[Elasticsearch] 邻近匹配 (一) - 短语匹配以及slop参数
本文翻译自Elasticsearch官方指南的Proximity Matching一章。
邻近匹配(Proximity Matching)
使用了TF/IDF的标准全文搜索将文档,或者至少文档中的每个字段,视作"一大袋的单词"(Big bag of Words)。match查询能够告诉我们这个袋子中是否包含了我们的搜索词条,但是这只是一个方面。它不能告诉我们关于单词间关系的任何信息。
考虑以下这些句子的区别:
- Sue ate the alligator.
- The alligator ate Sue.
- Sue never goes anywhere without her alligator-skin purse.
一个使用了sue alligator的match查询会匹配以上所有文档,但是它无法告诉我们这两个词是否表达了部分原文的部分意义,或者是表达了完整的意义。
理解单词间的联系是一个复杂的问题,我们也无法仅仅依靠另一类查询就解决这个问题,但是我们至少可以通过单词间的距离来判断单词间可能的关系。
真实的文档也许比上面几个例子要长的多:Sue和alligator也许相隔了几个段落。也许我们仍然希望包含这样的文档,但是我们会给那些Sue和alligator出现的较近的文档更高的相关度分值。
这就是短语匹配(Phrase Matching),或者邻近度匹配(Proximity Matching)。
TIP
本章中,我们仍然会使用match查询中使用的示例文档。
短语匹配(Phrase Matching)
就像一提到全文搜索会首先想到match查询一样,当你需要寻找邻近的几个单词时,你会使用match_phrase查询:
GET /my_index/my_type/_search
{"query": {"match_phrase": {"title": "quick brown fox"}}
}
和match查询类似,match_phrase查询首先解析查询字符串来产生一个词条列表。然后会搜索所有的词条,但只保留含有了所有搜索词条的文档,并且词条的位置要邻接。一个针对短语quick fox的查询不会匹配我们的任何文档,因为没有文档含有邻接在一起的quick和box词条。
TIP
match_phrase查询也可以写成类型为phrase的match查询:
"match": {"title": {"query": "quick brown fox","type": "phrase"} }
词条位置
当一个字符串被解析时,解析器不仅只返回一个词条列表,它同时也返回每个词条的位置,或者顺序信息:
GET /_analyze?analyzer=standard Quick brown fox
会返回以下的结果:
{"tokens": [{"token": "quick","start_offset": 0,"end_offset": 5,"type": "<ALPHANUM>","position": 1 },{"token": "brown","start_offset": 6,"end_offset": 11,"type": "<ALPHANUM>","position": 2 },{"token": "fox","start_offset": 12,"end_offset": 15,"type": "<ALPHANUM>","position": 3 }]
}
位置信息可以被保存在倒排索引(Inverted Index)中,像match_phrase这样位置感知(Position-aware)的查询能够使用位置信息来匹配那些含有正确单词出现顺序的文档,在这些单词间没有插入别的单词。
短语是什么
对于匹配了短语"quick brown fox"的文档,下面的条件必须为true:
- quick,brown和fox必须全部出现在某个字段中。
- brown的位置必须比quick的位置大1。
- fox的位置必须比quick的位置大2。
如果以上的任何条件没有被满足,那么文档就不能被匹配。
TIP
在内部,match_phrase查询使用了低级的span查询族(Query Family)来执行位置感知的查询。span查询是词条级别的查询,因此它们没有解析阶段(Analysis Phase);它们直接搜索精确的词条。
幸运的是,大多数用户几乎不需要直接使用span查询,因为match_phrase查询通常已经够好了。但是,对于某些特别的字段,比如专利搜索(Patent Search),会使用这些低级查询来执行拥有非常特别构造的位置搜索。
混合起来(Mixing it up)
精确短语(Exact-phrase)匹配也许太过于严格了。也许我们希望含有"quick brown fox"的文档也能够匹配"quick fox"查询,即使位置并不是完全相等的。
我们可以在短语匹配使用slop参数来引入一些灵活性:
GET /my_index/my_type/_search
{"query": {"match_phrase": {"title": {"query": "quick fox","slop": 1}}}
}
slop参数告诉match_phrase查询词条能够相隔多远时仍然将文档视为匹配。相隔多远的意思是,你需要移动一个词条多少次来让查询和文档匹配?
我们以一个简单的例子来阐述这个概念。为了让查询quick fox能够匹配含有quick brown fox的文档,我们需要slop的值为1:
-
Pos 1 Pos 2 Pos 3 -
----------------------------------------------- -
Doc: quick brown fox -
----------------------------------------------- -
Query: quick fox -
Slop 1: quick ↳ fox
尽管在使用了slop的短语匹配中,所有的单词都需要出现,但是单词的出现顺序可以不同。如果slop的值足够大,那么单词的顺序可以是任意的。
为了让fox quick查询能够匹配我们的文档,需要slop的值为3:
-
Pos 1 Pos 2 Pos 3 -
----------------------------------------------- -
Doc: quick brown fox -
----------------------------------------------- -
Query: fox quick -
Slop 1: fox|quick ↵ -
Slop 2: quick ↳ fox -
Slop 3: quick ↳ fox
相关文章:
 - 短语匹配以及slop参数)
[Elasticsearch] 邻近匹配 (一) - 短语匹配以及slop参数
本文翻译自Elasticsearch官方指南的Proximity Matching一章。 邻近匹配(Proximity Matching) 使用了TF/IDF的标准全文搜索将文档,或者至少文档中的每个字段,视作"一大袋的单词"(Big bag of Words)。match查询能够告诉我们这个袋子中是否包含了…...

Bootstrap中让元素尽可能往父容器的左侧靠近或右侧造近(左浮动和右浮动)
在Bootstrap中,float-left是一个用于浮动元素的CSS类。它的作用是将一个元素向左浮动,使其在父容器内尽可能靠近左侧边缘,同时允许其他元素在其右侧排列。 使用float-left类可以创建多列布局,将元素水平排列在一行上,…...
网络流量安全分析-工作组异常
在网络中,工作组异常分析具有重要意义。以下是网络中工作组异常分析的几个关键点: 检测网络攻击:网络中的工作组异常可能是由恶意活动引起的,如网络攻击、病毒感染、黑客入侵等。通过对工作组异常的监控和分析,可以快…...
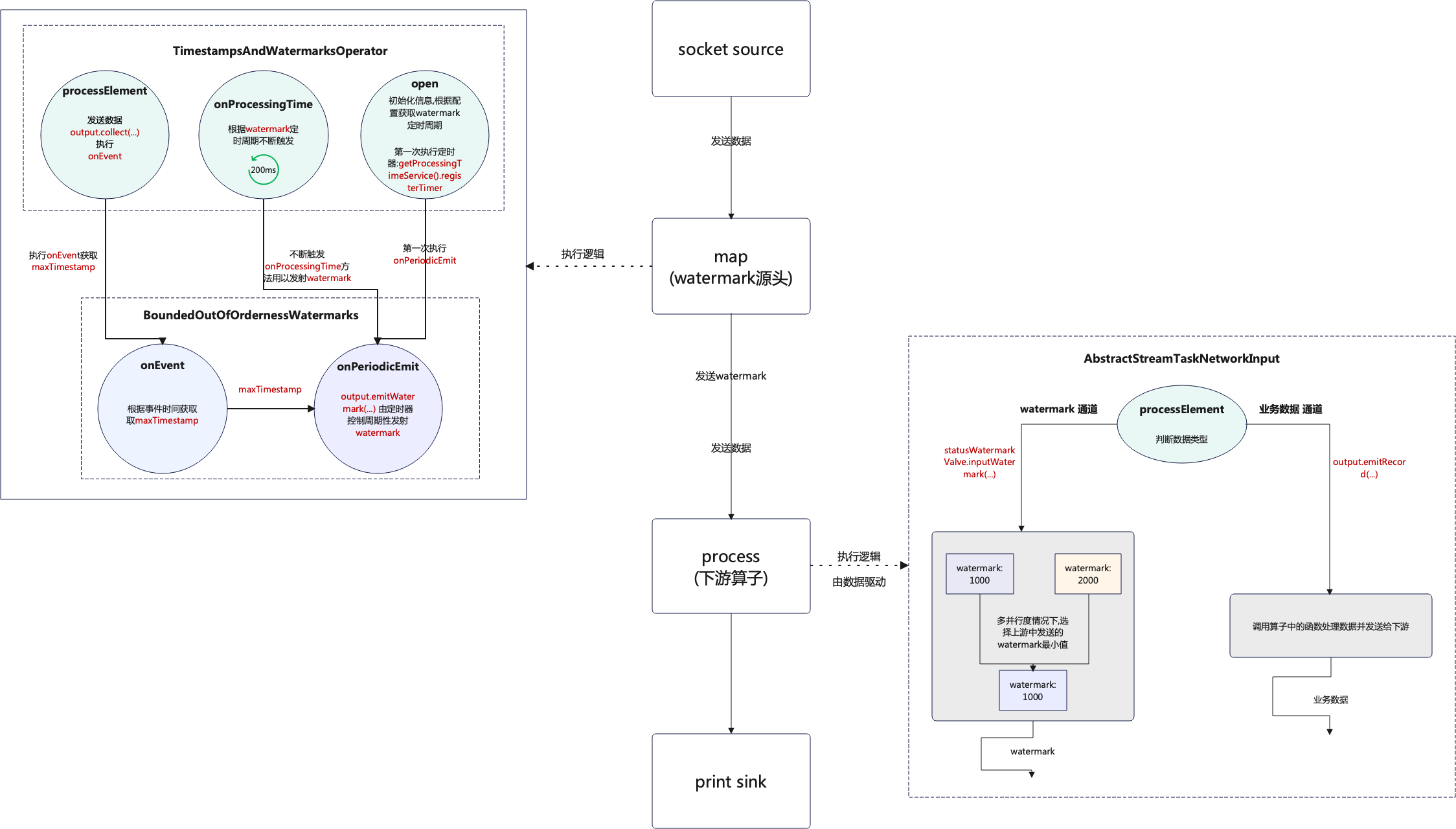
Flink之Watermark源码解析
1. WaterMark源码分析 在Flink官网中介绍watermark和数据是异步处理的,通过分析源码得知这个说法不够准确或者说不够详细,这个异步处理要分为两种情况: watermark源头watermark下游 这两种情况的处理方式并不相同,在watermark的源头确实是异步处理的,但是在下游只是做的判断,这…...
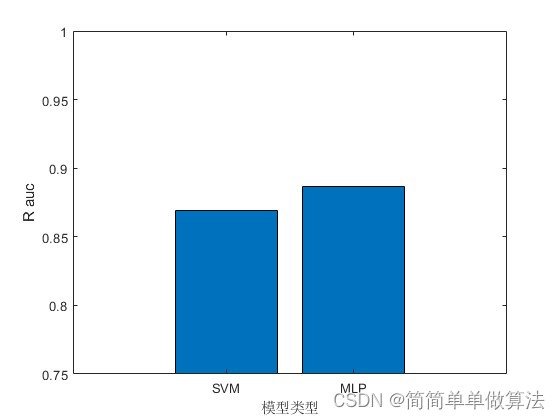
基于支持向量机SVM和MLP多层感知神经网络的数据预测matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 一、支持向量机(SVM) 二、多层感知器(MLP) 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 .…...

【微服务】RedisSearch 使用详解
目录 一、RedisJson介绍 1.1 RedisJson是什么 1.2 RedisJson特点 1.3 RedisJson使用场景 1.3.1 数据结构化存储 1.3.2 实时数据分析 1.3.3 事件存储和分析 1.3.4 文档存储和检索 二、当前使用中的问题 2.1 刚性数据库模式限制了敏捷性 2.2 基于磁盘的文档存储导致瓶…...
第三章 栈、队列和数组
第三章 栈、队列、数组 栈栈的基本概念栈的顺序实现栈的链接实现栈的简单应用和递归 队列队列的基本概念队列的顺序实现队列的链接实现 数组数组的逻辑结构和基本运算数组的存储结构矩阵的压缩存储 小试牛刀 栈和队列可以看作是特殊的线性表,是运算受限的线性表 栈 …...
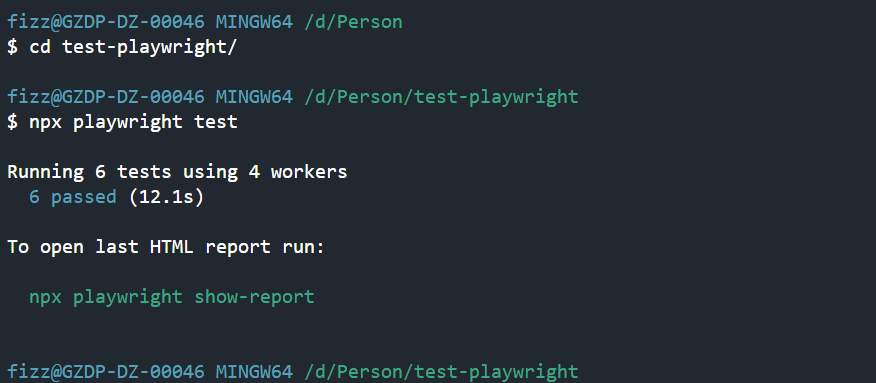
使用GitLab CI/CD 定时运行Playwright自动化测试用例
创建项目并上传到GitLab npm init playwright@latest test-playwright # 一路enter cd test-playwright # 运行测试用例 npx playwright test常用指令 # Runs the end-to-end tests. npx playwright test# Starts the interactive UI mode. npx playwright...

Suricata + Wireshark离线流量日志分析
目录 一、访问一个404网址,触发监控规则 1、使用python搭建一个虚拟访问网址 2、打开Wireshark,抓取流量监控 3、在Suricata分析数据包 流量分析经典题型 入门题型 题目:Cephalopod(图片提取) 进阶题型 题目:抓到一只苍蝇(数据包筛选…...

JMeter基础 —— 使用Badboy录制JMeter脚本!
1、使用Badboy录制JMeter脚本 打开Badboy工具开始进行脚本录制: (1)当我们打开Badboy工具时,默认就进入录制状态。 如下图: 当然我们也可以点击录制按钮进行切换。 (2)在地址栏中输入被测地…...
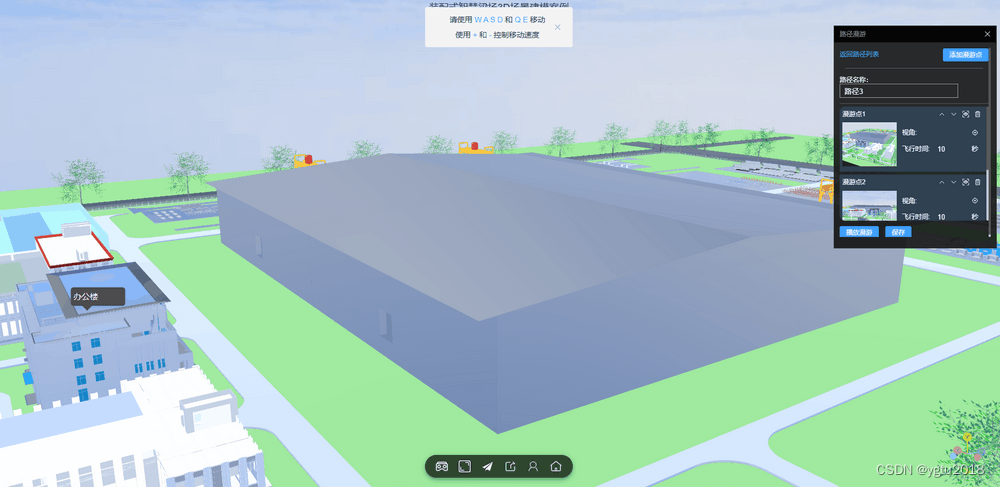
3D孪生场景搭建:3D漫游
上一篇 文章介绍了如何使用 NSDT 编辑器 制作模拟仿真应用场景,今天这篇文章将介绍如何使用NSDT 编辑器 设置3D漫游。 1、什么是3D漫游 3D漫游是指基于3D技术,将用户带入一个虚拟的三维环境中,通过交互式的手段,让用户可以自由地…...

三、综合——计算机应用基础
文章目录 一、计算机概述二、计算机系统的组成三、计算机中数据的表示四、数据库系统五、多媒体技术5.1 多媒体的基本概念5.2 多媒体计算机系统组成5.3 多媒体关键硬件一、计算机概述 1854 年,英国数学家布尔(George Boo1e,1824-1898 年)提出了符号逻辑的思想,数十年后形成了…...
【Redis】SpringBoot整合redis
文章目录 一、SpringBoot整合二、RedisAutoConfiguration自动配置类1、整合测试一下 三、自定义RedisTemplete1、在测试test中使用自定义的RedisTemplete2、自定义RedisTemplete后测试 四、在企业开发中,大部分情况下都不会使用原生方式编写redis1、编写RedisUtils代…...
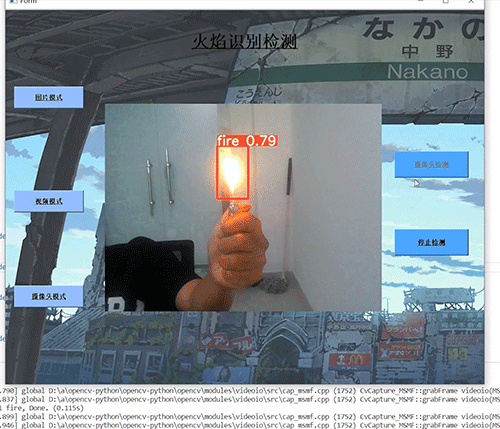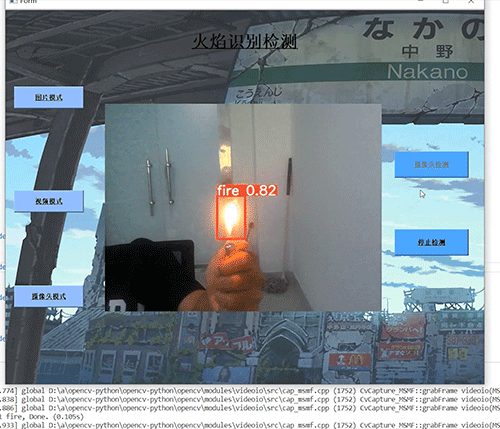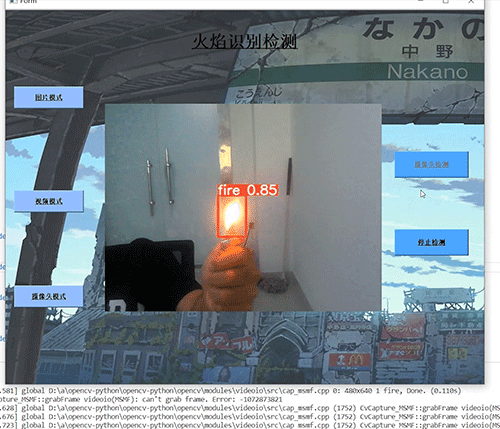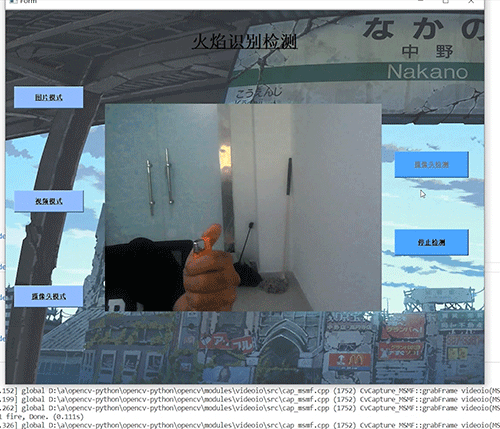
竞赛选题 深度学习 python opencv 火焰检测识别 火灾检测
文章目录 0 前言1 基于YOLO的火焰检测与识别2 课题背景3 卷积神经网络3.1 卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 YOLOV54.1 网络架构图4.2 输入端4.3 基准网络4.4 Neck网络4.5 Head输出层 5 数据集准备5.1 数…...

Python Parser 因子计算性能简单测试
一直以来,Python 都在量化金融领域扮演着至关重要的角色。得益于 Python 强大的库和工具,用户在处理金融数据、进行数学建模和机器学习时变得更加便捷。但作为一种解释性语言,相对较慢的执行速度也限制了 Python 在一些需要即时响应的场景中的…...
【java学习】特殊流程控制语句(8)
文章目录 1. break语句2. continue语句3. return语句4. 特殊流程语句控制说明 1. break语句 break语句用于终止某个语句块的执行,终止当前所在循环。 语法结构: { ...... break; ...... } 例子如下: (1&…...

pyinstaller 使用
python 打包不依赖于系统环境的应用总结 【pyd库和pyinstaller可执行程序的区别: 在实际开发中,对于多人协作的大型项目, 或者是基于支持Python的商业软件的二次开发等, 如果将py脚本打包成exe可执行文件,不仅不方便调用ÿ…...

ELK集群 日志中心集群
ES:用来日志存储 Logstash:用来日志的搜集,进行日志格式转换并且传送给别人(转发) Kibana:主要用于日志的展示和分析 kafka Filebeat:搜集文件数据 es-1 本地解析 vi /etc/hosts scp /etc/hosts es-2:/etc/hosts scp /etc…...

有哪些适合初级程序员看的书籍?
1、《C Primer Plus》(中文版名《C Primer Plus(第五版)》) 作者:Stephen Prata 该书以C语言为例,详细介绍了编程语言的基础知识、控制结构、函数、指针、数组、字符串、结构体等重要概念。并且࿰…...
)
uniapp iosApp H5+本地文件操作(写入修改删除等)
h5 地址 html5plus 以csv文件为例,写入读取保存修改删除文件内容,传输文件等 1.save 文件保存 function saveCsv(data,pathP,path){// #ifdef APP-PLUSreturn new Promise((resolve, reject) > {plus.io.requestFileSystem( plus.io.PUBLIC_DOCUMEN…...
)
告别点灯:用STM32+FPGA+FSMC做个数据吞吐测试仪(附Quartus与标准库工程)
STM32与FPGA联袂打造:高性能数据吞吐测试仪实战指南 在嵌入式系统开发中,总线通信性能往往是决定整体系统响应速度的关键瓶颈。对于硬件爱好者、电子工程师和学生群体而言,如何直观测量和优化总线传输效率,是一个既具挑战性又充满…...

高效AI专著生成:20万字专著一键搞定,AI写专著工具实测推荐!
学术专著写作挑战与AI工具助力 对于初次尝试编写学术专著的研究者来说,写作过程就像是在“摸索着走过一条未知的小路”,处处都有挑战等待着他们。在选题上常常感到迷惘,难以在“有意义”与“可操作性”之间找到合适的平衡:有的研…...

如何彻底解决C盘空间不足问题:Windows Cleaner开源工具终极指南
如何彻底解决C盘空间不足问题:Windows Cleaner开源工具终极指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾因C盘爆红而束手无策…...

AdvancedLiterateMachinery的LORE-TSR:逻辑位置回归网络在表格结构识别中的突破
AdvancedLiterateMachinery的LORE-TSR:逻辑位置回归网络在表格结构识别中的突破 【免费下载链接】AdvancedLiterateMachinery A collection of original, innovative ideas and algorithms towards Advanced Literate Machinery. This project is maintained by the…...

dropin-minimal-css框架质量评估标准:如何选择最适合的CSS框架
dropin-minimal-css框架质量评估标准:如何选择最适合的CSS框架 【免费下载链接】dropin-minimal-css Drop-in switcher for previewing minimal CSS frameworks 项目地址: https://gitcode.com/gh_mirrors/dr/dropin-minimal-css 在当今前端开发的世界中&…...

ncmdumpGUI:解锁网易云音乐ncm加密格式的图形化解决方案
ncmdumpGUI:解锁网易云音乐ncm加密格式的图形化解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐的世界里,格式兼容性…...

如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案
如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否为WeMod免费版的诸多限制感到…...
软件?|应用现状以及发展趋势)
什么制造业电子数据交换(EDI)软件?|应用现状以及发展趋势
一、什么是电子数据交换(EDI)软件电子数据交换(EDI),是制造企业之间按照行业标准,自动完成业务数据传输的数字化工具。EDI软件能够将订单、预测、发货、发票、物料主数据等信息,在企业ERP、MES、…...

手把手教你写JS逆向通用模板:一键提取加密参数
在JS逆向实战中,你一定遇到过这种情况:同一个网站,换个接口就要重新扣代码、调环境、处理依赖;换个网站,又要从头再来一遍,重复劳动浪费大量时间。 其实90%的JS逆向场景,都可以用一套通用模板搞定。不管是MD5/SHA1签名、AES/RSA加密、还是混淆后的动态加密函数,这套模…...

3步深度解决方案:彻底修复Krita AI Diffusion插件IP-Adapter缺失问题
3步深度解决方案:彻底修复Krita AI Diffusion插件IP-Adapter缺失问题 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: h…...