深度神经网络压缩与加速技术
//
深度神经网络是深度学习的一种框架,它是一种具备至少一个隐层的神经网络。与浅层神经网络类似,深度神经网络也能够为复杂非线性系统提供建模,但多出的层次为模型提供了更高的抽象层次,因而提高了模型的能力。深度神经网络是一种判别模型,可以使用反向传播算法进行训练。随着深度神经网络使用的越来越多,相应的压缩和加速技术也孕育而生。LiveVideoStackCon 2023上海站邀请到了胡浩基教授为我们分享他们实验室的一些实践。
文/胡浩基
编辑/LiveVideoStack
大家好,我是来自浙江大学信息与电子工程学院的胡浩基。今天我分享的主题是《深度神经网络压缩与加速技术》。
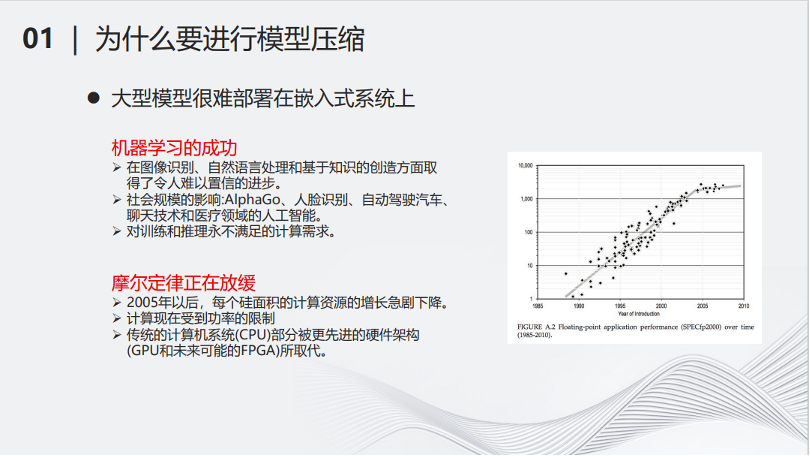
首先一个问题是,为什么要做深度神经网络压缩?有两个原因:第一个原因是大型的深度神经网络很难部署在小型化的设备上。另一个原因是当深度模型越来越大,需要消耗的计算和存储资源越来越多,但是物理的计算资源跟不上需求增长的速度。
从右边的图可以看出,从2005年开始,硬件的计算资源增长趋于放缓,而随着深度学习领域的蓬勃发展,对算力的需求却是指数级增长,这就导致了矛盾。因此,对深度模型进行简化,降低其计算量,成了当务之急。近年来,以ChatGPT为代表的大模型诞生,将这个问题变得更加直接和迫切。如果想要应用大模型,必须有能够负担得起的相对低廉计算和存储资源,在寻找计算和存储资源的同时,降低大模型的计算量,将是对解决算力问题的有益补充。
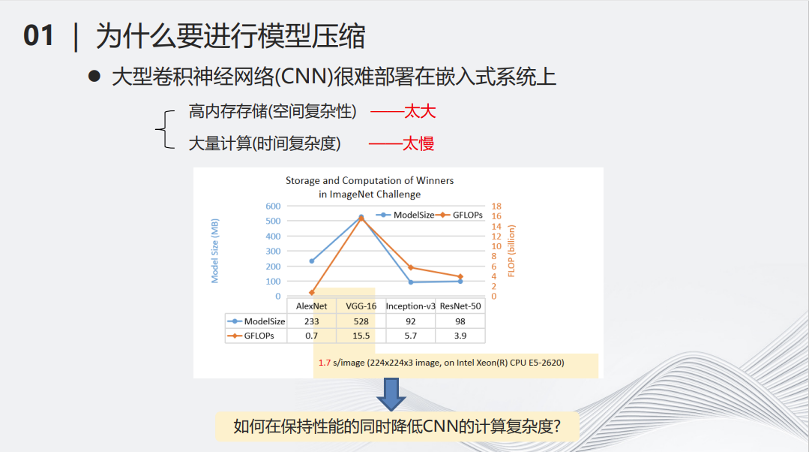
例如2017年流行的VGG-16网络,在当时比较主流的CPU上处理一张图片,可能需要1.7秒的时间,这样的时间显然不太适合用部署在小型化的设备当中。

深度神经网络的压缩用数学表述就是使用一个简单的函数来模拟复杂的函数。虽然这是一个已经研究了几百年的函数逼近问题,但是在当今的环境下,如何将几十亿甚至上千亿自由参数的模型缩小,是一个全新的挑战。这里有三个基本思想 -- 更少参数、更少计算和更少比特。在将参数变少的同时,用较为简单的计算来代替复杂的计算。用低精度量化的比特数来模拟高精度的数据,都可以让函数的计算复杂性大大降低。
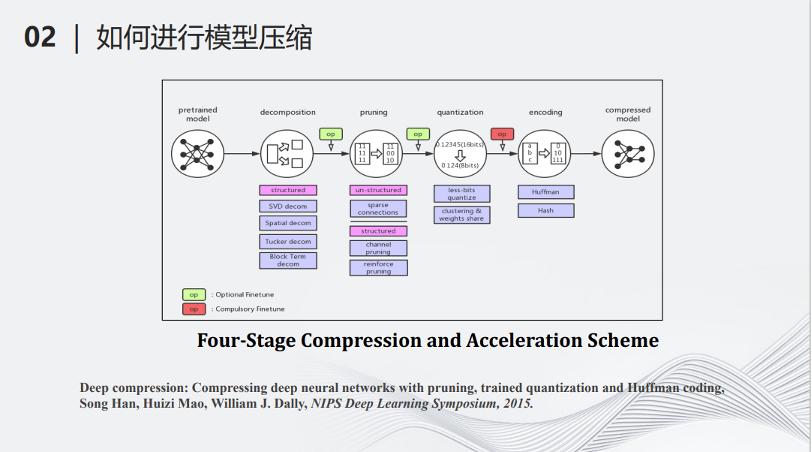
深度模型压缩和加速领域开创人MIT的副教授韩松在2015年的一篇文章,将深度学习的模型压缩分成了如下的5个步骤。最左边输入了一个深度学习的模型,首先要经过分解(decomposition),即用少量的计算代替以前复杂的计算,例如可以把很大的矩阵拆成多个小矩阵,将大矩阵的乘法变成小矩阵的乘法和加法。第二个操作叫做剪枝(pruning),它是一个减少参数的流程,即将一些对整个计算不那么重要的参数找出来并把它们从原来的神经网络中去掉。第三个操作叫做量化(Quantization),即将多比特的数据变成少比特的数据,用少比特的加法和乘法模拟原来的多比特的加法乘法,从而减少计算量。做完以上三步操作之后,接下来需要编码(encoding),即用统一的标准将网络的参数和结构进行一定程度的编码,进一步降低网络的储存量。经过以上四步的操作,最后可以得到一个被压缩的模型。
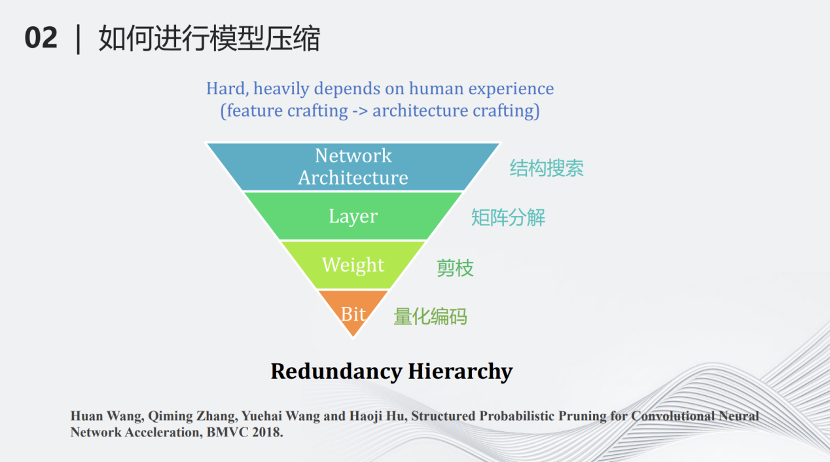
我们团队提出了另外一种基于层次的模型压缩分类。最上面一个层级叫做网络结构搜索(network architecture design),即搜索一个计算量较少但对于某些特定任务很有效的网络,这也可以看作另一种压缩方式。第二个层级叫做分层压缩(Layer)。深度学习网络基本上是分层的结构,每一层有一些矩阵的加法和乘法,对每一层的这些加法和乘法进行约束,例如将矩阵进行分解等,这样可以进一步降低计算量。第三个压缩层级是参数(weight),将每一层不重要的参数去掉,这也就是剪枝。最下面的层级是比特(bit),用量化对每个参数做比特层级的压缩,变成量化的编码。
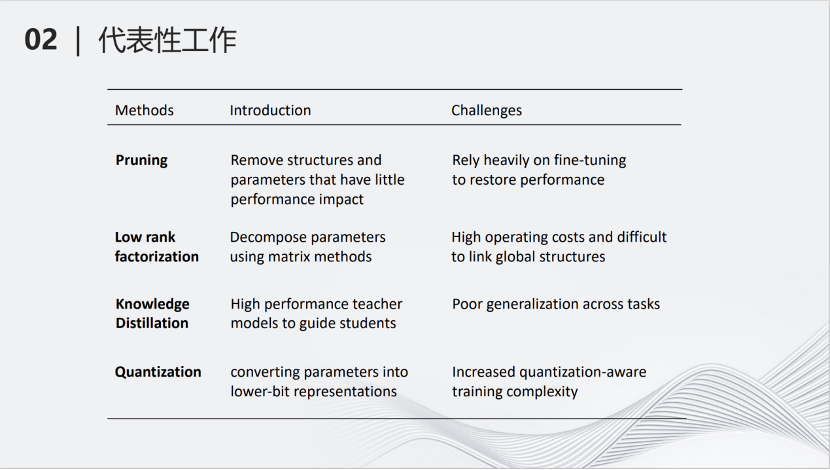
这里是各种压缩方式的介绍以及它们的挑战。剪枝(Pruning)减少模型的参数;低秩分解(Low rank factorization)将大矩阵拆成小矩阵;知识蒸馏(Knowledge Distillation)用大的网络教小的网络学习,从而使小的网络产生的结果跟大的网络类似;量化(Quantization将深度神经网络里的参数进行量化,变为低比特参数,降低计算量。
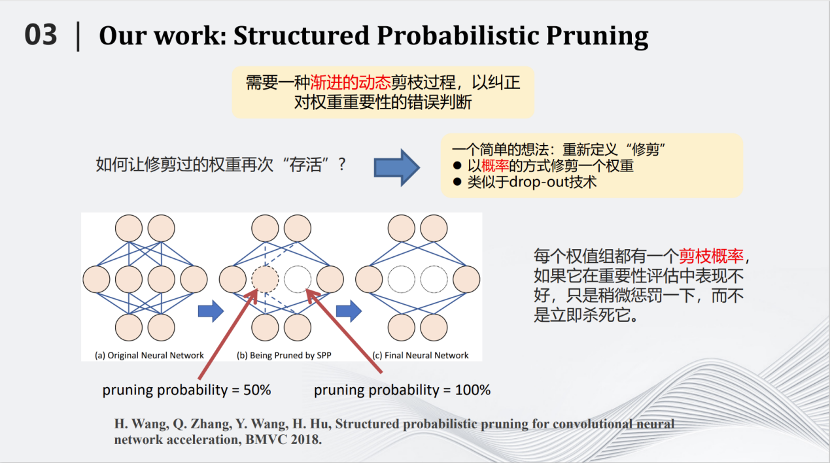
2018年BMVC会议,我们团队提出了一种基于概率的剪枝方法,叫做Structured Probabilistic Pruning。这种方法的核心思路是将神经网络里不重要的参数去掉。那么如何划分重要与不重要,是首要问题。最好的标准是去掉某个参数以后测试对于结果的影响。但是在整个网络中那么多的参数,如果每去掉一个参数都测试对结果的影响,时间就会非常漫长。所以需要用一些简单的标准,例如参数绝对值的大小来评判参数的重要性。但有一个矛盾是,简单标准对于衡量参数重要性来说并不准确。那么如何解决上述矛盾呢?我们提出的方案形象一点就是,用多次考试代替一次考试。我们将在训练到一定的地步之后,去掉不重要的参数,这个过程叫做一次考试。但是每次考试都有偏差。于是我们发明了这种基于概率的剪枝方法,将一次考试变成多次考试。即每训练一段时间测试参数重要性,如果在这段时间内它比较重要,就会给它一个较小的剪枝概率,如果在这一段时间内不那么重要,就会给它一个较大的剪枝概率。接下来继续训练一段时间,再进行第二次考试。在新的考试中,以前不重要的参数可能变得重要,以前重要的参数也可能变得不重要,把相应的概率进行累加,一直随着训练的过程累加下去,直到最后在训练结束时,根据累加的分数来决定哪些参数需要被剪枝。

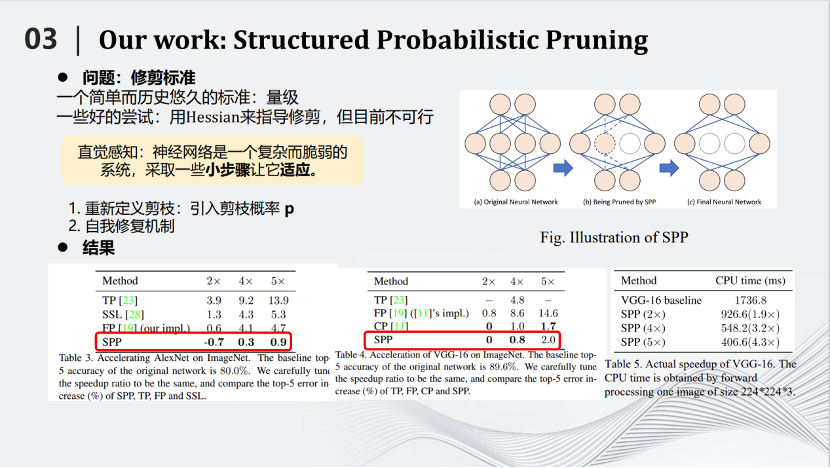
这种方式叫做SPP——Structured Probabilistic Pruning。SPP算法相对于其他的算法有一定的优势,具体体现在左边的图片里。例如我们将AlexNet压缩两倍,识别准确率反而提高了0.7,说明对于AlexNet这样比较稀疏的网络效果很好。从别的图片也可以看到,相对于其他的算法也有一定优势,这里不详细展开介绍。

2020年我们又提出一种基于增量正则化的卷积神经网络剪枝算法。通过对网络的目标函数加入正则化项,并变换正则化参数,从而达到剪枝的效果。

我们通过严格的数学推导证明了一个命题,即如果网络函数是二阶可导,那么当我们增加每一个网络参数对应正则化系数时,该参数的绝对值会在训练过程中会减小。所以我们可以根据网络参数的重要程度,实时分配其对应正则化系数的增量,从而将一些不太重要的参数绝对值逐渐压缩到零。通过这种方式,可以将神经网络的训练和剪枝融合到一起,在训练过程中逐步压缩不重要参数的绝对值,最终去除它们。
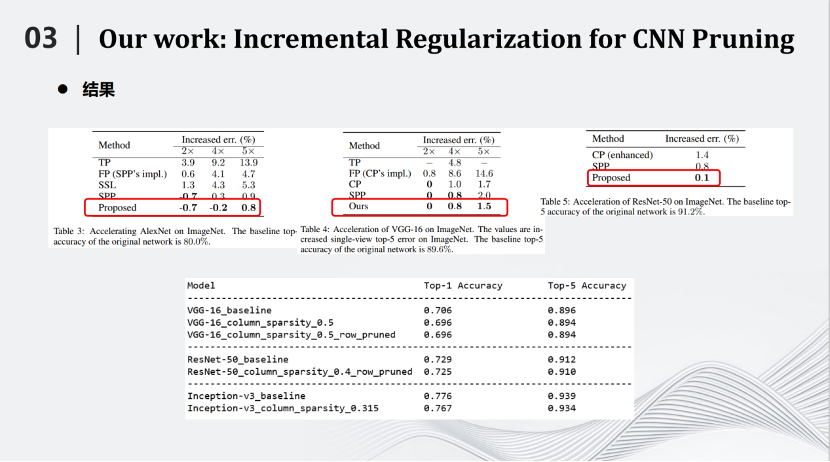
相比SPP, 增量正则化方法在AlexNet(ImageNet)上将推理速度提高到原来的4倍,也能够提高0.2%的识别率。在将网络推理速度提高5倍情况下,识别率也仅仅下降了0.8,这相比其他压缩算法也有很大的优势。

增量正则化方法对于三维卷积网络的也有一定的压缩效果,在3D-ResNet18上,将推理速度提高2倍,识别率下降了0.41%;将推理速度提高4倍,识别率下降2.87%。

基于增量正则化方法,我们参与了AVS和IEEE标准的制定,提出的算法成功的写入到国家标准《信息技术 神经网络表示与模型压缩 第1部分 卷积神经网络》中,同时也被写入“IEEE Model Representation, Composition, Distribution and Management”标准中并获得今年的新兴标准技术奖。

最近几年,我们还将深度模型压缩技术应用到图像风格迁移、图像超分辨率等底层视觉任务中。2020年的CVPR论文,我们利用知识蒸馏来压缩风格迁移网络。这里是风格迁移网络的例子,即输入两张图片,一张是内容图片,一张是风格图片。通过风格迁移网络生成一张图片,将内容和风格融合起来。我们需要做的事就是压缩风格迁移网络的大小。
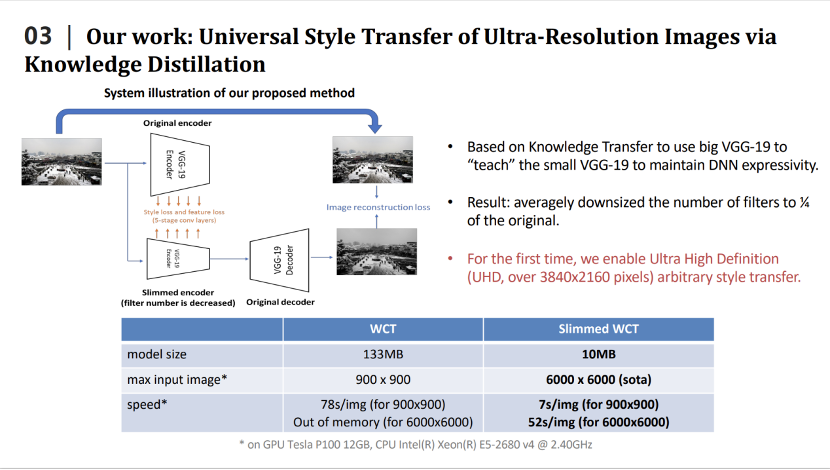
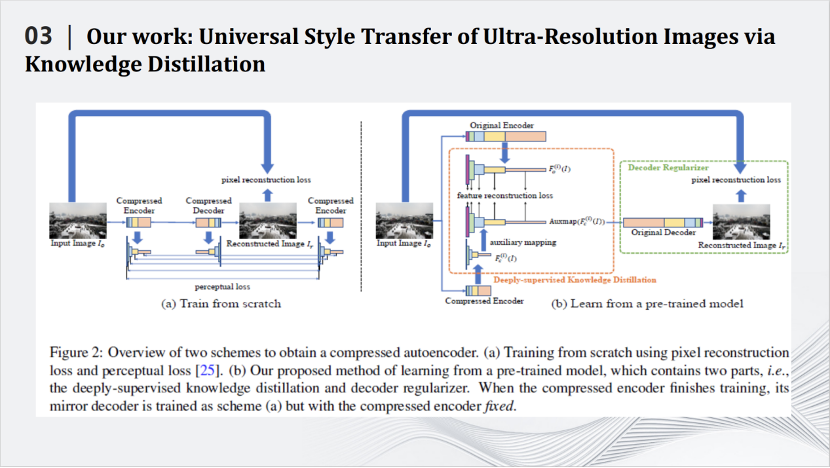
我们利用知识蒸馏来压缩风格迁移网络,即设计小的学生模型,用小的学生模型来模拟大的教师模型的输出,从而达到压缩大的教师模型的目的。我们也设计了针对风格迁移网络的损失函数,更好的完成了知识蒸馏的任务。我们提出的方法有很好的性能,例如在2020年效果比较好的WCT风格迁移网络,整个模型的大小是133m,经过压缩之后只有10m。一块GPU上使用WCT最多可以同时处理900×900的图片,压缩之后,同样的GPU上能够处理6000×6000的图片,在处理速度上,处理900×900的图片,WCT需要花费78秒,压缩之后只需要7秒,同时处理6000×6000的图片,在单卡的GPU也只要花费52秒的时间。



可以看到,通过我们的模型压缩技术,即便是4,000万像素图片的风格迁移,放大后的图像细节依然清晰。

在人脸识别方面,我们也使用了知识蒸馏的方法。这是2019年发表在ICIP的论文,人脸识别中有个三元组的损失,即图片左上角。其中有一个超参数m。这个m是不可以变化的。通过改进,我们将m变成了一个可变的参数,这个参数能够由学生网络计算两个图之间的距离,用距离的方式将m确定下来。基于这种动态的超参数,我们规划了知识蒸馏算法,获得了不错的效果。

我们实现了可能是世界上第一个公开的2M左右的人脸识别模型,同时在LFW数据上达到99%以上的识别率。同时,我们将所做的小型化人脸识别模型嵌入到芯片中,让人脸识别获得了更多的应用。
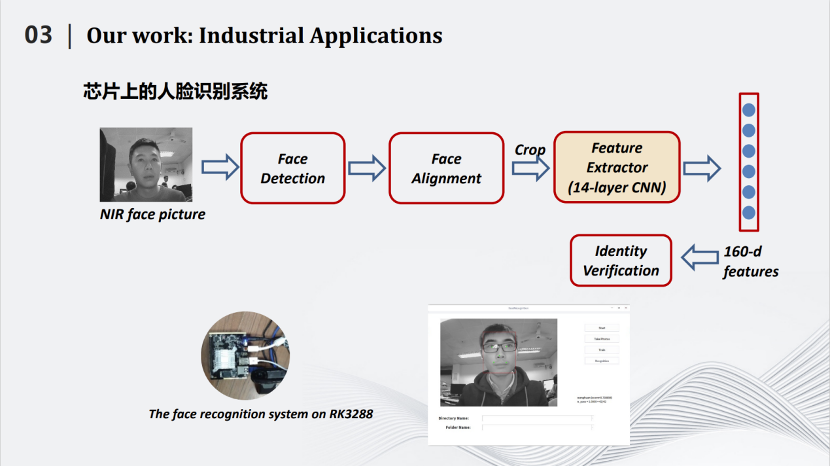

在瑞芯微RK3288上,原有的模型处理一张图片大概在0.31秒。而我们这个压缩后只有2M左右的模型,处理一张图片的时间在0.17秒左右。
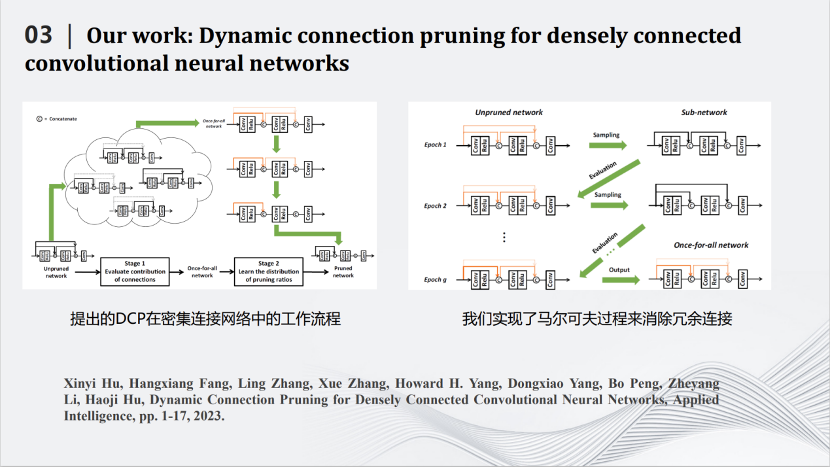
2020年开始,我们和华为合作,将深度压缩模型应用在图像超分辨率上。卷积神经网络是一个先处理局部,再处理全局的模型。而在超分辨率网络中,局部信息很重要,需要用跳线连接前面和后面的层。每一个跳线不仅把数据传送过去,还要同时将那一层的特征图传过去。后面的层不仅仅要处理自己那一层产生的特征图,还要处理前面传送过来的特征图。然而,不是每一个跳线都重要,都需要保留。于是我们规划算法,删除一些不重要的跳线,同时也删除了传送过来的特征图,从而降低了图像超分辨率网络的计算量。我们采用马尔科夫过程建模目标函数,消除冗余的跳线,从而完成对超分辨率网络的压缩。
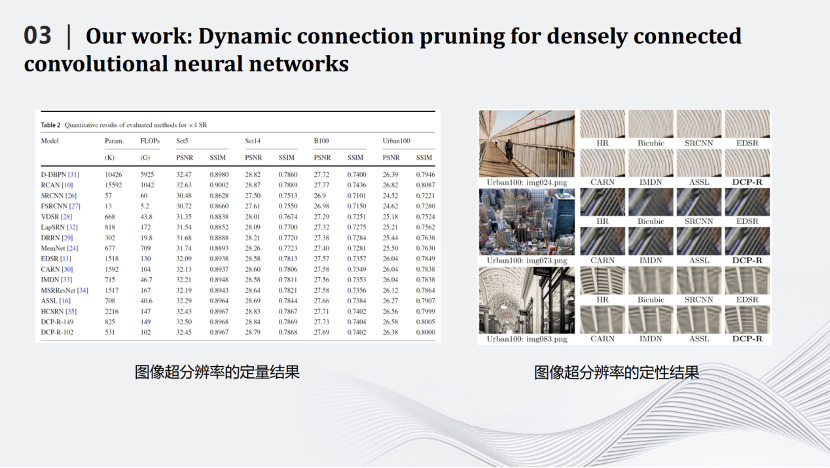
左边表格是一些定量的结果。FLOPs是网络中加法和乘法的次数。经过压缩之后的模型DCP-R-102的FLOPs只有102G,与计算量最大的网络D-DBPN相差50多倍的计算量,而图像的PSNR和SSIM基本不变。右边图片是定性结果,可见,我们的网络DCP-R可以很好的恢复图片的纹理和细节。

这是关于图像超分辨率的另一个工作。这里我们将将蓝色的大网络拆成两块,通过互蒸馏(cross knowledge distillation)这种方式进一步完成对超分辨率网络的压缩。右图是具体的定性和定量的结果。

这篇发表在期刊Pattern Recognition上的文章所做的事情是对深度模型进行量化。最极致的量化叫做二值化(binarization),即对每个参数只用+1和-1两个值来表示。如果每个参数都只是+1和-1,那么网络计算中矩阵的乘法将可以变为加减法,这样就比较适用于类似FPGA这种对于乘法不友好的硬件系统中。但是二值化也会带来一定的坏处,由于每个参数取值范围变小,整个网络的性能会有极大的下降。我们在将网络二值化的同时,为网络加一些辅助的并行结构,这些并行结构是通过网络搜索出来的,也都是一些二值化的分支,即图中红色的部分。加入并行结构后一方面让二值化的性能有了提升,另一方面也让计算增量保持在可控的范围内。利用下方的公式,综合考量精度(accuracy)、特征图相似性(similarity)和复杂度(complexity)三个方面,构造目标函数,在提高精度的前提下尽量减小复杂度,从而达到模型精度和复杂度的平衡。最近我们也在尝试使用重参数化的方式,将这些增加的结构合并到以前的网络当中,从而使网络结构不发生改变的前提下,进一步增加网络二值化的效果。
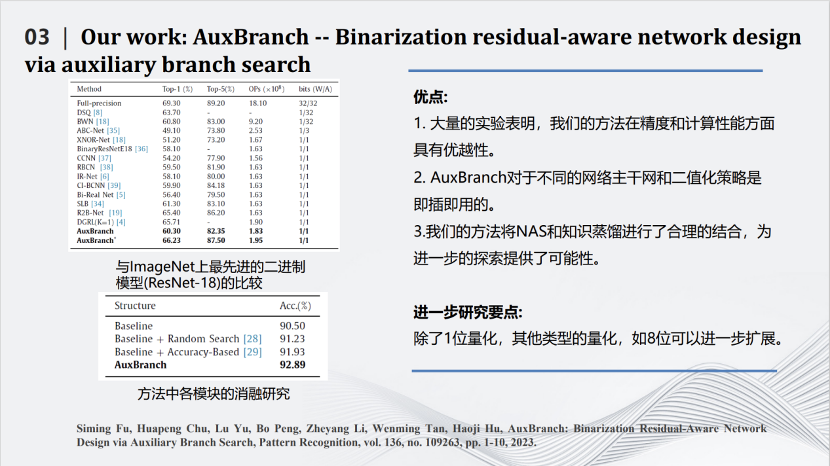
在ResNet-18上可以看到,使用上述方法可以把90.5%的识别准确度变成92.8%,同时计算量没有提升特别多。
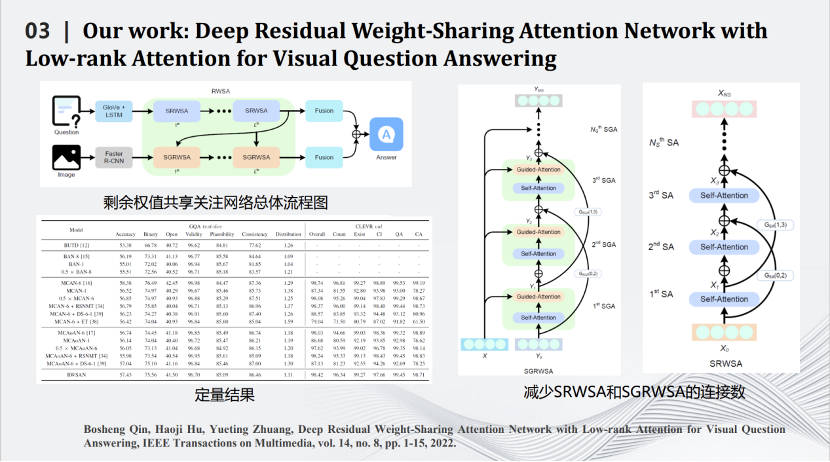
我们也是比较早做Transformer压缩的实验室。Transformer压缩的第一步是用矩阵理论对Transformer中Q、K、V三个矩阵进行分解,用小的矩阵相乘和相加代替大矩阵的相乘。通过一些理论推导,证明在特定场合下相比原有的矩阵计算准确度上界会有一定提升。压缩的第二步是减掉Transformer网络里的跳线。通过这两个相对简单的压缩方式完成对Transformer网络的压缩,同时将其用在智能视觉问答任务中。
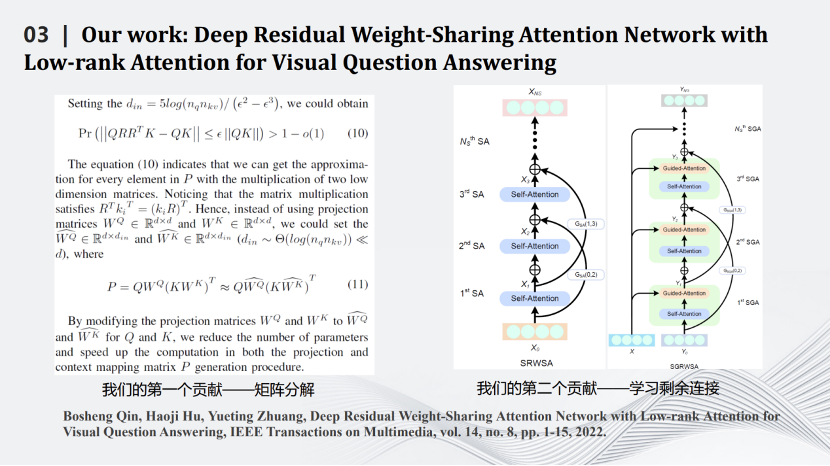
这是一些定量和定性结果的比较,可以看到我们的算法在保留原来性能的同时大幅度减少了网络的计算量。


最后,讲一下我认为这个领域可能有前途的未来发展方向。
首先,利用神经网络压缩技术弥补大规模语言和视觉基础模型的不足是迫在眉睫的方向。大模型消耗过多的计算量和存储量,如何将大模型变小是一个重要的科学问题。一些具体的问题包括,如果大模型是可以做100种任务的通才,那么如何将其转变为只能做1种任务小模型,也就是专才?这里有很多空间,值得继续挖掘。
第二,针对流行的特定任务网络进行压缩,例如Nerf和扩散模型等。但是,如果我们不能在方法上有所创新,只是一昧追逐流行的网络进行压缩,也会陷入内卷的困境。
第三,我认为软硬结合的的网络压缩算法是值得深入研究的方向。将硬件参数和硬件结构作为优化函数的一部分写入到网络压缩算法中,这样压缩出来的网络就能够直接适配到专门的硬件上。
第四,神经网络压缩算法和通信领域的结合。例如增量压缩,即设计神经网络压缩算法,在发送端首先传输网络最重要的部分,接收端首先收到一个识别精度较低的模型;随着更多的传输,接收端能逐步接收到越来越精确的模型。这个想法与图像或视频的压缩类似,可以完成神经网络模型在不同环境和资源下的个性化部署。
最后,我比较关注的是理论方面的研究,我暂且把它称为深度神经网络的信息论。目前的模型压缩算法设计主要靠经验,欠缺理论基础。一个重大的理论问题是,对于特定的任务、数据和网络架构,实现特定的精度所需要的最小计算是多少?这个问题当然是有一个明确的答案,但目前我们离这个答案仍然非常遥远。就像香农的信息论在通信领域的基础地位一样,我们也期待深度神经网络的信息论早日诞生。
我的演讲就到这里,以下是我们实验室的网页、联系方式,以及一些开源的代码,欢迎有兴趣的听众和我们联系。谢谢大家。

相关文章:
深度神经网络压缩与加速技术
// 深度神经网络是深度学习的一种框架,它是一种具备至少一个隐层的神经网络。与浅层神经网络类似,深度神经网络也能够为复杂非线性系统提供建模,但多出的层次为模型提供了更高的抽象层次,因而提高了模型的能力。深度神经网络是一…...

系统架构设计:11 论湖仓一体架构及其应用
目录 一 湖仓一体(Lakehouse) 1 数据仓库 2 数据湖 3 数据仓库和数据湖 4 湖仓一体(Lakehouse)...
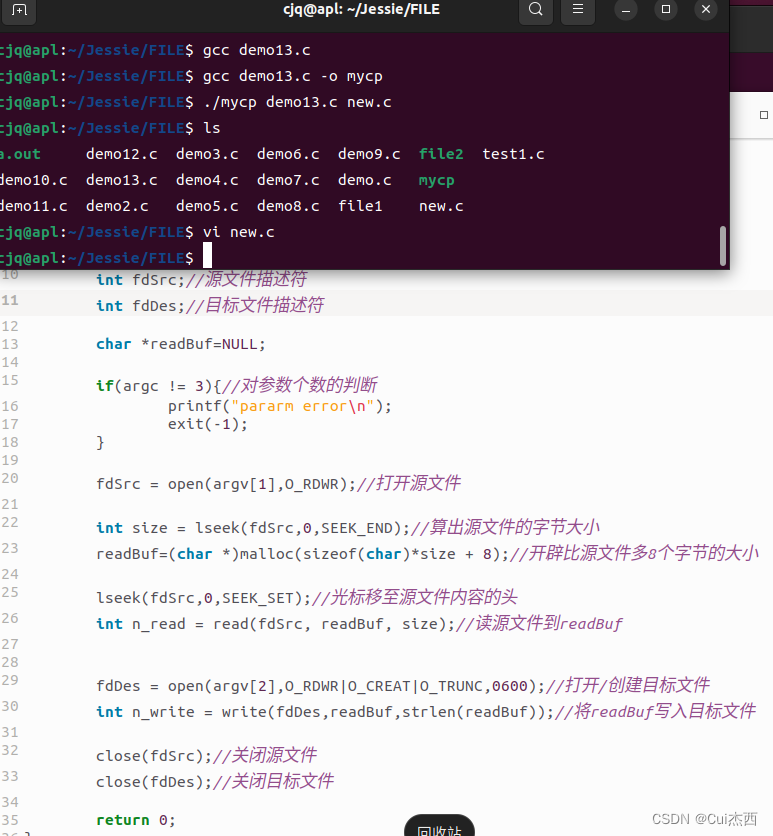
Linux系统编程_文件编程第1天:打开、写入、读取、关闭文件等编程
1. 文件编程概述(399.1) 内容超多: 文件系统原理及访问机制文件在内核中的管理机制什么是文件信息节点inode文件的共享文件权限,各种用户对其权限。。。。。。 应用为王,如: 账单游戏进度配置文件等 关心如…...

scapy构造ND报文
控制报文之:找邻居报文 什么是ND报文 ND报文是指网络中的 Neighbor Discovery(ND)控制报文。Neighbor Discovery 是 IPv6 网络中的一种协议,它用于管理网络节点之间的邻居关系、地址解析、路由缓存维护和自动配置等任务。ND 协议…...

c++设计模式之单例设计模式
💂 个人主页:[pp不会算法v](https://blog.csdn.net/weixin_73548574?spm1011.2415.3001.5343) 🤟 版权: 本文由【pp不会算法^v^】原创、在CSDN首发、需要转载请联系博主 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦…...

App自动化测试环境搭建
目录 1、java jdk安装 2、node.js安装 3、安装模拟器安装 4、Android SDK 安装 5、Appium-Server安装 6、appium客户端安装 7、Appium-Python-Client安装 只做记录和注意点,详细内容不做解释 环境:winappium夜神模拟器python 需要用到的工具&a…...
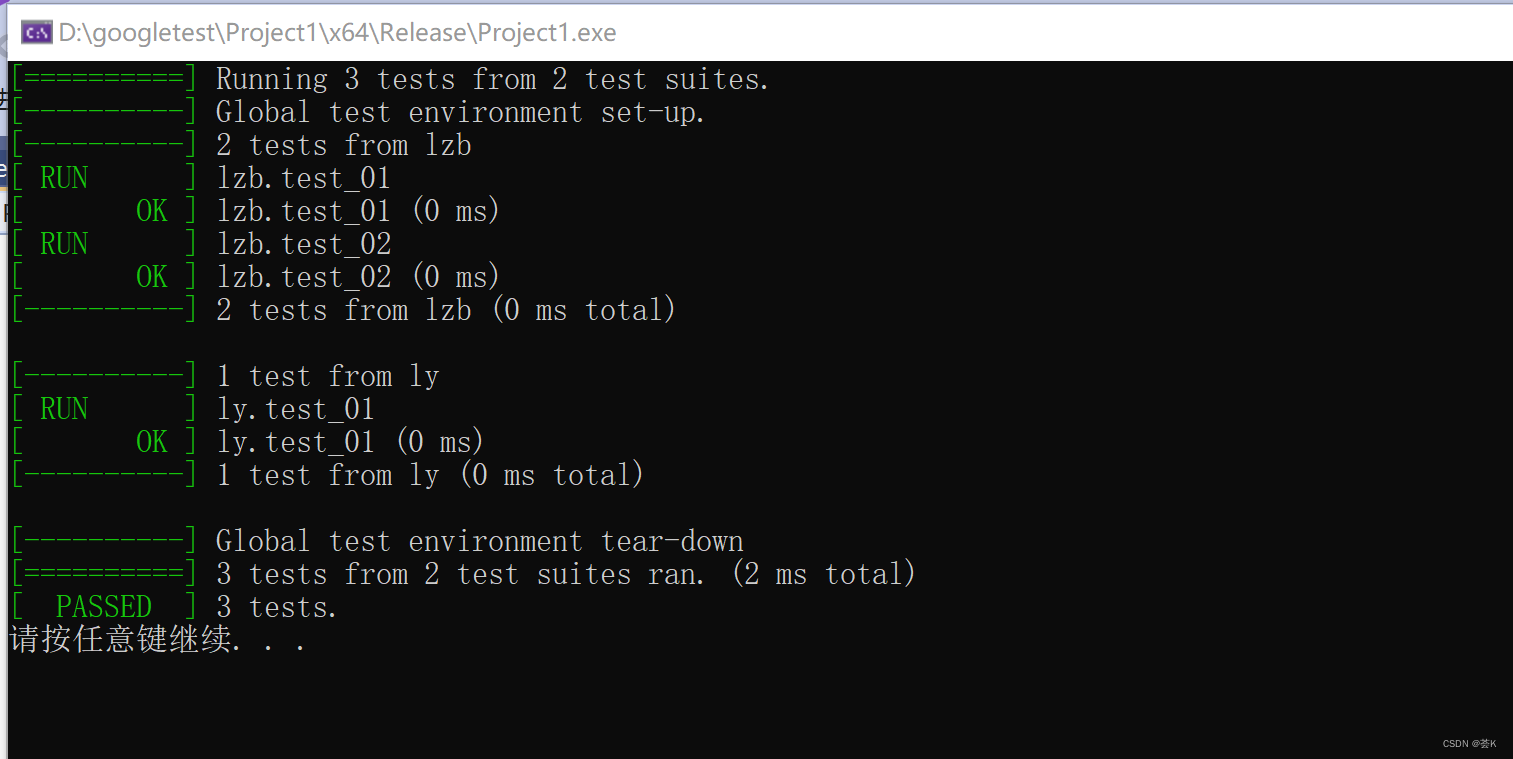
win10搭建gtest测试环境+vs2019
首先是下载gtest,这个我已经放在了博客上方资源绑定处,这个适用于win10vs版本,关于liunx版本的不能用这个。 或者百度网盘链接: 链接:https://pan.baidu.com/s/15m62KAJ29vNe1mrmAcmehA 提取码:vfxz 下…...

【代码随想录】算法训练营 第二天 第一章 数组 Part 2
977. 有序数组的平方 题目 暴力解法 思路 原地更新所有数组元素为其平方数后,再使用sort函数排序,对vector使用sort函数时,两个参数分别是vector的起始元素和终止元素。 代码 class Solution { public:vector<int> sortedSquares(…...

在深度学习中,累计不同批次的损失估计总体损失
在深度学习中,累计不同批次的损失估计总体损失 在深度学习训练模型的过程中,通常会通过计算不同批次间的损失和,当作模型在这个训练集上的总体损失,这种做法是否具有可行性呢? 什么是总体损失? 总体损失是计算模型在…...
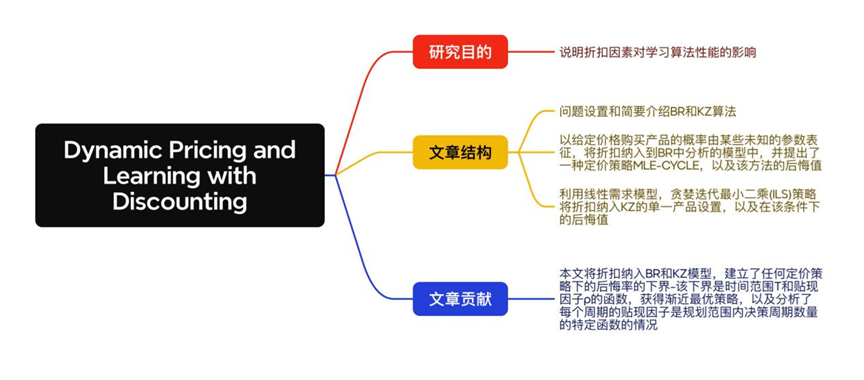
论文导读|八月下旬Operations Research文章精选:定价问题专题
编者按: 在“ Operations Research论文精选”中,我们有主题、有针对性地选择了Operations Research中一些有趣的文章,不仅对文章的内容进行了概括与点评,而且也对文章的结构进行了梳理,旨在激发广大读者的阅读兴…...

(三)Apache log4net™ 手册 -演示
0、引言 在开始本文之前,推荐您首先阅读 Apache log4net™ 手册中有关 介绍 与 配置 的相关内容。本文将通过实践分别为您演示如何使用 Visual Studio 2022 在 .NET Framework 项目和 .NET 项目下配置并使用 Log4Net。 1、为 .NET Framework 项目配置 Log4Net 1.1…...
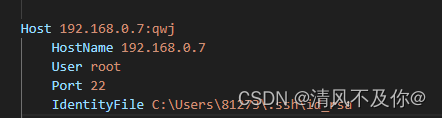
VScode远程root权限调试
尝试诸多办法无法解决的情况下,允许远程登陆用户直接以root身份登录 编辑sshd_config文件 sudo vim /etc/ssh/sshd_config 激活配置 注释掉PermitRootLogin without-password,即#PermitRootLogin without-password 增加一行:PermitRootLo…...

【ARM CoreLink 系列 7 -- TZC-400控制器简介】
文章目录 背景介绍1.1 TZC-400 简介1.2 TZC-400 使用示例1.3 TZC-400 interfaces1.3.1 FPID1.3.2 NSAID Regionregion 检查规则 1.4 Features1.5 Register summary1.6 TZC-400和TZPC和TZASC区别 背景介绍 为了确保内存能够正确识别总线的信号控制位,新增一个TrustZ…...
【C++】-c++11的知识点(中)--lambda表达式,可变模板参数以及包装类(bind绑定)
💖作者:小树苗渴望变成参天大树🎈 🎉作者宣言:认真写好每一篇博客💤 🎊作者gitee:gitee✨ 💞作者专栏:C语言,数据结构初阶,Linux,C 动态规划算法🎄 如 果 你 …...
浅析倾斜摄影三维模型(3D)几何坐标精度偏差的几个因素
浅析倾斜摄影三维模型(3D)几何坐标精度偏差的几个因素 倾斜摄影是一种通过倾斜角度较大的相机拍摄建筑物、地形等场景,从而生成高精度的三维模型的技术。然而,在进行倾斜摄影操作时,由于多种因素的影响,导致…...

【广州华锐互动】智轨列车AR互动教学系统
智轨列车,也被称为路面电车或拖电车,是一种公共交通工具,它在城市的街头巷尾提供了一种有效、环保的出行方式。智轨列车的概念已经存在了很长时间,但是随着科技的发展,我们现在可以更好地理解和欣赏它。通过使用增强现…...
驾驶数字未来:汽车业界数字孪生技术的崭新前景
随着数字化时代的到来,汽车行业正经历着前所未有的变革。数字孪生技术,作为一种前沿的数字化工具,正在为汽车行业带来革命性的影响,不仅改变着汽车制造和维护的方式,也为消费者带来了前所未有的体验。让我们一起探讨&a…...

JVM 性能调优参数
JVM分为堆内存和非堆内存 堆的内存分配用-Xms和-Xmx -Xms分配堆最小内存,默认为物理内存的1/64; -Xmx分配最大内存,默认为物理内存的1/4。 非堆内存分配用-XX:PermSize和-XX:MaxPermSize -XX:PermSize分配非堆最小内存,默认为物理…...

11在SpringMVC中响应到浏览器的数据格式,@ResponseBody注解和@RestController复合注解的功能详解
响应数据/转发或重定向页面 参考文章数据交换的常见格式,如JSON格式和XML格式 服务器将接收到请求处理完以后需要将处理结果告知给浏览器即响应,通常有响应要转发/重定向到的页面和响应数据(文本数据/json数据)两种方式 如果控制器方法返回值类型为void并且没有通过response…...

go 流程控制之switch 语句介绍
go 流程控制之switch 语句介绍 文章目录 go 流程控制之switch 语句介绍一、switch语句介绍1.1 认识 switch 语句1.2 基本语法 二、Go语言switch语句中case表达式求值顺序2.1 switch语句中case表达式求值次序介绍2.2 switch语句中case表达式的求值次序特点 三、switch 语句的灵活…...

AI 系统多模型路由与降级架构设计:从流量调度到无感切换的工程实践
背景 / 现象 在一个典型的 AI 应用系统中,主模型(如 GPT-4o、Claude 3.5 等)通常承担核心推理任务。但在生产环境中,主模型可能因额度耗尽、响应超时、服务不可用或突发限流等原因导致调用失败。此时,用户侧可能表现为…...

如何快速掌握unnpk:网易游戏资源解包的完整入门指南
如何快速掌握unnpk:网易游戏资源解包的完整入门指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否曾经好奇过网易游戏《阴阳师》中那些精美的角色立绘…...

Adobe-GenP 3.0:5分钟解锁Adobe全系列软件的终极秘籍
Adobe-GenP 3.0:5分钟解锁Adobe全系列软件的终极秘籍 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列…...

Page Assist终极指南:在浏览器侧边栏运行本地AI模型的完整解决方案
Page Assist终极指南:在浏览器侧边栏运行本地AI模型的完整解决方案 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist Page Assist是一款…...

第2篇_写MQTTBroker第一关不是PUBLISH_而是怎么让多个客户端稳稳连上同一个端口
写 Broker 最容易一上来就盯着 PUBLISH。但实际测试时,第一关通常不是消息转发,而是:两个客户端都连 192.168.20.100:1883,为什么一个都连不上,或者槽位刚置位就释放?先给结论:MQTT Broker 不是…...

从逻辑实体到系统工程:深度解析软件危机的起源与软件工程的三大支柱
从逻辑实体到系统工程:深度解析软件危机的起源与软件工程的三大支柱 摘要:在计算机科学的浩瀚星图中,“软件”无疑是那颗最耀眼却也最神秘的恒星。它无形无质,却驱动着现代文明的运转。然而,正是这种“无形”ÿ…...

用Python lifetimes库实战:手把手教你用BG/NBD+Gamma-Gamma模型预测电商用户未来3个月价值
用Python lifetimes库实战:电商用户价值预测的极简指南 电商行业的核心挑战之一是如何精准识别高价值用户。想象一下,你手头有一份过去12个月的交易数据,老板要求你在下周的预算会议前,预测未来三个月哪些用户最值得投入营销资源。…...

植物树枝叶片果实检测数据集7220张VOC+YOLO格式
植物树枝叶片果实检测数据集7220张VOCYOLO格式数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):7220 标注数量(xml文件个数):7220…...

【工具实战】告别网页操作:利用Alist+Rclone打造无缝云盘本地化体验
1. 为什么需要云盘本地化? 每次想从网盘下载文件都要打开浏览器、登录账号、找到文件、点击下载,这一套流程走下来至少得花两三分钟。更别提上传大文件时网页端动不动就卡死,或是遇到网络波动导致传输中断的糟心体验。我去年整理家庭照片时就…...

2026届必备的AI辅助论文网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于学术研究的范畴之内,高效且可靠的AI辅助工具正逐渐演变成学者以及学生的得力帮…...