kafka、rabbitmq 、rocketmq的区别
一、语言不同
RabbitMQ是由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。
kafka是采用Scala语言开发,它主要用于处理活跃的流式数据,大数据量的数据处理上
RocketMQ是采用java语言开发的
二、吞吐量
kafka吞吐量更高:
1)Zero Copy机制,内核copy数据直接copy到网络设备,没必要通过内核到用户再到内核的copy,减少了copy次数和上下文切换次数,大大提升了效率。
2)磁盘顺序读写,减小了寻道等待的时间。
3)批量处理机制,服务端批量存储,客户端主动批量pull数据,消息处理效率高。
4)存储具备O(1)的复杂度,读物由于分区和segment,是O(log(n))的复杂度。
5)分区机制,有助于提升吞吐量。
三、可靠性
rabbitmq可靠性更好:
1)确认机制(生产者和exchange,消费者和队列);
2)支持事务,但会形成阻塞;
3)委托(添加回调来处理发送失败的消息)和备份交换器(将发送失败的消息存下来后面再处理)机制;
四、高可用
1)rabbitmq采用mirror queue,即主从模式,数据是异步同步的,当消息过来,主从所有写完后,回ack,这样保障了数据的一致性。
2)每一个分区均可以有一个或多个副本,这些副本保存在不一样的broker上,broker信息存储在zookeeper上,当broker不可用会从新选举leader。
kafka支持同步负责消息和异步同步消息(有丢消息的可能),生产者从zk获取leader信息,发消息给leader,follower从leader pull数据而后回ack给leader。
五、负责均衡
1)kafka经过zk和分区机制实现:zk记录broker信息,生产者能够获取到并经过策略完成负载均衡;经过分区,投递消息到不一样分区,消费者经过服务组完成均衡消费。
2)须要外部支持。
六、模型
1)rabbitmq:
producer,broker遵循AMQP(Advanced Message Queuing Protocol,高级消息队列协议是一个进程间传递异步消息的网络协议)(由Exchange,Binding,queue组成),consumer;
broker为中心,exchange分topic,direct,fanout和header,路由模式适合多种场景;
consumer消费位置由broker经过确认机制保存;
2)kafka:
producer,broker,consumer,未遵循AMQP;
consumer为中心,获取消息模式由consumer本身决定;
offset保存在消费者这边,broker无状态;
消息是名义上的永久存储,每一个parttition按segment保存本身的消息为文件(可配置清理周期);
consumer能够经过重置offset消费历史消息;
须要绑定zk;

kafka采用mq结构:broker 有part 分区的概念
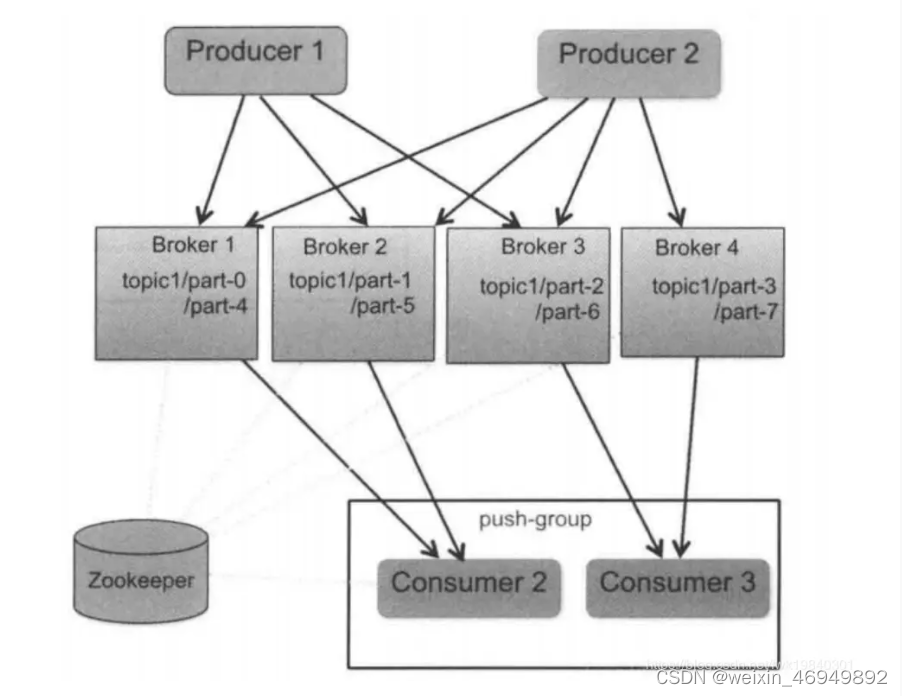
RabbitMQ 采用push的方式
kafka采用pull的方式
rabbitMQ的负载均衡需要单独的loadbalancer进行支持。
kafka采用zookeeper对集群中的broker、consumer进行管理
数据可靠性
- RocketMQ支持异步实时刷盘,同步刷盘,同步Replication,异步Replication
- Kafka使用异步刷盘方式,异步Replication
总结:RocketMQ的同步刷盘在单机可靠性上比Kafka更高,不会因为操作系统Crash,导致数据丢失。 同时同步Replication也比Kafka异步Replication更可靠,数据完全无单点。另外Kafka的Replication以topic为单位,支持主机宕机,备机自动切换,但是这里有个问题,由于是异步Replication,那么切换后会有数据丢失,同时Leader如果重启后,会与已经存在的Leader产生数据冲突。开源版本的RocketMQ不支持Master宕机,Slave自动切换为Master,阿里云版本的RocketMQ支持自动切换特性。
性能对比
- Kafka单机写入TPS约在百万条/秒,消息大小10个字节
- RocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节
总结:Kafka的TPS跑到单机百万,主要是由于Producer端将多个小消息合并,批量发向Broker。
RocketMQ为什么没有这么做?
- Producer通常使用Java语言,缓存过多消息,GC是个很严重的问题
- Producer调用发送消息接口,消息未发送到Broker,向业务返回成功,此时Producer宕机,会导致消息丢失,业务出错
- Producer通常为分布式系统,且每台机器都是多线程发送,我们认为线上的系统单个Producer每秒产生的数据量有限,不可能上万。
- 缓存的功能完全可以由上层业务完成。
单机支持的队列数
- Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长
- RocketMQ单机支持最高5万个队列,Load不会发生明显变化
队列多有什么好处?
- 单机可以创建更多Topic,因为每个Topic都是由一批队列组成
- Consumer的集群规模和队列数成正比,队列越多,Consumer集群可以越大
消息投递实时性
- Kafka使用短轮询方式,实时性取决于轮询间隔时间
- RocketMQ使用长轮询,同Push方式实时性一致,消息的投递延时通常在几个毫秒。
消费失败重试
- Kafka消费失败不支持重试
- RocketMQ消费失败支持定时重试,每次重试间隔时间顺延
总结:例如充值类应用,当前时刻调用运营商网关,充值失败,可能是对方压力过多,稍后在调用就会成功,如支付宝到银行扣款也是类似需求。
这里的重试需要可靠的重试,即失败重试的消息不因为Consumer宕机导致丢失。
严格的消息顺序
- Kafka支持消息顺序,但是一台Broker宕机后,就会产生消息乱序
- RocketMQ支持严格的消息顺序,在顺序消息场景下,一台Broker宕机后,发送消息会失败,但是不会乱序
Mysql Binlog分发需要严格的消息顺序
定时消息
- Kafka不支持定时消息
- RocketMQ支持两类定时消息
- 开源版本RocketMQ仅支持定时Level
- 阿里云ONS支持定时Level,以及指定的毫秒级别的延时时间
分布式事务消息
- Kafka不支持分布式事务消息
- 阿里云ONS支持分布式定时消息,未来开源版本的RocketMQ也有计划支持分布式事务消息
消息查询
- Kafka不支持消息查询
- RocketMQ支持根据Message Id查询消息,也支持根据消息内容查询消息(发送消息时指定一个Message Key,任意字符串,例如指定为订单Id)
总结:消息查询对于定位消息丢失问题非常有帮助,例如某个订单处理失败,是消息没收到还是收到处理出错了。
消息回溯
- Kafka理论上可以按照Offset来回溯消息
- RocketMQ支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息
总结:典型业务场景如consumer做订单分析,但是由于程序逻辑或者依赖的系统发生故障等原因,导致今天消费的消息全部无效,需要重新从昨天零点开始消费,那么以时间为起点的消息重放功能对于业务非常有帮助。
消费并行度
-
Kafka的消费并行度依赖Topic配置的分区数,如分区数为10,那么最多10台机器来并行消费(每台机器只能开启一个线程),或者一台机器消费(10个线程并行消费)。即消费并行度和分区数一致。
-
RocketMQ消费并行度分两种情况
- 顺序消费方式并行度同Kafka完全一致
- 乱序方式并行度取决于Consumer的线程数,如Topic配置10个队列,10台机器消费,每台机器100个线程,那么并行度为1000。
消息轨迹
- Kafka不支持消息轨迹
- 阿里云ONS支持消息轨迹
开发语言友好性
- Kafka采用Scala编写
- RocketMQ采用Java语言编写
Broker端消息过滤
- Kafka不支持Broker端的消息过滤
- RocketMQ支持两种Broker端消息过滤方式
- 根据Message Tag来过滤,相当于子topic概念
- 向服务器上传一段Java代码,可以对消息做任意形式的过滤,甚至可以做Message Body的过滤拆分。
消息堆积能力
理论上Kafka要比RocketMQ的堆积能力更强,不过RocketMQ单机也可以支持亿级的消息堆积能力,我们认为这个堆积能力已经完全可以满足业务需求。
开源社区活跃度
- Kafka社区更新较慢
- RocketMQ的github社区有250个个人、公司用户登记了联系方式,QQ群超过1000人。
商业支持
- Kafka原开发团队成立新公司,目前暂没有相关产品看到
- RocketMQ在阿里云上已经开放公测近半年,目前以云服务形式免费供大家商用,并向用户承诺99.99%的可靠性,同时彻底解决了用户自己搭建MQ产品的运维复杂性问题
成熟度
- Kafka在日志领域比较成熟
- RocketMQ在阿里集团内部有大量的应用在使用,每天都产生海量的消息,并且顺利支持了多次天猫双十一海量消息考验,是数据削峰填谷的利器。
五、使用场景
rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
金融场景中经常使用
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度(与分区上的存储大小无关),消息处理的效率很高。(大数据)
补充:
Server:又称Broker,接受客户端的连接,实现AMQP实体服务
Connection:连接,应用程序与Broker的网络连接
Channel:网络信道,几乎所有的操作都在Channel中进行,Channel是进行消息读写的通道。客户端可建立多个Channel,每个Channel代表一个会话任务。
Message:消息,服务器和应用程序之间传送的数据,由Properties和Body组成。Properties可以对消息进行修饰,比如消息的优先级、延迟等高级特性;Body则就是消息体内容。
Virtual host:虚拟地址,用于进行逻辑隔离,最上层的消息路由。一个Virtual Host里面可以有若干个Exchange和Queue,同一个VirtualHost 里面不能有相同名称的Exchange或Queue
Exchange:交换机,接收消息,根据路由键转发消息到绑定的队列
Binding:Exchange和Queue之间的虚拟连接,binding中可以包含routing key
Routing key:一个路由规则,虚拟机可用它来确定如何路由一个特定消息
Producer:消息生产者,向Broker发送消息的客户端
Consumer:消息消费者,从Broker读取消息的客户端
Broker:消息中间的处理节点,这里和kafka不同,kafka的Broker没有主从的概念,都可以写入请求以及备份其他节点数据,RocketMQ只有主Broker节点才能写,一般也通过主节点读,当主节点有故障或者一些其他特殊情况才会使用从节点读,有点类似- 于mysql的主从架构。
Topic:消息主题,一级消息类型,生产者向其发送消息, 消费者读取其消息。
Group:分为ProducerGroup,ConsumerGroup,代表某一类的生产者和消费者,一般来说同一个服务可以作为Group,同一个Group一般来说发送和消费的消息都是一样的。
Tag:Kafka中没有这个概念,Tag是属于二级消息类型,一般来说业务有关联的可以使用同一个Tag,比如订单消息队列,使用Topic_Order,Tag可以分为Tag_食品订单,Tag_服装订单等等。
Queue: 在kafka中叫Partition,每个Queue内部是有序的,在RocketMQ中分为读和写两种队列,一般来说读写队列数量一致,如果不一致就会出现很多问题。
NameServer:Kafka中使用的是ZooKeeper保存Broker的地址信息,以及Broker的Leader的选举,在RocketMQ中并没有采用选举Broker的策略,所以采用了无状态的NameServer太存储,由于NameServer是无状态的,集群节点之间并不会通信,所以上传数据的时候都需要向所有节点进行发送。
引用:https://www.jianshu.com/p/0364a171c2ae
相关文章:
kafka、rabbitmq 、rocketmq的区别
一、语言不同 RabbitMQ是由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。 kafka是采用Scala语言开发,它主要用于处理活跃的流式数据,大数据量的数据处理上 RocketMQ是采用java语言开发的 二、吞吐量 kafka吞吐量更高&…...

java的amazonaws接口出现无法执行http请求:管道中断
java使用amazonaws的接口上传文件到minio出现以下异常: com.amazonaws.SdkClientException: Unable to execute HTTP request: Broken pipe (Write failed) at com.amazonaws.http.AmazonHttpClient R e q u e s t E x e c u t o r . h a n d l e R e t r y a b l e…...

cmake 多线程编译 指定 Visual Studio 编译器 命令行
当使用CMake来配置和构建一个Visual Studio 项目时,以下命令是关键的。 第一行是用于配置项目,而第二行用于构建项目。 Visual Studio 15 2017 Visual Studio 16 2019 Visual Studio 17 2022 在CMake中,DCMAKE_BUILD_TYPE是用于指定项目的构建…...
将 mysql 数据迁移到 clickhouse (最新版)
一、前驱知识 已经在mysql中插入了海量的数据了,这个时候mysql 承载不了这么大的数据,并且数据只需要查询,修改和删除非常少,并且不需要支持事务,这个时候需要换一个底层存储,这里选用的是 clickhouse 来进…...

LeetCode 69.x的平方
LeetCode 69.x的平方 思路: 二分查找。从1到x进行二分查找,每次判断mid的平方是否<x, 如果是,则更新ansmid,并缩小区间; 如果不是,则缩小区间; 最后则找到最接近的ans࿰…...

【小白入门】ASP.NET Core 创建 Web API
ASP.NET Core 支持使用 C# 创建 RESTful 服务,也称为 Web API。 若要处理请求,Web API 使用控制器。 Web API 中的 控制器 是派生自 ControllerBase 的类。 本文介绍了如何使用控制器处理 Web API 请求。 Web API 包含一个或多个派生自 ControllerBase …...
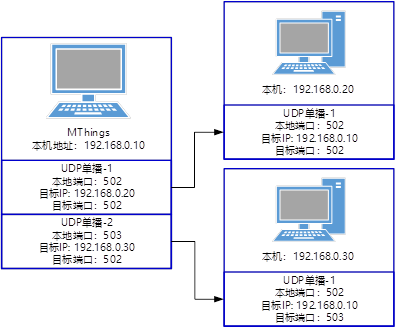
如何使用摩尔信使MThings连接网络设备
帽子: 摩尔信使MThings支持Modbus-TCP、Modbus-RTU Over TCP、Modbus-TCP Over UDP、Modbus-RTU Over UDP。 TCP链接中,摩尔信使MThings支持灵活的连接方式,主机可作为客户端也可以作为服务端,同时支持模拟从机以客户端方式向远…...

2023自动驾驶 车道线检测数据集
目录 2023自动驾驶 车道线检测关键数据集 下载链接 labelme标注制作数据: 车道线分割项目记录-tusimple数据集处理 2023自动驾驶 车道线检测关键数据集 下载链接 2023自动驾驶 车道线检测关键数据集 下载链接_Xiaobai_Zhao的博客-CSDN博客 labelme标注制作数据:...
排序算法-冒泡排序法(BubbleSort)
排序算法-冒泡排序法(BubbleSort) 1、说明 冒泡排序法又称为交换排序法,是从观察水中的气泡变化构思而成的,原理是从第一个元素开始,比较相邻元素的大小,若大小顺序有误,则对调后再进行下一个…...
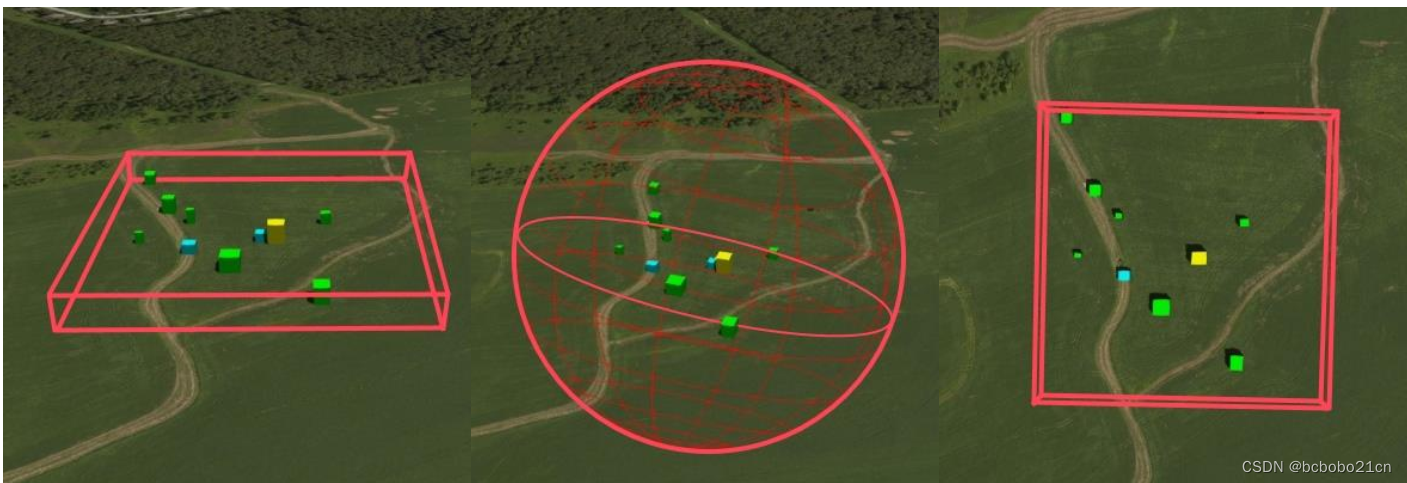
3d tiles规范boundingVolume属性学习
3d tiles的瓦片(Tiles)包含一些属性,其中第一项是boundingVolume;下面学习boundingVolume; boundingVolume,这个翻译为边界范围框,如果直译为边界体积可能有问题,其实就是包围盒的意…...

【开题报告】如何借助chatgpt完成毕业论文开题报告
步骤 1:确定论文主题和研究问题 首先,你需要确定你的论文主题和研究问题。这可以是与软件开发、算法、人工智能等相关的任何主题。确保主题具有一定的研究性和可行性。 步骤 2:收集相关文献和资料 在开始撰写开题报告之前,收集相…...
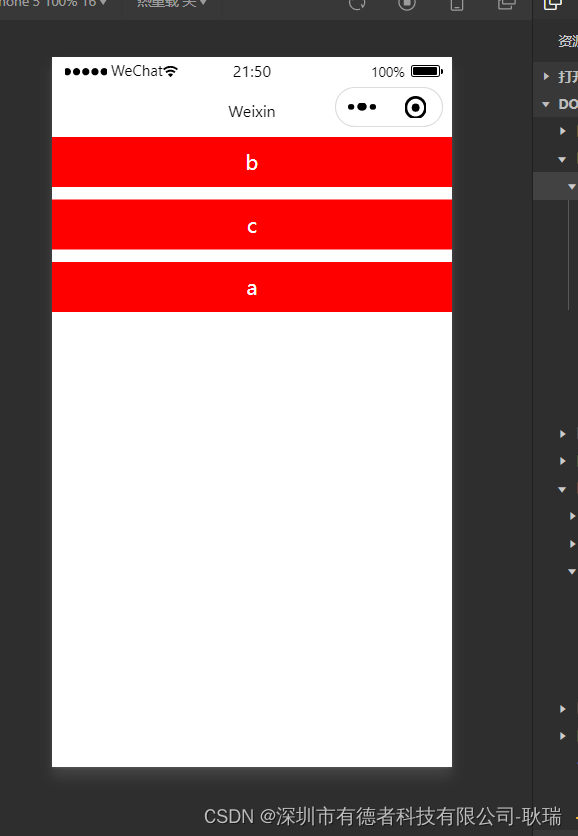
微信小程序通过 movable-area 做一个与vuedraggable相似的上下拖动排序控件
因为只是做个小案例 我就直接代码写page页面里了 其实很简单 组件稍微改一下就好了 wxss /* 设置movable-area的宽度 */ .area{width: 100%; }/* a b c 每条元素的样式 */ movable-view {width: 100%;background-color: red;height: 40px;line-height: 40px;color: #FFFFFF;tex…...

Ceph入门到精通-Nginx超时参数分析设置
nginx中有些超时设置,本文汇总了nginx中几个超时设置 Nginx 中的超时设置包括: “client_body_timeout”:设置客户端向服务器发送请求体的超时时间,单位为秒。 “client_header_timeout”:设置客户端向服务器发送请…...

TCP/IP(十)TCP的连接管理(七)CLOSE_WAIT和TCP保活机制
一 CLOSE_WAIT探究 CLOSE_WAIT 状态出现在被动关闭方,当收到对端FIN以后回复ACK,但是自身没有发送FIN包之前 ① 服务器出现大量 CLOSE_WAIT 状态的原因有哪些? 1、通常来讲,CLOSE_WAIT状态的持续时间应该很短,正如SYN_RCVD状态2、但是在一些特殊情况下,就会出现大量连接长…...

LeetCode 面试题 08.10. 颜色填充
文章目录 一、题目二、C# 题解 一、题目 编写函数,实现许多图片编辑软件都支持的「颜色填充」功能。 待填充的图像用二维数组 image 表示,元素为初始颜色值。初始坐标点的行坐标为 sr 列坐标为 sc。需要填充的新颜色为 newColor。 「周围区域」是指颜色相…...

内排序算法
排序算法是面试中常见的问题,不同算法的时间复杂度、稳定性和适用场景各不相同。按照数据量和存储方式可以将排序算法分为 内排序(Internal Sorting)和 外排序(External Sorting)。 内排序是指对所有待排序的数据都可…...

options.html 页面设计成聊天框,左侧是功能列表,右侧是根据左侧的功能切换成不同的内容。--chatGpt
gpt: 要将 options.html 页面设计成一个聊天框式的界面,其中左侧是功能列表,右侧根据左侧的功能切换成不同的内容,你可以按照以下步骤进行设计和实现: 1. 首先,创建 options.html 文件,并在其中定义基本的…...
排序算法-选择排序法(SelectionSort)
排序算法-选择排序法(SelectionSort) 1、说明 选择排序法也是枚举法的应用,就是反复从未排序的数列中取出最小的元素,加入另一个数列中,最后的结果即为已排序的数列。选择排序法可使用两种方式排序,即在所…...
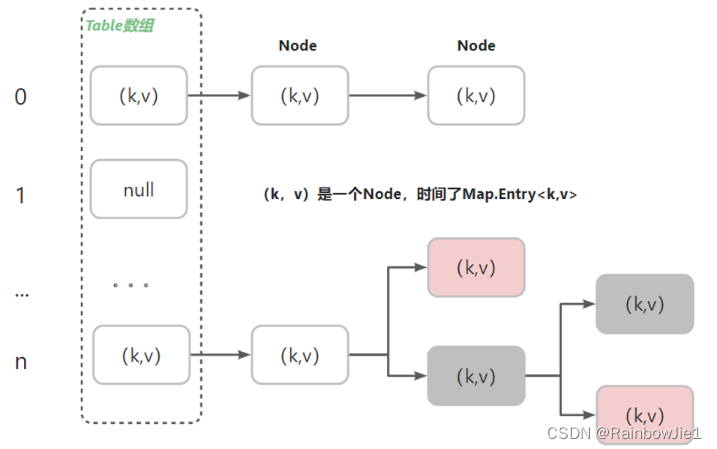
Java-集合框架
文章目录 摘要CollectionCollection集合遍历Iterator迭代器增强for循环 排序 ListArrayListLinkedListVector SetHashSet Map小结 摘要 Java的集合框架提供了一组用于存储、管理和操作数据的类和接口。这个框架提供了各种数据结构,如列表、集合、队列和映射&#x…...

联想携中国移动打造车路协同方案 助力重庆实现32类车联网场景
10月11日,联想集团在中国移动全球合作伙伴大会上首次分享了与中国移动等合作伙伴共同打造的5G车路协同案例——重庆两江协同创新区车路协同应用。联想利用基于5G智能算力技术,在总里程55公里路段实现了32类车联网场景。 据了解,重庆两江协同创…...

Cursor/AI 助手用自然语言操作监控与告警
主要用途告警管理:查询活跃告警和历史告警,查看告警规则和订阅目标监控:浏览和搜索被监控的主机,分析目标状态事件响应:创建和管理告警屏蔽规则、通知规则和事件流水线团队协作:查询用户、团队和业务组快速…...

OpenCode-Tokenscope 安装和使用指南
OpenCode-Tokenscope 安装和使用指南全面的 OpenCode AI 会话 token 使用分析和成本追踪插件安装 方法 1: npm (推荐) 步骤 1: 全局安装 npm install -g ramtinj95/opencode-tokenscope步骤 2: 配置 opencode.json 在以下位置之一创建 opencode.json: 项目根目录~/.…...

数据仓库实战:查询优化器工作原理深度解析 + 性能提升实战指南
数据仓库实战:查询优化器工作原理深度解析 性能提升实战指南摘要一、基础认知:数据仓库查询优化器是什么?1.1 核心定义1.2 数仓优化器与数据库优化器的区别1.3 优化器核心目标二、工作流程:查询优化器完整执行链路(带…...

YimMenu全面指南:GTA V游戏体验的终极优化方案
YimMenu全面指南:GTA V游戏体验的终极优化方案 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

Baichuan-7B代码生成能力:编程助手的最佳选择 - 7B参数大模型的终极指南
Baichuan-7B代码生成能力:编程助手的最佳选择 - 7B参数大模型的终极指南 【免费下载链接】Baichuan-7B A large-scale 7B pretraining language model developed by BaiChuan-Inc. 项目地址: https://gitcode.com/gh_mirrors/ba/Baichuan-7B Baichuan-7B是由…...

如何15分钟搞定黑苹果配置:OpCore-Simplify零代码自动化终极指南
如何15分钟搞定黑苹果配置:OpCore-Simplify零代码自动化终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果配置头…...

QPdf:Qt生态下的PDF渲染技术深度解析与现代应用实践
QPdf:Qt生态下的PDF渲染技术深度解析与现代应用实践 【免费下载链接】qpdf PDF viewer widget for Qt 项目地址: https://gitcode.com/gh_mirrors/qpd/qpdf 在Qt应用开发中,PDF文档处理一直是个技术痛点。传统方案要么依赖平台原生组件导致跨平台…...

WSL网络桥接实战:从Kali到Ubuntu的跨系统网络配置
1. 为什么需要WSL网络桥接? 很多开发者同时使用Windows和Linux系统工作,WSL(Windows Subsystem for Linux)的出现让这两个系统能够更好地协同。但默认情况下,WSL使用的是NAT网络模式,这就导致了一些不便&am…...

音频的爬虫
1.前提准备需要在终端中下载requests模块 --- 终端在软件的左下角,下方图案例下载的语法:pip install requests(1)下载成功会报出的结果,如下图所示:(2)下载失败会报出的结果&#…...

如何让10美元鼠标超越苹果触控板:Mac Mouse Fix终极指南
如何让10美元鼠标超越苹果触控板:Mac Mouse Fix终极指南 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 你是否曾经为macOS对第三方…...