MySQL InnoDB引擎深入学习的一天(InnoDB架构 + 事务底层原理 + MVCC)
目录
逻辑存储引擎
架构
概述
内存架构
Buffer Pool
Change Buffe
Adaptive Hash Index
Log Buffer
磁盘结构
System Tablespace
File-Per-Table Tablespaces
General Tablespaces
Undo Tablespaces
Temporary Tablespaces
Doublewrite Buffer Files
Redo Log
后台线程
事务原理
事务基础回顾
效果
特性
编辑原理实现划分
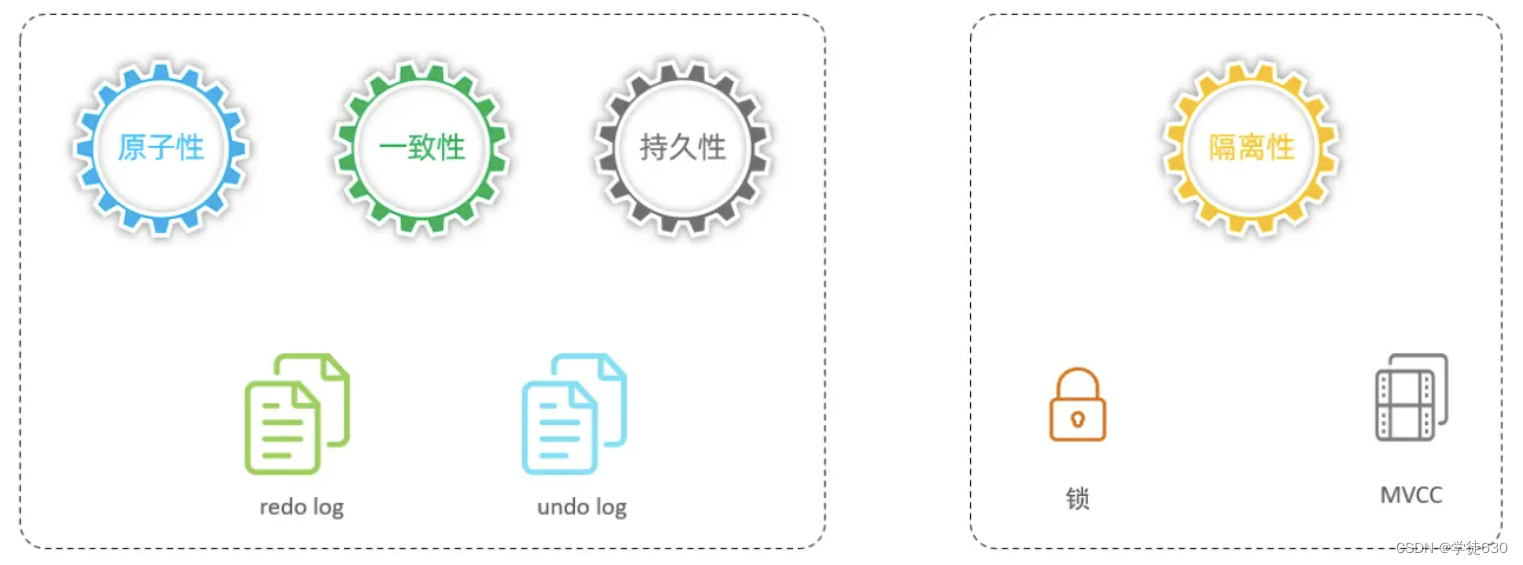
redo log保证事务持久性
undo log保证事务原子性
细节分辨:redo log 和 undo log的区别
undo log + redo log保证事务一致性
锁 + MVCC 保证事务隔离性
MVCC
基本概念
当前读
快照读
MVCC
隐藏字段
undolog
版本链
readview
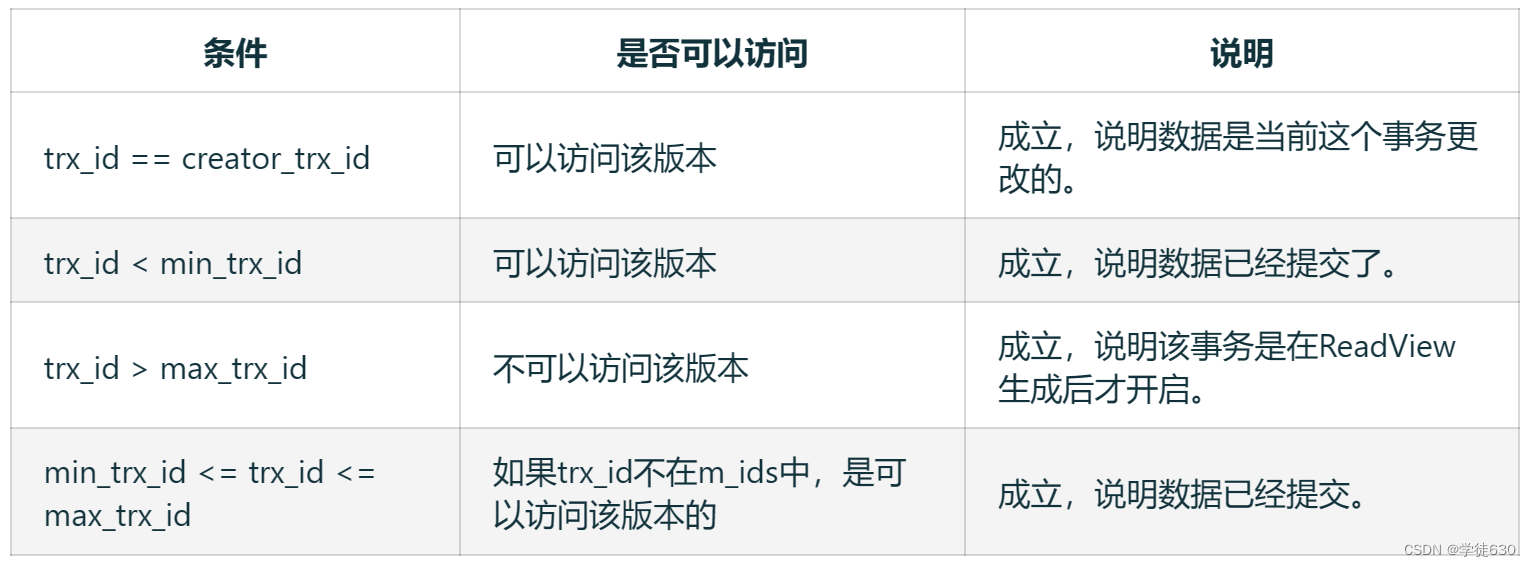
版本链数据访问规则
RC读已提交隔离级别原理
RR可重复读隔离级别原理
事务原理总结
逻辑存储引擎
InnoDB的逻辑存储结构如下图所示:
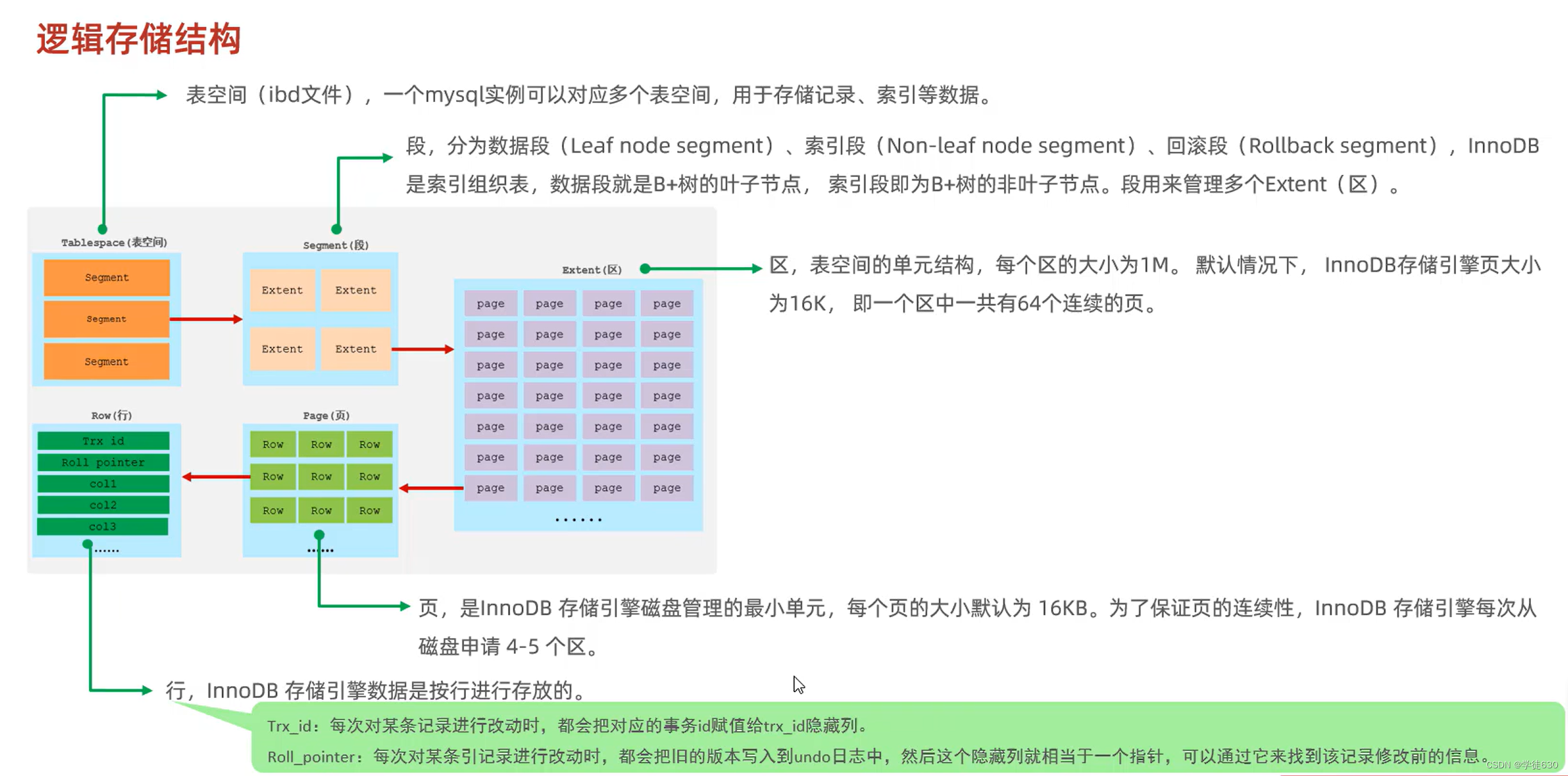
-
表空间(Tablespace):可以理解为一个大容器,用于存储数据库对象的物理结构。一个数据库可以有多个表空间,每个表空间可以包含多个表和索引。
-
段(Segment):在表空间内部,数据被组织为一个个段。一个段可以是一个表或一个索引,用于存储对应的数据或索引结构。
-
区(Extent):每个段由多个区组成。一个区是一组连续的磁盘页,通常为多个连续的数据页。在InnoDB中,一个区大小通常为1MB。
-
页(Page):每个段内的数据被划分为多个数据页。一个数据页通常为16KB。每个数据页是存储数据的最小单位,其中包含一部分行数据。表的数据(可以是多条)和索引都是以数据页的形式进行存储
-
行(Row):数据页内部存储一行一行的数据记录。每一行代表了表中的一个记录,包含各个列的具体值。
架构
概述
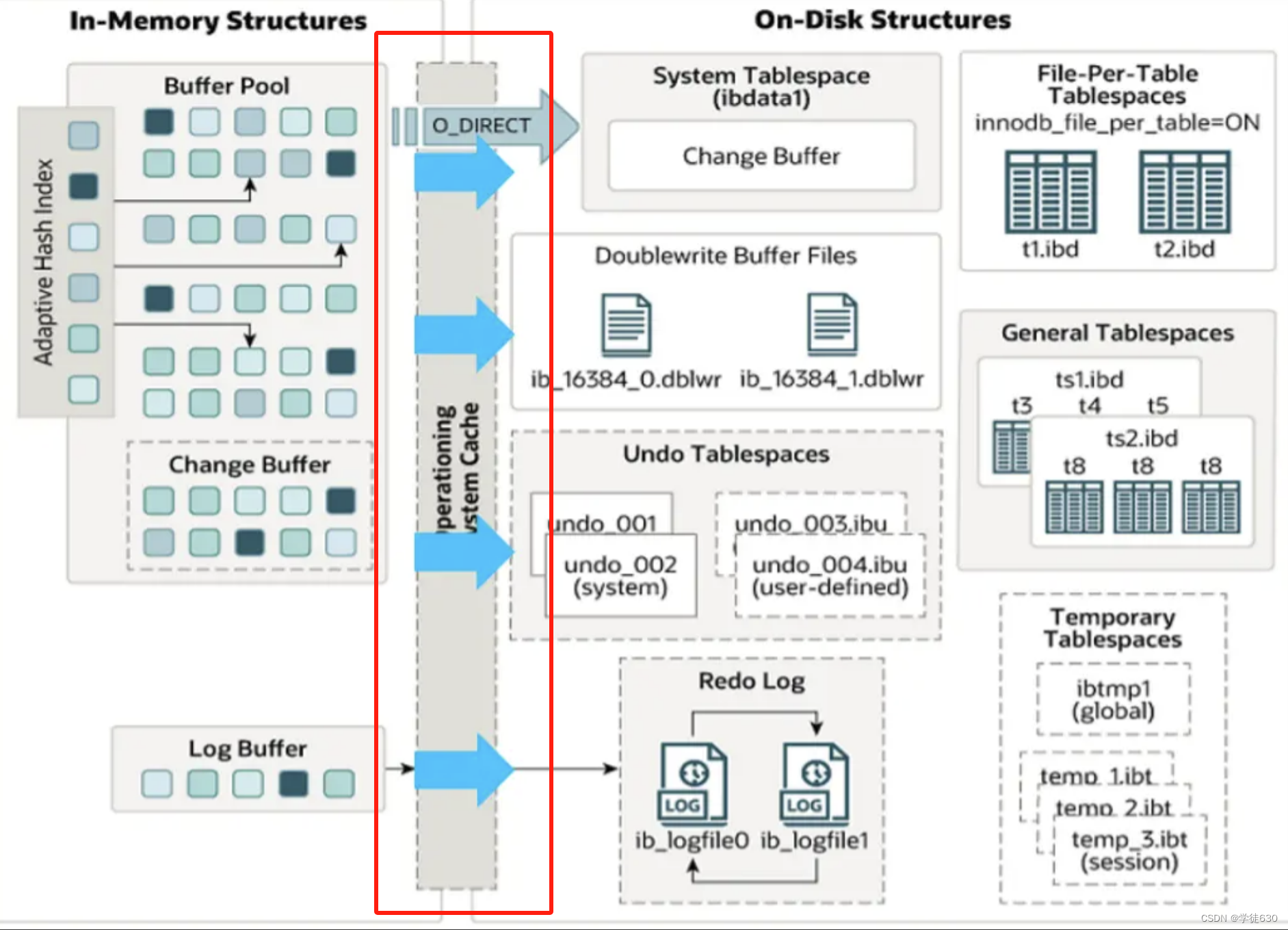
MySQL5.5 版本开始,默认使用InnoDB存储引擎,它擅长事务处理,具有崩溃恢复特性,在日常开发中使用非常广泛。下面是InnoDB架构图,左侧为内存结构,右侧为磁盘结构。
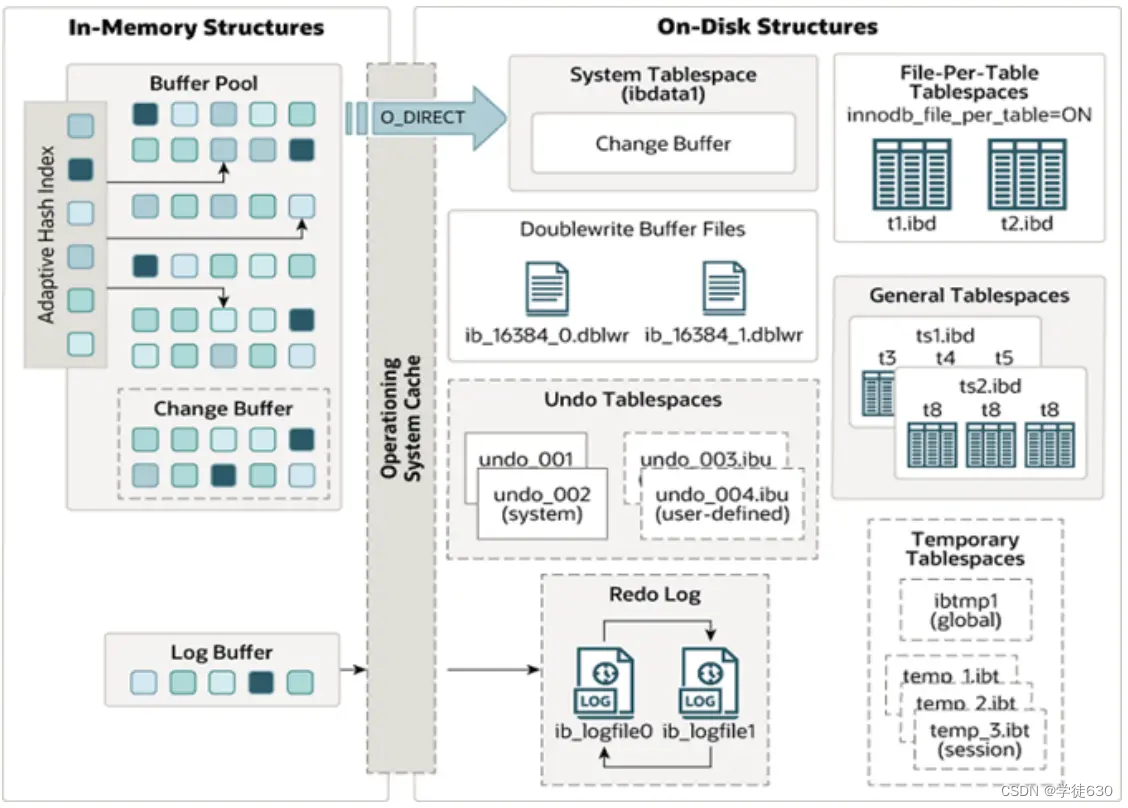
InnoDB是MySQL数据库中常用的存储引擎之一,它具有强大的事务支持和高并发能力。下面是InnoDB的架构图,左侧为内存结构,右侧为磁盘结构。
内存架构
Buffer Pool
InnoDB存储引擎基于磁盘文件存储,访问物理硬盘和在内存中进行访问,速度相差很大,为了尽可能弥补这两者之间的I/O效率的差值,就需要把经常使用的数据加载到缓冲池中,避免每次访问都进行磁盘I/O。
在InnoDB的缓冲池中不仅缓存了索引页和数据页,还包含了undo页、插入缓存、自适应哈希索引以及InnoDB的锁信息等等。
缓冲池 Buffer Pool,是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据
在执行CRUD操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
缓冲池以Page页为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三种类型:
- free page:空闲page,未被使用。
- clean page:被使用page,数据没有被修改过。
- dirty page:脏页,被使用page,数据被修改过,也中数据与磁盘的数据产生了不一致。
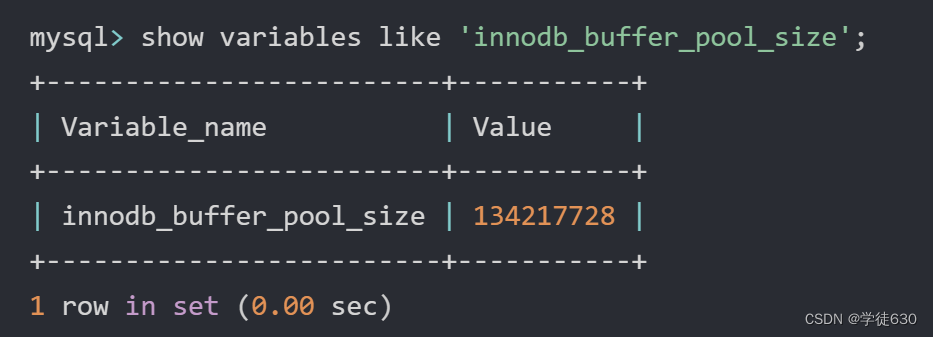
在专用服务器上,通常将多达80%的物理内存分配给缓冲池 。参数设置: show variables like 'innodb_buffer_pool_size';
Change Buffe
Change Buffer,更改缓冲区(针对于非唯一二级索引页),在执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接操作磁盘,而会将修改操作记录到Change Buffer(更改缓冲区)中,存在更改缓冲区 Change Buffer中,当需要访问或查询数据时,InnoDB会首先查看更改缓冲区中是否存在相应的修改操作。如果存在,则会将这些修改操作应用到内存中的数据页,然后返回所需的数据。再将合并后的数据刷新到磁盘中。
Change Buffer与内存数据的同步不一定是被动懒加载的,当满足一定条件时,InnoDB会将更改缓冲区中的修改操作应用到磁盘上的数据页中。一般情况下,当数据页从磁盘读取到Buffer Pool中,或者更改缓冲区中的操作量达到一定程度时,会触发将修改应用到磁盘的操作,从而保证数据的一致性。
Change Buffer的意义是什么呢?
先来看一幅图,这个是二级索引的结构图:
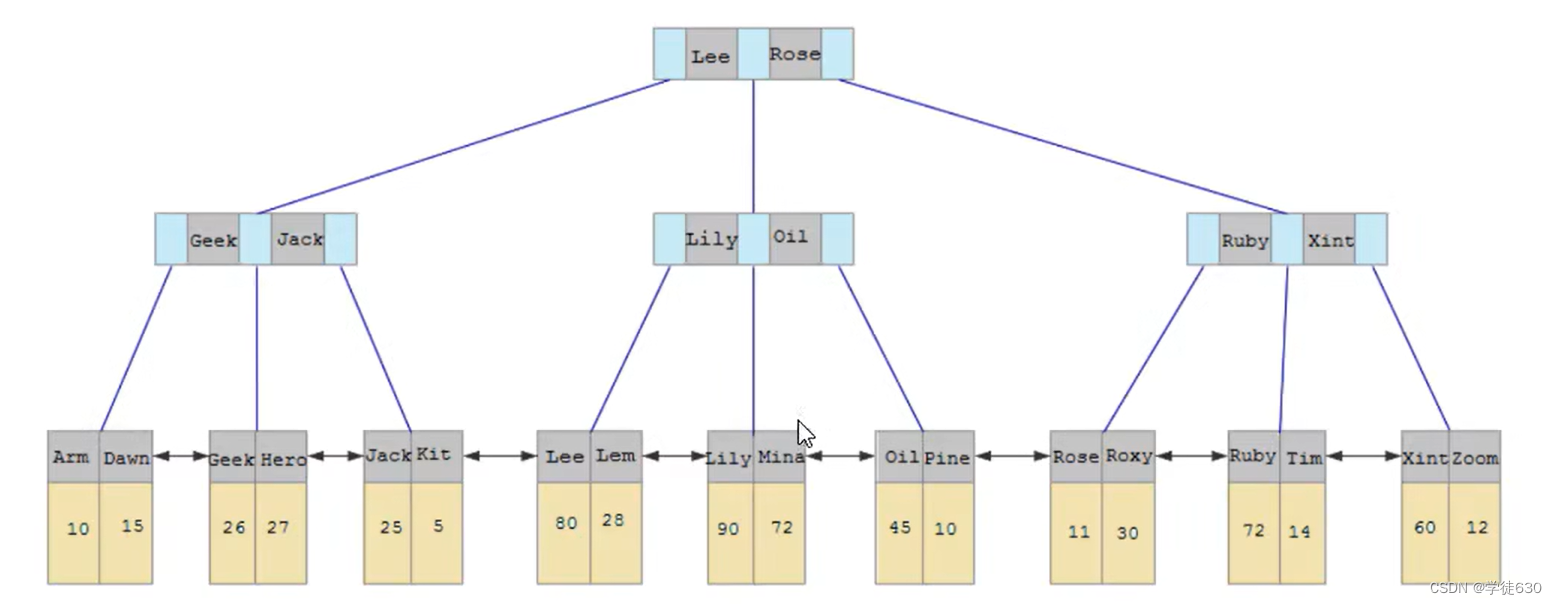
与聚集索引(有序)不同,二级索引通常是非唯一的,并且以相对随机的顺序插入二级索引。同样,删除和更新可能会影响索引树中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了ChangeBuffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
在二级索引中有存储该数据行的引用,比如主键值或者其他唯一性标识。删除或更新这个数据行时,InnoDB需要相应地修改或删除二级索引中对应的引用。
如果被删除或更新的数据行分布在不相邻的二级索引页上,意味着这些索引页不在物理上相连的位置,可能需要对这些不相邻的索引页进行修改或删除操作。为了维护索引的一致性,InnoDB会通过对这些不相邻的索引页进行修改或删除引用的操作,以确保索引与实际数据行的关联是准确的。
此过程可能导致涉及到的二级索引页的磁盘IO操作,因为修改或删除索引页中的引用需要写入到磁盘上的对应页。当这些索引页不在内存的Buffer Pool中时,InnoDB需要从磁盘读取这些索引页到内存中,进行相应的修改或删除操作,然后再写回到磁盘。
Change Buffer(变更缓冲区)在InnoDB存储引擎中起到了减少对磁盘IO操作的作用,从而帮助解决了删除或更新数据行时涉及到的不相邻二级索引页的问题。
当删除或更新一个数据行时,涉及到它在二级索引中的引用。如果被删除或更新的数据行在不相邻的二级索引页上,传统的做法是直接在磁盘上修改或删除这些索引页中的引用,这是一种相对较慢且低效的操作,需要频繁的随机磁盘访问。
而Change Buffer的作用是在这种情况下将修改操作暂时存储在内存中的缓冲区中,而不是直接写入磁盘中的索引页。具体的步骤如下:
当删除或更新操作需要修改不相邻的二级索引页时,InnoDB会将这些修改操作记录到Change Buffer中,而不是直接写入磁盘。
Change Buffer是一个内存结构,它会暂时存储这些修改操作,而不是立即将它们应用到磁盘上的索引页。
这些修改操作会在适当的时机被批量地应用到磁盘上的索引页中。一般情况下,当涉及的索引页从磁盘读取到内存时,或者Change Buffer中的操作量达到一定程度时,会触发将修改应用到磁盘的操作。
如果需要访问或查询受到修改影响的数据,InnoDB会先检查Change Buffer中是否存在修改记录,并将其应用到内存中的数据页中,然后返回所需的数据。
通过使用Change Buffer,InnoDB推迟了对磁盘的随机写入操作,而是在内存中批量处理这些修改操作。这种批量处理可以减少随机磁盘访问的需求,提高了删除或更新操作的性能,并降低了IO成本。同时,Change Buffer还可以减轻磁盘的压力,提高整体系统的并发处理能力。
Adaptive Hash Index
自适应hash索引,用于优化对Buffer Pool数据的查询。MySQL的innoDB引擎中虽然没有直接支持hash索引,但是给我们提供了一个功能就是这个自适应hash索引。因为前面我们讲到过,hash索引在进行等值匹配时,一般性能是要高于B+树的,因为hash索引一般只需要一次IO即可,而B+树,可能需要几次匹配,所以hash索引的效率要高,但是hash索引又不适合做范围查询、模糊匹配等。
当查询已经访问过一次B+树索引并且数据位于缓冲池内存中时,InnoDB会将访问过的索引页加入自适应哈希索引中的散列结构。下次相同查询到来时,InnoDB首先在自适应哈希索引中查找,避免了磁盘IO操作,从而提高了索引查找的性能。
自适应哈希索引使用一种LRU(最近最少使用)算法来管理内存中索引页的缓存。当缓存空间有限时,较久未被使用的索引页会被淘汰,腾出空间供新的索引页加入。
自适应哈希索引,无需人工干预,是系统根据情况自动完成。
Log Buffer
日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log 、undo log),默认大小为 16MB,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘 I/O。
当事务提交时,相关的日志记录会被刷新到磁盘。
当日志缓冲区达到一定的阈值,需要腾出空间给新的日志记录时,旧的日志记录会被刷新到磁盘。
参数:
innodb_log_buffer_size:缓冲区大小
innodb_flush_log_at_trx_commit:日志刷新到磁盘时机,取值主要包含以下三个:
1 :日志在每次事务提交时写入并刷新到磁盘,默认值。
0 :每秒将日志写入并刷新到磁盘一次。
2 :日志在每次事务提交后写入,并每秒刷新到磁盘一次。
mysql> show variables like 'innodb_flush_log_at_trx_commit';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
1 row in set (0.00 sec)
磁盘结构
接下来,再来看看InnoDB体系结构的右边部分,也就是磁盘结构:
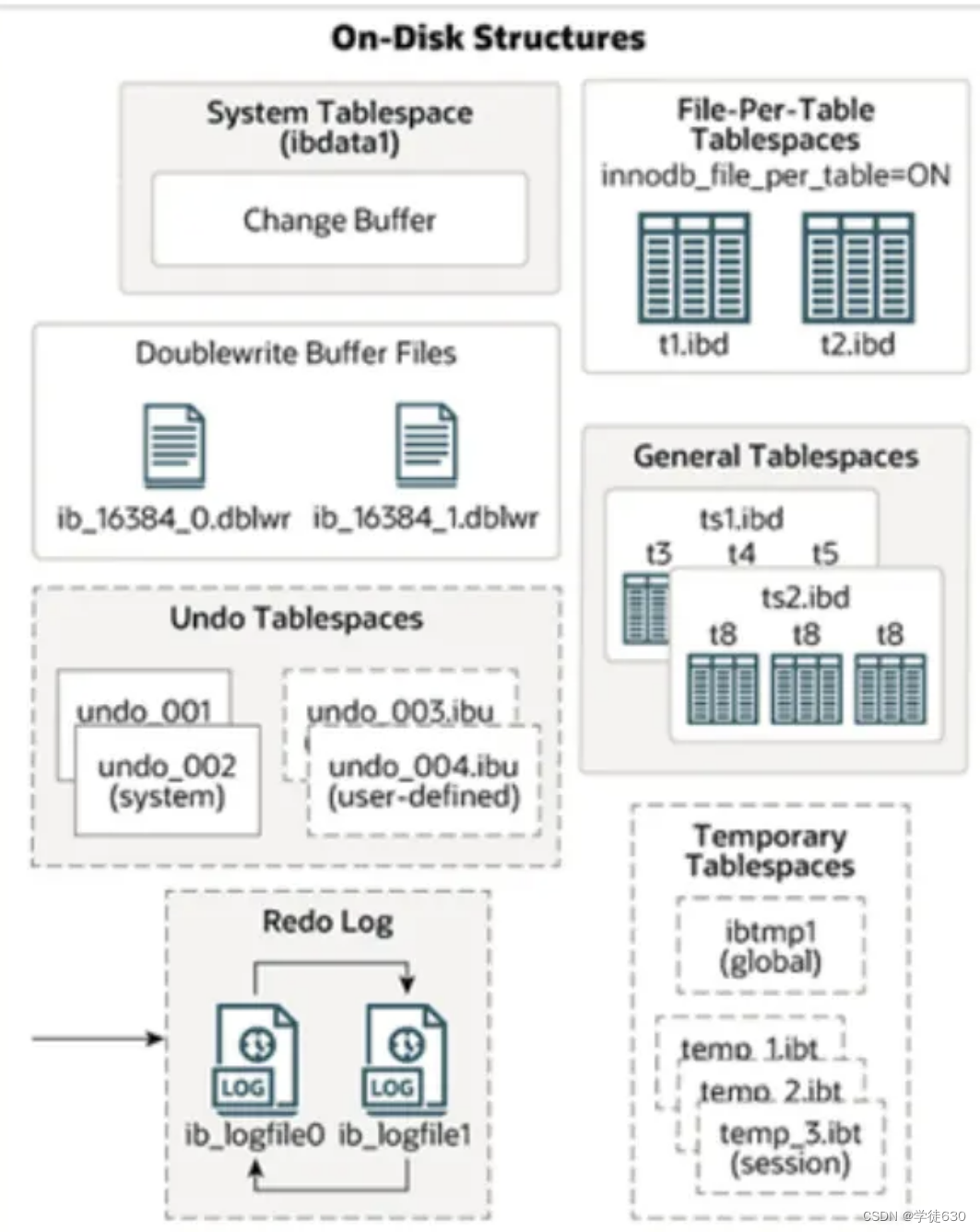
System Tablespace
系统表空间(System Tablespace)是MySQL数据库中存储系统元数据的重要部分。
在MySQL中,系统元数据包括表定义、索引信息、权限信息等。这些信息被组织成系统表,用于管理和控制数据库对象和用户权限。系统表空间是存储这些系统表的物理文件。
在InnoDB存储引擎下,默认的系统表空间文件名为ibdata1。它存储了InnoDB引擎的多个结构和关键元数据,包括数据字典、事务信息、回滚段和undo日志等。
参数:innodb_data_file_path
mysql> show variables like 'innodb_data_file_path';
+-----------------------+------------------------+
| Variable_name | Value |
+-----------------------+------------------------+
| innodb_data_file_path | ibdata1:12M:autoextend |
+-----------------------+------------------------+
1 row in set (0.00 sec)
File-Per-Table Tablespaces
“每表一个表空间”(File-Per-Table Tablespaces)是MySQL中InnoDB存储引擎的一个特性,它指的是每个InnoDB表都有自己独立的表空间文件存储在文件系统中。
默认情况下,InnoDB使用一个共享的系统表空间(System Tablespace)来存储所有表的数据和索引。但是通过启用每表一个表空间的配置,每个表将被分配一个独立的表空间文件(以.ibd为后缀)放置在MySQL数据目录中。
"每表一个表空间"的配置提供了几个优点:
-
简化维护:通过表空间每表一个文件的配置,可以更方便地管理和维护各个表。可以轻松地移动、复制或备份单个表,而不会影响整个InnoDB数据。
-
提高性能:在某些场景下,"每表一个表空间"可以提供性能优势,例如在扩展或分区表时,或在对特定表有大量写入操作的工作负载上。将数据和索引分离到不同的表空间中可以减少争用和锁争用问题。
-
资源分配高效:每个表空间文件根据其相应的表的大小来分配空间,避免了表大小不同造成的空间浪费。它可以更好地控制和优化存储资源的利用。
需要注意的是,启用"每表一个表空间"的配置会引入一些额外开销,因为管理多个表空间文件需要一定的系统资源。在使用此配置时,应考虑系统资源(如打开文件的数量和文件系统限制)的限制。
开关参数:innodb_file_per_table,该参数默认开启。
mysql> show variables like 'innodb_file_per_table';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | ON |
+-----------------------+-------+
1 row in set (0.00 sec)
General Tablespaces
General Tablespaces(通用表空间)是在MySQL 8.0中引入的一个功能,它允许在MySQL数据目录之外创建表空间。它提供了一种灵活的方式来管理和组织数据库对象,例如表和索引,通过将它们存储在特定目录或存储设备中的单独数据文件中。
通过通用表空间,您可以独立于数据库模式创建表空间,以更细粒度地控制数据库对象的存储。这个功能在数据分区、管理大型数据库或与外部存储系统集成等场景下特别有用。
A. 创建表空间
CREATE TABLESPACE ts_name ADD DATAFILE 'file_name' ENGINE = engine_name;
mysql> CREATE TABLESPACE ts_itheima ADD DATAFILE 'myitheima.ibd' ENGINE = innodb;
Query OK, 0 rows affected (0.00 sec)
B. 创建表时指定表空间
CREATE TABLE xxx ... TABLESPACE ts_name;
mysql> create table a(id int primary key auto_increment,name varchar(10)) engine=innodb tablespace ts_itheima;
Query OK, 0 rows affected (0.01 sec)Undo Tablespaces
Undo Tablespaces(回滚表空间)是MySQL数据库中用于管理事务回滚操作的特殊类型的表空间。在MySQL InnoDB存储引擎中,事务的回滚操作需要使用回滚段(undo segment),而每个回滚段都需要分配相应的存储空间。MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储 undo log日志。
Undo Tablespaces用于存储这些回滚段所需的数据。它包含了用于记录和撤销事务所做的更改的信息,以便在事务回滚或查询需要读取数据的之前状态时使用。
Temporary Tablespaces
InnoDB 使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
Doublewrite Buffer Files
Doublewrite buffer files(双写缓冲文件)是MySQL InnoDB存储引擎中的一个关键组件,用于提高数据的可靠性和一致性。
在InnoDB存储引擎中,双写缓冲文件用于写入数据页的副本,以提供冗余和保证数据一致性。当InnoDB引擎执行写操作时,它会将数据写入双写缓冲文件中的副本,然后再异步地将数据写入实际的数据文件。这种写入数据的方式可以防止数据页部分写入的情况,从而保证了数据的完整性。
innoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。
Redo Log
重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。
当数据库执行事务时,对被修改的数据进行的操作(如插入、更新或删除)会首先记录到Redo Log中,然后才会写入实际的数据文件。这样做的目的是确保在数据库的持久化存储之前,所有的事务修改都被记录在持久的Redo Log中。当事务提交之后会把所有修改信息都会存到该日志中, 用于在刷新脏页到磁盘时,发生错误时, 进行数据恢复使用。
以循环方式写入重做日志文件,涉及两个文件:
-rw-r-----. 1 mysql mysql 50331648 10月 2 22:52 ib_logfile0
-rw-r-----. 1 mysql mysql 50331648 10月 2 22:52 ib_logfile1前面我们介绍了InnoDB的内存结构,以及磁盘结构,那么内存中我们所更新的数据,又是如何到磁盘中的呢? 此时,就涉及到一组后台线程,接下来,就来介绍一些InnoDB中涉及到的后台线程。
后台线程
主要作用:将InnoDB缓存池中的数据,在合适的时机刷新到磁盘中
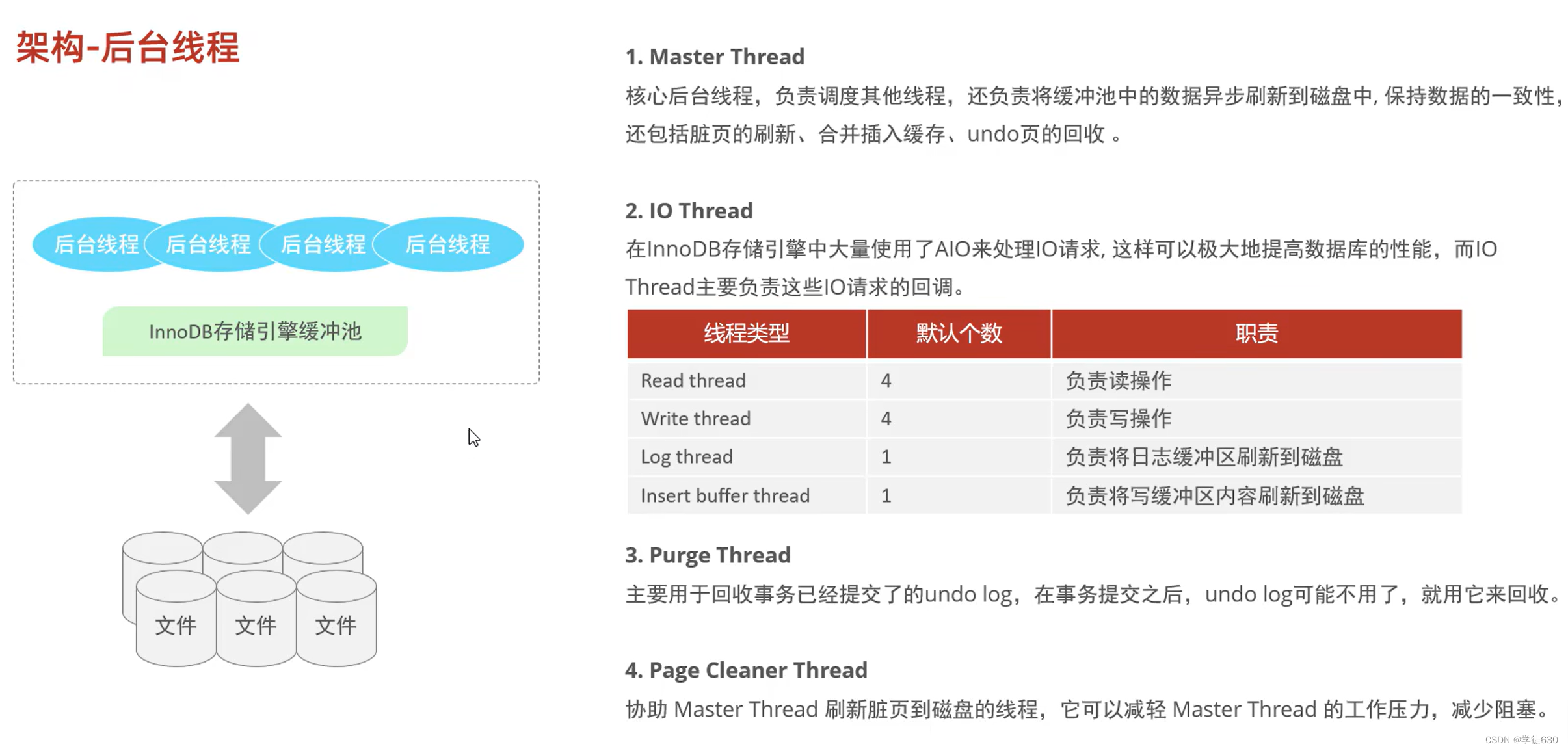
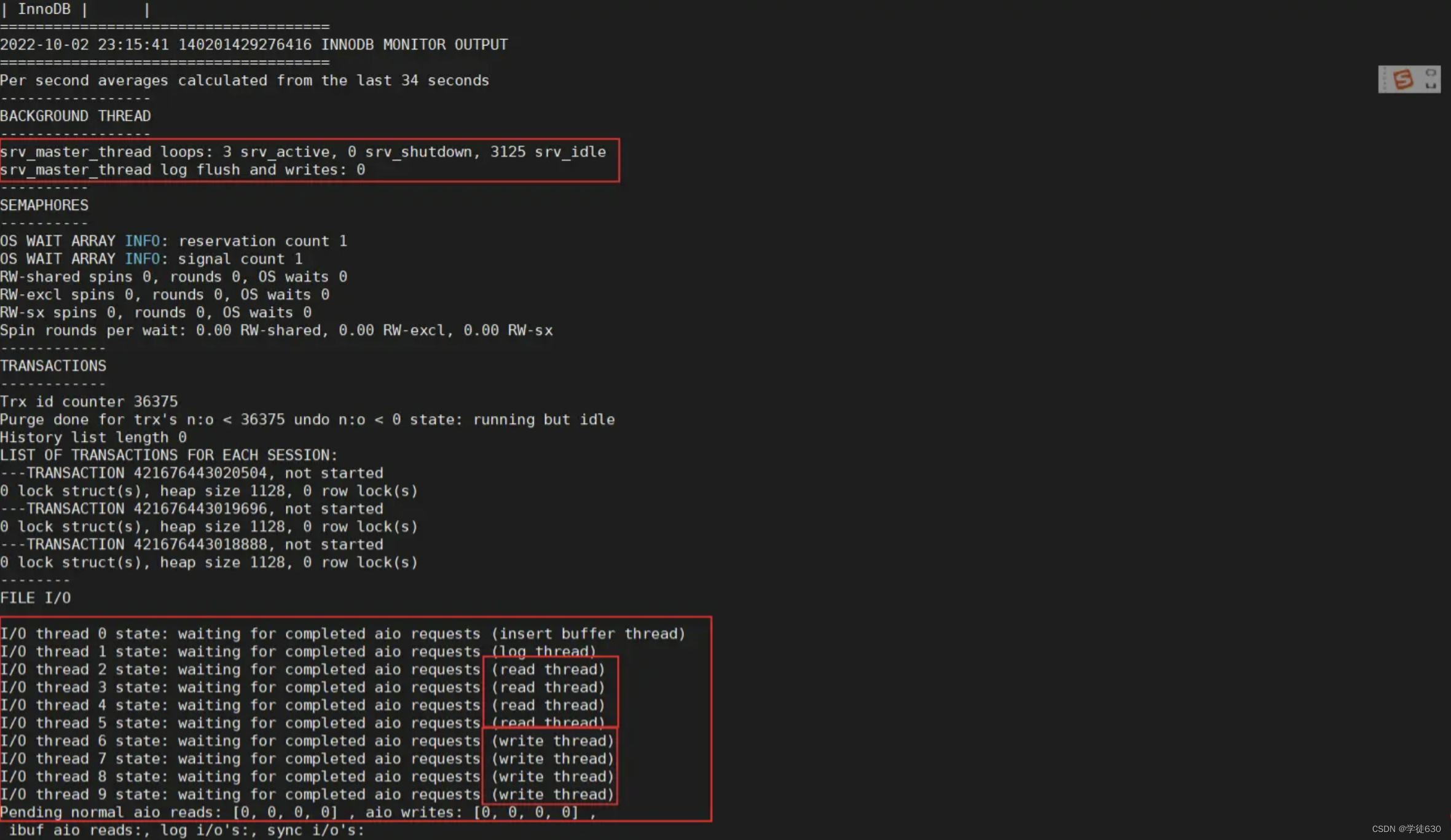
我们可以通过以下的这条指令,查看到InnoDB的状态信息,其中就包含IO Thread信息。
show engine innodb status;
事务原理
事务基础回顾
效果
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
特性
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
那实际上,我们研究事务的原理,就是研究MySQL的InnoDB引擎是如何保证事务的这四大特性的。
 原理实现划分
原理实现划分
对于这四大特性,实际上分为两个部分。 其中的原子性、一致性、持久化,实际上是由InnoDB中的两份日志来保证的,一份是redo log日志,一份是undo log日志。 而持久性是通过数据库的锁,加上MVCC来保证的。
redo log保证事务持久性
在InnoDB引擎中的内存结构中,主要的内存区域就是缓冲池,在缓冲池中缓存了很多的数据页。 当我们在一个事务中,执行多个增删改的操作时,InnoDB引擎会先操作缓冲池中的数据,如果缓冲区没有对应的数据,会通过后台线程将磁盘中的数据加载出来,存放在缓冲区中,然后将缓冲池中的数据修改,修改后的数据页我们称为脏页。 而脏页则会在一定的时机,通过后台线程刷新到磁盘中,从而保证缓冲区与磁盘的数据一致。 而缓冲区的脏页数据并不是实时刷新的,而是一段时间之后将缓冲区的数据刷新到磁盘中
假如刷新到磁盘的过程出错了,而提示给用户事务提交成功,而数据却没有持久化下来,这就出现问题了,没有保证事务的持久性。

那么,如何解决上述的问题呢? 在InnoDB中提供了一份日志 redo log,接下来我们再来分析一下,通过redolog如何解决这个问题
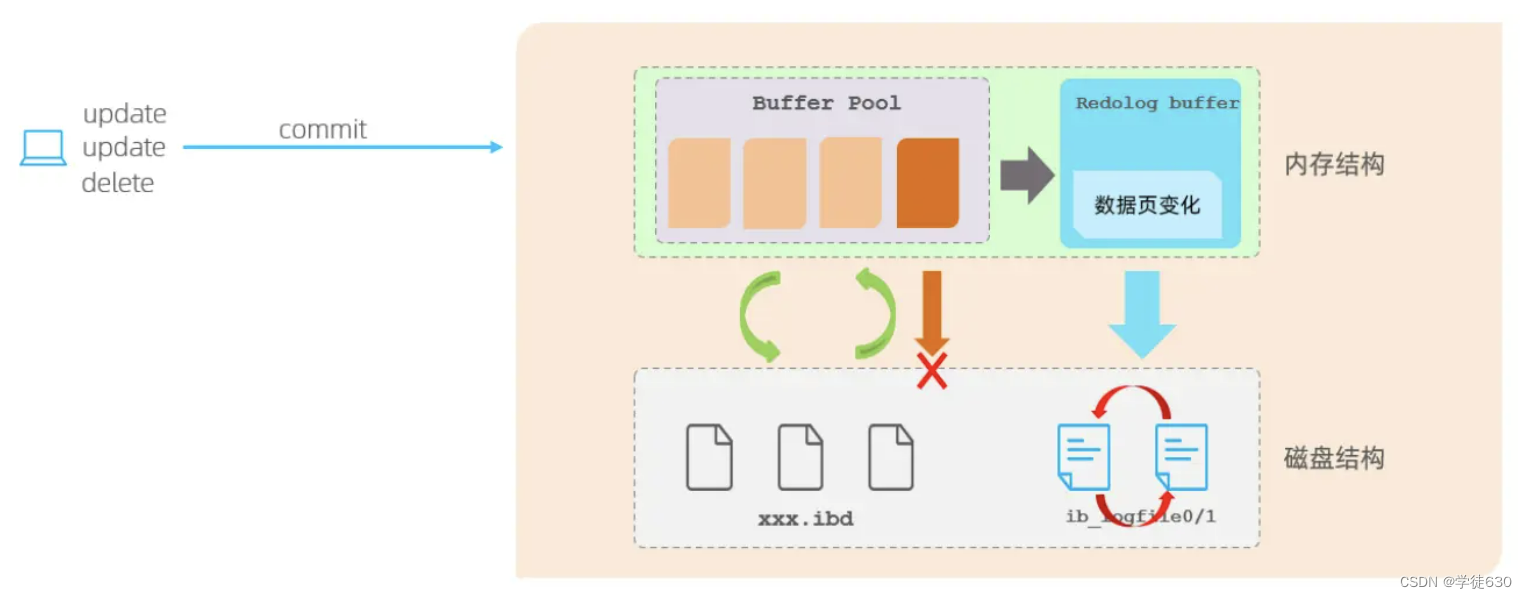
有了redolog之后,当对缓冲区的数据进行增删改之后,会首先将操作的数据页的变化,记录在redo log buffer中。在事务提交时,会将redo log buffer中的数据刷新到redo log磁盘文件中。过一段时间之后,如果刷新缓冲区的脏页到磁盘时,发生错误,此时就可以借助于redo log进行数据恢复,这样就保证了事务的持久性。 而如果脏页成功刷新到磁盘 或 涉及到的数据已经落盘,此时redolog就没有作用了,就可以删除了,所以存在的两个redolog文件是循环写的。
那为什么每一次提交事务,要刷新redo log 到磁盘中呢,而不是直接将buffer pool中的脏页刷新到磁盘呢 ?
因为在业务操作中,我们操作数据一般都是随机读写磁盘的,而不是顺序读写磁盘。 而redo log在往磁盘文件中写入数据,由于是日志文件,所以都是顺序拼接写的。顺序写的效率,要远大于随机写。 这种先写日志的方式,称之为 WAL(Write-Ahead Logging)。
总结:redo log用于在刷新脏页到磁盘,发生错误时, 进行数据恢复使用,确保了事务的持久性。
undo log保证事务原子性
回滚日志,用于记录数据被修改前的信息 , 作用包含两个 : 提供回滚(保证事务的原子性) 和MVCC(多版本并发控制) 。
undo log和redo log记录物理日志不一样,它是逻辑日志(你加了,我就记录与之相反的减操作)。可以认为当delete一条记录时,undolog中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
当事务需要回滚时,系统会使用Undo Log中的undo记录来撤销该事务对数据所做的修改操作,将数据恢复到事务开始前的原始状态。这样就可以确保事务的回滚操作是原子的,即要么所有修改生效,要么全部撤销,并且在任何时候如果事务被中断或回滚,数据都能够保持一致性。
Undo log销毁:undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
Undo log存储:undo log采用段的方式进行管理和记录,存放在前面介绍的 rollback segment回滚段中,内部包含1024个undo log segment。
细节分辨:redo log 和 undo log的区别
Redo Log(重做日志)和 Undo Log(回滚日志)是MySQL中两种不同的日志机制,它们的作用和功能有所不同。
功能:
- Redo Log:Redo Log记录了事务对数据库的修改操作,包括插入、更新和删除等操作。它用于持久化写入磁盘,以确保在数据库发生故障时,可以通过重放Redo Log中的操作来恢复数据。
- Undo Log:Undo Log记录了事务对数据库的修改操作的逆操作,也就是说,它记录了事务执行过程中对数据库做出的修改操作的撤销操作。Undo Log用于在事务回滚或数据库恢复时,将数据恢复到修改之前的状态。
使用场景:
- Redo Log:Redo Log主要用于故障恢复和崩溃恢复。发生数据库故障时,系统可以使用Redo Log进行重放,以重新执行事务的修改操作,以达到数据的恢复和一致性。
- Undo Log:Undo Log用于支持事务级别的回滚操作。当事务回滚时,可以使用Undo Log中的信息来撤销对数据库的修改,将数据恢复到事务执行之前的状态。
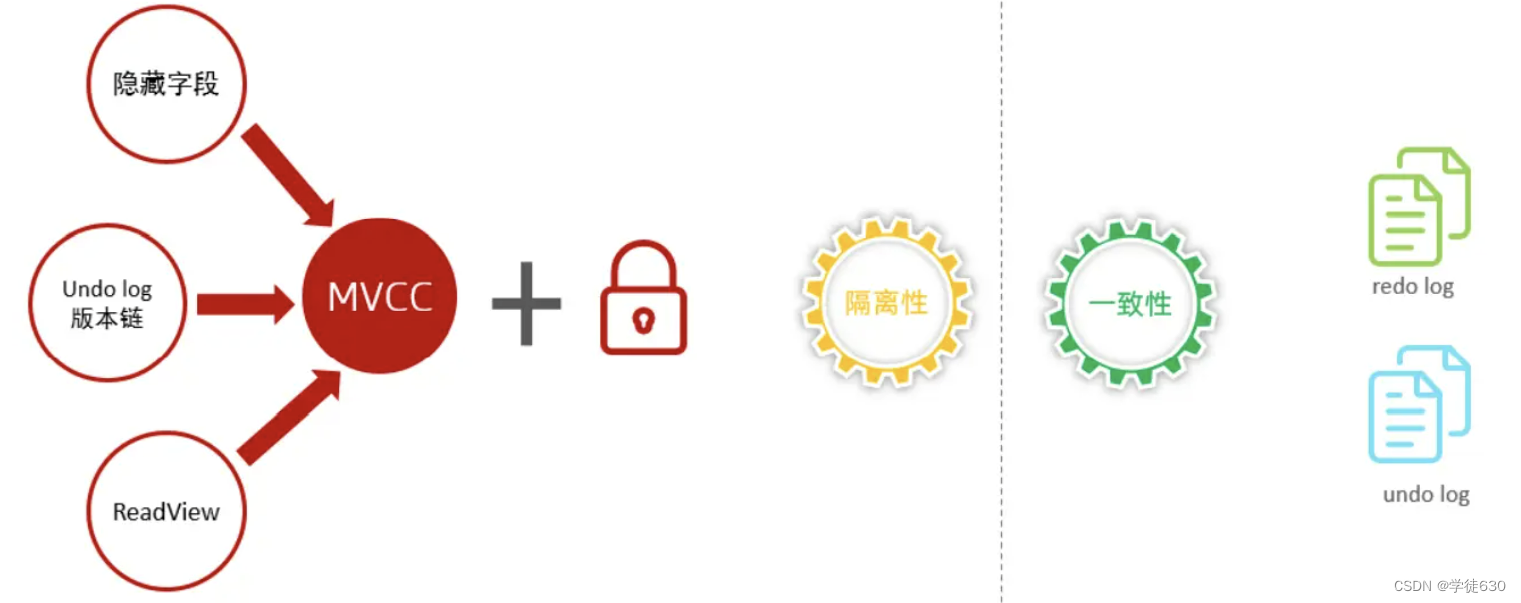
undo log + redo log保证事务一致性
Undo Log用于记录事务执行过程中对数据的修改操作,在事务回滚时可以根据Undo Log中的信息将数据恢复到修改之前的状态。当事务执行过程中发生错误或回滚时,Undo Log记录的数据修改操作可以帮助回滚事务,确保事务的一致性。
Redo Log则用于记录事务对数据做的修改操作,可以在事务提交之前将修改操作写入磁盘。这样,即使在事务提交后数据库发生故障(如系统崩溃),通过Redo Log中的信息,可以重新执行事务的修改操作,确保事务的持久性和一致性。
单靠Redo Log是无法保证事务的一致性的。
人话理解:redo log只记录正常运行的DML操作,不记录事务回滚后带来的变化。eg:我赚了10块钱,但是被发现是非法所得,被没收了(redo log记录赚了十块钱 undo logo 记录了减少十块钱,必须两个日志共同作用才能确保我的钱钱在我钱包的一致性)
锁 + MVCC 保证事务隔离性
锁机制通过对数据库中的数据资源进行加锁,控制事务的并发访问,以避免并发事务对同一数据资源进行不一致的操作。通过使用锁,可以实现以下隔离级别:读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。
MVCC是一种并发控制机制,它通过在数据库中维护数据版本和事务的可见性来实现事务的隔离。每个事务在开始时会获得一个开始时间戳,事务执行期间只能看到在其开始之前已经提交的数据版本。
锁和MVCC可以结合使用来保证事务的隔离性:
- 锁机制主要用于处理写操作,在写操作时会对相关的数据加锁,防止其他事务对同一数据进行修改。锁会限制其他事务的并发访问,从而保证了事务的隔离性。
- MVCC机制主要适用于读操作,通过记录数据版本和事务的时间戳,保证每个事务读取到的数据是一致的快照。事务在读取数据时不会受到其他事务的修改影响,从而避免了脏读、不可重复读和幻读等问题。
MVCC
基本概念
当前读
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:
select ... lock in share mode(共享锁),select ...for update、update、insert、delete(排他锁)都是一种当前读。
当前读(Current Read):当前读是指读取数据库中最新提交的数据。MySQL中的当前读有两种方式:
读取提交的读(Read Committed)和可重复读(Repeatable Read)。
- 读取提交的读(Read Committed):在读取数据时,只能读取已经提交事务所做的修改。在同一个事务内,后续的查询也会读取到其他已提交的事务所做的修改。每次读取都会获取最新的快照,因此可能会出现读取到不同事务所做的修改。
- 可重复读(Repeatable Read):在事务开始后,会创建一个一致性视图(Consistent View),该视图可以保证在整个事务执行期间读取的数据与其他事务所做的修改保持一致。即使其他事务提交了新的修改,可重复读的事务也只会读取到事务开始时的快照数据。只有在事务结束之前,其他事务的修改对可重复读的事务才可见

在测试中我们可以看到,即使是在默认的RR隔离级别下,事务A中依然可以读取到事务B最新提交的内容,因为在查询语句后面加上了
lock in share mode共享锁,此时是当前读操作。当然,当我们加排他锁的时候,也是当前读操作。
快照读
简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
快照读是指读取数据库中特定时刻的数据快照,通常是事务开始前的一个一致性视图。快照读是基于MVCC(Multi-Version Concurrency Control)机制实现的。通过读取历史版本的数据,可以实现在事务开始前的一致性视图下读取数据,不受其他事务对数据的修改影响。
- Read Committed:每次select,都生成一个快照读。
- Repeatable Read:开启事务后第一个select语句才是快照读的地方。
- Serializable:快照读会退化为当前读。

在测试中,我们看到即使事务B提交了数据,事务A中也查询不到。 原因就是因为普通的select是快照读,而在当前默认的RR隔离级别下,开启事务后第一个select语句才是快照读的地方,后面执行相同的select语句都是从快照中获取数据,可能不是当前的最新数据,这样也就保证了可重复读。
MVCC
全称 Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的 三个隐式字段 + undo log日志 + readView
简单来说,MVCC通过在数据库中保存多个数据版本来实现并发控制。每个事务在开始时会创建一个唯一的事务ID,用于标识该事务的执行。当事务进行修改操作时,会生成一个版本号,并将修改前的数据版本保存为旧版本。其他并发事务可以读取旧版本的数据,而不会受到正在修改的事务的影响。
接下来,我们再来介绍一下InnoDB引擎的表中涉及到的隐藏字段 、undolog 以及 readview,从而来介绍一下MVCC的原理。
隐藏字段

当我们创建了上面的这张表,我们在查看表结构的时候,就可以显式的看到这三个字段。 实际上除了这三个字段以外,InnoDB还会自动的给我们添加两到三个隐藏字段及其含义分别是:

而上述的前两个字段是肯定会添加的, 是否添加最后一个字段DB_ROW_ID,得看当前表有没有主键,如果有主键,则不会添加该隐藏字段。
undolog
回滚日志,在insert、update、delete的时候产生的便于数据回滚的逻辑日志。
当insert的时候,产生的undo log日志只在回滚时需要,在事务提交后,可被立即删除。
而update、delete的时候,产生的undo log日志不仅在回滚时需要,在快照读时也需要,不会立即被删除。
版本链
DB_TRX_ID: 代表最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID,是自增的。
DB_ROLL_PTR: 回滚指针,用于指向上一个版本的DB_TRX_ID,回滚指针用来指定如果发生回滚,回滚到哪一个版本。
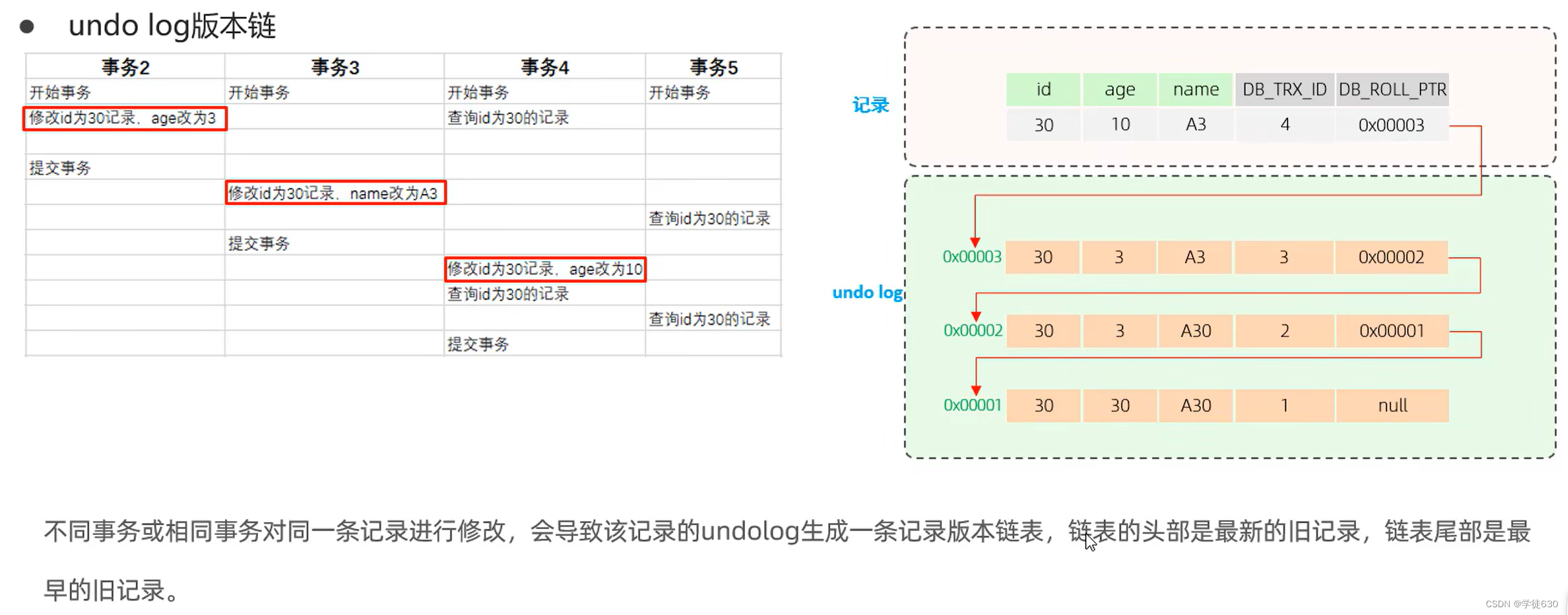
版本链的作用是为并发事务提供一致性的读取视图。事务可以根据自己的事务ID和需要的一致性级别,从版本链中选取适当的版本来读取数据。当事务结束时,旧的版本将被清理或回收,以防止版本链无限增长。
readview
ReadView(读视图)是 快照读 SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。活跃事务指的是尚未提交或回滚的事务,也被称为未完成的事务。
ReadView中包含了四个核心字段:
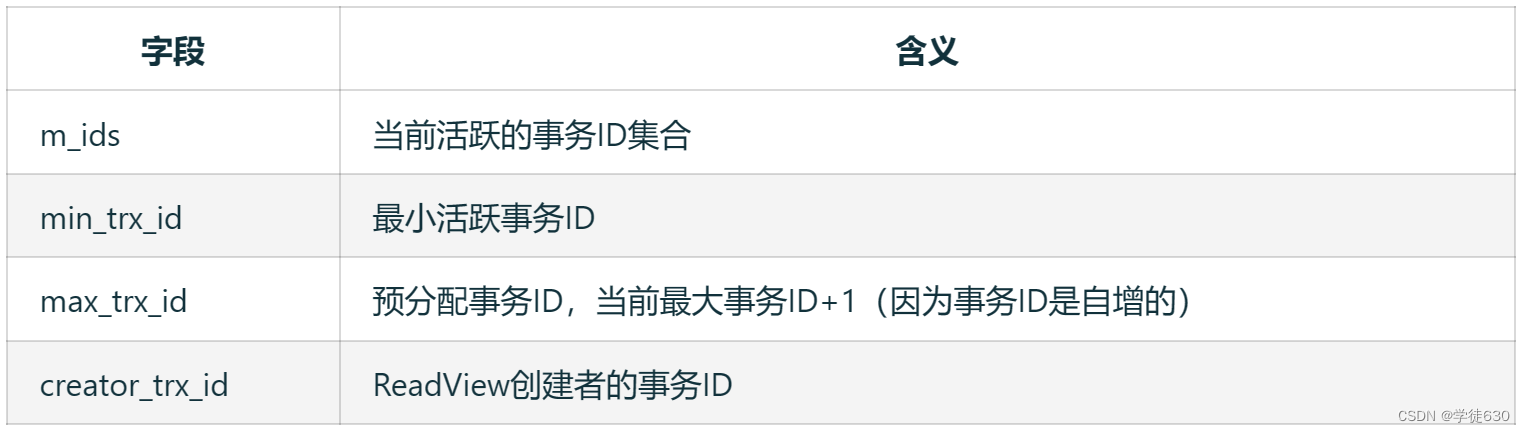
版本链数据访问规则
不同的隔离级别,生成ReadView的时机不同:
- READ COMMITTED (RC):在事务中每一次执行快照读时生成ReadView。
- REPEATABLE READ:仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。
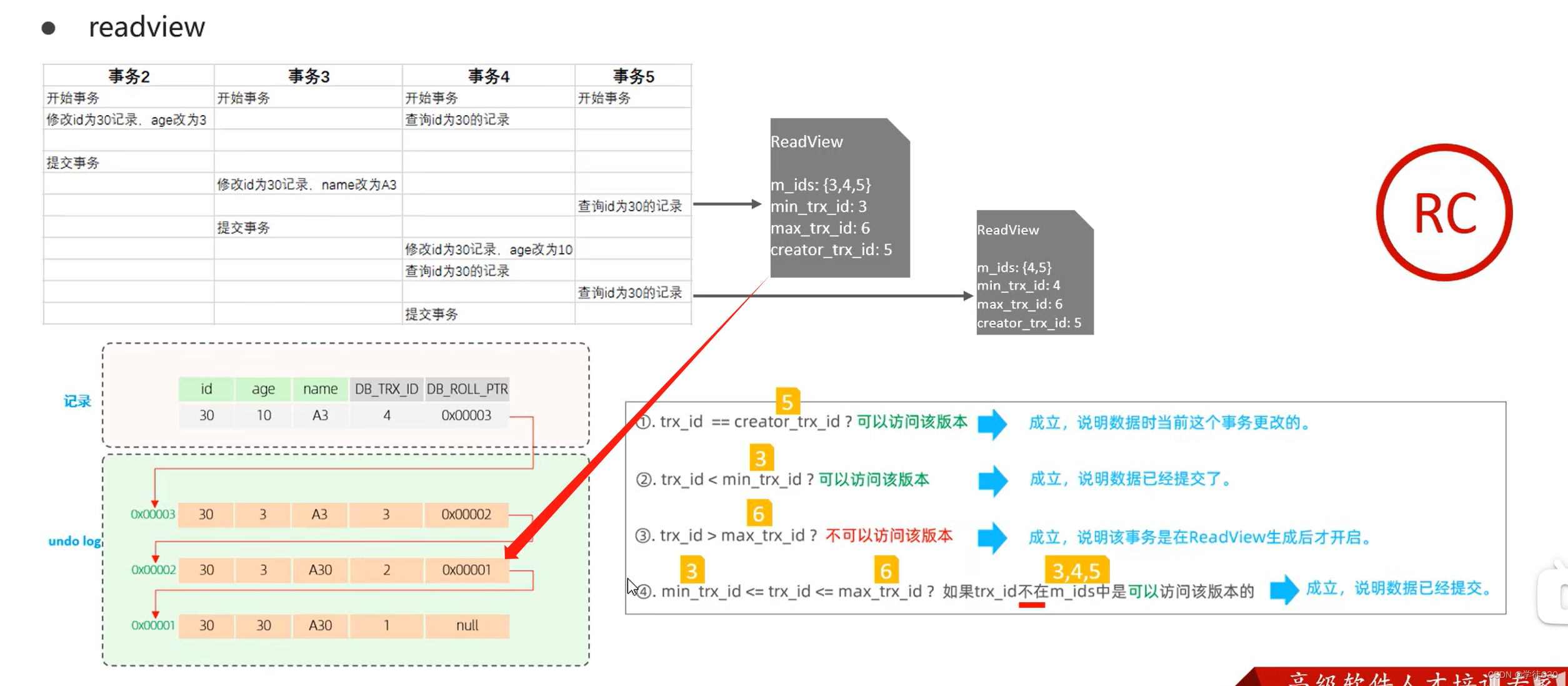
RC读已提交隔离级别原理
在事务中每一次执行快照读时生成ReadView。
RR可重复读隔离级别原理
仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView
我们看到,在RR隔离级别下,只是在事务中第一次快照读时生成ReadView,后续都是复用该ReadView,那么既然ReadView都一样, ReadView的版本链匹配规则也一样, 那么最终快照读返回的结果也是一样的。
事务原理总结
- 读未提交(Read Uncommitted):
在读未提交隔离级别下,事务可以读取其他事务尚未提交的修改。这意味着可能发生脏读,即读取到未提交的数据。MVCC不会对读取的数据应用任何锁或版本控制,因此可能会读取到其他事务未完成的中间状态。
- 读已提交(Read Committed):
读已提交隔离级别下,事务只能读取其他事务已经提交的修改。在读取数据时,MVCC会基于事务启动的快照构建读视图,只能看到已提交的数据版本吗,而无法看到活跃(未提交)事务的修改,所以就解决了脏读问题(由于读未提交允许事务读取未提交的数据,其他事务在此期间可能回滚或修改该数据,导致读取到不一致的数据)。
- 可重复读(Repeatable Read)【默认隔离级别】:
可重复读隔离级别下,事务在执行期间多次快照读,始终看到同一个快照,所以就不会有不一致的问题。因此可以解决不可重复读问题(在读已提交级别下,同一事务内的两次读取可能看到不同的数据版本。这是因为在两次读取之间,其他事务可能提交了修改,导致数据版本发生变化)。
- 串行化(Serializable):
串行化是最高级别的隔离级别,它将事务彼此完全隔离,每个事务按顺序逐个执行。当一个事务执行时,MVCC会对所有锁定的行进行排他锁,确保其他事务无法对这些行进行修改。因此没有了并发的概念,就没有事务的问题了
相关文章:
MySQL InnoDB引擎深入学习的一天(InnoDB架构 + 事务底层原理 + MVCC)
目录 逻辑存储引擎 架构 概述 内存架构 Buffer Pool Change Buffe Adaptive Hash Index Log Buffer 磁盘结构 System Tablespace File-Per-Table Tablespaces General Tablespaces Undo Tablespaces Temporary Tablespaces Doublewrite Buffer Files Redo Log 后台线程 事务原…...
TX Text Control .NET Server for ASP.NET 32.0 Crack
TX Text Control .NET Server for ASP.NET 是VISUAL STUDIO 2022、ASP.NET CORE .NET 6 和 .NET 7 支持,将文档处理集成到 Web 应用程序中,为您的 ASP.NET Core、ASP.NET 和 Angular 应用程序添加强大的文档处理功能。 客户端用户界面 文档编辑器 将功能…...
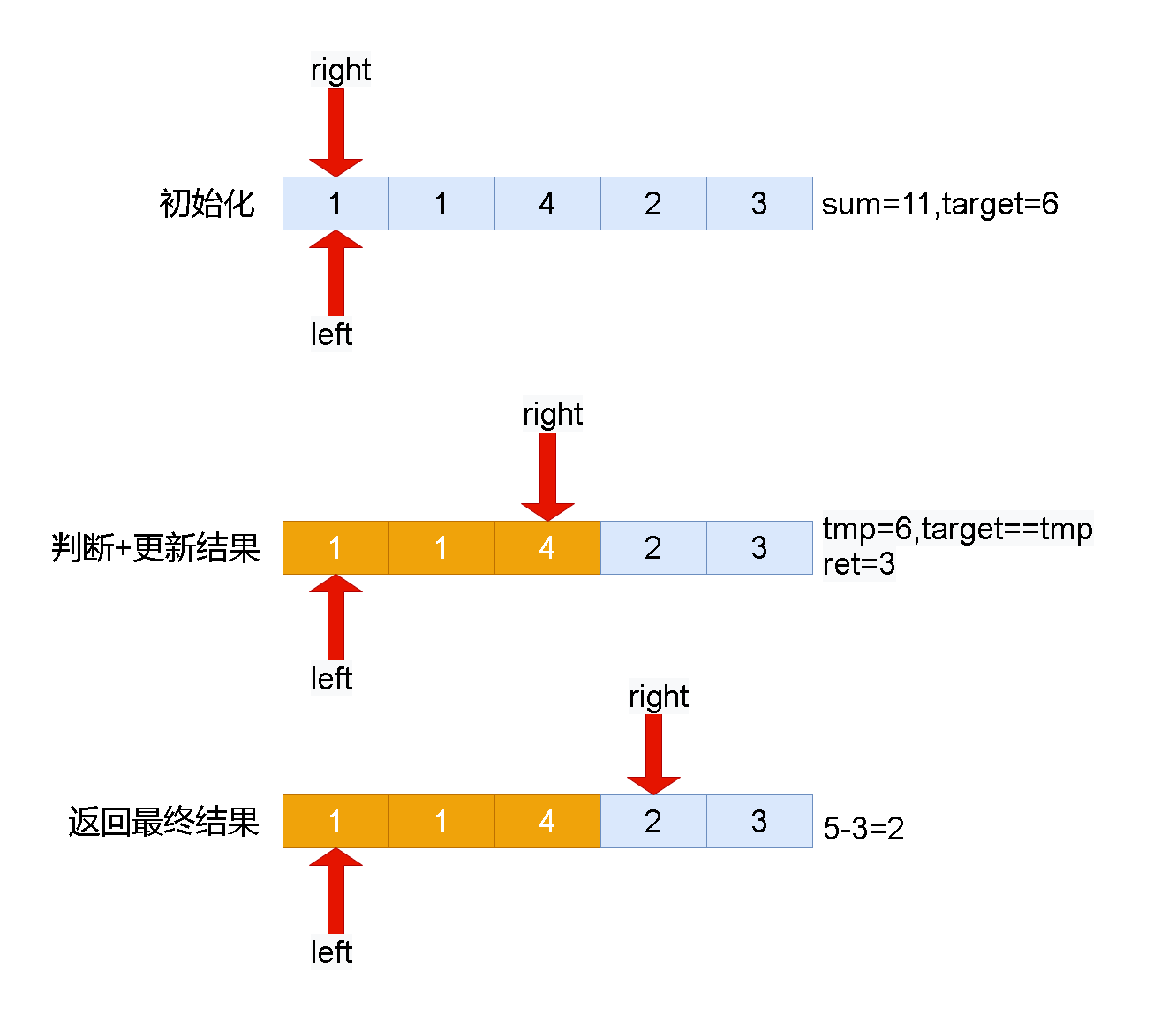
Leetcode刷题详解——将x减到0的最小操作数
1. 题目链接:1658. 将 x 减到 0 的最小操作数 2. 题目描述: 给你一个整数数组 nums 和一个整数 x 。每一次操作时,你应当移除数组 nums 最左边或最右边的元素,然后从 x 中减去该元素的值。请注意,需要 修改 数组以供接下来的操作…...

精选免费热门api接口分享
IP归属地-IPv4城市级:根据IP地址查询归属地信息,支持到城市级,包含国家、省、市、和运营商等信息。IP归属地-IPv6城市级:根据IP地址(IPv6版本)查询归属地信息,支持到中国大陆地区(不…...
androidx.appcompat.widget.Toolbar最右边设置控件不能仅靠最右边
androidx.appcompat.widget.Toolbar最右边设置控件不能仅靠最右边 Android Toolbar左、中、右对齐-CSDN博客Android Toolbar左、中、右对齐默认的Android Toolbar中添加子元素view是从左到右依次添加。需要注意的是,Android Toolbar为自身的…...
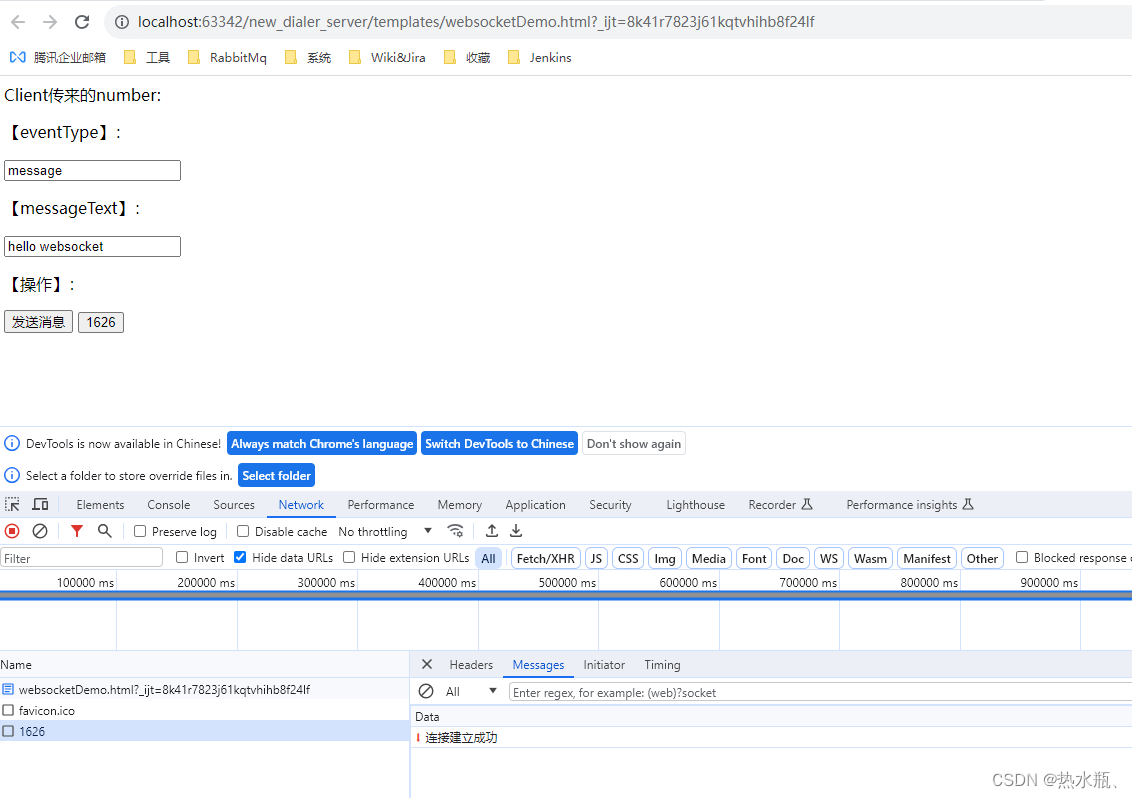
Springboot整合WebSocket实现浏览器和服务器交互
Websocket定义 代码实现 引入maven依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency>配置类 import org.springframework.context.annotation.Bean;i…...

这些 channel 用法你都用起来了吗?
channel 是什么? channel 是GO语言中一种特殊的类型,是连接并发goroutine的管道 channel 通道是可以让一个 goroutine 协程发送特定值到另一个 goroutine 协程的通信机制。 关于 channel 的原理,channel通道需要注意的地方,之前…...

纽交所上市公司安费诺宣布将以1.397亿美元收购无线解决方案提供商PCTEL
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,纽交所上市公司安费诺(APH)宣布将以每股7美元现金,总价格1.397亿美元收购无线解决方案提供商PCTEL(PCTI)。 该交易预计将在第四季度或2024年初完成。 Lake Street Capital Markets担任…...
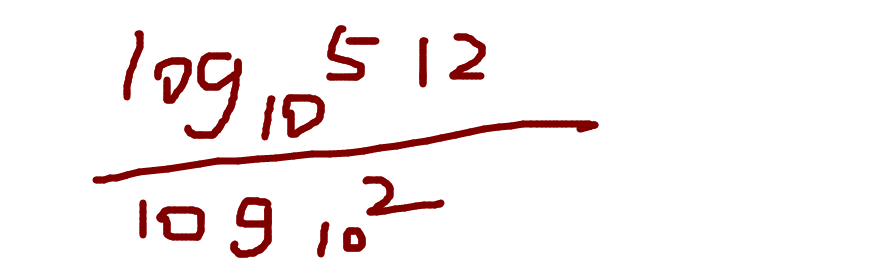
二分查找算法(Python)
目录 1、概念 2、思路 3、实现算法 1、概念 二分查找又称折半查找,它是一种效率较高的查找方法 原理:首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成…...

“第四十二天”
这个,之前用的b去存储a的总和和排名,后来在比较的过程中,只改变的b的值,却没有改变a的值,但在比较语文成绩的时候用的还是a,这个时候a和b同样是第i个对应的可能不是同一个对象了 ,因为上面b的值…...

Qt/C++编写物联网组件/支持modbus/rtu/tcp/udp/websocket/mqtt/多线程采集
一、功能特点 支持多种协议,包括Modbus_Rtu_Com/Modbus_Rtu_Tcp/Modbus_Rtu_Udp/Modbus_Rtu_Web/Modbus_Tcp/Modbus_Udp/Modbus_Web等,其中web指websocket。支持多种采集通讯方式,包括串口和网络等,可自由拓展其他方式。自定义采…...
windows常用命令
一.文件操作 dir:查看文件当前路径目录列表 cd .. :返回上一级目录 cd 路径:进入路径...
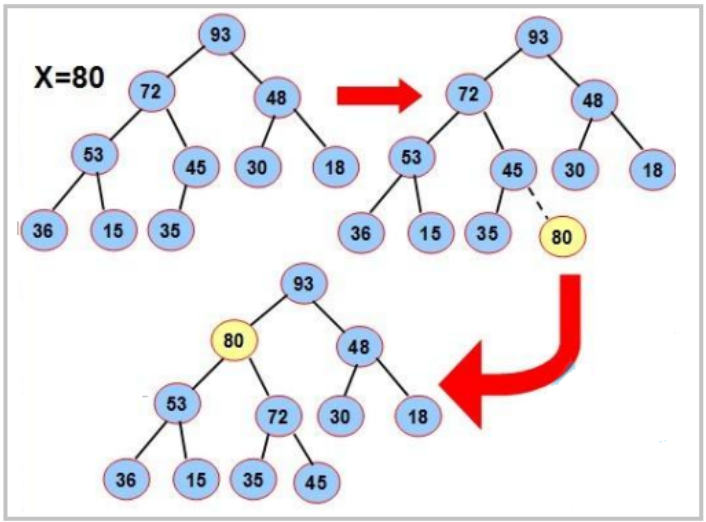
数据结构--堆
一. 堆 1. 堆的概念 堆(heap):一种有特殊用途的数据结构——用来在一组变化频繁(发生增删查改的频率较高)的数据集中查找最值。 堆在物理层面上,表现为一组连续的数组区间:long[] array &…...

Android12之报错 error: BUILD_COPY_HEADERS is obsolete(一百六十七)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...

vue前端中v-model与ref的区别
v-model <template><input type"text" v-model"message"> </template>作用:将输入框与message绑定,及将用户输入的内容绑定到message这个变量上,但是message是无法在script中获取到的,要想…...

探索未来:硬件架构之路
文章目录 🌟 硬件架构🍊 基本概念🍊 设计原则🍊 应用场景🍊 结论 📕我是廖志伟,一名Java开发工程师、Java领域优质创作者、CSDN博客专家、51CTO专家博主、阿里云专家博主、清华大学出版社签约作…...

Linux 系统安装 Redis7 —— 超详细操作演示!
内存数据库 Redis7 一、Redis 概述1.1 Redis 简介1.2 Redis 的用途1.3 Redis 特性1.4 Redis 的IO模型 二、Redis 的安装与配置2.1 Redis 的安装2.2 连接前的配置2.3 Redis 客户端分类2.4 Redis 配置文件详解 三、Redis 命令四、Redis 持久化五、Redis 主从集群六、Redis 分布式…...
首次建站用香港服务器有影响没?
对于首次租用香港服务器的朋友来说,难免会对它没有一个很清晰的认知。因此,本文就从香港服务器适用人群,以及建站影响,选择技巧上做一个全方位的解答。 1. 哪一类人群适合使用香港服务器建站? 做外贸业务的网站。香港走的国…...

大数据Flink(九十八):SQL函数的归类和引用方式
文章目录 SQL函数的归类和引用方式 一、SQL 函数的归类...
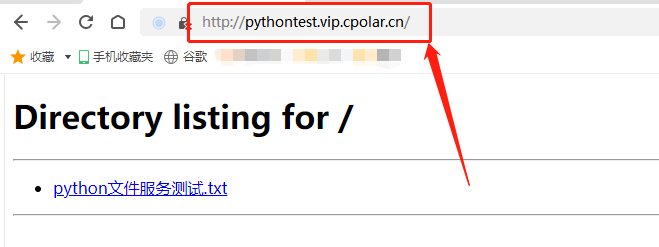
Python文件共享+cpolar内网穿透:轻松实现公网访问
文章目录 1.前言2.本地文件服务器搭建2.1.Python的安装和设置2.2.cpolar的安装和注册 3.本地文件服务器的发布3.1.Cpolar云端设置3.2.Cpolar本地设置 4.公网访问测试5.结语 1.前言 数据共享作为和连接作为互联网的基础应用,不仅在商业和办公场景有广泛的应用&#…...

SSHFS-Win完整指南:如何在Windows上安全访问远程文件系统
SSHFS-Win完整指南:如何在Windows上安全访问远程文件系统 【免费下载链接】sshfs-win SSHFS For Windows 项目地址: https://gitcode.com/gh_mirrors/ss/sshfs-win 如果你需要在Windows系统中安全地访问远程Linux服务器的文件,SSHFS-Win正是你需要…...

Hertz.dev实时音频对话实战:构建智能语音助手的最佳实践指南
Hertz.dev实时音频对话实战:构建智能语音助手的最佳实践指南 【免费下载链接】hertz-dev first base model for full-duplex conversational audio 项目地址: https://gitcode.com/gh_mirrors/he/hertz-dev Hertz.dev是一个开创性的全双工会话音频基础模型&a…...

5分钟快速上手:如何为Windows安装程序添加简体中文界面支持
5分钟快速上手:如何为Windows安装程序添加简体中文界面支持 【免费下载链接】Inno-Setup-Chinese-Simplified-Translation :earth_asia: Inno Setup Chinese Simplified Translation 项目地址: https://gitcode.com/gh_mirrors/in/Inno-Setup-Chinese-Simplified-…...

LiveSplit终极指南:为速度跑者量身定制的精准计时神器
LiveSplit终极指南:为速度跑者量身定制的精准计时神器 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款专为速度跑者打造的轻量级、高度可定制的计…...

macOS运行Windows程序的终极指南:Whisky完全攻略
macOS运行Windows程序的终极指南:Whisky完全攻略 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想在Mac上无缝运行Windows软件和游戏,但又不想安装虚拟机或双…...

Python盲水印终极指南:3个简单步骤保护你的数字版权
Python盲水印终极指南:3个简单步骤保护你的数字版权 【免费下载链接】BlindWatermark 使用盲水印保护创作者的知识产权using invisible watermark to protect creators intellectual property 项目地址: https://gitcode.com/gh_mirrors/bl/BlindWatermark 在…...

Photoshop图层批量导出终极指南:告别手动操作,提升10倍工作效率
Photoshop图层批量导出终极指南:告别手动操作,提升10倍工作效率 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Ad…...
3分钟解决BT下载慢:trackerslist让你的下载速度飙升5倍的秘密
3分钟解决BT下载慢:trackerslist让你的下载速度飙升5倍的秘密 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 你是不是也经历过这样的场景?找到一个…...

OBS背景移除插件:零绿幕实现专业直播效果的完整指南
OBS背景移除插件:零绿幕实现专业直播效果的完整指南 【免费下载链接】obs-backgroundremoval An OBS plugin for removing background in portrait images (video), making it easy to replace the background when recording or streaming. 项目地址: https://gi…...

DownKyi终极教程:3步掌握B站视频下载,免费打造个人媒体库
DownKyi终极教程:3步掌握B站视频下载,免费打造个人媒体库 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、…...