32、Flink table api和SQL 之用户自定义 Sources Sinks实现及详细示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、用户自定义 Sources & Sinks 介绍
- 1、Metadata元数据
- 2、Planning解析器
- 3、Runtime运行时的实现
- 4、maven依赖
- 5、需要实现的点
- 1)、动态表的工厂类DynamicTableFactory
- 2)、动态表的 source 端
- 1、Scan Table Source
- 2、Lookup Table Source
- 3、source 端的功能接口
- 3)、动态表的 sink 端
- 1、sink 端的功能接口
- 4)、编码与解码
- 二、用户自定义source 示例
- 1、maven依赖
- 2、工厂实现
- 1)、动态工厂实现-SocketDynamicTableFactory
- 2)、解码器工厂实现-ChangelogCsvFormatFactory
- 3、source 端与解码实现
- 1)、source端实现-SocketDynamicTableSource
- 2)、数据解码-ChangelogCsvFormat
- 4、运行时
- 1)、接收数据源数据-SocketSourceFunction
- 2)、接收的数据解析-ChangelogCsvDeserializer
- 5、工厂类配置
- 6、验证
- 1)、确保nc已经完成并可用
- 2)、mysql创建表UserScoresSink
- 3)、创建java验证类
- 4)、验证插入INSERT数据
- 5)、验证删除DELETE数据
- 6)、验证更新UPDATE数据
- 7)、验证输入非string和int数据类型
本文简单介绍了Flink table api & SQL用户自定义实现source和sink的步骤,并以实际示例介绍了实现source端和验证步骤。
本文依赖flink和mysql集群能正常使用。
本文分为2个部分,即自定义实现source和sink的需要做的工作以及自定义实现source端的具体示例、验证步骤。
本文示例均是在Flink 1.17版本的环境中运行的。
一、用户自定义 Sources & Sinks 介绍
动态表是 Flink Table & SQL API的核心概念,用于统一有界和无界数据的处理。
动态表只是一个逻辑概念,因此 Flink 并不拥有数据。相应的,动态表的内容存储在外部系统( 如数据库、键值存储、消息队列 )或文件中。
动态 sources 和动态 sinks 可用于从外部系统读取数据和向外部系统写入数据。
Flink 为 Kafka、Hive 和不同的文件系统提供了预定义的连接器。有关内置 table sources 和 sinks 的更多信息参考4、介绍Flink的流批一体、transformations的18种算子详细介绍、Flink与Kafka的source、sink介绍
从 Flink v1.16 开始, TableEnvironment 引入了一个用户类加载器,以在 table 程序、SQL Client、SQL Gateway 中保持一致的类加载行为。该类加载器会统一管理所有的用户 jar 包,包括通过 ADD JAR 或 CREATE FUNCTION … USING JAR … 添加的 jar 资源。 在用户自定义连接器中,应该将 Thread.currentThread().getContextClassLoader() 替换成该用户类加载器去加载类。否则,可能会发生 ClassNotFoundException 的异常。该用户类加载器可以通过 DynamicTableFactory.Context 获得。
在许多情况下,开发人员不需要从头开始创建新的连接器,而是希望稍微修改现有的连接器或 hook 到现有的 stack。在其他情况下,开发人员希望创建专门的连接器。
本节对这两种用例都有帮助。它解释了表连接器的一般体系结构,从 API 中的纯粹声明到在集群上执行的运行时代码
实心箭头展示了在转换过程中对象如何从一个阶段到下一个阶段转换为其他对象。
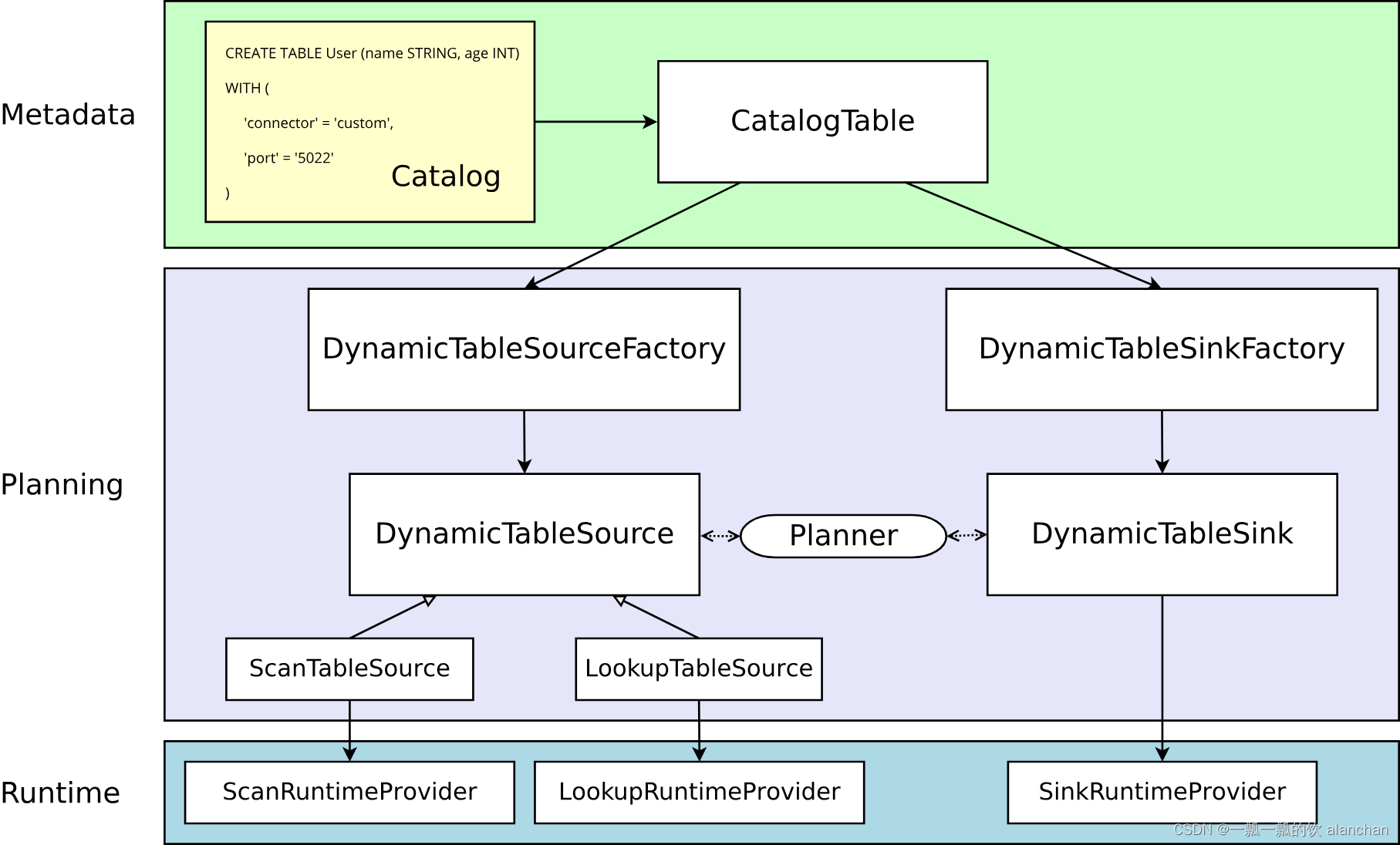
1、Metadata元数据
Table API 和 SQL 都是声明式 API。这包括表的声明。因此,执行 CREATE TABLE 语句会导致目标 catalog 中的元数据更新。
对于大多数 catalog 实现,外部系统中的物理数据不会针对此类操作进行修改。特定于连接器的依赖项不必存在于类路径中。在 WITH 子句中声明的选项既不被验证也不被解释。
动态表的元数据( 通过 DDL 创建或由 catalog 提供 )表示为 CatalogTable 的实例。必要时,表名将在内部解析为 CatalogTable。
2、Planning解析器
在解析和优化以 table 编写的程序时,需要将 CatalogTable 解析为 DynamicTableSource( 用于在 SELECT 查询中读取 )和 DynamicTableSink( 用于在 INSERT INTO 语句中写入 )。
DynamicTableSourceFactory 和 DynamicTableSinkFactory 提供连接器特定的逻辑,用于将 CatalogTable 的元数据转换为 DynamicTableSource 和 DynamicTableSink 的实例。在大多数情况下,以工厂模式设计的目的是验证选项(例如示例中的 ‘port’ = ‘5022’ ),配置编码解码格式( 如果需要 ),并创建表连接器的参数化实例。
默认情况下,DynamicTableSourceFactory 和 DynamicTableSinkFactory 的实例是使用 Java的 [Service Provider Interfaces (SPI)] (https://docs.oracle.com/javase/tutorial/sound/SPI-intro.html) 发现的。 connector 选项(例如示例中的 ‘connector’ = ‘custom’)必须对应于有效的工厂标识符。
尽管在类命名中可能不明显,但 DynamicTableSource 和 DynamicTableSink 也可以被视为有状态的工厂,它们最终会产生具体的运行时实现来读写实际数据。
规划器使用 source 和 sink 实例来执行连接器特定的双向通信,直到找到最佳逻辑规划。取决于声明可选的接口( 例如 SupportsProjectionPushDown 或 SupportsOverwrite),规划器可能会将更改应用于实例并且改变产生的运行时实现。
3、Runtime运行时的实现
一旦逻辑规划完成,规划器将从表连接器获取 runtime implementation。运行时逻辑在 Flink 的核心连接器接口中实现,例如 InputFormat 或 SourceFunction。
这些接口按另一个抽象级别被分组为 ScanRuntimeProvider、LookupRuntimeProvider 和 SinkRuntimeProvider 的子类。
例如,OutputFormatProvider( 提供 org.apache.flink.api.common.io.OutputFormat )和 SinkFunctionProvider( 提供org.apache.flink.streaming.api.functions.sink.SinkFunction)都是规划器可以处理的 SinkRuntimeProvider 具体实例。
4、maven依赖
如果要实现自定义连接器或自定义格式,通常以下依赖项就足够了:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>1.17.1</version><scope>provided</scope>
</dependency>如果开发一个需要与 DataStream API 桥接的连接器( 即:如果你想将 DataStream 连接器适配到 Table API),你需要添加此依赖项:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>1.17.1</version><scope>provided</scope>
</dependency>在开发 connector/format 时,我们建议同时提供 Thin JAR 和 uber JAR,以便用户可以轻松地在 SQL 客户端或 Flink 发行版中加载 uber JAR 并开始使用它。 uber JAR 应该包含连接器的所有第三方依赖,不包括上面列出的表依赖。
你不应该在生产代码中依赖 flink-table-planner_2.12。 使用 Flink 1.15 中引入的新模块 flink-table-planner-loader,应用程序的类路径将不再直接访问 org.apache.flink.table.planner 类。 如果你需要 org.apache.flink.table.planner 的包和子包内部可用的功能,请开启一个 issue。
5、需要实现的点
这一部分主要介绍扩展 Flink table connector 时可能用到的接口。
1)、动态表的工厂类DynamicTableFactory
在根据 catalog 与 Flink 运行时上下文信息,为某个外部存储系统配置动态表连接器时,需要用到动态表的工厂类。
-
通过实现 org.apache.flink.table.factories.DynamicTableSourceFactory 接口完成一个工厂类,来生产 DynamicTableSource 类。
-
通过实现 org.apache.flink.table.factories.DynamicTableSinkFactory 接口完成一个工厂类,来生产 DynamicTableSink 类。
默认情况下,Java 的 SPI 机制会自动识别这些工厂类,同时将 connector 配置项作为工厂类的”IDENTIFIER标识符“。
在 JAR 文件中,需要将实现的工厂类路径放入到下面这个配置文件:
META-INF/services/org.apache.flink.table.factories.Factory
Flink 会对工厂类逐个进行检查,确保其“标识符”是全局唯一的,并且按照要求实现了上面提到的接口 (比如 DynamicTableSourceFactory)。
如果必要的话,也可以在实现 catalog 时绕过上述 SPI 机制识别工厂类的过程。即在实现 catalog 接口时,在org.apache.flink.table.catalog.Catalog#getFactory 方法中直接返回工厂类的实例。
2)、动态表的 source 端
按照定义,动态表是随时间变化的。
在读取动态表时,表中数据可以是以下情况之一:
- changelog 流(支持有界或无界),在 changelog 流结束前,所有的改变都会被源源不断地消费,由 ScanTableSource 接口表示。
- 处于一直变换或数据量很大的外部表,其中的数据一般不会被全量读取,除非是在查询某个值时,由 LookupTableSource 接口表示。
一个类可以同时实现这两个接口,Planner 会根据查询的 Query 选择相应接口中的方法。
1、Scan Table Source
在运行期间,ScanTableSource 接口会按行扫描外部存储系统中所有数据。
被扫描的数据可以是 insert、update、delete 三种操作类型,因此数据源可以用作读取 changelog (支持有界或无界)。在运行时,返回的 changelog mode 表示 Planner 要处理的操作类型。
在常规批处理的场景下,数据源可以处理 insert-only 操作类型的有界/无界数据流。
在变更日志数据捕获(即 CDC)场景下,数据源可以处理 insert、update、delete 操作类型的有界或无界数据流。
可以实现更多的功能接口来优化数据源,比如实现 SupportsProjectionPushDown 接口,这样在运行时在 source 端就处理数据。在 org.apache.flink.table.connector.source.abilities 包下可以找到各种功能接口,下文中有列出。
实现 ScanTableSource 接口的类必须能够生产 Flink 内部数据结构,因此每条记录都会按照org.apache.flink.table.data.RowData 的方式进行处理。Flink 运行时提供了转换机制保证 source 端可以处理常见的数据结构,并且在最后进行转换。
2、Lookup Table Source
在运行期间,LookupTableSource 接口会在外部存储系统中按照 key 进行查找。
相比于ScanTableSource,LookupTableSource 接口不会全量读取表中数据,只会在需要时向外部存储(其中的数据有可能会一直变化)发起查询请求,惰性地获取数据。
同时相较于ScanTableSource,LookupTableSource 接口目前只支持处理 insert-only 数据流。
暂时不支持扩展功能接口,可查看 org.apache.flink.table.connector.source.LookupTableSource 中的文档了解更多。
LookupTableSource 的实现方法可以是 TableFunction 或者 AsyncTableFunction,Flink运行时会根据要查询的 key 值,调用这个实现方法进行查询。
3、source 端的功能接口
| 接口名称 | 接口描述 |
|---|---|
| SupportsFilterPushDown | 支持将过滤条件下推到 DynamicTableSource。为了更高效处理数据,source 端会将过滤条件下推,以便在数据产生时就处理。 |
| SupportsLimitPushDown | 支持将 limit(期望生产的最大数据条数)下推到 DynamicTableSource。 |
| SupportsPartitionPushDown | 支持将可用的分区信息提供给 planner 并且将分区信息下推到 DynamicTableSource。在运行时为了更高效处理数据,source 端会只从提供的分区列表中读取数据。 |
| SupportsProjectionPushDown | 支持将查询列(可嵌套)下推到 DynamicTableSource。为了更高效处理数据,source 端会将查询列下推,以便在数据产生时就处理。如果 source 端同时实现了 SupportsReadingMetadata,那么 source 端也会读取相对应列的元数据信息。 |
| SupportsReadingMetadata | 支持通过 DynamicTableSource 读取列的元数据信息。source 端会在生产数据行时,在最后添加相应的元数据信息,其中包括元数据的格式信息。 |
| SupportsWatermarkPushDown | 支持将水印策略下推到 DynamicTableSource。水印策略可以通过工厂模式或 Builder 模式来构建,用于抽取时间戳以及水印的生成。在运行时,source 端内部的水印生成器会为每个分区生产水印。 |
| SupportsSourceWatermark | 支持使用 ScanTableSource 中提供的水印策略。当使用 CREATE TABLE DDL 时,<可以使用> SOURCE_WATERMARK() 来告诉 planner 调用这个接口中的水印策略方法。 |
| SupportsRowLevelModificationScan | 支持将读数据的上下文 RowLevelModificationScanContext 从 ScanTableSource 传递给实现了 SupportsRowLevelDelete,SupportsRowLevelUpdate 的 sink 端。 |
上述接口当前只适用于 ScanTableSource,不适用于LookupTableSource。
3)、动态表的 sink 端
动态表是随时间变化的。
当写入一个动态表时,数据流可以被看作是 changelog (有界或无界都可),在 changelog 结束前,所有的变更都会被持续写入。在运行时,返回的 changelog mode 会显示 sink 端支持的数据操作类型。
在常规批处理的场景下,sink 端可以持续接收 insert-only 操作类型的数据,并写入到有界/无界数据流中。
在变更日志数据捕获(即 CDC)场景下,sink 端可以将 insert、update、delete 操作类型的数据写入有界或无界数据流。
可以实现 SupportsOverwrite 等功能接口,在 sink 端处理数据。可以在 org.apache.flink.table.connector.sink.abilities 包下找到各种功能接口,更多内容可查看下文接口介绍。
实现 DynamicTableSink 接口的类必须能够处理 Flink 内部数据结构,因此每条记录都会按照 org.apache.flink.table.data.RowData 的方式进行处理。Flink 运行时提供了转换机制来保证在最开始进行数据类型转换,以便 sink 端可以处理常见的数据结构。
1、sink 端的功能接口
| 接口名称 | 接口描述 |
|---|---|
| SupportsOverwrite | 支持 DynamicTableSink 覆盖写入已存在的数据。默认情况下,如果不实现这个接口,在使用 INSERT OVERWRITE SQL 语法时,已存在的表或分区不会被覆盖写入 |
| SupportsPartitioning | 支持 DynamicTableSink 写入分区数据。 |
| SupportsWritingMetadata | 支持 DynamicTableSink 写入元数据列。Sink 端会在消费数据行时,在最后接受相应的元数据信息并进行持久化,其中包括元数据的格式信息。 |
| SupportsDeletePushDown | 支持将 DELETE 语句中的过滤条件下推到 DynamicTableSink,sink 端可以直接根据过滤条件来删除数据。 |
| SupportsRowLevelDelete | 支持 DynamicTableSink 根据行级别的变更来删除已有的数据。该接口的实现者需要告诉 Planner 如何产生这些行变更,并且需要消费这些行变更从而达到删除数据的目的。 |
| SupportsRowLevelUpdate | 支持 DynamicTableSink 根据行级别的变更来更新已有的数据。该接口的实现者需要告诉 Planner 如何产生这些行变更,并且需要消费这些行变更从而达到更新数据的目的。 |
4)、编码与解码
有的表连接器支持 K/V 型数据的各类编码与解码方式。
编码与解码格式器的工作原理类似于 DynamicTableSourceFactory -> DynamicTableSource -> ScanRuntimeProvider,其中工厂类负责传参,source 负责提供处理逻辑。
由于编码与解码格式器处于不同的代码模块,类似于table factories,它们都需要通过 Java 的 SPI 机制自动识别。为了找到格式器的工厂类,动态表工厂类会根据该格式器工厂类的”标识符“来搜索,并确认其实现了连接器相关的基类。
比如,Kafka 的 source 端需要一个实现了 DeserializationSchema 接口的类,用来为数据解码。那么 Kafka 的 source 端工厂类会使用配置项 value.format 的值来发现 DeserializationFormatFactory。
截至版本Flink 1.17,支持使用如下格式器工厂类:
org.apache.flink.table.factories.DeserializationFormatFactory
org.apache.flink.table.factories.SerializationFormatFactory
格式器工厂类再将配置传参给 EncodingFormat 或 DecodingFormat。这些接口是另外一种工厂类,用于为所给的数据类型生成指定的格式器。
例如 Kafka 的 source 端工厂类 DeserializationFormatFactory 会为 Kafka 的 source 端返回 EncodingFormat
二、用户自定义source 示例
本示例介绍从一个自定义的数据源读取数据,并存入mysql数据库中。实现的功能有自定义的解码器和scan table的source。数据源以socket为示例。
本示例是在IDE中运行的,也可以放在Flink sql cli中运行,前提是打包放在flink lib的目录,此处不再赘述。
本部分涉及到配置factory,所以示例代码将包名称带上了。
该示例实现的功能包含:
- 创建工厂类实现配置项的解析与校验
- 实现表连接器
- 实现与发现自定义的编码/解码格式器
- 其他工具类,数据结构的转换器以及一个FactoryUtil类
source 端通过实现一个单线程的 SourceFunction 接口,绑定一个 socket 端口来监听字节流字节流会被解码为一行一行的数据,解码器是可插拔的。解码方式是将第一列数据作为这条数据的操作类型。
1、maven依赖
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>${flink.version}</version><scope>provided</scope></dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-gateway --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-gateway</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-uber --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-uber</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-runtime --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version><scope>provided</scope></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency></dependencies>
2、工厂实现
介绍如何从 catalog 中解析元数据信息来构建表连接器的实例。
1)、动态工厂实现-SocketDynamicTableFactory
SocketDynamicTableFactory 根据 catalog 表信息,生成表的 source 端。由于 source 端需要进行对数据解码,通过 FactoryUtil 类来找到解码器。
package org.tablesql.userdefine.factory;import java.util.HashSet;
import java.util.Set;import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.DeserializationFormatFactory;
import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.types.DataType;
import org.tablesql.userdefine.source.SocketDynamicTableSource;/*** @author alanchan**/
public class SocketDynamicTableFactory implements DynamicTableSourceFactory {// 定义ddl中的with子句内容public static final ConfigOption<String> HOSTNAME = ConfigOptions.key("hostname").stringType().noDefaultValue();public static final ConfigOption<Integer> PORT = ConfigOptions.key("port").intType().noDefaultValue();// 等同于 '\n'public static final ConfigOption<Integer> BYTE_DELIMITER = ConfigOptions.key("byte-delimiter").intType().defaultValue(10);// 用于匹配: `connector = '...'`public static final String IDENTIFIER = "alan_socket";// 用于匹配: `connector = '...'`@Overridepublic String factoryIdentifier() {return IDENTIFIER;}@Overridepublic Set<ConfigOption<?>> requiredOptions() {final Set<ConfigOption<?>> options = new HashSet<>();options.add(HOSTNAME);options.add(PORT);// 解码的格式器使用预先定义的配置项options.add(FactoryUtil.FORMAT);return options;}@Overridepublic Set<ConfigOption<?>> optionalOptions() {final Set<ConfigOption<?>> options = new HashSet<>();options.add(BYTE_DELIMITER);return options;}@Overridepublic DynamicTableSource createDynamicTableSource(Context context) {// 使用提供的工具类或实现你自己的逻辑进行校验final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);// 找到合适的解码器final DecodingFormat<DeserializationSchema<RowData>> decodingFormat = helper.discoverDecodingFormat(DeserializationFormatFactory.class, FactoryUtil.FORMAT);// 校验所有的配置项helper.validate();// 获取校验完的配置项final ReadableConfig options = helper.getOptions();final String hostname = options.get(HOSTNAME);final int port = options.get(PORT);final byte byteDelimiter = (byte) (int) options.get(BYTE_DELIMITER);// 从 catalog 中抽取要生产的数据类型 (除了需要计算的列)final DataType producedDataType = context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType();// 创建并返回动态表 sourcereturn new SocketDynamicTableSource(hostname, port, byteDelimiter, decodingFormat, producedDataType);}}2)、解码器工厂实现-ChangelogCsvFormatFactory
ChangelogCsvFormatFactory 根据解码器相关的配置构建解码器。SocketDynamicTableFactory 中的 FactoryUtil 会适配好配置项中的键,并处理 changelog-csv.column-delimiter 这样带有前缀的键。
由于这个工厂类实现了 DeserializationFormatFactory 接口,它也可以为其他连接器(比如 Kafka 连接器)提供反序列化的解码支持。
package org.tablesql.userdefine.factory;import java.util.Collections;
import java.util.HashSet;
import java.util.Set;import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.DeserializationFormatFactory;
import org.apache.flink.table.factories.DynamicTableFactory.Context;
import org.apache.flink.table.factories.FactoryUtil;
import org.tablesql.userdefine.source.ChangelogCsvFormat;/*** @author alanchan**/
public class ChangelogCsvFormatFactory implements DeserializationFormatFactory {// 定义所有配置项,由于使用了新的changlog,其他源端实现的csv编码格式的定义不再适用// 使用“,”作为数据的分隔符public static final ConfigOption<String> COLUMN_DELIMITER = ConfigOptions.key("column-delimiter").stringType().defaultValue(",");// with子句中的 'format' = 'alan_changelog-csv' 和 'alan_changelog-csv.column-delimiter' = ','public static final String IDENTIFIER = "alan_changelog-csv";@Overridepublic DecodingFormat<DeserializationSchema<RowData>> createDecodingFormat(Context context, ReadableConfig formatOptions) {// 1、使用提供的工具类或实现你自己的逻辑进行校验FactoryUtil.validateFactoryOptions(this, formatOptions);// 2、获取校验完的配置项final String columnDelimiter = formatOptions.get(COLUMN_DELIMITER);// 3、创建并返回解码器return new ChangelogCsvFormat(columnDelimiter);}@Overridepublic String factoryIdentifier() {return IDENTIFIER;}@Overridepublic Set<ConfigOption<?>> requiredOptions() {return Collections.emptySet();}@Overridepublic Set<ConfigOption<?>> optionalOptions() {final Set<ConfigOption<?>> options = new HashSet<>();options.add(COLUMN_DELIMITER);return options;}}3、source 端与解码实现
这部分介绍在计划阶段的 source 与 解码器实例,是如何转化为运行时实例,以便于提交给集群。
1)、source端实现-SocketDynamicTableSource
SocketDynamicTableSource 在计划阶段中会被用到。本示例中,我们不会实现任何功能接口,因此,getScanRuntimeProvider(…) 方法中就是主要逻辑:对 SourceFunction 以及其用到的 DeserializationSchema 进行实例化,作为运行时的实例。两个实例都被参数化来返回内部数据结构(比如 RowData)。
package org.tablesql.userdefine.source;import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.connector.source.ScanTableSource;
import org.apache.flink.table.connector.source.SourceFunctionProvider;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
import org.tablesql.userdefine.runtime.SocketSourceFunction;/*** @author alanchan**/
public class SocketDynamicTableSource implements ScanTableSource {private final String hostname;private final int port;private final byte byteDelimiter;private final DecodingFormat<DeserializationSchema<RowData>> decodingFormat;private final DataType producedDataType;public SocketDynamicTableSource(String hostname, int port, byte byteDelimiter, DecodingFormat<DeserializationSchema<RowData>> decodingFormat, DataType producedDataType) {this.hostname = hostname;this.port = port;this.byteDelimiter = byteDelimiter;this.decodingFormat = decodingFormat;this.producedDataType = producedDataType;}@Overridepublic DynamicTableSource copy() {return new SocketDynamicTableSource(hostname, port, byteDelimiter, decodingFormat, producedDataType);}@Overridepublic String asSummaryString() {return "Socket Table Source";}@Overridepublic ChangelogMode getChangelogMode() {// 在该示例中,由解码器来决定 changelog 支持的模式, 但是在 source 端指定也可以return decodingFormat.getChangelogMode();}/*** 对 SourceFunction 以及其用到的 DeserializationSchema 进行实例化,作为运行时的实例。* 两个实例都被参数化来返回内部数据结构(比如 RowData)*/@Overridepublic ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {// 创建运行时类用于提交给集群final DeserializationSchema<RowData> deserializer = decodingFormat.createRuntimeDecoder(runtimeProviderContext, producedDataType);final SourceFunction<RowData> sourceFunction = new SocketSourceFunction(hostname, port, byteDelimiter, deserializer);return SourceFunctionProvider.of(sourceFunction, false);}}2)、数据解码-ChangelogCsvFormat
ChangelogCsvFormat 在运行时使用 DeserializationSchema 为socket的输入数据进行解码,这里支持处理 INSERT、DELETE 变更类型的数据,如果输入数据类型为UPDATE_BEFORE或UPDATE_AFTER,则忽略;如果需要该种类型的数据则直接addContainedKind即可。 输入数据格式:
// INSERT,alanchan,5
// DELETE,alan,10
package org.tablesql.userdefine.source;import java.util.List;import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource.Context;
import org.apache.flink.table.connector.source.DynamicTableSource.DataStructureConverter;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
import org.apache.flink.table.types.logical.LogicalType;
import org.apache.flink.types.RowKind;
import org.tablesql.userdefine.runtime.ChangelogCsvDeserializer;/*** @author alanchan**/
public class ChangelogCsvFormat implements DecodingFormat<DeserializationSchema<RowData>> {private final String columnDelimiter;public ChangelogCsvFormat(String columnDelimiter) {this.columnDelimiter = columnDelimiter;}@Overridepublic ChangelogMode getChangelogMode() {// 支持处理 `INSERT`、`DELETE` 变更类型的数据,如果输入数据类型为UPDATE_BEFORE或UPDATE_AFTER,则忽略;如果需要该种类型的数据则直接addContainedKind即可// 输入数据格式:// INSERT,alanchan,5// DELETE,alan,10return ChangelogMode.newBuilder().addContainedKind(RowKind.INSERT).addContainedKind(RowKind.DELETE).build();}@Overridepublic DeserializationSchema<RowData> createRuntimeDecoder(Context context, DataType producedDataType) {// 为 DeserializationSchema 创建类型信息 (TypeInformation<RowData>)final TypeInformation<RowData> producedTypeInfo = context.createTypeInformation(producedDataType);// DeserializationSchema 中的大多数代码无法处理内部数据结构, 在最后为转换创建一个转换器final DataStructureConverter converter = context.createDataStructureConverter(producedDataType);// 在运行时,为解析过程提供逻辑类型final List<LogicalType> parsingTypes = producedDataType.getLogicalType().getChildren();// 创建运行时类return new ChangelogCsvDeserializer(parsingTypes, converter, producedTypeInfo, columnDelimiter);}}4、运行时
该部分不是定义source端的必须部分,仅是为了验证source端的自定义数据运行情况,而实际的开发中该部分是必须的,否则自定义的数据源不可能不被识别。
这部分介绍接收数据源数据( SourceFunction)和解析数据源数据(DeserializationSchema)。
1)、接收数据源数据-SocketSourceFunction
SocketSourceFunction 会监听一个 socket 端口并持续消费字节流。它会按照给定的分隔符拆分每条记录,并由 DeserializationSchema 进行解码。
package org.tablesql.userdefine.runtime;import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.InetSocketAddress;
import java.net.Socket;import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.ResultTypeQueryable;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.metrics.MetricGroup;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.table.data.RowData;
import org.apache.flink.util.UserCodeClassLoader;/*** @author alanchan**/
public class SocketSourceFunction extends RichSourceFunction<RowData> implements ResultTypeQueryable<RowData> {private final String hostname;private final int port;private final byte byteDelimiter;private final DeserializationSchema<RowData> deserializer;private volatile boolean isRunning = true;private Socket currentSocket;public SocketSourceFunction(String hostname, int port, byte byteDelimiter, DeserializationSchema<RowData> deserializer) {this.hostname = hostname;this.port = port;this.byteDelimiter = byteDelimiter;this.deserializer = deserializer;}/*** 监听ddl定义的 socket 端口并持续消费字节流,即从socket端持续读取数据并解析数据,该示例的并行度为1*/@Overridepublic void run(SourceContext<RowData> ctx) throws Exception {while (isRunning) {try (final Socket socket = new Socket()) {currentSocket = socket;socket.connect(new InetSocketAddress(hostname, port), 0);try (InputStream stream = socket.getInputStream()) {ByteArrayOutputStream buffer = new ByteArrayOutputStream();int b;while ((b = stream.read()) >= 0) {// 持续写入 buffer 直到遇到分隔符if (b != byteDelimiter) {buffer.write(b);}// 解码并处理记录else {ctx.collect(deserializer.deserialize(buffer.toByteArray()));buffer.reset();}}}} catch (Throwable t) {t.printStackTrace(); }Thread.sleep(1000);}}@Overridepublic void cancel() {isRunning = false;try {currentSocket.close();} catch (Throwable t) {// 忽略}}@Overridepublic TypeInformation<RowData> getProducedType() {return deserializer.getProducedType();}@Overridepublic void open(Configuration parameters) throws Exception {deserializer.open(new DeserializationSchema.InitializationContext() {@Overridepublic UserCodeClassLoader getUserCodeClassLoader() {return (UserCodeClassLoader) getRuntimeContext().getUserCodeClassLoader();}@Overridepublic MetricGroup getMetricGroup() {return getRuntimeContext().getMetricGroup();}});}}2)、接收的数据解析-ChangelogCsvDeserializer
ChangelogCsvDeserializer 的解析逻辑比较简单:将字节流数据解析为由 Integer 和 String 组成的 Row 类型,并附带这条数据的操作类型,最后将其转换为内部数据结构。
package org.tablesql.userdefine.runtime;import java.io.IOException;
import java.util.List;import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.table.connector.RuntimeConverter.Context;
import org.apache.flink.table.connector.source.DynamicTableSource.DataStructureConverter;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.LogicalType;
import org.apache.flink.table.types.logical.LogicalTypeRoot;
import org.apache.flink.types.Row;
import org.apache.flink.types.RowKind;import com.google.re2j.Pattern;/*** @author alanchan* 将字节流数据解析为由 Integer 和 String 组成的 Row 类型,并附带这条数据的操作类型,最后将其转换为内部数据结构*/
public class ChangelogCsvDeserializer implements DeserializationSchema<RowData> {private final List<LogicalType> parsingTypes;private final DataStructureConverter converter;private final TypeInformation<RowData> producedTypeInfo;private final String columnDelimiter;public ChangelogCsvDeserializer(List<LogicalType> parsingTypes, DataStructureConverter converter, TypeInformation<RowData> producedTypeInfo, String columnDelimiter) {this.parsingTypes = parsingTypes;this.converter = converter;this.producedTypeInfo = producedTypeInfo;this.columnDelimiter = columnDelimiter;}@Overridepublic TypeInformation<RowData> getProducedType() {// 为 Flink 的核心接口提供类型信息。return producedTypeInfo;}@Overridepublic void open(InitializationContext context) {// 转化器必须要被开启。converter.open(Context.create(ChangelogCsvDeserializer.class.getClassLoader()));}@Overridepublic RowData deserialize(byte[] message) throws IOException {// 按列解析数据,其中一列是 changelog 标记。数据格式形如:INSERT,alan,10final String[] columns = new String(message).split(Pattern.quote(columnDelimiter));final RowKind kind = RowKind.valueOf(columns[0]);final Row row = new Row(kind, parsingTypes.size());for (int i = 0; i < parsingTypes.size(); i++) {row.setField(i, parse(parsingTypes.get(i).getTypeRoot(), columns[i + 1]));}// 转换为内部数据结构return (RowData) converter.toInternal(row);}//解析输入数据类型,本文定义的数据有2种数据类型,即string和int,如果有更多的数据类型,则在该处进行解析private static Object parse(LogicalTypeRoot root, String value) {switch (root) {case INTEGER:return Integer.parseInt(value);case VARCHAR:return value;default:throw new IllegalArgumentException();}}@Overridepublic boolean isEndOfStream(RowData nextElement) {return false;}}5、工厂类配置
如果确保工厂类配置能正常使用,则需要进行配置。
本示例的目录结构如下:
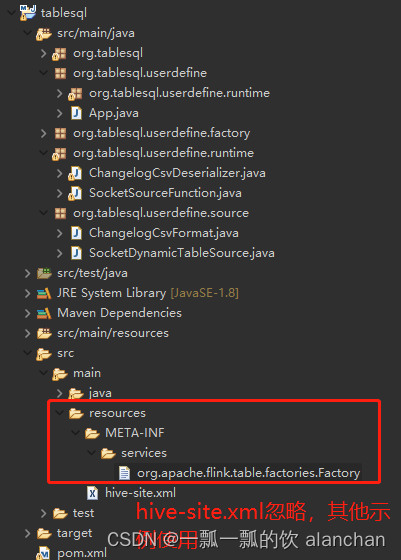
org.apache.flink.table.factories.Factory文件内容如下:
即工厂实现部分定义的2个工厂类。
org.tablesql.userdefine.factory.SocketDynamicTableFactory
org.tablesql.userdefine.factory.ChangelogCsvFormatFactory
6、验证
1)、确保nc已经完成并可用
2)、mysql创建表UserScoresSink
3)、创建java验证类
该处功能有2个,即创建自定义source端的表,然后将源端数据解析并分组存储至mysql。
UserScores (name STRING, score INT)表只定义了String和int类型,因为数据解析器只实现这两种实现方式,如果有更多的实现方式则需要在解析器中实现。
package org.tablesql.userdefine;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;/*** @author alanchan**/
public class App {public static String sql = "CREATE TABLE UserScores (name STRING, score INT)\r\n" + "WITH (\r\n" + " 'connector' = 'alan_socket',\r\n" + " 'hostname' = '192.168.10.42',\r\n" + " 'port' = '9999',\r\n" + " 'byte-delimiter' = '10',\r\n" + " 'format' = 'alan_changelog-csv',\r\n" +" 'alan_changelog-csv.column-delimiter' = ','\r\n" + ");";public static String sqlSink = "CREATE TABLE UserScoresSink (name STRING, scores BIGINT,"+ "PRIMARY KEY(name) NOT ENFORCED"+ ") with ("+ "'connector' = 'jdbc',\r\n" + " 'url' = 'jdbc:mysql://192.168.10.44:3306/test',\r\n" + " 'table-name' = 'UserScoresSink'"+ ")";public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);tenv.executeSql(sql);tenv.executeSql(sqlSink);tenv.executeSql("INSERT INTO UserScoresSink SELECT name, sum(score) as sumScore FROM UserScores group by name");Table sink = tenv.sqlQuery("select * from UserScoresSink");// interpret the insert-only Table as a DataStream againDataStream<Row> resultStream = tenv.toDataStream(sink);// add a printing sink and execute in DataStream APIresultStream.print();env.execute();}
}4)、验证插入INSERT数据
验证数据插入以及是否计算分组求和
- nc输入数据
[alanchan@server2 bin]$ nc -lk 9999
INSERT,alan,10
INSERT,alanchan,5
INSERT,alan,30
INSERT,alanchan,15
INSERT,alanchan,20- mysql数据库存储数据

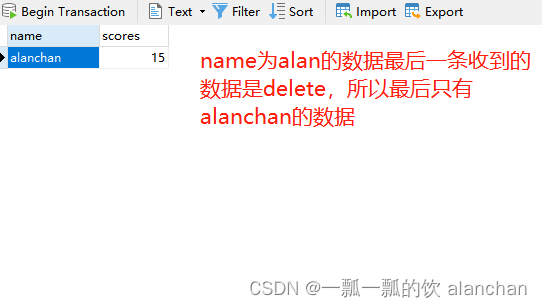
5)、验证删除DELETE数据
验证输入delete数据是否进行了删除。为了保持数据的干净,在验证的时候会删除上述示例中的数据。
验证该示例的时候,注意逐条执行,逐条观察mysql数据库的变化。
- nc输入数据
[alanchan@server2 bin]$ nc -lk 9999
INSERT,alan,10
DELETE,alan,10
INSERT,alan,15
DELETE,alan,5
INSERT,alan,15
DELETE,alan,20
INSERT,alanchan,15
INSERT,alan,15
DELETE,alan,20- mysql数据库存储数据
6)、验证更新UPDATE数据
验证输入delete数据是否进行了更新。该示例是在撒谎功能书验证删除的基础上做的。
验证该示例的时候,注意逐条执行,逐条观察mysql数据库的变化。
- nc输入数据
[alanchan@server2 bin]$ nc -lk 9999
UPDATE_BEFORE,alanchan,15
UPDATE_AFTER,alanchan,10
UPDATE_AFTER,alan,20-
mysql数据变化
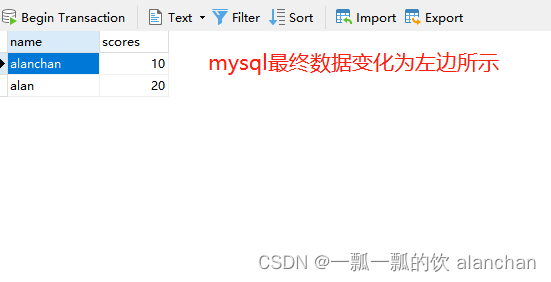
-
应用程序控制台是否出现异常
应用程序控制台无异常
7)、验证输入非string和int数据类型
该示例是在 验证update的数据示例基础上做的。
- nc 输入数据
[alanchan@server2 bin]$ nc -lk 9999
INSERT,alan,10
INSERT,alan,10.5-
mysql数据
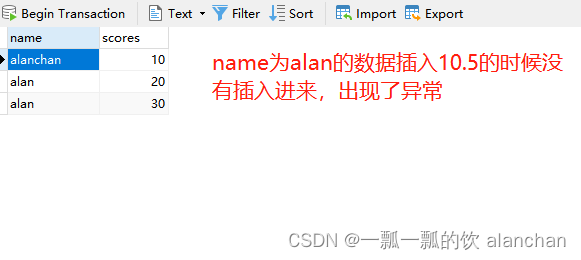
-
应用程序控制台
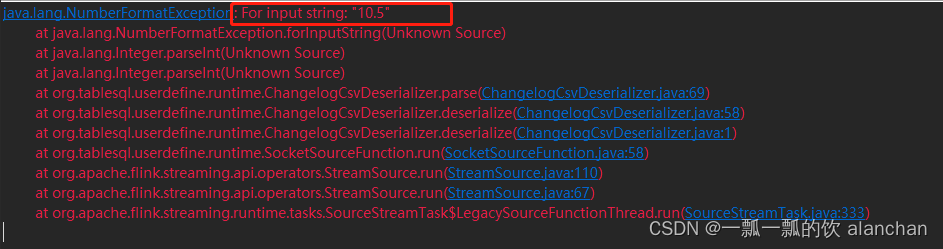
以上,简单介绍了用户自定义实现source和sink的步骤,并以实际示例介绍了实现source端和验证步骤。
相关文章:
32、Flink table api和SQL 之用户自定义 Sources Sinks实现及详细示例
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

Java练习题-用冒泡排序法实现数组排序
✅作者简介:CSDN内容合伙人、阿里云专家博主、51CTO专家博主、新星计划第三季python赛道Top1🏆 📃个人主页:hacker707的csdn博客 🔥系列专栏:Java练习题 💬个人格言:不断的翻越一座又…...

【SV中的多线程fork...join/join_any/join_none】
SV中fork_join/fork_join_any/fork_join_none 1 一目了然1.1 fork...join1.2 fork...join_any1.3 fork...join_none 2 总结 SV中fork_join和fork_join_any和fork_join_none; Note: fork_join在Verilog中也有,只有其他的两个是SV中独有的; 1 一目了然 1.…...
翻译:网站整站翻译 / 网站国际化 / 极简实现
一、本文目标 以极简单的方法实现整站翻译,轻松实现国际化。 二、js 文件 https://res.zvo.cn/translate/translate.js 三、代码 代码放在浏览器控制台即可实现 var head document.getElementsByTagName(head)[0];var script document.createElement(script);sc…...
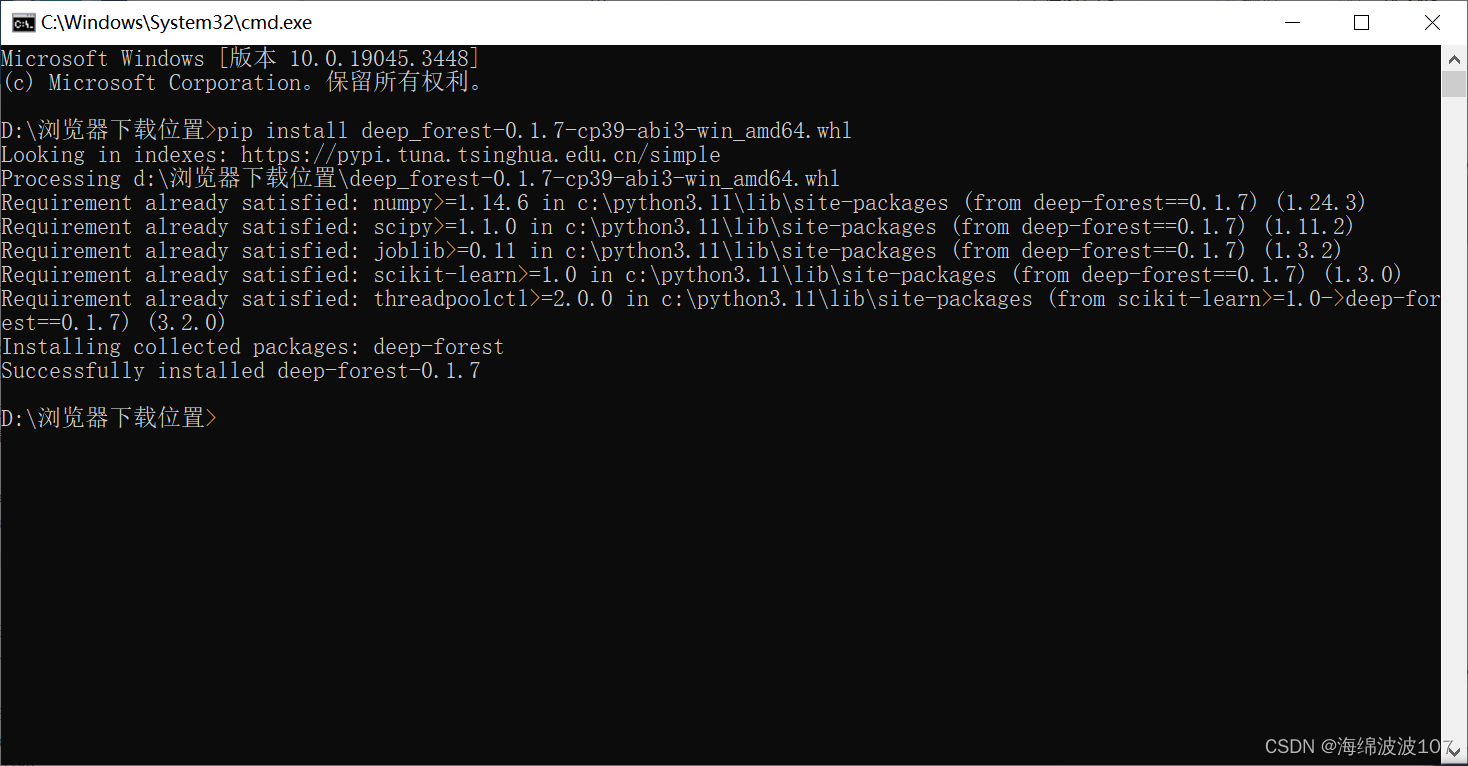
深度森林(deep-forest)安装
深度森林(deep-forest)安装 1、打开https://pypi.org/,搜索deep-forest,下载wheel文件 在下载好之后,打开文件下载的位置 首先对下载好的wheel文件进行改名,原名是: deep_forest-0.1.7-cp39-c…...

ping.pe ping 检测IP全球延迟
可以把结果保存为照片 https://ping.pe/全球ping ping ip端口检测 IP:PORT路由追踪 mtr IP 参考 ping.pe...

nodejs 16版本
Index of /download/release/latest-v16.x/...
NSSCTF做题(7)
[第五空间 2021]pklovecloud 反序列化 <?php include flag.php; class pkshow { function echo_name() { return "Pk very safe^.^"; } } class acp { protected $cinder; public $neutron; …...

【GIT版本控制】--高级分支策略
一、分支合并策略 在Git中,高级分支策略是为了有效地管理和整合分支而设计的。其中一个关键方面是分支合并策略,它定义了如何将一个分支的更改合并到另一个分支。以下是几种常见的分支合并策略: 合并提交策略(Merge Commit Stra…...

【Qt控件之QDialog】使用及技巧
简介 QDialog是Qt中的一个类,继承自QWidget类,用于创建对话框窗口,可以显示模态(阻塞当前窗口)或非模态的对话框。对话框可以包含各种控件,如按钮、文本框等,用于与用户进行交互。 主要函数说…...
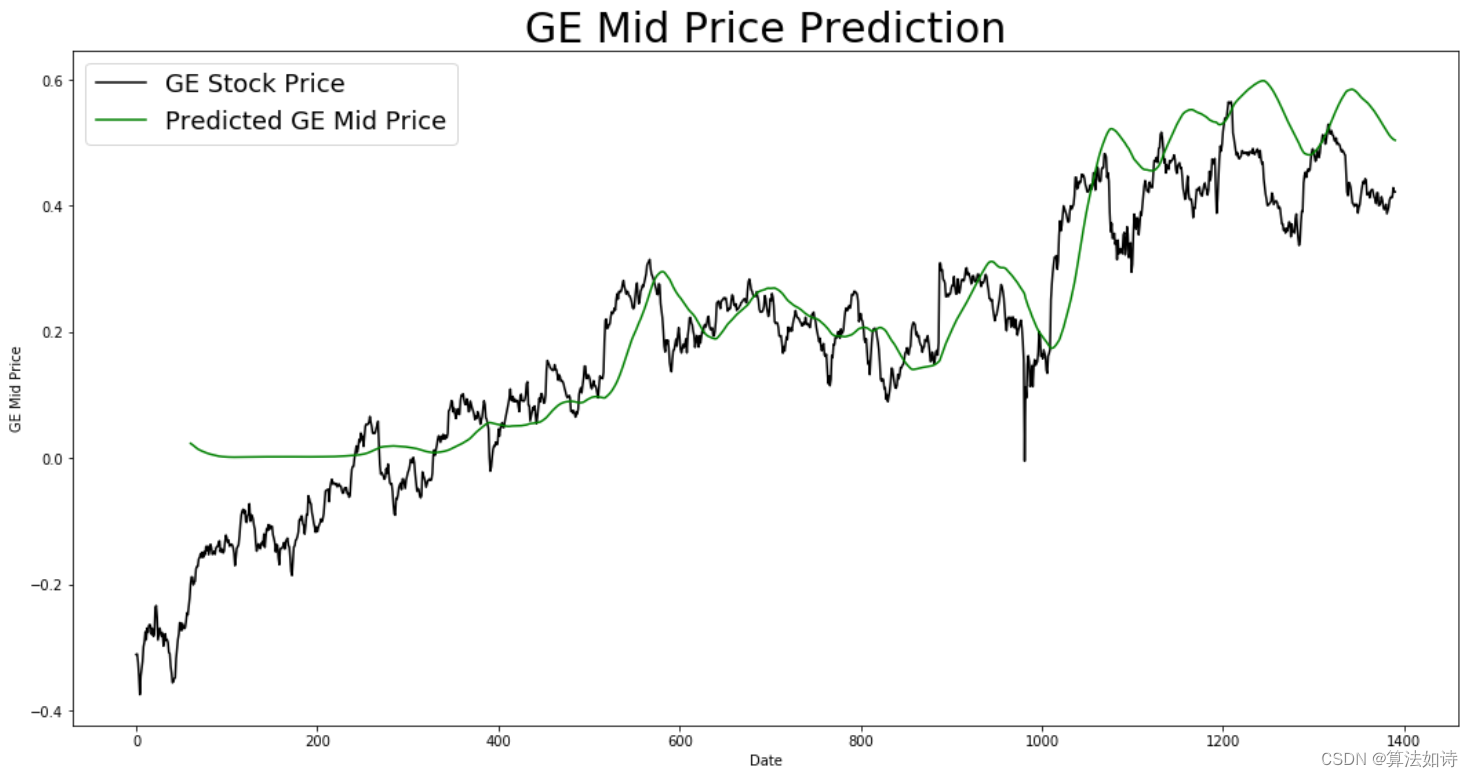
Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow)
文章目录 效果一览文章概述程序设计参考资料效果一览 文章概述 Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow) 程序设计 import numpy as np import matplotlib.pyplot...

spark sql如何行转列
在数据仓库中,行转列通常称为”变形”(Pivoting) 或 “透视”(Pivoting),可使用Spark SQL的pivot语句实现。下面是一个简单的示例: 假设我们有如下表格: -------------------- | name | brand | year | -------------------- |…...
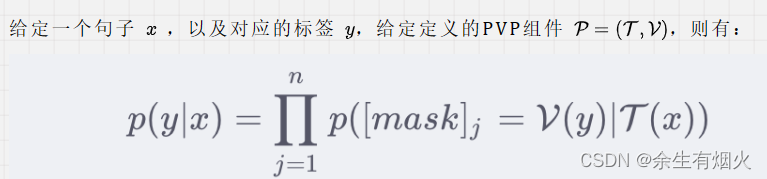
Prompt-Tuning(一)
一、预训练语言模型的发展过程 第一阶段的模型主要是基于自监督学习的训练目标,其中常见的目标包括掩码语言模型(MLM)和下一句预测(NSP)。这些模型采用了Transformer架构,并遵循了Pre-training和Fine-tuni…...
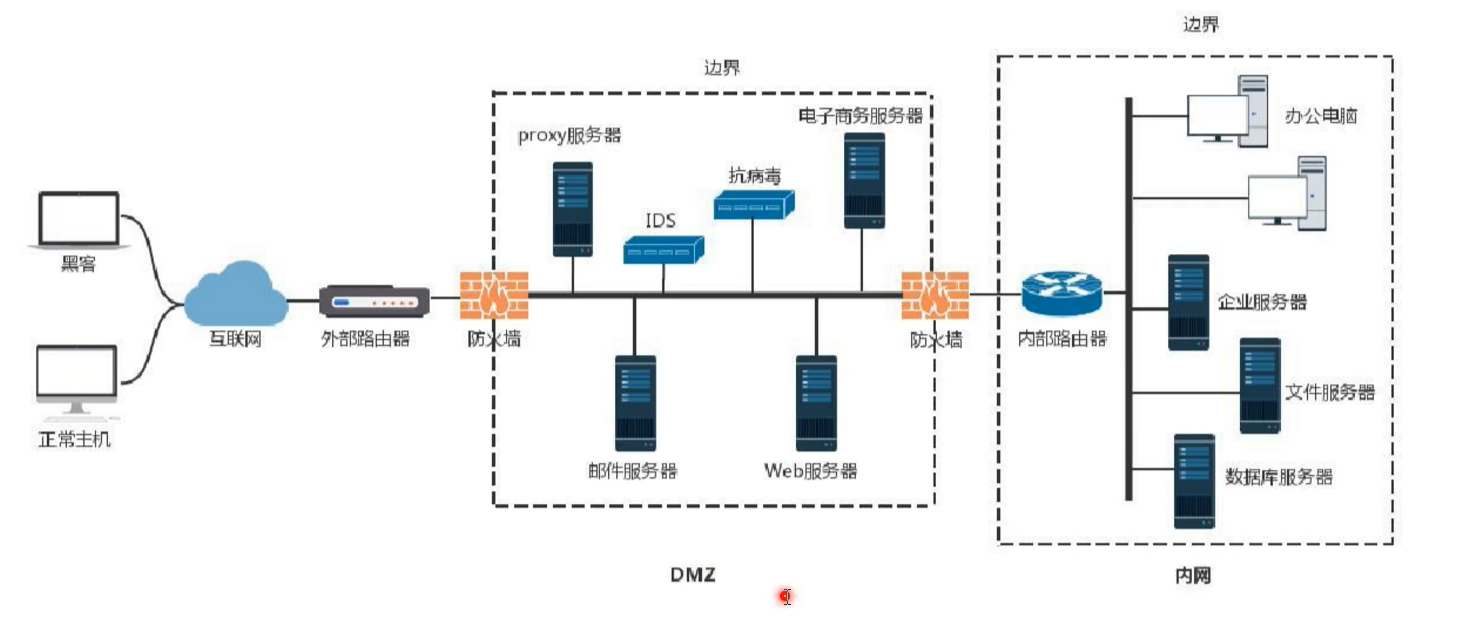
域信息收集
DMZ,是英文“demilitarized zone”的缩写,中文名称为“隔离区”,也称“非军事化区”。它是为了解决安装防火墙后外部网络的访问用户不能访问内部网络服务器的问题,而设立的一个非安全系统与安全系统之间的缓冲区。该缓冲区位于企业…...

MySQ 学习笔记
1.MySQL(老版)基础 开启MySQL服务: net start mysql mysql为安装时的名称 关闭MySQL服务: net stop mysql 注: 需管理员模式下运行Dos命令 . 打开服务窗口命令 services.msc 登录MySQL服务: mysql [-h localhost -P 3306] -u root -p****** Navicat常用快捷键 键动作CTRLG设…...
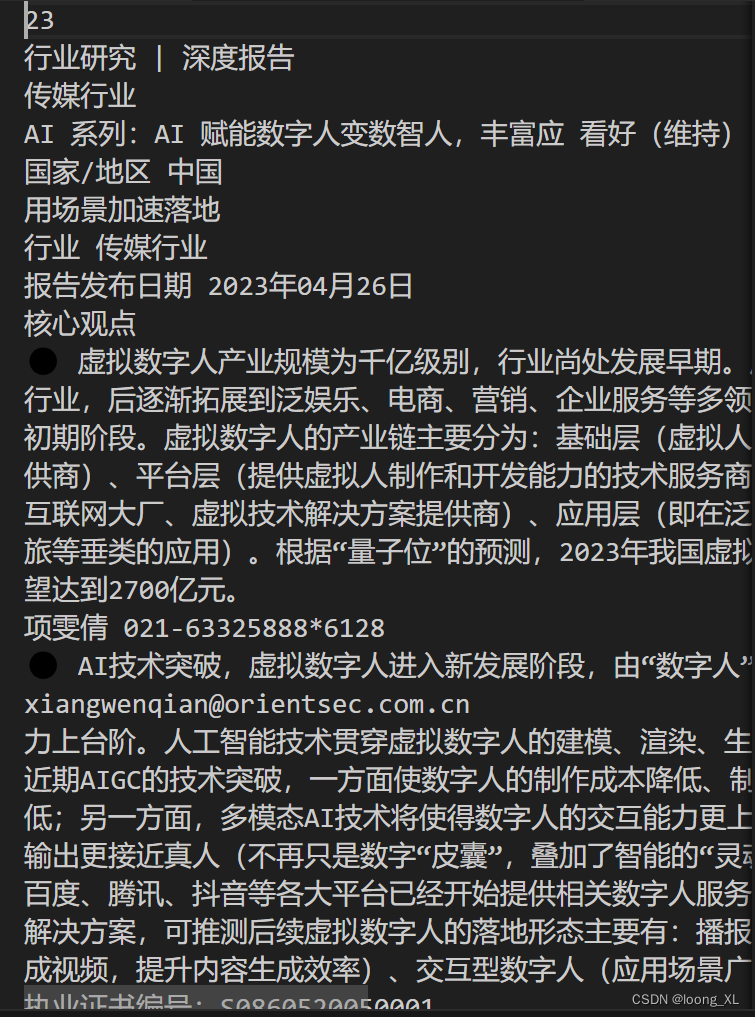
pdf文档内容提取pdfplumber、PyPDF2
测试pdfplumber识别效果好些;另外pdf这两个如果超过20多页就没法识别了,结果为空 1、pdfplumber 安装:pip install pdfplumber -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com代码: import pdfpl…...
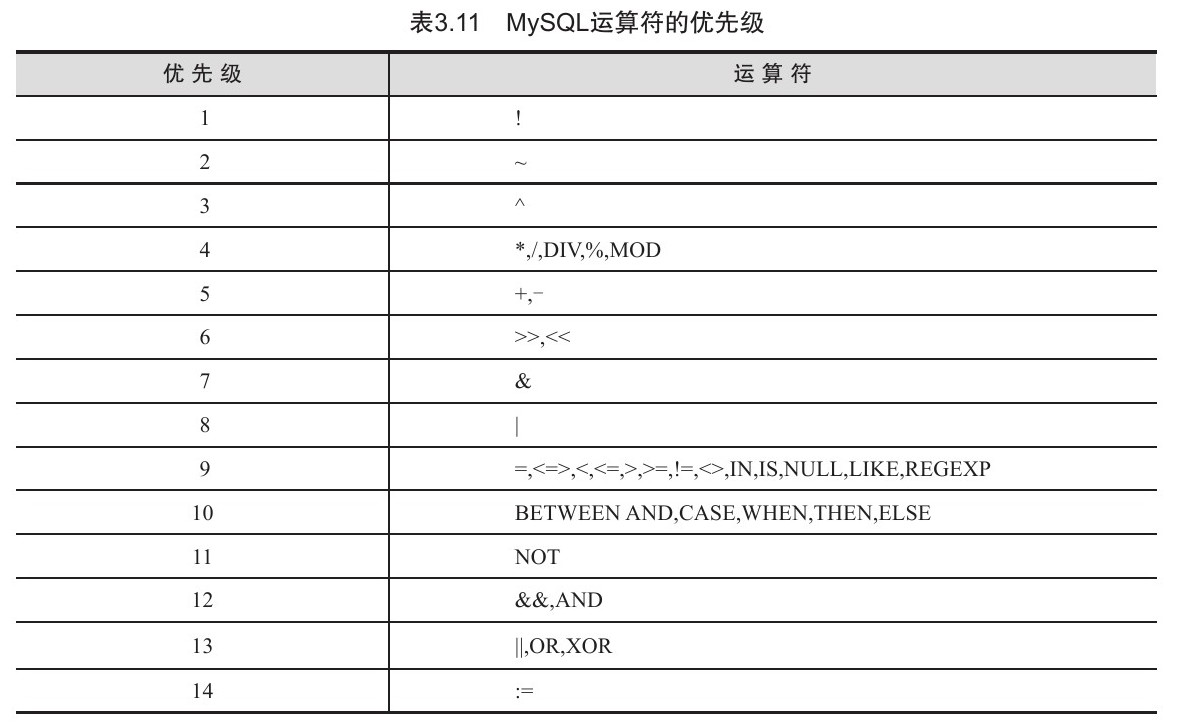
运算符
目录 算术运算符 比较运算符 逻辑运算符 位运算符 运算符的优先级 MySQL从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article/details/129334507?spm1001.2014.3001.5502 数据库中的表结构确立后,表中的数据代表的意义就已经确定。而…...

利用freesurfer6进行海马分割的环境配置和步骤,以及获取海马体积
利用freesurfer6进行海马分割的环境配置和步骤 Matlab Runtime 安装1. 运行recon-all:2. 利用 recon-all -s subj -hippocampal-subfields-T1 进行海马分割3. 结束后需要在/$SUBJECTS_DIR/subject/的文件夹/mri路径下输入下面的代码查看分割情况4. 在文件SUBJECTS_DIR路径下输…...

haproxy使用
haproxy使用 安装使用yum安装 配置文件global 全局配置Proxies配置Proxies配置-defaultsProxies配置-listen 简化配置 安装 社区版官网链接:http://www.haproxy.org CentOS 7 的默认的base仓库中包含haproxy的安装包文件,但是版本比较旧,是1…...
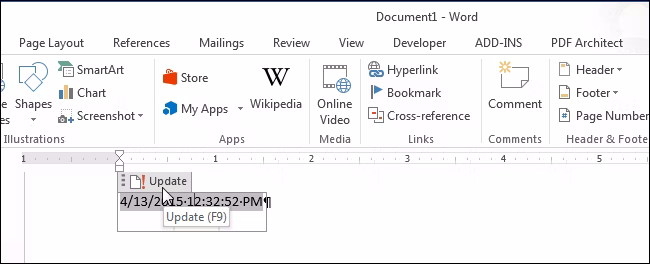
轻松实现时间录入自由!如何在Microsoft Word中轻松插入格式化的日期和时间
在文档中插入当前日期和时间有几个原因。你可能希望将其插入信函或页眉或页脚中。无论是什么原因,Word都可以轻松地将日期和时间插入文档。 如果希望在打开或打印文档时自动更新日期和时间,可以将其作为自动更新的字段插入。该字段也可以随时手动更新。…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...
)
别再乱装CUDA了!用Anaconda为你的3060 Ti一键搞定PyTorch GPU环境(含CUDA 11.3实战)
3060 Ti显卡玩家的PyTorch环境配置指南:用Anaconda避开CUDA版本地狱 在深度学习领域,GPU加速已经成为提升模型训练效率的标配。然而,对于许多刚入门的开发者来说,配置PyTorch的GPU支持往往成为第一道门槛——尤其是当涉及到CUDA版…...

从零到一:Android Studio集成Uniapp离线SDK打包实战
1. 环境准备:工具选择与版本匹配 第一次接触Uniapp离线打包时,最让我头疼的就是工具版本匹配问题。记得去年接手一个混合开发项目时,因为HBuilderX和SDK版本不兼容,整整浪费了两天时间排查问题。为了避免大家重蹈覆辙,…...

Hitboxer终极指南:专业级游戏键盘重映射与SOCD清理工具完全教程
Hitboxer终极指南:专业级游戏键盘重映射与SOCD清理工具完全教程 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd Hitboxer是一款专为竞技游戏玩家设计的专业级键盘按键重映射和SOCD清理工具ÿ…...

终极FGO自动化助手:告别枯燥刷本,每天节省3小时游戏时间
终极FGO自动化助手:告别枯燥刷本,每天节省3小时游戏时间 【免费下载链接】FGA Auto-battle app for F/GO Android 项目地址: https://gitcode.com/gh_mirrors/fg/FGA Fate/Grand Automata(简称FGA)是一款专为Fate/Grand Or…...

Kubernetes部署Valheim游戏服务器:云原生技术赋能游戏运维实践
1. 项目概述:当维京英灵殿遇上容器编排如果你和我一样,既沉迷于《英灵神殿》(Valheim)里与好友共建家园、挑战上古巨兽的乐趣,又恰好是一名整天和Kubernetes(k8s)打交道的开发者或运维ÿ…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...
pydantic-settings、核心BaseModel、字段约束Field()、FastAPI)
Python Pydantic介绍(数据校验、自动类型转换、结构化数据建模、序列化JSON、配置管理)pydantic-settings、核心BaseModel、字段约束Field()、FastAPI
文章目录Python 数据校验神器:Pydantic 完全指南一、什么是 Pydantic二、Pydantic 能解决什么问题1)数据校验(Validation)2)自动类型转换(Parsing)3)结构化数据建模4)序列…...

多智能体涌现环境:从局部交互到群体智能的深度解析与实践
1. 项目概述:多智能体涌现环境的深度探索最近在复现和深入研究一个名为“multi-agent-emergence-environments”的开源项目,它来自OpenAI。这个项目名听起来有点学术,但它的核心思想非常迷人:在一个模拟的物理沙盒环境中ÿ…...

PowerInfer:基于稀疏激活的LLM推理引擎,消费级GPU运行百亿大模型
1. 项目概述:当大模型推理遇见“热点激活”最近在折腾本地大模型部署的朋友,可能都绕不开一个核心痛点:显存。动辄几十GB的模型,配上动辄几十GB的推理显存需求,让消费级显卡(比如我们常见的24GB显存的RTX 4…...