ChatGPT 的工作原理:机器人背后的模型
这篇对支持 ChatGPT 的机器学习模型的温和介绍,将从大型语言模型的介绍开始,深入探讨使 GPT-3 得到训练的革命性自我注意机制,然后深入研究人类反馈的强化学习,使 ChatGPT 与众不同的新技术。
大型语言模型
ChatGPT 是一类被称为大型语言模型 (LLM) 的机器学习自然语言处理模型的外推。LLM 消化大量文本数据并推断文本中单词之间的关系。随着我们看到计算能力的进步,这些模型在过去几年中得到了发展。随着输入数据集和参数空间大小的增加,LLM 的能力也会增加。
语言模型最基本的训练涉及预测单词序列中的单词。最常见的是,这被观察为下一个标记预测和屏蔽语言建模。
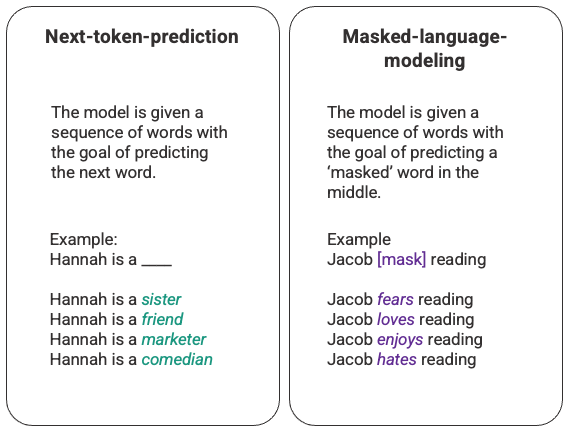
下一个标记预测和屏蔽语言建模的任意示例。
在这种通常通过长短期记忆 (LSTM) 模型部署的基本排序技术中,该模型使用给定周围上下文的统计上最可能的词来填充空白。这种顺序建模结构有两个主要限制。
- 该模型无法比其他词更重视周围的一些词。在上面的例子中,虽然“阅读”可能最常与“讨厌”联系在一起,但在数据库中,“雅各布”可能是一个狂热的读者,因此模型应该给予“雅各布”比“阅读”更多的权重,并选择“爱” '而不是'讨厌'。
- 输入数据是单独和顺序处理的,而不是作为整个语料库处理的。这意味着当 LSTM 被训练时,上下文窗口是固定的,仅扩展到序列中几个步骤的单个输入之外。这限制了单词之间关系的复杂性和可以导出的含义。
针对这个问题,2017 年 Google Brain 的一个团队引入了 transformers。与 LSTM 不同,转换器可以同时处理所有输入数据。使用自注意力机制,该模型可以根据语言序列的任何位置为输入数据的不同部分赋予不同的权重。此功能在将意义注入 LLM 方面实现了巨大改进,并支持处理更大的数据集。
GPT 和自注意力
Generative Pre-training Transformer (GPT) 模型于 2018 年由 openAI 作为 GPT-1 首次推出。这些模型在 2019 年继续发展 GPT-2,2020 年发展 GPT-3,最近在 2022 年发展 InstructGPT 和 ChatGPT。在将人类反馈集成到系统之前,GPT 模型进化的最大进步是由计算效率的成就推动的,这使得 GPT-3 能够接受比 GPT-2 多得多的数据训练,从而赋予它更多样化的知识库和执行更广泛任务的能力。

GPT-2(左)和 GPT-3(右)的比较。由作者生成。
所有 GPT 模型都利用了 transformer 架构,这意味着它们有一个编码器来处理输入序列和一个解码器来生成输出序列。编码器和解码器都有一个多头自注意力机制,允许模型对序列的不同部分进行不同的加权以推断含义和上下文。此外,编码器利用掩码语言建模来理解单词之间的关系并产生更易于理解的响应。
驱动 GPT 的自注意力机制通过将标记(文本片段,可以是单词、句子或其他文本分组)转换为表示标记在输入序列中的重要性的向量来工作。为此,模型,
- 为输入序列中的每个标记创建查询、键和值向量。
- 通过取两个向量的点积来计算第一步中的查询向量与每个其他标记的键向量之间的相似度。
- 通过将步骤 2 的输出输入softmax 函数来生成归一化权重。
- 通过将步骤 3 中生成的权重乘以每个标记的值向量,生成一个最终向量,表示标记在序列中的重要性。
GPT 使用的“多头”注意机制是自我注意的演变。模型不是执行一次步骤 1-4,而是并行地多次迭代此机制,每次生成查询、键和值向量的新线性投影。通过以这种方式扩展自注意力,该模型能够掌握输入数据中的子含义和更复杂的关系。

尽管 GPT-3 在自然语言处理方面取得了显着进步,但它在符合用户意图方面的能力有限。例如,GPT-3 可能产生的输出
- 缺乏帮助意味着他们不 遵循用户的明确指示。
- 包含反映不存在或不正确事实的幻觉。
- 缺乏可解释性使人类难以理解模型是如何得出特定决策或预测的。
- 包括有害或令人反感并传播错误信息的有毒或有偏见的内容。
ChatGPT 中引入了创新的培训方法,以解决标准 LLM 的一些固有问题。
聊天GPT
ChatGPT 是 InstructGPT 的衍生产品,它引入了一种新颖的方法,将人类反馈纳入训练过程,以更好地使模型输出与用户意图保持一致。人类反馈强化学习 (RLHF) 在中有深入描述openAI 的 2022纸训练语言模型以遵循带有人类反馈的指令并在下面进行了简化.
第 1 步:监督微调 (SFT) 模型
第一项开发涉及通过雇用 40 名承包商创建监督训练数据集来微调 GPT-3 模型,其中输入具有供模型学习的已知输出。输入或提示是从实际用户输入到 Open API 中收集的。然后,贴标签者对提示做出适当的回应,从而为每个输入创建一个已知的输出。然后使用这个新的监督数据集对 GPT-3 模型进行微调,以创建 GPT-3.5,也称为 SFT 模型。
为了最大化提示数据集中的多样性,任何给定的用户 ID 只能发出 200 个提示,并且删除了任何共享长公共前缀的提示。最后,删除了所有包含个人身份信息 (PII) 的提示。
在汇总来自 OpenAI API 的提示后,标注者还被要求创建样本提示以填写只有最少真实样本数据的类别。感兴趣的类别包括
- 普通提示:任意任意询问。
- Few-shot 提示:包含多个查询/响应对的指令。
- 基于用户的提示:对应于为 OpenAI API 请求的特定用例。
在生成响应时,标注者被要求尽最大努力推断用户的指令是什么。本文介绍了提示请求信息的主要三种方式。
- 直接: “告诉我关于……”
- Few-shot:鉴于这两个故事的例子,写另一个关于同一主题的故事。
- Continuation:给定一个故事的开始,结束它。
来自 OpenAI API 的提示汇编和标注人员手写的提示产生了 13,000 个输入/输出样本,用于监督模型。
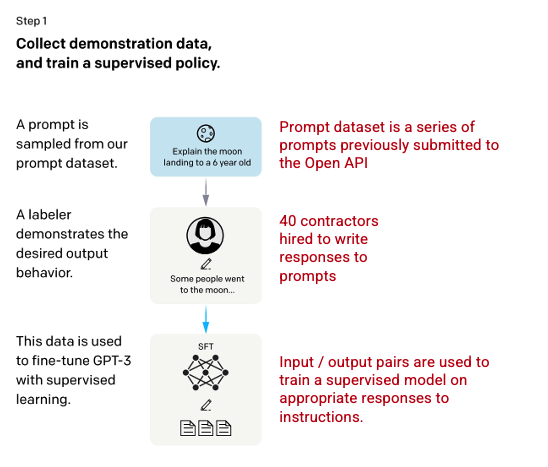
图片(左)从训练语言模型插入以遵循人类反馈的指令OpenAI 等,2022 https://arxiv.org/pdf/2203.02155.pdf。作者以红色(右)添加的附加上下文。
第二步:奖励模式
在步骤 1 中训练 SFT 模型后,该模型会对用户提示生成更一致的响应。下一个改进以训练奖励模型的形式出现,其中模型输入是一系列提示和响应,输出是一个缩放值,称为奖励。需要奖励模型以利用强化学习,在强化学习中模型学习产生输出以最大化其奖励(参见步骤 3)。
为了训练奖励模型,为单个输入提示向贴标机提供 4 到 9 个 SFT 模型输出。他们被要求将这些输出从最好到最差进行排名,创建输出排名组合如下。

响应排名组合示例。
将模型中的每个组合作为单独的数据点包括在内会导致过度拟合(无法推断超出可见数据的范围)。为了解决这个问题,该模型是利用每组排名作为单个批处理数据点构建的。
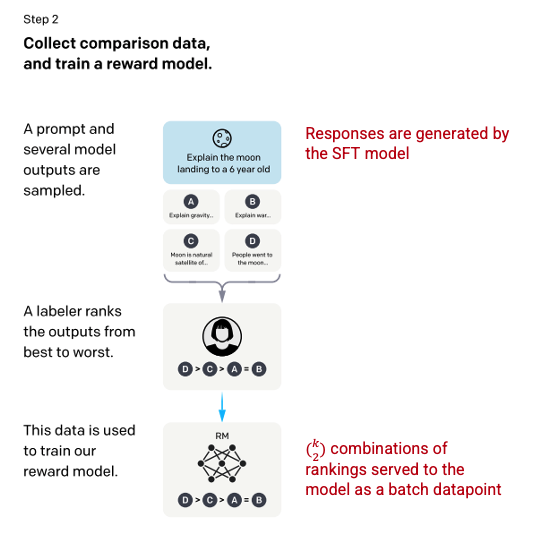
图片(左)从训练语言模型插入以遵循人类反馈的指令OpenAI 等,2022 https://arxiv.org/pdf/2203.02155.pdf。作者以红色(右)添加的附加上下文。
第三步:强化学习模型
在最后阶段,模型会收到随机提示并返回响应。响应是使用模型在步骤 2 中学习的“策略”生成的。策略表示机器已经学会使用以实现其目标的策略;在这种情况下,最大化其奖励。基于在步骤 2 中开发的奖励模型,然后为提示和响应对确定缩放器奖励值。然后奖励反馈到模型中以改进策略。
2017 年,舒尔曼等人。引入了近端策略优化 (PPO),该方法用于在生成每个响应时更新模型的策略。PPO 包含来自 SFT 模型的每个代币 Kullback–Leibler (KL) 惩罚。KL 散度衡量两个分布函数的相似性并对极端距离进行惩罚。在这种情况下,使用 KL 惩罚会减少响应与步骤 1 中训练的 SFT 模型输出之间的距离,以避免过度优化奖励模型和与人类意图数据集的偏差太大。
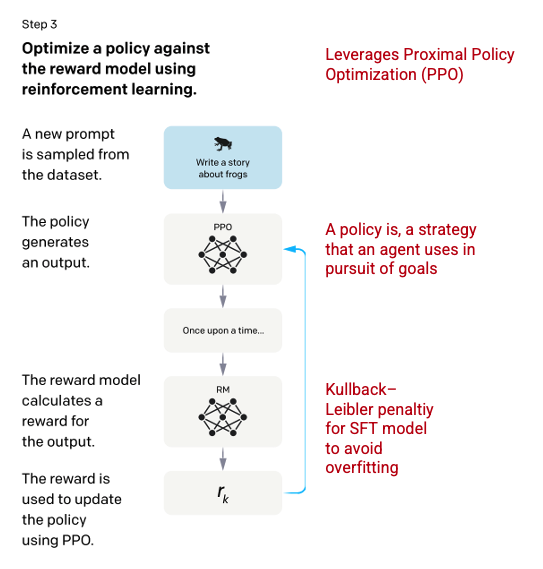
图片(左)从训练语言模型插入以遵循人类反馈的指令OpenAI 等,2022 https://arxiv.org/pdf/2203.02155.pdf。作者以红色(右)添加的附加上下文。
该过程的第 2 步和第 3 步可以重复进行,但在实践中并没有广泛这样做。

生成的 ChatGPT 的屏幕截图。
模型评估
模型的评估是通过在训练期间留出模型未见过的测试集来执行的。在测试集上,进行了一系列评估,以确定该模型是否比其前身 GPT-3 更好地对齐。
有用性:模型推断和遵循用户指令的能力。在 85 ± 3% 的时间里,贴标签者更喜欢 InstructGPT 而非 GPT-3 的输出。
真实性:模型产生幻觉的倾向。当使用TruthfulQA数据集进行评估时,PPO 模型产生的输出显示真实性和信息量略有增加。
无害性:模型避免不当、贬损和诋毁内容的能力。使用 RealToxicityPrompts 数据集测试了无害性。测试在三种条件下进行。
- 指示提供尊重的回应:导致毒性反应显着减少。
- 指示提供响应,没有任何尊重的设置:毒性没有显着变化。
- 指示提供毒性反应:反应实际上比 GPT-3 模型毒性大得多。
有关创建 ChatGPT 和 InstructGPT 所用方法的更多信息,请阅读 OpenAI Training language models to follow instructions with human feedback发表的原始论文,2022 https://arxiv.org/pdf/2203.02155.pdf。
生成的 ChatGPT 的屏幕截图。
相关文章:
ChatGPT 的工作原理:机器人背后的模型
这篇对支持 ChatGPT 的机器学习模型的温和介绍,将从大型语言模型的介绍开始,深入探讨使 GPT-3 得到训练的革命性自我注意机制,然后深入研究人类反馈的强化学习,使 ChatGPT 与众不同的新技术。 大型语言模型 ChatGPT 是一类被称…...

FreeRTOS入门(04):中断、内存、追踪与调试
文章目录目的中断内存堆(heap)栈(stack)断言调试总结目的 有了前面的几篇文章 FreeRTOS 基本上已经可以在项目中使用上了: 《FreeRTOS入门(01):基础说明与使用演示》 《FreeRTOS入门…...

【C语言】带你彻底理解指针(1)
✨✨✨✨如果文章对你有帮助记得点赞收藏关注哦!!✨✨✨✨ 文章目录指针的介绍:一、简单指针🌈1.1 指针的定义与使用1.2 指针与数组二、指针数组✨三、数组指针🌞3.1 数组指针的定义3.2 ”数组名“与”&数组名“3.…...
)
C/C++ 中 JSON 库的使用 (CJSON/nlohmann)
C/C 中 JSON 库的使用 (CJSON/nlohmann)概述cjson基本操作从(字符指针)缓冲区中解析出JSON结构转成成JS字符串(将传入的JSON结构转化为字符串)将JSON结构所占用的数据空间释放JSON 值的创建创建一个值类型的数据创建一个对象(文档)…...

【Opencv项目实战】目标检测:自动检测出现的所有动态目标
文章目录一、项目思路二、算法详解2.1、计算两个数组或数组与标量之间的每个元素的绝对差。2.2、轮廓检测 绘制物体轮廓 绘制矩阵轮廓2.3、连续窗口显示2.4、读取视频,显示视频,保存视频三、项目实战:实时动态目标检测实时动态目标检测一、…...

活动报名:Tapdata Cloud V3 最新功能全解与核心应用场景演示
作为中国的 “Fivetran/Airbyte”, Tapdata Cloud 自初版公测以来,已累积10,000 注册用户。核心场景包括 Any Source → Any Target 的实时数据库同步、数据入湖入仓,以及通用 ETL 处理等。近期,功能特性全面优化的 Tapdata Cloud V3 也已开放…...

人工智能AI威武,爱也……恨也……
人工智能AI威武,爱也!恨也!!它会创作会代码,从它那儿能仿到更好的思维;多它那里可以学到更好的代码。它聪慧全能,成为一坨人偷懒神器;变成“智者”作弊的“倚天屠龙”!&a…...

SpringBoot-基础篇
SpringBoot基础篇 在基础篇中,我给学习者的定位是先上手,能够使用SpringBoot搭建基于SpringBoot的web项目开发,所以内容设置较少,主要包含如下内容: SpringBoot快速入门SpringBoot基础配置基于SpringBoot整合SSMP…...
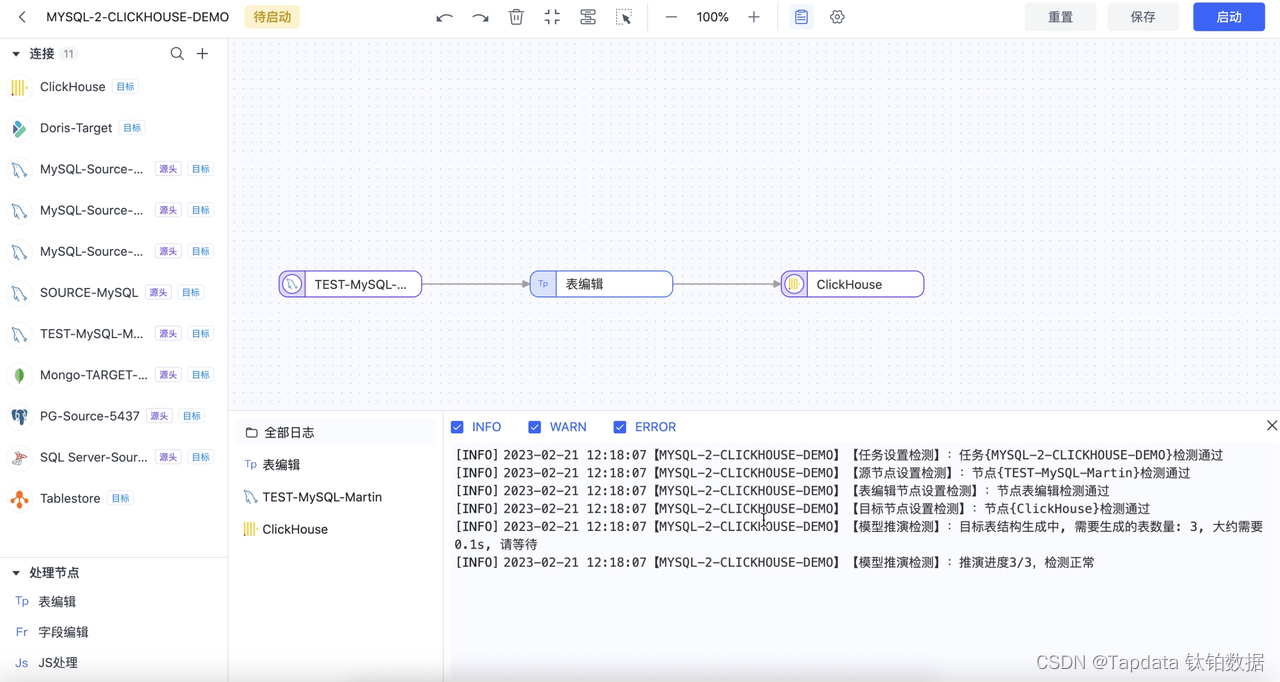
Tapdata Connector 实用指南:实时数仓场景之数据实时同步至 ClickHouse
【前言】作为中国的 “Fivetran/Airbyte”, Tapdata 是一个以低延迟数据移动为核心优势构建的现代数据平台,内置 60 数据连接器,拥有稳定的实时采集和传输能力、秒级响应的数据实时计算能力、稳定易用的数据实时服务能力,以及低代码可视化操作…...
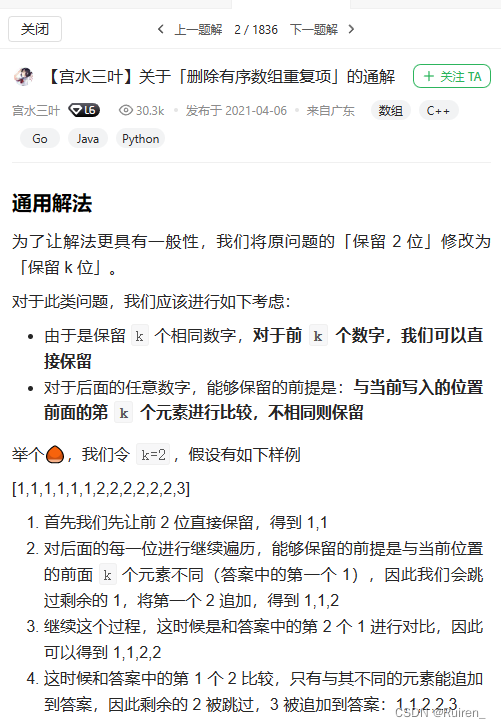
刷题专练之数组移除元素
文章目录前言一、移除元素1.题目介绍2.思路:3.代码二、移动零1.题目介绍2.思路3.代码三、删除有序数组中的重复项1.题目介绍2.思想3.代码四、80. 删除有序数组中的重复项 II1.题目介绍2.思路3.代码4.推荐题解前言 我每个刷题篇的题目顺序都是特别安排的,…...
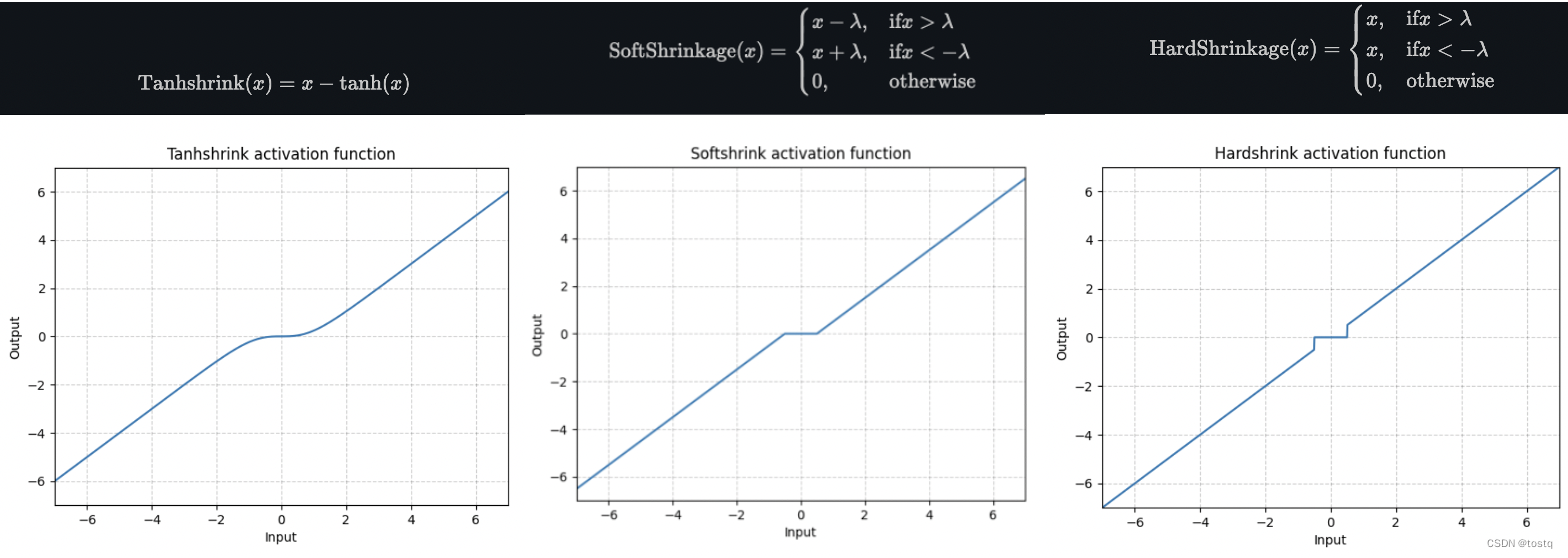
常见激活函数Activation Function的选择
Activation Function激活函数一般会神经网络中隐层和输出层上,其中作用在输出层主要用于适配输出,比如sigmoid函数可用于生成[0,1]之间的概率估计值。而作用于隐层主要用于增加神经网络的非线性,增加了网络的表达能力,本文主要介绍…...

大厂跟进ChatGPT,为什么百度“文心一言”成色最好?【快评】
作者 | 曾响铃 文 | 响铃说 赶ChatGPT热度,百度3月初就要发布与ChatGPT类似的人工智能聊天机器人服务“文心一言”(英文名:ERNIE Bot),似乎无法提振资本市场对百度的信心。 2022年第四季度及全年未经审计的财报发布…...

ChatGPT和Web3:人工智能如何帮助您建立和发展您的 Web3 公司
ChatGPT是OpenAI在2022年11月推出的聊天机器人。该机器人建立在OpenAI的GPT-3人工智能家族上,并通过监督学习和强化学习技术进行了优化。 与ChatGPT机器人聊天时,你会感觉自己在与一个懂得一切并以非常教育性的方式回答的朋友交谈。回答在许多知识领域非…...
?核心技术有哪些?)
【人工智能 AI】怎样实施RPA 机器人流程自动化(Robotic Process Automation)?核心技术有哪些?
文章目录 RPA 简介RPA的实施RPA的核心技术1. 自动化测试(1)自动化测试工具(2)自动化测试框架2. 自动化脚本(1)自动化脚本语言(2)自动化脚本框架3. 机器学习(1)机器学习模型(2)机器学习框架(3)自然语言处理(4)图像处理(5)深度学习(6)机器人操作系统RPA核心能…...
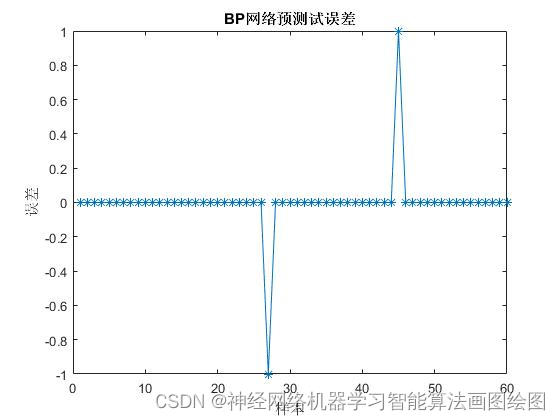
基于BP神经网络的性别识别,BP神经网络详细原理,自编码神经网络代码,神经网络案例之18
目标 背影 BP神经网络的原理 BP神经网络的定义 BP神经网络的基本结构 BP神经网络的神经元 BP神经网络的激活函数, BP神经网络的传递函数 数据 神经网络参数 基于BP神经网络 性别识别的MATLAB代码 效果图 结果分析 展望 背影 男人体内蛋白质比例大,女生…...
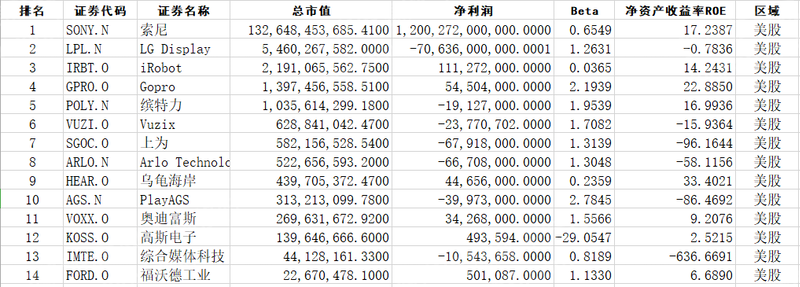
2023年消费电子行业研究报告
第一章 行业概况 消费电子行业是电子信息行业的子行业。消费电子是指围绕着消费者应用而设计的与生活、工作和娱乐息息相关的电子类产品,通常会应用于娱乐、通讯以及文书用途,最终实现消费者自由选择资讯、享受娱乐的目的,主要侧重于个人购买…...

CSDN 编程竞赛三十一期题解
竞赛总览 CSDN 编程竞赛三十一期:比赛详情 (csdn.net) 本次竞赛的最后一道题的描述部分有些问题(题目描述与样例不符),另外,测试数据似乎也有点问题,试了多种方式,但最多只能通过10%的测试点。…...
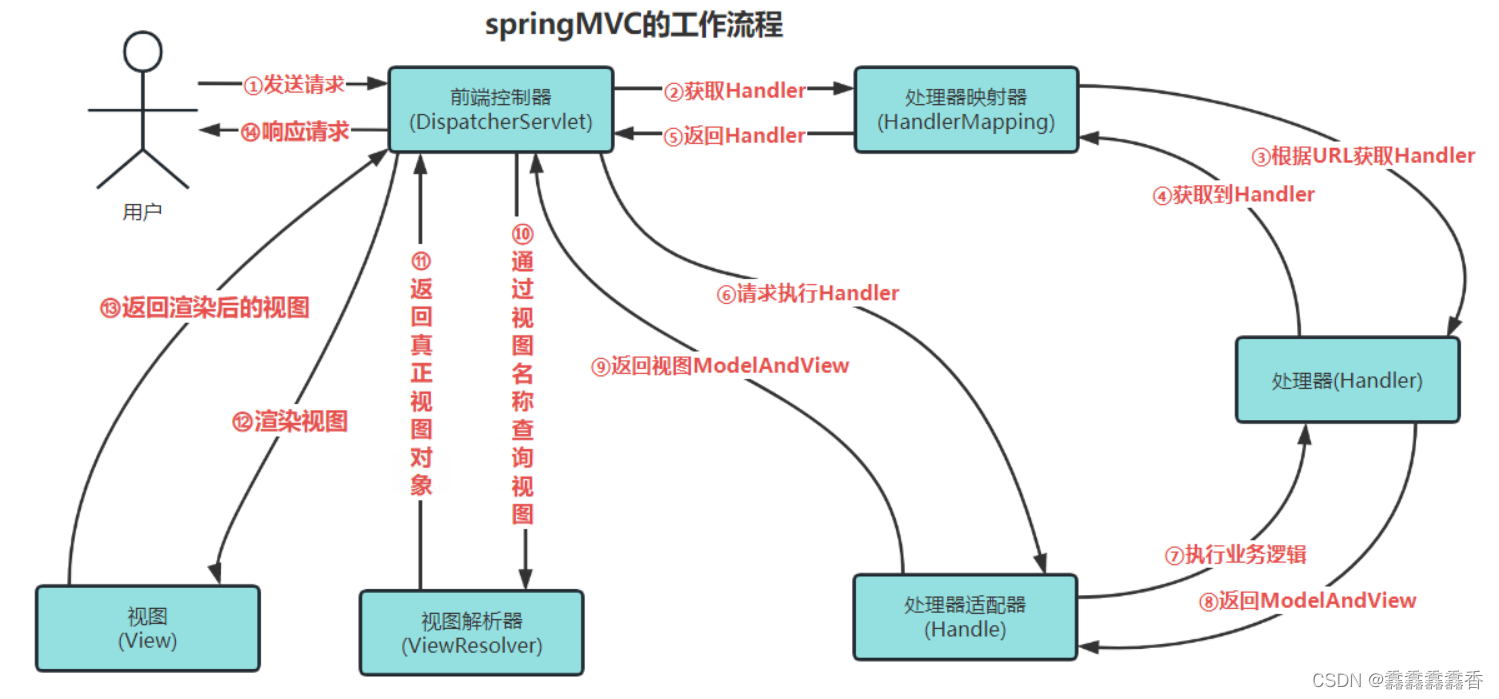
SpringMVC常见面试题(2023最新)
目录前言1.简单介绍下你对springMVC的理解?2.说一说SpringMVC的重要组件及其作用3.SpringMVC的工作原理或流程4.SpringMVC的优点5.SpringMVC常用注解6.SpringMVC和struts2的区别7.怎么实现SpringMVC拦截器8.SpringMvc的控制器是不是单例模式?如果是,有什…...

【正点原子FPGA连载】第十六章DP彩条显示实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第十六章DP彩条显…...
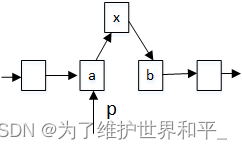
数据结构与算法—链表list
目录 链表 链表类型 链表插入 链表删除 写程序注意点 与数组区别 链表应用 LRU 实现思想 链表 链表,一种提高数据读取性能的技术,在硬件设计、软件开发中有广泛应用。常见CPU缓存,数据库缓存,浏览器缓存等。缓存满时&#…...

从仿真曲线到实际性能:手把手教你用IPKISS分析MZI Lattice Filter的插损与带宽
从仿真曲线到实际性能:手把手教你用IPKISS分析MZI Lattice Filter的插损与带宽 在光子集成电路设计中,仿真结果往往只是第一步。真正考验工程师功力的,是如何从这些曲线中提取出有工程价值的性能指标。本文将带您深入解读MZI Lattice Filter的…...

五轴龙门机床厂家推荐,五轴龙门机床哪家好?
五轴龙门机床厂家推荐,五轴龙门机床哪家好?五轴龙门机床性能参数与场景适配分析。五轴龙门机床是高端装备制造的核心加工设备,广泛应用于航空航天、新能源、重工装备等领域。本文基于海天精工、纽威数控、环球工业机械、济南二机床四款主流国…...

嵌入式开发硬件生态构建:MIPI屏、UVC摄像头与4G模块的选型与集成实战
1. 项目概述:一次面向嵌入式开发者的硬件生态补全最近,我们团队负责的睿擎派(一个基于瑞芯微RK3566/RK3588等主流芯片的嵌入式开发板品牌)项目,迎来了一次重要的硬件配件更新。这次上新不是简单的“换个壳”࿰…...
)
手把手教你用WSL搞定RAX3000M路由器的SSH配置修改(Win10/Win11适用)
在Windows系统下通过WSL高效配置RAX3000M路由器的完整指南 对于习惯Windows操作系统的技术爱好者来说,想要修改路由器配置文件常常面临一个尴尬的处境——大多数高级配置工具和教程都默认用户已经熟悉Linux环境。本文将彻底解决这个痛点,教你如何在不安装…...

终极指南:如何用WeChatExporter永久备份微信聊天记录,打造你的数字记忆宝库
终极指南:如何用WeChatExporter永久备份微信聊天记录,打造你的数字记忆宝库 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾有过这样的经…...

3大远程管理痛点解决方案:MobaXterm中文版实现一站式终端效率革命
3大远程管理痛点解决方案:MobaXterm中文版实现一站式终端效率革命 【免费下载链接】Mobaxterm-Chinese Mobaxterm simplified Chinese version. Mobaxterm 的简体中文版. 项目地址: https://gitcode.com/gh_mirrors/mo/Mobaxterm-Chinese 远程服务器管理面临…...

JDeferred入门教程:从零开始构建高效异步Java应用
JDeferred入门教程:从零开始构建高效异步Java应用 【免费下载链接】jdeferred Java Deferred/Promise library similar to JQuery. 项目地址: https://gitcode.com/gh_mirrors/jd/jdeferred 想要掌握Java异步编程的终极秘诀吗?JDeferred库为您提供…...
,python和c++哪个更值得学)
python入门教程(非常详细),python和c++哪个更值得学
python入门教程(非常详细),python和c哪个更值得学 这篇文章主要介绍了python入门教程(非常详细),具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。 python 怎么读 python&…...

如何通过Play Integrity API完整检测Android设备安全状态
如何通过Play Integrity API完整检测Android设备安全状态 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker-app 在移动应用生…...

深度解析Python SECS/GEM协议实现:secsgem库的现代架构设计
深度解析Python SECS/GEM协议实现:secsgem库的现代架构设计 【免费下载链接】secsgem Simple Python SECS/GEM implementation 项目地址: https://gitcode.com/gh_mirrors/se/secsgem 在半导体制造行业,设备与主机系统之间的标准化通信是自动化生…...