数据库:Hive转Presto(四)
这次补充了好几个函数,并且新加了date_sub函数,代码写的比较随意,有的地方比较繁琐,还待改进,而且这种文本处理的东西,经常需要补充先前没考虑到的情况,要经常修改。估计下一篇就可以补充完所有代码。
import re
import os
import tkinter.filedialog
from tkinter import *class Hive2Presto:def __int__(self):self.t_funcs = ['substr', 'nvl', 'substring', 'unix_timestamp'] + \['to_date', 'concat', 'sum', 'avg', 'abs', 'year', 'month', 'ceiling', 'floor']self.time_funcs = ['date_add', 'datediff', 'add_months', 'date_sub']self.funcs = self.t_funcs + self.time_funcsself.current_path = os.path.abspath(__file__)self.dir = os.path.dirname(self.current_path)self.result = []self.error = []self.filename = ''def main(self):self.root = Tk()self.root.config(bg='#ff741d') # 背景颜色设置为公司主题色^_^self.root.title('Hive转Presto')self.win_width = 550self.win_height = 500self.screen_width = self.root.winfo_screenwidth()self.screen_height = self.root.winfo_screenheight()self.x = (self.screen_width - self.win_width) // 2self.y = (self.screen_height - self.win_height) // 2self.root.geometry(f'{self.win_width}x{self.win_height}+{self.x}+{self.y}')font = ('楷体', 11)self.button = Button(self.root, text='转换', command=self.trans, bg='#ffcc8c', font=font, anchor='e')self.button.grid(row=0, column=0, padx=100, pady=10, sticky=W)self.file_button = Button(self.root, text='选择文件', command=self.choose_file, bg='#ffcc8c', font=font,anchor='e')self.file_button.grid(row=0, column=1, padx=0, pady=10, sticky=W)self.entry = Entry(self.root, width=65, font=font)self.entry.insert(0, '输入Hive代码')self.entry.grid(row=1, column=0, padx=10, pady=10, columnspan=2)self.entry.bind('<Button-1>', self.delete_text)self.text = Text(self.root, width=75, height=20)self.text.grid(row=2, column=0, padx=10, pady=10, columnspan=2)self.des_label = Label(self.root, text='可以复制结果,也有生成的文件,与选取的文件同文件夹', bg='#ffcc8c',font=('楷体', 10))self.des_label.grid(row=3, column=0, padx=10, pady=10, columnspan=2)s = ''for i in range(0, (n := len(self.funcs)), 4):if i + 4 <= n:s += ','.join(self.funcs[i:i + 4]) + '\n'else:s += ','.join(self.funcs[i:]) + '\n's = s[:-1]self.des_label1 = Label(self.root, text=s, bg='#ffcc8c',font=('楷体', 10))self.des_label1.grid(row=4, column=0, padx=10, pady=10, columnspan=2)self.root.columnconfigure(0, minsize=10)self.root.columnconfigure(1, minsize=10)self.root.columnconfigure(0, pad=5)self.root.mainloop()def replace_func(self, s, res):"""把搜索到函数整体取出来,处理括号中的参数:param s::param res::return:"""for f in res:f1 = f.replace('\n', '').strip()f1 = re.sub(r'(\s*)', '(', f1)# 搜索括号里的字符串if re.findall(r'(\w*)\(', f1):func_name = re.findall(r'(\w*)\(', f1)[0].strip()else:continuetry:if 'date_add' == func_name.lower():date, date_num = self.extact_func(f1, func_name)s_n = f"date_add('day',{date_num},cast(substr(cast{date} as varchar,1,10) as date))"s = s.replace(f, s_n)elif 'datediff' == func_name.lower():date1, date2 = self.extact_func(f1, func_name)s_n = f"date_add('day',{date2},cast(substr(cast{date} as varchar,1,10) as date),cast(substr(cast{date1} as varchar),1,10) as date))"s = s.replace(f, s_n)elif 'nvl' == func_name.lower():s1, s2 = self.extact_func(f1, func_name)s_n = f"coalesce({s1},{s2})"s = s.replace(f, s_n)elif 'substr' == func_name.lower():date, start, end = self.extact_func(f1, func_name)s_n = f"substr(cast({date} as varchar),{start},{end}"s = s.replace(f, s_n)elif 'substring' == func_name.lower():date, start, end = self.extact_func(f1, func_name)s_n = f"substring(cast({date} as varchar),{start},{end}"s = s.replace(f, s_n)elif 'unit_timestamp' == func_name.lower():date = self.extact_func(f1, func_name)[0]s_n = f"to_unixtime(cast({date} as timestanp))"s = s.replace(f, s_n)elif 'to_date' == func_name.lower():date = self.extact_func(f1, func_name)[0]s_n = f"cast({date} as date)"s = s.replace(f, s_n)elif 'concat' == func_name.lower():res = self.extact_func(f1, func_name)[0]s_n = f'concat('for r in res:r = r.strip().replace('\n', '')s_n += f"cast({r} as varchar),"s_n = s_n[:-1] + ')'s = s.replace(f, s_n)elif 'sum' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'avg' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'abs' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'ceiling' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'floor' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'year' == func_name.lower():date = self.extact_func(f1, func_name)[0]s_n = f"year(cast(substr(cast({date} as varchar,1,10) as date))"s = s.replace(f, s_n)elif 'month' == func_name.lower():date = self.extact_func(f1, func_name)[0]s_n = f"month(cast(substr(cast({date} as varchar,1,10) as date))"s = s.replace(f, s_n)elif 'date_sub' == func_name.lower():date, date_num = self.extact_func(f1, func_name)s_n = f"date_add('day',-{date_num},cast(substr(cast{date} as varchar,1,10) as date))"s = s.replace(f, s_n)except:self.error.append(f"源代码中{func_name}函数参数输入可能有错误,具体为:{f1}")continueif self.error:self.entry.delete(0, END)self.text.delete("1.0", END)self.text.insert("end", f"{s}")self.error.insert(0, '转换失败,有部分没有转成功\n')root_ex = Tk()root_ex.title('错误')win_width = 600win_height = 200screen_width = root_ex.winfo_screenwidth()screen_height = root_ex.winfo_screenheight()x = (screen_width - win_width) // 2y = (screen_height - win_height) // 2root_ex.geometry(f'{win_width}x{win_height}+{x}+{y}')label_ex = Label(root_ex, text="\n".join(self.error), font=("楷体", 10))label_ex.pack()root_ex.mainloop()return sdef func_trans(self, f, f1, func_name, ss, s):if not ('+' in ss or '-' in ss or '*' in ss or '/' in ss):date = self.extact_func(f1, func_name)[0]s_n = f'{func_name}(cast{date} as double))'s = s.replace(f, s_n)else:res1 = self.mysplit(f1)s_n = fn = len(s_n)for item in res1:if any(c.isalpha() for c in item.replace(' ', '')):idxs = s_n.find(item)idxs = [idxs] if type(idxs) != list else idxsfor idx in idxs:if idx + len(item) + 3 <= n:if not 'as' in s_n[idx:idx + len(item) + 4]:s_n = re.sub(rf'\b{item}\b', f'cast({item} as double)', s_n)else:s_n = re.sub(rf'\b{item}\b', f'cast({item} as double)', s_n)s = s.replace(f, s_n)return sdef choose_file(self):"""如果代码太多,从text中输入会很卡,直接选择代码文件输入会很快:return:"""self.filename = tkinter.filedialog.askopenfilename()if '/' in self.filename:self.filename = self.filename.replace('/', '\\')self.entry.delete(0, END)self.entry.insert(0, self.filename)def findvar(self, ss):"""搜索与计算有关的字段:param ss::return:"""global r1b = ['+', '-', '*', '/', '=', '!=', '>', '<', '<=', '>=', '<>']result1 = []result2 = []result1_n = []result2_n = []res_ops = []res1_ops = []res_adj = []res1_adj = []for op in b:s_temp1 = ss.replace('\n', ' ')s_temp2 = ss.replace('\n', ' ')s_temp3 = ss.replace('\n', ' ')if op == '/' or op == '=':op = opelif op == '+' or op == '-' or op == '*' or op == '>' or op == '<':op = f'\\{op[0]}'else:op = f'\\{op[0]}\\{op[1]}'parttern = f'\s*-*\d+\s*{op}\s*\w+|' + f'\s*-*\d+\.\s*{op}\s*\w+\.\s*\w+|' \+ f'\s*\w+\.\s*\w+\s*{op}\s*\w+\.\s*\w+|' + f'\s*\w+\s*{op}\s*\w+\.\s*\w+|' \+ f'\s*\w+\.\s*\w+\s*{op}\s*\w+|' + f'\s*\w+\s*{op}\s*\w+'parttern1 = f'\s*\)+\s*{op}\s*\w+|' + f'\s*\)+\s*{op}\s*\w+\.\s*\w+|' \+ f'\s*\w+\s*{op}\s*\(+|' + f'f\s*\w+\.\s*{op}\s*\(+'parttern2 = f'\s*\w+\s*{op}\s*\w+|' + f'\s*\w+\s*{op}\s*\w+\.\s*\w+|' \+ f'\s*\w+\s*{op}\s*\w+|' + f'f\s*\w+\.\s*{op}\s*\w+'while True:res = re.findall(parttern, s_temp1)if not res:breakresult2.extend(res)for r in res:r1 = r.replace(' ', '').split(f'op')result1.append(r1)res_ops.append(f'{op}')res_adj.append(False)s_temp1 = s_temp1.replace(f'{r1[0]}', '')# 搜索带括号的计算if op == '+' or op == '-' or op == '*' or op == '/':while True:res = re.findall(parttern1, s_temp2)if not res:breakresult2.extend(res)for r in res:r1 = r.replace(' ', '').split(f'{op}')result1.append(r1)res_ops.append(f'{op}')res_adj.append(False)tem = r1[0] if r1[0].strip() not in ['(', ')'] else r1[1]s_temp2 = s_temp2.replace(f'{tem}', '')else:res = re.findall(parttern2, s_temp3)result2.extend(res)for r in res:r1 = r.replace(' ', '').split(f'{op}')result1.append(r1)res_ops.append(f'{op}')res_adj.append(True)str_ = re.findall(r'\'([^\']*)\'', ss)str_ = list(set(str_))str_ = [v.rstrip(' \n') for v in str_]for i, fun in enumerate(result1):flag = 0for item in fun:if any(item.strip() in v for v in str_) or any(item.strip() == v for v in self.t_funcs):breakflag += 1if flag == 2 and result1[i] not in result1_n:result1_n.append(result1[i])result2_n.append(result2[i])res1_ops.append(res_ops[i])adj = result1[i][0] in self.time_funcs or result1[i][0] in self.time_funcsres1_adj.append(adj)if result1_n:z = zip(result1_n, result2_n, res1_ops, res1_adj)z1 = sorted(z, key=lambda x: len(x[1].replace(' ', '')), reverse=True)result1_n, result2_n, res1_ops, res1_adj = zip(*z1)return result1_n, result2_n, res1_ops, res1_adjdef mysplit(self, s):"""分割字段:param s::return:"""s = s.strip().replace(')', '').replace('(', '')b = ['+', '-', '*', '/']res = [s]result = []for op in b:n_res = []for item in res:n_res.extend(item.split(op))res = n_resfor item in res:if ' as ' not in item:result.append(re.findall(r'^[\w+_*]+$', item.replace(' ', ''))[0])result = list(set(res))return resultdef extact_func(self, s, func_name):res = []s = s[:-1].replace(f'{func_name}(', '', 1)com_idx = [i for i, v in enumerate(s) if v == ',']jd_com_idx = []for i in com_idx:s1 = s[0:i]if s1.count('(') == s1.count(')'):jd_com_idx.append(i)jd_com_idx.append(len(s))jd_com_idx.insert(0, 1)for i in range(1, len(jd_com_idx)):res.append(s[jd_com_idx[i - 1] + 1:jd_com_idx[i]])return resdef sort_funcs(self, li):li = sorted(li, key=lambda x: x.count('('), reverse=True)li_n = []for l in li:li_n.append(l)return li_ndef delete_text(self, event):self.entry.delete(0, END)self.filename = ''def trans(self):passif __name__ == '__main__':pro = Hive2Presto()pro.__int__()pro.main()
相关文章:
)
数据库:Hive转Presto(四)
这次补充了好几个函数,并且新加了date_sub函数,代码写的比较随意,有的地方比较繁琐,还待改进,而且这种文本处理的东西,经常需要补充先前没考虑到的情况,要经常修改。估计下一篇就可以补充完所有…...
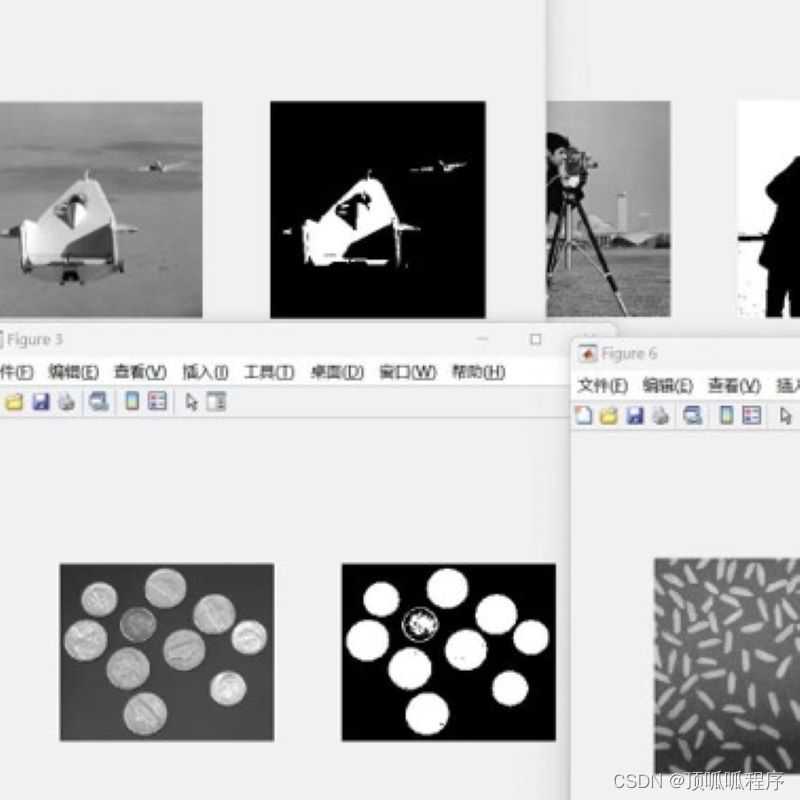
16基于otsuf方法的图像分割,程序已调通,可更换自己的图片进行分割,程序具有详细的代码注释,可轻松掌握。基于MATLAB平台,需要直接拍下。
基于otsuf方法的图像分割,程序已调通,可更换自己的图片进行分割,程序具有详细的代码注释,可轻松掌握。基于MATLAB平台,需要直接拍下。 16matlab图像处理图像分割 (xiaohongshu.com)...

2、使用阿里云镜像加速器提升Docker的资源下载速度
1、注册阿里云账号并登录 https://www.aliyun.com/ 2、进入个人控制台,找到“容器镜像服务” 3、在“容器镜像服务”中找到“镜像加速器” 4、在右侧列表中会显示你的加速器地址,复制地址 5、进入/etc/docker目录,编辑daemon.json࿰…...
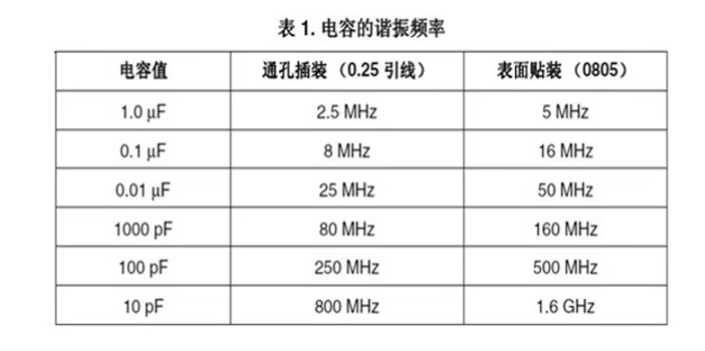
贴片电容材质的区别与电容的主要作用
一、贴片电容材质NPO、COG、X7R、X5R、Y5V、Z5U区别 主要是介质材料不同,不同介质种类由于它的主要极化类型不一样,其对电场变化的响应速度和极化率也不一样。在相同的体积下的容量就不同,随之带来的电容器介质的损耗、容量的稳定性也就不同…...
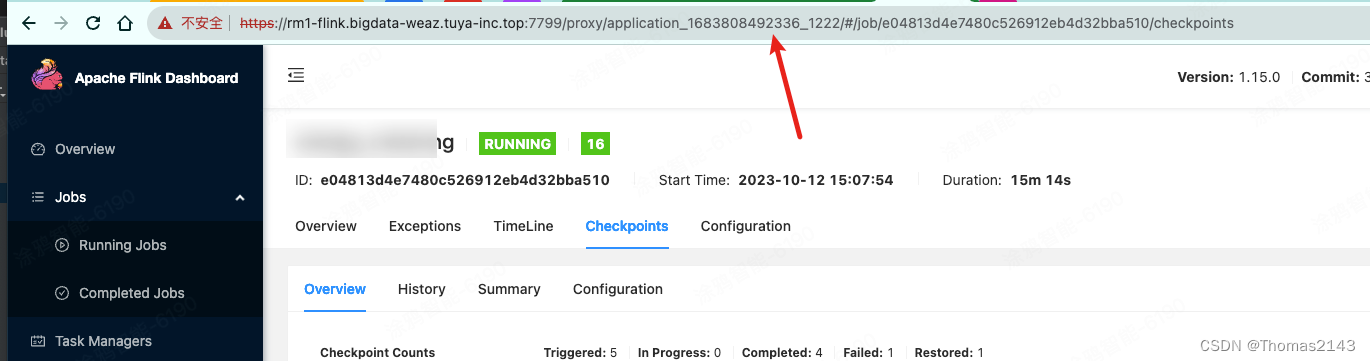
flink1.15 savepoint 超时报错 java.util.concurrent.TimeoutException
savepoint命令 flink savepoint e04813d4e7480c526912eb4d32bba510 hdfs://flink/flink/migration/savepoint56650 -Dyarn.application.id=application_1683808492336_1222报错内容 org.apache.flink.util.FlinkException: Triggering a savepoint for the job e04813d4e7480…...

并发编程——1.java内存图及相关内容
这篇文章,我们来讲一下java的内存图及并发编程的预备内容。 首先,我们来看一下下面的这两段代码: 下面,我们给出上面这两段代码在运行时的内存结构图,如下图所示: 下面,我们来具体的讲解一下。…...
Android studio安装详细教程
Android studio安装详细教程 文章目录 Android studio安装详细教程一、下载Android studio二、安装Android Studio三、启动Android Studio 一、下载Android studio Android studio安装的前提是必须保证安装了jdk1.8版本以上 1、打开android studio的官网:Download…...

Jetson Orin NX 开发指南(7): EGO-Swarm 的编译与运行
一、前言 EGO-Planner 浙江大学 FAST-LAB 实验室的开源轨迹规划算法是,受到 IEEE Spectrum 等知名科技媒体的报道,其理论技术较为前沿,是一种不依赖于ESDF,基于B样条的规划算法,并且规划成功率、算法消耗时间、代价数…...
nginx的重定向
nginx重定向--rewrite重写功能介绍 rewrite 的功能介绍 rewrite功能就是,使用nginx提供的全局变量或自己设置的变量,结合正则表达式和标记位实现URL重写以及重定向。 比如:更换域名后需要保持旧的域名能跳转到新的域名上、某网页发生改变需…...
和切片(Slice))
理解Go中的数组(Array)和切片(Slice)
引言 在Go中,数组和切片是由有序的元素序列组成的数据结构。当需要处理许多相关值时,这些数据集非常适合使用。它们使你能够将本应放在一起的数据放在一起,压缩代码,并一次性对多个值执行相同的方法和操作。 尽管Go中的数组和切…...

计算机毕业设计选什么题目好?springboot 高校学生综合测评管理系统
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 |…...

在liunx下读取串口的数据
1. 设置串口参数 首先是通过stty工具设置串口参数: sudo stty -F /dev/ttyUSB0 比特率 cs8 -cstopb如:sudo stty -F /dev/ttyUSB0 115200 cs8 -cstopb. 注意: 需要注意的是这里需要sudo权限; 2. 读取串口数据 然后读取串口的…...

Python中使用IDLE调试程序
在IDLE中,使用菜单栏中的“Debug”对IDLE打开的python程序进行调试。 1 打开调试开关 选择IDLE菜单栏的“Debug->Debugger”,如图1①所示;此时在IDLE中会显示“[DEBUG ON]”,即“调试模式已打开”,如图1②所示&am…...

发个地区和对应的价格方案
在当今数字化的世界中,网络工程师面临着各种挑战,从跨界电商到爬虫,从出海业务到网络安全,再到游戏领域。为了应对这些挑战,网络工程师需要了解并利用各种技术,其中Socks5代理和代理IP技术成为了他们的得力…...

启动Java应用的黑魔法:初始化性能解密@PostConstrut,InitialzingBean,init-method,BeanPostProcessor
我们在项目中经常会遇到启动时做一些逻辑的处理,比如配置信息的预加载,缓存信息的预加载等等,那都有哪些方法了,我们一起来探讨一下: 1. 方式 1. 构造方法初始化: 使用构造方法进行对象的基本属性初始化。…...

STM32-C语言结构体地址
定义2个结构体 typedef struct _demo_node_{ //结构体本身的地址struct _demo_node_* pprenode; //实际地址开始的位置,最下面的输出结果可以看出struct _demo_node_* pnextnode;unsigned long member_num;unsigned short age;char addr[0]; …...
)
Go HTTP 调用(下)
今天分享的内容是 Go HTTP 调用。如果本文对你有帮助,不妨点个赞,如果你是 Go 语言初学者,不妨点个关注,一起成长一起进步,如果本文有错误的地方,欢迎指出! 前言 上篇文章 Go HTTP 调用&#…...

mysql5.7获取json数组中的某个对象
前言 表中的一个字段类型是字符串,存的是一个对象数据。 现在要根据对象中的某个属性,获取到整个对象信息。 如果是mysql8,则可以使用JSON_TABLE。 示例:https://blog.csdn.net/weixin_44071721/article/details/123347229 sele…...
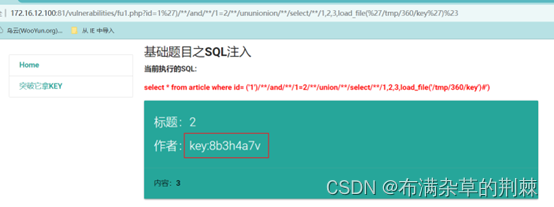
PTE考试解析
Pte 考试题目 注入漏洞 空格被过滤 用/**/代替空格,发现#被过滤 对#进行url编码为%23 输入构造好的payload http://172.16.12.100:81/vulnerabilities/fu1.php?id1%27)/**/and/**/11%23 http://172.16.12.100:81/vulnerabilities/fu1.php?id1%27)/*…...
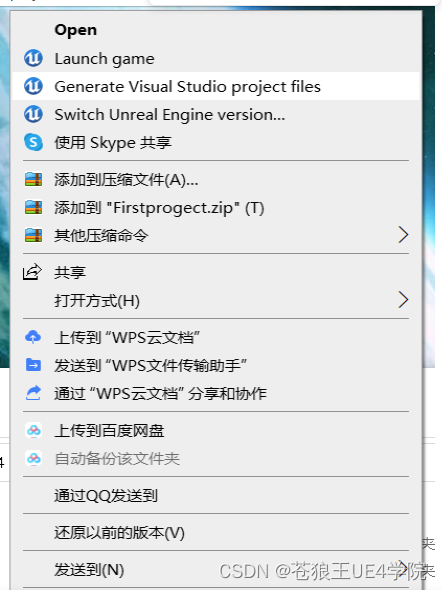
UE4和C++ 开发-UE4怎么删除C++类
1 关闭visual stdio,关闭UE4引擎。 2 打开你的项目文件夹。找到你要删除的.h,.cpp文件删除。 3、删除Binaries文件夹。 4 右击.uproiect文件,点击Generate Visual Studio project files. 5 双击.uproiect文件,忽略警告打开就看到已经删除了想要删除的C类…...

OpenClaw用户如何通过CLI子命令快速完成Taotoken接入配置
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何通过CLI子命令快速完成Taotoken接入配置 对于使用OpenClaw进行AI智能体开发的开发者而言,快速接入稳定…...

系统架构设计师-2025年05月综合案例回忆版
试题 试题一(必选题) 某公司开发一个在线大模型训练平台,支持Python代码编写、模型训练和部署,用户通过python编写模型代码,将代码交给系统进行模型代码的解析,最终由系统匹配相应的计算机资源进行输出,用户不需要关心底层硬件平台,在开发该平台架构时,设计了以下质…...

如何在Inkscape中实现专业级光学设计与光线追踪:矢量绘图软件的光学模拟完整指南
如何在Inkscape中实现专业级光学设计与光线追踪:矢量绘图软件的光学模拟完整指南 【免费下载链接】inkscape-raytracing An extension for Inkscape that makes it easier to draw optical diagrams. 项目地址: https://gitcode.com/gh_mirrors/in/inkscape-rayt…...

别再用默认筛选器了!用Tableau集和计算字段打造“老板最爱看”的交互仪表板
别再用默认筛选器了!用Tableau集和计算字段打造“老板最爱看”的交互仪表板 每次给管理层汇报数据时,最怕遇到什么场景?当你精心准备了20页分析报告,老板却直接翻到最后一页说:"我只关心A事业部和B事业部的表现&a…...

嵌入式网络开发避坑:LwIP软件定时器溢出处理与链表排序的实战细节
嵌入式网络开发避坑:LwIP软件定时器溢出处理与链表排序的实战细节 在嵌入式网络开发中,LwIP协议栈因其轻量级和高度可裁剪性成为众多开发者的首选。然而,在实际应用中,软件定时器的溢出处理和链表排序逻辑往往是引发隐蔽问题的重灾…...

用 TensorFlow Estimator 实现 用户行为预测 的正确姿势
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 用 TensorFlow Estimator 实现用户行为预测的正确姿势:从数据工程到生产部署的全流程实践指南目录用 TensorFlow Est…...

Creo二次开发避坑:用ProAsmcomppathInit搞定装配体遍历,别再卡在ProFeature转ProAsmcomppath了
Creo二次开发实战:高效构建装配体遍历路径的深度解析 在Creo二次开发领域,装配体遍历是许多高级功能的基础操作,但开发者常常会在ProFeature到ProAsmcomppath的转换过程中遭遇瓶颈。本文将从底层数据结构入手,揭示一种被多数文档忽…...
)
为什么你的Perplexity查不到正确代码?——基于127个失败Query的日志审计报告(附修复清单)
更多请点击: https://codechina.net 第一章:为什么你的Perplexity查不到正确代码?——基于127个失败Query的日志审计报告(附修复清单) 我们对127条在Perplexity平台中返回空结果、过时答案或完全偏离编程意图的用户Qu…...

PDF转换器,PDF转换成Word, pdf转换成word文件,如何将pdf转换成word格式,pdf转换成word免费版,pdf转word免费版下载,pdf转换成可编辑的word
文章底部获取资源 PDF文件因其跨平台、格式固定的特性而被广泛应用。PDF文件的编辑难题时常困扰,想要对PDF文件进行修改或提取其中的内容时,却发现如同“铁板一块”,难以撼动。为了解决这一痛点,今天向大家推荐一款高效实用的PDF…...

Cadence OrCAD Capture 层次化电路设计:用NetGroup信号线束高效管理多路SPI/I2C
Cadence OrCAD Capture 层次化电路设计:用NetGroup信号线束高效管理多路SPI/I2C 在嵌入式系统设计中,多路复用接口(如SPI、I2C)的拓扑结构已成为工程师日常面临的挑战。当主控芯片需要连接多个传感器、存储设备或外设模块时&…...