相关类相关的可视化图像总结
目录
一、散点图
二、气泡图
三、相关图
四、热力图
五、二维密度图
六、多模态二维密度图
七、雷达图
八、桑基图
九、总结
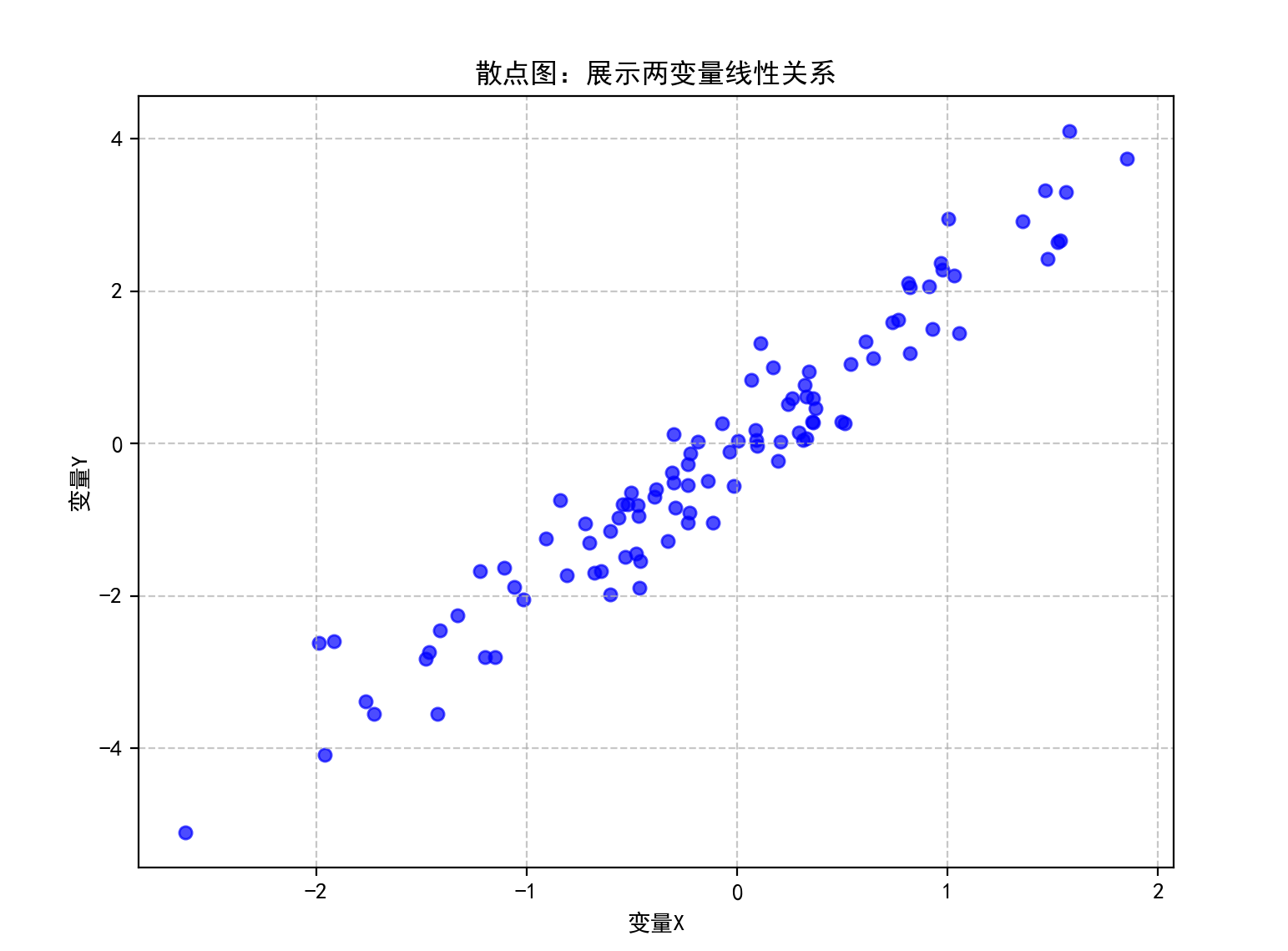
一、散点图
特点
通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密度和趋势反映相关性强弱。
应用场景
探索性数据分析、验证变量间关系假设,如身高与体重的关系、温度与销售额的关联。
实现过程
import numpy as np
import matplotlib.pyplot as plt
# 设置支持中文的字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC", "sans-serif"]
# 解决负号显示问题
plt.rcParams["axes.unicode_minus"] = False
# 生成示例数据
np.random.seed(42)
x = np.random.randn(100)
y = 2 * x + np.random.randn(100) * 0.5
# 绘制散点图
plt.figure(figsize=(8, 6))
plt.scatter(x, y, color='blue', alpha=0.7, s=30)
plt.title('散点图:展示两变量线性关系')
plt.xlabel('变量X')
plt.ylabel('变量Y')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
# 计算相关系数
correlation = np.corrcoef(x, y)[0, 1]
print(f'皮尔逊相关系数: {correlation:.4f}')
结果
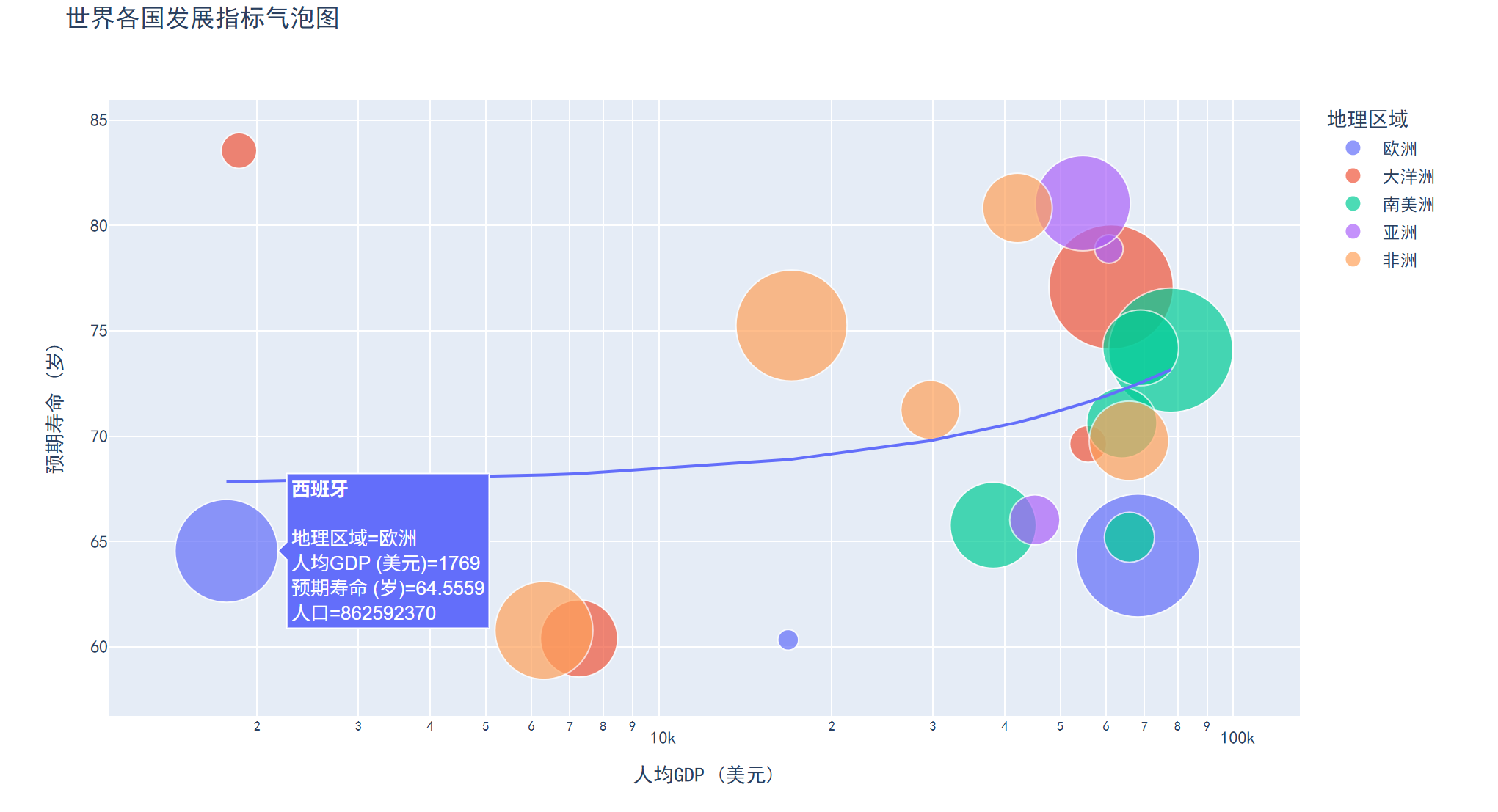
二、气泡图
特点
在散点图基础上增加第三个变量(气泡大小),可展示三维数据关系,气泡颜色还可表示第四维变量。
应用场景
市场分析(如销售额、利润、市场份额)、城市数据可视化(人口、GDP、面积)。
实现过程
import plotly.express as px
import pandas as pd
import numpy as np
# 设置随机种子
np.random.seed(42)
# 生成模拟数据
n_countries = 20
countries = ['中国', '美国', '日本', '德国', '法国', '英国', '意大利', '加拿大','俄罗斯', '巴西', '印度', '澳大利亚', '西班牙', '墨西哥', '韩国','印度尼西亚', '土耳其', '沙特阿拉伯', '瑞士', '荷兰'
]
# 生成随机数据
gdp_per_capita = np.random.randint(1000, 80000, n_countries)
population = np.random.randint(5e6, 1.5e9, n_countries)
life_expectancy = np.random.uniform(60, 85, n_countries)
region = np.random.choice(['亚洲', '欧洲', '北美洲', '南美洲', '非洲', '大洋洲'], n_countries)
# 创建DataFrame
df = pd.DataFrame({'国家': countries,'人均GDP': gdp_per_capita,'人口': population,'预期寿命': life_expectancy,'地区': region
})
# 创建气泡图
fig = px.scatter(df, x="人均GDP", y="预期寿命", size="人口", color="地区",hover_name="国家", log_x=True, size_max=60,title="世界各国发展指标气泡图",labels={"人均GDP": "人均GDP (美元)","预期寿命": "预期寿命 (岁)","地区": "地理区域"})
# 更新布局
fig.update_layout(font=dict(family="SimHei", size=12),legend_title="地理区域",height=600,width=1000
)
# 添加趋势线
fig.add_traces(px.scatter(df, x="人均GDP", y="预期寿命", trendline="ols").data[1]
)
# 显示图表
fig.show()
# 导出为HTML文件
fig.write_html("bubble_chart.html")
结果
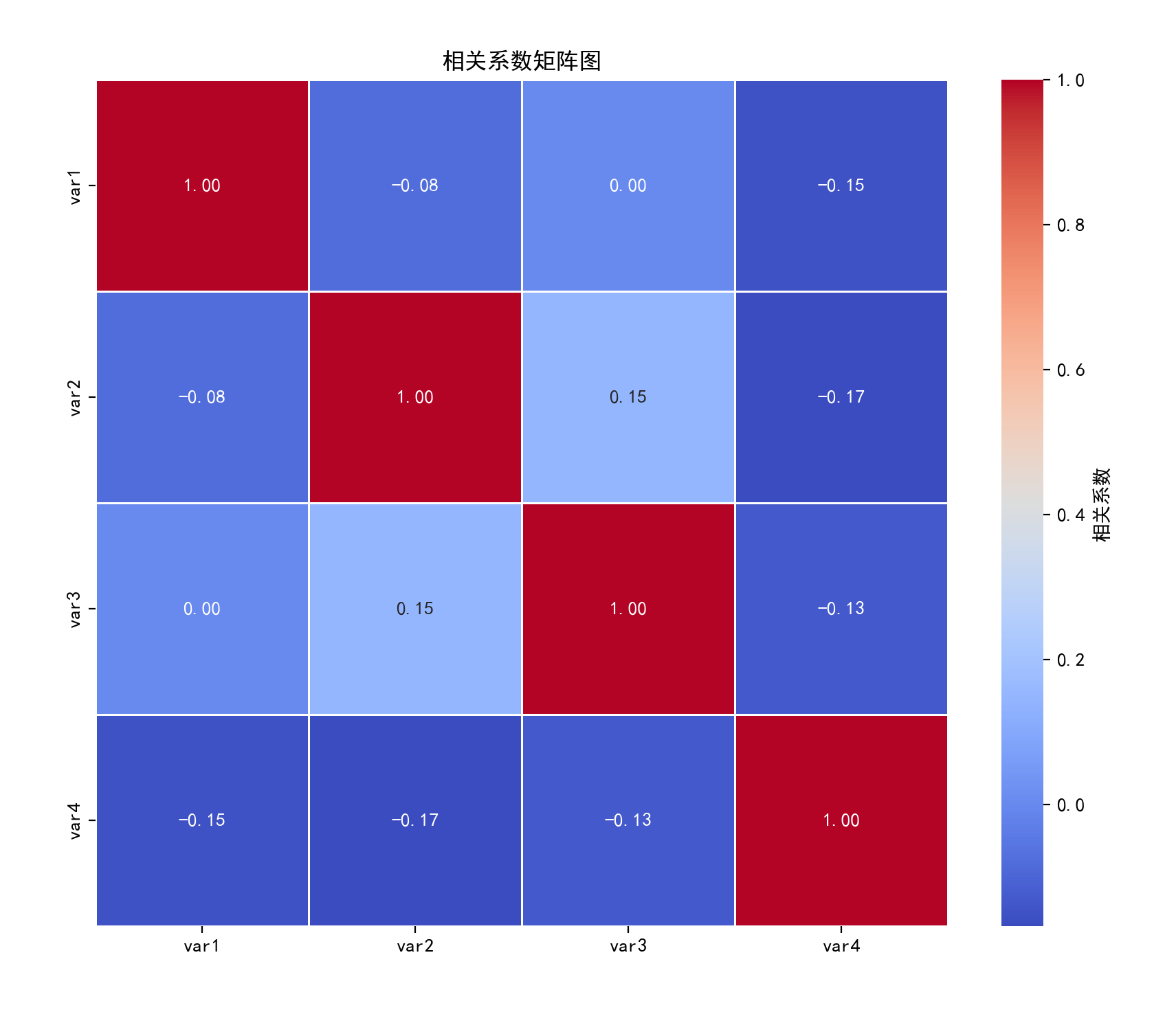
三、相关图
特点
展示多个变量间的相关系数矩阵,通常以数值或图形(如颜色、形状)表示相关强度和方向。
应用场景
多变量数据分析、特征选择(如机器学习前筛选相关变量)。
实现过程
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 生成示例数据
np.random.seed(42)
data = pd.DataFrame({'var1': np.random.randn(100),'var2': 0.8 * np.random.randn(100) + 0.2 * np.random.randn(100),'var3': -0.5 * np.random.randn(100) + 0.5 * np.random.randn(100),'var4': np.random.randn(100)
})
# 计算相关系数矩阵
corr_matrix = data.corr()
# 绘制相关图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt='.2f',linewidths=1, cbar_kws={'label': '相关系数'})
plt.title('相关系数矩阵图')
plt.show()结果
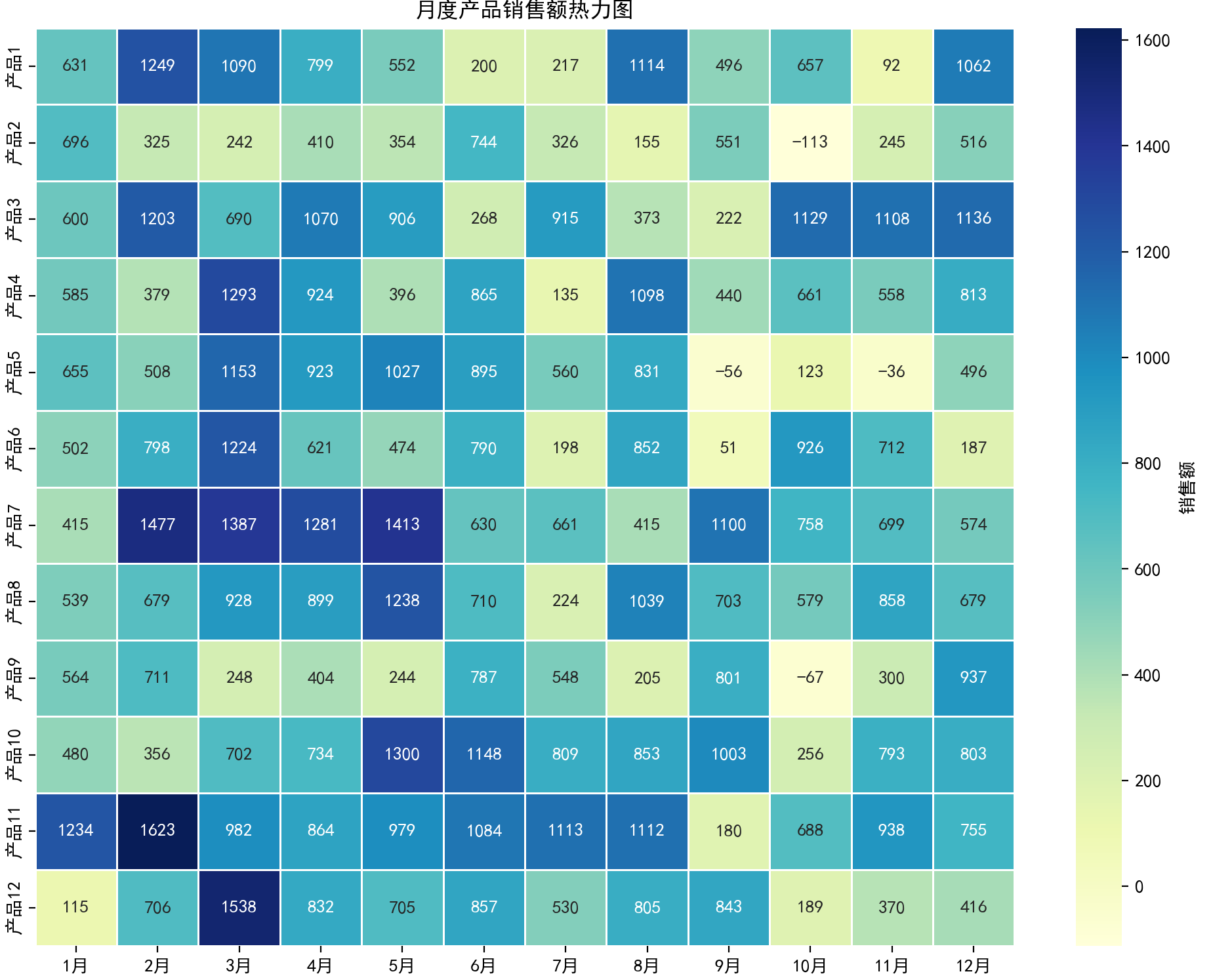
四、热力图
特点
用颜色矩阵展示数据值大小,可直观呈现二维数据的分布模式和热点区域。
应用场景
基因表达数据、时间序列数据(如年度销售热力图)、矩阵数据可视化。
实现过程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.cluster import hierarchy
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 生成示例数据:月度销售数据
np.random.seed(42)
n_products = 12
n_months = 12
# 创建产品名称和月份名称
products = [f'产品{i+1}' for i in range(n_products)]
months = [f'{i+1}月' for i in range(n_months)]
# 生成基础销售数据(有季节性和产品类别效应)
base_sales = np.random.rand(n_products, n_months) * 1000
# 添加季节性效应
seasonal_effect = np.sin(np.linspace(0, 2*np.pi, n_months)) * 300
for i in range(n_products):base_sales[i, :] += seasonal_effect * (0.5 + i/24)
# 添加产品类别效应
category_effect = np.random.rand(n_products) * 500
for i in range(n_products):base_sales[i, :] += category_effect[i]
# 添加随机噪声
sales_data = base_sales + np.random.randn(n_products, n_months) * 100
# 转换为DataFrame
df = pd.DataFrame(sales_data, index=products, columns=months)
plt.figure(figsize=(12, 10))
sns.heatmap(df, cmap="YlGnBu", annot=True, fmt=".0f",linewidths=0.5, cbar_kws={"label": "销售额"})
plt.title('月度产品销售额热力图')
plt.tight_layout()
plt.show()结果
五、二维密度图
特点
通过颜色或等高线展示二维数据的分布密度,比散点图更适合大数据量场景,可识别数据聚类和分布形态。
应用场景
概率密度分析、金融数据分布(如股票收益率)、空间数据热点分析。
实现过程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
n_samples = 1000
mean = [0, 0]
cov = [[1, 0.7], [0.7, 1]]
x, y = np.random.multivariate_normal(mean, cov, n_samples).T
# 创建DataFrame
df_single = pd.DataFrame({'X': x,'Y': y
})
# 绘制二维密度图
plt.figure(figsize=(12, 10))
sns.kdeplot(x='X', y='Y', data=df_single, fill=True, cmap='Blues', alpha=0.7)
plt.title('二维密度图')
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()结果

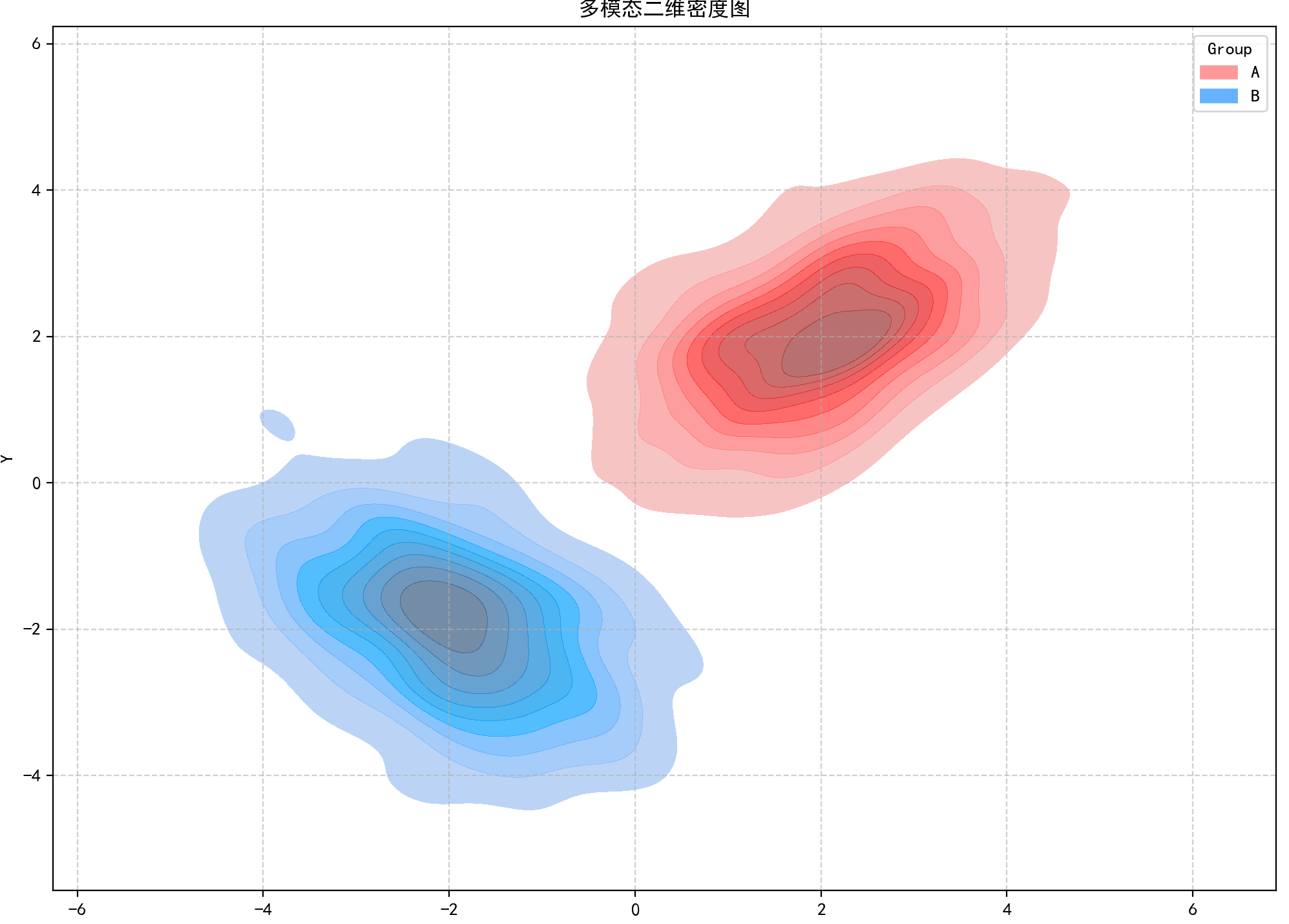
六、多模态二维密度图
特点
捕捉数据中多个密度峰值(模态),反映复杂集群结构,无需预设聚类数。
应用场景
客户分群(消费行为)、金融风险(市场状态分类)、生物信息(细胞亚型)。
实现过程
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 2. 多模态分布
# 创建两个不同的分布
n1 = 800
n2 = 500
# 第一个分布
mean1 = [2, 2]
cov1 = [[1, 0.5], [0.5, 1]]
x1, y1 = np.random.multivariate_normal(mean1, cov1, n1).T
# 第二个分布
mean2 = [-2, -2]
cov2 = [[1, -0.5], [-0.5, 1]]
x2, y2 = np.random.multivariate_normal(mean2, cov2, n2).T
# 合并数据
x_multi = np.concatenate([x1, x2])
y_multi = np.concatenate([y1, y2])
groups = np.concatenate([['A']*n1, ['B']*n2])
# 创建DataFrame
df_multi = pd.DataFrame({'X': x_multi,'Y': y_multi,'Group': groups
})
# 绘制多模态二维密度图
plt.figure(figsize=(12, 10))
sns.kdeplot(x='X', y='Y', hue='Group', data=df_multi,fill=True, common_norm=False, alpha=0.7,palette=['#FF9999', '#66B2FF'])
plt.title('多模态二维密度图')
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()结果
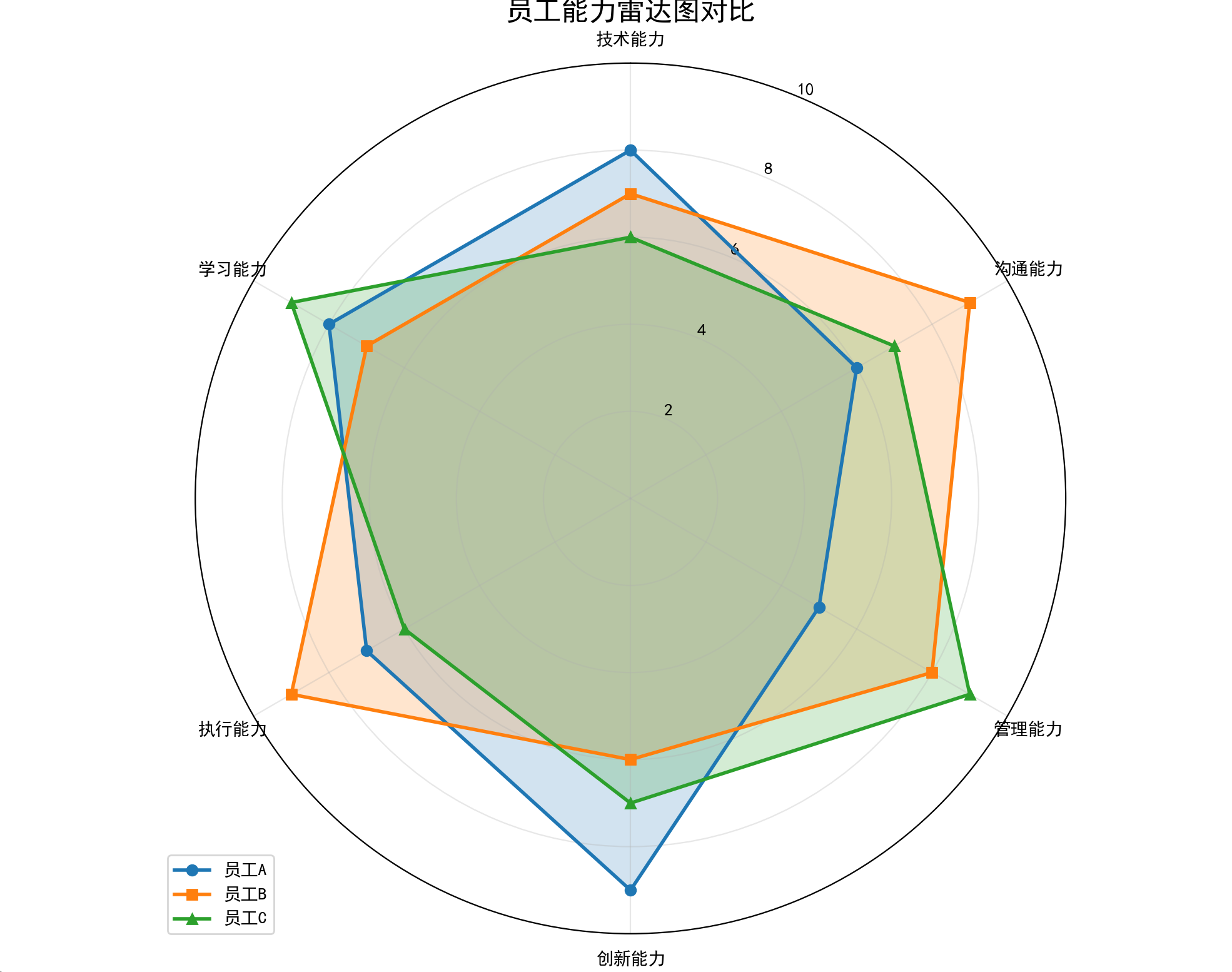
七、雷达图
特点
以原点为中心辐射出多条坐标轴,每个样本用多边形连接各维度值,直观比较多变量综合表现。适合展示样本在多个维度的均衡性或偏科情况。
应用场景
产品多维度评分(如手机的性能、价格、续航、拍照等)。人才评估(如员工的沟通、技术、管理、创新能力)。竞争对手分析(多指标对比)。
实现过程
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei"]
plt.rcParams["axes.unicode_minus"] = False
# 定义评估维度
dimensions = ['技术能力', '沟通能力', '管理能力', '创新能力', '执行能力', '学习能力']
n_dims = len(dimensions)
# 生成3名员工的评分数据(1-10分)
employee1 = [8, 6, 5, 9, 7, 8] # 技术和创新突出
employee2 = [7, 9, 8, 6, 9, 7] # 沟通和执行突出
employee3 = [6, 7, 9, 7, 6, 9] # 管理和学习突出
# 准备雷达图数据(闭合多边形)
angles = np.linspace(0, 2*np.pi, n_dims, endpoint=False).tolist()
employee1 += employee1[:1]
employee2 += employee2[:1]
employee3 += employee3[:1]
angles += angles[:1]
# 绘制雷达图
plt.figure(figsize=(10, 10))
ax = plt.subplot(111, polar=True)
# 绘制各维度网格线
ax.set_theta_offset(np.pi/2) # 起始角度设为上方
ax.set_theta_direction(-1) # 顺时针旋转
ax.set_thetagrids(np.degrees(angles[:-1]), dimensions)
ax.set_ylim(0, 10)
ax.grid(True, alpha=0.3)
# 绘制员工评分
ax.plot(angles, employee1, 'o-', linewidth=2, label='员工A')
ax.fill(angles, employee1, alpha=0.2)
ax.plot(angles, employee2, 's-', linewidth=2, label='员工B')
ax.fill(angles, employee2, alpha=0.2)
ax.plot(angles, employee3, '^-', linewidth=2, label='员工C')
ax.fill(angles, employee3, alpha=0.2)
# 添加图例和标题
plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1))
plt.title('员工能力雷达图对比', fontsize=16)
plt.tight_layout()
plt.show()结果
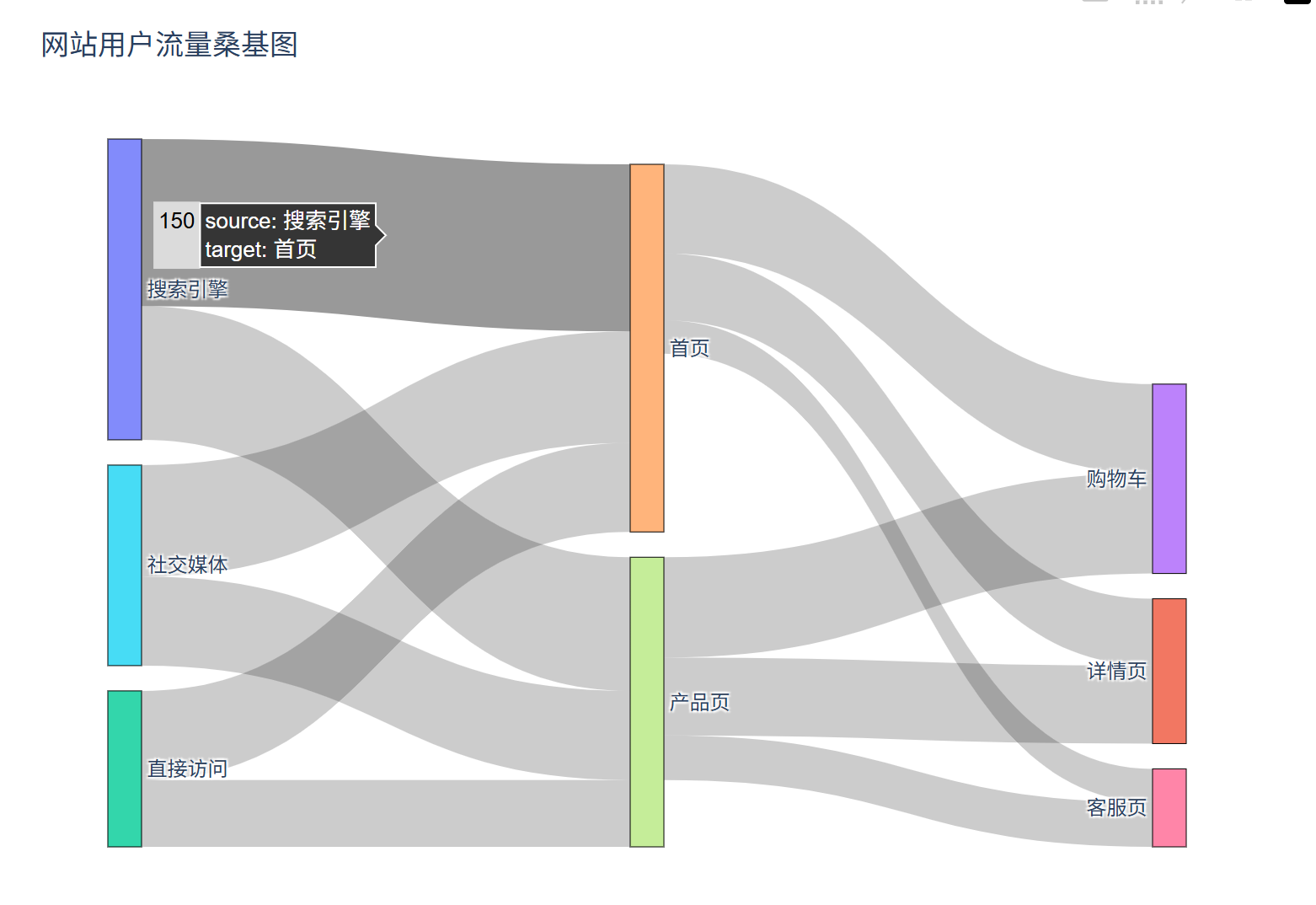
八、桑基图
特点
用带箭头的流线表示数据流向,流线宽度反映流量大小,适合展示物质、能量、资金等的传递路径与分配比例。
应用场景
供应链分析(原材料→加工→成品的价值流动)。网站流量分析(用户从不同渠道到各页面的跳转路径)。
实现过程
import plotly.graph_objects as go
import pandas as pd
# 生成用户流量数据(渠道→页面→转化的流向)
source = ['搜索引擎', '社交媒体', '直接访问', '搜索引擎', '社交媒体', '直接访问','产品页', '产品页', '产品页', '首页', '首页', '首页']
target = ['首页', '首页', '首页', '产品页', '产品页', '产品页','购物车', '详情页', '客服页', '购物车', '详情页', '客服页']
value = [150, 100, 80, 120, 80, 60, 90, 70, 40, 80, 60, 30] # 流量值
# 创建DataFrame
data = pd.DataFrame({'source': source,'target': target,'value': value
})
# 定义节点标签
all_nodes = list(set(source + target))
node_indices = {node: i for i, node in enumerate(all_nodes)}
data['source_idx'] = data['source'].map(node_indices)
data['target_idx'] = data['target'].map(node_indices)
# 绘制桑基图
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=all_nodes),link=dict(source=data['source_idx'],target=data['target_idx'],value=data['value'])
)])
# 更新布局
fig.update_layout(title_text="网站用户流量桑基图",width=800,height=600
)
fig.show()结果
九、总结
| 图表类型 | 特点 | 应用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 散点图 | 两点坐标展示变量关系 | 探索两变量关联、异常值检测 | 直观易读,发现线性关系 | 仅支持两变量,大数据量易乱 |
| 气泡图 | 散点 + 大小 / 颜色展示 3-4 维数据 | 市场分析、城市数据可视化 | 多维数据同屏展示,信息密度高 | 维度过多易重叠,布局复杂 |
| 相关图 | 矩阵展示多变量相关系数 | 特征选择、多变量探索 | 全面呈现相关性,数值颜色双标注 | 仅反映线性相关,需结合验证 |
| 热力图 | 颜色矩阵展示二维数据分布 | 基因表达、时间序列、点击数据 | 突出热点区域,适合模式识别 | 数值精度低,颜色映射需谨慎 |
| 二维密度图 | 等高线 / 颜色展示数据分布密度 | 金融数据、空间数据、生物数据 | 识别聚类和密度峰值,适合大数据 | 抽象度高,参数影响结果 |
| 多模态密度图 | 捕捉数据多个密度峰值 | 客户分群、金融风险、细胞亚型 | 自动识别集群,无需预设聚类数 | 计算复杂,对噪声敏感 |
| 雷达图 | 多轴多边形展示多维度均衡性 | 产品对比、能力评估、综合实力分析 | 直观展示优劣维度,适合综合评估 | 维度限≤8,数值比较不精确 |
| 桑基图 | 流线宽度展示数据流向与流量 | 供应链、流量分析、贸易进出口 | 清晰展示流动路径,流量对比直观 | 节点过多易混乱,布局较复杂 |
相关文章:
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...
海云安高敏捷信创白盒SCAP入选《中国网络安全细分领域产品名录》
近日,嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,海云安高敏捷信创白盒(SCAP)成功入选软件供应链安全领域产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解…...
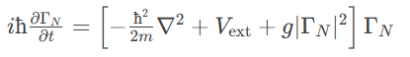
解析“道作为序位生成器”的核心原理
解析“道作为序位生成器”的核心原理 以下完整展开道函数的零点调控机制,重点解析"道作为序位生成器"的核心原理与实现框架: 一、道函数的零点调控机制 1. 道作为序位生成器 道在认知坐标系$(x_{\text{物}}, y_{\text{意}}, z_{\text{文}}…...

基于开源AI智能名片链动2 + 1模式S2B2C商城小程序的沉浸式体验营销研究
摘要:在消费市场竞争日益激烈的当下,传统体验营销方式存在诸多局限。本文聚焦开源AI智能名片链动2 1模式S2B2C商城小程序,探讨其在沉浸式体验营销中的应用。通过对比传统品鉴、工厂参观等初级体验方式,分析沉浸式体验的优势与价值…...

对象回调初步研究
_OBJECT_TYPE结构分析 在介绍什么是对象回调前,首先要熟悉下结构 以我们上篇线程回调介绍过的导出的PsProcessType 结构为例,用_OBJECT_TYPE这个结构来解析它,0x80处就是今天要介绍的回调链表,但是先不着急,先把目光…...

TCP/IP 网络编程 | 服务端 客户端的封装
设计模式 文章目录 设计模式一、socket.h 接口(interface)二、socket.cpp 实现(implementation)三、server.cpp 使用封装(main 函数)四、client.cpp 使用封装(main 函数)五、退出方法…...

数据库——redis
一、Redis 介绍 1. 概述 Redis(Remote Dictionary Server)是一个开源的、高性能的内存键值数据库系统,具有以下核心特点: 内存存储架构:数据主要存储在内存中,提供微秒级的读写响应 多数据结构支持&…...
Java后端检查空条件查询
通过抛出运行异常:throw new RuntimeException("请输入查询条件!");BranchWarehouseServiceImpl.java // 查询试剂交易(入库/出库)记录Overridepublic List<BranchWarehouseTransactions> queryForReagent(Branch…...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...

PH热榜 | 2025-06-08
1. Thiings 标语:一套超过1900个免费AI生成的3D图标集合 介绍:Thiings是一个不断扩展的免费AI生成3D图标库,目前已有超过1900个图标。你可以按照主题浏览,生成自己的图标,或者下载整个图标集。所有图标都可以在个人或…...

C++--string的模拟实现
一,引言 string的模拟实现是只对string对象中给的主要功能经行模拟实现,其目的是加强对string的底层了解,以便于在以后的学习或者工作中更加熟练的使用string。本文中的代码仅供参考并不唯一。 二,默认成员函数 string主要有三个成员变量,…...

JS红宝书笔记 - 3.3 变量
要定义变量,可以使用var操作符,后跟变量名 ES实现变量初始化,因此可以同时定义变量并设置它的值 使用var操作符定义的变量会成为包含它的函数的局部变量。 在函数内定义变量时省略var操作符,可以创建一个全局变量 如果需要定义…...

2025年低延迟业务DDoS防护全攻略:高可用架构与实战方案
一、延迟敏感行业面临的DDoS攻击新挑战 2025年,金融交易、实时竞技游戏、工业物联网等低延迟业务成为DDoS攻击的首要目标。攻击呈现三大特征: AI驱动的自适应攻击:攻击流量模拟真实用户行为,差异率低至0.5%,传统规则引…...
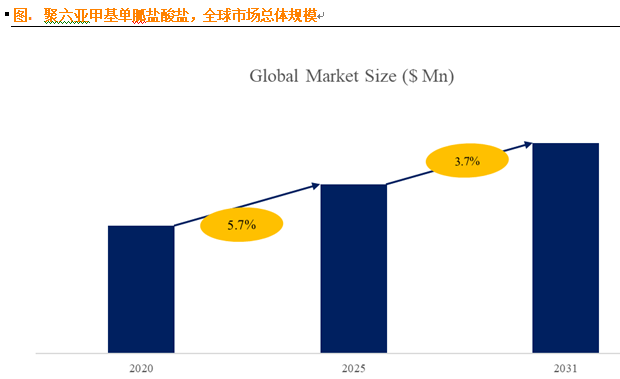
聚六亚甲基单胍盐酸盐市场深度解析:现状、挑战与机遇
根据 QYResearch 发布的市场报告显示,全球市场规模预计在 2031 年达到 9848 万美元,2025 - 2031 年期间年复合增长率(CAGR)为 3.7%。在竞争格局上,市场集中度较高,2024 年全球前十强厂商占据约 74.0% 的市场…...
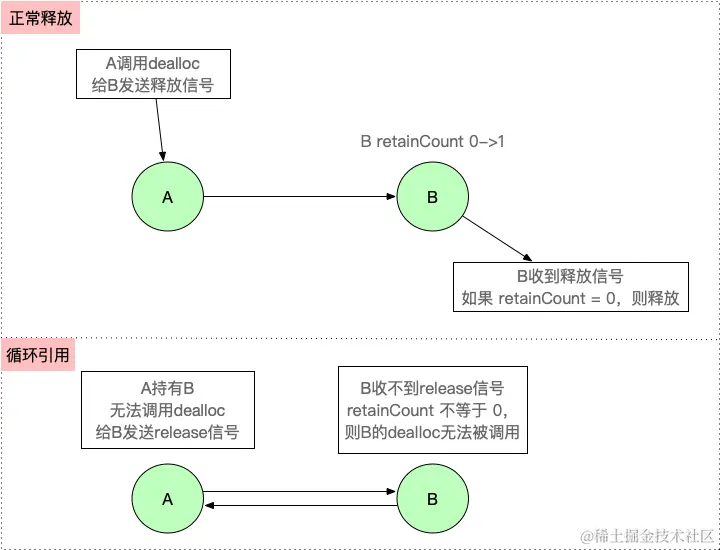
【iOS】 Block再学习
iOS Block再学习 文章目录 iOS Block再学习前言Block的三种类型__ NSGlobalBlock____ NSMallocBlock____ NSStackBlock__小结 Block底层分析Block的结构捕获自由变量捕获全局(静态)变量捕获静态变量__block修饰符forwarding指针 Block的copy时机block作为函数返回值将block赋给…...
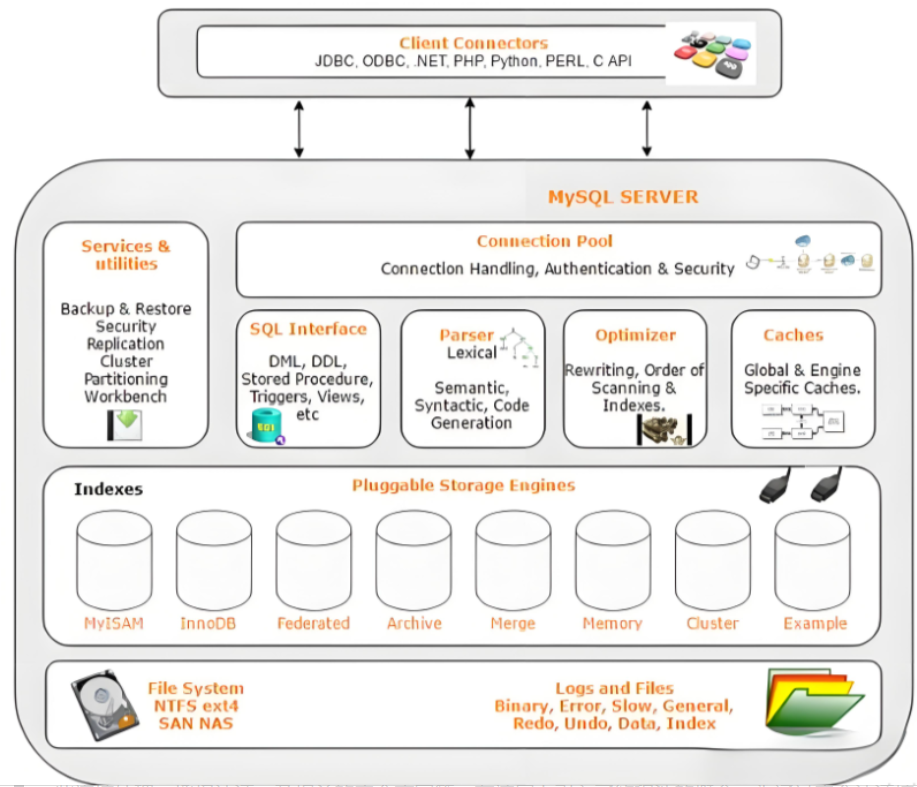
Mysql故障排插与环境优化
前置知识点 最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可…...

文件上传漏洞防御全攻略
要全面防范文件上传漏洞,需构建多层防御体系,结合技术验证、存储隔离与权限控制: 🔒 一、基础防护层 前端校验(仅辅助) 通过JavaScript限制文件后缀名(白名单)和大小,提…...
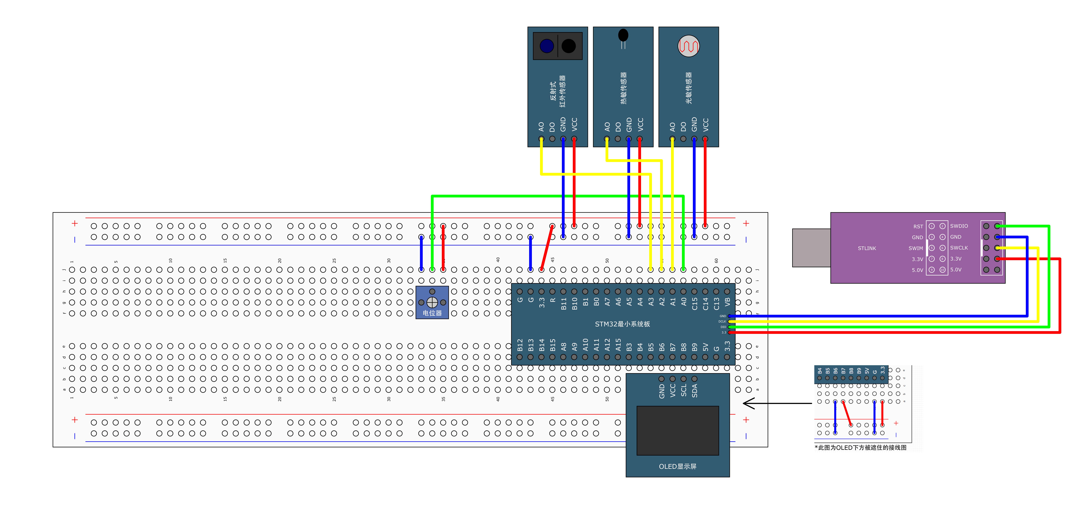
STM32标准库-ADC数模转换器
文章目录 一、ADC1.1简介1. 2逐次逼近型ADC1.3ADC框图1.4ADC基本结构1.4.1 信号 “上车点”:输入模块(GPIO、温度、V_REFINT)1.4.2 信号 “调度站”:多路开关1.4.3 信号 “加工厂”:ADC 转换器(规则组 注入…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...

node.js的初步学习
那什么是node.js呢? 和JavaScript又是什么关系呢? node.js 提供了 JavaScript的运行环境。当JavaScript作为后端开发语言来说, 需要在node.js的环境上进行当JavaScript作为前端开发语言来说,需要在浏览器的环境上进行 Node.js 可…...
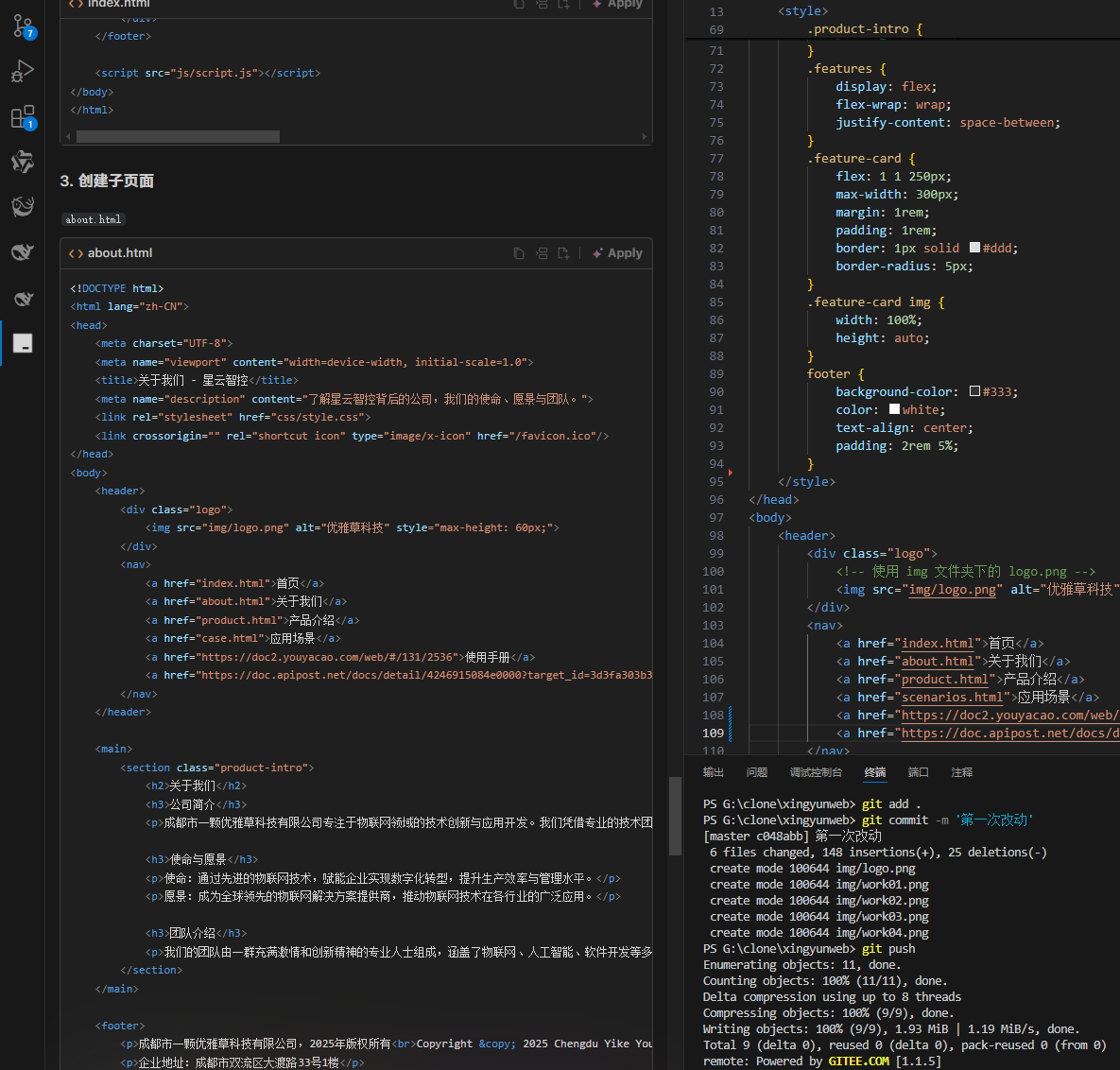
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡 背景 我们以建设星云智控官网来做AI编程实践,很多人以为AI已经强大到不需要程序员了,其实不是,AI更加需要程序员,普通人…...
【若依】框架项目部署笔记
参考【SpringBoot】【Vue】项目部署_no main manifest attribute, in springboot-0.0.1-sn-CSDN博客 多一个redis安装 准备工作: 压缩包下载:http://download.redis.io/releases 1. 上传压缩包,并进入压缩包所在目录,解压到目标…...

深入浅出WebGL:在浏览器中解锁3D世界的魔法钥匙
WebGL:在浏览器中解锁3D世界的魔法钥匙 引言:网页的边界正在消失 在数字化浪潮的推动下,网页早已不再是静态信息的展示窗口。如今,我们可以在浏览器中体验逼真的3D游戏、交互式数据可视化、虚拟实验室,甚至沉浸式的V…...

2025年- H71-Lc179--39.组合总和(回溯,组合)--Java版
1.题目描述 2.思路 当前的元素可以重复使用。 (1)确定回溯算法函数的参数和返回值(一般是void类型) (2)因为是用递归实现的,所以我们要确定终止条件 (3)单层搜索逻辑 二…...

数据库正常,但后端收不到数据原因及解决
从代码和日志来看,后端SQL查询确实返回了数据,但最终user对象却为null。这表明查询结果没有正确映射到User对象上。 在前后端分离,并且ai辅助开发的时候,很容易出现前后端变量名不一致情况,还不报错,只是单…...
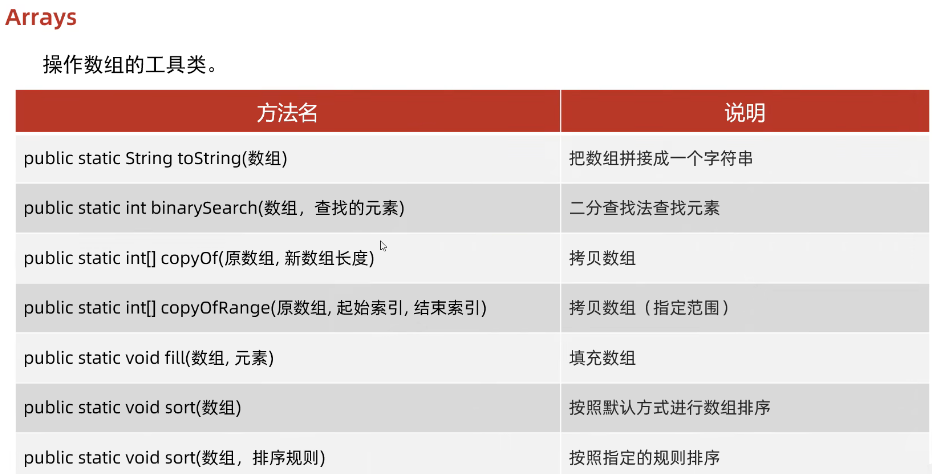
Java数组Arrays操作全攻略
Arrays类的概述 Java中的Arrays类位于java.util包中,提供了一系列静态方法用于操作数组(如排序、搜索、填充、比较等)。这些方法适用于基本类型数组和对象数组。 常用成员方法及代码示例 排序(sort) 对数组进行升序…...
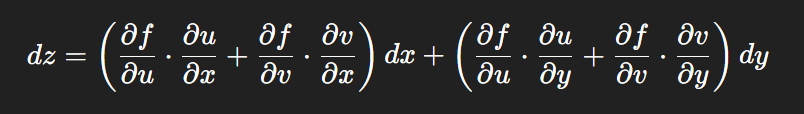
链式法则中 复合函数的推导路径 多变量“信息传递路径”
非常好,我们将之前关于偏导数链式法则中不能“约掉”偏导符号的问题,统一使用 二重复合函数: z f ( u ( x , y ) , v ( x , y ) ) \boxed{z f(u(x,y),\ v(x,y))} zf(u(x,y), v(x,y)) 来全面说明。我们会展示其全微分形式(偏导…...
 ----- Python的类与对象)
Python学习(8) ----- Python的类与对象
Python 中的类(Class)与对象(Object)是面向对象编程(OOP)的核心。我们可以通过“类是模板,对象是实例”来理解它们的关系。 🧱 一句话理解: 类就像“图纸”,对…...

ThreadLocal 源码
ThreadLocal 源码 此类提供线程局部变量。这些变量不同于它们的普通对应物,因为每个访问一个线程局部变量的线程(通过其 get 或 set 方法)都有自己独立初始化的变量副本。ThreadLocal 实例通常是类中的私有静态字段,这些类希望将…...

Python 高级应用10:在python 大型项目中 FastAPI 和 Django 的相互配合
无论是python,或者java 的大型项目中,都会涉及到 自身平台微服务之间的相互调用,以及和第三发平台的 接口对接,那在python 中是怎么实现的呢? 在 Python Web 开发中,FastAPI 和 Django 是两个重要但定位不…...