【LeetCode高频SQL50题-基础版】打卡第7天:第36~40题
文章目录
- 【LeetCode高频SQL50题-基础版】打卡第7天:第36~40题
- ⛅前言
- 按分类统计薪水
- 🔒题目
- 🔑题解
- 上级经理已离职的公司员工
- 🔒题目
- 🔑题解
- 换座位
- 🔒题目
- 🔑题解
- 电影评分
- 🔒题目
- 🔑题解
- 餐馆营业额变化增长
- 🔒题目
- 🔑题解
【LeetCode高频SQL50题-基础版】打卡第7天:第36~40题
⛅前言
在这个博客专栏中,我将为大家提供关于 LeetCode 高频 SQL 题目的基础版解析。LeetCode 是一个非常受欢迎的编程练习平台,其中的 SQL 题目涵盖了各种常见的数据库操作和查询任务。对于计算机科班出身的同学来说,SQL 是一个基础而又重要的技能。不仅在面试过程中经常会遇到 SQL 相关的考题,而且在日常的开发工作中,掌握 SQL 的能力也是必备的。
本专栏的目的是帮助读者掌握 LeetCode 上的高频 SQL 题目,并提供对每个题目的解析和解决方案。我们将重点关注那些经常出现在面试中的题目,并提供一个基础版的解法,让读者更好地理解问题的本质和解题思路。无论你是准备找工作还是提升自己的技能,在这个专栏中,你可以学习到很多关于 SQL 的实践经验和技巧,从而更加深入地理解数据库的操作和优化。
我希望通过这个专栏的分享,能够帮助读者在 SQL 的领域里取得更好的成绩和进步。如果你对这个话题感兴趣,那么就跟随我一起,开始我们的 LeetCode 高频 SQL 之旅吧!
- 博客主页💖:知识汲取者的博客
- LeetCode高频SQL100题专栏🚀:LeetCode高频SQL100题_知识汲取者的博客-CSDN博客
- Gitee地址📁:知识汲取者 (aghp) - Gitee.com
- 题目来源📢:高频 SQL 50 题(基础版) - 学习计划 - 力扣(LeetCode)全球极客挚爱的技术成长平台
按分类统计薪水
🔒题目
题目来源:1907.按分类统计薪水

🔑题解
- 考察知识点:
union、sum
分析:这一题的难点(当然这个难点是对于我而言的,可能对你而言很简单😄)在于对于将不同列名映射到同一个列名中来,也就是 category 这一列,居然是直接使用一个字符串常量来实现映射,平常没怎么见过这种写法,所以一时也没有想到,其实把这一点想到了应该会很简单,因为 union 还是很常见的
1)查询出处于 Low Salary 的账号数量
select 'Low Salary' category, sum(if(income < 20000, 1, 0)) accounts_count
from Accounts;
| category | accounts_count |
| ---------- | -------------- |
| Low Salary | 1 |
2)查询出处于 Average Salary 的账号数量
select 'Average Salary' category, sum(if(income between 20000 and 50000, 1, 0)) accounts_count
from Accounts;
当然这里也可以使用 <= 和 >= 加一个 and 进行连接,用于替代 between and
| category | accounts_count |
| -------------- | -------------- |
| Average Salary | 0 |
3)查询出处于 High Salary 的账号数量
select 'High Salary' category, sum(income > 50000) accounts_count
from Accounts;
| category | accounts_count |
| ----------- | -------------- |
| High Salary | 3 |
4)使用 union 将前面所有的结果集进行合并
select 'Low Salary' category, sum(if(income < 20000, 1, 0)) accounts_count
from Accounts
union
select 'Average Salary' category, sum(if(income between 20000 and 50000, 1, 0)) accounts_count
from Accounts
union
select 'High Salary' category, sum(income > 50000) accounts_count
from Accounts;
温馨提示:这里更加推荐使用 union all ,性能更高,通过提交测试可以发现,使用 union 普遍在 5%~20%,union all 普遍在 50%~70%
这里也不仅仅只能使用 sum 函数,也可以使用 count 函数
select 'Low Salary' category, count(*) accounts_count
from Accounts
where income < 20000
union all
select 'Average Salary' category, count(*) accounts_count
from Accounts
where income between 20000 and 50000
union all
select 'High Salary' category, count(*) accounts_count
from Accounts
where income > 50000;
经过提交测试,发现这种写法的性能更高,普遍高达 90% 以上
上级经理已离职的公司员工
🔒题目
题目来源:1978.上级经理已离职的公司员工
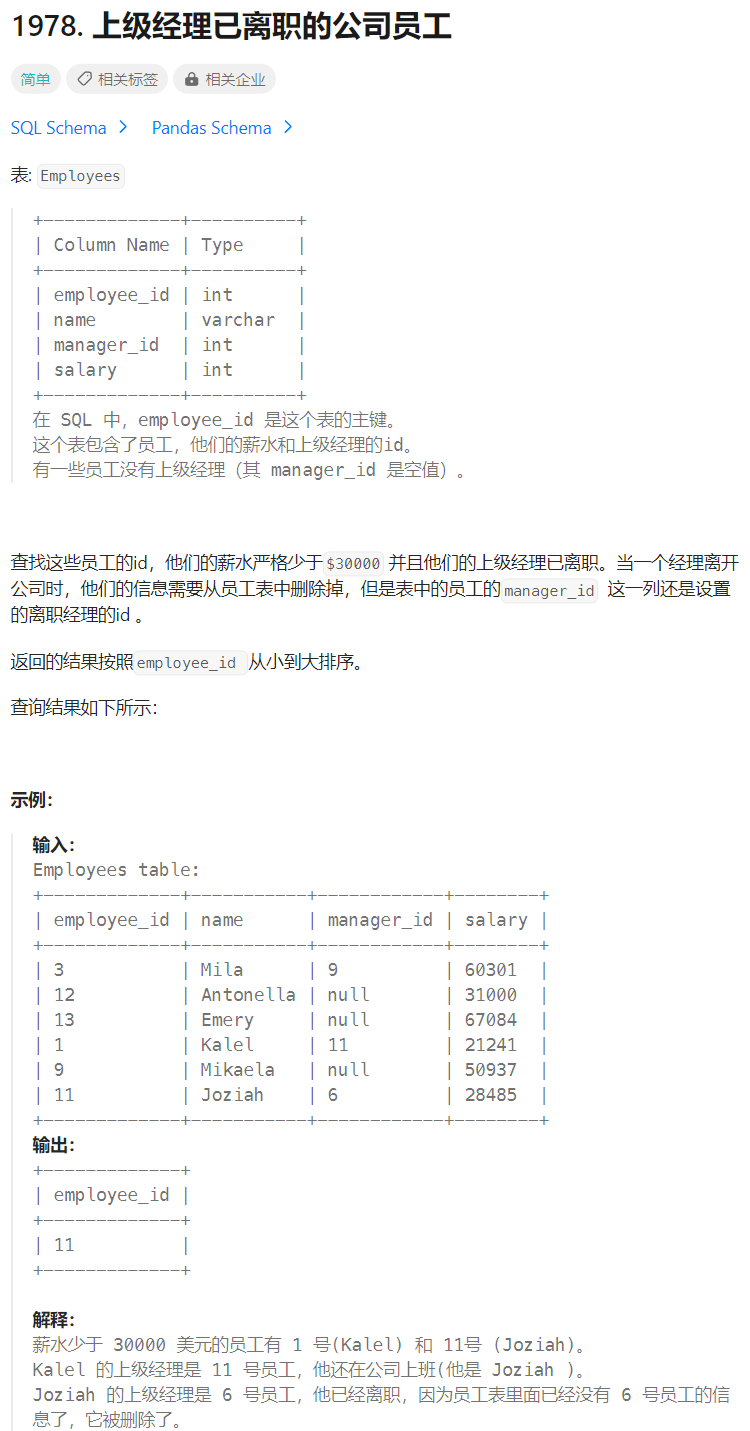
🔑题解
- 考察知识点:
分析:主要分为三步
- 查询处薪资小于30000的员工
- 查询出所有在职员工的id
- 判断小于30000的员工的 manger_id 是否在 2 所查询的结果集中
1)查询处薪资小于30000的员工
select *
from Employees
where salary < 30000;
| employee_id | name | manager_id | salary |
| ----------- | ------ | ---------- | ------ |
| 1 | Kalel | 11 | 21241 |
| 11 | Joziah | 6 | 28485 |
2)查询出所有在职员工的 id
select distinct employee_id
from Employees;
| employee_id |
| ----------- |
| 3 |
| 12 |
| 13 |
| 1 |
| 9 |
| 11 |
3)判断小于30000的员工的 manger_id 是否在 2 所查询的结果集中
select employee_id
from Employees
where salary < 30000 and manager_id not in (select distinct employee_idfrom Employees
)
order by employee_id asc;
换座位
🔒题目
题目来源:626.换座位

🔑题解
- 考察知识点:
mod、
分析:陷入了思维定式,我下意识的选择奖两个记录像冒泡排序一样进行两两交换,结果发现自己并不知道如何实现。后面看了题解,发现居然就是通过修改id即可实现两两交换😆,一下没想到,看完之后我就悟了,具体的实现思路如下:
- id为奇数的统一加一
- id为偶数的统一都减一
- 如果记录总数为奇数,最后一条记录的id不需要改变
解法一:自连接
1)第一步,先查询出记录的总数
select count(*) counts
from seat;
| counts |
| ------ |
| 5 |
2)将查询道的记录连接每条记录中
select *
from seat, (select count(*) counts from seat) seat_counts;
| id | student | counts |
| -- | ------- | ------ |
| 1 | Abbot | 5 |
| 2 | Doris | 5 |
| 3 | Emerson | 5 |
| 4 | Green | 5 |
| 5 | Jeames | 5 |
3)对上面查询出的结果集使用 case 对 id 进行判断,最后进行应该排序
select (casewhen mod(id, 2) != 0 and counts != id then id + 1 -- id为奇数并且不为最后一条记录when mod(id, 2) != 0 and counts = id then id -- id为奇数但为最后一条记录else id - 1 -- id为偶数end) id,student
from seat, (select count(*) counts from seat) seat_counts
order by id asc;
备注:上面的case when结果全部可以由if替代
解法二:子查询
解法一通过自连接将将总记录数添加到每一条记录上,然后进行查询,我们也可以不这些写,直接使用最大id数来判断是否是最后一条记录,这种写法可能效率没有那么高,因为每一行都需要去查询表的最大id
注意:不要使用max函数去判断是否是最后一条记录,max聚合函数会将所有结果聚合为一条记录
错误写法:
select (casewhen mod(id, 2) != 0 and max(id) != id then id + 1 -- id为奇数并且不为最后一条记录when mod(id, 2) != 0 and max(id) = id then id -- id为奇数但为最后一条记录else id - 1 -- id为偶数end) id,student
from seat
order by id asc;
这样只会得到一条记录,因为max是遍历所有结果后
select (casewhen mod(id, 2) != 0 and (select max(id) from seat) != id then id + 1 -- id为奇数并且不为最后一条记录when mod(id, 2) != 0 and (select max(id) from seat) = id then id -- id为奇数但为最后一条记录else id - 1 -- id为偶数end) id,student
from seat
order by id asc;
解法三:使用窗口函数
select (casewhen mod(id, 2) != 0 and counts != id then id + 1 -- id为奇数并且不为最后一条记录when mod(id, 2) != 0 and counts = id then id -- id为奇数但为最后一条记录else id - 1 -- id为偶数end) id,student
from(select *, count(*) over() counts from seat) seat_counts
order by id asc;
电影评分
🔒题目
题目来源:1341.电影评分

🔑题解
- 考察知识点:
count、sum、union all、month、year、子查询、order by、group by、limit
分析:这一题的想要写出来比较简单,但是需要一步一步来,我写的这个SQL可能比较长,涉及到的知识点也比较多
主要思路如下所示:
- 查询出一个结果,查找评论电影数量最多的用户名
- 查询出第二个结果,查找在 February 2020 平均评分最高 的电影名称。如果出现平局,返回字典序较小的电影名称。
- 通过
union all将两个结果聚合起来
1)查询出第一个结果,查找评论电影数量最多的用户名
select *, count(*) counts
from MovieRating mr left join Users u on mr.user_id = u.user_id
group by mr.user_id
order by counts desc, u.name asc;
| movie_id | user_id | rating | created_at | user_id | name | counts |
| -------- | ------- | ------ | ---------- | ------- | ------ | ------ |
| 1 | 1 | 3 | 2020-01-12 | 1 | Daniel | 3 |
| 1 | 2 | 4 | 2020-02-11 | 2 | Monica | 3 |
| 1 | 3 | 2 | 2020-02-12 | 3 | Maria | 2 |
| 1 | 4 | 1 | 2020-01-01 | 4 | James | 1 |
然后取第一个记录即可
select name results
from (select u.name, count(*) countsfrom MovieRating mr left join Users u on mr.user_id = u.user_idgroup by mr.user_idorder by counts desc, u.name asclimit 1) t1;
| results |
| ------- |
| Daniel |
2)查询出第二个结果
select m.title, sum(mr.rating)/count(*) average
from Movies m left join MovieRating mr on m.movie_id = mr.movie_id
where month(mr.created_at) = 2
group by m.movie_id
order by average desc, title asc
备注:其实这里的sum(mr.rating)/count(*)可以直接由avg(mr.rating)进行替换
| title | average |
| -------- | ------- |
| Frozen 2 | 3.5 |
| Joker | 3.5 |
| Avengers | 3 |
然后取第一条记录即可
select title results
from (select m.title, sum(mr.rating)/count(*) averagefrom Movies m left join MovieRating mr on m.movie_id = mr.movie_idwhere month(mr.created_at) = 2 and year(mr.created_at) = 2020group by m.movie_idorder by average desc, title asclimit 1) t2;
备注:这里的 month(mr.created_at) = 2 and year(mr.created_at) = 2020可以直接替换为date_formate(created_at, '%Y-%m') = '2020-02'
| results |
| -------- |
| Frozen 2 |
3)将两个结果集进行合并
select name results
from (select u.name, count(*) countsfrom MovieRating mr left join Users u on mr.user_id = u.user_idgroup by mr.user_idorder by counts desc, u.name asclimit 1) t1
union all
select title results
from (select m.title, sum(mr.rating)/count(*) averagefrom Movies m left join MovieRating mr on m.movie_id = mr.movie_idwhere month(mr.created_at) = 2 and year(mr.created_at) = 2020group by m.movie_idorder by average desc, title asclimit 1) t2;
注意点:
- 这里一定要使用
union all而不是union,因为当电影名和用户名重叠时,union得到的记录只有一条 - 不要被示例数据给干扰了,真实的数据中并不都是2020年的,所以需要添加一个判断,只查询出2020年的
- 对于字符串类型的数据,如果使用
order by默认就按照字典进行排序的
这里在提供一种使用窗口函数的解法
SELECT results
FROM (SELECT name AS results, RANK() OVER(ORDER BY COUNT(*) DESC, name) AS RANKINGFROM UsersINNER JOIN MovieRating USING(user_id)GROUP BY user_idUNION ALLSELECT title AS results, RANK() OVER(ORDER BY AVG(rating) DESC, title) AS RANKINGFROM MovieRatingINNER JOIN Movies USING(movie_id)WHERE DATE_FORMAT(created_at, '%Y-%m') = '2020-02'GROUP BY movie_id
) T
WHERE T.RANKING = 1
餐馆营业额变化增长
🔒题目
题目来源:1321.餐馆营业额变化增长
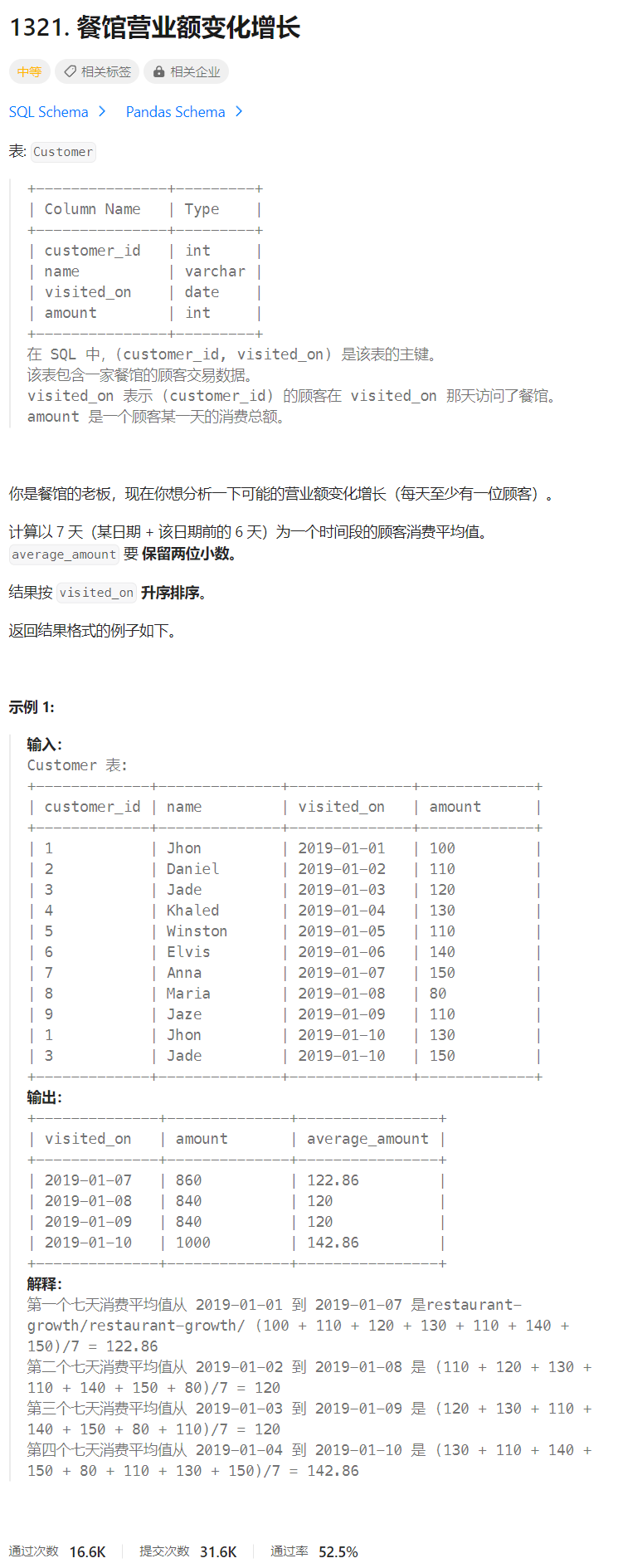
🔑题解
- 考察知识点:
子查询、sum、join、group by、order by
分析:这题难点在于筛选出前七天的数据,只要将这个点解决了,其实就不难了,其实就是子查询的灵活运用,通过构造出合适的临时表,才能够更方便的操作,主要有以下几步
- 通过自连接得到所有当前天前七天的顾客购买情况
- 过滤出没有前面不够七天的商品
- 分组,从第七天开始,没天商品的购买总价值、已经平均值
方法一:自连接
1)首先我们通过join自连接查询出当前天开始前六天的用户,同时需要排除连续天数小于六天的
select *
from (select distinct visited_on from Customer) t1 join Customer t2 on datediff(t1.visited_on, t2.visited_on) between 0 and 6
where t1.visited_on >= (select min(visited_on) from Customer ) + 6
order by t1.visited_on;
备注:这里的order by只是为了更好查看结果集,最终的结果可以去掉这个order by,没有必要耗费多余的资源去进行一个排序
+------------+-------------+---------+------------+--------+
| visited_on | customer_id | name | visited_on | amount |
+------------+-------------+---------+------------+--------+
| 2019-01-07 | 1 | Jhon | 2019-01-01 | 100 |
| 2019-01-07 | 2 | Daniel | 2019-01-02 | 110 |
| 2019-01-07 | 3 | Jade | 2019-01-03 | 120 |
| 2019-01-07 | 4 | Khaled | 2019-01-04 | 130 |
| 2019-01-07 | 5 | Winston | 2019-01-05 | 110 |
| 2019-01-07 | 6 | Elvis | 2019-01-06 | 140 |
| 2019-01-07 | 7 | Anna | 2019-01-07 | 150 |
| 2019-01-08 | 2 | Daniel | 2019-01-02 | 110 |
| 2019-01-08 | 3 | Jade | 2019-01-03 | 120 |
| 2019-01-08 | 4 | Khaled | 2019-01-04 | 130 |
| 2019-01-08 | 5 | Winston | 2019-01-05 | 110 |
| 2019-01-08 | 6 | Elvis | 2019-01-06 | 140 |
| 2019-01-08 | 7 | Anna | 2019-01-07 | 150 |
| 2019-01-08 | 8 | Maria | 2019-01-08 | 80 |
| 2019-01-09 | 3 | Jade | 2019-01-03 | 120 |
| 2019-01-09 | 4 | Khaled | 2019-01-04 | 130 |
| 2019-01-09 | 5 | Winston | 2019-01-05 | 110 |
| 2019-01-09 | 6 | Elvis | 2019-01-06 | 140 |
| 2019-01-09 | 7 | Anna | 2019-01-07 | 150 |
| 2019-01-09 | 8 | Maria | 2019-01-08 | 80 |
| 2019-01-09 | 9 | Jaze | 2019-01-09 | 110 |
| 2019-01-10 | 4 | Khaled | 2019-01-04 | 130 |
| 2019-01-10 | 5 | Winston | 2019-01-05 | 110 |
| 2019-01-10 | 6 | Elvis | 2019-01-06 | 140 |
| 2019-01-10 | 7 | Anna | 2019-01-07 | 150 |
| 2019-01-10 | 8 | Maria | 2019-01-08 | 80 |
| 2019-01-10 | 9 | Jaze | 2019-01-09 | 110 |
| 2019-01-10 | 1 | Jhon | 2019-01-10 | 130 |
| 2019-01-10 | 3 | Jade | 2019-01-10 | 150 |
+------------+-------------+---------+------------+--------+
2)最难想到的是第一步,其实只要得到了上面那张表,我们接下来的操作就会简单很多。我们只需要利用聚合函数对上面的结果进行一个聚合,然后求取平均值即可
select visited_on, sum(amount) amount, round(sum(amount) / 7, 2) average_amount
from(select t1.visited_on, t2.amountfrom (select distinct visited_on from Customer) t1 join Customer t2 on datediff(t1.visited_on, t2.visited_on) between 0 and 6where t1.visited_on >= (select min(visited_on) from Customer ) + 6
) t
group by visited_on
order by visited_on asc;
方法二:窗口函数
这里如果使用窗口函数,可能会显得很简单,比那个分组要好理解的多😄,但是唯一的缺点就是MySQL的版本至少得是8.0
select *, dense_rank() over(order by visited_on) `row_number`,sum(amount) over(order by visited_on range interval 6 day preceding) total
from Customer;
| customer_id | name | visited_on | amount | row_number | total |
| ----------- | ------- | ---------- | ------ | ---------- | ----- |
| 1 | Jhon | 2019-01-01 | 100 | 1 | 100 |
| 2 | Daniel | 2019-01-02 | 110 | 2 | 210 |
| 3 | Jade | 2019-01-03 | 120 | 3 | 330 |
| 4 | Khaled | 2019-01-04 | 130 | 4 | 460 |
| 5 | Winston | 2019-01-05 | 110 | 5 | 570 |
| 6 | Elvis | 2019-01-06 | 140 | 6 | 710 |
| 7 | Anna | 2019-01-07 | 150 | 7 | 860 |
| 8 | Maria | 2019-01-08 | 80 | 8 | 840 |
| 9 | Jaze | 2019-01-09 | 110 | 9 | 840 |
| 1 | Jhon | 2019-01-10 | 130 | 10 | 1000 |
| 3 | Jade | 2019-01-10 | 150 | 10 | 1000 |
select distinct visited_on, total amount, round(total/7, 2) average_amount
from(select visited_on, dense_rank() over(order by visited_on) `row_number`,sum(amount) over(order by visited_on range interval 6 day preceding) totalfrom Customer) t
where `row_number` > 6
order by visited_on asc;
注意:上面这条SQL只能对于连续日期可以通过,如果日期不连续就无法通过,这个题目是有问题的,题目中说

也就是说每天都有一名顾客,这就说明日期必定是连续的,但是经过提交发现有一些示例数据并不是连续的,也就是说明题目的描述是有问题的!!!
所以我们需要对上面的SQL进行一个调整,既然无法使用时间间隔表达式,我们就可以换一种思路,直接利用datediff函数来实现过滤
select distinct visited_on, total amount, round(total/7, 2) average_amount
from(select visited_on, dense_rank() over(order by visited_on) `row_number`,sum(amount) over(order by visited_on range interval 6 day preceding) totalfrom Customer) t
where datediff(visited_on, (select min(visited_on) from Customer)) >= 6
order by visited_on asc;
方法三:通用表达式
分析:略……今天累了,后面补上讲解吧
关于通用表达式可以参考博主的这篇文章:MySQL8新特性通用表达式详解
with t as (select visited_on, sum(amount) amountfrom Customer group by visited_on)
select t1.visited_on, sum(t2.amount) amount,round(sum(t2.amount)/7, 2) average_amount
from t t1, t t2
where datediff(t1.visited_on, t2.visited_on) between 0 and 6
group by t1.visited_on
having datediff(visited_on, (select min(visited_on) from Customer)) >= 6
order by visited_on asc
相关文章:
【LeetCode高频SQL50题-基础版】打卡第7天:第36~40题
文章目录 【LeetCode高频SQL50题-基础版】打卡第7天:第36~40题⛅前言按分类统计薪水🔒题目🔑题解 上级经理已离职的公司员工🔒题目🔑题解 换座位🔒题目🔑题解 电影评分🔒题目&#x…...
C++入门1
C入门1 1.前言2.命名空间1.C语言对于命名空间方面的缺陷2.命名空间的语法特性1.域作用限定符2.命名空间的可嵌套性 3.声明与定义分离的命名空间4.命名空间的展开5.多个命名空间中命名冲突6.对于命名空间的推荐写法 3.iostream1.cout和endl2.cin 3.缺省参数1.缺省参数的形式2.缺…...
Matlab论文插图绘制模板第118期—进阶气泡图
之前的文章中,分享过Matlab气泡图的绘制模板: 图虽说好看,但有一个缺点:需要手动调节两个图例的位置。 为了解决这一问题,我们不妨结合前段时间分享的紧凑排列多子图的绘制模板: 从而达到自动对齐排列的效…...
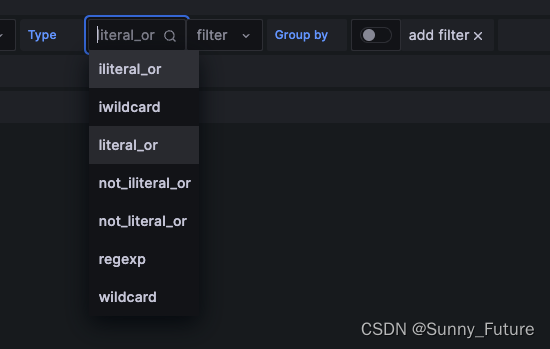
grafana接入OpenTSDB设置大盘语法
目录 1、filter过滤语法1.1 精准匹配1.2 正则匹配1.3 通配符匹配 完整示例1、 展示应用app的CPU利用率监控2)展示应用app的在线核数 1、filter过滤语法 1.1 精准匹配 literal_or : tagv的过滤规则: 精确匹配多项迭代值,多项迭代值以’|分隔&a…...
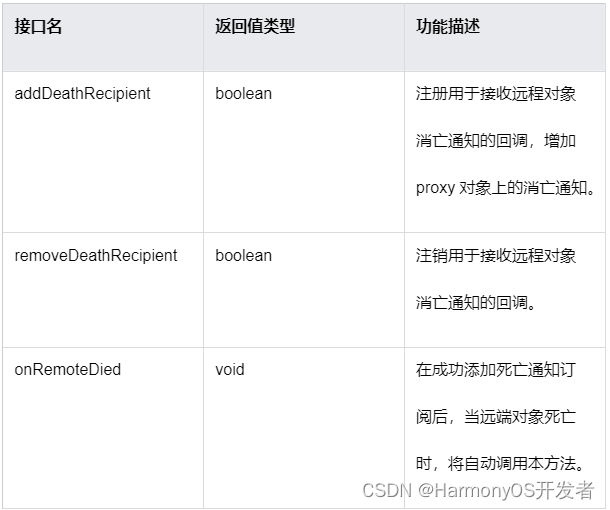
HarmonyOS 远端状态订阅开发实例
IPC/RPC 提供对远端 Stub 对象状态的订阅机制, 在远端 Stub 对象消亡时,可触发消亡通知告诉本地 Proxy 对象。这种状态通知订阅需要调用特定接口完成,当不再需要订阅时也需要调用特定接口取消。使用这种订阅机制的用户,需要实现消…...

实战一:Http轮询弹幕拦截
系列文章目录 训练地址:https://www.qiulianmao.com websocket逆向http拦截websocket拦截视频号直播弹幕采集实战一:Http轮询更新中实战一:Http轮询 系列文章目录前言一、判断消息传输技术二、用户进入直播间三、 用户发言四、 用户送礼五、点赞事件六、用户唯一id的获取七…...
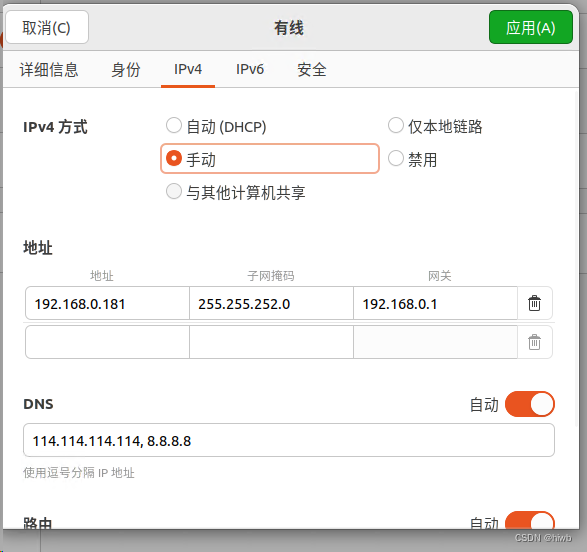
虚拟机独立 IP 配置
虚拟机独立 IP 配置 1. 点击虚拟网络编辑器 2. 点击更改设置 3. 查看本地电脑网卡型号并设置虚拟网络编辑器桥接网卡为同型号网卡 4. 设置有限网络信息 5. 点击网络编辑按钮并点击身份 6. 编辑名称并选择MAC地址 7. 配置 IPv4 地址后点击应用即可...

升级教育技术软件的多合一解决方案
当今时代技术和教育联系越来越紧密,教育机构对强大、安全、灵活的 IT 解决方案的探索至关重要。 全球事件、技术进步以及学生和教职员工不断变化的需求影响着不断变化的教育格局,我们要采取变革性的方法来确保教育的连续性和质量提升。 Splashtop Ente…...

c++视觉检测-----角点检测
角点检测:cornerHarris() cornerHarris()函数是OpenCV中用于执行Harris角点检测的函数。Harris角点检测是一种用于检测图像中角点的技术,通常用于特征检测和图像匹配。以下是cornerHarris()函数的用法: void cornerHarris(InputArray src, …...

虚拟机安装Docker
安装Docker Docker 分为 CE 和 EE 两大版本。CE 即社区版(免费,支持周期 7 个月),EE 即企业版,强调安全,付费使用,支持周期 24 个月。 Docker CE 分为 stable test 和 nightly 三个更新频道。…...
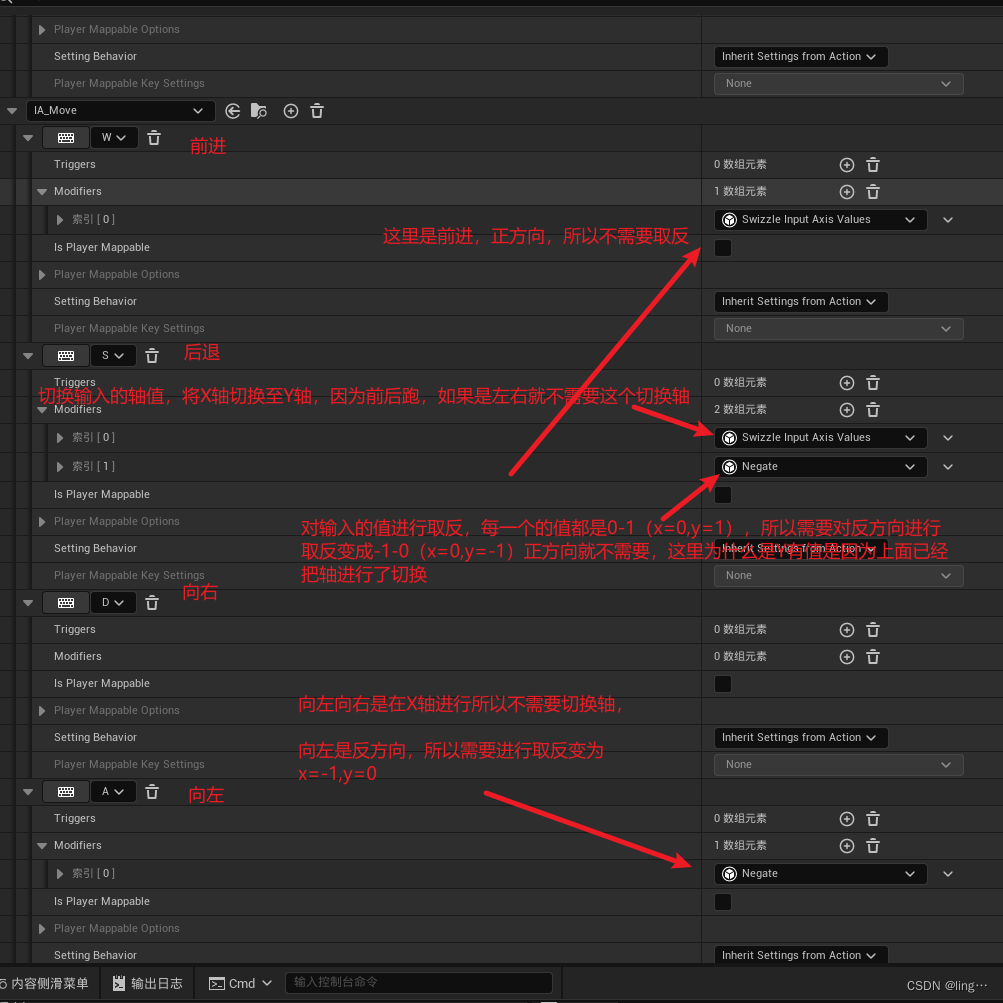
虚幻引擎5:增强输入的使用方法
一、基本配置 1.创建一个输入映射上下文(映射表) 2.创建自己需要的操作映射或者轴映射 3.创建完成之后进入这个映射,来设置类型,共有4个类型 1.Digital:是旧版操作映射类型,一般是按下抬起来使用,像跳跃…...

buffer overflow detected
背景 在应用上云改造中,业务场景如下: 在使用ecs的场景中,应用的ip都是固定的;在使用k8s之后pod的ip就变的不固定了,k8s提供了statefulset的模式来支持这种场景,以固定域名的方式支持。 问题 在平台pod开…...

【c++源码】老飞飞源码完整v15源码(包含数据库前端后端源文件)
老飞飞源码完整v15源码(包含数据库前端后端源文件)程序来源于国外网站。程序仅供参考学习游戏开发流程。以及框架内容。 测试环境搭建 Visual Studio 2013 SQL Server 2008r Windows 10 和 11 专业版 这些文件已经过测试,搭建,运行…...

MySQL创建数据库、创建表操作和用户权限
1、创建数据库school,字符集为utf8 2、在school数据库中创建Student和Score表 3、授权用户tom,密码Mysql123,能够从任何地方登录并管理数据库school 4、使用mysql客户端登录服务器,重置root密码...

时间序列分析基础篇
**时间序列分析(time series analysis)是量化投资中的一门基本技术。时间序列是指在一定时间内按时间顺序测量的某个变量的取值序列。**比如变量是股票价格,那么它随时间的变化就是一个时间序列;同样的,如果变量是股票…...
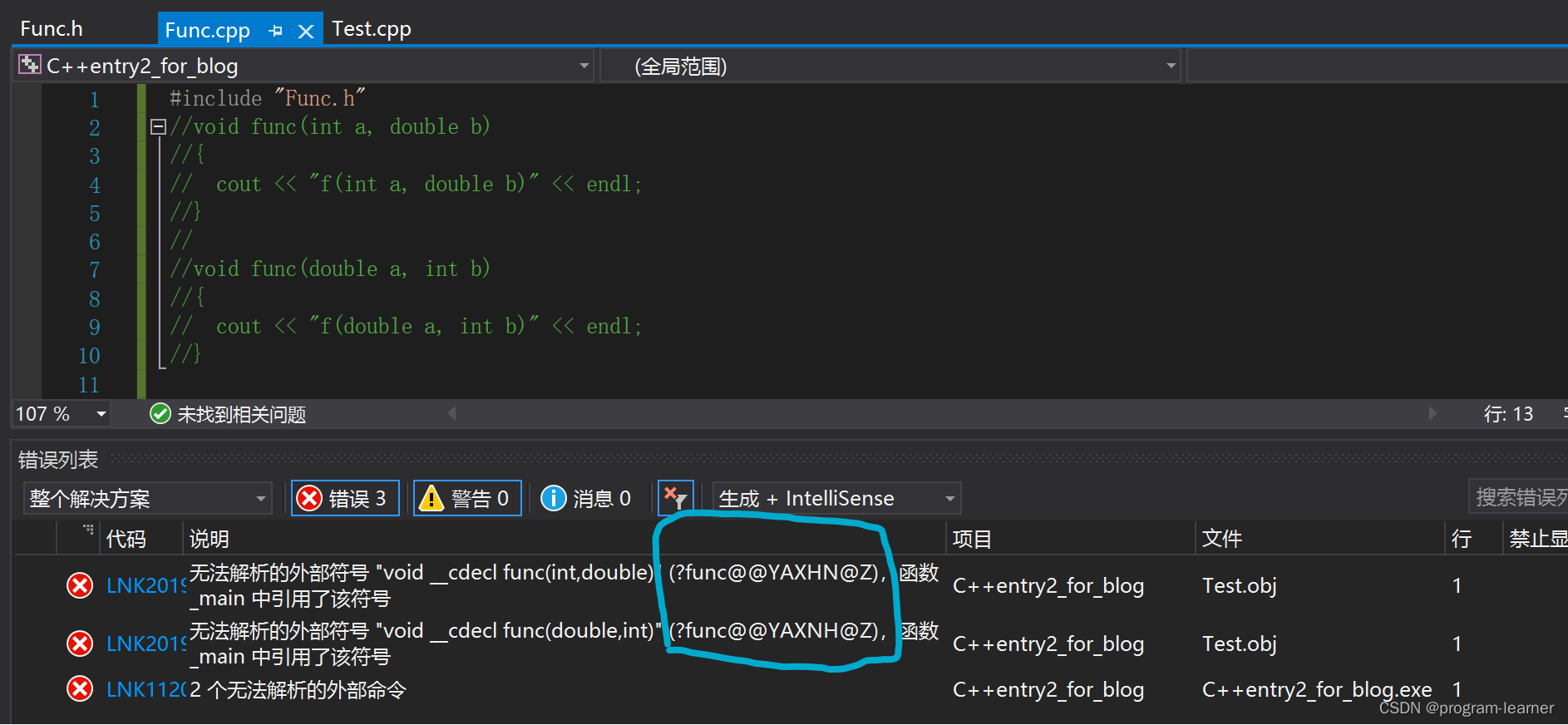
Idea JavaWeb项目,继承自HttpFilter的过滤器,启动Tomcat时部署工件出错
JDK版本:1.8 Tomcat版本:8.5 10-Oct-2023 13:55:17.586 严重 [RMI TCP Connection(3)-127.0.0.1] org.apache.catalina.core.StandardContext.startInternal One or more Filters failed to start. Full details will be found in the appropriate conta…...

02Maven核心程序的下载与settings.xml文件的配置,环境变量的配置
Maven核心程序的解压与配置 Maven的下载与解压 Maven官网下载安装包 将下载的Maven核心程序压缩包apache-maven-3.8.4-bin.zip解压到一个非中文且没有空格的目录 Maven的核心配置文件 在Maven的解压目录conf中我们需要配置Maven的核心配置文件settings.xml 配置本地仓库位置…...
栈实现深度优先搜索
引言 之前刚学DFS的时候并不完全理解为什么递归可以一直往下做,后来直到了递归的本质是栈,就想着能不能手写栈来代替递归呢。当时刚学,自己觉得水平不够就搁置了这个想法,今天上数据结构老师正好讲了栈的应用,其中就有…...
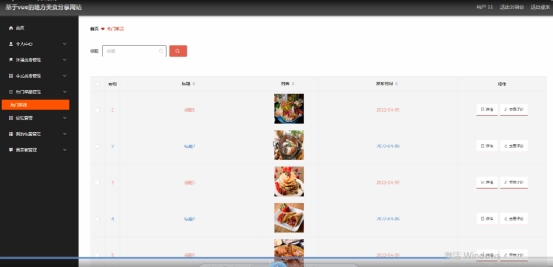
Java 基于SpringBoot的某家乡美食系统
1 简介 《Java 基于SpringBoot的某家乡美食系统》该项目含有源码、文档等资料、配套开发软件、软件安装教程等。系统功能完整,适合作为毕业设计、课程设计、数据库大作业学习使用。 功能介绍 这个项目是基于 SpringBoot和 Vue 开发的地方美食系统,包括…...

splice 和 slice 会改变原数组吗? 怎么删除数组最后一个元素?
1、splice 和 slice 会改变原数组吗? splice() 会改变原数组,返回的是改变的内容; splice() 方法可能是数组中的最强大的方法之一了,使用它的形式有很多种,它会向/从数组中添加/删除项目,然后返回被删除的项目。 该方…...
)
Altium Designer 22 导出嘉立创SMT文件保姆级教程(附BOM/坐标文件避坑指南)
Altium Designer 22 导出嘉立创SMT文件全流程解析与实战技巧 在电子设计领域,从手工焊接转向SMT贴片生产是一个关键的进阶步骤。对于使用Altium Designer(简称AD)的设计师来说,掌握正确的文件导出方法不仅能节省大量时间ÿ…...

KMS_VL_ALL_AIO终极指南:5分钟免费激活Windows和Office的完整方案
KMS_VL_ALL_AIO终极指南:5分钟免费激活Windows和Office的完整方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office的激活问题而烦恼吗?KMS_VL_ALL_…...

Linux依赖冲突回溯生产排障流程
Linux依赖冲突回溯生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在依赖冲突回溯,重点讨论库版本关系、安装失败和升级影响。在真实生产环境中,依赖冲突回溯相关问题往往不会以单一错误形式出现,而是混杂在日志、…...

Solopreneur 7×24 Agent 工作流:从 ARIS 论文里抠出 5 个可落地步骤
论文:ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration arXiv:2605.03042(2026.5.4 上海交大) 适合人群:独立开发者 / Solopreneur / 想搭"睡眠工作流"的人 一、先讲一个我自己的故事 我做独立开…...

终极罗技鼠标宏指南:3步实现PUBG完美压枪
终极罗技鼠标宏指南:3步实现PUBG完美压枪 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的武器后坐力…...

图形引擎的跨平台之舞:Skia与Direct2D的深度对话
图形引擎的跨平台之舞:Skia与Direct2D的深度对话 【免费下载链接】skia Skia is a complete 2D graphic library for drawing Text, Geometries, and Images. See documentation for contribution instructions. 项目地址: https://gitcode.com/gh_mirrors/ski/sk…...

Arm Neoverse V2内存架构与PCIe地址管理解析
1. Arm Neoverse V2内存架构设计精要 在Arm Neoverse V2的体系结构中,内存映射机制是其高性能计算能力的基石。这套架构通过精细的地址空间划分,实现了对各类硬件资源的高效管理。我们先来看一个典型的多芯片系统内存布局示例: Chip 0: 0x0…...
)
告别全屏地球!用Cesium.js在地图上只显示一个县(附完整代码)
用Cesium.js实现区域聚焦:打造专属行政区划三维地图 在WebGIS开发中,我们经常遇到需要将三维地球的显示范围限定在特定行政区划内的需求。无论是为了突出展示某个城市的发展规划,还是为了制作县域级别的专题地图,区域聚焦技术都能…...

西安小程序制作优质服务推荐
在西安,小程序制作已成为众多企业实现数字化转型的核心一步。企业在这个领域的选择尤为重要,因为市场上的服务供应商数量庞大、难以判断其服务质量。因此专业背景、以往案例以及客户评价,这些都能够反映出公司的整体实力。还有,成…...

第二章 小程序目录结构与核心文件详解
第二章 小程序目录结构与核心文件详解 📚 系列教程:微信小程序投票系统完整开发 🔗 上一章:第一章 - 微信小程序概述与开发准备 🔗 下一章:第三章 - WXML 所有表单组件与使用 2.1 完整目录结构 wx/page/ …...