安装hadoop,并配置hue
0、说明
对于大数据学习的初始阶段,我也曾尝试搭建相应的集群环境。通过搭建环境了解组件的一些功能、配置、原理。
在实际学习过程中,我更多的还是使用docker来快速搭建环境。
这里记录一下我搭建hadoop的过程。
1、下载hadoop
下载地址:Apache Hadoop
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz# 解压
tar -zxvf hadoop-2.10.1.tar.gz# 复制到 /usr/hadoop/目录下
# sudo mkdir /usr/hadoop/
# cp -r hadoop-2.10.1 /usr/hadoop/# 添加HADOOP_HOME
sudo /etc/profile
# 添加如下内容,并保存退出
#HADOOP_HOME
export HADOOP_HOME=/home/airwalk/bigdata/soft/hadoop-2.10.1
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/sbin:$PATH# 使生效
source /etc/profile# 测试
hdfs version#结果如下
airwalk@svr43:/usr/hadoop/hadoop-2.10.1$ hdfs version
Hadoop 2.10.1
Subversion https://github.com/apache/hadoop -r 1827467c9a56f133025f28557bfc2c562d78e816
Compiled by centos on 2020-09-14T13:17Z
Compiled with protoc 2.5.0
From source with checksum 3114edef868f1f3824e7d0f68be03650
This command was run using /home/airwalk/bigdata/soft/hadoop-2.10.1/share/hadoop/common/hadoop-common-2.10.1.jar# 测试
cd bigdata/soft/hadoop-2.10.1
mkdir input
cp etc/hadoop/* input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar grep input/ output '[a-z.]+'至此,在一台机器上的hadoop安装成功
2、配置
| svr43 | server42 | server37 | |
|---|---|---|---|
| hdfs | namenode,datanode | datanode | SecondaryNamenode,datanode |
| yarn | nodeManager | resourceManager,nodeManager | nodeManager |
0:免密登录配置
- 在svr43机器上生成密钥(hdfs的namenode节点)
cd ~/.ssh
## 下面一直回车即可
ssh-keygen -t rsa## 然后在该目录下执行
ssh-copy-id server42
ssh-copy-id server37
# 自己也需要免密登录自己
ssh-copy-id svr43- 在 server42机器上生成密钥,免密登录其它节点,因为该节点是yarn 的resourceManger
cd ~/.ssh
## 下面一直回车即可
ssh-keygen -t rsa## 然后在该目录下执行
# 自己也需要免密登录自己
ssh-copy-id server42
ssh-copy-id server37
ssh-copy-id svr43
!! 注意,出现如下异常
airwalk@server42:~/.ssh$ ssh svr43
Warning: the ECDSA host key for 'svr43' differs from the key for the IP address '192.168.0.43'
Offending key for IP in /home/airwalk/.ssh/known_hosts:3
Matching host key in /home/airwalk/.ssh/known_hosts:11
Are you sure you want to continue connecting (yes/no)? yes
Welcome to Ubuntu 16.04.6 LTS (GNU/Linux 4.4.0-142-generic x86_64)# 解决方法
ssh-keygen -R 192.168.0.43
- 在svr43机器上生成root密钥(hdfs的namenode节点)
# 切换到root账户下
sudo su root
cd /root/.ssh
ssh-keygen -t rsa
ssh-copy-id server42
ssh-copy-id server37
ssh-copy-id svr43
1:配置core-site.xml
临时文件的位置,注意不能放在太小的磁盘里,这里使用的是如下目录
/home/airwalk/bigdata/soft/hadoop-2.10.1/data/tmp
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.43:9000</value>
<!-- 这里直接使用配置ip的方式 -->
#<value>hdfs://svr43:9000</value>
</property><property>
<name>hadoop.tmp.dir</name>
<value>/home/airwalk/bigdata/soft/hadoop-2.10.1/data/tmp</value>
</property>
2:hdfs的配置文件
配置hadoop-env.sh
echo $JAVA_HOME
vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
配置hdfs-site.xml
因为集群时3个,所以这里改为副本为3
<property><name>dfs.replication</name><value>3</value></property><!-- 指定hadoop辅助namenode节点主机配置 --><property><name>dfs.namenode.secondary.http-address</name><value>server37:50090</value></property>
3:yarn配置
配置yarn-env.sh
vim yarn-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
配置yarn-site.xml
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
<!-- 指定hadoop辅助namenode节点主机配置 -->
<property><name>yarn.resourcemanager.hostname</name><!-- 这里直接使用配置ip的方式 --><value>192.168.0.42</value><!-- <value>server42</value> -->
</property>
4:MapReduce配置
配置mapred-env.sh
vim yarn-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
配置mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value></property>3、启动
- 在namenode节点上,进行格式化操作
hdfs namenode -format
- 启动namenode
cd sbin
./hadoop-daemon.sh start namenode
./sbin/hadoop-daemon.sh start namenode
- 启动datanode
# 三台机器均启动
./sbin/hadoop-daemon.sh start datanode
- 退出
./sbin/hadoop-daemon.sh stop namenode
# 三台机器均退出
./sbin/hadoop-daemon.sh stop datanode
4、集群启动
1:配置slaves, 所有节点都要修改
cd /home/airwalk/bigdata/soft/hadoop-2.10.1/etc/hadoop
vim salves
# 添加从主机的名字,不允许有空格和空行
svr43
server42
server37
2: 启动hdfs集群
可以自动启动集群中的所有datanode和namenode
# 在hdfs的namenode节点上执行下面的命令
./sbin/start-dfs.sh
3:启动yarn
# 需要再resourceManger节点上进行处理(server42)
./sbin/start-yarn.shstarting yarn daemons
resourcemanager running as process 10206. Stop it first.
server42: nodemanager running as process 10550. Stop it first.
svr43: starting nodemanager, logging to /home/airwalk/bigdata/soft/hadoop-2.10.1/logs/yarn-airwalk-nodemanager-svr43.out
server37: starting nodemanager, logging to /home/airwalk/bigdata/soft/hadoop-2.10.1/logs/yarn-airwalk-nodemanager-server37.out5、查看
namenode 节点上的链接
http://192.168.0.43:50070/

6、配置hue
Hadoop配置文件修改
hdfs-site.xml
<property><name>dfs.webhdfs.enabled</name><value>true</value>
</property>
core-site.html
<property><name>hadoop.proxyuser.airwalk.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.airwalk.groups</name><value>*</value>
</property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
httpfs-site.xml配置
<!-- Hue HttpFS proxy airwalk setting --><property><name>httpfs.proxyuser.airwalk.hosts</name><value>*</value></property><property><name>httpfs.proxyuser.airwalk.groups</name><value>*</value></property>
HUE配置文件修改
[[hdfs_clusters]] [[[default]]]fs_defaultfs=hdfs://myclusterwebhdfs_url=http://node1:50070/webhdfs/v1hadoop_bin=/usr/hadoop-2.5.1/binhadoop_conf_dir=/usr/hadoop-2.5.1/etc/hadoop
启动hdfs、重启hue
解决方法:
1、 关闭hdfs的权限验证
hdfs-site.xml
<property><name>dfs.permissions.enabled</name><value>false</value>
</property>
docker run -tid --name hue88 -p 8888:8888 -v /home/airwalk/bigdata/soft/hadoop-2.10.1/etc/hadoop:/etc/hadoop gethue/hue:latestdocker cp hue.ini hue88:/usr/share/hue/desktop/conf/docker restart hue88docker exec -it --user root <container id> /bin/bash
sudo apt-get install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-devel rsync# 作者:一拳超疼
# 链接:https://www.jianshu.com/p/a80ec32afb27
# 来源:简书
# 参考文档
[Install :: Hue SQL Assistant Documentation (gethue.com)](https://docs.gethue.com/administrator/installation/install/)
# 安装完所以的依赖后,再
# /home/airwalk/bigdata/soft/hue 是想要安装的目录
sudo PREFIX=/home/airwalk/bigdata/soft/hue make install
- python3.8 安装
https://blog.csdn.net/qq_39779233/article/details/106875184
- 安装npm
sudo apt install npm
npm install --unsafe-perm=true --allow-root- 安装node
# 选择源,及版本号,这里是10.x,其它版本只需要更改为一些如:12.x,注意后面就是一个x
curl -sL https://deb.nodesource.com/setup_10.x | sudo -E bash -# 安装相应的node
sudo apt-get install -y nodejs# 查看
node --version- 问题
# gyp ERR! stack Error: EACCES: permission denied, mkdir问题解决方案
# npm 有些命令不允许在root用户下执行,会自动从root用户切换到普通用户,这里设置一下,就可以在当前用户下执行sudo npm i --unsafe-perm# 然后在root权限下执行如下命令
PREFIX=/home/airwalk/bigdata/soft/hue make install
编译安装成功!!!
相关文章:
安装hadoop,并配置hue
0、说明 对于大数据学习的初始阶段,我也曾尝试搭建相应的集群环境。通过搭建环境了解组件的一些功能、配置、原理。 在实际学习过程中,我更多的还是使用docker来快速搭建环境。 这里记录一下我搭建hadoop的过程。 1、下载hadoop 下载地址:…...
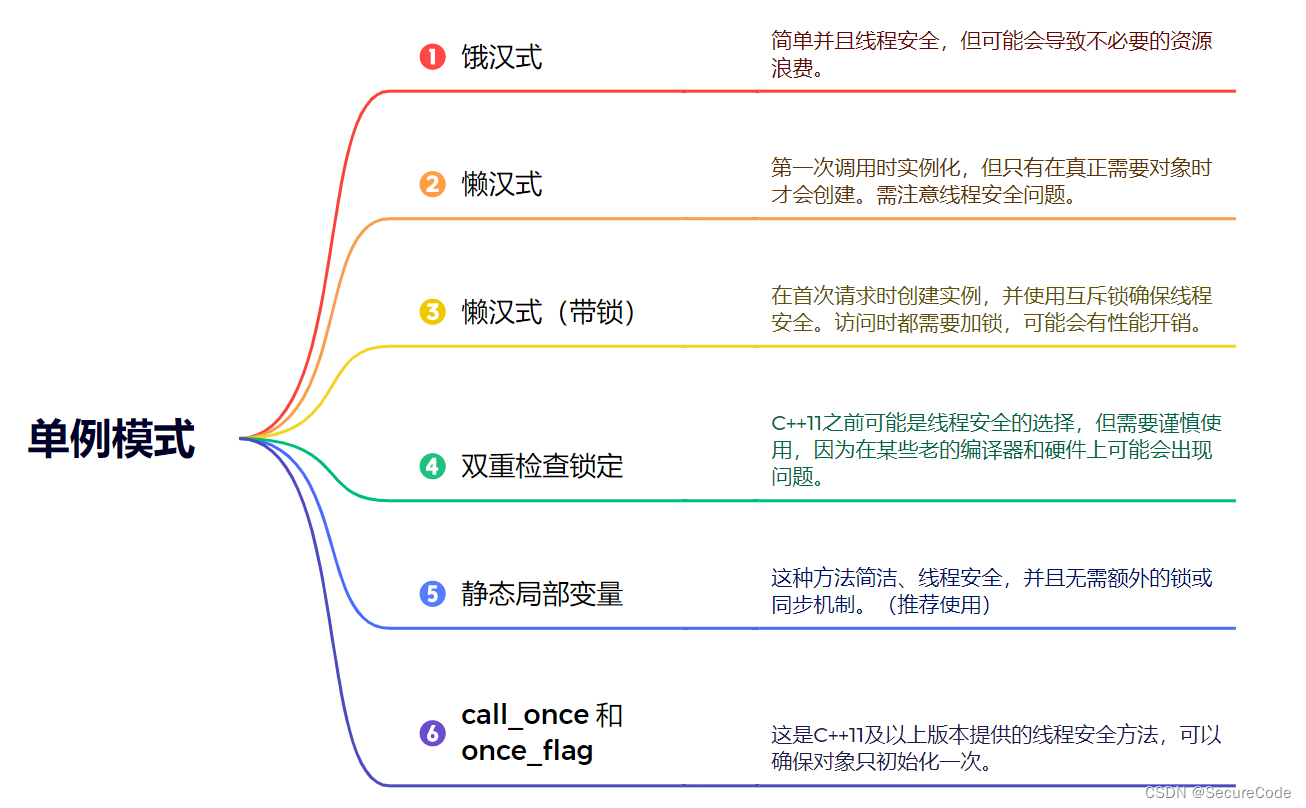
23种经典设计模式:单例模式篇(C++)
前言: 博主将从此篇单例模式开始逐一分享23种经典设计模式,并结合C为大家展示实际应用。内容将持续更新,希望大家持续关注与支持。 什么是单例模式? 单例模式是设计模式的一种(属于创建型模式 (Creational Pa…...

ros中对move_base的调用
move_base包中自带costmap2d, global planner 等功能 也可以直接调用其中make_plan进行路径规划 #include "geometry_msgs/PoseStamped.h" #includde "nav_msgs/GetPlan.h"void fillPathRequest(nav_msgs::GetPlan::Request &request, float start_x…...

Git从本地库撤销已经添加的文件或目录
场景 在提交时, 误将一个目录添加到了暂存区, 而且commit 了本地库,同批次commit 的还有其他需要提交的文件。 commit 之后发现这个目录下所有的文件都不需要提交, 现在需要撤销这个提交, 使这个目录不被push到远端库。 这里以远端服务器github 为例,在Git GUI下看到的…...

百度SEO优化的特点(方式及排名诀窍详解)
百度SEO优化的特点介绍: 百度SEO优化是指对网站进行优化,使其在百度搜索引擎中获得更好的排名,进而获取更多的流量和用户。百度SEO优化的特点是综合性强、效果持久、成本低廉、投资回报高。百度的搜索算法不断更新,所以长期稳定的…...
Gin 文件上传操作(单/多文件操作)
参考地址: 单文件 | Gin Web Framework (gin-gonic.com)https://gin-gonic.com/zh-cn/docs/examples/upload-file/single-file/ 单文件 官方案例: func main() {router := gin.Default()// 为 multipart forms 设置较低的内存限制 (默认是 32 MiB)router.MaxMultipartMem…...

分类预测 | MATLAB实现KOA-CNN-LSTM开普勒算法优化卷积长短期记忆神经网络数据分类预测
分类预测 | MATLAB实现KOA-CNN-LSTM开普勒算法优化卷积长短期记忆神经网络数据分类预测 目录 分类预测 | MATLAB实现KOA-CNN-LSTM开普勒算法优化卷积长短期记忆神经网络数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现KOA-CNN-LSTM开普勒算法优化…...

Qt应用开发(基础篇)——列表视图 QListView
一、前言 QListView类继承于QAbstractItemView类,提供了一个列表或者图标视图的模型。 视图基类 QAbstractItemView QListView效果相当于Windows文件夹右键->查看->图标和列表,使用setViewMode()设置视图模式,并且提供setIconSize()函数…...

vue-6
一、声明式导航-导航链接 1.需求 实现导航高亮效果 如果使用a标签进行跳转的话,需要给当前跳转的导航加样式,同时要移除上一个a标签的样式,太麻烦!!! 2.解决方案 vue-router 提供了一个全局组件 router…...

温度在线检测技术在电力电缆线路的应用
在电力电缆的日常运行检测中,针对电缆温度的状况,所采用的电力温度在线检测技术也得到了大范围的普及。电网系统中,其单位时间内可输送的电力能源受到其温度的变化影响。因此,采用更有效的方式实时检测电缆系统运行温度࿰…...
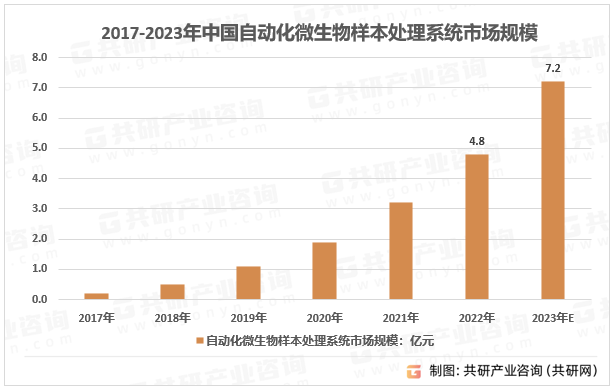
2023年中国自动化微生物样本处理系统竞争现状及行业市场规模分析[图]
微生物检测能够对感染性疾病的病原体或者代谢物进行检测分析,是IVD的细分领域之一。2022年中国体外诊断市场规模1424亿元。 2015-2022年中国体外诊断市场规模 资料来源:共研产业咨询(共研网) 微生物检测由于样本类型多样…...

硬链接和软连接的区别
软链接(也称为软连接或符号链接)是一种特殊的文件,其内容是另一个文件的路径。当你使用软链接时,实际上是在操作另一个文件。软链接的优点是它可以跨文件系统使用,因此可以跨分区或磁盘链接文件。此外,软链…...

保护隐私与增强网络安全之网络代理技术
目录 前言 一、网络代理技术原理 二、网络代理技术类型 1. HTTP代理 2. SOCKS代理 3. DNS代理 4. 加密代理 5. 反向代理 三、网络代理技术应用 1. 加速网络访问速度 2. 绕过网络限制 3. 保护个人隐私 4. 节省带宽 5. 改善网络安全 四、网络代理技术优缺点 网络…...

【每日一题】CF1680C. Binary String | 双指针 | 简单
题目内容 原题链接 给定一个长度为 n n n 的 01 01 01 字符串,对于一个子串 s u b sub sub ,子串内部的 0 0 0 的数量为 x x x ,子串以外的 1 1 1 的数量为 y y y ,子串的代价为 m a x ( x , y ) max(x, y) max(x,y) &…...
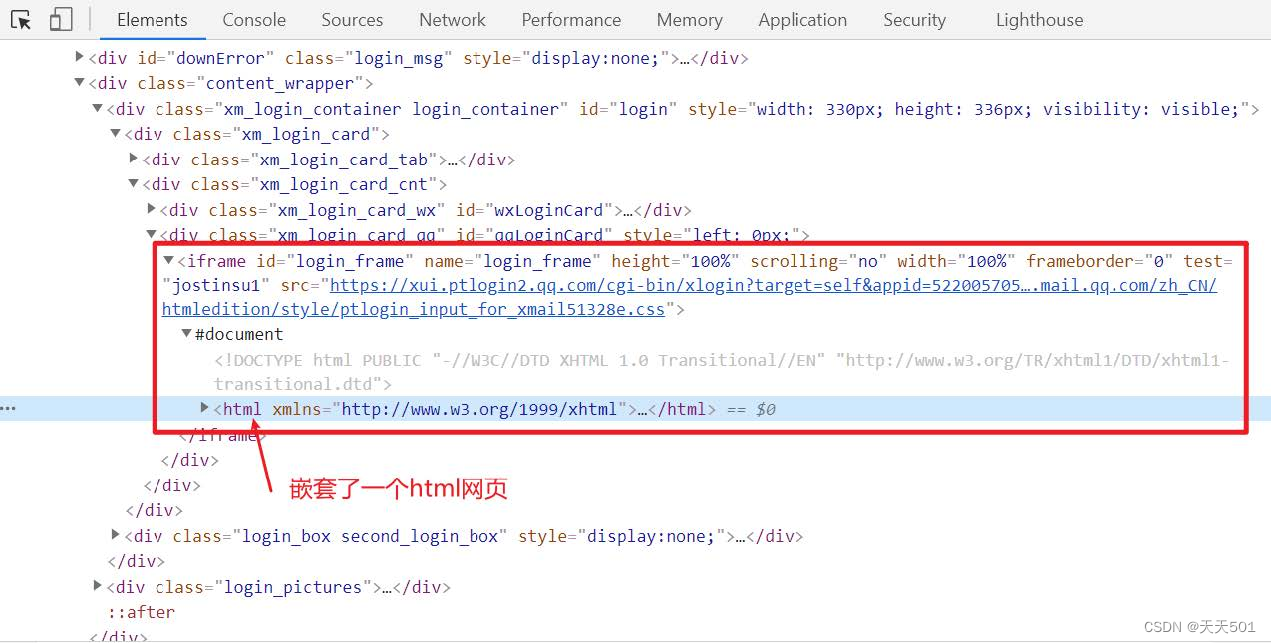
10.selenium进阶
文章目录 1、嵌套网页1、1 什么是嵌套页面1、2 selenium获取嵌套页面的数据 2、执行JavaScript代码3、鼠标动作链4、selenium键盘事件5、其他方法5、1 选择下拉框5、2 弹窗的处理 6、selenium设置无头模式7、selenium应对检测小结 1、嵌套网页 在前端开发中如果有这么一个需…...
【安全】 Java 过滤器 解决存储型xss攻击问题
文章目录 XSS简介什么是XSS?分类反射型存储型 XSS(cross site script)跨站脚本攻击攻击场景解决方案 XSS简介 跨站脚本( cross site script )为了避免与样式css(Cascading Style Sheets层叠样式表)混淆,所以简称为XSS。 XSS是一种经常出现在web应用中的计算机安全…...
一、Excel VBA 是个啥?
Excel VBA 从入门到出门一、Excel VBA 是个啥?二、Excel VBA 简单使用 👋Excel VBA 是个啥? ⚽️1. Excel 中的 VBA 是什么?⚽️2. 为什么 VBA 很重要?⚽️3. 是否有无代码方法可以在 Excel 中实现工作流程自动化&…...

Spring Boot读取配置文件
Spring Boot 是一种用于快速构建基于Spring的应用程序的框架,它提供了很多便利的功能和约定,使开发者可以快速搭建、配置和部署应用程序。在Spring Boot中,读取配置文件是一个非常常见的任务,本文将介绍如何在Spring Boot应用程序…...
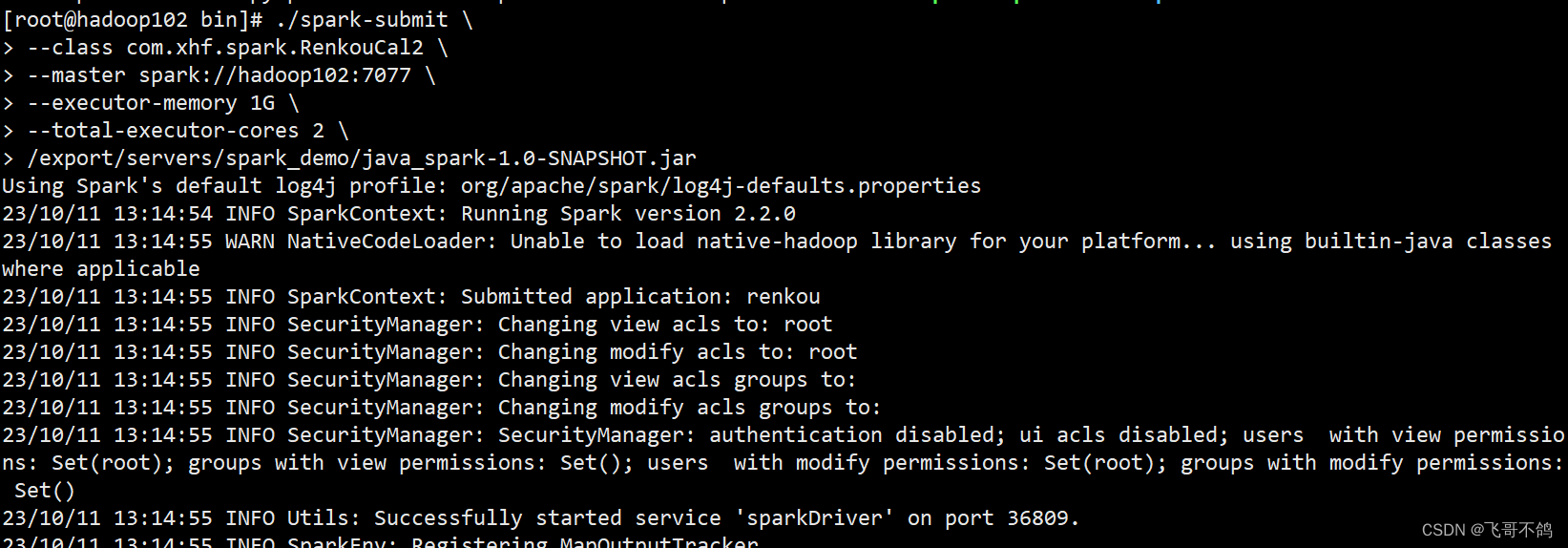
spark集群环境下,实现人口平均年龄计算
文章目录 任务目标0. 版本信息1. 计算生成renkou.txt2. 文件上传至spark3. 上传文件时,可能出现的常见错误4. 编写spark文件5. 上传集群6. 集群环境下提交任务 任务目标 在虚拟机上部署spark集群,给定renkou.txt文件,输出平均年龄 renkou.t…...

[羊城杯 2020]black cat - 文件隐写+RCE(hash_hmac绕过)
[羊城杯 2020]black cat 1 解题流程1.1 第一步1.2 第二步1.3 第三步 1 解题流程 1.1 第一步 打开网站有首歌,按F12也是提示听歌,ctf-wscan扫描就flag.php下载歌,用010打开,发现有一段内容if(empty($_POST[Black-Cat-Sheriff]) |…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

通过TaotokenCLI工具一键配置开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境接入参数 对于需要接入多个大模型服务的开发者而言,手动配置每个项目的API密钥、…...

深度解析:JetBrains IDE试用期重置机制的技术实现
深度解析:JetBrains IDE试用期重置机制的技术实现 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在软件开发工作流中,JetBrains IDE试用期管理是一个常见的技术挑战,尤其是在多…...

想深耕网络安全行业,这些必备条件缺一不可
网络空间的攻防对抗日益激烈,网络安全已成为企业生存和国家安全的命脉,它负责构筑数字世界的坚固防线,保护核心资产与用户隐私免受侵害。 想要成为一名优秀的网络安全专家,除了敏锐的安全意识和高度的责任感,更需要锤…...

终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题
终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否还在为Windows…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...