MongoDB-基本常用命令
基本常用命令
- MongoDB常用命令
- a) 案例需求
- b) 数据库操作
- b.1) 选择和创建数据库
- b.2) 删除数据库
- c) 集合操作
- c.1) 集合的显示创建
- c.2) 集合的隐式创建
- c.3) 集合的删除
- d) 文档基本CRUD
- d.1) 文档的插入
- (1) 单个文档的插入
- (2) 批量插入
- d.2) 文档的基本查询
- (1) 查询所有
- (2) 投影查询(Projection Query)
- d.3) 文档的更新
- (1) 覆盖的修改
- (2) 局部的修改
- (3) 批量的修改
- (4) 列值增长的修改
- d.4) 文档的删除
- e) 文档的分页查询
- e.1) 统计查询
- (1) 统计所有记录数
- (2) 按条件统计记录数
- e.2) 分页列表查询
- e.3) 排序查询
- f) 文档的更多查询
- f.1) 正则的复杂条件查询
- f.2) 比较查询
- f.3) 包含查询
- f.4) 条件连接查询
- g) 常用命令总结
MongoDB常用命令
a) 案例需求
存放文章评论的数据存放到MongoDB中,数据结构参考如下:
数据库:articledb
| 专栏文章评论 | comment | ||
|---|---|---|---|
| 字段名称 | 字段含义 | 字段类型 | 备注 |
| _id | ID | ObjectId或String | Mongo的主键的字段 |
| articleid | 文章ID | String | |
| content | 评论内容 | String | |
| userid | 评论人ID | String | |
| nickname | 评论人昵称 | String | |
| createdatetime | 评论的日期时间 | Date | |
| likenum | 点赞数 | Int32 | |
| replynum | 回复数 | Int32 | |
| state | 状态 | String | 0:不可见;1:可见; |
| parentid | 上级ID | String | 如果为0表示文章的顶级评论 |
b) 数据库操作
b.1) 选择和创建数据库
选择和创建数据库的语法格式:
use 数据库名称
如果数据库不存在则自动创建,例如,以下语句创建 spitdb 数据库:
use articledb
查看有权限查看的所有的数据库命令
show dbs
或
show databases
注意:在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
查看当前正在使用的数据库命令
db
MongoDB 中默认的数据库为 test,如果你没有选择数据库,集合将存放在 test 数据库中。
另外:
数据库名可以是满足以下条件的任意UTF-8字符串:
-
不能是空字符串(“”)
-
不得含有’ '(空格)、.、$、/、\和\0 (空字符)
-
应全部小写
-
最多64字节
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库:
-
admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特
定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
-
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
-
config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
b.2) 删除数据库
MongoDB 删除数据库的语法格式如下:
db.dropDatabase()
提示:主要用来删除已经持久化的数据库
c) 集合操作
集合,类似关系型数据库中的表。
可以显示的创建,也可以隐式的创建。
c.1) 集合的显示创建
基本语法格式:
db.createCollection(name)
参数说明:
- name: 要创建的集合名称
例如:创建一个名为 mycollection 的普通集合
db.createCollection("mycollection")
查看当前库中的表:show tables命令
show collections
或
show tables
c.2) 集合的隐式创建
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合。
提示:通常我们使用隐式创建文档即可。
c.3) 集合的删除
集合删除语法格式如下:
db.collection.drop()
或
db.集合.drop()
d) 文档基本CRUD
文档(document)的数据结构和 JSON 基本一样。
所有存储在集合中的数据都是 BSON 格式。
d.1) 文档的插入
(1) 单个文档的插入
使用insert() 或 save() 方法向集合中插入文档,语法如下:
db.collection.insert(<document or array of documents>,{writeConcern: <document>,ordered: <boolean>}
)
参数:
- document: 要插入到集合中的文档或文档数组。((json格式)
- writeConcern: 性能可靠性的级别
- ordered:是否排序
【示例】
要向comment的集合(表)中插入一条测试数据:
db.comment.insert({"articleid":"100000","content":"今天天气真好,阳光明媚","userid":"1001","nickname":"Rose","createdatetime":new Date(),"likenum":NumberInt(10),"state":null})
提示:
- 1)comment集合如果不存在,则会隐式创建
- 2)mongo中的数字,默认情况下是double类型,如果要存整型,必须使用函数NumberInt(整型数字),否则取出来就有问题了。
- 3)插入当前日期使用 new Date()
- 4)插入的数据没有指定 _id ,会自动生成主键值
- 5)如果某字段没值,可以赋值为null,或不写该字段。
注意:
-
1.文档中的键/值对是有序的。
-
2.文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
-
3.MongoDB区分类型和大小写。
-
4.MongoDB的文档不能有重复的键。
-
5.文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符
(2) 批量插入
语法:
db.collection.insertMany([ <document 1> , <document 2>, ... ],{writeConcern: <document>,ordered: <boolean>}
)
参数:
【示例】
批量插入多条文章评论:
db.comment.insertMany([
{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我
他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-
05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},
{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔
悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},
{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船
长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},
{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯
撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},
{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫
嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-
06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}
]);
提示:
插入时指定了 _id ,则主键就是该值。
如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。
因为批量插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理,测试的时候可以不处理。如(了解):
try {
db.comment.insertMany([{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}]);
} catch (e) {print (e);
}
d.2) 文档的基本查询
(1) 查询所有
查询数据的语法格式如下:
db.collection.find(<query>, [projection])
如果我想按一定条件来查询,比如我想查询userid为1003的记录,怎么办?很简单!只 要在find()中添加参数即可,参数也是json格式,如下:
db.comment.find({userid:'1003'})
如果你只需要返回符合条件的第一条数据,我们可以使用findOne命令来实现,语法和find一样。
如:查询用户编号是1003的记录,但只最多返回符合条件的第一条记录:
db.comment.findOne({userid:'1003'})
(2) 投影查询(Projection Query)
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)。
如:查询结果只显示 _id、userid、nickname :
db.comment.find({userid:"1003"},{userid:1,nickname:1})
默认 _id 会显示。
如:查询结果只显示 userid、nickname ,不显示 _id :
db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0})
d.3) 文档的更新
更新文档的语法:
db.collection.update(query, update, options)//或db.collection.update(<query>,<update>,{upsert: <boolean>,multi: <boolean>,writeConcern: <document>,collation: <document>,arrayFilters: [ <filterdocument1>, ... ],hint: <document|string> // Available starting in MongoDB 4.2}
)
【示例】
(1) 覆盖的修改
如果我们想修改_id为1的记录,点赞量为1001,输入以下语句:
db.comment.update({_id:"1"},{likenum:NumberInt(1001)})
执行后,我们会发现,这条文档除了likenum字段其它字段都不见了
(2) 局部的修改
为了解决这个问题,我们需要使用修改器$set来实现,命令如下:
我们想修改_id为2的记录,浏览量为889,输入以下语句:
db.comment.update({_id:"2"},{$set:{likenum:NumberInt(889)}})
(3) 批量的修改
更新所有用户为 1003 的用户的昵称为 凯撒大帝
//默认只修改第一条数据
db.comment.update({userid:"1003"},{$set:{nickname:"凯撒2"}})
//修改所有符合条件的数据
db.comment.update({userid:"1003"},{$set:{nickname:"凯撒大帝"}},{multi:true})
(4) 列值增长的修改
如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用 $inc 运算符来实现。
需求:对3号数据的点赞数,每次递增1
db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})
d.4) 文档的删除
删除文档的语法结构:
db.集合名称.remove(条件)
以下语句可以将数据全部删除,请慎用
db.comment.remove({})
如果删除_id=1的记录,输入以下语句
db.comment.remove({_id:"1"})
e) 文档的分页查询
e.1) 统计查询
统计查询使用count()方法,语法如下:
db.collection.count(query, options)
【示例】
(1) 统计所有记录数
统计comment集合的所有的记录数:
db.comment.count()
(2) 按条件统计记录数
例如:统计userid为1003的记录条数
db.comment.count({userid:"1003"})
默认情况下
count()方法返回符合条件的全部记录条数。
e.2) 分页列表查询
可以使用limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数量的数据
基本语法如下所示:
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
如果你想返回指定条数的记录,可以在find方法后调用limit来返回结果(TopN),默认值20,例如:
db.comment.find().limit(3)
skip方法同样接受一个数字参数作为跳过的记录条数。(前N个不要),默认值是0
db.comment.find().skip(3)
e.3) 排序查询
sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法如下所示:
db.COLLECTION_NAME.find().sort({KEY:1})
或
db.集合名称.find().sort(排序方式)
例如:
对userid降序排列,并对访问量进行升序排列
db.comment.find().sort({userid:-1,likenum:1})
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关
f) 文档的更多查询
f.1) 正则的复杂条件查询
MongoDB的模糊查询是通过正则表达式的方式实现的。格式为:
db.collection.find({field:/正则表达式/})
或
db.集合.find({字段:/正则表达式/})
提示:正则表达式是js的语法,直接量的写法。
例如,我要查询评论内容包含“开水”的所有文档,代码如下:
db.comment.find({content:/开水/})
如果要查询评论的内容中以“专家”开头的,代码如下:
db.comment.find({content:/^专家/})
f.2) 比较查询
<, <=, >, >= 这个操作符也是很常用的,格式如下:
db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value
db.集合名称.find({ "field" : { $lt: value }}) // 小于: field < value
db.集合名称.find({ "field" : { $gte: value }}) // 大于等于: field >= value
db.集合名称.find({ "field" : { $lte: value }}) // 小于等于: field <= value
db.集合名称.find({ "field" : { $ne: value }}) // 不等于: field != value
示例:查询评论点赞数量大于700的记录
db.comment.find({likenum:{$gt:NumberInt(700)}})
f.3) 包含查询
包含使用$in操作符。 示例:查询评论的集合中userid字段包含1003或1004的文档
db.comment.find({userid:{$in:["1003","1004"]}})
不包含使用$nin操作符。 示例:查询评论集合中userid字段不包含1003和1004的文档
db.comment.find({userid:{$nin:["1003","1004"]}})
f.4) 条件连接查询
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联。(相 当于SQL的and) 格式为:
$and:[ { },{ },{ } ]
示例:查询评论集合中likenum大于等于700 并且小于2000的文档:
db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})
如果两个以上条件之间是或者的关系,我们使用 操作符进行关联,与前面 and的使用方式相同 格式为:
$or:[ { },{ },{ } ]
示例:查询评论集合中userid为1003,或者点赞数小于1000的文档记录
db.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]})
g) 常用命令总结
选择切换数据库:use articledb
插入数据:db.comment.insert({bson数据})
查询所有数据:db.comment.find();
条件查询数据:db.comment.find({条件})
查询符合条件的第一条记录:db.comment.findOne({条件})
查询符合条件的前几条记录:db.comment.find({条件}).limit(条数)
查询符合条件的跳过的记录:db.comment.find({条件}).skip(条数)
修改数据:db.comment.update({条件},{修改后的数据}) 或db.comment.update({条件},{$set:{要修改部分的字段:数据})
修改数据并自增某字段值:db.comment.update({条件},{$inc:{自增的字段:步进值}})
删除数据:db.comment.remove({条件})
统计查询:db.comment.count({条件})
模糊查询:db.comment.find({字段名:/正则表达式/})
条件比较运算:db.comment.find({字段名:{$gt:值}})
包含查询:db.comment.find({字段名:{$in:[值1,值2]}})或db.comment.find({字段名:{$nin:[值1,值2]}})
条件连接查询:db.comment.find({$and:[{条件1},{条件2}]})或db.comment.find({$or:[{条件1},{条件2}]})
相关文章:

MongoDB-基本常用命令
基本常用命令 MongoDB常用命令a) 案例需求b) 数据库操作b.1) 选择和创建数据库b.2) 删除数据库 c) 集合操作c.1) 集合的显示创建c.2) 集合的隐式创建c.3) 集合的删除 d) 文档基本CRUDd.1) 文档的插入(1) 单个文档的插入(2) 批量插入 d.2) 文档的基本查询(1) 查询所有(2) 投影查…...

Linux 常用systemctl service 脚本
文章目录 1. jar 包部署 service 脚本2. nginx 服务安装 脚本3.artemis 服务安装脚本 1. jar 包部署 service 脚本 默认jdk 执行: [Service] Typesimple Userroot WorkingDirectory/opt/app/webserver ExecStart/usr/bin/java -Xms512m -Xss256k -jar /opt/app/we…...

flask-sqlalchemy实现读写分离完整版
1. 依赖版本: alembic==1.6.5 click==8.0.1 colorama==0.4.4 Flask==1.1.2 Flask-Migrate==2.7.0 Flask-Script==2.0.6 Flask-SQLAlchemy==2.4.4 greenlet==1.1.0 itsdangerous==2.0.1 Jinja2==3.0.1 Mako==1.1.4 MarkupSafe==2.0.1 protobuf==3.17.3 PyMySQL==1.0.2 python-…...
windows下在cmd和git bash中执行bash download.sh失败
cmd报错信息: 解决办法: win64-wget-1.21.4 安装软件wget,如下这是64位的包,解压后,下面有个wget.exe,拷贝到C:\Windows\System32、 然后打开cmd,执行wget -V 如上,有版本信息就O…...

rust流程控制
一、分支 (一)if 1.if 语法格式 if boolean_expression { }例子 fn main(){let num:i32 5;if num > 0 {println!("正数");} }条件表达式不需要用小括号。 条件表达式必须是bool类型。 2.if else 语法格式 if boolean_expression { } …...
虚拟机软件Parallels Desktop 19 mac功能介绍
Parallels Desktop 19 mac是一款虚拟机软件,它允许用户在Mac电脑上同时运行Windows、Linux和其他操作系统。Parallels Desktop提供了直观易用的界面,使用户可以轻松创建、配置和管理虚拟机。 PD19虚拟机软件具有快速启动和关闭虚拟机的能力,让…...

在工业机器视觉领域中应用钡铼技术有限公司的EtherCAT网关
钡铼技术有限公司作为一家专注于业物联网关、工业智能网关、边缘计算网关、ARM嵌入式工业计算机、PLC远程采集网关、Modbus转MQTT网关、OPC UA网关、BACnet网关路由器、Lora网关、工业4G边缘路由器、4G无线远程数据采集模块、4G DTU RTU、以太网远程IO模块、工业总线分布式I/O模…...

ssh指定的密钥协商方式以及Ansible的hosts文件修改密钥协商方式
一、首先你要知道用什么加密协商。 [WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details 10.10.2.190 | UNREACHABLE! > {"changed": false,"msg": "Failed to connect to the host via ssh: U…...

NLP 项目:维基百科文章爬虫和分类【01】 - 语料库阅读器
自然语言处理是机器学习和人工智能的一个迷人领域。这篇博客文章启动了一个具体的 NLP 项目,涉及使用维基百科文章进行聚类、分类和知识提取。灵感和一般方法源自《Applied Text Analysis with Python》一书。 一、说明 该文是系列文章,揭示如何对爬取文…...

QT sqlite的简单用法
1、相关头文件 #include <QSqlDatabase> #include <QSqlError> #include <QSqlQuery> #include <QSqlRecord> #include <QSqlIndex> #include <QSqlField> #include <QFile> #include <QDebug> 2、数据库对象 QSqlDatabas…...
大模型部署手记(12)LLaMa2+Chinese-LLaMA-Plus-2-7B+Windows+text-gen+中文对话
1.简介: 组织机构:Meta(Facebook) 代码仓:https://github.com/facebookresearch/llama 模型:chinese-alpaca-2-7b-hf 下载:使用百度网盘下载 硬件环境:暗影精灵7Plus Windows版…...

C#导出本机Win32native dll
C# 使用 "3f/DllExport" 工具导出C风格的本机函数 [文 / 张赐荣] 首先,让我们来了解一下什么是争渡读屏软件,以及什么是争渡文本预处理API。争渡读屏软件是一款屏幕朗读软件,用于协助视力障碍人士操作电脑。 争渡文本预处理API是一…...
express-generator快速构建node后端项目
express-generator是express官方团队开发者准备的一个快速生成工具,可以非常快速的生成一个基于express开发的框架基础应用。 npm安装 npm install express-generator -g初始化应用 express my_node_test 创建了一个名为 my_node_test 的express骨架项目通过 Exp…...
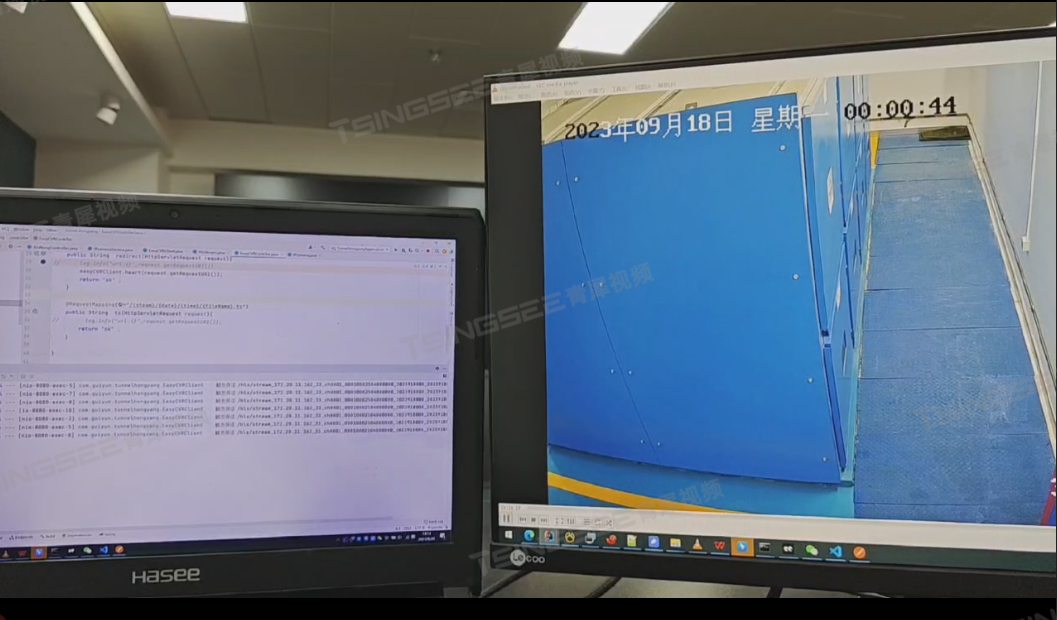
视频监控系统/视频汇聚平台EasyCVR如何反向代理进行后端保活?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...
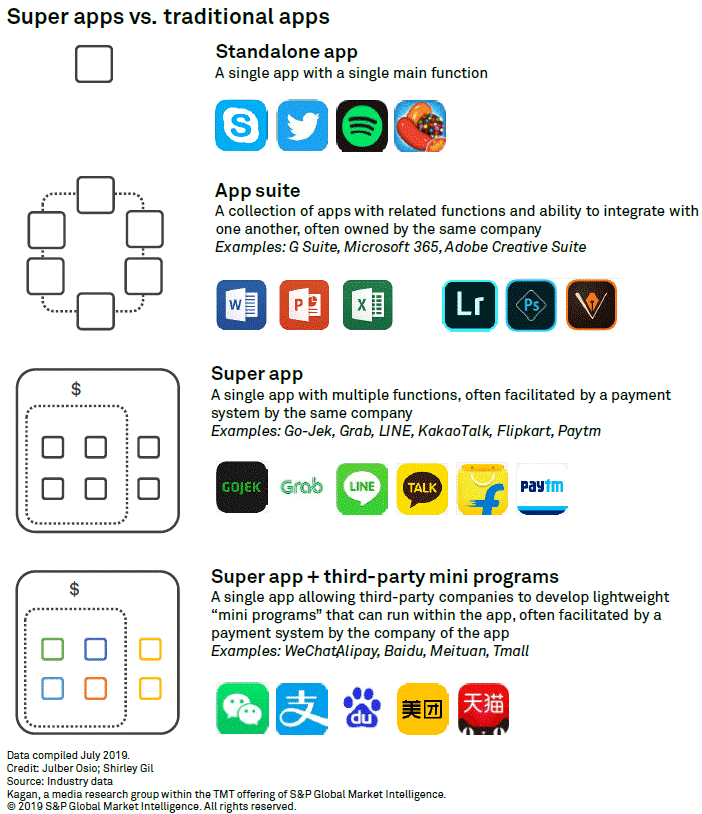
金融信创黄金三年:小程序生态+跨端技术框架构建
小程序应用场景生态的发展,受益于开源技术的发展,以及响应快速开发的实际业务需求,一些跨端框架如:Electron、wxPython、FinClip、Tauri、Flutter等发展也非常迅速,小程序生态跨端技术框架,不仅能满足自有超…...
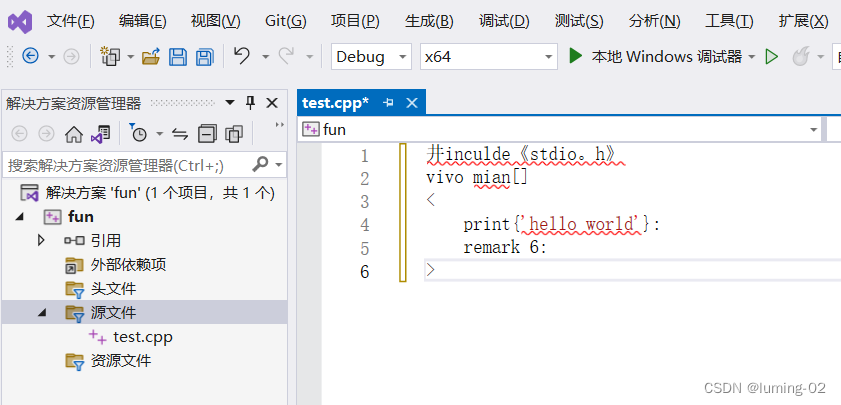
这短短 6 行代码你能数出几个bug?
前言:本文仅仅只是分享笔者一年前见到的诡异代码,大家可以看看乐子,随便数一数一共有多少个bug,这数bug多少还是要点水平的 在初学编程的时候,写的第一个代码大多都是 hello world,可是就算是 hello world…...

【毕设选题】深度学习 机器视觉 车位识别车道线检测 - python opencv
0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。 为了大家能够顺利以及最少的精力通过…...

不同数据类型在单片机内存中占多少字节?
文章目录 前言一、不同编译器二、C51* 指针型 三、sizeof结构体联合体 前言 在C语言中,数据类型指的是用于声明不同类型的变量或者函数的一个广泛的系统。变量的类型决定了变量存储占用的空间 一、不同编译器 类型16位编译器大小32位编译器大小64位编译器大小char…...

安卓LinearLayout让控件居中的办法
在控件属性上,是处理不了的。必须是在LinearLayout处理: 垂直居中 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width&…...

uniapp下拉刷新
为什么要使用uniapp的下拉刷新呢 跨平台兼容性: Uniapp 允许你一次编写代码,然后在多个平台(如微信小程序、H5、iOS 和 Android 等)上运行。使用 Uniapp 的下拉刷新功能,可以确保在不同平台上都能提供一致的用户体验&a…...

基于容器技术的在线代码沙盒:架构设计与安全实践
1. 项目概述:一个开箱即用的在线代码运行沙盒最近在折腾一些需要快速验证代码片段、或者给团队做技术分享的场景,我发现一个痛点:环境配置太麻烦了。你想让新人跑个Python脚本,他可能得先装Python、配环境变量、装依赖库ÿ…...

基于声明式Web自动化框架Hydra的电商数据监控实战
1. 项目概述:一个被低估的自动化利器 如果你经常需要处理一些重复性的、基于Web界面的操作,比如批量下载某个网站的资源、定时填写表单、或者监控网页内容的变化,那么你很可能已经厌倦了手动点击和等待。传统的脚本编写,尤其是涉及…...

Flutter桌面端窗口控制:从隐藏标题栏到自定义全屏交互
1. 为什么需要自定义窗口控制? 当你用Flutter开发Windows桌面应用时,系统默认的标题栏和窗口样式往往显得格格不入。想象一下,你精心设计了一套深色主题的UI,结果顶部突然冒出一条灰白色的标准标题栏——就像给西装革履的绅士戴了…...

基于Stellar的智能体经济安全与效率优化框架解析
1. 项目概述:一个面向智能体经济的安全与效率优化框架最近在探索智能体(Agent)应用生态时,我遇到了一个普遍存在的痛点:如何在一个去中心化、多智能体协作的网络中,既保证交互的安全与可信,又能…...

告别命令行启动!在Ubuntu 20.04上为Clion创建桌面快捷方式的保姆级教程
告别命令行启动!在Ubuntu 20.04上为Clion创建桌面快捷方式的保姆级教程 每次打开Clion都要在终端输入./clion.sh?作为从Windows转战Linux的开发者,这种操作简直让人抓狂。本文将彻底解决这个痛点,手把手教你用.desktop文件创建专业…...

Agent 的记忆也会被投毒:长期记忆安全的六阶段框架
过去,我们更习惯把大模型的风险理解为“这一轮输入有没有问题”“这一轮输出会不会越界”。但有了长期记忆之后,风险结构发生了变化。恶意内容不一定在当场触发,也不一定在同一轮任务里显现出来。它可以先悄悄进入记忆,在几天后、…...

Topit:macOS窗口置顶的终极解决方案,开源高效的多任务开发利器
Topit:macOS窗口置顶的终极解决方案,开源高效的多任务开发利器 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit Topit是一款专为macOS系统…...

蓝桥杯EDA赛题深度解析:从客观题看电子设计核心考点
1. 蓝桥杯EDA赛题概述与备赛策略 蓝桥杯EDA设计与开发科目作为电子设计领域的重要赛事,每年吸引着众多高校学子参与。这个比赛最独特的地方在于它全面考察参赛者的电子设计自动化能力,从基础理论到软件操作,从元器件认知到电路分析࿰…...

【ElevenLabs卡纳达文语音实战指南】:2024年唯一经生产环境验证的7步本地化部署方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs卡纳达文语音技术概览与生产价值定位 ElevenLabs 作为全球领先的文本转语音(TTS)平台,自2023年Q4起正式支持卡纳达语(Kannada)&…...

Linux网络运维实战:从ifconfig、ethtool到网络状态深度诊断
1. 从ifconfig开始:你的网络诊断第一课 刚接手一台Linux服务器时,我习惯性敲下的第一个命令永远是ifconfig。这个看似简单的命令就像汽车仪表盘,能快速告诉你当前网络接口的基本状态。记得有次凌晨处理线上故障,就是通过ifconfig…...