【大数据 - Doris 实践】数据表的基本使用(一):基本概念、创建表
数据表的基本使用(一):基本概念、创建表
- 1.创建用户和数据库
- 2.Doris 中数据表的基本概念
- 2.1 Row & Column
- 2.2 Partition & Tablet
- 3.建表实操
- 3.1 建表语法
- 3.2 字段类型
- 3.3 创建表
- 3.3.1 Range Partition
- 3.3.2 List Partition
1.创建用户和数据库
mysql -h hadoop1 -P 9030 -u root -p
-u:指定用户名-p:指定密码-h:主机-P:端口
(1)创建 test 用户
create user 'test' identified by 'test';
(2)创建数据库
create database test_db;
(3)用户授权
grant all on test_db to test;
2.Doris 中数据表的基本概念
在 Doris 中,数据都以 关系表(Table)的形式进行逻辑上的描述。
2.1 Row & Column
一张表包含 行(Row)和 列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
在默认的数据模型中,Column 只分为 排序列 和 非排序列。存储引擎会按照排序列对数据进行排序存储,并建立稀疏索引,以便在排序数据上进行快速查找。
而在聚合模型中,Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应 维度列 和 指标列。从聚合模型的角度来说,Key 列相同的行,会聚合成一行。其中 Value 列的聚合方式由用户在建表时指定。
2.2 Partition & Tablet
在 Doris 的存储引擎中,用户数据首先被划分成若干个 分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。而在每个分区内,数据被进一步的按照 Hash 的方式 分桶,分桶的规则是要找用户指定的分桶列的值进行 Hash 后分桶。每个分桶就是一个 数据分片(Tablet),也是数据划分的最小逻辑单元。
Tablet之间的数据是没有交集的,独立存储的。Tablet也是数据移动、复制等操作的最小物理存储单元。Partition可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个Partition进行。
3.建表实操
3.1 建表语法
使用 CREATE TABLE 命令建立一个表(Table)。更多详细参数可以查看:
help create table;
建表语法:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...]
[, index_definition1[, index_definition2, ...]])
[ENGINE = [olap|mysql|broker|hive|iceberg]]
[key_desc]
[COMMENT "table comment"]
[partition_desc]
[distribution_desc]
[rollup_index]
[PROPERTIES ("key"="value", ...)]
[BROKER PROPERTIES ("key"="value", ...)];
Doris 建表是一个同步命令,命令返回成功,即表示建表成功。
Doris 支持支持单分区和复合分区两种建表方式。
- 复合分区:既有分区也有分桶。
- 第一级称为
Partition,即 分区。用户可以指定某一维度列作为分区列(当前只支持 整型 和 时间类型 的列),并指定每个分区的取值范围。 - 第二级称为
Distribution,即 分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
- 第一级称为
- 单分区:只做 HASH 分布,即只分桶。
3.2 字段类型
| 字段类型名 | 类型字节 | 长度 |
|---|---|---|
| TINYINT | 1 字节 | 范围: − 2 7 + 1 -2^7 + 1 −27+1 ~ 2 7 − 1 2^7 - 1 27−1 |
| SMALLINT | 2 字节 | 范围: − 2 15 + 1 -2^{15} + 1 −215+1 ~ 2 15 − 1 2^{15} - 1 215−1 |
| INT | 4 字节 | 范围: − 2 31 + 1 -2^{31} + 1 −231+1 ~ 2 31 − 1 2^{31} - 1 231−1 |
| BIGINT | 8 字节 | 范围: − 2 63 + 1 -2^{63} + 1 −263+1 ~ 2 63 − 1 2^{63} - 1 263−1 |
| LARGEINT | 16 字节 | 范围: − 2 127 + 1 -2^{127} + 1 −2127+1 ~ 2 127 − 1 2^{127} - 1 2127−1 |
| FLOAT | 4 字节 | 支持科学计数法 |
| DOUBLE | 12 字节 | 支持科学计数法 |
| DECIMAL[(precision, scale)] | 16 字节 | 保证精度的小数类型。默认是 DECIMAL(10, 0),precision:1 ~ 27,scale:0 ~ 9,其中整数部分为 1 ~ 18,不支持科学计数法 |
| DATE | 3 字节 | 范围:0000-01-01 ~ 9999-12-31 |
| DATETIME | 8 字节 | 范围:0000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| CHAR[(length)] | 定长字符串。长度范围:1 ~ 255。默认为 1 | |
| VARCHAR[(length)] | 变长字符串。长度范围:1 ~ 65533 | |
| BOOLEAN | 与 TINYINT 一样, 0 0 0 代表 false, 1 1 1 代表 true | |
| HLL | 1~16385 个字节 | hll 列类型,不需要指定长度和默认值、长度根据数据的聚合程度系统内控制,并且 hll 列只能通过配套的 hll_union_agg、hll_cardinality、hll_hash 进行查询或使用 |
| BITMAP | bitmap 列类型,不需要指定长度和默认值。表示整型的集合,元素最大支持到 2 64 − 1 2^{64} - 1 264−1 | |
| STRING | 变长字符串, 0.15 0.15 0.15 版本支持,最大支持 2147483643 字节(2GB - 4),长度还受 be 配置 string_type_soft_limit,实际能存储的最大长度取两者最小值。只能用在 Value 列,不能用在 Key 列和分区、分桶列 |
注意:聚合模型在定义字段类型后,可以指定字段的聚合类型 agg_type,如果不指定,则该列为 Key 列。否则,该列为 Value 列,类型包括:SUM、MAX、MIN、REPLACE。
3.3 创建表
3.3.1 Range Partition
CREATE TABLE IF NOT EXISTS example_db.expamle_range_tbl
(`user_id` LARGEINT NOT NULL COMMENT "用户 id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`,`date`,`timestamp`,`city`,`age`,`sex`)
partition by range(`date`)
(PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
("replication_num" = "3","storage_medium" = "SSD","storage_cooldown_time" = "2018-01-01 12:00:00"
);
3.3.2 List Partition
CREATE TABLE IF NOT EXISTS example_db.expamle_list_tbl
(`user_id` LARGEINT NOT NULL COMMENT "用户 id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),PARTITION `p_jp` VALUES IN ("Tokyo")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
("replication_num" = "3","storage_medium" = "SSD","storage_cooldown_time" = "2018-01-01 12:00:00"
);
相关文章:
:基本概念、创建表)
【大数据 - Doris 实践】数据表的基本使用(一):基本概念、创建表
数据表的基本使用(一):基本概念、创建表 1.创建用户和数据库2.Doris 中数据表的基本概念2.1 Row & Column2.2 Partition & Tablet 3.建表实操3.1 建表语法3.2 字段类型3.3 创建表3.3.1 Range Partition3.3.2 List Partition 1.创建用…...
剑指Offer || 038.每日温度
题目 请根据每日 气温 列表 temperatures ,重新生成一个列表,要求其对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1: 输入: temperatures…...
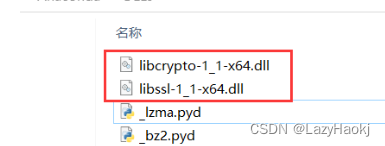
URL because the SSL module is not available
Could not fetch URL https://pypi.org/simple/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host‘pypi.org’, port443): Max retries exceeded with url: /simple/pip/ (Caused by SSLError(“Can’t connect to HTT PS URL because the…...
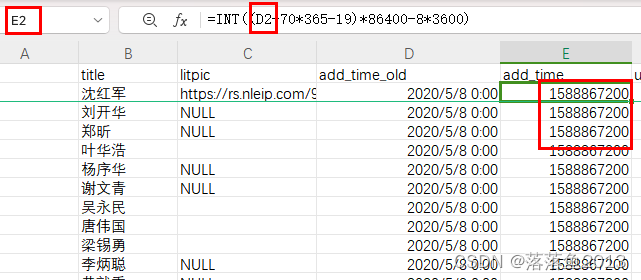
excel 日期与时间戳的相互转换
1、日期转时间戳:B1INT((A1-70*365-19)*86400-8*3600)*1000 2、时间戳转日期:A1TEXT((B1/10008*3600)/8640070*36519,"yyyy-mm-dd hh:mm:ss") 以上为精确到毫秒,只精确到秒不需要乘或除1000。 使用以上方法可以进行excel中日期…...

MongoDB中的嵌套List操作
前言 MongoDB区别Mysql的地方,就是MongoDB支持文档嵌套,比如最近业务中就有一个在音频转写结果中进行对话场景,一个音频中对应多轮对话,这些音频数据和对话信息就存储在MongoDB中文档中。集合结构大致如下 {"_id":234…...
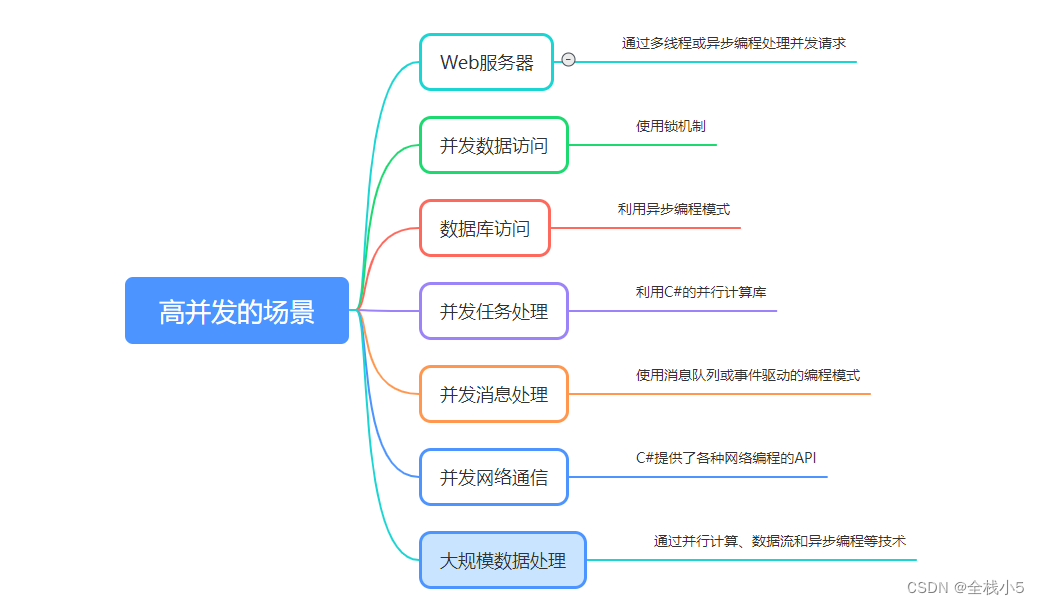
【C#】什么是并发,C#常规解决高并发的基本方法
给自己一个目标,然后坚持一段时间,总会有收获和感悟! 在实际项目开发中,多少都会遇到高并发的情况,有可能是网络问题,连续点击鼠标无反应快速发起了N多次调用接口, 导致极短时间内重复调用了多次…...
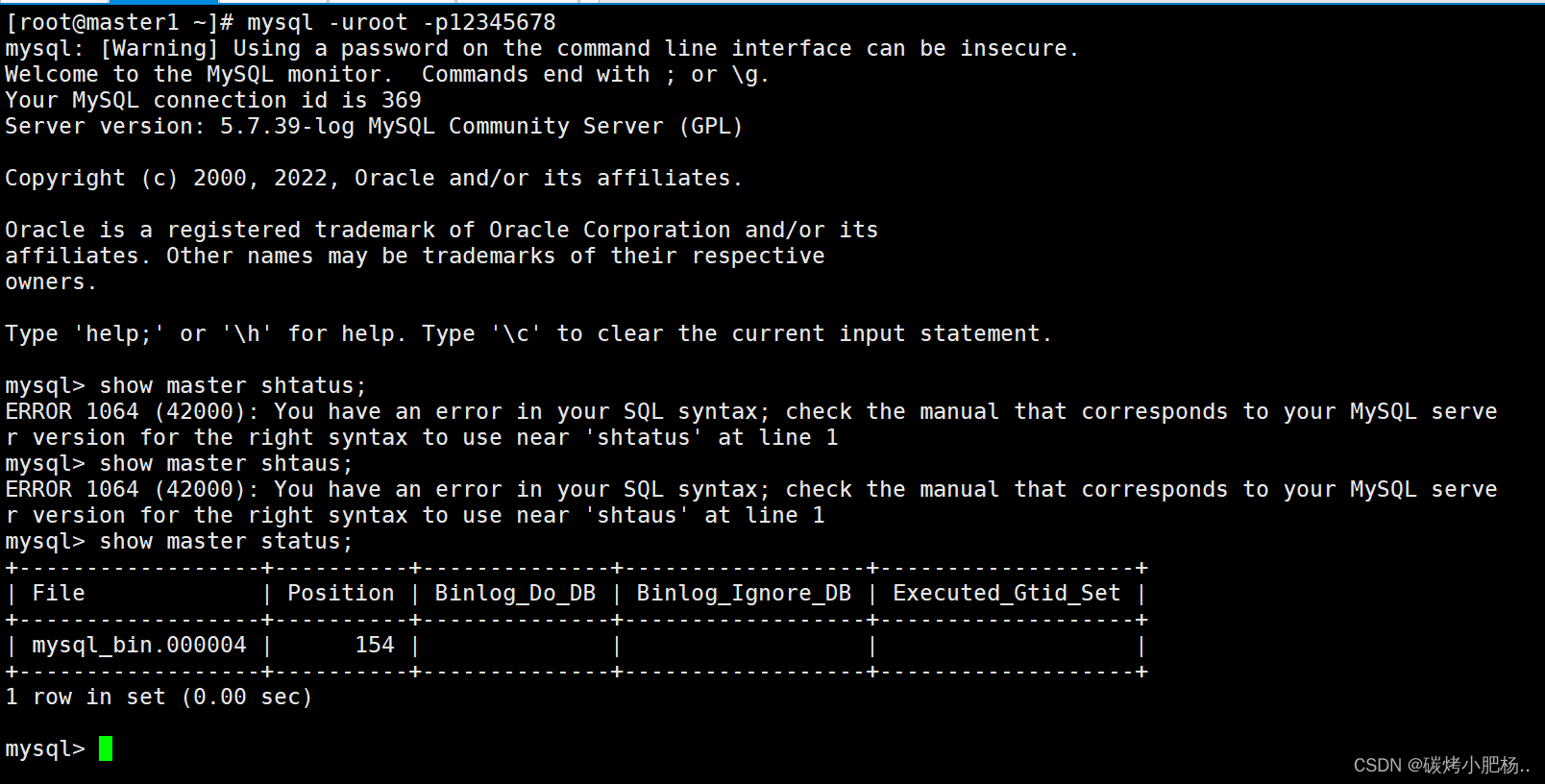
MySQL双主一从高可用
MySQL双主一从高可用 文章目录 MySQL双主一从高可用环境说明1.配置前的准备工作2.配置yum源 1.在部署NFS服务2.安装主数据库的数据库服务,并挂载nfs3.初始化数据库4.配置两台master主机数据库5.配置m1和m2成为主数据库6.安装、配置keepalived7.安装部署从数据库8.测…...

#力扣:2894. 分类求和并作差@FDDLC
2894. 分类求和并作差 - 力扣(LeetCode) 一、Java class Solution {public int differenceOfSums(int n, int m) {return (1n)*n/2-n/m*(mn/m*m)/2;} } 二、C class Solution { public:int differenceOfSums(int n, int m) {return (1n)*n/2-n/m*(mn…...
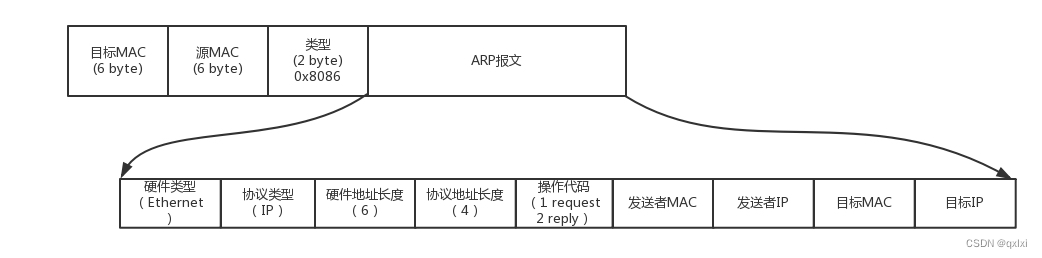
【网络协议】聊聊从物理层到MAC层 ARP 交换机
物理层 物理层其实就是电脑、交换器、路由器、光纤等。组成一个局域网的方式可以使用集线器。可以将多台电脑连接起来,然后进行将数据转发给别的端口。 数据链路层 Hub其实就是广播模式,如果A电脑发出一个包,B、C电脑也可以收到。那么数据…...
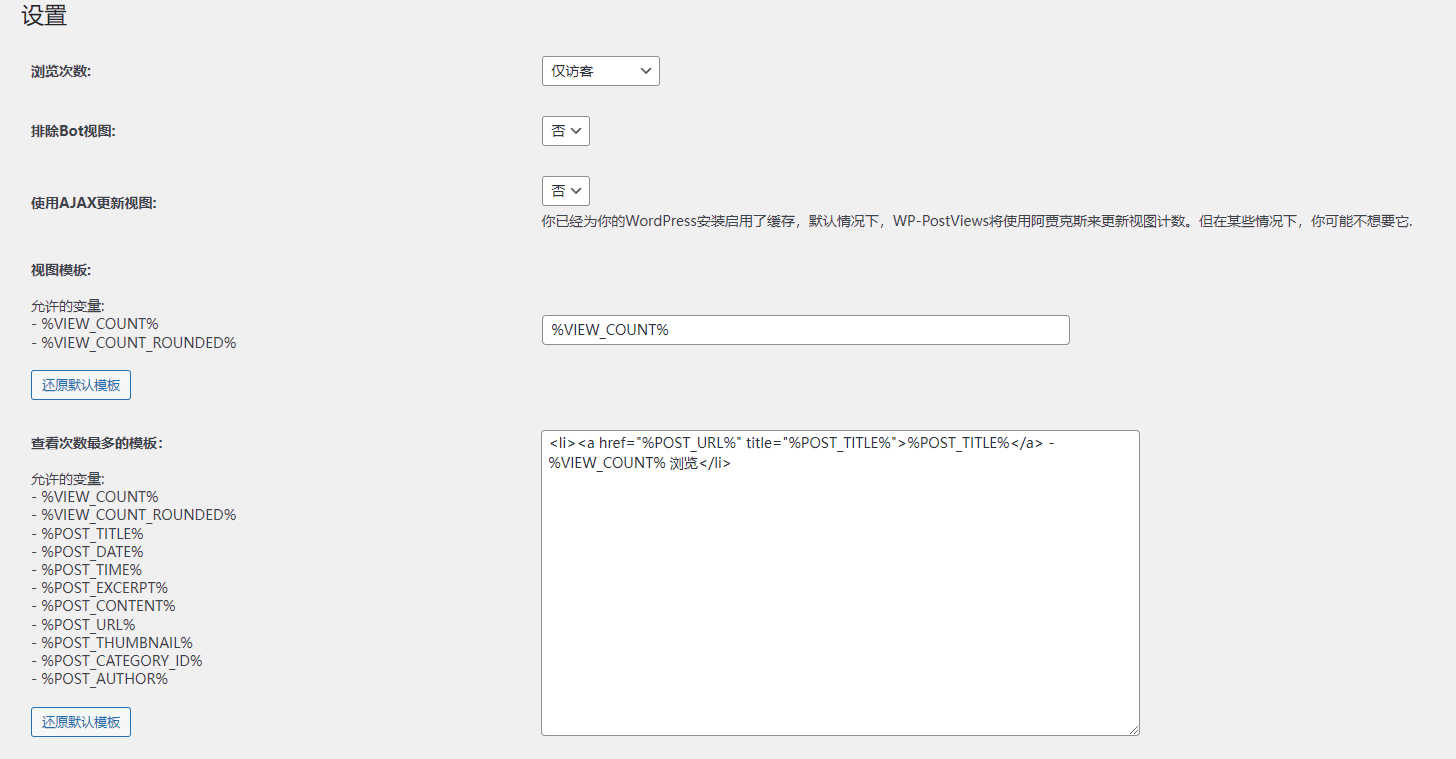
WordPress插件 WP-PostViews 汉化语言包
WP-PostViews汉化语言包 WP-PostViews是一款很受欢迎的文章浏览次数统计插件,记录每篇文章展示次数、根据展示次数显示历史最热或最衰的文章排行、展示范围可以是全部文章和页面,也可以是某些目录下的文章和页面。本文还介绍了一些隐藏的功能࿰…...
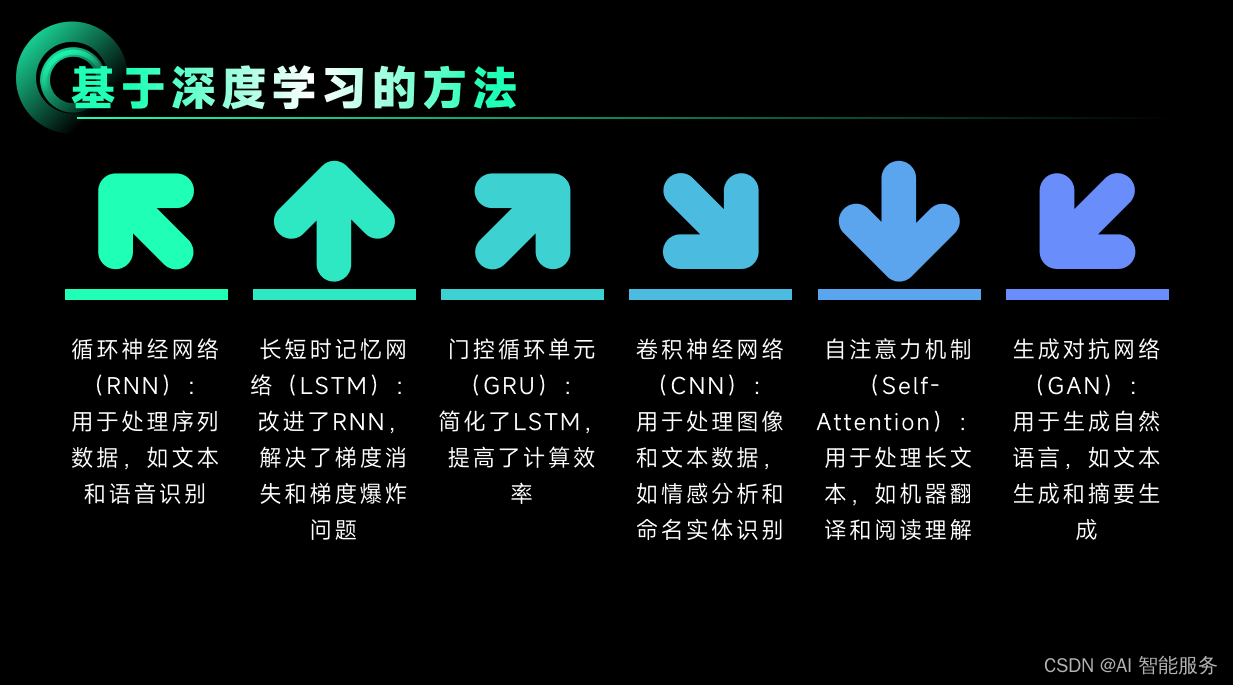
基础课2——自然语言处理
1.概念 自然语言处理(Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。 自然语言处理的主要研究方向包括: 语言学研究&…...

有趣的GPT指令
1 从现在开始,你的回答必须把所有字替换emoji,并保持原来的含义。你不能使用任何汉字或英文。如果有不适当的词语,将它们替换成对应的emoji。下面是一个例子: 原文:爷吐啦 翻译:👴ὃ…...

小样本学习--(1)概论
目录 一、概述 二、小样本学习的数据集 1、Omniglot 2、MiniimageNet 三、孪生网络 四、三元组损失函数 一、概述 小样本学习用于处理训练数据集中样本数量少的情况,一般来说,小样本学习流程是这样的,从一个多种类少量样本的巨大数据集…...
数据结构之手撕顺序表(讲解➕源代码)
0.引言 在本章之后,就要求大家对于指针、结构体、动态开辟等相关的知识要熟练的掌握,如果有小伙伴对上面相关的知识还不是很清晰,要先弄明白再过来接着学习哦! 那进入正题,在讲解顺序表之前,我们先来介绍…...

小微企业是怎样从客户管理系统中获益的?
大企业普遍拥有成熟的客户管理系统,而对小微企业而言,客户管理系统的重要性更为突出。这是因为小微企业管理相对薄弱,资源有限,人力资金需要更加精细化的管理。那么,小微企业如何从客户管理系统中获益? 一…...

mysql整库备份表结构和数据
命令 mysqldump -P 端口 -h 主机 -u 用户名 -p 数据库 > xxxxbak.sql 将导出数据库的表结构及数据(建表语句和insert语句) 举例 mysqldump -P 3306 -h 100.120.56.23 -u my_username-p sys > system-230510.sql...
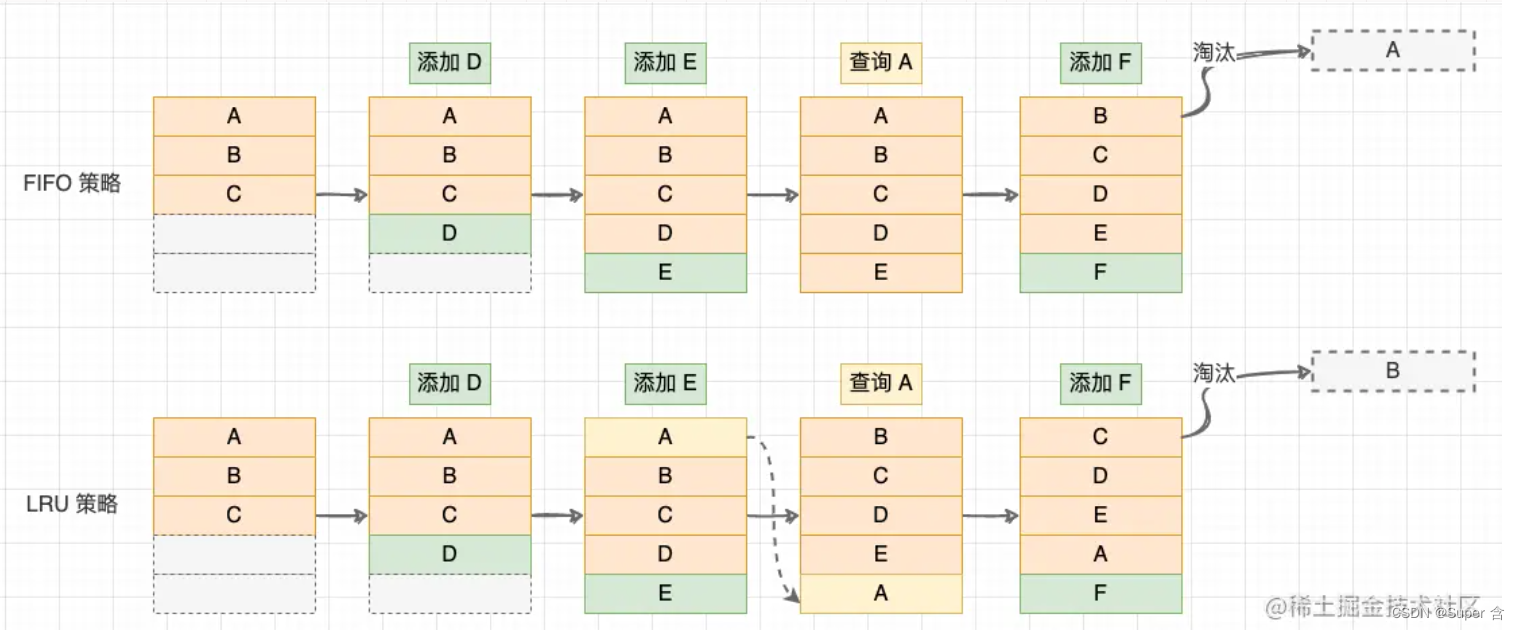
LinkedHashMap与LRU缓存
序、慢慢来才是最快的方法。 背景 LinkedHashMap 是继承于 HashMap 实现的哈希链表,它同时具备双向链表和散列表的特点。事实上,LinkedHashMap 继承了 HashMap 的主要功能,并通过 HashMap 预留的 Hook 点维护双向链表的逻辑。 1.缓存淘汰算法…...

2023大联盟6比赛总结
比赛链接 反思 A 为什么打表就我看不出规律!!! 定式思维太严重了T_T B 纯智障分块题,不知道为什么 B 100 B100 B100 比理论最优 B 300 B300 B300 更优(快了 3 倍),看来分块还是要学习一…...
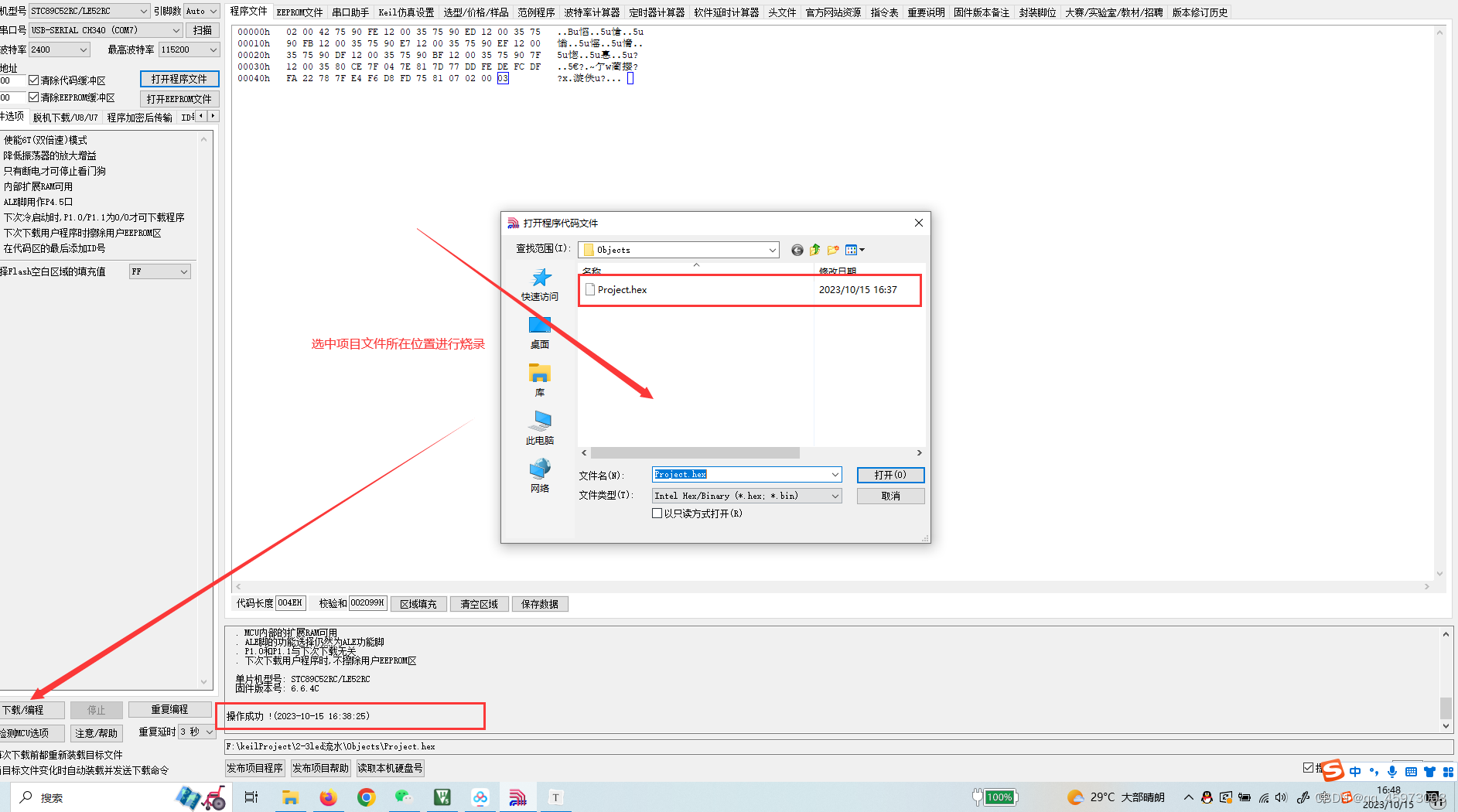
05_51单片机led流水线的实现
1:step创建一个新的项目并将程序烧录进入51单片机 以下是51单片机流水线代码的具体实现 #include <REGX52.H>void Delay500ms() //11.0592MHz {unsigned char i, j, k;i 4;j 129;k 119;do{do{while (--k);} while (--j);} while (--i); }void main(){while(1){P1 0…...
Java系列 | 如何讲自己的JAR包上传至阿里云maven私有仓库【云效制品仓库】
什么是云效 云效是云原生时代一站式 BizDevOps 平台,产研数字化同行者,支持公共云、专有云和混合云多种部署形态,通过云原生新技术和研发新模式,助力创新创业和数字化转型企业快速实现产研数字化,打造“双敏”组织&…...
年度深度战略研究报告)
中国民办高职教育的未来10年发展趋势(2025-2035)年度深度战略研究报告
陈天伟 (四川城市职业学院,四川 成都 610110) 宏观战略背景:教育现代化2035与职业教育的定位转型 在迈向2035年基本实现社会主义现代化的征程中,中国职业教育正经历着从“补充教育”向“类型教育”的根本性转变。根…...

React Hooks 服务器端渲染测试终极指南:如何避免 SSR 常见陷阱 [特殊字符]
React Hooks 服务器端渲染测试终极指南:如何避免 SSR 常见陷阱 🚀 【免费下载链接】react-hooks-testing-library 🐏 Simple and complete React hooks testing utilities that encourage good testing practices. 项目地址: https://gitco…...

Kandinsky-5.0-I2V-Lite-5s效果展示:背景变化趋势+主体动作精准还原案例
Kandinsky-5.0-I2V-Lite-5s效果展示:背景变化趋势主体动作精准还原案例 1. 惊艳的轻量级图生视频体验 想象一下,你只需要上传一张照片,再简单描述想要的动态效果,就能获得一段5秒的专业级短视频。这就是Kandinsky-5.0-I2V-Lite-…...

Phi-4-mini-reasoning镜像部署实操:7.2GB模型在24GB显存设备稳定运行
Phi-4-mini-reasoning镜像部署实操:7.2GB模型在24GB显存设备稳定运行 1. 项目概述 Phi-4-mini-reasoning是由微软Azure AI Foundry推出的轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。这个3.8B参数的模型虽然体积小巧࿰…...

学术论文利器:使用LaTeX撰写cv_unet_image-colorization技术报告与实验图表
学术论文利器:使用LaTeX撰写cv_unet_image-colorization技术报告与实验图表 写技术报告或者论文,尤其是涉及图像处理、深度学习这类需要大量公式和图表的领域,你是不是也遇到过这些烦恼?用Word排版,公式稍微复杂一点就…...

24小时无人值守:OpenClaw+Phi-3-vision-128k-instruct自动化监控系统
24小时无人值守:OpenClawPhi-3-vision-128k-instruct自动化监控系统 1. 为什么需要自动化监控系统 去年我负责一个内部数据看板项目时,经常遇到凌晨突发故障却无人值守的情况。直到第二天上班才发现问题,损失了宝贵的响应时间。传统监控工具…...

外贸企业如何提高搜索引擎优化效果_外贸企业如何利用社交媒体进行SEO优化
外贸企业如何提高搜索引擎优化效果 在当今数字化时代,外贸企业为了在全球市场中脱颖而出,如何提高搜索引擎优化(SEO)效果成为了关键问题。搜索引擎优化不仅仅是为了提升网站在搜索结果中的排名,更是为了吸引更多的潜在…...

DeepSeek总结的DuckLake 中的数据内联:为数据湖解锁流式处理
原文地址:https://ducklake.select/2026/04/02/data-inlining-in-ducklake/ DuckLake 中的数据内联:为数据湖解锁流式处理 Pedro Holanda 2026-04-02 TL;DR: DuckLake 的数据内联功能将小批量更新直接存储在目录中,从而消除了“小…...

在Vivado里调通3/4删余卷积码Viterbi译码:从分支度量到回溯的完整避坑指南
Vivado平台实现3/4删余卷积码Viterbi译码的工程实践 在数字通信系统中,卷积码因其优异的纠错性能被广泛应用。802.11a等标准中采用的删余卷积码技术,通过有选择地删除部分编码比特来提高码率。本文将深入探讨如何在Vivado平台上实现3/4删余卷积码的Viter…...

设计工程师到底应不应该自己验证自己的设计?
让设计工程师自己跑仿真、自己查波形。效率是真的高,问题也确实能发现不少。但有一个麻烦没法回避——人很难发现自己思维盲区里的东西。设计一个模块的时候,工程师脑子里已经有了一套逻辑假设。写验证用例的时候,这套假设还在,测…...