【PyTorchTensorBoard实战】GPU与CPU的计算速度对比(附代码)
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文基于PyTorch通过tensor点积所需要的时间来对比GPU与CPU的计算速度,并介绍tensorboard的使用方法。
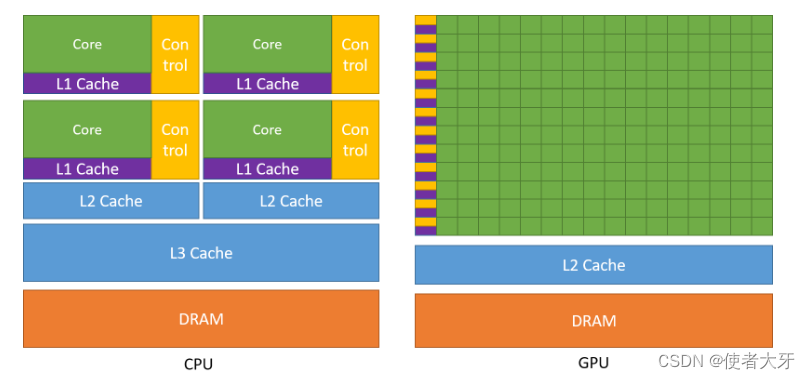
我在前面的科普文章——GPU如何成为AI的加速器GPU如何成为AI的加速器_使者大牙的博客-CSDN博客GPU如何成为AI的加速器 解释了GPU的多核心架构相比CPU更适合简单大量的计算,而深度学习计算的底层算法就是大量矩阵的点积和相加,本文将通过张量的点积运算来说明:与CPU相比,GPU有多“适合”深度学习算法。
加法相比于点积的计算量太小了,我感觉体现不出GPU的优势,所以没有用加法来对比两者的算力差距。
1. 准备工作
1.0 一台有Nvidia独立显卡的电脑
既然要使用GPU计算,一台有Nvidia独立显卡=支持CUDA的GPU的电脑就是必须的前置条件。如果不清楚CUDA、GPU和Nvidia关系的同学,可以再看下我的文章:GPU如何成为AI的加速器_使者大牙的博客-CSDN博客
1.1 PyTorch
在PyTorch的官网:Start Locally | PyTorch 选择合适的版本:

这里需要注意的是PyTorch的CUDA版本需要匹配电脑的GPU的CUDA版本,一般来说电脑>PyTorch的CUDA版本就没问题了。
例如我安装的PyTorch是CUDA 11.8版本,我的GPU驱动版本是12.2(查看路径:Nvidia控制面板>帮助>系统信息)。

1.2 Tensorboard
Tensorboard是TensorFlow官方提供的一个可视化工具,用于可视化训练过程中的模型图、训练误差、准确率、训练后的模型参数等,同时还提供了交互式的界面,让用户可以更加方便、直观地观察和分析模型。
这里需要注意的是Tensorboard虽然是由TensorFlow提供的,但是使用Tensorboard不需要安装TensorFlow!只要在虚拟环境下安装TensorboardX和Tensorboard即可,我使用的是Anaconda Prompt:
pip install tensorboardX
pip install tensorboard其使用方法为:
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("../logs") #这里有两个"."writer.add_scalars(main_tag, tag_scalar_dict, global_step=None):writer.close()另外需要注意SummaryWriter后面的路径要有两个“.”,这是因为我的代码文件在D:\DL\CUDA_test二级文件夹下面,我们需要把生成的tensorboard的event文件放在D:\DL\logs下面,而不是D:\DL\CUDA_test\logs路径下。这样做的理由是避免tensorboard报“No scalar data was found”

这里使用的是.add_scalars()方法来绘制多条曲线,参数如下:
- main_tag:字符串类型,要绘制的曲线主标题,本实例为“GPU vs CPU”
- tag_scalar_dict:字典类型,要绘制多条曲线的因变量,本实例为GPU和CPU的计算时间
{'GPU':CUDA,'CPU':CPU} - global_step: 标量,要绘制多条曲线的因变量,本实例为张量的大小tensor_size
在event文件生成后再在PyCharm的终端输入 tensorboard --logdir=logs ,点击链接就可以在浏览器中查看生成的曲线了。
2. 对比GPU与CPU的计算速度
本文的实例问题非常简单:分别使用CPU和GPU对尺寸为[tensor_size, tensor_size]的2个张量进行点积运算,使用time库工具对计算过程进行计时,对比CPU和GPU所消耗的时间。张量的大小tensor_size取值从1到10000。
我使用的硬件信息如下:
CPU:AMD Ryzen 9 7940H
GPU:NVIDIA GeForce RTX 4060
CPU计算时间:
import torch
import timedef CPU_calc_time(tensor_size):a = torch.rand([tensor_size,tensor_size])b = torch.rand([tensor_size,tensor_size])start_time = time.time()torch.matmul(a,b)end_time = time.time()return end_time - start_timeGPU计算时间:
import torch
import timedef CUDA_calc_time(tensor_size):device = torch.device('cuda')a = torch.rand([tensor_size,tensor_size]).to(device)b = torch.rand([tensor_size,tensor_size]).to(device)start_time = time.time()torch.matmul(a,b).to(device)end_time = time.time()return end_time - start_time3. 结果分析
最终生成的CPU和GPU计算张量点积的时间曲线如下:
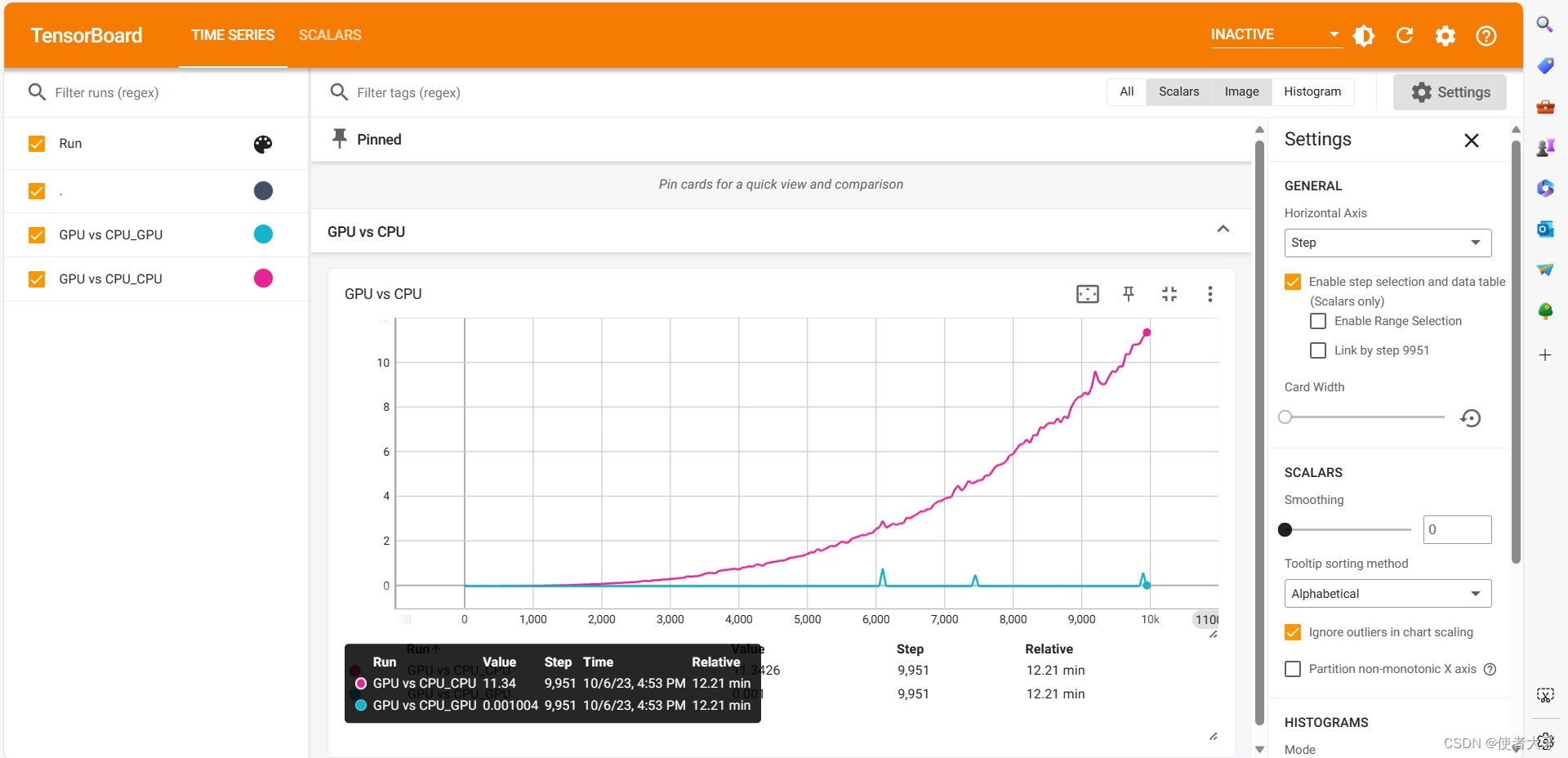
从图中可以看出,随着张量尺寸的增大,CPU计算时间明显增加(0~11.3s),而GPU的计算时间基本不变(0.001s左右),张量尺寸越大GPU的计算优势就越明显。
4. 完整代码
import torch
import time
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdmtorch.manual_seed(1)def CPU_calc_time(tensor_size):a = torch.rand([tensor_size,tensor_size])b = torch.rand([tensor_size,tensor_size])start_time = time.time()torch.matmul(a,b)end_time = time.time()return end_time - start_timedef CUDA_calc_time(tensor_size):device = torch.device('cuda')a = torch.rand([tensor_size,tensor_size]).to(device)b = torch.rand([tensor_size,tensor_size]).to(device)start_time = time.time()torch.matmul(a,b).to(device)end_time = time.time()return end_time - start_timeif __name__ == "__main__":writer = SummaryWriter("../logs")for tensor_size in tqdm(range(1,10000,50)):CPU = CPU_calc_time(tensor_size)CUDA = CUDA_calc_time(tensor_size)writer.add_scalars('GPU vs CPU',{'GPU':CUDA,'CPU':CPU},tensor_size)writer.close()# Command Prompt "tensorboard --logdir=logs"相关文章:
【PyTorchTensorBoard实战】GPU与CPU的计算速度对比(附代码)
0. 前言 按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。 本文基于PyTorch通过tensor点积所需要的时…...

npm 常用指令总结
1. 初始化包 一个存放了代码的文件夹,如果里面有 package.json 文件,则可以把这个文件夹称之为包。 npm init -y 注意: 由于包名不能有中文,不能有大写,不能和未来要下载的包重名. 所以我们快速初始化包时,我们的文件夹也不能违反前面说的规则.(因为默认会将文件夹的名称,作…...

布朗大学发现GPT-4存在新问题,可通过非常见语言绕过限制
🦉 AI新闻 🚀 布朗大学发现GPT-4存在新漏洞,可通过非常见语言绕过限制 摘要:布朗大学计算机科学研究人员发现了OpenAI的GPT-4存在新漏洞,利用不太常见的语言如祖鲁语和盖尔语可以绕过各种限制。研究人员测试了GPT-4对…...

ESP32网络编程-TCP客户端数据传输
TCP客户端数据传输 文章目录 TCP客户端数据传输1、IP/TCP简单介绍2、软件准备3、硬件准备4、TCP客户端实现本文将详细介绍在Arduino开发环境中,实现一个ESP32 TCP客户端,从而达到与TCP服务器数据交换的目标。 1、IP/TCP简单介绍 Internet 协议(IP)是 Internet 的地址系统,…...

微信小程序入门级
目录 一.什么是小程序? 二.小程序可以干什么? 三.入门使用 3.1. 注册 3.2. 安装 3.3.创建项目 3.4.项目结构 3.5.应用 好啦今天就到这里了,希望能帮到你哦!!! 一.什么是小程序? 微信小程…...
)
博客文档续更(二)
十五、博客前台模块-个人信息 1. 接口分析 进入个人中心的时候需要能够查看当前用户信息。请求不需要参数 请求方式 请求地址 请求头 GET /user/userInfo 需要token请求头 响应格式 {"code":200,"data":{"avatar":"头像的网络地址…...

Centos切换yum源
Centos切换yum源 常用命令 #查看内核/操作系统/CPU信息 uname -a #查看yum源 yum list repolist all切换步骤 1.备份yum源文件 cp -a /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak2.下载新的CentOS-Base.repo文件到/etc/yum.repos.d/目录下 …...
milvus和相似度检索
流程 milvus的使用流程是 创建collection -> 创建partition -> 创建索引(如果需要检索) -> 插入数据 -> 检索 这里以Python为例, 使用的milvus版本为2.3.x 首先按照库, python3 -m pip install pymilvus Connect from pymilvus import connections c…...
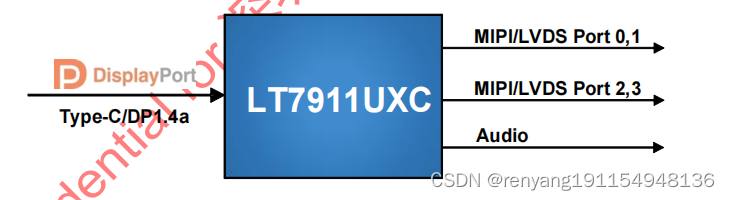
龙迅LT7911UXC 是一款高性能TYPE-C/DP/EDP转换四端口MIPI/LVDS的芯片,还支持图像处理
龙迅LT7911UXC 1.描述: LT7911UXC是一款用于VR/显示应用的高性能Type-C/DP1.4a到MIPI或LVDS芯片。HDCP RX作为 HDCP中继器的上游端,可以与其他芯片的HDCP TX协同工作,实现中继器的功能。对于DP1.4a 输入,LT7911UXC可以配置为1…...
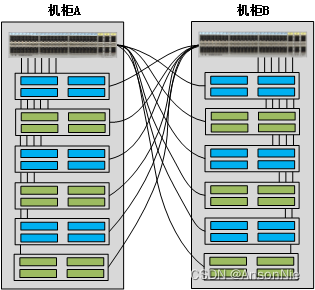
TOR(Top of Rack)
TOR TOR(Top of Rack)指的是在每个服务器机柜上部署1~2台交换机,服务器直接接入到本机柜的交换机上,实现服务器与交换机在机柜内的互联。虽然从字面上看,Top of Rack指的是“机柜顶部”,但实际T…...
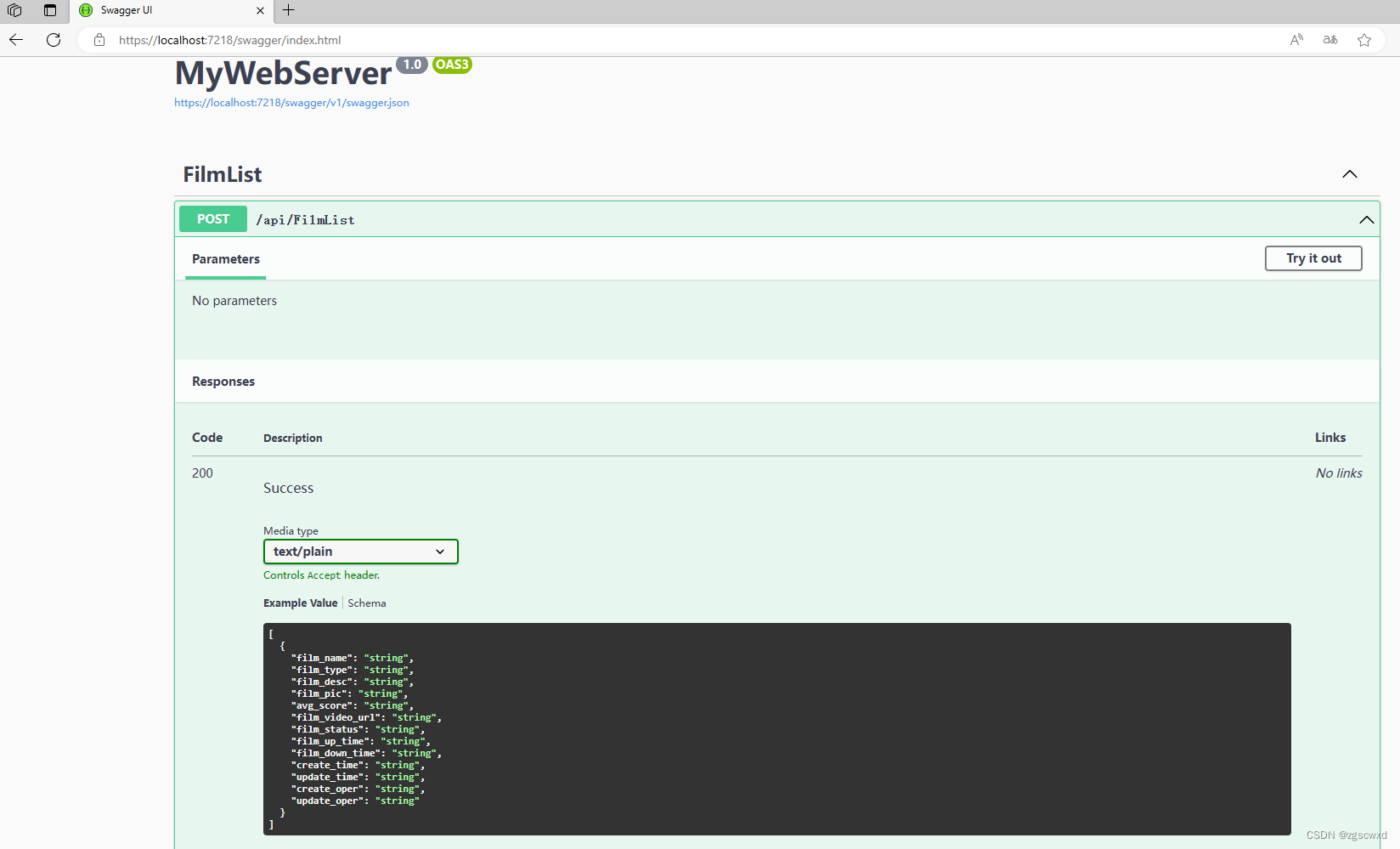
使用asp.net core web api创建web后台,并连接和使用Sql Server数据库
前言:因为要写一个安卓端app,实现从服务器中获取电影数据,所以需要搭建服务端代码,之前学过C#,所以想用C#实现服务器段代码用于测试,本文使用C#语言,使用asp.net core web api组件搭建服务器端&…...
LaTeX 公式与表格绘制技巧
LaTeX 公式与绘图技巧公式基本可以分为 单一公式单一编号单一公式按行编号单一公式多个子编号单一公式部分子编号分段公式现在给出各自的代码单一公式单一编号 公式1:equationaligned\begin{equation}\begin{aligned}a&bc\\b&a2\\c&b-3\end{aligned}\en…...
Spring Cloud--Nacos+@RefreshScope实现配置的动态更新
原文网址:Spring Cloud--NacosRefreshScope实现配置的动态更新_IT利刃出鞘的博客-CSDN博客 简介 说明 本文介绍SpringCloud整合Nacos使用RefreshScope实现动态更新配置。 官网 Nacos Spring Cloud 快速开始 动态更新的介绍 动态更新的含义:修改应…...
Elasticsearch安装
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

【JavaSE API 】生成随机数的2种方法:Random类和Math类的Random方法
生成随机数的两种方法 Random类和Math类的random方法都可以用来生成随机数 而Math类的random方法则是基于系统时间的伪随机数生成器,大于等于0.0小于1.0的随机double值范围[0,1)。例如: double num1 Math.random() * 5 4;//范围[4,9) Random类是基于种…...

微软和OpenAI正在开发AI芯片, 并计划下个月发布
今年初,Chat**引起了无数网友关注,一度成为了热门话题。这是由人工智能研究实验室OpenAI开发的一款聊天机器人模型,也称为一种人工智能(AI)技术驱动的自然语言处理工具。能够通过学习和理解人类的语言来进行对话&#…...
记一次Hbase2.1.x历史数据数据迁移方案
查看待迁移的表 list_namespace_tables vaas_dwm2. 制作待迁移表“DWM_TRIP_PART”的快照 snapshot vaas_dwm:DWM_TRIP_PART,dwm_trip_part_snapshot3. 统计待迁移表数据总数 hbase org.apache.hadoop.hbase.mapreduce.RowCounter vaas_dwm:DWM_TRIP_PART...

luajit简介
LuaJIT是一种高效的Lua解释器,其通过即时编译技术将Lua代码转换为机器代码,从而提供了非常快速的执行速度。在本文中,我们将介绍LuaJIT的原理、使用方法以及在嵌入式Linux系统中的应用示例。 LuaJIT的原理 LuaJIT基于Lua 5.1实现࿰…...

1.2 switch实现两个数的四则运算
注意: 1、每一个case后面要有break 2、/运算的时候注意分母不能为0 int a, b;char c;cin>>a>>b>>c;switch (c){case :cout << a << << b << << a b << endl;break;case -:cout << a << - …...

mysql面试题47:MySQL中Innodb的事务实现原理
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:Innodb的事务实现原理 InnoDB是MySQL中一种常用的存储引擎,它支持事务和行级锁等特性。以下是InnoDB事务实现的简要原理: 事务定义: 事务是指一…...

Chrome扩展开发实战:打造浏览器侧边栏ChatGPT助手
1. 项目概述:一个让ChatGPT常驻浏览器侧边栏的利器如果你和我一样,每天的工作和学习都离不开浏览器,并且频繁地与ChatGPT对话来获取灵感、润色文案或者调试代码,那么你肯定对在无数个标签页之间来回切换感到厌烦。每次都要打开一个…...

AI智能体编排平台:从任务自动化到生态协作的架构与实践
1. 项目概述:一个面向AI编排与技能提升的生态协作平台最近在和一些做AI应用开发的朋友聊天,大家普遍有个痛点:现在AI工具和模型太多了,从大语言模型到图像生成,再到各种自动化脚本,每个都很强大,…...

Java并发编程:CompletableFuture实战
Java并发编程:CompletableFuture实战 引言 Java 8引入的CompletableFuture是现代异步编程的重要工具,它不仅解决了Future的局限性,还提供了丰富的API用于组合、转换和处理异步结果。相比传统的Future,CompletableFuture支持流式调…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

从TPM到机密计算:远程证明技术原理与zap1项目实践指南
1. 项目概述与核心价值最近在整理一些零散的学习笔记时,发现了一个挺有意思的项目,叫Frontier-Compute/zap1-learning-attestation。乍一看这个标题,可能有点让人摸不着头脑,尤其是对于刚接触可信计算或者硬件安全领域的朋友来说。…...

KIVI开源工具箱:模块化设计赋能开发者效率提升
1. 项目概述:一个面向开发者的开源工具箱最近在GitHub上闲逛,发现了一个挺有意思的项目,叫KIVI。第一眼看到这个名字,我以为是某种新的UI框架或者设计系统,毕竟“KIVI”听起来有点像是“Kiwi”的变体,容易联…...

基于GitHub Actions的自动化代码质量守护:CodeBuddy实战指南
1. 项目概述与核心价值最近在和一些团队做代码评审和协作时,我经常遇到一个痛点:大家写的代码风格各异,注释要么缺失要么过时,一些潜在的安全漏洞和性能问题在提交前很难被系统性地发现。虽然市面上有各种静态分析工具,…...

认识Python数据包套接字
如你所知,数据包格式套接字(Datagram Sockets)也叫“无连接的套接字”,在代码中使用 SOCK_DGRAM 表示。可以将 SOCK_DGRAM 比喻成高速移动的摩托车快递,它有以下特征:强调快速传输而非传输顺序;…...

用C++和RealSense D435i搞个3D手势识别?从像素坐标到相机坐标的保姆级避坑指南
3D手势识别实战:用RealSense D435i实现像素到相机坐标的高精度转换 当你的手指在空气中划出一道弧线,计算机能否精准捕捉这个三维动作?这正是3D手势识别技术试图解决的问题。作为人机交互领域的前沿方向,3D手势识别正在VR游戏、医…...