使用Elasticsearch来进行简单的DDL搜索数据
说明:Elasticsearch提供了多种多样的搜索方式来满足不同使用场景的需求,我们可以使用Elasticsearch来进行各种复制的查询,进行数据的检索。
1.1 精准查询
用来查询索引中某个类型为keyword的文本字段,类似于SQL的“=”查询。
创建一个test-3-2-1的索引
PUT test-3-2-1
{"mappings": {"properties": {"id": {"type": "integer"},"sex": {"type": "boolean"},"name": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"born": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"location": {"type": "geo_point"}}}
}
搜索name为张三的
POST test-3-2-1/_search
{"query": {"term": {"name.keyword": {"value": "张三"}}}
}
返回的结果中,took表示搜索耗费的毫秒数,_shards中的total代表本次搜索一共使用了多少个分片,该值一般等于索引主分片数。hits里面的total代表一共搜索到多少结果;max_score代表搜索结果中相关度得分的最大值,默认搜索结果会按照相关度得分降序排列;_score代表单个文档的相关度得分;_source是数据的原始JSON内容。
如果想查询用户名为张三和王五的可以这样写。
POST test-3-2-1/_search
{"query": {"terms": {"name.keyword": ["张三","王五"]}}
}
1.2 范围查询
范围查询也很简单,可以返回某个数值或日期字段处于某一区间的数据。区间筛选参数gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于。由于索引中保存的时间是UTC时间,以下查询表示查询born日期处于2020/09/1100:00:00(UTC)至2020/09/13 00:00:00(UTC)范围内的数据,可以使用format参数自定义查询的日期格式。
POST test-3-2-1/_search
{"query": {"range": {"born": {"gte": "2020/09/11 00:00:00","lte": "2020/09/13 00:00:00","format": "yyyy/MM/dd HH:mm:ss"}}}
}
1.3 存在查询
存在(exists)查询用于筛选某个字段不为空的文档,其作用类似于SQL的“is not null”语句的作用。先往索引test-3-2-1中添加一条数据,这条数据有一个age年龄字段。
POST test-3-2-1/_doc/5
{"id": "5","sex": true,"name": "刘大","born": "2020-02-18 00:02:20","age": 20,"location": {"lat": 21.12,"lon": -71.34}
}
然后,使用exists查询查找age字段存在的数据。
POST test-3-2-1/_search
{"query": {"exists": {"field": "age"}}
}
1.3 正则查询
正则查询允许查询内容是正则表达式,它会查询出某个字段符合正则表达式的所有文档。例如:
.POST test-3-2-1/_search
{"query": {"regexp": {"name.keyword": ".*大.*"}}
}
1.4 匹配搜索
匹配搜索(match query)和术语查询(term query)不一样,匹配搜索会比较搜索词和每个文档的相似度,只要搜索词能命中文档的分词就会被搜索到,而term query要么搜不到,要么搜到的内容就和索引内容一模一样。Match query主要用于对指定的text类型的字段做全文检索。
先给索引ik-text和my_analyzer-text添加一些数据。
PUT ik-text/_doc/1
{"content":"武汉大学","abstract":"200210452014"
}
PUT my_analyzer-text/_doc/1
{"content":"武汉大学","abstract":"200210452014"
}
尝试用IK分词器来测试match query的效果。
POST ik-text/_search
{"query": {"match": {"content": {"query": "武汉大学是一所好学校","analyzer": "ik_max_word"}}}
}
IK分词器有两种分词模式:ik_max_word和ik_smart模式。ik_max_word (常用) 会将文本做最细粒度的拆分,而ik_smart模式是做粗粒度的拆分,下面的可以看他们是如何划分的。
POST _analyze
{"analyzer": "ik_max_word","text": "武汉大学是一所好学校"
}
下面这个可以进行多个条件查询
POST ik-text/_search
{"query": {"match_bool_prefix" : {"content" : "武大 一所 武汉"}}
}
1.5 经纬度搜索
经纬度搜索在GIS开发中较为常见,比如你想在地图上搜索有哪些坐标点落在某个圆形、矩形或者多边形的区域内,这时经纬度搜索就会特别管用。
1.5.1 圆形搜索
圆形搜索(geo-distance)用于搜索距离某个圆心一定长度的检索半径之内的全部数据,传参时需要传入圆心坐标和检索半径。
先新建一个索引geo-shop,并添加一些测试数据。
PUT geo-shop
{"mappings": {"properties": {"name":{"type": "keyword"},"location": {"type": "geo_point"}}}
}
PUT geo-shop/_bulk
{"index":{"_id":"1"}}
{"name":"北京","location":[116.4072154982,39.9047253699]}
{"index":{"_id":"2"}}
{"name":"上海","location":[121.4737919321,31.2304324029]}
{"index":{"_id":"3"}}
{"name":"天津","location":[117.1993482089,39.0850853357]}
{"index":{"_id":"4"}}
{"name":"顺义","location":[116.6569478577,40.1299127031]}
{"index":{"_id":"5"}}
{"name":"石家庄","location":[114.52,38.05]}
{"index":{"_id":"6"}}
{"name":"香港","location":[114.10000,22.20000]}
{"index":{"_id":"7"}}
{"name":"杭州","location":[120.20000,30.26667]}
{"index":{"_id":"8"}}
{"name":"青岛","location":[120.33333,36.06667]}
下面的请求会创建一个圆形搜索,它会搜索以经纬度[116.4107, 39.96820]为圆心,以100km为检索半径的城市列表。
POST geo-shop/_search
{"query": {"geo_distance": {"distance": "100km","location": {"lat": 39.96820,"lon": 116.4107}}}
}
1.5.2 矩形搜索
与圆形搜索不同,矩形搜索(geo-bounding box)需要提供左上角(top_left)和右下角(bottom_right)的经纬度坐标,这样才能查出所有的矩形范围内的数据。例如:
POST geo-shop/_search
{"query": {"geo_bounding_box": {"location": {"top_left": {"lat": 40.82,"lon": 111.65},"bottom_right": {"lat": 36.07,"lon": 120.33}}}}
}
1.5.3 多边形搜索
多边形搜索(geo-polygon)需要传入至少3个坐标点的数据,geo-polygon会搜索出坐标点围成的多边形范围内的数据。例如:
POST geo-shop/_search
{"query": {"geo_polygon": {"location": {"points": [{"lat": 39.9,"lon": 116.4},{"lat": 41.8,"lon": 123.38},{"lat": 30.52,"lon": 114.31}]}}}
}
1.6 布尔查询
布尔查询应该是项目开发中应用得很多的复合搜索方法了,它可以按照布尔逻辑条件组织多条查询语句,只有符合整个布尔条件的文档才会被搜索出来。在布尔条件中,可以包含两种不同的上下文。
(1)搜索上下文(query context):使用搜索上下文时,Elasticsearch需要计算每个文档与搜索条件的相关度得分,这个得分的计算需使用一套复杂的计算公式,有一定的性能开销,带文本分析的全文检索的查询语句很适合放在搜索上下文中。
(2)过滤上下文(filter context):使用过滤上下文时,Elasticsearch只需要判断搜索条件跟文档数据是否匹配,例如使用Term query判断一个值是否跟搜索内容一致,使用Range query判断某数据是否位于某个区间等。过滤上下文的查询不需要进行相关度得分计算,还可以使用缓存加快响应速度,很多术语级查询语句都适合放在过滤上下文中。布尔查询一共支持4种组合类型,它们的使用说明如表5.2所示。

下面发起一个布尔查询请求,如下所示。
POST test-3-2-1/_search
{"query": {"bool": {"must": [{"match": {"name": "张 刘 赵"}}],"should": [{"range": {"age": {"gte": 10}}}],"filter": [{"term": {"sex": "true"}}],"must_not": [{"term": {"born": {"value": "2020-10-14 00:02:20"}}}]}}
}
注意:虽然你可以把match放在filter里面,但是这样不会计算相关度得分,可能导致搜索结果的排序并不理想;你也可以把term放在must里面,但是这样就无法用到缓存,还要计算相关度得分,会导致查询变慢。因此,请在使用时养成好的搜索习惯,把需要文本分词的检索条件放到must里面,把不需要分词的检索条件放到filter里面。
1.7 析取最大查询
析取最大查询(disjunction max)允许添加多个查询条件,符合任意条件的文档就会被搜索到,每个文档的相关度得分取匹配搜索条件的最大的那一个值。某些文档可能会同时匹配多个搜索条件,但可能由于得分均不高而无法排名靠前,这时可以在查询中添加tie_breaker参数,将其他匹配的查询得分也计入在内。例如:
POST sougoulog/_search
{"query": {"dis_max": {"queries": [{"match": {"keywords": "火车"}},{"match": {"rank": "1"}}],"tie_breaker": 0.8}},"from": 0,"size": 10
}
这个请求添加了两个match查询条件,还设置了tie_breaker为0.8,你可以把它的值设置为0~1范围内的任意小数,这个值越大,文档匹配的查询条件越多,排名就可以越靠前。该请求的搜索结果会返回至少匹配了一个match查询条件的文档。
1.8 相关度增强查询
相关度增强查词(boosting query)包含一个positive查询条件和一个negative查询条件,该查询会返回所有匹配positive查询条件的相关文档,在这些返回的文档中,匹配negative查询条件的文档相关度得分会降低,得分降低的程度可以使用negative_boost参数进行控制。例如:
POST sougoulog/_search
{"query": {"boosting": {"positive": {"match": {"keywords": "车"}},"negative": {"range": {"rank": {"lte": 10}}},"negative_boost": 0.5}}
}
上述代码会返回所有keywords字段包含“车”的文档,但是对于rank字段小于等于10的文档会将相关度乘0.5作为最后得分。上述代码会使符合negative查询条件的搜索结果的文档排序靠后,而其他文档的排序则靠前。
1.9 搜索结果的总数
从Elasticsearch 7.x开始,搜索结果中的total值会带有value和relation两个字段,当搜索结果总数小于等于10000时,返回的relation为“eq”,表示此时的搜索结果的总数是准确的。一旦搜索结果的总数超过10000,就默认会返回下面的内容。
…
"hits" : {"total" : {"value" : 10000,"relation" : "gte"},
发现此时搜索结果的relation变成了“gte”,表示实际的总数值比现在返回的值10000要大。默认最大只能返回10000,这样设置是为了在不需要搜索结果的精确总数时可以提高查询性能。如果想获得搜索结果的准确总数,需要在查询中将参数track_total_hits设置为true。
…
"query": {"match_all": {}},"track_total_hits": true
…
2.0 Search after分页
滚动分页无法实时显示最新的数据,Search after分页则可以有效避免这个问题,它的原理是每次根据上一次分页的最后一条记录的位置来寻找下一页的记录。使用时先发起一个查询请求获取第一页的数据,与普通分页的唯一区别在于,这个查询请求必须添加一个唯一字段来进行排序,如果你的映射中没有唯一字段,可以使用文档自带的主键字段“_id”。例如:
POST sougoulog/_search
{"query": {"match_all": {}},"track_total_hits": true,"size": 10,"from": 0,"sort": [{"id": {"order": "asc"}}]
}
上述代码会取出搜索结果的前10条记录,数据按照唯一的字段id进行升序排列,在以下结果中你只需要关注最后一条数据的sort值。
{"_index" : "sougoulog","_type" : "_doc","_id" : "10","_score" : null,"_source" : {"clicknum" : 2,"id" : 10,"keywords" : "[电脑创业]","rank" : 2,"url" : "ks.cn.yahoo.com/question/1307120203719.html","userid" : "9975666857142764","visittime" : "00:00:00"},"sort" : [10]}
再把这个sort值10作为search_after分页的参数传入下一次分页的请求,就能得到下一页的数据了。
POST sougoulog/_search
{"query": {"match_all": {}},"track_total_hits": true,"size": 10,"from": 0,"sort": [{"id": {"order": "asc"}}],"search_after": [10]
}
注意:在使用search_after参数的查询中,from参数必须为0,否则会报错。另外,排序选择的字段必须是唯一的,不然会因为该字段相同的数据无法决定先后顺序导致分页的结果不正确。
sort 是用来进行排序的,在指定排序字段时,不可以直接将分词的text类型字段作为排序依据,因为text类型字段没有在磁盘上保存doc value值,而且这样做在业务上没有任何意义。通常用来排序的字段是日期类型的字段、数值类型的字段、关键字类型的字段,可以多个字段进行排序的。
2.1 筛选搜索结果返回的字段
有时候索引的字段数目比较多,而前端并不需要展示或者导出这么多字段,这时候就需要对搜索结果返回的字段进行筛选。以下请求用_source参数筛选出需要返回的字段列表“born”和“name”。
POST test-3-2-1/_search
{"query": {"match_all": {}},"_source": [ "born", "name" ]
}
2.2 高亮搜索结果中的关键词
高亮是搜索引擎中很常见的功能,使用百度或者谷歌搜索引擎搜索内容的时候,被搜索的关键词会以高亮形式出现在搜索结果中。这个功能在实现时通常要用到倒排索引中像表2.2那样记录每个分词出现的位置信息,它们在文本分析的过程中就生成了。
高亮功能的使用比较简单,只需要在highlight中传入需要高亮显示的字段和高亮标签,默认的高亮标签是标签,你可以通过参数来自定义。例如:
POST my_analyzer-text/_search
{"query": {"query_string": {"query": "武术 \"210\""}},"highlight": {"pre_tags" : ["<tag1>"],"post_tags" : ["</tag1>"],"fields": {"abstract": {},"content": {}}}
}
这个请求表示在query_string查询的结果中,对abstract和content两个字段进行关键词高亮,使用了pre_tags和post_tags设置高亮标签。该请求会得到以下结果。
"hits" : [{"_index" : "my_analyzer-text","_type" : "_doc","_id" : "1","_score" : 1.1507283,"_source" : {"content" : "武汉大学","abstract" : "200210452014"},"highlight" : {"abstract" : ["200<tag1>2</tag1><tag1>1</tag1><tag1>0</tag1>452014"],"content" : ["<tag1>武</tag1>汉大学"]}}
2.3 折叠搜索结果
如果你想知道索引中某个字段存在哪些不同的数据,就可以使用搜索的折叠功能,它的效果类似于SQL中的“select distinct”的效果,只保留某个字段不重复的数据。
先建立一个索引collapse-test并导入测试数据。
POST collapse-test/_bulk
{"index":{"_id":"1"}}
{"id":"1","name":"王五","level":5,"score":90}
{"index":{"_id":"2"}}
{"id":"2","name":"李四","level":5,"score":70}
{"index":{"_id":"3"}}
{"id":"3","name":"黄六","level":5,"score":70}
{"index":{"_id":"4"}}
{"id":"4","name":"张三","level":5,"score":50}
{"index":{"_id":"5"}}
{"id":"5","name":"马七","level":4,"score":50}
{"index":{"_id":"6"}}
{"id":"6","name":"黄小","level":4,"score":90}
然后在查询中添加一个collapse参数,选择在level字段上进行数据折叠。
POST collapse-test/_search
{"query": {"match_all": {}},"collapse": {"field": "level"}
}
结果如下,每个level会选择一条数据进行展示。
"hits" : [{"_index" : "collapse-test","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : "1","name" : "王五","level" : 5,"score" : 90},"fields" : {"level" : [5]}},{"_index" : "collapse-test","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"id" : "5","name" : "马七","level" : 4,"score" : 50},"fields" : {"level" : [4]}}]
可以看到level字段重复的数据都被折叠了,两个level各显示了一条数据。如果想展示每个level所包含的详细数据,可以使用inner_hits参数来获取。
POST collapse-test/_search
{"query": {"match_all": {}},"collapse": {"field": "level","inner_hits": {"name": "by_level","size": 2,"sort": [ { "score": "asc" } ]}}
}
上面的请求在inner_hits中配置了每个相同的level数据最多展示两条,并且按照score字段升序排列,部分结果如下。
"hits" : [{"_index" : "collapse-test","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : "1","name" : "王五","level" : 5,"score" : 90},"fields" : {"level" : [5]},"inner_hits" : {"by_level" : {"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "collapse-test","_type" : "_doc","_id" : "4","_score" : null,"_source" : {"id" : "4","name" : "张三","level" : 5,"score" : 50},"sort" : [50]},{"_index" : "collapse-test","_type" : "_doc","_id" : "2","_score" : null,"_source" : {"id" : "2","name" : "李四","level" : 5,"score" : 70},"sort" : [70]}]}}…
可以看到level为5的数据一共有4条,但是只外显了2条。折叠效果可以嵌套到第二级,但是第二级不可以做inner_hits处理。例如下面的请求,我们在collapse参数中又嵌套了一个collapse,但是只能在第一个collapse中做inner_hits。
POST collapse-test/_search
{"query": {"match_all": {}},"collapse": {"field": "level","inner_hits": {"name": "by_level","size": 5,"sort": [ { "score": "asc" } ],"collapse": { "field": "score" }}}
}
相关文章:
使用Elasticsearch来进行简单的DDL搜索数据
说明:Elasticsearch提供了多种多样的搜索方式来满足不同使用场景的需求,我们可以使用Elasticsearch来进行各种复制的查询,进行数据的检索。 1.1 精准查询 用来查询索引中某个类型为keyword的文本字段,类似于SQL的“”查询。 创…...

【软考】9.3 二叉树存储/遍历/线索/最优/查找/平衡
《树与二叉树》 二叉树的顺序存储结构 顺序存储只适用于完全二叉树和满二叉树,一般二叉树不适用i 2 的左孩子为 2i 4,右孩子为 2i 1 5 二叉树的链式存储结构 链式存储适用于二叉树;空结点用“∧”表示二叉链表:左孩子࿰…...
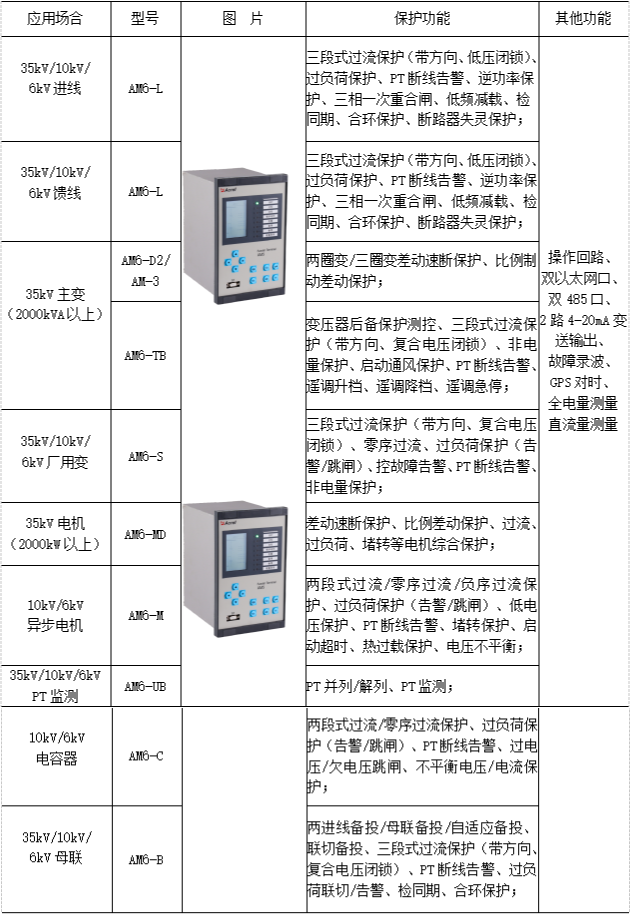
关于矿井地面电力综合自动化系统的研究与产品选型
安科瑞 崔丽洁 摘要:煤矿供电系统是煤矿生产的重要动力保障 , 一旦电力中断 , 生产将被迫停止 , 同时停电后容易发生瓦斯积聚爆炸、淹井等恶性事故,现有配电室采用不同厂商的保护装 置产品,没有形成有效的监控配电系统,不便于管…...
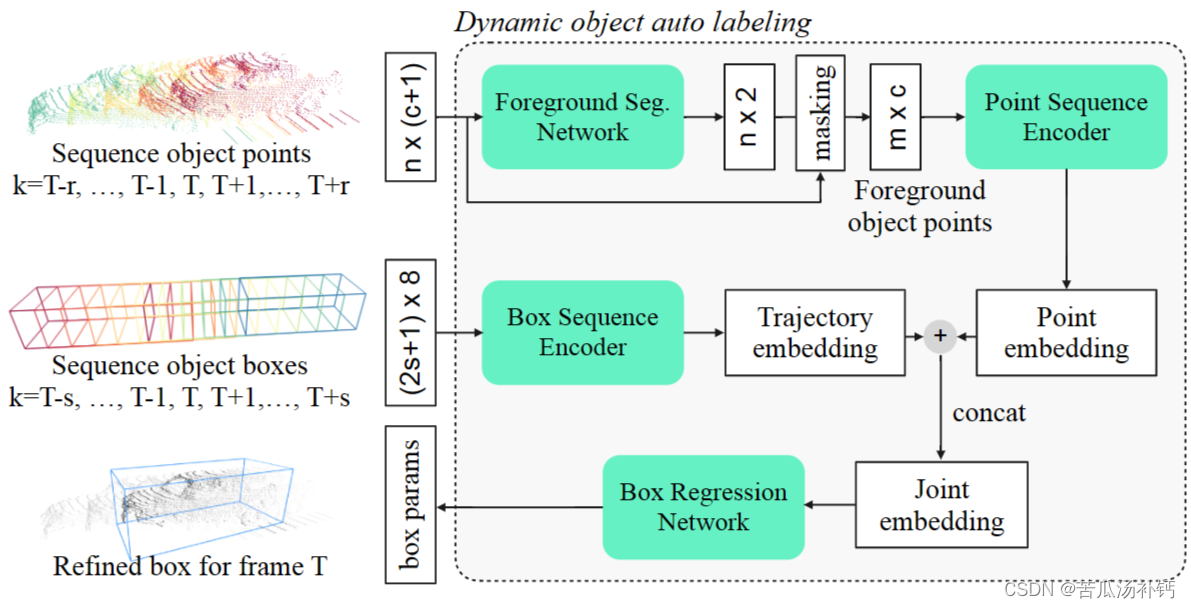
论文阅读:Offboard 3D Object Detection from Point Cloud Sequences
目录 概要 Motivation 整体架构流程 技术细节 3D Auto Labeling Pipeline The static object auto labeling model The dynamic object auto labeling model 小结 论文地址:[2103.05073] Offboard 3D Object Detection from Point Cloud Sequences (arxiv.o…...

Python学习基础笔记六十八——循环
循环是编程语言常见的流程控制。 Python语句要让计算机反复地做一些事情,就要用到循环语句。 有While和for循环。 while循环: command input("请输入命令:") while command ! exit:print(f输入的命令是{command})command input("请输…...
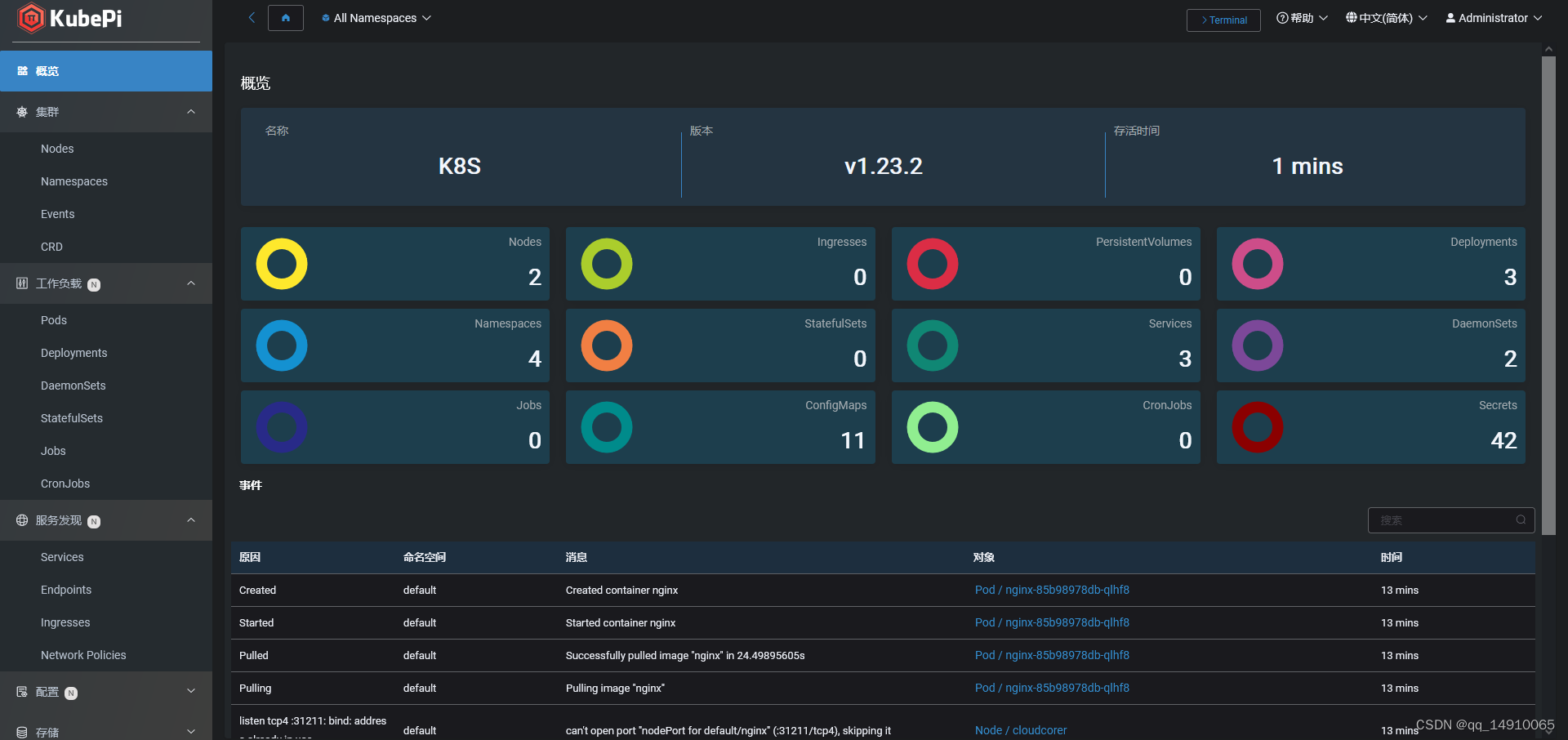
部署k8s dashboard(这里使用Kubepi)
9. 部署k8s dashboard(这里使用Kubepi) Kubepi是一个简单高效的k8s集群图形化管理工具,方便日常管理K8S集群,高效快速的查询日志定位问题的工具 部署KubePI(随便在哪个节点部署,我这里在主节点部署&#…...

Java Lambda表达式的使用
我们了解了 java Lambda 的概念并可以在匿名类的场合使用 Lambda 语法进行简单替换。本节主要介绍在 Java 中如何使用 Lambda 表达式。 作为参数使用Lambda表达式 Lambda 表达式一种常见的用途就是作为参数传递给方法,这需要声明参数的类型声明为函数式接口类型。…...

【初始C语言8】详细讲解初阶结构体的知识
前言 💓作者简介: 加油,旭杏,目前大二,正在学习C,数据结构等👀 💓作者主页:加油,旭杏的主页👀 ⏩本文收录在:再识C进阶的专栏…...
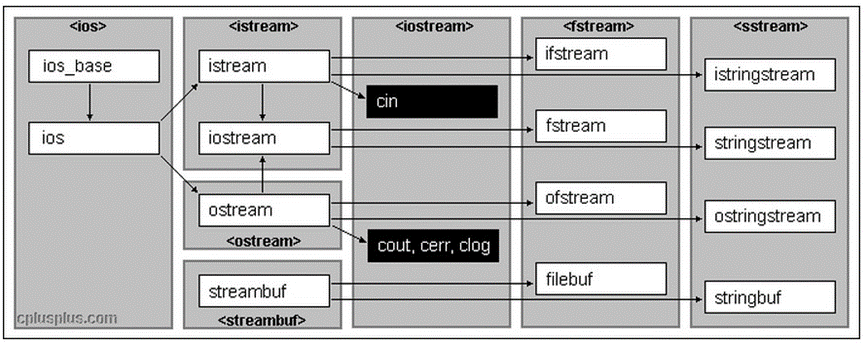
<C++> IO流
C语言的输入与输出 在C语言当中,我们使用最频繁的输入输出方式就是scanf与printf: scanf: 从标准输入设备(键盘)读取数据,并将读取到的值存放到某一指定变量当中。printf: 将指定的数据输出到…...

基于单目相机的2D测量(工件尺寸和物体尺寸)
目录 1.简介 2.基于单目相机的2D测量 2.1 想法: 2.2 代码思路 2.2 主函数部分 1.简介 基于单目相机的2D测量技术在许多领域中具有重要的背景和意义。 工业制造:在工业制造过程中,精确测量是确保产品质量和一致性的关键。基于单目相机的2…...
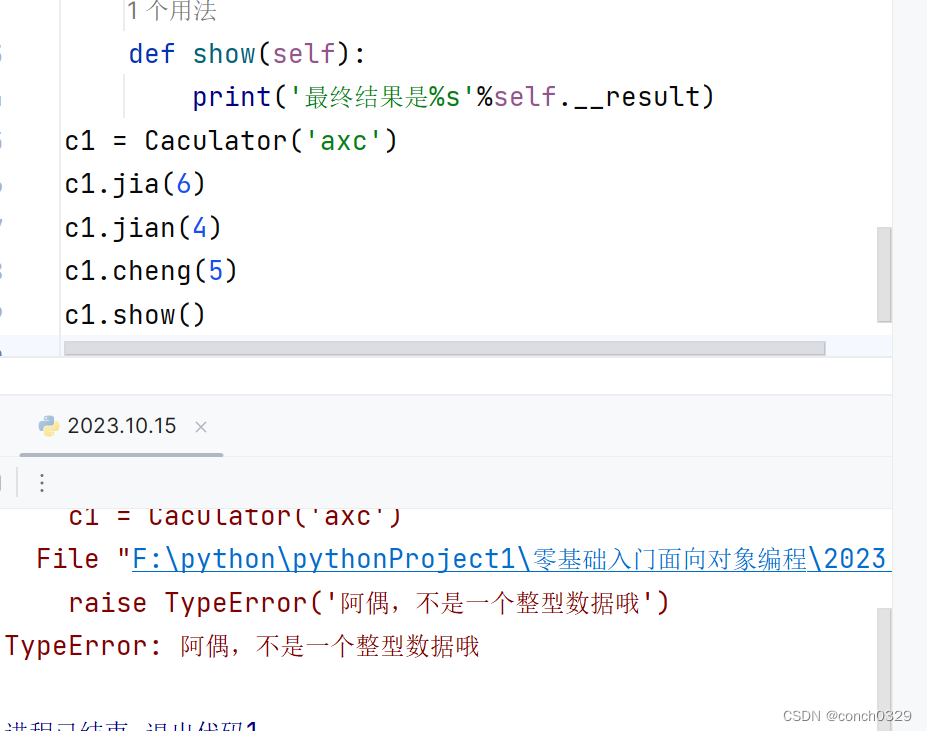
23面向对象案例1
目录 1、计算连续表达式的一个过程 2、优化后的代码 为什么不能return resultn? 3、用面向对象的方法可以解决冗余的问题,但是还是不能解决result的值可以被随意修改的问题 4、解决不能被随意修改的问题,可以将类属性改成私有变量吗&…...

go语言基础之常量与itoa
视频学习地址:Go零基础入门_在线视频教程-CSDN程序员研修院 一. 常量 定义:常量是一个简单值的标识符,在程序运行时,不会被修改的量。注意:常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数…...
民宿酒店订房房态商城小程序的作用是什么
外出旅游出差,酒店民宿总是很好的选择,随着经济复苏,各地旅游及外出办公人次增多,酒店成绩随之增加,市场呈现多品牌酒店经营形式。 区别于以前,如今互联网深入各个行业,酒店经营也面临着困境。…...

acwing算法基础之数据结构--栈和队列
目录 1 知识点2 模板 1 知识点 栈:先进后出。先进的就是栈底,后进的就是栈顶。后进先出嘛,所以在栈顶弹出元素。 队列:先进先出。先进的就是队头,后进的就是队尾。先进先出嘛,所以在队头弹出元素。 单调…...

关于导出的Excel文件的本质
上篇文章中提到关于xlsx改造冻结窗格的代码,我是怎么知道要加pane的呢,加下来就把我的心路历程记录一下。 我改造之前也是没有头绪的,我网上查了很多,只告诉我如何使用,但源码里没有针对!freeze的处理,所以…...

Rust中FnOnce如何传递给一个约束Fn的回调
Rust中FnOnce如何传递给一个约束Fn的回调 下面的代码,set_cb(func);会报错,如何包装能够做到这样的效果: fn set_cb<F: Fn() static>(handler: F) {handler(); }fn main() {let join_handle std::thread::spawn(|| {});let func |…...

【JUC】线程通信与等待唤醒机制
文章目录 1. 线程通信2. Object类中的wait和notify方法实现等待和唤醒3. Condition接口中的await和signal方法实现等待和唤醒4. LockSupport实现等待和唤醒4.1 优点 1. 线程通信 多个线程在处理同一个资源,但是处理的动作(线程的任务)却不相…...
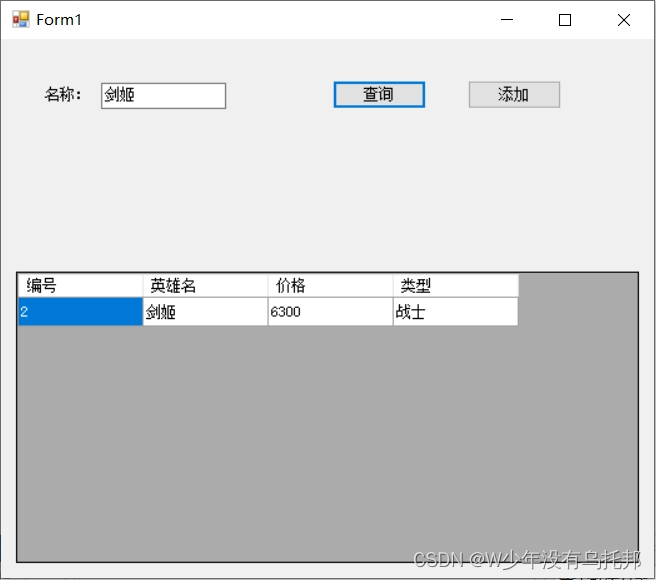
C#面对对象(英雄联盟人物管理系统)
目录 英雄信息类 因为要在两个窗体里面调用字典,所以要写两个类来构建全局变量 添加功能 查询功能 英雄信息类 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace WindowsFormsApp…...
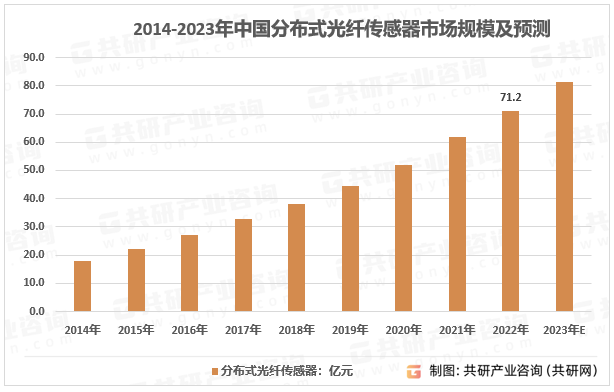
2023年中国分布式光纤传感产量、需求量及行业市场规模分析[图]
分布式光纤传感器中的光纤能够集传感、传输功能于一体,能够完成在整条光纤长度上环境参量的空间、时间多维连续测量,具有结构简单、易于布设、性价比高、易实现长距离等独特优点,常用的分布式光纤传感器有光时域反射仪、布里渊分析仪、喇曼反…...

B2R Raven: 2靶机渗透
B2R Raven: 2靶机渗透 视频参考:ajest :https://www.zhihu.com/zvideo/1547357583714775040?utm_id0 原文参考:ajest :https://zhuanlan.zhihu.com/p/270343652 文章目录 B2R Raven: 2靶机渗透1 启动靶机,查看后网卡…...

索尼相机隐藏功能完全解锁指南:OpenMemories-Tweak终极教程
索尼相机隐藏功能完全解锁指南:OpenMemories-Tweak终极教程 【免费下载链接】OpenMemories-Tweak Unlock your Sony cameras settings 项目地址: https://gitcode.com/gh_mirrors/op/OpenMemories-Tweak 还在为索尼相机的30分钟录制限制而烦恼吗?…...

告别逐行阅读:这个终端工具让你的阅读速度提升200%
告别逐行阅读:这个终端工具让你的阅读速度提升200% 【免费下载链接】speedread A simple terminal-based open source Spritz-alike (per-word RSVP aligned on optimal reading points) 项目地址: https://gitcode.com/gh_mirrors/sp/speedread 在信息爆炸的…...

如何10分钟快速上手:语音转换工具完全指南
如何10分钟快速上手:语音转换工具完全指南 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI 语音数据小于等于10分钟也可以用来训练一个优秀的变声模型! 项目地址: https://gitcode.com/GitHub_Trending/re/Retrieval-based-Voice-Conversion…...

LLM大模型开发实战:6个爆款开源项目,小白也能轻松入门!
本文介绍了6个GitHub上的热门LLM(大型语言模型)开源项目,包括Datawhale的"LLM-Universe"和"LLM-Cookbook"、微软的"Generative AI for Beginners"、mlabonne的"LLM-Course"、liguodongiot的"LL…...

WAF工程师实战笔记:如何用Suricata规则精准识别哥斯拉、冰蝎、蚁剑的Webshell流量
WAF工程师实战笔记:Suricata规则精准识别主流Webshell流量 在安全运维的日常工作中,Webshell流量的检测始终是一场攻防对抗的持久战。面对哥斯拉、冰蝎、蚁剑等主流Webshell管理工具不断升级的流量混淆技术,传统的特征匹配方法往往力不从心。…...

Qwen2.5-Coder-1.5B应用案例:快速生成网页爬虫代码实战
Qwen2.5-Coder-1.5B应用案例:快速生成网页爬虫代码实战 1. 引言:为什么选择Qwen2.5-Coder生成爬虫代码 在日常开发工作中,网页爬虫是数据采集和分析的重要工具。传统编写爬虫代码需要开发者熟悉HTTP请求、HTML解析、反爬机制处理等多个技术…...

3大突破!115proxy-for-Kodi实现云视频原码播放全攻略
3大突破!115proxy-for-Kodi实现云视频原码播放全攻略 【免费下载链接】115proxy-for-kodi 115原码播放服务Kodi插件 项目地址: https://gitcode.com/gh_mirrors/11/115proxy-for-kodi 副标题:突破存储限制,零缓冲流畅播放云端高清视频…...

告别数据丢失!用ArcMap的‘图层组’功能,一次性搞定Shapefile转KML和标注
告别数据丢失!用ArcMap的‘图层组’功能高效实现Shapefile转KML与标注一体化 在GIS数据处理中,Shapefile转KML是常见需求,但保留标注信息往往让用户头疼。传统方法需要分别处理数据和标注,步骤繁琐且容易出错。本文将介绍如何利用…...

5大场景重构AI协作流程:Awesome Claude Skills实战指南
5大场景重构AI协作流程:Awesome Claude Skills实战指南 【免费下载链接】awesome-claude-skills A curated list of awesome Claude Skills, resources, and tools for customizing Claude AI workflows 项目地址: https://gitcode.com/GitHub_Trending/aw/awesom…...
的经典思想)
从‘折半查找’到‘二分答案’:LeetCode实战中如何活用这个O(log n)的经典思想
从二分查找到二分答案:LeetCode实战中的O(log n)思想进阶指南 在算法学习与面试准备过程中,二分查找(Binary Search)往往是第一个让初学者感受到算法效率之美的经典案例。这个看似简单的"折半查找"思想,却能…...