Kafka生产者使用案例
1.生产者发送消息的过程
首先介绍一下 Kafka 生产者发送消息的过程:
1)Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发送的内容,同时还可以指定键和分区。在发送 ProducerRecord 对象前,生产者会先把键和值对象序列化成字节数组,这样它们才能够在网络上传输。
2) 接下来,数据被传给分区器。如果之前已经在 ProducerRecord 对象里指定了分区,那么分区器就不会再做任何事情。如果没有指定分区 ,那么分区器会根据 ProducerRecord 对象的键来选择一个分区,紧接着,这条记录被添加到一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上。有一个独立的线程负责把这些记录批次发送到相应的 broker 上。
3) 服务器在收到这些消息时会返回一个响应。如果消息成功写入 Kafka,就返回一个 RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区里的偏移量。如果写入失败,则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,如果达到指定的重试次数后还没有成功,则直接抛出异常,不再重试。

2.创建生产者
2.1 项目依赖
本项目采用 Maven 构建,想要调用 Kafka 生产者 API,需要导入 `kafka-clients` 依赖,如下:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
2.2 创建生产者
创建 Kafka 生产者时,以下三个属性是必须指定的:
bootstrap.servers:指定 broker 的地址清单,清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找 broker 的信息。不过建议至少要提供两个 broker 的信息作为容错;
key.serializer:指定键的序列化器;
value.serializer:指定值的序列化器。
创建的示例代码如下:
public class SimpleProducer {public static void main(String[] args) {String topicName = "Hello-Kafka";Properties props = new Properties();props.put("bootstrap.servers", "hadoop001:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");/*创建生产者*/Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>(topicName, "hello" + i, "world" + i);/* 发送消息*/producer.send(record);}/*关闭生产者*/producer.close();}
}
2.3 测试
2.3.1启动Kakfa
Kafka 的运行依赖于 zookeeper,需要预先启动,可以启动 Kafka 内置的 zookeeper,也可以启动自己安装的:
# zookeeper启动命令
bin/zkServer.sh start# 内置zookeeper启动命令
bin/zookeeper-server-start.sh config/zookeeper.properties启动单节点 kafka 用于测试:
# bin/kafka-server-start.sh config/server.properties2.3.2 创建topic
# 创建用于测试主题
bin/kafka-topics.sh --create \--bootstrap-server hadoop001:9092 \--replication-factor 1 --partitions 1 \--topic Hello-Kafka# 查看所有主题bin/kafka-topics.sh --list --bootstrap-server hadoop001:9092
2.3.3 启动消费者
启动一个控制台消费者用于观察写入情况,启动命令如下:
# bin/kafka-console-consumer.sh --bootstrap-server hadoop001:9092 --topic Hello-Kafka --from-beginning
2.3.4 运行项目
此时可以看到消费者控制台,输出如下,这里 `kafka-console-consumer` 只会打印出值信息,不会打印出键信息。
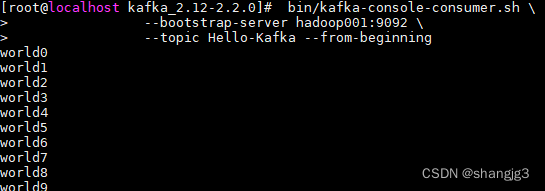
2.4 可能出现的问题
在这里可能出现的一个问题是:生产者程序在启动后,一直处于等待状态。这通常出现在你使用默认配置启动 Kafka 的情况下,此时需要对 `server.properties` 文件中的 `listeners` 配置进行更改:
# hadoop001 为我启动kafka服务的主机名,你可以换成自己的主机名或者ip地址
listeners=PLAINTEXT://hadoop001:90923.发送消息
上面的示例程序调用了 `send` 方法发送消息后没有做任何操作,在这种情况下,我们没有办法知道消息发送的结果。想要知道消息发送的结果,可以使用同步发送或者异步发送来实现。
3.1 同步发送
在调用 `send` 方法后可以接着调用 `get()` 方法,`send` 方法的返回值是一个 Future<RecordMetadata>对象,RecordMetadata 里面包含了发送消息的主题、分区、偏移量等信息。改写后的代码如下:
for (int i = 0; i < 10; i++) {try {ProducerRecord<String, String> record = new ProducerRecord<>(topicName, "k" + i, "world" + i);/*同步发送消息*/RecordMetadata metadata = producer.send(record).get();System.out.printf("topic=%s, partition=%d, offset=%s \n",metadata.topic(), metadata.partition(), metadata.offset());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}
}此时得到的输出如下:偏移量和调用次数有关,所有记录都分配到了 0 分区,这是因为在创建 `Hello-Kafka` 主题时候,使用 `--partitions` 指定其分区数为 1,即只有一个分区。
topic=Hello-Kafka, partition=0, offset=40
topic=Hello-Kafka, partition=0, offset=41
topic=Hello-Kafka, partition=0, offset=42
topic=Hello-Kafka, partition=0, offset=43
topic=Hello-Kafka, partition=0, offset=44
topic=Hello-Kafka, partition=0, offset=45
topic=Hello-Kafka, partition=0, offset=46
topic=Hello-Kafka, partition=0, offset=47
topic=Hello-Kafka, partition=0, offset=48
topic=Hello-Kafka, partition=0, offset=49
3.2 异步发送
通常我们并不关心发送成功的情况,更多关注的是失败的情况,因此 Kafka 提供了异步发送和回调函数。 代码如下:
for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>(topicName, "k" + i, "world" + i);/*异步发送消息,并监听回调*/producer.send(record, new Callback() {
@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception != null) {System.out.println("进行异常处理");} else {System.out.printf("topic=%s, partition=%d, offset=%s \n",metadata.topic(), metadata.partition(), metadata.offset());}}});
}
4.自定义分区器
Kafka 有着默认的分区机制:
如果键值为 null, 则使用轮询 (Round Robin) 算法将消息均衡地分布到各个分区上;
如果键值不为 null,那么 Kafka 会使用内置的散列算法对键进行散列,然后分布到各个分区上。
某些情况下,你可能有着自己的分区需求,这时候可以采用自定义分区器实现。这里给出一个自定义分区器的示例:
4.1 自定义分区器
/*** 自定义分区器*/
public class CustomPartitioner implements Partitioner {private int passLine; @Overridepublic void configure(Map<String, ?> configs) {/*从生产者配置中获取分数线*/passLine = (Integer) configs.get("pass.line");} @Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {/*key 值为分数,当分数大于分数线时候,分配到 1 分区,否则分配到 0 分区*/return (Integer) key >= passLine ? 1 : 0;} @Overridepublic void close() {System.out.println("分区器关闭");}
}
需要在创建生产者时指定分区器,和分区器所需要的配置参数:
public class ProducerWithPartitioner {public static void main(String[] args) {String topicName = "Kafka-Partitioner-Test";Properties props = new Properties();props.put("bootstrap.servers", "hadoop001:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");/*传递自定义分区器*/props.put("partitioner.class", "com.heibaiying.producers.partitioners.CustomPartitioner");/*传递分区器所需的参数*/props.put("pass.line", 6);Producer<Integer, String> producer = new KafkaProducer<>(props);for (int i = 0; i <= 10; i++) {String score = "score:" + i;ProducerRecord<Integer, String> record = new ProducerRecord<>(topicName, i, score);/*异步发送消息*/producer.send(record, (metadata, exception) ->System.out.printf("%s, partition=%d, \n", score, metadata.partition()));}producer.close();}
}
4.2 测试
需要创建一个至少有两个分区的主题:
bin/kafka-topics.sh --create \--bootstrap-server hadoop001:9092 \--replication-factor 1 --partitions 2 \--topic Kafka-Partitioner-Test
此时输入如下,可以看到分数大于等于 6 分的都被分到 1 分区,而小于 6 分的都被分到了 0 分区。
score:6, partition=1,
score:7, partition=1,
score:8, partition=1,
score:9, partition=1,
score:10, partition=1,
score:0, partition=0,
score:1, partition=0,
score:2, partition=0,
score:3, partition=0,
score:4, partition=0,
score:5, partition=0,
分区器关闭
5.生产者其他属性
上面生产者的创建都仅指定了服务地址,键序列化器、值序列化器,实际上 Kafka 的生产者还有很多可配置属性,如下:
1. acks
acks 参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的:
acks=0: 消息发送出去就认为已经成功了,不会等待任何来自服务器的响应;
acks=1: 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应;
acks=all:只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
2. buffer.memory
设置生产者内存缓冲区的大小。
3. compression.type
默认情况下,发送的消息不会被压缩。如果想要进行压缩,可以配置此参数,可选值有 snappy,gzip,lz4。
4. retries
发生错误后,消息重发的次数。如果达到设定值,生产者就会放弃重试并返回错误。
5. batch.size
当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
6. linger.ms
该参数制定了生产者在发送批次之前等待更多消息加入批次的时间。
7. clent.id
客户端 id,服务器用来识别消息的来源。
8. max.in.flight.requests.per.connection
指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量,把它设置为 1 可以保证消息是按照发送的顺序写入服务器,即使发生了重试。
9. timeout.ms, request.timeout.ms & metadata.fetch.timeout.ms
- timeout.ms 指定了 borker 等待同步副本返回消息的确认时间;
- request.timeout.ms 指定了生产者在发送数据时等待服务器返回响应的时间;
- metadata.fetch.timeout.ms 指定了生产者在获取元数据(比如分区首领是谁)时等待服务器返回响应的时间。
10. max.block.ms
指定了在调用 `send()` 方法或使用 `partitionsFor()` 方法获取元数据时生产者的阻塞时间。当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法会阻塞。在阻塞时间达到 max.block.ms 时,生产者会抛出超时异常。
11. max.request.size
该参数用于控制生产者发送的请求大小。它可以指发送的单个消息的最大值,也可以指单个请求里所有消息总的大小。例如,假设这个值为 1000K ,那么可以发送的单个最大消息为 1000K ,或者生产者可以在单个请求里发送一个批次,该批次包含了 1000 个消息,每个消息大小为 1K。
12. receive.buffer.bytes & send.buffer.byte
这两个参数分别指定 TCP socket 接收和发送数据包缓冲区的大小,-1 代表使用操作系统的默认值。
相关文章:
Kafka生产者使用案例
1.生产者发送消息的过程 首先介绍一下 Kafka 生产者发送消息的过程: 1)Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发送的内容,同时还可以指定键和分区。在发送 ProducerRecord 对象前,…...

EasyX图形库实现贪吃蛇游戏
⭐大家好,我是Dark Falme Masker,学习了动画制作及键盘交互之后,我们就可以开动利用图形库写一个简单的贪吃蛇小游戏,增加学习乐趣。 ⭐专栏:EasyX部分小游戏实现详细讲解 最终效果如下 首先包含头文件 #include<stdio.h> #…...
利用 Amazon CodeWhisperer 激发孩子的编程兴趣
我是一个程序员,也是一个父亲。工作之余我会经常和儿子聊他们小学信息技术课学习的 Scratch 和 Kitten 这两款图形化的少儿编程工具。 我儿子有一次指着书房里显示器上显示的 Visual Studio Code 问我,“为什么我们上课用的开发界面,和爸爸你…...
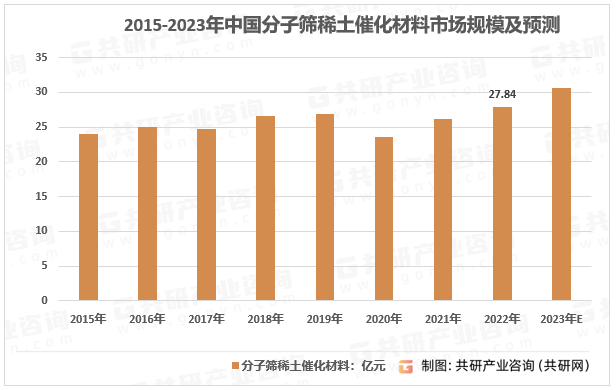
2023年中国分子筛稀土催化材料竞争格局及行业市场规模分析[图]
稀土催化材料能够起到提高催化剂热稳定性、催化剂活性、催化剂储氧能力,以及减少贵金属活性组分用量等作用,广泛应用于石油化工、汽车尾气净化、工业废气和人居环境净化、燃料电池等领域。 2015-2023年中国稀土催化材料规模及预测 资料来源:…...
vue3插件——vue-web-screen-shot——实现页面截图功能
最近在看前同事发我的vue3框架时,发现他们有个功能是要实现页面截图功能。 vue3插件——vue-web-screen-shot——实现页面截图功能 效果图如下:1.操作步骤1.1在项目中添加vvue-web-screen-shot组件1.2在项目入口文件导入组件——main.ts1.3在需要使用的页…...
简单总结Centos7安装Tomcat10.0版本
文章目录 前言JDK8安装部署Tomcat 前言 注意jdk与tomcat的兼容问题,其他的只要正确操作一般问题不大 Tomcat 是由 Apache 开发的一个 Servlet 容器,实现了对 Servlet 和 JSP 的支持,并提供了作为Web服务器的一些特有功能,如Tomca…...

ffmpeg中AVCodecContext和AVCodec的关系分析
怎么理解AVCodecContext和AVCodec的关系 AVCodecContext和AVCodec是FFmpeg库中两个相关的结构体,它们在音视频编解码中扮演着不同的角色。 AVCodecContext:是编解码器上下文结构体,用于存储音视频编解码器的参数和状态信息。它包含了进行音视…...

2023年中国门把手产量、销量及市场规模分析[图]
门把手行业是指专门从事门把手的设计、制造、销售和安装等相关业务的行业。门把手是门窗装饰硬件的一种,用于开启和关闭门窗,同时也具有装饰和美化门窗的作用。 门把手行业分类 资料来源:共研产业咨询(共研网) 随着消…...
HTML 核心技术点基础详细解析以及综合小案例
核心技术点 网页组成 排版标签 多媒体标签及属性 综合案例一 - 个人简介 综合案例二 - Vue 简介 02-标签语法 HTML 超文本标记语言——HyperText Markup Language。 超文本:链接 标记:标签,带尖括号的文本 标签结构 标签要成…...
常用语法元素与命令)
BAT学习——批处理脚本(也称为BAT文件)常用语法元素与命令
批处理脚本(也称为BAT文件)使用Windows的批处理语言编写,它具有一些常用的语法元素和命令。以下是一些BAT编程的常用语法元素和命令: 命令行命令: 批处理脚本通常包含一系列Windows命令,例如echo࿰…...
AMD AFMF不但能用在游戏,也适用于视频
近期AMD发布了AMD Software Adrenalin Edition预览版驱动程序,增加了对平滑移动帧(AMD Fluid Motion Frames,AFMF)功能的支持,也就是AMD的“帧生成”技术,与DLSS 3类似,作为FidelityFX Super Re…...

CSS 常用样式浮动属性
一、概述 CSS 中,浮动属性的作用是让元素向左或向右浮动,使其他元素围绕它排布,常用的浮动属性有以下几种: float: left; 使元素向左浮动,其他元素从右侧包围它。 float: right; 使元素向右浮动,其他元素…...
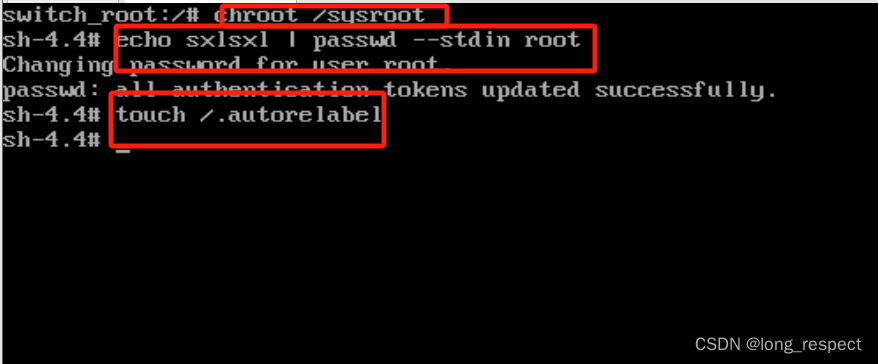
Linux引导故障排除:从问题到解决方案的详细指南
1 BIOS初始化 通电->对硬件检测->初始化硬件时钟 2 磁盘引导及其修复 2.1 磁盘引导故障 磁盘主引导记录(MBR)是在0磁道1扇区位置,446字节。 MBR作用:记录grub2引导文件的位置 2.2 修复 步骤:1、光盘进…...

【vim 学习系列文章 6 -- vim 如何从上次退出的位置打开文件】
文章目录 1.1 vim 如何从上次退出的位置打开文件1.2 autogroup 命令学习1.2.1 augroup 基本语法 1.3 vim call 命令详细介绍 1.1 vim 如何从上次退出的位置打开文件 假设我打开了文件 test.c,然后我向下滚动到第 50 行,然后我做了一些修改并关闭了文件。…...
怎样学习C#上位机编程?
怎样学习C#上位机编程? 00001. 掌握C#编程和.NET框架基础。 00002. 学WinForm应用开发,了解控件使用和事件编程。 00003. 熟悉基本数据结构和算法,如链表、栈、队列。 00004. 理解串口通信协议和方法,用于与硬件交互。 00005…...

【算法-动态规划】两个字符串的删除操作-力扣 583
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kuan 的首页,持续学…...

【06】基础知识:typescript中的泛型
一、泛型的定义 在软件开发中,我们不仅要创建一致的定义良好的API,同时也要考虑可重用性。 组件不仅能支持当前数据类型,同时也能支持未来的数据类型,这在创建大型系统时提供了十分灵活的功能。 在像 C# 和 Java 这样的语言中&…...
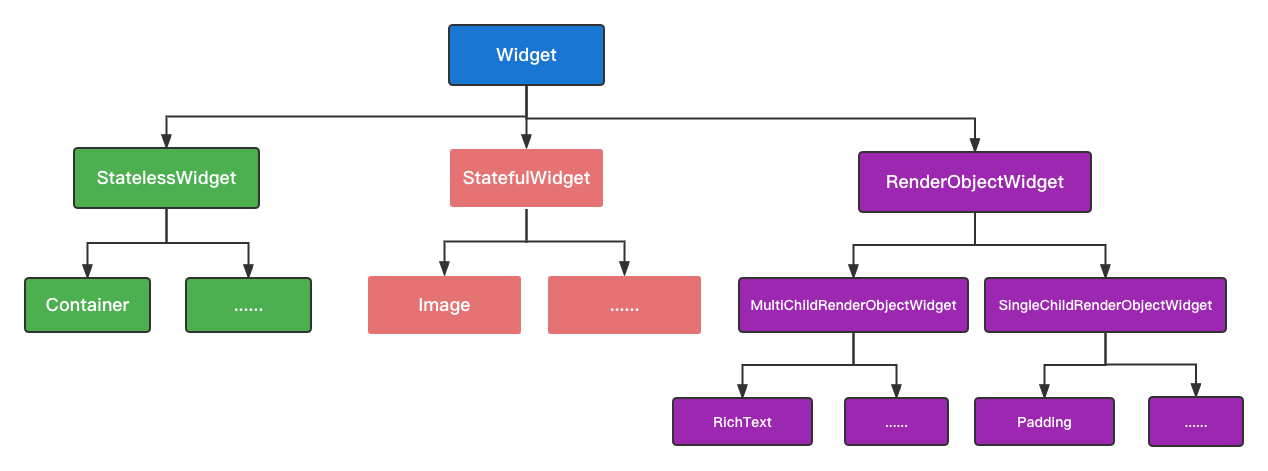
flutter 绘制原理探究
文章目录 Widget1、简介2、源码分析Element1、简介2、源码分析RenderObjectWidget 渲染过程总结思考Flutter 的核心设计思想便是“一切皆 Widget”,Widget 是 Flutter 功能的抽象描述,是视图的配置信息,同样也是数据的映射,是 Flutter 开发框架中最基本的概念。 在 Flutter…...

[Java]SPI扩展功能
一、什么是SPI Java SPI(Service Provider Interface)是Java官方提供的一种服务发现机制。 它允许在运行时动态地加载实现特定接口的类,而不需要在代码中显式地指定该类,从而实现解耦和灵活性。 二、实现原理 基于 Java 类加载…...

机器人命令表设计
演算命令 CLEAR 将数据 1 上被指定的编号以后的变数的内容,以及数据 2 上仅被指定的个数都清除至 0。 INC 在被指定的变数内容上加上 1。 DEC 在被指定的变数内容上减掉 1。 SET 在数据 1 上设定数据 2。 ADD 将数据 1 和数据 2 相加,得出的结果保存在数…...

STM32F407移植QP状态机踩坑实录:从编译报错到成功运行,我解决了这三个关键问题
STM32F407移植QP状态机踩坑实录:从编译报错到成功运行,我解决了这三个关键问题 在嵌入式开发中,状态机是一种极其重要的编程范式,它能有效管理复杂系统的行为逻辑。QP(Quantum Platform)作为一款轻量级的状…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

2019 年旧作升级!用木材与电路打造更美观的电压表时钟
2019 年旧作升级!用木材与电路打造更美观的电压表时钟早在 2019 年,作者制作了一个简单的电压表时钟,这类时钟使用模拟面板电压表来显示时间,而非传统钟面。不过,网上大多数此类设计过于复杂且不太美观,于是…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程
从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程 在开源硬件社区,GitHub上每天都有大量优秀的STM32项目被分享——从智能家居控制器到四轴飞行器飞控系统。但当开发者满怀期待地git clone后,却常常在第一步"编译通过&…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...

SoC片上系统:从架构原理到选型实战的深度解析
1. 项目概述:从“黑盒子”到“智慧核心”的认知跃迁在电子产品的世界里,我们常常惊叹于一部智能手机的纤薄与强大,它既能流畅播放高清视频,又能处理复杂的游戏画面,还能实时连接网络、定位导航。这一切的背后ÿ…...

解锁Midjourney V6黑白摄影隐藏指令:5个未公开--stylize与--sref协同技法,92%用户至今不会用
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6黑白摄影的美学本质与技术觉醒 黑白摄影在 Midjourney V6 中已超越简单的色彩剥离,成为一场基于对比度张力、纹理显影与光影叙事的深度建模重构。V6 的隐式扩散架构强化了灰阶…...

基于Python与Playwright的招聘信息自动化聚合与智能筛选工具实践
1. 项目概述:一个面向求职者的自动化信息聚合与投递工具最近在和一些做开发的朋友聊天,发现大家普遍有个痛点:找工作太费时间了。每天要在几个招聘App之间来回切换,重复筛选岗位、刷新列表、投递简历,机械性的操作占据…...

子高斯随机变量与深度学习异常检测原理
1. 子高斯随机变量基础解析子高斯随机变量是概率论中一类具有特殊尾部性质的分布。简单来说,一个随机变量X如果满足存在常数σ>0,使得对于所有λ∈R都有E[exp(λX)] ≤ exp(λσ/2),那么我们就称X是σ-子高斯的。这类分布的关键特征是它们…...