传输层 | UDP协议、TCP协议
之前讲过的http与https都是应用层协议,当应用层协议将报文构建好之后就要将报文往下层传输层进行传递,而传输层就是负责将数据能够从发送端传到接收端。
再谈端口号
端口号(port)标识了一个主机上进行通信的不同的应用程序,在TCP/IP协议中,用源IP,源端口号,目的IP,目的端口号,协议号,这样一个五元组来标识一个通信。
端口号范围划分
- 0 - 1023:知名端口号,HTTP,FTP,SSH等这些广为使用的应用层协议,他们的端口号都是固定的
- 1024 - 65535:操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的
执行指令cat /etc/services就可以看到知名端口号
netstat
netstat是一个用来检查网络状态的重要工具
语法: netstat [选项]
功能:查看网络状态
常用选项:
- n 拒绝显示别名,能显示数字的全部转化成数字
- l 仅列出有在 Listen (监听) 的服務状态
- p 显示建立相关链接的程序名
- t (tcp)仅显示tcp相关选项
- u (udp)仅显示udp相关选项
- a (all)显示所有选项,默认不显示LISTEN相关
pidof
在查看服务器的进程id时非常方便.
语法: pidof [进程名]
功能:通过进程名, 查看进程id
UDP协议
UDP协议端格式

- 16位UDP长度,表示整个数据报(UDP首部 + UDP数据)的最大长度;
- 如果校验和出错,就会直接丢弃;
- 有效载荷部分是从上层调用send或者write系统调用传入的。
- UDP协议的报头是固定长度的,因此很容易就可以将报头与有效载荷分离
- 通过16位的目的端口号就可以,做到报文的有效交付
报文的本质、封装、解包
tcp/ip是属于操作系统的,而Linux下操作系统是用C语言实现的,那么udp协议也就是用C语言实现的。报头(协议)的本质就是结构化数据struct
struct udp_header // 结构体
{uint16_t src_port;uint16_t dst_port;uint16_t udp_len;uint16_t check;
}
struct udp_header // 位段
{uint32_t src_port: 16;uint32_t dst_port: 16;// ...
}
// 使用的时候就可以申请空间,对空间进行强转
((struct udp_header*)p)->src_port = // ...
((struct udp_header*)p)->dst_port = // ...
((struct udp_header*)p)->udp_len= // ...
((struct udp_header*)p)->check= // ...
UDP的特点
UDP传输的过程类似于寄信。
- 无连接:知道对端的IP和端口号就直接进行传输,不需要建立连接;
- 不可靠:没有确认机制,没有重传机制;如果因为网络故障该段无法发到对方,UDP协议层也不会给应用层返回任何错误信息;
- 面向数据报:不能够灵活的控制读写数据的次数和数量;
面向数据报
应用层交给UDP多长的报文,UDP原样发送,既不会拆分,也不会合并;
用UDP传输100个字节的数据:
- 如果发送端调用一次sendto,发送100个字节,那么接收端也必须调用对应的一次recvfrom,接收100个字节;而不能循环调用10次recvfrom,每次接收10个字节;
UDP的缓冲区
- UDP没有真正意义上的发送缓冲区。调用sendto会直接交给内核,由内核将数据传给网络层协议进行后续的传输动作;
- UDP具有接收缓冲区。但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致;如果缓冲区满了,再到达的UDP数据就会被丢弃;
UDP的socket既能读,也能写,这个概念叫做全双工。UDP的发送缓冲区与接收缓冲区不是同一个,是线程安全的。
UDP使用注意事项
我们注意到,UDP协议首部中有一个16位的最大长度。也就是说一个UDP能传输的数据最大长度是64K(包含UDP首部)。
然而64K在当今的互联网环境下,是一个非常小的数字。如果我们需要传输的数据超过64K,就需要在应用层手动的分包,多次发送,并在接收端手动拼装;
基于UDP的应用层协议
- NFS:网络文件系统
- TFTP:简单文件传输协议
- DHCP:动态主机配置协议
- BOOTP:启动协议(用于无盘设备的启动)
- DNS:域名解析协议
TCP协议
TCP协议全称为"传输控制协议"
与UDP协议一样我们先来关注两个问题就是1.报头和有效载荷如何分离;2.有效载荷如何做到交付;
首先,在TCP的协议中新增了一个选项字段,若是没有这个字段就表示者报头的大小就是20字节,若是在选项字段中存有数据,那么其长度就可以从四位首部长度中进行获取。首部长度计算有基本单位:4字节,这个对应的就是报文每一行的长度,那么4位首部长度表示的就是报文的报头一共有多少行,这样进行计算的话就可以的值整个报头的范围就是0-60字节,因此选项的有效长度就是40字节。举例一个例子,没有选项字段的报头是20字节,经过折算就表示在4位首部长度中需要填写的数值就是5 -> 0101。
- 报头和有效载荷如何分离:提取报文前20字节,提取首部长度字段;首部长度字段 * 4 - 20 ? 报头完毕 : 有几个字节的选项;剩下的就是有效载荷。通过柔性数组的方式就可以选择是否需要携带选项字段
- 有效载荷如何做到交付:目的端口号
TCP协议段格式

众所周知,TCP的可靠的传输协议,那么下面我们就从可靠性出发来理解TCP协议:
要理解可靠性,我们首先就要知道什么情况是不可靠的:丢包(少量,大量)、乱序、重复、校验失败、发送太慢/太快,网络出问题,会出现上述问题的关键就是因为通信双方的距离变长了。以丢包来说,遇到这种情况有一个问题就是,收发双方怎么知道这个报文丢了,那么我们就需要正确的理解确认应答机制。
确认应答机制
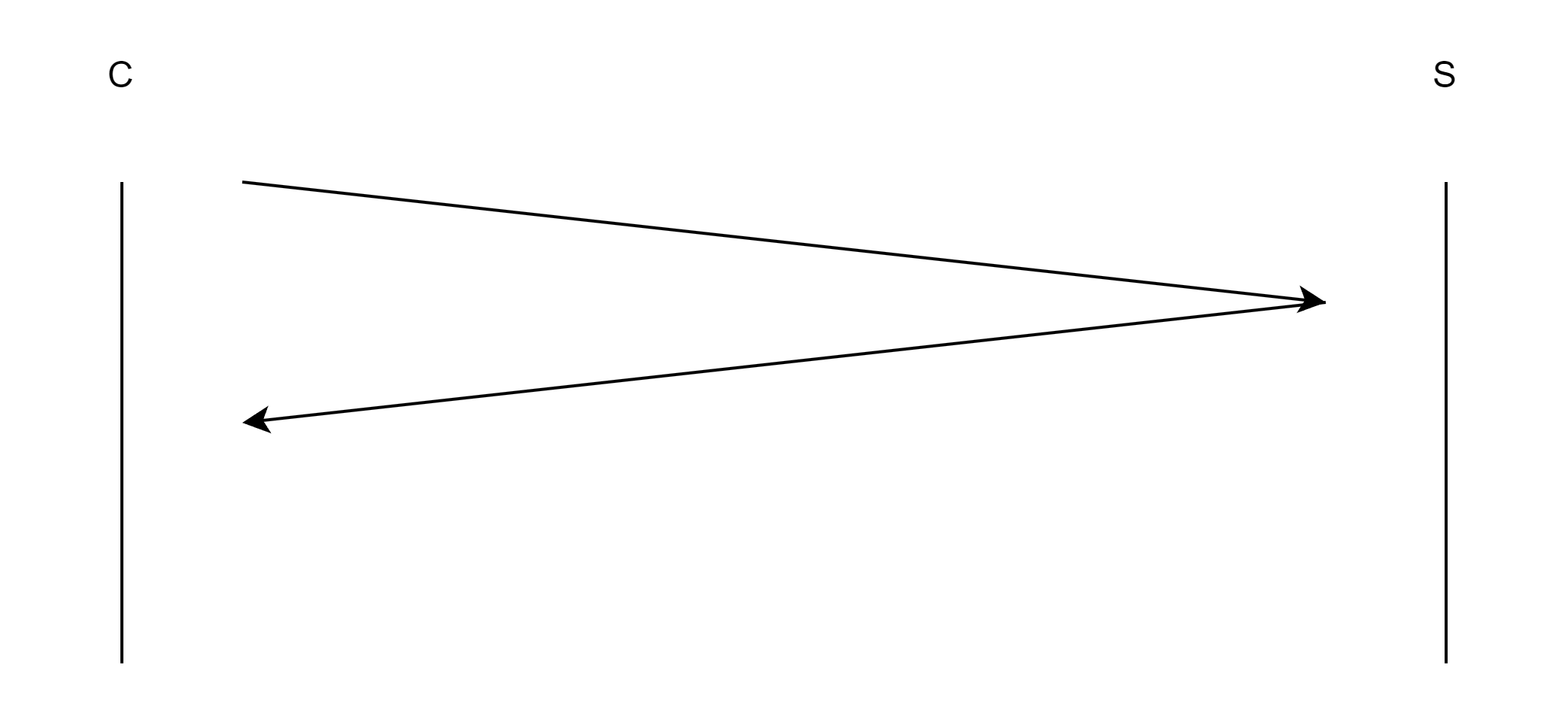
如上图所示,当C给S发送了数据时,当C收到了来自于S的应答,那么对于C来说S就100%收到了来自于C的数据,如果在等待了一段时间之后,C收不到来自于S的应答,那么C就会直接的认为报文丢失。TCP的可靠性就是通过收到应答来进行保证的。对于TCP来说server端与Cilent端的地位是对等的,都是通过这种确认应答的方式进行可靠性的保证的,但是上述就还有一个问题就是,虽然有着确认的机制,但是最新的一次报文始终无法保证能被可靠的送达。我们能保证的只有局部的可靠性,在收到确认应答的报文的时候意味着对应数据报文一定是被收到的。
TCP报头格式
序号与确认序号
在TCP报头中必定要包含序号,例如发送序号为10的一个报文,那么响应的报文的确认序号一定是11,假设响应的报文的确认序号也为10,下一次接收到的报文的序号是12,应答的报文也是12,这种情况下就无法判定11号报文是否收到,因此响应的报文的确认序号一定是发送序号的下一位,这样就可以表示X-1之前的报文已经全部收到了,下一次的发送请从X编号开始。
那为什么序号与确认序号不能是一个字段?必须是不同的字段,对于一条响应报文来说,他的首要功能就是对于报文的确认,同时因为响应报文与接收到的报文格式都差不多的,那么同样可以在这条响应报文中发送数据,这样就可以将原本需要两条报文的信息压缩成一个应答请求报文,32位序号表示S->C的数据序号,32位的确认序号表示S->C的历史数据的确认。
16位窗口大小 - 流量控制
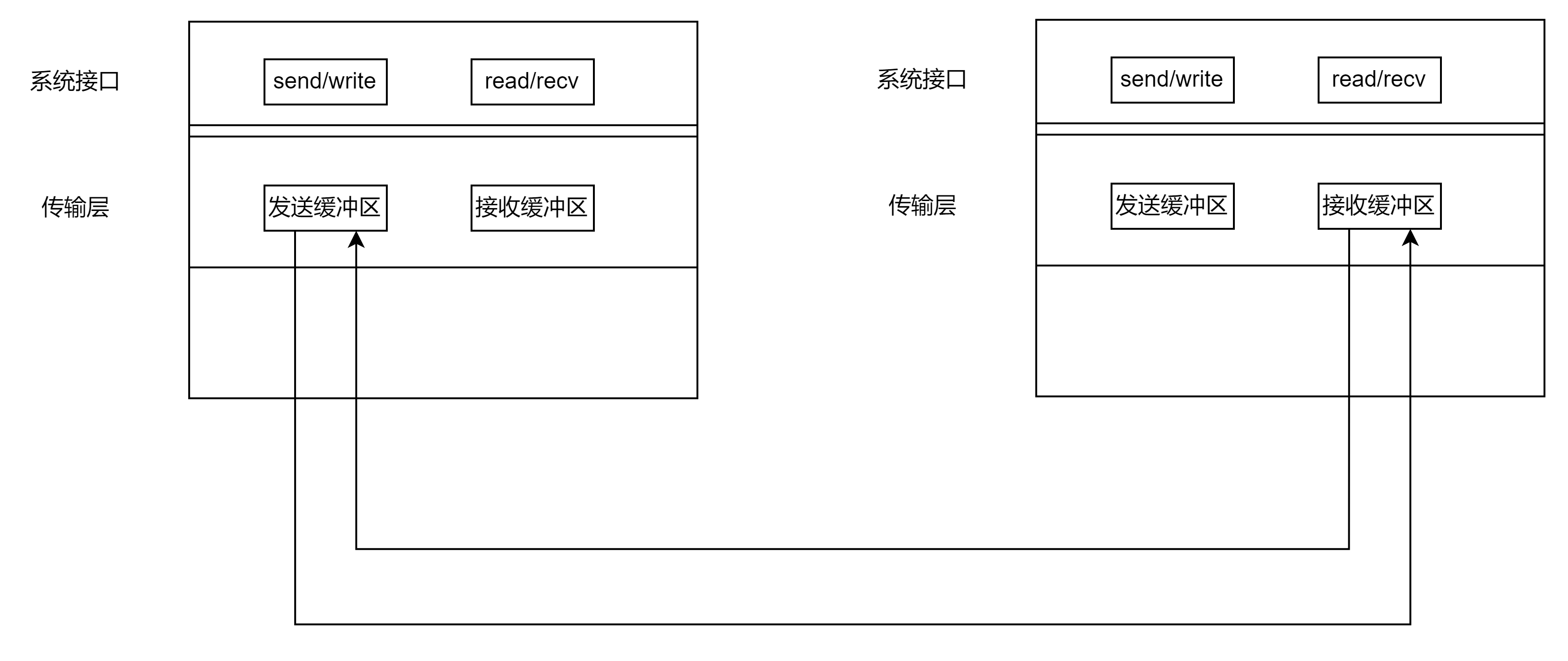
TCP协议进行工作时,将需要传输的数据拷贝到TCP的发送缓冲区,然后将数据发送到接受方的接收缓冲区,当接受方的接收缓冲区已经打满的时候,此时接收方就会直接将报文进行丢弃,但是这样的处理显然是不合理的,报文经过网络传输到接收端已经消耗了很多的网络资源,不能够随意地丢弃。因此我们就需要对传输的数据的大小进行判断,根据接收端的处理能力即接受缓冲区的大小来决定发送端的速度,这个机制就叫做流量控制,而16位窗口大小就是为了给对方发送自己的接受缓冲区的大小,告诉对方自己的接受能力。
- 接收端将自己可以接收的缓冲区大小放入TCP首部中的 “窗口大小” 字段,通过ACK端通知发送端;
- 窗口大小字段越大,说明网络的吞吐量越高;
- 接收端一旦发现自己的缓冲区快满了,就会将窗口大小设置成一个更小的值通知给发送端;
- 发送端接受到这个窗口之后,就会减慢自己的发送速度;
- 如果接收端缓冲区满了, 就会将窗口置为0; 这时发送方不再发送数据,但是需要定期发送一个窗口探测数据段,使接收端把窗口大小告诉发送端,同样接收端也会发送窗口更新的报文给发送端。
接收端如何把窗口大小告诉发送端呢? 回忆我们的TCP首部中,有一个16位窗口字段,就是存放了窗口大小信息;那么问题来了,16位数字最大表示65535,那么TCP窗口最大就是65535字节么?实际上,TCP首部40字节选项中还包含了一个窗口扩大因子M,实际窗口大小是窗口字段的值左移 M 位;
16位校验和
校验和是为了对UDP/TCP的报头和有效载荷进行校验,校验失败直接将报文丢弃。在TCP中就可以通过确认应答机制进行重传处理。
6位标志位
在同一个时刻有很多的客户端会向服务端发起各种各样的TCP请求,比如有发起链接的、结束链接的、维持通信的等等,正是因为报文是有不同的类型,那么对于不同的报文需要有不同的处理动作,而6位标志位就是为了用来表示不同类型的报文。
- ACK: 该报文是一个确认应答报文(可能会携带数据-> 捎带应答)
- PSH: 提示接收端应用程序立刻从TCP缓冲区把数据读走
- RST: 对方要求重新建立连接; 我们把携带RST标识的称为复位报文段
- SYN: 该报文是一个连接请求报文 (三次握手 1. SYN 2. SYN+ACK 3. ACK)
- FIN: 该报文是一个连接断开的请求报文(四次挥手)
- URG: 紧急指针是否有效。16位紧急指针 - 一个偏移量,紧急数据在有效载荷中的偏移量。紧急数据在有效载荷中只有一个字节。当有一些特殊的需求的时候就可以通过紧急指针的标志位的形式进行标识。(带外数据)在recv函数中的flag标志就有着这样的标志。

确认应答机制(补)
在TCP发送数据的时候需要将数据拷贝到发送缓冲区中,那么我们将发送缓冲区看做是一个char类型的数组,将每个字节的数据都进行了编号,即为序列号。
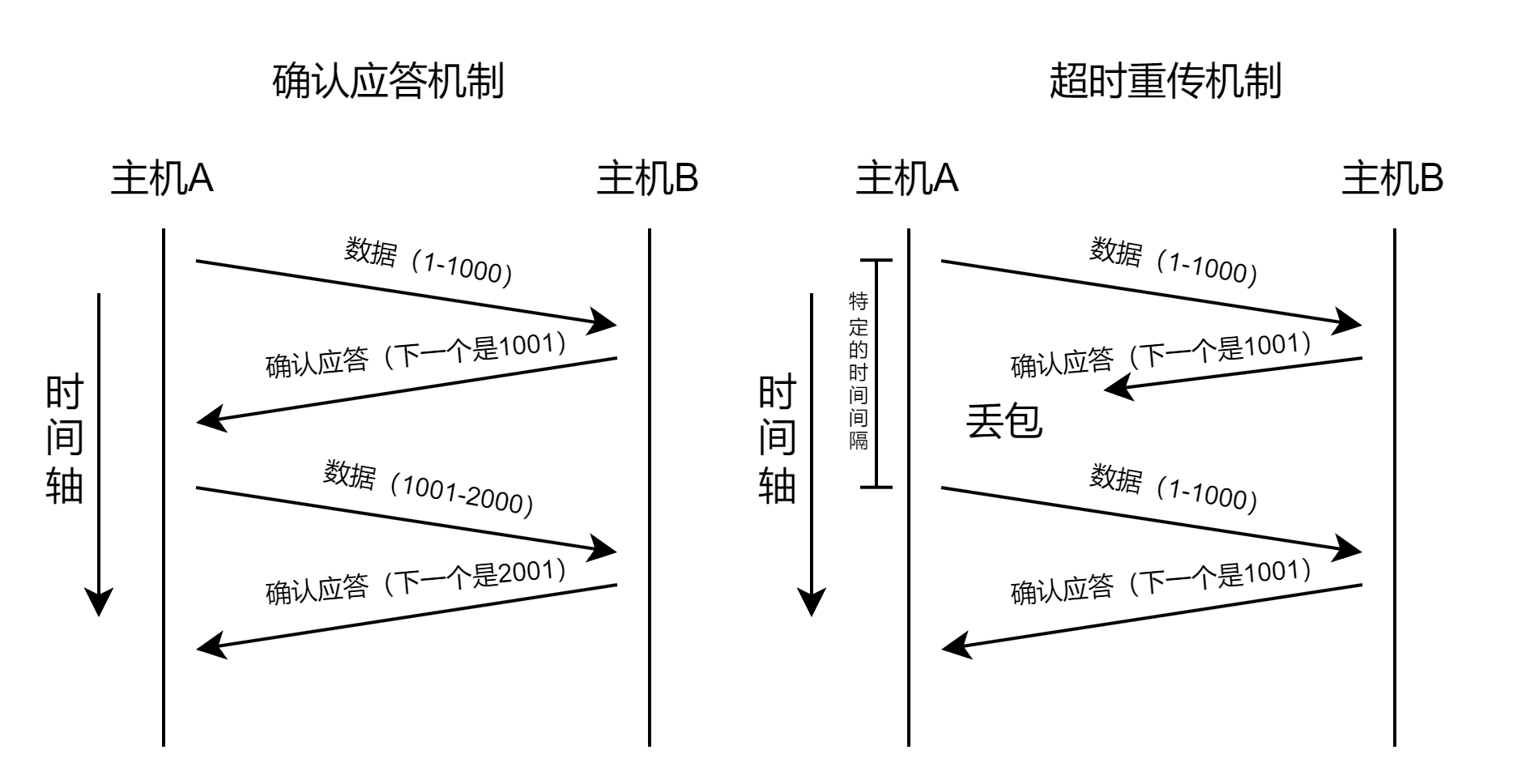
超时重传机制
主机A发送数据给B之后,可能因为网络拥堵等原因,数据无法到达主机B;如果主机A在一个特定时间间隔内没有收到B发来的确认应答, 就会进行重发;但是主机A未收到B发来的确认应答,也有可能是因为ACK丢失了因此主机B会收到很多重复数据。那么TCP协议需要能够识别出那些包是重复的包, 并且把重复的丢弃掉。这时候我们可以利用前面提到的序列号, 就可以很容易做到去重的效果。此时还有需要注意的就是在未接收到应答报文之前已经发送过的报文不能被发送缓冲区清理
超时时间确定
TCP为了保证无论在任何环境下都能比较高性能的通信,因此会动态计算这个最大超时时间。
- Linux中(BSD Unix和Windows也是如此),超时以500ms为一个单位进行控制,每次判定超时重发的超时时间都是500ms的整数倍。
- 如果重发一次之后,仍然得不到应答,等待 2*500ms 后再进行重传。
- 如果仍然得不到应答,等待 4*500ms 进行重传。依次类推,以指数形式递增。
- 累计到一定的重传次数,TCP认为网络或者对端主机出现异常,强制关闭连接。
连接管理机制
正常情况下,TCP要经过三次握手建立连接,四次挥手断开连接
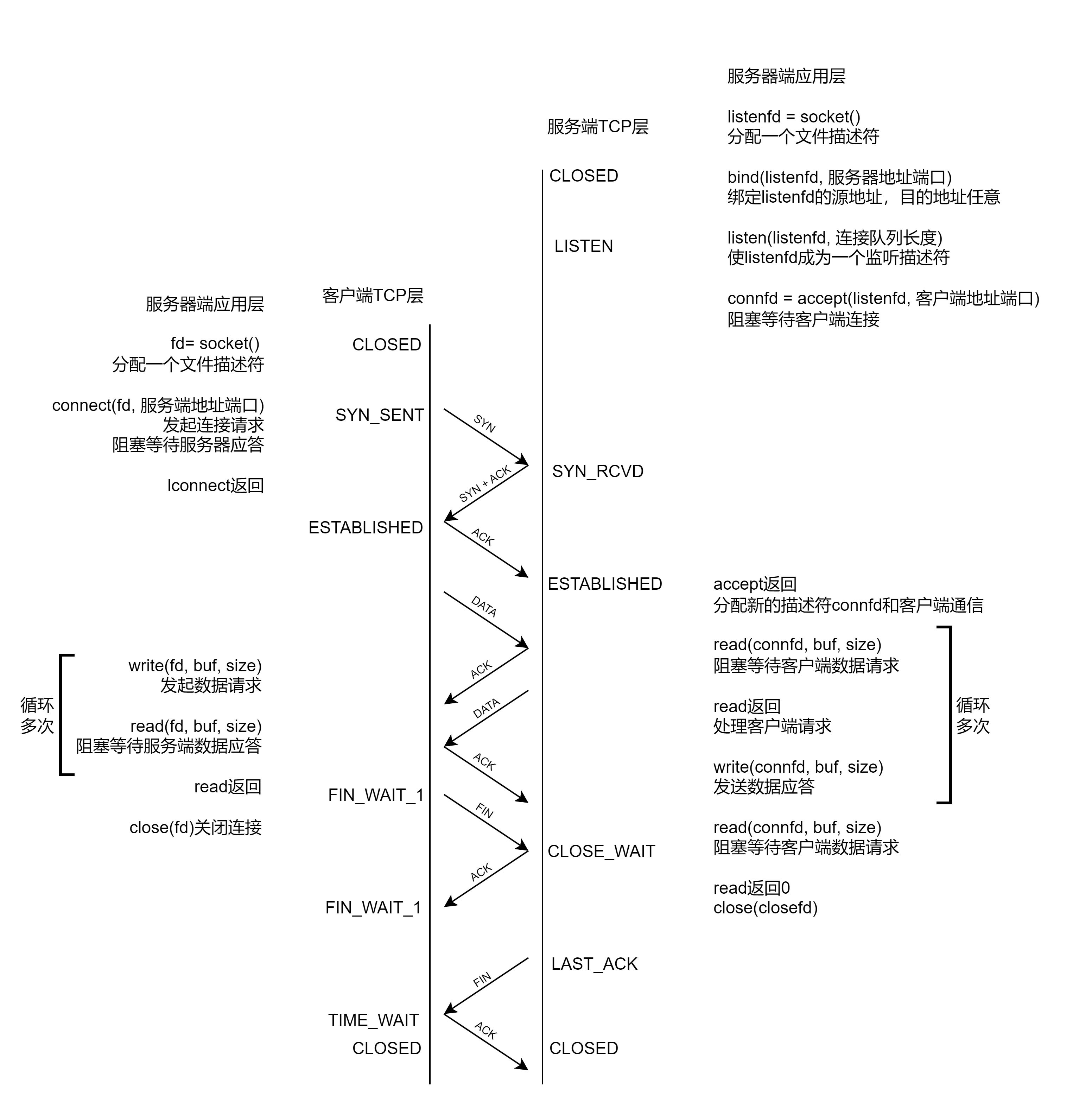
在进行TCP通信的时候在服务端和客户端会建立很多的连接,在OS内部一定会同时存在多个建立好的连接,并将这些建立好的连接进行管理 -> 先描述,再组织,OS同样要建立管理连接的数据的数据结构。创建维护连接是有成本的,这些操作都需要消耗内存与CPU。
三次握手
三次握手由客户端首先发起TCP的SYN报文,然后服务端会响应SYN+ACK的报文,当客户端收到服务端发送的报文之后就会在操作系统中建立连接,最后客户端会向服务端再次发送一个响应ACK报文,当服务端收到之后,便会在自己的OS中建立并管理相应的连接。三次握手的过程,由双方的OS中的TCP层自主完成。connect触发连接,等待完成;accept等待建立完成获取连接。在上述的建立连接的过程中,我们只能保证前两次报文是一定被对方收到的,至于最后一次的ACK报文,是无法保证对方一定收到,如果服务端收到就会完成连接,若是未收到此时客户端以为连接已经建立,开始发送数据报文,但服务端未建立,那么就会发送RST报文重新建立连接。因此三次握手的本质就是在赌最后一次的ACK被对方收到。
如果两次握手,就意味着服务端在第一次收到客户端的SYN报文的时候就要建立连接,连接很简单的就被建立,一旦由人不断地发送SYN报文就会不断的建立连接,这很容易就会受到攻击 – SYN洪水;如果是奇数次握手,由于一定是客户端先发起连接,那么最后一次的应答报文一定是客户端发起的,此时出现连接建立异常时的成本就会从服务端嫁接到客户端,服务端只需要发起重新建立连接的请求即可。如果是四次握手或者是偶数次握手,就有可能出现服务端先建立连接,客户端后建立连接的情况,这样一旦建立连接出现异常,服务端的资源一定会收到影响,这是不可取的。
- 三次握手,没有明显设计漏洞,一旦建立连接出现异常,成本嫁接到client,server端成本较低。
- 验证双方通信信道的畅通情况 – 三次握手是验证全双工通信信道通常的最小成本。第一二次连接确保了客户端到服务端的全双工畅通,第一三次连接确保了服务端的全双工畅通。
四次挥手
断开连接的四次挥手起始和建立连接的三次挥手是相似的,建立连接的三次挥手中的第二次了可以进行拆分,拆分为SYN与ACK两条报文,只不过在建立连接的时候进行了合并。断开连接是双向的,不仅客户端需要断开,服务端同样需要断开。若是客户端主动断开连接,客户端会进入FIN_WAIT_1状态,并发送FIN报文,然后服务端就会发出响应ACK报文,并将状态转变为CLOSE_WAIT,当客户端接收到ACK报文时将自己的状态转变为FIN_WAIT_2。然后服务端向客户端发起断开连接的报文,并将自己的状态转变为LAST_ACK,客户端收到FIN报文的时候,发送ACK应答报文并将自己的状态置为TIME_WAIT等待一段时间后,将连接关闭。
CLOSE_WAIT
从下图中就可以看出连接建立成功,将客户端先退出,再退出服务端的时候,客户端就会出现第二张图中的TIME_WAIT状态。
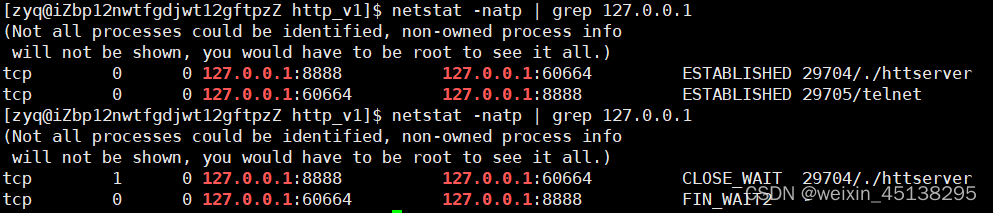

在上述的第一张图片中我们可以看到里面有CLOSE_WAIT和FIN_WAIT2状态,这是因为我们在编写代码的时候,在通信结束的时候没有关闭fd,这样服务端就会一直保持在CLOSE_WAIT状态,而客户端的状态在保持一定时间之后就会自动退出。因此编写代码的时候一旦忘记关闭fd,那么未使用的文件描述符就会越来越少,乃至于最后程序崩溃。
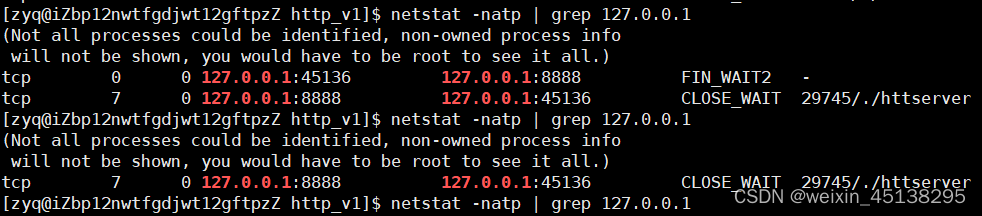
TIME_WAIT
现在做一个测试,首先启动server,然后启动client,然后用Ctrl-C使server终止,这时马上再运行server,结果是:
可以看到对应的TCP连接状态是如下图所示的: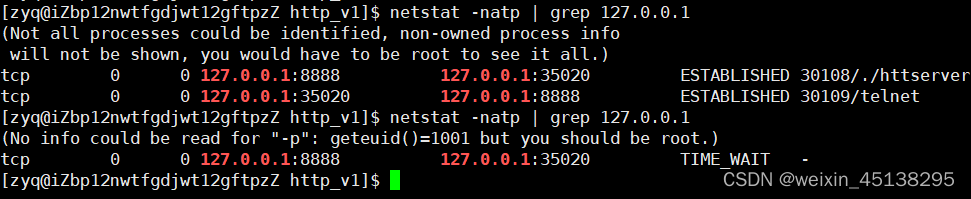
同样,我们如果在服务端与客户端连接已经建立完成的前提下,关闭客户端,也会出现客户端的TIME_WAIT现象,但是由于客户端是由OS自动分配端口号的,因此不会出现上述的问题。出现上述问题的原因就是:当服务端关闭应用程序的时候,此时底层的TCP连接并没有断开,相对应的端口号还在被占用,因此短时间内是无法使用重新该端口号的。
- TCP协议规定,主动关闭连接的一方要处于TIME_WAIT状态,等待两个MSL(maximum segment lifetime)的时间后才能回到CLOSED状态。
- 我们使用Ctrl-C终止了server,所以server是主动关闭连接的一方,在TIME_WAIT期间仍然不能再次监听同样的server端口;
- MSL在RFC1122中规定为两分钟,但是各操作系统的实现不同,在Centos7上默认配置的值是60s;
- 可以通过 cat /proc/sys/net/ipv4/tcp_fin_timeout 查看msl的值;
为什么TIME_WAIT的时间是2MSL?
- MSL是TCP报文的最大生存时间,因此TIME_WAIT持续存在2MSL的话,就能保证在两个传输方向上的尚未被接收或迟到的报文段都已经消失(否则服务器立刻重启,可能会收到来自上一个进程的迟到的数据,但是这种数据很可能是错误的);
- 同时也是在理论上保证最后一个报文可靠到达(假设最后一个ACK丢失,那么服务器会再重发一个FIN。这时虽然客户端的进程不在了,但是TCP连接还在,仍然可以重发LAST_ACK)。
解决TIME_WAIT状态引起的bind失败的方法
使用setsockopt()设置socket描述符的选项SO_REUSEADDR为1,表示允许创建端口号相同但IP地址不同的多个socket描述符int opt = 1; setsockopt(listenfd, SOLSOCKET, SO_REUSEADDR, &opt, sizeof(opt));
滑动窗口
从上述的内容中我们可以学习到对于每一个发送的数据段都要给一个ACK确认应答,收到确认应答之后再发送下一个数据段,这样做有一个比较大的缺点,收发的效率比较低下。既然一收一发的效率比较低下,我们就可以一次发送多条的数据,可以大大的提高性能。接收方是有接受能力上限的,发送方发送数据一定要在对方能接受的前提下进行并发的发送,根据目前我们将讲过的知识,发送数据的量由对方的窗口大小决定。
滑动窗口其实就是发送缓冲区的一部分,滑动窗口的大小和对方的接受能力有关,滑动窗口本质上就是一段用数组下标表示的缓冲区区间。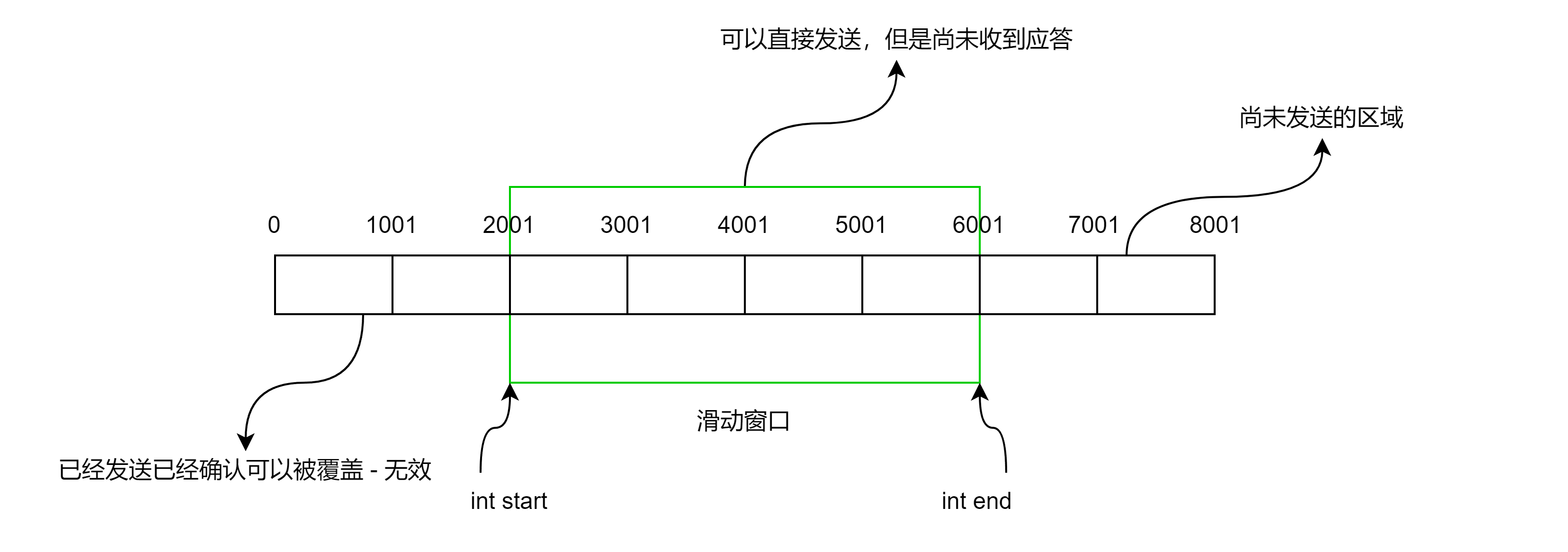
- 滑动窗口只能向右滑动
- 滑动窗口是浮动的取决于对方的接受能力即通告的窗口大小,能变大,end进行+=操作;也能变小end不动,start进行+=操作;变为0之后就表示对方不能再接收数据了。
- 应答也要按需到达,那么应答的seq,start = seq;应答的win,end = start+ win;
- 滑动窗口内的报文如果第一个报文丢失了,如果是ACK丢失,那么没有关系,应答报文中的确认序号表示的是X之前的报文全部收到了,一样可以确定第一个报文已经被收到;如果是数据丢失,即使收到了后面的报文,同样需要响应第一个报文的确认序号,因为第一个报文未被收到,发送方对报文进行补发。数据要支持重传,就需要被暂时保存起来,保存在滑动窗口中
快重传
当某一段报文段丢失之后,发送端会一直收到 1001 这样的ACK,就像是在提醒发送端 "我想要的是 1001"一样;如果发送端主机连续三次收到了同样一个 “1001” 这样的应答,就会将对应的数据 1001 - 2000 重新发送;这个时候接收端收到了 1001 之后,再次返回的ACK就是7001了(因为2001 - 7000)接收端其实之前就已经收到了,被放到了接收端操作系统内核的接收缓冲区中;这种机制被称为 “高速重发控制”(也叫 “快重传”)。超时重传与快重传,一个决定了重传的下限,一个决定了重传的上限。
拥塞控制
前面的叙述已经对收发双方的通信进行了部分讨论,但是TCP的通信不仅仅只有收发双方,还有网络,不同的网络状态同样会影响数据的传输。当出现少量丢包的时候,可以通过重传机制进行数据的重新发送,当出现大量丢包的情况时就说明网络出现问题,需要进行等待,但是光光的等待也是不行的,最佳的方案是减少发送量。当出现网络拥塞的时候1.要保证网络拥塞不能加重;2. 在网络拥塞有起色的情况下,尽快恢复网络通信。
TCP引入慢启动机制,先发少量的数据,探探路,摸清当前的网络拥堵状态,再决定按照多大的速度传输数据。
此处引入一个概念程为拥塞窗口:发生了网络拥塞,发送方要基本得知网络拥塞的严重情况,必须要进行网络状态的检测->对当前状态的网络情况进行衡量 – 拥塞窗口;网络的状态是变化的,衡量网络健康状态即拥塞窗口的大小一定是变化的;作为主机,我们为了知道网络的健康状况就需要不断的进行尝试与探测。想办法得到当前网络的拥塞窗口。因此前文中所述的滑动窗口的大小应该为对端主机接受能力与网络的拥塞窗口的较小值。
- 发送开始的时候,定义拥塞窗口大小为1;
- 每次收到一个ACK应答,拥塞窗口加1;
- 每次发送数据包的时候,将拥塞窗口和接收端主机反馈的窗口大小做比较,取较小的值作为实际发送的窗口;
- 为了不增长的那么快,因此不能使拥塞窗口单纯的加倍;
- 此处引入一个叫做慢启动的阈值,当拥塞窗口超过这个阈值的时候,不再按照指数方式增长,而是按照线性方式增长
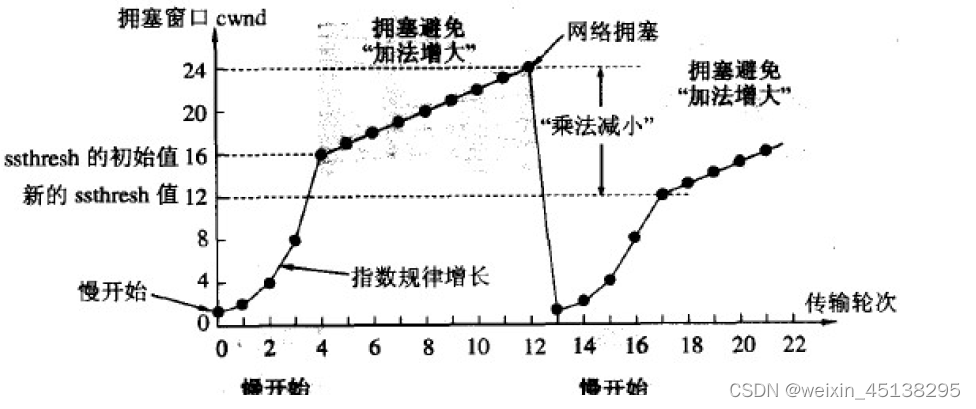
- 当TCP开始启动的时候,慢启动阈值等于窗口最大值;
- 在每次超时重发的时候,慢启动阈值会变成原来的一半, 同时拥塞窗口置回1
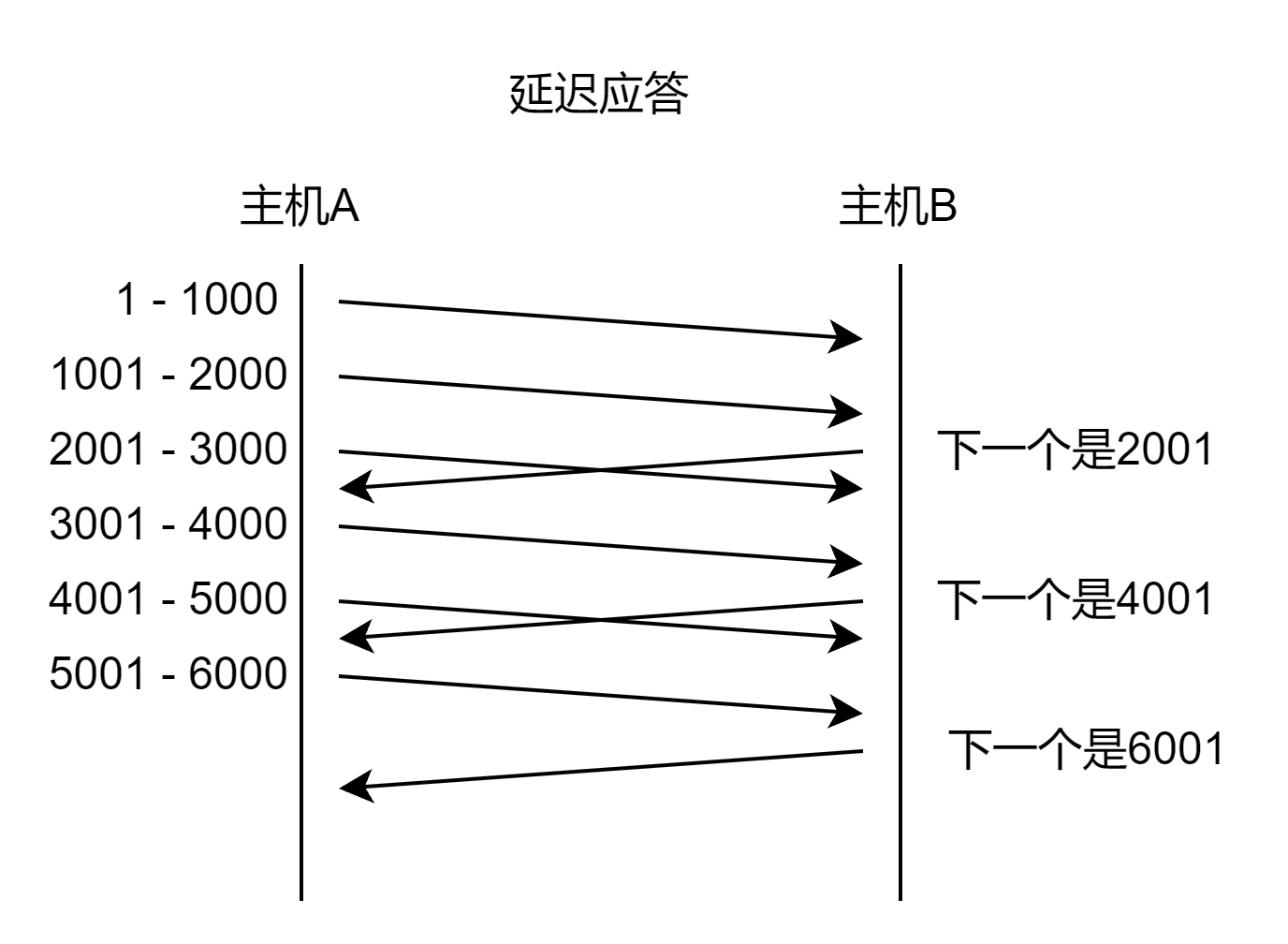
延迟应答
如果接收数据的主机立刻返回ACK应答,这时候返回的窗口可能比较小。
- 假设接收端缓冲区为1M。一次收到了500K的数据;如果立刻应答,返回的窗口就是500K;
- 但实际上可能处理端处理的速度很快,10ms之内就把500K数据从缓冲区消费掉了;
- 在这种情况下,接收端处理还远没有达到自己的极限,即使窗口再放大一些,也能处理过来;
- 如果接收端稍微等一会再应答,比如等待200ms再应答,那么这个时候返回的窗口大小就是1M;
一定要记得,窗口越大,网络吞吐量就越大,传输效率就越高。我们的目标是在保证网络不拥塞的情况下尽量提高传输效率;
那么所有的包都可以延迟应答么? 肯定也不是; - 数量限制:每隔N个包就应答一次;
- 时间限制:超过最大延迟时间就应答一次;
具体的数量和超时时间,依操作系统不同也有差异;一般N取2,超时时间取200ms;
面向字节流
创建一个TCP的socket,同时在内核中创建一个 发送缓冲区 和一个 接收缓冲区;
- 调用write时,数据会先写入发送缓冲区中;
- 如果发送的字节数太长,会被拆分成多个TCP的数据包发出;
- 如果发送的字节数太短,就会先在缓冲区里等待,等到缓冲区长度差不多了,或者其他合适的时机发送出去;
- 接收数据的时候,数据也是从网卡驱动程序到达内核的接收缓冲区;
- 然后应用程序可以调用read从接收缓冲区拿数据;
- 另一方面,TCP的一个连接,既有发送缓冲区,也有接收缓冲区,那么对于这一个连接,既可以读数据,也可以写数据。这个概念叫做 全双工
由于缓冲区的存在,TCP程序的读和写不需要一一匹配,例如: - 写100个字节数据时,可以调用一次write写100个字节,也可以调用100次write,每次写一个字节;
- 读100个字节数据时,也完全不需要考虑写的时候是怎么写的,既可以一次read 100个字节,也可以一次read一个字节,重复100次;
粘包问题
粘包问题中的"包"指的是应用层的数据包。在TCP的协议头中,没有如同UDP一样的 “报文长度” 这样的字段,但是有一个序号这样的字段。站在传输层的角度,TCP是一个一个报文过来的。按照序号排好序放在缓冲区中。站在应用层的角度,看到的只是一串连续的字节数据。那么应用程序看到了这么一连串的字节数据,就不知道从哪个部分开始到哪个部分,是一个完整的应用层数据包。
避免粘包问题就是要明确两个包之间的边界。
对于UDP,如果还没有上层交付数据,UDP的报文长度仍然在。同时,UDP是一个一个把数据交付给应用层。就有很明确的数据边界。站在应用层的角度,使用UDP的时候,要么收到完整的UDP报文,要么不收。不会出现"半个"的情况
TCP异常情况
进程终止:进程终止会释放文件描述符,仍然可以发送FIN,和正常关闭没有什么区别。
机器重启:和进程终止的情况相同。
机器掉电/网线断开:接收端认为连接还在,一旦接收端有写入操作,接收端发现连接已经不在了,就会进行reset。即使没有写入操作,TCP自己也内置了一个保活定时器,会定期询问对方是否还在。如果对方不在,也会把连接释放。
另外, 应用层的某些协议, 也有一些这样的检测机制。例如HTTP长连接中,也会定期检测对方的状态。例如QQ,在QQ断线之后,也会定期尝试重新连接。
TCP小结
为什么TCP这么复杂? 因为要保证可靠性,同时又尽可能的提高性能。
- 可靠性:
- 校验和
- 序列号(按序到达)
- 确认应答
- 超时重发
- 连接管理
- 流量控制
- 拥塞控制
- 提高性能:
- 滑动窗口
- 快速重传
- 延迟应答
- 捎带应答
- 其他:
- 定时器(超时重传定时器, 保活定时器, TIME_WAIT定时器等)
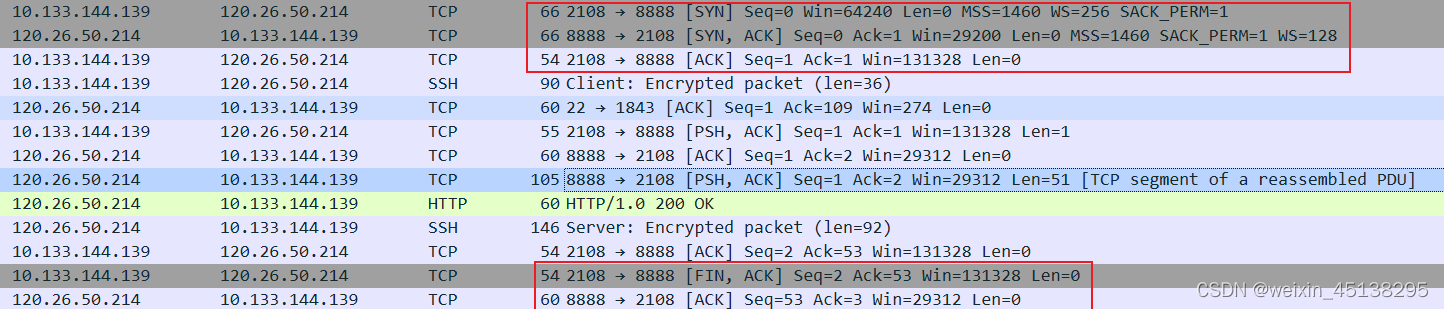
TCP相关实验
通过wireshark截取到的TCP流程
相关文章:
传输层 | UDP协议、TCP协议
之前讲过的http与https都是应用层协议,当应用层协议将报文构建好之后就要将报文往下层传输层进行传递,而传输层就是负责将数据能够从发送端传到接收端。 再谈端口号 端口号(port)标识了一个主机上进行通信的不同的应用程序,在TCP/IP协议中&…...

Webmin(CVE-2019-15107)远程命令执行漏洞复现
漏洞编号 CVE-2019-15107 webmin介绍 什么是webmin Webmin是目前功能最强大的基于Web的Unix系统管理工具。管理员通过浏览器访问Webmin的各种管理功能并完成相应的管理动作http://www.webmin.com/Webmin 是一个用 Perl 编写的基于浏览器的管理应用程序。是一个基于Web的界面…...
)
嵌入式实时操作系统的设计与开发 (前后台系统)
前后台结构 前后台系统也称为中断驱动系统,其软件结构的显著特点是运行的程序有前台和后台之分。 在后台,一组程序按照轮询方式访问CPU;在前台,当用户的请求到达时,首先向CPU触发中断,然后将该请求转交给后…...
Macos数字音乐库:Elsten Software Bliss for Mac
Elsten Software Bliss for Mac是一款优秀的音乐管理软件,它可以帮助用户自动化整理和标记数字音乐库,同时可以自动识别音乐信息并添加标签和元数据。 此外,Bliss还可以修复音乐库中的问题,例如重复的音乐文件和缺失的专辑封面等…...

基于SpringBoot的校园周边美食探索及分享平台的设计与实现
文章目录 项目介绍主要功能截图:登录注册个人信息管理后台首页轮播图管理美食鉴赏我的好友管理我的收藏管理用户管理部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给…...

GPT-4V的图片识别和分析能力
GPT-4V是OpenAI开发的大型语言模型,是GPT-4的升级版本。GPT-4V在以下几个方面进行了改进: 模型规模更大:GPT-4V的参数量达到了1.37T,是GPT-4的10倍。训练数据更丰富:GPT-4V的训练数据包括了1.56T的文本和代码数据。算…...

蓝桥杯(等差素数列,C++)
思路: 1、因为找的是长度为10,且公差最小的等差素数列,直接用枚举即可。 2、枚举用三重循环,第一重枚举首项,第二重枚举公差,第三重因为首项算一个,所以枚举九个等差素数。 代码:…...

Ceph 中的写入放大
新钛云服已累计为您分享769篇技术干货 介绍 Ceph 是一个开源的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。 Ceph 独一无二地在一个统一的系统中同时提供了对象、块、和文件存储功能。 Ceph 消除了对系统单一中心节点的依赖,实现了无中…...

Mabatis-puls强于Mybatis的地方
Mabatis-puls与Mybatis都是优秀的Java持久化框架,但是Mabatis-puls相较于Mybatis有以下几个方面的优势: 性能更优:Mabatis-puls采用了Javassist技术,使得它在运行时比Mybatis更快速,尤其是在执行大量SQL的情况下&#…...
vue项目npm intall时发生版本冲突的解决办法
在日常使用命令npm install / npm install XX下载依赖的操作中,我经常会遇到无法解析依赖树的问题(依赖冲突) 当遇到这种情况的时候,可以通过以下命令完成依赖安装: npm install --legacy-peer-deps npm install xxx…...
tomcat多实例部署jenkins
tomcat多实例部署jenkins 文章目录 tomcat多实例部署jenkins1.简介:2.优缺点:3.工作原理:4.工作流程:5.tomcat多实例部署jenkins流程5.1.环境说明5.2.部署前准备工作5.3.多实例部署tomcat5.4.部署jenkins5.5.创建一个jenkins项目5…...

强连通分量+缩点
[图论与代数结构 701] 强连通分量 题目描述 给定一张 n n n 个点 m m m 条边的有向图,求出其所有的强连通分量。 注意,本题可能存在重边和自环。 输入格式 第一行两个正整数 n n n , m m m ,表示图的点数和边数。 接下来…...

如何做系统架构设计
文章目录 1、如何进行架构设计体系架构需求体系架构设计体系架构文档化体系架构复审体系架构实现体系架构演化 2、架构设计注意事项分治原则服务自治拥抱变化可维护性考虑依赖和限制阅读代码注意事项 3、最后 系统架构应该如何设计,从自己做架构的经历来分享一些体…...

L14D6内核模块编译方法
一、内核模块基础代码解析 一个内核模块代码错误仍然会导致的内核崩溃。 GPL协议:开源规定,使用内核一些函数需要 1、单内核的缺点 单内核扩展性差的缺点减小内核镜像文件体积,一定程度上节省内存资源提高开发效率不能彻底解决稳定性低的缺…...
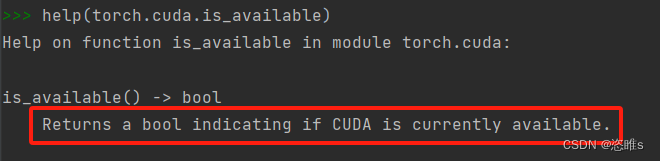
PyTorch入门教学——dir()函数和help()函数的应用
1、简介 已知PyTorch是一个工具包,其中包含许多功能函数。dir()函数和help()函数是学习PyTorch包的重要法宝。 dir():能让我们知道工具包以及工具包中的分隔区有什么东西。help():能让我们知道每个工具是如何使用的,即工具的使用…...

使用Elasticsearch来进行简单的DDL搜索数据
说明:Elasticsearch提供了多种多样的搜索方式来满足不同使用场景的需求,我们可以使用Elasticsearch来进行各种复制的查询,进行数据的检索。 1.1 精准查询 用来查询索引中某个类型为keyword的文本字段,类似于SQL的“”查询。 创…...

【软考】9.3 二叉树存储/遍历/线索/最优/查找/平衡
《树与二叉树》 二叉树的顺序存储结构 顺序存储只适用于完全二叉树和满二叉树,一般二叉树不适用i 2 的左孩子为 2i 4,右孩子为 2i 1 5 二叉树的链式存储结构 链式存储适用于二叉树;空结点用“∧”表示二叉链表:左孩子࿰…...
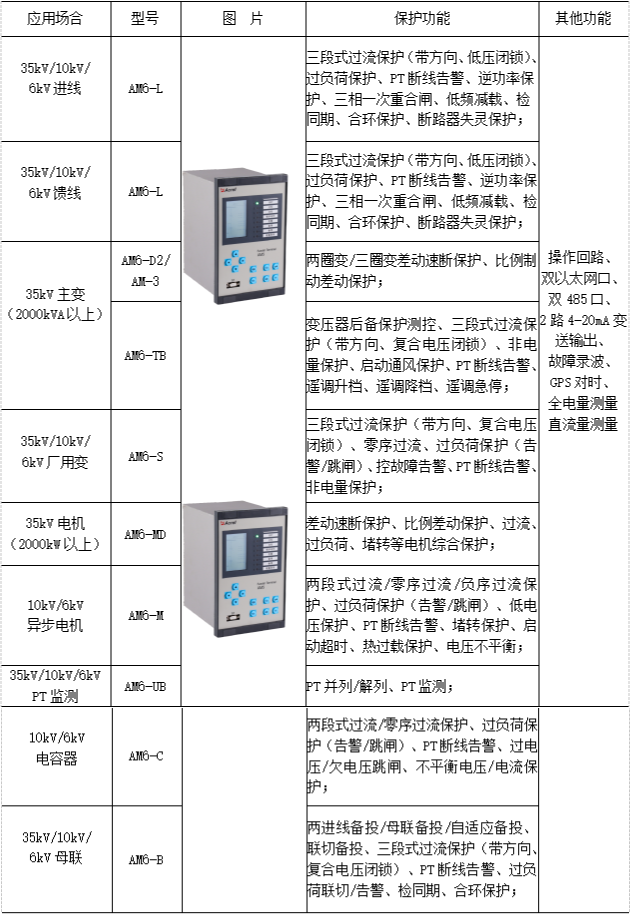
关于矿井地面电力综合自动化系统的研究与产品选型
安科瑞 崔丽洁 摘要:煤矿供电系统是煤矿生产的重要动力保障 , 一旦电力中断 , 生产将被迫停止 , 同时停电后容易发生瓦斯积聚爆炸、淹井等恶性事故,现有配电室采用不同厂商的保护装 置产品,没有形成有效的监控配电系统,不便于管…...
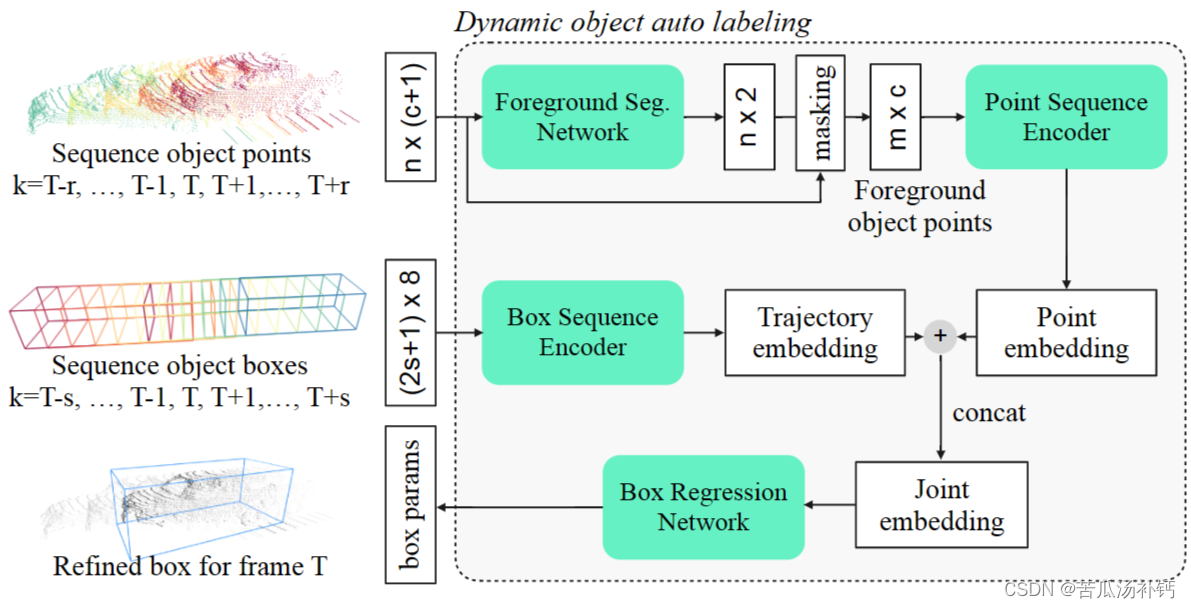
论文阅读:Offboard 3D Object Detection from Point Cloud Sequences
目录 概要 Motivation 整体架构流程 技术细节 3D Auto Labeling Pipeline The static object auto labeling model The dynamic object auto labeling model 小结 论文地址:[2103.05073] Offboard 3D Object Detection from Point Cloud Sequences (arxiv.o…...

Python学习基础笔记六十八——循环
循环是编程语言常见的流程控制。 Python语句要让计算机反复地做一些事情,就要用到循环语句。 有While和for循环。 while循环: command input("请输入命令:") while command ! exit:print(f输入的命令是{command})command input("请输…...

基于GA - XGBoost的时间序列预测:抑制过拟合与参数优化
基于遗传算法优化算法优化XGBoost(GA-XGBoost)的时间序列预测 GA-XGBoost时间序列 采用交叉验证抑制过拟合问题 优化参数为迭代次数、最大深度和学习率 matlab代码,注:暂无Matlab版本要求 -- 推荐 2016B 版本及以上 注:采用 XGBoost 工具箱&a…...

突破Wallpaper Engine资源壁垒:RePKG工具全方位应用指南
突破Wallpaper Engine资源壁垒:RePKG工具全方位应用指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 一、RePKG:解锁创意资源的技术钥匙 在数字创意领域…...

MySQL
我目前正在学习SQL语句,我所了解到的MySQL其实是一堆服务器,在下载服务器的时候,可以选择下载一些客户端,MySQL会自带一些客户端,像类似于终端的小黑框,还有什么bench;我还是喜欢外观好看的客户端 !我学SQL语句目前学到了数据类型,有数值型的,字符型的,二进制型的,值得一提的是…...

当今互联网安全的基石 - TLS/SSL
LS(Transport Layer Security)传输层安全协议 发展历程 TLS 是 SSL 协议的继任者。由于 SSL 协议存在一些安全漏洞,并且随着网络安全需求的不断提高,IETF(Internet Engineering Task Force)对 SSL 3.0 进…...

避开这些坑!Mapbox图层管理实战:动态加载GeoJSON数据的正确姿势
Mapbox高级图层管理实战:GeoJSON动态加载与性能优化全解析 当处理省级以上GIS数据可视化时,Mapbox的图层管理能力直接决定了应用的流畅度和用户体验。许多开发者在使用GeoJSON数据源时,常遇到内存泄漏、渲染卡顿、交互延迟等问题。本文将深入…...
)
Windows11状态栏图标失效?手把手教你修复注册表关联(附一键脚本)
Windows 11状态栏图标失效的终极修复指南:从原理到实战 Windows 11以其现代化的界面设计吸引了不少用户,但系统自定义过程中难免会遇到各种"小脾气"。最近不少用户反馈,在尝试去除桌面图标小箭头后,状态栏的应用程序图标…...
)
告别NMS!用RT-DETR在1080Ti上跑出108FPS的实时目标检测(保姆级部署教程)
在1080Ti上实现108FPS的RT-DETR实时目标检测实战指南 当目标检测遇上Transformer架构,一场关于速度与精度的革命正在悄然发生。RT-DETR作为DETR家族的最新成员,不仅继承了端到端集合预测的基因,更通过一系列创新设计突破了实时检测的瓶颈。本…...

别再只盯着数据了!用Arduino+GP2Y1014AU传感器,手把手教你做个能“看见”空气的PM2.5监测仪
用Arduino打造智能PM2.5监测仪:从硬件连接到可视化交互 在空气质量日益受到关注的今天,拥有一个实时监测PM2.5浓度的设备不仅能提升生活品质,还能为健康保驾护航。不同于市面上千篇一律的商用监测仪,自己动手打造一个兼具实用性和…...

效率倍增:用快马云端jupyter notebook打造可复现、易协作的数据分析流水线
效率倍增:用快马云端jupyter notebook打造可复现、易协作的数据分析流水线 最近在团队里做数据分析时,经常遇到这样的困扰:每次新同事加入项目,都要花半天时间配置本地jupyter环境;好不容易跑通的代码,换台…...

ROS与Webots协同开发:舵轮底盘运动控制实战解析
1. 舵轮底盘的核心原理与结构设计 舵轮底盘作为全向移动机器人的核心部件,其独特之处在于每个轮子都具备独立转向和驱动的能力。这种设计使得机器人能够在平面内实现任意方向的平移和旋转,完全突破了传统差速底盘的运动限制。我曾在物流AGV项目中实测过&…...