在 Elasticsearch 中实现自动完成功能 2:n-gram
在第一部分中,我们讨论了使用前缀查询,这是一种自动完成的查询时间方法。 在这篇文章中,我们将讨论 n-gram - 一种索引时间方法,它在基本标记化后生成额外的分词,以便我们稍后在查询时能够获得更快的前缀匹配。 但在此之前,让我们先看看什么是 n-gram。 根据维基百科 -
n-gram 是给定文本或语音序列中 n 个项目的连续序列
有关 n-gram 的更多详细的介绍,请参阅之前的文章 “Elasticsearch: Ngrams, edge ngrams, and shingles”。
是的,就是这么简单,只是一系列文本。 这里的 “n” 项在字符级 n-gram 的情况下表示 “n” 个字符,在单词级 n-gram 的情况下表示 “n” 个单词。 词级 n-gram 也称为 shingles。 此外,根据 “n” 的值,这些被分类为 uni-gram(n=1)、bi-gram(n=2)、tri-gram(n=3)等。
下面的例子会更清楚:
Character n-grams for input string = "harry":n = 1 : ["h", "a", "r", "r", "y"]n = 2 : ["ha", "ar", "rr", "ry"]n = 3 : ["har", "arr", "rry"]Word n-grams for input string = "harry potter and the goblet of fire":n = 1 : ["harry", "potter", "and", "the", "goblet", "of", "fire"]n = 2 : ["harry potter", "potter and", "and the", "the goblet","goblet of", "of fire"]n = 3 : ["harry potter and", "potter and the", "and the goblet","the goblet of", "goblet of fire"]
在这篇文章中,我们将讨论两种基于 n-gram 的方法 - 首先使用 edge n-gram 分词器,然后使用内置的 search-as-you-type 类型,该类型也在内部使用 n-gram 分词器。 这些额外的分词在索引文档时被输出到倒排索引中,从而最大限度地减少搜索时间延迟。 在这里,Elasticsearch 只需将输入与这些分词进行比较,这与前缀查询方法不同,它需要检查单个分词是否以给定输入开头。
Edge-n-gram 分词器
正如我们已经看到的,文本字段被分析并存储在倒排索引中。 分词是这个三步分析过程中的第二步,在过滤字符之后但在应用分词过滤器之前运行。 Edge-n-gram 分词器是 Elasticsearch 中可用的内置分词器之一。 它首先将给定文本分解为分词,然后为每个分词生成字符级 n-grams。
让我们为电影创建一个索引,这次使用 edge-n-gram 分词器:
PUT /movies
{"settings": {"analysis": {"analyzer": {"custom_edge_ngram_analyzer": {"type": "custom","tokenizer": "customized_edge_tokenizer","filter": ["lowercase"]}},"tokenizer": {"customized_edge_tokenizer": {"type": "edge_ngram","min_gram": 2,"max_gram": 10,"token_chars": ["letter","digit"]}}}},"mappings": {"properties": {"title": {"type": "text","analyzer": "custom_edge_ngram_analyzer"}}}
}在前缀查询示例中,我们没有将分析器参数传递给映射中的任何字段,而是依赖于默认的标准分析器。 上面,我们首先创建了一个自定义分析器custom_edge_ngram_analyzer,并传递给它类型为 edge_ngram 的自定义分词器 customized_edge_tokenizer。 Edge_ngram 分词器可以使用以下参数进行定制:
- min_gram ⇒ 放入 gram 中的最小字符数,默认为 1,类似于上面看到的 uni-gram 示例
- max_gram ⇒ 放入 gram 中的最大字符数,默认为 2,类似于上面看到的 bi-gram 示例
- token_chars ⇒ 要保留在 token 中的字符,如果 Elasticsearch 遇到任何不属于提供的列表的字符,它将使用该字符作为新 token 的断点。 支持的字符类包括字母、数字、标点符号、符号和空格。 在上面的映射中,我们保留了字母和数字作为 token 的一部分。 如果我们将输入字符串传递为“harry potter: Deathly Hallows”,Elasticsearch 将通过打破空格和标点符号来生成 ["harry", "potter", "deathly", "hallows"]。
让我们使用 _analyze API 来测试我们的自定义边 n-gram 分析器的行为:
GET /movies/_analyze
{"field": "title","text": "Harry Potter and the Order of the Phoenix"
}上面命令返回的结果为:
[ha, har, harr, harry, po, pot, pott, potte, potter, an,and, th, the, or, ord, orde, order, of, th, the, ph, pho,phoe, phoen, phoeni, phoenix]为了保持简洁,我没有包含实际响应,其中包含一组对象,每 gram 一个对象,包含有关该 gram 的元数据。 无论如何,正如可以观察到的,我们的自定义分析器按设计工作 - 为传递的字符串发出 gram,小写且长度在最小 - 最大设置内。 让我们索引一些电影来测试自动完成功能 -
POST /movies/_doc
{"title": "Harry Potter and the Half-Blood Prince"
}POST /movies/_doc
{"title": "Harry Potter and the Deathly Hallows – Part 1"
}Edge-n-grammed 字段也支持中缀匹配。 即,你也可以通过传递 “har” 和 “dead” 来匹配标题为 “harry potter and the deathly hallows” 的文档。 这使得它适合自动完成实现,其中输入文本中的单词没有固定的顺序。
GET /movies/_search?filter_path=**.hits
{"query": {"match": {"title": {"query": "deathly "}}}
}上面命令返回结果:
{"hits": {"hits": [{"_index": "movies","_id": "fb-HHIsByaLf0EuT7s0I","_score": 4.0647593,"_source": {"title": "Harry Potter and the Deathly Hallows – Part 1"}}]}
}GET /movies/_search?filter_path=**.hits
{"query": {"match": {"title": {"query": "harry pot"}}}
}上面的命令返回:
{"hits": {"hits": [{"_index": "movies","_id": "fL-HHIsByaLf0EuT5M2i","_score": 1.1879652,"_source": {"title": "Harry Potter and the Half-Blood Prince"}},{"_index": "movies","_id": "fb-HHIsByaLf0EuT7s0I","_score": 1.1377401,"_source": {"title": "Harry Potter and the Deathly Hallows – Part 1"}}]}
}GET /movies/_search?filter_path=**.hits
{"query": {"match": {"title": {"query": "potter har"}}}
}{"hits": {"hits": [{"_index": "movies","_id": "fL-HHIsByaLf0EuT5M2i","_score": 1.3746086,"_source": {"title": "Harry Potter and the Half-Blood Prince"}},{"_index": "movies","_id": "fb-HHIsByaLf0EuT7s0I","_score": 1.3159354,"_source": {"title": "Harry Potter and the Deathly Hallows – Part 1"}}]}
}默认情况下,对分析字段(上例中的 title)的搜索查询也会对搜索词运行分析器。 如果你将搜索词指定为“deathly potter”,希望它只匹配第二个文档,你会感到惊讶,因为它匹配两个文档。 这是因为搜索词 “deathly potter” 也将被分词,将 “deathly” 和 “potter” 输出为单独的分词。 尽管 “Harry Potter and the Deathly Hallows – Part 1” 与最高分相匹配,但输入查询分词是单独匹配的,从而为我们提供了两个文档作为结果。 如果你认为这可能会导致问题,你也可以为搜索查询指定分析器。
因此,edge-n-gram 通过在倒排索引中保存额外的分词来克服前缀查询的限制,从而最大限度地减少查询时间延迟。 但是,这些额外的分词确实会占用节点上的额外空间,并可能导致性能下降。 我们在选择 n-gram 字段时应该小心,因为某些字段的值可能具有无限大小,并且可能会导致索引膨胀。
Search_as_you_type
Search_as_you 类型数据类型是在 Elasticsearch 7.2 中引入的,旨在为自动完成功能提供开箱即用的支持。 与 edge-n-gram 方法一样,这也通过生成额外的分词来优化自动完成查询来完成索引时的大部分工作。 当特定字段映射为 search_as_you_type 类型时,会在内部为其创建其他子字段。 让我们将标题字段类型更改为 search_as_you_type:
DELETE moviesPUT /movies
{"mappings": {"properties": {"title": {"type": "search_as_you_type","max_shingle_size": 3}}}
}对于上述索引中的标题属性,将创建三个子字段。 这些子字段使用 shingle token 过滤器。 Shingles 只不过是一组连续的单词(单词 n-gram,如上所示)。
- 根 title 字段 ⇒ 使用映射中提供的分析器进行分析,如果未提供,则使用默认值
- title._2gram ⇒ 这会将标题分成各有两个单词的部分,即大小为 2 的 shingles。
- title._3gram ⇒ 这会将标题分成每个包含三个单词的部分。
- title._index_prefix ⇒ 这将对 title._3gram 下生成的分词执行进一步的 edge ngram 分词。
我们可以使用我们最喜欢的 _analyze API 来测试它的行为:
GET movies/_analyze
{"text": "Harry Potter and the Goblet of Fire","field": "title"
}上面返回:
harry, potter, and, the, goblet, of, fireGET movies/_analyze
{"text": "Harry Potter and the Goblet of Fire","field": "title._2gram"
}上面的命令返回:
harry potter, potter and, and the, the goblet, goblet of, of fireGET movies/_analyze
{"text": "Harry Potter and the Goblet of Fire","field": "title._3gram"
}上面的命令返回:
harry potter and,potter and the,and the goblet,the goblet of,goblet of fireGET movies/_analyze
{"text": "Harry Potter and the Goblet of Fire","field": "title._index_prefix"
}上面的命令返回:
h, ha, har, harr, harry, harry[空隔], harry p, harry po, harry pot, harry pott,
harry potte, harry potter, harry potter[空隔], harry potter a, harry potter an,
harry potter and,
p, po, pot, pott, potte, potter, potter[空隔], potter a, potter an, potter and,
potter and[空隔], potter and t, potter and th, potter and the,
a, an, and, and[空隔], and t, and th, and the, and the[空隔], and the g, and the go,
and the gob, and the gobl, and the goble, and the goblet,
t, th, the, the[空隔], the g, the go, the gob, the gobl, the goble, the goblet,
the goblet[空隔], the goblet o, the goblet of,
g, go, gob, gobl, goble, goblet, goblet o, goblet of, goblet of[空隔], goblet of f,
goblet of fi, goblet of fir, goblet of fire,
o, of, of[空隔], of f, of fi, of fir, of fire, of fire[空隔],
f, fi, fir, fire, fire[空隔], fire[空隔][空隔] 要创建多少个子字段由 max_shingle_size 参数决定,默认为 3,可以设置为 2、3 或 4。Search_as_you_type 是一个类似文本的字段,因此我们为文本字段使用其他选项(例如分析器、 还支持索引、存储、search_analyzer)。
你现在一定已经猜到了,它支持前缀和中缀匹配。 在查询时,我们需要使用 multi_match 查询,因为我们也需要定位其子字段:
POST movies/_doc
{"title": "Harry Potter and the Goblet of Fire"
}GET /movies/_search?filter_path=**.hits
{"query": {"multi_match": {"query": "the goblet","type": "bool_prefix","analyzer": "keyword","fields": ["title","title._2gram","title._3gram"]}}
}上面的查询返回:
{"hits": {"hits": [{"_index": "movies","_id": "fr-sHIsByaLf0EuThM2C","_score": 3,"_source": {"title": "Harry Potter and the Goblet of Fire"}}]}
}我们在这里将查询类型设置为 bool_prefix。 查询将匹配具有任何顺序的 title 的文档,但具有与查询中的文本匹配的顺序的文档将排名更高。 在上面的示例中,我们将 “the goblet” 作为查询文本传递,因此标题为 “the goblet of fire” 的文档的排名将高于标题为 “fire goblet” 的文档。
另外,我们将查询分析器指定为关键字,这样我们的查询文本 “the goblet” 就不会被分析,而是按原样进行匹配。 如果没有这个,标题为 “Harry Potter and the Goblet of Fire” 的文档以及标题为 “Harry Potter and the Deathly Hallows – Part 1” 的文档也会匹配。
这不是查询 search_as_you_type 字段的唯一方法,但肯定更适合我们的自动完成用例。
与 edge-n-gram 一样,search_as_you_type 通过存储针对自动完成进行优化的数据来克服前缀查询方法的限制。 因此,在这种方法中,我们也必须小心使用该字段存储的内容。 需要额外的空间来存储这些 n-gram 分词。
相关文章:
在 Elasticsearch 中实现自动完成功能 2:n-gram
在第一部分中,我们讨论了使用前缀查询,这是一种自动完成的查询时间方法。 在这篇文章中,我们将讨论 n-gram - 一种索引时间方法,它在基本标记化后生成额外的分词,以便我们稍后在查询时能够获得更快的前缀匹配。 但在此…...

美客多、亚马逊卖家如何运用自养账号进行有效测评?
到了10月,卖家朋友们都在忙着准备Q4旺季吧! 首先,祝愿所有看到这条推文的卖家朋友,今年旺季都能爆单,赚得盆满钵满! 测评是珑哥常谈,一直备受关注,不论是新老卖家都是一个逃不开的…...
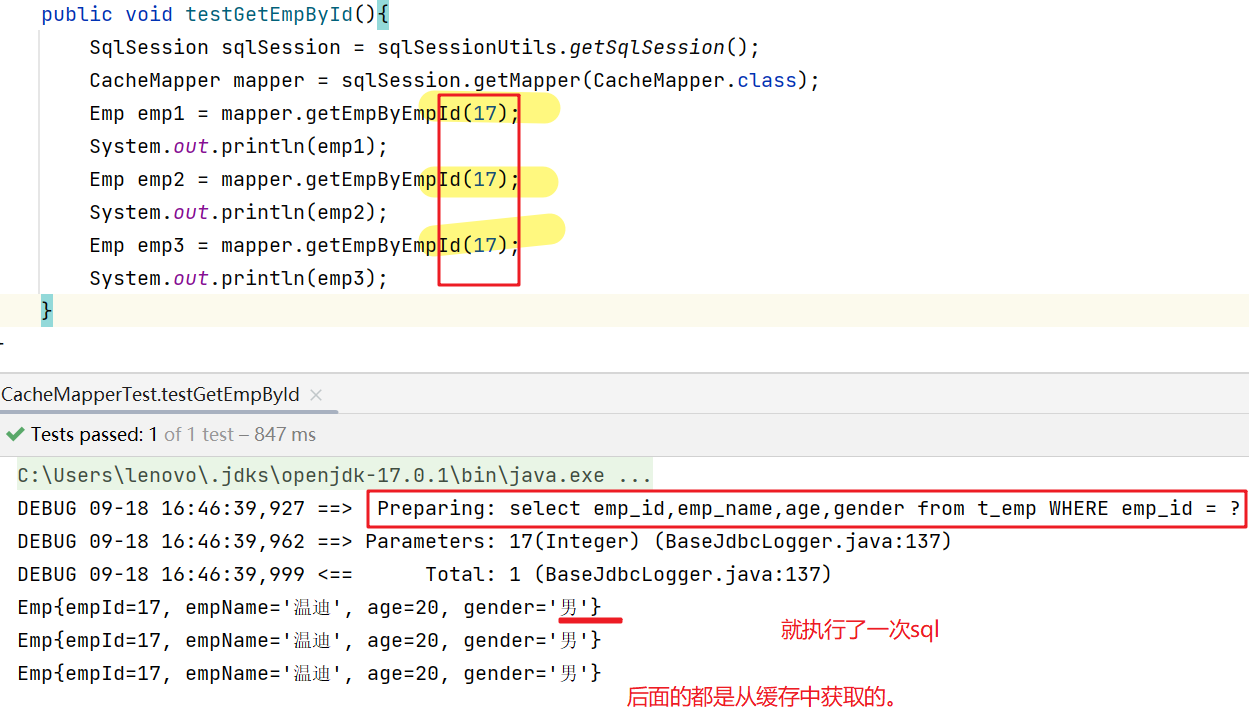
MyBatis的缓存,一级缓存,二级缓存
10、MyBatis的缓存 10.1、MyBatis的一级缓存 一级缓存是SqlSession级别的,通过同一个SqlSession对象 查询的结果数据会被缓存,下次执行相同的查询语句,就 会从缓存中(缓存在内存里)直接获取,不会重新访问…...
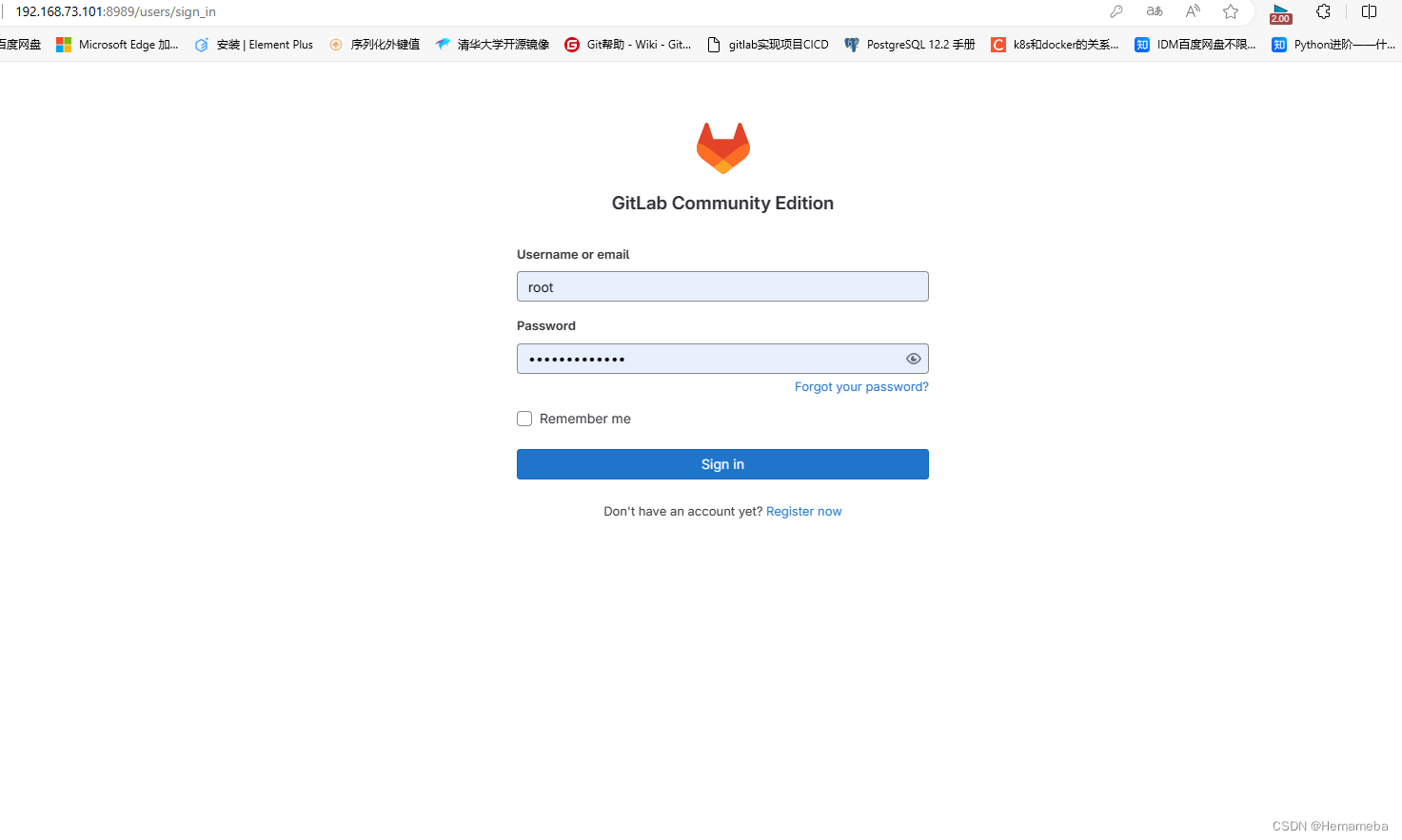
GitLab(1)——GitLab安装
目录 一、使用设备 二、使用rpm包安装 Gitlab国内清华源下载地址: ①下载命令如下: ②安装命令如下: ③删除rpm包 ④配置 ⑤重载 ⑥重启 ⑦配置自启动 ⑧打开8989端口并重启防火墙 三、GitLab登录 ①访问GitLab的URL ②输入用户…...

退税政策线上VR互动科普展厅为税收工作带来了强大活力
缴税纳税是每个公民应尽的义务和责任,由于很多人缺乏专业的缴税纳税操作专业知识和经验,因此为了提高大家的缴税纳税办事效率和好感度,越来越多地区税务局开始引进VR虚拟现实、web3d开发和多媒体等技术手段,基于线上为广大公民提供…...
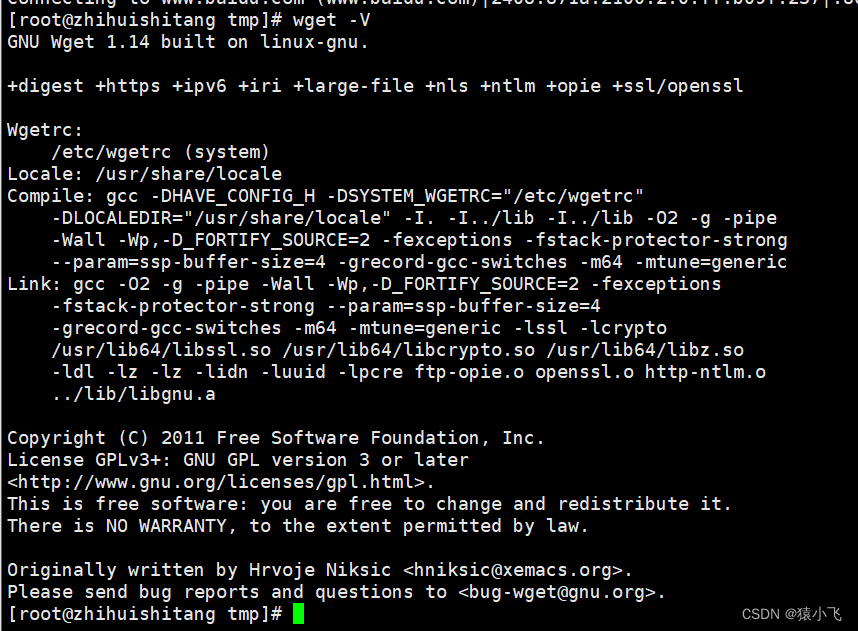
centos 7.9离线安装wget
1.下载安装包 登录到wget官网上下载最新的wget的rpm安装包到本地 http://mirrors.163.com/centos/7/os/x86_64/Packages/ 2.上传安装包到服务器 3.安装 rpm -ivh wget-1.14-18.el7_6.1.x86_64.rpm 4.查看版本 wget -V...

【Java学习之道】网络编程的基本概念
引言 这一章我们将一同进入网络编程的世界。在开始学习网络编程之前,我们需要先了解一些基本概念。那么,我们就从“什么是网络编程”这个问题开始吧。 一、网络编程的基本概念 1.1 什么是网络编程 网络编程,顾名思义,就是利用…...

Restful API 设计示例
Restful API 设计示例 一 ,HTTP状态码 ✔️正例: 200: 返回成功 说明:200表示成功,4xx表示客户端异常,5xx表示服务端异常,参见HTTP 的返回码含义 ❌反例: 除了200就是500 说明࿱…...
为知笔记一个日记模板
<!DOCTYPE HTML><html><head> <meta http-equiv"Content-Type" content"text/html; charsetunicode"> <title>日记:</title><style id"wiz_custom_css">html, .wiz-editor-body {font-siz…...
软件测试中如何测试算法?
广义的算法是指解决问题的方案,小到求解数学题,大到制定商业策略,都可以叫做算法。而我们 今天讨论的软件测试中的算法,对应的英文单词为Algorithm ,专指计算机处理复杂问题的程序或 指令。 随着最近几年人工智能等领域的快速发展,算法受到前所未有的重视,算法测试也随之兴起。…...

CMOS图像传感器——Sony Ta-Kuchi图像传感器
2023 年国际图像传感器研讨会于 5 月在苏格兰克里夫举行,第四场会议重点关注汽车传感器,汽车应用中 CMOS 图像传感器 (CIS) 的技术要求与消费(移动)设备中的要求不同。毕竟,很少有人关心车载摄像头的像素数或图像美观度。主要驱动因素是安全性、可靠性和成本。 而汽车领域…...
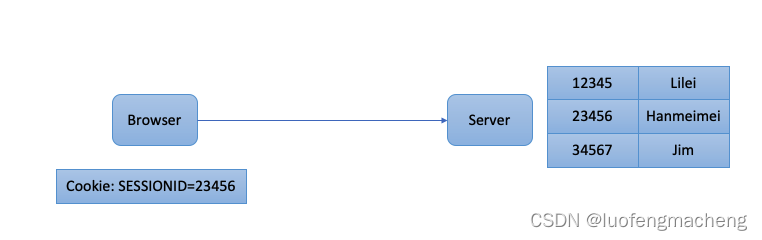
一文理解登录鉴权(Cookie、Session、Jwt、CAS、SSO)
1 前言 登录鉴权是任何一个网站都无法绕开的部分,当系统要正式上线前都会要求接入统一登陆系统,一方面能够让网站只允许合法的用户访问,另一方面,当用户在网站上进行操作时也需要识别操作的用户,用作后期的操作审计。…...
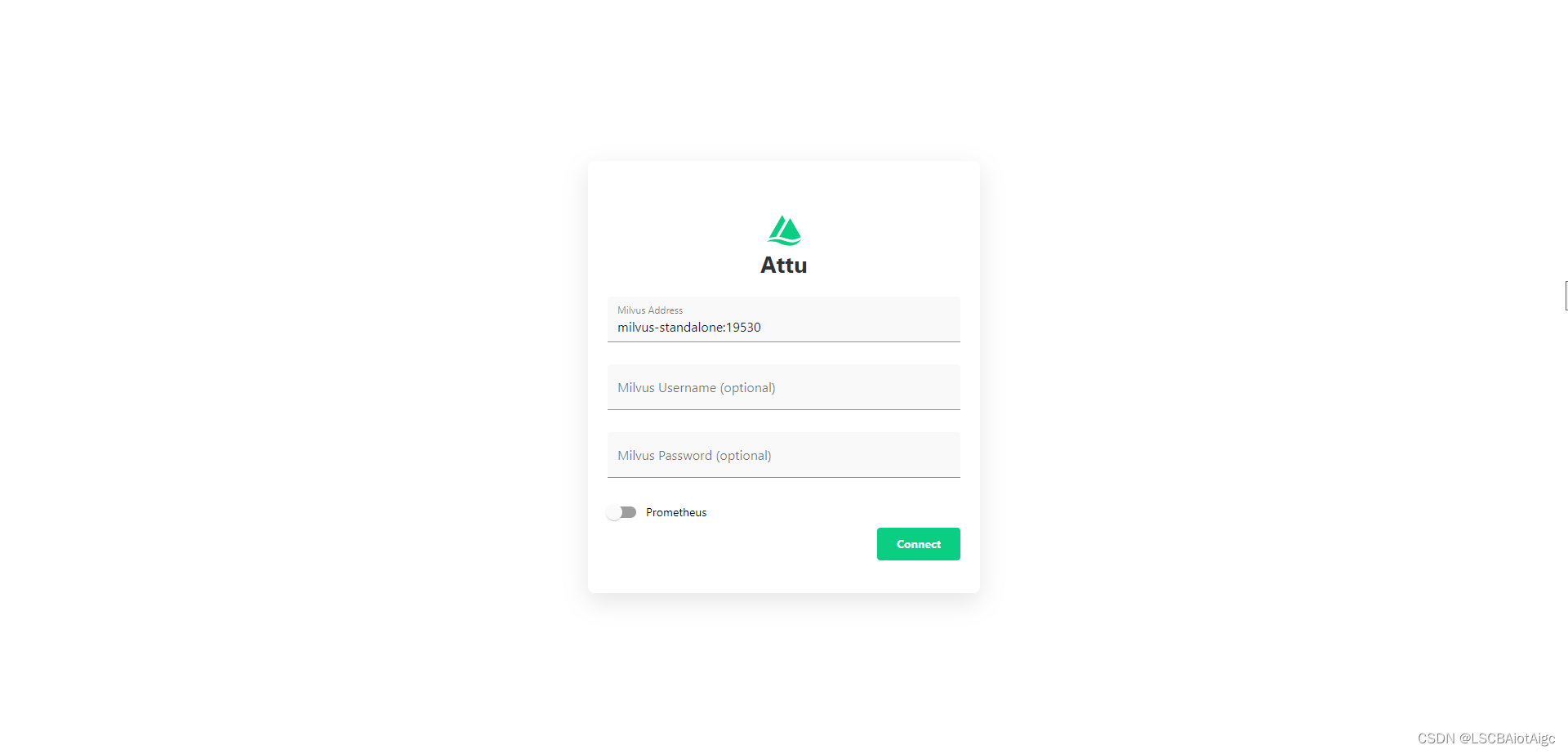
LangChain结合milvus向量数据库以及GPT3.5结合做知识库问答之一 --->milvus的docker compose安装
https://github.com/milvus-io/milvus/releaseshttps://github.com/milvus-io/milvus/releases 以下步骤均在Linux环境中进行: 将milvus-standalone-docker-compose.yml下载到本地。 1、新建一个目录milvus 2、将milvus-standalone-docker-compose.yml放到milvu…...

安装nginx,配置https,并解决403问题
nginx安装 下载nginx:下载地址 上传到/opt目录 解压nginx,并进入解压后到目录 cd /opt tar -zxvf nginx-1.25.2.tar.gz cd nginx-1.25.2编译(with-http_ssl_module为https模块) ./configure --with-http_ssl_module安装 make install默认的安装目录为…...

RustDay04------Exercise[11-20]
11.函数原型有参数时需要填写对应参数进行调用 这里原先call_me函数没有填写参数导致报错 添加一个usize即可 // functions3.rs // Execute rustlings hint functions3 or use the hint watch subcommand for a hint.fn main() {call_me(10); }fn call_me(num: u32) {for i i…...

【Python第三方包】快速获取硬件信息和使用情况(psutil、platform)
文章目录 前言一、psutil包1.1 安装psutil包1.2 psutil 使用方式获取CPU使用率获取内存使用情况将内存的获取的使用情况变成GB和MB获取磁盘使用情况磁盘内存进行转换获取网络信息网络info 二、platform2.1 platform的介绍2.2 platform 使用方式获取操作系统的名称获取架构的名称…...
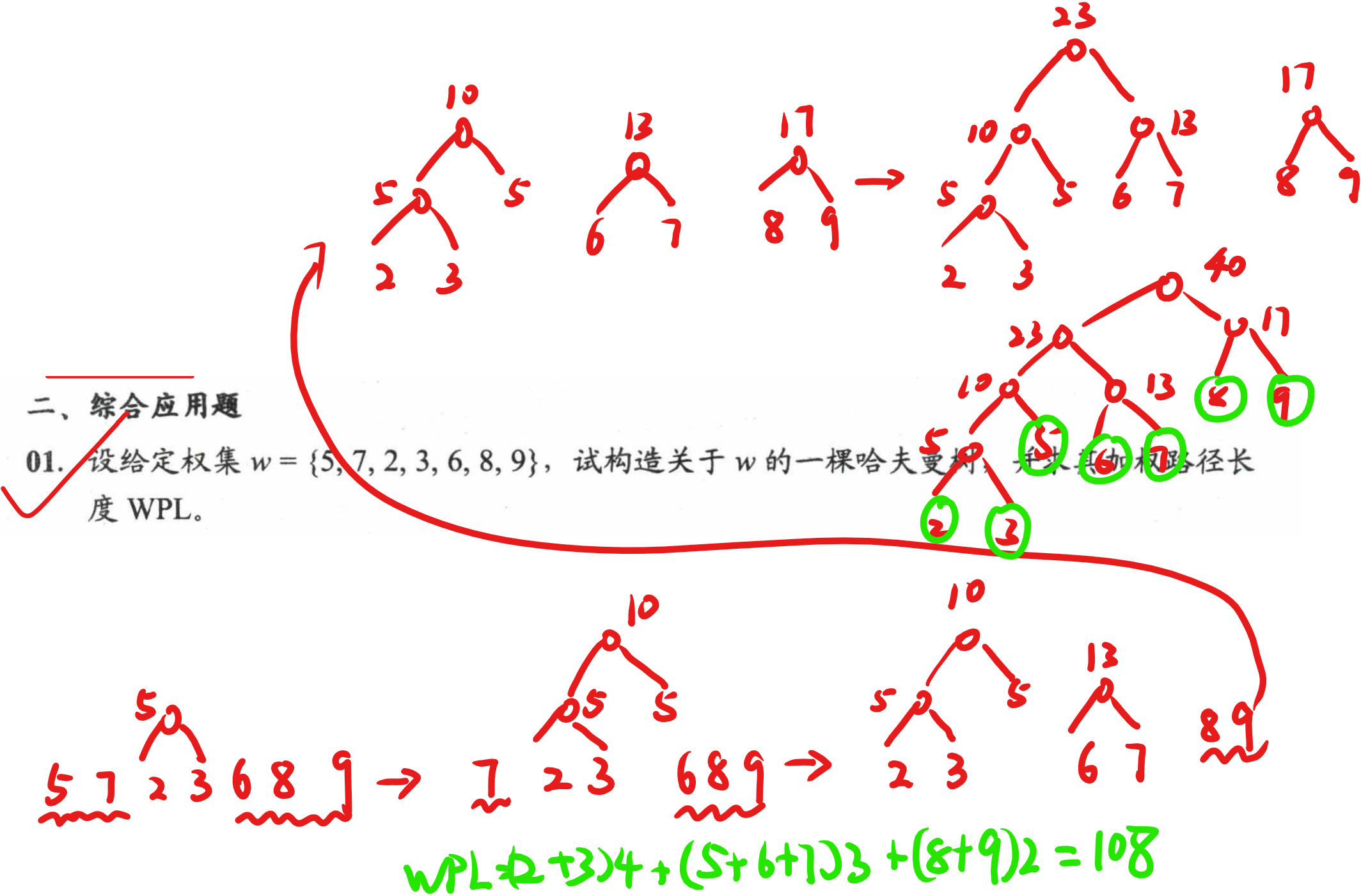
数据结构与算法课后题-第五章(哈夫曼树和哈夫曼编码)
文章目录 选择题1选择题2选择题3选择题4选择题5选择题6选择题7应用题7 选择题1 选择题2 选择题3 需要深究 选择题4 选择题5 选择题6 选择题7 应用题7...
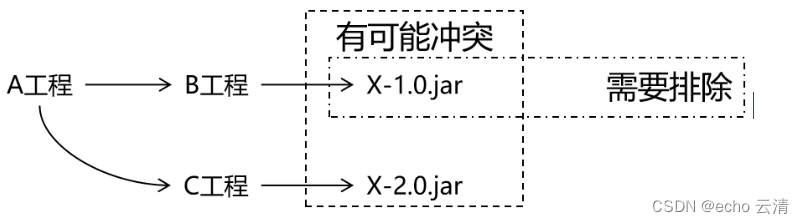
07测试Maven中依赖的范围,依赖的传递原则,依赖排除的配置
依赖的特性 scope标签在dependencies/dependency标签内,可选值有compile(默认值),test,provided,system,runtime,import compile:在项目实际运行时真正要用到的jar包都是以compile的范围进行依赖 ,比如第三方框架SSM所需的jar包test:测试过程中使用的j…...

科技为饮食带来创新,看AI如何打造智能营养时代
在当今社会,快节奏的生活方式、便捷的食品选择以及现代科技的快速发展正深刻地重塑着我们对健康的认知和实践,它已经不再仅仅是一个话题,而是一个备受关注的社会焦点。在这个纷繁复杂的交汇点上,AI技术的介入为我们开辟了前所未有…...
软件测试知识库+1,5款顶级自动化测试工具推荐和使用分析
“工欲善其事必先利其器”,在自动化测试领域,自动化测试工具的核心地位不容置疑的。目前市面上有很多可以支持接口测试的工具,在网上随便一搜就可以出来很多,利用自动化测试工具进行接口测试,可以很好的提高测试效率&a…...

p5.js Web Editor:免费在线创意编程的终极完整指南
p5.js Web Editor:免费在线创意编程的终极完整指南 【免费下载链接】p5.js-web-editor The p5.js Editor is a website for creating p5.js sketches, with a focus on making coding accessible and inclusive for artists, designers, educators, beginners, and …...
)
Spring AI完整学习路线:从Java开发到AI Agent的进阶之路(附15篇实战教程)
🔥 Java开发者必看!Spring AI完整学习路线:从CRUD到AI Agent的蜕变之路(2026终极指南) 作者:12年OTA公司资深程序员 技术栈:Spring Boot 3.5.9 Spring AI 1.1.4 Reactor 多模型集成 阅读时间…...
)
V型槽有灰还是镜头花了?三步排查图像模糊的真凶(工地实测版)
夏天的老旧小区弱电井,或者秋天刚刮过西北风的马路边,可以说是装维师傅们的"噩梦主场"。你蹲在逼仄的角落里,熟练地剥线、切割,把光纤小心翼翼地放入机器,按下防风盖。结果伴随着几声急促的"滴滴"…...

MATLAB集成大语言模型:无缝融合AI能力与工程计算生态
1. 项目概述:当MATLAB遇见大语言模型如果你是一位工程师、研究员或者数据分析师,并且你的日常工作离不开MATLAB,那么你很可能已经感受到了AI浪潮的冲击。大语言模型(LLMs)如ChatGPT、Llama等,正在重塑我们处…...

Android Studio中文界面解决方案:从语言障碍到开发效率提升
Android Studio中文界面解决方案:从语言障碍到开发效率提升 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 当你在And…...

Polymarket套利机器人:DeFi预测市场的自动化交易策略与实现
1. 项目概述:一个捕捉Polymarket预测市场套利机会的自动化交易机器人 最近在DeFi和预测市场领域,Polymarket这个基于Polygon链的平台热度持续攀升。它本质上是一个事件预测市场,用户可以就各类现实世界事件(比如“某球队能否赢得冠…...
)
RK3588 Android12在线视频播放拷机重启?手把手教你定位DMABUF内存泄漏(附/proc节点排查法)
RK3588 Android12视频播放内存泄漏实战:从崩溃日志到精准定位DMABUF泄漏进程 当RK3588平台在Android12系统上长时间播放在线视频时突然重启,这种看似随机的系统崩溃往往让开发者头疼不已。本文将带您深入内核层,通过一套可复用的方法论&#…...

从零构建千万级IM系统:微服务架构与核心消息流转实战
1. 项目概述:从零理解一个现代即时通讯系统的核心如果你正在寻找一个能支撑起千万级用户、功能对标主流商业产品的即时通讯(IM)系统开源实现,那么open-im-server绝对是一个绕不开的名字。这个由OpenIM项目开源的Go语言服务端&…...

开源项目如何从“用爱发电”变成可持续收入?
一、为什么测试领域的开源项目更需要可持续收入?在测试领域,开源工具早已成为基础设施。从UI自动化的Selenium、移动端的Appium,到性能压测的JMeter、新一代端到端框架Playwright,几乎每个测试工程师的日常工作都构建在开源软件之…...

[Cesium] 数字孪生实践 | 超图插件打通UE4/Unity三维GIS管线全解析
1. 数字孪生与三维GIS技术融合的现状 数字孪生技术正在改变我们理解和构建物理世界的方式。简单来说,数字孪生就是通过数字化手段,在虚拟空间中创建一个与真实世界完全对应的"双胞胎"。这个数字化的双胞胎可以实时反映真实世界的状态ÿ…...