信息增益,经验熵和经验条件熵——决策树
目录
1.经验熵
2.经验条件熵
3.信息增益
4.增益比率
5.例子1
6.例子2
在决策树模型中,我们会考虑应该选择哪一个特征作为根节点最好,这里就用到了信息增益
通俗上讲,信息增益就是在做出判断时,该信息对你影响程度的大小。比如你今天考虑要不要去郊游,你会考虑天气,距离,心情,是否空闲等等因素,非常纠结,但是如果信息中的天气显示今天暴雨,那大概率就不郊游了,那这个因素的信息增益就很强。

1.经验熵
Info(D)=-Σi=1...n(pilog2pi)
比如我们将一个立方体A抛向空中,记落地时着地的面为f1,f1的取值为{1,2,3,4,5,6},f1的熵entropy(f1)=-(1/6*log(1/6)+...+1/6*log(1/6))=-1*log(1/6)=2.58
- 信息熵描述随机变量的不确定性。
- 信息熵越小,信息的纯度越高,信息量就越少。
- 信息熵越大,信息的纯度越小,信息量就越多。
2.经验条件熵
在某一条件下,随机变量的不确定性。假设我们选择属性R作为分裂属性,数据集D中,R有k个不同的取值{V1,V2,...,Vk},于是可将D根据R的值分成k组{D1,D2,...,Dk},按R进行分裂后,将数据集D不同的类分开还需要的信息量为:
InfoR(D)=Σi=1...k(Di/D)Info(Di)
3.信息增益
在某一条件下,随机变量不确定性减少的程度。换句话说,信息增益代表了在一个条件下,信息复杂度(不确定性)减少的程度。那么我们现在也很好理解了,在决策树算法中,我们的关键就是每次选择一个特征,特征有多个,那么到底按照什么标准来选择哪一个特征。这个问题就可以用信息增益来度量。如果选择一个特征后,信息增益最大(信息不确定性减少的程度最大),那么我们就选取这个特征。
分裂前后,两个信息量只差:
Gain(R)=Info(D)-InfoR(D)
4.增益比率
信息增益选择方法有一个很大的缺陷,它总是会倾向于选择属性值多的属性,如果我们在上面的数据记录中加一个姓名属性,假设14条记录中的每个人姓名不同,那么信息增益就会选择姓名作为最佳属性,因为按姓名分裂后,每个组只包含一条记录,而每个记录只属于一类(要么购买电脑要么不购买,信息量计算为1/14(-1/1log1/1-0/1log0/1)*14=0,信息增益最大),因此纯度最高,以姓名作为测试分裂的结点下面有14个分支。但是这样的分类没有意义,它没有任何泛化能力。增益比率对此进行了改进,它引入一个分裂信息:
SplitInfoR(D)=-Σi=1...n(Di/D)log2(Di/D)
增益比率定义为信息增益与分裂信息的比率:
GainRatio(R)=Gain(R)/SplitInfoR(D)
我们找GainRatio最大的属性作为最佳分裂属性。如果一个属性的取值很多,那么SplitInfoR(D)会大,从而使GainRatio(R)变小。
不过增益比率也有缺点,SplitInfo(D)可能取0,此时没有计算意义;且当SplitInfo(D)趋向于0时,GainRatio(R)的值变得不可信,改进的措施就是在分母加一个平滑,这里加一个所有分裂信息的平均值:
GainRatio(R)=Gain(R)/(SplitInfo(D)+SplitInfoR(D))
5.例子1
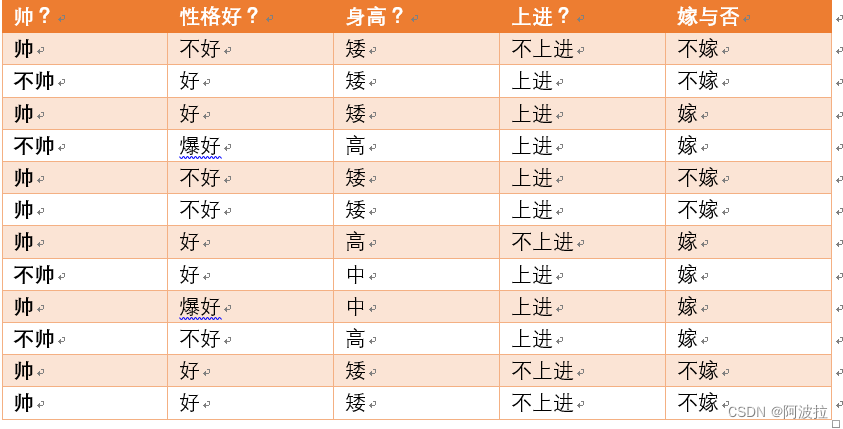
对于上述信息,可以求得随机变量X(嫁与不嫁)的信息熵为:
嫁的个数为6个,占1/2,那么信息熵为-1/2log1/2-1/2log1/2 = -log1/2=0.301
现在假如我知道了一个男生的身高信息。
身高有三个可能的取值{矮,中,高}
矮包括{1,2,3,5,6,11,12},嫁的个数为1个,不嫁的个数为6个
中包括{8,9} ,嫁的个数为2个,不嫁的个数为0个
高包括{4,7,10},嫁的个数为3个,不嫁的个数为0个
先回忆一下条件熵的公式如下:
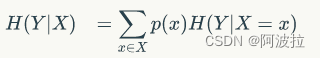
我们先求出公式对应的:
H(Y|X = 矮) = -1/7log1/7-6/7log6/7=0.178
H(Y|X=中) = -1log1-0 = 0
H(Y|X=高) = -1log1-0=0
p(X = 矮) = 7/12,p(X =中) = 2/12,p(X=高) = 3/12
则可以得出条件熵为:7/120.178+2/120+3/12*0 = 0.103
那么我们知道信息熵与条件熵相减就是我们的信息增益,为0.301-0.103=0.198
所以我们可以得出我们在知道了身高这个信息之后,信息增益是0.198
我们可以知道,本来如果我对一个男生什么都不知道的话,作为他的女朋友决定是否嫁给他的不确定性有0.301这么大。
当我们知道男朋友的身高信息后,不确定度减少了0.198.也就是说,身高这个特征对于我们广大女生同学来说,决定嫁不嫁给自己的男朋友是很重要的。
至少我们知道了身高特征后,我们原来没有底的心里(0.301)已经明朗一半多了,减少0.198了(大于原来的一半了)。
那么这就类似于非诚勿扰节目里面的桥段了,请问女嘉宾,你只能知道男生的一个特征。请问你想知道哪个特征。
假如其它特征我也全算了,信息增益是身高这个特征最大。那么我就可以说,我想知道男嘉宾的一个特征是身高特征。因为它在这些特征中,信息增益是最大的,知道了这个特征,嫁与不嫁的不确定度减少的是最多的。
来源:信息增益到底怎么理解呢?_南湖渔歌的博客-CSDN博客
6.例子2
| 记录ID | 年龄 | 收入层次 | 学生 | 信用等级 | 是否购买电脑 |
| 1 | 青少年 | 高 | 否 | 一般 | 否 |
| 2 | 青少年 | 高 | 否 | 良好 | 否 |
| 3 | 中年 | 高 | 否 | 一般 | 是 |
| 4 | 老年 | 中 | 否 | 一般 | 是 |
| 5 | 老年 | 低 | 是 | 一般 | 是 |
| 6 | 老年 | 低 | 是 | 良好 | 否 |
| 7 | 中年 | 低 | 是 | 良好 | 是 |
| 8 | 青少年 | 中 | 否 | 一般 | 否 |
| 9 | 青少年 | 低 | 是 | 一般 | 是 |
| 10 | 老年 | 中 | 是 | 一般 | 是 |
| 11 | 青少年 | 中 | 是 | 良好 | 是 |
| 12 | 中年 | 中 | 否 | 良好 | 是 |
| 13 | 中年 | 高 | 是 | 一般 | 是 |
| 14 | 老年 | 中 | 否 | 良好 | 否 |
1:计算Info(D)
Info(D)=-Σi=1...n(pilogpi)=-(5/14)log(5/14)-(9/14)log(9/14)=-0.3571*(-1.4856)-0.6429*(-0.6373)=0.1597+0.1234=0.5305+0.4097=0.9402
2:计算InfoR(D)
Info年龄(D)=(5/14)Info(D老年)+(4/14)Info(D中年)+(5/14)Info(D青少年)=(5/14)(-(3/5)log(3/5)-(2/5)log(2/5))+(4/14)(-(4/4)log(4/4)-(0/4)log(0/4))+(5/14)(-(2/5)log(2/5)-(3/5)log(3/5))
=(5/14)(0.6*0.737+0.4*1.3219)+(4/14)(0+0)+(5/14)(0.4*1.3219+0.6*0.737)
=(5/14)(0.4422+0.52876)+0+(5/14)(0.52876+0.4422)
=0.3571*0.97096+0+0.3571*0.97096
=0.694
同样可以计算出
Info收入层次(D)=0.911
Info学生(D)=0.789
Info信用等级(D)=0.892
3:计算信息增益:
Gain(年龄)=Info(D)-Info年龄(D)=0.940-0.694=0.246
Gain(收入层次)=Info(D)-Info收入层次(D)=0.940-0.911=0.029
Gain(学生)=Info(D)-Info学生(D)=0.940-0.789=0.151
Gain(信用等级)=Info(D)-Info信用等级(D)=0.940-0.892=0.058
4:计算分裂信息:
SplitInfo年龄(D)=-5/14log(5/14)-4/14log(4/14)-5/14log(5/14)=0.3571*1.4856+0.2857*1.8074+0.3571*1.4856=0.5305+0.5164+0.5305=1.5774
SplitInfo收入层次(D)=-4/14log(4/14)-6/14log(6/14)-4/14log(4/14)=0.2857*1.8074+0.4286*1.2223+0.2857*1.8074=0.5164+0.5139+0.5164=1.5467
SplitInfo学生(D)=-7/14log7/14-7/14log7/14=1
SplitInfo信用等级(D)=-6/14log(6/14)-8/14log(8/14)=0.4286*1.2223+0.5714*0.8074=0.5239+0.4613=0.9852
SplitInfo(D)=(SplitInfo年龄(D)+SplitInfo收入层次(D)+SplitInfo学生(D)+SplitInfo信用等级(D))/4=1.2773
5:计算增益比率:
GainRatio(年龄)=Gain(年龄)/(SplitInfo(D)+SplitInfo年龄(D))=0.246/(1.2773+1.5774)=0.0862
GainRatio(收入层次)=Gain(收入层次)/(SplitInfo(D)+SplitInfo收入层次(D))=0.029/(1.2773+1.5467)=0.0103
GainRatio(学生)=Gain(学生)/(SplitInfo(D)+SplitInfo学生(D))=0.151/(1.2773+1)=0.0663
GainRatio(信用等级)=Gain(信用等级)/(SplitInfo(D)+SplitInfo信用等级(D))=0.058/(1.2773+0.9852)=0.0256
相关文章:
信息增益,经验熵和经验条件熵——决策树
目录 1.经验熵 2.经验条件熵 3.信息增益 4.增益比率 5.例子1 6.例子2 在决策树模型中,我们会考虑应该选择哪一个特征作为根节点最好,这里就用到了信息增益 通俗上讲,信息增益就是在做出判断时,该信息对你影响程度的大小。比…...
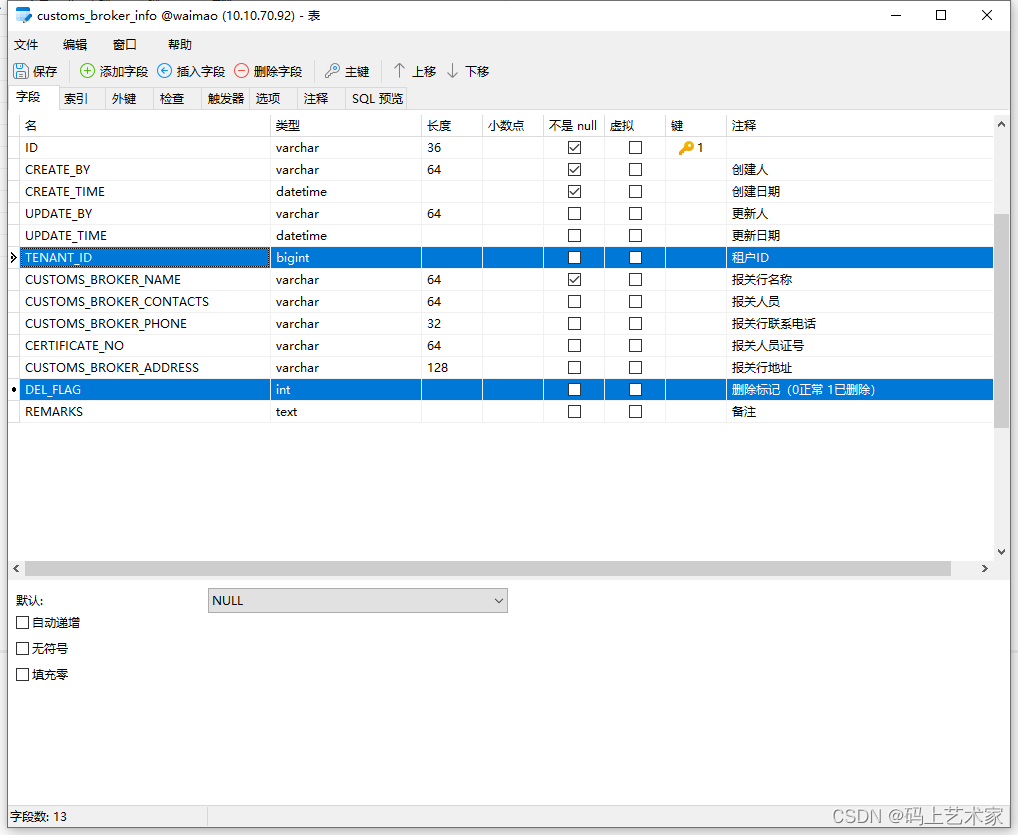
手摸手系列之批量修改MySQL数据库所有表中某些字段的类型
在迁移老项目的数据库时,使用Navicat Premium的数据传输功能同步了表结构和数据。但是,发现某些字段的数据类型出现了错误,例如,租户ID从Oracle的NUMBER类型变成了MySQL的decimal(10),正确的应该是bigInt(20)。此外&am…...

视频号直播弹幕采集
系列文章目录 websocket逆向http拦截websocket拦截视频号直播弹幕采集 系列文章目录前言技术分析分析技术选择前提准备事件分析消息去重用户进房用户发言用户送礼用户点赞用户唯一id前言 很多小伙伴倒在了礼物事件,还有用户唯一标识下。 本篇文章将讲解视频号直播弹幕的获取的…...
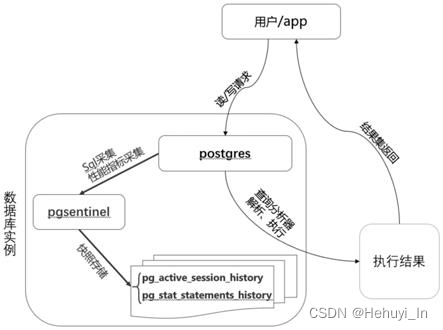
PostgreSQL ash —— pgsentinel插件 学习与踩坑记录
零、 注意事项 测试发现,pgsentinel插件在pg_active_session_history视图记录条数较多时,存在严重的内存占用问题,群里的其他朋友反馈还可能存在严重的内存泄漏问题。本文仅用于学习和测试,未用于生产环境。 设置 pgsentinel_ash.…...
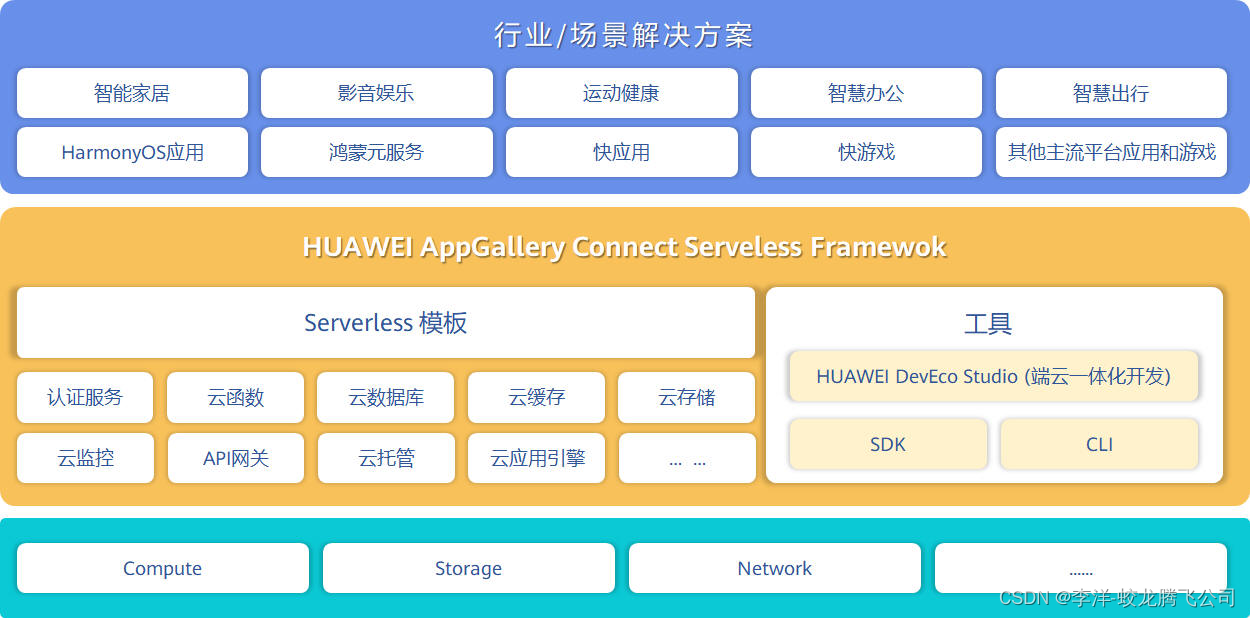
HarmonyOS/OpenHarmony原生应用开发-华为Serverless云端服务支持说明(一)
云端服务的实现是HarmonyOS/OpenHarmony原生应用开发的一个重要的环节,如果用户端是鸿蒙原生应用,但是服务端即云端还是基于传统的各种WEB网络框架、数据库与云服务器,那么所谓的原生应用开发实现的数据即后端服务是和以前、现在的互联网、移…...

3分钟基于Chat GPT完成工作中的小程序
1. 写在前面 GPT自从去年爆发以来,各大公司在大模型方面持续发力,行业大模型也如雨后春笋一般发展迅速,日常工作中比较多的应用场景还是问答模式,作为写程序的辅助也偶尔使用。今天看到一篇翻译的博客“我用 ChatGPT,…...
使用hugo+github搭建免费个人博客
使用hugogithub搭建免费个人博客 前提条件 win11电脑一台电脑安装了git电脑安装了hugogithub账号一个 个人博客本地搭建 初始化一个博客 打开cmd窗口,使用hugo新建一个博客工程 hugo new site blogtest下载主题 主题官网:themes.gohugo.io 在上面…...

打印字节流和字符流
打印字节流和字符流 printStream/ printWriter的构造器和方法都是一样的 package printfile;import java.io.FileOutputStream; import java.io.OutputStream; import java.io.PrintStream; import java.io.PrintWriter; import java.nio.charset.Charset;public class Prin…...

elementplus下载表格为excel格式
安装xlsx npm i --save https://cdn.sheetjs.com/xlsx-0.20.0/xlsx-0.20.0.tgz引入xlsx并使用 import XLSX from xlsx;const tableRef ref<any>(null); // 导出为 Excel const exportToExcel () > {// 获取 el-table 的引用tableRef.value tableRef.value || doc…...

聊聊僵尸进程
文章目录 1. 前言1.1 什么是僵尸进程1.2 为什么需要关注僵尸进程 2. 僵尸进程的产生2.2 为什么会产生僵尸进程2.3 举个栗子 3. 僵尸进程的影响3.1 僵尸进程为何会占用系统资源3.2 操作系统如何知道哪个资源需要被释放3.3 什么是进程表3.4 什么是PCB 5. 如何处理僵尸进程4.1 识别…...
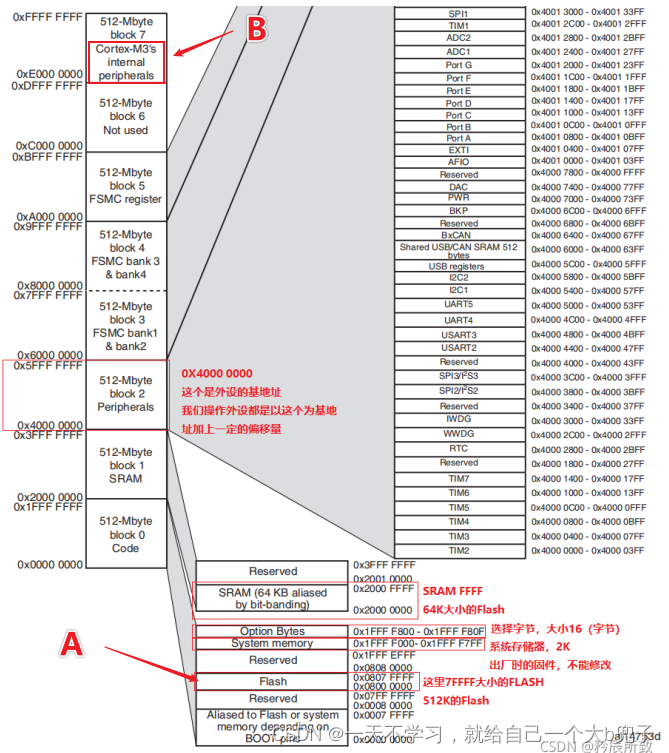
stm32的时钟、中断的配置(针对寄存器),一些基础知识
一、学习参考资料 (1)正点原子的寄存器源码。 (2)STM32F103最小系统板开发指南-寄存器版本_V1.1(正点) (3)STM32F103最小系统板开发指南-库函数版本_V1.1(正点࿰…...

Vue14 监视属性简写
监视属性简写 当监视属性只有handler时,可以使用简写 <!DOCTYPE html> <html><head><meta charset"UTF-8" /><title>天气案例_监视属性_简写</title><!-- 引入Vue --><script type"text/javascript&…...
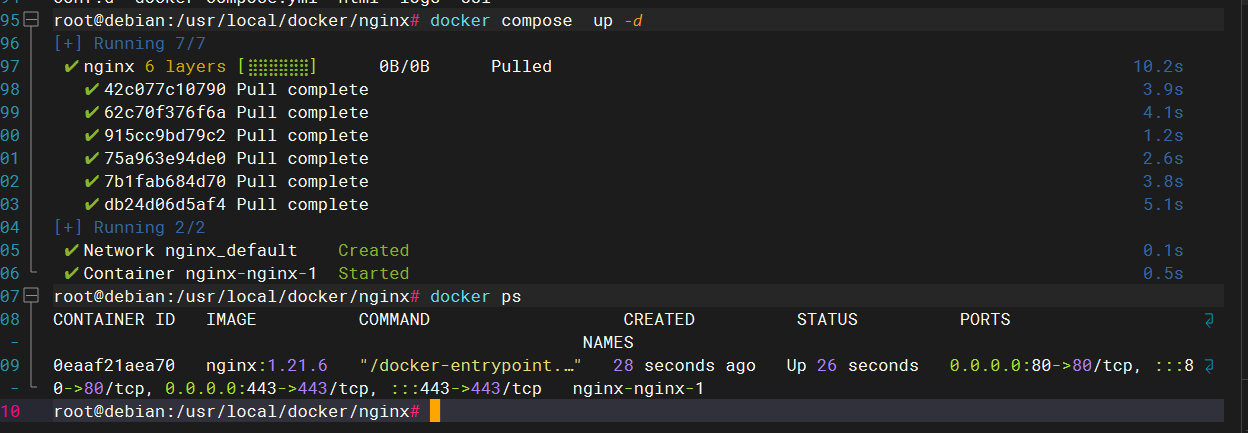
基于docker+Keepalived+Haproxy高可用前后的分离技术
基于dockerKeepalivedHaproxy高可用前后端分离技术 架构图 服务名docker-ip地址docker-keepalived-vip-iphaproxy-01docker-ip自动分配 未指定ip192.168.31.252haproxy-02docker-ip自动分配 未指定ip192.168.31.253 安装haproxy 宿主机ip 192.168.31.254 宿主机keepalived虚…...

安装配置deep learning开发环境
1. 下载安装anacondahttps://www.anaconda.com/download-success vim ~/.condarcchannels: - bioconda - https://mirrors.ustc.edu.cn/anaconda/pkgs/main/ - https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/ - https://mirrors.tuna.tsinghua.edu.cn/anaco…...

Docker基础(CentOS 7)
参考资料 hub.docker.com 查看docker官方仓库,需要梯子 Docker命令大全 黑马程序员docker实操教程 (黑马讲的真的不错 容器与虚拟机 安装 yum install -y docker Docker服务命令 启动服务 systemctl start docker停止服务 systemctl stop docker重启…...
HTTP的基本格式
HTTP/HTTPS HTTPhttp的协议格式 HTTP 应用层,一方面是需要自定义协议,一方面也会用到一些现成的协议. HTTP协议,就是最常用到的应用层协议. 使用浏览器,打开网站,使用手机app,加载数据,这些过程大概率都是HTTP来支持的 HTTP是一个超文本传输协议, 文本>字符串 超文本>除…...
Qt元对象系统 day5
Qt元对象系统 day5 内存管理 QObject以对象树的形式组织起来,当为一个对象创建子对象时,子对象回自动添加到父对象的children()列表中。父对象拥有子对象所有权,比如父对象可以在自己的析构函数中删除它的孩子对象。使用findChild()或findC…...

【audio】alsa pcm音频路径
文章目录 AML方案音频路径分析dump alsa pcm各个音频路径的原始音频流数据 AML方案音频路径分析 一个Audio Patch用来表示一个或多个source端到一个或多个sink端。这个是从代码的注释翻译来的,大家可以把它比作大坝,可以有好几个入水口和出水口…...
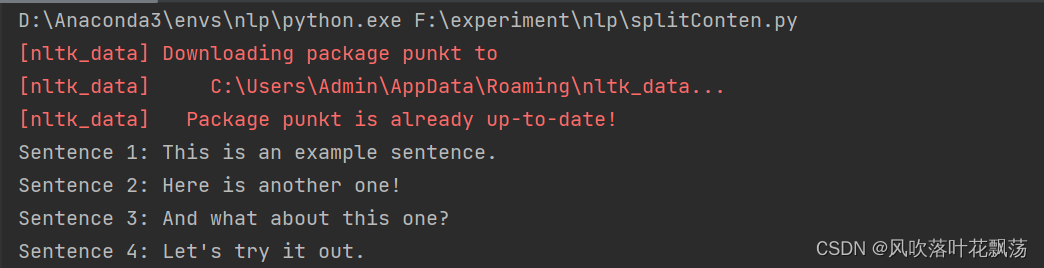
NLP - 数据预处理 - 文本按句子进行切分
NLP - 数据预处理 - 文本按句子进行切分 文章目录 NLP - 数据预处理 - 文本按句子进行切分一、前言二、环境配置1、安装nltk库2、下载punkt分句器 三、运行程序四、额外补充 一、前言 在学习对数据训练的预处理的时候遇到了一个问题,就是如何将文本按句子切分&#…...

【轻松玩转MacOS】常用软件篇
引言 在本篇文章中,我将介绍如何安装和使用一些常用的软件,如Safari浏览器、邮件、日历、地图等。让我们一起来看看吧! 一、Safari浏览器 Safari是MacOS自带的浏览器,具有简洁、快速、安全的特点。 以下是一些Safari浏览器的使…...

【NotebookLM要点提取黄金法则】:20年AI工具实战总结的5大避坑指南与3步精准萃取法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM要点提取方法论全景概览 NotebookLM 是 Google 推出的面向研究者与知识工作者的 AI 原生笔记工具,其核心能力在于对用户上传文档(PDF、TXT、Google Docs)进…...
)
5G入网第一步:手把手拆解Msg3 PUSCH传输的时频资源分配(附避坑指南)
5G入网第一步:手把手拆解Msg3 PUSCH传输的时频资源分配(附避坑指南) 当5G终端尝试接入网络时,随机接入流程中的Msg3 PUSCH传输往往是工程师们遇到的第一个技术深水区。作为首个由基站调度的上行共享信道传输,Msg3承载着…...

iOS App Clips实战:从开发限制到场景化触发全解析
1. App Clips到底是什么?为什么开发者需要关注它? 想象一下这样的场景:你走进一家咖啡店想用手机点单,但发现必须下载一个200MB的App才能完成操作。这时候如果店员说"扫这个二维码就能直接点单",10秒后你已经…...
)
AI 编程能力实战基准测试报告:编程能力评估体系 (Programming Capability Benchmark)
🤖 AI 编程能力实战基准测试报告:编程能力评估体系 (Programming Capability Benchmark) 文件目标: 一份用于评估当前顶级生成式模型(如GPT-5.5, Claude 4.7, Deepseek V4等)实际软件开发能力和系统级思维的权威指南。 核心原则: …...

Arm Compiler 6.16LTS功能安全认证语言扩展解析
1. Arm Compiler for Embedded FuSa 6.16LTS语言扩展支持现状解析在功能安全关键型嵌入式系统开发中,编译器工具链的认证状态直接关系到最终产品的合规性。Arm Compiler for Embedded FuSa 6.16LTS作为经过功能安全认证的工具链,其语言扩展支持情况需要开…...

如何快速掌握炉石传说游戏自动化:开源智能助手完整教程
如何快速掌握炉石传说游戏自动化:开源智能助手完整教程 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 你是否厌倦了每天重复的炉石传说日常…...

C51函数可重入性原理与实践指南
1. C51函数可重入性深度解析在嵌入式C51开发中,函数可重入性(Reentrancy)是一个直接影响系统稳定性的关键特性。简单来说,可重入函数是指能够被多个执行流(如主程序和中断服务例程)同时调用而不会引发数据冲…...

国产多模态大模型崛起:技术、场景与未来挑战全解析
国产多模态大模型崛起:技术、场景与未来挑战全解析 引言 在人工智能浪潮席卷全球的背景下,多模态大模型已成为技术竞争的新高地。以GPT-4V、Gemini为代表的国际巨头展现了强大的图文理解与生成能力,而国产模型正凭借对中文场景的深度优化、独…...

ncmdump技术解析:网易云音乐NCM加密格式的逆向工程与转换实现原理
ncmdump技术解析:网易云音乐NCM加密格式的逆向工程与转换实现原理 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 项目技术定位与核心价值 ncmdump是一款专注于网易云音乐NCM加密格式逆向解析的开源工具,通过…...

均匀辐照度和局部遮光条件下光伏系统的新型样条-MPPT技术附Simulink仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...