springcloud----检索中间件 ElasticSearch 分布式场景的运用
如果对es的基础知识有不了解的可以看
es看这个文章就会使用了
1.分布式集群场景下的使用
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份(replica )
ES集群相关概念:
-
集群(cluster):一组拥有共同的 cluster name 的 节点。
-
节点(node) :集群中的一个 Elasticearch 实例
-
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题。
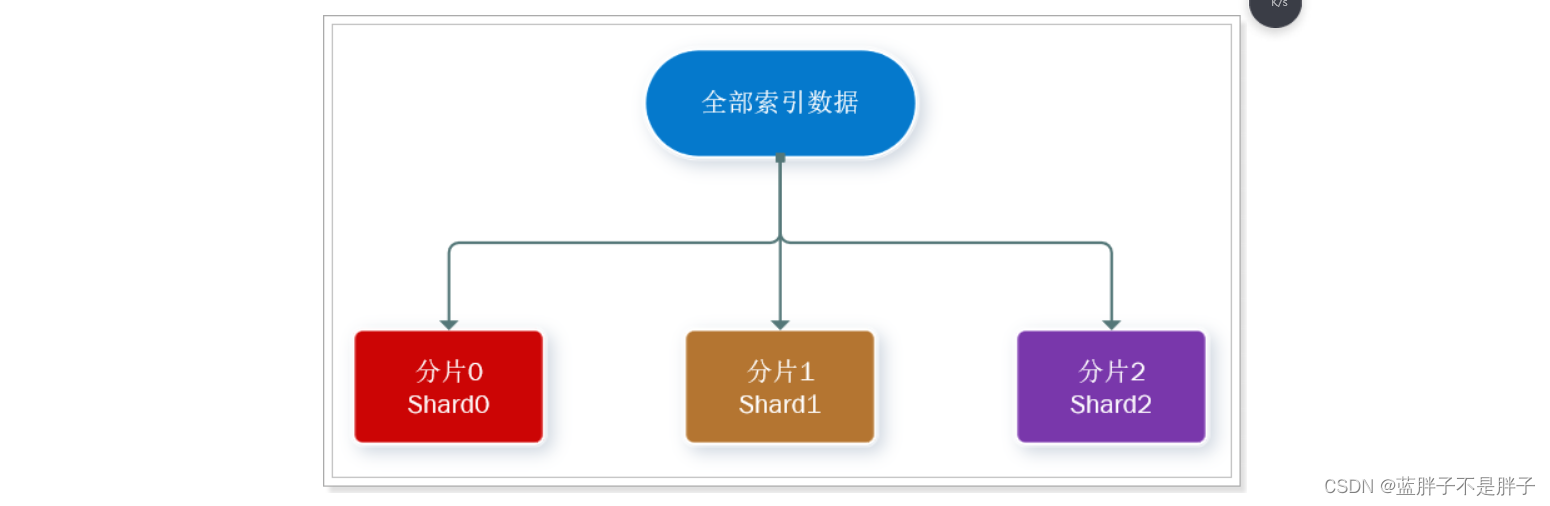
此处,我们把数据分成3片:shard0、shard1、shard2
-
主分片(Primary shard):相对于副本分片的定义。
-
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
- 首先对数据分片,存储到不同节点
- 然后对每个分片进行备份,放到对方节点,完成互相备份
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:
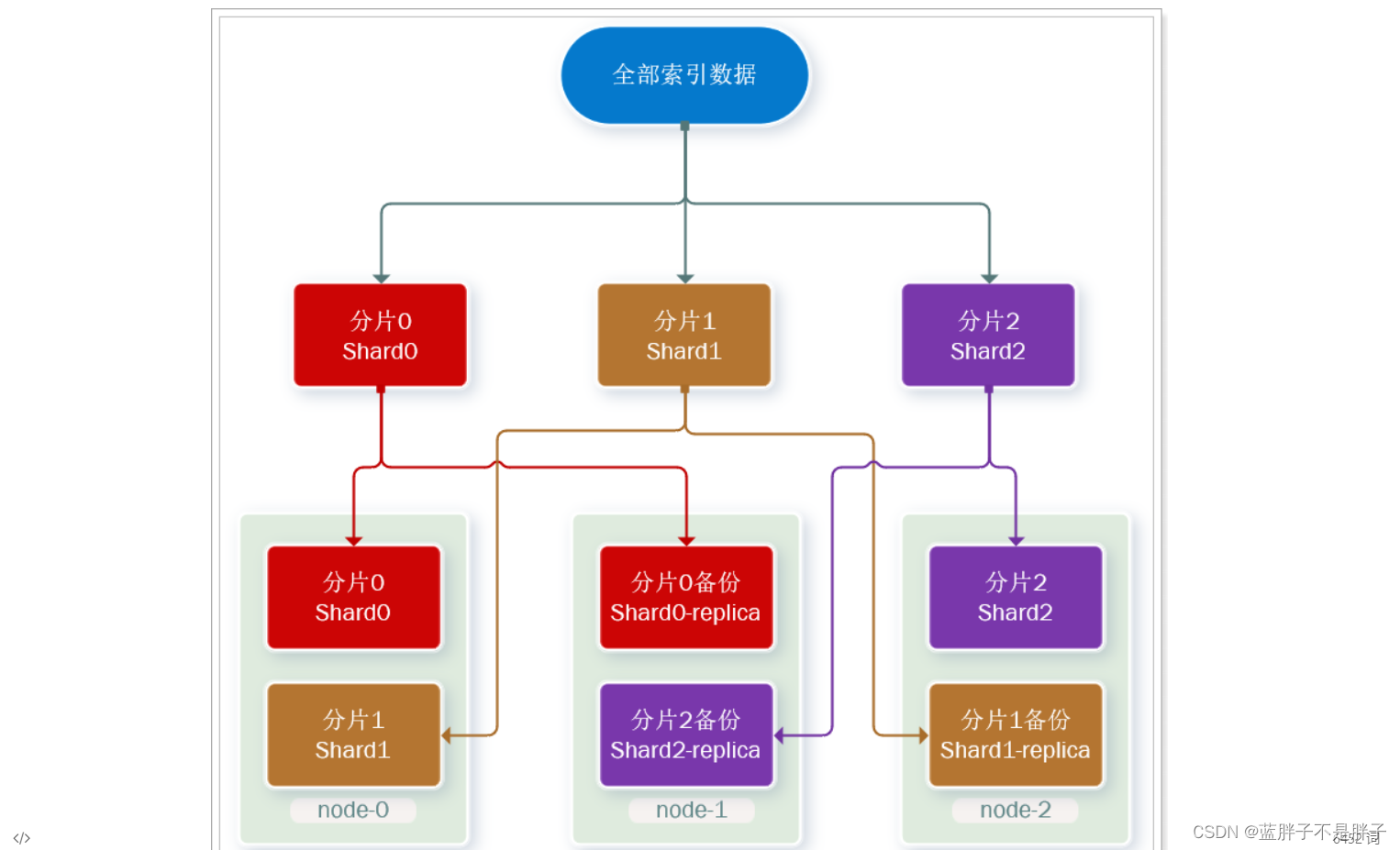
现在,每个分片都有1个备份,存储在3个节点:
- node0:保存了分片0和1
- node1:保存了分片0和2
- node2:保存了分片1和2
这样单一结点就算宕机,也可以备用
2.0.搭建ES集群
2.部署es集群
我们会在单机上利用docker容器(docker容器之间相互独立)运行多个es实例来模拟es集群。不过生产环境推荐大家每一台服务节点仅部署一个es的实例。
部署es集群可以直接使用docker-compose来完成,但这要求你的Linux虚拟机至少有4G的内存空间
2.1.创建es集群
首先编写一个docker-compose文件(yml或者yaml),内容如下:
- 9200端口已经在之前的结点中使用了,要么停止要么改端口,这三个结点都没有设置插件数据卷,实际开发记得指明
-
- discovery.seed_hosts 这里都是同一网络 ,实际开发中不同结点都是在不同网络机器上 比如 - discovery.seed_hosts=Machine1_IP:9200,Machine3_IP:9200
version: '2.2'
services:es01:image: docker.elastic.co/elasticsearch/elasticsearch:7.15.0container_name: es01environment:- node.name=es01- cluster.name=es-docker-cluster- discovery.seed_hosts=es02,es03- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data01:/usr/share/elasticsearch/dataports:- 9210:9200networks:- elastices02:image: docker.elastic.co/elasticsearch/elasticsearch:7.15.0container_name: es02environment:- node.name=es02- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es03- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data02:/usr/share/elasticsearch/dataports:- 9201:9200networks:- elastices03:image: docker.elastic.co/elasticsearch/elasticsearch:7.15.0container_name: es03environment:- node.name=es03- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es02- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data03:/usr/share/elasticsearch/datanetworks:- elasticports:- 9202:9200
volumes:data01:driver: localdata02:driver: localdata03:driver: localnetworks:elastic:driver: bridge
我的镜像名

es运行需要修改一些linux系统权限,修改/etc/sysctl.conf文件
vi /etc/sysctl.conf
添加下面的内容:
vm.max_map_count=262144
然后执行命令,让配置生效:
sysctl -p
在docker-c通过docker-compose启动集群:
docker-compose up -d
如果报错 bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.
bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
那么说明是内存警告问题 错误消息指出虚拟内存区域的 vm.max_map_count 参数设置得太低。
检查当前的 vm.max_map_count 值:运行以下命令来检查当前值:
sysctl vm.max_map_count
如果当前值低于 262144,那么你需要增加它。
增加 vm.max_map_count 的值:你可以使用以下命令来增加虚拟内存区域的值:
sudo sysctl -w vm.max_map_count=262144
这会立即更改 vm.max_map_count 的值,但在系统重新启动后会重置为默认值。如果要永久更改此设置,你需要编辑 /etc/sysctl.conf 或 /etc/sysctl.d/ 下的配置文件,并添加或修改以下行:
vm.max_map_count=262144
然后保存文件并重新加载配置:
sudo sysctl -p
重新启动 Elasticsearch:一旦你增加了 vm.max_map_count 的值,重新启动 Elasticsearch,问题应该得到解决。
启动成功
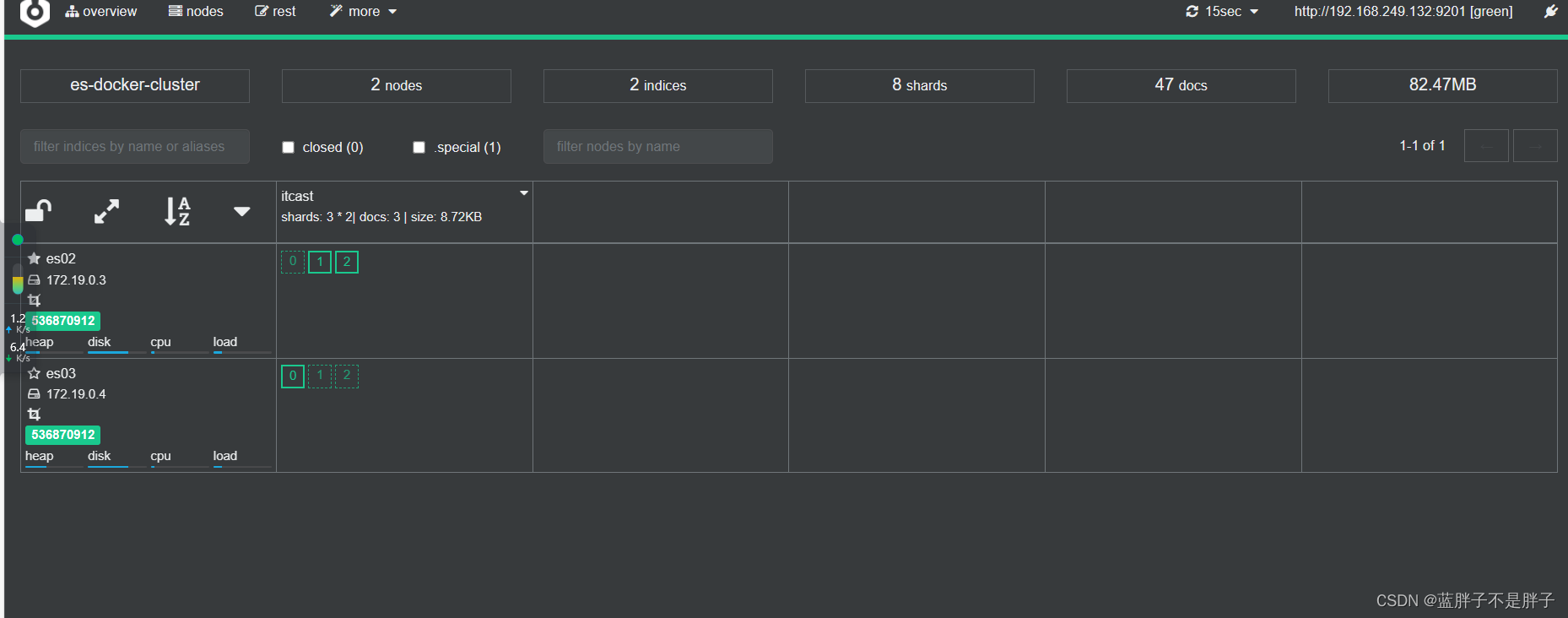
2.2.集群状态监控
kibana可以监控es集群,不过新版本需要依赖es的x-pack 功能并且默认是监控但点es,配置比较复杂。
这里推荐使用cerebro来监控es集群状态,官方网址:https://github.com/lmenezes/cerebro
解压即可使用,非常方便。
解压好的目录如下:

进入对应的bin目录:

双击其中的cerebro.bat文件即可启动服务。
访问http://localhost:9000 即可进入管理界面:
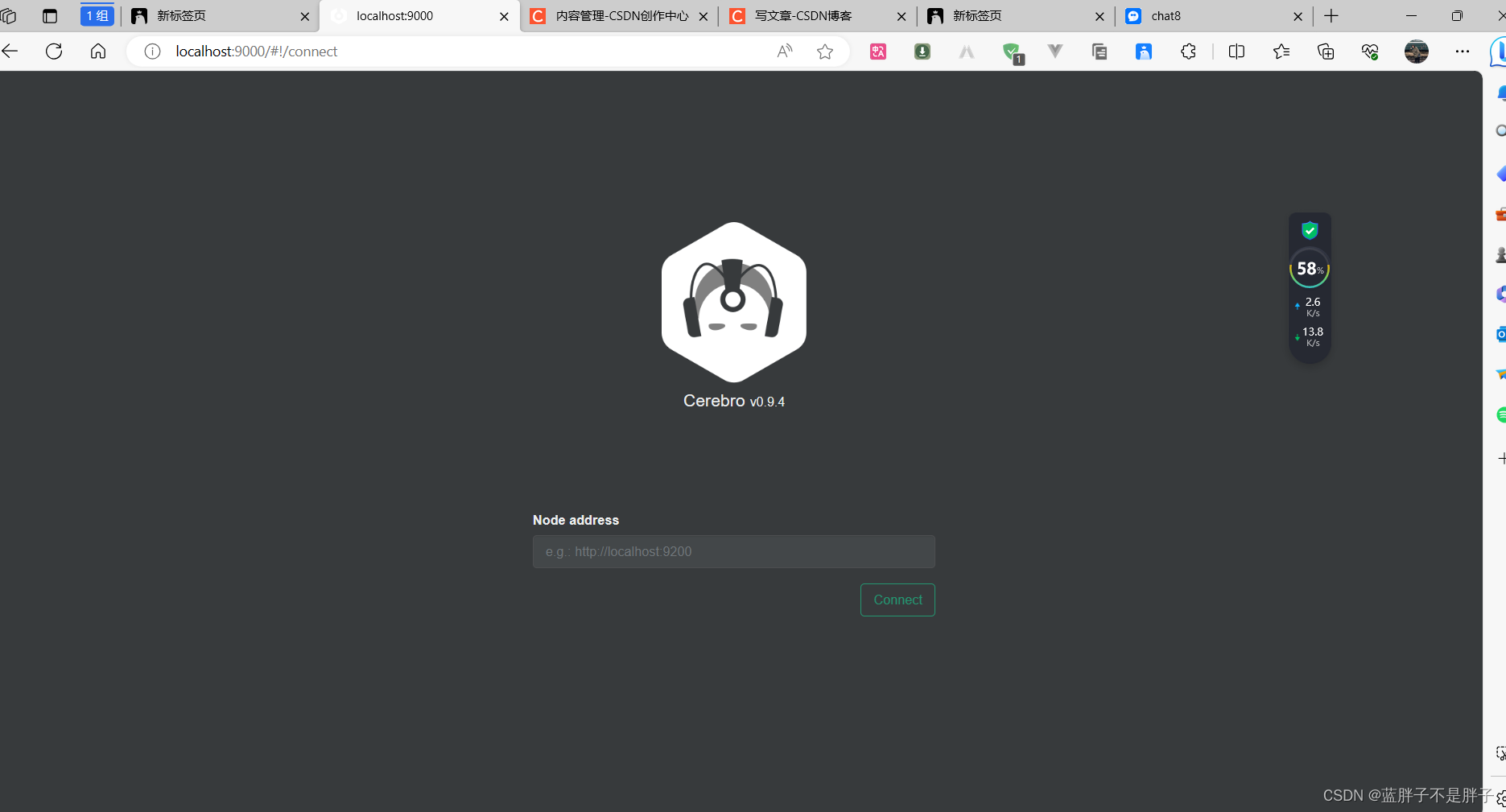
输入你的elasticsearch的任意节点的地址和端口,点击connect即可:
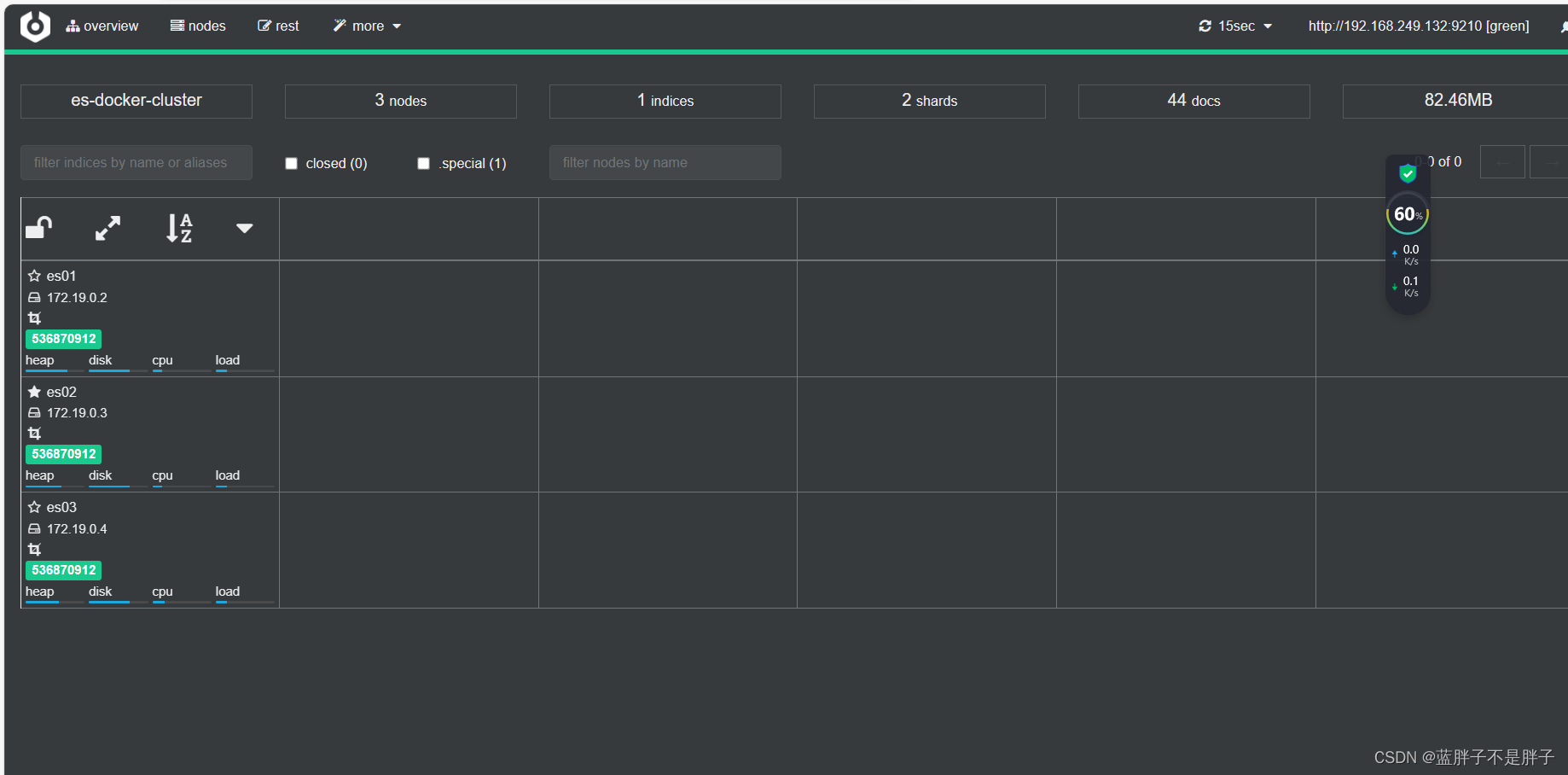
绿色的条,代表集群处于绿色(健康状态)。
图标星星是实的是当前主节点,其他的是备用结点

2.3.创建索引库
1)利用kibana的DevTools创建索引库
(这里集群不使用这种方式)
在DevTools中输入指令:
PUT /itcast
{"settings": {"number_of_shards": 3, // 分片数量"number_of_replicas": 1 // 副本数量},"mappings": {"properties": {// mapping映射定义 ...}}
}
2)利用cerebro创建索引库
利用cerebro还可以创建索引库:
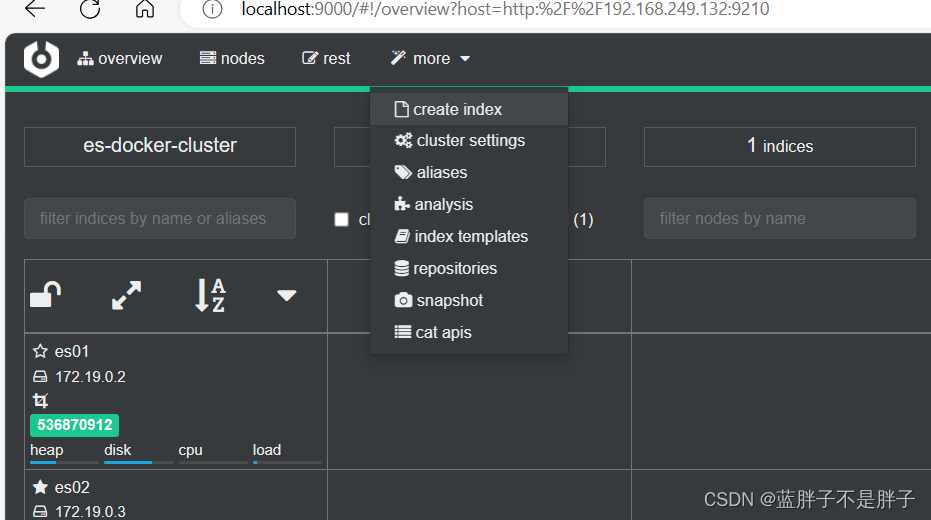
172是我的虚拟机所在的虚拟地址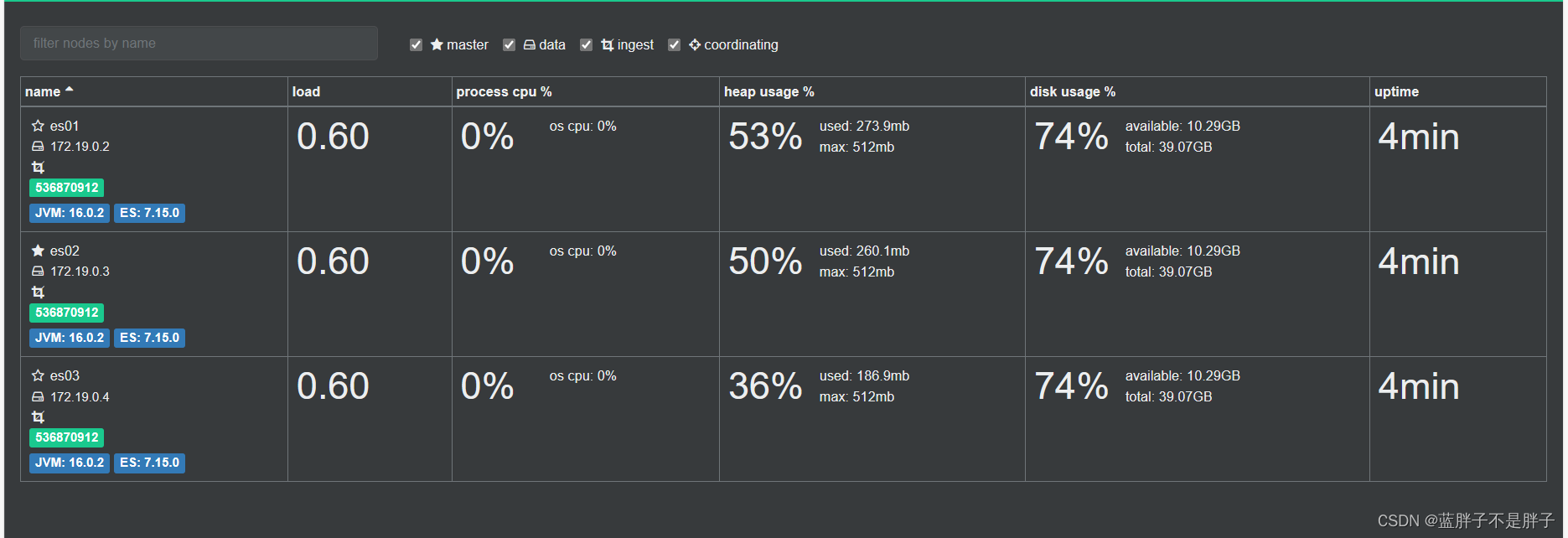
填写索引库信息:
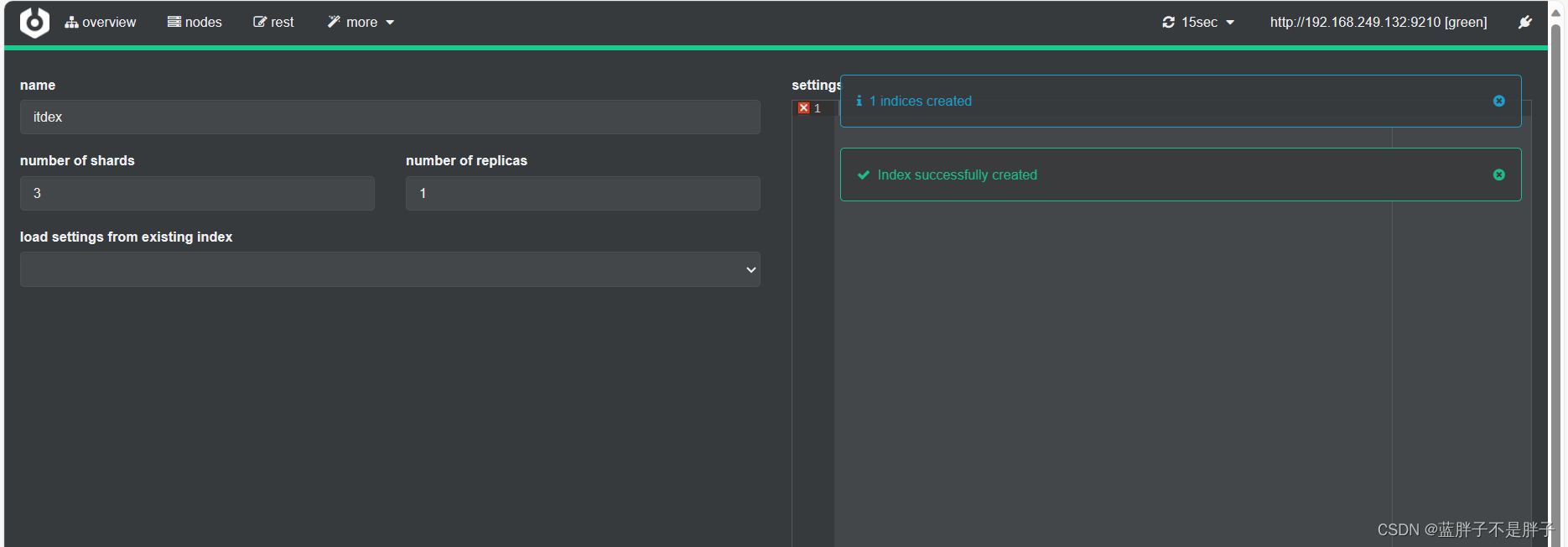
- 选项分别是索引名 几个分片 几个备份
点击右下角的create按钮:
2.4.查看分片效果
回到首页,即可查看索引库分片效果:
首页可以看到索引数据
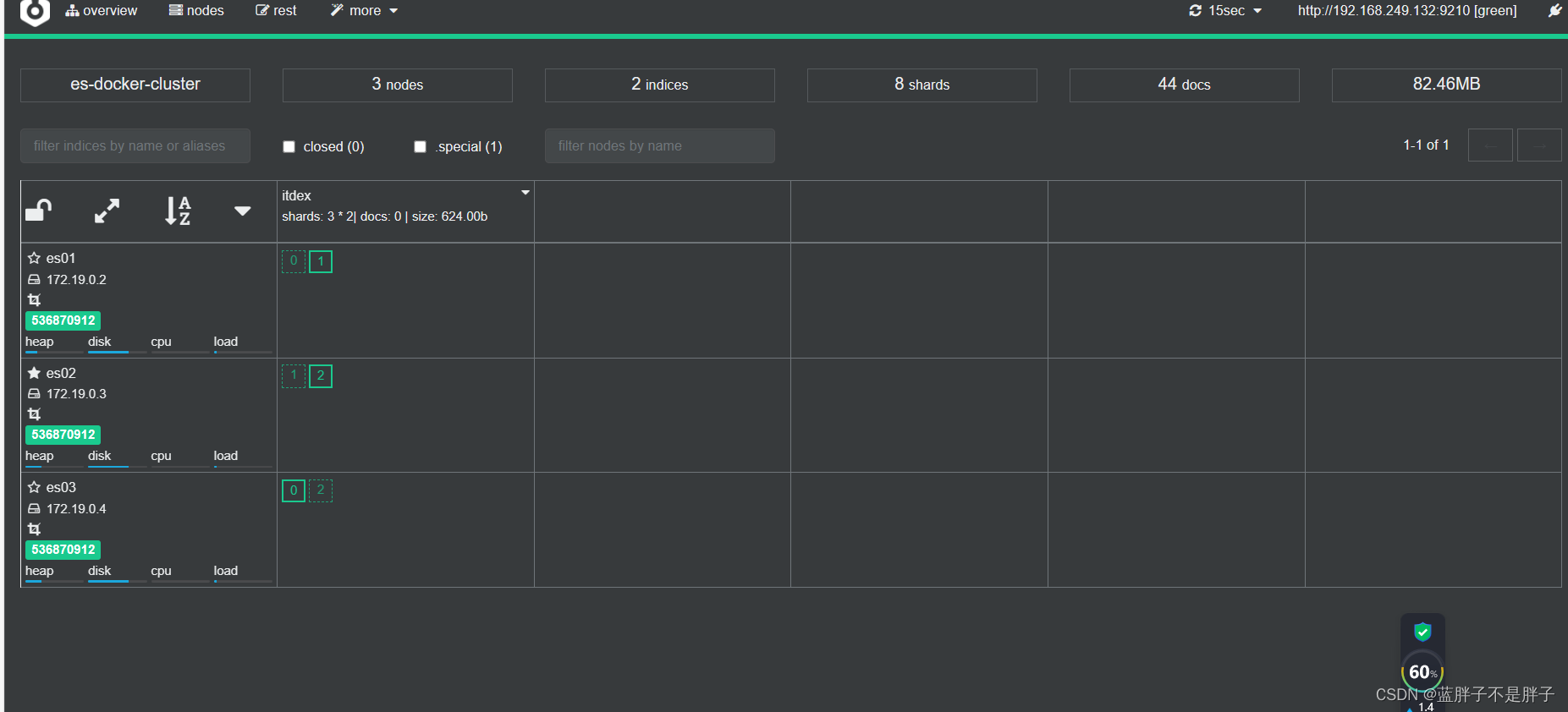
索引存储分为三个分片每个文档分片备份一份所以是6个数据,点击任意分片就可以看到索引信息
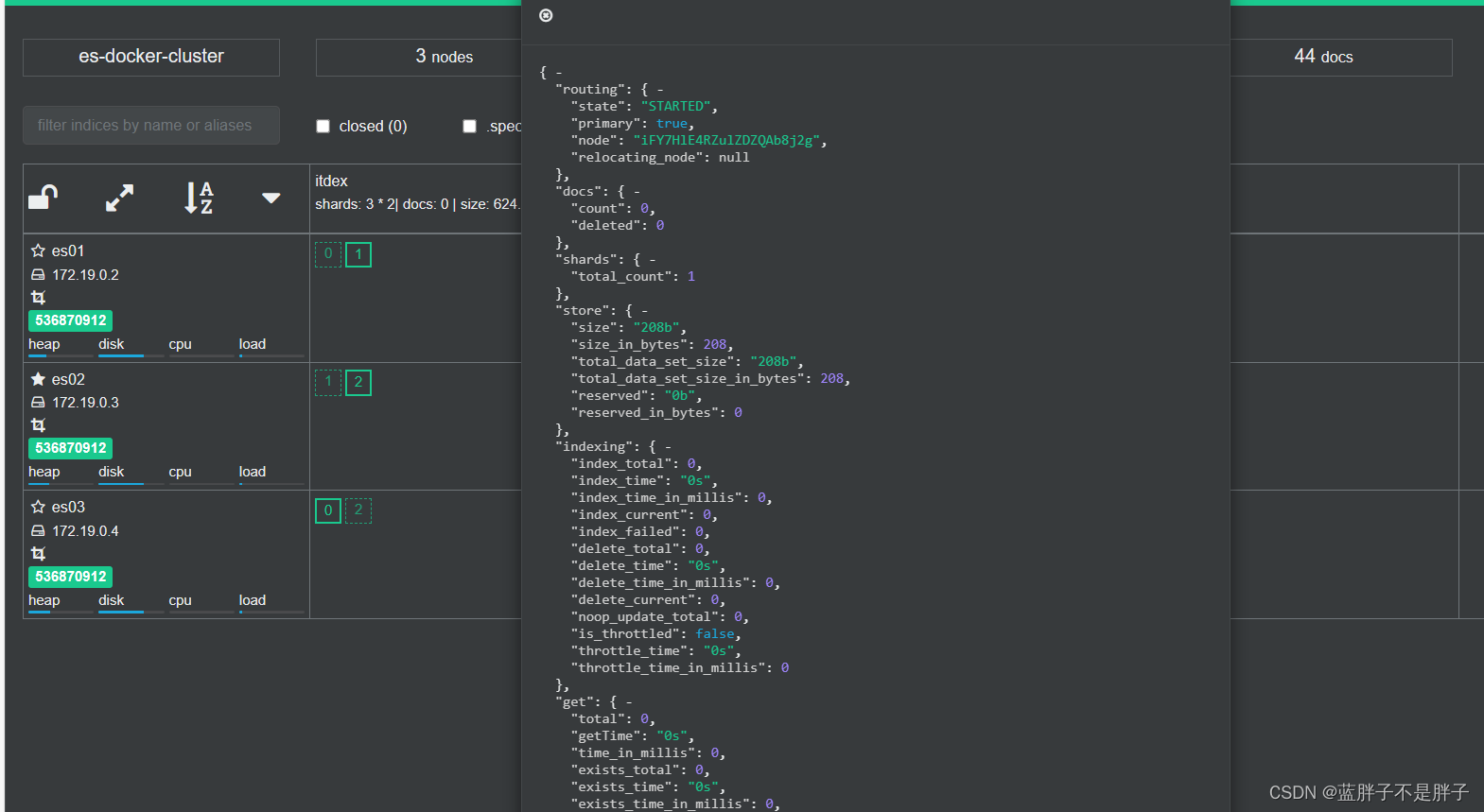
这样就可以保证任意结点宕机 ,其他结点把备份数据传递给宕机接结点
3.0.集群脑裂问题
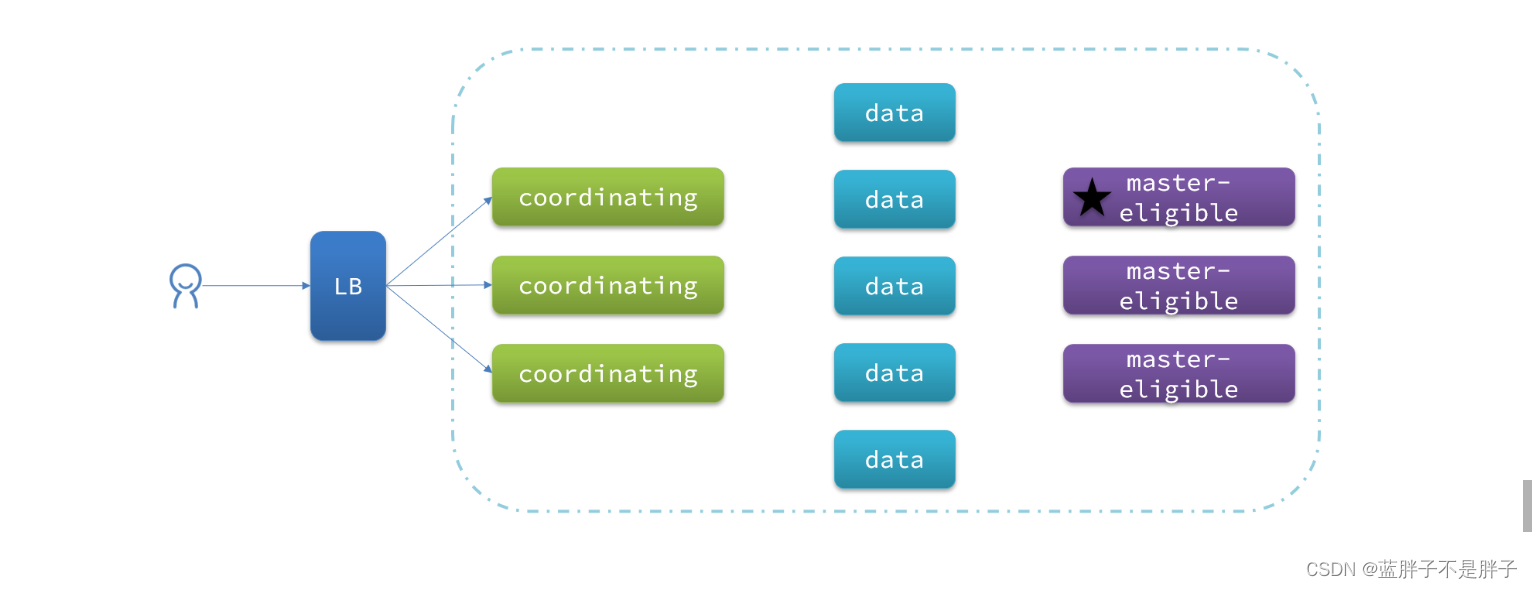
3.1.集群职责划分
elasticsearch中集群节点有不同的职责划分:
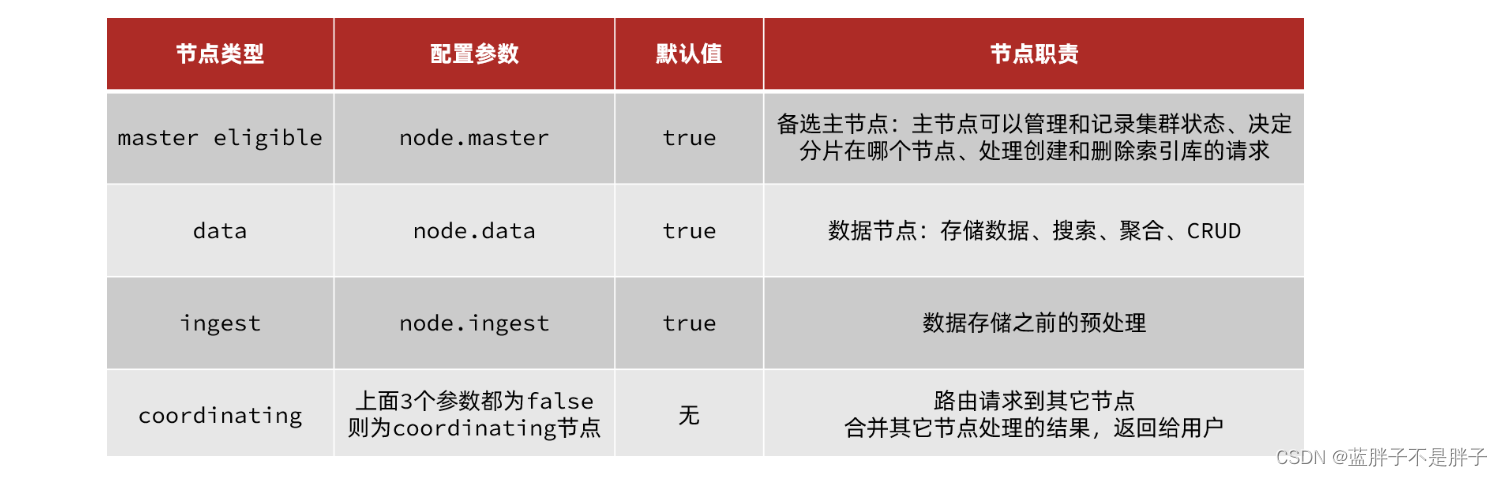
默认情况下,集群中的任何一个节点都同时具备上述四种角色。
但是真实的集群一定要将集群职责分离:
- master节点:对CPU要求高,但是内存要求第
- data节点:对CPU和内存要求都高
- coordinating节点:对网络带宽、CPU要求高
职责分离可以让我们根据不同节点的需求分配不同的硬件去部署。而且避免业务之间的互相干扰。
一个典型的es集群职责划分如图:
3.2.脑裂问题
但是采用分布式的主从架构的服务一般都会出现脑裂问题
脑裂是因为集群中的节点失联导致的。结点尚未宕机,但是失去通信(比如网络问题)
例如一个集群中,主节点与其它节点失联:
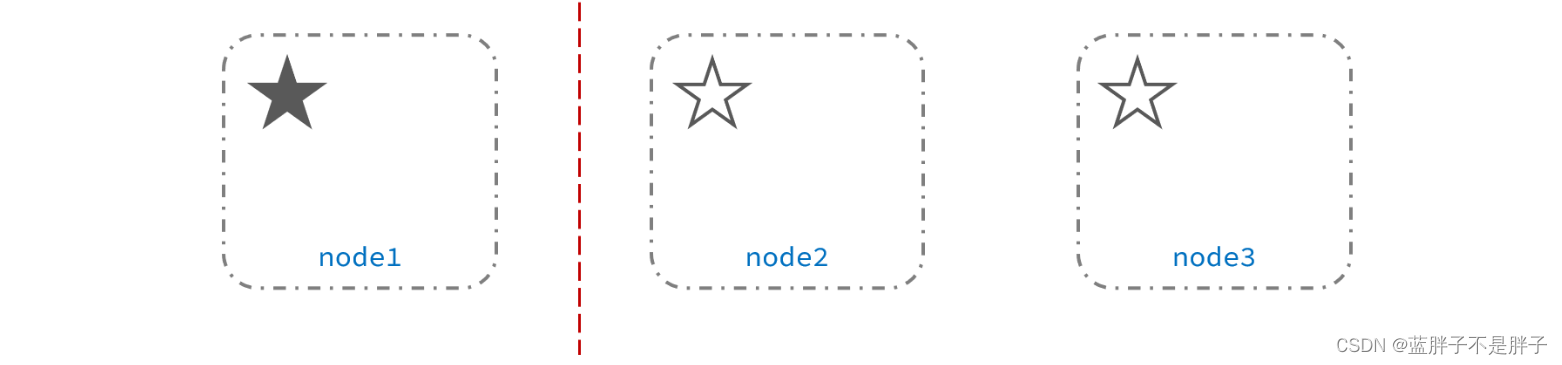
此时,node2和node3认为node1宕机,就会重新选主:
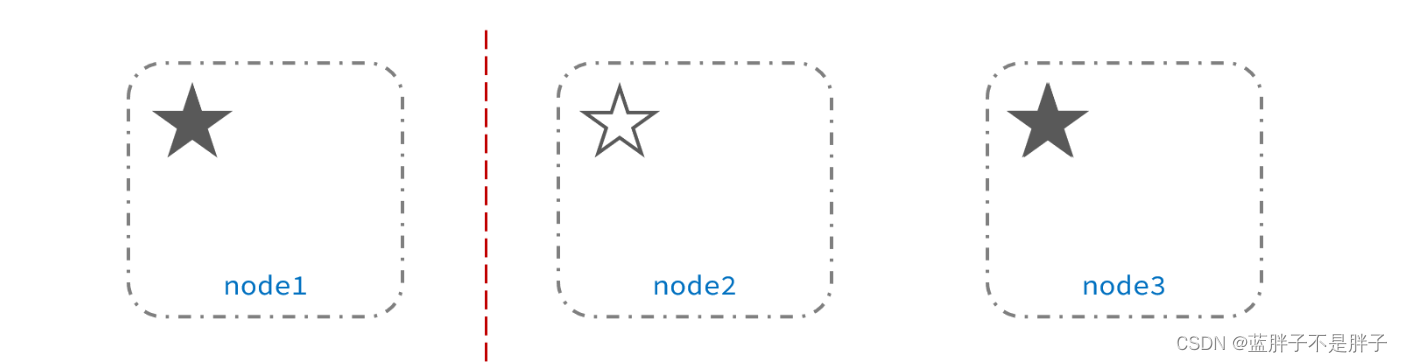
当node3当选后,集群继续对外提供服务,node2和node3自成集群,node1自成集群,两个集群数据不同步,出现数据差异,这个时候出现了俩个大脑
当网络恢复后,因为集群中有两个master节点,集群状态的不一致,出现脑裂的情况:
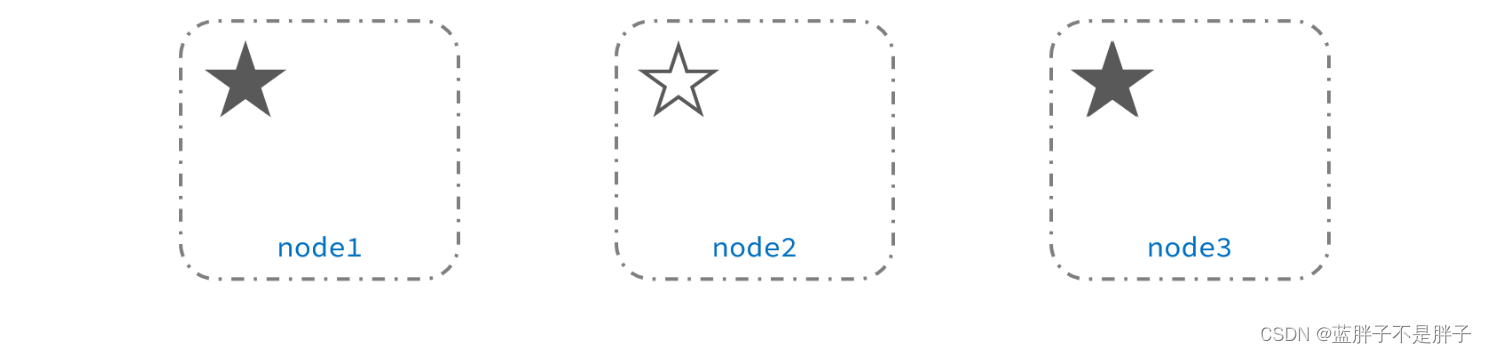
解决脑裂的方案是,要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
例如:3个节点形成的集群,选票必须超过 (3 + 1) / 2 ,也就是2票。node3得到node2和node3的选票,当选为主。node1只有自己1票,没有当选救失去主节点身份。集群中依然只有1个主节点,没有出现脑裂。
3.3.小结
master eligible节点的作用是什么?
- 参与集群选主
- 主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
data节点的作用是什么?
- 数据的CRUD
coordinator节点的作用是什么?
-
路由请求到其它节点
-
合并查询到的结果,返回给用户
3.4.集群分布式存储
当新增文档时,应该保存到不同分片,保证数据均衡,那么coordinating node如何确定数据该存储到哪个分片呢?
3.4.1.分片存储测试
插入三条数据:
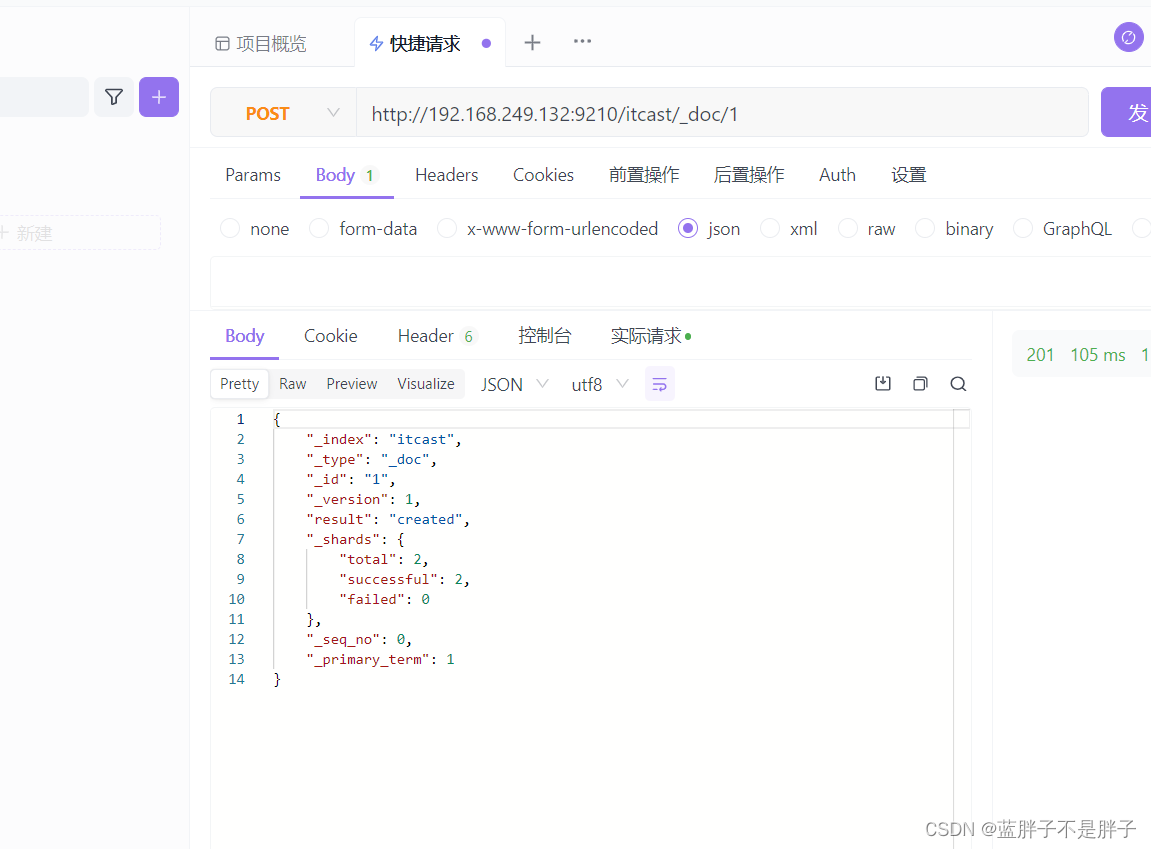
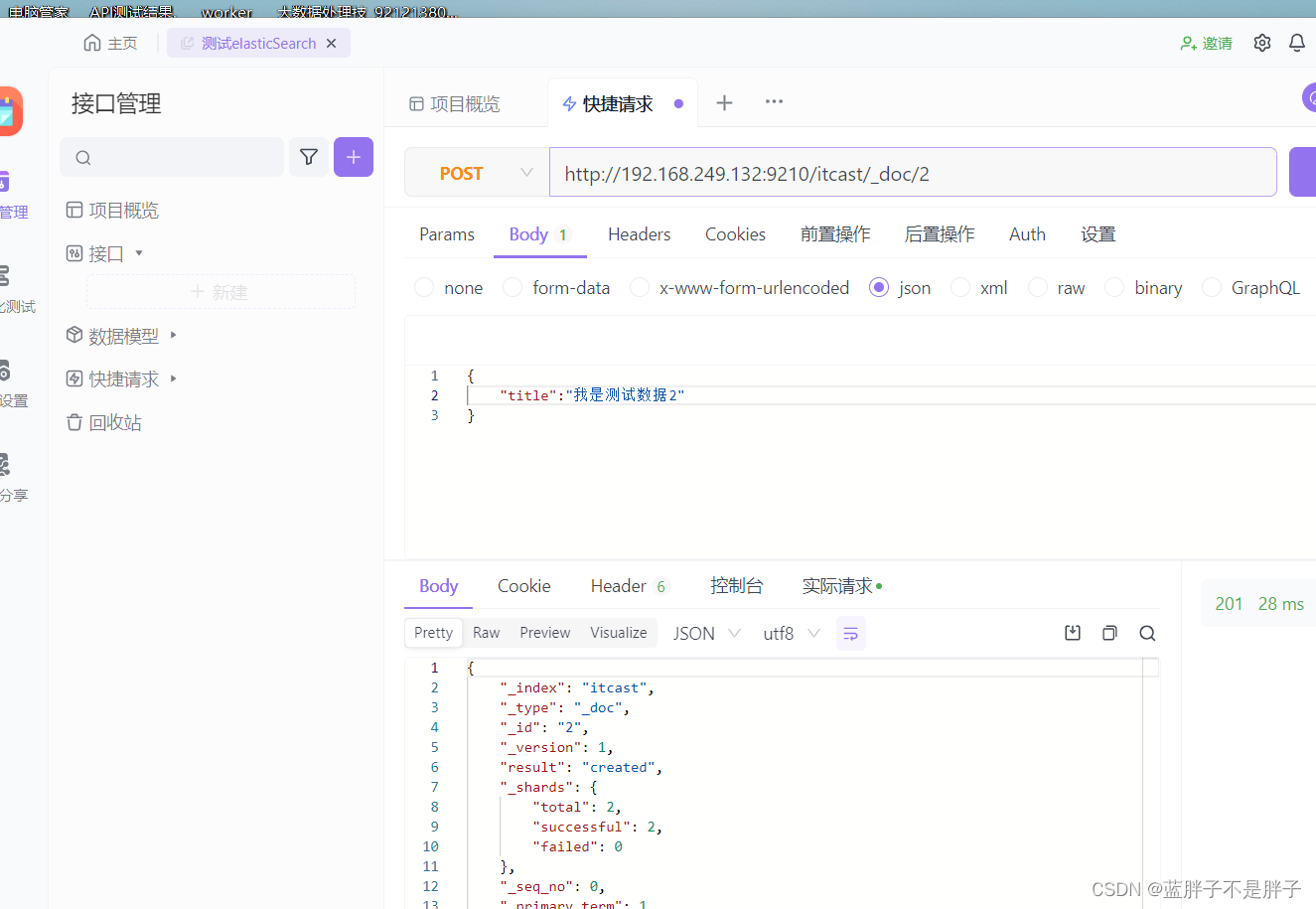
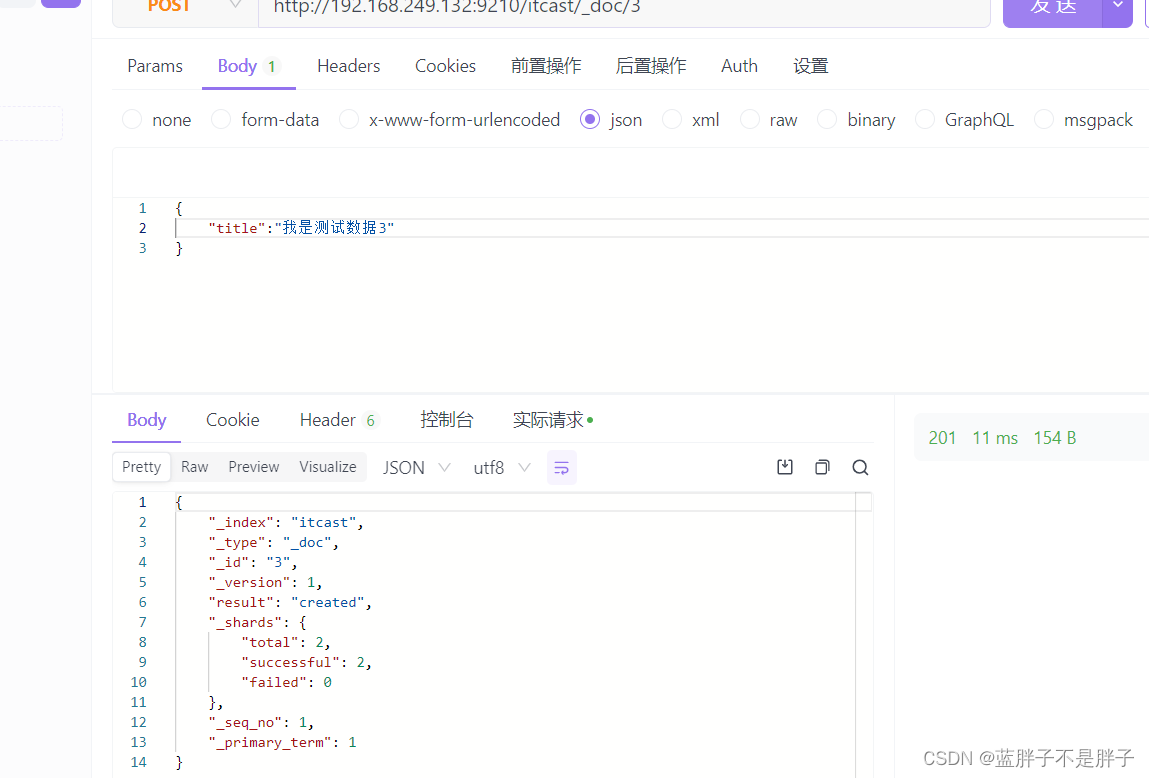
创建索引时候我没有没有添加索引mapping,也没有规定字段,在Elasticsearch中,如果你创建一个索引但没有显式定义映射(mapping)或字段(mapping),Elasticsearch会使用动态映射(dynamic mapping)来处理你插入的文档数据。动态映射允许Elasticsearch根据插入的文档数据自动推断字段的数据类型。
当你插入文档时,Elasticsearch会检查文档的字段,并根据字段值的类型自动创建相应的字段映射。例如,如果你插入一个包含字符串的字段,Elasticsearch会自动将其识别为文本字段,如果插入一个整数,它会将其识别为整数字段,以此类推。
测试可以看到,三条数据分别在不同分片,查询任意结点的数据
结果:
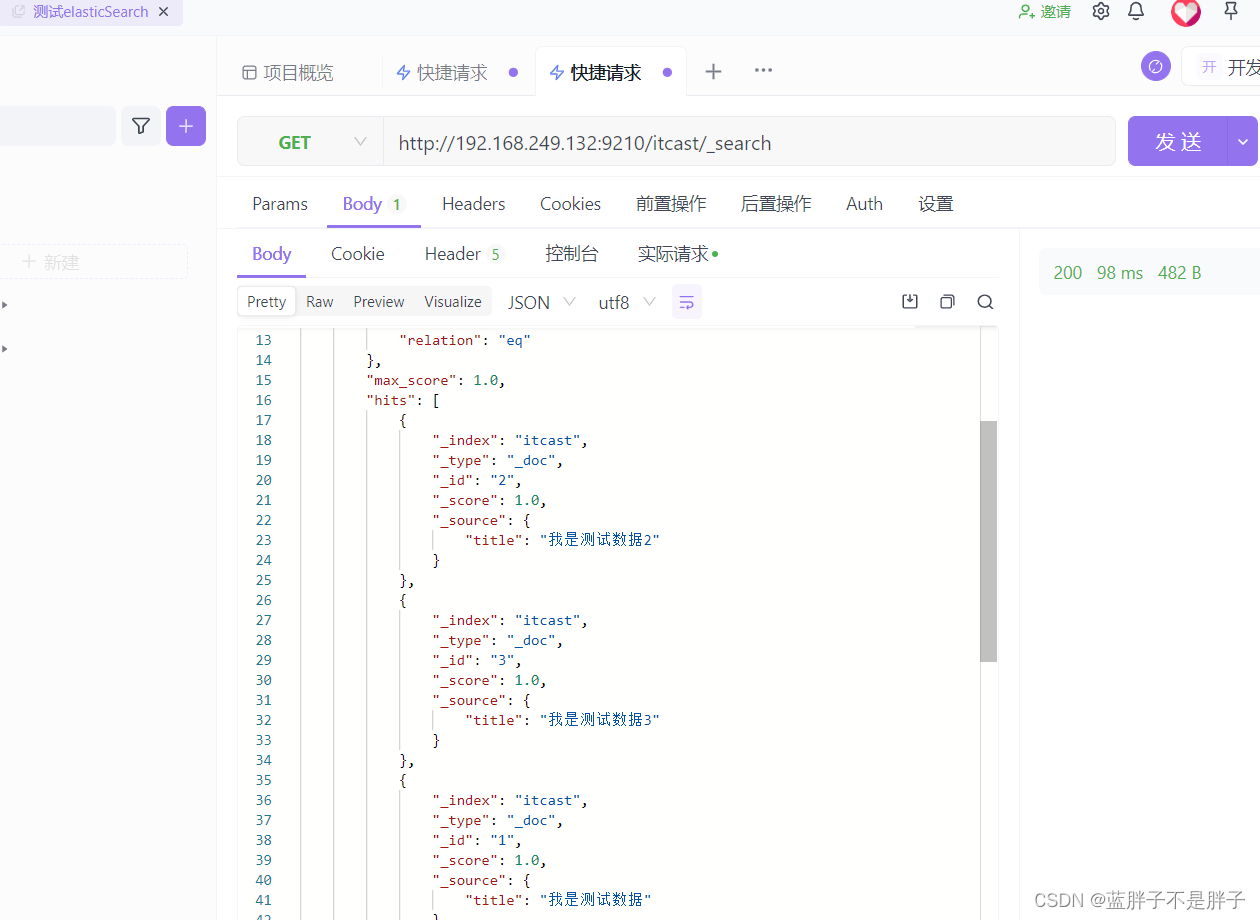
另一接待你查询
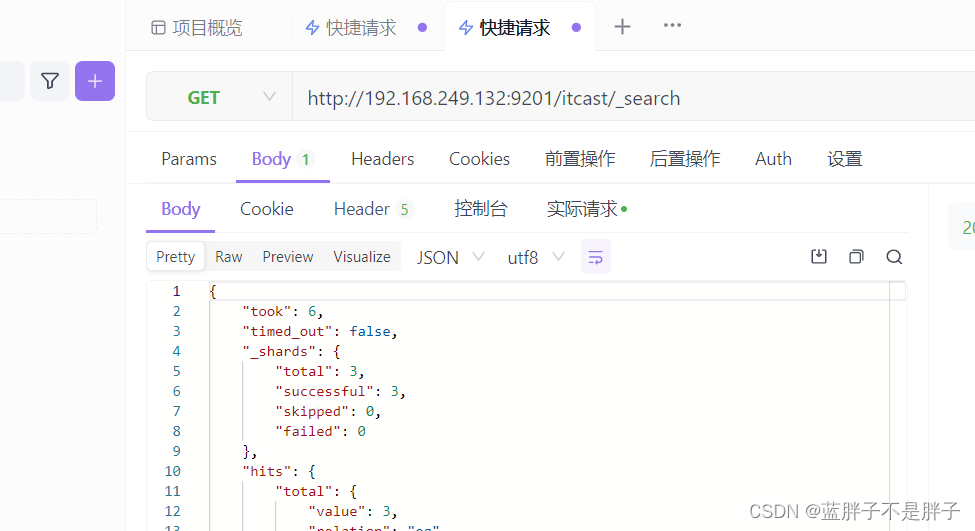
3.4.2.分片存储原理
elasticsearch会通过hash算法来计算文档应该存储到哪个分片:

说明:
- )_routing默认是文档的id
- ) 算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
新增文档的流程如下:
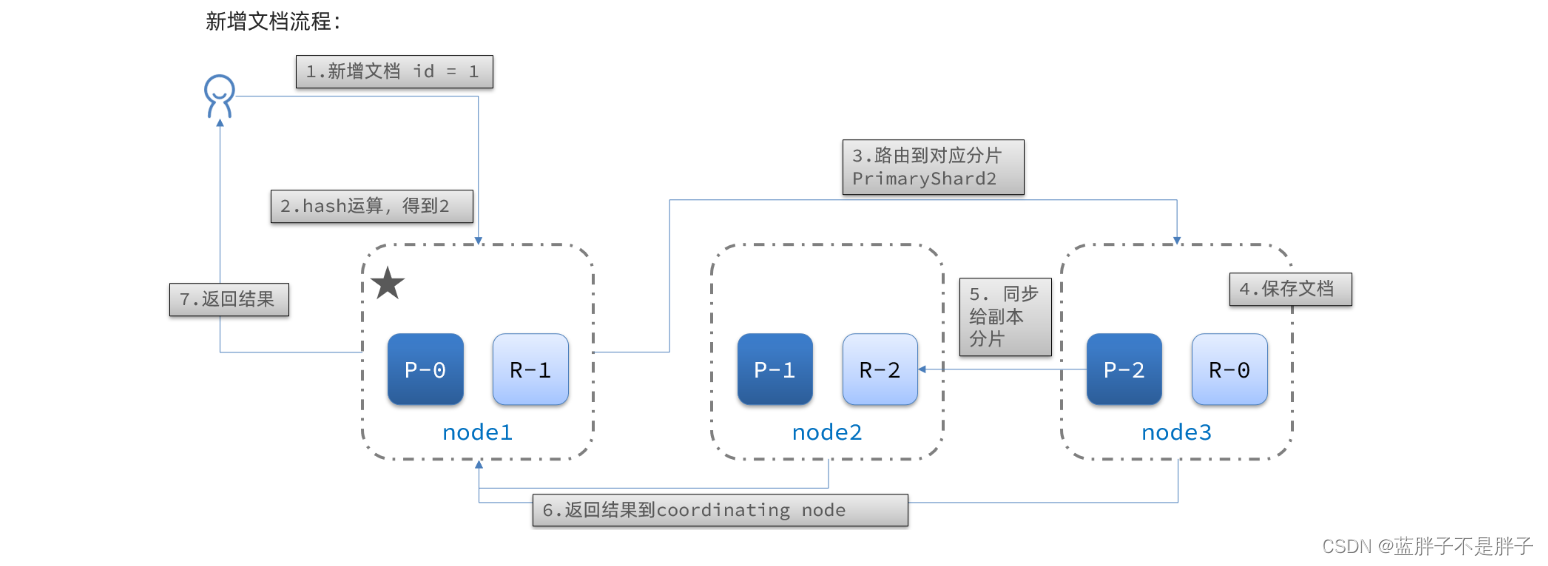
解读:
- 1)新增一个id=1的文档
- 2)对id做hash运算,假如得到的是2,则应该存储到shard-2
- 3)shard-2的主分片在node3节点,将数据路由到node3
- 4)保存文档
- 5)同步给shard-2的副本replica-2,在node2节点
- 6)返回结果给coordinating-node节点
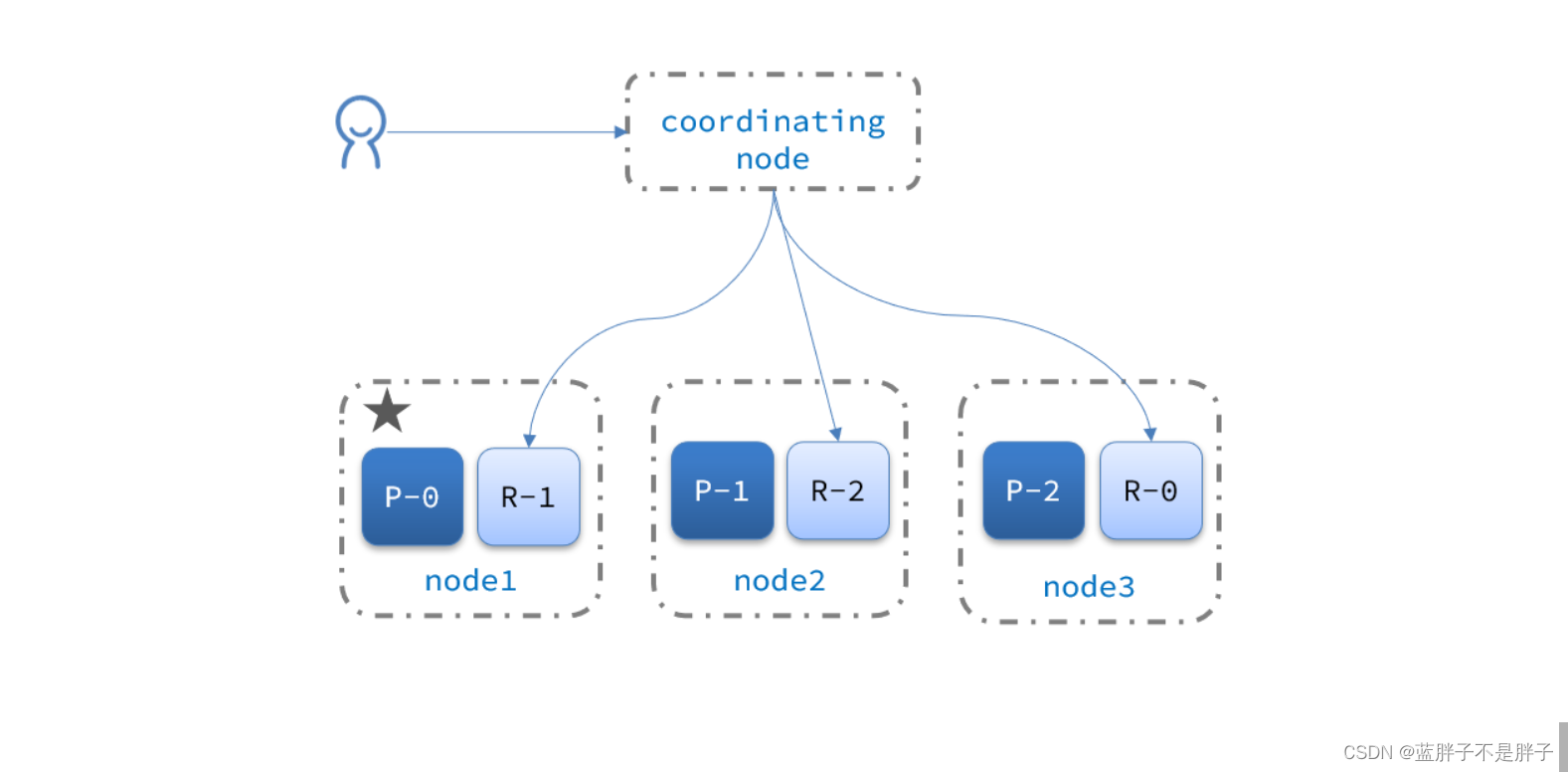
3.4.3集群分布式查询
elasticsearch的查询分成两个阶段:
- scatter phase:分散阶段,coordinating node会把请求分发到每一个分片(查询检索一般是根据text来查询,不知道具体数据id,所以会给每个结点发送查询)
所以之前查询任一结点,都会查询到全部数据,因为请求打到了所有数据
- gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
3.5.集群故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
1)例如一个集群结构如图:
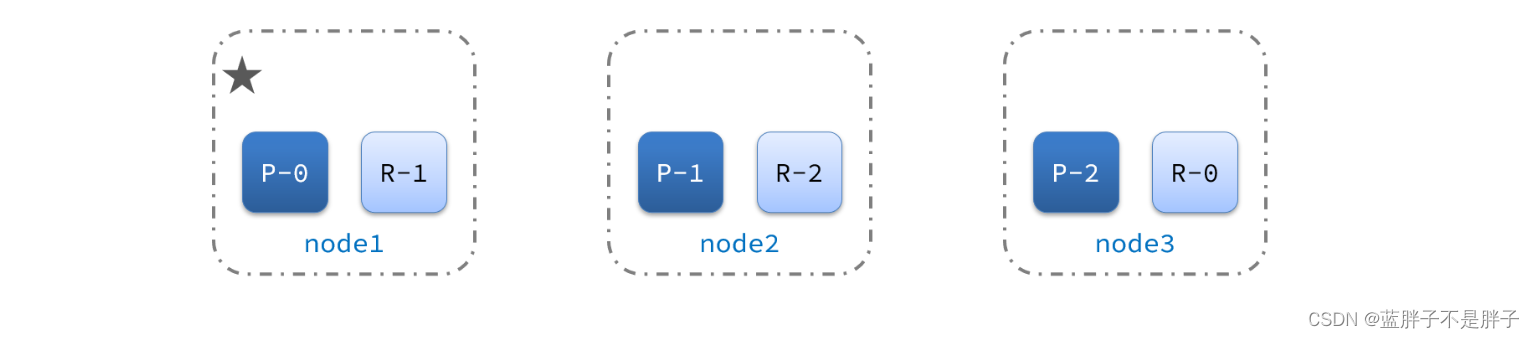
现在,node1是主节点,其它两个节点是从节点。
2)突然,node1发生了故障:
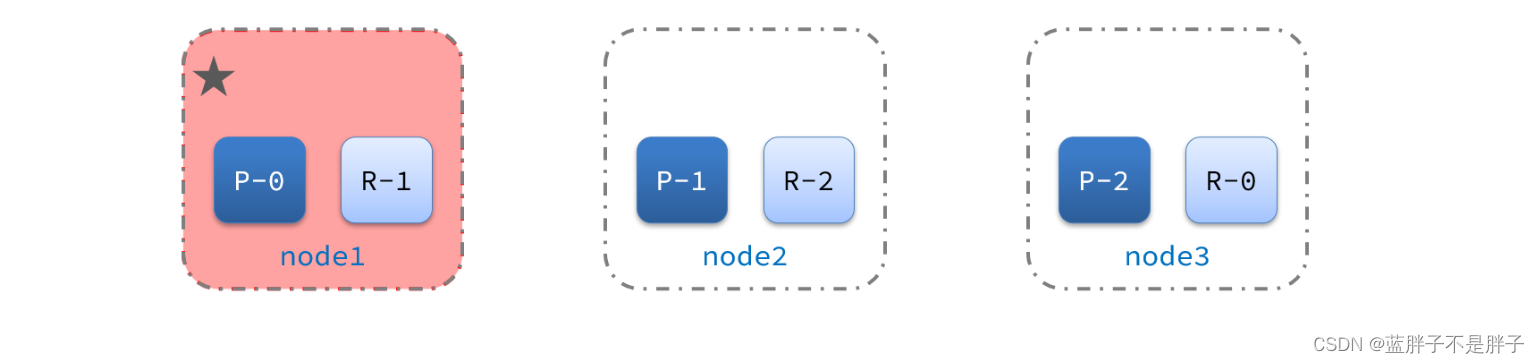
宕机后的第一件事,需要重新选主,例如选中了node2:
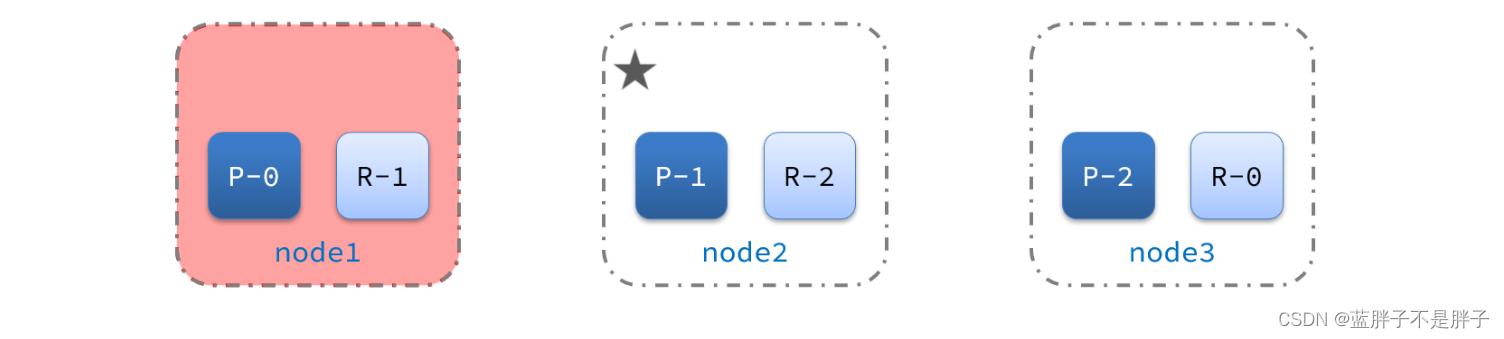
node2成为主节点后,会检测集群监控状态,发现:shard-1、shard-0没有副本节点。因此需要将node1上的数据迁移到node2、node3:
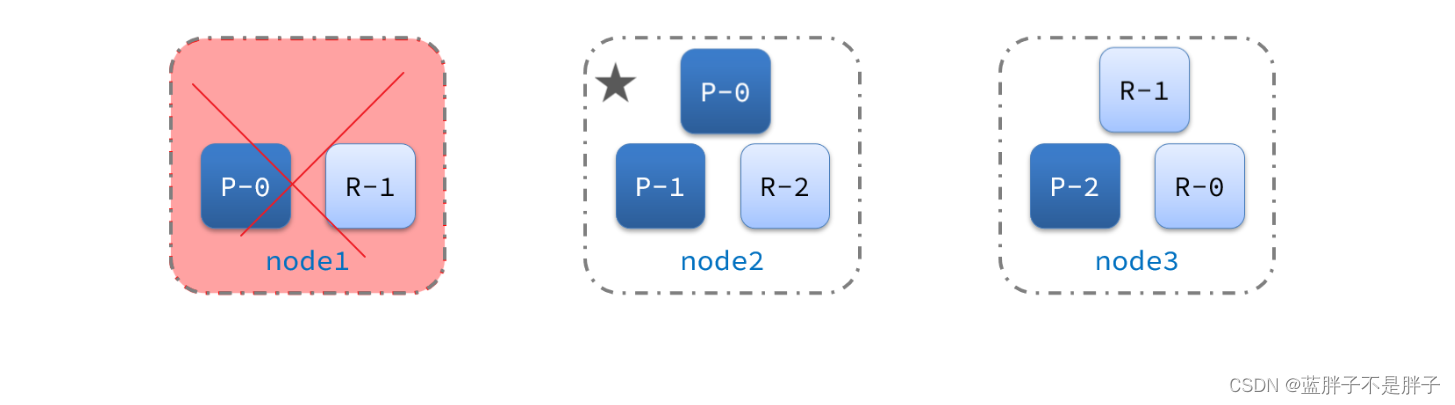
所以故障转移主要是进行了俩布,
- 主结点宕机后选择新节点为主结点
- 新的主节点为了保障宕机结点所存储的数据安全,第一时间转移到其他安全结点
这是es集群的默认策略 这里进行演示即可
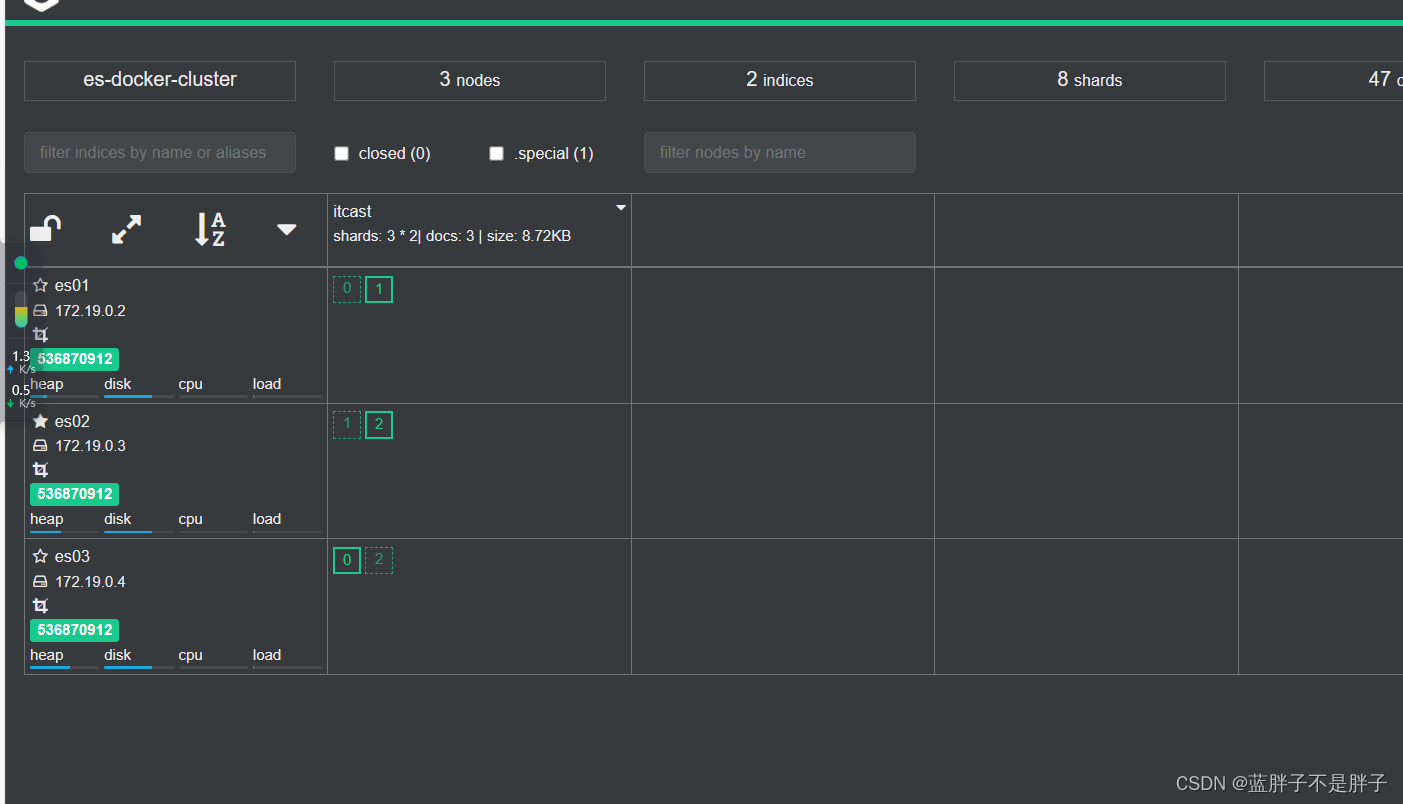
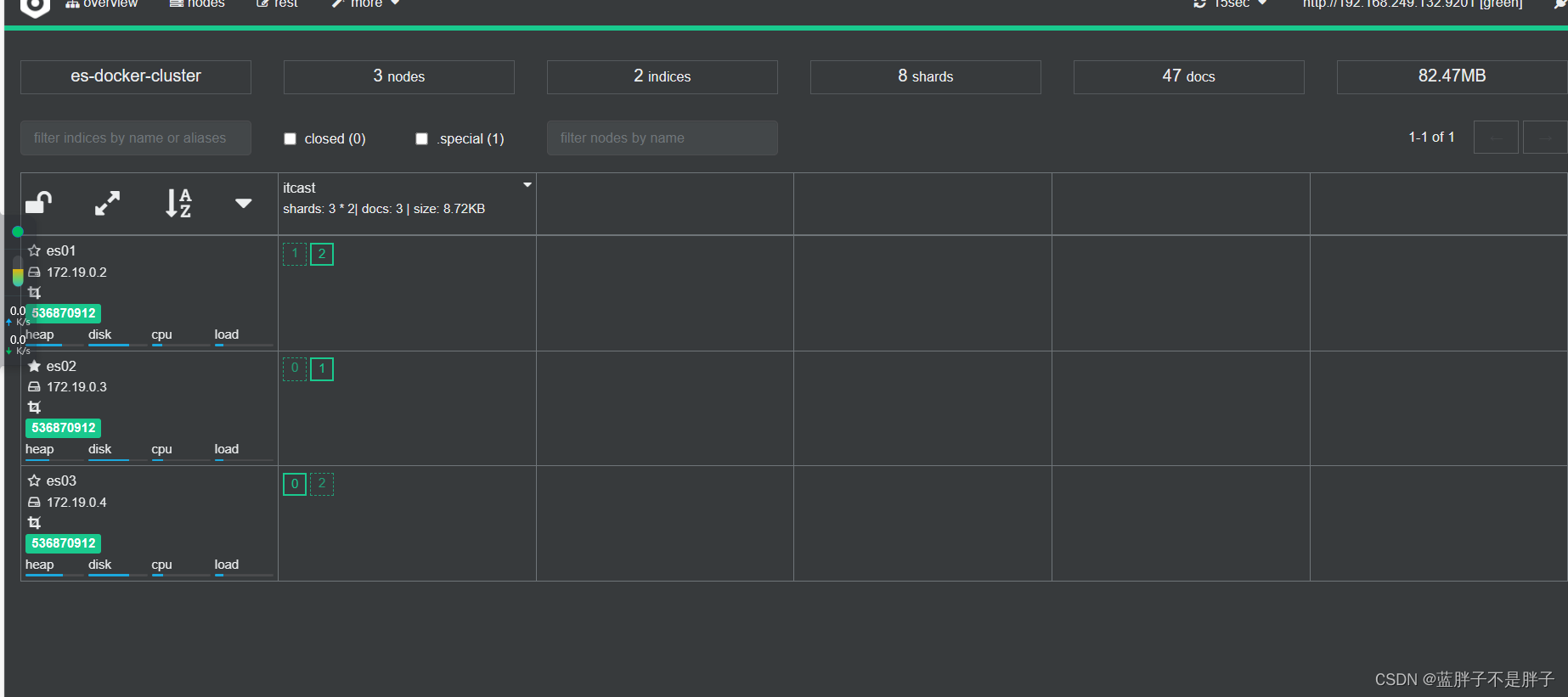
现在三个结点正常

关闭虚拟机的任一结点
等待一会后 集群自动迁移
当es01重新启动后 数据均衡又会把数据分给挂掉的结点
相关文章:
springcloud----检索中间件 ElasticSearch 分布式场景的运用
如果对es的基础知识有不了解的可以看 es看这个文章就会使用了 1.分布式集群场景下的使用 单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。 海量数据存储问题:将索引库从逻辑上拆分为N个分片(…...

qt创建线程类并实现通信 C++
需求描述: 通过VS创建了一个QT项目,我需要一个线程类去实时获取设备取流的图像,并将图像传给qt的类用于在QLabel上显示。 实现: 头文件: //include ...省略//Qt界面的类Your_Project class Your_Project : public Q…...

【elasticsearch】使用自建证书搭建elasticsearch8.0.1集群
概述 本文将分享使用自建证书搭建加密的es集群,如果想使用rpm包安装,前期的搭建过程请参考上面一篇文章https://blog.csdn.net/margu_168/article/details/133344675。后续的操作与使用tar包安装的类似,只是需要注意目录的区别。 es8.0.1安…...
一篇文章带你用动态规划解决打家劫舍问题
动态规划的解题步骤可以分为以下五步,大家先好好记住 1.创建dp数组以及明确dp数组下标的含义 2.制定递推公式 3.初始化 4.遍历顺序 5.验证结果 根据打家劫舍的题意:两个直接相连的房子在同一天晚上被打劫会触发警报 所以我们制定出核心策略——偷东…...
idea中导入eclipse的javaweb项目——tomact服务(保姆级别)
idea中导入eclipse的javaweb项目——tomact服务(保姆级别) 1. 导入项目2. Project Settings下的各种配置步骤2.1 检查/修改 jdk 的引入2.2 配置Modules-Dependencies2.2.1 删掉eclipse相关的多余配置2.2.2 删掉jar包2.2.3 添加tomcat的依赖 2.3 配置Libr…...

【开源】给ChatGLM写个,Java对接的SDK
作者:小傅哥 - 百度搜 小傅哥bugstack 博客:bugstack.cn 沉淀、分享、成长,让自己和他人都能有所收获!😄 大家好,我是技术UP主小傅哥。 清华大学计算机系的超大规模训练模型 ChatGLM-130B 使用效果非常牛&…...
基于Pytest+Allure+Excel的接口自动化测试框架
1. Allure 简介 简介 Allure 框架是一个灵活的、轻量级的、支持多语言的测试报告工具,它不仅以 Web 的方式展示了简介的测试结果,而且允许参与开发过程的每个人可以从日常执行的测试中,最大限度地提取有用信息。 Allure 是由 Java 语言开发的…...
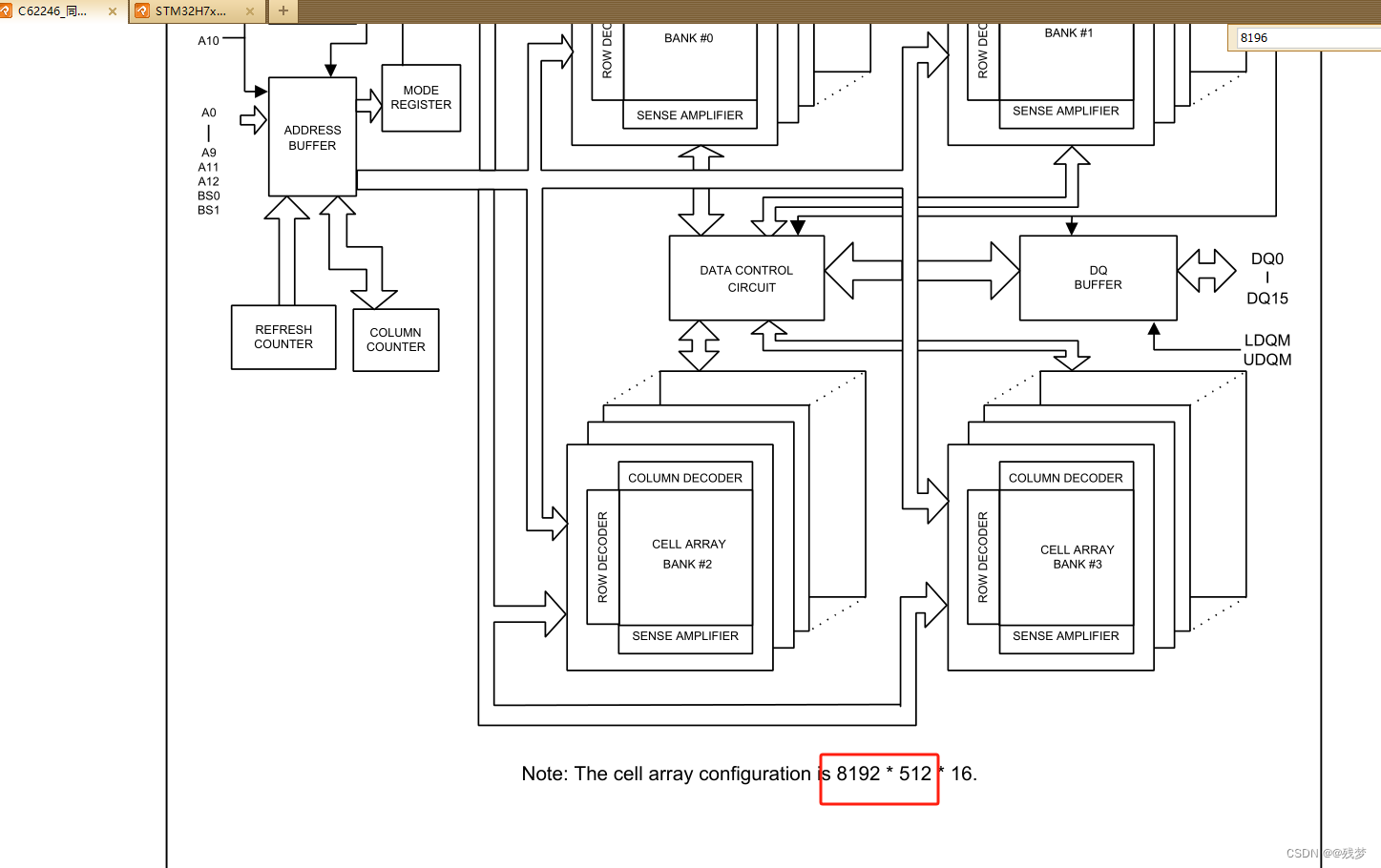
20.2 FMC驱动SDRAM的时序初始化实现及内存测试
继续上一篇的话题,写到SDRAM通过CubeMx配置后,在工程代码编写时直接引用的是我事先写好的时序初始化、内存测试文件,而未对其进行详细的解释,所以本篇文章就来娓娓道来。不多说,开始吧 SDRAM的初始化流程简述 SDRAM初…...
联想电脑一键重装系统Win10操作方法
很多用户都会利用重装系统的方法,来解决系统崩溃、病毒感染等问题。但是,很多新手用户不知道联想电脑Win10系统重装的详细方法步骤,下面小编给大家详细介绍关于联想电脑Win10系统重装的操作方法,帮助大家轻松快速地完成系统的重装…...
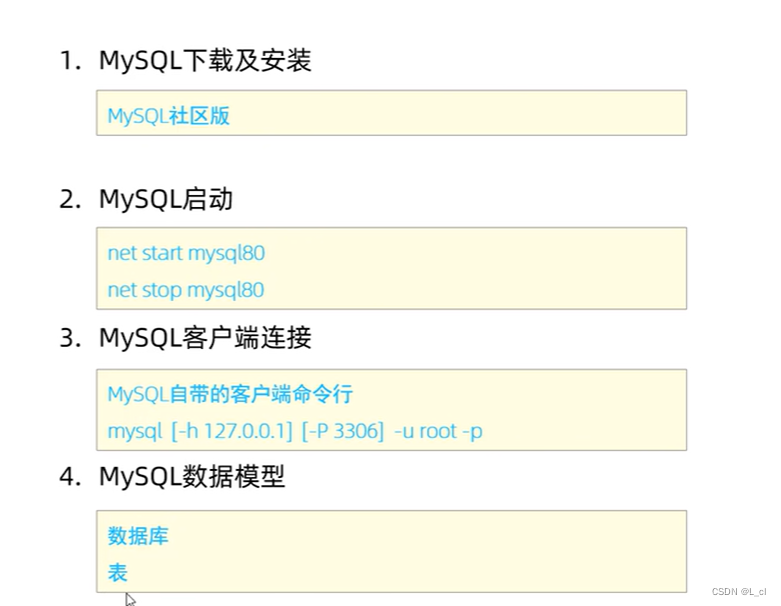
Mysql数据库 1.概述
Mysql内容概述 1. Mysql概述 数据库相关概念: 名称 全称 简称 数据库 存储数据的仓库,数据是有组织的进行存储 …...

Qt编程,文件操作、UDP通信
目录 1、文件类 QFile 2、 UPD/TCP网络编程 1、##UDP客户端 2、##UDP服务器端 1、文件类 QFile QFile file(filename); file.exists() file.setFileName(filename1); file.fileName() file.bytesAvailable() file.size() file.copy("2.txt") file1.errorString(…...
Docker 的数据管理和Dockerfile镜像的创建
目录 Docker 的数据管理 管理 Docker 容器中数据的方式 端口映射 容器互联(使用centos镜像) Docker 镜像的创建 Dockerfile 操作常用的指令 编写 Dockerfile 时格式 Dockerfile 案例 Docker 的数据管理 管理 Docker 容器中数据的方式 管理 Doc…...

[python] 利用 Pydoc 快速生成整个 Python 项目的文档
如何写注释 class MyClass:"""This is a simple example class.Attributes:param1 (int): The first parameter.param2 (str): The second parameter."""def __init__(self, param1, param2):"""The constructor for MyClass.:p…...

Maven 配置指南
目录 一、配置本地存储库 二、配置并行Artifact 解析 三、安全和部署设置 四、将镜像用于存储库 五、Profiles 六、可选配置 七、Settings 八、安全性 九、工具链 Maven配置发生在3个级别: 项目-大多数静态配置发生在pom.xml中安装-这是为Maven安装添加的…...

第十八章 类和对象——多态
一、多态的基本概念 多态是C面向对象三大特性之一 多态分为两类 静态多态: 函数重载 和 运算符重载属于静态多态,复用函数名 动态多态: 派生类和虚函数实现运行时多态 静态多态和动态多态区别: 静态多态的函数地址早绑定 - 编译阶段确定函数地址 动…...
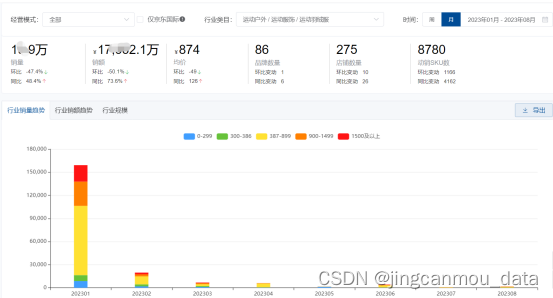
京东数据平台:2023年服饰行业销售数据分析
最近看到有些消费机构分析,不少知名的运动品牌都把“主战场”放到了冲锋衣,那么羽绒服市场就比较危险了。但其实羽绒服市场也有机会点可寻。 先来说冲锋衣。的确,从今年的销售数据以及增长情况,冲锋衣的确会是今年冬天的大热门品…...

Nginx proxy_set_header参数设置
一、不设置 proxy_set_header Host 不设置 proxy_set_header Host 时,浏览器直接访问 nginx,获取到的 Host 是 proxy_pass 后面的值,即 $proxy_host 的值,参考Module ngx_http_proxy_module 1 2 3 4 5 6 7 8 # cat ngx_header.c…...
如何用 ChatGPT 的 Advanced Data Analysis 帮你采集数据?
(注:本文为小报童精选文章,已订阅小报童或加入知识星球「玉树芝兰」用户请勿重复付费) 想采集网页数据却不会写 Python 爬虫?不会就不会吧,ChatGPT 会就可以了 😂 问题描述 朋友最近遇到了一点儿…...

Linux运行环境搭建系列-Flink安装
Flink安装 ## 下载 https://archive.apache.org/dist/flink/flink-1.16.2 ## 解压 tar -zxvf flink-1.16.2-bin-scala_2.12.tgz && rm -rf flink-1.16.2-bin-scala_2.12.tgz ## 启动 cd flink-1.16.2/bin ## 修改/etc/hosts文件,把第一行的127.0.0.1改成自…...
)
求最大bit数(java)
题目描述 求一个int类型数字对应的二进制数字中1的最大连续数 例如3的二进制为00000011,最大连续2个1 数据范围:数据组数:11t15,11n1500000进阶: 时间复杂度: O(logn),空间复杂度: O(1) 输入: 200 输出 2 说明 200的二进制表示是11001000&am…...

OAuth 2.0 and OIDC 三大安全机制对比:State vs Nonce vs PKCE
一、问题背景 OAuth 2.0 和 OpenID Connect 的授权流程依赖浏览器重定向,这天然暴露了多种攻击面: 攻击类型描述CSRF攻击者诱导用户的浏览器携带恶意授权码完成绑定Token 重放窃取的 id_token 被重复提交给客户端授权码劫持恶意应用在同一设备上拦截授…...

Fast-GitHub:三步安装解决国内GitHub访问难题的终极指南
Fast-GitHub:三步安装解决国内GitHub访问难题的终极指南 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否经常因为…...

移动端大语言模型本地部署:从模型轻量化到推理引擎实战
1. 项目概述:当GPT遇见移动端,一个开源项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫Taewan-P/gpt_mobile。光看名字,你大概就能猜到它的核心:把类似GPT这样的大语言模型(LLM&…...

从零到一:基于HappyBase的HBase Python应用实战指南
1. 环境准备与基础配置 第一次接触HBase和HappyBase时,环境配置往往是最让人头疼的部分。记得我刚开始搭建环境时,花了整整两天时间才把所有服务调通。为了让各位少走弯路,我把这些年积累的经验都整理在这里。 首先需要明确的是,…...

Excel MCP Server终极指南:3步实现无界面Excel自动化处理
Excel MCP Server终极指南:3步实现无界面Excel自动化处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了手动操作Excel的繁琐…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

告别标题栏!在RK3568 Buildroot固件上,让你的Qt应用开机全屏显示的保姆级教程
RK3568嵌入式全屏实战:从Weston配置到Qt应用独占显示的完整指南 在嵌入式Linux系统开发中,GUI应用的全屏显示往往成为工程师面临的第一个"拦路虎"。当你在RK3568平台上精心开发的Qt应用启动后,却发现屏幕顶部顽固地挂着Weston窗口管…...

Argo Workflows:Kubernetes原生工作流引擎从入门到生产实践
1. 项目概述:一个开源的容器化工作流引擎如果你在云原生、数据科学或者自动化运维领域摸爬滚打过一阵子,大概率听说过 Argo。它不是某个游戏里的角色,而是一个在 Kubernetes 生态中,用来编排和运行复杂工作流的强大引擎。简单来说…...