[Machine Learning] Learning with Noisy Data
文章目录
- Probabilistic Perspective of Noise
- Bias and Variance
- Robustness among Surrogate Loss Functions
- NMF
Probabilistic Perspective of Noise
假设数据来源于一个确定的函数,叠加了高斯噪声。我们有:
y = h ( x ) + ϵ y = h(x) + \epsilon y=h(x)+ϵ
其中 ϵ ∼ N ( 0 , β − 1 ) \epsilon \sim \mathcal{N}(0, \beta^{-1}) ϵ∼N(0,β−1)
等价地,给定输入 x x x,以及函数 h h h 和噪声的精度 β \beta β, y y y 的条件分布可以写作:
p { y ∣ x , h , β } = N ( y ∣ h ( x ) , β − 1 ) p\{y|x, h, \beta\} = \mathcal{N}(y|h(x), \beta ^ {-1}) p{y∣x,h,β}=N(y∣h(x),β−1)
即 y y y 的条件分布是以 h ( x ) h(x) h(x) 为均值、以 β − 1 \beta^{-1} β−1 为方差的正态分布。
我们现在有一个由 n n n 个数据点组成的数据集 S = { ( x 1 , y 1 ) , … , ( x n , y n ) } S = \{(x_1,y_1), \ldots, (x_n,y_n)\} S={(x1,y1),…,(xn,yn)}。我们假设数据点是独立同分布的,即每个数据点的生成不依赖于其他数据点。因此,整个数据集 S S S 的似然是所有单个数据点似然的乘积:
p ( S ∣ X , h , β − 1 ) = ∏ i = 1 n p ( y i ∣ h ( x i ) , β − 1 ) p(S|X, h, \beta^{-1}) = \prod\limits_{i=1}^n p(y_i|h(x_i), \beta^{-1}) p(S∣X,h,β−1)=i=1∏np(yi∣h(xi),β−1)
这个似然模型告诉我们,对于给定的函数 h h h 和噪声精度 β \beta β,数据集 S S S 的"可能性"或"合理性"是多少。
假设我们的模型参数为 h h h,先验分布为 p ( h ) p(h) p(h),那么基于贝叶斯定理,参数 h h h 的后验分布为:
p ( h ∣ S ) = p ( S ∣ h ) p ( h ) p ( S ) p(h|S) = \frac{p(S|h) p(h)}{p(S)} p(h∣S)=p(S)p(S∣h)p(h)
其中, p ( S ∣ h ) p(S|h) p(S∣h) 是似然, p ( S ) p(S) p(S) 是边缘似然,与参数 h h h 无关。
MAP估计就是找到使后验分布 p ( h ∣ S ) p(h|S) p(h∣S) 最大的参数 h h h。由于分母 p ( S ) p(S) p(S) 与 h h h 无关,所以MAP估计等价于:
h MAP = arg max h p ( S ∣ h ) p ( h ) h_{\text{MAP}} = \argmax_{h} p(S|h) p(h) hMAP=hargmaxp(S∣h)p(h)
取负对数,问题可以转化为:
h MAP = arg min h { − ln p ( S ∣ h ) − ln p ( h ) } h_{\text{MAP}} = \argmin_{h} \{-\ln p(S|h) - \ln p(h)\} hMAP=hargmin{−lnp(S∣h)−lnp(h)}
为了解决这个优化问题,你通常需要的是:
- 一个关于似然的负对数的表达式
- 一个关于先验的负对数的表达式
回顾我们的似然模型:
p ( S ∣ X , h , β − 1 ) = ∏ i = 1 n N ( y i ∣ h ( x i ) , β − 1 ) p(S|X, h, \beta^{-1}) = \prod_{i=1}^n \mathcal{N}(y_i|h(x_i), \beta^{-1}) p(S∣X,h,β−1)=i=1∏nN(yi∣h(xi),β−1)
根据正态分布的定义:
N ( y ∣ h ( x ) , β − 1 ) = β 2 π exp ( − β ( y − h ( x ) ) 2 2 ) \mathcal{N}(y|h(x), \beta^{-1}) = \frac{\beta}{\sqrt{2\pi}} \exp\left(-\frac{\beta (y - h(x))^2}{2}\right) N(y∣h(x),β−1)=2πβexp(−2β(y−h(x))2)
因此,我们可以写出似然函数为:
p ( S ∣ X , h , β − 1 ) = ∏ i = 1 n β 2 π exp ( − β ( y i − h ( x i ) ) 2 2 ) p(S|X, h, \beta^{-1}) = \prod_{i=1}^n \frac{\beta}{\sqrt{2\pi}} \exp\left(-\frac{\beta (y_i - h(x_i))^2}{2}\right) p(S∣X,h,β−1)=i=1∏n2πβexp(−2β(yi−h(xi))2)
对似然函数取对数,我们得到:
ln p ( S ∣ X , h , β − 1 ) = ∑ i = 1 n ln β 2 π − β ( y i − h ( x i ) ) 2 2 \ln p(S|X, h, \beta^{-1}) = \sum_{i=1}^n \ln \frac{\beta}{\sqrt{2\pi}} - \frac{\beta (y_i - h(x_i))^2}{2} lnp(S∣X,h,β−1)=i=1∑nln2πβ−2β(yi−h(xi))2
将上述式子进一步拆分并合并相似的项,我们可以得到:
ln p ( S ∣ X , h , β − 1 ) = n ln β − n 2 ln ( 2 π ) − β 2 ∑ i = 1 n ( y i − h ( x i ) ) 2 \ln p(S|X, h, \beta^{-1}) = n \ln \beta - \frac{n}{2} \ln(2\pi) - \frac{\beta}{2} \sum_{i=1}^n (y_i - h(x_i))^2 lnp(S∣X,h,β−1)=nlnβ−2nln(2π)−2βi=1∑n(yi−h(xi))2
此时, − β 2 ∑ i = 1 n ( y i − h ( x i ) ) 2 -\frac{\beta}{2} \sum_{i=1}^n (y_i - h(x_i))^2 −2β∑i=1n(yi−h(xi))2就是我们定义的风险 R S ( h ) R_S(h) RS(h)的部分,它表示模型在训练数据上的平均误差。
因此,我们有:
− ln p ( S ∣ h ) = − n 2 ln β + n 2 ln ( 2 π ) + β 2 n R S ( h ) -\ln p(S|h) = -\frac{n}{2} \ln \beta + \frac{n}{2} \ln(2\pi) + \frac{\beta}{2} n R_S(h) −lnp(S∣h)=−2nlnβ+2nln(2π)+2βnRS(h)
这就是似然的负对数的表达式。
为了完整地解决优化问题,你还需要一个先验的负对数形式。比如,如果 h h h的先验是高斯分布,那么负对数先验的形式会是 h h h的二次函数。
结合似然和先验的负对数形式,你可以使用优化技巧(例如梯度下降)来求解 h MAP h_{\text{MAP}} hMAP。这样得到的 h MAP h_{\text{MAP}} hMAP既考虑了数据的似然,又考虑了先验知识,从而可能得到更好、更稳定的估计结果。
Bias and Variance
当 λ \lambda λ 很小或为0时:模型可能会过于复杂,拟合训练数据中的每一个细节,包括噪声。这会导致低偏差但高方差,即模型容易过拟合。
当 λ \lambda λ 很大时:模型会变得过于简单,参数值会被强烈地压缩,导致模型不能很好地捕获数据中的模式。这会导致高偏差但低方差,即模型容易欠拟合。
Robustness among Surrogate Loss Functions
在许多优化问题中,直接对目标函数进行操作可能会非常困难。可能是因为这个函数在数学上很复杂,或者它涉及到的计算量太大,导致直接优化不切实际。在这些情况下,转化或重参数化问题可以使其更容易处理。
在这里,考虑 g ( t ) = f ( t h ) g(t) = f(th) g(t)=f(th) 是一个这样的尝试。通过引入新的变量 t t t 并考虑如何改变 h h h 的长度(即通过 t t t 来缩放),我们试图在某种程度上简化问题。
当 t = 1 t=1 t=1 时,我们实际上是在查看原始函数 f f f 在点 h h h 的行为。如果 g ′ ( 1 ) = 0 g'(1) = 0 g′(1)=0,那么我们知道 f f f 在 h h h 这点取得极值(可能是最小值或最大值)。因此,这个技巧为我们提供了另一种方式来寻找 f ( h ) f(h) f(h) 的最小值点,而不是直接对 f f f 进行操作。
现在考虑四种损失函数及其对应的 g ′ ( 1 ) g'(1) g′(1):
-
最小二乘损失 (Least squares loss):
ℓ ( h ( x i ) , y i ) = ( y i − h ( x i ) ) 2 \ell(h(x_i), y_i) = (y_i - h(x_i))^2 ℓ(h(xi),yi)=(yi−h(xi))2
这意味着,
g ′ ( 1 ) = − 2 ∑ i = 1 n ( y i − h ( x i ) ) h ( x i ) g'(1) = -2 \sum_{i=1}^n (y_i - h(x_i)) h(x_i) g′(1)=−2i=1∑n(yi−h(xi))h(xi) -
绝对损失 (Absolute loss):
ℓ ( h ( x i ) , y i ) = ∣ y i − h ( x i ) ∣ \ell(h(x_i), y_i) = |y_i - h(x_i)| ℓ(h(xi),yi)=∣yi−h(xi)∣
这的导数与误差的符号有关。 -
Cauchy损失 (Cauchy loss):
ℓ ( h ( x i ) , y i ) = log ( 1 + ( y i − h ( x i ) ) 2 σ 2 ) \ell(h(x_i), y_i) = \log(1 + \frac{(y_i - h(x_i))^2}{\sigma^2}) ℓ(h(xi),yi)=log(1+σ2(yi−h(xi))2)
其中, σ \sigma σ是一个正的常数。 -
Correntropy损失 (Welsch loss):
ℓ ( h ( x i ) , y i ) = σ 2 2 ( 1 − exp ( − ( y i − h ( x i ) ) 2 σ 2 ) ) \ell(h(x_i), y_i) = \frac{\sigma^2}{2}(1 - \exp(-\frac{(y_i - h(x_i))^2}{\sigma^2})) ℓ(h(xi),yi)=2σ2(1−exp(−σ2(yi−h(xi))2))
对于每个损失函数, g ′ ( 1 ) g'(1) g′(1)都会有一个与 c i = ( y i − h ( x i ) ) ( − h ( x i ) ) c_i = (y_i - h(x_i))(- h(x_i)) ci=(yi−h(xi))(−h(xi))相关的项。这个项可以被看作是数据点 ( x i , y i ) (x_i, y_i) (xi,yi)对损失函数的贡献与 h ( x i ) h(x_i) h(xi)的关系。具体地说, c i c_i ci可以被看作为两部分的乘积:
-
( y i − h ( x i ) ) (y_i - h(x_i)) (yi−h(xi)):这是观测值 y i y_i yi与预测值 h ( x i ) h(x_i) h(xi)之间的误差。此误差项衡量了模型在特定数据点上的预测准确性。
-
− h ( x i ) - h(x_i) −h(xi):这是模型预测的负值,这种乘积形式通常是为了衡量模型的响应强度和误差之间的关系。在某些情境中,更强烈的模型响应(无论正负)可能与更大的误差相关。
整体来说, c i c_i ci是一个衡量在数据点 ( x i , y i ) (x_i, y_i) (xi,yi)上模型响应强度与模型误差之间关系的量。不同的损失函数会对这些项赋予不同的权重,当误差(或噪声)增大时,某些损失函数会对这些项赋予更小的权重,从而更"鲁棒"。
NMF
-
标准的NMF (Basic NMF):
使用欧氏距离或Frobenius范数来最小化重建误差。此方法对噪声敏感。
min W , H ∥ X − W H ∥ F 2 subject to W ≥ 0 , H ≥ 0 \min_{W,H} \|X - WH\|_F^2 \text{ subject to } W \geq 0, H \geq 0 W,Hmin∥X−WH∥F2 subject to W≥0,H≥0 -
L1-Norm Regularized Robust NMF:
在NMF的基础上加入L1正则化项,旨在捕获噪声和离群值。
min W , H , E ∥ X − W H − E ∥ F 2 + λ ∥ E ∥ 1 subject to W ≥ 0 , H ≥ 0 \min_{W,H,E} \|X - WH - E\|_F^2 + \lambda \|E\|_1 \text{ subject to } W \geq 0, H \geq 0 W,H,Emin∥X−WH−E∥F2+λ∥E∥1 subject to W≥0,H≥0 -
L1-Norm Based NMF:
使用L1范数来衡量重建误差,使得分解更加鲁棒,尤其是对噪声和离群值。L1范数倾向于产生稀疏的解。
min W , H ∥ X − W H ∥ 1 subject to W ≥ 0 , H ≥ 0 \min_{W,H} \|X - WH\|_1 \text{ subject to } W \geq 0, H \geq 0 W,Hmin∥X−WH∥1 subject to W≥0,H≥0 -
L2,1-Norm Based NMF:
使用L2,1范数来增强鲁棒性。L2,1范数可以鼓励列的稀疏性,使得某些特定的特征在所有样本上都为零,这有助于去除离群值带来的影响。
min W , H ∥ X − W H ∥ 2 , 1 subject to W ≥ 0 , H ≥ 0 \min_{W,H} \|X - WH\|_{2,1} \text{ subject to } W \geq 0, H \geq 0 W,Hmin∥X−WH∥2,1 subject to W≥0,H≥0 -
Truncated Cauchy NMF:
这种方法使用截断的Cauchy损失来增加鲁棒性。与L1和L2范数相比,Cauchy损失更能够容忍较大的离群值,因此这种方法在面对有很多噪声和离群值的数据时更为鲁棒。 -
Hypersurface Cost Based NMF:
通过在损失函数中加入超曲面成本项来增加鲁棒性。此方法试图找到描述数据变化的超曲面,从而更好地应对噪声和离群值。
相关文章:

[Machine Learning] Learning with Noisy Data
文章目录 Probabilistic Perspective of NoiseBias and VarianceRobustness among Surrogate Loss FunctionsNMF Probabilistic Perspective of Noise 假设数据来源于一个确定的函数,叠加了高斯噪声。我们有: y h ( x ) ϵ y h(x) \epsilon yh(x)ϵ…...

C++中有哪些常用的标准库?
C中有许多常用的标准库,这些库提供了丰富的功能和工具,方便开发人员进行各种任务。以下是一些常见的C标准库: iostream:用于输入和输出操作,包括cin、cout和cerr等类和函数。algorithm:提供了许多常用的算…...

软考-信息安全工程师概述
本文为作者学习文章,按作者习惯写成,如有错误或需要追加内容请留言(不喜勿喷) 本文为追加文章,后期慢慢追加 2023年10月 信息考试大纲 通过本考试的合格人员能够掌握网络信息安全的基础知识和技术原理,…...

2023-2024年华为ICT网络赛道模拟题库
2023-2024年网络赛道模拟题库上线啦,全面覆盖网络,安全,vlan考点,都是带有解析 参赛对象及要求: 参赛对象:现有华为ICT学院及未来有意愿成为华为ICT学院的本科及高职院校在校学生。 参赛要求:…...

英特尔参与 CentOS Stream 项目
导读红帽官方发布公告欢迎英特尔参与进 CentOS Stream 项目,并表示 “这一举措不仅进一步深化了我们长期的合作关系,也构建在英特尔已经在 Fedora 项目中积极贡献的基础之上。” 目前,CentOS Stream 共包括以下特别兴趣小组(SIG&a…...

Centos 服务器 MySQL 8.0 快速开启远程访问
环境: MySQL 8.0(低版本会有些不同), Rocky Linux 9.0(CentOS) 直接上干货,相信大家看到这个文章的时候都已经安装完了。 1. 先从服务器上使用 root 进行登录(刚安装完默认只能本地…...
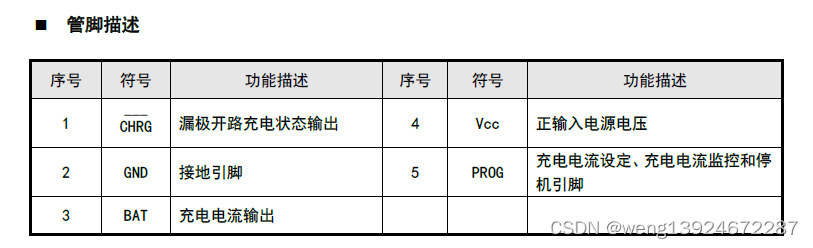
充电保护芯片TP4054国产替代完全兼容DP4054DP4054H 锂电充电芯片
■产品概述 DP4054H是-款完整的采用恒定电流/恒定电压单节锂离子电池充电管理芯片。其SOT小封装和较少的外部元件数目使其成为便携式应用的理想器件,DP4054H可 以适合USB电源和适配器电源工作。 由于采用了内部PMOSFET架构,加上防倒充电路,所以不需要外…...

Java Spring Boot中的爬虫防护机制
随着互联网的发展,爬虫技术也日益成熟和普及。然而,对于某些网站来说,爬虫可能会成为一个问题,导致资源浪费和安全隐患。本文将介绍如何使用Java Spring Boot框架来防止爬虫的入侵,并提供一些常用的防护机制。 引言&a…...

状态模式 行为型模式之六
1.定义 允许一个对象在其对象内部状态改变时改变它的行为。 2.组成结构 Context:定义客户感兴趣的接口;维护一个ConcreteState子类的实例,这个实例定义当前的状态。State:定义一个接口来封装Context的与特定状态相关的行为。Co…...
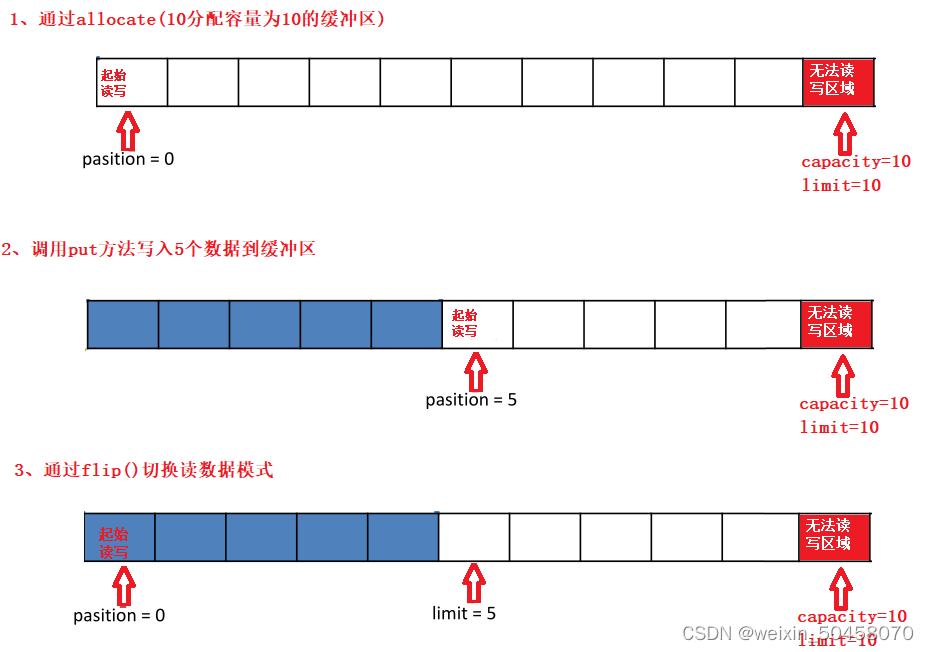
JAVA NIO深入剖析
4.1 Java NIO 基本介绍 Java NIO(New IO)也有人称之为 java non-blocking IO是从Java 1.4版本开始引入的一个新的IO API,可以替代标准的Java IO API。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的、基于通道的IO操作。NIO将以更加高效的方…...
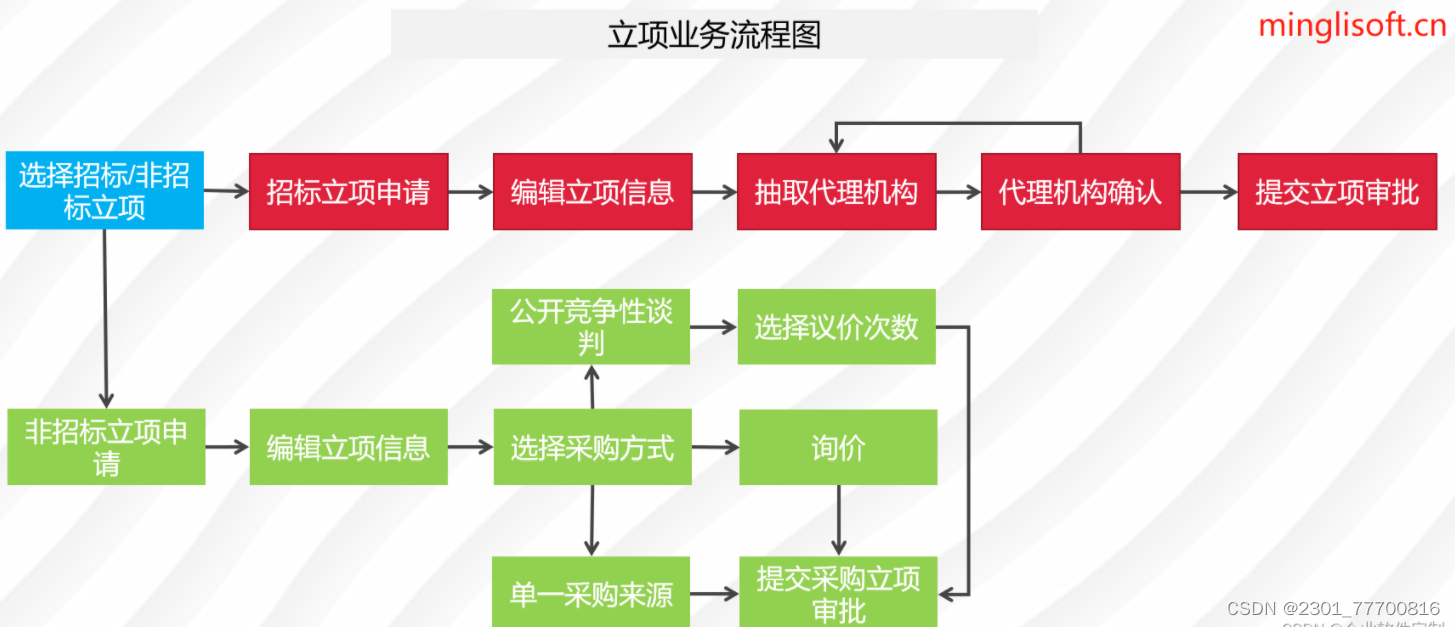
企业电子招投标系统源码之电子招投标系统建设的重点和未来趋势
功能描述 1、门户管理:所有用户可在门户页面查看所有的公告信息及相关的通知信息。主要板块包含:招标公告、非招标公告、系统通知、政策法规。 2、立项管理:企业用户可对需要采购的项目进行立项申请,并提交审批,查看所…...

基于正点原子alpha开发板的第三篇系统移植
系统移植的三大步骤如下: 系统uboot移植系统linux移植系统rootfs制作 一言难尽,踩了不少坑,当时只是想学习驱动开发,发现必须要将第三篇系统移植弄好才可以学习后面驱动,现将移植好的文件分享出来: 仓库&…...
数据结构与算法设计分析——贪心算法的应用
目录 一、贪心算法的定义二、贪心算法的基本步骤三、贪心算法的性质(一)最优子结构性质(二)贪心选择性质 四、贪心算法的应用(一)哈夫曼树——哈夫曼编码(二)图的应用——求最小生成…...

Leetcode 2895. Minimum Processing Time
Leetcode 2895. Minimum Processing Time 1. 解题思路2. 代码实现 题目链接:2895. Minimum Processing Time 1. 解题思路 这一题整体上来说其实没啥难度,就是一个greedy算法,只需要想明白耗时长的任务一定要优先执行,不存在某个…...

学信息系统项目管理师第4版系列21_范围管理
1. 产品范围 1.1. 某项产品、服务或成果所具有的特征和功能 1.2. 产品范围的完成情况是根据产品需求来衡量的 1.3. “需求”是指根据特定协议或其他强制性规范,产品、服务或成果必须具备的条件或能力 2. 项目范围 2.1. 包括产品范围,是为交付具有规…...

threejs 透明贴图,模型透明,白边
问题 使用Threejs加载模型时,模型出现了上面的问题。模型边缘部分白边,或者模型出现透明问题。 原因 出现这种问题是模型制作时使用了透明贴图。threejs无法直接处理贴图。 解决 场景一 模型有多个贴图时(一个透贴和其他贴图࿰…...

CCF CSP认证 历年题目自练Day21
题目一 试题编号: 201909-1 试题名称: 小明种苹果 时间限制: 2.0s 内存限制: 512.0MB 题目分析(个人理解) 先看输入,第一行输入苹果的棵树n和每一次掉的苹果数m还是先如何存的问题…...
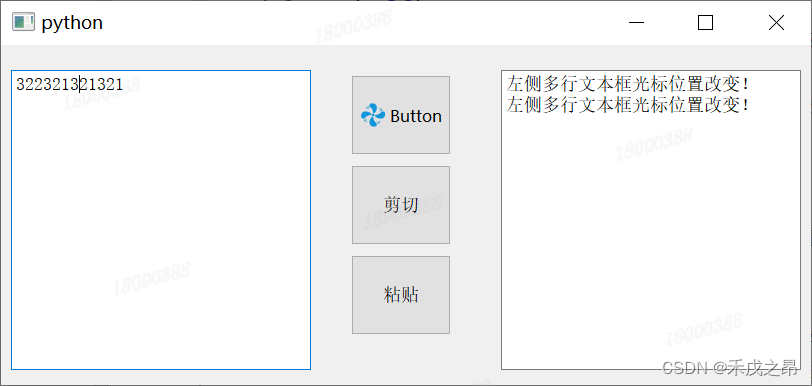
【Python_PySide2学习笔记(十六)】多行文本框QPlainTextEdit类的的基本用法
多行文本框QPlainTextEdit类的的基本用法 前言正文1、创建多行文本框2、多行文本框获取文本3、多行文本框获取选中文本4、多行文本框设置提示5、多行文本框设置文本6、多行文本框在末尾添加文本7、多行文本框在光标处插入文本8、多行文本框清空文本9、多行文本框拷贝文本到剪贴…...
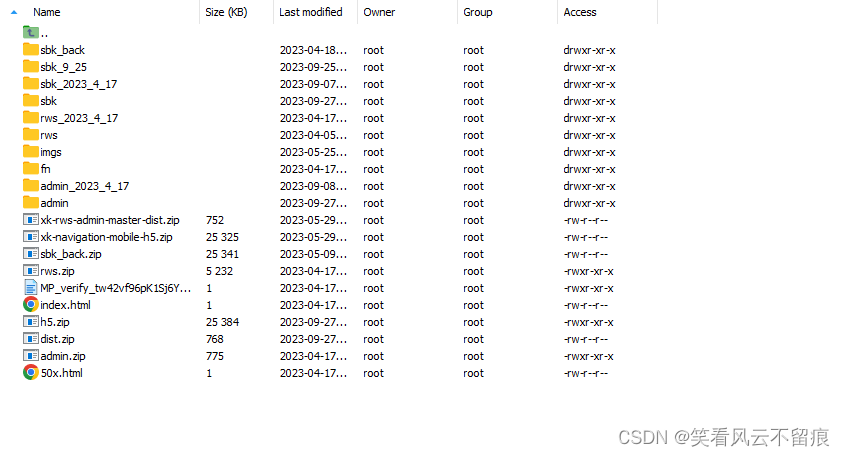
linux上negix部署静态页面
1.看配置文件 进入cndf.d 这里的是配置部署项目中的文件 进入一个查看下 上面的是服务的域名,服务是http://test.fun-med.cn/#/,后面加服务名(你的前端) 2.看下页面位置 和上面的路径要匹配...

41.说说Promise自身的静态方法
41.说说Promise自身的静态方法 Promise.all (有一个失败就失败,所有的都成功就成功)Promise.race (有一个成功就成功,有一个失败就失败)Promise.allSettled (所有的异步操作执行完毕之后&#…...

为什么你的NotebookLM总“读不懂”Nature论文?生信老炮拆解7类专业语义断层及5种Prompt工程修复方案
更多请点击: https://kaifayun.com 第一章:NotebookLM生物技术研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为知识密集型工作流设计。在生物技术领域,它可高效整合海量文献、实验报告与基因组数据库摘要&#x…...

基于MCP协议实现AI安全访问MongoDB:架构、部署与安全实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想让大语言模型(LLM)能直接操作数据库,比如MongoDB。这听起来很酷,对吧?想象一下,你直接告诉AI助手“帮我查一下上个月销量最高的产品”&…...

nardeas/ssh-agent:增强版SSH代理工具的设计、部署与实战应用
1. 项目概述:一个被低估的SSH代理工具如果你和我一样,日常需要在多台服务器、开发机、跳板机之间穿梭,手里捏着十几把甚至几十把SSH密钥,那你一定对ssh-agent这个工具又爱又恨。爱的是,它确实能让你免去一遍遍输入密钥…...

用户为中心交互系统工程在智能制造系统中应用
用户为中心交互系统工程(User-Centered Interaction System Engineering, UCI-SE)是智能制造与 AI 时代下,重塑传统工业软件(如 MES、ERP、SCADA)和硬件控制终端(如 HMI、具身智能教导盒)的核心…...

5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐
5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...

长期使用Taotoken的体验,账单清晰与模型切换便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的体验,账单清晰与模型切换便利性 作为长期将大模型能力集成到项目中的开发者,选择一个稳…...

SolidWorks二次开发踩坑记:Python调用SaveAs函数时,那些让人头疼的Errors和Warnings详解
SolidWorks二次开发实战:Python调用SaveAs函数时的错误码解析与解决方案 当你在深夜加班调试SolidWorks二次开发脚本时,SaveAs函数突然返回False,错误码像摩尔斯电码一样难以解读——这种经历恐怕每个工业软件开发者都深有体会。本文将深入剖…...

崩坏星穹铁道终极自动化指南:三月七小助手完整使用教程
崩坏星穹铁道终极自动化指南:三月七小助手完整使用教程 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中繁琐的日常…...

【AI Agent软件直控革命】:20年架构师亲授5大落地陷阱与3步安全接入法
更多请点击: https://intelliparadigm.com 第一章:AI Agent软件直控革命:从概念到产业拐点 AI Agent 已不再停留于对话式助手或任务调度器的初级形态,正加速演进为具备环境感知、自主决策与系统级直控能力的“数字执行体”。其核…...

BOX工控机在无人机机载系统中有什么优势?这 3 点是普通工控机比不了的
现在的无人机机载系统,越来越多的人选择用 BOX工控机。很多人问我,BOX工控机到底是什么?它和普通的工控机有什么区别?为什么大家都在用它?今天我就跟大家好好聊聊这个话题。我会从一个 17 年工控人的角度,给大家讲透 BOX工控机在无人机机载…...