【C++杂货铺】一文带你走进哈希:哈希冲突 | 哈希函数 | 闭散列 | 开散列

文章目录
- 一、unordered 系列关联式容器
- 二、unordered_map
- 1.1 unordered_map 介绍
- 1.2 unordered_map 的接口说明
- 1.2.1 unordered_map 的构造
- 1.2.2 unordered_map 的容量
- 1.2.3 unordered_map 的迭代器
- 1.2.4 unordered_map 的元素访问
- 1.2.5 unordered_map 的查询
- 1.2.6 unordered_map 的修改操作
- 1.2.7 unordered_map 的桶操作
- 三、底层结构
- 3.1 哈希概念
- 3.2 哈希冲突
- 3.3 哈希函数
- 3.3.1 直接定值法----(常用)
- 3.3.2 除留余数法----(常用)
- 3.3.3 平方取中法----(了解)
- 3.3.4 折叠法----(了解)
- 3.3.5 随机数法----(了解)
- 3.3.6 数学分析法----(了解)
- 3.4 哈希冲突解决
- 3.4.1 闭散列
- 3.4.1.1 线性探测
- 3.4.1.2 闭散列(开放定址法)模拟实现
- 3.4.1.3 二次探测
- 3.4.2 开散列
- 3.4.2.1 开散列模拟实现
- 四、模拟实现 unordered_set 和 unordered_map
- 4.1 哈希表的改造
- 4.1.1 模板参数列表的改造
- 4.1.2 增加迭代器操作
- 4.1.3 修改后的哈希表
- 4.2 unordered_set 模拟实现
- 4.3 unordered_map 模拟实现
- 五、结语
一、unordered 系列关联式容器
在 C++98 中,STL 提供了底层为红黑树结构的一些列关联式容器,在查询时效率可以达到 O ( l o g 2 N ) O(log2^N) O(log2N),即最差情况下需要比较红黑树高度次,当树中的结点非常多的时候,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到,因此在 C++11 中,STL 又提供了4个 unordered 系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方法基本类似,只是其底层结构不同,本文中只对 unordered_map 和 unordered_set 进行介绍,unordered_multimap 和 unordered_multiset 感兴趣的小伙伴可以自行查阅文档。
二、unordered_map
1.1 unordered_map 介绍
-
unordered_map 是存储 <key,value> 键值对的关联式容器,其允许通过 key 快速的索引到与其对应的 value。
-
在 unordered_map 中,键值通常用于唯一的标识元素,而映射值是一个对象,其内容与此键值关联。键和映射值的类型可能不同。
-
在内部,unordered_map 没有对 <key,value> 按照任何特定的顺序排序,为了能在常数范围内找到 key 所对应的 value,unordered_map 将相同哈希值的键值放在相同的桶中。
-
unordered_map 容器通过 key 访问单个元素要比 map 快,但它通常在遍历元素子集的范围迭代方面效率较低。
-
unordered_map 实现了直接访问操作符(operator[ ]),它允许使用 key 作为参数直接访问 value。
-
它的迭代器至少是前向迭代器(单向迭代器)。
1.2 unordered_map 的接口说明
1.2.1 unordered_map 的构造
| 函数声明 | 功能介绍 |
|---|---|
| unordered_map | 构造不同格式的 unordered_map 对象 |
1.2.2 unordered_map 的容量
| 函数声明 | 功能介绍 |
|---|---|
| bool empty() const | 检测 unordered_map 是否为空 |
| size_t size() const | 获取 unordered_map 有效元素的个数 |
1.2.3 unordered_map 的迭代器
| 函数声明 | 功能介绍 |
|---|---|
| begin() | 返回 unordered_map 第一个元素的迭代器 |
| end() | 返回 unordered_map 最后一个元素下一个位置的迭代器 |
| cbegin() | 返回 unordered_map 第一个元素的 const 迭代器 |
| cend() | 返回 unordered_map 最后一个元素下一个位置的 const 迭代器 |
1.2.4 unordered_map 的元素访问
| 函数声明 | 功能介绍 |
|---|---|
| operator[ ] | 返回与 key 对应的 value,没有一个默认值 |
小Tips:该函数中实际调用哈希桶的插入操作,用参数 key 与 V() 构造一个默认值往底层哈希桶中插入,如果 key 不在哈希桶中,插入成功,返回 V()。插入失败,说明 key 已经在哈希桶中,将 key 对应的 value 返回。
1.2.5 unordered_map 的查询
| 函数声明 | 功能介绍 |
|---|---|
| iterator find(const K& key) | 返回 key 在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中关键码为 key 的键值对的个数 |
小Tips:unordered_map 中 key 是不能重复的,因此 count 函数的返回值最大为1。
1.2.6 unordered_map 的修改操作
| 函数声明 | 功能介绍 |
|---|---|
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| void clear() | 清空容器中有效元素个数 |
| void swap(unordered_map& ump) | 交换两个容器中的元素 |
1.2.7 unordered_map 的桶操作
| 函数声明 | 功能介绍 |
|---|---|
| size_t bucket_count() const | 返回哈希桶中桶的总个数 |
| size_t bucket_size(size_t n) const | 返回 n 号桶中有效元素的总个数 |
| size_t bucket(const K& key) | 返回元素 key 所在的桶号 |
三、底层结构
unordered 系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
3.1 哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为 O ( N ) O(N) O(N),平衡树中为树的高度,即 O ( l o g 2 N ) O(log2^N) O(log2N),搜索的效率取决于搜索过程中关键码的比较次数。
理想的搜索方法:可以在不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。在结构中:
-
插入元素:根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放。
-
搜索元素:对元素的关键码进行相同的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜素成功。
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者散列表)

小Tips:用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快。但是也会出现问题,以上图为例,再向集合中插入44,计算出来的哈希函数值是4,但是下标为4的位置已经存储的有值了。
3.2 哈希冲突
对于两个数据元素的关键字 k_i 和 k_j (i != j),有 k_i != k_j,但有:Hash(k_i) == Hash(k_j),即:不同的关键字通过相同的哈希函数计算出相同的哈希值,该种现象称为哈希冲突或哈希碰撞。把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
3.3 哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。设计哈希函数应该遵循以下原则:
-
哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有 m 个地址时,其值域必须在 0~m-1 之间。
-
哈希函数计算出来的地址能均匀分布在整个空间中。
-
哈希函数应该比较简单。
下面给大家列举一些常见的哈希函数。
3.3.1 直接定值法----(常用)
取关键字的某个线性函数为散列地址:
H a s h ( K e y ) = A ∗ K e y + B Hash(Key) = A*Key +B Hash(Key)=A∗Key+B
小Tips:此方法的优点是简单、均匀。但是需要事先知道关键字的分布情况。适合查找比较小且连续的情况。
3.3.2 除留余数法----(常用)
设散列表中允许的地址数为 m,取一个不大于 m,但最接近或者等于 m 的质数 p 作为除数,按照哈希函数:
H a s h ( K e y ) = K e y % p ( p < = m ) Hash(Key) = Key \% p(p <= m) Hash(Key)=Key%p(p<=m)
3.3.3 平方取中法----(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再比如关键字为4321,对它的平方就是18671041,抽取中间的3位671(或710)作为哈希地址。平方取中法适合于不知道关键字的分布,而位数又不是很大的情况。
3.3.4 折叠法----(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短一些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
3.3.5 随机数法----(了解)
选择一个随机数,取关键字的随机函数值为它的哈希地址,即:
H a s h ( K e y ) = r a n d o m ( k e y ) Hash(Key) = random(key) Hash(Key)=random(key)
小Tips:其中 random 为随机数函数。
3.3.6 数学分析法----(了解)
设有 n 个d 位数,每一位可能有 r 种不同的符号在各个位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。例如:

假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是 相同的,那么我们可以选择后面的四位作为散列地址,如果这样的抽取工作还容易出现 冲突,还可以对抽取出来的数字进行反转(如1234改成4321)、右环位移(如1234改成4123)、左环移位、前两数与后两数叠加(如1234改成12+34=46)等方法。
小Tips:数学分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况。
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
3.4 哈希冲突解决
解决哈希冲突的两种常见方法是:闭散列和开散列。
3.4.1 闭散列
闭散列也叫开放定址法,当发生哈希冲突时,如果哈希表未被填满,说明在哈希函数表中必然还有空位置,那么可以把 Key 对应的元素存放到冲突位置中的下一个空位置中去。那如何寻找下一个空位置呢?
3.4.1.1 线性探测
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
插入:
-
通过哈希函数获取待插入元素在哈希表中的位置。
-
如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素。

查找:
-
通过哈希函数获取待查找元素在哈希表中的位置。
-
看该位置的值是否是我们要查找的值,如果不是,从当前位置依次往后进行比较,找到就结束,如果遇到空还没有找到,说明当前待查找的元素不在哈希表中。
小Tips:这里简介反映出哈希表中的元素不能太满了,如果太满,那么它的查找效率有可能就变成了 O ( N ) O(N) O(N)。
删除:采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其它元素的搜索。比如上图中,删除元素24,如果直接删掉,54查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。
扩容:散列表的载荷因子定义为:
α = 填入表中的元素个数 / 散列表的长度 α = 填入表中的元素个数 / 散列表的长度 α=填入表中的元素个数/散列表的长度
α α α 是散列表装满成都的标志因子。由于表长是定值, α α α 与“填入表中的元素个数”成正比,所以, α α α 越大,表明填入表中的元素越多,产生冲突的可能性就越大,但是空间利用率越高;反之, α α α 越小,表明填入表中的元素越少,产生冲突的可能性就越小,但是空间浪费会比较多。实际上,散列表的平均查找长度是载荷因子 α α α 的函数,只是不同处理冲突的方式有不同的函数。
对于闭散列(开放定址法),载荷因子是特别重要的因素,应严格限制在 0.7 − 0.8 0.7-0.8 0.7−0.8以下。超过 0.8 0.8 0.8,查表时的 CPU 缓存不命中按照指数曲线上升。因此,一些曹勇开放定址法的 hash 库,如 Java 的系统库限制了载荷因子为 0.75,超过此值将 resize 散列表。
小Tips:扩容后,元素的映射关系会发生变化,所以我们需要重新建立映射,即重新计算元素对应的存储位置。原来冲突的,现在不一定冲突了,原来不冲突的,现在可能冲突了,因此扩容后需要对原来表中的元素重新走一遍插入逻辑。
3.4.1.2 闭散列(开放定址法)模拟实现
enum STATE
{EXIST,EMPTY,DELETE
};//存储元素的结点
template<class K, class V>
struct HashData
{pair<K, V> _kv;STATE _state = EMPTY;
};//哈希表
template<class K, class V>
class HashTable
{
public:HashTable(){_table.resize(10);}bool Insert(const pair<K, V>& kv){//检查负载因子,扩容/*if ((double)_n / _table.size() >= 0.7){}*/if (_n * 10 / _table.size() >= 7){size_t newsize = _table.size() * 2;//重新建立映射关系//vector<HashData<K, V>> tmp;//tmp.resize(newsize);//for (const auto& e : _table)//{// if (e._state == EXIST)// {// size_t hashi = e._kv.first % tmp.size();// while (tmp[hashi]._state == EXIST)// {// ++hashi;// //当hashi == size 的时候要让它从 0 开始继续找。// /*if (hashi >= _table.size())// {// hashi = 0;// }*/// hashi %= _table.size();// }// tmp[hashi] = e;// }// //}//std::swap(tmp, _table);HashTable<K, V> newHT;newHT._table.resize(newsize);//遍历旧表的数据插入到新表即可for (size_t i = 0; i < _table.size(); ++i){if (_table[i]._state == EXIST){newHT.Insert(_table[i]._kv);}}_table.swap(newHT._table);}//线性探测size_t hashi = kv.first % _table.size();//注意这里//如果下标为hashi的地方没有存元素,那么就可以直接在hashi进行插入//如果下标为hashi的地方存的有元素,就需要进行线性探测//EMPTY、DELETE都可存储元素while (_table[hashi]._state == EXIST){++hashi;//当hashi == size 的时候要让它从 0 开始继续找。/*if (hashi >= _table.size()){hashi = 0;}*/hashi %= _table.size();}//注意方括号访问,底层会去断言,下标必须小于size,所以上面模的是size。_table[hashi]._kv = kv;_table[hashi]._state = EXIST;++_n;return true;}HashData<const K, V>* Find(const K& key){//线性探测size_t hashi = key % _table.size();//注意这里//如果下标为hashi的地方没有存元素,那么就可以直接在hashi进行插入//如果下标为hashi的地方存的有元素,就需要进行线性探测//EMPTY、DELETE都可存储元素while (_table[hashi]._state != EMPTY){if (_table[hashi]._state == EXIST && _table[hashi]._kv.first == key){return (HashData<const K, V>*)&_table[hashi];//这里会涉及类型转化,有的编译器可能不支持,所以这里最好自己强转一下}++hashi;hashi %= _table.size();}return nullptr;}bool Erase(const K& key){HashData<const K, V>* ret = Find(key);if (ret){ret->_state = DELETE;--_n;return true;}return false;}
private:vector<HashData<K, V>> _table;size_t _n = 0;//因为数据是分散存储的,所以不能用vector中的size去计算哈希表中元素的数量,这个_n存储的就是哈希表中有效数据的个数
};
小Tips:线性探测的优点是:实现起来非常简单。缺点是:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。可以利用下面的二次探测来解决该问题。
3.4.1.3 二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为: H i H_i Hi = ( H 0 H_0 H0 + i 2 i^2 i2 )% m 或者: H i H_i Hi = ( H 0 H_0 H0 - i 2 i^2 i2 )% m。其中:i = 1,2,3…, H 0 H_0 H0是通过散列函数 Hash(x) 对元素的关键码 key 进行计算得到的位置,m是表的大小。
研究表明:当表的长度为质数且表装载因子 α α α 不超过 0.5 时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表满的情况,但在插入时必须确保表的装载因子 α α α 不超过 0.5,如果超出,必须考虑增容。因此,闭散列最大的缺陷局势空间利用率比较低,这也是哈希的缺陷。
3.4.2 开散列
开散列又叫拉链法,首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。

小Tips:从上图中可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
3.4.2.1 开散列模拟实现
template<class K, class V>
struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv = pair<K, V>()):_kv(kv),_next(nullptr){}};template<class K, class V, class HashFunc = DefaultHasFunc<K>>class HashTable{typedef HashNode<K, V> Node;private:void swap(HashTable<K, V, HashFunc>& hbt){std::swap(hbt._table, this->_table);std::swap(hbt._n, this->_n);}public:HashTable(size_t size = 10){_table.resize(size, nullptr);}//拷贝构造HashTable(const HashTable<K, V, HashFunc>& htb){_table.resize(htb._table.size());for (size_t i = 0; i < htb._table.size(); ++i){Node* cur = htb._table[i];while (cur){Insert(cur->_kv);cur = cur->_next;}}/* HashTable<K, V, HashFunc> tmp;tmp._table = htb._table;//这里现代写法行不通,因为_table里面存的是指针,属于内置类型,进行的是浅拷贝。tmp._n = htb._n;swap(tmp);*/}bool Insert(const pair<K, V>& kv){//HashFunc hf;//先检查哈希桶中是否有这个元素,有就不能插入if (Find(kv.first)){return false;}//不扩容,不断插入,某些桶会越来越长,效率得不到保证//因此还是需要进行适当的扩容//这里一般把负载因子控制在1//这样,在理想状态下,平均每个桶一个数据if (_n == _table.size()){//扩容 方法一:会去创建新节点,然后还要把旧结点释放,效率低下/*HashTable<K, V, HashFunc> newTable(_table.size() * 2);for (size_t i = 0; i < _table.size(); ++i){if (_table[i] != nullptr){Node* cur = _table[i];while (cur){newTable.Insert(cur->_kv);cur = cur->_next;}}}_table.swap(newTable._table);*///扩容 方法二:vector<Node*> newtable;newtable.resize(_table.size() * 2, nullptr);for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t hashi = hf(cur->_kv.first) % newtable.size();cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}size_t hashi = hf(kv.first) % _table.size();//检查当前桶里面是否已经有该元素Node* cur = _table[hashi];while (cur){if (cur->_kv.first == kv.first){return false;}cur = cur->_next;}//到这里说明当前桶里没有该元素,可以插入Node* newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;}//打印哈希桶void Print(){for (size_t i = 0; i < _table.size(); ++i){printf("Hash[%d]:", i);Node* cur = _table[i];while (cur){cout << cur->_kv.first << ':' << cur->_kv.second << "--->";cur = cur->_next;}cout << "nullptr" << endl;}}//查找Node* Find(const K& key){size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}//删除bool erase(const K& key){size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur){if (cur->_kv.first == key){if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;cur = nullptr;--_n;return true;}prev = cur;cur = cur->_next;}return false;}~HashTable(){for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}private:vector<Node*> _table;//指针数组//这里的_table属于自定义类型,如果我们不写析构函数,编译器会去调用vector自己的析构函数//对于vector的析构函数来说,Node* 是一个指针,属于内置类型//因此vector的析构函数不会对 Node* 做任何处理//因此这里我们需要自己写析构函数,去释放哈希桶中的结点size_t _n = 0;//记录存储的有效数据个数HashFunc hf;};
四、模拟实现 unordered_set 和 unordered_map
4.1 哈希表的改造
这里我们使用开散列的方法来实现 unordered_set 和 unordered_map。
4.1.1 模板参数列表的改造
//哈希表
template<class K, class T, class KeyOfT, class HashFunc = DefaultHasFunc<K>>//K的作用是为了方便查找和删除
class HashTable
小Tips:
-
K:关键码类型。
-
T:不同容器 T 的类型不同,如果是
unordered_map,T 代表一个键值对,如果是unordered_set,V 为 K。 -
KeyOfT:因为 T 的类型不同,通过 value 取 key 的方式就不同,详细代码参考下面
unordered_set/map的实现。 -
HashFunc:哈希函数仿函数对象类型,哈希函数使用除留余数法,需要将 key 转换为整形数字才能取模。
4.1.2 增加迭代器操作
//HashTable.h
//哈希桶的迭代器template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc>struct HTIterator{typedef HashNode<T> Node;typedef HTIterator<K, T, Ptr, Ref, KeyOfT, HashFunc> Self;typedef HashTable<K, T, KeyOfT, HashFunc> Ht;typedef HTIterator<K, T, T*, T&, KeyOfT, HashFunc> iterator;Node* _node;const Ht* _pht;HTIterator(Node* node = nullptr, const Ht* pht = nullptr):_node(node),_pht(pht){}HTIterator(const iterator& it)//如果是普通迭代器,这里就是拷贝构造函数:_node(it._node) //如果是 const 迭代器,这里就是用一个普通迭代器来构造一个 const 迭代器。, _pht(it._pht){}Self& operator++(){if (_node->_next){_node = _node->_next;}else{//如果_node->_next == nullptr//说明要到下一个桶去,因此迭代器类里面需要一个哈希表的指针,指向当前迭代器维护的哈希表//这样才能找到下一个桶//先找到我当前在那个桶KeyOfT kot;HashFunc hf;size_t hashi = hf(kot(_node->_data)) % _pht->_table.size();//从下一个位置开始查找下一个不为空的桶++hashi;while (hashi < _pht->_table.size()){if (_pht->_table[hashi]){_node = _pht->_table[hashi];return *this;}else{++hashi;}}_node = nullptr;}return *this;}bool operator != (const Self& s) const{return _node != s._node;}Ref operator*() const{return _node->_data;}Ptr operator->() const{return &(_node->_data);}};
小Tips:因为哈希表本质上是由一个个哈希桶组成,迭代器走完当前桶,需要跳到下一个桶,迭代器要能指向下一个哈希桶,最简单的做法就是在迭代器里面存一份哈希表。实际代码中我们在迭代器中增加了一个哈希表类型的指针,指向当前迭代器维护的哈希表,又因为该指针会去访问哈希表里面的成员变量数组,所以该迭代器类必须是哈希表的友元类,关于友元类的具体声明参考下面修改后的哈希表。这里还有一个问题,迭代器里面使用了哈希表类型,哈希表里面又实用的迭代器类型,这里就会涉及到谁先谁后的问题,我这里的解决方法是将迭代器类定义在哈希表的前面,然后在迭代器的前面对哈希表的类做一个前置声明。其次,因为哈希桶在底层是单链表结构,所以哈希桶的迭代器不需要 - - 操作。
4.1.3 修改后的哈希表
//HashTable.h
//哈希表template<class K, class T, class KeyOfT, class HashFunc = DefaultHasFunc<K>>//K的作用是为了方便查找和删除class HashTable{//模板的友元template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc>friend struct HTIterator;typedef HashNode<T> Node;private:void swap(HashTable<K, T, HashFunc>& hbt){std::swap(hbt._table, this->_table);std::swap(hbt._n, this->_n);}public:typedef HTIterator<K, T, T*, T&, KeyOfT, HashFunc> iterator;typedef HTIterator<K, T, const T*, const T&, KeyOfT, HashFunc> const_iterator;iterator begin(){//找第一个桶for (size_t i = 0; i < _table.size(); ++i){if (_table[i]){return iterator(_table[i], this);}}return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}const_iterator begin() const{//找第一个桶for (size_t i = 0; i < _table.size(); ++i){if (_table[i]){return const_iterator(_table[i], this);}}return const_iterator(nullptr, this);}const_iterator end() const{return const_iterator(nullptr, this);}HashTable(size_t size = 10){_table.resize(size, nullptr);}//拷贝构造HashTable(const HashTable<K, T, HashFunc>& htb){_table.resize(htb._table.size());for (size_t i = 0; i < htb._table.size(); ++i){Node* cur = htb._table[i];while (cur){Insert(cur->_data);cur = cur->_next;}}/* HashTable<K, T, HashFunc> tmp;tmp._table = htb._table;//这里现代写法行不通,因为_table里面存的是指针,属于内置类型,进行的是浅拷贝。tmp._n = htb._n;swap(tmp);*/}pair<iterator, bool> Insert(const T& data){HashFunc hf;KeyOfT kt;//HashFunc hf;//先检查哈希桶中是否有这个元素,有就不能插入if (Find(kt(data)) != end()){return make_pair(Find(kt(data)), false);}//扩容if (_n == _table.size()){vector<Node*> newtable;newtable.resize(_table.size() * 2, nullptr);for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t hashi = hf(kt(cur->_data)) % newtable.size();cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}size_t hashi = hf(kt(data)) % _table.size();//到这里说明当前桶里没有该元素,可以插入Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return make_pair(iterator(newnode, this), true);}//查找iterator Find(const K& key)const{HashFunc hf;KeyOfT kt;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];while (cur){if (kt(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}return iterator(nullptr, this);}//删除bool erase(const K& key){HashFunc hf;KeyOfT kt;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur){if (kt(cur->_data) == key){if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;cur = nullptr;--_n;return true;}prev = cur;cur = cur->_next;}return false;}~HashTable(){for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}private:vector<Node*> _table;//指针数组//这里的_table属于自定义类型,如果我们不写析构函数,编译器会去调用vector自己的析构函数//对于vector的析构函数来说,Node* 是一个指针,属于内置类型//因此vector的析构函数不会对 Node* 做任何处理//因此这里我们需要自己写析构函数,去释放哈希桶中的结点size_t _n = 0;//记录存储的有效数据个数};
小Tips:哈希表的修改主要体现在增加通过 key 获取 value 的操作。
4.2 unordered_set 模拟实现
//unorderedset.h
#include "HashTable.h"template<class K, class HashFunc = DefaultHasFunc<K>>
class unordered_set
{
private:struct SetKeyOfT{const K& operator()(const K& key){return key;}};
public:typedef typename HashTable<K, K, SetKeyOfT, HashFunc>::const_iterator iterator;typedef typename HashTable<K, K, SetKeyOfT, HashFunc>::const_iterator const_iterator;iterator begin() const{return _ht.begin();}iterator end() const{return _ht.end();}pair<iterator, bool> insert(const K& key){/*pair<typename HashTable<K, K, SetKeyOfT, HashFunc>::iterator, bool> ret = _ht.Insert(key);return make_pair(iterator(ret.first._node, ret.first._pht), ret.second);*/return _ht.Insert(key);//这种写法如果编译器检查的严格可能过不了//上面两种插入方法都可以,这一块是精华,好好品味}K& operator[](const K& key){pair<typename HashTable<K, K, SetKeyOfT, HashFunc>::iterator, bool> ret = _ht.Insert(key);return *(ret.first);}private:HashTable<K, K, SetKeyOfT, HashFunc> _ht;
};
小Tips:unordered_set 是一种 key 结构,所以它的普通迭代器和 const 迭代器都是不允许被修改的。因此 unordered_set 中的普通迭代器本质上还是 HashTable 中的 const 迭代器。此时就会出现一个问题,插入调用的是 HashTable 中的 Insert,其返回值是一个 pair,其中 first 是一个普通迭代器,而在 unordered_set 这一层,insert 的返回值也是一个 pair,它的 first 看起来是一个普通迭代器,但本质上是用 HashTable 中的 const 迭代器进行封装的,因此这里涉及到从普通迭代器转换成 const 迭代器,随然普通迭代器和 const 迭代器共用同一个类模板,但是它们的模板参数不同,所以普通迭代器和 const 迭代器本质上属于两种不同类型。因此要将一个普通迭代器转化成 const 迭代器本质上涉及类型转换。要用一个 A 类型的对象去创建一个 B 类型的对象 ,可以在 A 类里面增加一个构造函数,该构造函数的参数是 B 类型。因此,这里我们需要在迭代器类里面增加一个用普通迭代器构造 const 迭代器的构造函数。除了这种方法外,上面我还提供了一种方法,即先用 HashTable 中的普通迭代器创建一个 pair 对象 ret 接收 HashTable 中 Insert 的返回值,然后再去取出 pair 里面迭代器中的成员变量,用取出来的成员变量去构造一个 const 迭代器,然后再用这个 const 迭代器去构建一个 pair,最后返回这个 pair。这种方法的前提是迭代器类中的成员变量是 public,否则就不能再迭代器类的外面拿到其成员变量。
4.3 unordered_map 模拟实现
template<class K, class V, class HashFunc = DefaultHasFunc<K>>
class unordered_map
{
private:struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};
public:typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, HashFunc>::iterator iterator;typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, HashFunc>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator begin() const{return _ht.begin();}const_iterator end() const{return _ht.end();}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}
private:HashTable<K, pair<const K, V>, MapKeyOfT, HashFunc> _ht;
};
小Tips:对 unordered_map 结构来说无论是普通迭代器还是 const 迭代器,它的 key 永远都不能被修改。这里的解决方案是在 unordered_map 中用 pair<cons K, V> 去实例化出一个哈希表的模板,此时哈希表的节点中存的就是 pair<const K, V> _data;,此时无论是普通迭代器还是 const 迭代器去解引用该结点,返回的 _data,它里面的 key 是 const K 类型,是不支持修改的,这样以来问题就解决了。由于这里我们是用 pair<cons K, V> 去实例化的模板,所以 unordered_map 中的哈希表本质上存的就是 pair<cons K, V>,但是在用户层我们插入的是 pair<K, V>,这是两种不同的类型,和上面的普通迭代去创建 const 迭代器一样,这里还是需要通过构造函数来解决,但是这里不需要我们自己来解决,因为 pair 是库中的内容,库中已经帮我们实现好啦,所以这里我们无需做任何处理。这里本质上会去调用下面这个构造函数。

五、结语
今天的分享到这里就结束啦!如果觉得文章还不错的话,可以三连支持一下,春人的主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是春人前进的动力!

相关文章:
【C++杂货铺】一文带你走进哈希:哈希冲突 | 哈希函数 | 闭散列 | 开散列
文章目录 一、unordered 系列关联式容器二、unordered_map1.1 unordered_map 介绍1.2 unordered_map 的接口说明1.2.1 unordered_map 的构造1.2.2 unordered_map 的容量1.2.3 unordered_map 的迭代器1.2.4 unordered_map 的元素访问1.2.5 unordered_map 的查询1.2.6 unordered_…...

docker 搭建本地Chat GPT
要在CentOS7上安装Docker,您可以按照以下步骤进行操作: 1、更新系统包列表 sudo yum update2、安装Docker存储库的必要软件包 sudo yum install -y yum-utils device-mapper-persistent-data lvm23、添加Docker存储库 sudo yum-config-manager --add…...
电脑怎么剪辑视频?高手分享的独家秘诀
视频剪辑是一项有趣而具有创造性的活动,可以帮助您将录制的视频片段转化为有趣、有启发性的作品。无论您是想创建家庭影片、Vlog视频、教程,还是其他任何类型的视频,掌握视频剪辑技巧都是必要的。那电脑怎么剪辑视频呢?在本篇文章…...

LCR 171.训练计划 V
题目来源: leetcode题目,网址:LCR 171. 训练计划 V - 力扣(LeetCode) 解题思路: 双指针。node1 指向headA,node2 指向headB,将两节点每次移动一个节点直至两指针指向同一节点或…...

CH6-中断和异常处理
6.1 中断和异常处理概述 中断和异常概述(INTERRUPT AND EXCEPTION OVERVIEW) 中断和异常向量:中断和异常在处理器中都有对应的编号,被称为向量。当中断或异常发生时,处理器会根据向量找到相应的中断处理程序或异常处理…...

Hive的文件合并
背景:Flink数据写入到stage层,然后再入ods层,中间导致hive数据实时性不强,随后做优化,Flink之间以orc格式写入到hive 问题:单表日800亿数据量,产生过多的小文件,影响Impala查询 解决:对hive小文件进行合并, ALTER TABLE lt_ipsy_xdr_temp PARTITION (day20230829, hour9,type…...
Mac删除不在程序坞的程序
现象描述:删除某个程序时(通过‘程序’列表中将该应用移动到废纸篓里),该应用程序正在运行中,删除过程该程序未提示正在运行中,仅仅删除了图标(在此吐槽下该程序的交互,产品没有考虑…...

c#删除数组中符合条件的元素
错误写法 List<int> list new List<int>() { 1, 2, 3, 4 }; for (int i 0; i < sz; i){if (i 1 || i 2)list.RemoveAt(i);}在迭代过程中删除数组元素会有很大的问题,例如删除后位置移动,导致不该被删除的元素被删除。还可能导致数组…...

sqoop 脚本密码管理
1:背景 生产上很多sqoop脚本的密码都是铭文,很不安全,找了一些帖子,自己尝试了下,记录下细节,使用的方式是将密码存在hdfs上然后在脚本里用别名来替代。 2:正文 第一步:创建密码对…...
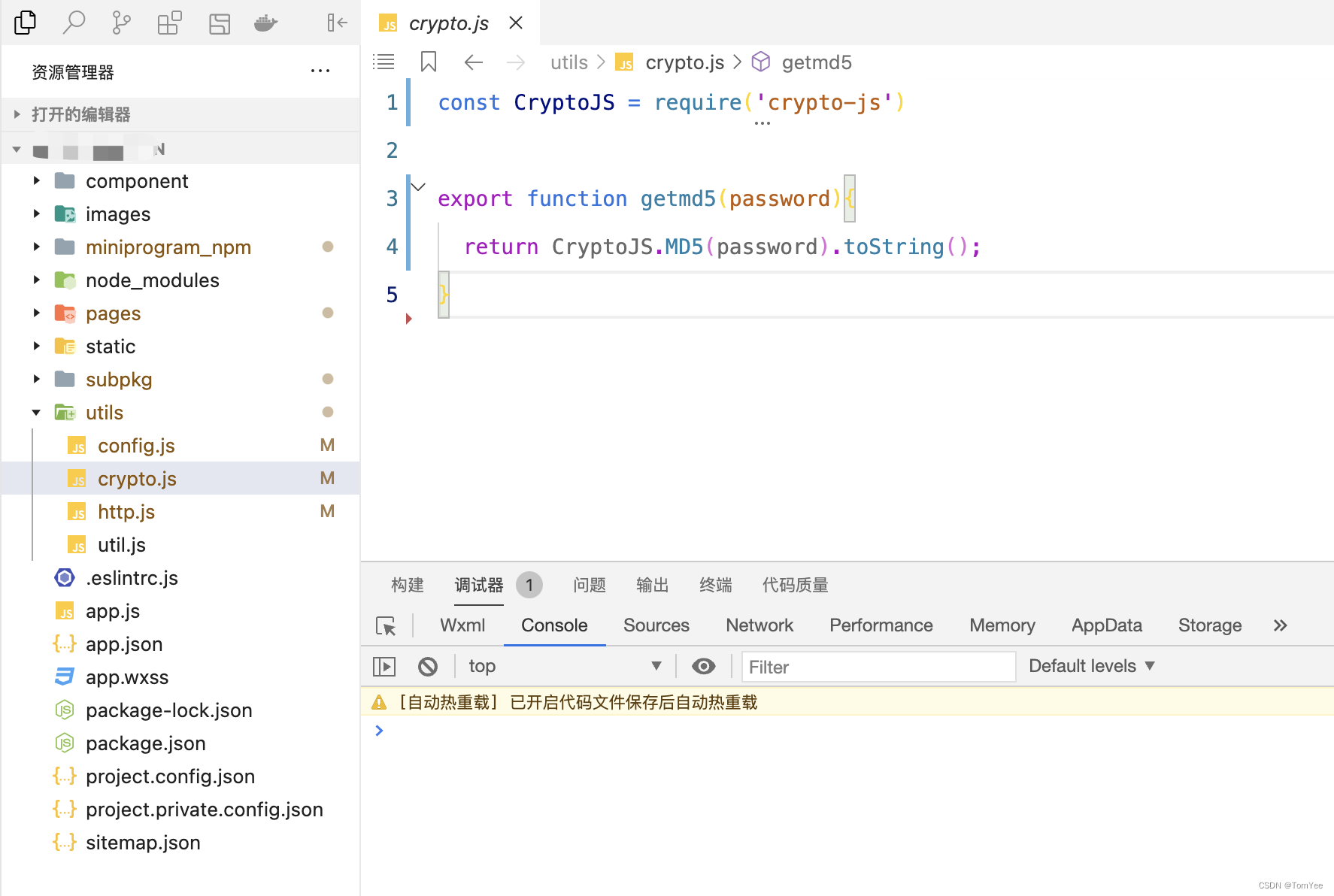
微信小程序使用CryptoJS加密PassWord(MD5)
微信小程序使用CryptoJS加密PassWord(MD5) 背景及环境: 微信小程序登录页面,需要加密登录密码发送给后端,使用 MD5 来加密密码 开发工具:微信开发者工具 npm安装CryptoJS 查看有哪些crypto的包 npm search crypto 找到自己需要的包…...

国有企业合同领域的合规管理
随着中国经济的快速发展和市场经济体制的完善,国有企业在国民经济中的地位和作用日益凸显。作为经济主体之一,国有企业必须积极适应市场环境的变化,加强合同管理,提高合规水平,以实现持续发展目标。本文将围绕国有企业…...

Joe主题魔改:正文内容实现图片懒加载
引言 有个哥们问我Joe主题的正文部分,如何同样图片懒加载,于是便研究了一下。 探索过程 因为PHP语言我用的很少,并不擅长,于是我去网上搜了一下。 方案一:用一个叫Jquery Lazyload的JavaScript脚本,我尝…...

网络爬虫实践小结
背景 近期工作中要解决两个问题,一个是数据组需要网爬一些图片数据,另外一个是要批量爬取公司用于文档协同的一个网站上的附件。于是乎,就写了两个脚本去完成任务。 爬虫思路 第一步:向确定的url发送请求,接收服务器…...

逍遥魔兽:如何在服务器上挂机器人?
逍遥魔兽是一款备受欢迎的魔兽世界经典版本,对于许多玩家来说,为了提升游戏体验和效率,他们希望能够在服务器上挂机器人。本文将为您详细讲解如何实现在逍遥魔兽服务器上挂机器人,以提高游戏进程的自动化效率。 第一部分&#x…...

软件工程与计算总结(九)软件体系结构基础
目录 编辑 一.体系结构的发展 二.理解体系结构 1.定义 2.区分体系结构的抽象与实现 3.部件 4.连接件 5.配置 三.体系结构风格初步 1.主程序/子程序 2.面向对象式 3.分层 4.MVC 一.体系结构的发展 小规模编程的重点在于模块内部的程序结构非常依赖于程序设计语言…...
bootz启动 Linux内核涉及do_bootm_linux 函数
一. bootz启动Linux uboot 启动Linux内核使用bootz命令。当然还有其它的启动命令,例如,bootm命令等等。 本文只分析 bootz命令启动 Linux内核的过程中涉及的几个重要函数。具体分析 do_bootm_linux函数执行过程。 本文继上一篇文章,地址…...
ipad有必要用手写笔吗?性价比电容笔排行榜
随着技术的进步,各种新型的数字电子产品不断涌现。比如说,智能手机、ipad、电容笔之类的东西。但事实上,要将iPad的功能发挥到极致,我认为,这款电容笔,就必不可少的了。这就好像我们在ipad平板上书写东西&a…...
jmeter怎样的脚本设计才能降低资源使用
官网地址:Apache JMeter - Users Manual: Best Practices 1、用好断言 频繁的使用断言会加大资源的消耗,尽可能减少断言的使用,或者在使用的过程中断言数据文本尽量精简,断言内容尽量以status/code、msg/message来判断࿰…...
如何避免 IDEA 每次重启都index
如何避免 IDEA 每次重启都index 在 IntelliJ IDEA 中,可以通过以下几个步骤来避免每次重启时索引: 打开 File -> Settings 菜单。在左侧的菜单栏中选择 “Appearance & Behavior” -> “System Settings” -> “Synchronization”。 在右…...

ImagePreview查看gif图,关闭之后原图不动了
vant的ImagePreview查看大图,当查看的是gif图的时候,关闭查看大图弹窗,原图不动了,ios上几乎必现。 解决的方案是,监听onclose事件,在关闭的时候把原图的gif图地址重新设置一下就好了 sceneImg(url: stri…...
)
从选型到设计:手把手教你根据7系列FPGA数据手册做项目选型(以Kintex-7为例)
从选型到设计:手把手教你根据7系列FPGA数据手册做项目选型(以Kintex-7为例) 在硬件系统设计中,FPGA选型往往决定着项目的成败。面对Xilinx 7系列丰富的产品线,工程师需要像外科医生选择手术器械一样精准——既要考虑当…...

录音会议纪要整理教程
无论是整理课堂录音复习、小组讨论纪要,还是调研访谈整理,很多新手都会陷入困扰:要么逐句听录耗时费力,要么转写内容错漏多、找不到重点。这篇零基础教程,步骤简洁易懂,看完可直接上手,帮你大幅…...

为什么你的 Multi-Agent 系统越加 Agent 越慢:并发与调度的反直觉陷阱
为什么你的 Multi-Agent 系统越加 Agent 越慢:并发与调度的反直觉陷阱 一、引言 钩子:90% 大模型开发者都踩过的性能悖论 你是否有过这样的经历:花了两周时间把单 Agent 的文档分析系统改造成多 Agent 协作架构,原本预期 5 个 Agent 能把处理速度提升 4 倍,结果上线后发…...

MifareOneTool完全指南:零基础掌握Windows最强NFC卡片管理工具
MifareOneTool完全指南:零基础掌握Windows最强NFC卡片管理工具 【免费下载链接】MifareOneTool A GUI Mifare Classic tool on Windows(停工/最新版v1.7.0) 项目地址: https://gitcode.com/gh_mirrors/mi/MifareOneTool 你是否曾经面对…...

赛事直播预告|高含金量智能车竞赛,邀你逐梦无人驾驶赛道!
简 介: 第二十一届全国大学生智能汽车竞赛创意组"智慧城市Robotaxi挑战赛"即将启动。作为教育部认可的A类国家级学科竞赛,赛事聚焦纯视觉无人驾驶技术,依托百度多模态能力与边缘AI算力,考验参赛者的视觉、语言、执行融合…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan集成详细攻略
2026年京东云OpenClaw/Hermes Agent配置Token Plan集成详细攻略。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

Elasticsearch聚合查询优化实战
Elasticsearch聚合查询优化实战 一、聚合查询概述 Elasticsearch的聚合功能是数据分析的核心,支持多种聚合类型来满足不同的分析需求。 1.1 聚合类型 类型说明使用场景Metric指标聚合求和、平均值、最大值、最小值Bucket桶聚合分组统计、区间统计Pipeline管道聚合基…...

MSP430F5438 RTC模块配置与低功耗应用实战指南
1. 项目概述与核心价值最近在整理一个老项目的资料,翻到了当年用TI的MSP430F5438做的一个数据记录仪。这个项目里,实时时钟(RTC)模块的稳定性和低功耗配置是关键,当时为了搞定它,可没少花功夫。今天就把关于…...

指纹浏览器用户行为模拟机制与平台风控识别对抗逻辑研究
一、行业发展现状与研究背景当下互联网平台风控体系已经完成从基础设备筛查到全维度行为研判的全面升级,早期依靠修改网络地址、更换登录设备就能规避限制的方式早已失去实际作用。各大内容平台、电商交易平台、社交互动平台均搭建起完善的用户行为数据模型…...

IDM激活脚本终极指南:如何免费锁定30天试用期无限使用
IDM激活脚本终极指南:如何免费锁定30天试用期无限使用 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script IDM Activation Script是一款开源工具…...