一文带你快速初步了解云计算与大数据
目录
🔍一、云计算基础
1、云计算的概念、特点、关键技术
2、云计算的分类
3、云计算的部署模式
4、云计算的服务模式:IaaS、PaaS、SaaS分别是什么,具体含义要清楚
5、物联网的概念
6、物联网和云计算、大数据的关系
7、了解云计算的数据中心是什么,有什么特点
8、主流云计算平台的主要云产品名称及作用
🔦二、大数据基础
1、常用的数据计量单位及其换算
2、大数据的概念,了解大数据的来源及其多样性
3、大数据的5V特征
4、科学研究的4个范式
5、大数据对思维方式的影响
6、大数据的处理流程
7、大数据的关键技术
8、主要的大数据处理系统及代表产品
9、云计算之父、大数据之父
🔑三、虚拟化与容器技术
1、虚拟化的概念、特征
2、虚拟化的好处
3、虚拟化的分类:从计算体系结构层次上分为哪几类
4、系统虚拟化是什么
5、服务器虚拟化的关键技术哪三个
6、知道常用的虚拟化软件有哪些
7、虚拟化和容器的区别
8、Docker是什么,技术支柱是什么,容器、镜像、仓库三个基本概念
📑四、Hadoop
1、Hadoop是什么
2、Hadoop的核心组件有什么
4、Hadoop的优点
6、Hadoop2.0中加入Yarn的原因
7、Hadoop的三种安装模式
8、Hadoop集群配置的步骤
10、Linux中最基本的shell命令:如cd、cat、rm、cp、mv、source、vim….
📚五、HDFS
1、GFS是什么、HDFS是什么
2、HDFS的体系结构
3、HDFS的存储原理:分块策略和副本策略
4、名称节点、数据节点出错时怎么处理
5、支持三种shell 命令格式:hadoop fs、Hadoop dfs、hdfs dfs
⏳六、MapReduce
1、MapReduce是什么
2、MapReduce的核心思想:
3、MapReduce的体系结构,主从式,了解每个组件的功能
4、Map函数和Reduce函数分别做什么以及MapReduce的工作过程
5、MapReduce适合做哪类任务,它的优缺点
⏲️七、HBase
1、HBase是什么,和Bigtable底层技术的对应关系
2、Hbase与Hadoop其他组件的关系
3、Hbase的数据模型,数据模型中各概念的含义,能够举出例子(参考ppt中)
4、Hbase和传统关系数据库的区别
5、region是什么
6、HBase Shell常用命令
🧧八、NoSQL数据库、云数据库
1、NoSQL的含义
2、了解NoSQL数据库兴起的原因
3、NoSQL数据库的四大类型
4、CAP理论
5、BASE
6、强一致性、弱一致性,最终一致性是什么意思
7、知道云数据库是什么,和传统数据库、NoSQL、NewSQL的关系
🎛️九、Hive
1、什么是Hive?
2、了解Hive的工作原理:转换为MapReduce
3、Hive定义的类SQL语言,是什么,可以做什么
4、Hive不需要搭建在Hbase上,Hadoop中其他组件的关系
🎧十、流计算及Storm
1、流计算的概念
2、了解流计算的典型应用场景
3、Storm是典型的流计算系统
🔍一、云计算基础
1、云计算的概念、特点、关键技术
概述(维基百科):云计算是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机和其他设备,它就像我们日常生活中用水和用电一样,按需付费,而无需关心水、电是从何而来的一种资源管理模式。
特点:①资源池弹性可扩张 ②按需提供资源服务 ③网络化的资源接入 ④虚拟化 ⑤可靠性和安全性
关键技术:①虚拟化 ②分布式存储 ③分布式计算 ④多租
2、云计算的分类
按技术路线分为 ①资源整合型 ②资源切分型
3、云计算的部署模式
①公有云 ②私有云 ③混合云 ④社区云
4、云计算的服务模式:IaaS、PaaS、SaaS分别是什么,具体含义要清楚
①IaaS:基础设施即服务
IaaS把计算和存储资源不经封装地直接通过网络以服务的形式提供的用户使用。
IaaS为上层云计算服务提供必要的硬件资源,同时在虚拟化技术的支持下,IaaS层可以实现硬件资源的按需配置,创建虚拟的计算、存储中心,使得其能够把计算单元、存储器、I/O设备、带宽等计算机基础设施,集中起来成为一个虚拟的资源池来对外提供服务(如硬件服务器租用)。
②Paas:平台即服务
PaaS将计算和存储资源经封装后,以某种接口和协议的形式提供给用户调用,资源的使用者不再直接面对底层资源。
PaaS既要为SaaS层提供可靠的分布式编程框架,又要为IaaS层提供资源调度,数据管理,屏蔽底层系统的复杂性等,同时PaaS又将自己的软件研发平台作为一种服务开放给用户。PaaS的关键技术包括并行编程模型、海量数据库、资源调度与监控、超大型分布式文件系统等分布式并行计算平台技术。
③SaaS:软件即服务
SaaS将计算和存储资源封装为用户可以直接使用的应用并通过网络提供给用户,SaaS面向的服务对象为最终用户,用户只是对软件功能进行使用,无需了解任何云计算系统的内部结构,也不需要用户具有专业的技术开发能力。
SaaS 层部署在PaaS和IaaS平台之上,同时用户可以在PaaS平台上开发并部署SaaS服务,SaaS面向的是云计算终端用户,提供基于互联网的软件应用服务。随着网络技术的成熟与标准化,SaaS 应用近年来发展迅速。典型的SaaS 应用包括Google Apps、Salesforce等。
5、物联网的概念
物联网是通过射频识别(RFID)装置、红外感应器、全球定位系统、激光扫描器等信息传感设备,按约定的协议,把任何物品与互联网相连接,进行信息交换和通信,以实现智能化识别、定位、跟踪、监控和管理的一种网络。
6、物联网和云计算、大数据的关系
云计算、大数据和物联网代表了IT领域最新的技术发展趋势,三者既有区别又有联系
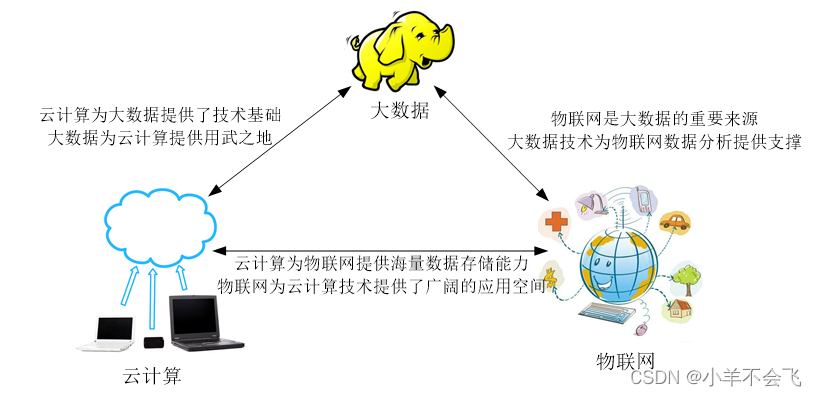
7、了解云计算的数据中心是什么,有什么特点
定义:数据中心是用于存放计算机系统和与之配套的网络、存储等设备的综合系统,数据中心需要具备冗余的数据通信连接、环境控制设备、监控设备以及各种安全装置。
特点:大规模、高密度、低成本、绿色化、自动化、容灾方式
8、主流云计算平台的主要云产品名称及作用
亚马逊(EC2、S3、EBS、SimpleDB等)
①Amazon的云计算平台弹性计算云EC2(elastic compute cloud)可以为用户或开发人员提供一个虚拟的集群环境,既满足了小规模软件开发人员对集群系统的需求,减小维护的负担,又有效解决了设备闲置的问题
②Amazon的S3云存储服务
Google(App Engine,Picasa)
①App Engine 是基于Google数据中心的开发、托管Web应用程序的平台。通过该平台,程序开发者可以构建规模可扩展的Web应用程序,而不用考虑底硬件基础设施的管理。
②Google的Picasa相册
③Google Apps也是主流的协作云产品
微软(SkyDrive)
①SkyDrive网络硬盘
🔦二、大数据基础
1、常用的数据计量单位及其换算
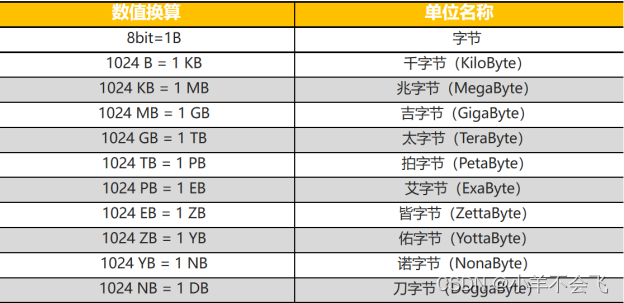
2、大数据的概念,了解大数据的来源及其多样性
概念:维基(Wiki)百科给出的大数据概念是:在信息技术中,“大数据”是指一些使用目前现有数据库管理工具或者传统数据处理应用很难处理的大型而复杂的数据集。其挑战包括采集、管理、存储、搜素、共享、分析和可视化。
来源:随着人类活动的进一步扩展,数据规模急剧膨胀,包括金融、汽车、零售、餐饮、电信、能源、政务、医疗、体育、娱乐等在内的各行业累积的数据量越来越大,数据类型也越来越多、越来越复杂,已经超越了传统数据管理系统、处理模式的能力范围,于是“大数据”这样一个概念才会应运而生。
多样性:大数据的信息量是海量的,这个海量并不是某个时间端点的量级总结,而是持续更新,持续增量。由于大数据产生的过程中诸多的不确定性,使得大数据的表现形态多种多样。
3、大数据的5V特征
大体量(Volume)。需要采集、处理、传输的数据容量大,数据量可从数百TB到数百PB甚至EB的规模。
多样化(Variety)。大数据所处理的数据类型早已不是单一的文本数据或者结构化的数据库中的表,而是包括各种格式和形态的数据,数据结构种类多,复杂性高。
时效性(Velocity)。很多大数据需要在一定时间限度下得到及时处理,处理数据的效率决定企业的生命。
准确性(Veracity)。大数据处理的结果要保证一定的准确性。
大价值(Value)。大数据包含很多深度的价值,通过强大的机器学习和高级分析对数据进行“提纯”,能够带来巨大商业价值。
4、科学研究的4个范式
①实验 ②理论 ③计算 ④数据
5、大数据对思维方式的影响
①全样而非抽样 ②效率而非精确 ③相关而非因果
6、大数据的处理流程
(数据采集、数据存储与管理、数据处理与分析、数据呈现)
①数据采集 ②数据存储与管理 ③数据处理与分析 ④数据呈现
7、大数据的关键技术
①分布式存储
②分布式处理
8、主要的大数据处理系统及代表产品
①批处理系统:Hadoop、Spark
②数据查询分析计算系统:HBase、Hive、Cassandra、Dremel、Spark、Hana
③流计算系统:Facebook的Scribe、Apache的Flume、Twitter的Storm、Yahoo的S4、UCBerkeley的Spark Streaming
④迭代计算系统:Haloop、iMapReduce、Twister、Spark
⑤图计算系统:Google公司的Pregel、Pregel的开源版本Giraph、微软的Trinity、Berkeley AMPLab的GraphX以及高速图数据处理系统PowerGraph。
⑥内存计算系统:分布式内存计算系统Spark、全内存式分布式数据库系统Hana、Google的可扩展交互式查询系统Dremel。
9、云计算之父、大数据之父
云计算之父—约翰·麦卡锡(John McCarthy)
大数据之父—吉姆·格雷(Jim Gray)
🔑三、虚拟化与容器技术
1、虚拟化的概念、特征
概念:
广义地定义虚拟化技术:虚拟化技术就是一种逻辑简化技术,实现物理层向逻辑层的变化。
特征:
①分区:在单一物理服务器上同时运行多个虚拟机
②隔离:在同一服务器上的虚拟机之间相互隔离
③封装:虚拟机以文件夹方式保持,可以转换成.ovf/ova的文件来移动和复制该虚拟机
④相对于硬件独立:无需修改即可在任何服务器上运行虚拟机
2、虚拟化的好处
虚拟化平台效益:减少服务器总体数量;减少网口和网络设备总体数量;节省存储空间;节省机房、机柜空间;提高系统管理员工作效率
提高运维效率:降低运行成本、提高服务水平
3、虚拟化的分类:从计算体系结构层次上分为哪几类
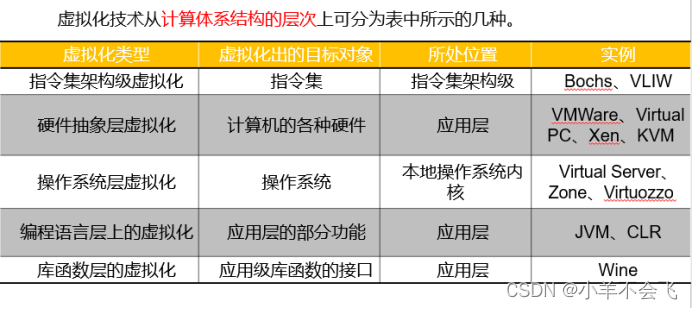
4、系统虚拟化是什么
概念:系统虚拟化是在一台物理计算机系统上虚拟出一台或多台虚拟计算机系统。虚拟计算机系统(简称虚拟机)是指使用虚拟化技术运行在一个隔离环境中的具有完整硬件功能的逻辑计算机系统,包括操作系统和应用程序。
分类:服务器虚拟化、桌面虚拟化、网络虚拟化
5、服务器虚拟化的关键技术哪三个
服务器虚拟化的关键技术是对CPU、内存、I/O硬件资源的虚拟化。
6、知道常用的虚拟化软件有哪些
VirtualBox、VMware Workstation、KVM、Xen、OpenVZ
7、虚拟化和容器的区别

8、Docker是什么,技术支柱是什么,容器、镜像、仓库三个基本概念
概念:
- Docker是dotCloud公司的一个开源项目,诞生于 2013 年初,基于 Go 语言实现,并遵从Apache 2.0协议,基于容器技术的轻量级虚拟化解决方案。
- Docker是容器引擎,把Linux的cgroup、namespace等容器底层技术进行封装抽象,为用户提供了创建和管理容器的便捷界面(包括命令行和API)。
- Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
技术支柱:Namespaces、Control Groups、UnionFS
三个基本概念:
容器:类似于从模板中创建虚拟机;容器是从镜像创建的运行实例。它可以被启动、开始、停止、删除。每个容器都是相互隔离的;可以把容器看做是一个简易版的 Linux 环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。
镜像:Docker 的镜像类似虚拟机的模板,但是更轻量;一个镜像可以包含一个完整的 Linux 操作系统环境,里面仅安装了 Tomcat;镜像可以用来创建容器
仓库:仓库是集中存放镜像文件的场所;仓库注册服务器上往往存放着多个仓库,每个仓库中又包含了多个镜像,每个镜像有不同的标签;仓库分为公开仓库(Public)和私有仓库(Private)两种形式;push镜像到仓库,从仓库pull镜像
📑四、Hadoop
1、Hadoop是什么
概念:Hadoop是一种处理大数据的分布式软件框架,具有可靠、高效、扩展、低成本、兼容性等特点。Hadoop擅长于在廉价机器搭建的集群上进行海量数据(结构化与非结构化)的存储与离线处理。
2、Hadoop的核心组件有什么
三大核心组件:
HDFS(Hadoop Distribute File System):hadoop的数据存储工具。
YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器。
Hadoop MapReduce:分布式计算框架
3、Hadoop和Google三驾马车的关系
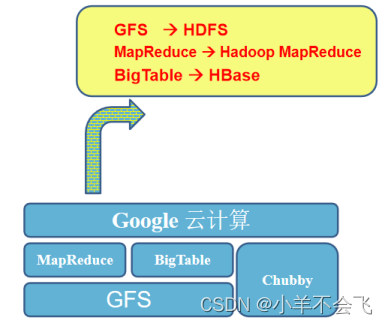
相当于衍生出来的HDFS、Hadoop MapReduce、HBase都是Google三驾马车的山寨版
4、Hadoop的优点
①高可靠性 ②高扩展性 ③高效性 ④高容错性 ⑤低成本
5、知道Hadoop生态系统中主要的项目名称及作用
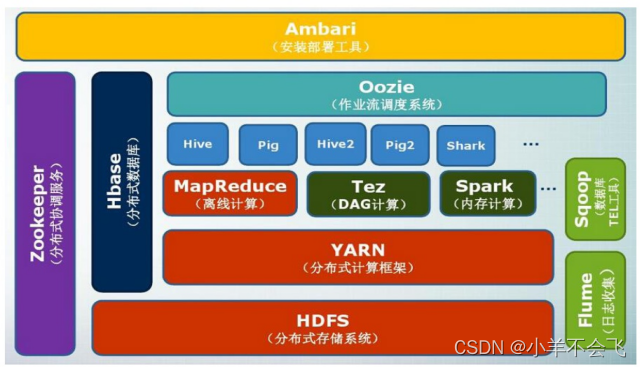
6、Hadoop2.0中加入Yarn的原因
为了实现一个Hadoop集群的集群共享、可伸缩性和可靠性。
7、Hadoop的三种安装模式
单机模式:只在一台机器上运行,存储采用本地文件系统,没有采用分布式文件系统HDFS;
伪分布式模式:存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上;
分布式模式:存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。
8、Hadoop集群配置的步骤
1、选定一台机器作为 Master;
2、在Master节点上创建hadoop用户、安装SSH服务端、安装Java环境;
3、在Master节点上安装Hadoop,并完成配置;
4、在其他Slave节点上创建hadoop用户、安装SSH服务端、安装Java环境;
5、将Master节点上的“/usr/local/hadoop”目录复制到其他Slave节点;
6、在Master节点上开启Hadoop;
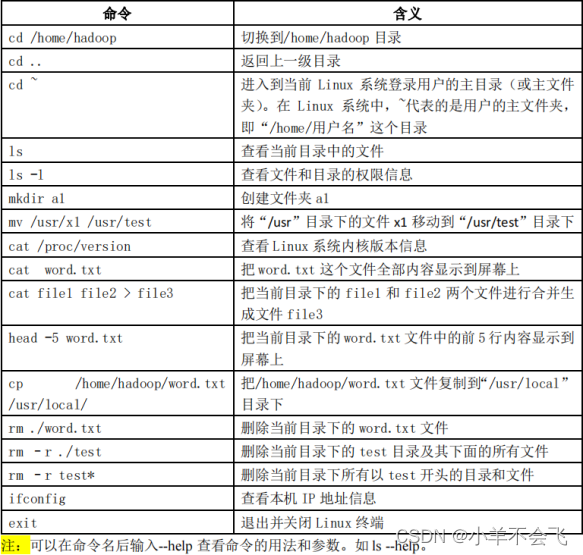
10、Linux中最基本的shell命令:如cd、cat、rm、cp、mv、source、vim….
cd:打开目录
cat:查看文件内容
rm:删除
cp:复制文件
mv:移动文件,相当于剪切
source:读取并执行文件中的命令
vim:编辑文本
📚五、HDFS
1、GFS是什么、HDFS是什么
GFS:Google文件系统(GFS)Google文件系统是一个可扩展的分布式文件系统,用于对大量数据进行访问的大型、分布式应用。GFS是一种面向不可信服务器节点而设计的文件系统。
HDFS:Hadoop的文件系统称为HDFS(Hadoop Distributed File System)。
2、HDFS的体系结构
NameNode:Master节点,在hadoop1.X中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。
DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
Secondary NameNode:辅助NameNode,分担其工作量;定期合并fsimage和fsedits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
工作过程:
①用户请求创建文件的指令由Namenode进行接收。
②Namenode将存储数据的Datanode的IP返回给用户,并通知其他接收副本的Datanode,由用户直接与Datanode进行数据传送。
3、HDFS的存储原理:分块策略和副本策略
分块策略:一个文件被分成多个块,以块作为存储单位。数据块会被分别存储在不同的Datanode节点上
副本策略:HDFS对数据块典型的副本策略为3个副本,第一个副本存放在本地节点,第二个副本存放在同一个机架的另一个节点,第三个本副本存放在不同机架上的另一个节点。
4、名称节点、数据节点出错时怎么处理
HDFS设置了备份机制,把这些核心文件备份到SecondaryNameNode上。当名称节点出错时,就可以根据SecondaryNameNode中的FsImage和Editlog数据进行恢复。
名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本。
5、支持三种shell 命令格式:hadoop fs、Hadoop dfs、hdfs dfs
hadoop fs:适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs:只能适用于HDFS文件系统
hdfs dfs:跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
⏳六、MapReduce
1、MapReduce是什么
分布式计算框架MapReduce是Google系统和Hadoop系统中的一项核心技术。
2、MapReduce的核心思想:
分而治之
3、MapReduce的体系结构,主从式,了解每个组件的功能
1)Client:
用户编写的MapReduce程序通过Client提交到JobTracker端。
用户可通过Client提供的一些接口查看作业运行状态。
2)JobTracker:
JobTracker负责资源监控和作业调度。
JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点。
JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源。
3)TaskTracker:
TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用。
4)Task:
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动。
4、Map函数和Reduce函数分别做什么以及MapReduce的工作过程
(切分、map、shuffle、reduce,四步大致)
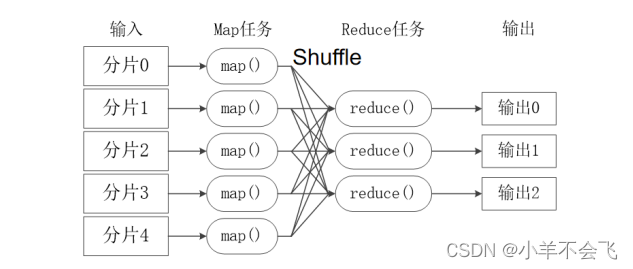
Map:
InputFormat根据输入文件产生键值对,并传送到map函数中;
map输出键值对到一个没有排序的缓冲内存中;
当缓冲内存达到给定值或者map任务完成,在缓冲内存中的键值对就会被排序,然后输出到磁盘中的溢出文件;
如果有多个溢出文件,那么就会整合这些文件到一个文件中,且是排序的;
这些排序过的、在溢出文件中的键值对会等待Reducer的获取。
Reduce:
Reducer获取Mapper的记录;
shuffle相同的key被传送到同一个的Reducer中;
当有一个Mapper完成后,Reducer就开始获取相关数据,所有的溢出文件; 会被排序到一个内存缓冲区中;
当内存缓冲区满了后,就会产生溢出文件到本地磁盘;
当Reducer所有相关的数据都传输完成后,所有溢出文件就会被整合和排序;
Reducer中的reduce方法针对每个key调用一次;
Reducer的输出到HDFS。
5、MapReduce适合做哪类任务,它的优缺点
特点:
1)需要在集群条件下使用。
2)需要有相应的分布式文件系统的支持。
3)不需要特别的硬件支持。
4)假设节点的失效为正常情况。
5)适合对大数据进行处理。
6)计算向存储迁移。
7)MapReduce的计算效率会受最慢的Map任务影响
优点:
MapReduce易于编程
良好的扩展性
廉价、容错性高
适合海量数据的离线处理
缺点:
不擅长实时计算
不擅长流式计算
不擅长图计算
⏲️七、HBase
1、HBase是什么,和Bigtable底层技术的对应关系
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。
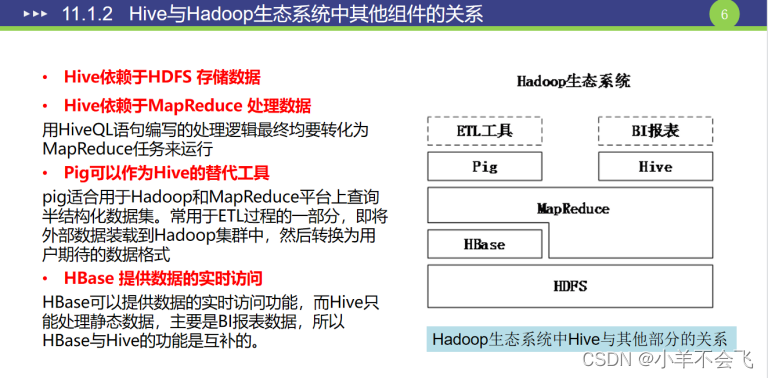
2、Hbase与Hadoop其他组件的关系
HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持,MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持。Sqoop则为HBase提供了方便的关系数据库管理系统数据导入功能。
3、Hbase的数据模型,数据模型中各概念的含义,能够举出例子(参考ppt中)
表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
列族:一个HBase表被分组成许多“列族”(Column Family),它是基本的访问控制单元
列限定符(列):一个列族可以有多个列,列族里的数据通过列限定符来定位
单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
4、Hbase和传统关系数据库的区别

5、region是什么
元数据表,又名.META.表,存储了Region和Region服务器的映射关系
Region是分布式存储的最小单元
6、HBase Shell常用命令
create:创建表
put:向表、行、列指定的单元格添加数据
list:列出HBase中所有的表信息
put:向表、行、列指定的单元格添加数据
drop:删除表
🧧八、NoSQL数据库、云数据库
1、NoSQL的含义

2、了解NoSQL数据库兴起的原因
关系数据库已经无法满足Web2.0的需求
(1)无法满足海量数据的管理需求
(2)无法满足数据高并发的需求
(3)无法满足高可扩展性和高可用性的需求
3、NoSQL数据库的四大类型

4、CAP理论
C(Consistency):一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的,或者说,所有节点在同一时间具有相同的数据。
A:(Availability):可用性,是指快速获取数据,可以在确定的时间内返回操作结果,保证每个请求不管成功或者失败都有响应。
P(Tolerance of Network Partition):分区容忍性,是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行,也就是说,系统中任意信息的丢失或失败不会影响系统的继续运作。
CAP指出,一个分布式系统不可能同时能满足一致性(Consistency)、可用性(Availability)和分区容错性(Partion Tolerance)这3个要求,最多同时满足其中2个。
5、BASE
BASE的基本含义是基本可用(Basically Availble)、软状态(Soft-state)和最终一致性(Eventual consistency)
6、强一致性、弱一致性,最终一致性是什么意思
强一致性:强一致性系统会在所有副本都完全相同后才返回,系统在未达到一致时是不能访问的,强一致性能保证所有的访问结果是一致的。
弱一致性:弱一致性系统中的数据更新后,后续对数据的读取操作得到的不一定是更新后的值。
最终一致性:最终一致性允许系统在实现一致性前有一个不一致的窗口期,窗口期完成后系统最终能保证一致性。
7、知道云数据库是什么,和传统数据库、NoSQL、NewSQL的关系
概念:云数据库是部署和虚拟化在云计算环境中的数据库。它极大地增强了数据库的存储能力,消除了人员、硬件、软件的重复配置,让软、硬件升级变得更加容易。云数据库具有高可扩展性、高可用性、采用多租形式和支持资源有效分发等特点。
关系:

🎛️九、Hive
1、什么是Hive?
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),是一个可以提供有效、合理、直观组织和使用数据的模型。
2、了解Hive的工作原理:转换为MapReduce
当用户向Hive输入一段命令或查询时,Hive需要与Hadoop交互工作来完成该操作。首先,驱动模块接收该命令或查询。接着,对该命令或查询进行解析编译。然后,由优化器对该命令或查询进行优化计算。最后该命令或查询通过执行器进行执行。执行器通常的任务是启动一个或多个MapReduce任务,有时也不需要启动MapReduce任务,像执行包含*的操作(如select * from 表)时。
3、Hive定义的类SQL语言,是什么,可以做什么
Hive定义了简单的类SQL查询语言,称为QL,它允许熟悉SQL的用户查询数据。用户可以通过编写的HiveQL语句运行MapReduce任务。
4、Hive不需要搭建在Hbase上,Hadoop中其他组件的关系
🎧十、流计算及Storm
1、流计算的概念
实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息
知道流计算的基本处理流程,流计算的处理流程一般包含三个阶段:
数据实时采集
数据实时计算
实时查询服务
2、了解流计算的典型应用场景
流计算是针对流数据的实时计算,可以应用在多种场景中,如Web服务、机器翻译、广告投放、自然语言处理、气候模拟预测等。流计算适合于需要处理持续到达的流数据、对数据处理有较高实时性要求的场景。
应用场景1: 实时分析
应用场景2: 实时交通
3、Storm是典型的流计算系统
Twitter Storm是一个免费、开源的分布式实时计算系统,Storm对于实时计算的意义类似于Hadoop对于批处理的意义,Storm可以简单、高效、可靠地处理流数据,并支持多种编程语言。
Storm框架可以方便地与数据库系统进行整合,从而开发出强大的实时计算系统
Twitter是全球访问量最大的社交网站之一,Twitter开发Storm流处理框架是为了应对其不断增长的流数据实时处理需求。
相关文章:
一文带你快速初步了解云计算与大数据
目录 🔍一、云计算基础 1、云计算的概念、特点、关键技术 2、云计算的分类 3、云计算的部署模式 4、云计算的服务模式:IaaS、PaaS、SaaS分别是什么,具体含义要清楚 5、物联网的概念 6、物联网和云计算、大数据的关系 7、了解云计算的…...
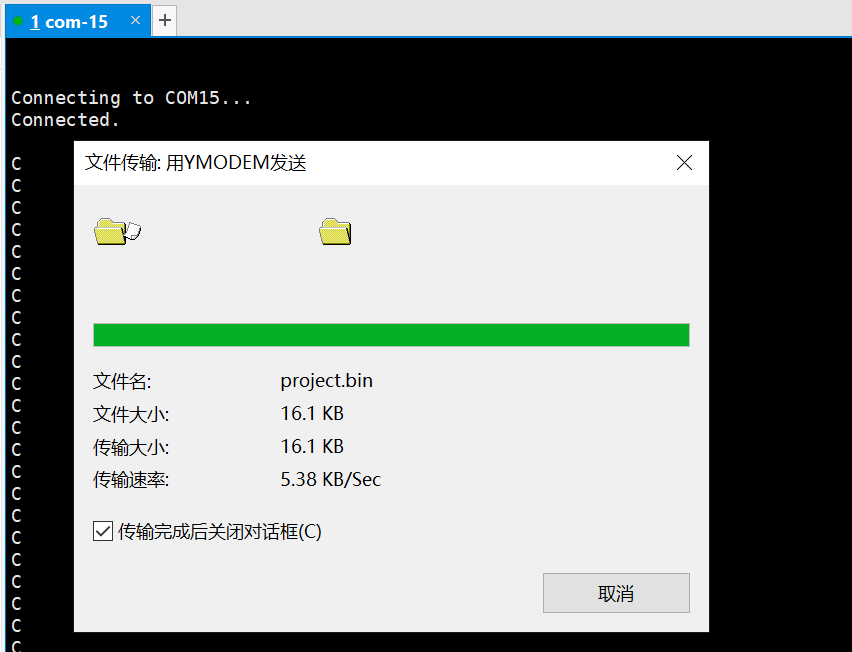
STM32 OTA应用开发——通过USB实现OTA升级
STM32 OTA应用开发——通过USB实现OTA升级 目录STM32 OTA应用开发——通过USB实现OTA升级前言1 环境搭建2 功能描述3 BootLoader的制作4 APP的制作5 烧录下载配置6 运行测试结束语前言 什么是OTA? 百度百科:空中下载技术(Over-the-Air Techn…...

JavaScript高级程序设计读书分享之6章——6.2Array
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 除了 Object,Array 应该就是 ECMAScript 中最常用的类型了。 创建数组 使用 Array 构造函数 在使用 Array 构造函数时,也可以省略 new 操作符。 let colors new Array() let …...
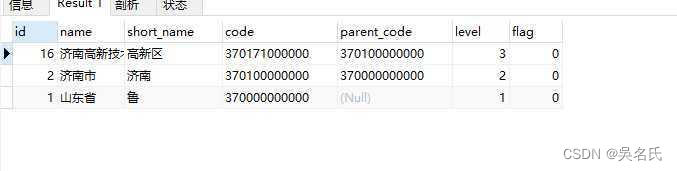
MySQL递归查询 三种实现方式
1 建表脚本1.1 建表DROP TABLE IF EXISTS sys_region; CREATE TABLE sys_region (id int(50) NOT NULL AUTO_INCREMENT COMMENT 地区主键编号,name varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT 地区名称,short_name varchar(50) CHARA…...
:过滤器)
Servle笔记(7):过滤器
1、过滤器的作用与目的 过滤器的目的 在客户端的请求访问后端资源之前,拦截请求在服务器的响应发送回客户端之前,处理响应 2、过滤器的类型 身份验证过滤器(Authentication Filters)数据压缩过滤器(Data compressio…...

2023年:我成了半个外包
边线业务与主线角色被困外包; 012022年,最后一个工作日,裁员的小刀再次挥下; 商务区楼下又多了几个落寞的身影,办公室内又多了几头暴躁的灵魂; 随着裁员的结束,部门的人员结构简化到了极致&am…...

HTTP中GET与POST方法的区别
1. HTTP HTTP即超文本传输协议(Hyper Text Transfer Protocol),是因特网上应用最广的一种协议。 设计目的:保证客户端与服务器之间的通信(发布和接受HTML页面);工作方式:客户端-服务器端的请求-应答协议 …...
使用ChatGPT需要避免的8个错误
如果ChatGPT是未来世界为每个登上新大陆人发放的一把AK47, 那么现在大多数人做的事,就是突突突一阵扫射, 不管也不知道有没有扫射到自己想要的目标。每个人都在使用 ChatGPT。但几乎每个人都停留在新手模式。 避免下面常见的8个ChatGPT的错…...
ELK日志分析--Kibana
Kibana 概述 部署安装浏览页面并使用 1.Kibana 概述 Kibana-是进入Elastic的窗口使用Kibana,可以 1 搜索,观察和保护。 从发现文档到分析日志再到发现安全漏洞,Kibana是您访问这些功能及其他功能的门户。 2 可视化和分析您的数据。 搜索隐藏的…...
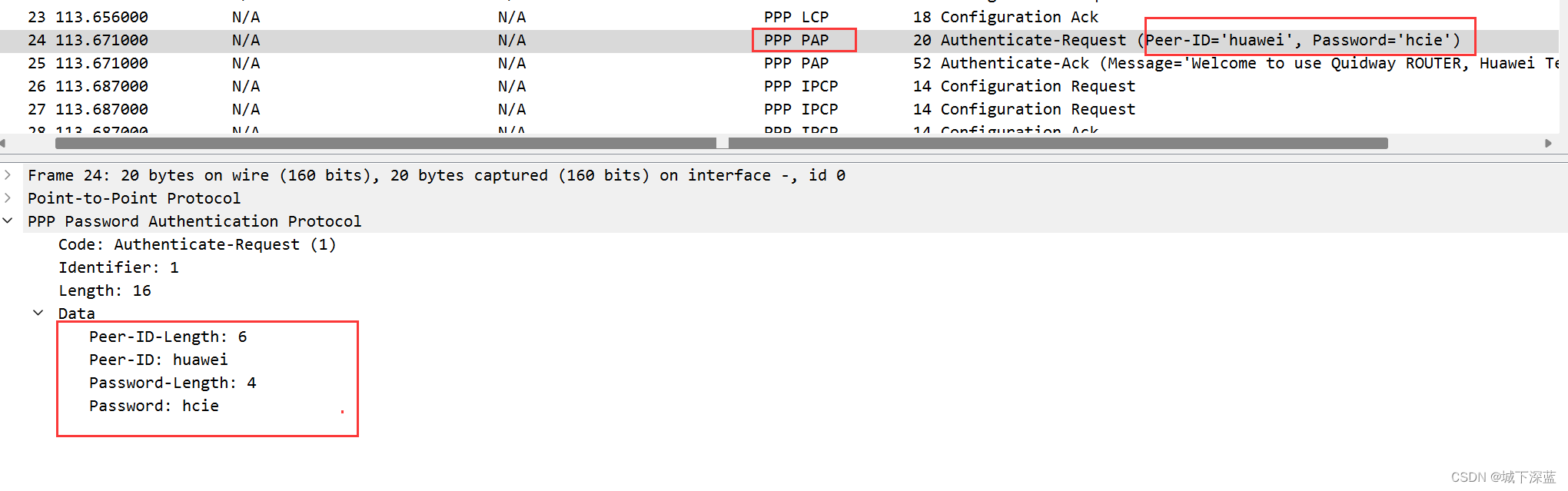
PPP点到点协议认证之PAP认证
PPP点到点协议认证之PAP认证 需求 如图配置接口的IP地址将R1配置为认证端,用户名和密码是 huawei/hcie ,使用的认证方式是pap确保R1和R2之间可以互相ping通 拓扑图 配置思路 确保接口使用协议是PPP确保接口的IP地址配置正确在R1 的端口上,…...
设计模式之建造者模式(C++)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 一、建造者模式是什么? 建造者模式是一种创建型的软件设计模式,用于构造相对复杂的对象。 建造者模式可以…...

linux常见的系统日志
我们了解一下常见的系统日志,知道哪些需要收集 1. /var/log/boot.log linux中/var/log/boot.log是系统启动时的日志,其包括自启动服务。 2. /var/log/btmp linux中/var/log/btmp是记录登录失败信息的日志,是一种非文本文件,可以使…...

支付系统中的设计模式09:组合模式
现在就剩下怎么能够实现运营部提出的「打印出平台顾客购买的商品小票」这个需求了。 我们去超市买完东西之后,都会收到收银员打印出来的小票,就是商品清单、价格、数量和汇总的信息。下面这个我想应该99%的人都见过吧。 图三十七:超市购物小票 线上也是一样,也会有这种购物…...

Linux 文件权限之umask
目录一、文件默认创建权限二、文件默认创建权限掩码三、文件权限的修改本文主要讲解Linux中的文件默认创建权限相关的内容,涉及到的内容有:文件默认创建权限、文件默认创建权限掩码、文件访问权限的修改。 文件访问者共三类:文件所有者、文件…...
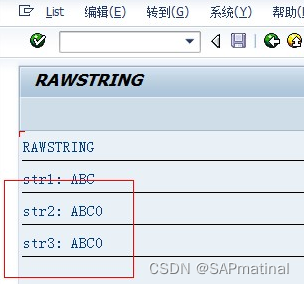
SAP ABAP 理解RAWSTRING(XSTRING) 类型
用F1查看的时候,这里是这样说的: The types RAWSTRING and STRING have a variable length. A maximum length for these types can be specified, but has no upper limit. The type SSTRING is available as of release 6.10 and it has a variable …...

Linux核心技能:2023主流监控Prometheus详解,附官方可复制中文文档教程
Prometheus既是一个时序数据库,又是一个监控系统,更是一套完备的监控生态解决方案。作为时序数据库,目前Prometheus已超越了老牌的时序数据库OpenTSDB、Graphite、RRDtool、KairosDB等,如图所示。 (来源网络࿰…...

金山文档这样玩,效率「狂飙」
1985年,微软发布了第一代的Excel。现在,Excel成为了许多打工人的必备工具,却也在很多人的日常工作中,带来了海量跨表同步、大批数据对齐的日常繁琐工作,逐渐沦为“表哥”“表妹”。多维表,是新一代数据效率…...

【类与对象】封装对象的初始化及清理
C面向对象的三大特性:封装、继承、多态。具有相同性质的对象,抽象为类。 文章目录1 封装1.1 封装的意义(一)1.2 封装的意义(二)1.3 struct 和 class区别1.4 成员属性设置为私有练习案例:1 设计…...

【算法】——并查集
作者:指针不指南吗 专栏:算法篇 🐾或许会很慢,但是不可以停下🐾 文章目录1.思想2.模板3.应用3.1 合并集合3.2 连通块中点的数量1.思想 并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题…...
Python3,为了无损压缩gif动图,我不得不写了一个压缩神器,真香。
gif动图无损压缩1、引言2、代码实战2.1 模块介绍2.2 安装2.3 代码示例3、总结1、引言 小屌丝:鱼哥, 求助~ 求助~ 求助~ 小鱼:你这是告诉我,重要的事情 说三遍吗? 小屌丝:你可以这么理解。 小鱼:…...

商复形持续同调:从晶体周期性拓扑到材料带隙预测的实践
1. 项目概述:当拓扑学遇见材料科学在材料科学,尤其是新兴的二维钙钛矿研究领域,一个核心的挑战是如何从原子坐标这种看似简单的点云数据中,高效、准确地提取出与宏观物理性质(如电子带隙)强相关的特征。传统…...

生成式AI驱动业务流程自动化:从流程挖掘到智能重构
1. 从流程执行到流程创造:生成式AI如何重塑BPM在业务流程管理(BPM)领域摸爬滚打了十几年,我亲眼见证了它从一套僵化的流程图和审批流,演变为一个动态的、数据驱动的智能决策中枢。传统的BPM核心在于“建模-执行-监控-优…...

DS4Windows终极指南:3步让PS4手柄在PC上完美工作
DS4Windows终极指南:3步让PS4手柄在PC上完美工作 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 想要在电脑上使用PS4手柄玩游戏,却总是遇到兼容性问题?…...

IGND算法:融合高斯牛顿法与增量学习的优化新范式
1. IGND算法:当高斯牛顿法遇见增量学习在机器学习的世界里,模型训练的本质就是一场持续的优化之旅。我们手握一个由参数构成的复杂函数,目标是在浩瀚的参数空间中,找到那个能让预测误差最小化的“甜蜜点”。多年来,随机…...

【芯片测试】:6. 向量、Sequencer 指令与高速串行 IO
Pattern 详解:向量、Sequencer 指令与高速串行 IO系列: Advantest V93000 SmarTest 8 核心概念解析|第 6 篇(共 8 篇) 适合读者: 需要理解数字测试激励数据结构的工程师前言 Pattern(模式&#…...

数字-模拟量子机器学习:NISQ时代AI的务实路径
1. 量子机器学习:当AI遇见量子世界最近几年,一个词在科技圈里被反复提及:量子优势。听起来很科幻,对吧?但如果你深入了解一下当前最前沿的量子计算硬件——那些被称为NISQ(含噪声中等规模量子)的…...

昇腾CANN ATB KV Cache 与 PagedAttention:显存碎片消除的完整方案
LLM 推理的最大瓶颈不是计算——是显存。长上下文下,KV Cache 的显存占用是二次增长的:seq_len128K → KV Cache 128K 每层 KV 大小 128K (2 hidden head_num) 128K 2 8192 32 32GB。加上模型参数(70B 2bytes 140GB)…...

黑群晖硬盘满了别慌!手把手教你用SSH命令行扩容,Linux系统也通用
黑群晖存储扩容实战:SSH命令行全流程指南与Linux通用技巧当你发现黑群晖的存储空间亮起红灯时,那种焦虑感我深有体会。去年我的媒体服务器突然报出"存储空间不足"警告,当时存放的4TB家庭影像资料和重要工作备份几乎占满了整个磁盘。…...

AI驱动的高能物理探测器协同优化设计与实践
1. 高能物理探测器设计的范式转变在大型强子对撞机(LHC)时代,探测器设计面临前所未有的挑战。以CMS实验为例,其硅像素跟踪器的材料预算曾引发激烈讨论——虽然40-60%的光子转换概率有助于希格斯玻色子双光子衰变通道的识别&#x…...

Android HTTPS抓包全解:从Charles配置到证书固定绕过
1. 为什么你手机App的HTTPS请求总像黑箱?——从“看不到”到“全透明”的真实起点你有没有过这种经历:在测试一个安卓App时,明明界面上显示加载失败,但Logcat里翻来覆去全是D/OkHttp: <-- HTTP FAILED: java.net.SocketTimeout…...