hive 知识总结
编辑
- 社区
- 公告
- 教程
- 下载
- 分享
- 问答
- JD
- 登 录 注册
01 hive 介绍与安装
1 hive介绍与原理分析
Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL(hiveSQL)语句作为数据访问接口。
1.1 hive的优缺点#
优点:
1)Hive 使用类SQL 查询语法, 最大限度的实现了和SQL标准的兼容,大大降低了传统数据分析人员处理大数据的难度
2)使用JDBC 接口,开发人员更易开发应用;
3)以MR 作为计算引擎、HDFS 作为存储系统,为超大数据集设计的计算/ 扩展能力;
4)统一的元数据管理(Derby、MySql等),并可与Pig 、spark等共享;
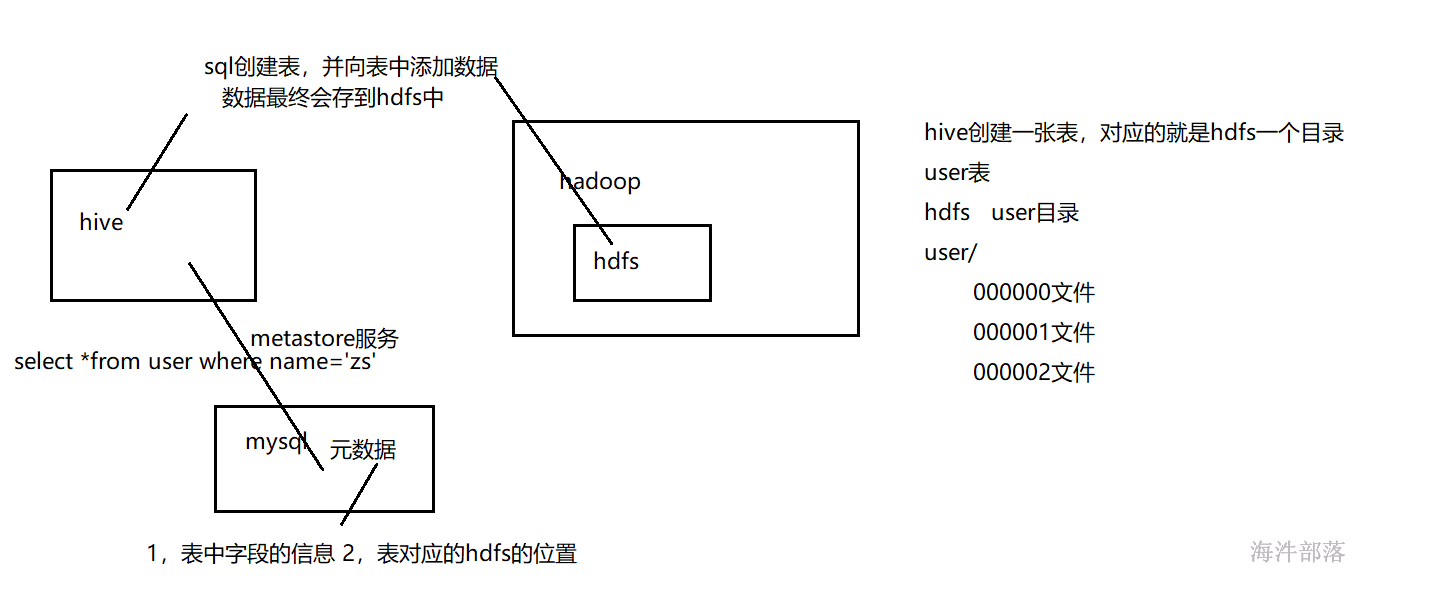
元数据:hive表所对应的字段、属性还有表所对应存储的HDFS目录。
缺点:
1)Hive 的HQL 表达的能力有限,比如不支持UPDATE、非等值连接、DELETE、INSERT单条等;
insert单条代表的是 创建一个文件。
2)由于Hive自动生成MapReduce 作业, HQL 调优困难;
3)粒度较粗,可控性差,是因为数据是读的时候进行类型的转换,mysql关系型数据是在写入的时候就检查了数据的类型。
4)hive生成MapReduce作业,高延迟,不适合实时查询。
1.2 与关系数据库的区别#
1)hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
2)hive使用mapreduce做运算,与传统数据库相比运算数据规模要大得多;
3)关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据统计分析的,实时性很差;实时性差导致hive的应用场景和关系数据库有很大的区别;
4)Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比Hive差很多。
| Hive | 关系型数据库 | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 执行 | MapReduce spark | 数据库引擎 |
| 数据存储校验 | 存储不校验 | 存储校验 |
| 可扩展性 | 强 | 有限 |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
1.3 hive架构#
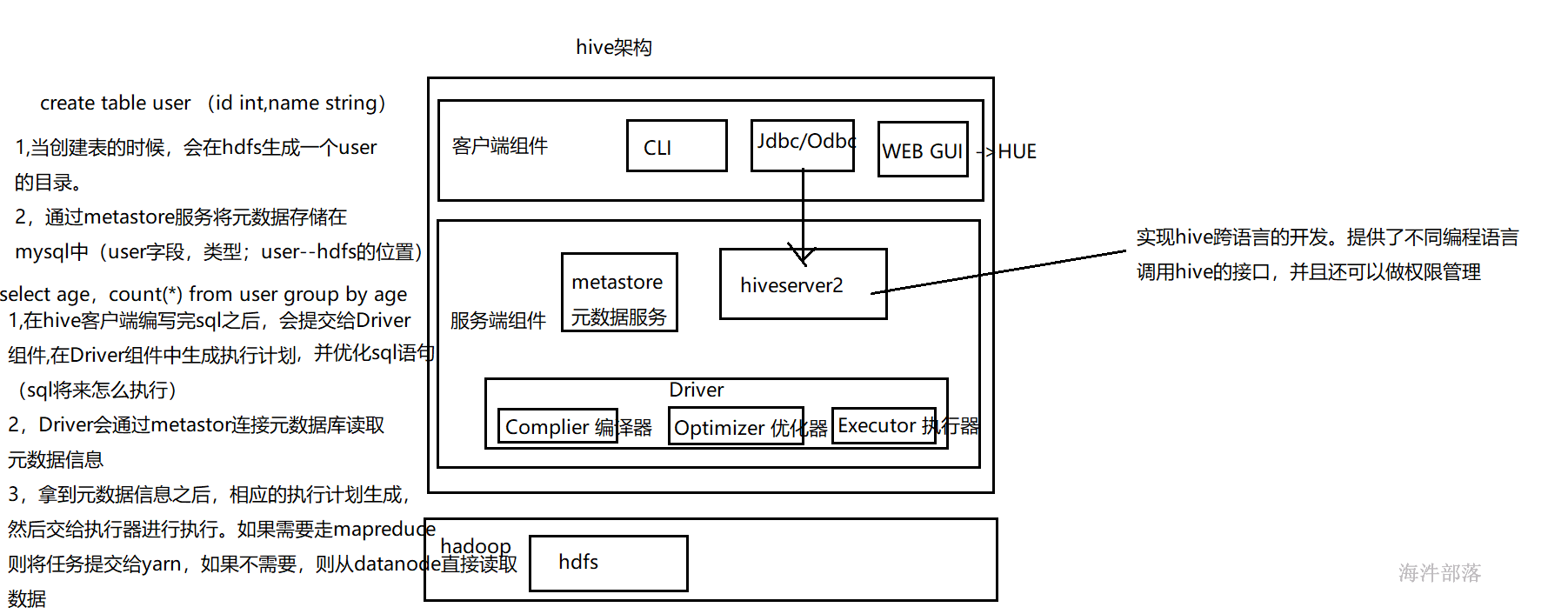
服务端组件:
Driver组件:该组件包括Complier(编译)、Optimizer(优化)和Executor(执行),它的作用是将HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架。
Metastore组件:元数据服务组件,这个组件存取Hive的元数据,Hive的元数据存储在关系数据库里,Hive支持的关系数据库有Derby和Mysql。作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。
HiveServer2服务:HiveServer2是Facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive的接口。还可以做权限管理。
客户端组件:
CLI:Command Line Interface,命令行接口。
JDBC/ODBC:Hive架构的JDBC和ODBC接口是建立在HiveServer2客户端之上。
WEBGUI:Hive客户端提供了一种通过网页的方式访问Hive所提供的服务。这个接口对应Hive的HWI组件(Hive Web Interface),使用前要启动HWI服务。
1.4 Hive查询的执行过程#
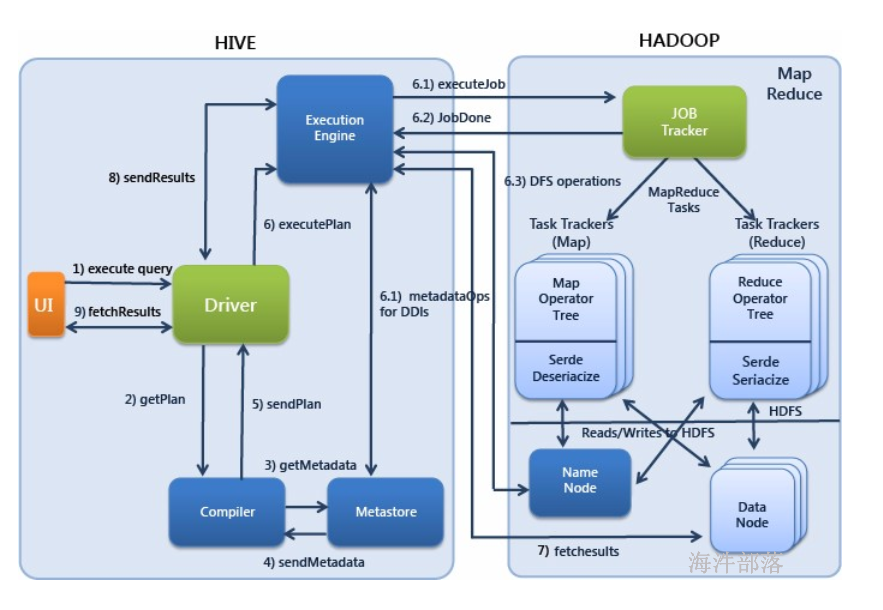
1)Execute Query:hive界面如命令行或Web UI将查询发送到Driver(任何数据库驱动程序如JDBC、ODBC,等等)来执行。
2)Get Plan:Driver根据查询编译器解析query语句,验证query语句的语法,查询计划或者查询条件。
3)Get Metadata:编译器将元数据请求发送给Metastore(数据库)。
4)Send Metadata:Metastore将元数据作为响应发送给编译器。
5)Send Plan:编译器检查要求和重新发送Driver的计划。到这里,查询的解析和编译完成。
6)Execute Plan:Driver将执行计划发送到执行引擎。
6.1)Execute Job:hadoop内部执行的是mapreduce工作过程,任务执行引擎发送一个任务到资源管理节点(resourcemanager),资源管理器分配该任务到任务节点,由任务节点上开始执行mapreduce任务。
6.1)Metadata Ops:在执行引擎发送任务的同时,对hive的元数据进行相应操作。
7)Fetch Result:执行引擎接收数据节点(data node)的结果。
8)Send Results:执行引擎发送这些合成值到Driver。
9)Send Results:Driver将结果发送到hive接口。
2 hive 安装
安装hive可以使用已经搭建好的hadoop集群,或者海牛实验室的公用hadoop组件
薪牛老师的hadoop完全分布式镜像环境http://cloud.hainiubl.com/#/privateImageDetail?id=2919&imageType=private,可以直接添加镜像使用。
2.1 在nn1节点上安装MYSQL#
下载地址:MySQL :: Download MySQL Community Server (Archived Versions)
# 由于网络原因,本课程采用离线安装方式
# 解压安装包mkdir -p /opt/tools/mysql
tar -xf mysql-5.7.22-1.el7.x86_64.rpm-bundle.tar -C /opt/tools/mysql# 删除系统自带的MySQL-libs
yum remove -y mysql-libs# 安装server时要依赖
yum install -y net-tools# 离线安装
rpm -vih /opt/tools/mysql/mysql-community-common-5.7.22-1.el7.x86_64.rpm
rpm -vih /opt/tools/mysql/mysql-community-libs-5.7.22-1.el7.x86_64.rpm
rpm -vih /opt/tools/mysql/mysql-community-client-5.7.22-1.el7.x86_64.rpm
rpm -vih /opt/tools/mysql/mysql-community-server-5.7.22-1.el7.x86_64.rpm
rpm -ivh /opt/tools/mysql/mysql-community-libs-compat-5.7.22-1.el7.x86_64.rpm# 启动MySQL
systemctl start mysqldsystemctl status mysqld
systemctl enable mysqld# cat /var/log/mysqld.log | grep password 查看初始化密码# 登录
mysql -uroot -p
# 输入初始化密码# 设置校验密码的长度
set global validate_password_policy=LOW;
# 修改密码
set password=PASSWORD('12345678');# 修改my.cnf,默认在/etc/my.cnf,执行:vim /etc/my.cnf,添加如下内容:
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character_set_server=utf8# 重启生效
systemctl restart mysqld
# 对外开放权限
set global validate_password_policy=LOW;
grant all privileges on *.* to 'root'@'%' identified by '12345678';
flush privileges;
2.2 安装hive#
1)root 用户上传并解压hive的tar包
#解压到/usr/local/目录下
tar -xzf apache-hive-3.1.3-bin.tar.gz -C /usr/local/
2)创建软链接
ln -s /usr/local/apache-hive-3.1.3-bin /usr/local/hive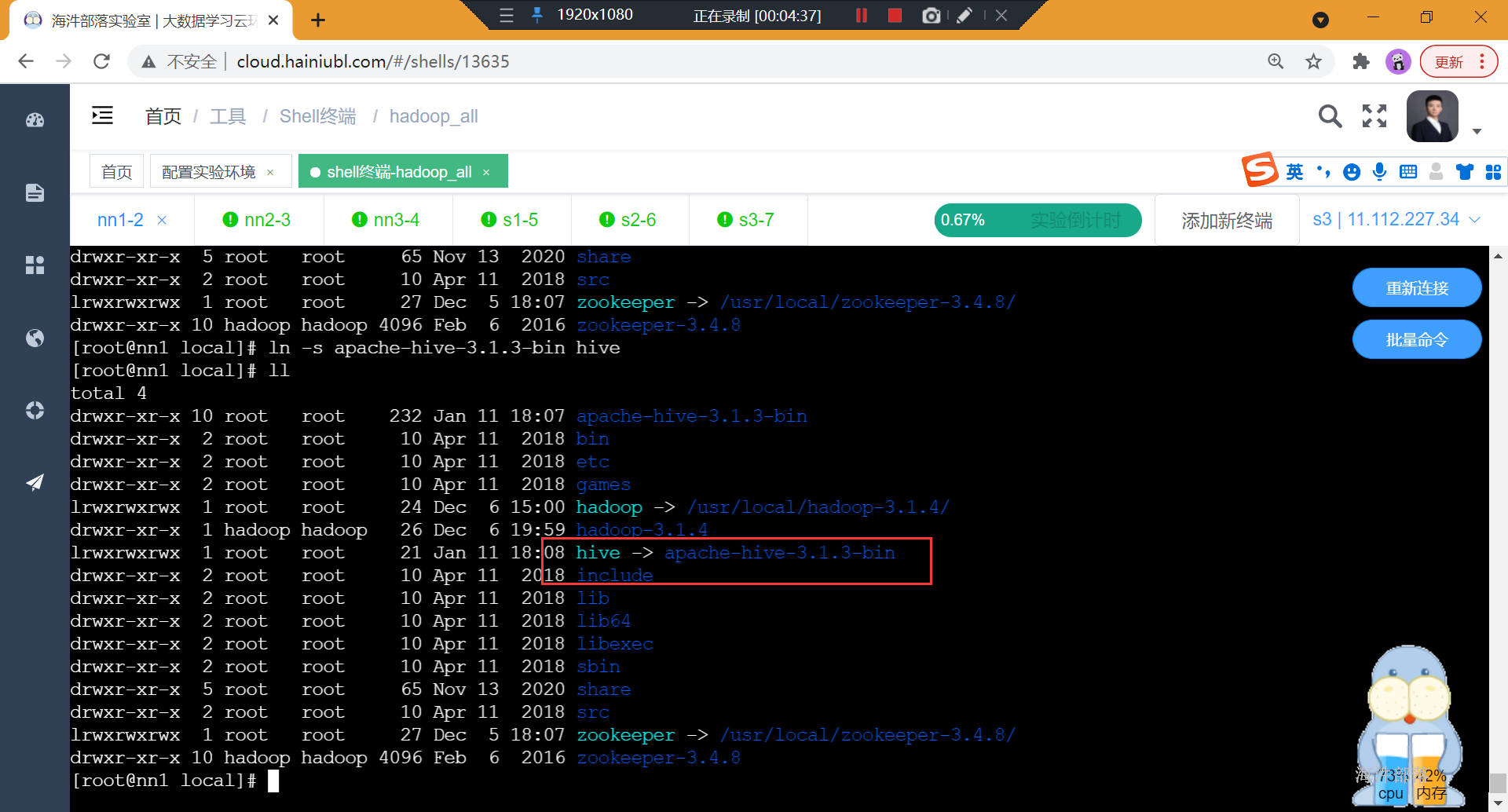
3)修改/usr/local/hive/apache-hive-3.1.3-bin目录所有者
chown -R hadoop:hadoop /usr/local/apache-hive-3.1.3-bin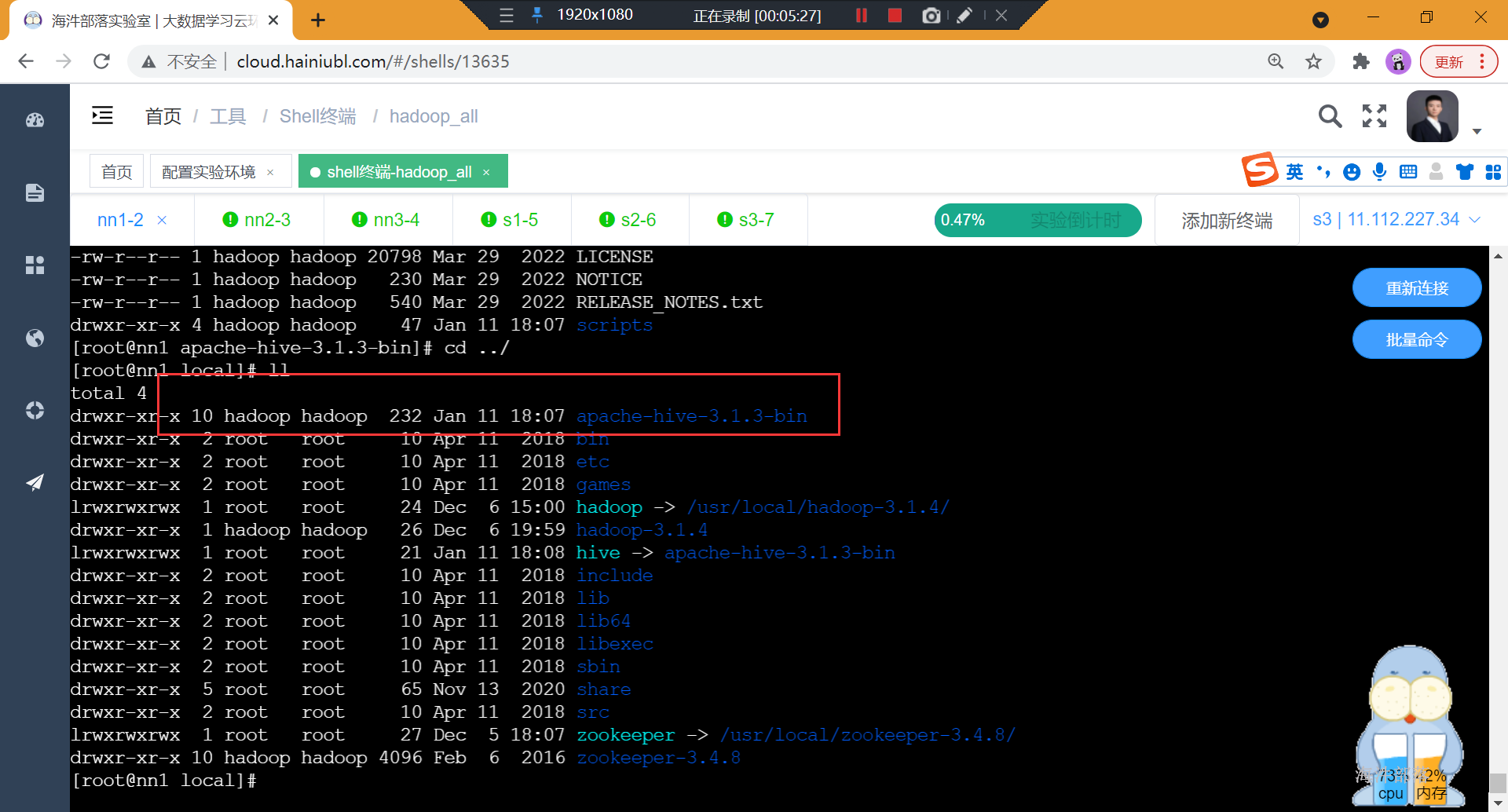
4)配置环境变量
增加HIVE_HOME和HIVE_CONF_DIR
export HIVE_HOME=/usr/local/hive
export HIVE_CONF_DIR=/usr/local/hive/conf
export PATH=$PATH:$HIVE_HOME/bin
#更新配置
source /etc/profile5)修改配置文件
切换到hadoop用户,拷贝/usr/local/hive/conf目录下的hive-default.xml.template改名为hive-site.xml
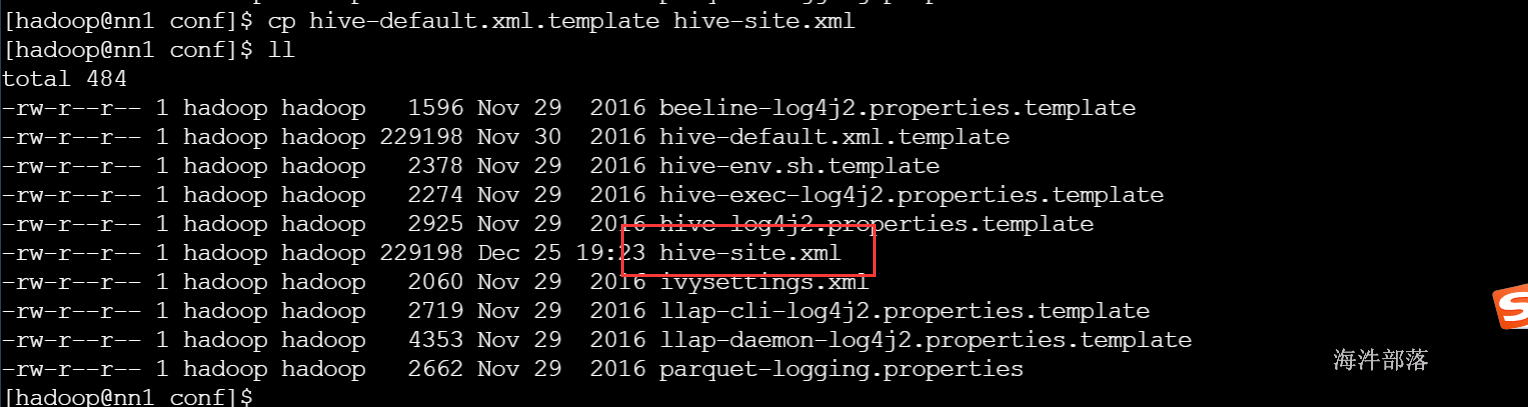
#拷贝配置文件
cp hive-default.xml.template hive-site.xml
#对hive-env.sh.template改名
mv hive-env.sh.template hive-env.sh
#对hive-log4j2.properties.template改名
mv hive-log4j2.properties.template hive-log4j2.properties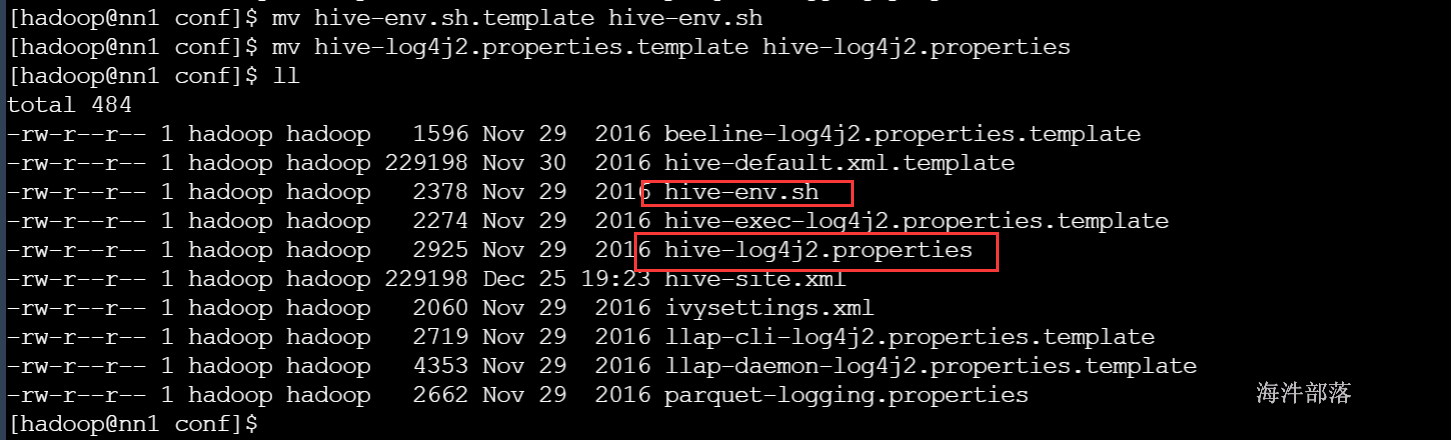
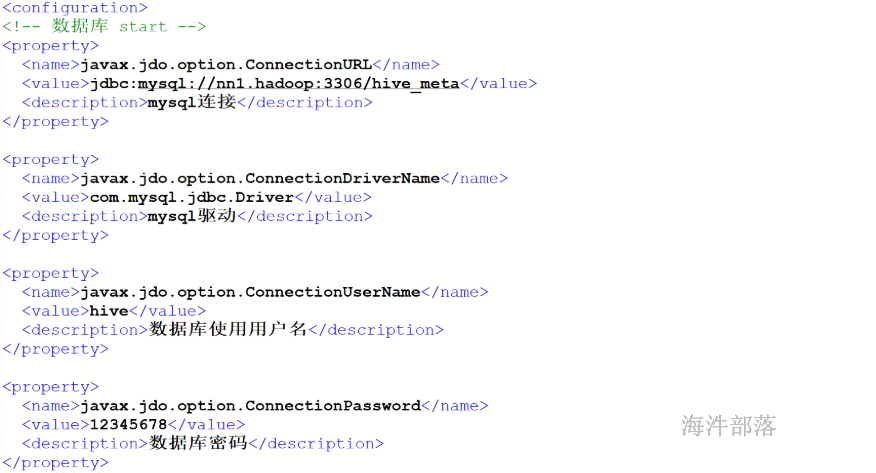
修改hive-site.xml
<configuration><!-- 数据库 start --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://nn1:3306/hive_meta?useSSL=false</value><description>mysql连接</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>mysql驱动</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>hive</value><description>数据库使用用户名</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>12345678</value><description>数据库密码</description></property><!-- 数据库 end --><property> <name>hive.metastore.warehouse.dir</name><value>/hive/warehouse</value><description>hive使用的HDFS目录</description></property><property> <name>hive.cli.print.current.db</name><value>true</value></property><!-- 其它 end -->
</configuration>
6)在mysql中创建hive用的数据库和hive用户
--登录mysql
mysql -uroot -p'12345678'
--创建hive用户
CREATE USER 'hive'@'%' IDENTIFIED BY '12345678';
--在mysql中创建hive_meta数据库
create database hive_meta default charset utf8 collate utf8_general_ci;
--给hive用户增加hive_meta数据库权限
grant all privileges on hive_meta.* to 'hive'@'%' identified by '12345678';
--更新
flush privileges; 7)拷贝mysql驱动jar 到/usr/local/hive/lib/
cp /public/software/database/mysql-connector-java-5.1.49.jar /usr/local/hive/lib/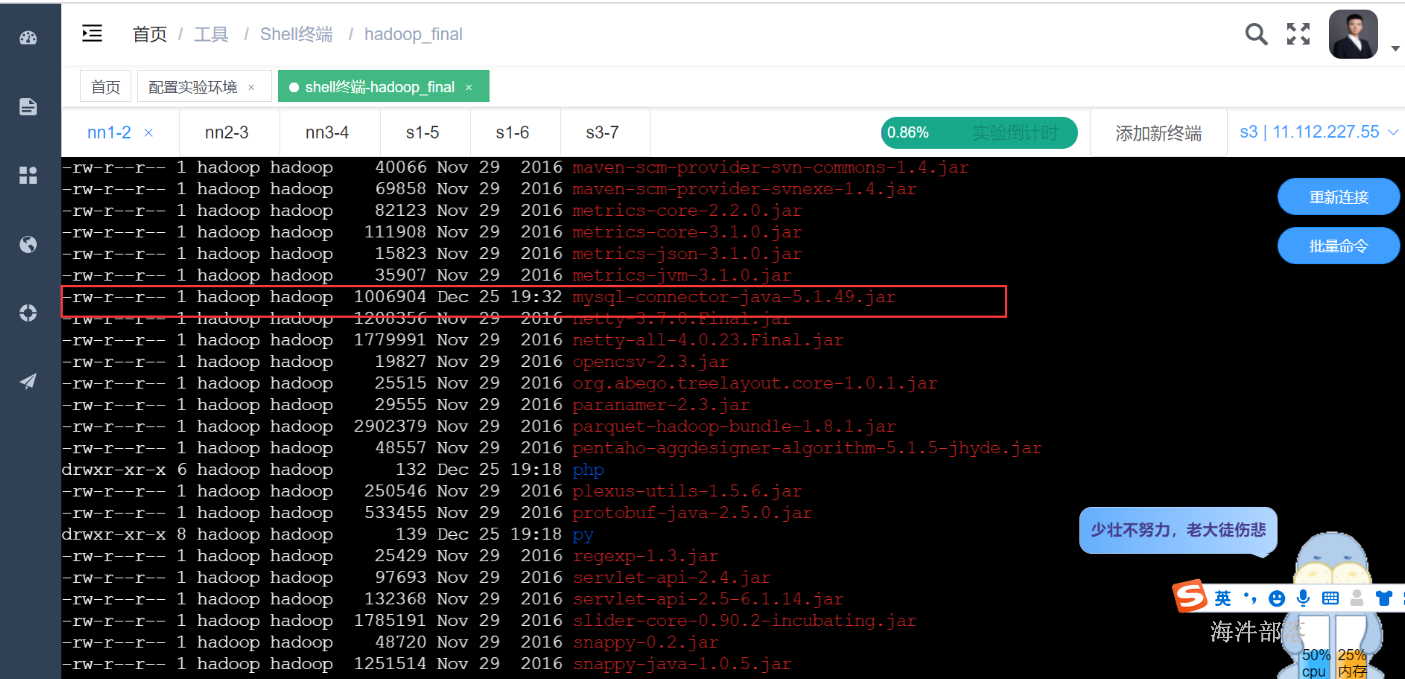
8)删除冲突的log4j
rm -f /usr/local/hive/lib/log4j-slf4j-impl-2.4.1.jar
9)hive初始化mysql
schematool -dbType mysql -initSchema
报错:
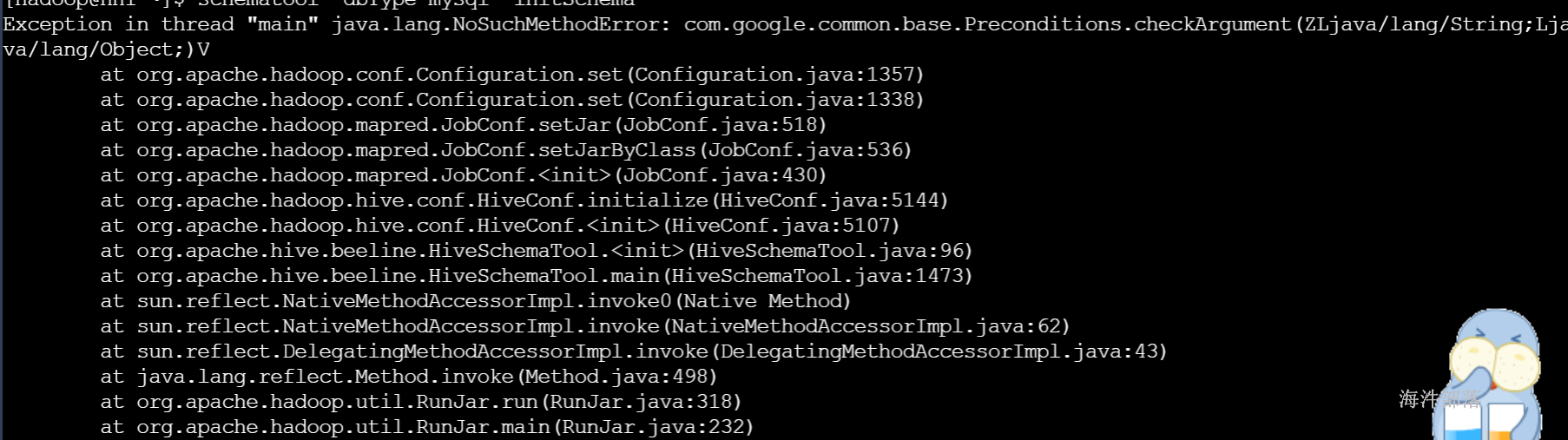
原因:查看该jar包在hadoop和hive中的版本信息

删除hive自带的guava jar包

rm -rf guava-19.0.jar
10)在客户端用hive用户 连接 hive的元数据库hive_meta
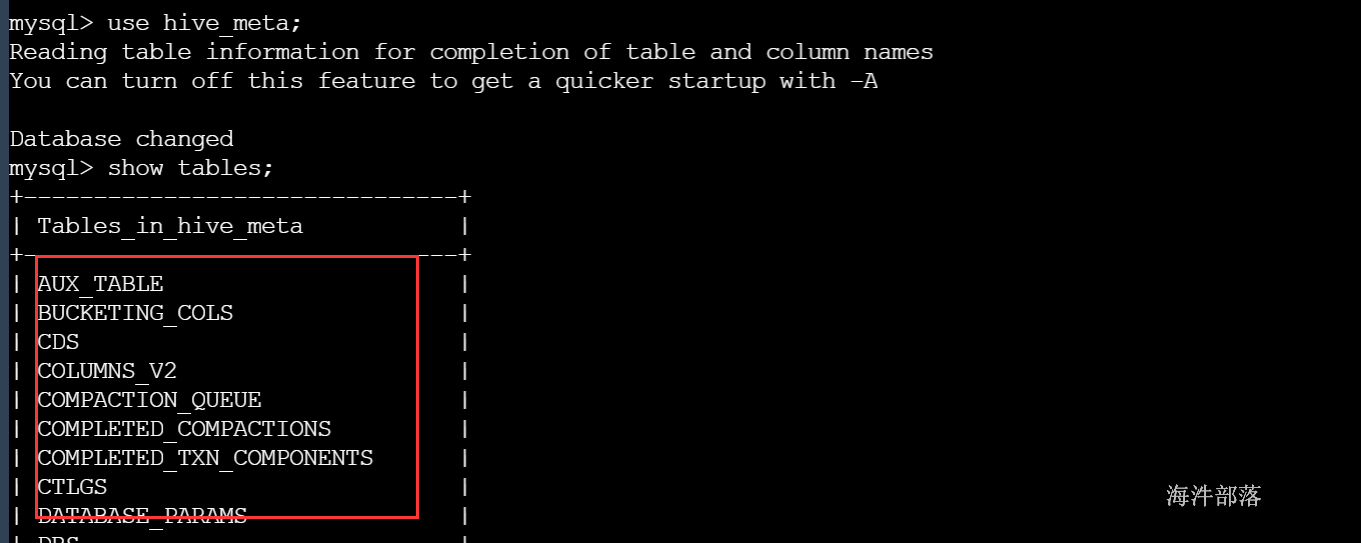
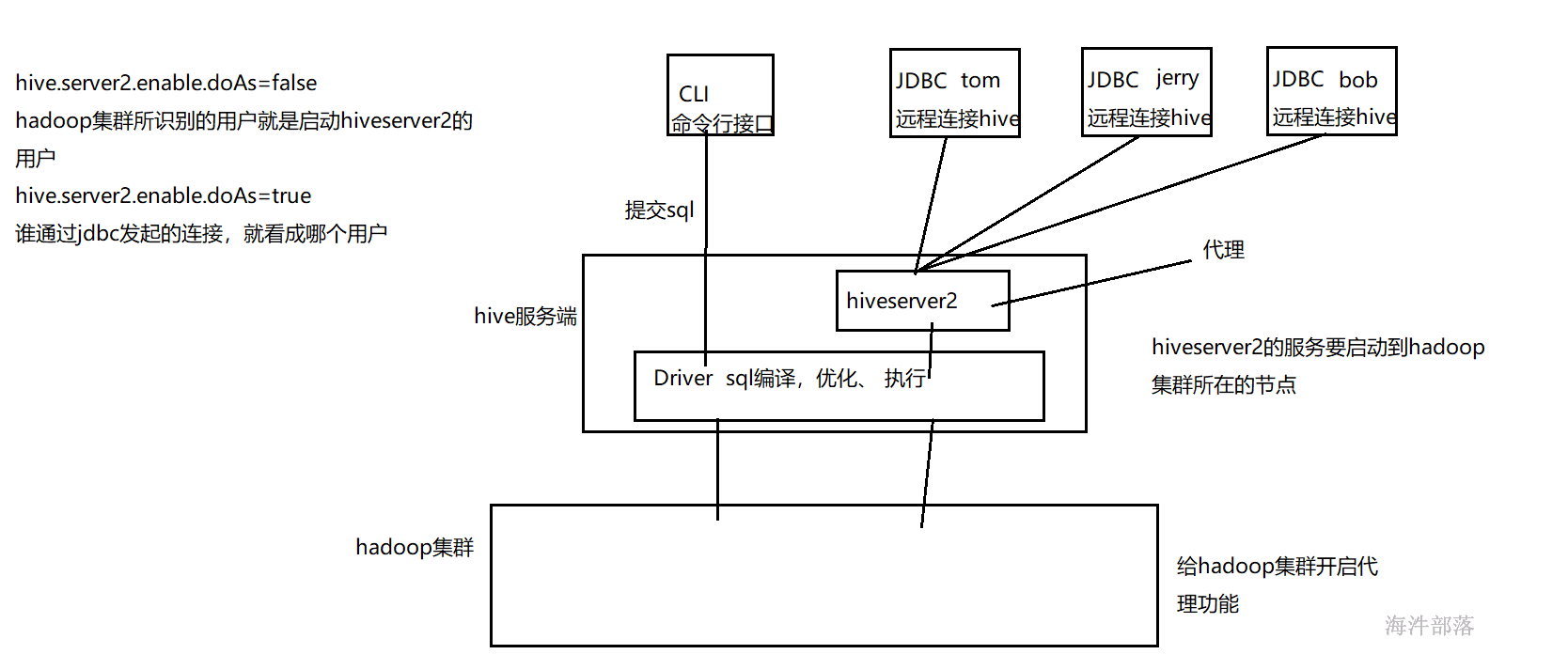
2.2.1 配置hiveserver2服务#
修改/usr/local/hadoop/etc/hadoop/core-site.xml 开启hadoop代理功能
<property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value><description>配置hadoop(超级用户)允许通过代理用户所属组</description>
</property>
<property><name>hadoop.proxyuser.hadoop.hosts</name><value>nn1</value><description>配置hadoop(超级用户)允许通过代理访问的主机节点</description>
</property><property><name>hadoop.proxyuser.hadoop.users</name><value>*</value></property>修改hive-site.xml 添加hiveserver2服务
<property><name>hive.server2.thrift.bind.host</name><value>nn1</value><description>hive开启的thriftServer地址</description></property><property><name>hive.server2.thrift.port</name><value>10000</value><description>hive开启的thriftServer端口</description></property><property><name>hive.server2.enable.doAs</name><value>true</value></property>启动hiveserver2服务
nohup hiveserver2 >/dev/null 2>&1 &
通过beeline方式连接hive
beeline -u jdbc:hive2://nn1:10000 -n hadoop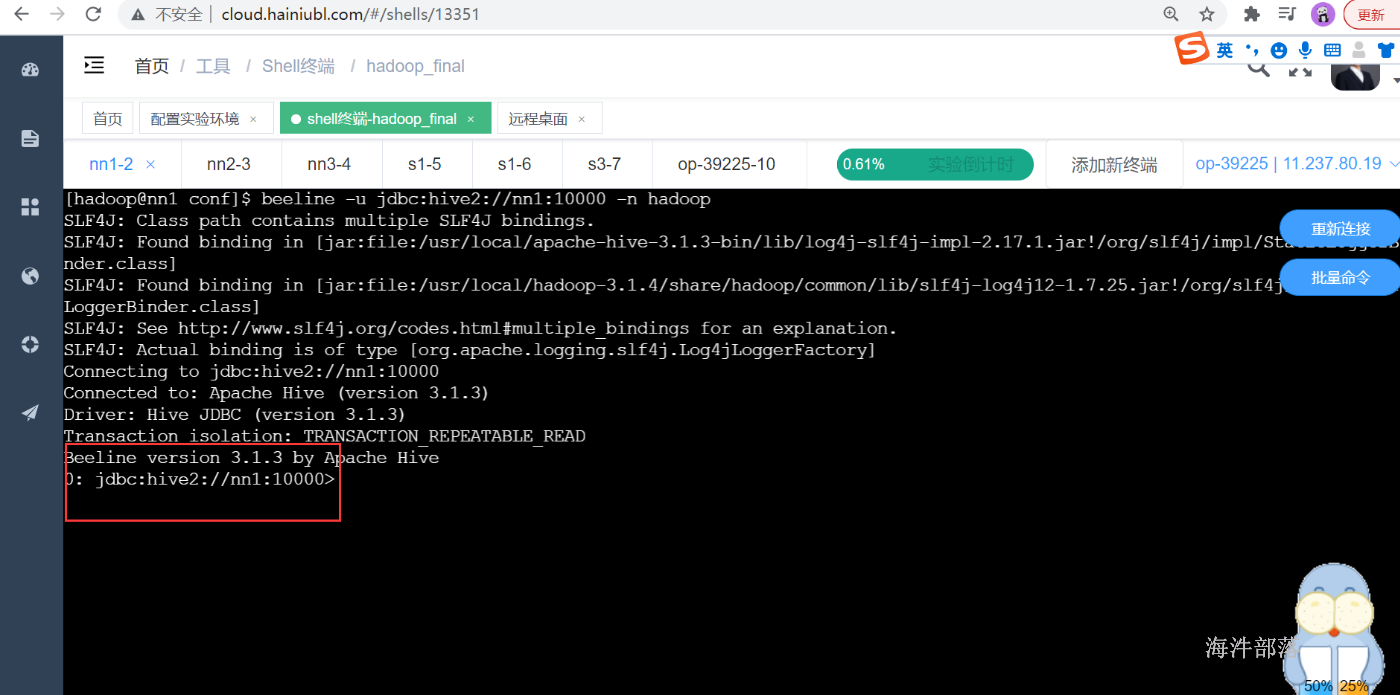
2.2.2 配置metastore服务#
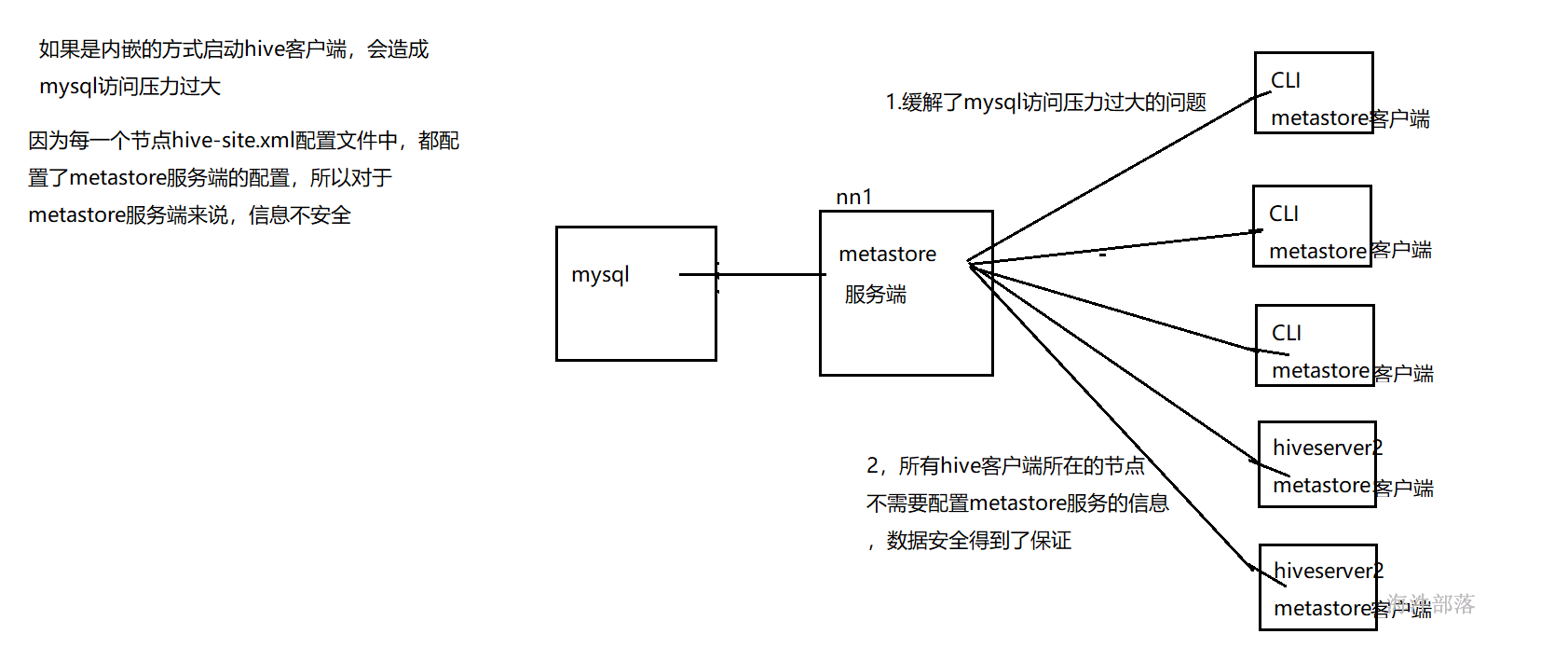
默认hive cli和hiveserver2服务内嵌了metastore服务,可以直接连接mysql数据库,但是如果连接过多会造成mysql数据库压力过大,(一般练习时可以使用).另外对于metastore服务来说不安全,因为所有的配置信息在配置文件中都能看到。
在企业中我们可以采用metastore服务单独的方式来进行设计
在nn2上配置metastore的客户端
<property><name>hive.metastore.uris</name><value>thrift://nn1:9083</value></property>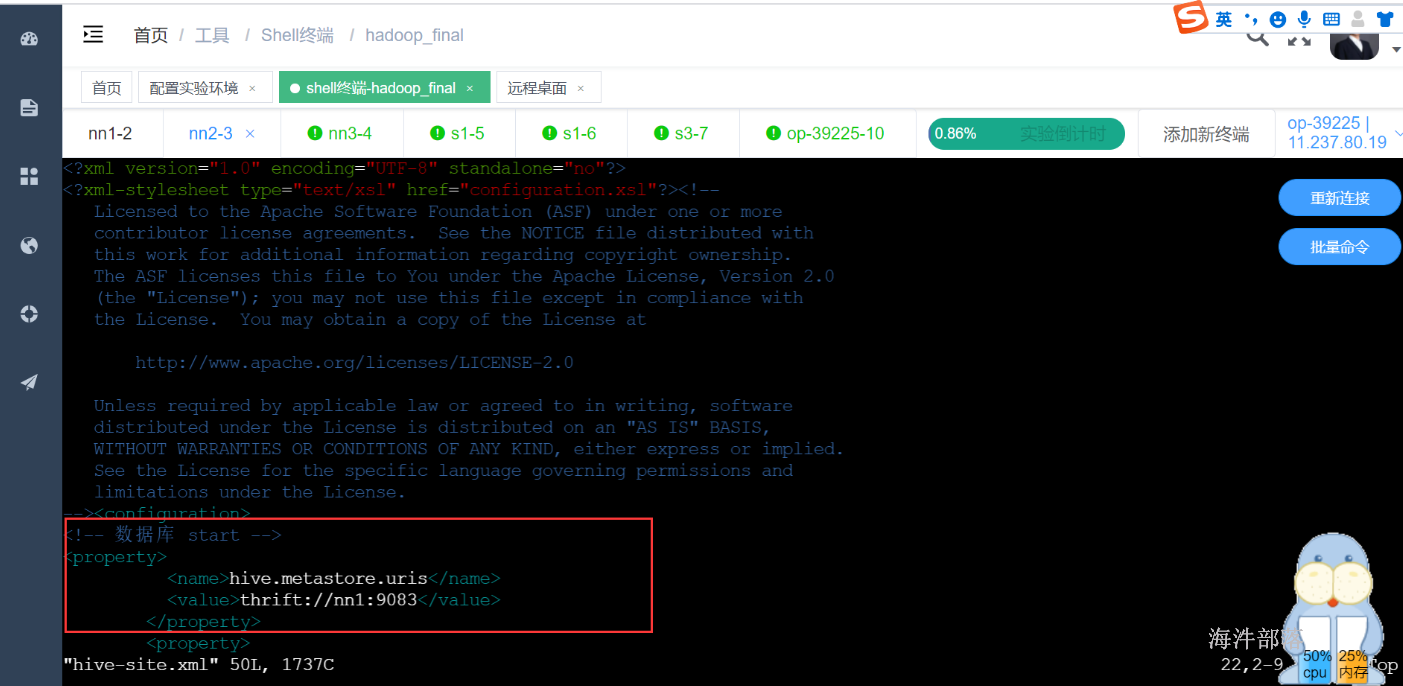
在nn1上启动metastore服务
nohup hive --service metastore > /dev/null 2>&1 &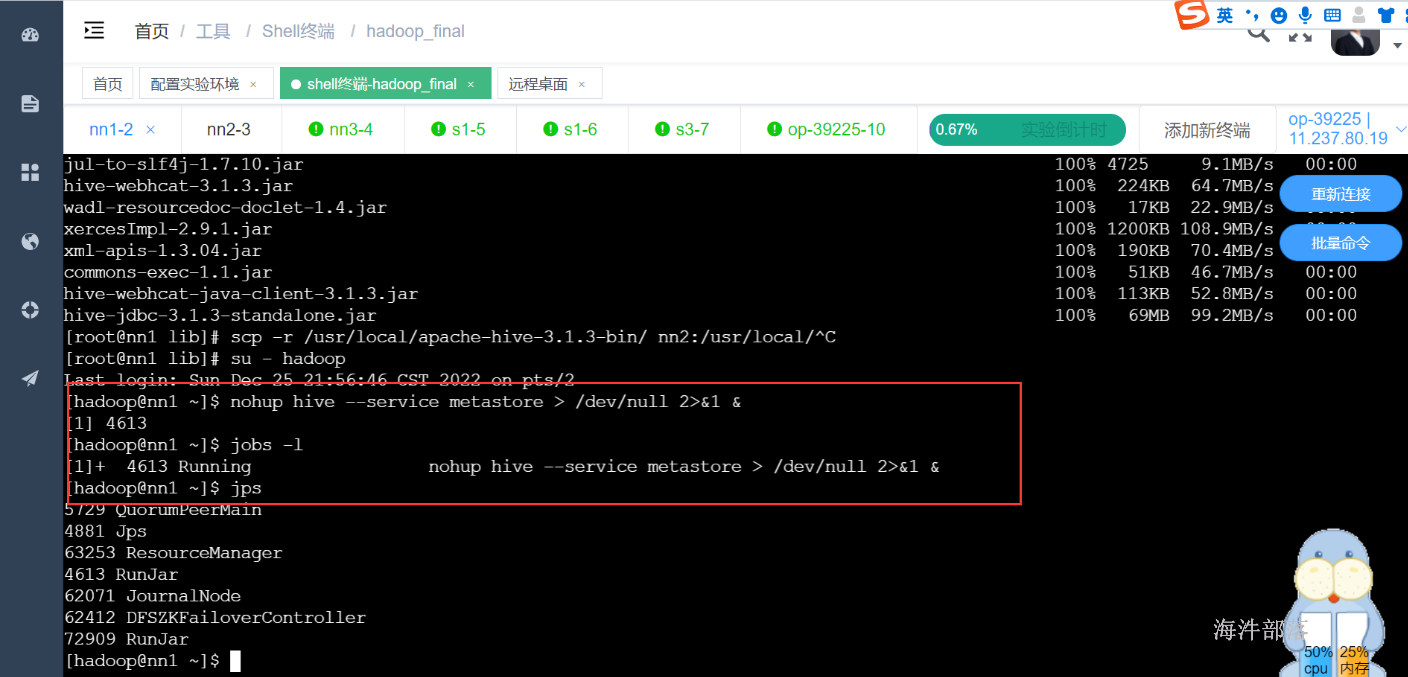
在nn2通过hive cli连接到hive执行命令,发现可以成功查看数据库并创建表
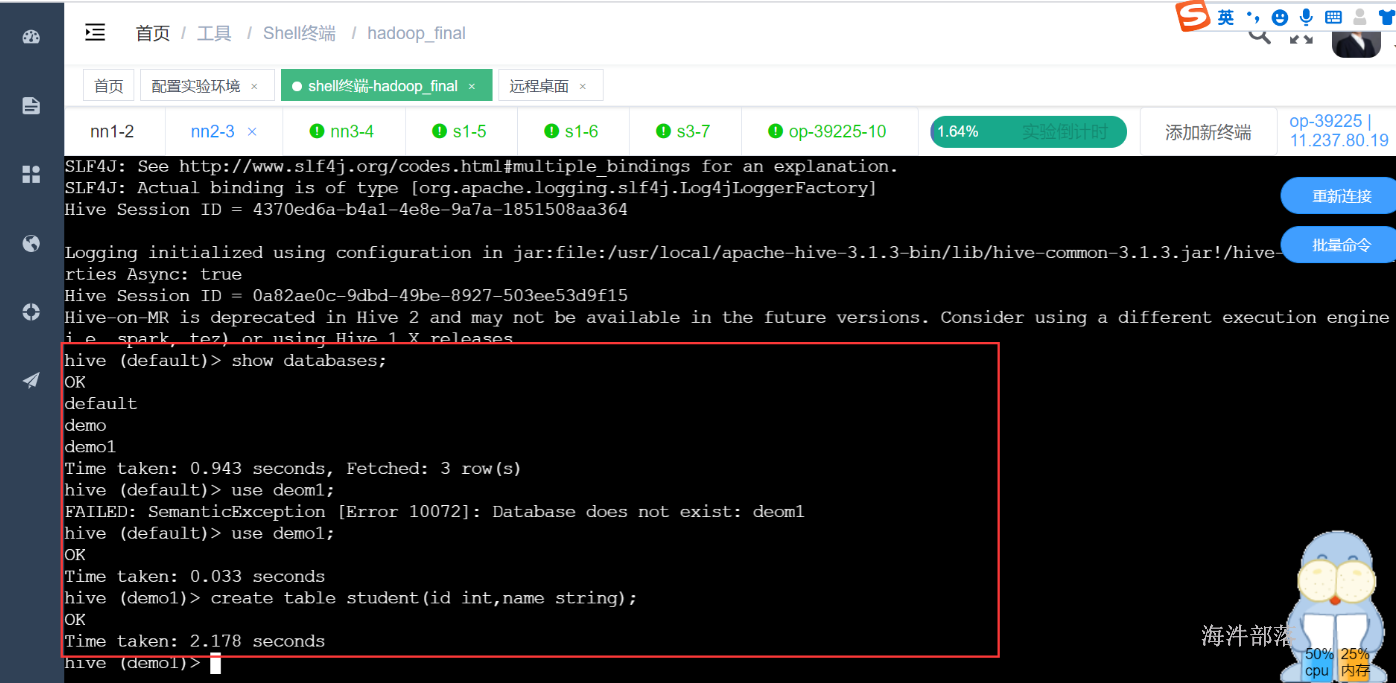
用hiveserver2连接测试
创建hive安装包的软连接,并修改/etc/profile环境变量文件
#创建软连接
chown -R hadoop:hadoop /usr/local/apache-hive-3.1.3-bin
#修改环境变量文件
export HIVE_HOME=/usr/local/hive
export HIVE_CONF_DIR=/usr/local/hive/conf
export PATH=$PATH:$HIVE_HOME/bin
#更新配置
source /etc/profile将hive-site.xml中hiveserver2的地址换成nn2
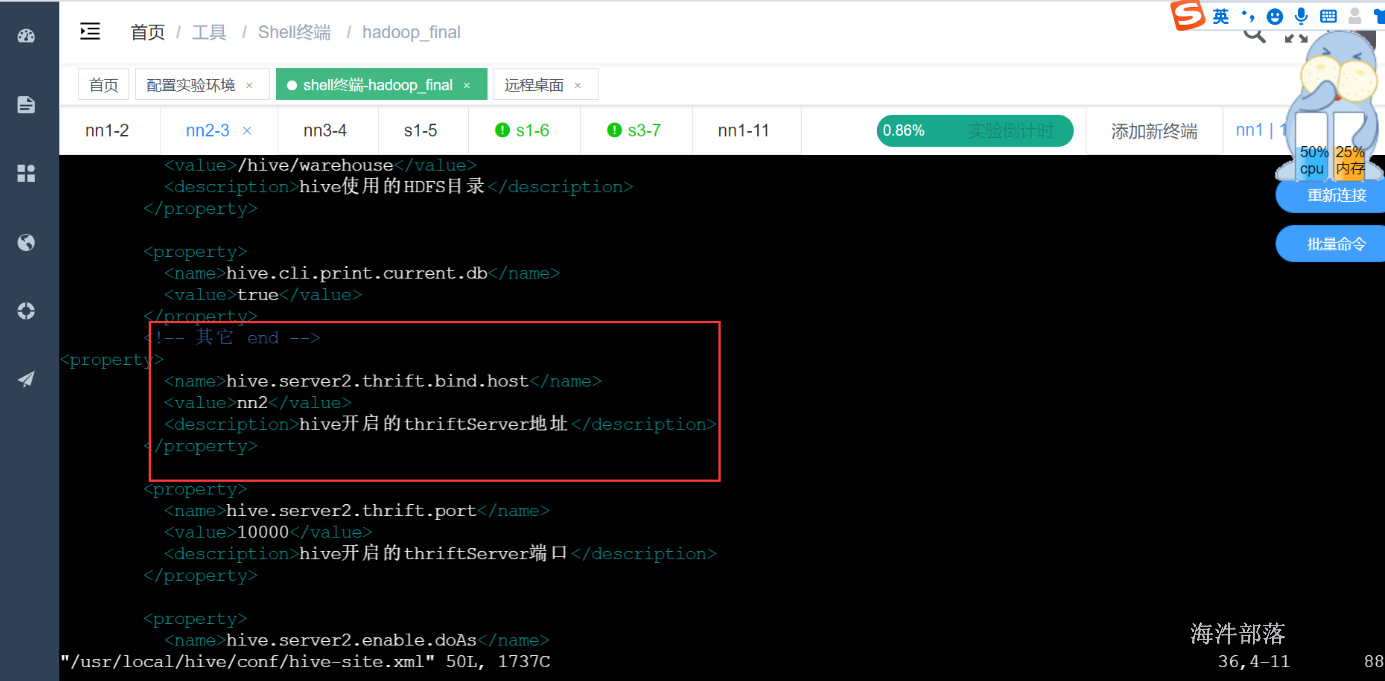
启动hiveserver2
nohup hiveserver2 >/dev/null 2>&1 &
启动测试
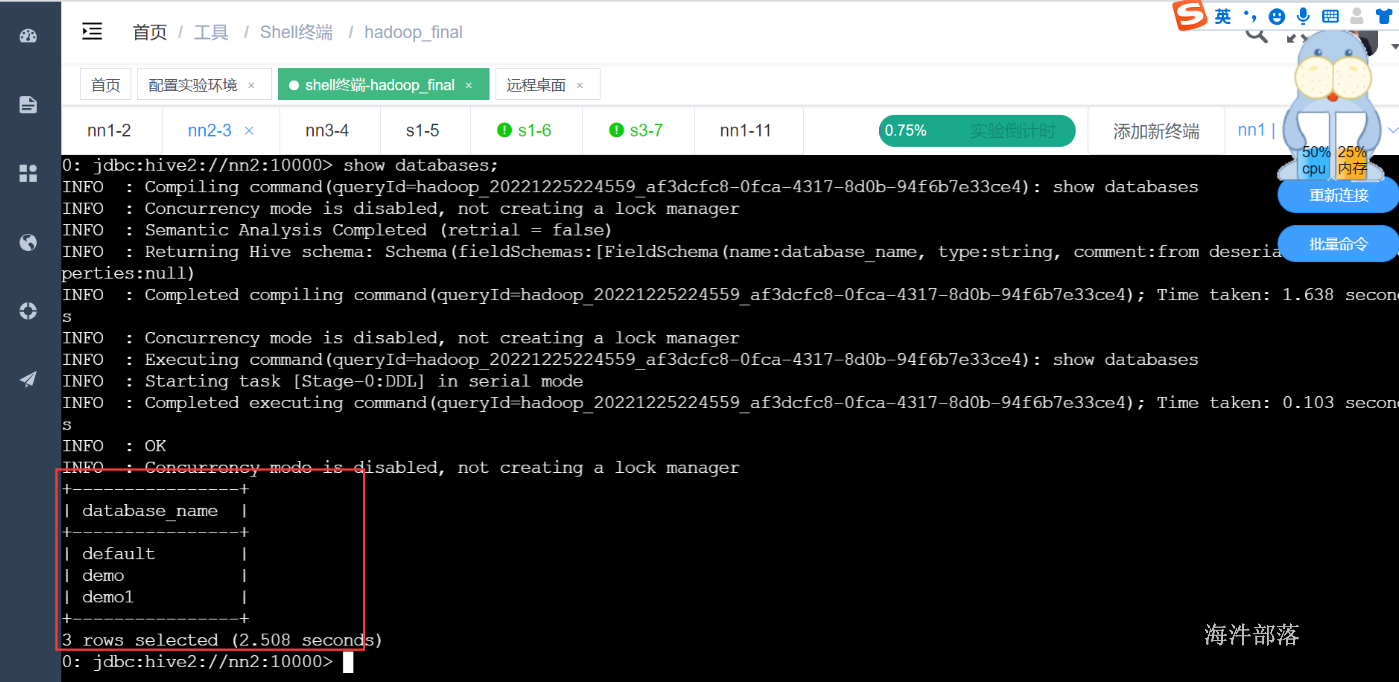
如果停掉metastore服务
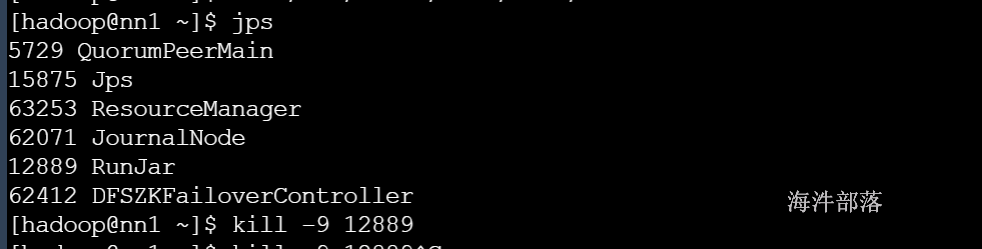
查询报错
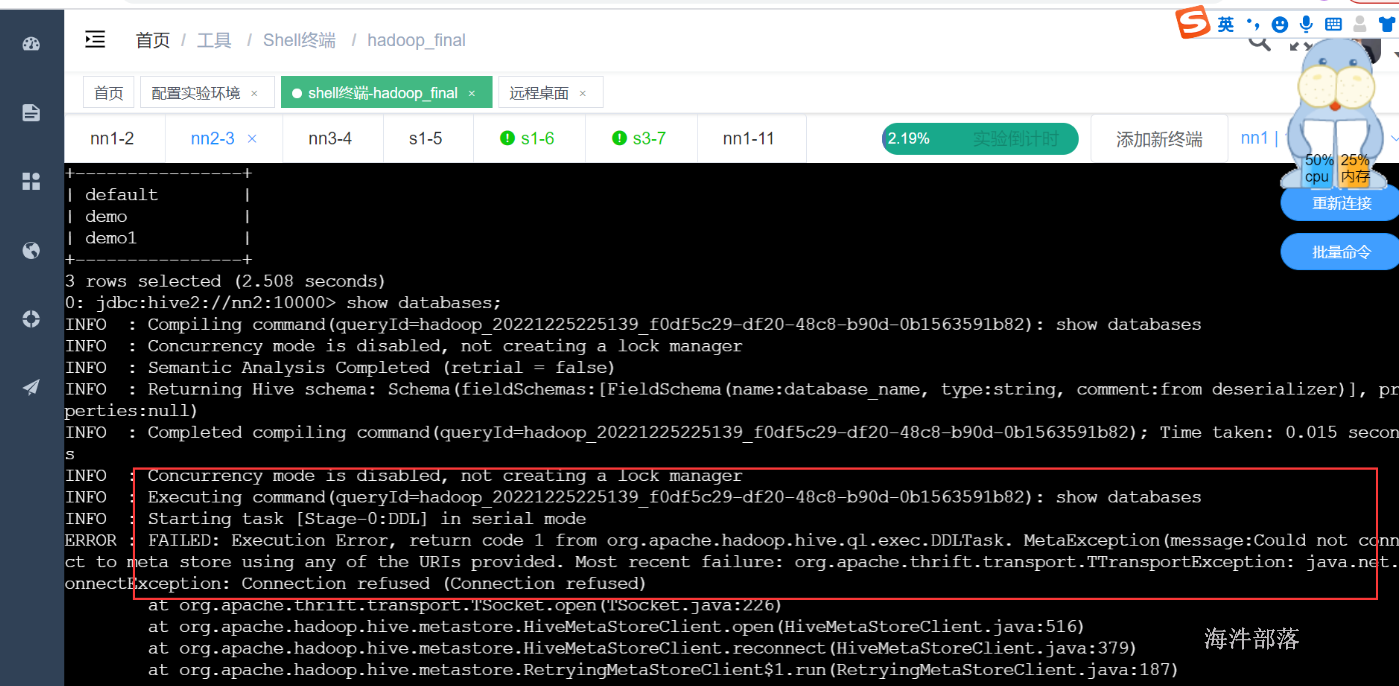
3 启动hive
3.1 hive的三种模式#
3.1.1 使用内置的derby数据库做元数据的存储#
使用内置的derby数据库做元数据的存储,操作derby数据库做元数据的管理,使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,目录不同时元数据也无法共享,不适合生产环境只适合练习。
3.1.2 本地模式#
使用mysql做元数据的存储,操作mysql数据库做元数据的管理,可以多个hive client一起使用,并且可以共享元数据。但mysql的连接信息明文存储在客户端配置,不便于数据库连接信息保密和以后对元数据库进行更改,如果客户端太多也会对mysql造成较大的压力,因为每个客户端都自己发起连接。
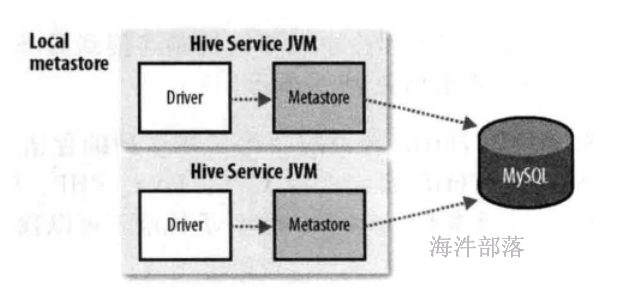
安全角度:metastore存储mysql连接的数据库信息,driver和 metastore在一台机器上,数据库信息不安全。
当多台机器的Driver 、 metastore都指向一个mysql 时,mysql的压力会增大。
3.1.3 远程模式#
使用mysql做元数据的存储,使用metastore服务做元数据的管理,优点便于元数据库信息的保密,因为只需要在运行metastore的机器上配置元数据库连接信息,客户端只需要配置metastore连接信息即可,缺点会引发单点问题,例如metastore服务挂了,其它hive终端就获取不到元数据信息了。企业环境推荐使用此种模式。
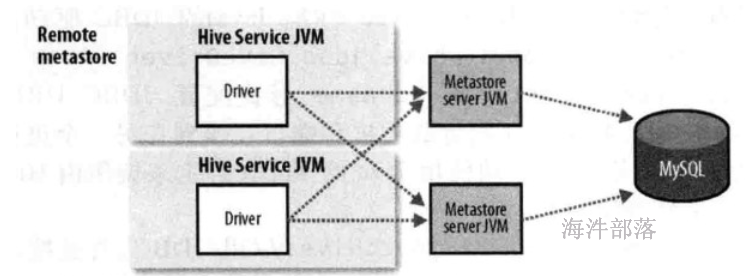
安全角度:meta从hive的driver上分离出来,在单独的机器上, 这样数据库的连接信息会安全。
启动时,需要分别启动driver和metastore
本地模式和远程模式的区别是:
1)本地模式不安全,远程模式安全。
2)本地模式不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。
远程模式需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。
服务端指的是Metastore服务所在的机器,即安装metastore的机器
metastore服务端配置
metastore客户端配置

3.2 启动hive#
配置完成之后,先启动matesotre服务,再启动hive client
# 启动zookeeper、hdfs、yarn、代理、历史
# 启动metastore
nohup hive --service metastore > /dev/null 2>&1 &
# 启动hive客户端
hive4 测试hive
1)创建库
# 创建数据库
create database hainiu;
# 显示建库语句
show create database hainiu;
# 进入数据库
use hainiu;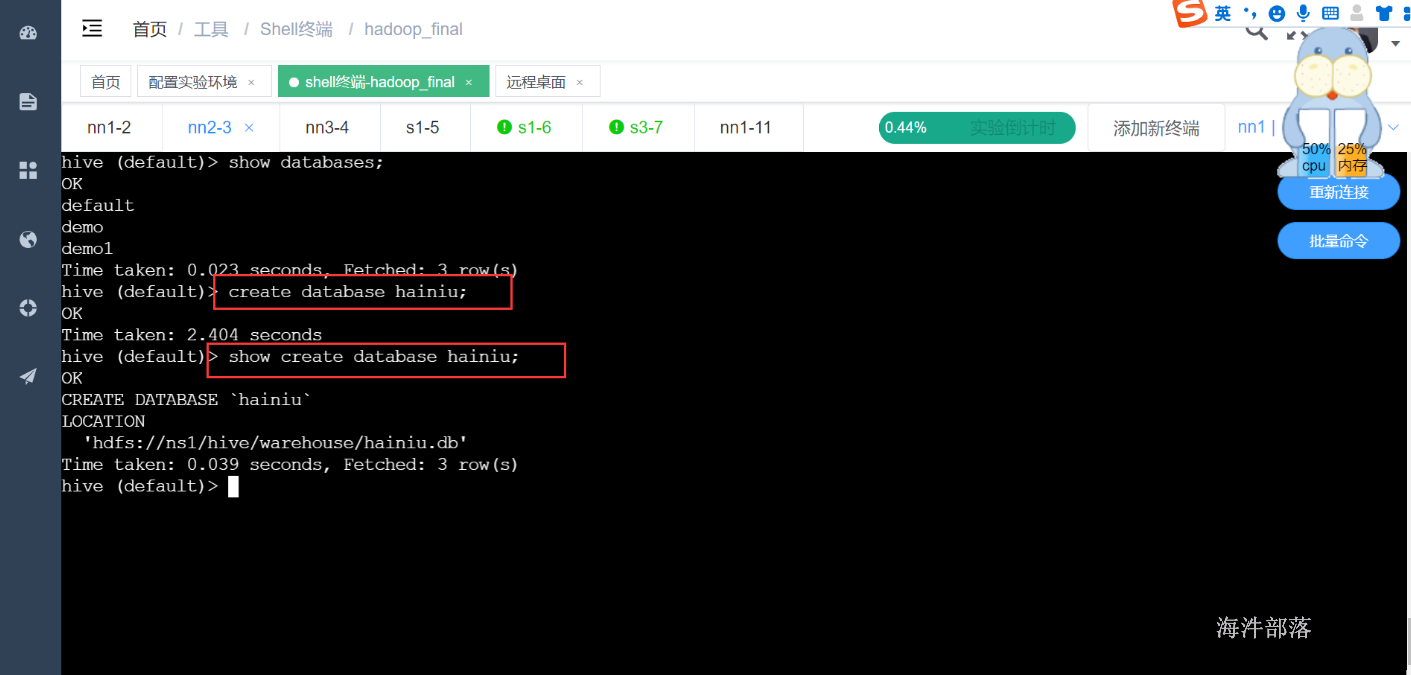
数据库在hdfs的位置

2)新建表
如果想在某个数据库下创建表,首先进入数据库(use 数据库名),
如果没有进入数据库,那默认是default
# 创建user_info 数据表
create table user_info(id int,name string);
# 查看表结构
desc user_info;
# 查看建表语句
show create table user_info;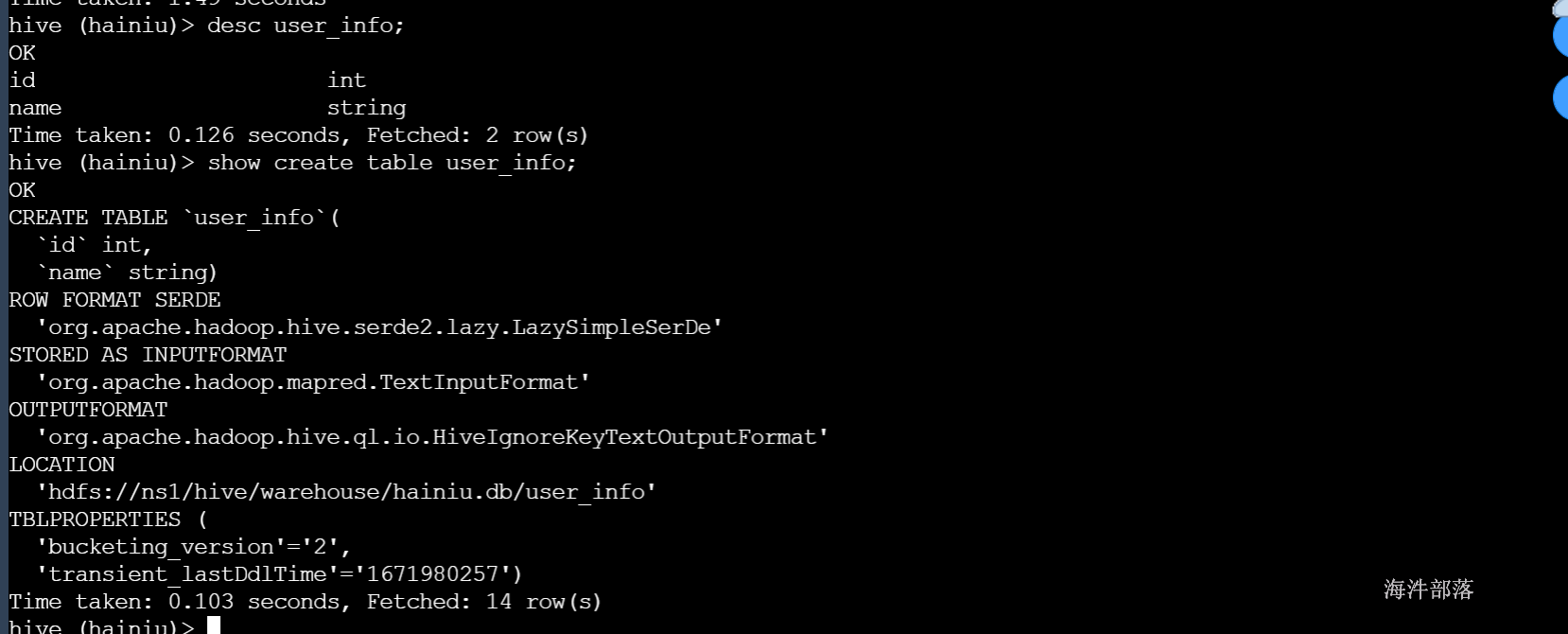
3)测试插入数据
#默认会走mapreduce程序
insert into user_info values(1,'zs');
#报错需要指定提交队列的名字
set mapreduce.job.queuename=hainiu查询数据

将数据下载下来查看
![]()
默认'\001'分割,vim中输入方法ctrl+v ctrl+a
不建议单条insert向hive表中插入数据
所以我们需要准备好数据,放到hive表所在的目录
touch user.txt
echo "1 hangsan" >> user.txt
echo "2 lisi" >> user.txt
echo "3 wangwu" >> user.txt
echo "4 zhaoliu" >> user.txt
#将数据放入表所在的路径
hadoop fs -put user.txt /hive/warehouse/hainiu.db/user_info4)测试查询
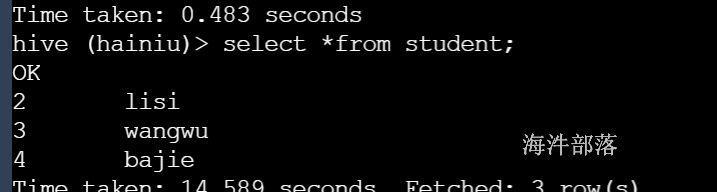
select * from user_info;
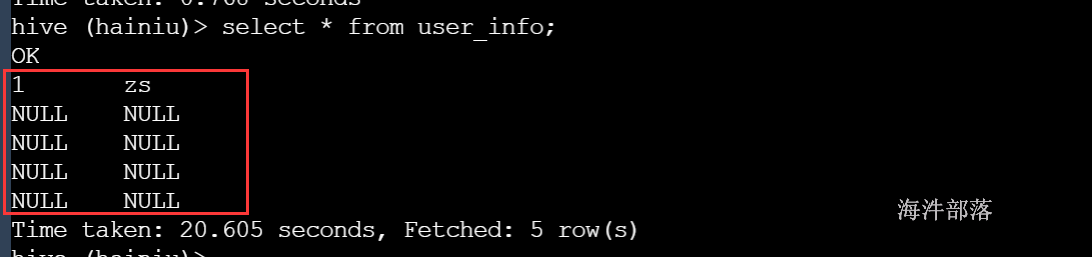
数据错乱原因就是文件数据分隔符不对,需要修改成\001的方式

重新上传测试
hadoop fs -put -f user.txt /hive/warehouse/hainiu.db/user_info
建表指定字段分隔符为空格
create table student(id int,name string) row format delimited fields terminated by ' ';上传数据并测试

数据成功显示
5 元数据库中相关表的解释
-- 数据库信息 (数据库id,数据库名称,数据库对应的hdfs存储位置)
select * from DBS;
-- 数据表信息(数据表id,数据库id,存储id,表名)
select * from TBLS;
-- 存储信息 (存储id,表对应的hdfs存储位置)
select * from SDS;
-- 数据库和表的关系
select t1.`NAME`, t1.DB_LOCATION_URI, t2.TBL_NAME
from DBS t1, TBLS t2
where t1.DB_ID=t2.DB_ID and t1.`NAME` like 'hai%';select t1.`NAME`, t1.DB_LOCATION_URI, t2.TBL_NAME
from DBS t1
inner join TBLS t2
on t1.DB_ID=t2.DB_ID and t1.`NAME` like 'hai%';
-- 数据表和存储的关系
select t1.TBL_NAME, t2.LOCATION from TBLS t1, SDS t2
where t1.SD_ID=t2.SD_ID and t1.TBL_NAME = 'user_info';
-- 数据库、表、存储的关系
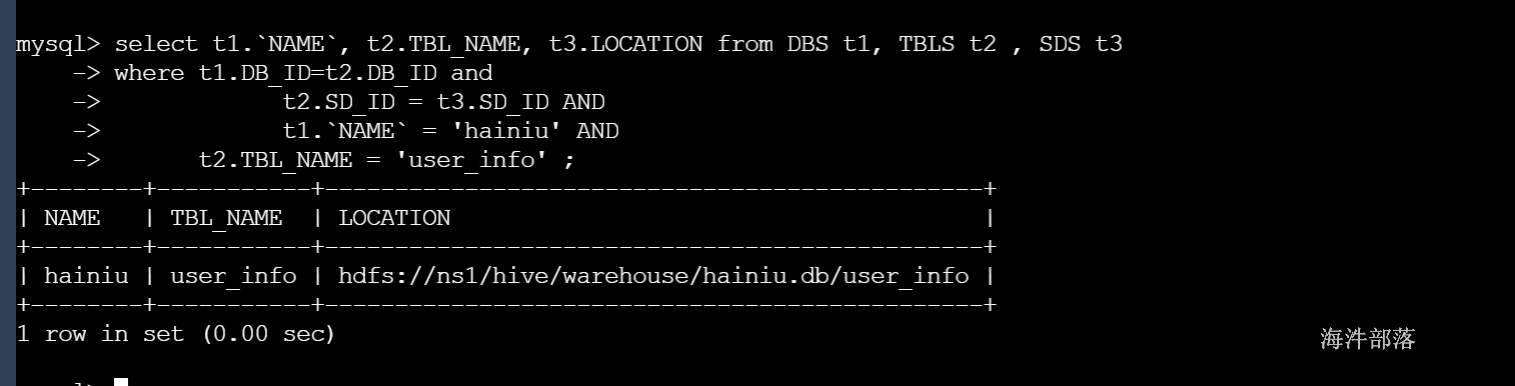
select t1.`NAME`, t2.TBL_NAME, t3.LOCATION from DBS t1, TBLS t2 , SDS t3
where t1.DB_ID=t2.DB_ID and t2.SD_ID = t3.SD_ID ANDt1.`NAME` = 'hainiu' ANDt2.TBL_NAME = 'user_info' ;执行结果:
相关文章:
hive 知识总结
编辑 社区公告教程下载分享问答JD 登 录 注册 01 hive 介绍与安装 1 hive介绍与原理分析 Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL…...

golang/云原生/Docker/DevOps/K8S/持续 集成/分布式/etcd 教程
3-6个月帮助学员掌握golang后端开发岗位必备技术点 教程时长: 150小时 五大核心专栏,原理源码案例分析项目实战直击工作岗位 golang:解决go语言编程问题 工程组件:解决golang工程化问题 分布式中间件:解决技术栈单一及分布式开发问题 云原生…...
jeecg库login登录过程分析笔记
jeecg库(版本jeecg-boot-v3.5.1last)实现了用户登录功能,二开时为了借鉴jeecg用户登录的方法,跑了一遍登录方法: org.jeecg.modules.system.controller.LoginController#login 定义这个方法的类的路径是:…...
echarts仪表盘vue
<div class"ybptx" ref"btryzb"></div>mounted() {this.getBtData();},getBtData() {var chart this.$echarts.init(this.$refs.btryzb);var data_czzf 88;var option {series: [{name: 内层数据刻度,type: gauge,radius: 80%,min: 0,max: 1…...

管道和重定向分号-连接符
本文介绍shell脚本常用命令连接符:管道符( | )、重定向( < 、>、>>、2> 、&> )、分号( ; ) 本文内容同微信公众号【凡登】,关注不迷路,学习上高速,欢迎关注共同学习。 1、管道 进程的通信方式之一…...
)
WSL VScode连接文件后无法修改(修改报错)
权限问题 usrname:用户名 dirpath:要修改的文件夹路径 sudo chown -R usrname /dirpath...
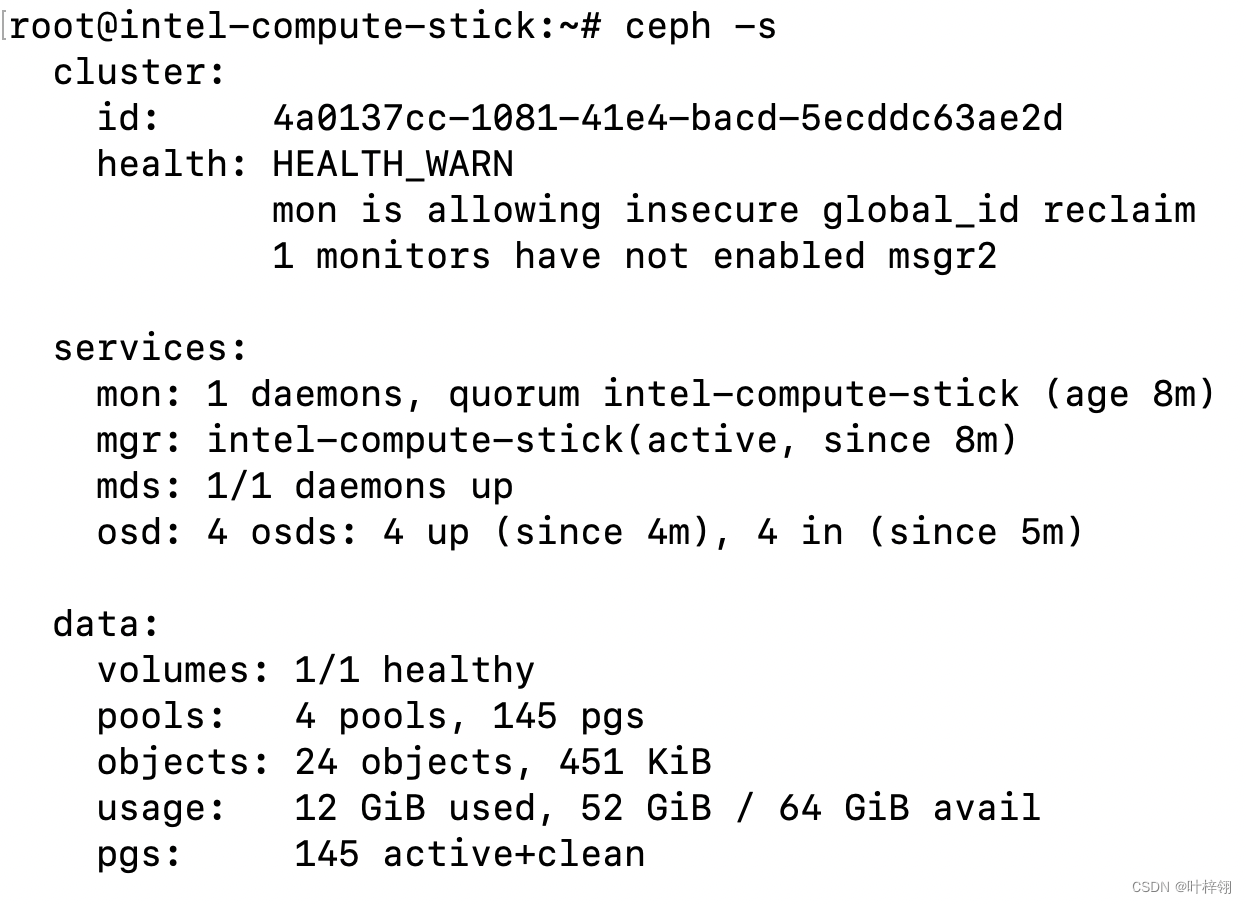
迷你Ceph集群搭建(超低配设备)
我的博客原文链接:https://blog.gcc.ac.cn/post/2023/%E8%BF%B7%E4%BD%A0ceph%E9%9B%86%E7%BE%A4%E6%90%AD%E5%BB%BA/ 环境 机器列表: IP角色说明10.0.0.15osdARMv7,512M内存,32G存储,百兆网口10.0.0.16clientARM64…...

Python数据挖掘项目实战——自动售货机销售数据分析
摘要:本案例将主要结合自动售货机的实际情况,对销售的历史数据进行处理,利用pyecharts库、Matplotlib库进行可视化分析,并对未来4周商品的销售额进行预测,从而为企业制定相应的自动售货机市场需求分析及销售建议提供参…...

TortoiseGit使用教程
文章目录 一. 创建仓库二. Clone仓库三. 查看修改记录四. 版本回溯五. 创建分支六. 切换分支七. 合并分支八. 删除分支九. TortoiseGit配置1. 常规配置2. 配置远程仓库账户密码3. 配置远程仓库 一. 创建仓库 在需要创建仓库的文件上右键→Git Create repository here… 创建仓…...

如何测量GNSS信号和高斯噪声功率及载波比?
引言 本文将介绍如何测量德思特Safran GSG-7或GSG-8 GNSS模拟器的输出信号功率。此外,还展示了如何为此类测量正确配置德思特Safran Skydel仿真引擎以及如何设置射频设备,从而使用频谱分析仪准确测量信号的射频功率。 什么是载波噪声密度C/N0 GNSS接收…...
动态壁纸软件iWall mac中文特色
iWall for mac是一款动态壁纸软件,它可以使用任何格式的漂亮视频(无须转换),音频(可视化功能),图片,动画,Flash,gif,swf,程序,网页,网站做为您的动态壁纸&…...
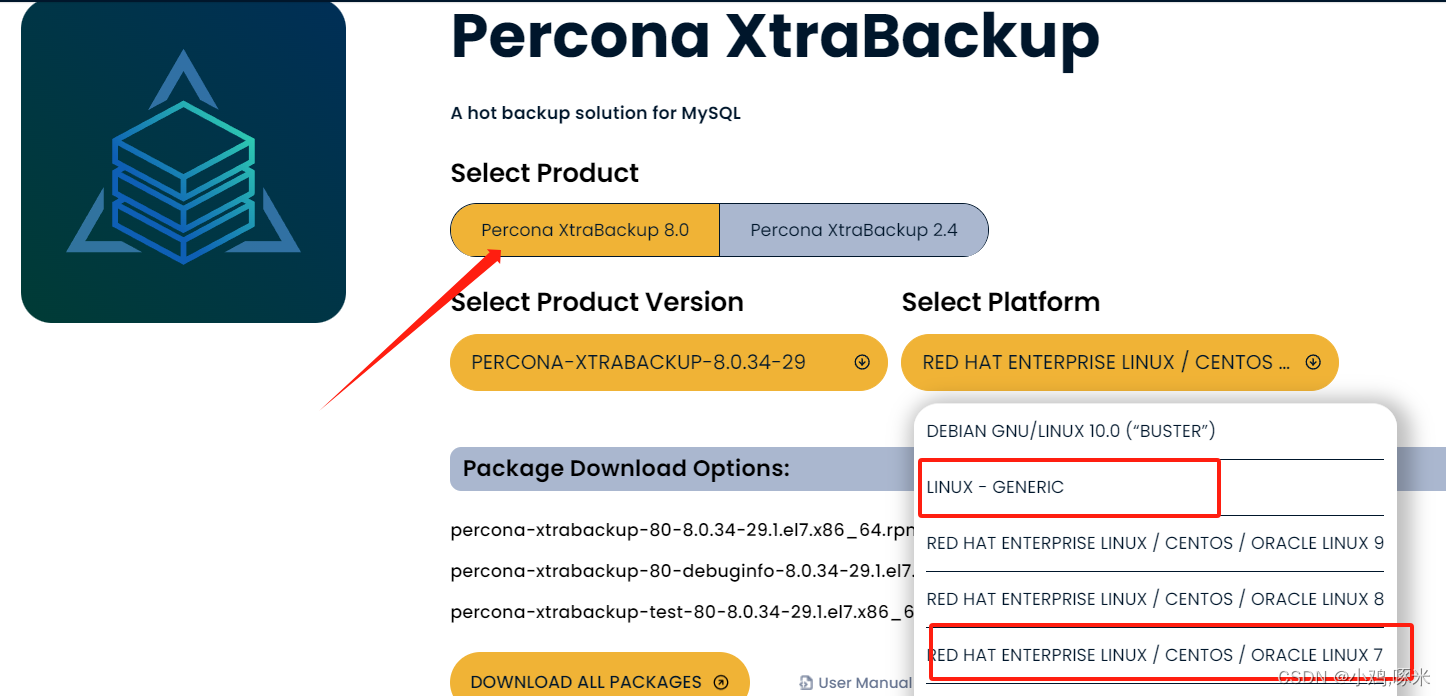
xtrabackup全备 增备
版本针对mysql8.0版本 官方下载地址 https://www.percona.com/downloads 自行选择下载方式 yum安装方式 1、下载上传服务器 安装软件 [rootmaster mysql]# ll percona-xtrabackup-80-8.0.33-28.1.el7.x86_64.rpm -rw-r--r--. 1 root root 44541856 Oct 10 13:25 percona-x…...

【广州华锐互动】灭火器使用VR教学系统应用于高校消防演练有什么好处?
在科技发展的大潮中,虚拟现实(VR)技术以其独特的沉浸式体验赢得了各个领域的青睐,其中包括教育和培训。在高校消防演练中,VR也成为了一种新的消防教育方式。 由广州华锐互动开发的VR消防演练系统,就包含了校…...
Pymol做B因子图
分子动力学模拟结束后,获得蛋白的平均结构, 比如获得的平均结构为WT-average.pdb 然后将平均结构导入到Pymol 中,可以得到B因子图。 gmx rmsf -f md_0_100_noPBC.xtc -s md_0_100.tpr -o rmsf-per-residue.xvg -ox average.pdb -oq bfactors…...

EKF例程 matlab
% 不含IMU误差方程的EKF滤波典型程序,适用于多次滤波的第二级 % author:Evand % date: 2023-09-20 % Ver1 clear;clc;close all; global T %% initial T 0.1; %采样率 t [T:T:100]; Q 0.1diag([1,1,1]);wsqrt(Q)randn(size(Q,1),length(t)); R 1diag([1,1,1]);v…...

【C语言】atoi函数的模拟
atoi对于初学者来说大概率是一个陌生的函数 但不要害怕,我们可以通过各种网站去查询 例如: cplusplus就是一个很好的查询网站 目录 函数介绍模拟实现需要注意的点 函数介绍 我们发现这是一个将字符串转换为整形数字的函数 例如: int main()…...
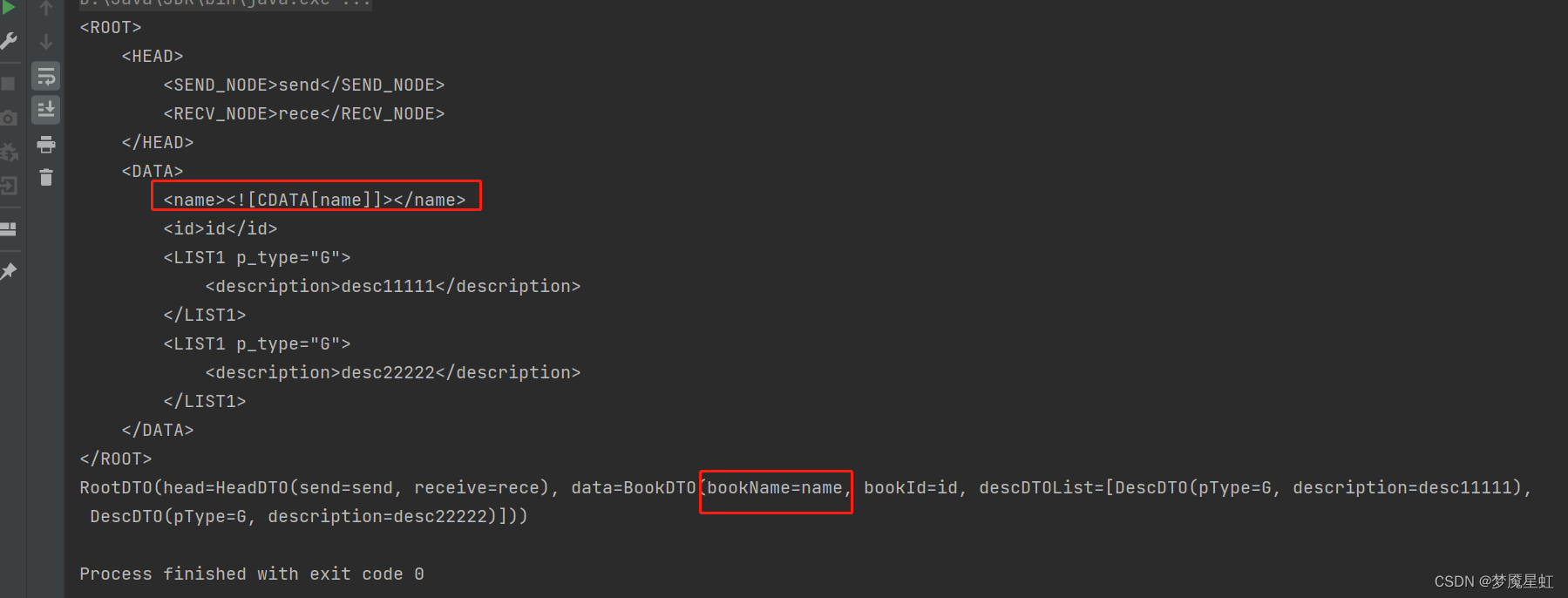
JAXB 使用记录 bean转xml xml转bean 数组 继承 CDATA(转义问题)
JAXB 使用记录 部分内容引自 https://blog.csdn.net/gengzhy/article/details/127564536 基础介绍 JAXBContext类:是应用的入口,用于管理XML/Java绑定信息 Marshaller接口:将Java对象序列化为XML数据 Unmarshaller接口:将XML数…...
Linux Centos安装Sql Server数据库,结合cpolar内网穿透实现公网访问
目录 前言 1. 安装sql server 2. 局域网测试连接 3. 安装cpolar内网穿透 4. 将sqlserver映射到公网 5. 公网远程连接 6.固定连接公网地址 7.使用固定公网地址连接 前言 简单几步实现在Linux centos环境下安装部署sql server数据库,并结合cpolar内网穿透工具…...
Vulnhub系列靶机---Raven: 2
文章目录 信息收集主机发现端口扫描目录扫描用户枚举 漏洞发现漏洞利用UDF脚本MySQL提权SUID提权 靶机文档:Raven: 2 下载地址:Download (Mirror) 信息收集 靶机MAC地址:00:0C:29:15:7F:17 主机发现 sudo nmap -sn 192.168.8.0/24sudo arp…...

计算机视觉与深度学习 | 视觉惯性SLAM的基础理论
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 视觉惯性SLAM的基础理论 引言三维空间刚体的运动表示旋转矩阵(Rotatio…...

从标签页混乱到高效工作流:Tabee如何彻底改变我的浏览器体验
从标签页混乱到高效工作流:Tabee如何彻底改变我的浏览器体验 【免费下载链接】chrome-tab-modifier Take control of your tabs 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-tab-modifier 你是否曾经在几十个标签页中迷失方向?每个标签页…...

基于CW32F030的BLDC电机控制:从国产MCU到完整评估方案
1. 项目概述:从一颗国产MCU到一套完整的BLDC评估方案最近在做一个直流无刷电机(BLDC)的小项目,选型时发现了一款挺有意思的国产MCU——武汉芯源的CW32F030C8T6,以及围绕它打造的一套完整的评估套件CW32_BLCD_EVA。对于…...

ncmdumpGUI:专业音频解密工具实现网易云音乐跨平台播放自由
ncmdumpGUI:专业音频解密工具实现网易云音乐跨平台播放自由 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,平台间的格…...

从OpenMV2到4代,我踩过的那些坑:画面变绿、传感器接触不良与内存擦除的避坑实录
从OpenMV2到4代:硬件升级中的稳定性挑战与实战解决方案 作为一名长期使用OpenMV系列开发视觉项目的工程师,我从OpenMV2一路升级到4代,见证了硬件性能的飞跃,也深刻体会到稳定性问题带来的困扰。其中最令人头疼的莫过于"画面变…...

告别BiSeNet的臃肿:手把手教你用STDC网络在MMSegmentation中实现更快的实时语义分割
从BiSeNet到STDC:在MMSegmentation中构建高效实时语义分割模型的实战指南 当你在深夜调试一个需要实时反馈的无人机视觉系统时,BiSeNet的多路径结构是否正在消耗你宝贵的计算资源?STDC网络的出现,为这类场景带来了新的可能性。本文…...
:从Token溢出到模型幻觉全击破)
Perplexity编程问题解答实战手册(2024最新版):从Token溢出到模型幻觉全击破
更多请点击: https://intelliparadigm.com 第一章:Perplexity编程问题解答实战手册(2024最新版):从Token溢出到模型幻觉全击破 Perplexity 作为面向开发者优化的AI问答平台,其底层依赖大语言模型的上下文理…...
)
告别ICMP被墙!用TCP Traceroute精准探测服务器网络路径(附Win/Mac/Linux三平台保姆级教程)
告别传统路径探测:TCP Traceroute的跨平台实战指南 当服务器访问异常时,传统ICMP traceroute往往在第一个防火墙处就戛然而止。想象一下,你正面临生产环境突发性网络延迟,而常规工具返回的只有一串令人沮丧的"***"——此…...
)
保姆级教程:在Ubuntu上为Ouster激光雷达配置PTP时间同步(含linuxptp/phc2sys避坑指南)
在Ubuntu上为Ouster激光雷达实现纳秒级PTP时间同步的完整指南 当自动驾驶车辆以60公里时速行驶时,1毫秒的时间误差会导致1.7厘米的位置偏差——这正是我们需要为激光雷达实现纳秒级时间同步的原因。本文将手把手带您完成Ouster激光雷达在Ubuntu系统上的PTP精确时间…...

5个技巧快速掌握猫抓插件:免费高效的浏览器资源下载终极指南
5个技巧快速掌握猫抓插件:免费高效的浏览器资源下载终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在当今数字内容爆炸的时代…...

对比直接使用厂商API体验Taotoken聚合调用在延迟上的优化感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API体验Taotoken聚合调用在延迟上的优化感受 作为一名长期直接调用单一模型API的开发者,我的日常工作…...