AI 大框架基于python来实现基带处理之TensorFlow(信道估计和预测模型,信号解调和解码模型)
AI 大框架基于python来实现基带处理之TensorFlow(信道估计和预测模型,信号解调和解码模型)
基带处理(Baseband Processing)是一种信号处理技术,用于在通信系统中处理和调制基带信号。基带信号是指未经过调制的信号,通常包含原始数据的信息。在数字通信系统中,基带信号通常是由数字数据流组成的。
基带处理包括以下几个主要步骤:
数据处理和预处理通常包括在信号处理阶段,用于对信号进行预处理、降噪、滤波等操作,以提高后续解调和处理的效果。具体的步骤和方法可能因应用和需求而有所不同。
采样(Sampling):将连续时间的基带信号转换为离散时间信号。采样的目的是以一定的时间间隔取样基带信号,以便进行数字信号处理。
量化(Quantization):将采样后的连续幅度信号转换为离散幅度信号。量化的目的是将连续幅度的信号离散化为一系列离散幅度级别,以便数字信号处理和传输。
编码(Encoding):将离散幅度信号映射为数字形式,以便数字信号处理和传输。编码的目的是将量化后的离散幅度信号转换为二进制码流,以便进行数字信号处理和传输。
调制(Modulation):将数字编码信号转换为模拟基带信号。调制的目的是将数字编码信号与载波信号相乘,以便将其转换为高频信号,以便进行传输和接收。
解调(Demodulation):将接收到的调制信号转换为基带信号。解调的目的是从接收到的调制信号中提取出原始基带信号,以便进行后续数字信号处理和解码。
解码(Decoding):将解调后的数字信号恢复为原始数据。解码的目的是将解调后的数字信号转换为原始数据流,以便进行后续的处理和使用。
信道估计和预测模型通常属于基带处理的第五个阶段,即信号处理阶段。
在这个阶段,通过对接收到的信号进行处理和分析,可以估计和预测信道的状态和特性。
信道估计是一种用于估计无线通信系统中信道的状态或特性的技术。在无线通信中,信道是信号在传输过程中受到的各种影响(如多径衰落、噪声等)的结果。准确的信道估计可以帮助我们更好地理解信道的行为,优化通信系统的设计和性能。
在信道估计中,我们希望通过接收到的信号数据来推断信道的状态或特性。这可以通过不同的方法来实现,包括传统的方法(如最小二乘法、最大似然估计等)和基于机器学习的方法(如神经网络)。
Sequential模型是TensorFlow中的一种模型,它允许我们按照顺序将不同的层组合在一起,构建一个多层的神经网络。这种模型对于一些简单的问题和任务来说非常方便和易于使用。
对于信道估计任务,我们可以使用Sequential模型来构建一个适当的神经网络结构。通过适当的设计和训练,这个模型能够学习到输入信号数据与信道状态之间的关系,从而实现信道估计的功能。
具体来说,我们可以将接收到的信号数据作为模型的输入,将已知的信道状态或特性作为模型的输出。通过训练模型,我们可以优化模型的参数,从而使得模型能够准确地估计信道的状态或特性。
import tensorflow as tf# 准备输入数据
input_data = ... # 输入数据,例如接收到的基带信号序列
output_data = ... # 预期的输出数据,例如已知的信道状态或特性# 定义神经网络模型
model = tf.keras.models.Sequential([tf.keras.layers.Dense(9, activation='relu', input_shape=(3,3)),tf.keras.layers.Dense(9, activation='relu'),tf.keras.layers.Dense(3,3) # 输出层节点数与输出数据的维度相同,神经元数量不仅仅是一个数字,它还取决于输入数据的维度
])# 编译模型
model.compile(optimizer='adam', loss='mse') # 使用均方误差作为损失函数# 训练模型
model.fit(input_data, output_data, epochs=10, batch_size=32) # 进行多轮训练,每次训练使用的批次大小为32# 使用模型进行预测
predicted_output = model.predict(input_data) # 对输入数据进行预测,得到输出数据的估计值
在这里,mse代表均方误差(Mean Squared Error)。均方误差是一种常用的损失函数,用于衡量预测值与真实值之间的差异程度。在回归问题中,均方误差可以用来评估模型的性能,其中较小的均方误差表示模型的预测与真实值更接近。在这个例子中,mse被用作神经网络模型的损失函数,优化器会根据这个损失函数来调整模型的参数,以最小化均方误差。
batch_size=32代表的是每个批次中的样本数量。在深度学习中,为了加快训练速度和提高模型的泛化能力,通常将数据分成小批次进行训练。batch_size=32表示每个批次中有32个样本。
这里用的方法详细讲解:点这里
TensorFlow可以用于开发和训练信号解调和解码模型,用于从基带信号中恢复原始信息和数据。
# 创建信号解调
import tensorflow as tf
import numpy as np# 定义信号解调方法
def demodulate_signal(input_data, model):# 对输入数据进行预测,得到输出数据的估计值predicted_output = model.predict(input_data)# 对输出数据进行解码操作decoded_output = np.argmax(predicted_output, axis=1)return decoded_output# 准备输入数据
input_data = ... # 输入数据,例如接收到的基带信号序列# 加载训练好的模型
model = tf.keras.models.load_model('trained_model.h5')# 使用解调方法对输入数据进行处理
demodulated_signal = demodulate_signal(input_data, model)# 打印解调结果
print(demodulated_signal)
np.argmax(predicted_output, axis=1)是NumPy库中的一个函数,用于在指定轴上找到数组中最大值的索引。具体地说,np.argmax函数接受一个数组作为输入,并返回该数组沿着指定轴上具有最大值的元素的索引。在给定的矩阵中,每一行代表一个子数组,每一列代表一个元素。因此,轴0对应于行方向,轴1对应于列方向。索引是从0开始的整数,表示该元素在数组中的位置;如果你想要找到每一行的最大值,可以使用np.max(arr, axis=1),这将返回沿着轴1的最大值。
在信号解调的示例中,使用np.argmax(predicted_output, axis=1)的目的是找到预测输出中具有最大概率值的类别索引。这样可以将输出数据解码为最有可能的类别。
在基带处理中,解码是通过找到数据的索引位置来还原原始数据。这是因为在基带处理中,原始数据通常被编码为一系列离散的符号或样本。解码的目标是将这些离散的符号或样本还原为原始数据。为了实现这一点,接收端需要知道每个符号或样本对应的原始数据。这种映射关系通常是通过事先约定的编码方案来定义的。因此,在解码过程中,接收端会查找每个离散符号或样本在编码方案中对应的原始数据的索引位置。通过找到每个符号或样本的索引位置并映射到对应的原始数据,解码过程可以还原原始数据。
在数字通信系统中,解调和解码是两个不同的过程,用于将接收到的信号转换回原始数据。
解调(Demodulation)是指将调制过程中转换为模拟信号的调制信号还原为基带信号或数字信号的过程。在调制过程中,数字数据被转换为模拟信号,例如通过振幅、频率或相位的变化来表示不同的数据。解调的目标是还原这些模拟信号,将其转换回基带信号或数字信号,以便进行后续的处理。
解码(Decoding)是指将经过解调后的基带信号或数字信号转换回原始数据的过程。在解调后得到的信号可能是一系列的符号、样本或编码数据。解码的目标是将这些符号、样本或编码数据映射回原始的数字数据,以还原最初的信息。
import tensorflow as tf# 构建模型
model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation='relu', input_shape=(input_shape,)),tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(output_shape, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(train_data, train_labels, epochs=10, batch_size=32)# 评估模型
test_loss, test_acc = model.evaluate(test_data, test_labels, verbose=2)
print('Test accuracy:', test_acc)# 使用模型进行解码
decoded_data = model.predict(decoded_signals)
在构建模型时,input_shape参数用于指定输入数据的形状。对于第一个隐藏层,需要指定输入的形状,而不需要在括号中再次指定。因此,input_shape=(input_shape,)中的括号是用于创建一个包含input_shape的元组。
对于output_shape,通常在构建模型时不需要显式指定。输出层的形状会根据模型的结构和数据的特性自动确定。
sparse_categorical_crossentropy是一种用于多分类问题的损失函数。它适用于目标变量是整数形式的情况,而不是经过one-hot编码的情况。
在多分类问题中,目标变量通常被编码为整数形式,例如类别标签的整数值。而sparse_categorical_crossentropy损失函数会将目标变量和模型的输出进行比较,并计算相应的损失值。它会自动将目标变量转换为one-hot编码形式,然后计算交叉熵损失。
相比之下,categorical_crossentropy损失函数适用于目标变量已经经过one-hot编码的情况。在这种情况下,目标变量是一个二维数组,每一行表示一个样本的类别概率分布。
所以,如果目标变量是整数形式的类别标签,可以使用sparse_categorical_crossentropy作为损失函数。如果目标变量已经进行了one-hot编码,则可以使用categorical_crossentropy作为损失函数。
关于one-hot编码,它是一种将离散变量表示为二进制向量的方法。对于具有n个可能取值的离散变量,one-hot编码将其表示为长度为n的二进制向量,只有对应取值的位置上为1,其他位置上为0。这种编码方式可以有效地表示离散变量的类别信息,并在机器学习模型中使用。
相关文章:
)
AI 大框架基于python来实现基带处理之TensorFlow(信道估计和预测模型,信号解调和解码模型)
AI 大框架基于python来实现基带处理之TensorFlow(信道估计和预测模型,信号解调和解码模型) 基带处理(Baseband Processing)是一种信号处理技术,用于在通信系统中处理和调制基带信号。基带信号是指未经过调制的信号,通常包含原始数…...

阿里云上了新闻联播
我是卢松松,点点上面的头像,欢迎关注我哦! 阿里新任的CEO吴泳铭上央视新闻联播了! 在昨天的新闻联播里,出席科技座谈会,有一个特别镜头,出现了阿里新任CEO吴泳铭的镜头。 这个信号意义明显,我…...

算法练习12——跳跃游戏
LeetCode 55 跳跃游戏 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 贪…...

Java架构师系统架构设计服务拆分
目录 1 服务拆分和子系统模块拆分1.1 服务化架构的优势2 描绘系统蓝图里面的详解服务2.1 为什么拆分服务3 服务拆分的基本要求3.1 服务功能是自包含的3.2 服务呢应该具备独立性和专业性3.3 服务是无状态的3.4 服务之间采用轻量级的通讯机制4 服务拆分的基本方法4.1 按业务边界拆…...

通用任务批次程序模板
通用批次任务模板 我们总会遇到需要使用批次任务处理问题的场景,任务有很多不同类型的任务,同时这些任务可能都有大致相同,甚至抽象出来共同的执行阶段状态。 任务的执行肯定无法保证一帆风顺,总会在某个时间阶段被打断ÿ…...
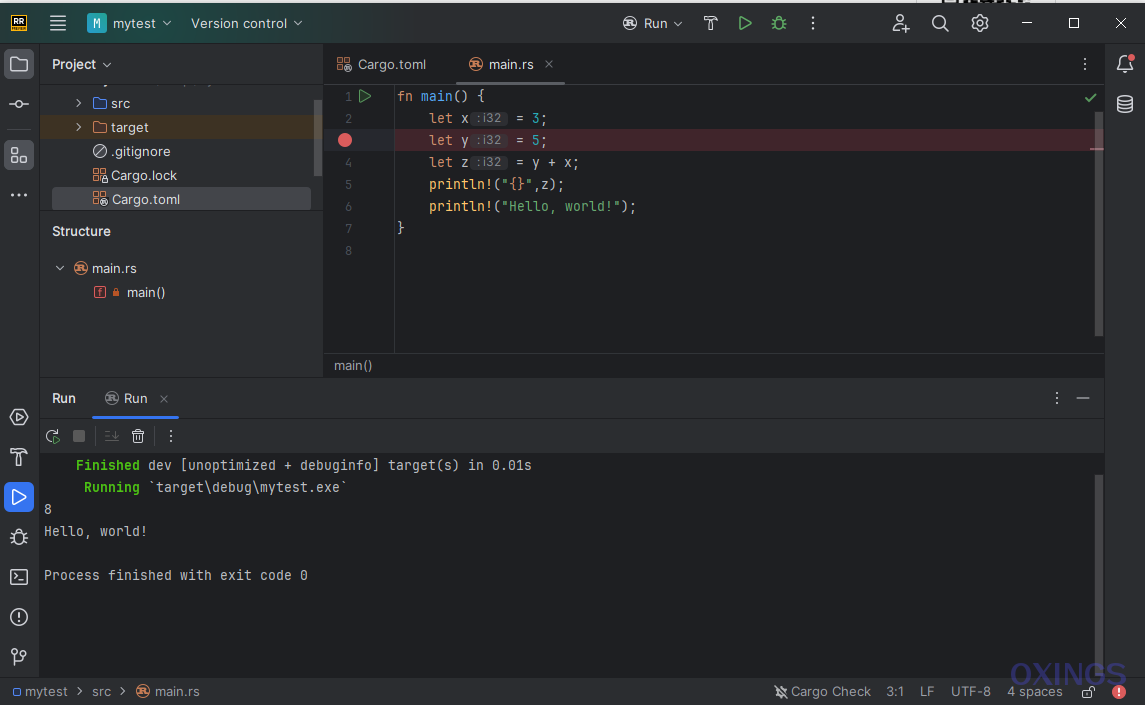
Rust专属开发工具——RustRover发布
JetBrains最近推出的Rust集成开发工具——RustRover已经发布,官方网站:RustRover: Rust IDE by JetBrains JetBrains出品过很受欢迎的开发工具IntelliJ IDEA、PyCharm等。 RustRover优势 Rust集成环境,根据向导可自动下载安装rust开发环境提…...
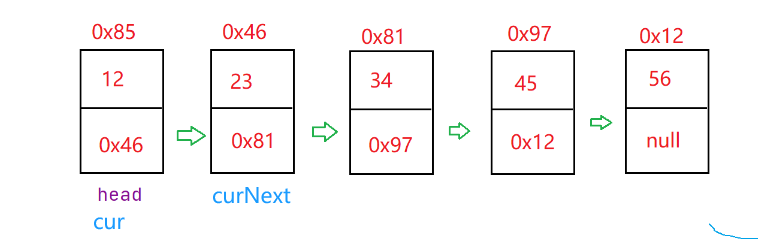
数据结构:链表(1)
顺序表的优缺点 缺点: 1.插入数据必须移动其他数据,最坏情况下,就是插入到0位置。时间复杂度O(N) 2.删除数据必须移动其他数据,最坏情况下,就是删除0位置。时间复杂度O(N) 3.扩容之后,有可能会浪费空间…...
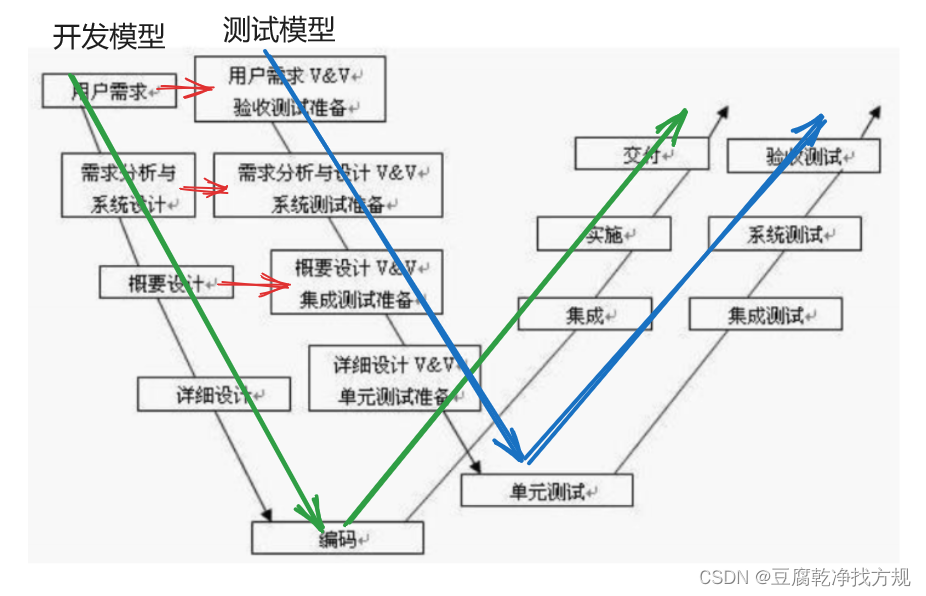
软件测试之概念篇2(瀑布模型、螺旋模型、增量模型和迭代模型、敏捷模型,V模型、W模型)
目录 开发模型 (1)瀑布模型 (2)螺旋模型 (3)增量模型和迭代模型 (4)敏捷模型 (5)测试模型(V模型、W模型) V模型 W模型 开发模型…...
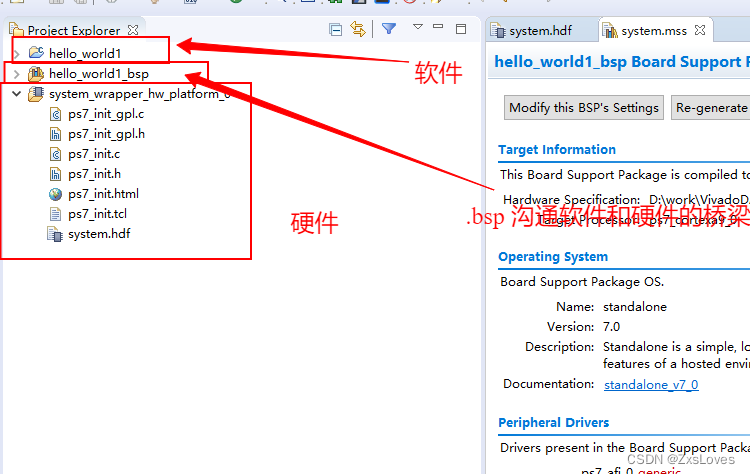
【【萌新的SOC学习之重新起航SOC】】
萌新的SOC学习之重新起航SOC ZYNQ PL 部分等价于 Xilinx 7 系列 FPGA PS端:Zynq 实际上是一个以处理器为核心的系统,PL 部分可以看作是它的一个外设。 我们可以通过使用AXI(Advanced eXtensible Interface)接口的方式调用 IP 核,系统通过 AX…...
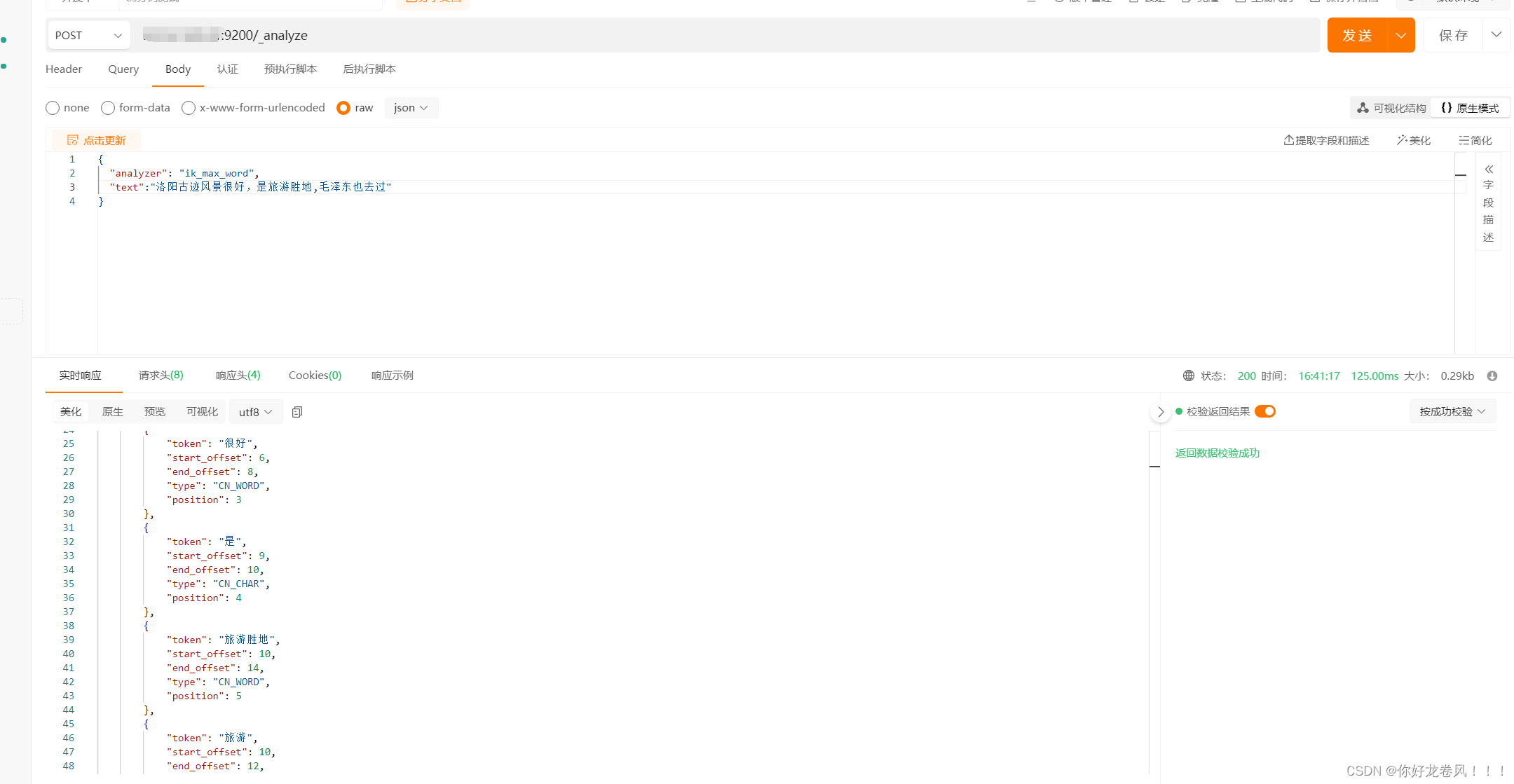
ElasticSearch 学习7 集成ik分词器
网上找了一大堆,很多都介绍的不详细,开始安装完一直报错找不到plugin-descriptor.properties,有些懵这个东西不应该带在里面吗,参考了一篇博客说新建一个这个,新建完可以启动,但是插入索引数据会报错找不到…...

[NewStarCTF 2023 公开赛道] week1
最近没什么正式比赛,都是入门赛,有moectf,newstar,SHCTF,0xGame都是漫长的比赛。一周一堆制。 这周newstar第1周结束了,据说py得很厉害,第2周延期了,什么时候开始还不一定,不过第一周已经结束提交了&#…...
ThreeJS-3D教学六-物体位移旋转
之前文章其实也有涉及到这方面的内容,比如在ThreeJS-3D教学三:平移缩放物体沿轨迹运动这篇中,通过获取轨迹点物体动起来,其它几篇文章也有旋转的效果,本篇我们来详细看下,另外加了tween.js知识点࿰…...

BC v1.2充电规范
1 JEITA Reference to https://www.mianbaoban.cn/blog/post/169964 符合 JEITA 规范的锂离子电池充电器解决方案 2 Battery Fuel Gauge 2.1 Cycle Count(充放电循环次数) 此指令回传一只读字段,代表电芯组已经历的完整充放电循环数。当放电容…...

判断一个整数是否回文
回文数字的定义:第一位和最后一位相等,第二位和倒数第二位相等...依次类推,比如1221,12321等等,也就是说一个数字如果是回文,那么将它反转之后,一定和原来的值相等 解法一:投机取巧,…...

【广州华锐互动】车辆零部件检修AR远程指导系统有效提高维修效率和准确性
在快速发展的科技时代,我们的生活和工作方式正在被重新定义。这种变化在许多领域都有所体现,尤其是在汽车维修行业。近年来,AR(增强现实)技术的进步为这个行业带来了前所未有的可能性。通过将AR技术与远程协助系统相结…...
简单实现接口自动化测试(基于python+unittest)
简介 本文通过从Postman获取基本的接口测试Code简单的接口测试入手,一步步调整优化接口调用,以及增加基本的结果判断,讲解Python自带的Unittest框架调用,期望各位可以通过本文对接口自动化测试有一个大致的了解。 引言 为什么要…...
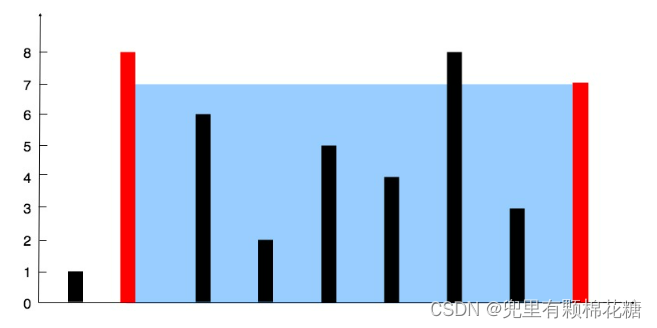
【算法|双指针系列No.4】leetcode11. 盛最多水的容器
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【手撕算法系列专栏】【LeetCode】 🍔本专栏旨在提高自己算法能力的同时,记录一下自己的学习过程,希望…...

数据结构全集介绍
以下列举了部分常见的数据结构: 数组(Array):数组是一种线性数据结构,可以用来存储固定大小的数据集合。在数组中,每个元素都有一个对应的索引,可以通过索引直接访问和更新元素。数组的优点是访…...

力扣刷题-字符串-反转字符串
344 反转字符串 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。 不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。 你可以假设数组中的所有字符都是 ASCII 码表中…...

【CCNP】第七章 动态路由协议-BGP
第一节 BGP的基本概念 BGP(Border Gateway Protocol),边界网关协议 是运行在网络和网络之间的协议,是一款EGP(外部网关协议) BGP基于TCP协议工作,目的端口号179。源端口随机,由路由…...

0.2mm间距测试探针技术解析与应用指南
1. 0.2mm间距测试探针的技术突破与应用价值在半导体测试领域,随着芯片封装尺寸的持续缩小和信号频率的不断提升,传统测试探针已难以满足高密度互连与高频测试的双重需求。Aries Electronics最新推出的0.2mm间距测试探针,采用镀金铍铜材料和特…...

Docker Compose实战:一键部署OpenClaw项目与环境管理
1. 项目概述:一个为OpenClaw项目量身定制的Docker助手 如果你正在折腾一个名为OpenClaw的开源项目,并且被它复杂的依赖环境、繁琐的配置步骤搞得焦头烂额,那么你很可能需要“vivganes/openclaw-docker-helper”这个工具。简单来说࿰…...

免费国产模型清单
下面给你整理了能在国内稳定使用、可通过中转接入 Claude Code 的国产免费模型,同时附接入方式和适配说明,帮你快速替换驱动👇 一、免费国产模型清单(公开 API / 兼容格式) 这些模型支持 OpenAI/Anthropic 兼容接口&a…...

Midjourney批量生成工作流终极提速方案:从单图2分钟到百图并发17秒,实测数据驱动的6大优化节点
更多请点击: https://intelliparadigm.com 第一章:Midjourney批量生成工作流的性能瓶颈全景图 在高并发图像生成场景中,Midjourney 的批量工作流常因 API 限流、提示词解析延迟、队列堆积及资源调度失衡而显著降速。其底层依赖 Discord 消息…...

基于Playwright的Instagram自动化技能包:原理、实现与智能体集成
1. 项目概述与核心价值最近在折腾个人智能助理,想让它能帮我处理一些社交媒体上的琐事,比如自动查看Instagram上的新动态、给特定帖子点赞或者保存一些有趣的图片。在网上搜了一圈,发现了一个叫adamanz/instagram-skill的开源项目,…...

开源灵巧手OpenClaw:从机械设计到AI抓取的完整实现指南
1. 项目概述:当开源机械爪遇上AI大脑 最近在机器人开源社区里,一个名为“OpenClaw”的项目引起了我的注意。这个由Turbo Labs团队发布的项目,其核心目标非常明确:打造一个低成本、高性能、且完全开源的机器人灵巧手(或…...

MacOS Telegram语音实时转译:本地化音频捕获与离线语音识别实践
1. 项目概述:一个为MacOS打造的Telegram语音实时转译工具如果你和我一样,经常在Telegram上参与多语言群组讨论,或者需要处理来自不同地区的语音消息,那么语言障碍绝对是一个头疼的问题。想象一下,你收到一条长达一分钟…...

车载以太网之要火系列 - 第43篇:郭大侠学SOME/IP :服务写死痛点多,SD出山更灵活
写在开篇蓉儿挖新坑上回说到,郭靖搞清楚了SOME/IP的报文头、Service ID、Instance ID、Method、Event、Field……学了一大堆。郭靖合上笔记本,信心满满:“蓉儿,SOME/IP我算是学完了!车窗服务用0x0300,左前窗…...

终极分子绘图工具Ketcher:免费在线化学结构编辑器完整指南
终极分子绘图工具Ketcher:免费在线化学结构编辑器完整指南 【免费下载链接】ketcher Web-based molecule sketcher 项目地址: https://gitcode.com/gh_mirrors/ke/ketcher 还在为复杂的化学结构绘图而烦恼吗?传统绘图工具操作繁琐、格式兼容性差、…...

9.5%复合增长率强势领航!2025年全球甲酸真空回流焊炉市场规模1.2亿美元,2032年剑指2.24亿,高增长动能全面释放
QYResearch调研显示,2025年全球甲酸真空回流焊炉市场规模大约为1.2亿美元,预计2032年将达到2.24亿美元,2026-2032期间年复合增长率(CAGR)为9.5%。结合QYResearch数据及行业深耕经验,当前甲酸真空回流焊炉行…...