ElasticSearch搜索引擎:数据的写入流程
一、ElasticSearch 写数据的总体流程:
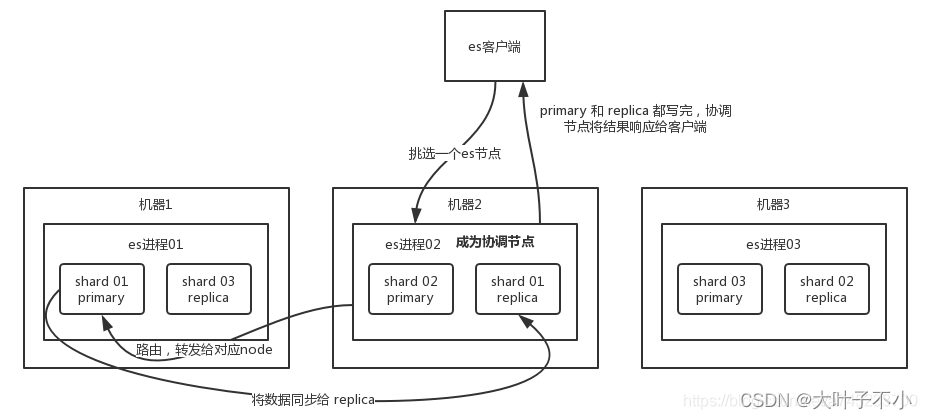
(1)ES 客户端选择一个节点 node 发送请求过去,这个节点就是协调节点 coordinating node
(2)协调节点对 document 进行路由,通过 hash 算法计算出数据应该落在哪个分片 shard 上,然后根据节点上维护的 shard 信息,将请求转发到对应的实际处理节点node上
shard = hash(document_id) % (num_of_primary_shards),
(3)实际的节点上的 primary shard 主分片处理请求,然后将数据同步到副本节点 replica node
(4)coordinating node 等到 primary node 和所有 replica node 都执行成功之后,就返回响应结果给客户端。
二、ES 的主分片写数据的详细流程:
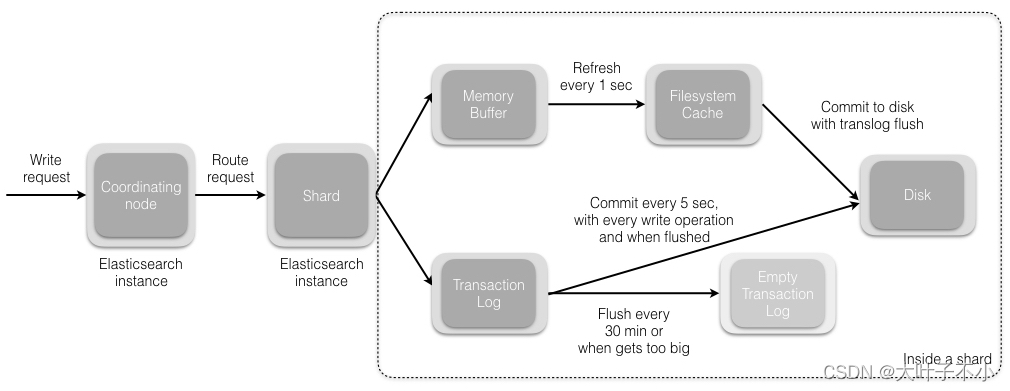
1、refresh 操作:
primary shard 主分片先将数据写入 memory buffer,然后定时(默认每隔1s)将 memory buffer 中的数据写入一个新的 segment 文件中,并进入 Filesystem cache(同时清空 memory buffer),这个过程就叫做 refresh;每个 Segment 文件实际上是一些倒排索引的集合, 只有经历了 refresh 操作之后,这些数据才能变成可检索的。
ES 的近实时性:当数据存在 memory buffer 时是搜索不到的,只有数据被 refresh 到 Filesystem cache 之后才能被搜索到,而 refresh 是每秒一次, 所以称 es 是近实时的,或者可以通过手动调用 es 的 api 触发一次 refresh 操作,让数据马上可以被搜索到;
上文讲到的 memory buffer,也称为 Indexing Buffer,这个区域默认的内存大小是 10% heap size。
2、写 translog 事务日志文件:
由于 memory Buffer 和 Filesystem Cache 都是基于内存,假设服务器宕机,那么数据就会丢失,所以 ES 通过 translog 日志文件来保证数据的可靠性,在数据写入 memory buffer 的同时,将数据写入 translog 日志文件中,在机器宕机重启时,es 会从磁盘中读取 translog 日志文件中最后一个提交点 commit point 之后的数据,恢复到 memory buffer 和 Filesystem cache 中去。
ES 数据丢失的问题:translog 也是先写入 Filesystem cache,然后默认每隔 5 秒刷一次到磁盘中,所以默认情况下,可能有 5 秒的数据会仅仅停留在 memory buffer 或者 translog 文件的 Filesystem cache中,而不在磁盘上,如果此时机器宕机,会丢失 5 秒钟的数据。也可以将 translog 设置成每次写操作必须是直接 fsync 到磁盘,但是性能会差很多。
3、flush 操作:
不断重复上面的步骤,translog 会变得越来越大,当 translog 文件默认每30分钟或者阈值超过 512M 时,就会触发 flush 操作,将 memory buffer 中所有的数据写入新的 Segment 文件中, 并将内存中所有的 Segment 文件全部落盘,最后清空 translog 事务日志。
(1)将 memory buffer 中的数据 refresh 到 Filesystem Cache 中的一个新的 segment 文件中去,然后清空 memory buffer;
(2)创建一个新的 commit point(提交点),同时强行将 Filesystem Cache 中目前所有的数据都 fsync 到磁盘文件中;
(3)删除旧的 translog 日志文件并创建一个新的 translog 日志文件,此时 flush 操作完成
ES 的 flush 操作主要通过以下几个参数控制:
index.translog.flush_threshold_period:每隔多长时间执行一次flush,默认30m
index.translog.flush_threshold_size:当事务日志大小到达此预设值,则执行flush,默认512mb
index.translog.flush_threshold_ops:当事务日志累积到多少条数据后flush一次。
————————————————
版权声明:本文为CSDN博主「张维鹏」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/a745233700/article/details/118076845
相关文章:
ElasticSearch搜索引擎:数据的写入流程
一、ElasticSearch 写数据的总体流程: (1)ES 客户端选择一个节点 node 发送请求过去,这个节点就是协调节点 coordinating node (2)协调节点对 document 进行路由,通过 hash 算法计算出数据应该…...

python3 调用 另外一个python脚本
3种python调用其他脚本脚本的方法_python 调用python脚本_linjingyg的博客-CSDN博客 Python之系统交互(调用系统命令)subprocess_subprocess.getoutput(cmd) 参数格式不正确-CSDN博客 subprocess.call()只能返回状态码。subprocess.getoutput(cmd)只能输出命令结果。 str(py…...

【13】c++设计模式——>简单工厂模式
工厂模式的定义 c中的工厂模式是一种创建型设计模式,它提供一种创建对象的接口,但具体创建的对象类型可以在运行时决定,这样可以将对象的创建与使用代码分离,提高代码的灵活性和可维护性。 在c中实现工厂模式,通常会定…...

系统架构设计:2 论软件设计方法及其应用
目录 一 软件设计方法 1结构化设计 2信息工程 3面向对象设计 4原型设计...

基于Winform的UDP通信
1、文件结构 2、UdpReceiver.cs using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Net.Sockets; using System.Text; using System.Threading.Tasks;namespace UDPTest.Udp {public class UdpStateEventArgs : EventArgs…...

掌握 BERT:自然语言处理 (NLP) 从初级到高级的综合指南(1)
简介 BERT(来自 Transformers 的双向编码器表示)是 Google 开发的革命性自然语言处理 (NLP) 模型。它改变了语言理解任务的格局,使机器能够理解语言的上下文和细微差别。在本文[1]中,我们将带您踏上从 BERT 基础知识到高级概念的旅…...
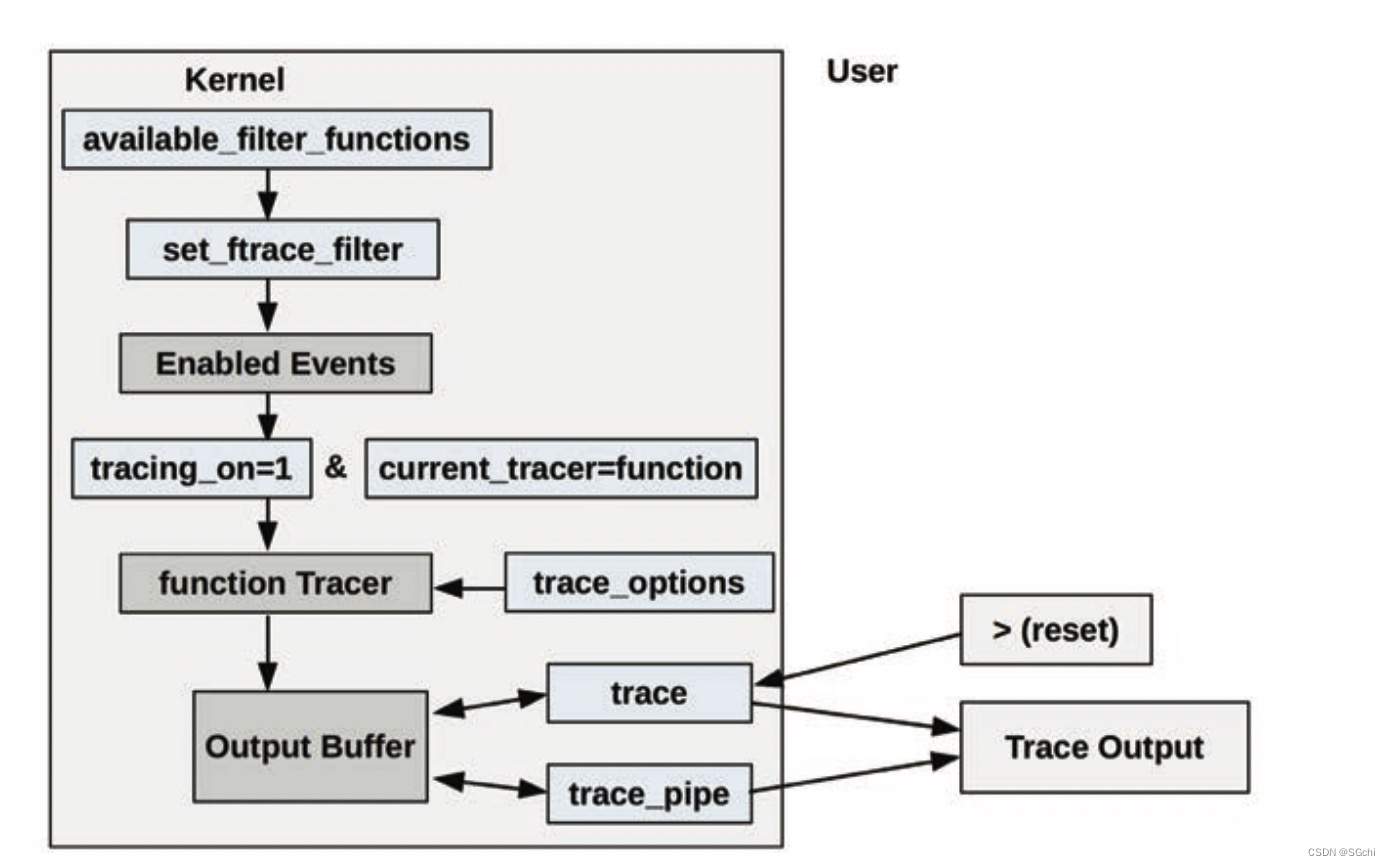
Linux Ftrace介绍
文章目录 一、简介二、内核函数调用跟踪参考链接: 一、简介 Ftrace 是 Linux 官方提供的跟踪工具,在 Linux 2.6.27 版本中引入。Ftrace 可在不引入任何前端工具的情况下使用,让其可以适合在任何系统环境中使用。 Ftrace 可用来快速排查以下相…...

Go语言进阶------>init()函数
Init()包初始化 执行优先级 Init()函数的执行优先级比main()函数的执行优先级要高,也就是说程序会优先执行Init()函数之后再执行main()函数. 代码如下 package mainimport "fmt"func init() {fmt.Println("执行了Init()函数") }func main() {fmt.Println…...

云计算:常用微服务框架
目录 一、理论 1.Java微服务框架 2.Go微服务框架 3.Python微服务框架 4.Node.js微服务框架 5..Net微服务框架 一、理论 1.Java微服务框架 Spring Cloud:最早最成熟,Java开源微服务框架方案 SpringBoot:全新框架,设计目的是…...

jmeter添加断言(详细图解)
先创建一个线程组,再创建一个http请求。 为了方便观察,我们添加两个监听器,察看结果树和断言结果。 添加断言:响应断言,响应断言也是比较常用的一个断言 设置响应断言:正常情况下响应代码是200。选择响应代…...
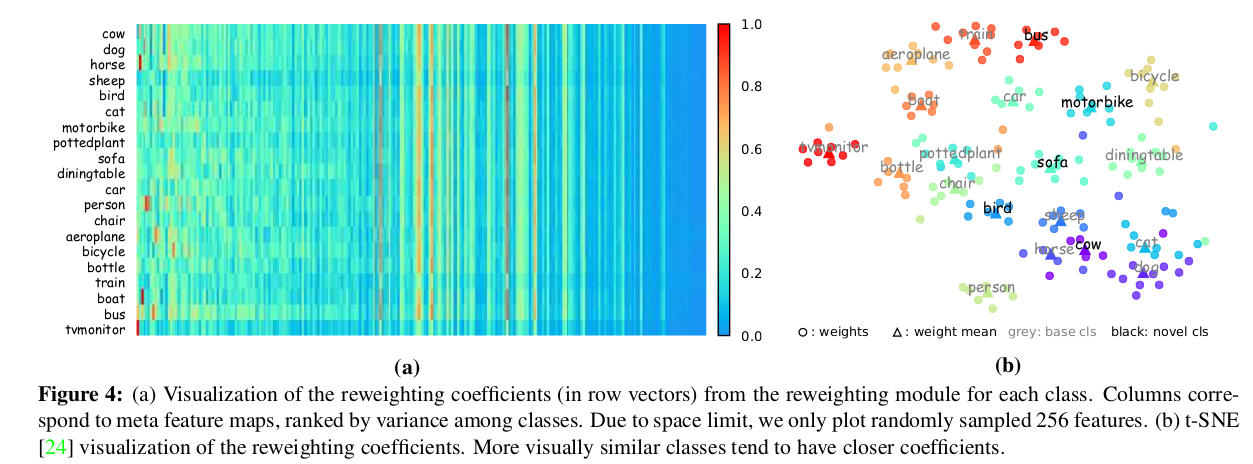
few shot object detection via feature reweight笔记
摘要部分 few shot很多用的都是faster R-CNN为基础,本文用的是one-stage 结构。 用了一个meta feature learner和reweighting模块。 和其他的few shot一样,先学习base数据集,再推广到novel数据集。 feature learner会从base数据集中提取meta…...

工会排队模式:电商新营销模式吸引消费者,提升销售!
随着电商行业的繁荣发展,私域流量已经成为了电商平台争夺消费者和促进销售的重要手段。工会排队模式正是在这种背景下应运而生的一种创新性的电商营销模式。这种模式通过奖金池的资金来为消费者和商家提供返现和排队奖励,构建了一个实现消费者和商家共赢…...
国际红外技术及设备展览会)
定档通知2024中国(北京)国际红外技术及设备展览会
时间:2024年7月14-16日 地点:北京国家会议中心 ◆展会背景background: 各有关红外企业厂商:2024年7月14~16日,2024中国国际红外技术及设…...
自助建站系统,一建建站系统api版,自动建站
安装推荐php7.2或7.2以下都行 可使用虚拟主机或者服务器进行搭建。 分站进入网站后台 域名/admin 初始账号123456qq.com密码123456 找到后台的网站设置 将主站域名及你在主站的通信secretId和通信secretKey填进去。 即可正常使用 通信secretId和通信secretKey在主站的【账号…...
算法框架-LLM-1-Prompt设计(一)
原文:算法框架-LLM-1-Prompt设计(一) - 知乎 目录 收起 1 prompt-engineering-for-developers 1.1 Prompt Engineering 1.1.1 提示原则 1. openai的环境 2. 两个基本原则 3. 示例 eg.1 eg.2 结构化输出 eg.3 模型检验 eg.4 提供示…...
一个rar压缩包如何分成三个?
一个rar压缩包体积太大了,想要将压缩包分为三个,该如何做到?其实很简单,方法就在我们经常使用的WinRAR当中。 我们先将压缩包内的文件解压出来,然后查看一下,然后打开WinRAR软件,找到文件&…...

批量获取拼多多商品详情数据,拼多多商品详情API接口
批量获取拼多多商品详情数据可以采用以下方式: 使用拼多多开放平台API接口。 拼多多开放平台提供了API接口,可以通过API接口获取拼多多平台上的商品信息,使用API接口需要进行权限申请和认证,操作较为复杂。 使用第三方工具。 市面…...

Redis Cluster Gossip Protocol: 目录
术语说明 server:当前的节点 cluster:每个节点的内存中都有一个集群信息结构,里面包含了集群中各个节点的状态信息(包括server自己) myself:当前节点在cluster中的实体 node:cluster节点字典中…...

HarmonyOS/OpenHarmony原生应用-ArkTS万能卡片组件Span
作为Text组件的子组件,用于显示行内文本的组件。无子组件 一、接口 Span(value: string | Resource) 从API version 9开始,该接口支持在ArkTS卡片中使用。 参数: 参数名 参数类型 必填 参数描述 value string | Resource 是 文本内…...

这些负载均衡都解决哪些问题?服务、网关、NGINX
这篇文章解答一下群友的一系列提问: 在微服务项目中,有服务的负载均衡、网关的负载均衡、Nginx的负载均衡,这几个负载均衡分别用来解决什么问题呢? 在微服务项目中,服务的负载均衡、网关的负载均衡和Nginx的负载均衡都…...

网站推广新纪元:品牌100工程引领下的精准引流与高效转化
在数字化转型的浪潮中,72%的企业网站上线后却陷入了“无人问津”的尴尬境地。缺乏系统的推广策略,仅31%的企业能通过科学推广实现流量与转化双提升。品牌100工程在深度陪跑实践中发现,2026年的网站推广已告别“盲目投放”时代,更注…...

Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列专业软件
Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列专业软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专门为Adobe Creative Clou…...

八大网盘直链解析工具:高效跨平台文件下载全攻略
八大网盘直链解析工具:高效跨平台文件下载全攻略 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...

DIY改造:为Hakko FX-901烙铁打造USB-C充电电池包
1. 项目概述:打造你的专属USB充电无线烙铁 如果你和我一样,经常需要带着烙铁跑现场——无论是调试RC模型、在Maker Faire上修复作品,还是在户外临时搭建一个电子装置——那你一定对传统无线烙铁的痛点深有体会。四节AA电池,用不了…...

告别Web Client:当ESXi主机SSH连不上时,我用这10条esxcli命令完成了紧急修复
告别Web Client:当ESXi主机SSH连不上时,我用这10条esxcli命令完成了紧急修复 凌晨三点,数据中心告警铃声刺破夜空。一台承载着核心业务的ESXi主机突然失联,vSphere Client和Web界面均无法访问,SSH连接也毫无响应。面对…...

构建可进化智能体系统:从架构蓝图到工程实践
1. 项目概述与核心价值最近在开源社区里,一个名为planck-lab/hermes-evolving-agents-public-blueprint的项目引起了我的注意。这个标题乍一看有点长,但拆解一下就能发现它的分量:planck-lab是组织名,hermes是项目代号,…...

LabVIEW PC端软件开发:架构设计、性能优化与工程化实践
1. 项目概述:为什么选择在PC上深耕LabVIEW开发?当大家谈论起LabVIEW,很多人的第一印象可能还停留在它与各种数据采集卡、PLC、嵌入式硬件绑定的场景里。作为一个在这个图形化编程环境里摸爬滚打了十多年的老工程师,我想说…...

如何快速为音乐库批量下载完美歌词?ZonyLrcToolsX 终极指南
如何快速为音乐库批量下载完美歌词?ZonyLrcToolsX 终极指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX 还在为音乐播放器缺少歌词而烦恼吗?是…...

Oto 核心架构深度解析:Context 与 Player 的设计哲学
Oto 核心架构深度解析:Context 与 Player 的设计哲学 【免费下载链接】oto ♪ A low-level library to play sound on multiple platforms ♪ 项目地址: https://gitcode.com/gh_mirrors/ot/oto Oto 是一个跨平台的低级音频播放库,其核心架构围绕…...

终极指南:FigmaCN中文插件让设计师告别英文障碍
终极指南:FigmaCN中文插件让设计师告别英文障碍 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的全英文界面而烦恼吗?Figma中文插件FigmaCN正是为你…...