数据结构 优先级队列(堆)
数据结构 优先级队列(堆)
文章目录
- 数据结构 优先级队列(堆)
- 1. 优先级队列
- 1.1 概念
- 2. 优先级队列的模拟实现
- 2.1 堆的概念
- 2.2 堆的存储方式
- 2.3 堆的创建
- 2.3.1 堆向下调整
- 2.3.2 堆的创建
- 2.3.3 建堆的时间复杂度
- 2.4 堆的插入与删除
- 2.4.1 堆的插入
- 2.4.2 堆的删除
- 2.5 用堆模拟实现优先级队列
- 3. 常用接口介绍
- 3.1 PriorityQueue的特性
- 3.2 PriorityQueue常用接口介绍
- **3.2.1 优先级队列的构造**
- 3.2.2 插入/删除/获取优先级最高的元素
- 3.3 OJ练习
- 4. 堆的应用
1. 优先级队列
1.1 概念
在前面的文章里曾介绍过队列,队列是一种先进先出的数据结构,但有些情况下,我们需要操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列
在这种情况下,数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)
2. 优先级队列的模拟实现
JDK1.8中的PriorityQueue底层使用了堆这种数据结构,而堆实际就是在完全二叉树的基础上进行了一些调整
2.1 堆的概念
如果有一个关键码的集合K = {k0, k1, k2, … , kn-1},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:ki<=k2i+1且ki <= k2i+2(ki>=k2i+1 且ki>=k2i+2) i = 0, 1, 2…, 则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
大根堆:根节点大于左右节点
小根堆:根节点小于左右节点
堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树

2.2 堆的存储方式
从堆的概念可知,堆是一棵完全二叉树,因此可以采用顺序存储的方式来进行高效存储

注:对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低
将元素存储到数组中后,可以根据我们在二叉树文章中介绍到的性质5堆树进行还原。假设i为节点在数组中的下标,则有:
- 如果i为0,则i表示的节点为根节点,否则i节点的双亲节点为
(i-1)/2 - 如果2 * i + 1 小于节点个数,则节点i的左孩子下标为
2 * i + 1,否则没有左孩子 - 如果2 * i + 2 小于节点个数,则节点i的右孩子下标为
2 * i + 2,否则没有右孩子
2.3 堆的创建
2.3.1 堆向下调整
对于集合{27, 15, 19, 18, 28, 34, 65, 49, 25, 37} 中的数据,如果想要将它创建成堆又该怎么操作?

仔细观察上图后发现:根节点的左右子树已经完全满足堆的性质,因此在这里只需要将根节点向下调整好即可
向下调整(这里我们以小根堆为例):
- 使用
parent标记需要标记的根节点,child标记parent的左孩子(parent如果有孩子一定是先有左孩子) - 如果parent的左孩子存在,即:child < size,进行以下操作,直到parent的左孩子不存在:
- 判断parent右孩子是否存在,存在找到左右孩子中最小的孩子,让child进行标记
- 将parent与较小的孩子child进行比较,如果:
- parent小于较小的孩子child,调整结束
- 否则:交换parent与较小的孩子child,交换完成之后,继续向下调整,即parent = child;child = parent * 2 + 1

代码示例:
public void shiftSmallDown(int parent,int len) {//左孩子int child = 2 * parent + 1;while(child < len) {//判断是否存在右孩子 且右孩子和左孩子哪个更小,小的为childif (child+1 < len && elem[child+1] < elem[child]) {child++;}//判断根节点和child的大小,若根节点小则结束遍历,否则交换两个节点if (elem[child] < elem[parent]) {swap(child, parent);parent = child;child = 2 * parent + 1;}else {break;}}}public void createSmallHeap() {for (int parent = (usderSize-1-1)/2;parent >= 0;parent--) {shiftSmallDown(parent, usderSize);}}public void swap(int x, int y) {int temp = elem[x];elem[x] = elem[y];elem[y] = temp;}

2.3.2 堆的创建
上述举的例子为特殊情况(即左右子树已经满足堆的特性,只需要修改根节点),那对于普通的序列{1, 5, 3, 8, 7, 6},即根节点的左右子树不满足堆的特性时,又该如何调整?(这里我们以大根堆为例)

在这里,我们找倒数第一个非叶子节点,从该节点位置开始往前一直到根节点,每遇到一个节点,应用向下调整
代码示例:
public void shiftBigDown(int parent,int len) {//左孩子int child = 2 * parent + 1;while(child < len) {//判断是否存在右孩子 且右孩子和左孩子哪个更大,大的为childif (child+1 < len && elem[child+1] > elem[child]) {child++;}//判断根节点和child的大小,若根节点大则结束遍历,否则交换两个节点if (elem[child] > elem[parent]) {swap(child, parent);parent = child;child = 2 * parent + 1;}else {break;}}}
public void swap(int x, int y) {int temp = elem[x];elem[x] = elem[y];elem[y] = temp;}
public void createBigHeap() {//找倒数第一个非叶子节点,从该节点位置开始往前一直到根节点,每遇到一个节点,应用向下调整for (int parent = (usderSize-1-1)/2;parent >= 0;parent--) {shiftBigDown(parent, usderSize);}}

2.3.3 建堆的时间复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果):

因此,建堆的时间复杂度为O(N)
2.4 堆的插入与删除
2.4.1 堆的插入
堆的插入总共需要两个步骤:
- 先将元素放到底层空间中(注:空间不够时需要扩容)
- 将最后新插入的节点向上调整,直到满足堆的性质

代码示例:
public void push(int val) {// 满了则扩容if (isFull()) {elem = Arrays.copyOf(elem,2*elem.length);}elem[usderSize] = val;//向上调整shiftBigUp(usderSize);usderSize++;}private boolean isFull() {return usderSize == elem.length;}/*** 向上调整* 这里以大根堆为例*/public void shiftBigUp(int child) {int parent = (child - 1)/2;while(child > 0) {if (elem[parent] < elem[child]) {swap(child,parent);child = parent;parent = (child - 1) / 2;}else {break;}}}public void swap(int x, int y) {int temp = elem[x];elem[x] = elem[y];elem[y] = temp;}

2.4.2 堆的删除
堆删除的一定是堆顶元素,操作方法如下:
- 将堆顶元素与堆中最后一个元素交换
- 将堆中有效数据个数减少一个
- 对堆顶元素进行向下调整

代码示例:
/*删除元素*/
public int pop() {if (empty()) {return -1;}int oldVal = elem[0];swap(0,usderSize-1);usderSize--;shiftBigDown(0,usderSize);return oldVal;}
public boolean empty() {return usderSize == 0;}public void shiftBigDown(int parent,int len) {//左孩子int child = 2 * parent + 1;while(child < len) {//判断是否存在右孩子 且右孩子和左孩子哪个更大,大的为childif (child+1 < len && elem[child+1] > elem[child]) {child++;}//判断根节点和child的大小,若根节点大则结束遍历,否则交换两个节点if (elem[child] > elem[parent]) {swap(child, parent);parent = child;child = 2 * parent + 1;}else {break;}}}

2.5 用堆模拟实现优先级队列
代码示例:
package demo2;public class MyPriorityQueue {public int[] arr = new int[100];public int size = 0;public void offer(int e) {arr[size] = e;shiftBigUp(size);size++;}public int poll() {int oldval = arr[0];swap(0,size-1);size--;shiftBigDown(0,size);return oldval;}public int peek() {return arr[0];}public void shiftBigUp(int child) {int parent = (child - 1)/2;while(child > 0) {if (arr[parent] < arr[child]) {swap(child,parent);child = parent;parent = (child - 1) / 2;}else {break;}}}public void shiftBigDown(int parent,int len) {//左孩子int child = 2 * parent + 1;while(child < len) {//判断是否存在右孩子 且右孩子和左孩子哪个更大,大的为childif (child+1 < len && arr[child+1] > arr[child]) {child++;}//判断根节点和child的大小,若根节点大则结束遍历,否则交换两个节点if (arr[child] > arr[parent]) {swap(child, parent);parent = child;child = 2 * parent + 1;}else {break;}}}public void swap(int x, int y) {int temp = arr[x];arr[x] = arr[y];arr[y] = temp;}public void display() {for (int i = 0;i < size;i++) {System.out.print(arr[i] + " ");}}
}

3. 常用接口介绍
3.1 PriorityQueue的特性
Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列,本文主要介绍PriorityQueue

使用PriorityQueue时需要注意:
-
使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue; -
PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出
ClassCastException异常 -
不能插入null对象,否则会抛出
NullPointeException -
没有容量限制,可以插入任意多个元素,其内部可以自动扩容
-
插入和删除元素的时间复杂度为O(log₂N)
-
PriorityQueue底层使用了堆数据结构
-
PriorityQueue默认情况下是小根堆–即每次获取到的元素都是最小的元素
3.2 PriorityQueue常用接口介绍
3.2.1 优先级队列的构造
| 构造器 | 功能介绍 |
|---|---|
| PriorityQueue() | 创建一个空的优先级队列,默认容量是11 |
| PriorityQueue(int initialCapacity) | 创建一个初始容量为initialCapacity的优先级队列,注意: initialCapacity不能小于1,否则会抛IllegalArgumentException异 常 |
| PriorityQueue(Collection<? extends E> c) | 用一个集合来创建优先级队列 |
package demo3;import java.util.ArrayList;
import java.util.PriorityQueue;public class TestPriorityQueue {public static void main(String[] args) {// 创建一个空的优先级队列,底层默认容量是11PriorityQueue<Integer> q1 = new PriorityQueue<>();// 创建一个空的优先级队列,底层默认容量是initialCapacityPriorityQueue<Integer> q2 = new PriorityQueue<>(100);ArrayList<Integer> list = new ArrayList<>();list.add(1234);list.add(123);list.add(12);list.add(1);// 用ArrayList对象来构造一个优先级队列的对象//此时q3中已经包含了三个元素PriorityQueue<Integer> q3 = new PriorityQueue<>(list);System.out.println(q3);System.out.println("size = " + q3.size());System.out.println("队头元素为:" + q3.peek());}}

注:默认情况下,PriorityQueue队列是小根堆,如果需要大根堆需要用户提供比较器
class IntCmp implements Comparator<Integer> {public int compare(Integer o1, Integer o2) {return o2 - o1;}
}//大根堆构建优先级队列PriorityQueue<Integer> q4 = new PriorityQueue<>(new IntCmp());q4.offer(4);q4.offer(3);q4.offer(2);q4.offer(1);q4.offer(5);System.out.println(q4);

此时创建出来的就是一个大根堆
3.2.2 插入/删除/获取优先级最高的元素
| 函数名 | 功能介绍 |
|---|---|
| boolean offer(E e) | 插入元素e,插入成功返回true,如果e对象为空,抛出NullPointerException异常,时 间复杂度 ,注意:空间不够时候会进行自动扩容 |
| E peek() | 获取优先级最高的元素,如果优先级队列为空,返回null |
| E poll() | 移除优先级最高的元素并返回,如果优先级队列为空,返回null |
| int size() | 获取有效元素的个数 |
| void clear() | 清空 |
| boolean isEmpty() | 检测优先级队列是否为空,空返回true |
package demo3;import java.util.PriorityQueue;public class TestPriorityQueue2 {public static void main(String[] args) {int[] arr = {4, 1, 9, 2, 8, 0, 7, 3, 6, 5};//如果知道元素个数建议直接给底层容量PriorityQueue<Integer> q = new PriorityQueue<>(arr.length); // 注:默认时为小根堆//插入元素for (int e:arr) {q.offer(e);}System.out.println(q);System.out.println(q.peek()); // 获取优先级最高的元素System.out.println(q.size()); // 打印优先级队列中有效元素的个数//弹出元素q.poll();System.out.println(q);q.offer(0); // 插入元素后优先级会发生改变System.out.println(q);//清空队列q.clear();if (q.isEmpty()) {System.out.println("优先级队列为空");}else {System.out.println("优先级队列不为空");}}
}

3.3 OJ练习
top-k问题:求最大或者最小的前k个数据
代码示例:
import java.util.PriorityQueue;
class Solution {public int[] smallestK(int[] arr, int k) {int[] ret = new int[k];if (k == 0 || arr == null) {return ret;}PriorityQueue<Integer> q = new PriorityQueue<>(arr.length);for (int e:arr) {q.offer(e);}for (int i = 0;i < k;i++) {ret[i] = q.poll();}return ret;}
}

4. 堆的应用
这里我们拓展一下堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
-
建堆:
- 升序:建大堆
- 降序:建小堆
-
利用堆删除思想来进行排序:
建堆和堆删除中都用到了向下调整,因此掌握向下调整,就可以完成堆排序

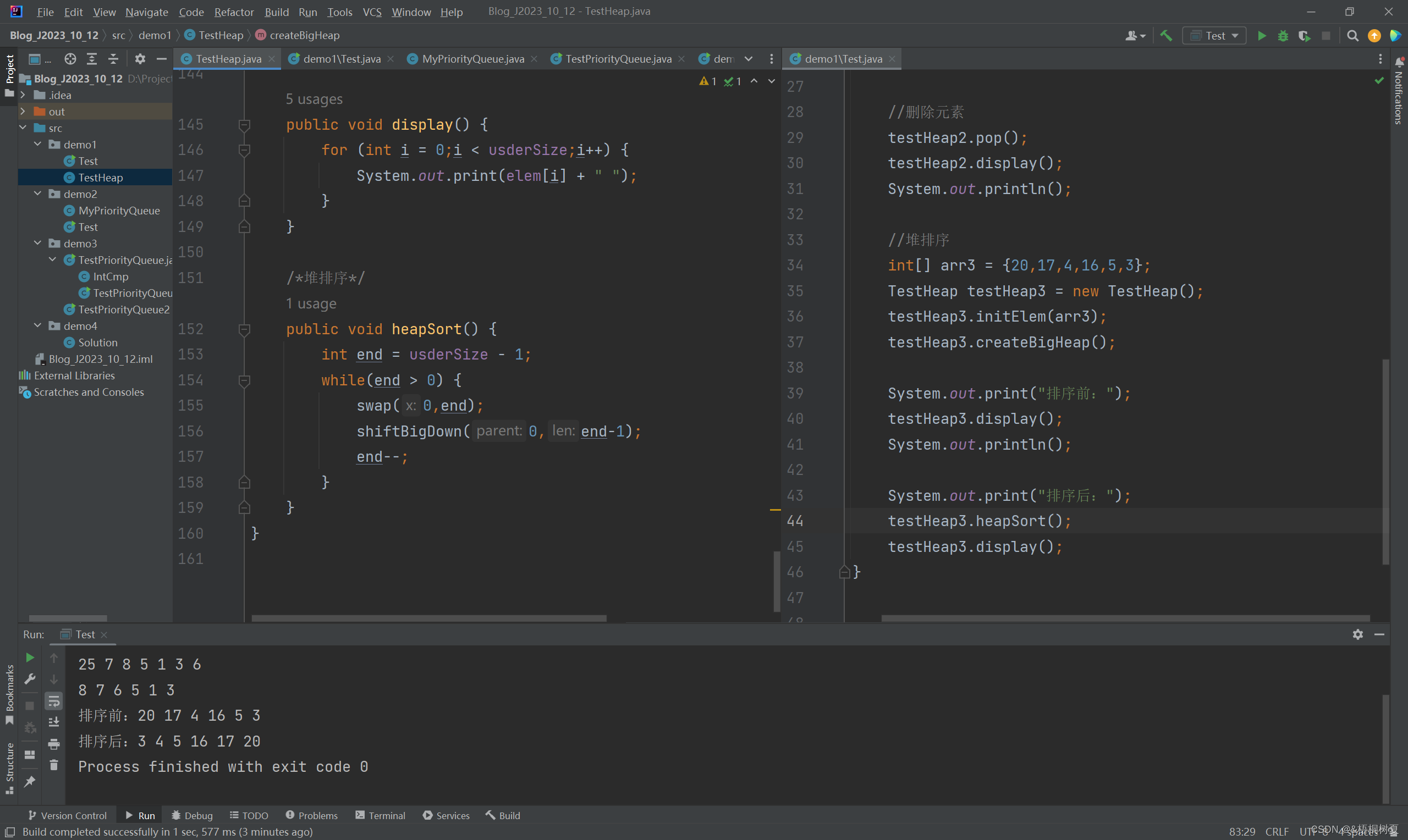
代码示例:
public void heapSort() {int end = usderSize - 1;while(end > 0) {swap(0,end);shiftBigDown(0,end-1);end--;}}public void shiftBigDown(int parent,int len) {//左孩子int child = 2 * parent + 1;while(child < len) {//判断是否存在右孩子 且右孩子和左孩子哪个更大,大的为childif (child+1 < len && elem[child+1] > elem[child]) {child++;}//判断根节点和child的大小,若根节点大则结束遍历,否则交换两个节点if (elem[child] > elem[parent]) {swap(child, parent);parent = child;child = 2 * parent + 1;}else {break;}}}
相关文章:
数据结构 优先级队列(堆)
数据结构 优先级队列(堆) 文章目录 数据结构 优先级队列(堆)1. 优先级队列1.1 概念 2. 优先级队列的模拟实现2.1 堆的概念2.2 堆的存储方式2.3 堆的创建2.3.1 堆向下调整2.3.2 堆的创建2.3.3 建堆的时间复杂度 2.4 堆的插入与删除2.4.1 堆的插入2.4.2 堆的删除 2.5 用堆模拟实现…...

如何在edge浏览器中给PDF添加文字批注
我用的edge浏览器是目前最新版的(一般自动更新到最新版) 最近,我喜欢用edge浏览器查看PDF,节省电脑资源,快捷且方便。 但edge对PDF的标注种类较少,主要是划线和涂色,文字批注功能尚未出现在工具…...
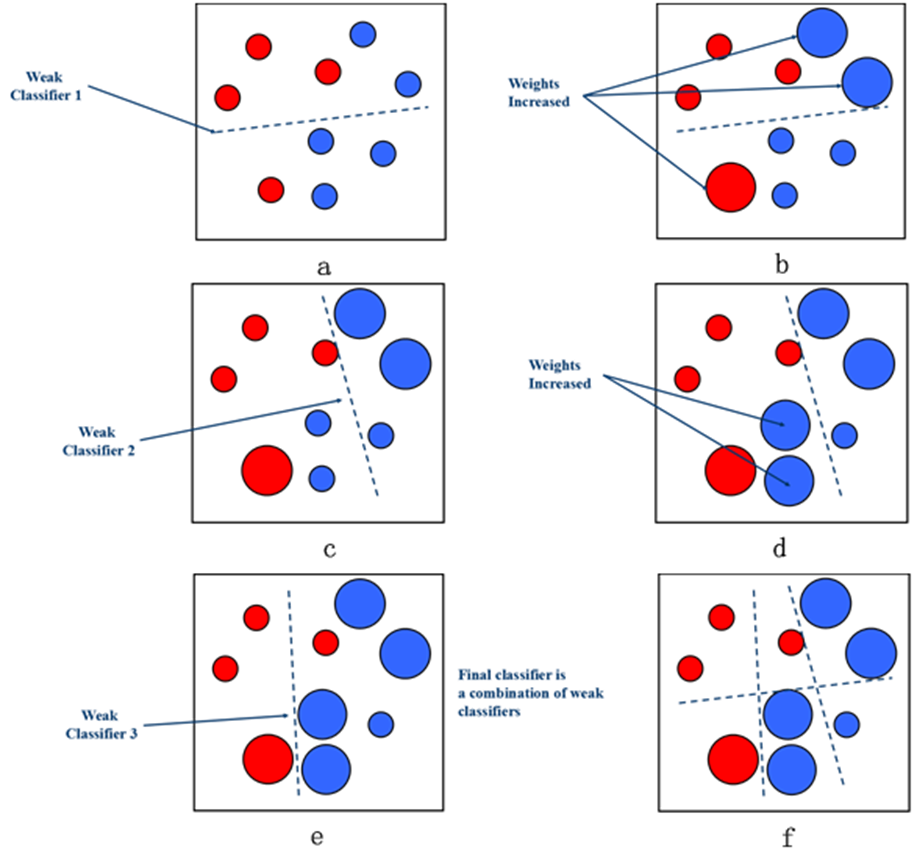
集成学习的小九九
集成学习(Ensemble Learning)是一种机器学习的方法,通过结合多个基本模型的预测结果来进行决策或预测。集成学习的目标是通过组合多个模型的优势,并弥补单个模型的不足,从而提高整体性能。 集成学习的主要策略 在集成…...
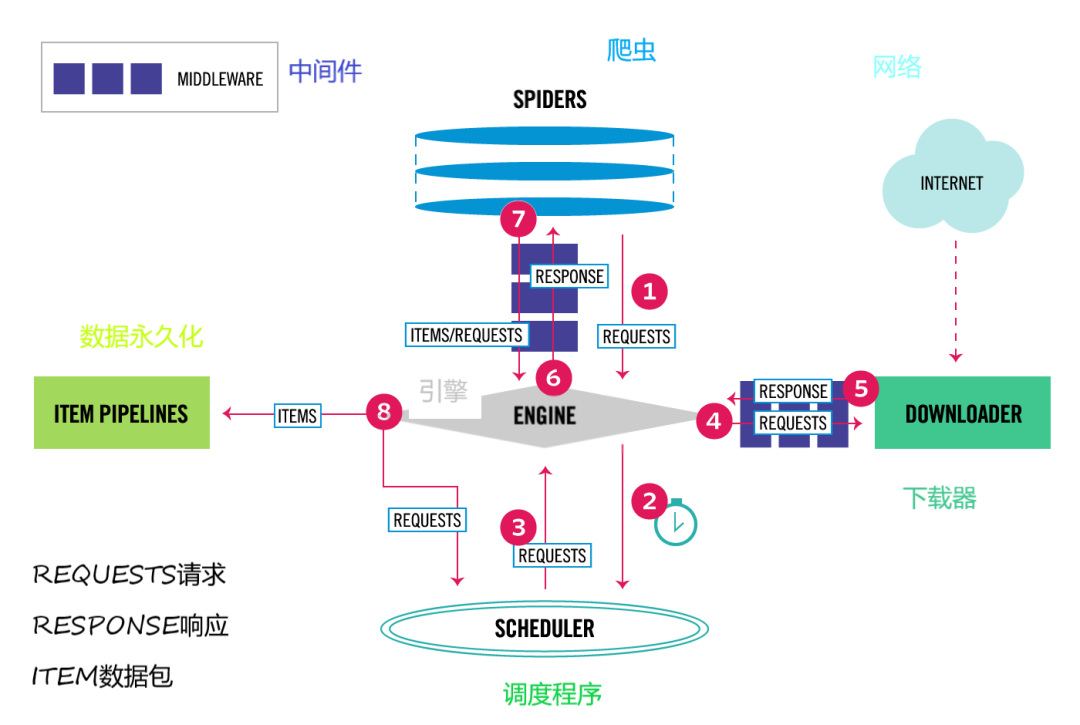
深入理解Scrapy
Scrapy是什么 An open source and collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way. Scrapy是适用于Python的一个快速、简单、功能强大的web爬虫框架,通常用于抓取web站点并从页面中提取结构化的数…...
想做WMS仓库管理系统,找了好久才找到云表
公司内部仓库管理原方式均基于人工电子表格管理方式来实现收发存管理,没有流程化管理,无法保证数据的准确性和及时性,同时现场操作和数据核对会出现不同步的情况,无法提高仓库的运作效率,因此,我们基于云表…...
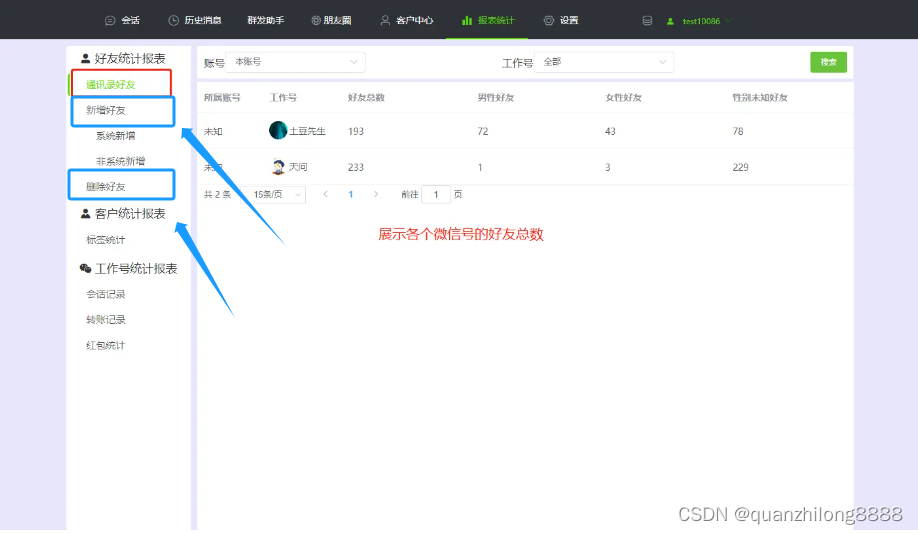
公司销售个人号如何管理?
微信管理系统可以帮助企业解决哪些问题呢? 一、解决聊天记录监管问题 1.聊天记录的保存,让公司的管理者可以随时查看公司任意销售与客户的聊天记录,不用一个一个员工逐一去看,方便管理; 2.敏感词监控,管理者…...

COLE HERSEE 48408 工业4.0、制造业X和元宇宙
COLE HERSEE 48408 工业4.0、制造业X和元宇宙 需要数据来释放工业4.0的全部潜力——价值链中的所有公司都可以访问大量数据。一个新的互联数据生态系统旨在提供解决方案:制造业x。 在德国联邦经济事务和气候行动部以及BDI、VDMA和ZVEI贸易协会的密切合作下,实施制…...
【Vue基础-数字大屏】加载动漫效果
一、需求描述 当网页正在加载而处于空白页面状态时,可以在该页面上显示加载动画提示。 二、步骤代码 1、全局下载npm install -g json-server npm install -g json-server 2、在src目录下新建文件夹mock,新建文件data.json存放模拟数据 {"one&…...

CSS 样式简写
在CSS中有许多简写的样式,它们被广泛使用。简写最好按照如下顺序进行书写 font font: font-style font-weight font-size/line-height font-familyfont-style italic//斜体 normal//正常字体(默认)font-weight 一般填写数字 400 normal(默认值) 700 bold(默认值)f…...

SQL Server创建数据库
简单创建写法 默认初始大小为5MB,增长速度为2MB create database DBTEST自定义 用户创建的数据库都被存放在sys.database中,每个数据库在表中占一行,name字段存放的数据库的名称,具体字段可以看此博客sys.database系统表详细说明 所以判断…...
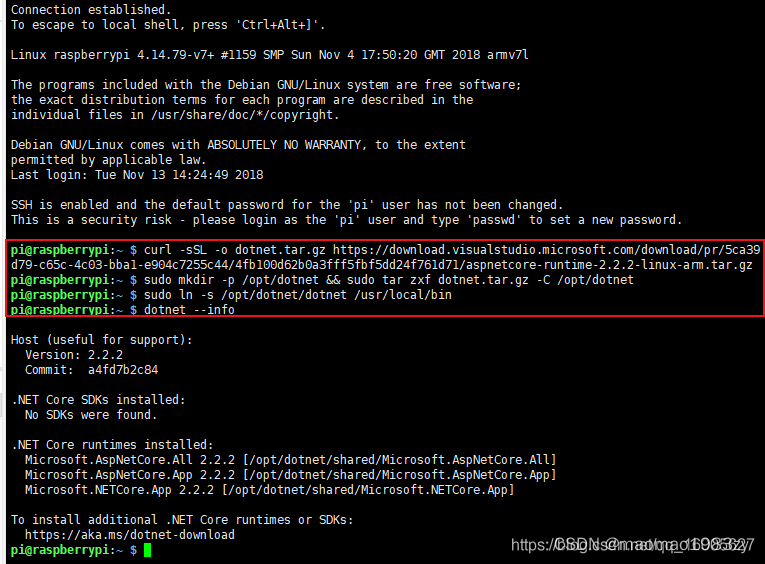
树莓派安装.NET 6.0
首先安装.Net Core依赖(未使用) sudo apt install -y libunwind8 libunwind8-dev gettext libicu-dev liblttng-ust-dev libcurl4 libcurl4-openssl-dev libssl-dev uuid-dev unzip libgdiplus libc6-dev libkrb5-3 需要安装的依赖微软官方文档已经列出…...

小华HC32F448串口使用
目录 1. 串口GPIO配置 2. 串口波特率配置 3. 串口接收超时配置 4. 串口中断注册 5. 串口初始化 6. 串口数据接收处理 7. DMA接收配置和处理 1. 串口GPIO配置 端口号和Pin脚号跟STM32没什么区别。 串口复用功能跟STM32大不一样。 如下图,选自HC32F448 表 2…...

Redis实现简易消息队列的三种方式
Redis实现简易消息队列的三种方式 消息队列简介 消息队列是一种用于在计算机系统中传递和处理数据的重要工具。如果你完全不了解消息队列,不用担心,我将尽力以简单明了的方式来解释它。 首先,想象一下你正在玩一个游戏,而游戏中…...
基于SpringBoot的在线小说阅读平台系统
基于SpringBoot的在线小说阅读平台系统的设计与实现~ 开发语言:Java数据库:MySQL技术:SpringBootMyBatisVue工具:IDEA/Ecilpse、Navicat、Maven 系统展示 主页 个人中心 登录界面 管理员界面 摘要 基于Spring Boot的在线小说阅读…...
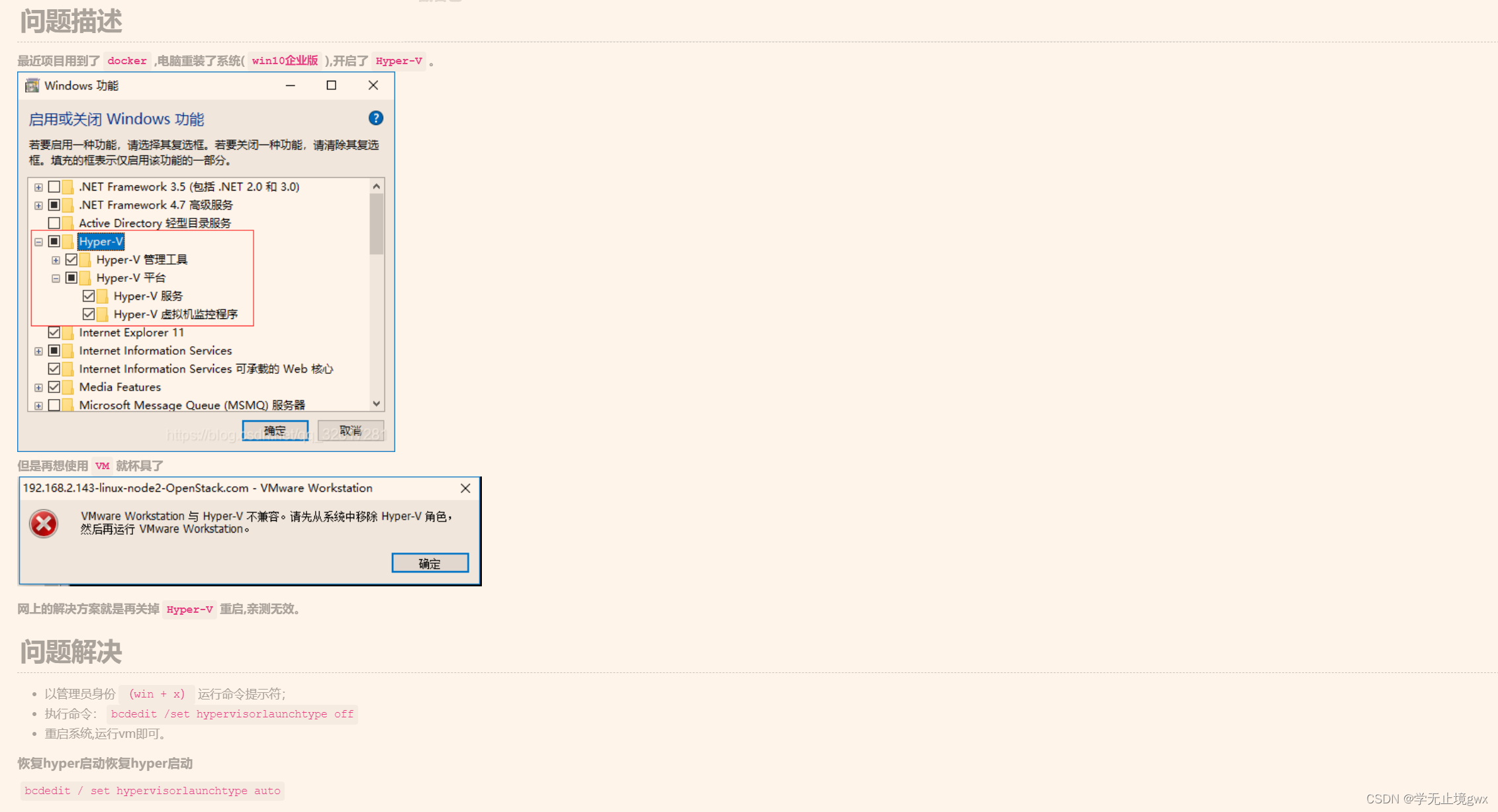

uniapp h5 MD5加密
文章目录 1.当使用 CryptoJS 进行 MD5 加密时,你需要先引入 CryptoJS 库并确保它已经正确安装。下面是一个更详细的示例代码:2.然后,在需要使用 MD5 加密的地方,引入 CryptoJS 代码库:3.接下来,我们定义一个…...
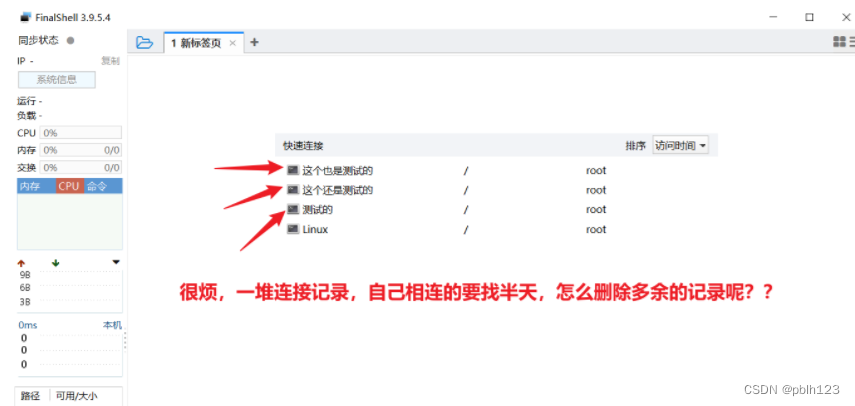
2023_Spark_实验十八:安装FinalShell
下载安装包 链接:https://pan.baidu.com/s/14cOJDcezzuwUYowPsOA-sg?pwd6htc 提取码:6htc 下载文件名称:FinalShell.zip 二、安装 三、启动FinalShell 四、连接远程 linux 服务器 先确保linux系统已经开启,不然连接不上 左边…...

文件服务器管理服务器怎么设置
文件服务器是一种提供文件存储和共享服务的服务器,它可以方便企业内部的员工共享文件,提高工作效率。为了更好地管理和维护文件服务器,需要对其进行合理的设置。下面小编将介绍文件服务器管理服务器的基本设置方法。 一、选择合适的操作系统 …...

LeetCode每日一题——Single Number
文章目录 一、题目二、题解 一、题目 136. Single Number Given a non-empty array of integers nums, every element appears twice except for one. Find that single one. You must implement a solution with a linear runtime complexity and use only constant extra …...
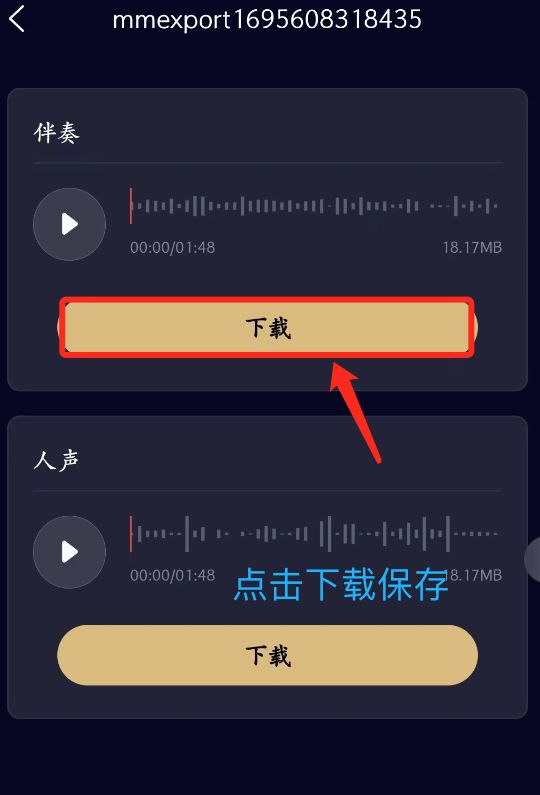
有什么手机软件能分离人声和音乐?
很多人在制作混剪视频,需要二次创作的时候,就经常会把人声分离、背景音乐伴奏提取出来,然后重新加入自己的创意跟想法。下面就一起来看看如何用手机软件分离人声和音乐的吧! 音分轨 一款可以分离人声和背景音乐的手机软件&#x…...

ESLyric歌词源一站式配置:Foobar2000多平台格式转换高效解决方案
ESLyric歌词源一站式配置:Foobar2000多平台格式转换高效解决方案 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource ESLyric歌词源是Foobar2000播…...

南北阁4.1-3B WebUI代码实例:TextIteratorStreamer多线程流式实现解析
南北阁4.1-3B WebUI代码实例:TextIteratorStreamer多线程流式实现解析 今天咱们来聊聊一个特别有意思的项目——一个为南北阁4.1-3B模型量身定做的Web交互界面。如果你用过Streamlit,可能会觉得它的界面有点“官方”,布局也比较固定。但这个…...
—— 基于电力大客户运营的大数据落地拓展)
大数据在电力行业的应用案例解析 -【电力技术】(一)—— 基于电力大客户运营的大数据落地拓展
目录 一、电力大客户运营场景与大数据价值 二、大数据平台架构(大客户运营专用) 三、落地应用案例一:电力大客户价值分群与精准画像 1. 业务目标 2. 数据宽表(工程常用) 3. 核心算法:K-Means 用户分群(简化示例代码) 4. 应用效果 四、落地应用案例二:大客户负荷…...

SEO排名专家的工作内容是什么_如何成为一名出色的SEO排名专家
<h2>SEO排名专家的工作内容是什么</h2> <p>SEO排名专家,全称搜索引擎优化专家,是一类致力于提升网站在搜索引擎中排名的专业人士。他们的工作内容涵盖了广泛的技术和策略,旨在让网站在搜索结果中获得更高的曝光率ÿ…...

从CISCN2019华北赛区Web1看SQL注入的巧妙绕过技巧
1. 从CISCN2019华北赛区Web1看SQL注入的巧妙绕过技巧 在CTF比赛中,Web安全题目常常会设置各种过滤规则来阻止常见的攻击手法。CISCN2019华北赛区的Web1题目"Hack World"就是一个典型的例子,它通过组合过滤的方式限制了传统SQL注入手段。这道题…...
)
Pyodide vs Rust-Python vs WASI-NN:Python WASM性能终极对决(含13项微基准测试原始数据)
第一章:Pyodide vs Rust-Python vs WASI-NN:Python WASM性能终极对决(含13项微基准测试原始数据) WebAssembly 正在重塑 Python 在浏览器与边缘环境中的执行范式。本章基于统一测试平台(WASI SDK 20.0、Chrome 124、In…...

OpenClaw智能书签:用nanobot自动归类收藏网页内容
OpenClaw智能书签:用nanobot自动归类收藏网页内容 1. 为什么需要智能书签 作为一个每天要浏览大量技术文档和行业资讯的开发者,我发现自己陷入了"收藏即学会"的陷阱。Chrome书签栏里堆满了未分类的链接,Notion数据库里散落着零碎…...

从LLaVA到Stable Diffusion:多模态融合选拼接还是交叉注意力?一张图帮你做技术选型
多模态融合技术选型指南:拼接与交叉注意力的深度对比与实践策略 在构建现代多模态AI系统时,工程师们常常面临一个关键决策点:如何有效地融合来自不同模态的信息?想象一下,你正在开发一个智能医疗影像分析系统ÿ…...

Zotero终极指南:高效文献管理的开源解决方案
Zotero终极指南:高效文献管理的开源解决方案 【免费下载链接】zotero Zotero is a free, easy-to-use tool to help you collect, organize, annotate, cite, and share your research sources. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero Zotero是…...

Kazam vs OBS:Ubuntu 24.04 屏幕录制工具对比与选择指南
Kazam vs OBS:Ubuntu 24.04 屏幕录制工具深度评测与实战选择 在数字内容创作爆发的时代,屏幕录制已成为游戏实况、在线教学、产品演示的标配技能。对于Ubuntu 24.04用户而言,Kazam和OBS Studio这两款开源工具常被拿来比较——前者以轻量简洁著…...