Mysql故障排插与环境优化
前置知识点
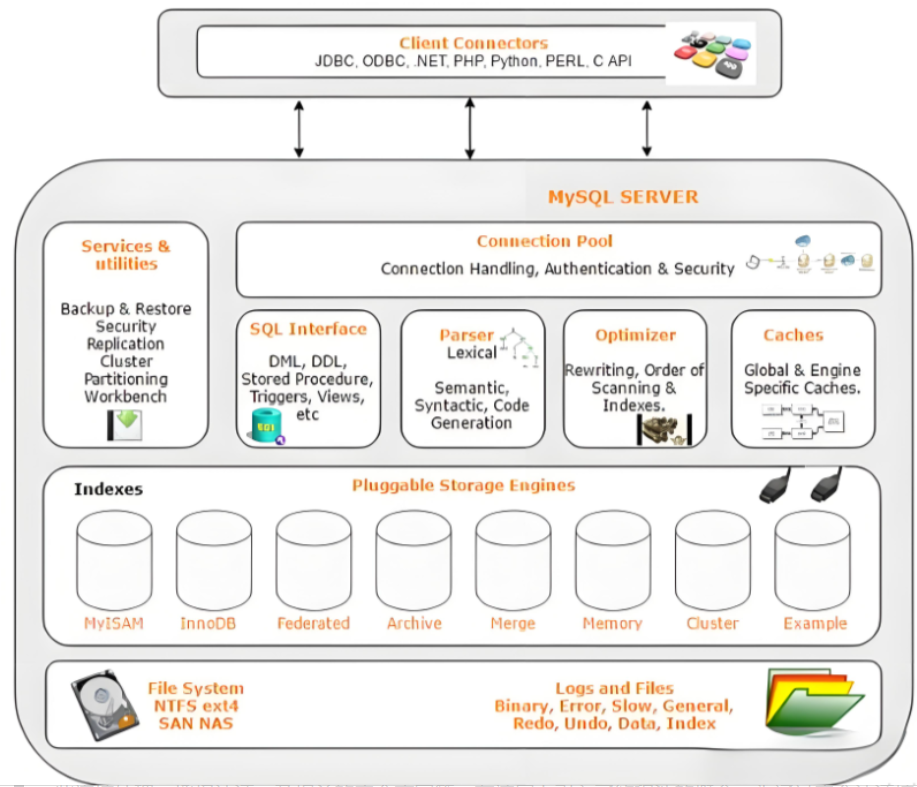
最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可以实现基于 SSL 的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
第二层架构主要完成大多数的核心服务功能,如 SQL 接口、缓存的查询、SQL 的分析和优化以及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。在该层上服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化,如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。如果是 select 语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
存储引擎层,存储引擎真正的负责了 MySQL 中数据的存储和提取,服务器通过 API 与存储引擎进行通信。不同的存储引擎具有的功能不同,可以根据自己的实际需要进行选取。数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
案例实施
MySql单实例排查故障
故障现象 1
ERROR 2002 (HY000): Can't connect to local MySQL server through socket
'/data/mysql/mysql.sock' (2)问题分析:以上这种情况一般都是数据库未启动、mysql 配置文件未指定 socket
文件或者数据库端口被防火墙拦截导致。
解决方法:启动数据库或者防火墙开放数据库监听端口。
故障现象 2
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)问题分析:密码不正确或者没有权限访问。
解决方法:
修改 my.cnf 主配置文件,在 [mysqld] 下添加 skip-grant-tables=on,重启数据库。最后修改密码命令如下。
Mysql5.7 版本
mysql> update mysql.user set authentication_string=password ('123456') where user='root'
and Host = 'localhost';
mysql> flush privileges;Mysql8.0
mysql> UPDATE mysql.user SET authentication_string='' WHERE user='root' AND Host='localhost';
mysql> FLUSH PRIVILEGES;
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';再删除刚刚添加的 skip-grant-tables 参数,重启数据库,使用新密码即可登录。重新授权,命令如下。
Mysql5.7
mysql>grant all on . to 'root'@'mysql-server' identified by '123456';Mysql8.0
mysql> CREATE USER 'root'@'mysql-server' IDENTIFIED BY '123456';
mysql> GRANT all ON . TO 'root'@'mysql-server';
故障现象 3
在使用远程连接数据库时偶尔会发生远程连接数据库很慢的问题。
问题分析:如果 MySQL 主机查询 DNS 很慢或是有很多客户端主机时会导致连接很慢。由于开发机器是不能够连接外网的,在进行 MySQL 连接时,DNS 解析是不可能完成的,从而也就明白了为什么连接那么慢了。
解决方法:修改 my.cnf 主配置文件,在 [mysqld] 下添加 skip-name-resolve,重启数据库可以解决。注意在以后授权里面不能再使用主机名授权。
Can't open file: 'xxx_forums.MYI'. (errno: 145)服务器非正常关机,数据库所在空间已满,或一些其它未知的原因,对数据库表造成了损坏。
可能是操作系统下直接将数据库文件拷贝移动,会因为文件的属组问题而产生这个错误.
解决方法:
- 可以使用下面的两种方式修复数据表(第一种方法仅适合独立主机用户)
- 使用 MySQL 自带的专门用户数据表检查和修复工具 myisamchk。一般情况下只有在命令行下面才能运行 myisamchk 命令。常用的修复命令为:
myisamchk -r 数据文件目录 / 数据表名.MYI; - 通过 phpMyAdmin 修复,phpMyAdmin 带有修复数据表的功能,进入到某一个表中后,点击 “操作”,在下方的 “表维护” 中点击 “修复表” 即可。
注意:以上两种修复方式在执行前一定要备份数据库。
修改文件的属组(仅适合独立主机用户):
- 复制数据库文件的过程中没有将数据库文件设置为 MySQL 运行的帐号可读写(一般适用于 Linux 和 FreeBSD 用户)。
故障现象 5
ERROR 1129 (HY000): Host 'xxx.xxx.xxx.xxx' is blocked because of many connection errors;
unblock with 'mysqladmin flush-hosts'问题分析:由于 mysql 数据库的参数:max_connect_errors,其默认值是 10。当大量 (max_connect_errors) 的主机去连接 MySQL,总连接请求超过了 10 次,新的连接就再也无法连接上 MySQL 服务。同一个 ip 在短时间内产生太多中断的数据库连接而导致的阻塞(超过 mysql 数据库 max_connection_errors 的最大值)。
解决方法:
使用 mysqladmin flush-hosts 命令清除缓存,命令执行方法如下:
mysqladmin -uroot -p -h 192.168.241.48 flush-hostsEnter password:修改 mysql 配置文件,在 [mysqld] 下面添加 max_connect_errors=1000,然后重启 MySQL。
客户端报 Too many connections。在 my.cnf 配置文件里面增大连接数,然后重启 MySQL 服务
max_connections = 10000临时修改最大连接数,重启后不生效。需要在 my.cnf 里面修改配置文件,下次重启生效。
set GLOBAL max_connections=10000;Warning: World-writable config file '/etc/my.cnf' is ignored
ERROR! MySQL is running but PID file could not be found问题分析:MySQL 的配置文件 /etc/my.cnf 权限不对。
解决方法:
chmod 644 /et/my.cnf故障现象 8
InnoDB: Error: page 14178 log sequence number 29455369832
InnoDB: is in the future! Current system log sequence number 29455369832问题分析:innodb 数据文件损坏。
解决方法:修 my.cnf 配置文件,在 [mysqld] 下添加 innodb_force_recovery=4, 启动数据库后备份数据文件,然后去掉该参数,利用备份文件恢复数据。
MySQL 主从故障排查
从库的 Slave_IO_Running 为 NO
The slave I/O thread stops because master and slave have equal MySQL server ids; these ids must be different for replication to work (or the --replicate-same-server-id option must be used on slave but this does not always make sense; please check the manual before using it).问题分析:主库和从库的 server-id 值一样。
解决方法:
修改从库的 server-id 的值,修改为和主库不一样。修改完后重启,再同步即可。
故障现象 2
从库的 Slave_IO_Running 为 NO
问题分析:造成从库线程为 NO 的原因会有很多,主要原因是主键冲突或者主库删除或更新数据,从库找不到记录,数据被修改导致。通常状态码报错有 1007、1032、1062、1452 等。
解决方法一:
mysql> stop slave;
mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
mysql> start slave;解决方法二:
设置用户权限,设置从库只读权限
set global read_only=true;
故障现象 3
Error initializing relay log position: I/O error reading the header from the binary log
分析问题:从库的中继日志 relay-bin 损坏。
解决方法:手工修复,重新找到同步的 binlog 和 pos 点,然后重新同步即可。
mysql>CHAN GEMASTER TO
MASTER_LOG_FILE='mysql-bin.xxx',MASTER_LOG_POS=xxx;MySQL 优化
硬件方面
说到服务器硬件,最主要的无非 CPU、内存、磁盘三大关键因素。
关于 CPU
CPU 对于 MySQL 应用,推荐使用 S.M.P. 架构的多路对称 CPU。例如:可以使用两颗 Intel Xeon 3.6GHz 的 CPU。现在比较推荐用 4U 的服务器来专门做数据库服务器,不仅仅是针对于 MySQL。
关于内存
物理内存对于一台使用 MySQL 的 Database Server 来说,服务器内存建议不要小于 2GB,推荐使用 4GB 以上的物理内存。不过内存对于现在的服务器而言可以说是一个可以忽略的问题,工作中遇到了高端服务器基本上内存都超过了 32G。
关于磁盘
磁盘寻道能力(磁盘 I/O)。以目前市场上普遍高转速 SAS 硬盘 (15000 转 / 秒) 为例,这种硬盘理论上每秒寻道 15000 次,这是物理特性决定的,没有办法改变。MySQL 每秒钟都在进行大量、复杂的查询操作,对磁盘的读写量可想而知。所以通常认为磁盘 I/O 是制约 MySQL 性能的最大因素之一,通常是使用 RAID - 0 + 1 磁盘阵列,注意不要尝试使用 RAID - 5,MySQL 在 RAID - 5 磁盘阵列上的效率并不高。如果不考虑硬件的投入成本,也可以考虑固态(SSD)硬盘专门作为数据库服务器使用。数据库的读写性能肯定会提高很多。
MySQL 配置文件
核心性能优化项
| 参数 | 作用 | 建议配置 | 注意事项 |
|---|---|---|---|
| innodb_buffer_pool_size | InnoDB 缓冲池大小,缓存数据和索引,直接影响读性能 | 设置为物理内存的 50% - 70%(如 64GB 内存配 40G ) | 避免超过物理内存,防止系统交换(Swap) |
| innodb_log_file_size | 单个 InnoDB 重做日志文件大小,影响(innodb_log_file ) | 建议 1G - 4G(如 2G ),总日志大小 | 修改需停止 MySQL,删除旧日志文件后重启 |
| innodb_flush_log_at_trx_commit | 控制事务日志刷新策略,平衡性能(折中,每秒刷盘)与数据安全(高性能,风险高) | 默认完全持久化;高并发写入场景可设为 2 | 设为 2 需容忍最多 1 秒数据丢失 |
| max_connections | 最大客户端连接数,避免连接耗尽 | 建议 500 - 2000 ,监控 Threads_connected 和 Threads_running 调整 | 可配合 thread_cache_size(如 100 )缓存线程 |
| tmp_table_size 、max_heap_table_size | 内存临时表大小上限,影响复杂查询(如 GROUP BY、JOIN ) | 建议 64M - 256M(如 128M ),两者值需一致 |
日志与监控
| 参数 | 作用 | 建议配置 |
|---|---|---|
| long_query_time | 记录执行时间长的 SQL,定义慢查询阈值(秒) | 1~2(根据业务容忍度调整) |
| log_error | 错误日志路径,用于故障排查 | 指定路径(如 /var/log/mysql/error.log ) |
| binlog_format | 二进制日志格式(主从复制依赖) | ROW(推荐,数据一致性高) |
| expire_logs_days | 自动清理旧的二进制日志天数 | 7~14(根据备份策略调整) |
InnoDB 高级优化
| 参数 | 作用 | 建议配置 |
|---|---|---|
| innodb_io_capacity | InnoDB 后台任务的 I/O 能力(如刷新脏页) | SSD 建议 2000~4000,HDD 建议 200~400 |
| innodb_flush_method | 控制数据文件与日志文件的刷新方式 | O_DIRECT(默认,避免双缓冲) |
| innodb_thread_concurrency | InnoDB 并发线程数限制 | 0(默认,自适应),高并发场景可设为 CPU 核数 * 2 |
| innodb_autoinc_lock_mode | 自增锁模式,影响插入性能 | 2(连续模式,高并发插入推荐) |
示例配置片段(my.cnf)
物理资源:32 核 CPU、64G 内存、500G SSD
[mysqld]
核心配置
innodb_buffer_pool_size = 40G
innodb_log_file_size = 2G
innodb_flush_log_at_trx_commit = 2
max_connections = 1000
thread_cache_size = 100查询优化
tmp_table_size = 128M
max_heap_table_size = 128M
sort_buffer_size = 4M
join_buffer_size = 8M日志与监控
slow_query_log = ON
long_query_time = 1
log_error = /var/log/mysql/error.log
binlog_format = ROW
expire_logs_days = 7InnoDB 高级
innodb_io_capacity = 2000
innodb_flush_method = O_DIRECT
innodb_thread_concurrency = 0
innodb_autoinc_lock_mode = 2
SQL 方面
QL 优化是确保数据库高效运行的关键,其核心在于通过减少资源消耗(如 CPU、内存、磁盘 I/O )来提升查询响应速度,避免慢查询导致用户体验下降或系统崩溃。未优化的 SQL 可能引发全表扫描、冗余计算或锁竞争,尤其在数据量大或高并发场景下,会导致服务器负载飙升、响应延迟,甚至影响业务连续性(如交易超时 )。通过索引调优、查询改写、执行计划分析等手段,可显著降低数据库压力,支撑业务规模扩展,同时控制硬件成本与运维复杂度。
-- 创建测试库
Create database test;
-- 创建用户表
use test;CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
age INT NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);-- 插入 10 万条测试数据(使用存储过程生成)
DELIMITER $
CREATE PROCEDURE insert_users()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 100000 DO
INSERT INTO users (name, email, age)
VALUES (CONCAT('user', i), CONCAT('user', i, '@example.com'), FLOOR(RAND() * 100));
SET i = i + 1;
END WHILE;
END$
DELIMITER ;CALL insert_users();
使用 EXPLAIN 进行 SQL 优化的步骤及实验验证
EXPLAIN 是 MySQL 中用于分析 SQL 执行计划的工具,通过模拟查询执行过程输出关键信息(如访问类型 type、使用索引 key、预估扫描行数 rows、额外操作 Extra 等 ),帮助开发者识别全表扫描、索引失效等性能瓶颈,从而指导优化方向(如添加索引、改写查询或调整表结构 ),是提升数据库效率不可或缺的手段。
mysql>EXPLAIN SELECT * FROM users WHERE name = 'user123';mysql> EXPLAIN SELECT * FROM users WHERE name = 'user123';
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 99870 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
1 row in set, 1 warning (0.00 sec)EXPLAIN 用于显示MYSQL 如何执行 SQL 语句,关键字段如下:
| 字段 | 说明 | 优化关注点 |
|---|---|---|
| id | 查询序列号,相同 id 为同一执行层,不同 id 按序执行(如子查询) | 复杂查询的嵌套层级 |
| select_type | 查询类型(SIMPLE、PRIMARY、SUBQUERY、DERIVED 等) | 识别子查询或临时表操作 |
| table | 访问的表名或别名 | 确认查询涉及的表 |
| type | 访问类型,性能从优到劣:system > const > eq_ref > ref > range > index > ALL | 避免 ALL(全表扫描),优先优化为 ref 或 range |
| possible_keys | 可能使用的索引 | 检查是否有合适索引未被使用 |
| key | 实际使用的索引 | 确认是否命中最佳索引 |
| rows | 预估扫描的行数 | 行数越少,查询效率越高 |
| Extra | 附加信息(如 Using where、Using index、Using temporary 等) | 发现潜在性能问题(如临时表、文件排序) |
根据关键字说明,对 explain SELECT * FROM users WHERE name = 'user123'; 的结果分析如下:
type=ALL:全表扫描,效率极低。
possible_keys=NULL:未命中索引。
rows=100000:扫描全部数据。优化步骤:添加索引
mysql>ALTER TABLE users ADD INDEX idx_name (name);优化后查询及 EXPLAIN 分析
mysql> ALTER TABLE users ADD INDEX idx_name (name);
Query OK, 0 rows affected (0.23 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> EXPLAIN SELECT * FROM users WHERE name = 'user123';
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | users | NULL | ref | idx_name | idx_name | 152 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
优化后结果分析如下:
type=ref:索引查找,效率高。
key=idx_name:命中新创建的索引。
rows=1:仅扫描一行数据。
数据库拒绝连接(ERROR 2003)
原因:服务未启动或端口被拦截
解决步骤:
- 检查服务状态:
systemctl status mysqld - 开放防火墙:
firewall-cmd --add-port=3306/tcp --permanent - 验证网络连通性:
telnet <IP> 3306
查询性能低下
原因:未使用索引或复杂查询
解决步骤:
- 分析执行计划:
EXPLAIN SELECT... - 添加缺失索引:
ALTER TABLE t ADD INDEX idx_col(column); - 优化SQL:避免
SELECT *,拆分子查询
表锁/行锁冲突
原因:长事务或未提交事务阻塞其他操作
解决步骤:
- 查看锁状态:
SHOW ENGINE INNODB STATUS\G - 终止阻塞进程:
KILL <process_id>; - 优化事务:缩短事务时长,避免大事务
磁盘空间不足
原因:日志文件或临时文件暴增
解决步骤:
- 清理日志:
PURGE BINARY LOGS BEFORE '2025-05-01'; - 调整日志大小:
innodb_log_file_size=1G - 监控空间:设置
df -h定时任务
配置文件错误
原因:参数错误或语法问题
解决步骤:
- 验证配置:
mysqld --verbose --help | grep -A1 "Default options" - 逐段检查:使用
mysqld --validate-config - 回滚配置:保留多版本
my.cnf备份
备份恢复失败
原因:备份文件损坏或版本不兼容
解决步骤:
- 验证备份:
mysqlcheck -r <database> - 分阶段恢复:先恢复结构再导入数据
- 使用物理备份工具:如Percona XtraBackup
内存溢出(OOM Killer触发)
原因:innodb_buffer_pool_size设置过大
解决步骤:
- 计算合理值:总内存 * 0.75 - 系统预留
- 动态调整:SET GLOBAL innodb_buffer_pool_size=8G;
- 监控内存:free -m和cat /proc/meminfo
相关文章:
Mysql故障排插与环境优化
前置知识点 最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可…...

文件上传漏洞防御全攻略
要全面防范文件上传漏洞,需构建多层防御体系,结合技术验证、存储隔离与权限控制: 🔒 一、基础防护层 前端校验(仅辅助) 通过JavaScript限制文件后缀名(白名单)和大小,提…...
STM32标准库-ADC数模转换器
文章目录 一、ADC1.1简介1. 2逐次逼近型ADC1.3ADC框图1.4ADC基本结构1.4.1 信号 “上车点”:输入模块(GPIO、温度、V_REFINT)1.4.2 信号 “调度站”:多路开关1.4.3 信号 “加工厂”:ADC 转换器(规则组 注入…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...

node.js的初步学习
那什么是node.js呢? 和JavaScript又是什么关系呢? node.js 提供了 JavaScript的运行环境。当JavaScript作为后端开发语言来说, 需要在node.js的环境上进行当JavaScript作为前端开发语言来说,需要在浏览器的环境上进行 Node.js 可…...
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡 背景 我们以建设星云智控官网来做AI编程实践,很多人以为AI已经强大到不需要程序员了,其实不是,AI更加需要程序员,普通人…...
【若依】框架项目部署笔记
参考【SpringBoot】【Vue】项目部署_no main manifest attribute, in springboot-0.0.1-sn-CSDN博客 多一个redis安装 准备工作: 压缩包下载:http://download.redis.io/releases 1. 上传压缩包,并进入压缩包所在目录,解压到目标…...

深入浅出WebGL:在浏览器中解锁3D世界的魔法钥匙
WebGL:在浏览器中解锁3D世界的魔法钥匙 引言:网页的边界正在消失 在数字化浪潮的推动下,网页早已不再是静态信息的展示窗口。如今,我们可以在浏览器中体验逼真的3D游戏、交互式数据可视化、虚拟实验室,甚至沉浸式的V…...

2025年- H71-Lc179--39.组合总和(回溯,组合)--Java版
1.题目描述 2.思路 当前的元素可以重复使用。 (1)确定回溯算法函数的参数和返回值(一般是void类型) (2)因为是用递归实现的,所以我们要确定终止条件 (3)单层搜索逻辑 二…...

数据库正常,但后端收不到数据原因及解决
从代码和日志来看,后端SQL查询确实返回了数据,但最终user对象却为null。这表明查询结果没有正确映射到User对象上。 在前后端分离,并且ai辅助开发的时候,很容易出现前后端变量名不一致情况,还不报错,只是单…...
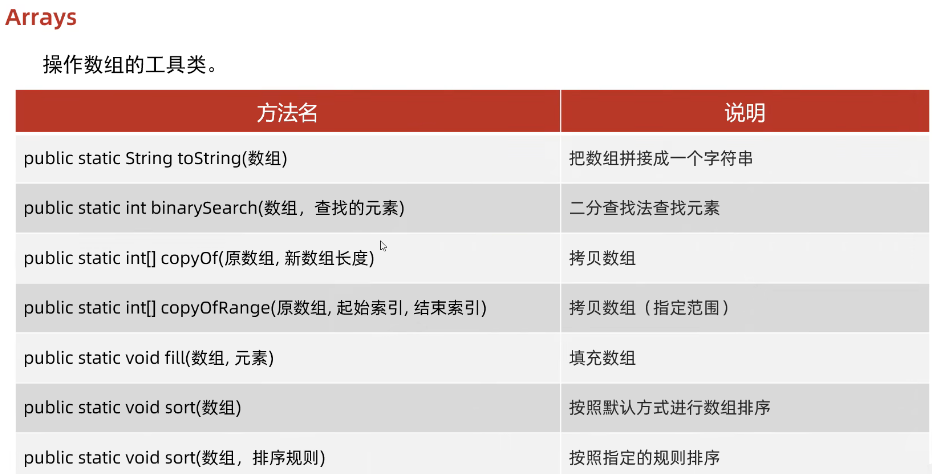
Java数组Arrays操作全攻略
Arrays类的概述 Java中的Arrays类位于java.util包中,提供了一系列静态方法用于操作数组(如排序、搜索、填充、比较等)。这些方法适用于基本类型数组和对象数组。 常用成员方法及代码示例 排序(sort) 对数组进行升序…...
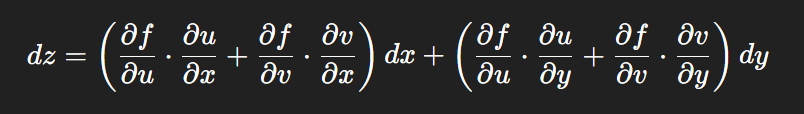
链式法则中 复合函数的推导路径 多变量“信息传递路径”
非常好,我们将之前关于偏导数链式法则中不能“约掉”偏导符号的问题,统一使用 二重复合函数: z f ( u ( x , y ) , v ( x , y ) ) \boxed{z f(u(x,y),\ v(x,y))} zf(u(x,y), v(x,y)) 来全面说明。我们会展示其全微分形式(偏导…...
 ----- Python的类与对象)
Python学习(8) ----- Python的类与对象
Python 中的类(Class)与对象(Object)是面向对象编程(OOP)的核心。我们可以通过“类是模板,对象是实例”来理解它们的关系。 🧱 一句话理解: 类就像“图纸”,对…...

ThreadLocal 源码
ThreadLocal 源码 此类提供线程局部变量。这些变量不同于它们的普通对应物,因为每个访问一个线程局部变量的线程(通过其 get 或 set 方法)都有自己独立初始化的变量副本。ThreadLocal 实例通常是类中的私有静态字段,这些类希望将…...

Python 高级应用10:在python 大型项目中 FastAPI 和 Django 的相互配合
无论是python,或者java 的大型项目中,都会涉及到 自身平台微服务之间的相互调用,以及和第三发平台的 接口对接,那在python 中是怎么实现的呢? 在 Python Web 开发中,FastAPI 和 Django 是两个重要但定位不…...

rm视觉学习1-自瞄部分
首先先感谢中南大学的开源,提供了很全面的思路,减少了很多基础性的开发研究 我看的阅读的是中南大学FYT战队开源视觉代码 链接:https://github.com/CSU-FYT-Vision/FYT2024_vision.git 1.框架: 代码框架结构:readme有…...
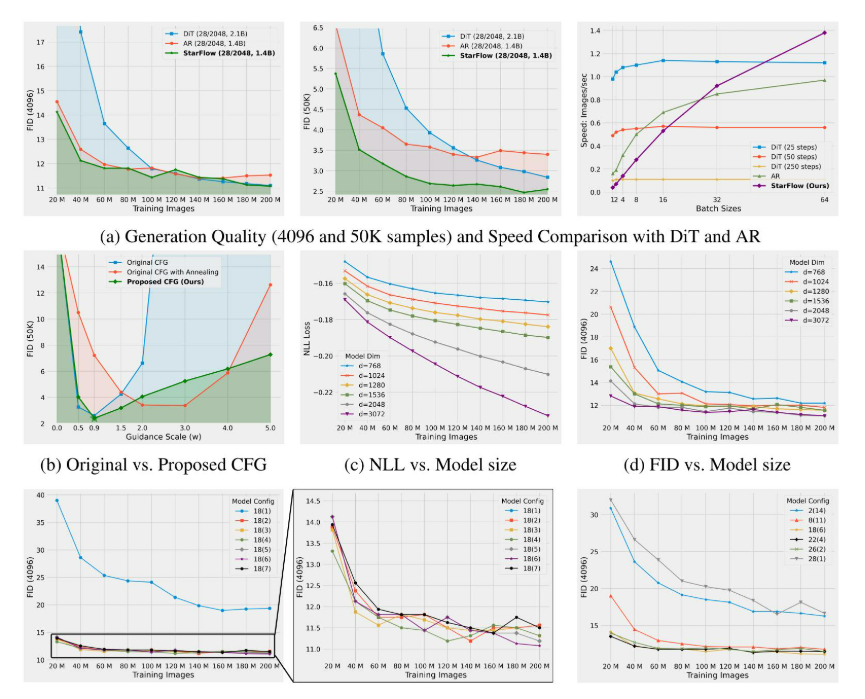
高分辨率图像合成归一化流扩展
大家读完觉得有帮助记得关注和点赞!!! 1 摘要 我们提出了STARFlow,一种基于归一化流的可扩展生成模型,它在高分辨率图像合成方面取得了强大的性能。STARFlow的主要构建块是Transformer自回归流(TARFlow&am…...

负载均衡器》》LVS、Nginx、HAproxy 区别
虚拟主机 先4,后7...

命令行关闭Windows防火墙
命令行关闭Windows防火墙 引言一、防火墙:被低估的"智能安检员"二、优先尝试!90%问题无需关闭防火墙方案1:程序白名单(解决软件误拦截)方案2:开放特定端口(解决网游/开发端口不通)三、命令行极速关闭方案方法一:PowerShell(推荐Win10/11)方法二:CMD命令…...

算法—栈系列
一:删除字符串中的所有相邻重复项 class Solution { public:string removeDuplicates(string s) {stack<char> st;for(int i 0; i < s.size(); i){char target s[i];if(!st.empty() && target st.top())st.pop();elsest.push(s[i]);}string ret…...
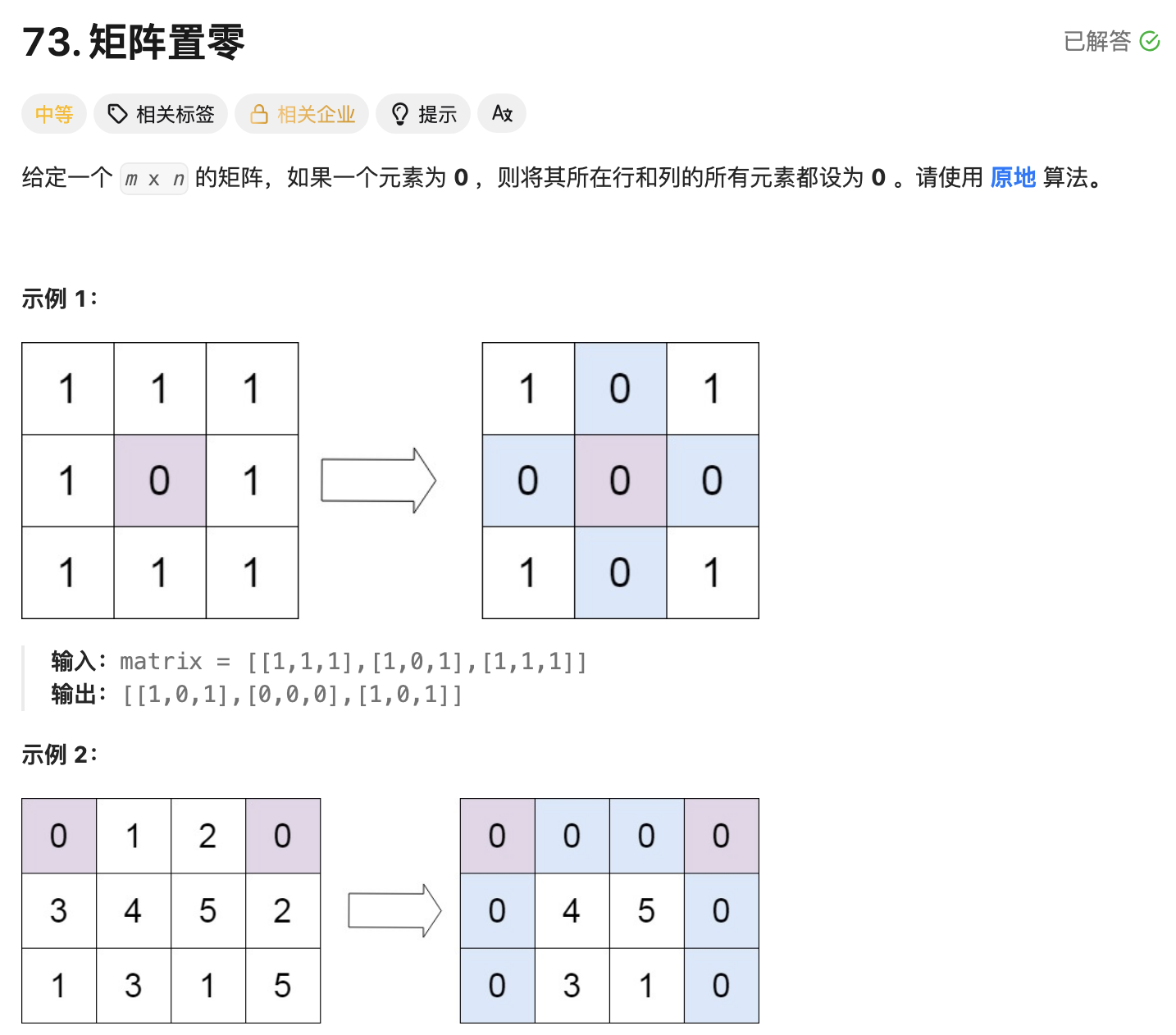
leetcode73-矩阵置零
leetcode 73 思路 记录 0 元素的位置:遍历整个矩阵,找出所有值为 0 的元素,并将它们的坐标记录在数组zeroPosition中置零操作:遍历记录的所有 0 元素位置,将每个位置对应的行和列的所有元素置为 0 具体步骤 初始化…...
)
ArcPy扩展模块的使用(3)
管理工程项目 arcpy.mp模块允许用户管理布局、地图、报表、文件夹连接、视图等工程项目。例如,可以更新、修复或替换图层数据源,修改图层的符号系统,甚至自动在线执行共享要托管在组织中的工程项。 以下代码展示了如何更新图层的数据源&…...
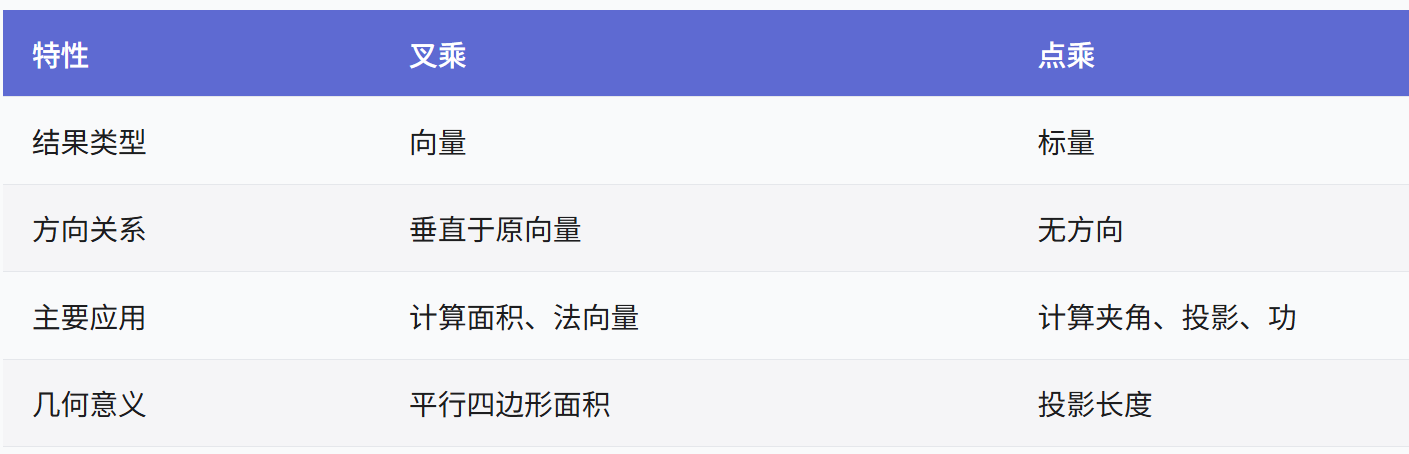
向量几何的二元性:叉乘模长与内积投影的深层联系
在数学与物理的空间世界中,向量运算构成了理解几何结构的基石。叉乘(外积)与点积(内积)作为向量代数的两大支柱,表面上呈现出截然不同的几何意义与代数形式,却在深层次上揭示了向量间相互作用的…...
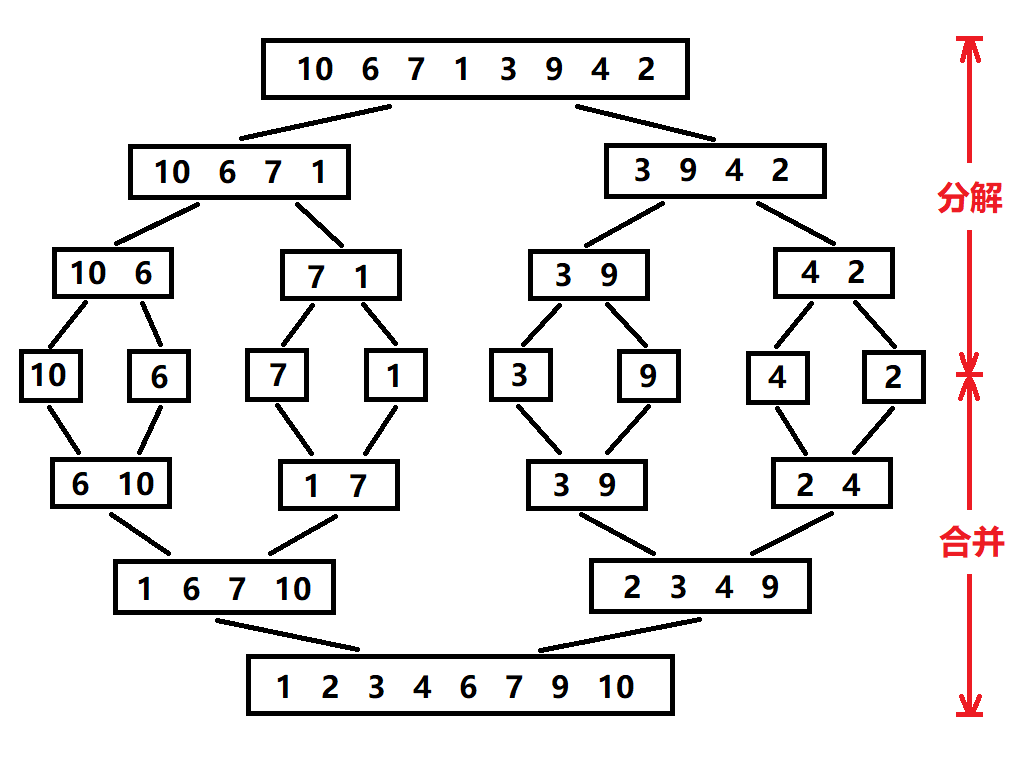
归并排序:分治思想的高效排序
目录 基本原理 流程图解 实现方法 递归实现 非递归实现 演示过程 时间复杂度 基本原理 归并排序(Merge Sort)是一种基于分治思想的排序算法,由约翰冯诺伊曼在1945年提出。其核心思想包括: 分割(Divide):将待排序数组递归地分成两个子…...
Xcode 16 集成 cocoapods 报错
基于 Xcode 16 新建工程项目,集成 cocoapods 执行 pod init 报错 ### Error RuntimeError - PBXGroup attempted to initialize an object with unknown ISA PBXFileSystemSynchronizedRootGroup from attributes: {"isa">"PBXFileSystemSynchro…...
Mac flutter环境搭建
一、下载flutter sdk 制作 Android 应用 | Flutter 中文文档 - Flutter 中文开发者网站 - Flutter 1、查看mac电脑处理器选择sdk 2、解压 unzip ~/Downloads/flutter_macos_arm64_3.32.2-stable.zip \ -d ~/development/ 3、添加环境变量 命令行打开配置环境变量文件 ope…...

Windows 下端口占用排查与释放全攻略
Windows 下端口占用排查与释放全攻略 在开发和运维过程中,经常会遇到端口被占用的问题(如 8080、3306 等常用端口)。本文将详细介绍如何通过命令行和图形化界面快速定位并释放被占用的端口,帮助你高效解决此类问题。 一、准…...
[拓扑优化] 1.概述
常见的拓扑优化方法有:均匀化法、变密度法、渐进结构优化法、水平集法、移动可变形组件法等。 常见的数值计算方法有:有限元法、有限差分法、边界元法、离散元法、无网格法、扩展有限元法、等几何分析等。 将上述数值计算方法与拓扑优化方法结合&#…...
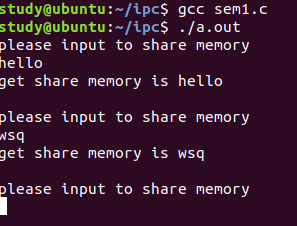
Linux-进程间的通信
1、IPC: Inter Process Communication(进程间通信): 由于每个进程在操作系统中有独立的地址空间,它们不能像线程那样直接访问彼此的内存,所以必须通过某种方式进行通信。 常见的 IPC 方式包括&#…...

用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法
用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法 大家好,我是Echo_Wish。最近刷短视频、看直播,有没有发现,越来越多的应用都开始“懂你”了——它们能感知你的情绪,推荐更合适的内容,甚至帮客服识别用户情绪,提升服务体验。这背后,神经网络在悄悄发力,撑起…...