被面试官问到分布式ID,别再傻乎乎只会答雪花算法了...
文章目录
- 1. 分布式ID
- 2. 数据库主键自增
- 3. 数据库号段模式
- 4. Redis自增
- 5. UUID
- 6. Snowflake (雪花算法)
- 7. Leaf (美团分布式ID生成系统)
- 7.1 Leaf-segment 号段方案
- 7.1.2 双buffer优化
- 7.2 Leaf-snowflake方案
- 7.3 Leaf-snowflake Demo
1. 分布式ID
在分布式系统中,通常都需要对大量数据和消息进行唯一标识,这个表示通常被称为分布式ID。
分布式ID是用于识别不同实体或数据对象的,这就要求分布式ID必须具有全局唯一性,不能出现重复的ID。
并且,由于在复杂的分布式系统下,分布式ID使用的场景很多,这就要求分布式ID的生成速度应该足够快,并且对本地资源消耗小。除此之外,生成分布式ID必须是高可用的,因为分布式ID关联着众多系统,必须要求分布式ID的生成的服务可用性无限趋向于100%。
在业务方面,ID通常有以下两个需求,但是这两个需求是互斥的:
- 单调递增:在某些业务场景,ID必须是单调递增的,也就是上一个ID要比下一个ID要小。例如MySQL事务的版本号。
- 无规则:上述的这种ID生成策略,如果遇到恶意的人就能从ID号得到信息。比如存储图片进MySQL的时候,图片的重名是ID自增的,那么别人就可以恶意猜测到下一张图片的URL是啥;再比如,我们所熟悉的订单号,如果订单号是递增的,那么别人就可以知道一天的单量。
现如今,分布式ID的生成方案有很多
- 数据库主键自增
- Redis自增
- UUID
- Snowflake (雪花算法)
- Leaf (美团分布式ID生成系统)
- uid-generator (百度分布式ID生成系统)
- Tinyid (滴滴分布式ID生成系统)
本文重点介绍前五种,后两种以后有机会再做介绍~
2. 数据库主键自增
在MySQL数据库,我们可以通过创建一个具有主键ID自增字段的表。
每次向数据库中插入一条数据,那么数据库插入的记录的ID就会自增ID。
接着,将这个操作抽象成一个服务,那么这就是一个简单的分布式ID生成服务了。
这样的方式实现的分布式ID系统,显而易见的简单,优点也是简单方便。
但是,这样的实现方式会存在以下缺点:
- 并发性能并不好,受限于MySQL的性能
- 当数据量上来的时候,需要进行分库分表,操作起来复杂

3. 数据库号段模式
在前面这种通过数据库自增的方式生成ID,每次都需要访问一次数据库,很容易受到数据库上限导致并发低。
因此可以改造为批量获取然后存进内存里,需要用到的时候直接在内存拿即可。
这就是数据库的号段模式,每次请求分配一个号段,号段模式相比主键自增,性能有一定提升。
4. Redis自增
Redis可以通过自增命令INCR将某一个Key进行自增。
并且这一过程是线程安全的,利用这些特性,我们就可以实现一个分布式ID生成系统,也可以在分布式系统中使用。
这样的分布式ID生成系统,可用性依赖于Redis。
虽然Redis有AOF与RDB持久化,但是依然会存在数据丢失问题。一旦数据发送丢失,那么就可以出现ID重复问题,但是系统出现异常。

5. UUID
UUID是通用唯一标识符(Universally Unique Identifier)的缩写。它是由数字和字母组成的32位字符串,用于在计算机系统中唯一地标识实体或资源。UUID的生成算法能够保证在正常情况下几乎不会生成重复的标识符。
UUID中包含了网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,其就是利用这些元素生成UUID的。
UUID的优点在于UUID的生成性能非常高,因为UUID是本地生成的,没有任何网络消耗。
不过,UUID也存在以下缺点:
- 不易存储:UUID包含了32个16进制的数字,形成8-4-4-4-12的36个字符,生成的ID太长在很多场景不适用
- 信息不安全:UUID看似无规则,实际其是基于MAC地址生成的,因此有可能泄漏MAC地址,MAC地址是可以被用到定位位置的
- 不适用于MySQL主键:在MySQL官方文档中提到,主键的长度应该越短越好

6. Snowflake (雪花算法)
Snowflake,也称雪花算法,是一种用于生成分布式系统中唯一ID的算法。它是Twitter公司开发的,目的是为了解决分布式系统中高并发场景下生成ID的问题。
Snowflake算法生成的ID是一个64位整数,其中包含41位的时间戳、10位的机器ID和12位的序列号。
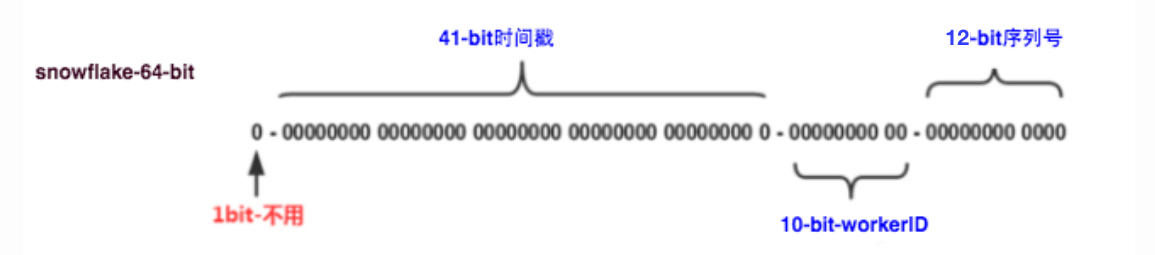
41-bit的时间可以表示(1L<<41)/(1000L360024*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
由于前41为是时间戳,也就是毫秒数,因此雪花算法生成的ID是趋势自增的。
雪花算法不依赖与第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
另外,可以根据业务特性分配bit位,非常灵活。
当然,雪花算法也存在缺点,那就是雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
这是一个雪花算法生成的工具类,是基于hutool工具类生成的
@Component
public class SnowFlake{private Snowflake snowflake;@PostConstructpublic void init() {// 0 ~ 31 位,可以采用配置的方式使用long workerId;try {workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());} catch (Exception e) {workerId = NetUtil.getLocalhostStr().hashCode();}workerId = workerId >> 16 & 31;long dataCenterId = 1L;snowflake = IdUtil.createSnowflake(workerId, dataCenterId);}public synchronized long nextId() {return snowflake.nextId();}}
7. Leaf (美团分布式ID生成系统)

Leaf 是美团开源的一个分布式 ID 解决方案。提供了号段模式 和 Snowflake这两种模式来生成分布式 ID。
Leaf 具有高可靠、低延迟、全局唯一的特点。
7.1 Leaf-segment 号段方案
Leaf-segment 号段方案是基于数据库自增方案做的改进。
在数据库自增方案中,每次获取新的ID都需要请求一次数据库,会造成数据库压力很大。
而在Leaf-segment 号段方案中,改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
在使用 Leaf-segment 号段方案需要建立DB表
CREATE DATABASE leaf
CREATE TABLE `leaf_alloc` (`biz_tag` varchar(128) NOT NULL DEFAULT '',`max_id` bigint(20) NOT NULL DEFAULT '1',`step` int(11) NOT NULL,`description` varchar(256) DEFAULT NULL,`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')
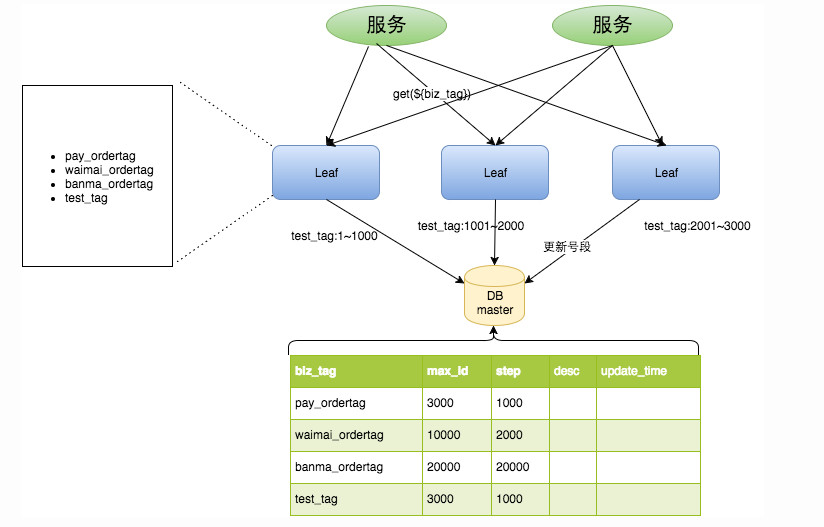
biz_tag是用于区分业务的
max_id表示该biz_tag目前所被分配的ID号段的最大值
step表示每次分配的号段长度原来获取ID每次都需要写数据库,现在只需要把
step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step
test_tag在第一台Leaf机器上是11000的号段,当这个号段用完时,会去加载另一个长度为`step`=1000的号段,假设另外两台号段都没有更新,这个时候第一台机器新加载的号段就应该是30014000。同时数据库对应的biz_tag这条数据的max_id会从3000被更新成4000,更新号段的SQL语句如下:Begin UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx SELECT tag, max_id, step FROM table WHERE biz_tag=xxx Commit
并配置leaf.jdbc.url, leaf.jdbc.username, leaf.jdbc.password
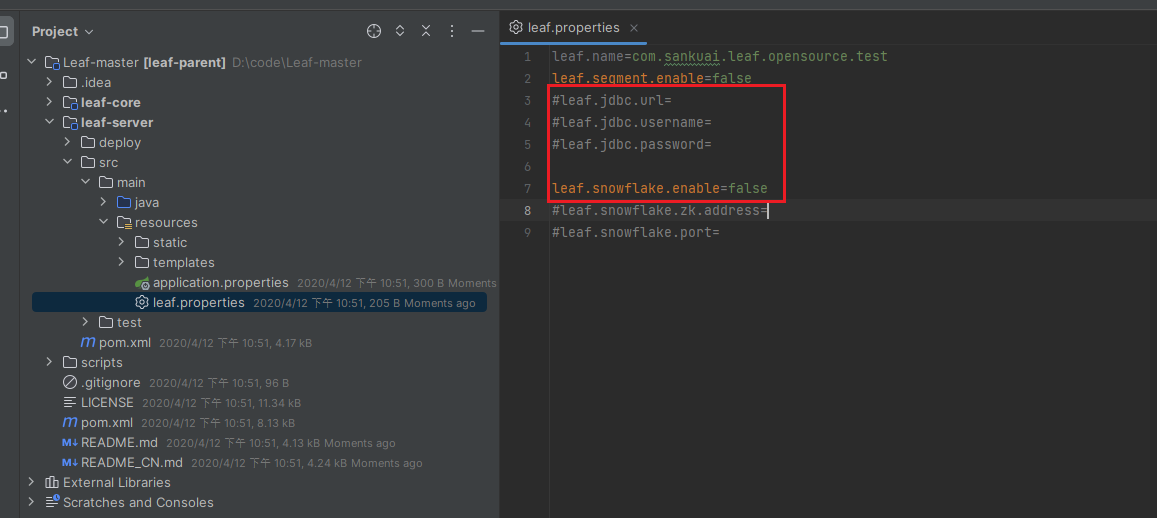
如果不想使用该模式配置leaf.segment.enable=false即可。
Leaf-segment 号段方案有以下优缺点
优点:
- Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
- ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务。
- 可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来。
缺点:
- ID号码不够随机,能够泄露发号数量的信息,不太安全。
- TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tg999数据会出现偶尔的尖刺。
- DB宕机会造成整个系统不可用。
7.1.2 双buffer优化
针对第二个缺点TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tg999数据会出现偶尔的尖刺。
这其中的耗时主要体现在Leaf取号时机是在号段消耗完进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,也就是这段时间内会导致线程阻塞,倘若请求DB的网络和性能不稳定,会导致整体响应时间变慢。
优化思路也很简单,就是希望DB取号段的过程做到无阻塞,也就是在号段消费到某个程度的时候就异步将下一个号段加载进内存中,而不是等待号段消耗完成才去更新号段。
什么是TP999?
TP90就是满足百分之九十的网络请求所需要的最低耗时。
TP99就是满足百分之九十九的网络请求所需要的最低耗时。
同理TP999就是满足千分之九百九十九的网络请求所需要的最低耗时。
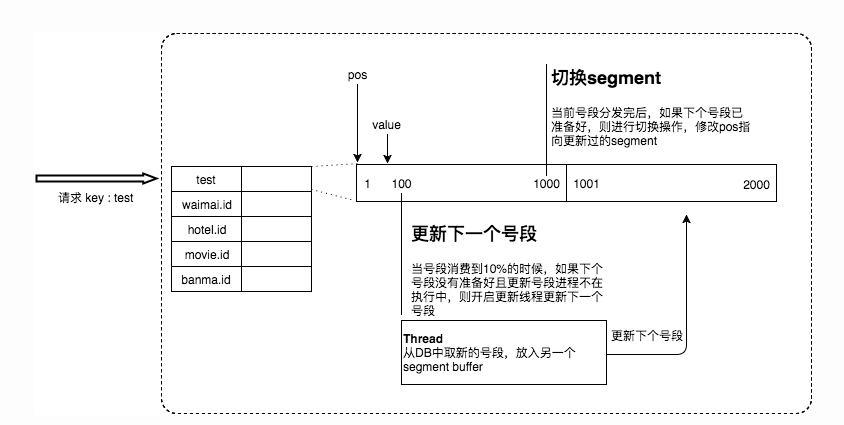
美团Leaf对此的优化是采用双Buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复。
- 每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响。
- 每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新。
7.2 Leaf-snowflake方案
Leaf-segment 号段方案生成的ID是递增的,并不适用与订单场景。
于是Leaf还提供了Leaf-snowflake方案。
Leaf-snowflake方案沿用了Snowflake 的设计思想,也就1+41+10+12的方式装订ID。

对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。Leaf-snowflake是按照下面几个步骤启动的:
- 启动
Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。 - 如果有注册过直接取回自己的
workerID(zk顺序节点生成的int类型ID号),启动服务。 - 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的
workerID号,启动服务。
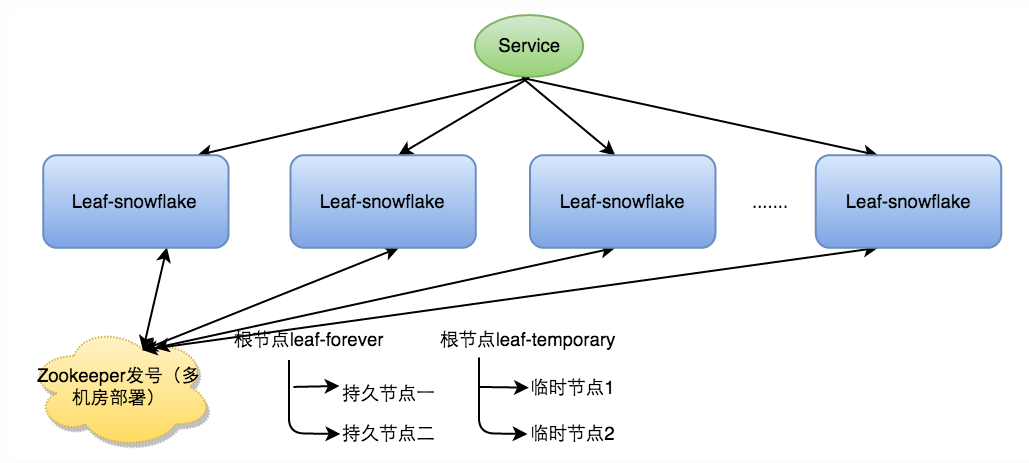
该方式除了每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件。这样的好处在于ZK出现问题的时候,能确保服务能够正常启动,这样使得Leaf-snowflake弱依赖于第三方组件。
那么
Leaf-snowflake是如何解决时钟问题呢?
snowflake算法当时钟回拨的时候,有可能出现重复ID的情况,在Leaf-snowflake是这也解决时钟问题的。
- 服务会先检查自己是否写过
ZooKeeper leaf_forever节点- 如果写过,则用自身系统时间与leaf_forever/${self}节点记录时间做比较,如果小于则认为机器时间发生回拨,服务启动失败并报警
- 如果没写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。
- 若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约。
- 否则认为本机系统时间发生大步长偏移,启动失败并报警。
- 每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}。
由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警,如下:
//发生了回拨,此刻时间小于上次发号时间if (timestamp < lastTimestamp) {long offset = lastTimestamp - timestamp;if (offset <= 5) {try {//时间偏差大小小于5ms,则等待两倍时间wait(offset << 1);//waittimestamp = timeGen();if (timestamp < lastTimestamp) {//还是小于,抛异常并上报throwClockBackwardsEx(timestamp);} } catch (InterruptedException e) { throw e;}} else {//throwthrowClockBackwardsEx(timestamp);}}//分配ID
7.3 Leaf-snowflake Demo
想要使用Leaf-snowflake方案,首先需要上GitHub将项目clone下来
美团Leaf:下载,
然后安装并启动Zookeeper,这里可以参考这个博客:Zookeeper 安装(Windows)_zookeeper windows安装_coder i++的博客-CSDN博客
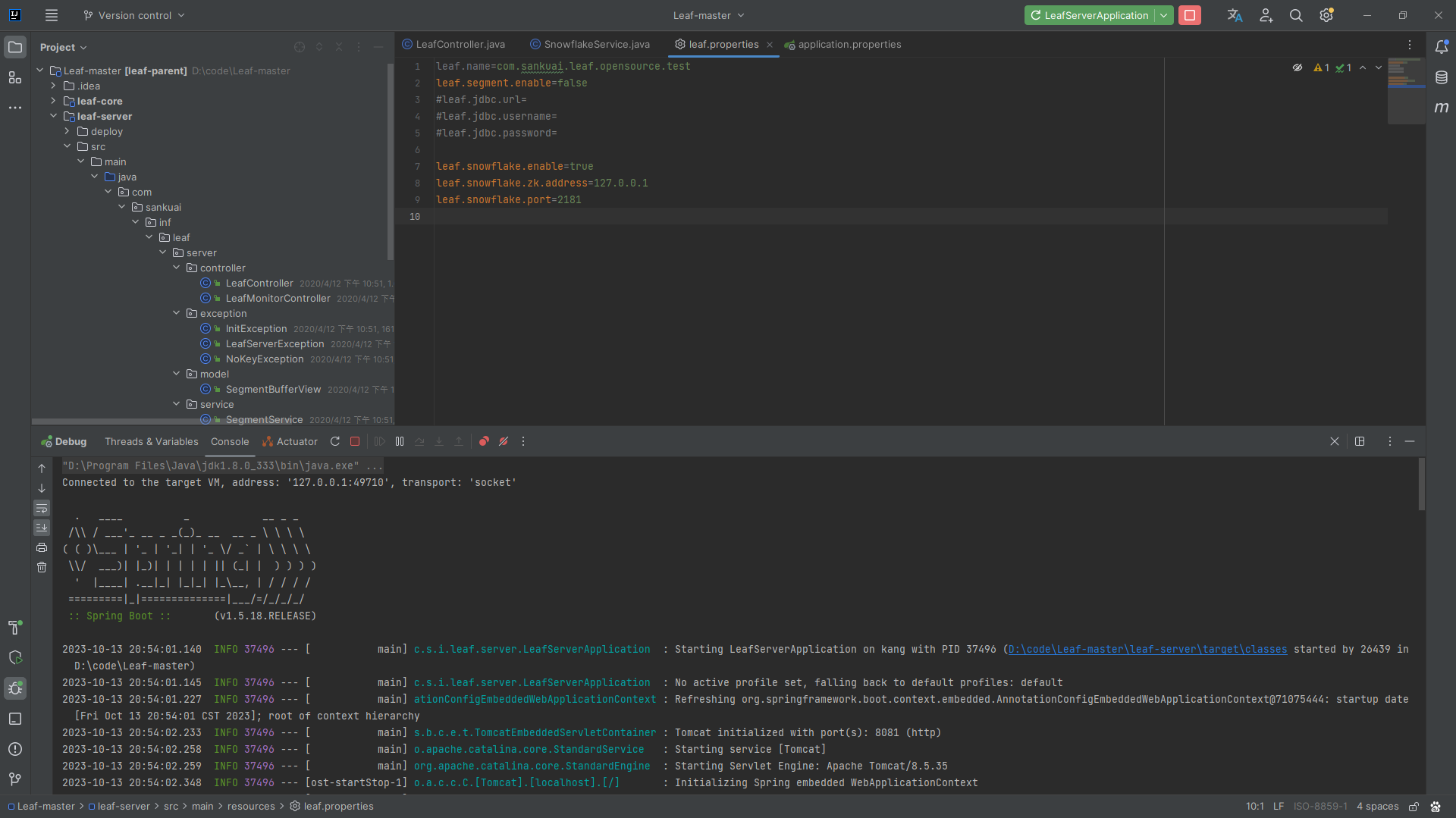
完成后,配置leaf.properties,因为这里使用的snowflake 方案,所以leaf.segment.enable设置为false,leaf.snowflake.enable设置为true,并配置Zookeeper的地址和端口
leaf.name=com.sankuai.leaf.opensource.test
leaf.segment.enable=false
#leaf.jdbc.url=
#leaf.jdbc.username=
#leaf.jdbc.password=leaf.snowflake.enable=true
leaf.snowflake.zk.address=127.0.0.1
leaf.snowflake.port=2181
启动leaf-server服务,默认端口为8080。但是由于这里我冲突了,所以我将端口设置为8081。
浏览器访问(http://127.0.0.1:8081/api/snowflake/get/leaf-test),就会得到一个ID

对应的调用就是LeafController的getSnowflakeId方法,这里需要传入一个Key,这个Key可以是用到这个分布式ID生成的服务表示,这样可以做到不同模块之间的分布式ID隔离。

Leaf的简单使用就到这里了,在项目中可以将该项目单独为一个服务,使用OpenFeign或是Dubbo等RPC框架远程调用获取接口。
参考:
- Leaf——美团点评分布式ID生成系统 - 美团技术团队 (meituan.com)
- 面试总被问分布式ID? 美团(Leaf)了解一下 - 掘金 (juejin.cn)
- 不能错过的分布式ID生成器(Leaf ),好用的一批! - 掘金 (juejin.cn)
- 分布式ID生成服务的技术原理和项目实战 - 掘金 (juejin.cn)
- 【分布式系统】10种分布式唯一ID生成方案总结 - 掘金 (juejin.cn)
- 常见分布式ID解决方案总结:数据库、算法、开源组件 - 掘金 (juejin.cn)
相关文章:
被面试官问到分布式ID,别再傻乎乎只会答雪花算法了...
文章目录 1. 分布式ID2. 数据库主键自增3. 数据库号段模式4. Redis自增5. UUID6. Snowflake (雪花算法)7. Leaf (美团分布式ID生成系统)7.1 Leaf-segment 号段方案7.1.2 双buffer优化 7.2 Leaf-snowflake方案7.3 Leaf-snowflake Demo 1. 分布式ID 在分布式系统中,通…...

使用Boto3访问AWS S3服务
安装Boto3,执行如下命令: python -m venv .venv . .venv/bin/activate python -m pip install boto3创建配置文件,执行如下命令: mkdir -p ~/.aws touch ~/.aws/credentials touch ~/.aws/config编辑 ~/.aws/credentials&#x…...

ODrive移植keil(五)—— 开环控制和电流变换
目录 一、开环控制1.1、控制原理1.2、硬件接线1.3、代码说明1.4、程序演示1.5、程序架构的体现 二、电流变换2.1、理论说明2.2、代码说明 ODrive、VESC和SimpleFOC 教程链接汇总:请点击 一、开环控制 在SimpleFOC系列中有开环控制的教程,SimpleFOC移植S…...

【Java学习之道】日期与时间处理类
引言 在前面的章节中,我们介绍了Java语言的基础知识和核心技能,现在我们将进一步探讨Java中的常用类库和工具。这些工具和类库将帮助我们更高效地进行Java程序开发。在本节中,我们将一起学习日期与时间处理类的使用。 一、为什么需要日期和…...
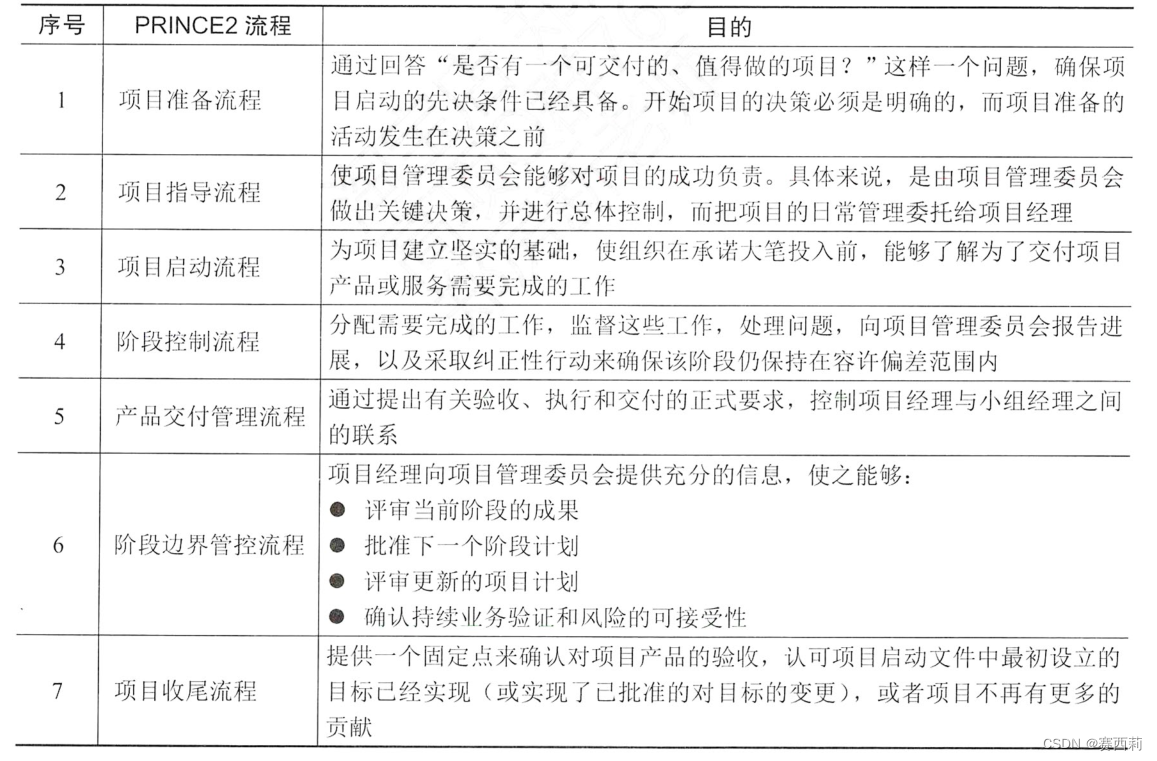
信息系统项目管理师第四版学习笔记——高级项目管理
项目集管理 项目集管理角色和职责 在项目集管理中涉及的相关角色主要包括:项目集发起人、项目集指导委员会、项目集经理、其他影响项目集的干系人。 项目集发起人和收益人是负责承诺将组织的资源应用于项目集,并致力于使项目集取得成功的人。 项目集…...

MySQL建表操作和用户权限
1.创建数据库school,字符集为utf8 mysql> create database school character set utf8; 2.在school数据库中创建Student和Score表 mysql> create table school.student( -> Id int(10) primary key, -> Stu_id int(10) not null, -> C_n…...

TCP/IP(十一)TCP的连接管理(八)socket网络编程
一 socket网络编程 socket 基本操作函数 bind、listen、connect、accept、recv、send、select、close 说明: 本文需要C语言、syscall系统调用、OS 操作系统基础理论,如果不了解可以暂时跳过目标: 知道对应库函数的更底层机制思考: socket函数与FIN、A…...
第五章 图
第五章 图 图的基本概念图的应用背景图的定义和术语 图的存储结构邻接矩阵邻接表 图的遍历连通图的深度优先搜索连通图的广度优先搜索 图的应用最小生成树拓扑排序 小试牛刀 图的基本概念 图结构中,任意两个结点之间都可能相关;而在树中,结点…...

深度学习实战:用Keras搭建深度学习网络做手写数字识别
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...

算法解析:LeetCode——机器人碰撞和最低票价
摘要:本文由葡萄城技术团队原创并首发。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 机器人碰撞 问题: 现有 n 个机器人,编号从 1 开始,每个…...
LeetCode刷题总结 - LeetCode 热题 100 - 持续更新
LeetCode 热题 100 其他系列哈希1. 两数之和49. 字母异位词分组128. 最长连续序列 双指针27. 移除元素283. 移动零11. 盛最多水的容器剑指 Offer II 007. 数组中和为 0 的三个数42. 接雨水 滑动窗口438. 找到字符串中所有字母异位词3. 无重复字符的最长子串 字串560. 和为 K 的…...
Spring是什么?为什么要使用Spring?
目录 前言 一、Spring是什么? 1.1 轻量级 1.2 JavaEE的解决方案 二、为什么要使用Spring 2.1 传统方式完成业务逻辑 2.2 使用Spring模式完成业务逻辑 三、为什么使用Spring? 前言 本文主要介绍Spring是什么,并且解释为何要去使用Spring&…...

自我监督学习日志
学习日志 10.12 一天学不了一分钟,不知道为什么也就是了 今天一定要学一个小时! 机器学习就是机器帮我们找一个函数 语音辨识,语音,声音讯号 转化为文字 帮我们找一个人类写不出来的复杂函数 类神经网络 输入 一张图片用一个矩…...

配置CA证书
前置条件 配置Java环境变量。 具体操作 windows环境 以管理员方式执行CMD窗口,输入命令; cd /d %JAVA_HOME%\jre\lib\securitycurl -kv https://xxx/artifactory/CMC-Release/certificates/xxxRootCA.cer -o xxxRootCA.cercurl -kv https://xxx/art…...

计算机毕业设计选什么题目好?springboot 高校就业管理系统
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 |…...

上海-华为全联接大会|竹云受邀参加华为云ROMAConnect行业生态联盟成立联合发布会
2023年9月22日,在上海举办的华为全联接大会上,竹云作为华为云全方位合作伙伴代表,受邀参加华为云ROMAConnect行业生态联盟成立联合发布会。华为云PaaS服务产品部副部长张甲磊以及联盟主要成员企业出席发布仪式,共同见证华为云ROMA…...

走进GraalVM
是什么 GraalVM是一个高性能的JDK,旨在加速用Java和其他JVM语言编写的应用程序的执行,同时还为JavaScript,Python,Ruby和许多其他流行语言提供运行特点 GraalVM可以代替JDK、JVM之前的工作。 GraalVM除了支持Java,也支…...
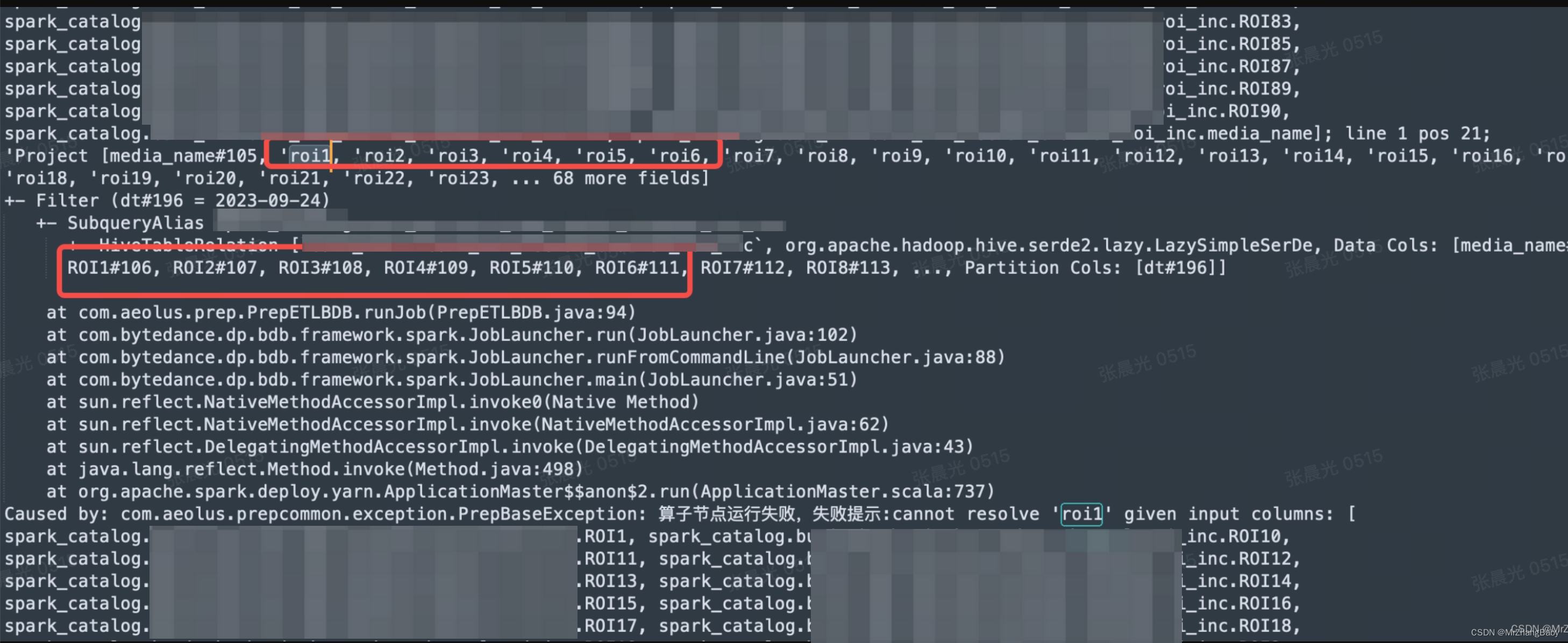
spark读取hive表字段,区分大小写问题
背景 spark任务读取hive表,查询字段为小写,但Hive表字段为大写,无法读取数据 问题错误: 如何解决呢? In version 2.3 and earlier, when reading from a Parquet data source table, Spark always returns null for any column …...
 和实现文件(.cpp)区别)
UE4和C++ 开发-头文件(.h) 和实现文件(.cpp)区别
.h文件和.cpp文件是C程序中的两种不同类型的文件。 .h文件通常包含类、函数和变量的声明, 而.cpp文件包含这些声明的实现。 .h文件中的声明通常是公共的,可以被其他文件包含和使用。.cpp文件中的实现通常是私有的,只能在该文件中使用。 在…...
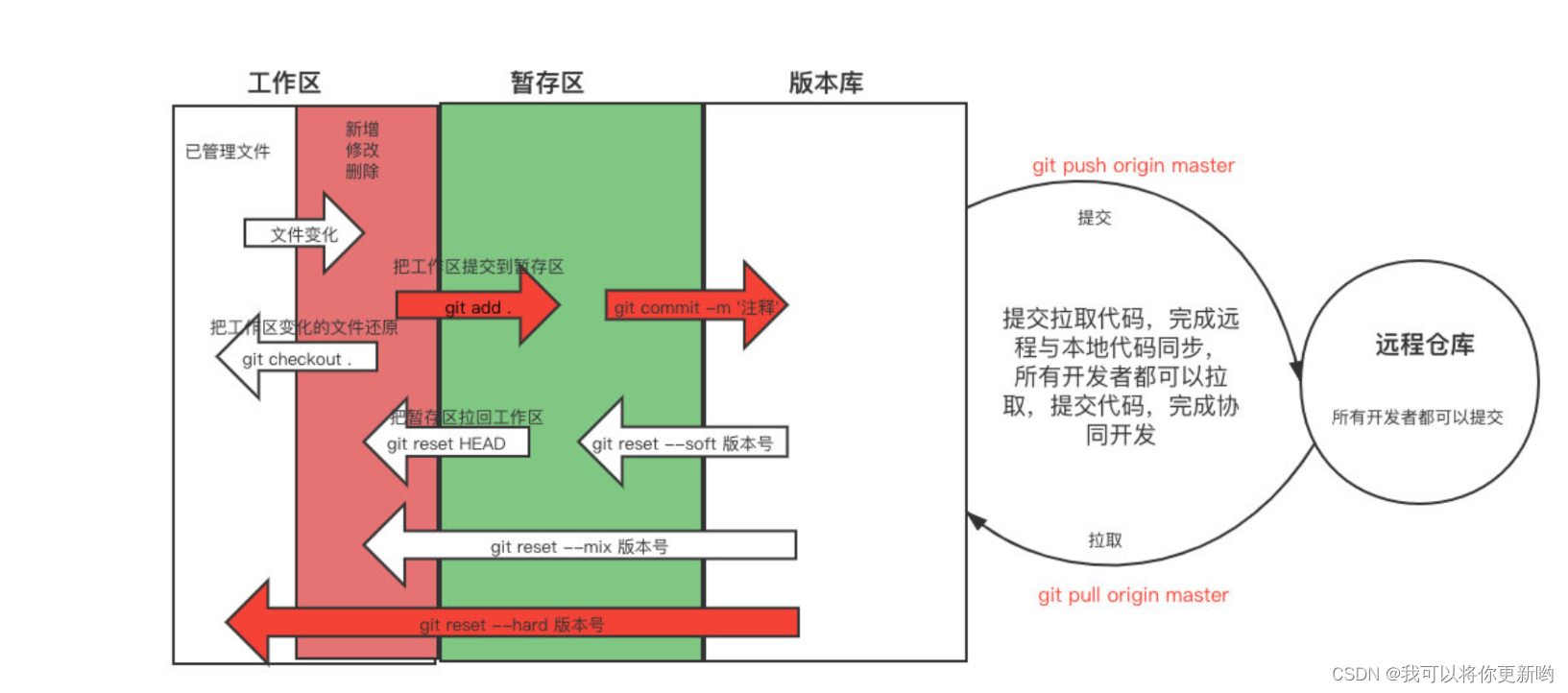
git介绍和安装、(git,github,gitlab,gitee介绍)、git工作流程、git常用命令、git忽略文件
1 git介绍和安装 2 git,github,gitlab,gitee介绍 3 git工作流程 4 git常用命令 5 git忽略文件 1 git介绍和安装 首页功能写完了---》正常应该提交到版本仓库---》大家都能看到这个---》 运维应该把现在这个项目部署到测试环境中---》测试…...

英雄联盟个性化改造神器:3分钟打造专属游戏身份
英雄联盟个性化改造神器:3分钟打造专属游戏身份 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 还在为千篇一律的英雄联盟个人资料感到乏味吗?想要在好友面前展示与众不同的游戏身份却苦于官方限制&…...

这种界面和额外附加认证要求以前从来没有过
注册github账号很早就有了,但这种认证要求以前从来没有过。 自从上传了这个代码: mcp 桥接器 就多了认证要求。 发生了什么 :GitHub 现在要求所有活跃开发者都必须开启双重身份验证(2FA),以保护账号不被黑…...

【紧急预警】NotebookLM 2.3版本将关闭本地PDF语义隔离模式——社会科学研究者必须在48小时内完成知识库迁移
更多请点击: https://kaifayun.com 第一章:NotebookLM 2.3版本语义隔离模式终止的技术动因与社会科学研究范式冲击 语义隔离模式终止的核心技术动因 NotebookLM 2.3 版本正式移除了“语义隔离(Semantic Isolation)”模式&#x…...

【亲测免费】 高效便捷的AD域管理Web工具:简化您的域管理流程
高效便捷的AD域管理Web工具:简化您的域管理流程 【下载地址】AD域管理Web版工具 本资源提供了一个基于微软官方文档,使用.NET技术开发的Web AD域管理工具。该工具采用简单的HTML和一般处理程序(Generic Handler)来实现,…...

对比直接使用官方API体验Taotoken在用量可视化方面的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API体验Taotoken在用量可视化方面的优势 效果展示类,分享开发者在同时使用官方渠道与Taotoken聚合服务…...

从Typora迁移到Obsidian,我踩过的那些坑和高效配置方案
从Typora迁移到Obsidian:无缝过渡的深度实践指南 当我在2022年决定将积累了5年的技术笔记库从Typora迁移到Obsidian时,最初以为只是换个编辑器那么简单。直到实际操作时才发现,这两个看似相似的Markdown工具在使用哲学和操作细节上存在诸多差…...

终极GBFR Logs指南:掌握碧蓝幻想Relink伤害分析的完整教程
终极GBFR Logs指南:掌握碧蓝幻想Relink伤害分析的完整教程 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr-logs …...

粉笔事业单位适合备考资格复审后面试吗?从材料确认、题型训练到岗位表达的评测
更新日期:2026年5月 很多事业单位考生在进入资格复审后,会搜索“粉笔事业单位怎么样”“粉笔事业单位面试适合资格复审后准备吗”“事业单位资格复审后怎么准备面试”。这些问题背后,真正关心的是:资格复审通过后距离面试通常不远…...

ARM架构操作系统内核设计与多线程优化实践
1. 操作系统内核基础与多线程实现1.1 内核架构与资源管理现代操作系统内核作为计算机系统的核心,承担着硬件抽象和资源管理的双重职责。在Raspberry Pi这样的ARM架构设备上,内核需要特别处理以下关键组件:内存管理单元(MMU):通过两…...

C++ STL set与multiset容器:红黑树实现、核心操作与性能优化指南
1. 容器概览:为什么我们需要 set 和 multiset?在C的日常开发里,尤其是处理需要快速查找、去重或排序的数据集合时,std::set和std::multiset这两个关联容器出场率极高。很多刚从顺序容器(如vector、list)转过…...