HyperGBM用Adversarial Validation解决数据漂移问题
本文作者:杨健,九章云极 DataCanvas 主任架构师
数据漂移问题近年在机器学习领域来越来越得到关注,成为机器学习模型在实际投产中面对的一个主要挑战。当数据的分布随着时间推移逐渐发生变化,需要预测的数据和用于训练的数据分布表现出明显的偏移,这就是数据漂移问题。
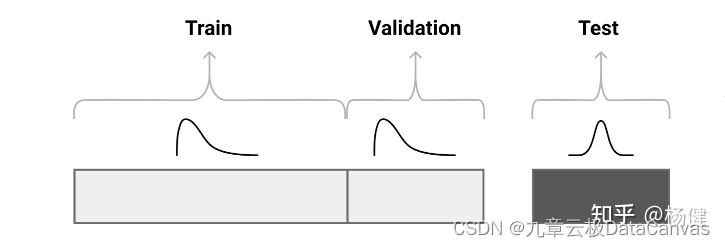
数据漂移分为三种类型:
-
变量偏移(Covariate Drift),某些独立的特征发生偏移
-
先验概率偏移(Prior probability Drift),目标变量发生偏移
-
概念偏移(Concept Drift),特征和目标变量之间的关系发生偏移
为什么不能通过提升泛化能力来解决数据漂移问题?
数据漂移问题无法通过提升模型泛化能力的方法来解决,因为我们目前的机器学习方法基本是建立在IID(独立同分布)前提下的。在一个真实分布下可观测的训练数据有限,训练好模型在预测时遇到了符合同一个分布但未观测到的样本时准确度下降,这种情况我们通过选择合适的算法、交叉验证、正则化、Ensemble等方式是可以有效改善模型的泛化能力的。但数据漂移的本质是数据的真实分布发生了较大的变化,因此仅仅提升泛化能力是无法有效提升模型效果的。
常用的解决方案
数据漂移常见的解决方案是不断的引入最新的数据重新训练模型,但这种方案存在很大的缺陷,例如:我们在客户流失预警中通常会用历史标注的数据训练模型来预测当月是否有用户流失,模型预测的结果要等下个月通过用户行为反馈后得到标注才能评估,如果我们发现结果大幅下降才能判断数据发生了漂移,因此这种方案存在比较明显的滞后性,这也是有监督学习的主要短板。
使用Adversarial Validation半监督学习解决数据漂移
随着近年来无监督和半监督学习的发展,一种基于Adversarial Validation(对抗验证)的半监督学习技术被提出用于解决数据漂移问题。它的核心思想是通过训练一个Adversarial Classifier来判断是否发生漂移以及哪些特征发生了漂移,进而删除发生漂移的特征来保证模型在新数据上的效果。如下图所示:
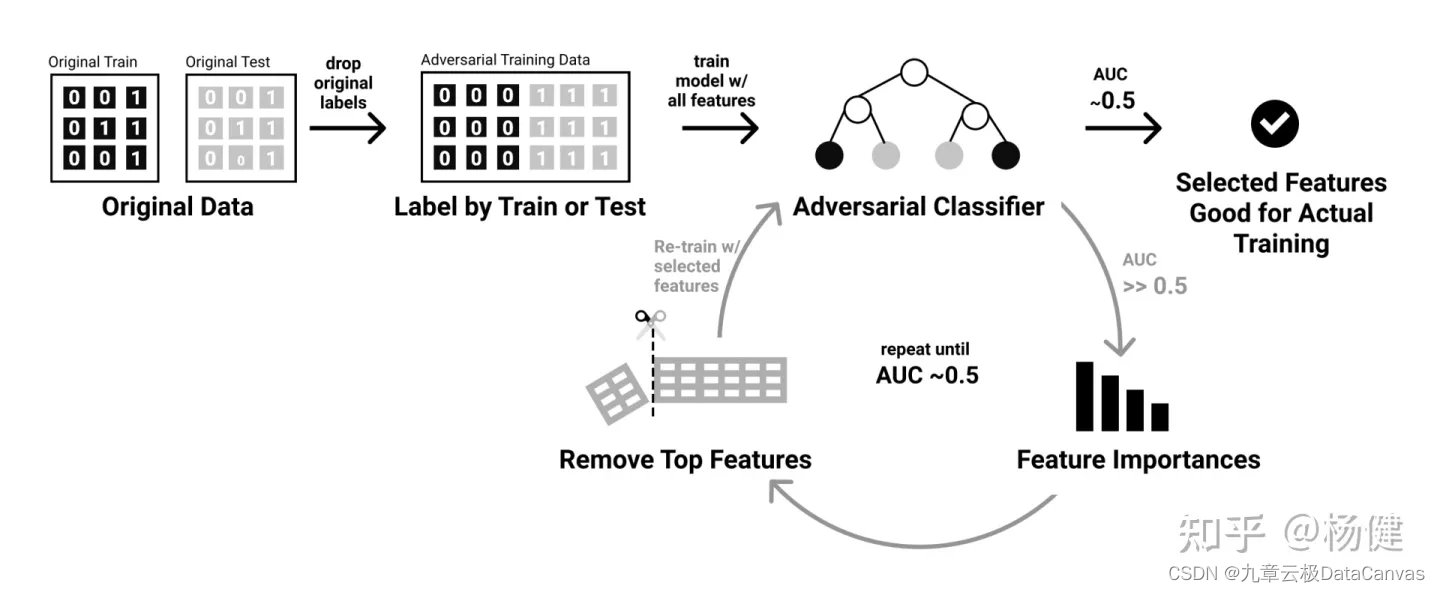
对抗验证的基本过程是把训练数据(先删除目标列)和待预测数据(数据中本身就没有目标列)合并后添加新的二分类目标列(来自训练集为0, 来自测试集为1)。新的数据集shuffle后使用分层采样分割成训练集和评估集,用训练数据fit模型后使用评估集评估AUC,通常如果数据没有发生偏移AUC会接近0.5,否则就可以判断发生了不同程度的数据漂移。接下来就是识别哪些特征发生了漂移,有两种方法:一种是把每一个特征列做为X,单独训练Adversarial Classifier来评估AUC,超过一定阈值(如>0.6),就确定该列发生了漂移。另一种方法是:用全部特征训练Classifier然后评估AUC,如果超过一定阈值,就删除掉特征重要性最高的n个特征,然后重复迭代这个过程,直到AUC降到可接受的范围内。
上面的方法是通过删除漂移特征来保证模型不被干扰,还有一种方法是通过选择合适的验证集来获得更接近于测试集(待预测数据)的模型评估结果,被成为Validation Data Selection。这种方法是训练一个模型来识别训练集中的哪些样本的分布和测试集更相似,把这些样本拿出来做为Validation Data来指导模型训练,让模型可以更好的拟合测试数据的分布。
在HyperGBM中如何自动完成数据漂移检测和处理?
以上这些方法在很多数据集上可以很明显的改善模型的预测效果,目前在HyperGBM中都已经支持,通过配置参数就可以完成。HyperGBM中只需要在构建experiment时设置drift_detection=True就会自动完成数据漂移的检测和处理,需要注意的是Adversarial Validation是一种半监督学习,所以训练时需要提供未观测到目标数据的测试集(比如待预测的下个月的数据,Kaggle竞赛中的测试集),在下面示例中我们只是从数据集中分割了一部分数据删除目标列做为测试集:
from tabular_toolbox.datasets import dsutils
from sklearn.model_selection import train_test_split
from hypergbm.search_space import search_space_general
from hypergbm import make_experiment
# load data into Pandas DataFrame
df = dsutils.load_bank()
target = 'y'
train, test = train_test_split(df, test_size=0.3)
test.pop(target)
#create an experiment
experiment = make_experiment(train, target=target, test_data=test,drift_detection=True)
#run experiment
estimator = experiment.run()
# predict on test data without target values
pred = estimator.predict(test)
实现Validation Data Selection只需要设置train_test_split_strategy=‘adversarial_validation’,示例代码入下:
from tabular_toolbox.datasets import dsutils
from sklearn.model_selection import train_test_split
from hypergbm.search_space import search_space_general
from hypergbm import make_experiment
# load data into Pandas DataFrame
df = dsutils.load_bank()
target = 'y'
train, test = train_test_split(df, test_size=0.3)
test.pop(target)
#create an experiment
experiment = make_experiment(train, target=target, test_data=test,train_test_split_strategy='adversarial_validation')
#run experiment
estimator = experiment.run()
# predict on test data without target values
pred = estimator.predict(test)
更多HyperGBM相关内容请参考:
https://github.com/DataCanvasIO/HyperGBM
相关文章:
HyperGBM用Adversarial Validation解决数据漂移问题
本文作者:杨健,九章云极 DataCanvas 主任架构师 数据漂移问题近年在机器学习领域来越来越得到关注,成为机器学习模型在实际投产中面对的一个主要挑战。当数据的分布随着时间推移逐渐发生变化,需要预测的数据和用于训练的数据分布…...

关基系统三月重保安全监测怎么做?ScanV提供纯干货!
三月重保当前,以政府、大型国企央企、能源、金融等重要行业和领域为代表的关键信息基础设施运营单位都将迎来“网络安全大考”。 对重要关基系统进行安全风险监测并收敛暴露面,响应监管要求进行安全加固,重保期间实时安全监测与数据汇报等具体…...
RK3588关键电路 PCB Layout设计指南
1、音频接口电路 PCB 设计(1)所有 CLK 信号建议串接 22ohm 电阻,并靠近 RK3588 放置,提高信号质量;(2)所有 CLK 信号走线不得挨在一起,避免串扰;需要独立包地,…...

二分边界详细总结
一、查找精确值 从一个有序数组中找到一个符合要求的精确值(如猜数游戏)。如查找值为Key的元素下标,不存在返回-1。 //这里是left<right。 //考虑这种情况:如果最后剩下A[i]和A[i1](这也是最容易导致导致死循环的…...
STM32---备份寄存器BKP和 FLASH学习使用
BKP库函数 学习BKP,首先就是知道BKP每一个函数的作用然后如何使用即可 使用备份域的作用只需要操作上面的两个函数即可,其余的都是它的其他功能 BKP简介 备份寄存器是42个16位的寄存器,可用来存储84个字节的用户应用程序数据。他们处在备份…...
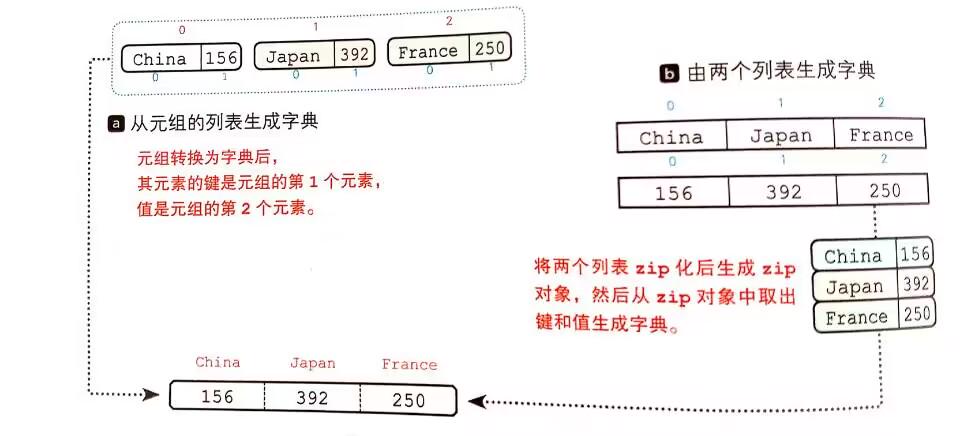
Python-生成元组和字典
1.生成元组元组是元素按顺序组合后的产物,元组对象的类型是tuple型含有两个元素的元组成为数据对元组可以包含任意数量和任意类型的元素,其元素总数可以为0、1、2等,并且元素的先后顺序是由意义的。另外,元组中的元素类型没有必要…...
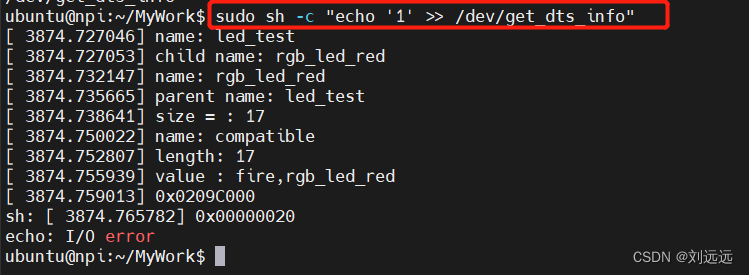
I.MX6ULL内核开发10:设备树
目录 一、设备树简介 二、设备树源码 三、获取设备树信息 1、增加设备节点 2、内核编译设备树 3、替换设备树文件 4、查看设备树节点 5、在驱动中获取节点的属性 6、编译驱动模块 7、加载模块 一、设备树简介 设备树的作用是描述一个硬件平台的硬件资源。这个“设备树…...

【大数据】记一次hadoop集群missing block问题排查和数据恢复
问题描述 集群环境总共有2个NN节点,3个JN节点,40个DN节点,基于hadoop-3.3.1的版本。集群采用的双副本,未使用ec纠删码。 问题如下: bin/hdfs fsck -list-corruptfileblocks / The list of corrupt files under path…...

国产音质好的蓝牙耳机有哪些?国产音质最好的耳机排行
随着时间的推移,真无线蓝牙耳机逐渐占据耳机市场的份额,成为人们日常生活中必备的数码产品之一。蓝牙耳机品牌也多得数不胜数,哪些国产蓝牙耳机音质好?下面,我们从音质出来,来给大家介绍几款国产蓝牙耳机&a…...
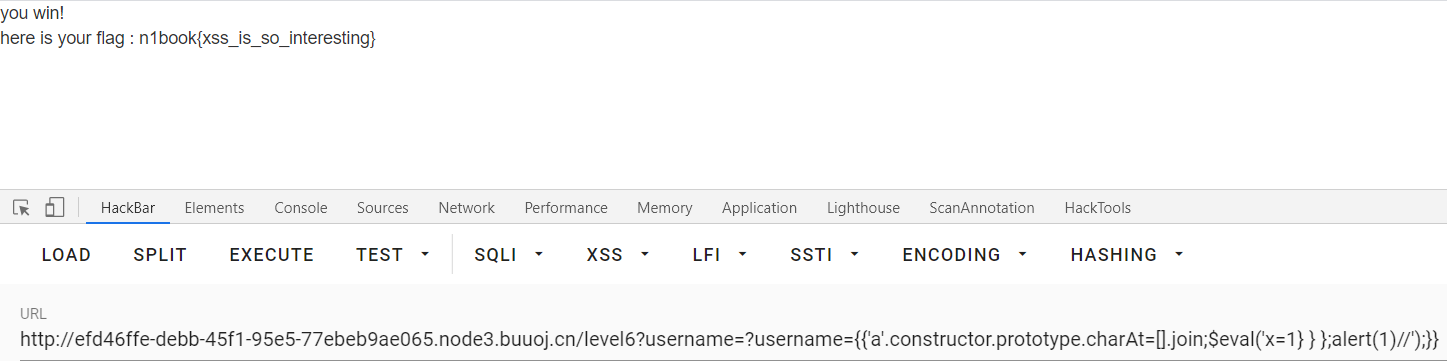
CTFer成长之路之XSS的魔力
XSS的魔力CTF XSS闯关 题目描述: 你能否过关斩将解决所有XSS问题最终获得flag呢? docker-compose.yml version: "3.2"services:xss:image: registry.cn-hangzhou.aliyuncs.com/n1book/web-xss:latestports:- 3000:3000启动方式 docker-compose up -…...
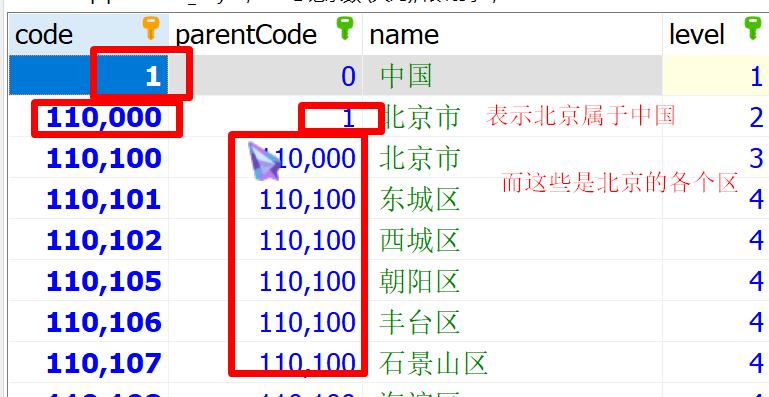
行锁、表锁、主键外键、表之间的关联关系
Java知识点总结:想看的可以从这里进入 目录2.4、行锁、表锁2.5、主键、外键2.5.1、主键2.5.2、外键2.6、表的关联关系2.4、行锁、表锁 MyISAM默认采用表级锁,InnoDB默认采用行级锁。 表锁:开销小,加锁快,不会出现死锁…...
JavaScript 进阶(面试必备)--charater4
文章目录前言一、深浅拷贝:one: 浅拷贝:two:深拷贝二、异常处理:one: throw 抛异常:two: try /catch 捕获异常:three:debugger三、处理thisthis指向 :one:普通函数this指向this指向 :two: 箭头函数this指向3.2 改变this:one: call():two: apply():three: bind()四、性能优化:on…...
ARM+FPGA架构开发板PCIE2SCREEN示例分析与测试-米尔MYD-JX8MMA7
本篇测评由电子发烧友的优秀测评者“zealsoft”提供。 本次测试内容为米尔MYD-JX8MMA7开发板其ARM端的测试例程pcie2screen并介绍一下FPGA端程序的修改。 01. 测试例程pcie2screen 例程pcie2screen是配合MYD-JX8MMA7开发板所带的MYIR_PCIE_5T_CMOS 工程的测试例&#…...

51单片机入门 - SDCC / Keil_C51 会让没有调用的函数参与编译吗?
Small Device C Compiler(SDCC)是一款免费 C 编译器,适用于 8 位微控制器。 不想看测试过程的话可以直接划到最下面看结论:) 关于软硬件环境的信息: Windows 10STC89C52RCSDCC (构建HEX文件&…...
OpenCV只含基本图像模块编译
编译OpenCV4.5.5只含基本图像模块,环境为Windows10 x64CMake3.23.3VS2019。默认编译选项编译得到的OpenCV库往往大几百MB甚至上GB,本文配置下编译得到的库压缩后得到的zip包大小仅6.25MB,适合使用OpenCV基本图像功能模块的项目移植而不牵涉其…...
Java实现阴历日历表(附带星座)
准备工作 1.无敌外挂(GitHub直达源码) Nobb 直击灵魂 https://github.com/xuyishanBD/Java_create_calendar.git2.maven配置(如果没有走上面的捷径) <dependencies><dependency><groupId>net.sourceforge.javacsv</groupId><artifactId>javac…...
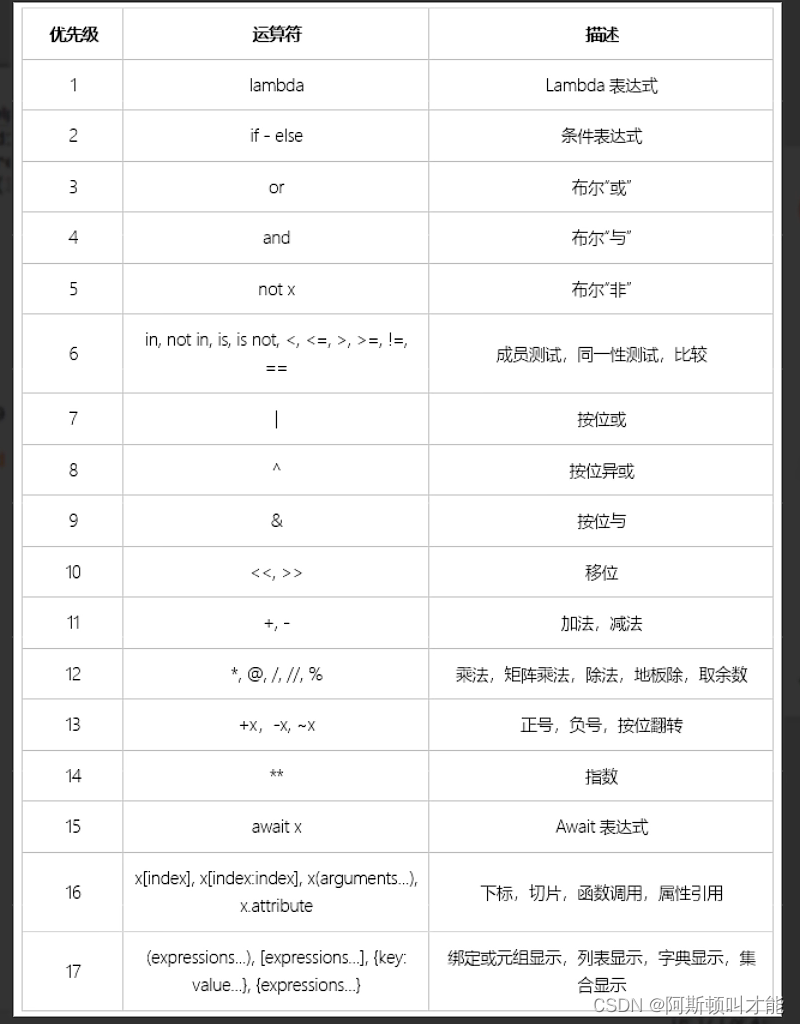
Python入门之最基础
Python入门之最基础 IDLE有两种模式,一种是交互模式,通俗讲就是写一个代码,会得到相应的反馈,另一种为编辑模式. 注意事项: 标点符号一定要用英文符号 要注意缩进 dir(builtins)可以看到python所有的内置函数&#…...
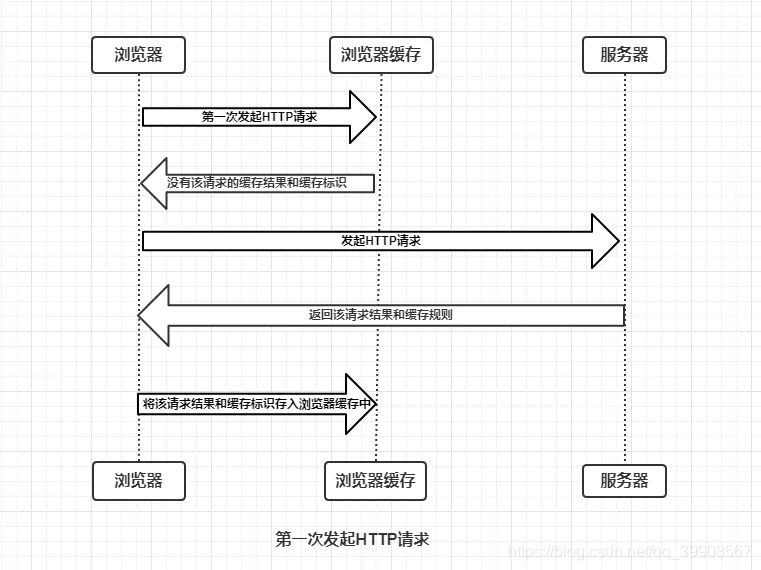
浏览器缓存策略
先走强缓存,再走协商缓存 强缓存 不发送请求,直接使用缓存的内容 状态码200 当前会话没有关闭的话就是走memory cache,否则就是disk cache 由响应头的 Pragma(逐渐废弃,优先级最高),catch-…...

高清无码的MP4如何采集?python带你保存~
前言 大家早好、午好、晚好吖 ❤ ~ 又是我,我又来采集小姐姐啦~ 这次我们采集的网站是(看下图): 本文所有模块\环境\源码\教程皆可点击文章下方名片获取此处跳转 话不多少,我们赶快开始吧~ 第三方模块: requests >>> pip install requests 如果安装python第三方模块…...

python+pytest接口自动化(1)-接口测试基础
接口定义一般我们所说的接口即API,那什么又是API呢,百度给的定义如下:API(Application Programming Interface,应用程序接口)是一些预先定义的接口(如函数、HTTP接口),或…...

端侧AI平民化:轻量专家模型+动态调度实现千元机本地大模型推理
1. 项目概述:这不是又一个“AI手机App”,而是一次对算力平民化的重新定义 “Enter Project Gecko: AI in Your Pocket, Without the Premium Price Tag”——这个标题里没有一个生僻词,但每个词都在精准刺向当前AI消费端的痛点。我做终端AI落…...

UDS_自动化脚本生成_10服务_V01
1、原子元素 1.1 会话原子 Session.Default() Session.Extended() Session.Programming() Session.Developer() 1.2 请求原子 10 01 10 02 10 03 10 76 10 81 10 82 10 83 10 F6 10 04 10 84 10 / 10 01 00 / 10 02 00 / 10 03 00 / 10 76 00 1.3 响应原子 50 01 00 32 01 F4 …...

Java Web中基于JWT的七层权限控制系统设计
1. 为什么JWT不是“万能钥匙”,而是一个需要精心设计的权限信封在Java Web开发中,一提到权限控制,很多人第一反应就是“加个Spring Security,配个JWT,不就完事了?”我去年接手一个医疗SaaS系统的权限模块重…...

深入理解关系数据库三范式
一、范式化设计的意义非规范化的数据库可能导致:数据冗余:相同数据在多处重复存储(如用户姓名在订单表、日志表重复出现)更新异常:修改一处数据需同步更新多处,易遗漏引发数据不一致插入/删除异常ÿ…...

Gemini 访问要不要额外网络工具?国内直连体验怎么看
最近不少开发者开始把 Gemini 放进日常工作流里:查资料、写代码注释、整理技术方案、做内容大纲。但实际使用前,大家最关心的往往不是模型参数,而是“能不能顺畅访问”。如果只是想先体验模型能力,可以通过 库拉 这类 AI模型聚合平…...

精准监测,畅行无阻——DX-SZ3200系列在交通领域的应用
在铁路、高速及各类交通系统中,信号监测与管理的精准性和实时性至关重要。DX-SZ3200系列数字化射频实时频谱侦测接收机模块,凭借其卓越的性能和广泛的应用场景,成为了交通领域信号监测的得力助手。DX-SZ3200系列模块集成了先进的数字化射频接…...

Jetson Orin AGX INT4 推理优化实践:super 分支从 9 tok/s 到 24 tok/s
Jetson Orin AGX INT4 推理优化实践:super 分支从 9 tok/s 到 24 tok/s 项目地址:https://github.com/luogantt/LLM-inference-engine 本文总结 jetson-orin-agx-super 分支上的一次端侧大模型推理优化实践。目标设备是 Jetson Orin AGX,目…...

通过Taotoken的CLI工具一键配置Python开发环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken的CLI工具一键配置Python开发环境 对于希望快速开始使用大模型API的Python开发者而言,手动配置API密钥、B…...
)
Flink架构与集群部署(一)
Apache Flink架构Flink组件栈在Flink的整个软件架构体系中,同样遵循这分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富且友好的接口。上图是Flink基本组件栈,从上图可以看出整个Flink的架构体系可…...

平均 CPU 利用率指标为何该摒弃?多个案例揭示真相!
1. 作者信息与文章背景Jeremy Theocharis 是《平凡即卓越》作者、UMH 联合创始人兼首席技术官。文章基于其在 2026 年 4 月云原生亚琛聚会上的演讲,探讨为何应摒弃平均 CPU 利用率指标。2. 应用程序问题引出我们应用程序中的一个 Go 函数在生产环境总是被取消执行。…...