【神经网络】如何在Pytorch中从零开始将MNIST网络量化为8位
论文:
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
下载地址:https://arxiv.org/pdf/1712.05877.pdf
更新:量化感知训练的博客文章是在线的,并在这里链接,通过它我们可以训练和量化我们的模型以运行在4比特!
你好,我想分享我如何能够使用定点算术(8位算术)运行神经网络推理的旅程。截至目前,Pytorch的状态只允许32位或16位浮点训练和推理。如果现在想要使用量化压缩Pytorch神经网络,他/她需要将其导入onnx,转换为caffe,并在计算图上运行辉光量化编译器,最终产生量化网络。
在深入研究如何量化一个网络之前,让我们看看为什么我们需要量化一个网络。简单的答案是提高推理速度,浮点运算通常比定点(整数)运算需要更长的计算时间。另一个优势是节省空间,浮点网络的大小是8位量化网络的4倍。这与边缘设备(手机、物联网)尤其相关,因为低存储空间和计算需求对其成为可生产的解决方案至关重要。
在继续之前,这里有一个工作的Colab笔记本,供那些只想查看代码的人运行和验证这个量化网络。此示例在普通Pytorch中从头开始实现量化(没有外部库或框架)
现在我们已经证明了量化的必要性,让我们看看如何量化一个简单的MNIST模型。让我们使用一个简单的模型架构来解决MNIST,它使用2个conv层和2个全连接层。
class Net(nn.Module):def __init__(self, mnist=True):super(Net, self).__init__()if mnist:num_channels = 1else:num_channels = 3self.conv1 = nn.Conv2d(num_channels, 20, 5, 1)self.conv2 = nn.Conv2d(20, 50, 5, 1)self.fc1 = nn.Linear(4*4*50, 500)self.fc2 = nn.Linear(500, 10)def forward(self, x):x = F.relu(self.conv1(x))x = F.max_pool2d(x, 2, 2)x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2, 2)x = x.view(-1, 4*4*50) x = F.relu(self.fc1(x))x = self.fc2(x)return F.log_softmax(x, dim=1)
让我们使用下面的简单训练脚本来训练这个网络:
def train(args, model, device, train_loader, optimizer, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % args["log_interval"] == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))def main():batch_size = 64test_batch_size = 64epochs = 10lr = 0.01momentum = 0.5seed = 1log_interval = 500save_model = Falseno_cuda = Falseuse_cuda = not no_cuda and torch.cuda.is_available()torch.manual_seed(seed)device = torch.device("cuda" if use_cuda else "cpu")kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True, **kwargs)test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=test_batch_size, shuffle=True, **kwargs)model = Net().to(device)optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)args = {}args["log_interval"] = log_intervalfor epoch in range(1, epochs + 1):train(args, model, device, train_loader, optimizer, epoch)test(args, model, device, test_loader)if (save_model):torch.save(model.state_dict(),"mnist_cnn.pt")return model
现在,我们可以使用简单的```model = main()``命令来训练这个网络。一旦模型被训练了10个epoch,让我们通过以下测试函数来测试这个模型。
def test(args, model, device, test_loader):model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch losspred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probabilitycorrect += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))
经过测试,我们得到了99%的准确率。(~9900/10000)正确分类。现在让我们研究一下通过一种称为后训练量化的技术来执行量化。
要点是我们将神经网络的激活和权重转换为8位整数(范围为0到255)。因此,我们在不动点上执行所有算法,希望精度不会显著下降。
为了量化和去量化一个张量,我们使用以下公式:
x_Float =缩放*(x_Quant -zero_point)。因此,
x_Quant = (x_Float/scale) +零点。
这里缩放等于(max_val - min_val) / (qmax - qmin)
其中max_val和min_val分别是X张量的最大值和最小值。Qmin和q_max表示8位数字的范围(分别为0和255)。刻度会缩放量化网络,零点会移动数字。下面给出的去量化和量化函数更清楚地说明了浮点张量如何转换为8位张量,反之亦然。
QTensor = namedtuple('QTensor', ['tensor', 'scale', 'zero_point'])def quantize_tensor(x, num_bits=8):qmin = 0.qmax = 2.**num_bits - 1.min_val, max_val = x.min(), x.max()scale = (max_val - min_val) / (qmax - qmin)initial_zero_point = qmin - min_val / scalezero_point = 0if initial_zero_point < qmin:zero_point = qminelif initial_zero_point > qmax:zero_point = qmaxelse:zero_point = initial_zero_pointzero_point = int(zero_point)q_x = zero_point + x / scaleq_x.clamp_(qmin, qmax).round_()q_x = q_x.round().byte()return QTensor(tensor=q_x, scale=scale, zero_point=zero_point)def dequantize_tensor(q_x):return q_x.scale * (q_x.tensor.float() - q_x.zero_point)
需要注意的是,刻度是浮点数,而零点是整数(8位)。然而,现代实现通过一些花哨的位技巧(即近似)绕过了这种规模的浮点乘法,这些技巧被证明对网络的精度影响可以忽略不计。
现在我们已经准备好了这些函数,我们可以通过修改MNIST网络的前向传递来量化我们的权重和激活。修改后的前向传球看起来像这样。
def calcScaleZeroPoint(min_val, max_val,num_bits=8):# Calc Scale and zero point of next qmin = 0.qmax = 2.**num_bits - 1.scale_next = (max_val - min_val) / (qmax - qmin)initial_zero_point = qmin - min_val / scale_nextzero_point_next = 0if initial_zero_point < qmin:zero_point_next = qminelif initial_zero_point > qmax:zero_point_next = qmaxelse:zero_point_next = initial_zero_pointzero_point_next = int(zero_point_next)return scale_next, zero_point_nextdef quantizeLayer(x, layer, stat, scale_x, zp_x):# for both conv and linear layersW = layer.weight.dataB = layer.bias.data# scale_x = x.scale# zp_x = x.zero_pointw = quantize_tensor(layer.weight.data) b = quantize_tensor(layer.bias.data)layer.weight.data = w.tensor.float()layer.bias.data = b.tensor.float()##################################################################### This is Quantisation !!!!!!!!!!!!!!!!!!!!!!!!!!!!!scale_w = w.scalezp_w = w.zero_pointscale_b = b.scalezp_b = b.zero_pointscale_next, zero_point_next = calcScaleZeroPoint(min_val=stat['min'], max_val=stat['max'])# Perparing input by shiftingX = x.float() - zp_xlayer.weight.data = (scale_x * scale_w/scale_next)*(layer.weight.data - zp_w)layer.bias.data = (scale_b/scale_next)*(layer.bias.data + zp_b)# All intx = layer(X) + zero_point_nextx = F.relu(x)# Resetlayer.weight.data = Wlayer.bias.data = Breturn x, scale_next, zero_point_nextdef quantForward(model, x, stats):# Quantise before inputting into incoming layersx = quantize_tensor_act(x, stats['conv1'])x, scale_next, zero_point_next = quantizeLayer(x.tensor, model.conv1, stats['conv2'], x.scale, x.zero_point)x = F.max_pool2d(x, 2, 2)x, scale_next, zero_point_next = quantizeLayer(x, model.conv2, stats['fc1'], scale_next, zero_point_next)x = F.max_pool2d(x, 2, 2)x = x.view(-1, 4*4*50)x, scale_next, zero_point_next = quantizeLayer(x, model.fc1, stats['fc2'], scale_next, zero_point_next)# Back to dequant for final layerx = dequantize_tensor(QTensor(tensor=x, scale=scale_next, zero_point=zero_point_next))x = model.fc2(x)return F.log_softmax(x, dim=1)
在这里,我们在输入卷积层conv1之前对激活进行量化,并使用名为quantizeLayer的函数,该函数接受conv或线性层以及量化激活的激活、缩放和零点,quantizeLayer()函数执行完全量化的层的前向传递。如果您有任何疑问,请查看上面的代码。您可能想知道quantize_tensor_act()函数是做什么的,它只是通过遍历1000个示例并平均结果,使用张量x通常具有的最小值和最大值对激活x进行量化。它使用这些统计数据来计算尺度,从而计算零点,这是量化张量的必要条件。现在,让我们将所有这些放在一起,并使用这种新的quantForward方法运行网络,并检查最终的准确性。
仍然是99% !当然,这只是一个玩具例子,我已经严重跳过了量化理论,但这是神经网络中如何执行量化的基本要点。它不是巫毒魔法,而是简单的线性代数和一些巧妙的技巧来绕过pytorch层。
希望这对你们来说是一个有趣的旅程,请查看这个正在工作的Colab笔记本,以运行和验证这个量化网络!
如果你们中有人想了解更多关于量化的知识,我已经把我从下面学到的资源嵌入其中。它们的确是无价的。
相关文章:

【神经网络】如何在Pytorch中从零开始将MNIST网络量化为8位
论文: Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference 下载地址:https://arxiv.org/pdf/1712.05877.pdf 更新:量化感知训练的博客文章是在线的,并在这里链接,通过它我们可以训…...

智慧水利:山海鲸数字孪生的革新之路
一、概念 什么是港口? "港口"通常指的是一个水域或岸边的设施,用于装载、卸载、储存和处理货物、以及提供与海上、河流或湖泊交通相关的服务。港口可以包括各种类型的码头、码头设备、仓库、货物运输设施、以及各种管理和物流设施。 什么是数…...

【unity】【VR】白马VR课堂系列-VR开发核心基础04-主体设置-XR Rig的引入和设置
接下来我们开始引入并构建XR Rig。 你可以将XR Rig理解为玩家在VR世界中的替身。 我们先删除Main Camera,在Hierarchy右键点击删除。 然后再在场景层右键选择XR下的XR Origin。这时一个XR Origin对象就被添加到了Hierarchy。 重设XR Origin的Position和Rotation…...
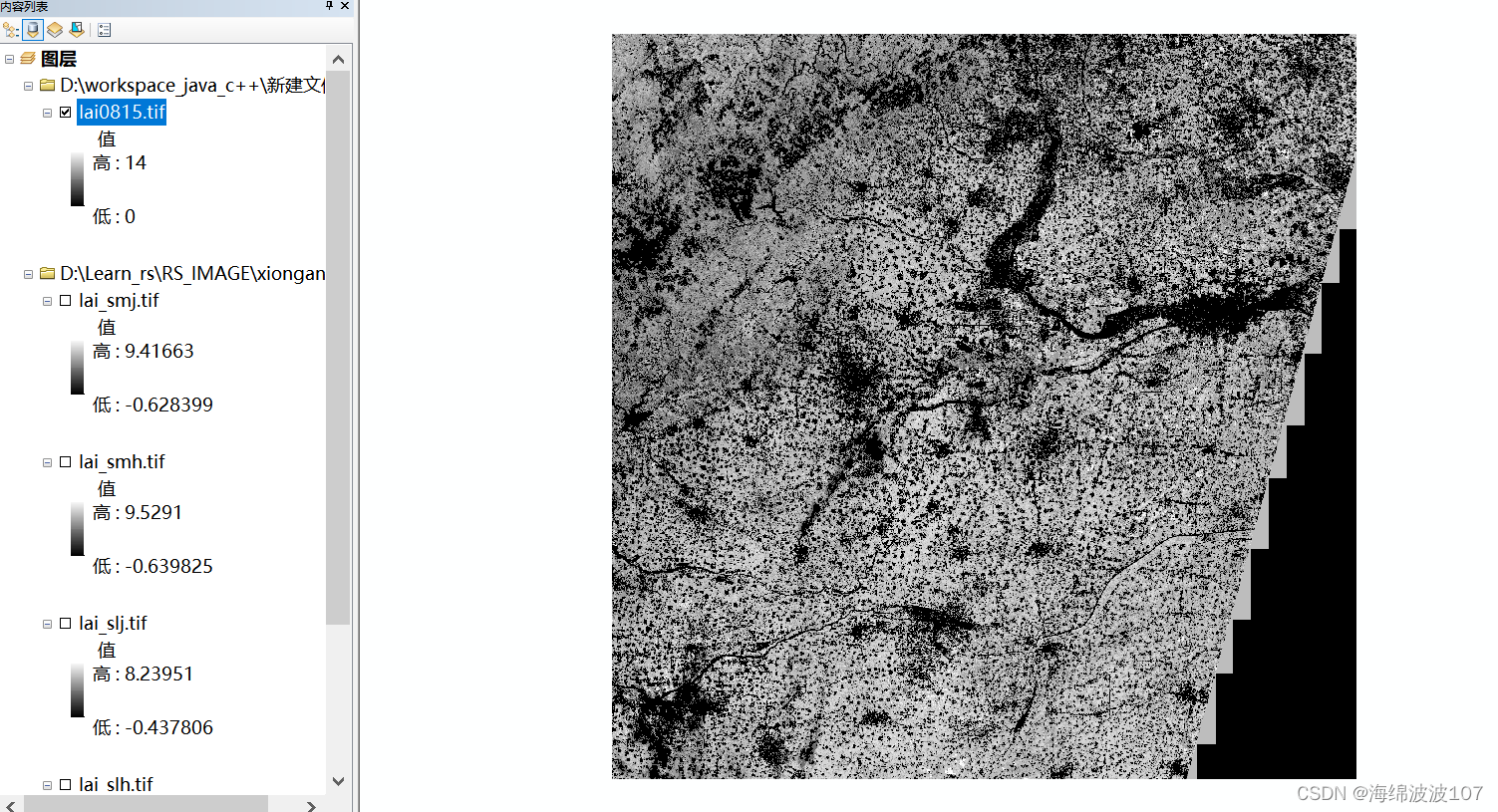
Arcgis实现Tiff合并
Arcgis实现Tiff合并 现有四幅Tiff影像 打开数据管理工具 输入使用这四幅影像 下面这个就是建立数据库,这个不对 点击确定 合成完毕...

将已有jar包放进maven仓库
mvn install:install-file -DfileD:\sapjco3.jar -DgroupIdcom.sap.conn.jco -DartifactIdsapjco3 -Dversion3.0.14 -Dpackagingjar...

从0开始学go第八天
gin获取URL路径参数 package main//获取path(URL)参数 import ("net/http""github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/:name/:age", func(c *gin.Context) {//获取路径参数name : c.Param(&quo…...
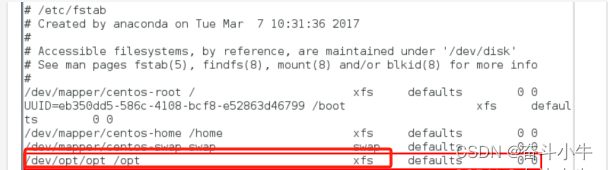
centos7为例进行数据盘挂载详解
以centos7为例进行数据盘挂载的操作演示,挂载一个200G盘 1、切换至root用户 z 2、查看要挂载的硬盘 执行sfdisk -s 或 fdisk -l可以看到有一个200G。 sfdisk -s fdisk -l 需要挂载200G的这块硬盘。 3、执行lvs查看当前的lvm信息 4、执行pvcreate /dev/sdb创建…...

网络安全——自学(黑客技术)
前言 前几天发布了一篇 网络安全(黑客)自学 没想到收到了许多人的私信想要学习网安黑客技术!却不知道从哪里开始学起!怎么学?如何学? 今天给大家分享一下,很多人上来就说想学习黑客,…...

Npm——yalc本地库调试工具
全局安装 npm i -g yalc本地库发布 yalc publish项目中安装 yalc add 库名本地库更新后推送 yalc push项目中删除库 yalc remove --all...

【Java基础面试一】、为什么Java代码可以实现一次编写、到处运行?
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官:为什么Java代码可以实现…...
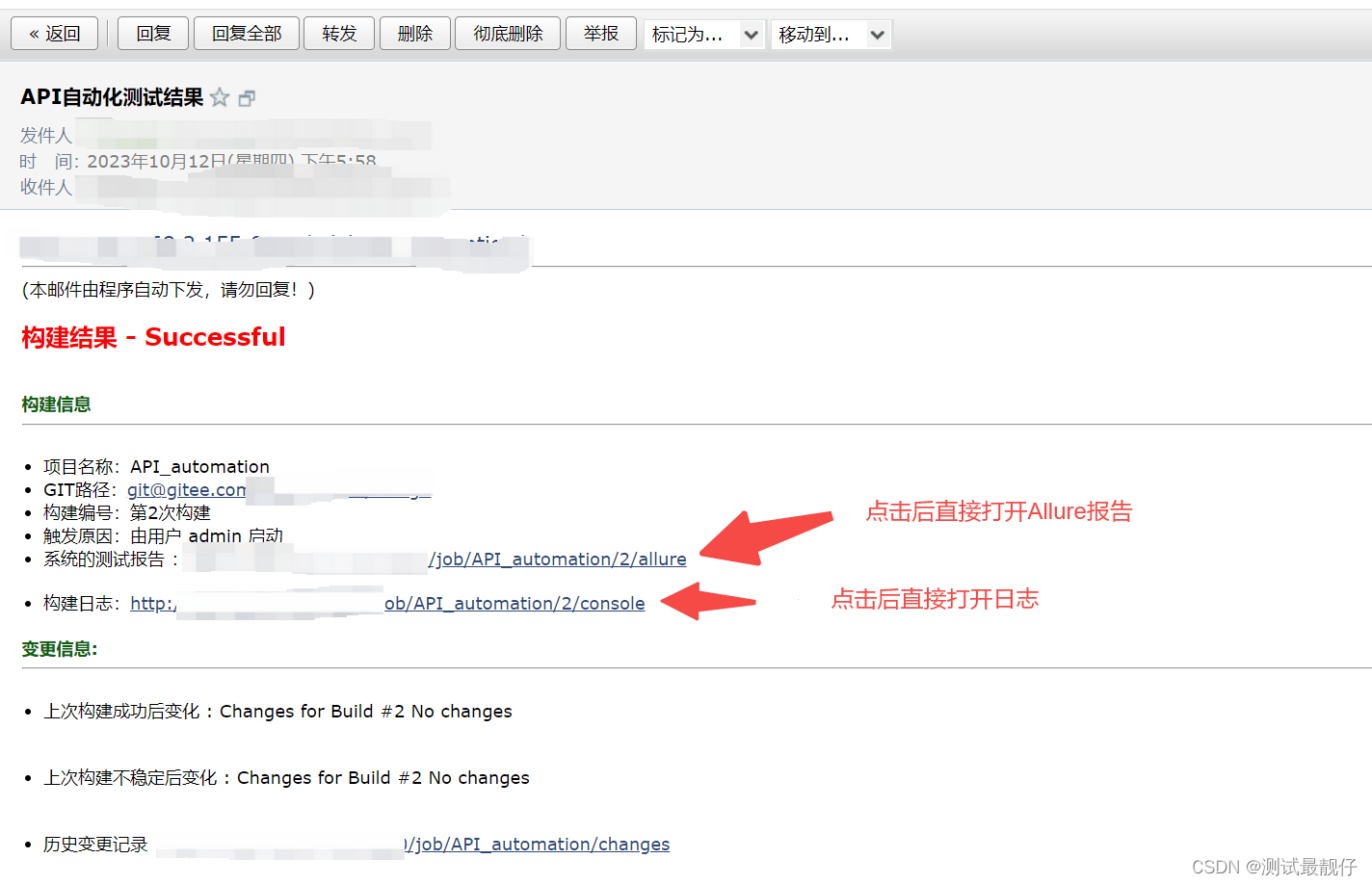
docker部署的jenkins配置(接口自动化)
目录 一、jenkins汉化1.点击Manage Jenkins(系统管理),点击Plugins(插件)2.安装Locale插件 二、jenkins配置allure报告1.安装allure插件2.配置 三、配置jenkins项目1.新建任务2.创建项目3.源码管理4.构建触发器5.增加构…...

qemu 运行 linux
文章目录 qemu 运行 linuxlinux 内核版本生成配置文件编译设备树编译内核报错与解决运行 linux附录脚本参考 qemu 运行 linux linux 内核版本 linux-6.5.7linux 内核下载地址 https://www.kernel.org/可以在浏览器中点击下载,也可以使用命令行下载 wget https:/…...

线程安全问题 的小案例
package Thread_api_test;public class ThreadSafety {//模拟线程安全问题public static void main(String[] args) {//1:创建一个账户对象 代表两个人的共享账户Account accnew Account("ICBC",10000);//创建两个线程 分别两个人 再去同一个账户里取钱10000new Draw…...
高效PPT制作与演示技巧大揭秘
PPT是职场必备技能,尤其在商务活动中,企业宣传、项目提案、路演宣讲……都需要用好PPT。然而,很多人的PPT效率低、效果差,客户不认可、老板不满意。 PPT不仅是办公软件,更是以汇报对象为中心、以共同的目标为导向、以…...

探究Socks5代理和代理IP在技术领域的多重应用
随着数字化时代的不断发展,网络工程师在跨界电商、爬虫数据采集、出海业务拓展以及游戏优化等领域扮演着关键角色。而Socks5代理和代理IP作为他们的得力工具,在这些领域中发挥着至关重要的作用。本文将深入探讨这两种技术在技术领域中的应用,…...

解决Vue2封装组件含有echarts时多次调用出现id重复问题
解决Vue2封装组件含有echarts时多次调用出现id重复问题 1、前言2、解决方法 1、前言 封装组件中使用echarts时,多次调用导致id重复,出现页面不渲染、数据覆盖等问题。 2、解决方法 把id改成动态传参(这里就不作代码展示了) 把i…...

IntelliJ IDEA 中 Maven 相关操作详解
在这篇文章中,我们将详细探讨 IntelliJ IDEA 中 Maven 的相关操作。我们将从以下三个角度进行讲解: IntelliJ IDEA 中 Maven 插件的 "Reimport All Maven Projects" 和 "Generate Sources and Update Folders For All Projects" 按…...

3分钟,快速上手Postman接口测试!
Postman是一个用于调试HTTP请求的工具,它提供了友好的界面帮助分析、构造HTTP请求,并分析响应数据。实际工作中,开发和测试基本上都有使用Postman来进行接口调试工作。有一些其他流程的工具,也是模仿的Postman的风格进行接口测试工…...

【微前端】single-spa 到底是个什么鬼
前言 说起微前端框架,很多人第一反应就是 single-spa。但是再问深入一点:它是干嘛的,它有什么用,可能就回答不出来了。 一方面没多少人研究和使用微前端。可能还没来得及用微前端扩展项目,公司就已经倒闭了。 另一方…...
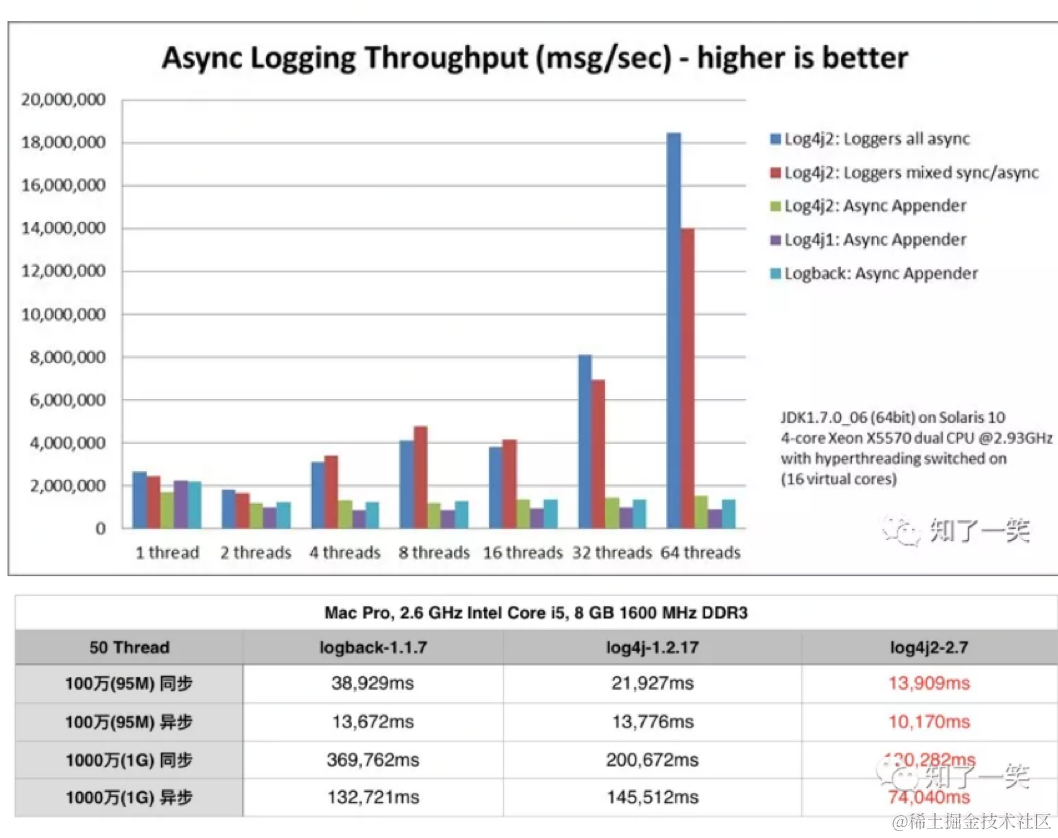
log4j2同步日志引发的性能问题 | 京东物流技术团队
1 问题回顾 1.1 问题描述 在项目的性能测试中,相关的接口的随着并发数增加,接口的响应时间变长,接口吞吐不再增长,应用的CPU使用率较高。 1.2 分析思路 谁导致的CPU较高,阻塞接口TPS的增长?接口的响应时…...

基于vLLM的DeepSeek模型本地部署:从环境配置到生产级调优
1. 项目概述:一个面向开发者的AI模型本地化部署方案最近在开发者圈子里,关于如何将前沿的AI模型私有化部署到本地环境,已经成了一个高频讨论话题。大家不再满足于仅仅调用云端API,而是希望能在自己的服务器、工作站甚至个人电脑上…...

Android系统安全漏洞深度剖析:从Stagefright到权限提升攻击链
1. 从Stagefright到MediaServer:一场持续的安全风暴2015年的夏天,对于Android生态圈的安全工程师和开发者来说,绝对称得上是一个“多事之秋”。如果你当时正负责某个移动应用的安全审计,或者正在为自家公司的设备进行固件加固&…...

云原生任务调度引擎tausik-core:设计、实践与高可用部署
1. 项目概述:一个面向未来的云原生应用核心引擎最近在梳理团队的技术栈,发现一个挺有意思的现象:很多项目在向云原生转型时,总会遇到一个“核心引擎”的选择难题。是直接上Kubernetes全家桶,还是基于某个框架自研&…...

ARM中断控制器架构演进与Redistributor关键设计
1. ARM中断控制器架构演进与Redistributor定位现代多核处理器系统中,中断控制器作为连接外设与CPU的核心枢纽,其设计直接影响系统实时性和吞吐量。ARM架构从GICv2到GICv4的演进过程中,最显著的变革之一是引入了Redistributor模块。这个位于CP…...

2025终极指南:Cursor Free VIP破解工具如何帮你免费解锁AI编程助手所有功能
2025终极指南:Cursor Free VIP破解工具如何帮你免费解锁AI编程助手所有功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Yo…...

【紧急通告】DeepSeek-R1毒性分类器存在语境盲区?3小时内验证并热修复的4种API级补丁
更多请点击: https://intelliparadigm.com 第一章:【紧急通告】DeepSeek-R1毒性分类器存在语境盲区?3小时内验证并热修复的4种API级补丁 近期社区报告指出,DeepSeek-R1毒性分类器在处理嵌套反讽、多轮对话上下文拼接及跨语言混合…...

Flipper Zero红外遥控革新:XRemote应用实现物理按键直控与智能学习
1. 项目概述:Flipper Zero上的高级红外遥控应用如果你和我一样,是个喜欢折腾各种智能硬件和复古设备的玩家,那你大概率听说过或者已经拥有了一台Flipper Zero。这个小巧的设备因其强大的射频和红外功能,被大家戏称为“赛博海豚”。…...
)
8K 剪辑卡皇之争:RTX 4090 vs A6000 大显存显卡选型深度指南(下)
在上一篇文章中,我们探讨了 8K 视频剪辑对硬件的整体需求,并初步对比了 RTX 4090 和 RTX A6000 在理论性能上的差异。本文将深入分析实际剪辑过程中,大显存显卡对工作流程的影响,尤其是在处理复杂特效、多层合成以及高码率素材时&…...

在线教程丨单卡即可爆改,面壁智能等开源MiniCPM-V-4.6,1.3B端侧模型支持图像理解/视频理解/OCR/多轮多模态对话
过去几年,整个 AI 行业几乎都笼罩在 Scaling Law 的叙事之下。参数越大、训练数据越多,模型似乎就越接近「通用智能」。从千亿到万亿参数,大模型不断刷新人们对推理能力与世界知识的想象,也让「堆算力、卷规模」成为行业默认的发展…...

科技与科学领域重点新闻摘要-2026年5月13日
科技与科学领域重点新闻摘要 日期: 2026年5月13日 1. Nature发布2026年最值得关注的七大技术 核心要点: 《自然》杂志评选出2026年七大关键技术,包括异种生物器官移植、AI天气预报、可控核聚变、光学显微脑图谱、mRNA疗法、高精度天文成像和量子计算,这…...