机器学习基础之《回归与聚类算法(1)—线性回归》
一、线性回归的原理
1、线性回归应用场景
如何判定一个问题是回归问题的,目标值是连续型的数据的时候
房价预测
销售额度预测
贷款额度预测、利用线性回归以及系数分析因子
2、线性回归定义
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式
找到一种函数关系,来表示特征值和目标值之间的关系
3、函数关系
(1)首先假定特征值x1、x2、x3
(2)目标值是h(w)
(3)每个特征前还有个系数,w1、w2、w3,叫做权重值,也叫回归系数
(4)右边+b,叫做偏置系数
(5)只有一个自变量的情况称为单变量回归,大于一个自变量情况的叫做多元回归
用习惯的写法:
y = w1x1 + w2x2 + w3x3 + ... + wnxn + b
= wTx + b
PS:wT叫做w的转置
例子:
期末成绩:0.7×考试成绩 + 0.3×平时成绩
预测房子价格 = 0.02×中心区域的距离 + 0.04×城市一氧化氮浓度 + (-0.12×自住房平均房价) + 0.254×城镇犯罪率
4、广义线性模型
线性回归当中的关系有两种,一种是线性关系,另一种是非线性关系。在这里我们只能画一个平面更好去理解,所以都用单个特征举例子
(1)线性关系
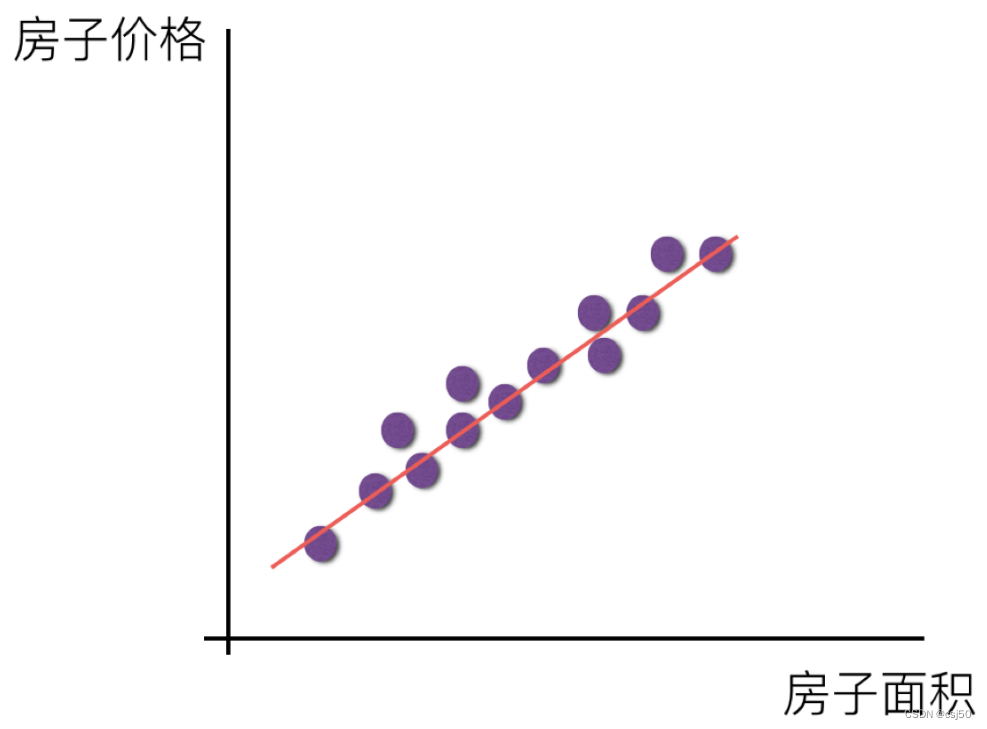
特征只有一个房屋面积,预测房屋价格,在一个平面当中,可以找到一条直线去拟合他们之间的关系,y = kx + b
如果有两个特征: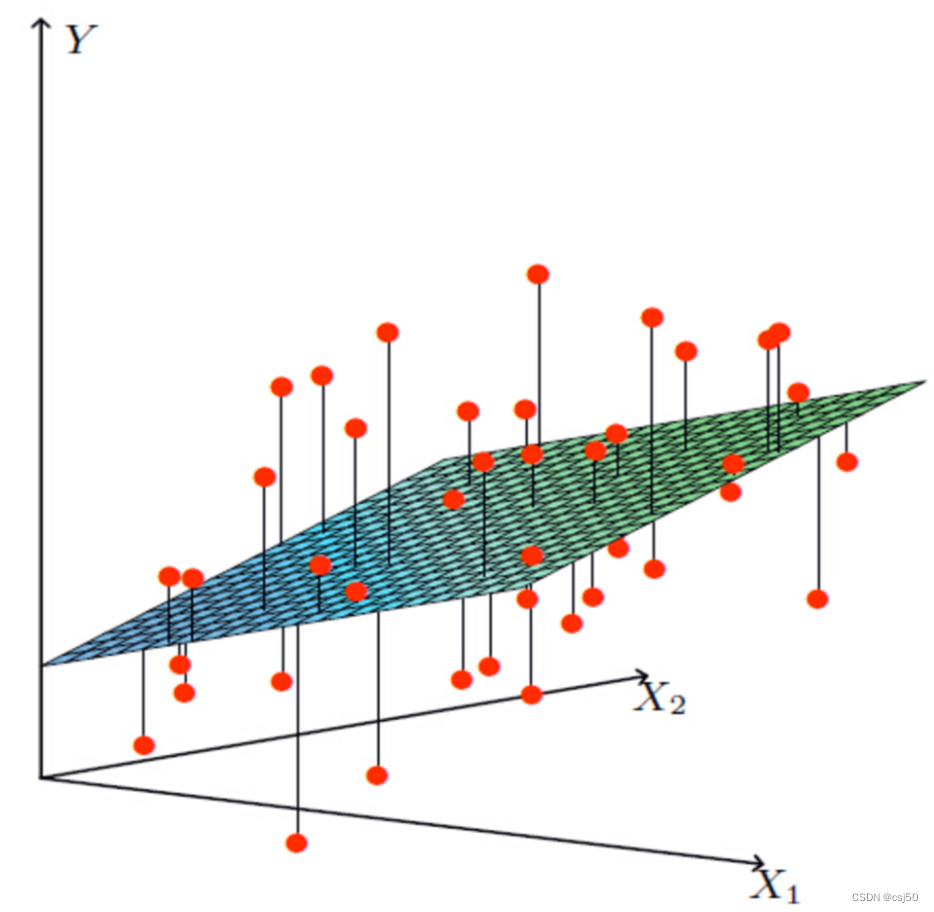
要拟合x1、x2和y之间的关系,y = w1x1 + w2x2 + b
如果在单特征与目标值的关系呈直线关系,或者两个特征与目标值呈现平面的关系
更高维度的我们不用自己去想,记住这种关系即可
(2)非线性关系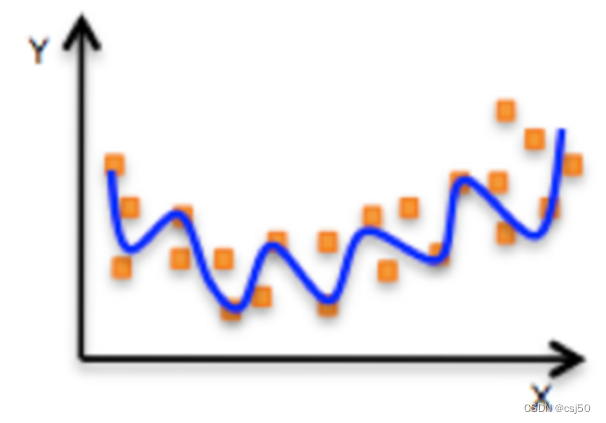
为什么非线性关系,也叫线性模型
线性模型
自变量一次
y = w1x1 + w2x2 + w3x3 + ... + wnxn + b
参数一次
y = w1x1 + w2x1^2 + w3x1^3 + w4x2^3 + ... + b
就是w和x有一个是一次的,不是多次的,都可以叫线性模型
(3)线性关系&线性模型
线性关系一定是线性模型,线性模型不一定是线性关系
二、线性回归的损失和优化原理
1、目标:求模型参数
模型参数能够使得预测准确
2、预测房屋价格
真实关系:真实房子价格 = 0.02×中心区域的距离 + 0.04×城市一氧化氮浓度 + (-0.12×自住房平均房价) + 0.254×城镇犯罪率
随意假定关系:预测房子价格 = 0.25×中心区域的距离 + 0.14×城市一氧化氮浓度 + 0.42×自住房平均房价 + 0.34×城镇犯罪率
当我们把特征值代入到假定的关系当中,预测价格和真实价格肯定有一个误差,如果我们有一种方法,将这个误差不断的减少,让它最终接近于0的话,是不是就意味着模型参数比较准确了
3、真实值和预测值之间的差距如何去衡量
衡量的关系,叫做损失函数/cost/成本函数/目标函数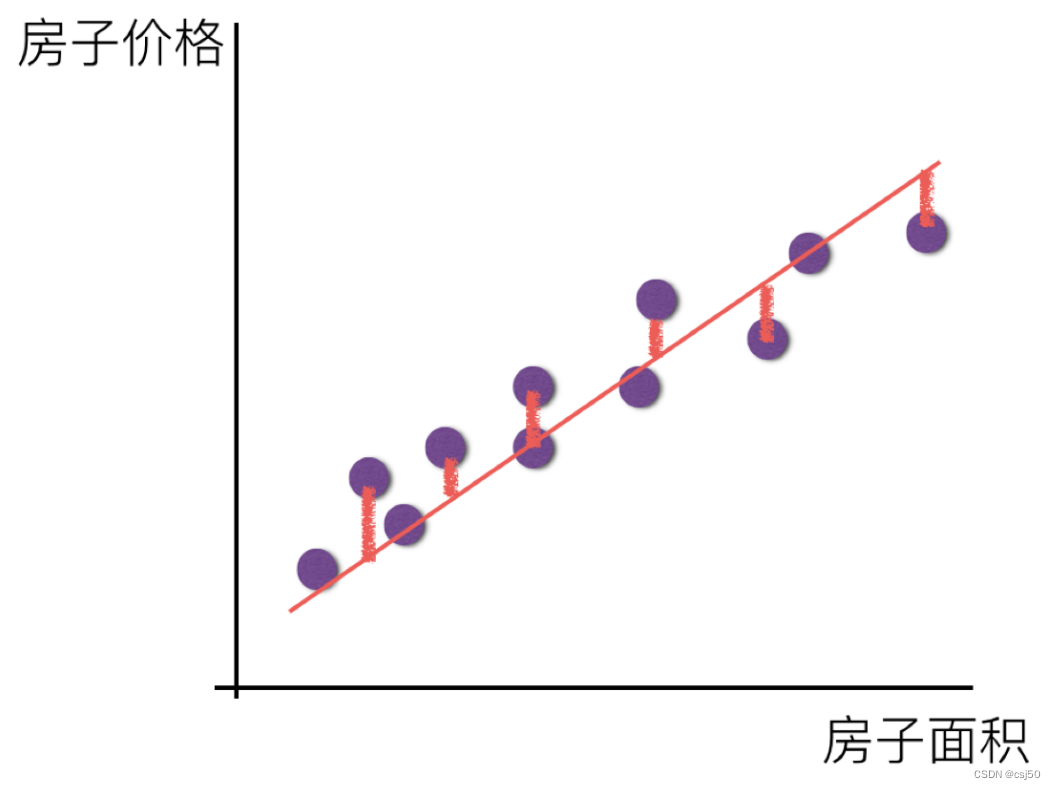
目标:希望找到所有真实的样本,到预测的距离之和比较小,可以求出比较合适的权重和偏置
4、损失函数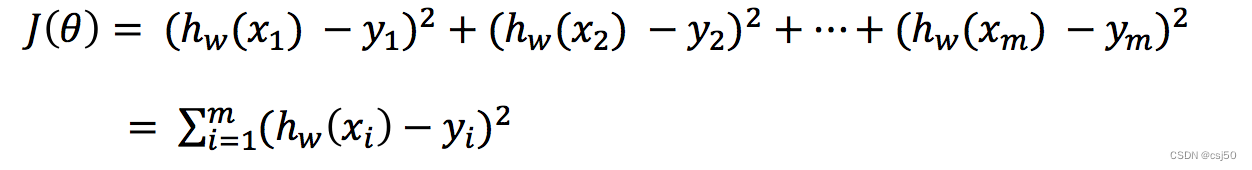
y1:真实值
hw(x1):预测值
预测值-真实值,再求个平方,因为预测值有可能小于真实值
这个公式又叫最小二乘法,有计算平方,又希望这个损失越小越好
为什么不用绝对值:
(1)如果不加绝对值或者平方,距离是会相互抵消的,这是不正确的
(2)加绝对值也就是平方再开根号,而且绝对值求导麻烦,所以直接用了平方
如何去减少这个损失,使我们预测的更加准确些?既然存在了这个损失,我们一直说机器学习有自动学习的功能,在线性回归这里更是能够体现。这里可以通过一些优化方法去优化(其实是数学当中的求导功能)回归的总损失!
5、优化算法
正规方程和梯度下降,正规方程相当于一个天才,梯度下降相当于一个勤奋努力的普通人
6、正规方程(用的少)
通过一个矩阵运算,先求特征值转置,然后乘以它本身,再求一个逆,再乘以它的转置,再乘以y,直接求出w权重
理解:X为特征值矩阵,y为目标值矩阵。直接求到最好的结果
缺点:当特征过多过复杂时,求解速度太慢并且得不到结果

7、梯度下降(常用)
一开始随便给一组权重和偏置,不断的改进、试错
第二组的w1、w0等于上一组的w1、w0减去一个数
我们通过两个图更好理解梯度下降的过程: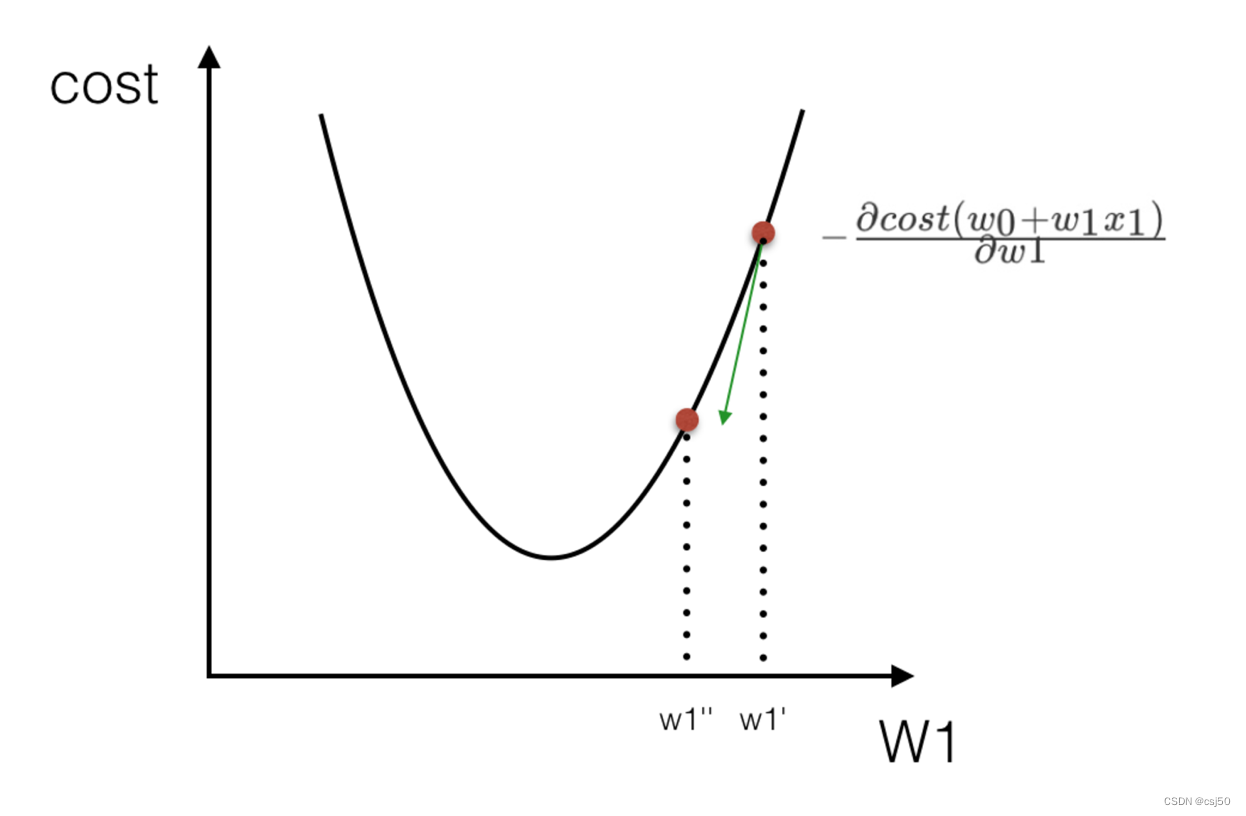
理解:α为学习速率(步长),需要手动指定(超参数),α旁边的整体表示方向(坡度最陡的)
沿着这个函数下降的方向找,最后就能找到山谷的最低点,然后更新w值
使用:面对训练数据规模十分庞大的任务,能够找到较好的结果
8、动态图演示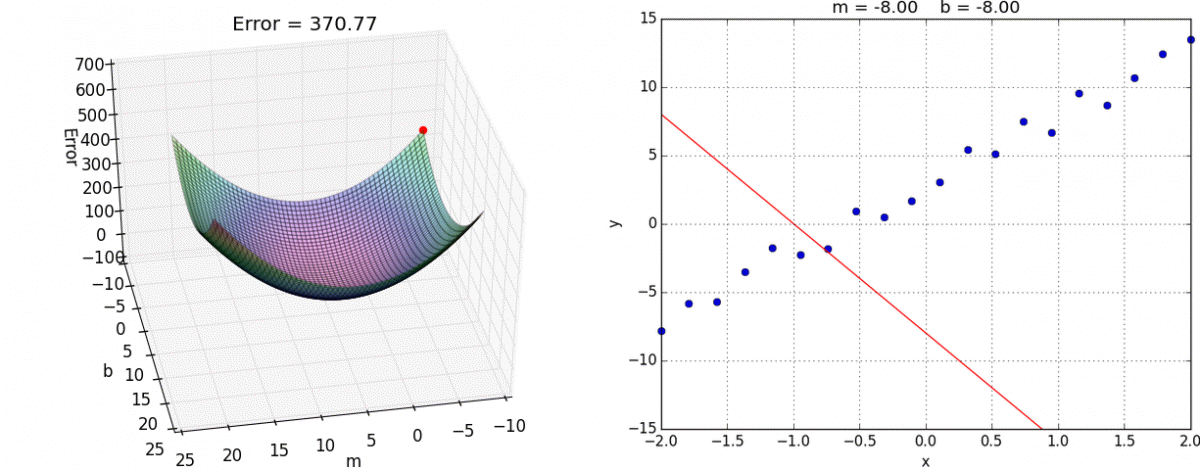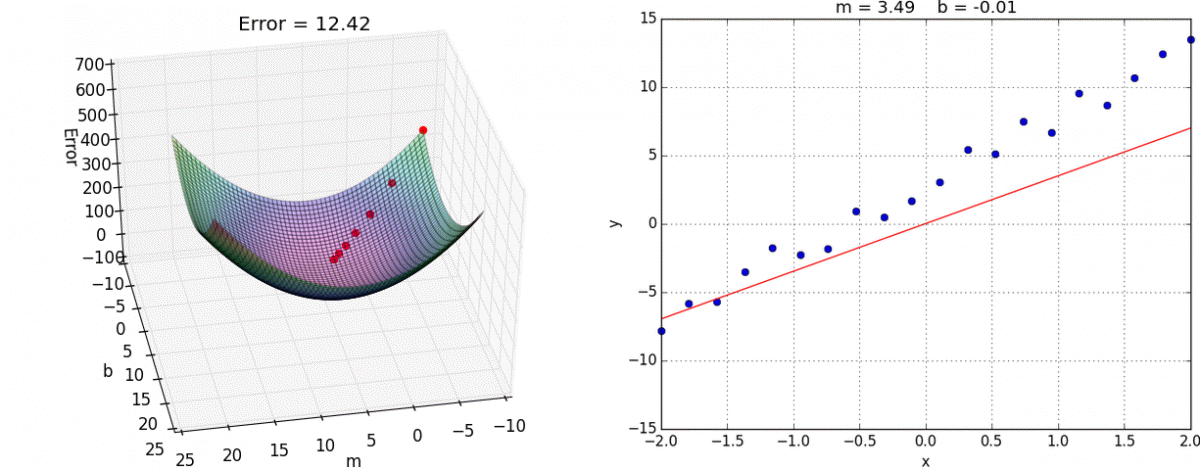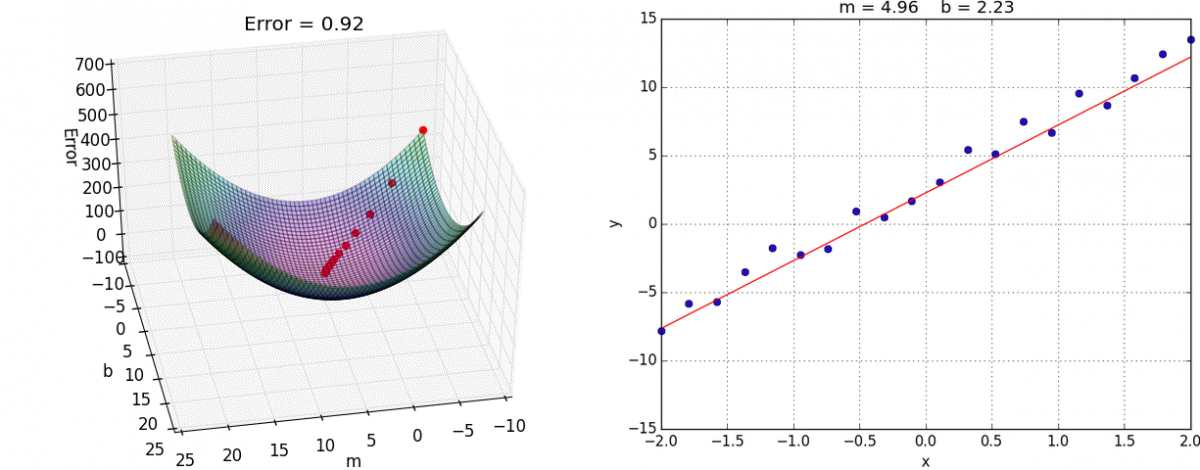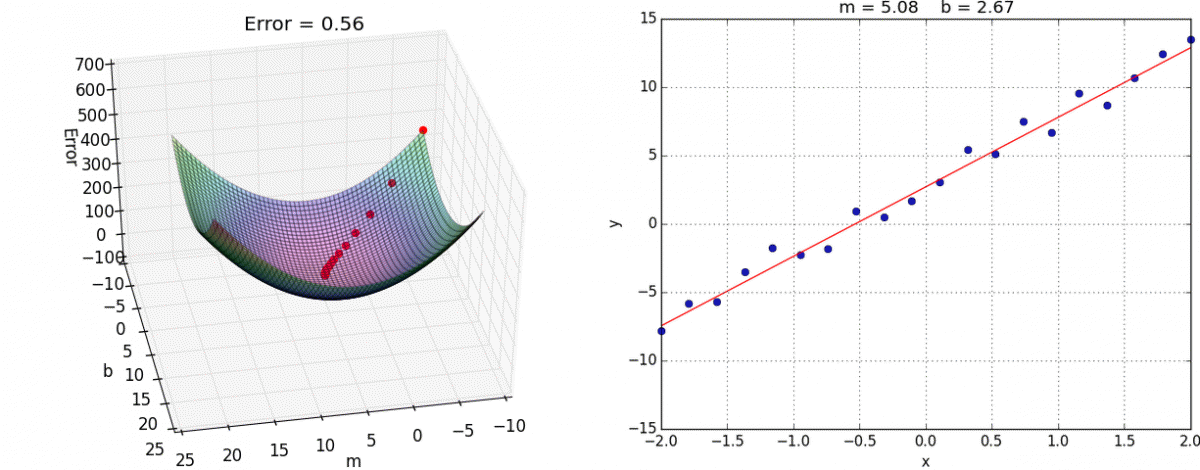
三、线性回归API
1、sklearn.linear_model.LinearRegression(fit_intercept=True)
通过正规方程优化
fit_intercept:是否计算偏置(截距)
查看参数
LinearRegression.coef_:回归系数
LinearRegression.intercept_:偏置
2、sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
通过梯度下降优化,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型
loss:损失函数
loss="squared_loss",普通最小二乘法
fit_intercept:是否计算偏置
learning_rate:学习率(步长),指定学习率算法
'constant':eta = eta0
'optimal':eta = 1.0 / (alpha * (t + t0)) [default]
'invscaling':eta = eta0 / pow(t, power_t),看动态图演示,步长一开始很长,越接近最低点,越小
power_t=0.25:存在父类当中
对于一个常数值的学习率来说,可以使用learning_rate=’constant’ ,并使用eta0来指定学习率
查看参数
SGDRegressor.coef_:回归系数
SGDRegressor.intercept_:偏置
四、波士顿房价预测
1、数据集地址
下载数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data
该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型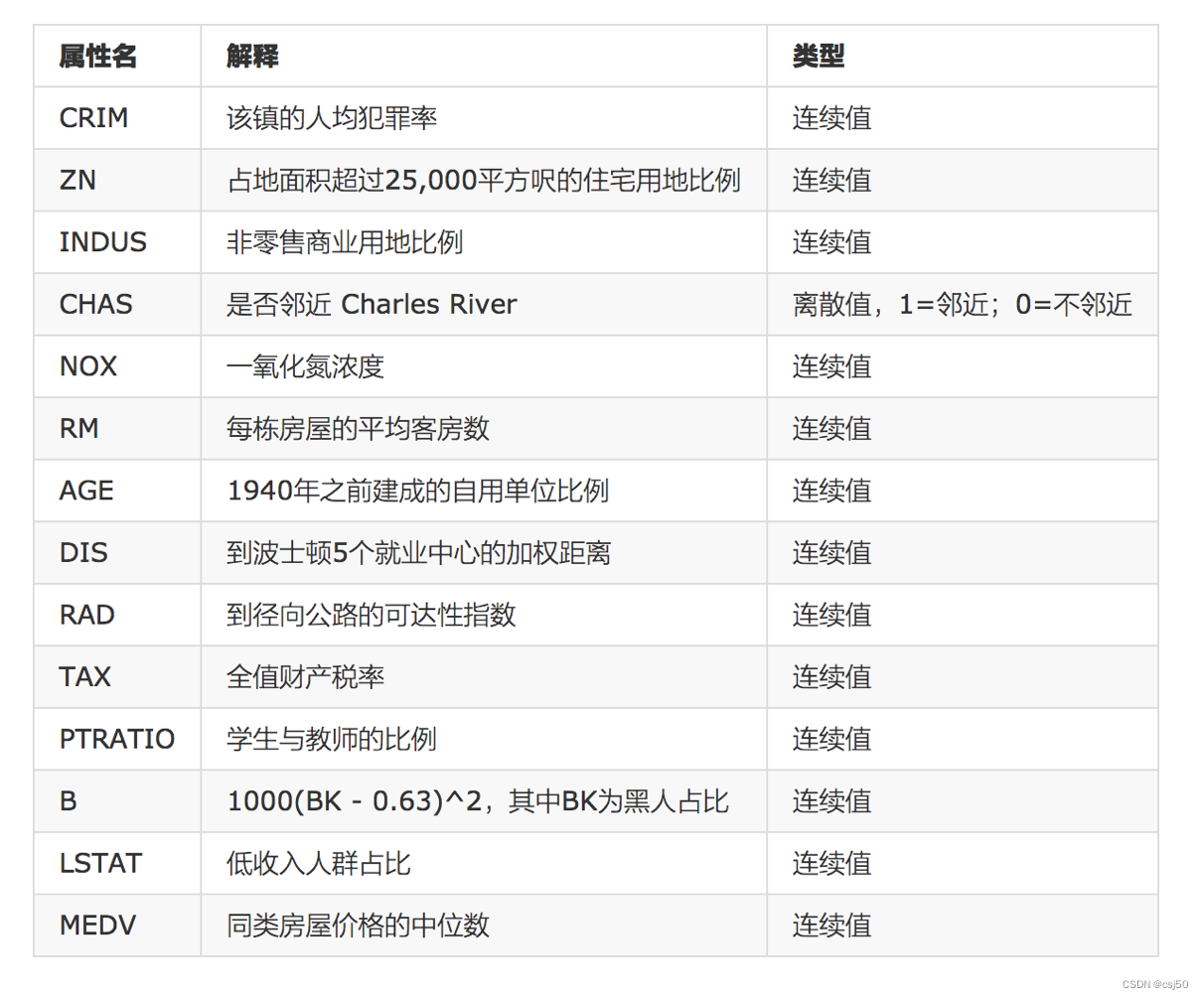
2、分析流程
流程:
1)获取数据集
2)划分数据集
3)特征工程
无量纲化 - 标准化
4)预估器流程
fit() --> 模型
coef_ intercept_
5)模型评估
3、代码 day03_machine_learning.py
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressordef linear1():"""正规方程的优化方法对波士顿房价进行预测"""# 1、获取数据boston = load_boston()# 2、划分数据集x_train,x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=10)# 3、标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4、预估器estimator = LinearRegression()estimator.fit(x_train, y_train)# 5、得出模型print("正规方程-权重系数为:\n", estimator.coef_)print("正规方程-偏置为:\n", estimator.intercept_)# 6、模型评估return Nonedef linear2():"""梯度下降的优化方法对波士顿房价进行预测"""# 1、获取数据boston = load_boston()# 2、划分数据集x_train,x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=10)# 3、标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4、预估器estimator = SGDRegressor()estimator.fit(x_train, y_train)# 5、得出模型print("梯度下降-权重系数为:\n", estimator.coef_)print("梯度下降-偏置为:\n", estimator.intercept_)# 6、模型评估return Noneif __name__ == "__main__":# 代码1:正规方程的优化方法对波士顿房价进行预测linear1()# 代码2:梯度下降的优化方法对波士顿房价进行预测linear2()
运行结果:
正规方程-权重系数为:[-1.16537843 1.38465289 -0.11434012 0.30184283 -1.80888677 2.341711660.32381052 -3.12165806 2.61116292 -2.10444862 -1.80820193 1.19593811-3.81445728]
正规方程-偏置为:21.93377308707127
梯度下降-权重系数为:[-1.10621345 1.29133856 -0.27846867 0.33474439 -1.69384501 2.41354660.29053621 -3.08390938 2.01002437 -1.44580391 -1.77085656 1.20016946-3.77661902]
梯度下降-偏置为:[21.9475731]五、回归的性能评估
1、均方误差(Mean Squared Error)MSE评价机制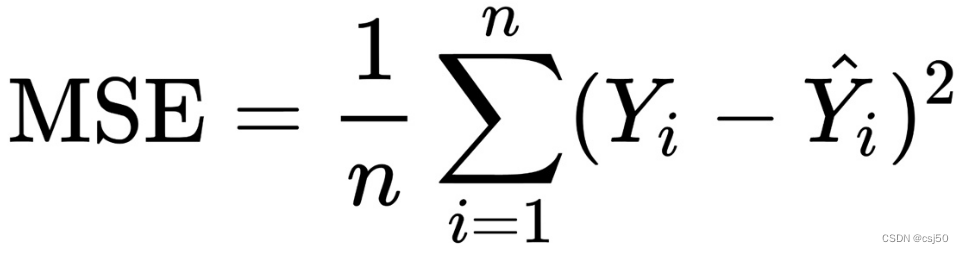
MSE 计算模型的预测值 Ŷ 与真实值 Y 的接近程度
2、sklearn.metrics.mean_squared_error(y_true, y_pred)
均方误差回归损失
y_true:真实值
y_pred:预测值
return:浮点数结果
3、修改day03_machine_learning.py
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.metrics import mean_squared_errordef linear1():"""正规方程的优化方法对波士顿房价进行预测"""# 1、获取数据boston = load_boston()# 2、划分数据集x_train,x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=10)# 3、标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4、预估器estimator = LinearRegression()estimator.fit(x_train, y_train)# 5、得出模型print("正规方程-权重系数为:\n", estimator.coef_)print("正规方程-偏置为:\n", estimator.intercept_)# 6、模型评估y_predict = estimator.predict(x_test)print("预测房价:\n", y_predict)error = mean_squared_error(y_test, y_predict)print("正规方程-均方误差为:\n", error)return Nonedef linear2():"""梯度下降的优化方法对波士顿房价进行预测"""# 1、获取数据boston = load_boston()# 2、划分数据集x_train,x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=10)# 3、标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 4、预估器estimator = SGDRegressor()estimator.fit(x_train, y_train)# 5、得出模型print("梯度下降-权重系数为:\n", estimator.coef_)print("梯度下降-偏置为:\n", estimator.intercept_)# 6、模型评估y_predict = estimator.predict(x_test)print("预测房价:\n", y_predict)error = mean_squared_error(y_test, y_predict)print("梯度下降-均方误差为:\n", error)return Noneif __name__ == "__main__":# 代码1:正规方程的优化方法对波士顿房价进行预测linear1()# 代码2:梯度下降的优化方法对波士顿房价进行预测linear2()
运行结果:
正规方程-权重系数为:[-1.16537843 1.38465289 -0.11434012 0.30184283 -1.80888677 2.341711660.32381052 -3.12165806 2.61116292 -2.10444862 -1.80820193 1.19593811-3.81445728]
正规方程-偏置为:21.93377308707127
预测房价:[31.11439635 31.82060232 30.55620556 22.44042081 18.80398782 16.2762532236.13534369 14.62463338 24.56196194 37.27961695 21.29108382 30.6125824127.94888799 33.80697059 33.25072336 40.77177784 24.3173198 23.2977324125.50732006 21.08959787 32.79810915 17.7713081 25.36693209 25.0381105932.51925813 20.4761305 19.69609206 16.93696274 38.25660623 0.7015249932.34837791 32.21000333 25.78226319 23.95722044 20.51116476 19.537272583.87253095 34.74724529 26.92200788 27.63770031 34.47281616 29.8051127118.34867051 31.37976427 18.14935849 28.22386149 19.25418441 21.7149039538.26297011 16.44688057 24.60894426 19.48346848 24.49571194 34.4891563526.66802508 34.83940131 20.91913534 19.60460332 18.52442576 25.0017879919.86388846 23.46800342 39.56482623 42.95337289 30.34352231 16.893355923.88883179 3.33024647 31.45069577 29.07022919 18.42067822 27.4431489719.55119898 24.73011317 24.95642414 10.36029002 39.21517151 8.3074326218.44876989 30.31317974 22.97029822 21.0205003 19.99376338 28.647549730.88848414 28.14940191 26.57861905 31.48800196 22.25923033 -5.3597325221.66621648 19.87813555 25.12178903 23.51625356 19.23810222 19.046423427.32772709 21.92881244 26.69673066 23.25557504 23.99768158 19.2845825921.19223276 10.81102345 13.92128907 20.8630077 23.40446936 13.9168948428.87063386 15.44225147 15.60748235 22.23483962 26.57538077 28.6420362324.16653911 18.40152087 15.94542775 17.42324084 15.6543375 21.0413626433.21787487 30.18724256 20.92809799 13.65283665 16.19202962 29.2515560313.28333127]
正规方程-均方误差为:32.44253669600673
梯度下降-权重系数为:[-1.10720669 1.25231283 -0.31509564 0.34535296 -1.64340471 2.455330740.24591813 -3.00623279 1.86680194 -1.35635736 -1.75927819 1.21751662-3.75820164]
梯度下降-偏置为:[21.93446341]
预测房价:[30.5553054 31.9029657 30.49644841 23.21944515 18.96884856 16.1863263636.24105194 14.87804697 24.3895523 37.20352522 21.5386604 30.6095118727.65148152 33.50851129 33.21249389 40.83380512 24.46605375 22.8883214825.52501927 21.58868475 32.80656665 17.73245419 25.66824551 25.0860486432.97047549 20.30353258 19.68164294 16.91361879 38.1855976 0.2776093232.54896674 32.02576312 25.94574949 23.97039625 20.35535178 19.780879863.89351738 34.35969722 26.90276862 27.75996947 34.54094573 29.5499409618.27465483 31.39534921 18.00180158 28.4390917 19.23254806 21.5245233237.97845293 16.57097091 24.5471993 19.39657317 24.21252437 34.922785526.80416589 34.74661413 21.23727026 19.59775567 18.39910461 25.052394220.19548887 23.82772896 40.02092877 43.04844803 30.42801759 17.2069933723.93074887 3.06161671 31.11592258 29.56981815 18.4009017 27.3705844719.36967055 24.60927521 25.32075297 10.35369309 39.25900753 8.179007518.11059373 30.75396941 22.93518314 21.69853793 20.21950513 28.4923592131.07597036 28.29348444 26.43666514 31.70687029 22.21769412 -5.4580019221.63087532 19.7545147 25.08781498 23.61546397 18.84729974 19.1030671627.25447935 22.00263139 26.57769298 23.53325788 23.87869699 19.5128190521.00527045 10.1261844 14.03654344 21.12885311 23.21744834 15.1778369128.87985666 15.68906271 15.61491721 22.063714 26.98392894 28.6436898424.01307784 18.36664466 15.87301799 17.66160742 15.84512198 20.8421702733.17275758 30.60002844 21.15789543 14.11621048 16.30693791 29.1771885813.16315128]
梯度下降-均方误差为:32.55418193625462六、正规方程和梯度下降对比
1、对比
| 梯度下降 | 正规方程 |
| 需要选择学习率 | 不需要 |
| 需要迭代求解 | 一次运算得出 |
| 特征数量较大可以使用 | 需要计算方程,时间复杂度高O(n3) |
2、选择
小规模数据:
LinearRegression(不能解决拟合问题)
岭回归
大规模数据:
SGDRegressor
七、梯度下降预估器优化方法-GD、SGD、SAG
1、GD
梯度下降(Gradient Descent),原始的梯度下降法需要计算所有样本的值才能够得出梯度,计算量大,所以后面才有会一系列的改进
2、SGD
随机梯度下降(Stochastic gradient descent)是一个优化方法。它在一次迭代时只考虑一个训练样本
SGD的优点是:
高效
容易实现
SGD的缺点是:
SGD需要许多超参数:比如正则项参数、迭代数
SGD对于特征标准化是敏感的
3、SAG
随机平均梯度法(Stochasitc Average Gradient),由于收敛的速度太慢,有人提出SAG等基于梯度下降的算法
Scikit-learn:SGDRegressor、岭回归、逻辑回归等当中都会有SAG优化
参考资料:
通俗易懂讲解均方误差 (MSE) - haltakov - 知乎 (zhihu.com)
相关文章:
机器学习基础之《回归与聚类算法(1)—线性回归》
一、线性回归的原理 1、线性回归应用场景 如何判定一个问题是回归问题的,目标值是连续型的数据的时候 房价预测 销售额度预测 贷款额度预测、利用线性回归以及系数分析因子 2、线性回归定义 线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(…...
如何实现制造业信息化转型?
一、制造业信息化历史 (1)1930年代 库存控制、管理 当时计算机系统尚未出现,人们为了解决库存管控的难题,提出了订货点法——当库存量降低到某一预先设定的点时,即开始发出订货单补充库存,直至库存量降低…...
stable diffusion艰难炼丹之路
文章目录 概要autoDL系统盘爆满autoDL python3.8切换python3.10dreambooth训练大模型完成后报错 概要 主要是通过autoDL服务器部署stable diffusion,通过dreambooth训练大模型。 问题: autoDL系统盘爆满autoDL python3.8切换python3.10dreambooth训练大…...
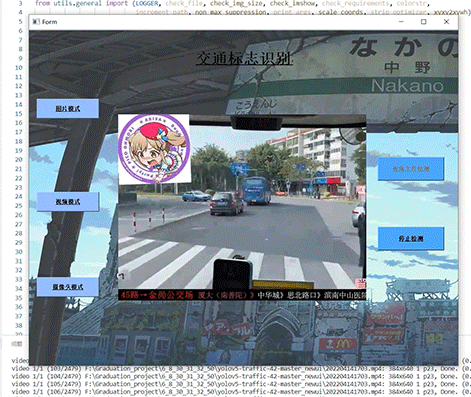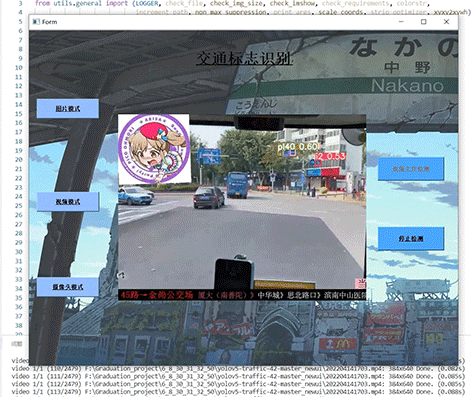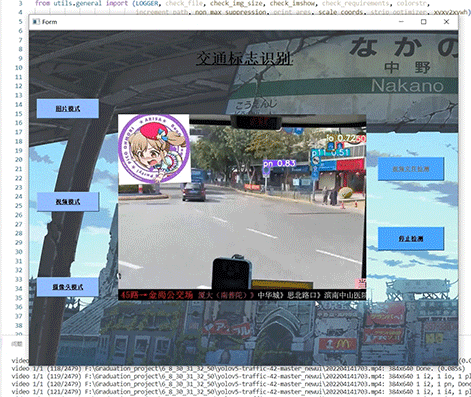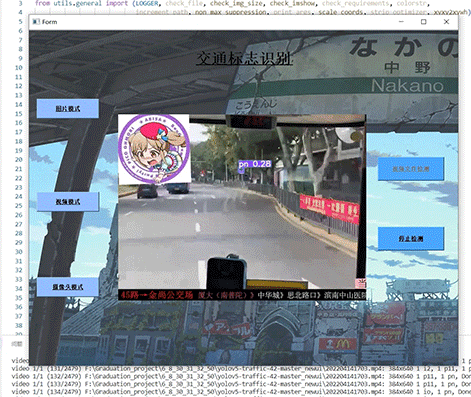
竞赛 深度学习 opencv python 实现中国交通标志识别
文章目录 0 前言1 yolov5实现中国交通标志检测2.算法原理2.1 算法简介2.2网络架构2.3 关键代码 3 数据集处理3.1 VOC格式介绍3.2 将中国交通标志检测数据集CCTSDB数据转换成VOC数据格式3.3 手动标注数据集 4 模型训练5 实现效果5.1 视频效果 6 最后 0 前言 🔥 优质…...

用Python实现数据透视表、音频文件格式转换
用Python实现数据透视表、音频文件格式转换 1.用Python实现数据透视表 import pandas as pdif __name__ __main__:# df pd.read_excel(广告-资源位变现效率监测看板-1.xlsx, sheet_name各业务在该资源位的明细数据)df pd.read_excel(填充率分析-Q3.xlsx, sheet_name库存底…...

java枚举中写抽象方法
之前写java枚举时,都是中规中矩的写,从来没见过在枚举中写抽象方法的,但最近换了新公司,接手了新项目,发现枚举中竟然写了抽象方法,由于之前没接触过这种写法,所以这里记录下 实体类student代码…...
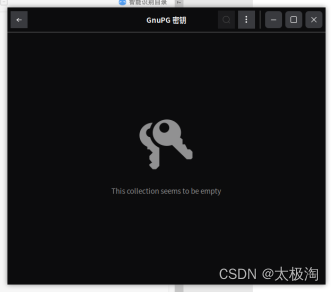
麒麟操作系统提示“默认密钥环已上锁”的解决办法
在国产麒麟操作系统上,有的时候不知道为啥,打开vscode或者其他应用软件时,总是提示“密钥环已上锁”,该怎么处理呢? 需要点击“开始”,在搜索框中输入“password” 点击打开“密码和密钥”,看到如下图。 然后点击左上角的箭头,回退,打开如下图:...

云原生周刊:Docker 推出 Docker Debug | 2023.10.9
开源项目推荐 SchemaHero SchemaHero 是一个 Kubernetes Operator,用于各种数据库的声明式架构管理。SchemaHero 有以下目标: 数据库表模式可以表示为可以部署到集群的 Kubernetes 资源。可以编辑数据库模式并将其部署到集群。SchemaHero 将计算所需的…...
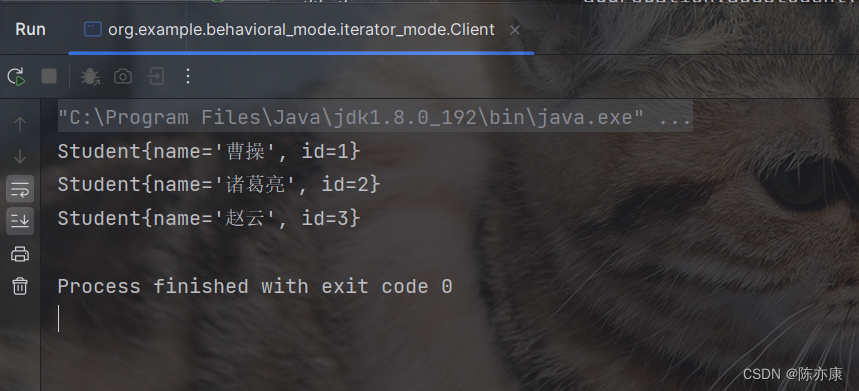
设计模式 - 行为型模式考点篇:迭代器模式(概述 | 案例实现 | 优缺点 | 使用场景)
目录 一、行为型模式 一句话概括行为型模式 1.1、迭代器模式 1.1.1、概述 1.1.2、案例实现 1.1.3、优缺点 1.1.4、使用场景 一、行为型模式 一句话概括行为型模式 行为型模式:类或对象间如何交互、如何划分职责,从而更好的完成任务. 1.1、迭代器…...
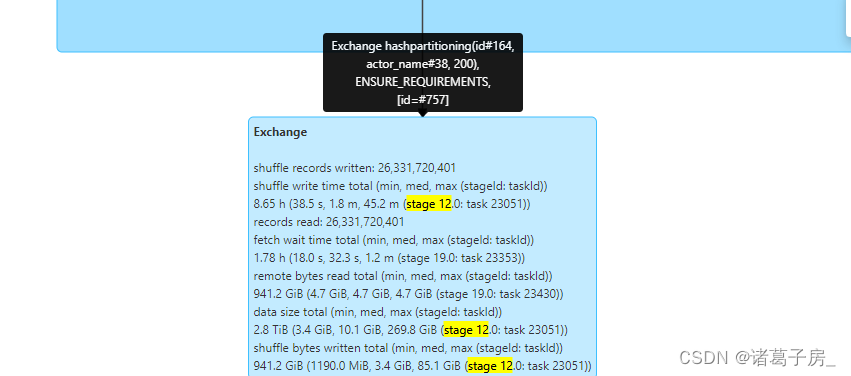
Spark任务优化分析
一、背景 首先需要掌握 Spark DAG、stage、task的相关概念 Spark的job、stage和task的机制论述 - 知乎 task数量和rdd 分区数相关 二、任务慢的原因分析 找到运行时间比较长的stage 再进去看里面的task 可以看到某个task 读取的数据量明显比其他task 较大。 如果是sql 任…...

最新数据库流行度最新排名(每月更新)
2023年10月数据库流行度最新排名 TOP DB顶级数据库索引是通过分析在谷歌上搜索数据库名称的频率来创建的 一个数据库被搜索的次数越多,这个数据库就被认为越受欢迎。这是一个领先指标。原始数据来自谷歌Trends 如果您相信集体智慧,那么TOP DB索引可以帮…...

Python:如何在一个月内学会爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得…...
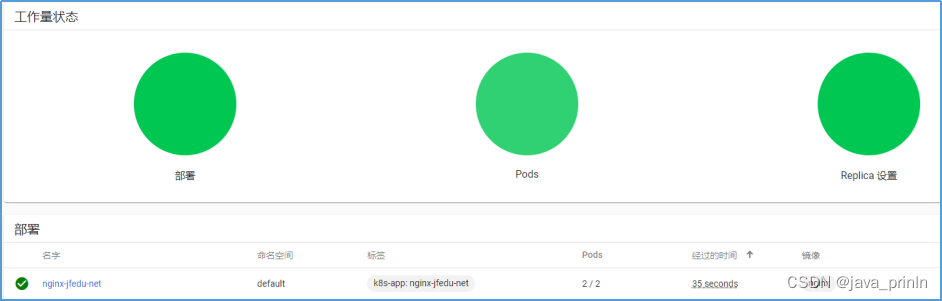
K8S云计算系列-(4)
K8s Dashboard UI 部署实操 Kubernetes实现的最重要的工作是对Docker容器集群统一的管理和调度,通常使用命令行来操作Kubernetes集群及各个节点,命令行操作非常不方便,如果使用UI界面来可视化操作,会更加方便的管理和维护。如下为…...
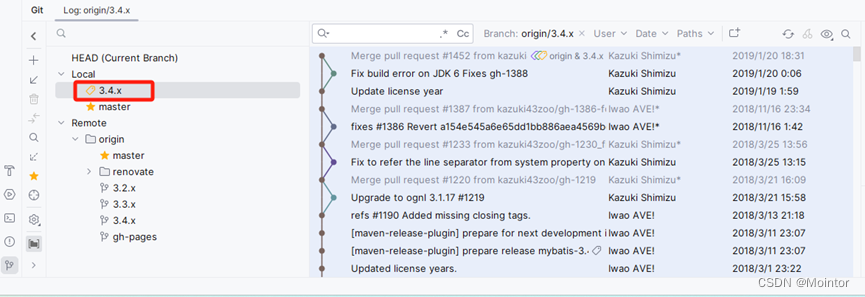
【Mybatis源码】IDEA中Mybatis源码环境搭建
一、Mybatis源码源 在github中找到Mybatis源码地址:https://github.com/mybatis/mybatis-3 找到Mybatis git地址 二、IDEA导入Mybatis源码 点击Clone下载Mybatis源码 三、选择Mybatis分支 选择Mybatis分支,这里我选择的是3.4.x分支...

VUE如何使得大屏自适应的几种方法?
VUE学习大屏自适应的几种方法 1.自适屏幕,始终保持16:9的比例 <!-- 大屏固定比例16:9自适应 --> <template><div class"container"><div class"content" :style"getAspectRatioStyle"><!-- …...
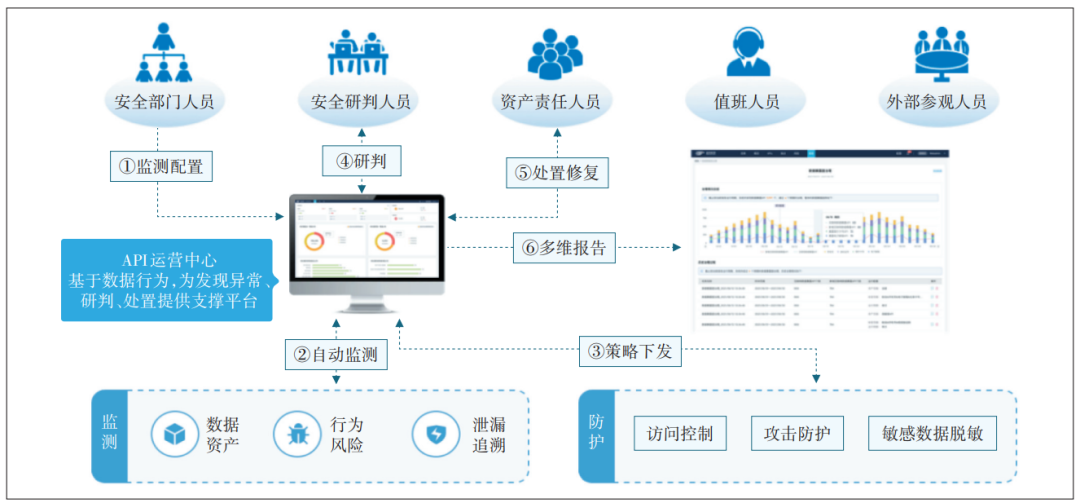
API接口安全运营研究(内附官方开发平台api接口接入方式)
摘 要 根据当前API技术发展的趋势,从实际应用中发生的安全事件出发,分析并讨论相关API安全运营问题。从风险角度阐述了API接口安全存在的问题,探讨了API检测技术在安全运营中起到的作用,同时针对API安全运营实践,提出…...

信钰证券:股票交易费用计算方法?
股票生意是股市参加者之间进行的买入和卖出股票的进程。其中,股票生意费用是参加股市生意的重要组成部分。本文将从多个视点分析股票生意费用计算方法。 首先,股票生意费用一般包含三部分。分别是佣钱、印花税和过户费。佣钱是证券公司为代理股票生意而收…...

通过js获取用户网络ip地址
<!DOCTYPE html> <html><head><meta charset"utf-8"><title>js获取本地ip</title> </head><body><script>var xmlhttp;if (window.XMLHttpRequest) {xmlhttp new XMLHttpRequest();} else {xmlhttp new Act…...
微信小程序wxml使用过滤器
微信小程序wxml使用过滤器 1. 新建wxs2. 引用和使用 如何在微信小程序wxml使用过滤器? 犹如Angular使用pipe管道这样子方便,用的最多就是时间格式化。 下面是实现时间格式化的方法和步骤: 1. 新建wxs 插入代码: /*** 管道过滤工…...
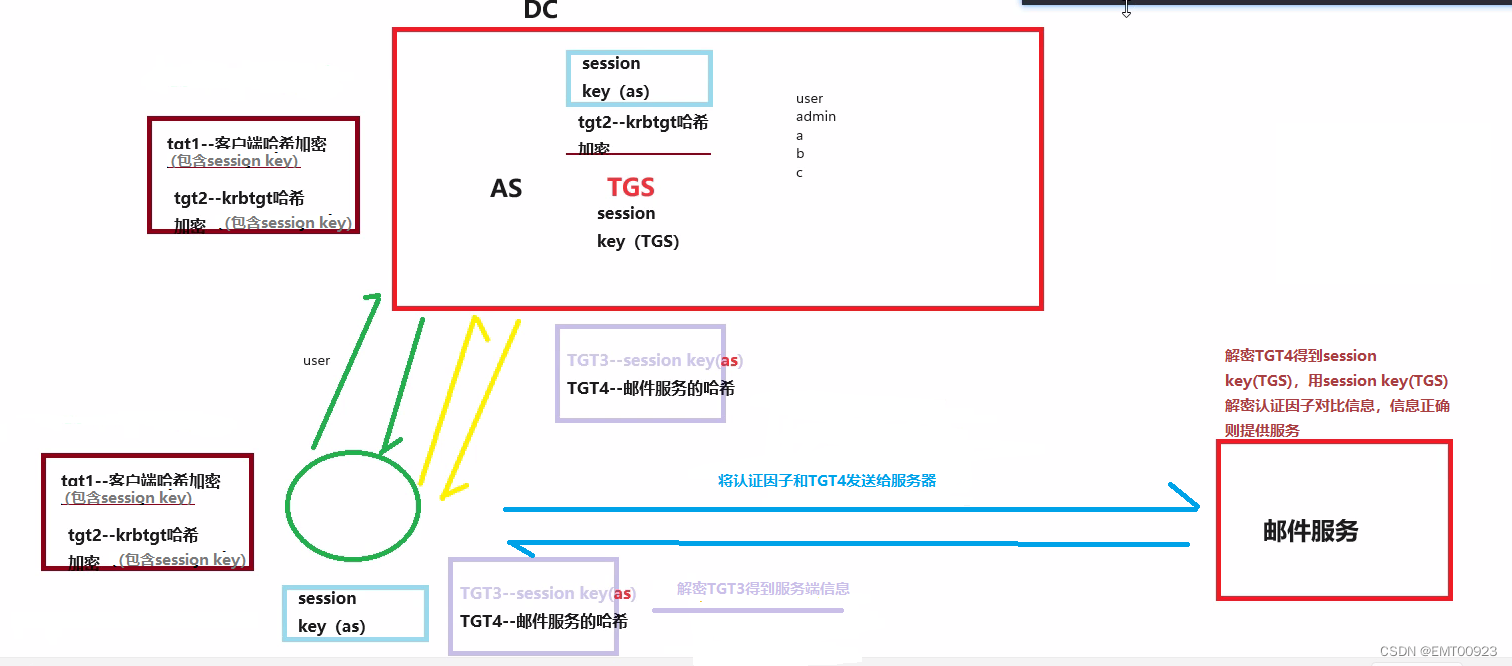
内网渗透面试问题
文章目录 1、熟悉哪些域渗透的手段2、详细说明哈希传递的攻击原理NTLM认证流程哈希传递 3、聊一下黄金票据和白银票据4、shiro反序列化漏洞的形成原因,尝试使用burp抓包查看返回包内容安装环境漏洞验证 5、log4j组件的命令执行漏洞是如何造成的6、画图描述Kerberos协…...

颠覆式Alienware设备控制:500KB轻量工具实现10倍性能提升与个性化体验
颠覆式Alienware设备控制:500KB轻量工具实现10倍性能提升与个性化体验 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 当你启动Alienware电…...

BetterNCM安装器完全指南:3分钟掌握网易云音乐插件管理技巧
BetterNCM安装器完全指南:3分钟掌握网易云音乐插件管理技巧 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否厌倦了网易云音乐客户端的功能限制?想要为你的…...

定制化水源热泵技术,实现低品位余热高效捕获
低品位余热的高效回收利用,核心在于能否打造出适配水源特性与工况需求的核心热泵机组,只有实现对余热资源的精准捕获,才能真正将闲置余热转化为可利用的清洁能源。针对鲁西南矿区的水源特性与极端气候工况,瑞冬为当地某铁矿项目针…...

终极指南:如何用Python SDK快速集成飞书开放平台API
终极指南:如何用Python SDK快速集成飞书开放平台API 【免费下载链接】oapi-sdk-python Larksuite development interface SDK 项目地址: https://gitcode.com/gh_mirrors/oa/oapi-sdk-python 想要在Python应用中快速集成飞书开放平台的强大功能,却…...

MiniCPM-o-4.5-nvidia-FlagOS插件开发指南:为谷歌浏览器打造智能阅读与摘要助手
MiniCPM-o-4.5-nvidia-FlagOS插件开发指南:为谷歌浏览器打造智能阅读与摘要助手 你是不是经常在网上冲浪时,面对一篇长文感到头疼,只想快速抓住核心要点?或者遇到一篇外文资料,需要逐句翻译才能理解?又或者…...

3大核心功能解锁QtScrcpy:实现跨平台Android设备高效控制
3大核心功能解锁QtScrcpy:实现跨平台Android设备高效控制 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy QtScrcpy是一款开源的跨平台Android实时显示与控制工具&#x…...

免费终极指南:使用memtest_vulkan快速检测GPU显存稳定性问题
免费终极指南:使用memtest_vulkan快速检测GPU显存稳定性问题 【免费下载链接】memtest_vulkan Vulkan compute tool for testing video memory stability 项目地址: https://gitcode.com/gh_mirrors/me/memtest_vulkan memtest_vulkan是一款基于Vulkan计算AP…...

终极指南:如何用VideoSrt在5分钟内为视频自动生成字幕
终极指南:如何用VideoSrt在5分钟内为视频自动生成字幕 【免费下载链接】video-srt-windows 这是一个可以识别视频语音自动生成字幕SRT文件的开源 Windows-GUI 软件工具。 项目地址: https://gitcode.com/gh_mirrors/vi/video-srt-windows 还在为手动添加字幕…...

【Axure教程】字母定位选择器
今天教大家用一个中继器制作字母分类定位选择器的原型模板,模版我们用中继器制作的,所以使用也很方便,只需要在中继器表格对应位置填写选项信息,即可自动生成交互效果,具体效果可以打开下方预览地址体验。 【原型效果…...

暗黑破坏神2存档编辑器终极指南:3步掌握可视化修改技巧
暗黑破坏神2存档编辑器终极指南:3步掌握可视化修改技巧 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2存档修改而烦恼吗?传统的十六进制编辑不仅操作复杂,还容易导致存档损…...