Hadoop3教程(十七):MapReduce之ReduceJoin案例分析
文章目录
- (113)ReduceJoin案例需求分析
- (114)ReduceJoin案例代码实操 - TableBean
- (115)ReduceJoin案例代码实操 - TableMapper
- (116)ReduceJoin案例代码实操 - Reducer及Driver
- 参考文献
(113)ReduceJoin案例需求分析
现在有两个文件:
- orders.txt,存放的是订单ID、产品ID、产品数量
- pd.txt,这是一个产品码表,存放的是产品ID、产品中文名;
现在是想通过join,来实现这么一个预期输出,即订单ID、产品中文名、产品数量。
以上是本次案例需求。
简单思考一下思路。我们需要将关联条件作为Map输出的key,将两表满足Join条件的数据以及数据所来源的文件信息,发往同一个ReduceTask,在Reduce中进行数据的串联。
具体该怎么做呢?
Map中在处理的时候,需要获取输入的文件内容和文件名(这个是可以在切片的时候获取的),然后不同文件分别做不同处理,处理完成后封装bean对象输出。
注意,Map在输出的时候,需要以产品ID作为key,只有这样做,才能将相同产品ID的orders.txt记录和pd.txt记录,放在同一个reduceTask里,进而实现最终的替换。value的话,选择订单ID、订单数量、文件名。这里传入文件名的原因是Reduce阶段需要根据不同文件名实现不同处理,所以一定得需要传一个文件名进来。
另外提一句,封装bean对象的时候,需要把两个文件里的所有字段合起来作为一个bean对象,这样子,orders文件的数据可以用这个bean对象,pd.txt里的数据也可以用这个bean对象。相当于做一个大宽表。
reduce阶段就很简单了,相同产品ID的orders.txt记录和pd.txt记录,被放在同一个reduceTask里,可以把来自orders的bean放在一个集合里,来自pd的bean放在一个集合里,然后遍历set覆盖就可以。
(114)ReduceJoin案例代码实操 - TableBean
首先需要定义一个Bean对象,用来序列化两个输入文件的数据,我们命名为TableBean。
package com.atguigu.mapreduce.reducejoin;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class TableBean implements Writable {private String id; //订单idprivate String pid; //产品idprivate int amount; //产品数量private String pname; //产品名称private String flag; //判断是order表还是pd表的标志字段public TableBean() {}public String getId() {return id;}public void setId(String id) {this.id = id;}public String getPid() {return pid;}public void setPid(String pid) {this.pid = pid;}public int getAmount() {return amount;}public void setAmount(int amount) {this.amount = amount;}public String getPname() {return pname;}public void setPname(String pname) {this.pname = pname;}public String getFlag() {return flag;}public void setFlag(String flag) {this.flag = flag;}@Overridepublic String toString() {return id + "\t" + pname + "\t" + amount;}// 序列化方法@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(id);out.writeUTF(pid);out.writeInt(amount);out.writeUTF(pname);out.writeUTF(flag);}// 反序列化方法// 注意,序列化的顺序必须要跟反序列化的顺序一致@Overridepublic void readFields(DataInput in) throws IOException {this.id = in.readUTF();this.pid = in.readUTF();this.amount = in.readInt();this.pname = in.readUTF();this.flag = in.readUTF();}
}
注意,序列化的顺序必须要跟反序列化的顺序一致。
(115)ReduceJoin案例代码实操 - TableMapper
TableMapper的主要作用,就是将输入的数据,划分成指定的KV对,以供Reduce阶段使用。
命名为TableMapper,获取文件名称的代码也包含在这里。
package com.atguigu.mapreduce.reducejoin;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;public class TableMapper extends Mapper<LongWritable,Text,Text,TableBean> {private String filename;private Text outK = new Text();private TableBean outV = new TableBean();@Overrideprotected void setup(Context context) throws IOException, InterruptedException {//获取对应文件名称InputSplit split = context.getInputSplit();FileSplit fileSplit = (FileSplit) split;filename = fileSplit.getPath().getName();}@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//获取一行String line = value.toString();//判断是哪个文件,然后针对文件进行不同的操作if(filename.contains("order")){ //订单表的处理String[] split = line.split("\t");//封装outKoutK.set(split[1]);//封装outVoutV.setId(split[0]);outV.setPid(split[1]);outV.setAmount(Integer.parseInt(split[2]));outV.setPname("");outV.setFlag("order");}else { //商品表的处理String[] split = line.split("\t");//封装outKoutK.set(split[0]);//封装outVoutV.setId("");outV.setPid(split[0]);outV.setAmount(0);outV.setPname(split[1]);outV.setFlag("pd");}//写出KVcontext.write(outK,outV);}
}
(116)ReduceJoin案例代码实操 - Reducer及Driver
主要是编写Reduce部分。Mapper之后,一组相同的key的数据会进入一个ReduceTask,接下来需要编写自定义逻辑,让Reduce可以实现关联后输出。
需要创建两个集合,每个集合接收不同文件,一个接收order文件数据,另一个接收码表数据。然后循环遍历order集合,把码表集合里的值set进去。
新建TableReducer:
package com.atguigu.mapreduce.reducejoin;import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;public class TableReducer extends Reducer<Text,TableBean,TableBean, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException {ArrayList<TableBean> orderBeans = new ArrayList<>();TableBean pdBean = new TableBean();for (TableBean value : values) {//判断数据来自哪个表if("order".equals(value.getFlag())){ //订单表//创建一个临时TableBean对象接收valueTableBean tmpOrderBean = new TableBean();try {BeanUtils.copyProperties(tmpOrderBean,value);} catch (IllegalAccessException e) {e.printStackTrace();} catch (InvocationTargetException e) {e.printStackTrace();}//将临时TableBean对象添加到集合orderBeansorderBeans.add(tmpOrderBean);}else { //商品表try {BeanUtils.copyProperties(pdBean,value);} catch (IllegalAccessException e) {e.printStackTrace();} catch (InvocationTargetException e) {e.printStackTrace();}}}//遍历集合orderBeans,替换掉每个orderBean的pid为pname,然后写出for (TableBean orderBean : orderBeans) {orderBean.setPname(pdBean.getPname());//写出修改后的orderBean对象context.write(orderBean,NullWritable.get());}}
}
根据教程上说的,这里只有一个地方需要注意,但是用处也不是很大,就是 集合在add value的时候,不能直接add 传进来的value,而是需要重新new一个TableBean,将value值赋值给这个新的TableBean,最后add这个新的TableBean。
这么做的原因是,传进来的values,其实是一个Iterable<TableBean> ,不是传统意义上的迭代器,可以简单理解成,Iterable<TableBean> 里的每个value用的是同一个内存地址,每次读取出value就总是赋给那个内存地址,所以不能直接add value,否则add 一百次,也只会记住最后一次add的那个value。
这似乎是Hadoop为了避免因创建过多实例引起资源浪费,而做的优化。
没有测过,做简单了解吧。
最后在驱动类里注册:
package com.atguigu.mapreduce.reducejoin;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class TableDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Job job = Job.getInstance(new Configuration());job.setJarByClass(TableDriver.class);job.setMapperClass(TableMapper.class);job.setReducerClass(TableReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(TableBean.class);job.setOutputKeyClass(TableBean.class);job.setOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job, new Path("D:\\input"));FileOutputFormat.setOutputPath(job, new Path("D:\\output"));boolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}
}
大功告成
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
:MapReduce之ReduceJoin案例分析)
Hadoop3教程(十七):MapReduce之ReduceJoin案例分析
文章目录 (113)ReduceJoin案例需求分析(114)ReduceJoin案例代码实操 - TableBean(115)ReduceJoin案例代码实操 - TableMapper(116)ReduceJoin案例代码实操 - Reducer及Driver参考文献…...
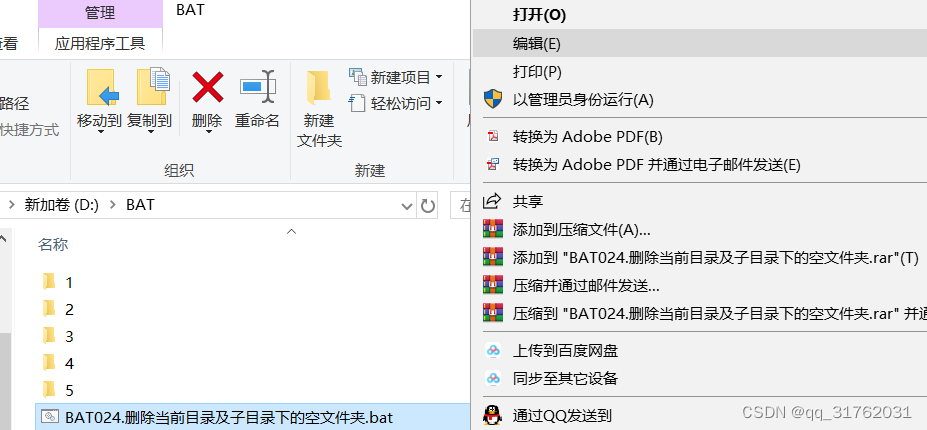
BAT026:删除当前目录及子目录下的空文件夹
引言:编写批处理程序,实现批量删除当前目录及子目录下的空文件夹。 一、新建Windows批处理文件 参考博客: CSDNhttps://mp.csdn.net/mp_blog/creation/editor/132137544 二、写入批处理代码 1.右键新建的批处理文件,点击【编辑…...

nodejs+vue网课学习平台
目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章 相关技术 3 2.1 nodejs简介 4 2.2 express框架介绍 6 2.4 MySQL数据库 4 第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:…...

Can Language Models Make Fun? A Case Study in Chinese Comical Crosstalk
本文是LLM系列文章,针对《Can Language Models Make Fun? A Case Study in Chinese Comical Crosstalk》的翻译。 语言模型能制造乐趣吗?中国滑稽相声个案研究 摘要1 引言2 问题定义3 数据集4 使用自动评估生成基准5 人工评估6 讨论7 结论与未来工作 摘要 语言是…...
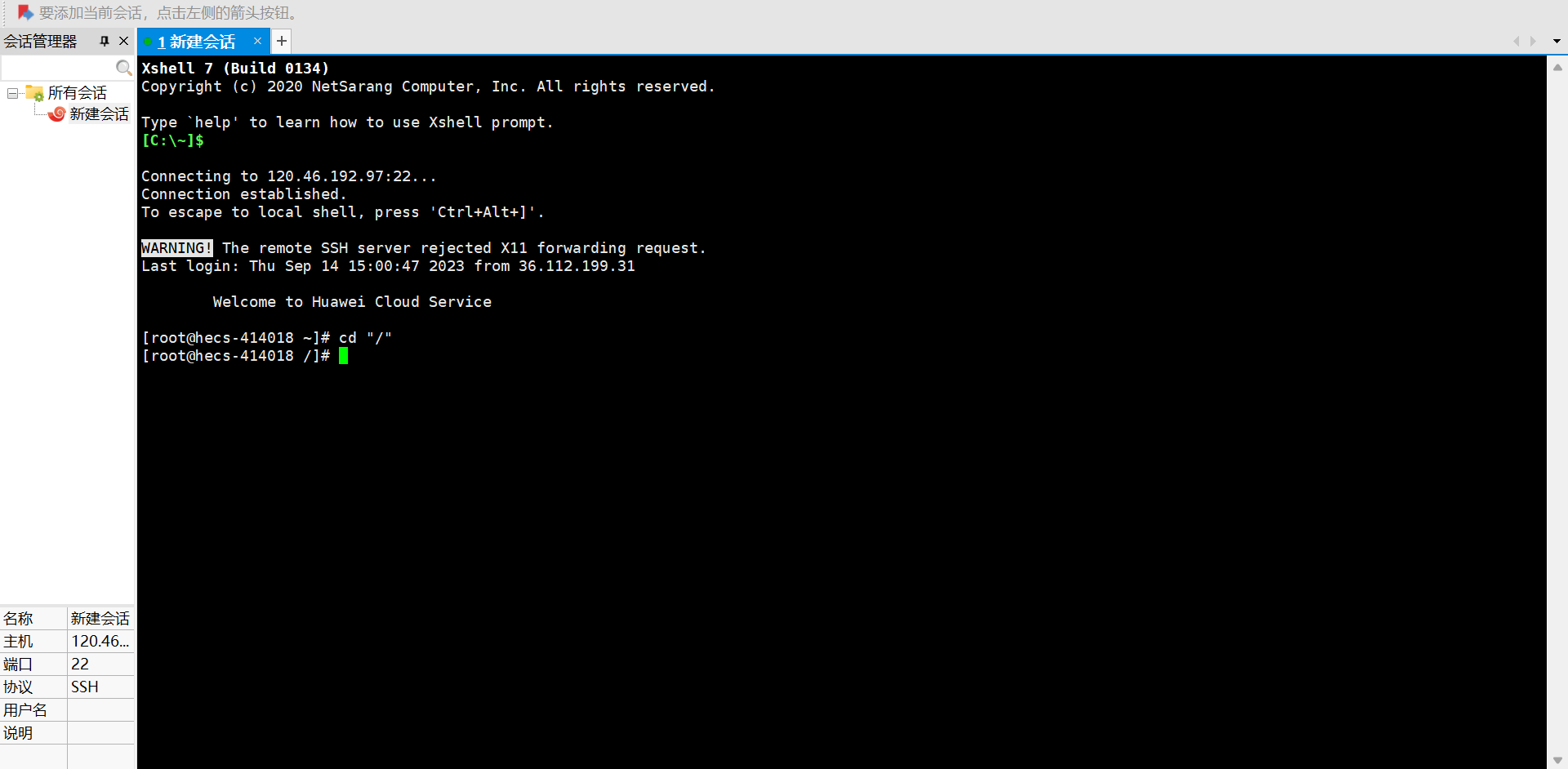
阿里云云服务器实例使用教学
目录 云服务器免费试用 详细步骤 Xshell 远程连接 云服务器免费试用 阿里云云服务器网址:阿里云免费试用 - 阿里云 详细步骤 访问阿里云免费试用。单击页面右上方的登录/注册按钮,并根据页面提示完成账号登录(已有阿里云账号)…...

promisify 是 Node.js 标准库 util 模块中的一个函数
promisify 是 Node.js 标准库 util 模块中的一个函数。它用于将遵循 Node.js 回调风格的函数转换为返回 Promise 的函数。这使得你可以使用 async/await 语法来等待异步操作完成,从而让异步代码看起来更像同步代码。 在 Node.js 的回调风格中,函数通常接…...

ArcGIS在VUE框架中的构建思想
项目快要上线了,出乎意料的有些空闲时间。想着就把其他公司开发的一期代码里面,把关于地图方面的代码给优化一下。试运行的时候,客户说控制台有很多飘红的报错,他们很在意,虽然很不情愿,但能改的就给改了吧…...

【Overload游戏引擎细节分析】视图投影矩阵计算与摄像机
本文只罗列公式,不做具体的推导。 OpenGL本身没有摄像机(Camera)的概念,但我们为了产品上的需求与编程上的方便,一般会抽象一个摄像机组件。摄像机类似于人眼,可以建立一个本地坐标系。相机的位置是坐标原点,摄像机的朝…...

什么是云原生?零基础学云原生难吗?
伴随着云计算的浪潮,云原生概念也应运而生,而且火得一塌糊涂,但真正谈起“云原生”,大多数非 IT 从业者的认知往往仅限于将服务应用放入云端,在云上处理业务。实际上,云原生远不止于此。 现在越来越多的企…...
Ubuntu18.04下载安装基于使用QT的pcl1.13+vtk8.2,以及卸载
一、QVTKWidget、QVTKWidget2、QVTKOpenGLWidget、QVTKOpenGLNativeWidget 区别 1.Qt版本 Qt5.4以前版本:QVTKWidget2/QVTKWidget。 Qt5.4以后版本:QVTKOpenGLWidget/QVTKOpenGLWidget。 2.VTK版本(Qt版本为5.4之后) 在VTK8.2以前的版本:QVT…...
7 使用Docker容器管理的tomcat容器中的项目连接mysql数据库
1、查看容器的IP 1)进入容器 docker exec -it mysql-test /bin/bash 2)显示hosts文件内容 cat /etc/hosts 这里容器的ip为172.17.0.2 除了上面的方法外,也可以在容器外使用docker inspect查看容器的IP docker inspect mysql-test 以下为…...

双节前把我的网站重构了一遍
赶在中秋国庆假期前,终于将我的网站(https://spacexcode.com/[1])结构定好了,如之前所说,这个网站的定位就是作为自己的前端知识沉淀。内容大致从:前端涉及的基础知识分类汇总(知识库࿰…...

基于 nodejs+vue网上考勤系统
目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章 相关技术 3 2.1 nodejs简介 4 2.2 express框架介绍 6 2.4 MySQL数据库 4 第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:…...
以数智化指标管理,驱动光伏能源行业的市场推进
近年来,碳中和、碳达峰等降低碳排放、提升环境健康度的政策和技术改进正在不断地被社会所认可和引起重视,也被越来越多的企业在生产运营和基础建设中列为重要目标之一。而光伏能源行业作为全球绿色能源、新能源的优秀解决方案,充分利用太阳能…...
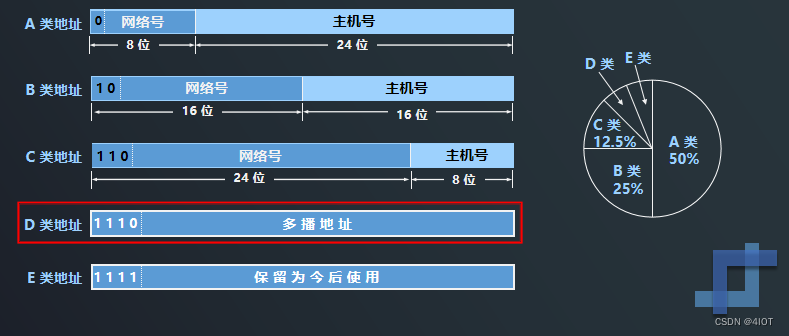
lv8 嵌入式开发-网络编程开发 18 广播与组播的实现
目录 1 广播 1.1 什么是广播? 1.2 广播地址 1.3 广播的实现 2 组播 2.1 分类的IP地址 2.2 多播 IP 地址 2.3 组播的实现 1 广播 1.1 什么是广播? 数据包发送方式只有一个接受方,称为单播 如果同时发给局域网中的所有主机࿰…...
)
前端面试题个人笔记(后面继续更新完善)
文章目录 填空题部分简答题部分 if有好答案请各位大佬们在底下评论上,感谢 填空题部分 1、常见的css选择器 2、getElementById获取元素的(DOM)对象 简答题部分 1、介绍一下你对RESTful API的理解以及它的优势? 答: …...
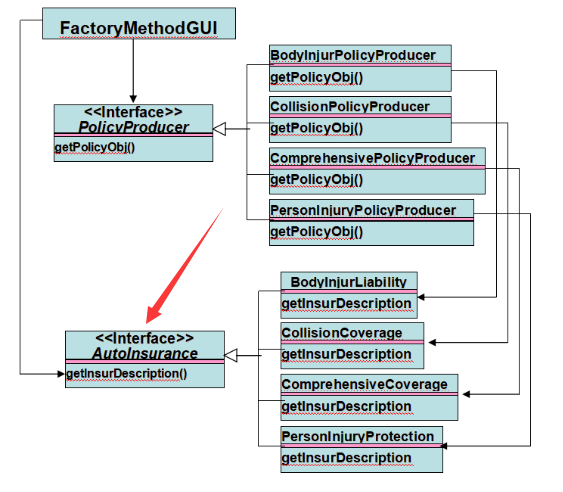
软件设计之工厂方法模式
工厂方法模式指定义一个创建对象的接口,让子类决定实例化哪一个类。 结构关系如下: 可以看到,客户端创建了两个接口,一个AbstractFactory,负责创建产品,一个Product,负责产品的实现。ConcreteF…...
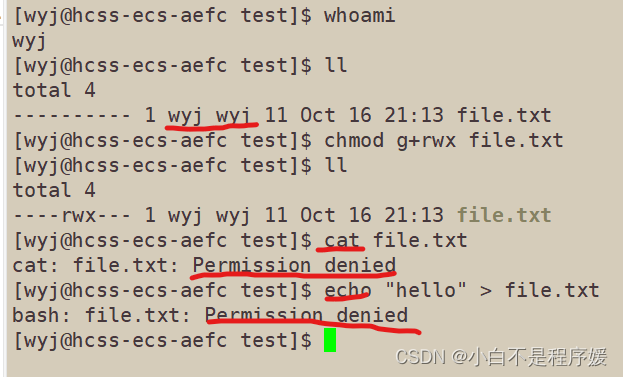
【Linux】shell运行原理及权限
主页点击直达:个人主页 我的小仓库:代码仓库 C语言偷着笑:C语言专栏 数据结构挨打小记:初阶数据结构专栏 Linux被操作记:Linux专栏 LeetCode刷题掉发记:LeetCode刷题 算法:算法专栏 C头疼…...

OA系统和ERP系统有什么区别?
在当今的企业管理领域,协同办公管理系统和ERP系统是两个非常重要的工具。它们在企业的日常运营中扮演着不同的角色,有着各自独特的功能和优势。那么,OA系统和ERP系统到底有什么区别呢?协同办公管理系统又是如何在这两者之间发挥协…...

c语言之strcat函数使用和实现
文章目录 前言一、strcat函数使用二、实现方法 前言 c语言之strcat 函数使用和实现 一、strcat函数使用 原型: char *strcat ( char * destination, const char * source );strcat追加拷贝,追加到目标空间后面,目标空间必须足够大,能容纳下…...

RevokeMsgPatcher实战指南:Windows微信QQ防撤回的终极秘籍
RevokeMsgPatcher实战指南:Windows微信QQ防撤回的终极秘籍 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcod…...

RANSAC算法调参指南:迭代次数和容差阈值到底怎么设?附Python/Matlab实例
RANSAC算法实战调参手册:从理论到代码的深度解析 在三维重建、自动驾驶和工业检测等机器视觉应用中,数据噪声和异常值一直是模型拟合的噩梦。传统最小二乘法就像一位过分认真的学生,试图让所有数据点都满意,结果却被少数离群点带偏…...

WPF老鸟的Avalonia初体验:用VS2022+Ubuntu虚拟机,从零到发布Linux安装包
WPF开发者实战Avalonia跨平台:VS2022Ubuntu全流程指南 当微软宣布.NET跨平台战略时,许多WPF开发者都看到了将桌面应用扩展到Linux和macOS的可能性。作为一个长期依赖WPF构建企业级应用的开发者,我第一次接触Avalonia时,最惊讶的是…...

告别笨重模拟器:Windows系统上直接安装APK的终极方案
告别笨重模拟器:Windows系统上直接安装APK的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经为了在电脑上运行一个简单的手机应用而不得…...

物联网超低功耗设计:从睡眠优先到能量自治的十年续航之道
1. 项目概述:让物联网节点运行数十年的设计哲学如果你正在部署一个大规模的物联网网络,无论是智慧城市的数千个路灯传感器,还是遍布数公里农田的环境监测节点,最让你头疼的问题恐怕不是通信协议,也不是数据处理&#x…...
)
保姆级教程:用Forge为你的Minecraft服务器添加热门Mod(附Curseforge选包清单)
从零打造高可玩性Minecraft Mod服务器:Forge环境配置与精品Mod组合指南 当你第一次打开Curseforge网站,面对超过10万个Minecraft Mod时,那种既兴奋又茫然的感觉我深有体会。作为从2013年就开始运营Mod服务器的老玩家,我见证了太多…...

如何用Python操控Photoshop?3步实现自动化图像处理的终极指南
如何用Python操控Photoshop?3步实现自动化图像处理的终极指南 【免费下载链接】photoshop-python-api Python API for Photoshop. 项目地址: https://gitcode.com/gh_mirrors/ph/photoshop-python-api Photoshop Python API是一个革命性的工具,让…...

Display Driver Uninstaller:显卡驱动问题的终极解决方案
Display Driver Uninstaller:显卡驱动问题的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstall…...

【最新版】heic格式转换器下载教程 livp格式转jpg超详细图文转换教程
文章目录准备工作安卓手机拍摄的heic格式转jpg教程苹果heic格式转jpg专用工具livp格式转jpg教程heic格式文件无法打开的原因及解决方法heic转换jpg后文件变大是什么原因本文将详细教你实现heic格式转jpg与livp格式转jpg的操作方法,同时免费提供实用的heic格式转换器…...

码森防伪溯源系统:一站式构建产品信任桥梁,赋能品牌全流程数字化管理
在假冒伪劣产品屡禁不止、消费者对产品来源与真实性日益关注的今天,如何高效实现防伪、溯源、营销、管理一体化,已成为品牌方与技术开发者共同关注的核心问题。 防伪溯源系统,正是这样一套集低成本、易操作、强扩展性于一体的综合性解决方案。…...