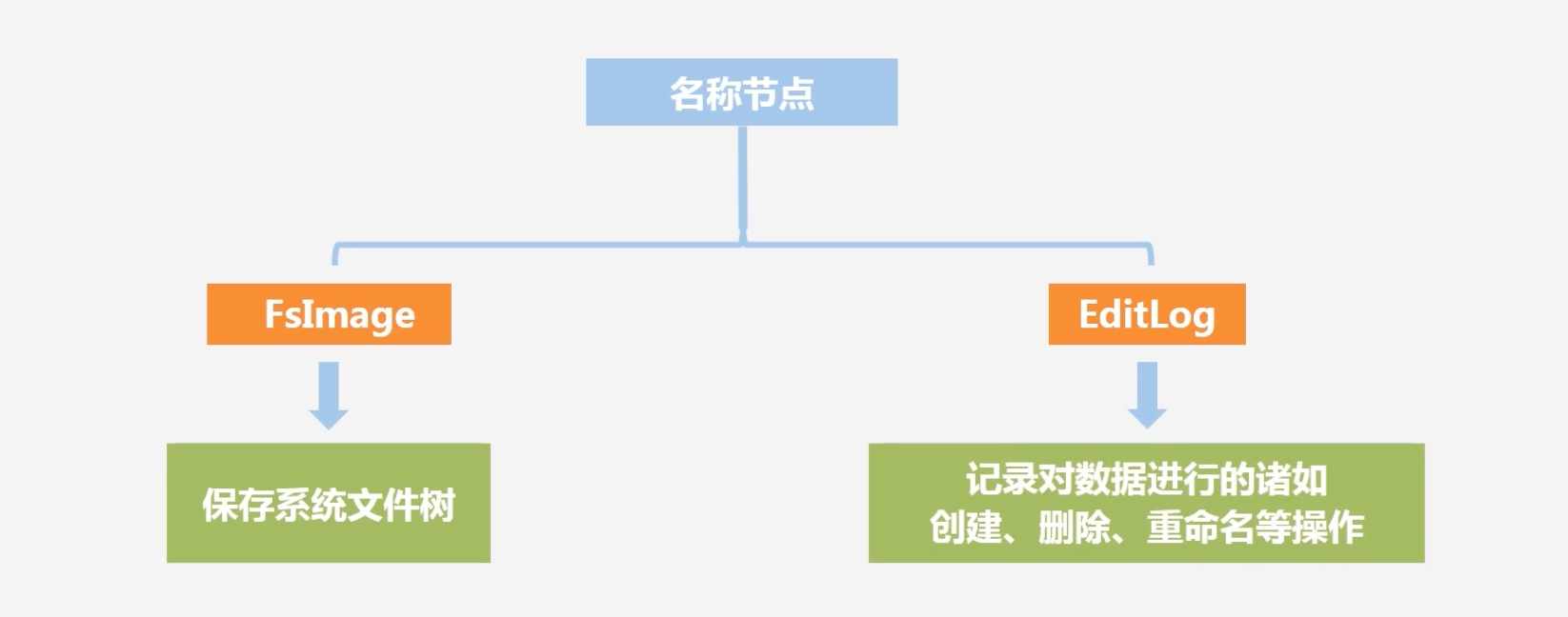
名称节点包含的两大结构:FsImage和EditLog
-
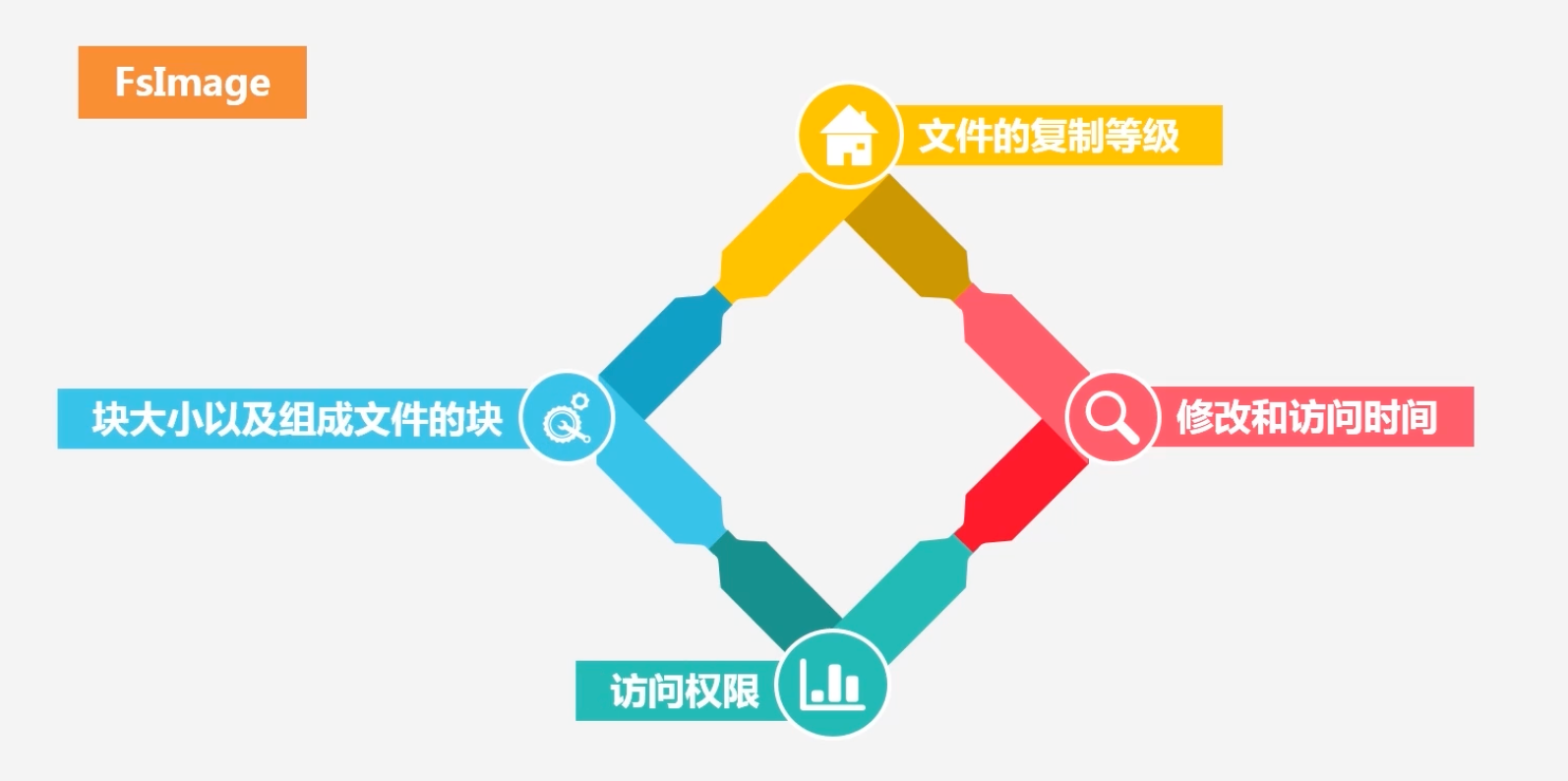
FsImage包含内容
注意FsImage不保存块具体在数据节点的位置,这个在单独的内存区域维护的
数据节点中加入新数据–>向名称节点汇报数据节点中包含哪些块–>名称节点构建清单:包含各个块的位置分布
-
-
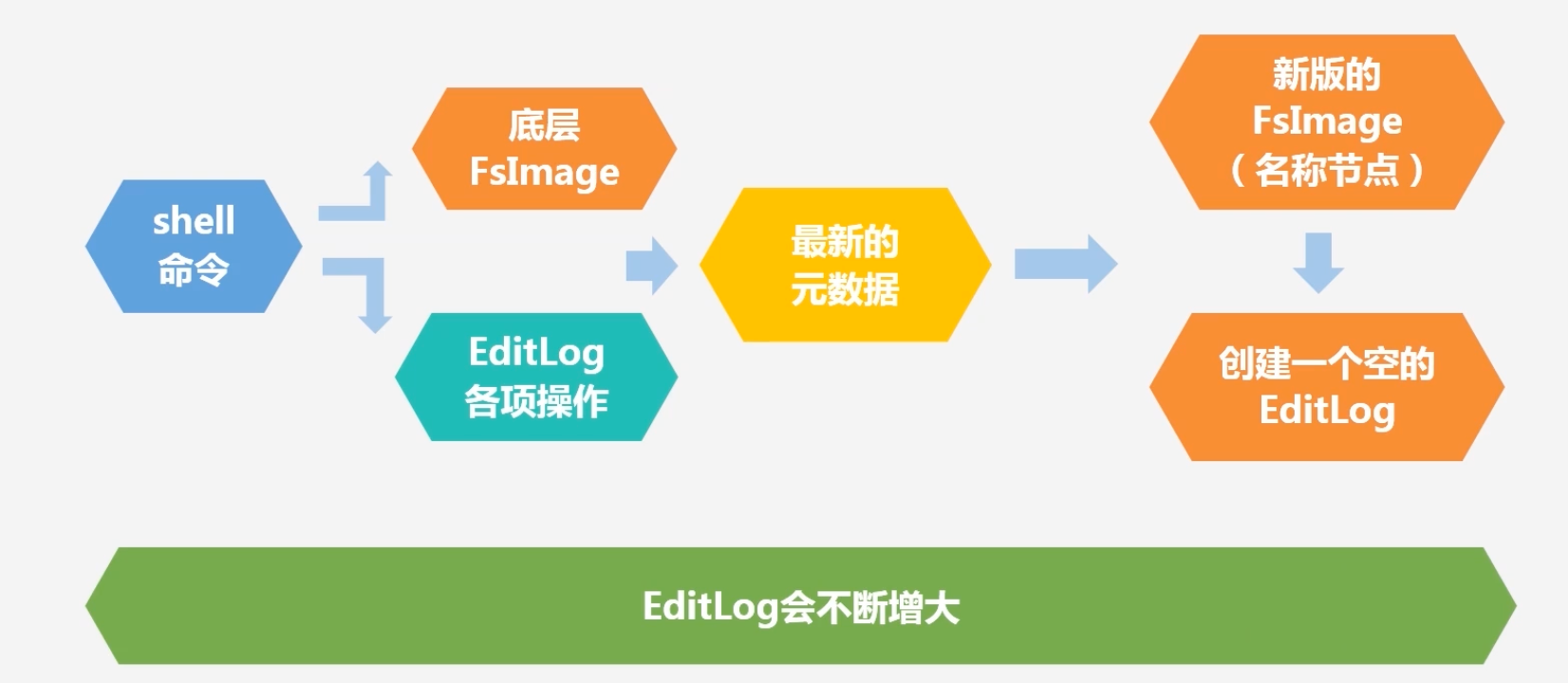
HDFS要如何利用NameNode的数据结构
- shell命令启动NameNode–>将FsImage从后台加载到内存中去,和EditLog中的内容进行合并(对数据结构的修改记录存储在EditLog中)–>得到最新元数据–>将新版FsImage保留,创建空的EditLog
- EditLog永远保存的是更新操作(增量操作),然后再将EditLog合并到FsImage中去
-
但是若是不断的修改操作,会使得EditLog不断增加,影响整体使用的性能?怎么办?
-
引入第二名称节点(SecondNameNode):
- 作为名称节点的冷备份
- 对EditLog的处理
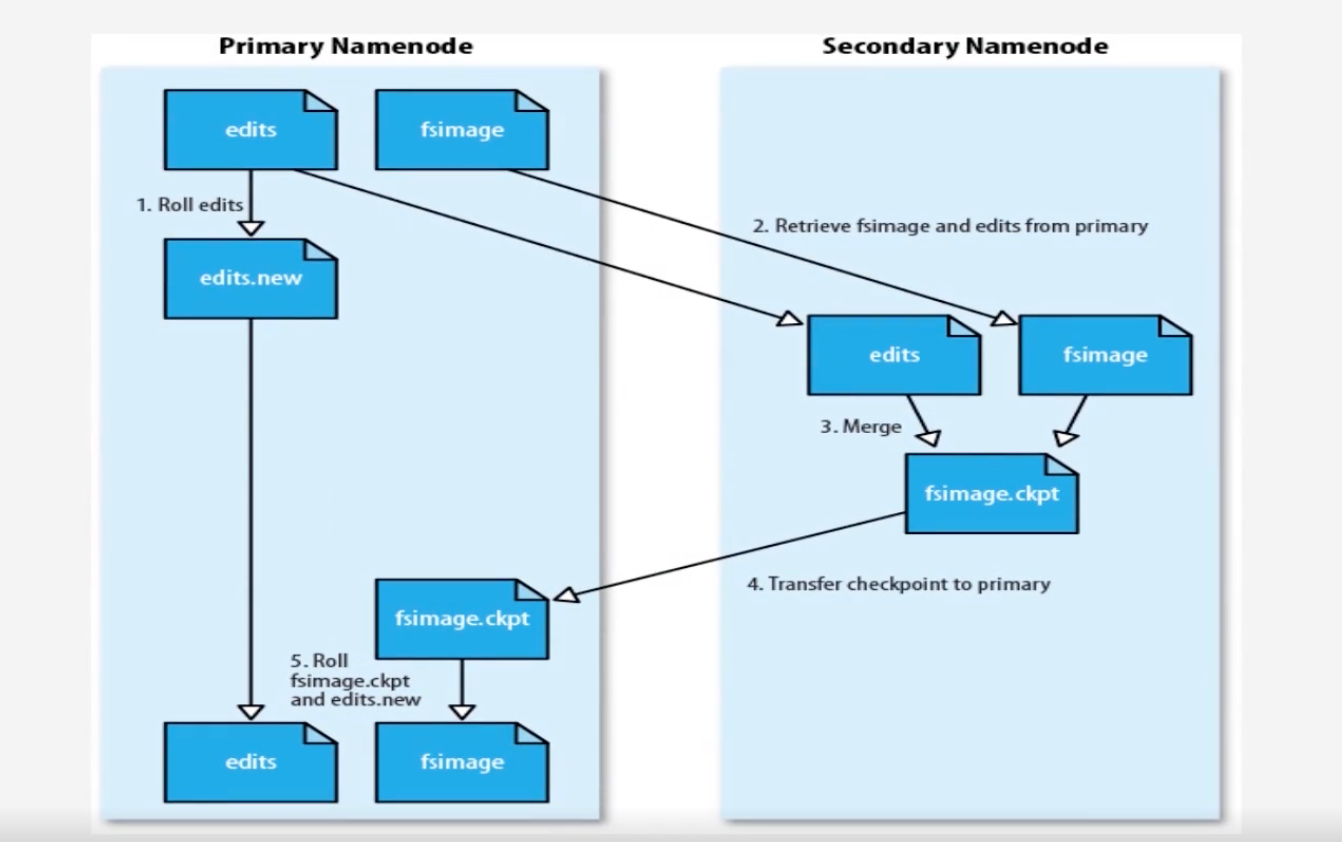
- 在第一名称节点的EditLog较大时,第二名称节点会告诉第一名称节点停止使用EditLog文件,并将EditLog写入自己机器

-
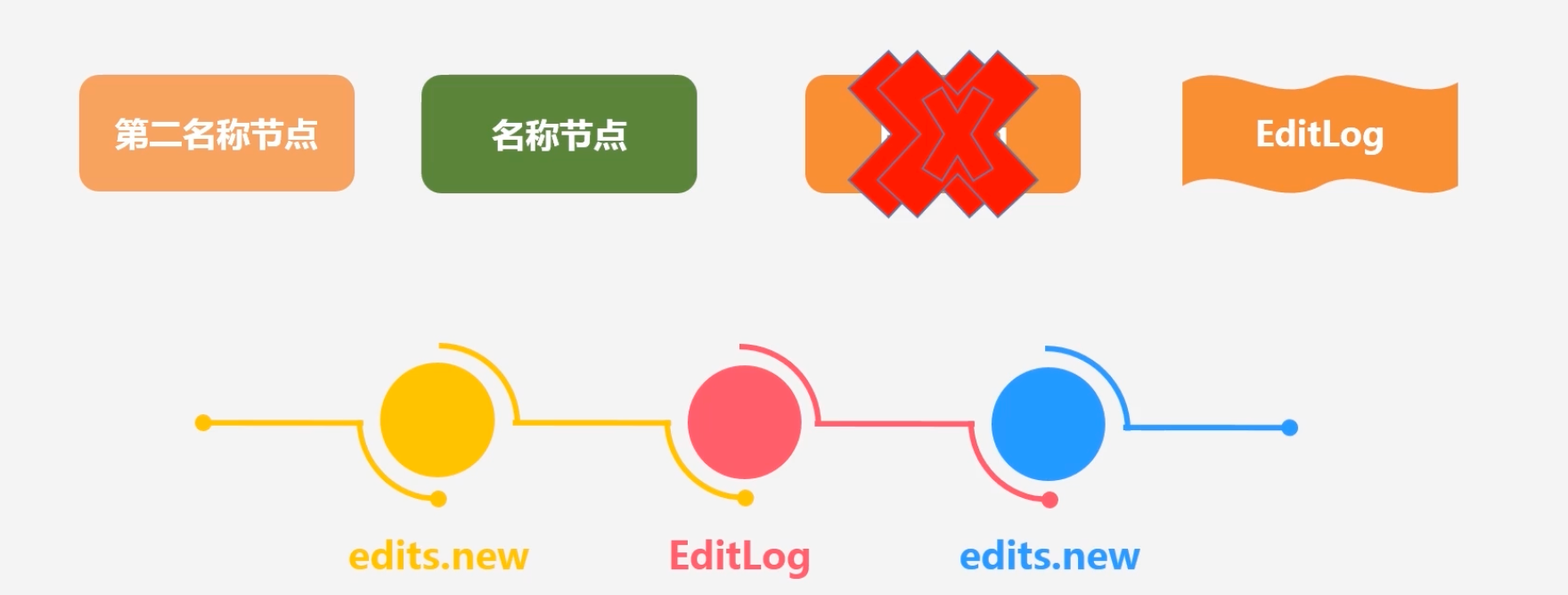
1.此时NameNode会马上停止,此时生成edits.new,将新到达的更新写到edits.new中,将原来旧的editlog内容由secondNameNode取走
-
2.SecondNameNode会通过http的get方式,将NameNode的FsImage和EditLog都下载到本地,然后在SecondNameNode做合并操作,得到新的FsImage,然后发送给NameNode

-
3.NameNode再将Edits.new更改为EditLog:即实现了不断增加的Editlog和FsImage合并,又实现了冷备份效果

-
数据节点:存储数据,数据节点拿到存储数据的文件目录,又将数据保留到各自的linux文件系统中去
3.3 HDFS的体系结构
-
主节点:管家作用;从节点:数据存储作用
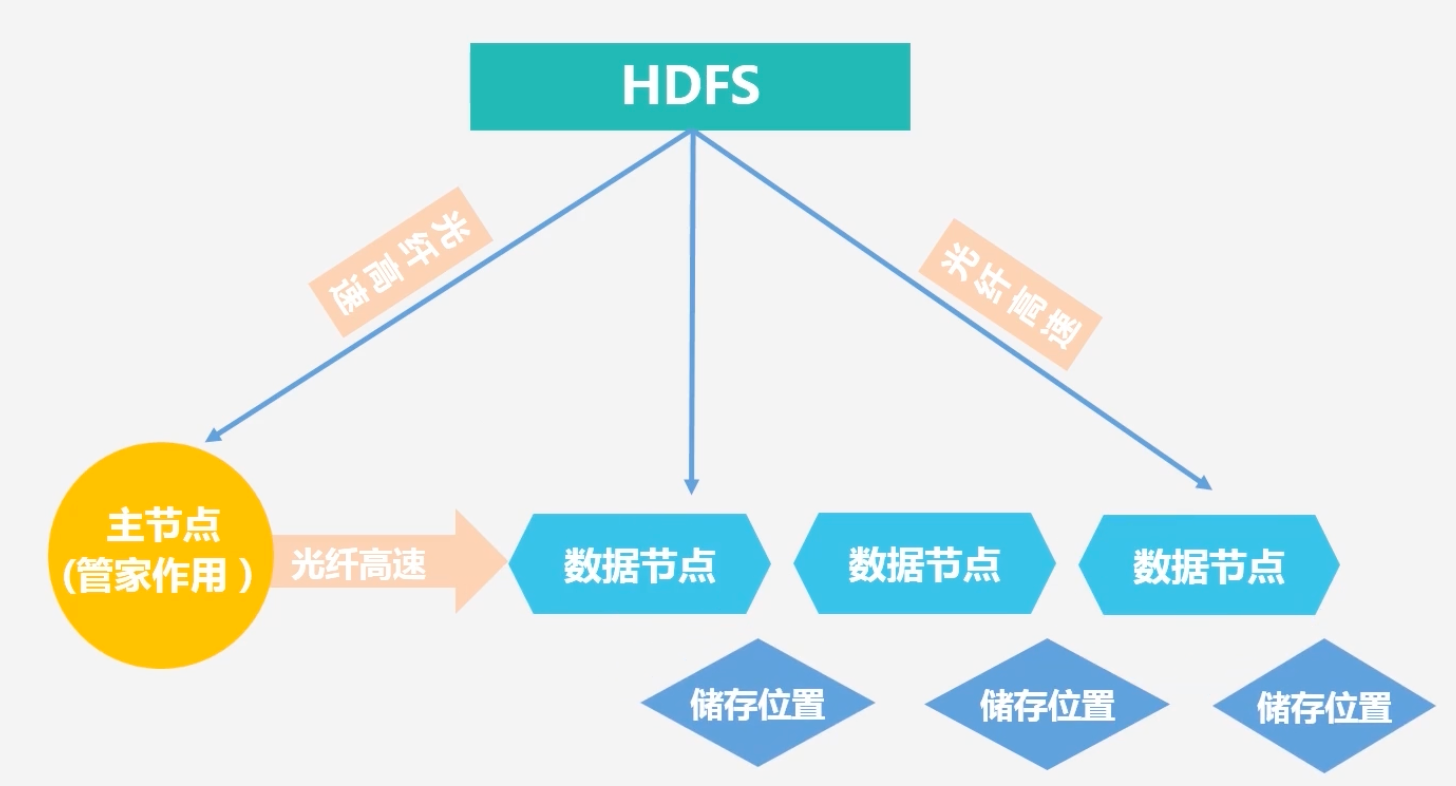
-
HDFS的命名空间
-
HDFS的目录访问和普通目录相同,都是通过/进行访问

-
所有的HDFS基于TCP/IP的通信协议,不同组件之间的通信协议有差异:例如客户端向名称节点发起TCP连接,使用客户端协议和名称节点进行交互;客户端和数据节点进行交互是通过远程调用:RPC来进行实现的
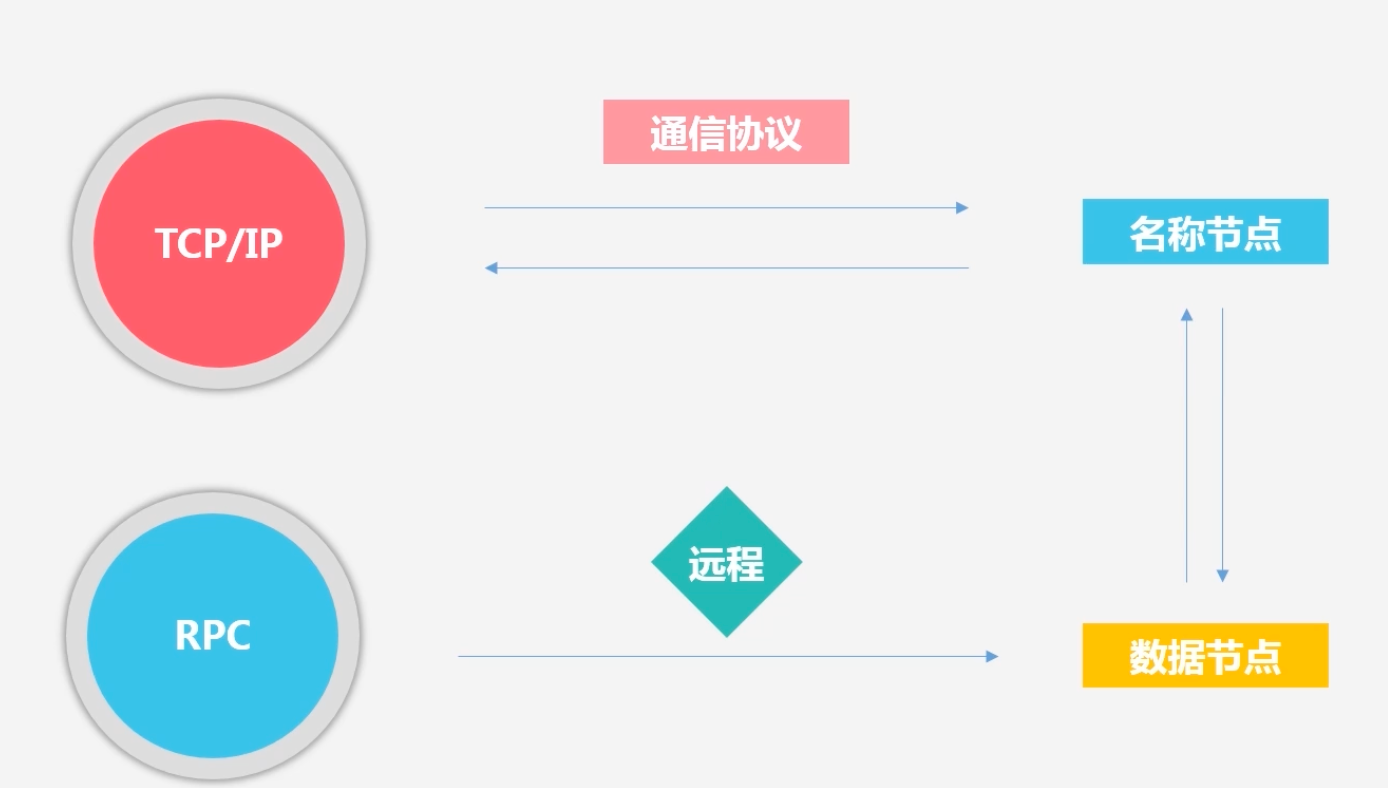
-
-
HDFS体系结构的局限性:

注意secondNamenode并不能保证集群的可用性:
因为secondNameNode是冷备份,就是在故障发生时,必须停止一段时间,慢慢恢复,这个恢复的过程会导致整个集群的不可用
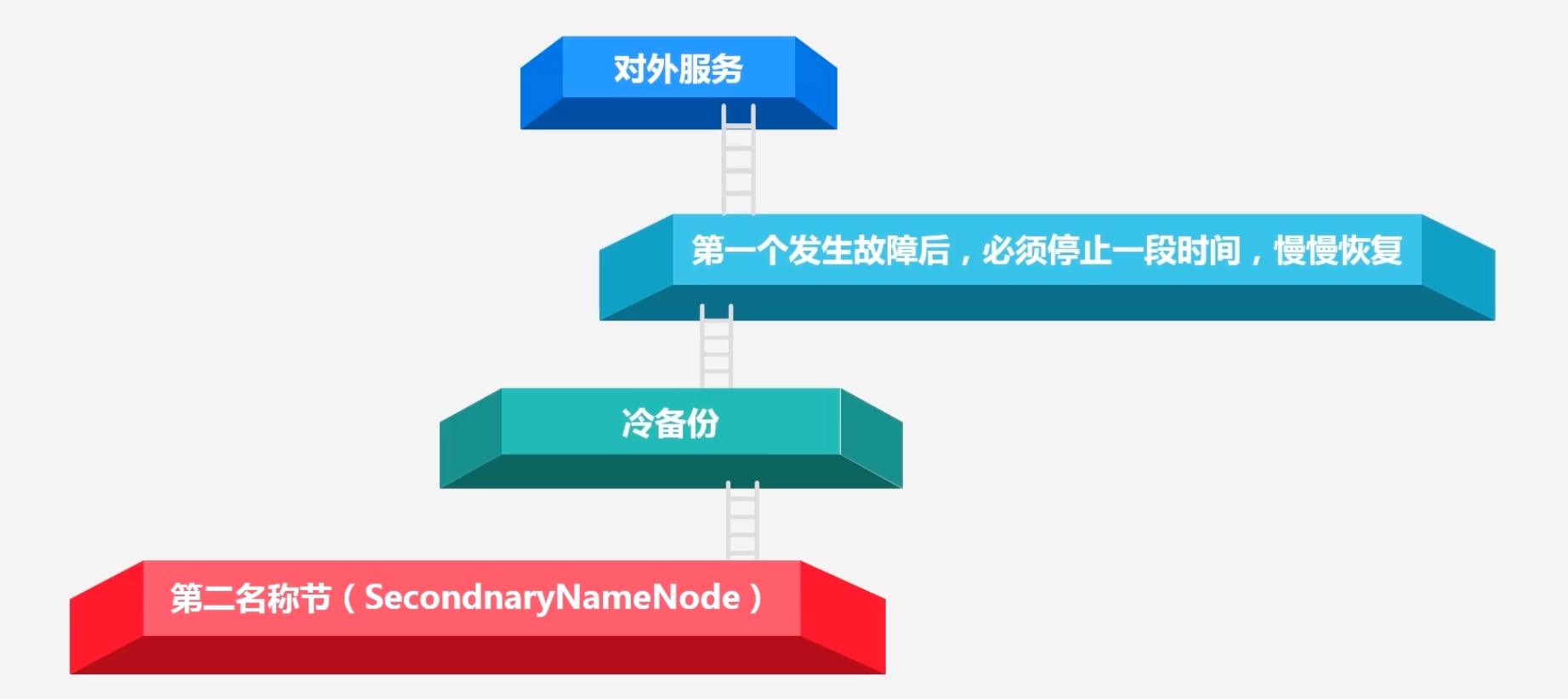
-
如何解决?HDFS2.0
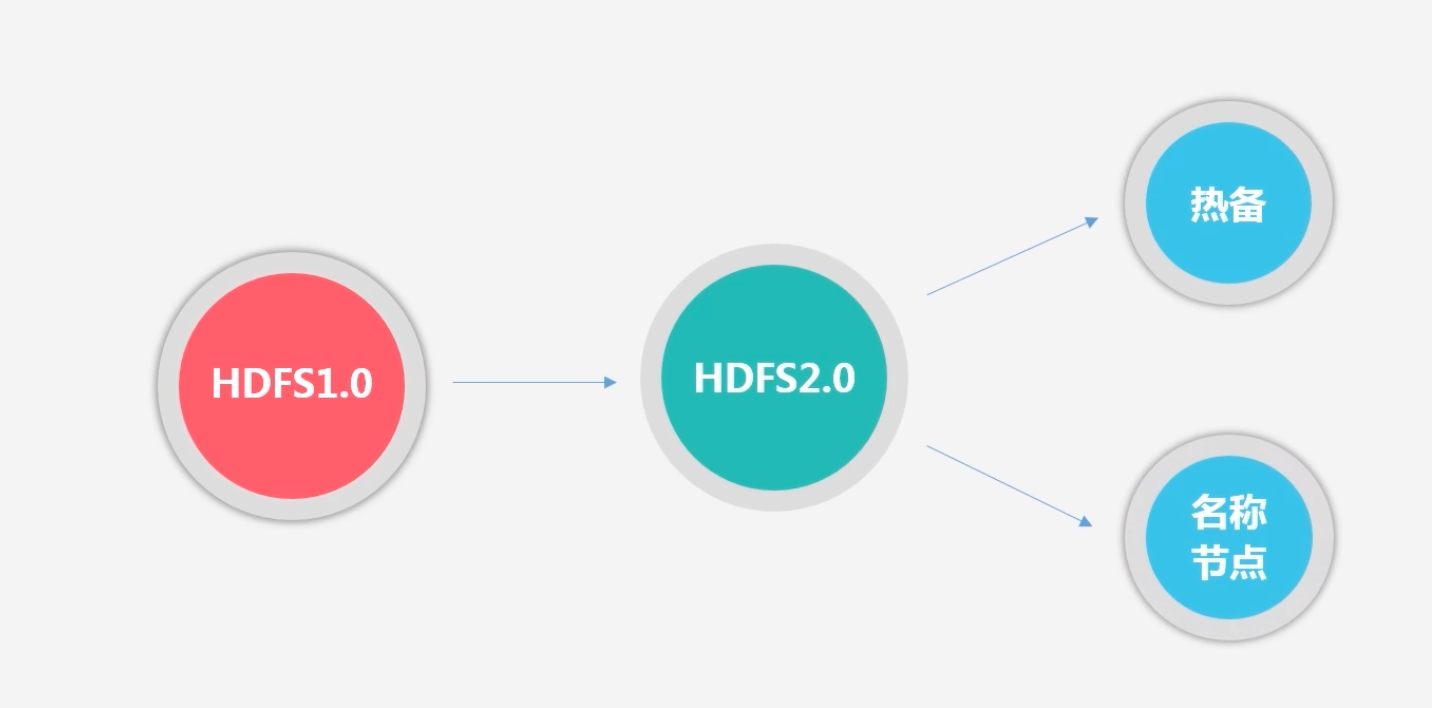
3.4 HDFS的存储原理
-
冗余数据保存问题
-
HDFS建立在廉价机器上,其缺点是会不停出故障,因此以块为单位,会将数据进行冗余保存,一般情况下一份数据会被保存为3份
-
有何好处?
-
加快数据传输速度:因为假设3个客户端ABC,需要访问同一个数据块,在冗余数据存储可以使三个客户端并行进行访问

-
很容易检查数据错误:可以通过三个副本之间对照来检查数据是否有误
-
保证数据可靠性:即使有机器down了,仍然能保有其他机器是可用的
-
-
-
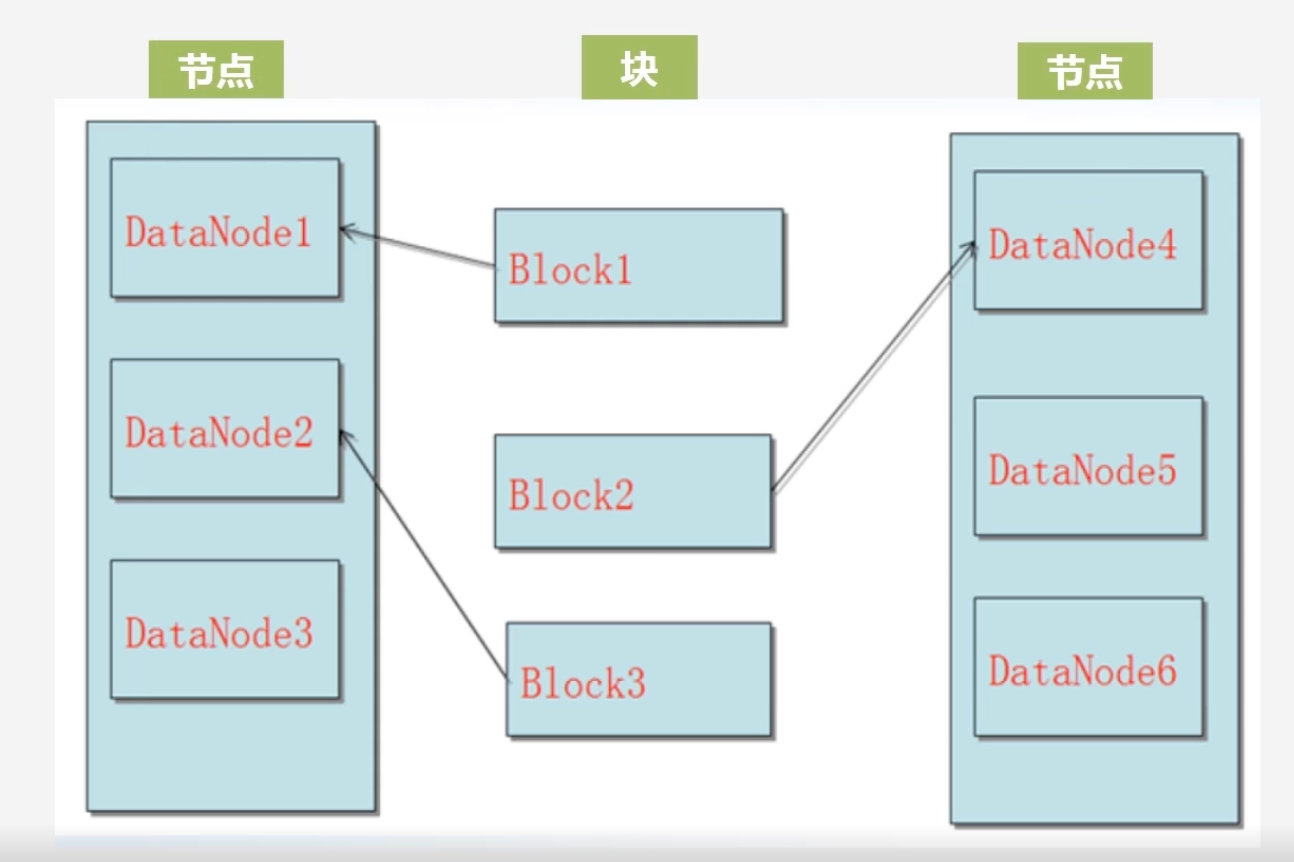
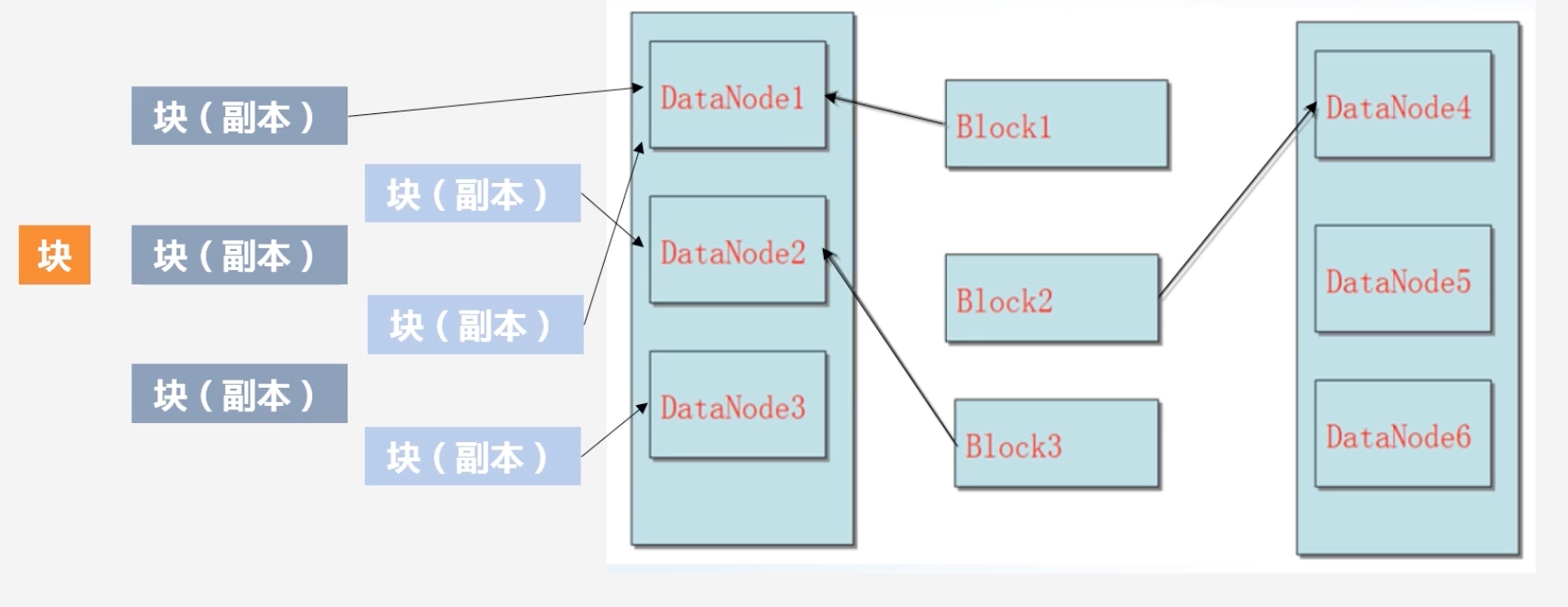
数据保存策略问题
-
假设此时有一个块存入
-
首先创建三个副本,假设块是由数据节点1发起的,这个副本称为第一副本,其则直接将其放在数据节点1上,不需要通过网络复制到其他节点上
-
若是集群外部的某个节点发起了写数据请求,HDFS会随机挑选一个磁盘不太满,cpu不太忙的节点作为第一副本。
-
第二副本会放置在和第一个副本不同的机架上
-
第三副本放置在第一个副本相同机架的其他节点上
-
若还有其他副本,则通过随机算法,放置在任意节点上
-
-
数据读取问题:

-
-
数据恢复的问题
-
名称节点出错?
-
HDFS1.0:会将整个HDFS暂停一段时间,即从secondNameNode中进行冷备份恢复一段时间,再进行对外服务
-
HDFS2.0:不需要暂停,直接热备份

-
-
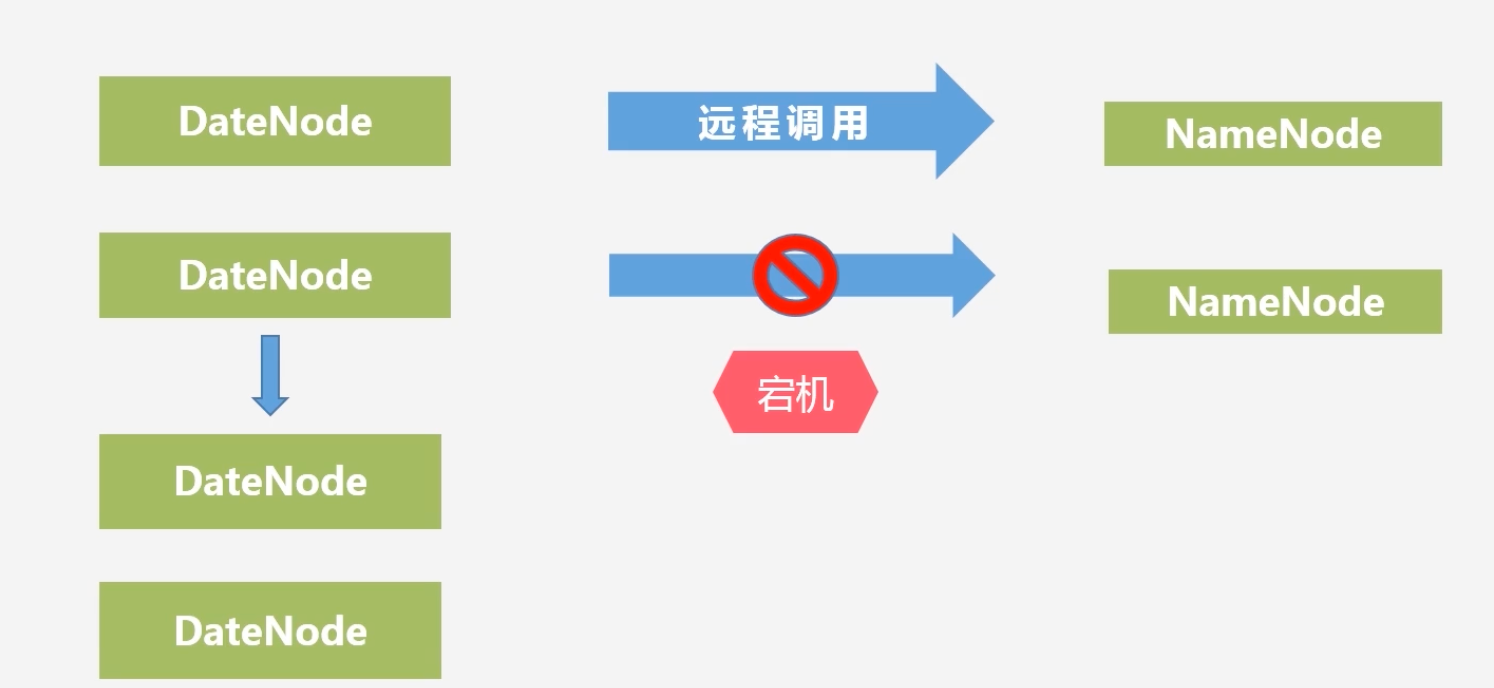
数据节点出错?
-
数据节点会隔一段时间向名称节点发送心跳信息,说明其还活着,若是名称节点收不到该数据节点的心跳信息,说明该数据节点发生故障
-
名称节点会在该数据节点列表上将其标记为宕机,即不可用,把存储在这个节点上的数据重新分发到其他的机器上去
-
当负载不均衡的时候,某个节点的负载过重,也会将这个节点的数据迁移到其他节点
-
-
数据本身出错?
-
客户端读取数据会对它进行校验码校验,如果发现校验码不正确,说明数据出错
-
这个校验码是在客户端写入数据时,为数据块生成校验码,保存在同一个文件目录中去,下次读数据块时,会对读到的数据进行校验码计算,
将计算的校验码和原来得到的校验码进行对比,不一致说明发生错误

-
-
3.5 HDFS数据读写
3.5.1 HDFS的读数据过程
-
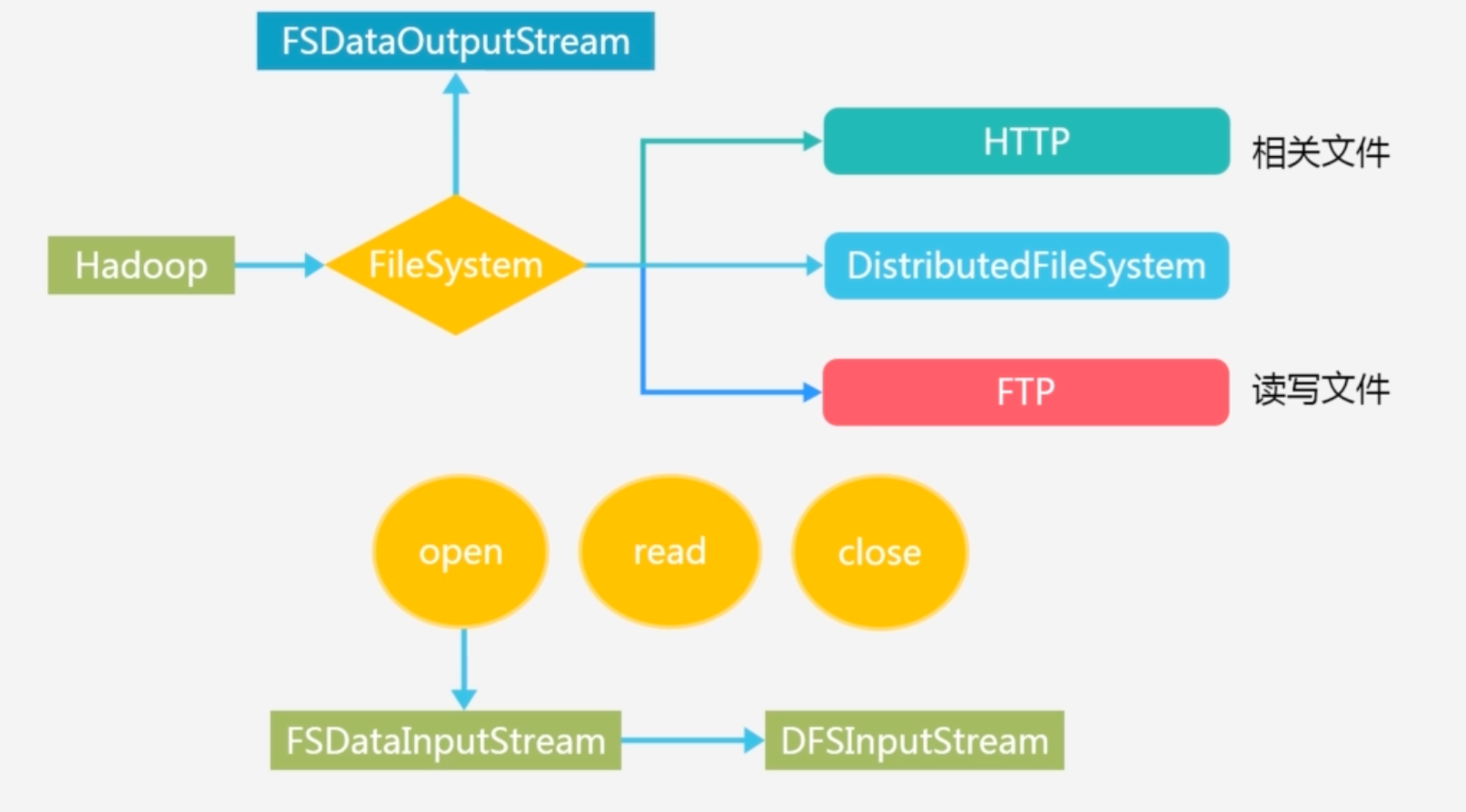
HDFS的FileSystem的基类,会有很有子类继承它而实现不同的功能
-
FileSystem基本方法:open read close 。open创建输入流封装了DFSInputStream, 是专门针对 HDFS的实现;create方法创建了FSoutputstream,同样封装了DFSoutputstream
-
FileSystem.get(conf):获得工程目录下的两个配置文件 hdfs-site.xml 和core-site.xml

-
HDFS读数据的整个流程
-
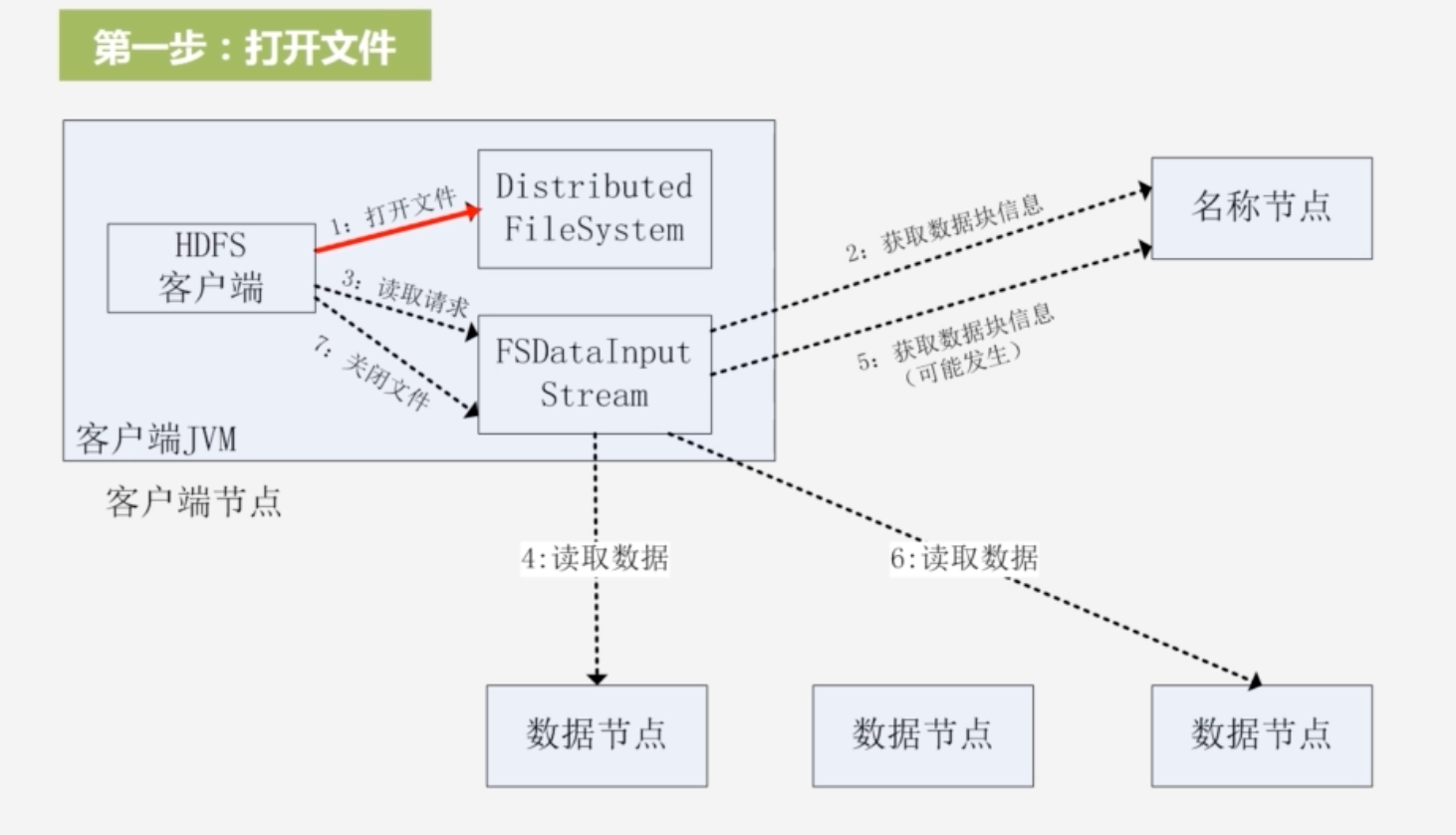
1.打开文件:用FileSystem声明文件对象,生成DistributedFileSystem的实例对象;创建输入流:FSDataInputStream,获取数据块信息,与名称节点通过远程过程调用进行沟通
-
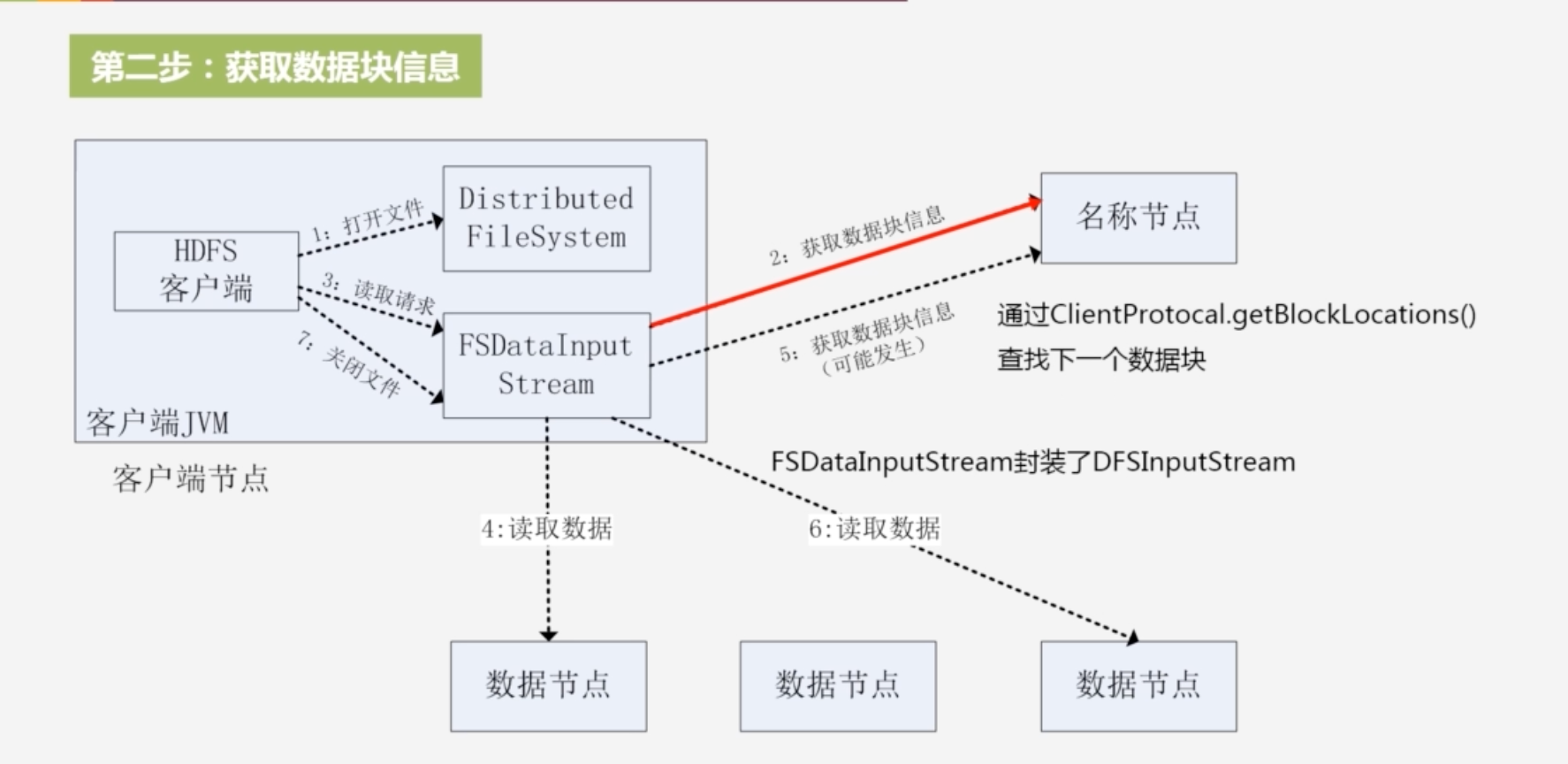
2.获取数据块信息:获取读取的数据块被保存在的数据节点位置信息,名称节点会把包含这个文件开始部分(文件可能包含很多块)的数据块位置信息返回
-
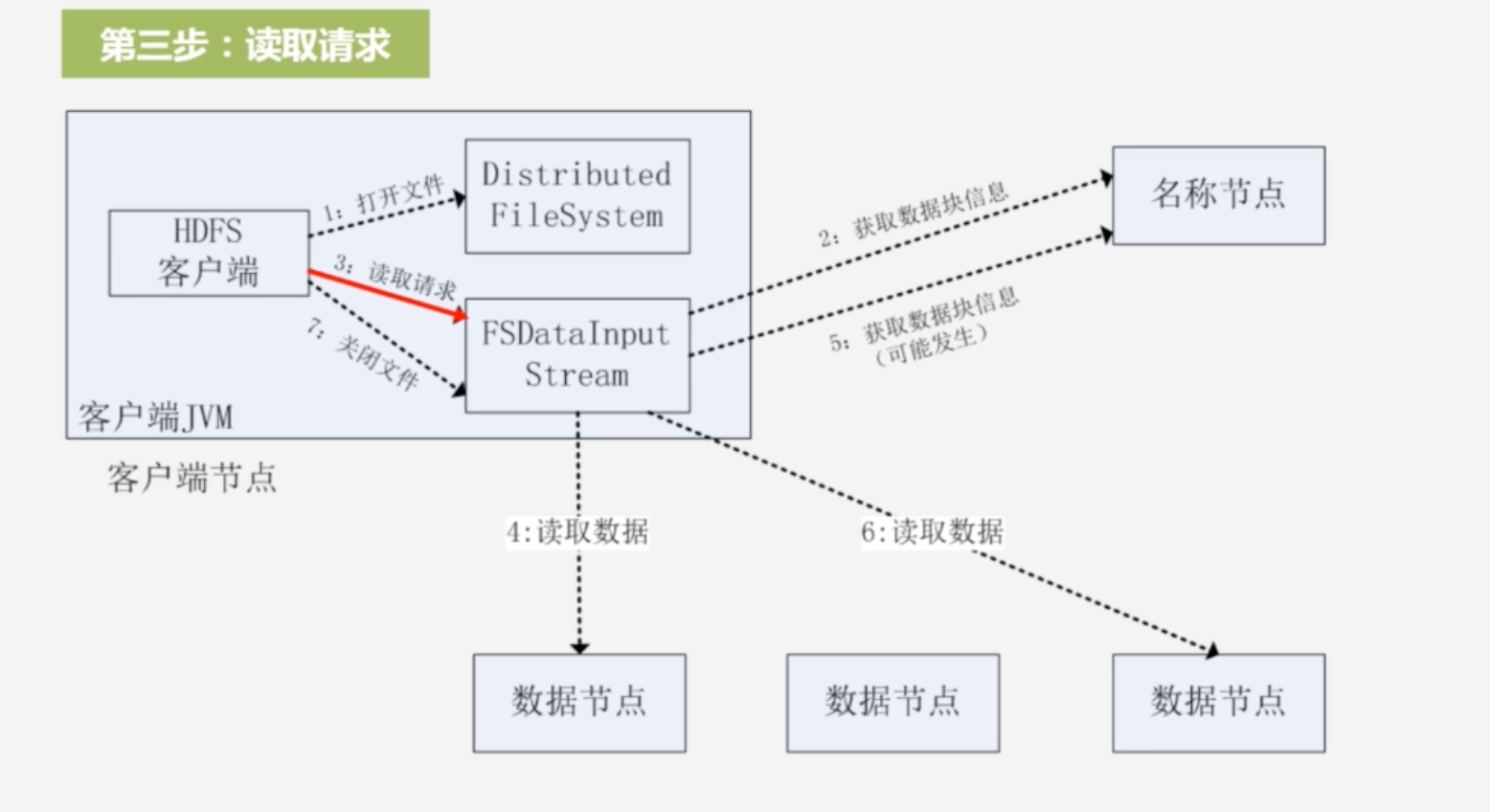
3.客户端获得输入流,可以调用read函数读取数据,会根据数据节点距离客户端的远近进行排序,客户端拿到排序后的数据节点位置列表,选择距离客户端最近的数据节点建立连接,读数据
-
- 将数据从数据节点读取到客户端
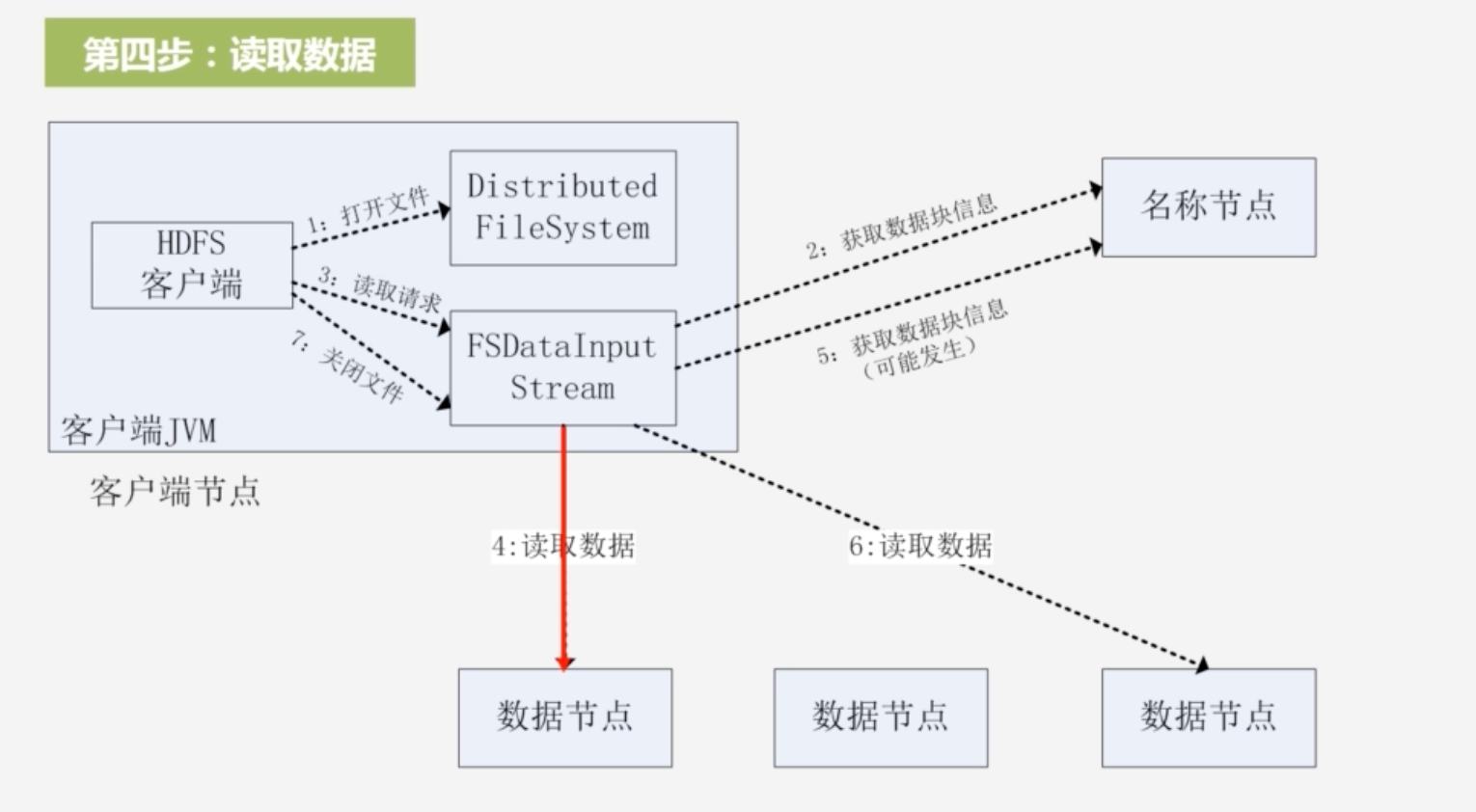
-
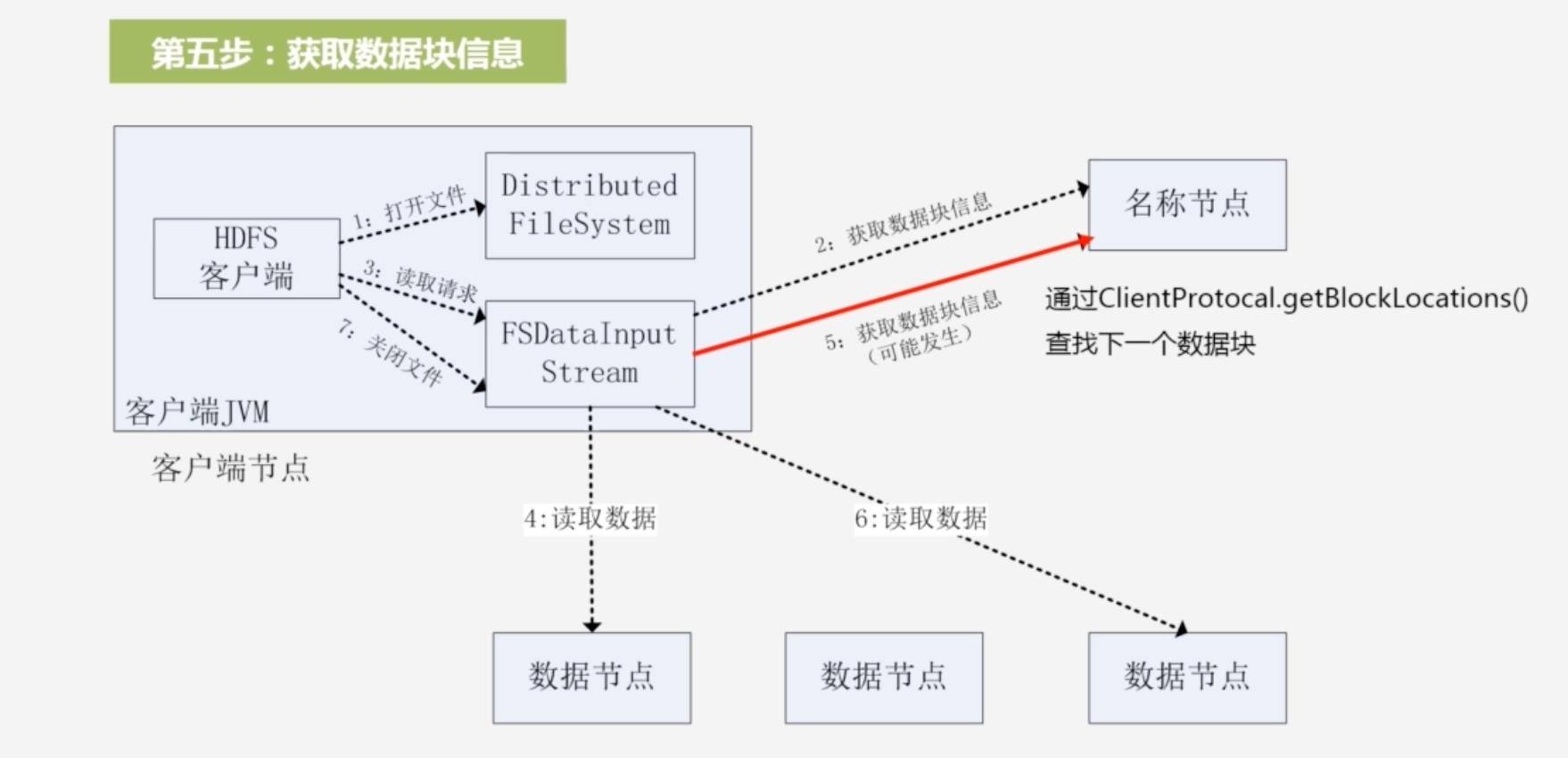
5.因为文件可能分为多个块,需要读取这个文件其他块的信息,通过ClientProtocal.getBlockLocations()查找下一数据块的位置
-
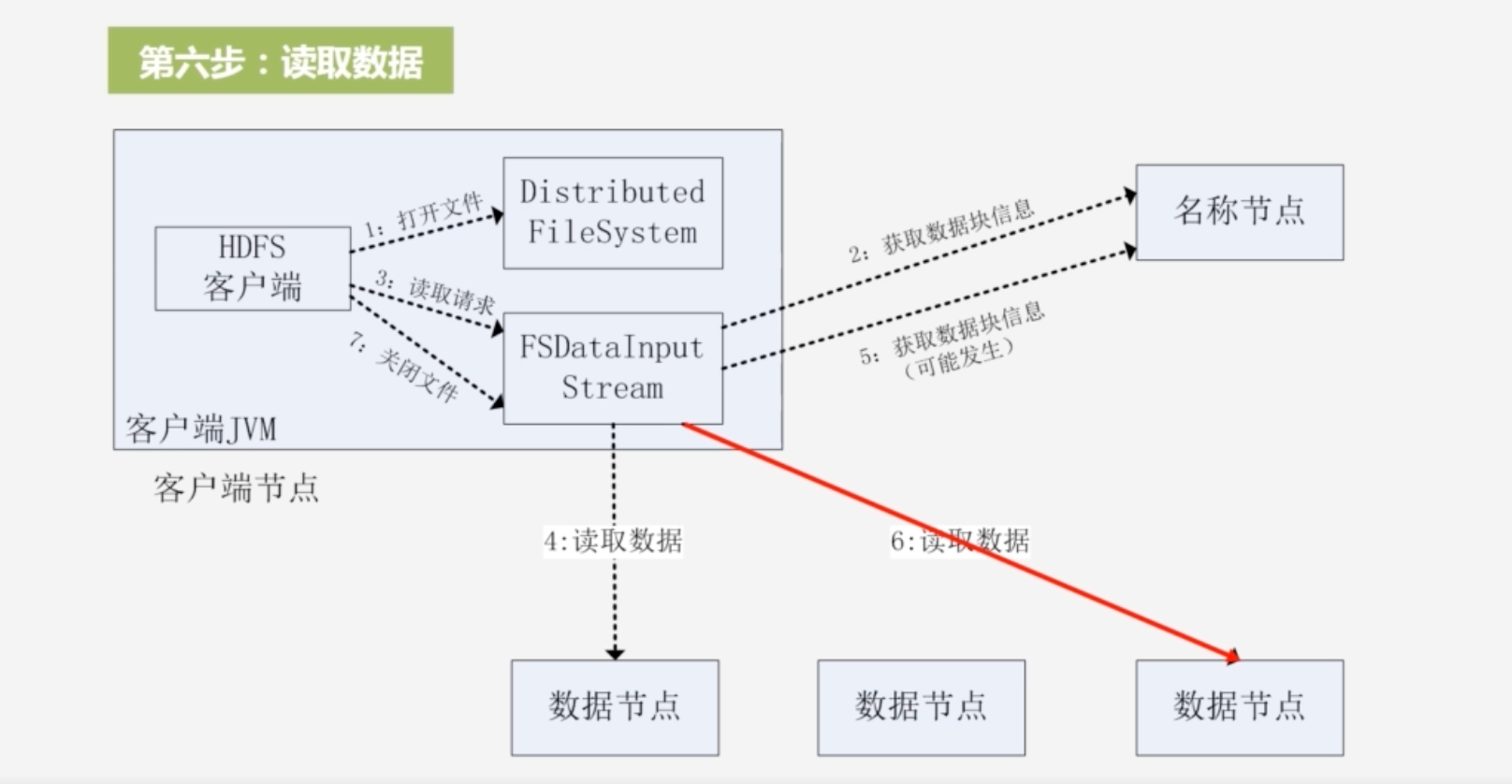
6.然后又读取该块节点的数据,又关闭输入流;一直循环直到完成这个文件所有块的读取
-
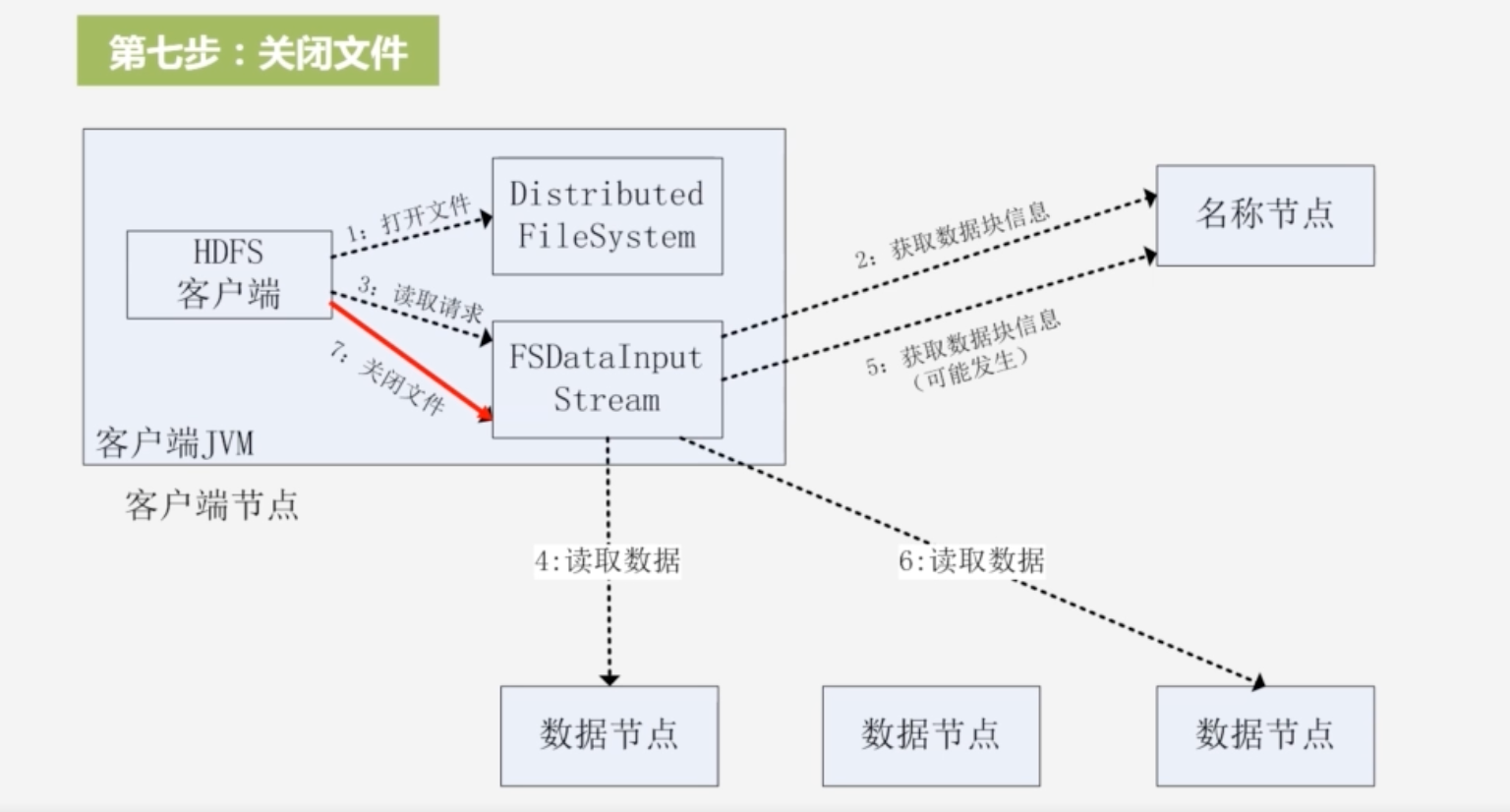
7.最后关闭文件
-
3.5.2 HDFS的写数据过程
-
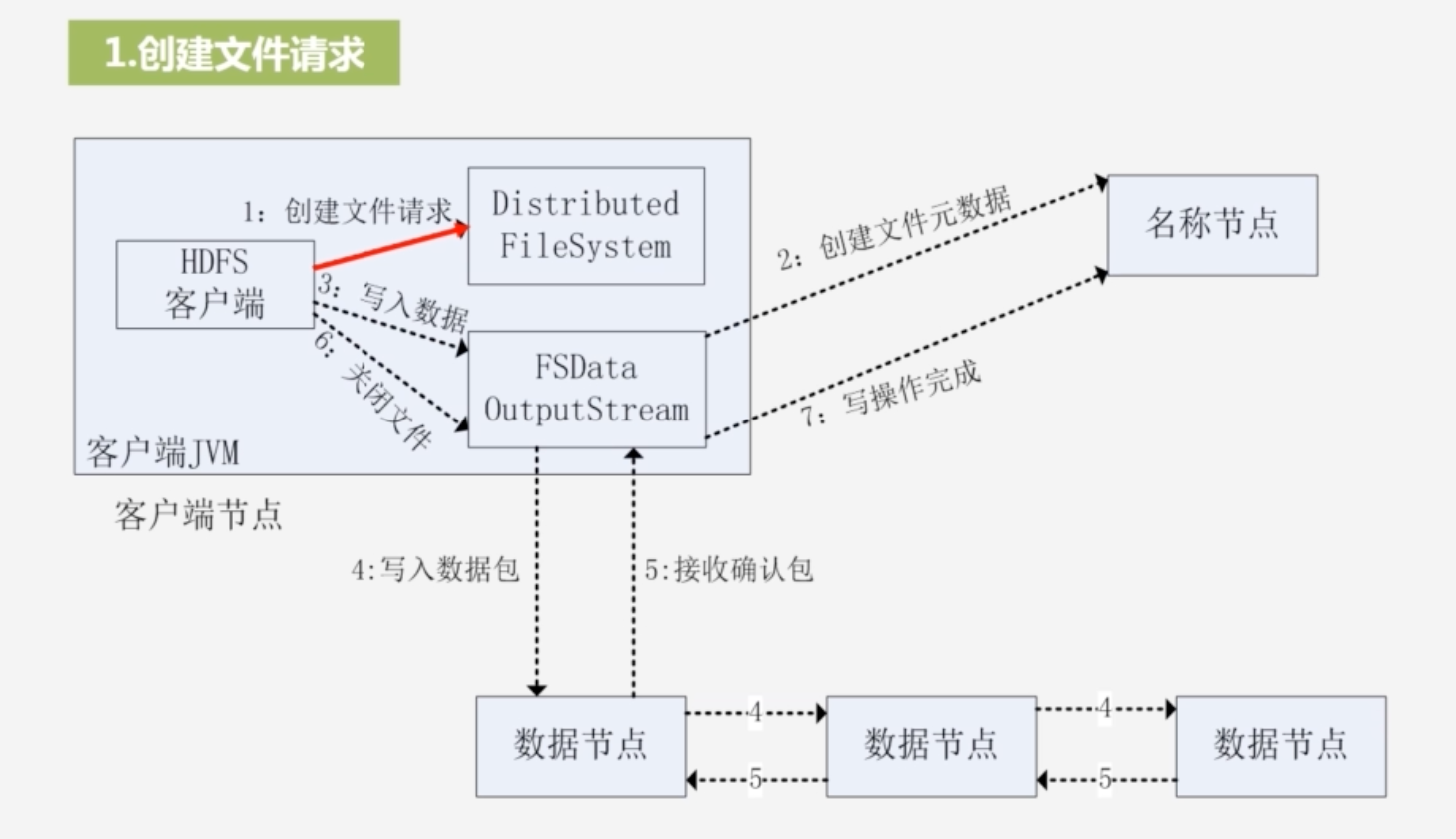
1.创建文件请求,实例化Distributed FileSystem;创建FSDataOutputStream,其内部封装DFSOutputStream,与名称节点打交道
-
-
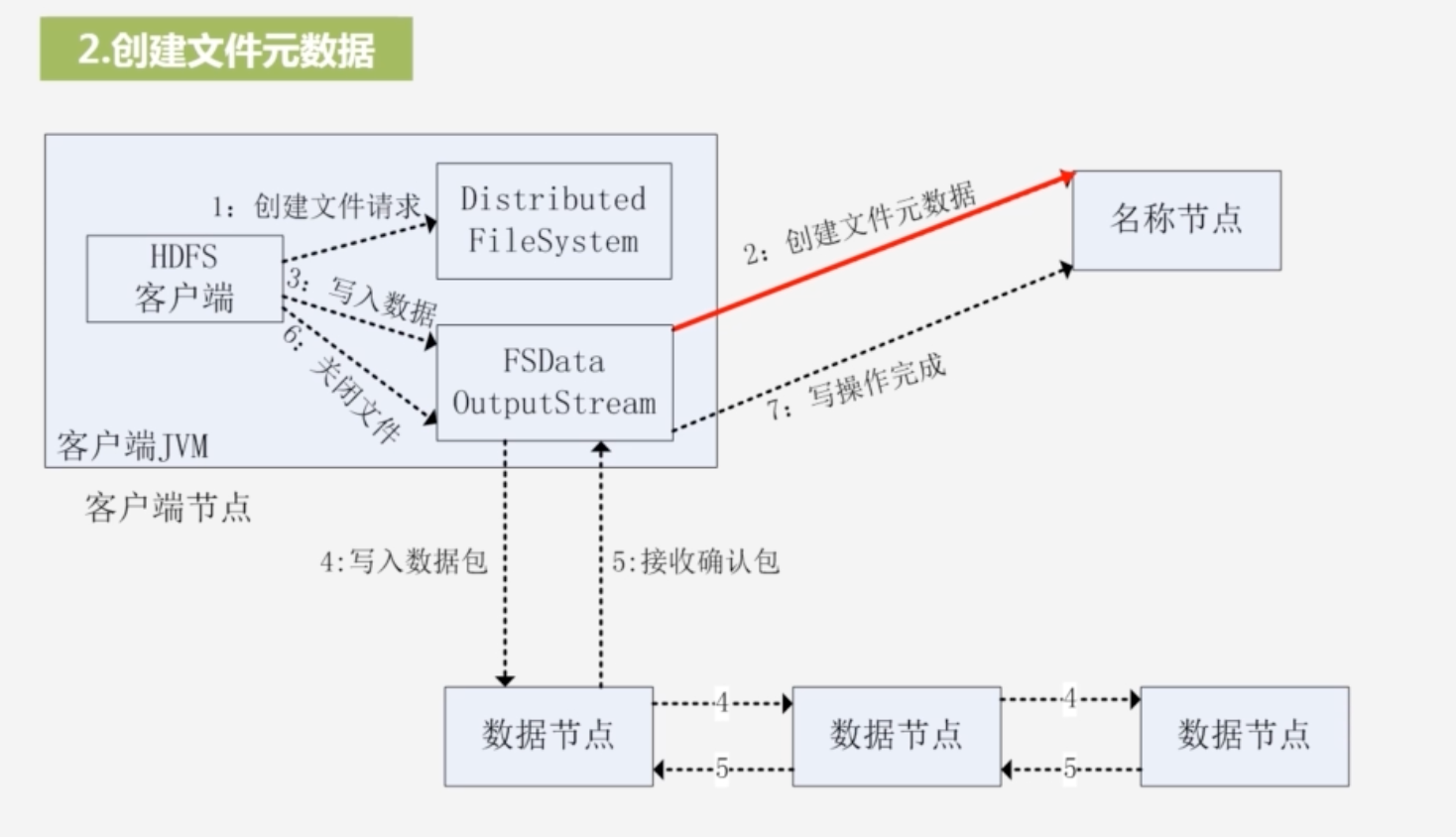
输出流通过远程过程调用rpc,让名称节点在文件系统命名空间中新建一个文件,名称节点会检查文件是否存在,以及客户端是否有权限创建这个文件,若是通过,则该名称节点会创建这个文件
-
-
3.写入数据
将整个数据分包:并将其放入DFSOutputStream的内部队列中去,DFSOutputStream向名称节点申请保存这个数据包的数据节点

-
-
写入数据包
流水线复制:将数据包复制到第一个节点,再由第一个节点复制到第二个节点,形成流水线复制

-
-
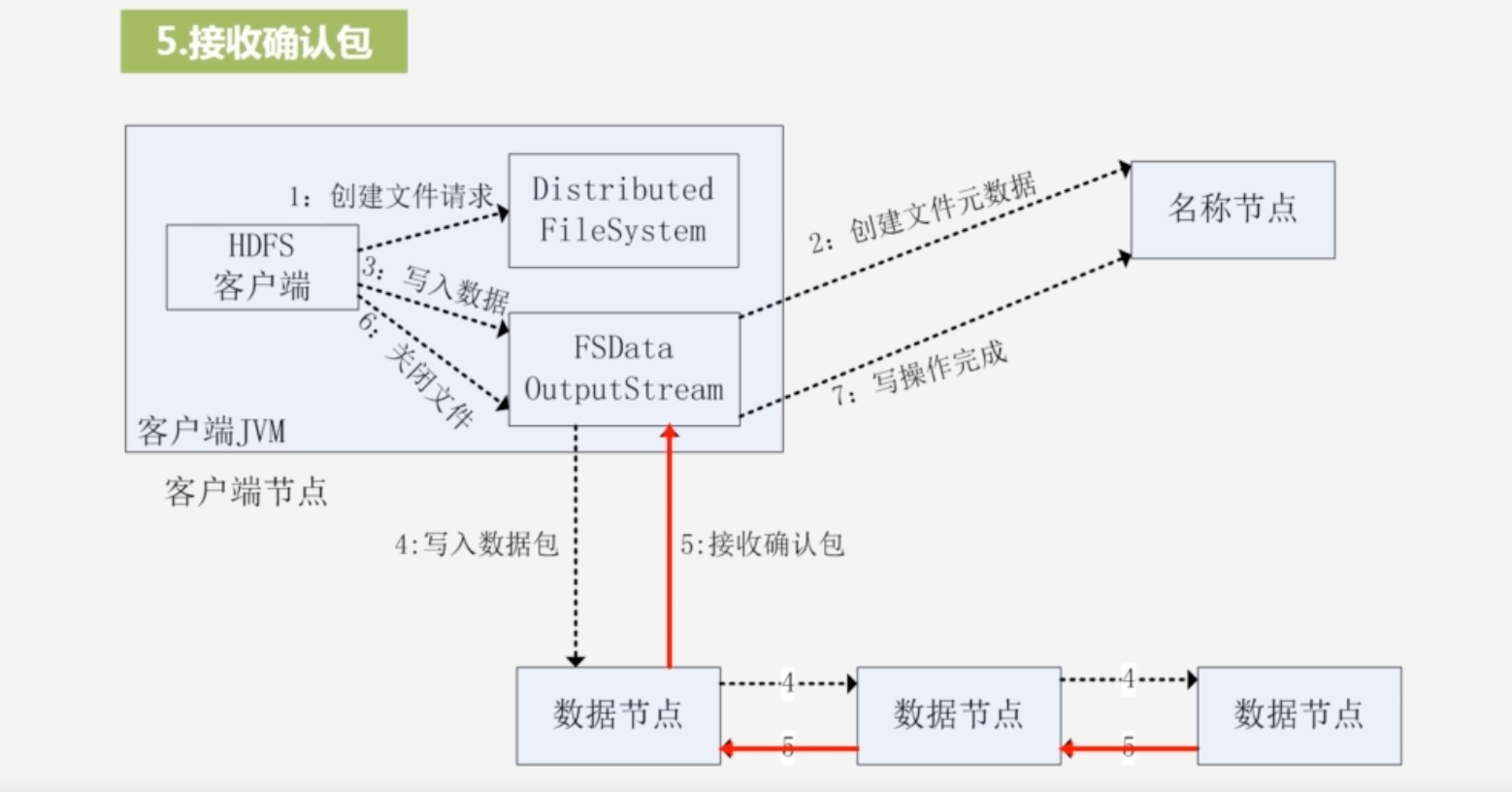
5.接受确认包
- 确认包由最后一个数据节点传到前一个数据节点,一直往前传,客户端收到确认信息,说明全都写完
-
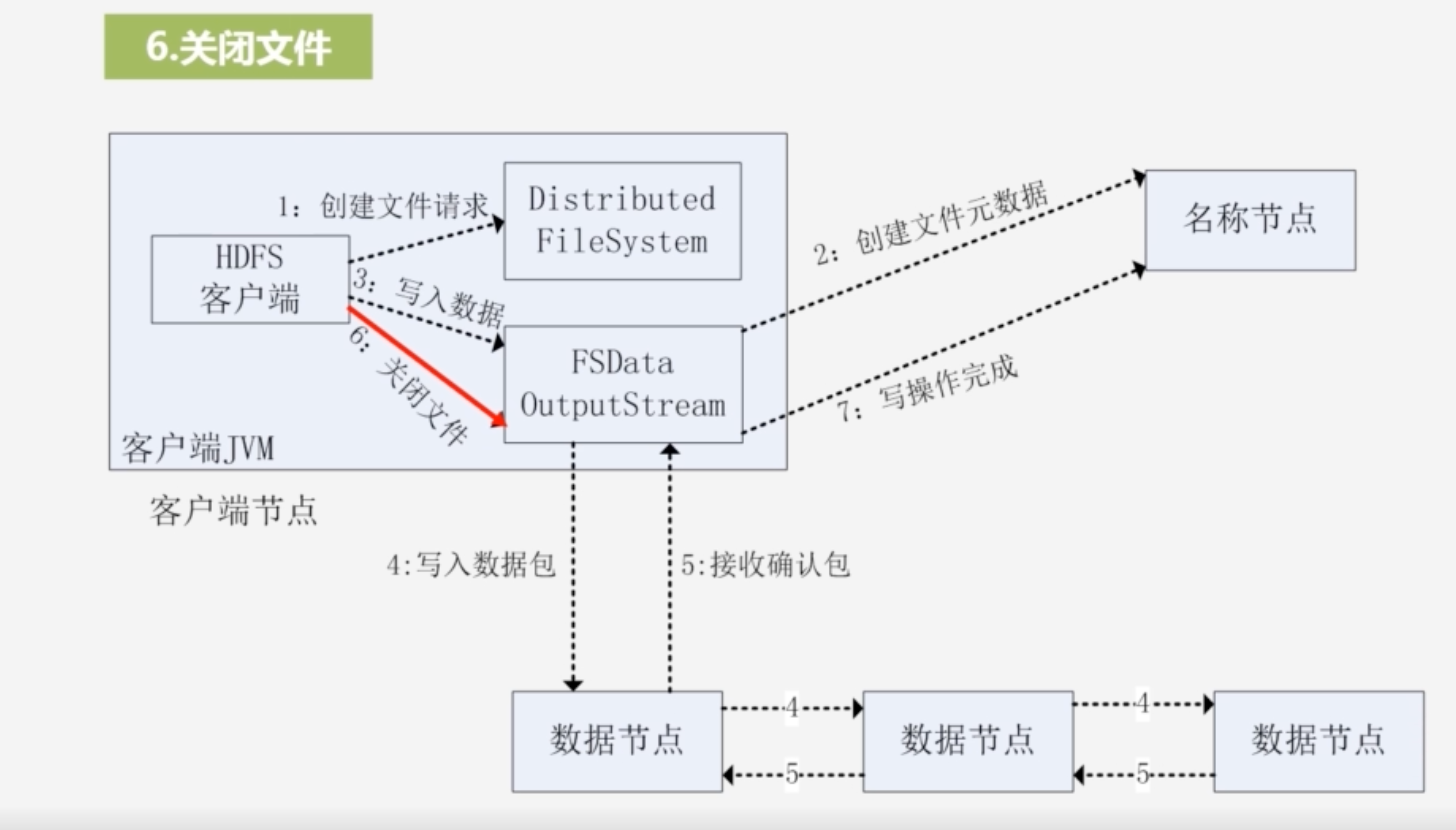
6.最后关闭文件
3.6 HDFS编程实战
见:HDFS编程实践(Hadoop3.3.5)_厦大数据库实验室博客 (xmu.edu.cn)
相关文章:
分布式文件系统HDFS(林子雨慕课课程)
文章目录 3. 分布式文件系统HDFS3.1 分布式文件系统HDFS简介3.2 HDFS相关概念3.3 HDFS的体系结构3.4 HDFS的存储原理3.5 HDFS数据读写3.5.1 HDFS的读数据过程3.5.2 HDFS的写数据过程 3.6 HDFS编程实战 3. 分布式文件系统HDFS 3.1 分布式文件系统HDFS简介 HDFS就是解决海量数据…...

CSS中:root伪类的使用
在CSS中,:root是一个伪类选择器,它选择的是文档树的根元素。在HTML文档中,这个根元素通常是<html>。:root伪类选择器常常被用于定义全局的CSS变量或者设置全局的CSS样式。 例如,你可以使用:root来定义一个全局的字体大小&a…...
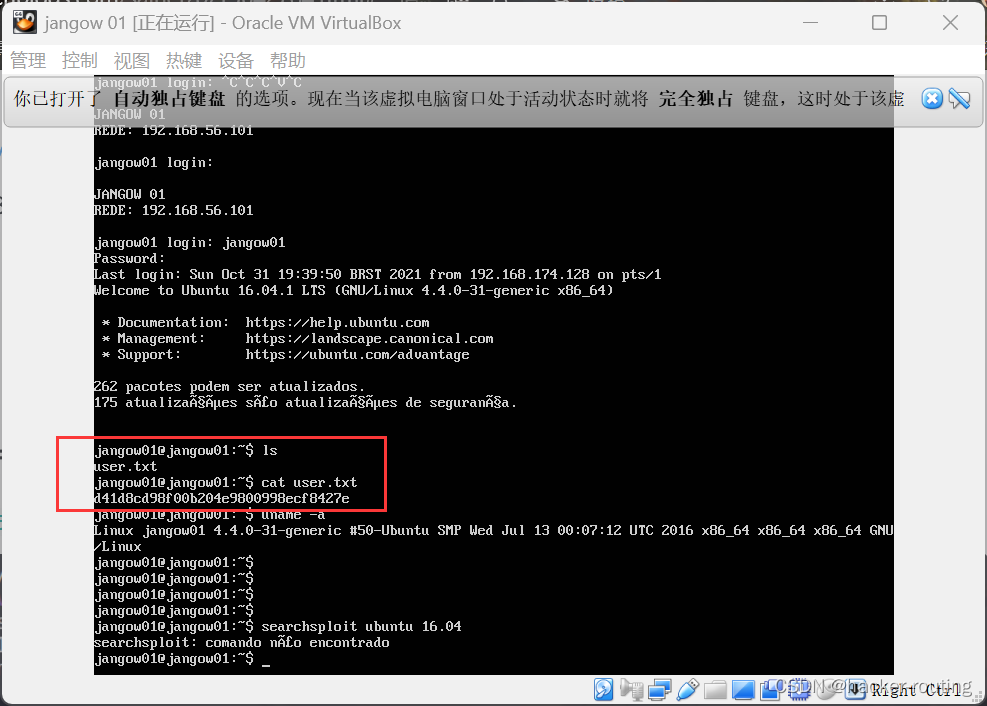
VulnHub JANGOW
提示(主机ip分配问题) 因为直接在VulnHub上下载的盒子,在VMware上打开,默认是不分配主机的 所以我们可以在VirtualBox上打开 一、信息收集 发现开放了21和80端口,查看一下80端口 80端口: 检查页面后发现…...

OpenMesh 获取网格面片各个顶点
文章目录 一、简介二、实现代码三、实现效果一、简介 OpenMesh中有很多循环器,这里便是其中一种面顶点循环器,以此来获得面片的各个顶点。 二、实现代码 #define _USE_MATH_DEFINES #include <iostream> #include <unordered_map>...

【前端设计模式】之原型模式
原型模式特性 原型模式(Prototype Pattern)是一种创建型设计模式,它通过克隆现有对象来创建新对象,而不是通过实例化类。原型模式的主要特性包括: 原型对象:原型对象是一个已经存在的对象,它作…...

软件设计原则
设计原则 一、单一原则 1. 如何理解单一职责原则 单一职责原则(Single Responsibility Principle,简称SRP),它要求一个类或模块应该只负责一个特定的功能。实现代码的高内聚和低耦合,提高代码的可读性和可维护性。 …...
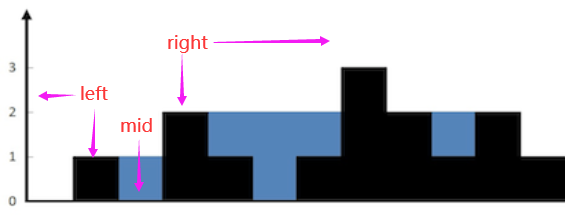
【面试HOT100】哈希双指针滑动窗口
系列综述: 💞目的:本系列是个人整理为了秋招面试的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于LeetCodeHot100进行的,每个知识点的修正和深入主要参考…...
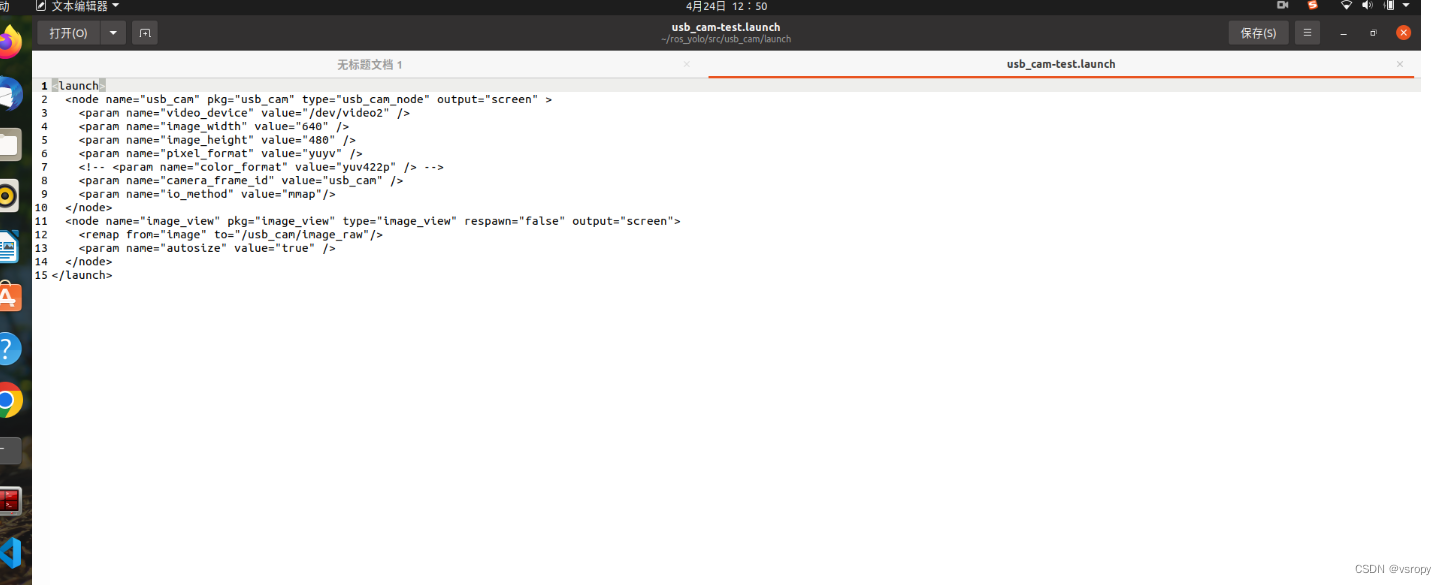
Ubuntu20.04 配置 yolov5_ros 功能包记录
文章目录 本文参考自博主源801,结合自己踩坑后修改 项目地址:https://github.com/mats-robotics/yolov5_ros 1.新建工作空间 新建一个工作空间 yolo_ros(名字可自定义),在 yolo_ros 下新建文件夹 src 并catkin_make进行编译 2. 安装相机驱动,可以选用较为主流的 usb_cam 或…...
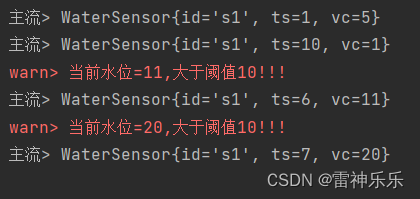
Flink的处理函数——processFunction
目录 一、处理函数概述 二、Process函数分类——8个 (1)ProcessFunction (2)KeyedProcessFunction (3)ProcessWindowFunction (4)ProcessAllWindowFunction ÿ…...

Linux系统中的ps命令详解及用法介绍
文章目录 一、介绍ps命令A. ps命令的作用B. ps命令的参数 二、常见的ps命令用法A. 显示所有进程信息B. 显示指定进程信息C. 显示指定用户的进程信息D. 按CPU使用率排序显示进程信息E. 按内存使用率排序显示进程信息 三、进一步了解ps命令A. 显示进程树信息B. 显示线程和进程关系…...

机器学习笔记 - 基于pytorch、grad-cam的计算机视觉的高级可解释人工智能
一、pytorch-gradcam简介 Grad-CAM是常见的神经网络可视化的工具,用于探索模型的可解释性,广泛出现在各大顶会论文中,以详细具体地描述模型的效果。Grad-CAM的好处是,可以在不额外训练的情况下,只使用训练好的权重即可获得热力图。 1、CAM是什么? CAM全称Class Activa…...

Python 编程基础 | 第五章-类与对象 | 5.1、定义类
一、类 1、定义类 Python中使用class关键字定义类,class之后为类的名称并以:结尾,类的结构如下: class 类名:多个(≥0)类属性...多个(≥0)类方法...下面定义一个Dog类,如…...
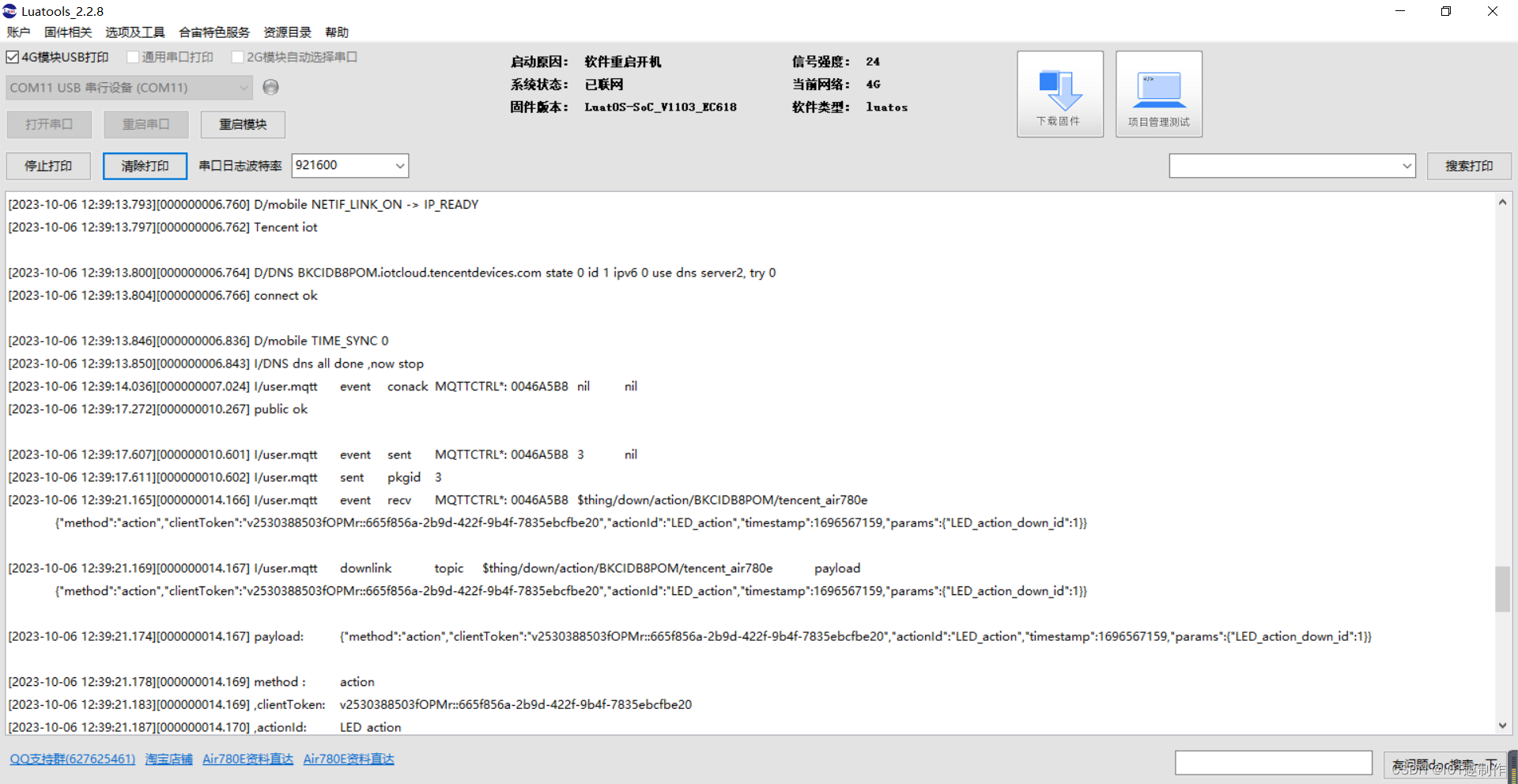
合宙Air780e+luatos+腾讯云物联网平台完成设备通信与控制(属性上报+4G远程点灯)
1.腾讯云物联网平台 首先需要在腾讯云物联网平台创建产品、创建设备、定义设备属性和行为,例如: (1)创建产品 (2)定义设备属性和行为 (3)创建设备 (4)准备参…...

c++系列之string的模拟实现
💗 💗 博客:小怡同学 💗 💗 个人简介:编程小萌新 💗 💗 如果博客对大家有用的话,请点赞关注再收藏 🌞 string() //注意事项: 1.初始化列表随声明的顺序进行初始化 2.cons…...

Spring的beanName生成器AnnotationBeanNameGenerator
博主介绍:✌全网粉丝4W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经验…...

FFmpeg 命令:从入门到精通 | ffmpeg 命令直播
FFmpeg 命令:从入门到精通 | ffmpeg 命令直播 FFmpeg 命令:从入门到精通 | ffmpeg 命令直播直播拉流直播推流 FFmpeg 命令:从入门到精通 | ffmpeg 命令直播 本节主要介绍了ffmpeg 命令进行直播拉流、推流的方法,并列举了一些例子…...

A (1087) : DS单链表--类实现
Description 用C语言和类实现单链表,含头结点 属性包括:data数据域、next指针域 操作包括:插入、删除、查找 注意:单链表不是数组,所以位置从1开始对应首结点,头结点不放数据 类定义参考 #include<…...
异常:找不到匹配的key exchange算法
目录 问题描述原因分析解决方案 问题描述 PC 操作系统:Windows 10 企业版 LTSC PC 异常软件:XshellPortable 4(Build 0127) PC 正常软件:PuTTY Release 0.74、MobaXterm_Personal_23.1 服务器操作系统:OpenEuler 22.03 (LTS-SP2)…...
Arcgis打开影像分析窗口没反应
Arcgis打开影像分析窗口没反应 问题描述 做NDVI计算的时候,一直点击窗口-影像分析,发现影像分析的小界面一直不跳出来。 原因 后来发现是被内容列表给遮住了,其实是已经出来了的。。 拖动内容列表就能找到。 解决方案 内容列表和影像分…...

Spring(JavaEE进阶系列1)
目录 前言: 1.Servlet与Spring对比 2.什么是Spring 2.1什么是容器 2.2什么是IoC 2.3SpringIoC容器的理解 2.4DI依赖注入 2.5IoC与DI的区别 3.Spring项目的创建和使用 3.1正确配置Maven国内源 3.2Spring的项目创建 3.3将Bean对象存储到Spring(…...

终极指南:使用OpenHTMLtoPDF快速构建专业PDF生成器
终极指南:使用OpenHTMLtoPDF快速构建专业PDF生成器 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF/U…...
)
别再手动敲命令了!用Kuboard-Spray v1.2.4图形化搞定K8s集群(附CentOS 7.9避坑实录)
图形化利器Kuboard-Spray v1.2.4:三分钟搭建生产级K8s集群的避坑指南 当你在凌晨三点盯着满屏的kubeadm init报错信息时,是否想过Kubernetes集群部署还能更简单?去年我们团队在客户现场部署一套生产环境时,传统命令行方式让我们在…...

光电效应实验避坑指南:从汞灯预热到遏止电压判读,新手常犯的5个错误
光电效应实验避坑指南:从汞灯预热到遏止电压判读的5个关键误区 在大学的物理实验室里,光电效应实验就像一位性格古怪的教授——看似简单明了,实则暗藏玄机。许多同学满怀信心地走进实验室,却在数据采集阶段屡屡碰壁,最…...

OV5640摄像头数据流抓取与仿真全攻略:从DVP时序到Testbench调试技巧
OV5640摄像头数据流抓取与仿真全攻略:从DVP时序到Testbench调试技巧 在FPGA图像处理系统中,OV5640作为一款高性价比的500万像素CMOS传感器,其DVP接口的数据采集可靠性直接影响整个系统的图像质量。本文将深入探讨如何构建稳健的数据捕获逻辑&…...

专业MTK设备Bootloader解锁与安全绕过技术指南
专业MTK设备Bootloader解锁与安全绕过技术指南 【免费下载链接】mtkclient-gui GUI tool for unlocking bootloader and bypassing authorization on Mediatek devices (Not maintained anymore) 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient-gui mtkclient-…...

Blender-Armatures
导航 (返回顶部) 1. Blender-Armatures 1.1 骨架位置1.2 分类1.3 骨骼结构 2. 编辑 2.1 骨骼扭转2.2 拆分 split2.3 分离骨骼 separate2.4 切换方向 3. 镜像编辑 3.1 镜像挤出3.2 命名惯例3.3 对称 4. 属性 4.1 属性结构表4.2 柔性骨骼 Bendy Bones4.3 姿态4.4 关系 5. 骨骼约束…...
:含12类经典数学场景Prompt+错误模式对照表+自动校验脚本)
Perplexity数学知识查询稀缺资源包(限时开放48小时):含12类经典数学场景Prompt+错误模式对照表+自动校验脚本
更多请点击: https://intelliparadigm.com 第一章:Perplexity数学知识查询 Perplexity 是衡量语言模型预测能力的核心指标,其数学定义源于信息论中的交叉熵。它本质上是模型对测试语料困惑程度的指数化表达,值越低表示模型对序列…...

千川素材外包月烧3万,转易元AI自产省70%成本,跑量还更猛——真实账单对比
很多商家做千川投放时,最开始以为最贵的是投流预算,后来才发现,真正长期烧钱的其实是素材。计划每天要新视频,爆款跑起来要裂变,素材疲劳了要补货,全域推广还要不同场景、不同卖点、不同人群的素材矩阵。外…...

别再只用labelme了!用ENVI 5.3的ROI工具给遥感影像打深度学习标签,保姆级避坑指南
遥感影像标注革命:ENVI ROI工具在深度学习标签制作中的专业实践 引言 在遥感影像分析与深度学习模型训练的工作流中,数据标注环节往往成为制约效率提升的关键瓶颈。传统标注工具如labelme虽然在小尺寸自然图像处理中表现出色,但当面对动辄数G…...

别再只怪MOS管了!BMS过压保护设计,PCB走线才是隐藏的‘刺客’
别再只怪MOS管了!BMS过压保护设计,PCB走线才是隐藏的‘刺客’ 在电池管理系统(BMS)的设计中,过压保护失效往往被简单归咎于MOS管的选型或钳位二极管的设计。然而,一个真实的案例揭示了更深层的问题…...